1. Introduction
Remote sensing images provide technical advantages, such as multiresolution, wide coverage, repeatable observation, and multispectral/hyperspectral recording. Therefore, they are widely used in urban area classification, vegetation cover monitoring, target identification, and national defence security [
1,
2,
3]. Among remote sensing images, multiresolution images provide users with the highest resolution in both the spatial and spectral domains. However, due to the limitations of remote sensing imaging principles and the physical structure of sensors, the instantaneous fields of view of sensors can differ [
4] therefore, satellites usually carry various sensors to acquire multiresolution images. For example, Earth observation satellites, such as QuickBird, WorldView-2 and, WorldView-3, carry two sensors to simultaneously capture two types of high-resolution remote sensing images: panchromatic (PAN) images with high spatial but low spectral resolution and multispectral (MS) images with high spectral but low spatial resolution (LRMS).
In practical remote sensing applications, MS images with high spatial and spectral resolution are often necessary, encouraging researchers to establish an effective method to generate such images from multiple images. The pansharpening algorithm was created to fully use the spatial information of PAN images and the spectral information of MS images.
Pansharpened images are important in remote sensing scenes and as a preprocessing step for image processing tasks, such as feature extraction, segmentation, and classification. In recent decades, researchers have proposed pansharpening algorithms in several directions, primarily classified into (1) component substitution (CS) methods [
5,
6,
7,
8], (2) multiresolution analysis (MRA) methods [
9,
10,
11,
12,
13], (3) variational optimisation (VO)-based methods [
14,
15,
16], and (4) deep learning methods.
The core idea of CS-based methods is to first project the MS image onto another space to separate the spatial structure component from the spectral information component. Then, a histogram matches the PAN image to the spatial structure component and replaces the spatial intensity component with the PAN image. Finally, a reverse projection returns the data to the original MS domain to obtain a sharpened MS image. Methods of this type include principal component analysis [
5], intensity–hue–saturation transform [
6], Gram–Schmidt (GS) sharpening [
7], and partial replacement adaptive component substitution (PRACS) [
8]. CS methods can obtain results with high spatial fidelity; however, this usually results in significant spectral distortion.
MRA-based methods retain more spectral information than CS methods. Moreover, MRA-based methods usually inject the spatial details extracted from PAN images into MS images through the MRA framework to obtain MS images with high spatial resolution. However, MRA methods suffer from spatial distortion, although they retain spectral information. Examples of such methods include smoothing filter-based intensity modulation (SFIM) [
9], additive wavelet luminance scaling [
10], “a-trous” wavelet transform [
11], Laplace pyramid [
12], and generalised Laplace pyramid [
13], among others.
In contrast, VO-based methods consider PAN sharpening to be an optimisation problem. The key concept of VO methods is to establish the objective function, which is used to determine an appropriate solution among variational optimisation schemes. Furthermore, VO methods can reduce the distortion of spectral information, but the optimisation calculation is complex, and the time complexity is high. Common methods include P+XS [
14] and Bayesian methods [
15], and sparse representation-based [
16] methods also belong to the VO category.
With the rapid development of hardware devices and machine learning, deep-learning-based models have achieved exciting results in various image processing fields, such as image super-resolution (SR), target detection, image segmentation, and other fields. In image SR, Dong et al. [
17] pioneered an SR convolutional neural network (CNN) model using CNNs and obtained good results. In target detection, Ghorbanzadeh et al. [
18] integrated CNN models with object-based image analysis (OBIA) capabilities to effectively support refugee/IDP (internally displaced person) camp planning and humanitarian assistance. In hazard detection, Ghorbanzadeh et al. [
19] first applied fully convolutional network (FCN) algorithms, such as U-Net and ResU-Net, to freely available data and achieved high landslide detection performance. In image segmentation, Ronneberger et al. [
20] proposed a U-Net architecture consisting of a contraction path and a symmetric expansion path and successfully trained deep networks.
Inspired by the SRCNN, Masi et al. [
21] designed a three-layer CNN architecture to achieve pansharpening using the powerful nonlinear mapping ability of CNNs. This CNN application was the first in the field of pansharpening. Since then, pansharpening algorithms using deep learning have become a research focus. Wei et al. [
22] designed a deep residual network with 11 layers to obtain rich detail information and strong nonlinear mapping ability. He et al. [
23] summarised a detail-injection-based CNN model, which solved the redundant part of the network structure and enhanced interpretability. Liu et al. [
24] combined the advantages of generative adversarial networks (GANs) and designed a GAN-based pansharpening algorithm called PSGAN. Fu et al. [
25] borrowed the idea of feedback connection [
26] to designed a two-path network with a feedback connection (TPNwFB), which refined the low-level features by feeding back the high-level features extracted from the feature extraction block to the low-level features. Xu et al. [
27] designed a cross-directional and progressive network (CPNet) from the input image, which considers that most methods only take the four-fold upsampled LRMS and source PAN images as input. Wu et al. [
28] proposed a new three-stage detail-injection-based network (TDPNet) that takes the difference between the PAN and MS images as input [
29]. They designed a cascaded cross-scale fusion method to fully utilize the detail information on different scales, using a detail compensation mechanism to supplement details lost in the fusion process.
However, pansharpening is subject to some drawbacks, as follow: (1) in order to achieve powerful performance, many researches have added various large functional modules, making the model increasingly large in size with an increased number of parameters; (2) many proposed models do not sufficiently consider and treat the input images; and (3) some frameworks do not reach their full potential.
To improve and solve the problems mentioned above, we propose a double-stack aggregation network using a feature-travel strategy for pansharpening. By capturing detailed feature information on different scales in a round-robin manner, information loss due to upsampling on LRMS is reduced. The main contributions of this study are as follow:
In the feature extraction stage, we propose a novel multiscale, large-kernel residual convolution block (MLRB) combining the ideas of large-kernel convolution and dilated convolution to extract more fine-grained detail information while effectively expanding the receptive field. The design of MLRB has positive significance for the subsequent feature fusion, especially with respect to preservation of spectral information.
We propose a powerful double-stack feature aggregation module (DSFAM) to make full use of the feature details extracted at different levels. We aggregate the features extracted by the shallow and deep networks through multiple skip connections so that the final extracted features can fully retain the details extracted at each level, including spatial and spectral details.
We propose a novel feature circumnavigation strategy to preserve as much detail as possible in response to the loss of sampling in LRMS images. We obtain source images at three scales as input by processing and constructing three network levels. The extracted features are looped at different scales by resampling. The looped features complement the information at the three scales, reduce the details lost in the input images due to resampling, and improve the final reconstruction results.
We let each network layer learn the spatial and spectral detail information missing from the LRMS images and attach the loss function to each network layer to ensure that each feature loop can be supplemented with the correct information.
The rest of this paper is organised as follows. In
Section 2, we review related work based on CNNs in other domains and summarise other pansharpening methods based on deep learning. In
Section 3, we details the proposed DFS-Net, including the motivation for the proposal, network architecture design, and loss function definition. In Section, we present the experimental results and qualitatively and quantitatively compare the proposed method with other methods in different datasets. In
Section 5, we discusses the validity of various network structures and the rationality of the overall framework. Finally, we summarize the work in
Section 6.
3. Proposed Network
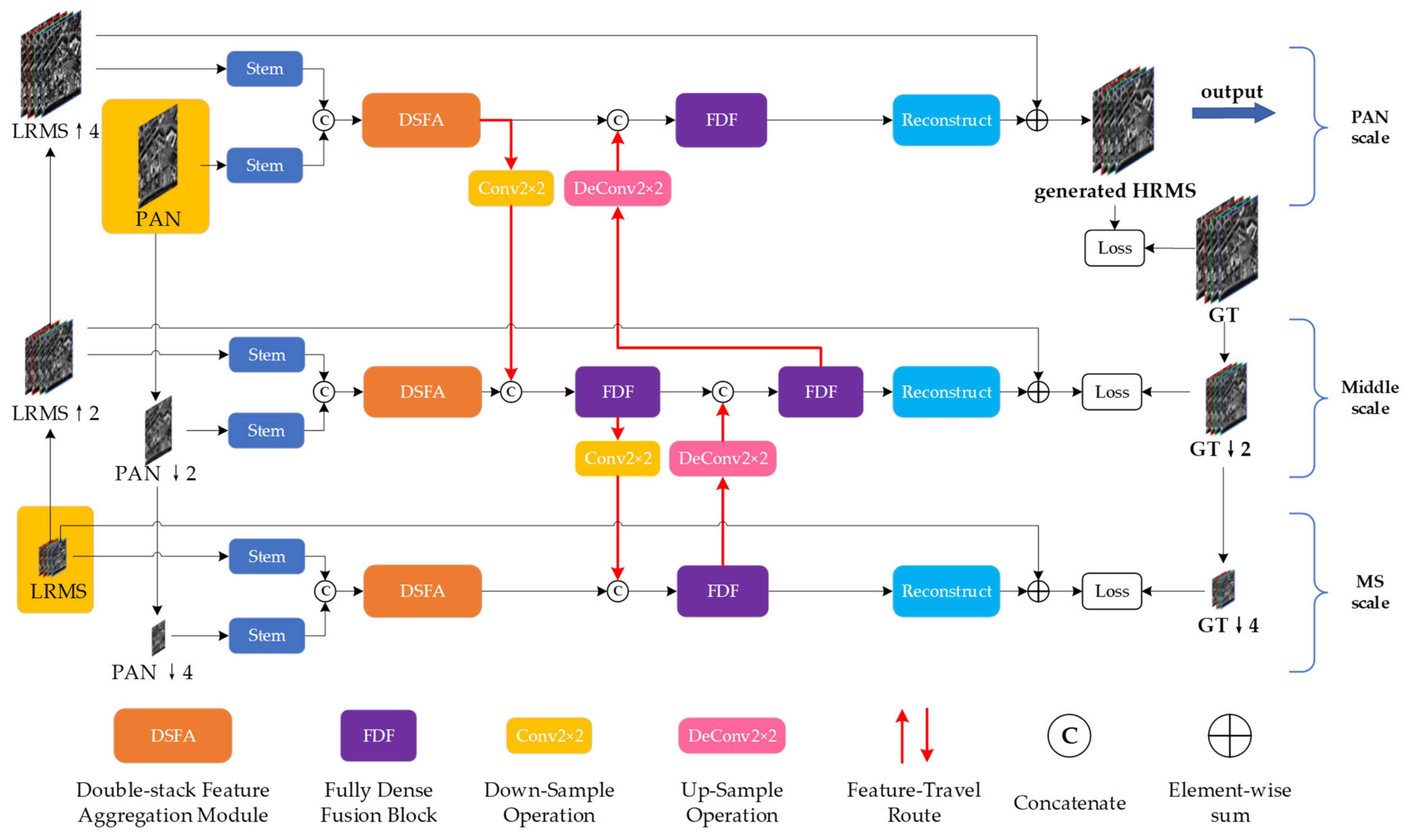
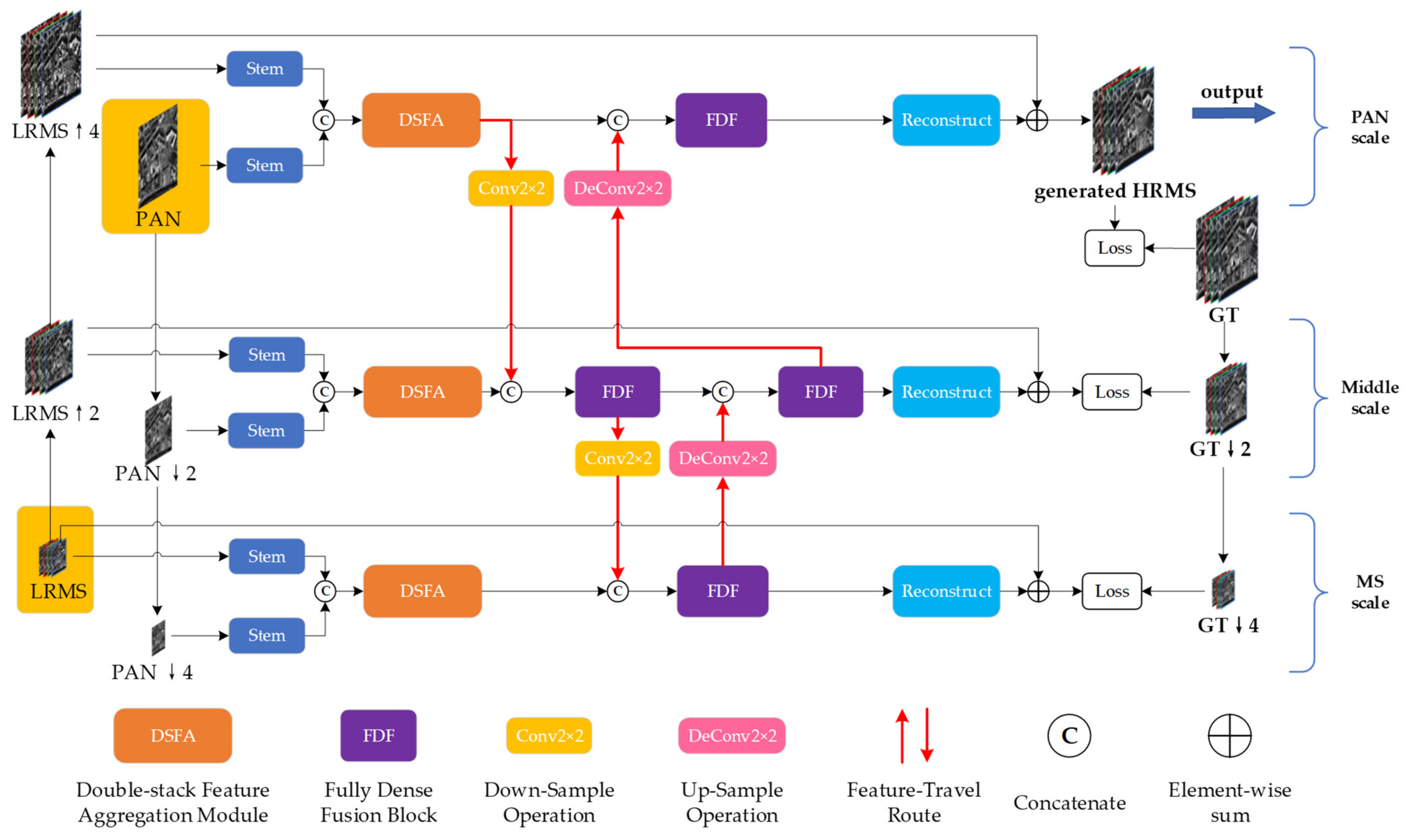
In this section, we describe the specific structure of the DFS-Net model proposed in this paper. The network follows the traditional idea of detail injection into the context by injecting extracted information into the resampled LRMS images. Thus, this network has good physical interpretability. The network structure must only learn detail information, making network training easier and effectively alleviating any gradient disappearance and explosion that may occur during the network learning process.
Most deep-learning-based methods directly upsample LRMS images by a factor of four as network input. However, the image upsampling process can affect the quality of the original image. To retain and extract the information lost during the resampling of LRMS images and fully employ the information from the source PAN and LRMS images at different scales, we upsampled and downsampled LRMS images and PAN images, respectively, to form three pairs of input images at different scales and constructed three network layers.
For each layer of the input, a two-stem network was used to extract the features of the PAN and LRMS images. After overlaying the features extracted by the two-stem network on the channels, a powerful DSFAM fully extracts and uses the features at different levels. The extracted features are downsampled and upsampled in a three-scale network, and the feature information extracted at different scales is fused using a fully connected dense fusion network. Then, the reconstruction module reconstructs the features to match the dimensions of the LRMS images. Finally, the extracted detail information is injected into the LRMS images to obtain the fused images.
The structure of each network scale primarily consists of a two-stem network, DSFAM, fully dense fusion block, feature-travel route, and reconstruction module. Loss functions are attached to all three network scales, forcing each scale to extract the correct feature information. The fused image obtained at the PAN scale is the desired result.
Figure 1 illustrates the main structure of DFS-Net.
3.1. Two-Stem Structure
Previous CNN-based pansharpening algorithms used only the PAN image as a carrier of spatial information and injected the information extracted from the PAN image into the LRMS image. However, in recent years, many studies [
29,
41] have revealed that both PAN and LRMS images contain certain spatial and spectral information. The PAN image contains rich spatial and spectral information unavailable in the LRMS image. For the backbone network to fully use the information from PAN and LRMS images, we set up two identical stem blocks for feature extraction of PAN and LRMS images and realised the fusion reconstruction and image recovery work of spatial and spectral information in the feature domain. In each network scale, one stem block takes the multiband LRMS image (size
H×
W×
N) as input, and the other stem block duplicates the PAN image and concatenates it on the channels to take the multichannel PAN image (size
H×
W×
N) as input.
Although the traditional method can achieve superior image resampling, we believe resampling the source image using the deep learning method is more consistent with the overall network architecture and retains the required detail information. Therefore, we used transpose and two-stride convolution to accomplish upsampling and downsampling of the LRMS and PAN images. To maintain the relative relationship between the ground-truth (GT) image and the PAN image, we used two-stride convolution with shared parameters for each layer for downsampling.
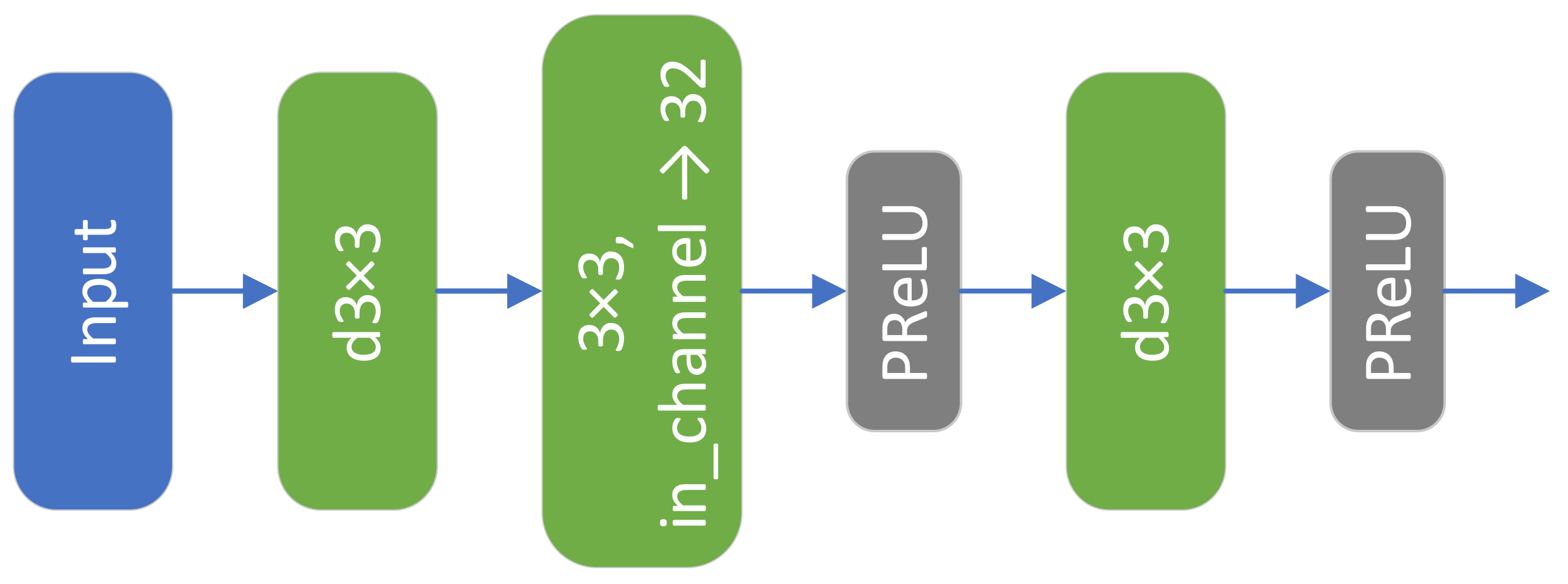
The detailed structure of the stem block is presented in
Figure 2. Inspired by PanNet’s use of high-pass filtering, we designed a depthwise convolutional layer similar to high-pass filtering in the first layer and did not add a nonlinear activation layer. Using high-pass filtering allows the network training to move from the image domain to the high-pass filtering domain. However, the parameter design of the high-pass filter significantly affects the final result. To take full advantage of the parametric learning capability of deep learning, we used deep convolution to simulate the role of high-pass filtering with good results. After the high-pass-like filter layer, we extracted features using a convolutional layer with a convolutional kernel size of 3 × 3 and boosted the number of channels to three. Then, we used deep convolution again to extract features channel by channel. In the stem block, we used parametric rectified linear units (PReLUs) after each convolutional layer, except for the high-pass-like filtering layer.
The two-stem structure consists of two stem blocks, each consisting of a layer, a
layer, and a
layer.
denotes a depthwise convolutional layer with a size
f f convolutional kernel and
n channels,
denotes a normal convolutional layer with a size
f f convolutional kernel and
n channels, and
denotes the PReLU activation function. In addition,
and
denote the extracted LRMS image and PAN image features, respectively; and
denotes the concatenate operation.
3.2. Double-Stack Feature Aggregation Module
In deep learning, VGG [
31] has demonstrated that depth is important for the network to extract features from images. Moreover, with the emergence of ResNet [
32], the network is difficult to train due to the increased depth. In addition, ResNet effectively solves the problems of gradient disappearance, gradient explosion, and network degradation by adding residual connections so that the gradient can be updated more directly. Network degradation indicates that model performance temporarily bottlenecks when the network reaches a certain depth, making it difficult to increase. When the network continues to deepen, model performance on the testing set instead declines. By adding residual connections, network training becomes easier, the network depth is considerably increased, and many deeper networks are developed, opening up a new phase of deep learning.
Although network layers have become deeper, recent research has tended to ignore the features extracted at each layer, which contains important information. The features extracted by shallow-layer networks are closer to the input and contain more information about pixel points, primarily fine-grained information, such as colour, texture, edge, and corner information. A shallow network has a smaller receptive field and a smaller receptive field overlap area, so the network is guaranteed to capture more details. The features extracted by deeper networks are closer to the output. They contain more abstract information (i.e., semantic information), primarily coarse-grained information, because the receptive field increases, the overlapping area between receptive fields increases, the image information is compressed, and information about the totality of the image is obtained. In pansharpening, a shallow network extracts more pixel-level information, containing colour and edge information, and deep networks extract additional semantic information. The flexible use of each level of information helps to preserving spectral and spatial information.
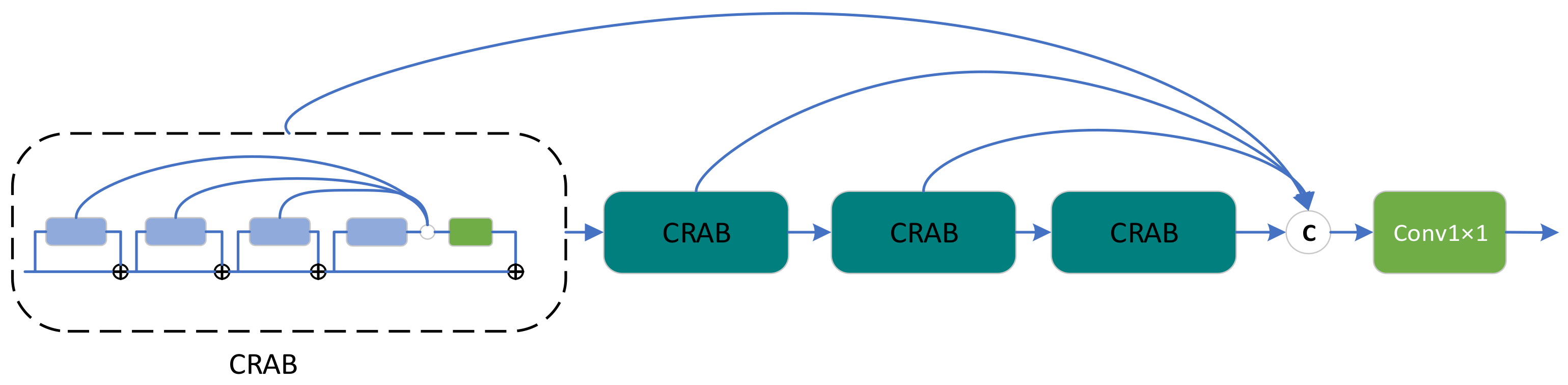
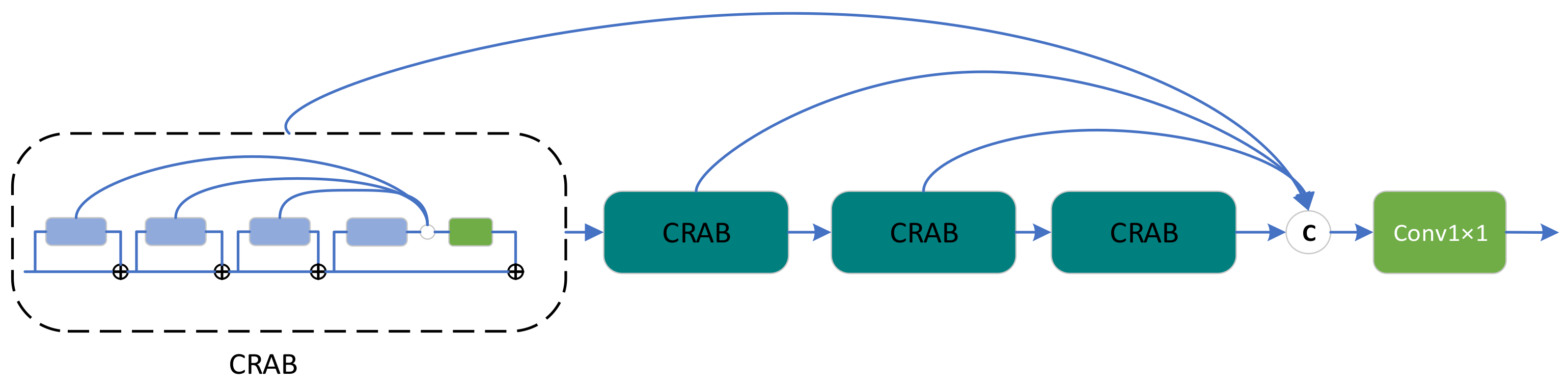
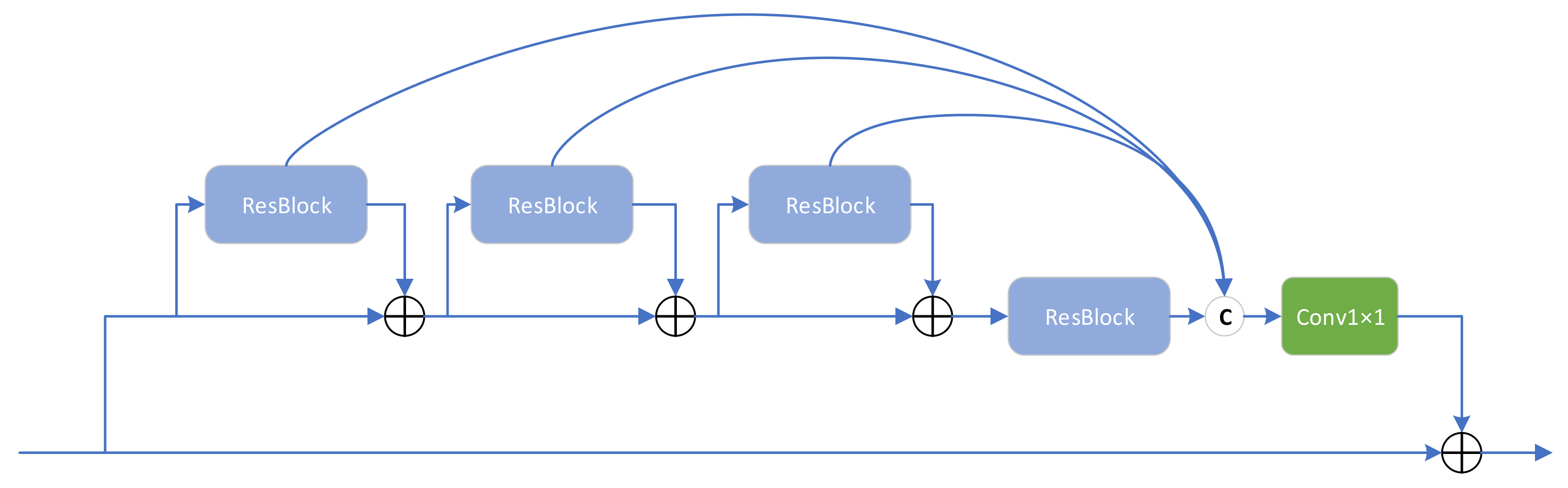
Inspired by the above ideas, we propose a DSFAM that can fully employ the features at each level. As depicted in
Figure 3, DSFAM consists of four continuous residual aggregation blocks (CRABs), and each CRAB contains four MLRBs, forming a double-stack aggregation structure. Finally, a 1 × 1 convolutional layer is used to weight the aggregated features and maintain the dimensionality, similar to the attention mechanism. In DSFAM, the double-stack aggregation structure is designed so that all parts of the deep network can be used effectively, and the final extracted features are very powerful. We believe that the increase in computation and number of parameters by properly adding skip connections would be less than by redesigning a new module, a classic example of which is U-Net [
20]. That is, a high-performance network structure design does not always require additional modules, and fully employing the original structure of the network may be a better approach, which is one of the manifestations of high efficiency.
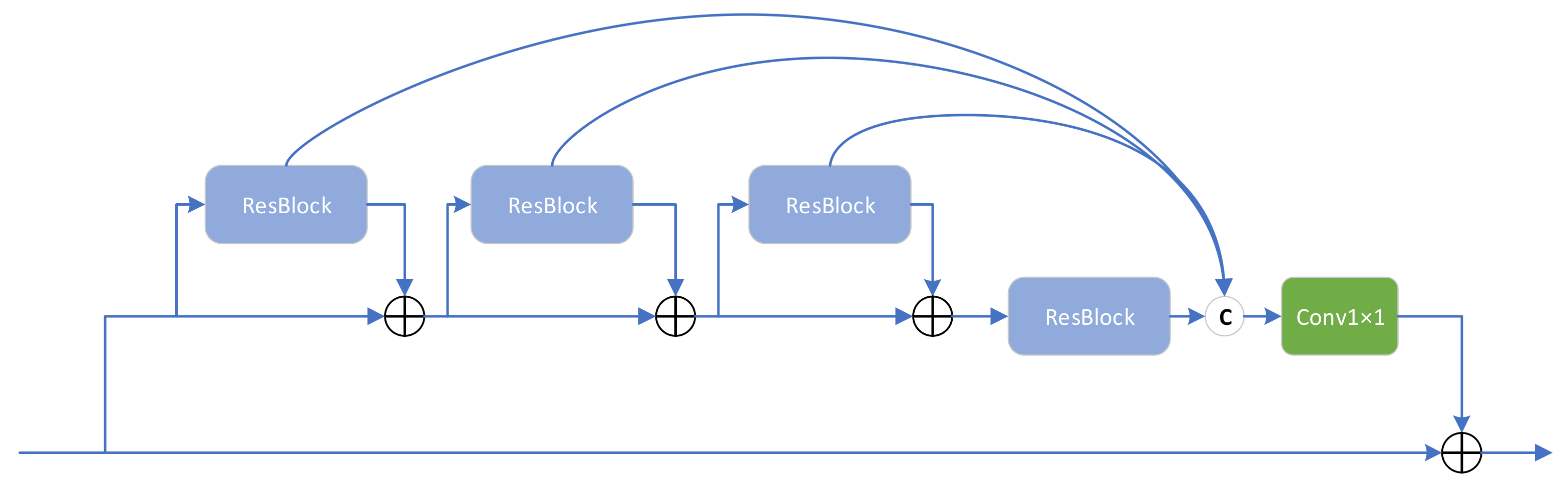
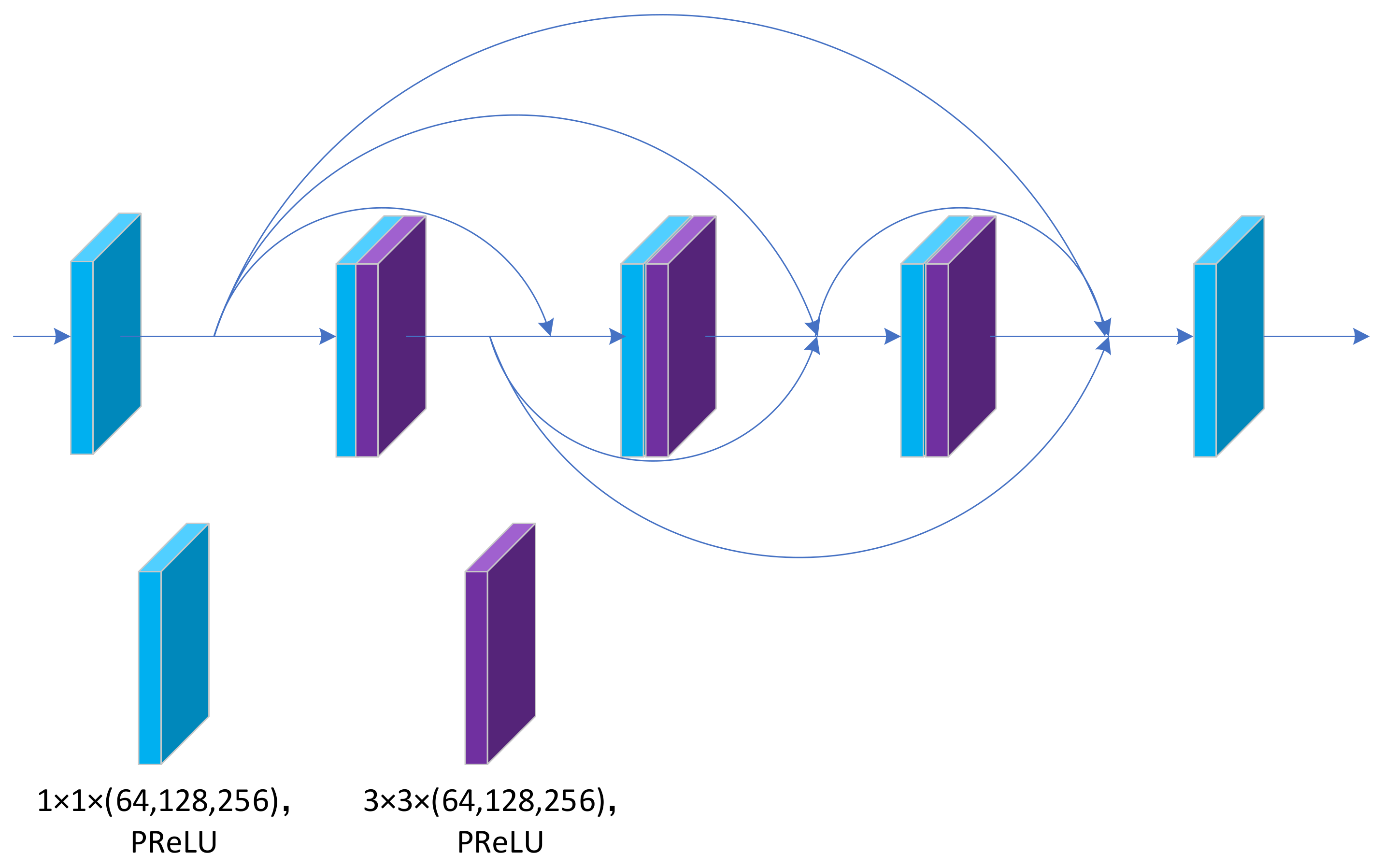
The CRAB structure is presented in
Figure 4. We borrowed the aggregated design of classical residual blocks from RFANet [
34] and repositioned the skip connections by combining the overall idea of DSFAM. In many networks, residual blocks are stacked together to form the network backbone. However, in multiple consecutive residual blocks, the features extracted from the first residual block must pass through long paths with repeated convolution and addition operations to reach the last residual block. As a result, the residual features at different levels are difficult to apply fully and play a very local role in the learning process of the whole network, which fits in with the idea of the DSFAM design.
Unlike RFANet, instead of aggregating multiple residual blocks within a residual range, we aggregated continuous residual blocks. The RFANet approach is to aggregate residual features within residual features rather than directly aggregate residual features, as displayed in
Figure 5. The advantage of the continuous residual aggregation used in the CRAB is that the residual features at each level can be used more directly, whereas the skip connection at each level makes the gradient update more easily. In addition, the CRAB results from a special optimisation based on DSFAM design ideas.
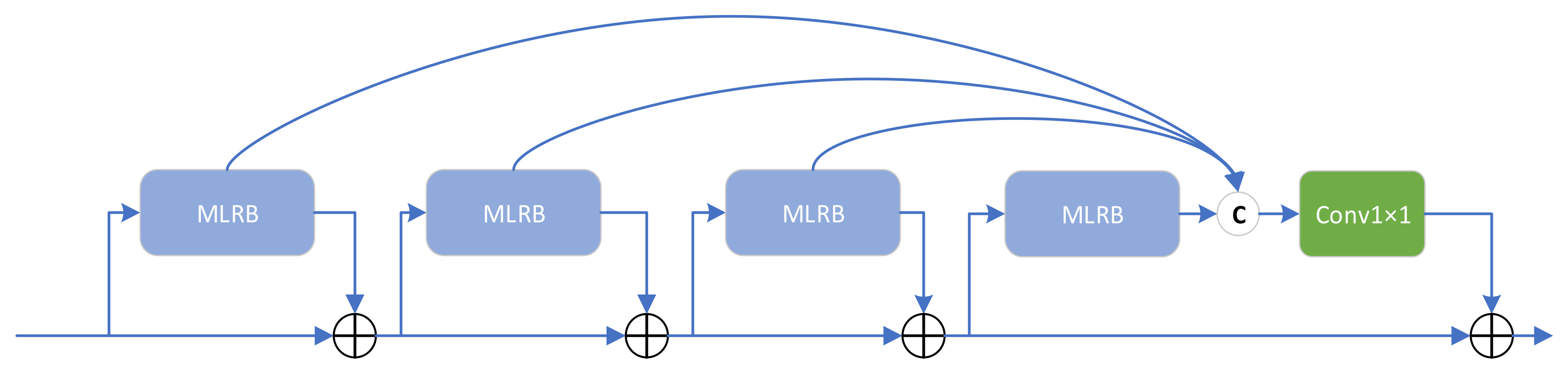
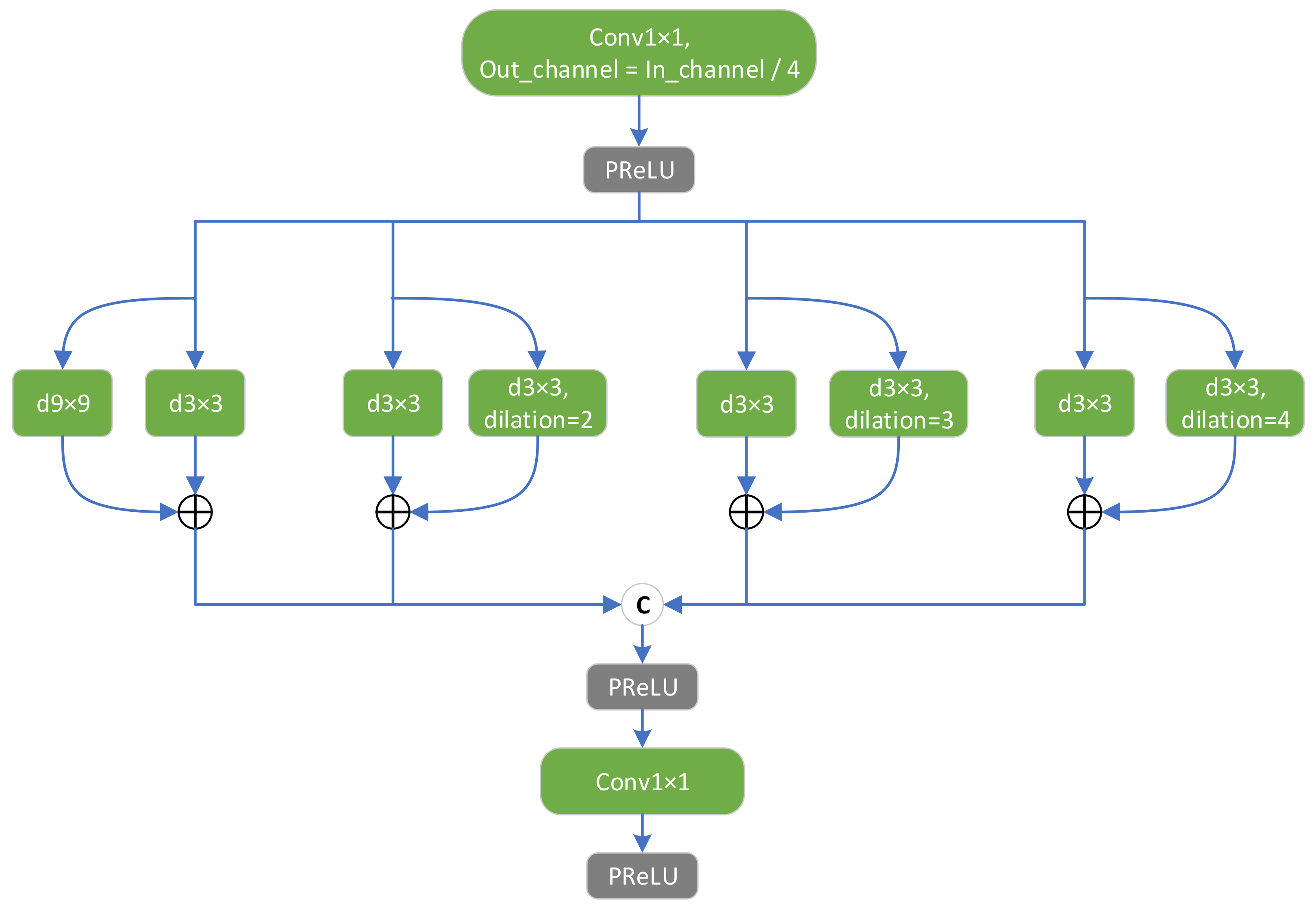
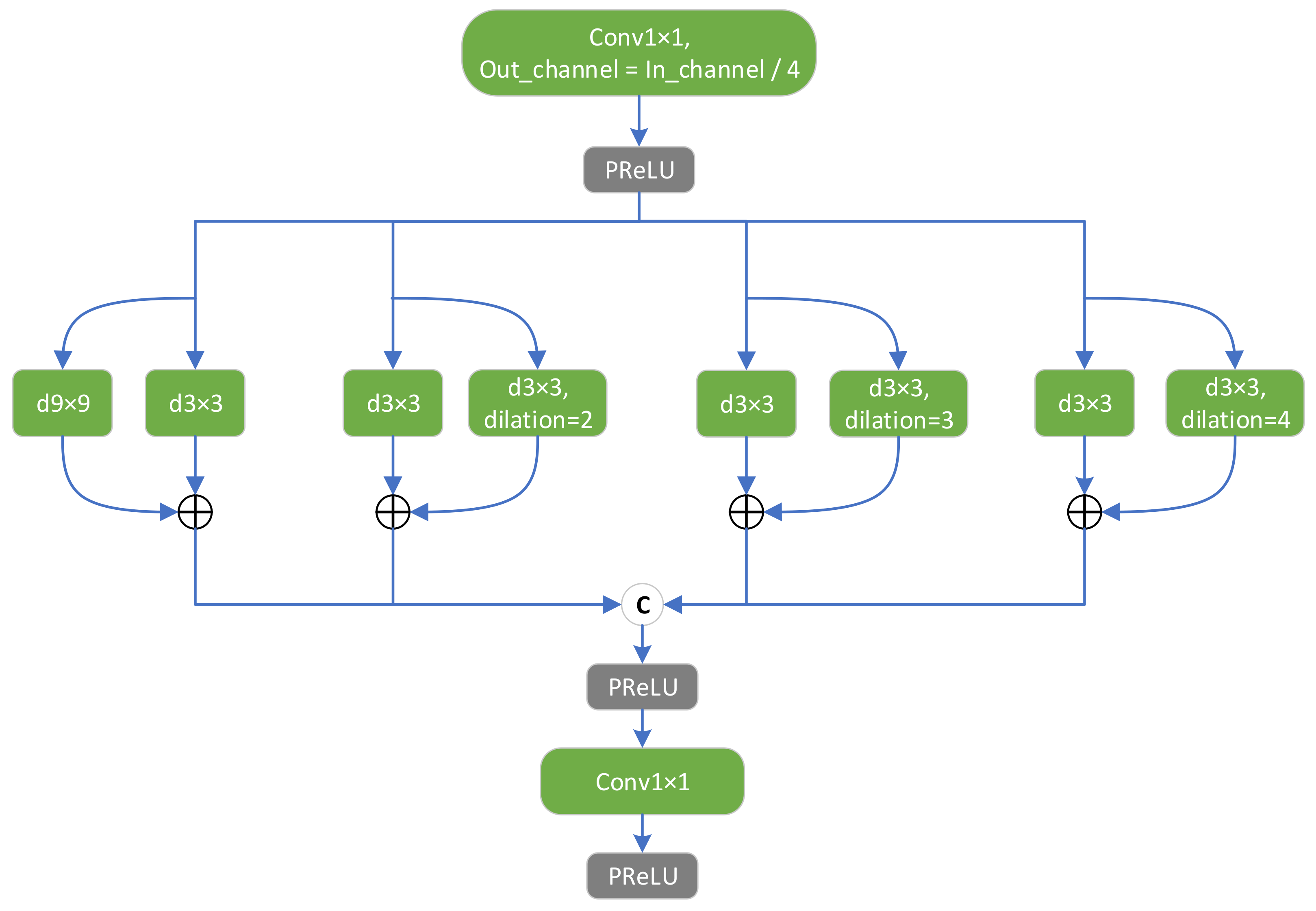
In the CRAB, to enhance the receptive field of the ordinary residual block and extract features on multiple scales, we designed an MLRB instead of an ordinary convolutional block; the structure of the MLRB is depicted in
Figure 6. We used four parallel branches for feature extraction to separately obtain features on different scales while maintaining computational volume. Inspired by DMDNet [
40] and related studies [
37], we extended the receptive field of small-scale convolutional kernels using dilated convolution to achieve feature extraction at multiple scales with different expansion coefficients.
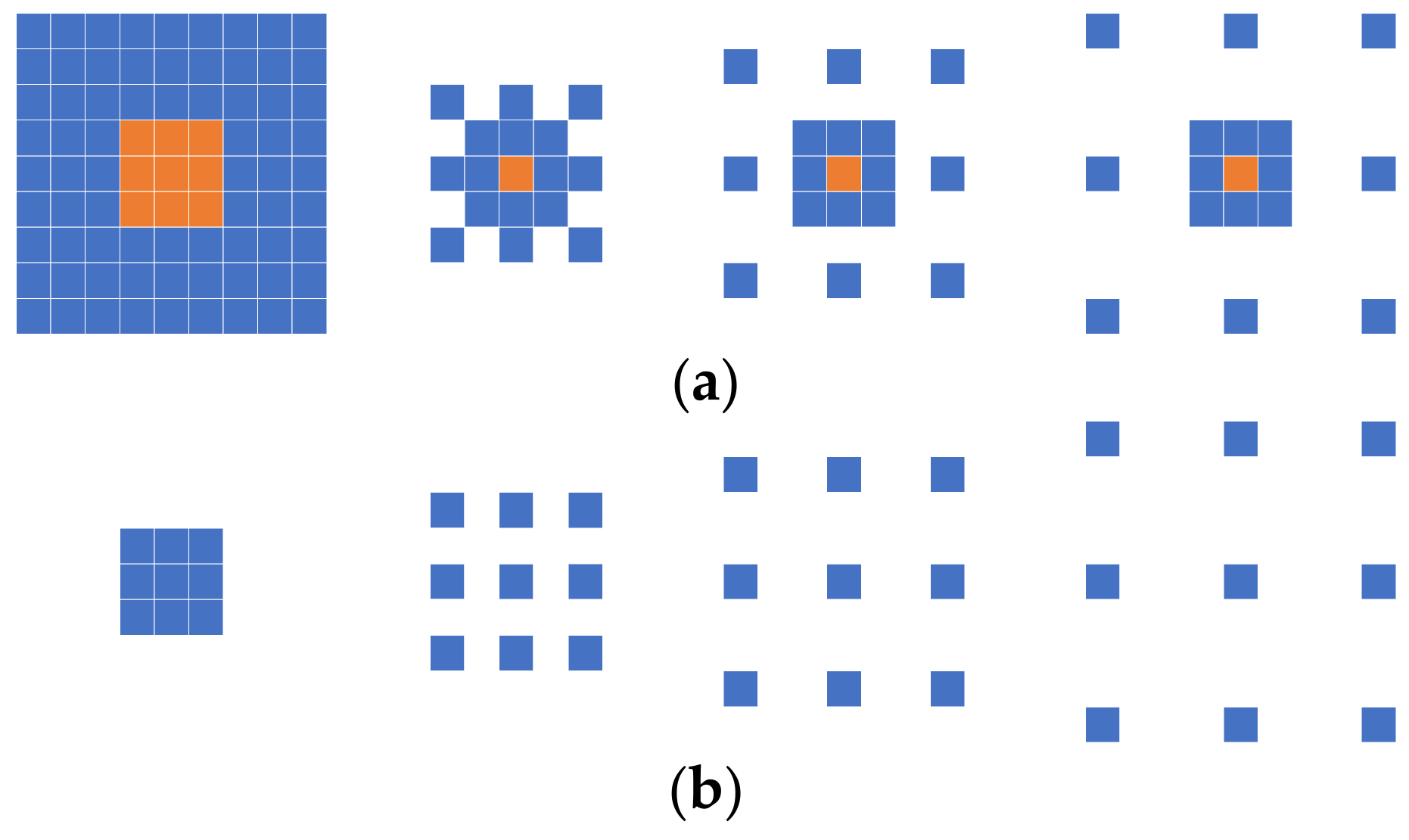
However, some studies [
38,
42] have demonstrated that dilation convolution may have grid effects. Although this drawback can be overcome by mixing convolutions with different expansion coefficients, information loss still occurs on edges, and some pixels in the image are not used. Some approaches propose using a compensation mechanism to compensate for the disadvantages of dilated convolution to address this problem. The compensation mechanism generally works by extracting features using a new module, concatenating them with the features extracted by the dilated convolution on the channel, and feeding them to the next part.
However, the problem with this approach is that although the compensation mechanism compensates for drawbacks, this is achieved by increasing the number of parameters and computational effort. The idea of large-kernel networks proposed by RepLKNet [
38] provides new inspiration. RepLKNet reviews the design of large kernels in CNNs. Large-kernel convolutions mostly appeared in early CNNs, such as AlexNet [
43], but in most networks after VGG, the strategy of stacking multiple 3 × 3 convolutional layers was used. Large-kernel convolution is a way to increase the receptive field, which is more sensitive to shape bias compared to multiple small convolutions. Both dilated and large-kernel convolution can increase the receptive field, and whether their combination is superior is the motivation to design the MLRB.
In the MLRB, we again set up two small branches within each parallel branch to combine large-kernel and dilated convolution, solving the possible lattice effect of dilated convolution. The inputs of these two small branches are the same in the large-kernel convolutional layer (the dilated convolutional kernel can be regarded as a large kernel) and the 3 × 3 basic convolutional layer. Next, the features extracted from the two small branches are numerically summed to obtain the composite features. Finally, the composite features extracted from all parallel branches are concatenated and fused using a 1 × 1 convolutional layer.
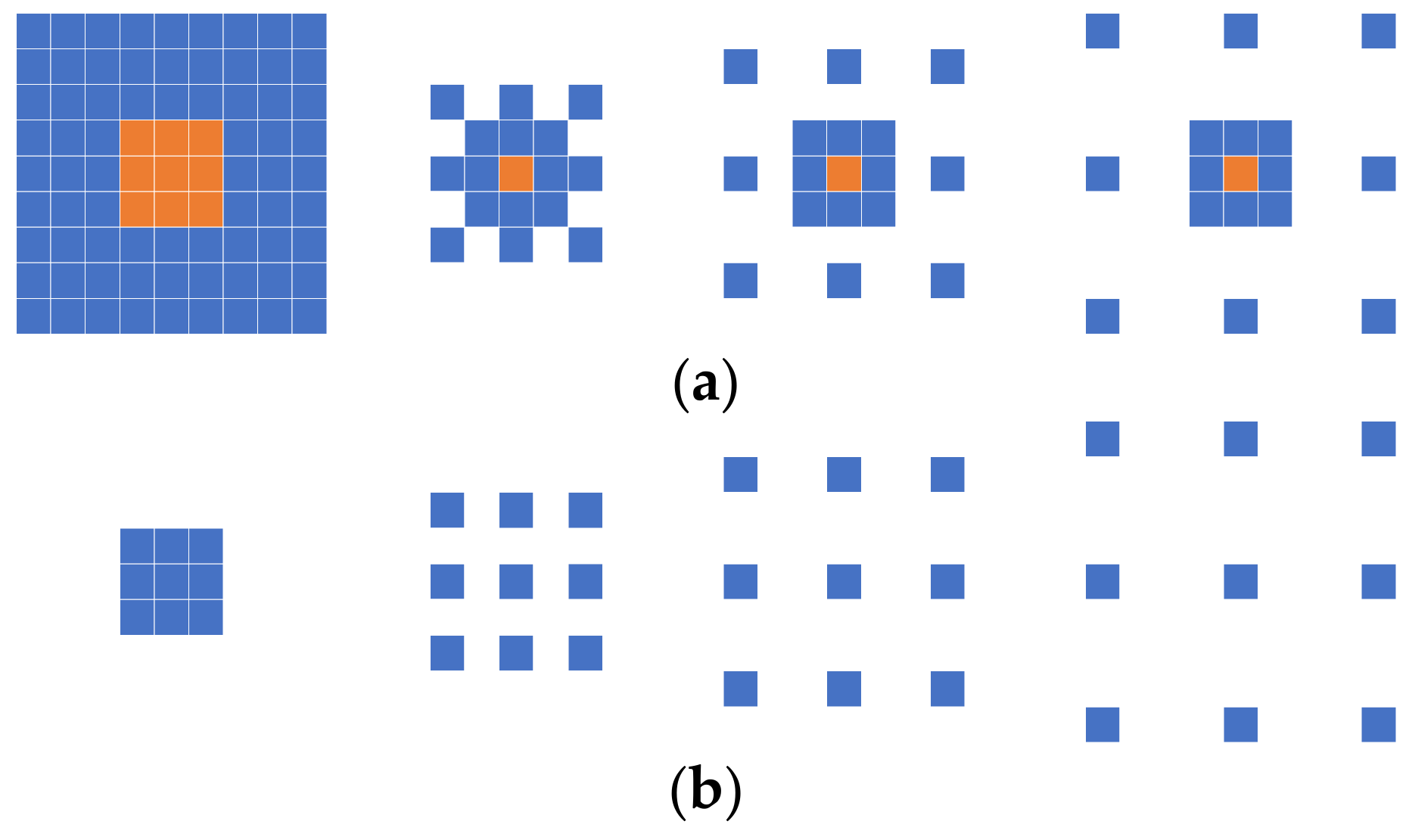
The numerical superposition of the features extracted on the two small branches is equivalent to the convolutional operation of the input image with a composite convolutional kernel. The structure of the composite convolutional kernel in the MLRB is depicted in
Figure 7, whereby we set a basic 3 × 3 convolution in each parallel branch, and each parallel branch is paired with a large-kernel convolution of varying sizes, with a 9 × 9 convolution on the leftmost side and an expansion on the right side, representing a dilated convolution with factors of 2, 3, and 4. Yellow indicates the composite part of the two convolutional kernels.
The entire DSFAM can be defined as:
where
denotes the convolutional layer with a convolutional kernel size of
f ×
f,
n is the number of channels,
is the PReLU activation function,
denotes the MLRB blocks of the four levels in CRAB,
denotes the CRAB blocks of the four levels in DSFAM,
x denotes the input image of each level of CRAB, and
denotes the concatenate operation.
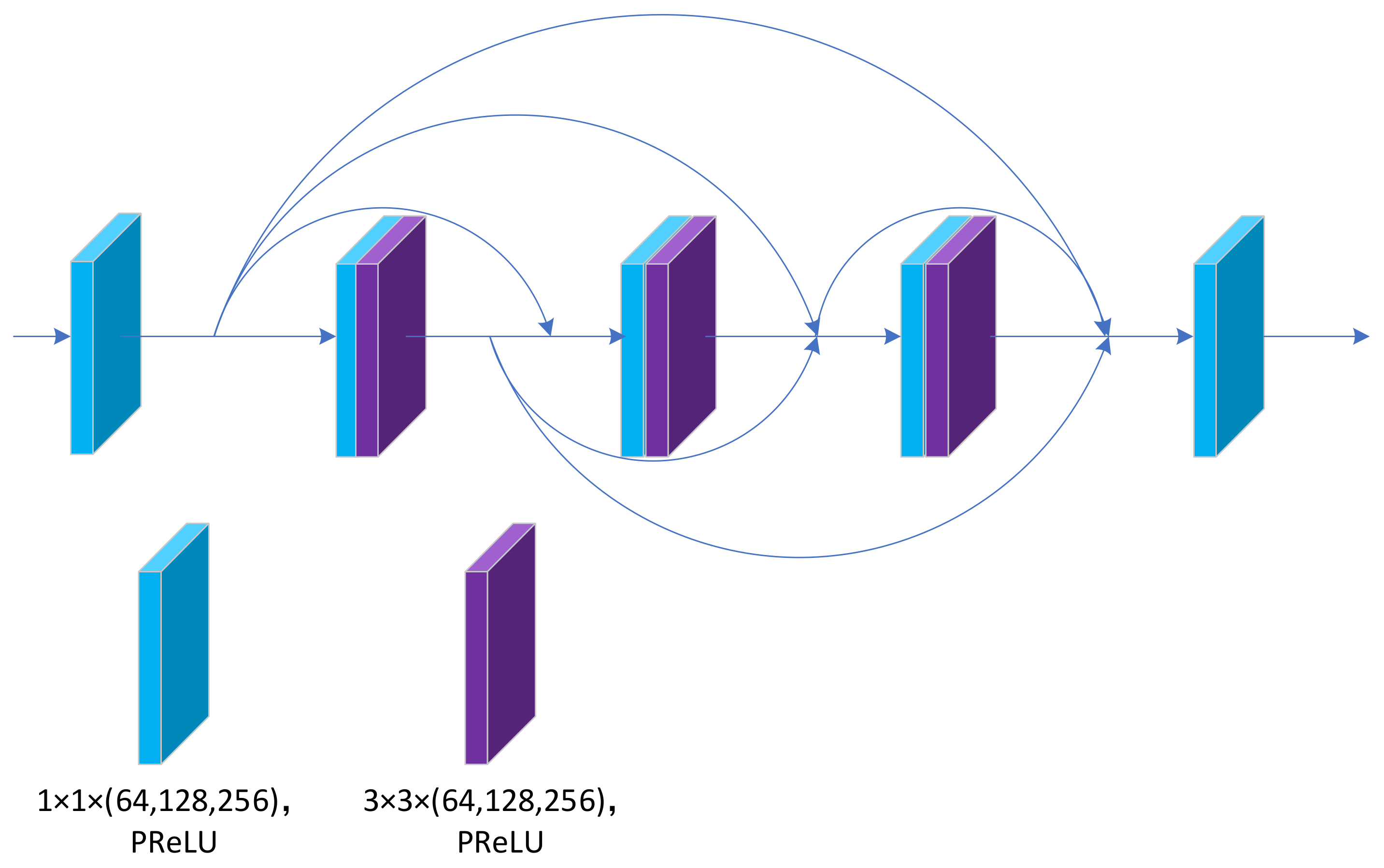
3.3. Fully Dense Fusion Block
To fully retain the feature information extracted from each layer and effectively fuse the features on different scales, we adopted a fully dense fusion (FDF) block. The specific structure of FDF is presented in
Figure 8. DenseNet was the first to employ the concept of dense connection, connecting each layer to all other layers in a feedforward manner, alleviating the gradient disappearance problem and enhancing feature propagation while reusing features. Many studies have employed the concept of dense connectivity, and pansharpening methods, such as TPNwFB and CPNet, have used dense connectivity and achieved good results.
We set up a 1 × 1 convolution at the beginning and end of the FDF to maintain the dimensionality. The basic component is a combination of 1 × 1 and 3 × 3 convolution. Considering the computational cost and experimental results, we set the number of basic components of the FDF to six. All convolutional layers of the FDF are followed by PReLU activation functions. In the framework design, the number of feature fusions at different levels is high, so the size of the FDF should not be too large. The main task of FDF is to perform the initial fusion of feature maps at different scales at the feature level to obtain improved and powerful features.
3.4. Feature-Travel Route
Fu et al. [
25] proposed a new pansharpening algorithm, TPNwFB, by combining the feedback connections in SR tasks. The TPNwFB implements the feedback mechanism by passing the deep features extracted in the previous time step to the same feature extraction block in the next time step. The deep features provide more information to the shallow features and continuously refine the shallow features to obtain powerful deep features.
Xu et al. [
27] extracted information from the LRMS image scale to make more use of the information on multiple scales of the input image. This method continuously passes the low-scale image information to the PAN image scale to progressively fuse PAN and MS images.
The feature-travel strategy is derived from feedback connections and progressive fusion. We also used images on three scales as input (PAN, middle, and MS scale) for the sake of description. The features first extracted at the PAN scale are cyclically fused with features extracted at other scales to enrich the missing multiscale feature information at the PAN scale. Specifically, the features extracted at the PAN scale are downsampled to the next scale for fusion as the prior information of the middle-scale features, and the process is cycled until the MS scale. After reaching the MS scale, the fused information is upsampled as a complement to the coarse-scale information in the previous layer and returns to the PAN scale. For each downsampling, the number of channels is twice as many as the original quantity. For each upsampling, the number of channels is half the original amount. The feature-travel strategy supplements the information on the three scales, reduces the details lost in the input image due to resampling, and improves the final reconstruction results.
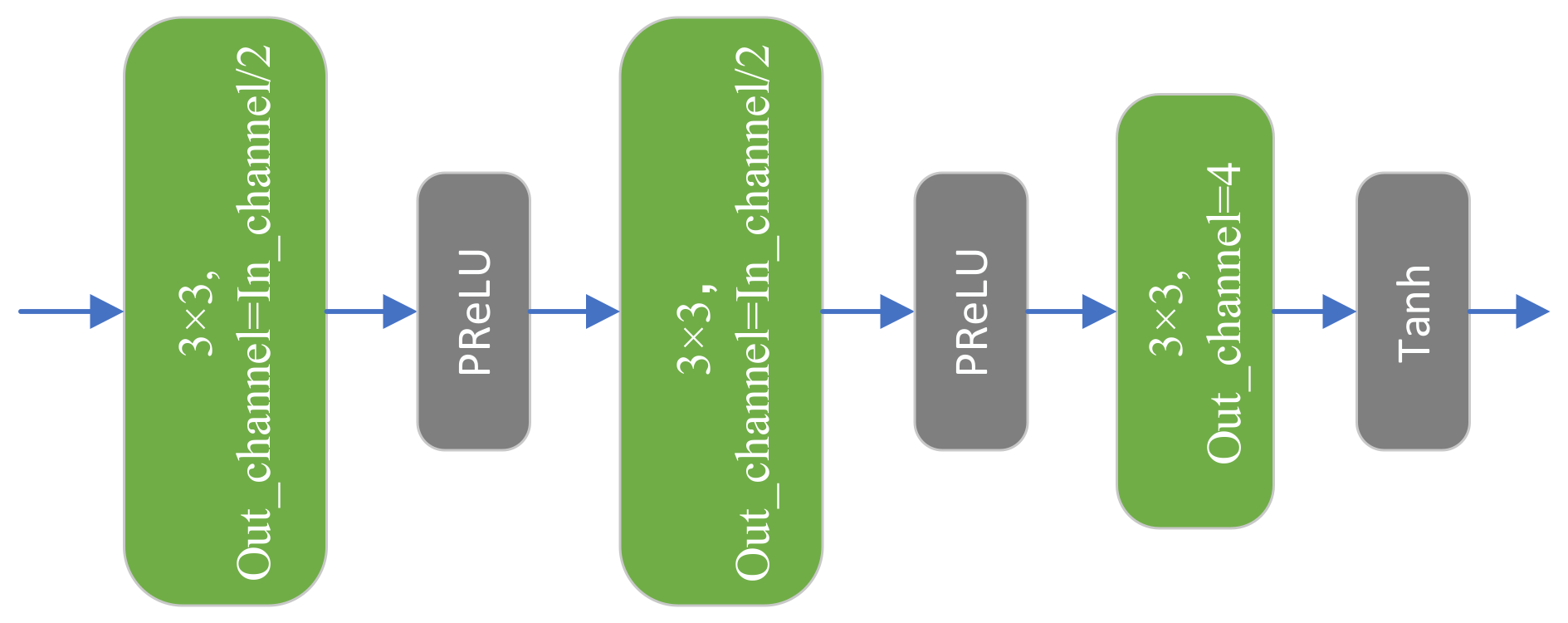
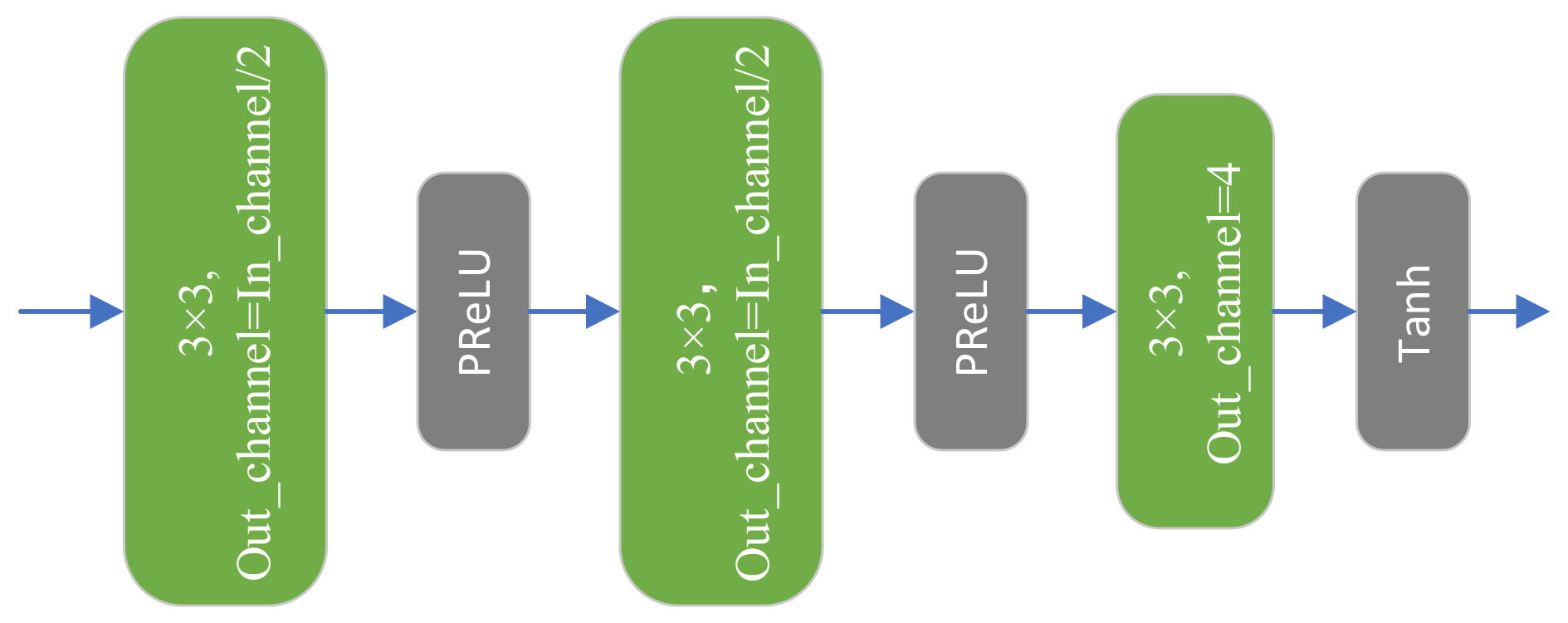
3.5. Reconstruction Block
For fused features, we used a three-layer reconstruction block for the final reconstruction task. The structure of the reconstruction block is presented in
Figure 9. We adopted a three-step strategy to consider the possible information loss problem of an excessively drastic channel dimension change during the reconstruction process. The number of channels output by each convolutional layer is half the input, and the number of channels output by the third convolutional layer is four, consistent with the number of channels of the LRMS image. Moreover, the activation function of the third convolutional layer is replaced with the tanh function to eliminate the effect of outliers. Combining the residual feature map and LRMS output from the reconstruction block provides required high-resolution multispectral (HRMS) image.
This process can be defined as:
The notation denotes the concatenate operation; denotes the convolutional layer; and f and n denote the convolutional kernel size and the number of channels, respectively. In Equation (9), In_channel represents the number of input channels; y represents the input image of the reconstruction block at each level; and and denote the tanh activation function and the PReLU activation function, respectively.
3.6. Loss Function
We chose the
loss function to optimise the network parameters. Because it squares the difference, the
function expands the influence of the outliers on network optimisation and obtains images that are usually smoother and have the potential for local minimisation problems. The
loss function is less sensitive to outliers and can obtain more edge information. Many studies and experimental results [
24,
41,
44] have demonstrated the superiority of the
function. We attached
loss functions to the network at each scale to ensure that feature travel is supplemented with valid multiscale feature information. We included three networks on the scales in one iteration, resulting in three sharpened images. The mathematical expression of the total loss function is as follows:
where
and
denote the ground truth images on the PAN scale and HRMS images output by the network on the PAN scale, respectively;
and
denote the ground-truth images on the middle scale and HRMS images output by the network on the middle scale, respectively;
and
denote the ground-truth images on the MS scale and HRMS images output by the network on the MS scale, respectively; and
N represents the number of samples in each training batch.
6. Conclusions
To efficiently preserve the spectral and spatial information of the input images, we propose a double-stack aggregation network using a feature-travel strategy for pansharpening. The method incorporates the concept of detail injection into the design of the overall framework to reduce the difficulty of network training using three pairs of source images at different scales as inputs to complement the information of the input images at these scales.
We designed a DSFAM to fully employ the features extracted at different levels and introduced a new multiscale large-kernel convolution block to expand the convolutional field of perception and extract effective features from finer levels. We propose a novel feature circulation strategy to circularly complement the features extracted at the three scales to more effectively use and complement the information from different image scales. The features at various levels are upsampled and downsampled for the initial fusion in the network at various scales, effectively linking the three scales and generating powerful fused features that improve the final image reconstruction results.
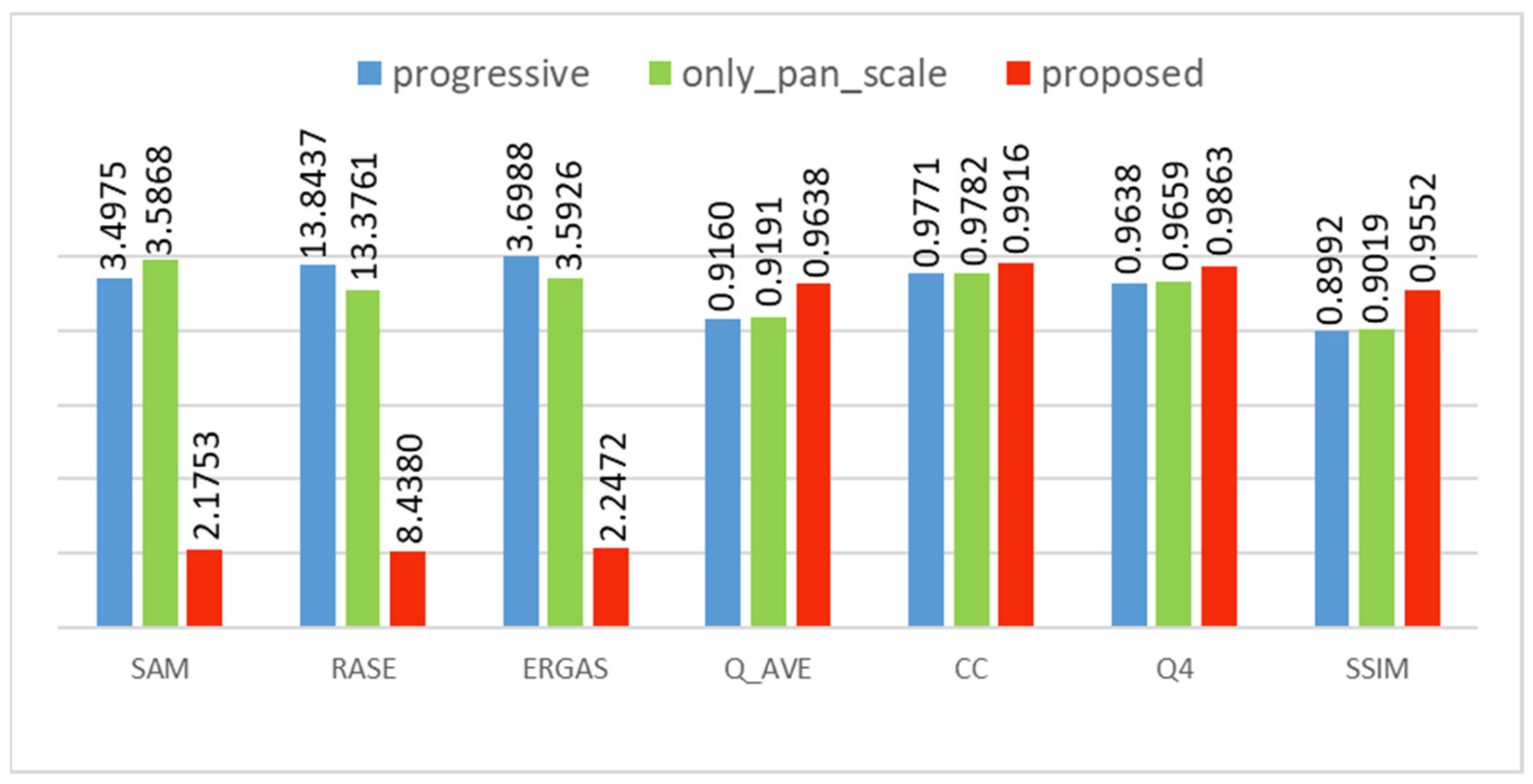
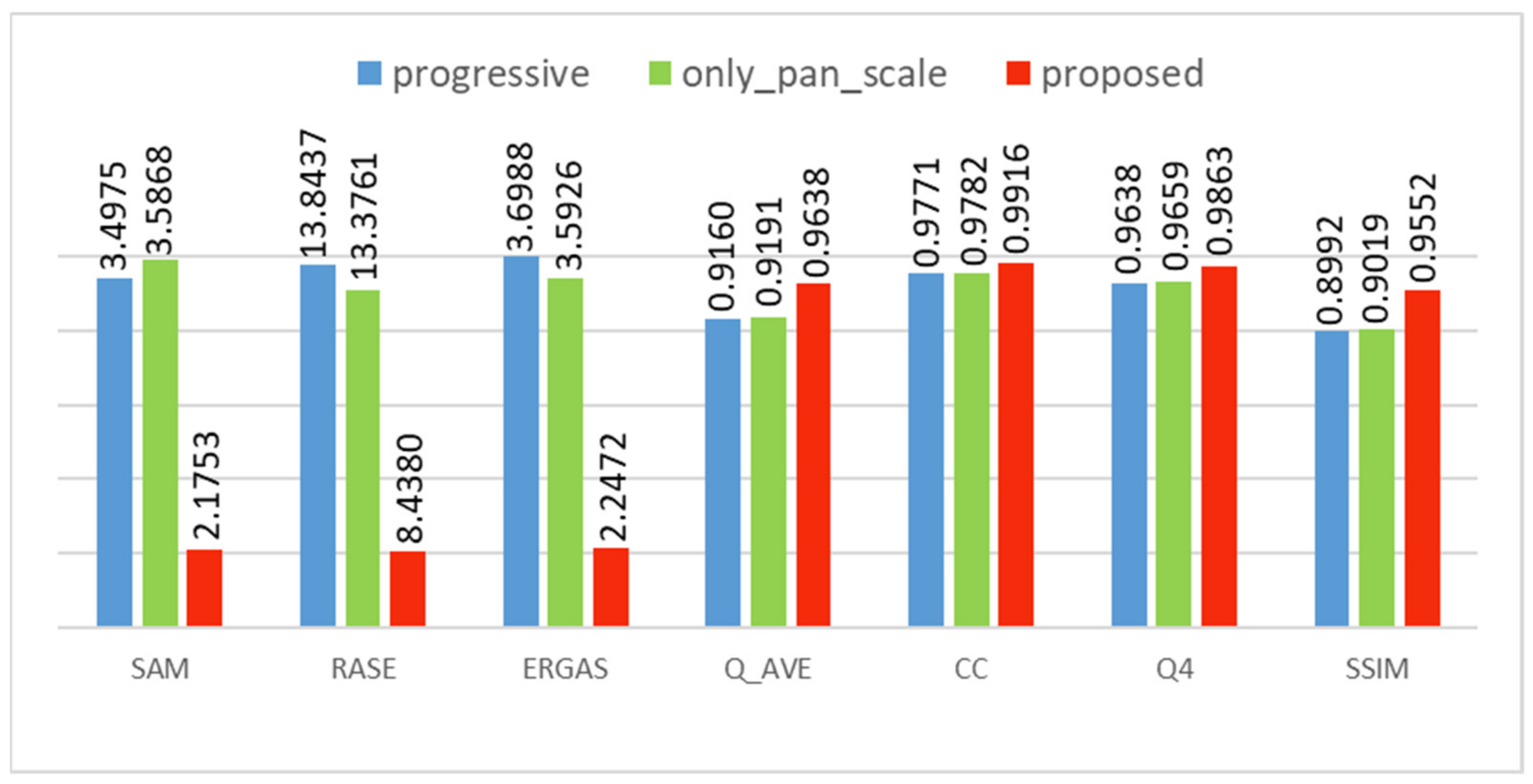
Extensive experiments and analyses on the WorldVIew-2, WorldVIew-3, and QuickBird datasets demonstrate that DFS-Net preserves the spectral and spatial information and obtains more detailed fusion results better than other methods, especially for the sections with a large amount of edge information, such as buildings, traffic paths, and vegetation. With respect to model efficiency, DFS-Net achieves better performance with lower cost than other comparative methods, improving the efficiency of existing algorithms and proving the potential value of the method.
The relatively small number of images used for training is one of the limitations of the present study due to the publicly available data used in our dataset. Furthermore, the number of parameters of our model, although less than some more recent methods, is still relatively large and has the potential impact the fusion performance. We will address these limitations in future research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}