
Large Aerial Image Tie Point Matching in Real and Difficult Survey Areas via Deep Learning Method


Abstract
:
1. Introduction
1.1. Related Work
1.1.1. Hand-Crafted Image Matching
1.1.2. Learned Image Matching
1.2. Contributions
- (1)
- Overcome the shortcomings of traditional methods for poor texture and large images in real and difficult surveying area.The classic SIFT method has huge applications in teaching in schools and software in corporations, but poor texture image matching cannot be solved well by SIFT, especially, for multiple image tie points in a difficult survey area. Fortunately, deep learning approaches have shown great power in weak texture image matching, such as SuperGlue. So, the proposed LR-SuperGlue will outperforms SIFT.
- (2)
- Make the SuperGlue method from open and small images to practical applications for large image matching in real aerial photogrammetry. Given the proposed image matching method, other image matching methods via deep learning may go into photogrammetry. Finally, photogrammetry will develop from automation to intelligent, in the theory and practice.
2. Methodology
2.1. Workflow
- (1)
- Accurately calculate the overlap of input large stereo image through a certain feature matching algorithm (e.g., SIFT or SuperGlue in this paper).
- (2)
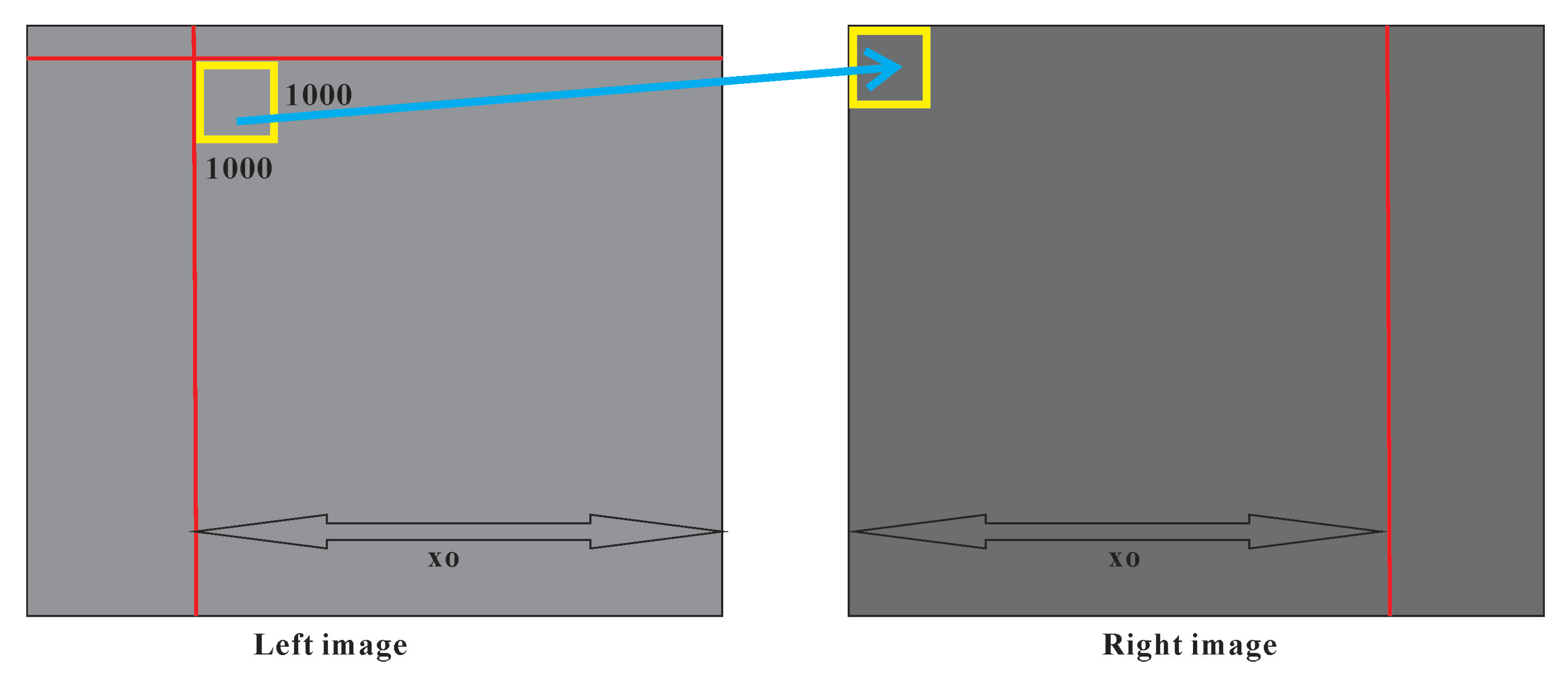
- Image blocking for large stereo image with block size 1000 × 1000 (if the GPU size is enough, the block size may be to 2000 × 2000) based on the overlap size in row (y) or column direction (x). If the images have invalid pixels in the image edge, image blocking should consider this situation.
- (3)
- Modify the default parameters of original SuperGlue (model test parameters not the trained model parameters). The specific parameters are the input image size and the window size of non-maximum suppression.
- (4)
- Perform block image matching with the improved SuperGlue. If the image gray contrast is poor, image enhancement processing can be performed.
- (5)
- Merge the block matching results and optimize the initial matching point with LSM for subpixel accuracy. The initial matching point may be processed with RANSAC (Random Sample Consensus) if needed.
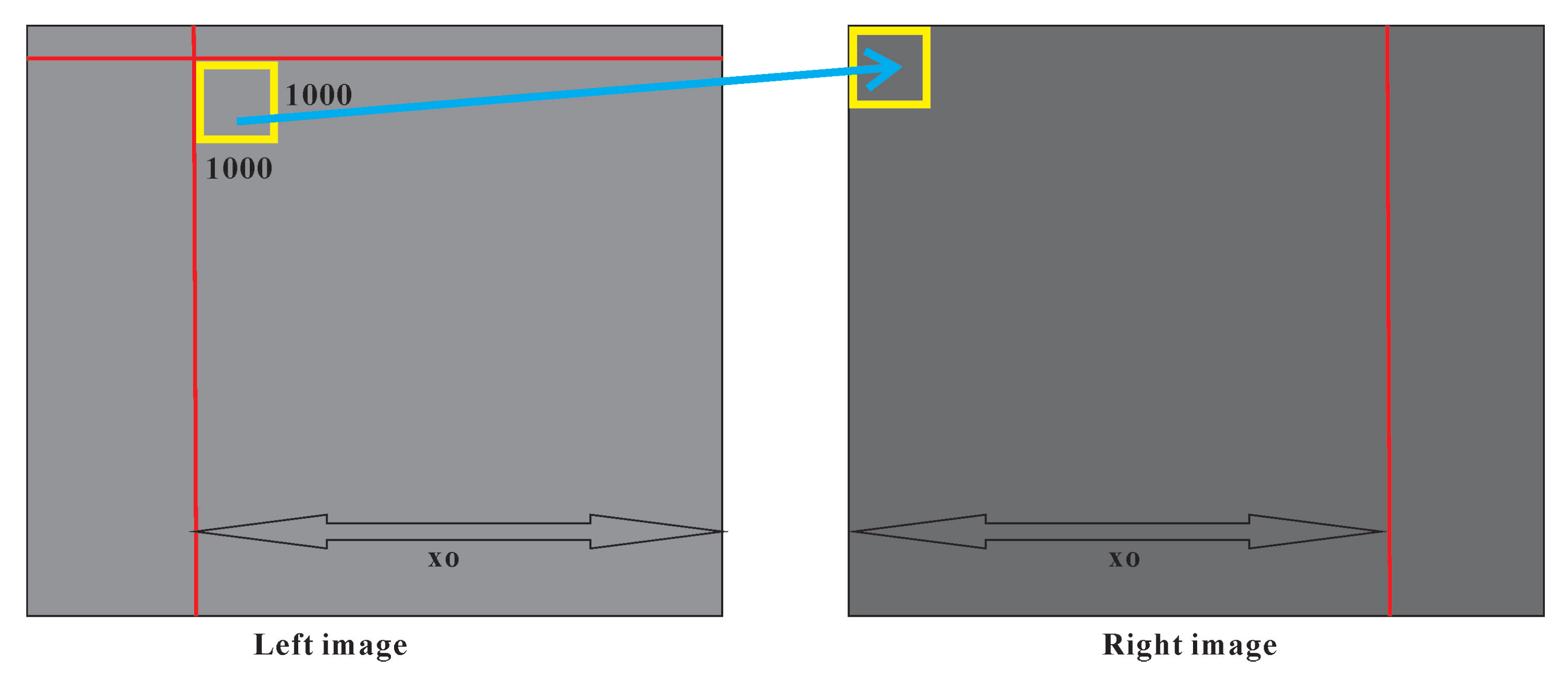
2.2. Accurately Calculate the Overlap and Start Matching Position
2.3. Image Blocking Based on Overlap
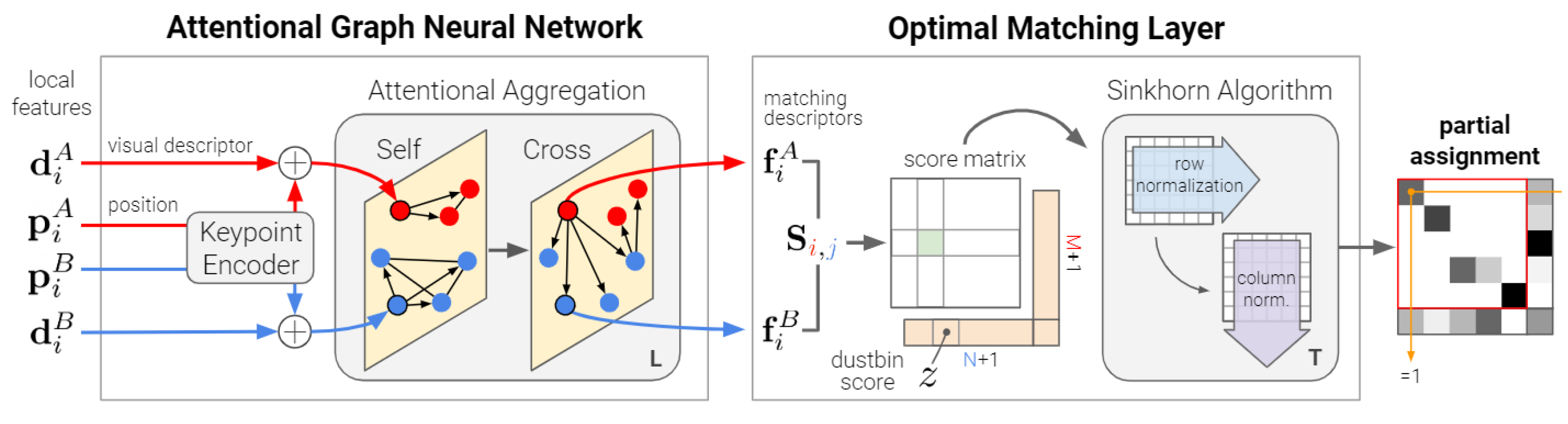
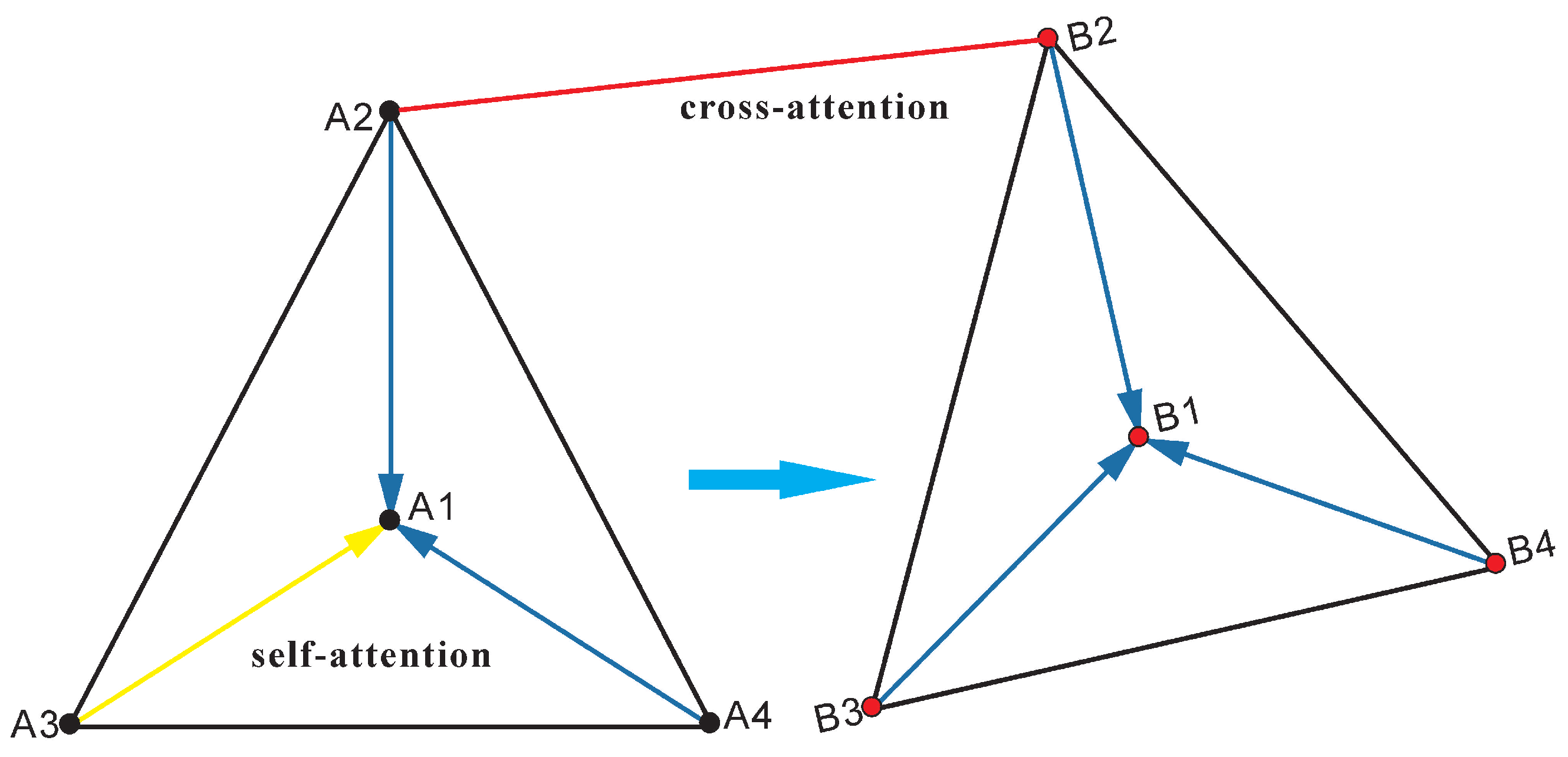
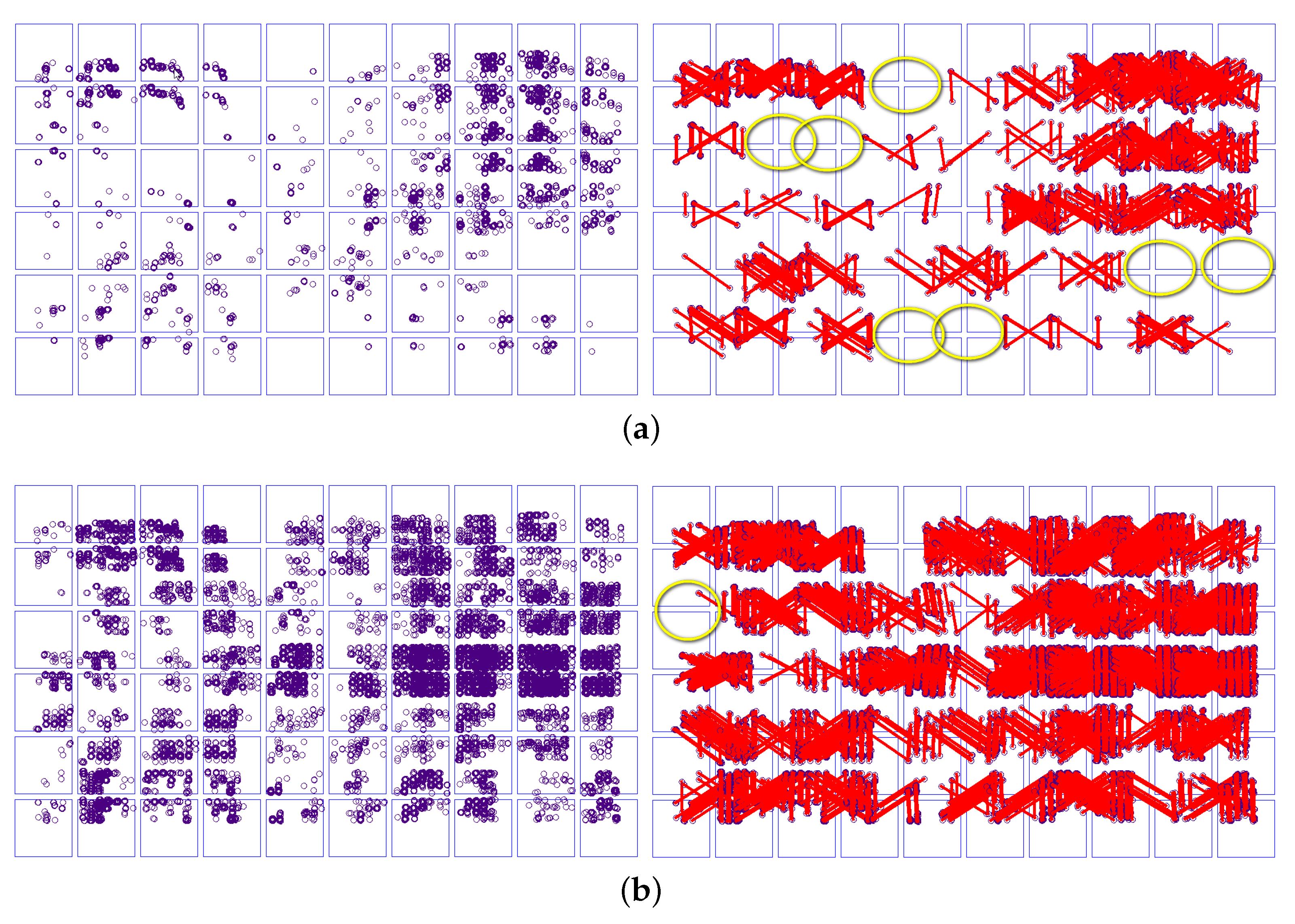
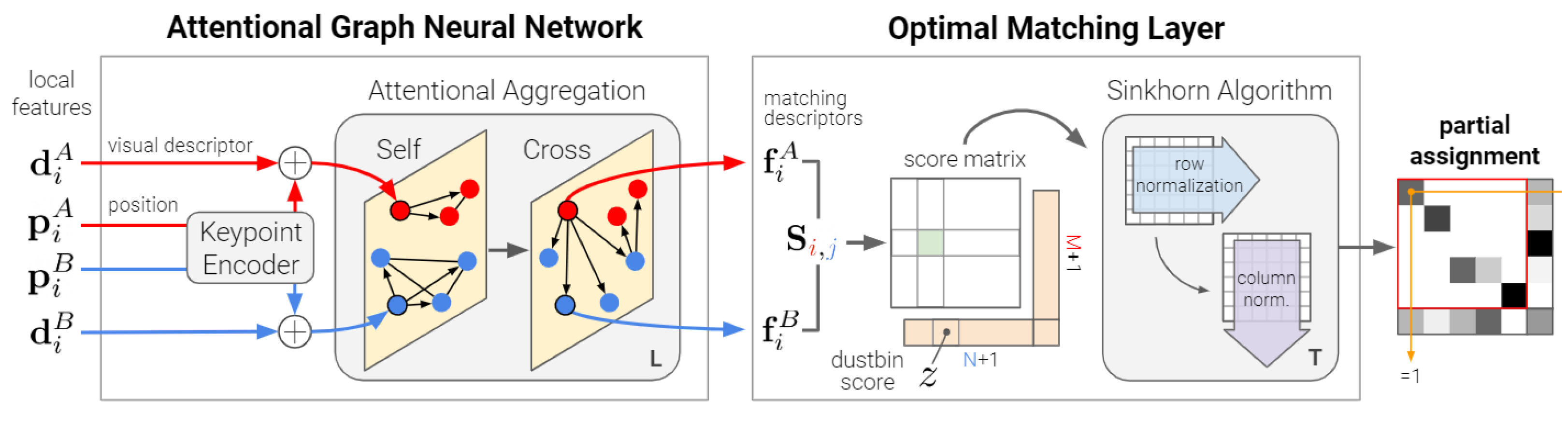
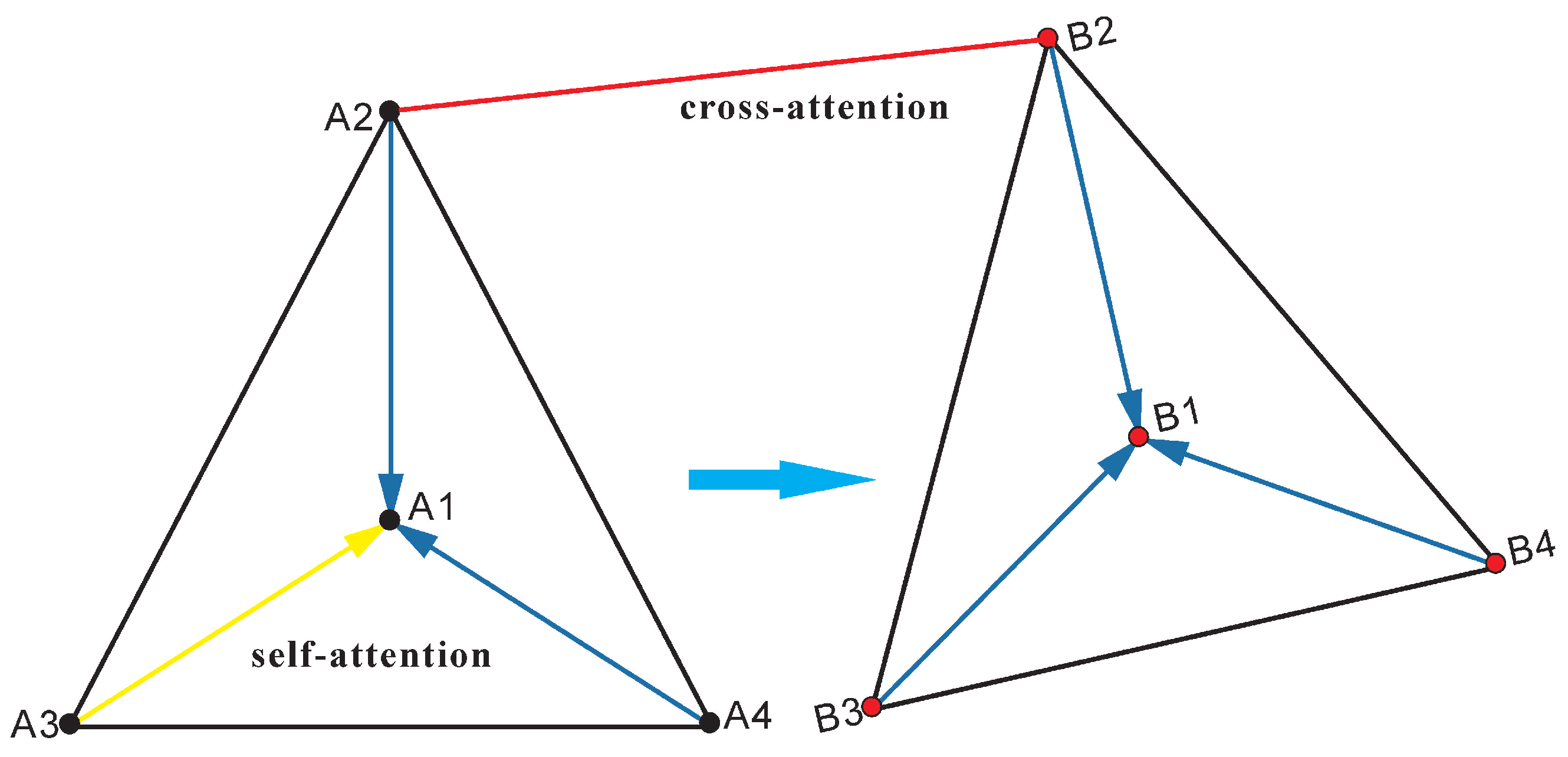
2.4. Superglue Matching after Image Blocking
2.5. Non-Maximum Suppression of Superglue Maching Points
2.6. Optimize Image Tie Points with RANSAC and LSM
| Algorithm 1 Large image matching in real surveying area | |
| Input: large images from forward and lateral direction | |
| Output: large image matching point sets | |
| 1: Pseudo-code: | |
| 2: //step1:calculate the overlap of two images | |
| 3: ; | |
| 4: for each do | |
| 5: if then | |
| 6: ; | |
| 7: end if | |
| 8: if then | |
| 9: ; | |
| 10: end if | |
| 11: end for | |
| 12: ; | |
| 13: //step2:image blocking based on overlap | |
| 14: if then | |
| 15: ; | |
| 16: ; | |
| 17: end if | |
| 18: if then | |
| 19: ; | |
| 20: ; | |
| 21: end if | |
| 22: //step3: block image matching with SuperGlue and NMS automatically | |
| 23: while do | |
| 24: do SuperGlue via Python | |
| 25: end while | |
| 26: ; | |
| 27: ; | |
| 28: ; | |
| 29: //step4:merge the block matching results | |
| 30: ; | |
| 31: //step5:optimize the initial matching point with LSM and RANSAC | |
| 32: ; |
3. Experiments and Results
3.1. Test Data
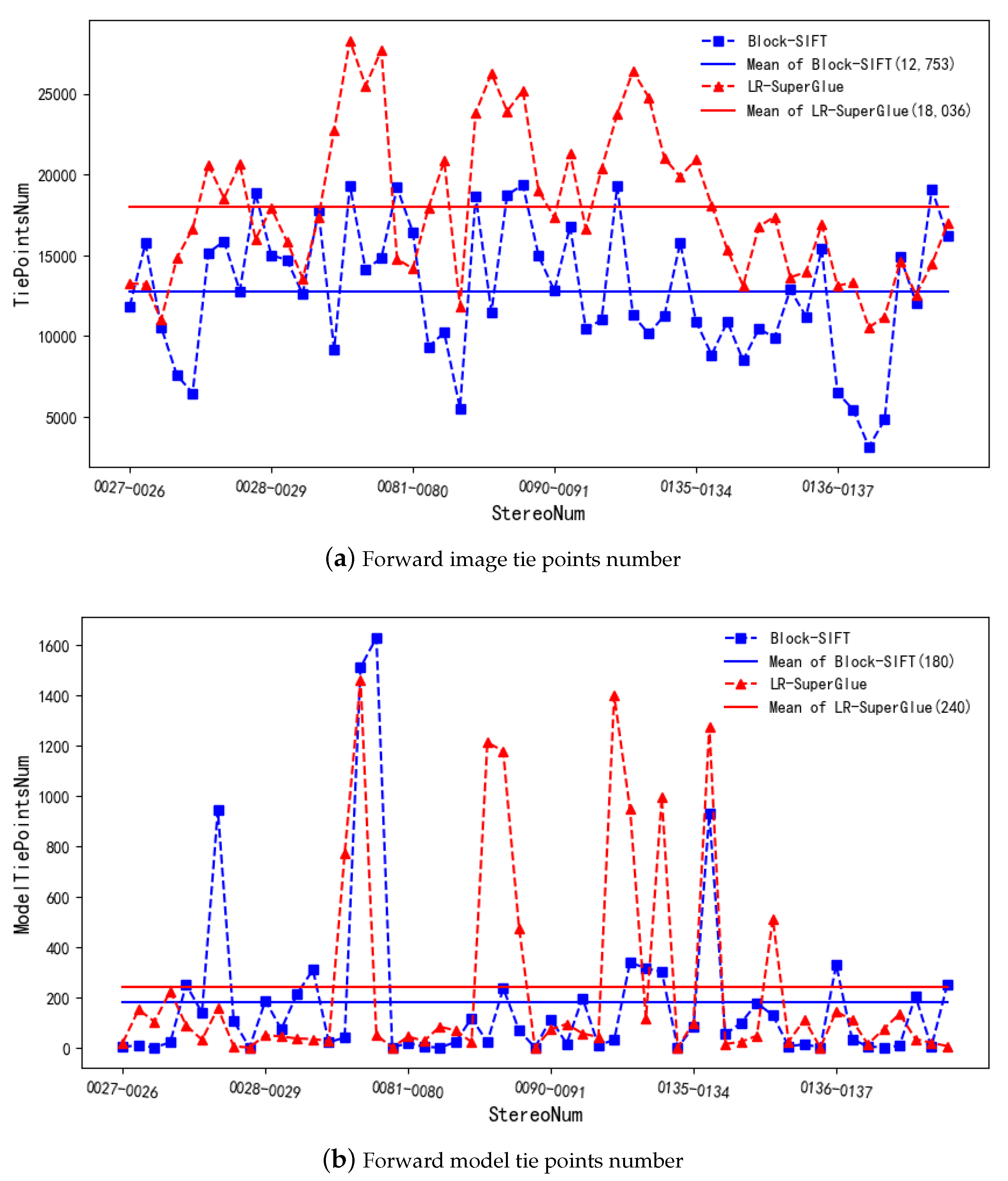
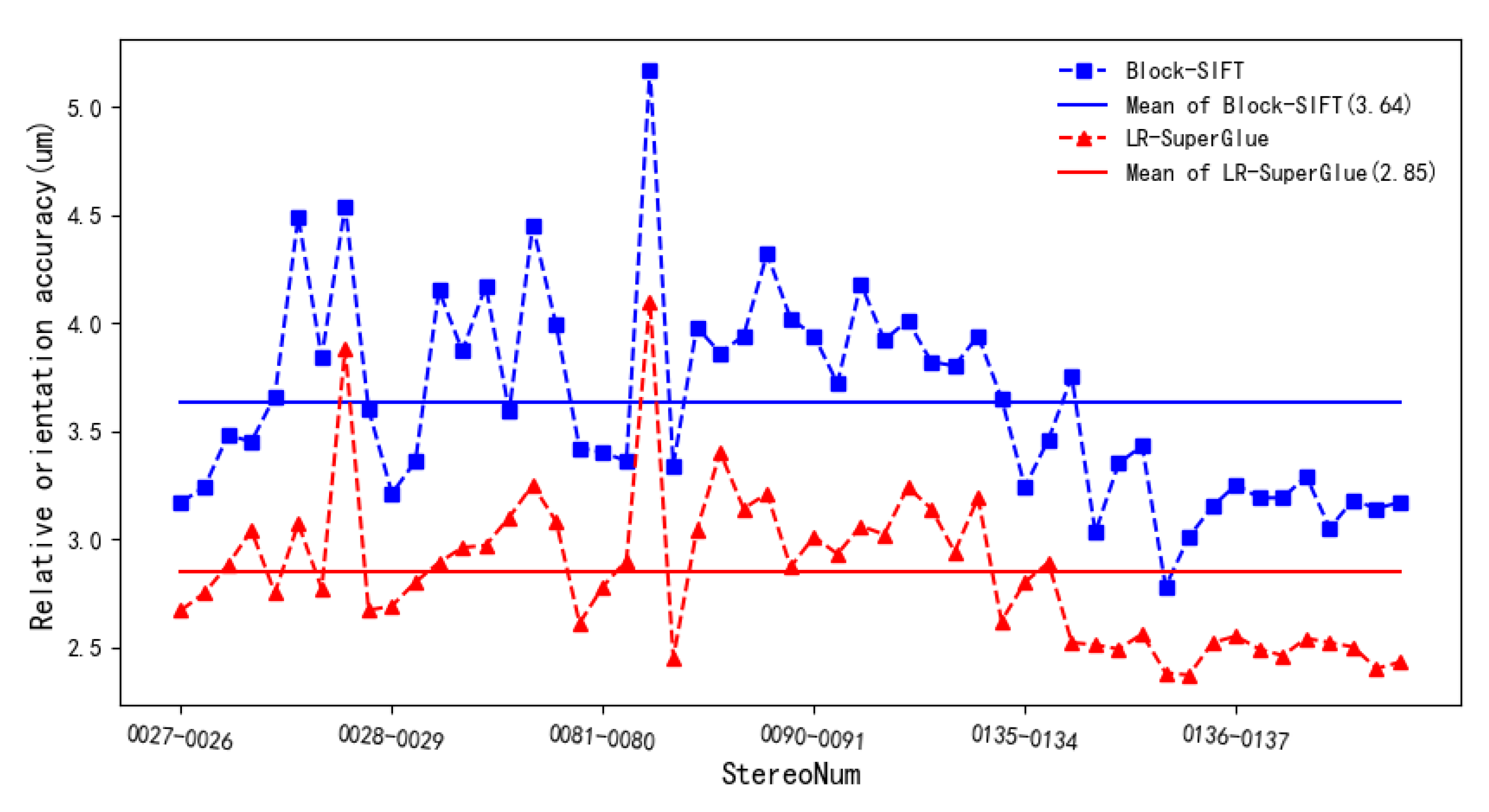
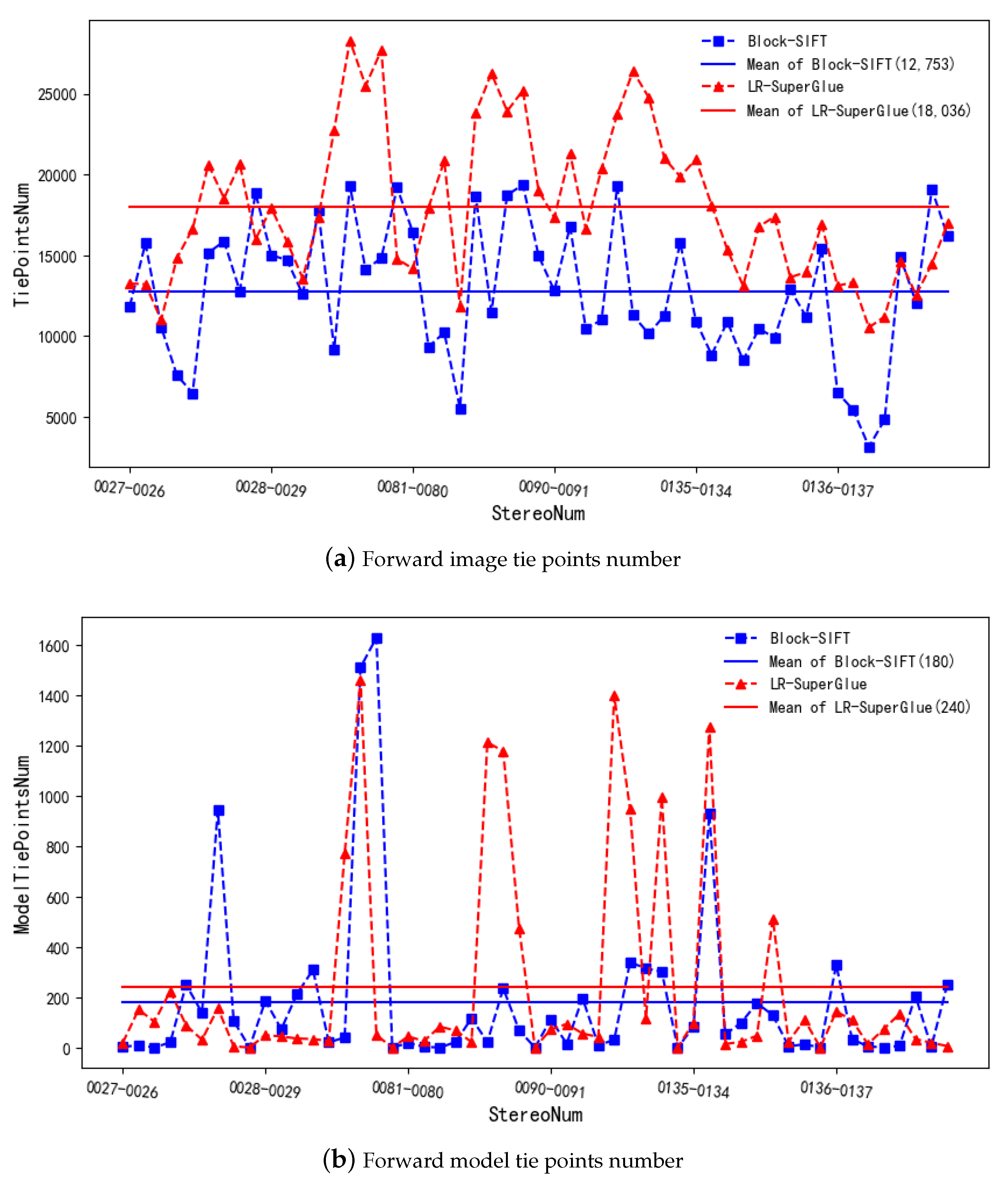
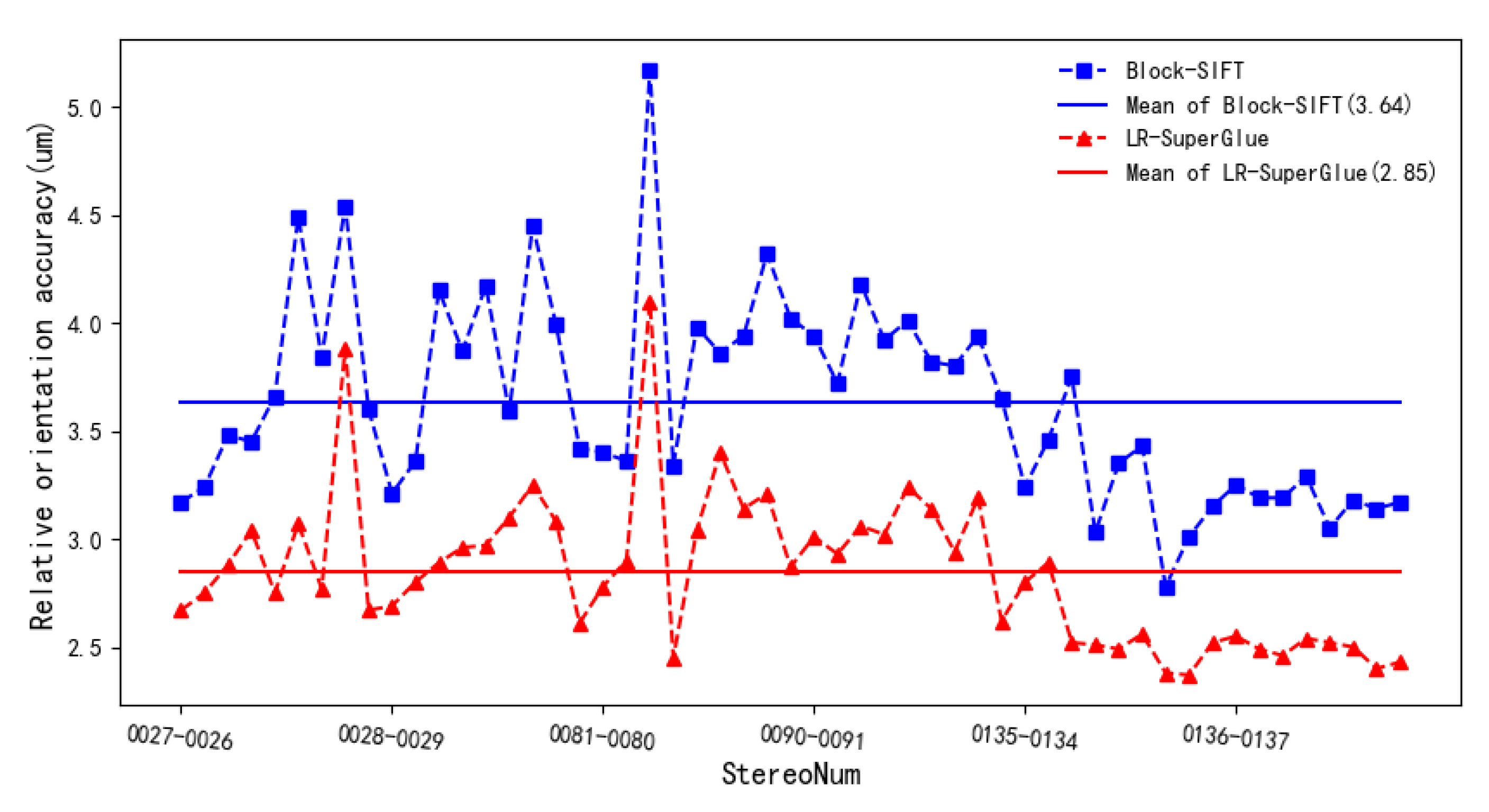
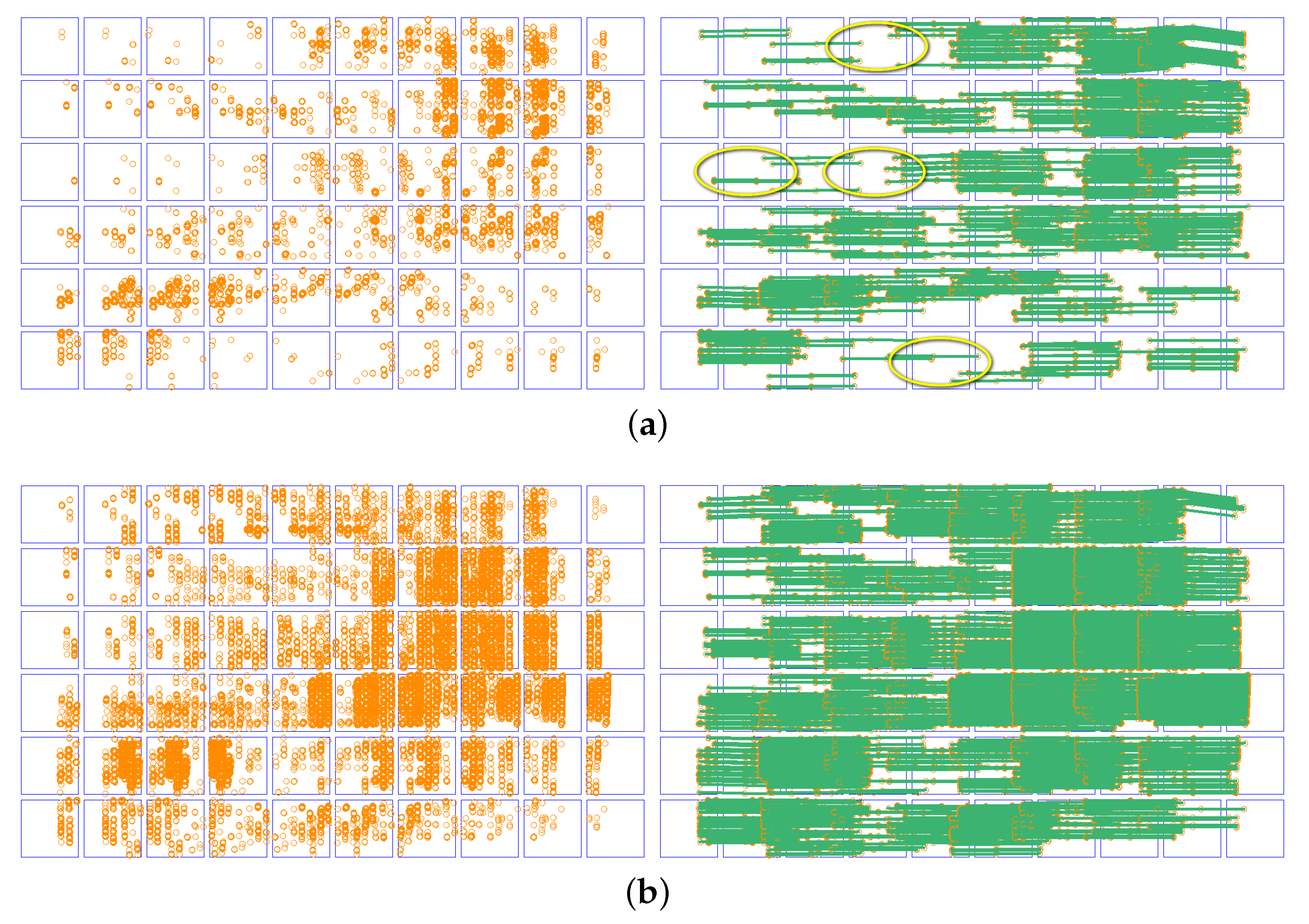
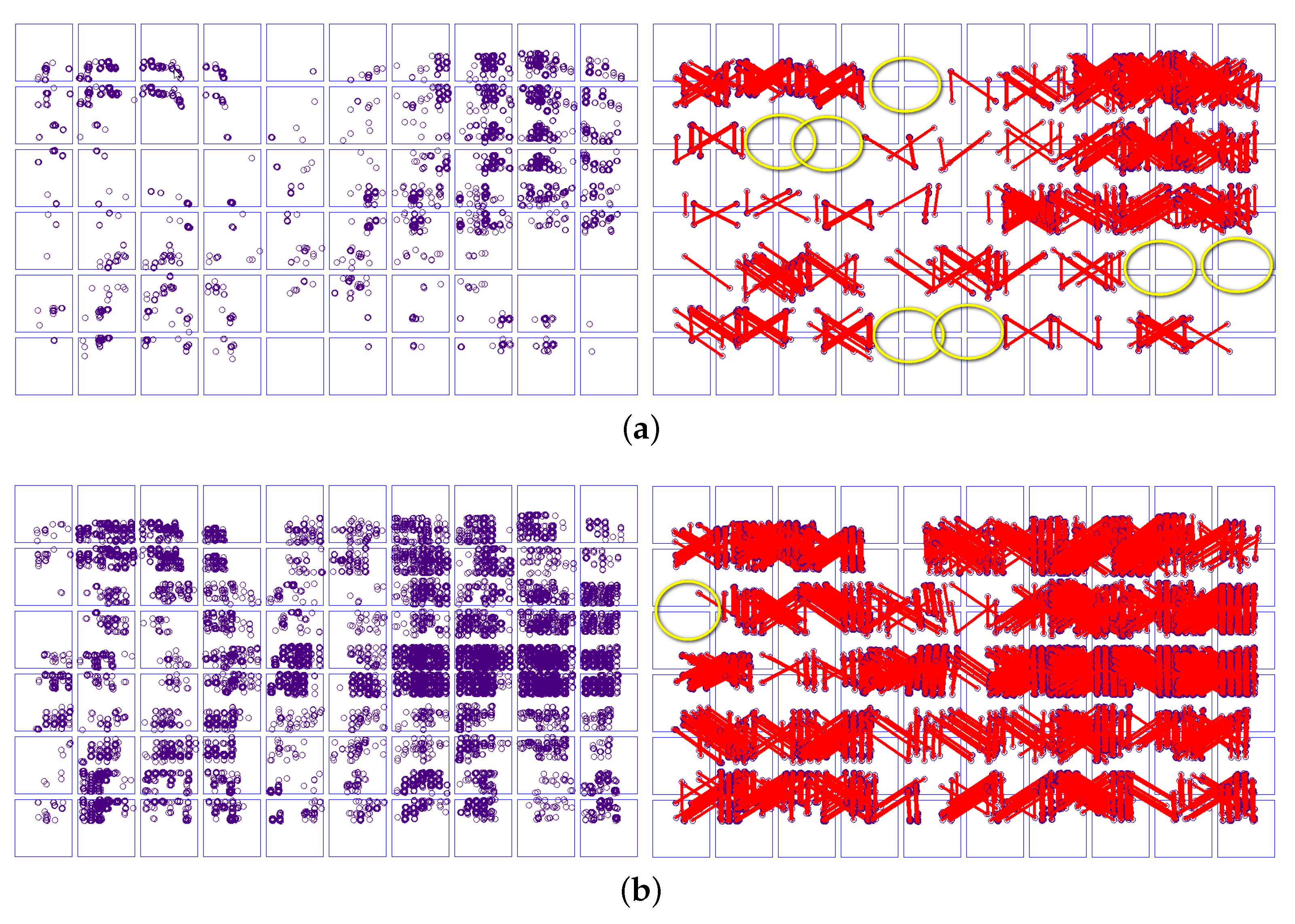
3.2. Matching Results in Forward Images
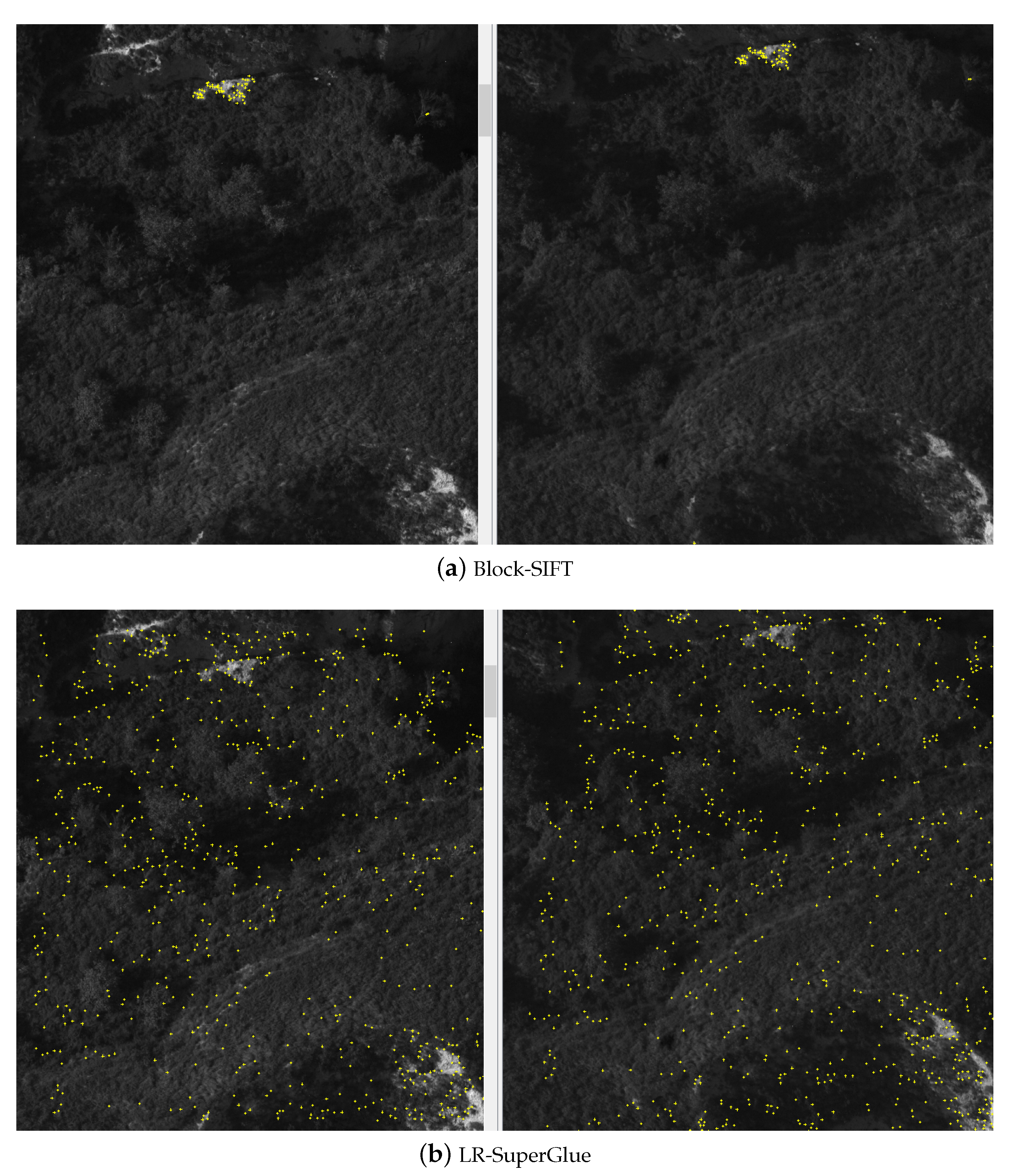
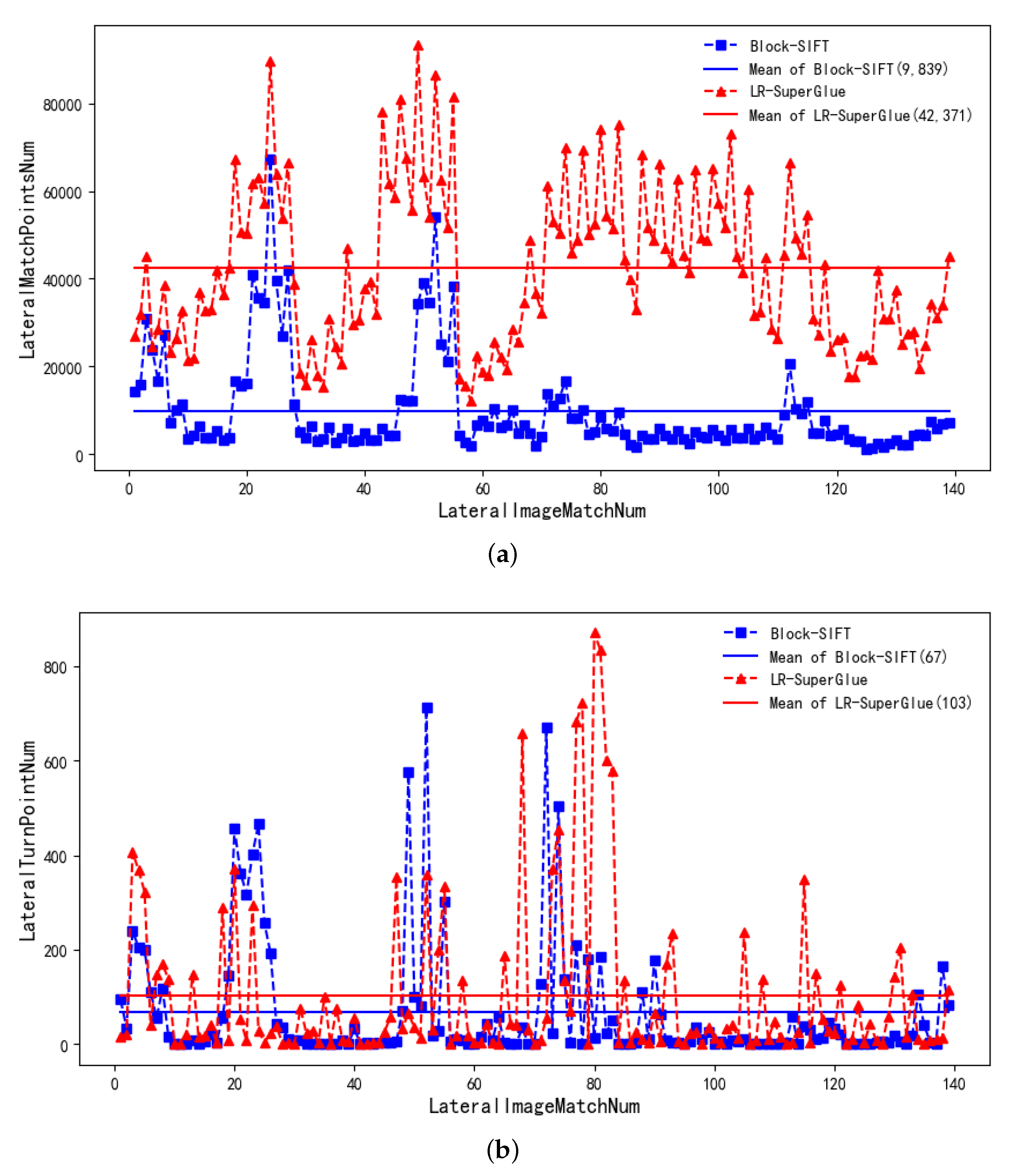
3.3. Matching Results in Lateral Images
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yao, W. Autocorrelation Techniques for Soft Photogrammetry. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 1997. [Google Scholar]
- Ackermann, F. Digital image correlation: Performance and potential application in photogrammetry. Photogramm. Rec. 1984, 11, 429–439. [Google Scholar] [CrossRef]
- Moravec, H.P. Rover Visual Obstacle Avoidance. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, IJCAI ’81, Vancouver, BC, Canada, 24–28 August 1981; Volume 81, pp. 785–790. [Google Scholar]
- Förstner, W.; Gülch, E. A fast operator for detection and precise location of distinct points, corners and centres of circular features. In Proceedings of the ISPRS Intercommission Conference on Fast Processing of Photogrammetric Data, Interlaken, Switzerland, 2–4 June 1987; pp. 281–305. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 147–151. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the ECCV 2006, 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Calonder, M.; Lepetit, V.; Vincent, S.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Berlin/Heidelberg, Germany, 5– 11 September 2010; pp. 778–792. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Sedaghat, A.; Mohammadi, N. Illumination-Robust remote sensing image matching based on oriented self-similarity. ISPRS J. Photogramm. Remote Sens. 2019, 153, 21–35. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR, Washington, DC, USA, 27 June–2 July 2004; Volume 2, p. II. [Google Scholar]
- Morel, J.M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Sedaghat, A.; Ebadi, H. Remote sensing image matching based on adaptive binning SIFT descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Sun, Y.; Zhao, L.; Huang, S.; Yan, L.; Dissanayake, G. L2-SIFT: SIFT feature extraction and matching for large images in large-scale aerial photogrammetry. ISPRS J. Photogramm. Remote Sens. 2014, 91, 1–16. [Google Scholar] [CrossRef]
- Sedaghat, A.; Mokhtarzade, M.; Ebadi, H. Uniform robust scale-invariant feature matching for optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4516–4527. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-invariant feature transform. arXiv 2018, arXiv:1804.09493. [Google Scholar]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and robust matching for multimodal remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Xiao, G.; Luo, H.; Zeng, K.; Wei, L.; Ma, J. Robust Feature Matching for Remote Sensing Image Registration via Guided Hyperplane Fitting. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–14. [Google Scholar] [CrossRef]
- Huang, X.; Wan, X.; Peng, D. Robust feature matching with spatial smoothness constraints. Remote Sens. 2020, 12, 3158. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Jiang, W.; Trulls, E.; Hosang, J.; Tagliasacchi, A.; Yi, K.M. COTR: Correspondence Transformer for Matching Across Images. arXiv 2021, arXiv:2103.14167. [Google Scholar]
- Jin, Y.; Mishkin, D.; Mishchuk, A.; Matas, J.; Fua, P.; Yi, K.M.; Trulls, E. Image matching across wide baselines: From paper to practice. Int. J. Comput. Vis. 2021, 129, 517–547. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- He, H.; Chen, M.; Chen, T.; Li, D. Matching of remote sensing images with complex background variations via Siamese convolutional neural network. Remote Sens. 2018, 10, 355. [Google Scholar] [CrossRef]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V.; Fua, P. Lift: Learned invariant feature transform. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8922–8931. [Google Scholar]
- Lindeberg, T. Edge detection and ridge detection with automatic scale selection. Int. J. Comput. Vis. 1998, 30, 117–156. [Google Scholar] [CrossRef]
- Sedaghat, A.; Mohammadi, N. Uniform competency-based local feature extraction for remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 135, 142–157. [Google Scholar] [CrossRef]
- Wei, D.; Zhang, Y.; Liu, X.; Li, C.; Li, Z. Robust line segment matching across views via ranking the line-point graph. ISPRS J. Photogramm. Remote Sens. 2021, 171, 49–62. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M.; Zhong, R. Robust feature matching via support-line voting and affine-invariant ratios. ISPRS J. Photogramm. Remote Sens. 2017, 132, 61–76. [Google Scholar] [CrossRef]
- Dong, Y.; Jiao, W.; Long, T.; Liu, L.; He, G.; Gong, C.; Guo, Y. Local deep descriptor for remote sensing image feature matching. Remote Sens. 2019, 11, 430. [Google Scholar] [CrossRef]
- Yang, T.Y.; Hsu, J.H.; Lin, Y.Y.; Chuang, Y.Y. DeepCD: Learning deep complementary descriptors for patch representations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3314–3322. [Google Scholar]
- Luo, Z.; Shen, T.; Zhou, L.; Zhu, S.; Zhang, R.; Yao, Y.; Fang, T.; Quan, L. Geodesc: Learning local descriptors by integrating geometry constraints. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 168–183. [Google Scholar]
- Zhang, Z.; Lee, W.S. Deep graphical feature learning for the feature matching problem. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5087–5096. [Google Scholar]
- Balntas, V.; Johns, E.; Tang, L.; Mikolajczyk, K. PN-Net: Conjoined triple deep network for learning local image descriptors. arXiv 2016, arXiv:1601.05030. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-Net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Chen, S.; Chen, J.; Rao, Y.; Chen, X.; Fan, X. A Hierarchical Consensus Attention Network for Feature Matching of Remote Sensing Images. ISPRS J. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Zhu, H.; Jiao, L.; Ma, W.; Liu, F.; Zhao, W. A novel neural network for remote sensing image matching. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2853–2865. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Ye, Y.; Tang, T.; Zhu, B.; Yang, C.; Li, B.; Hao, S. A multiscale framework with unsupervised learning for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, Y.; Cui, Q.; Zhou, Q.; Ma, L. Unsupervised SAR and Optical Image Matching Using Siamese Domain Adaptation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Cui, S.; Ma, A.; Zhang, L.; Xu, M.; Zhong, Y. MAP-net: SAR and optical image matching via image-based convolutional network with attention mechanism and spatial pyramid aggregated pooling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Xu, C.; Liu, C.; Li, H.; Ye, Z.; Sui, H.; Yang, W. Multiview Image Matching of Optical Satellite and UAV Based on a Joint Description Neural Network. Remote Sens. 2022, 14, 838. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust point matching via vector field consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef] [PubMed]
- Ramos, J.S.; Watanabe, C.Y.; Traina, C., Jr.; Traina, A.J. How to speed up outliers removal in image matching. Pattern Recognit. Lett. 2018, 114, 31–40. [Google Scholar] [CrossRef]
- Brachmann, E.; Rother, C. Neural-guided RANSAC: Learning where to sample model hypotheses. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4322–4331. [Google Scholar]
- Cavalli, L.; Larsson, V.; Oswald, M.R.; Sattler, T.; Pollefeys, M. Adalam: Revisiting handcrafted outlier detection. arXiv 2020, arXiv:2006.04250. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surveying Area Name | Width × Height of Image | Pixel Size (μm) | f of Camera (mm) | Total Number of Image | Forward Overlap | Lateral Overlap |
|---|---|---|---|---|---|---|
| SX500 | 28,820 × 30,480 | 4.6 | 142.4169 | 6 × 10 = 60 | 63% | 30% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, X.; Yuan, X.; Chen, J.; Wang, X. Large Aerial Image Tie Point Matching in Real and Difficult Survey Areas via Deep Learning Method. Remote Sens. 2022, 14, 3907. https://doi.org/10.3390/rs14163907
Yuan X, Yuan X, Chen J, Wang X. Large Aerial Image Tie Point Matching in Real and Difficult Survey Areas via Deep Learning Method. Remote Sensing. 2022; 14(16):3907. https://doi.org/10.3390/rs14163907
Chicago/Turabian StyleYuan, Xiuliu, Xiuxiao Yuan, Jun Chen, and Xunping Wang. 2022. "Large Aerial Image Tie Point Matching in Real and Difficult Survey Areas via Deep Learning Method" Remote Sensing 14, no. 16: 3907. https://doi.org/10.3390/rs14163907
APA StyleYuan, X., Yuan, X., Chen, J., & Wang, X. (2022). Large Aerial Image Tie Point Matching in Real and Difficult Survey Areas via Deep Learning Method. Remote Sensing, 14(16), 3907. https://doi.org/10.3390/rs14163907