


Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism


Abstract
:1. Introduction
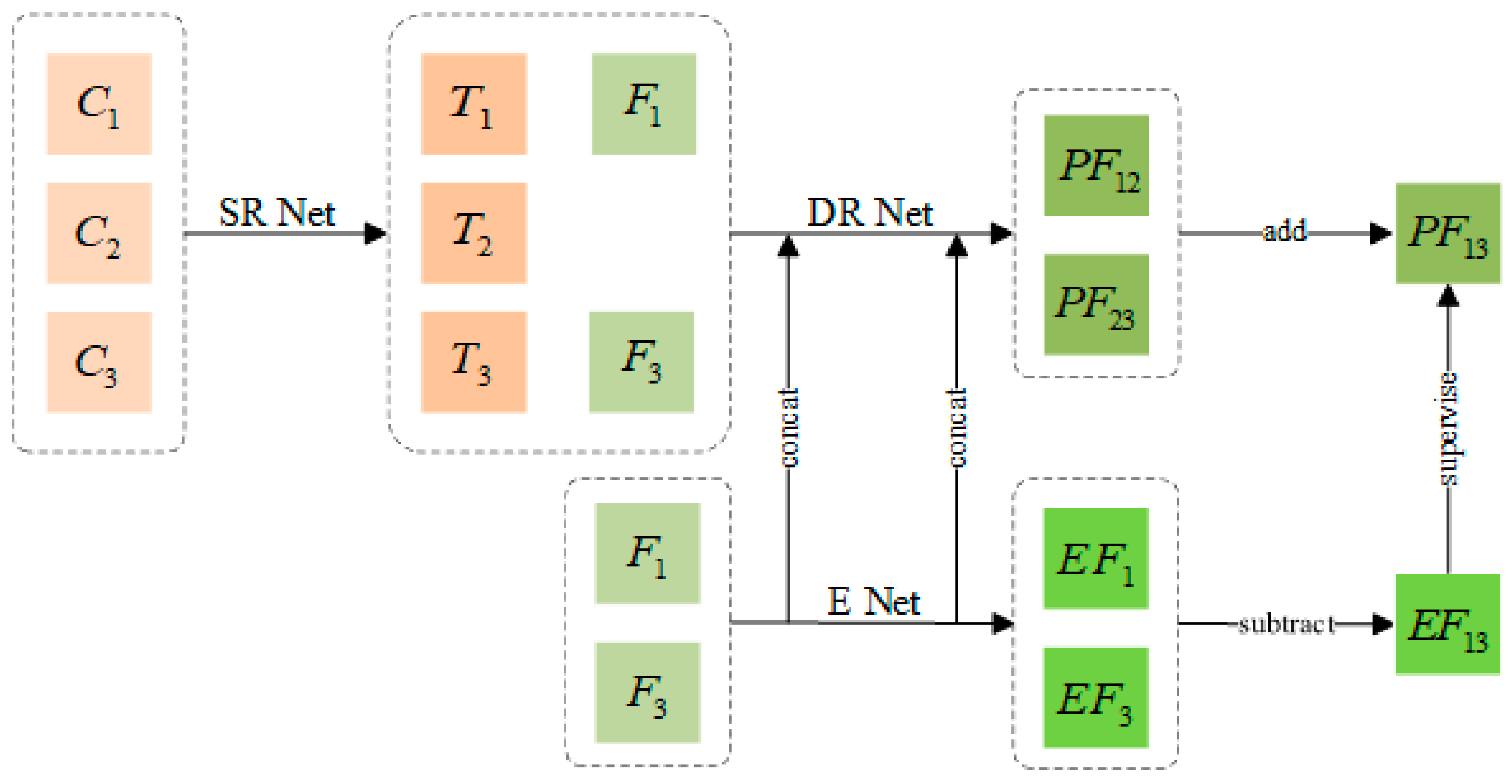
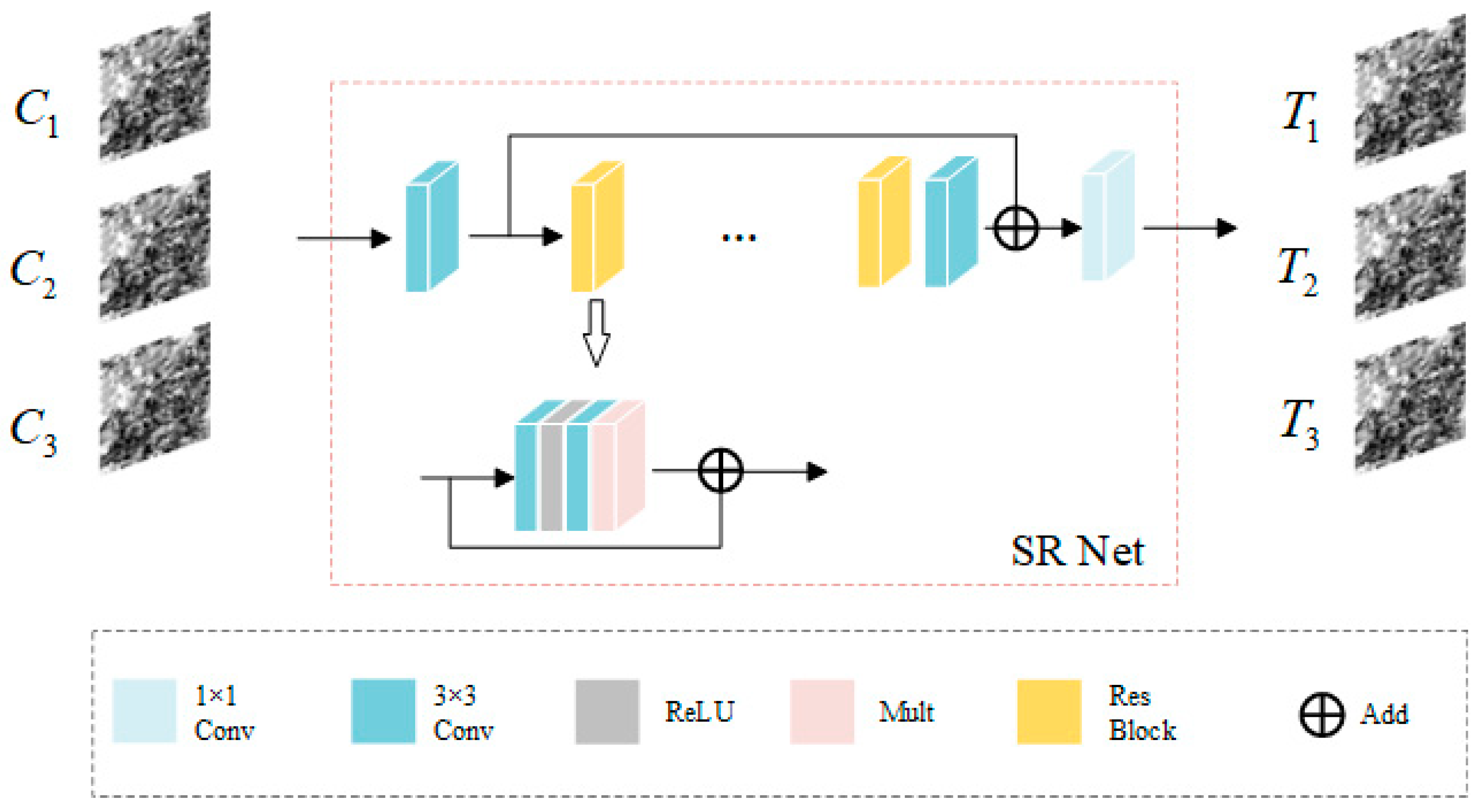
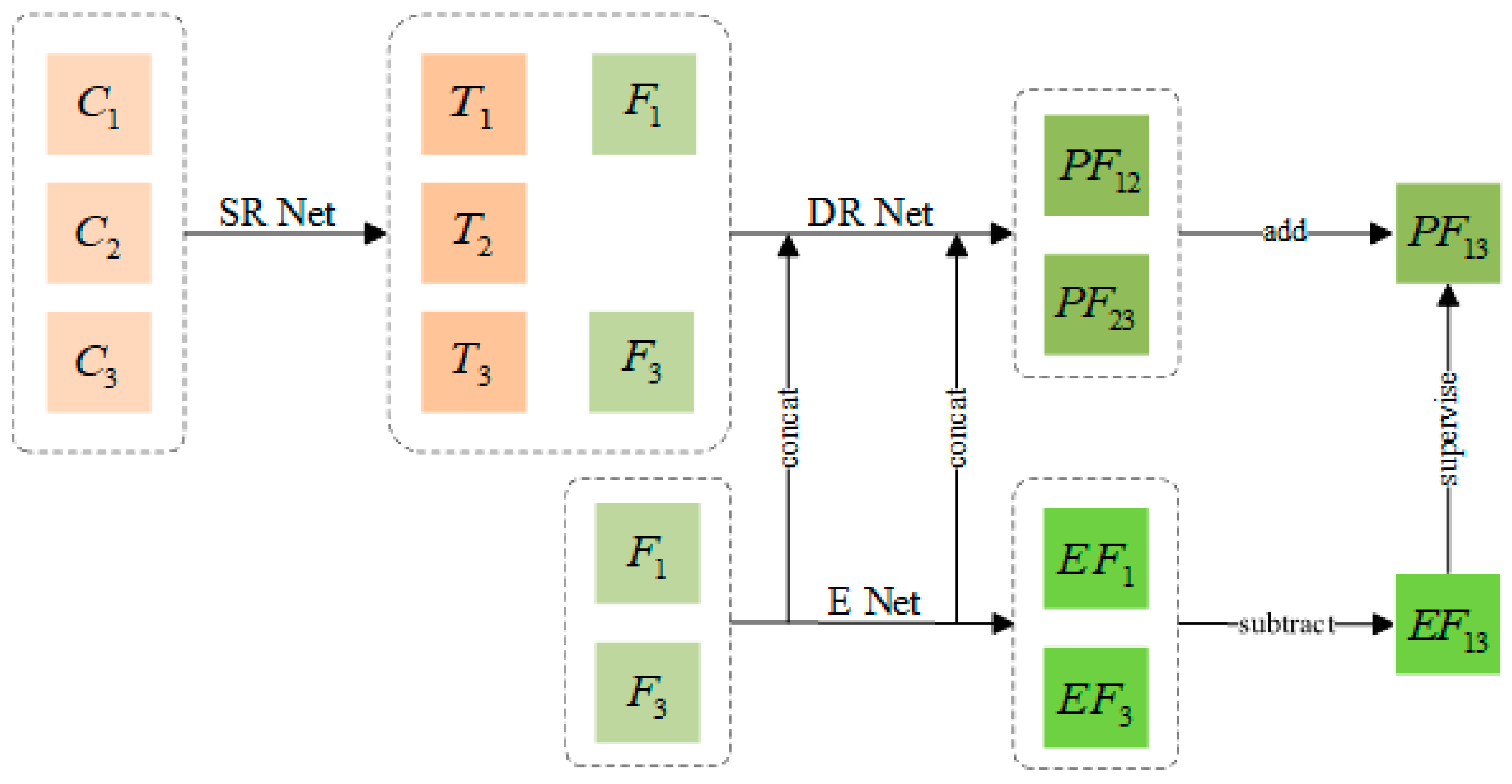
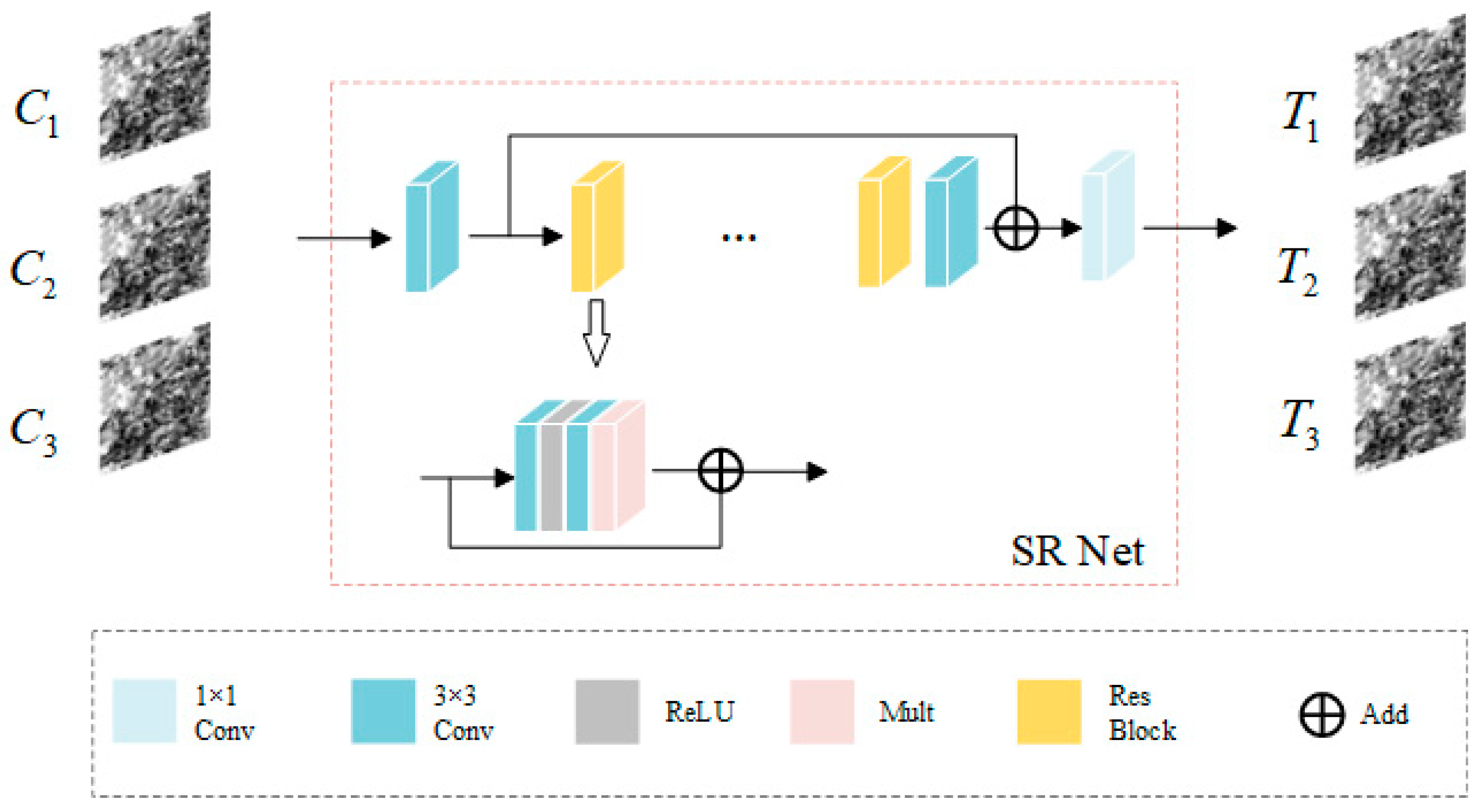
- It employs a super-resolution network (SR Net) to convert the coarse image into a transition image that matches the fine image, reducing the influence of the coarse image on the spatial details of the fusion result in subsequent reconstruction tasks.
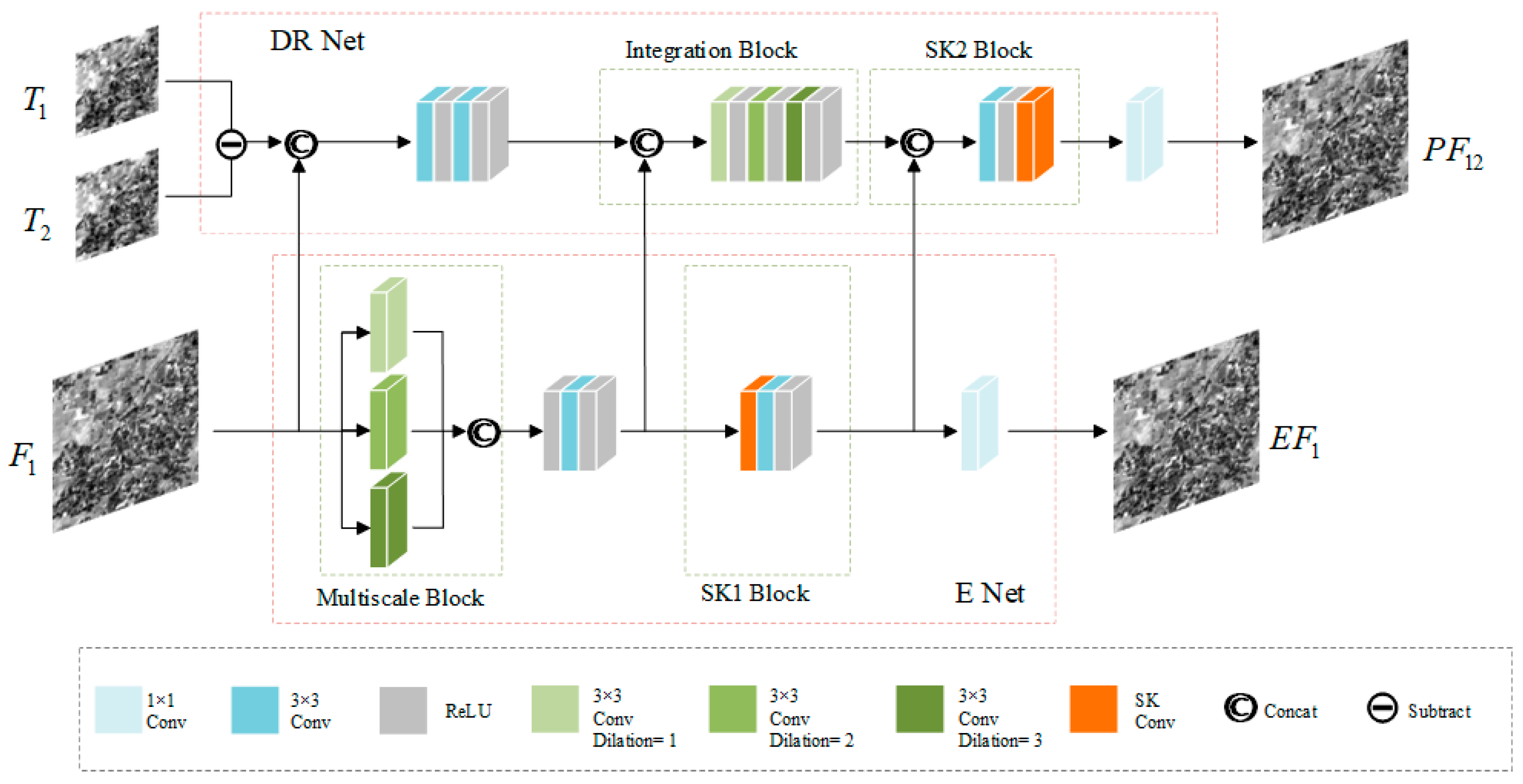
- It uses a separate branch to extract high-frequency features of fine images, as well as multi-scale extraction and convolution kernel adaptive mechanism extraction to retain the rich spatial and spectral information of fine images, so that accurate spatial details and spectral information can be fused later.
- The differential reconstruction network extracts the time change information in the image, integrates the high-frequency features from the fine-image extraction network, and finally, reconstructs the temporal and spatial information to obtain more accurate results.
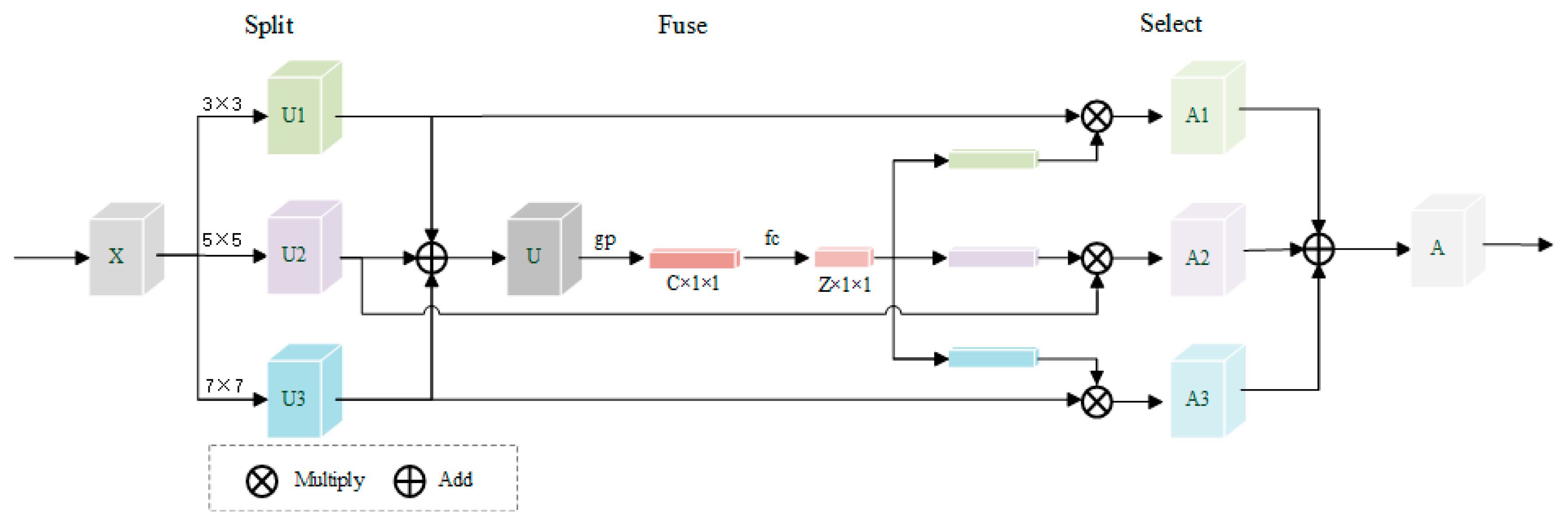
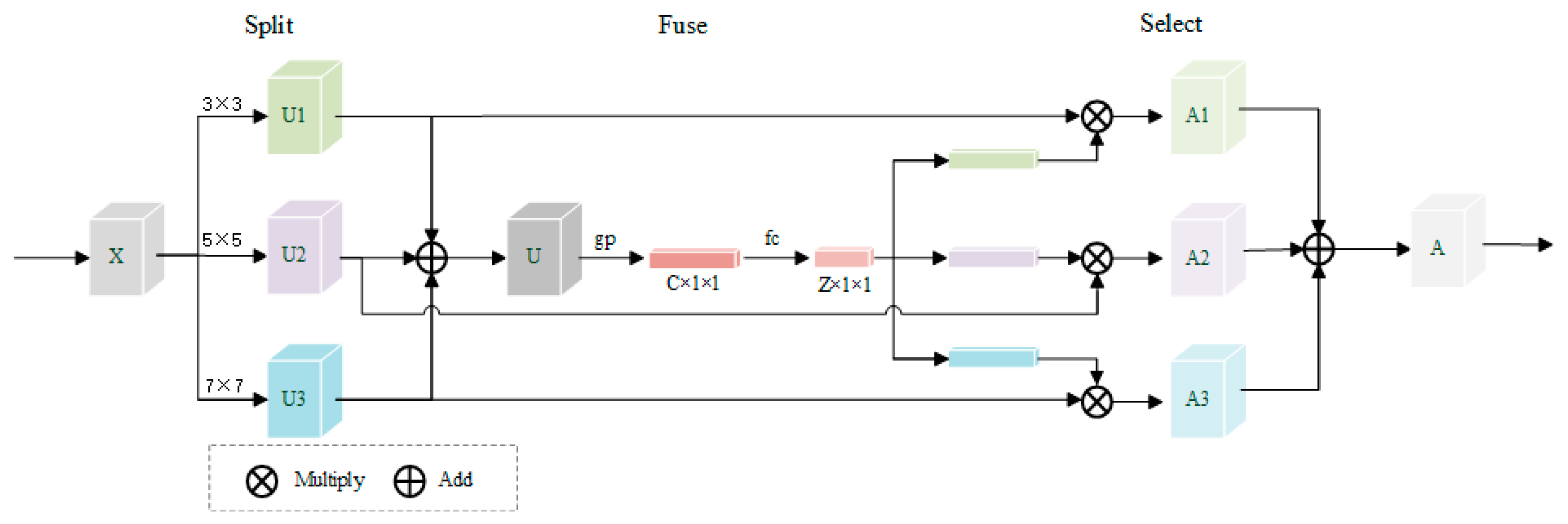
- The convolution kernel adaptive mechanism is introduced and the dynamic selection mechanism is used to allocate the size of the convolution kernel for diverse input data to increase the adaptive ability in the network.
- The compound loss function is used to help model training, retain the high-frequency information we need, and alleviate information loss caused by ℓ2 loss in the traditional reconstruction model.
2. Materials and Methods
2.1. Architecture
2.2. Super-Resolution Network
2.3. Difference Reconstruction and High-Frequency Feature Extraction Network
2.4. Select Kernel Convolution
2.5. Training and Prediction
3. Experimental Results and Analysis
3.1. Datasets
3.2. Parameter Setting
3.3. Evaluation
3.4. Analysis of Results
3.4.1. Subjective Evaluation
3.4.2. Objective Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, X.; Cai, F.; Tian, J.; Williams, T.K. Spatiotemporal Fusion of Multisource Remote Sensing Data: Literature Survey, Taxonomy, Principles, Applications, and Future Directions. Remote Sens. 2018, 10, 527. [Google Scholar] [CrossRef]
- Kumari, N.; Srivastava, A.; Dumka, U.C. A Long-Term Spatiotemporal Analysis of Vegetation Greenness over the Himalayan Region Using Google Earth Engine. Climate 2021, 9, 109. [Google Scholar] [CrossRef]
- Martín-Ortega, P.; García-Montero, L.G.; Sibelet, N. Temporal Patterns in Illumination Conditions and Its Effect on Vegetation Indices Using Landsat on Google Earth Engine. Remote Sens. 2020, 12, 211. [Google Scholar] [CrossRef]
- Schneider, A. Monitoring land cover change in urban and peri-urban areas using dense time stacks of Landsat satellite data and a data mining approach. Remote Sens. Environ. 2012, 124, 689–704. [Google Scholar] [CrossRef]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D.J.P.E.; Sensing, R. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Bjorgo, E. Using very high spatial resolution multispectral satellite sensor imagery to monitor refugee camps. Int. J. Remote Sens. 2000, 21, 611–616. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218–219, 74–84. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G.J.I.T.o.G.; Sensing, R. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Wu, M.; Niu, Z.; Wang, C.; Wu, C.; Wang, L.J.J.o.A.R.S. Use of MODIS and Landsat time series data to generate high-resolution temporal synthetic Landsat data using a spatial and temporal reflectance fusion model. J. Appl. Remote Sens. 2012, 6, 063507. [Google Scholar] [CrossRef]
- Wu, M.; Huang, W.; Niu, Z.; Wang, C. Generating Daily Synthetic Landsat Imagery by Combining Landsat and MODIS Data. Sensors 2015, 15, 24002–24025. [Google Scholar] [CrossRef] [Green Version]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G.J.R.S.o.E. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Wu, L.; Zou, X.; Jiang, T.; Zhao, B. A Modified Spatiotemporal Fusion Algorithm Using Phenological Information for Predicting Reflectance of Paddy Rice in Southern China. Remote Sens. 2018, 10, 772. [Google Scholar] [CrossRef]
- Cheng, Q.; Liu, H.; Shen, H.; Wu, P.; Zhang, L. A Spatial and Temporal Nonlocal Filter-Based Data Fusion Method. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4476–4488. [Google Scholar] [CrossRef]
- Wang, J.; Huang, B. A Rigorously-Weighted Spatiotemporal Fusion Model with Uncertainty Analysis. Remote Sens. 2017, 9, 990. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. A Bayesian Data Fusion Approach to Spatio-Temporal Fusion of Remotely Sensed Images. Remote Sens. 2017, 9, 1310. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. An Unmixing-Based Bayesian Model for Spatio-Temporal Satellite Image Fusion in Heterogeneous Landscapes. Remote Sens. 2019, 11, 324. [Google Scholar] [CrossRef]
- He, C.; Zhang, Z.; Xiong, D.; Du, J.; Liao, M. Spatio-Temporal Series Remote Sensing Image Prediction Based on Multi-Dictionary Bayesian Fusion. ISPRS Int. J. Geo-Inf. 2017, 6, 374. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A.J.R.S.o.E. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Liu, M.; Yang, W.; Zhu, X.; Chen, J.; Chen, X.; Yang, L.; Helmer, E.H. An Improved Flexible Spatiotemporal DAta Fusion (IFSDAF) method for producing high spatiotemporal resolution normalized difference vegetation index time series. Remote Sens. Environ. 2019, 227, 74–89. [Google Scholar] [CrossRef]
- Gevaert, C.M.; García-Haro, F.J. A comparison of STARFM and an unmixing-based algorithm for Landsat and MODIS data fusion. Remote Sens. Environ. 2015, 156, 34–44. [Google Scholar] [CrossRef]
- Huang, B.; Song, H.J.I.T.o.G.; Sensing, R. Spatiotemporal reflectance fusion via sparse representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Wang, S.; Huang, G.-B.; Zhao, B.; Lauren, P.J.I.G.; Letters, R.S. Fast and accurate spatiotemporal fusion based upon extreme learning machine. IEEE Geosci. Remote Sens. Lett. 2016, 13, 2039–2043. [Google Scholar] [CrossRef]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B.J.I.J.o.S.T.i.A.E.O.; Sensing, R. Spatiotemporal satellite image fusion using deep convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Chanussot, J.; Hong, D.; Zhao, B.J.I.T.o.G.; Sensing, R. StfNet: A two-stream convolutional neural network for spatiotemporal image fusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6552–6564. [Google Scholar] [CrossRef]
- Tan, Z.; Yue, P.; Di, L.; Tang, J.J.R.S. Deriving high spatiotemporal remote sensing images using deep convolutional network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]
- Tan, Z.; Di, L.; Zhang, M.; Guo, L.; Gao, M.J.R.S. An enhanced deep convolutional model for spatiotemporal image fusion. Remote Sens. 2019, 11, 2898. [Google Scholar] [CrossRef]
- Yin, Z.; Wu, P.; Foody, G.M.; Wu, Y.; Liu, Z.; Du, Y.; Ling, F.J.I.T.o.G.; Sensing, R. Spatiotemporal fusion of land surface temperature based on a convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1808–1822. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, K.; Ge, Y.; Zhou, Y. Spatiotemporal Remote Sensing Image Fusion Using Multiscale Two-Stream Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2021, 60, 9116. [Google Scholar] [CrossRef]
- Jia, D.; Song, C.; Cheng, C.; Shen, S.; Ning, L.; Hui, C. A Novel Deep Learning-Based Spatiotemporal Fusion Method for Combining Satellite Images with Different Resolutions Using a Two-Stream Convolutional Neural Network. Remote Sens. 2020, 12, 698. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wang, L.; Feng, R.; Liu, P.; Han, W.; Chen, X.J.I.T.o.G.; Sensing, R. CycleGAN-STF: Spatiotemporal fusion via CycleGAN-based image generation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5851–5865. [Google Scholar] [CrossRef]
- Tan, Z.; Gao, M.; Li, X.; Jiang, L. A Flexible Reference-Insensitive Spatiotemporal Fusion Model for Remote Sensing Images Using Conditional Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5601413. [Google Scholar] [CrossRef]
- Chen, G.; Jiao, P.; Hu, Q.; Xiao, L.; Ye, Z. SwinSTFM: Remote Sensing Spatiotemporal Fusion Using Swin Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410618. [Google Scholar] [CrossRef]
- Yang, G.; Qian, Y.; Liu, H.; Tang, B.; Qi, R.; Lu, Y.; Geng, J. MSFusion: Multistage for Remote Sensing Image Spatiotemporal Fusion Based on Texture Transformer and Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4653–4666. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Yuan, Q.; Zhang, L.; Shen, H. Hyperspectral Image Denoising With a Spatial–Spectral View Fusion Strategy. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2314–2325. [Google Scholar] [CrossRef]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss Functions for Image Restoration With Neural Networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Wu, B.; Duan, H.; Liu, Z.; Sun, G. SRPGAN: Perceptual generative adversarial network for single image super resolution. arXiv 2017, arXiv:1712.05927. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar]
- Emelyanova, I.V.; McVicar, T.R.; Van Niel, T.G.; Li, L.T.; Van Dijk, A.I.J.R.S.o.E. Assessing the accuracy of blending Landsat–MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; He, L.; Chen, J.; Plaza, A. Spatio-temporal fusion for remote sensing data: An overview and new benchmark. Sci. China Inf. Sci. 2020, 63, 140301. [Google Scholar] [CrossRef] [Green Version]
- Ponomarenko, N.; Ieremeiev, O.; Lukin, V.; Egiazarian, K.; Carli, M. Modified image visual quality metrics for contrast change and mean shift accounting. In Proceedings of the 2011 11th International Conference the Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), Polyana, Ukraine, 23–25 February 2011; pp. 305–311. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the Summaries 3rd Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992; pp. 147–149. [Google Scholar]
- Wald, L. Quality of high resolution synthesised images: Is there a simple criterion? In Proceedings of the Third Conference “Fusion of Earth Data: Merging Point Measurements, Raster Maps and Remotely Sensed Images”, Sophia Antipolis, France, 26–28 January 2000; pp. 99–103. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation | Band | Method | |||||
|---|---|---|---|---|---|---|---|
| STARFM | FSDAF | STFDCNN | StfNet | DCSTFN | Proposed | ||
| SAM | All | 0.17773 | 0.17796 | 0.16970 | 0.20599 | 0.17169 | 0.15714 |
| ERGAS | All | 2.76449 | 2.78928 | 2.71419 | 2.92699 | 2.72558 | 2.58776 |
| RMSE | Band1 | 0.01060 | 0.01099 | 0.00922 | 0.01250 | 0.01167 | 0.00756 |
| Band2 | 0.01169 | 0.01147 | 0.01013 | 0.01400 | 0.01169 | 0.01015 | |
| Band3 | 0.01708 | 0.01717 | 0.01605 | 0.02100 | 0.01661 | 0.01479 | |
| Band4 | 0.03415 | 0.03361 | 0.03486 | 0.04702 | 0.03078 | 0.03044 | |
| Band5 | 0.04454 | 0.04446 | 0.04414 | 0.04825 | 0.04343 | 0.04014 | |
| Band6 | 0.03639 | 0.03701 | 0.03680 | 0.04147 | 0.03398 | 0.03254 | |
| Average | 0.02574 | 0.02578 | 0.02520 | 0.03071 | 0.02469 | 0.02260 | |
| SSIM | Band1 | 0.94446 | 0.94522 | 0.95646 | 0.92610 | 0.94065 | 0.96267 |
| Band2 | 0.94504 | 0.94562 | 0.95411 | 0.93449 | 0.95058 | 0.95276 | |
| Band3 | 0.90046 | 0.90324 | 0.91601 | 0.88019 | 0.91294 | 0.92034 | |
| Band4 | 0.83292 | 0.84501 | 0.84645 | 0.79357 | 0.86850 | 0.85352 | |
| Band5 | 0.75389 | 0.76793 | 0.79580 | 0.73001 | 0.78953 | 0.77570 | |
| Band6 | 0.76974 | 0.77987 | 0.80288 | 0.72146 | 0.81009 | 0.79169 | |
| Average | 0.85775 | 0.86448 | 0.87862 | 0.83097 | 0.87872 | 0.87611 | |
| PSNR | Band1 | 39.49289 | 39.18375 | 40.70839 | 38.05897 | 38.65891 | 42.42943 |
| Band2 | 38.64465 | 38.80677 | 39.88719 | 37.07460 | 38.64650 | 39.87324 | |
| Band3 | 35.35086 | 35.30671 | 35.88878 | 33.55746 | 35.59164 | 36.60185 | |
| Band4 | 29.33261 | 29.46934 | 29.15324 | 26.55465 | 30.23396 | 30.33128 | |
| Band5 | 27.02466 | 27.04079 | 27.10341 | 26.33000 | 27.24463 | 27.92780 | |
| Band6 | 28.78060 | 28.63450 | 28.68286 | 27.64585 | 29.37578 | 29.75288 | |
| Average | 33.10438 | 33.07364 | 33.57064 | 31.53692 | 33.29190 | 34.48608 | |
| CC | Band1 | 0.84797 | 0.85166 | 0.87150 | 0.83892 | 0.84408 | 0.88373 |
| Band2 | 0.86051 | 0.86298 | 0.88375 | 0.85984 | 0.85926 | 0.88500 | |
| Band3 | 0.87724 | 0.88376 | 0.89932 | 0.88710 | 0.88883 | 0.91565 | |
| Band4 | 0.90270 | 0.91596 | 0.89701 | 0.89356 | 0.92388 | 0.92215 | |
| Band5 | 0.90852 | 0.90987 | 0.91291 | 0.92691 | 0.91272 | 0.92950 | |
| Band6 | 0.90019 | 0.90056 | 0.90333 | 0.91261 | 0.91375 | 0.92361 | |
| Average | 0.88285 | 0.88747 | 0.89464 | 0.88649 | 0.89042 | 0.90994 | |
| Evaluation | Band | Method | |||||
|---|---|---|---|---|---|---|---|
| STARFM | FSDAF | STFDCNN | StfNet | DCSTFN | Proposed | ||
| SAM | All | 0.21608 | 0.22644 | 0.07604 | 0.09966 | 0.07663 | 0.06262 |
| ERGAS | All | 3.06300 | 3.11580 | 1.81731 | 2.15066 | 1.92113 | 1.65701 |
| RMSE | Band1 | 0.01816 | 0.01835 | 0.00756 | 0.00948 | 0.00810 | 0.00621 |
| Band2 | 0.02400 | 0.02482 | 0.00884 | 0.01168 | 0.00934 | 0.00751 | |
| Band3 | 0.03240 | 0.03393 | 0.01271 | 0.01924 | 0.01334 | 0.01044 | |
| Band4 | 0.05954 | 0.06296 | 0.02088 | 0.02632 | 0.02251 | 0.01647 | |
| Band5 | 0.05706 | 0.06015 | 0.01794 | 0.02791 | 0.02329 | 0.01597 | |
| Band6 | 0.05292 | 0.05618 | 0.01836 | 0.02436 | 0.01785 | 0.01435 | |
| Average | 0.04068 | 0.04273 | 0.01438 | 0.01983 | 0.01574 | 0.01182 | |
| SSIM | Band1 | 0.88757 | 0.88306 | 0.98149 | 0.96998 | 0.97727 | 0.98387 |
| Band2 | 0.83975 | 0.83085 | 0.97864 | 0.95998 | 0.97093 | 0.98036 | |
| Band3 | 0.75378 | 0.73770 | 0.96847 | 0.92825 | 0.95294 | 0.97187 | |
| Band4 | 0.70891 | 0.68867 | 0.96167 | 0.93502 | 0.93549 | 0.96624 | |
| Band5 | 0.56660 | 0.54751 | 0.95494 | 0.90262 | 0.91548 | 0.95579 | |
| Band6 | 0.55919 | 0.53974 | 0.95339 | 0.90927 | 0.92969 | 0.95761 | |
| Average | 0.71930 | 0.70459 | 0.96643 | 0.93419 | 0.94697 | 0.96929 | |
| PSNR | Band1 | 34.81672 | 34.72829 | 42.43257 | 40.46277 | 41.83117 | 44.13334 |
| Band2 | 32.39649 | 32.10473 | 41.06673 | 38.65453 | 40.59295 | 42.49178 | |
| Band3 | 29.78853 | 29.38800 | 37.91901 | 34.31618 | 37.49373 | 39.62743 | |
| Band4 | 24.50316 | 24.01911 | 33.60717 | 31.59294 | 32.95422 | 35.66724 | |
| Band5 | 24.87328 | 24.41488 | 34.92580 | 31.08614 | 32.65612 | 35.93563 | |
| Band6 | 25.52769 | 25.00774 | 34.72062 | 32.26731 | 34.96878 | 36.86193 | |
| Average | 28.65098 | 28.27712 | 37.44532 | 34.72998 | 36.74949 | 39.11956 | |
| CC | Band1 | 0.51162 | 0.50533 | 0.91488 | 0.90620 | 0.92672 | 0.94631 |
| Band2 | 0.45152 | 0.43692 | 0.92854 | 0.91441 | 0.92870 | 0.94757 | |
| Band3 | 0.56210 | 0.53789 | 0.93428 | 0.92169 | 0.93941 | 0.95581 | |
| Band4 | 0.58434 | 0.56634 | 0.95389 | 0.95879 | 0.95941 | 0.97616 | |
| Band5 | 0.69701 | 0.67371 | 0.97069 | 0.96333 | 0.95990 | 0.97726 | |
| Band6 | 0.68504 | 0.65781 | 0.96704 | 0.96466 | 0.96558 | 0.97899 | |
| Average | 0.58194 | 0.56300 | 0.94488 | 0.93818 | 0.94662 | 0.96368 | |
| Evaluation | Band | Method | |||||
|---|---|---|---|---|---|---|---|
| STARFM | FSDAF | STFDCNN | StfNet | DCSTFN | Proposed | ||
| SAM | All | 0.17599 | 0.14161 | 0.13987 | 0.20507 | 0.17760 | 0.11674 |
| ERGAS | All | 5.26776 | 5.31239 | 2.97269 | 3.83521 | 3.52752 | 2.52962 |
| RMSE | Band1 | 0.00034 | 0.00034 | 0.00081 | 0.00116 | 0.00155 | 0.00024 |
| Band2 | 0.00577 | 0.00588 | 0.00163 | 0.00275 | 0.00210 | 0.00156 | |
| Band3 | 0.00595 | 0.00610 | 0.00174 | 0.00280 | 0.00234 | 0.00153 | |
| Band4 | 0.00446 | 0.00455 | 0.00144 | 0.00260 | 0.00177 | 0.00139 | |
| Band5 | 0.00145 | 0.00097 | 0.00156 | 0.00239 | 0.00146 | 0.00138 | |
| Band6 | 0.00201 | 0.00105 | 0.00168 | 0.00219 | 0.00149 | 0.00147 | |
| Average | 0.00333 | 0.00315 | 0.00148 | 0.00232 | 0.00178 | 0.00126 | |
| SSIM | Band1 | 0.99931 | 0.99929 | 0.99458 | 0.98874 | 0.97982 | 0.99963 |
| Band2 | 0.86470 | 0.85765 | 0.99037 | 0.97664 | 0.98603 | 0.99057 | |
| Band3 | 0.86977 | 0.86011 | 0.98959 | 0.97450 | 0.98120 | 0.99179 | |
| Band4 | 0.94349 | 0.94068 | 0.99624 | 0.98461 | 0.99390 | 0.99641 | |
| Band5 | 0.99387 | 0.99673 | 0.98949 | 0.97616 | 0.99279 | 0.99235 | |
| Band6 | 0.98878 | 0.99532 | 0.98609 | 0.97613 | 0.99062 | 0.99199 | |
| Average | 0.94332 | 0.94163 | 0.99106 | 0.97946 | 0.98739 | 0.99379 | |
| PSNR | Band1 | 69.42295 | 69.42746 | 61.82981 | 58.67503 | 56.20781 | 72.37595 |
| Band2 | 44.77567 | 44.60654 | 55.73295 | 51.20813 | 53.56492 | 56.15748 | |
| Band3 | 44.51268 | 44.29919 | 55.18479 | 51.06624 | 52.61050 | 56.28335 | |
| Band4 | 47.01360 | 46.83312 | 56.83543 | 51.68850 | 55.03054 | 57.16858 | |
| Band5 | 56.77382 | 60.25078 | 56.12355 | 52.44044 | 56.73506 | 57.22576 | |
| Band6 | 53.94259 | 59.56925 | 55.47859 | 53.20197 | 56.51348 | 56.62752 | |
| Average | 52.74022 | 54.16439 | 56.86419 | 53.04672 | 55.11038 | 59.30644 | |
| CC | Band1 | 0.84204 | 0.86895 | 0.85005 | 0.33176 | 0.00119 | 0.91827 |
| Band2 | 0.86498 | 0.89428 | 0.91020 | 0.86735 | 0.87435 | 0.93430 | |
| Band3 | 0.82886 | 0.90540 | 0.91612 | 0.87905 | 0.86938 | 0.93661 | |
| Band4 | 0.79782 | 0.82082 | 0.78346 | 0.62491 | 0.71780 | 0.84136 | |
| Band5 | 0.79034 | 0.88965 | 0.90013 | 0.15037 | 0.82164 | 0.90385 | |
| Band6 | 0.66197 | 0.89047 | 0.85566 | 0.58300 | 0.81597 | 0.82653 | |
| Average | 0.79767 | 0.87826 | 0.86927 | 0.57274 | 0.68339 | 0.89349 | |
| Method | SAM | ERGAS | RMSE | SSIM | PSNR | CC |
|---|---|---|---|---|---|---|
| No-SK | 0.06410 | 1.68862 | 0.01226 | 0.96855 | 38.82388 | 0.96204 |
| No-ER | 0.06376 | 1.66948 | 0.01215 | 0.96908 | 38.92764 | 0.96221 |
| No-MB | 0.06279 | 1.67319 | 0.01224 | 0.96907 | 38.93710 | 0.96365 |
| No-FIB | 0.06379 | 1.66509 | 0.01192 | 0.96895 | 39.02248 | 0.96248 |
| L2-loss | 0.06555 | 1.70390 | 0.01293 | 0.96818 | 38.51485 | 0.96037 |
| Proposed | 0.06262 | 1.65701 | 0.01182 | 0.96929 | 39.11956 | 0.96368 |
| Data | Res Block | SAM | ERGAS | RMSE | SSIM | PSNR | CC |
|---|---|---|---|---|---|---|---|
| CIA | 4 | 0.15750 | 2.60573 | 0.02275 | 0.87700 | 34.26018 | 0.90863 |
| 8 | 0.15645 | 2.59462 | 0.02282 | 0.87602 | 34.26894 | 0.90995 | |
| 16 | 0.15714 | 2.58776 | 0.02260 | 0.87611 | 34.48608 | 0.90994 | |
| LGC | 4 | 0.06460 | 1.70334 | 0.01228 | 0.96870 | 38.71426 | 0.96079 |
| 8 | 0.06262 | 1.65701 | 0.01182 | 0.96929 | 39.11956 | 0.96368 | |
| 16 | 0.06247 | 1.71455 | 0.01213 | 0.96877 | 38.76080 | 0.96447 | |
| AHB | 4 | 0.11507 | 2.53645 | 0.00137 | 0.99215 | 58.64425 | 0.90601 |
| 8 | 0.11831 | 2.54526 | 0.00136 | 0.99218 | 59.11255 | 0.89589 | |
| 16 | 0.11674 | 2.52962 | 0.00126 | 0.99379 | 59.30644 | 0.89349 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Wu, F.; Cao, D. Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism. Remote Sens. 2022, 14, 4282. https://doi.org/10.3390/rs14174282
Li W, Wu F, Cao D. Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism. Remote Sensing. 2022; 14(17):4282. https://doi.org/10.3390/rs14174282
Chicago/Turabian StyleLi, Weisheng, Fengyan Wu, and Dongwen Cao. 2022. "Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism" Remote Sensing 14, no. 17: 4282. https://doi.org/10.3390/rs14174282
APA StyleLi, W., Wu, F., & Cao, D. (2022). Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism. Remote Sensing, 14(17), 4282. https://doi.org/10.3390/rs14174282