1. Introduction
Agriculture has always played an important role in the history of Azerbaijan. Climatic and topographical conditions favour the cultivation of a variety of crops, with half of the country classified as mountainous and 18% of the land lying below sea level. Currently, agriculture generates approximately 6% of Azerbaijan’s GDP [
1]. A key element of Azerbaijan’s agricultural sector is that it is highly fragmented and includes a large number of small farmers [
2]. The number of agricultural producers in 2015 was 1.2 million, with all of them cultivating less than 2.2 million hectares of land in total. In addition, there are over 1200 state-owned and cooperative farms nationwide. Most of Azerbaijan’s cultivated land (over 1 million hectares) is irrigated. Following an oil price crisis in 2016 and the downward trend of the country’s fossil oil and natural gas prices ever since [
1], the government has recently adopted a series of strategies to strengthen the agricultural sector. The government’s goal is to improve the business climate for the development of a competitive Azerbaijani agrifood sector, to ensure the country’s food security and to economically empower the rural population.
Early estimates of crop yields enable farmers to optimise their farm planning, field management and product marketing decisions. Data-driven decisions allow for more informed decisions on optimising inputs (e.g., fertilisers, pesticides and water), determining the optimal harvesting method and timing, and most importantly, planning logistics related to product storage, transport and marketing. Therefore, yield estimates serve as an assessment tool for the expected income of each production unit and at the same time enable an efficient transfer of production from the farm to the food supply chain. In remote areas, where the logistics of transporting produce often need to be arranged in advance to plan transport to warehouses, which are often located close to urban centres, information on early yield forecasts can minimise potential risks and ensure optimal handling and storage of produce. For open-field crops, which are grown in the lowlands and therefore often have to travel shorter distances to storage units, the real critical factor for production safety is the storage itself. For high-value crops, and especially produce that is very susceptible to post-harvest quality degradation and has a very short life if left exposed, should be scheduled to be stored several weeks before the product arrives. In addition, the policy of any country can be greatly influenced by yield estimates, the two most important factors for these forecasts being their accuracy and how early they can be made. The importance of yield estimates is even greater in countries where agriculture is the main source of economic activity. Early forecasts can warn decision-makers of potential crop losses so that they can adjust their import and export decisions in time each season and avert a potential food shortage. In the agriculture of the digital age, data is the most valuable currency and the question of “how early” it becomes accessible is the decisive production factor.
Remote sensing encompasses a range of advanced technologies and data analysis techniques that provide a vast amount of information on key agricultural parameters, including crop type, crop status and yields, from the field level to larger geographical areas such as countries or continents. In various case studies, remote sensing applications have been used and evaluated for decision making in irrigation [
3,
4,
5], fertilisation [
6] and pesticide use [
7,
8] to minimise water and nutrient losses and other negative environmental impacts of agricultural practises. Today, the phenological development of crops during a seasonal cycle can be easily monitored from space. In combination with other data sources, stressed regions can be identified and crop yield estimates can be made. Satellite sensors have transformed agricultural activities by providing a timely and accurate picture of the agricultural sector, as they are capable of collecting information over large areas with high repetition frequency [
9]. The high resolution of Sentinel-2 has revolutionised crop monitoring and offers immense potential for agricultural management, especially in delineating management zones [
6], optimising agricultural inputs and predicting yields [
10].
The large spatial coverage and high temporal repetition frequency of satellite imagery make it particularly useful for obtaining near real-time information at the regional level. As it is a cost-effective technology, users can minimise field observations and a large number of users can share the same data [
11]. By using seasonal time series of satellite imagery, various phenological indicators, such as the beginning, peak and end of a crop cycle, can be modelled by specific vegetation indices (VIs). The latter are commonly used for crop phenotyping to assess the physiological state of plants under abiotic stress in different crops [
12,
13,
14]. Among VIs, the Normalised Difference Vegetation Index (NDVI) is the most widely used for estimating biomass production, plant vigour, stress level, yield and even as a proxy for photosynthesis [
15,
16]. In recent years, several approaches to the quantitative estimation of plant productivity parameters have been elaborated, including methods ranging from simple regression equations [
17] to the use of more complex plant growth models [
18]. Tucker et al., 1980 [
19] were among the first researchers to establish a relationship between NDVI and crop yield using experimental fields and ground-based spectral radiometer measurements. Thereafter, numerous studies have reported the good correlation between vegetation indices provided by RS and crop yield and biomass [
20,
21,
22].
Considering that global tomato production has increased to 186.8 million tonnes by 2020 (FAOSTAT, 2020), the social and economic importance of tomato at the international level is obvious. In Azerbaijan, the tomato production sector has occupied a prominent position among the branches of the country’s agricultural economy for many years. From 2007 to 2018, Azerbaijan achieved the highest growth rate in exports among the main exporting countries. In 2020, the country produced 774,877 tonnes of the raw product, while 19,371 ha were cultivated (FAOSTAT, 2020). Given the great importance of this particular crop and the limited research on this type of cultivation, satellite data were used in this study and NDVI-based work was produced to assess the potential to provide valuable information on tomato processing. Predictive yield maps can be used as spatial databases for the implementation of variable rate cropping (VRT) systems to achieve precise application of field-level inputs to optimise production across the field, especially for high-value crops such as tomato. Gianquinto et al., 2011 [
12] investigated yield prediction for tomato using different vegetation indices based on crop reflectance. Koller and Upadhyaya (2005) [
23] used a vegetation index based on plant greenness and found it to be reliable for evaluating the yield of processing tomatoes. As reported [
15], NDVI is a good estimator for predicting yield and can be used to plan the best time to harvest and transport for industrial processing.
In this study, the capacity of Sentinel-2 imagery to assess canopy growth, yield and field cultivation of tomato crops was evaluated. We used six (6) vegetation indices to extend the approach for early crop yield prediction and to investigate the predictive power of the developed models. A stepwise linear regression method was implemented to select the linear models based on the statistical evaluation of their fit for the entire data set, creating simple equations with easily interpretable coefficients that can forecast crop yield. The inclusion of remote sensing data is carried out to evaluate whether NDVI variables can successfully and accurately quantify yield performance of processing tomatoes at both regional and national levels. A novelty is the use of different cumulative NDVI ranges as predictors in statistical modelling, as satellite data availability is often limited (not constant availability of products in the desired temporal frequency) during prolonged periods of heavy cloud cover, requiring mid-season methodological adjustments (mainly based on frequency of data collection) to ensure data integrity. Therefore, the objectives of this study were to (1) assess the capacity of a cumulative NDVI-based model to accurately predict tomato field crop yields, (2) evaluate NDVI data from the Sentinel-2 satellite platform as a seasonal, near real-time monitoring tool for crop vigour and underlying variability through in situ observations and targeted ground truth sampling campaigns, and (3) test the accuracy of the proposed methodology for large-scale forecasting, ranging from a regional to a national level. The results can be used to support policy and regulatory decisions, while the method presented can be transferred to other countries and crops/cultivation systems, contributing to a better understanding of remote sensing data on estimating crop production.
2. Materials and Methods
2.1. Study Area
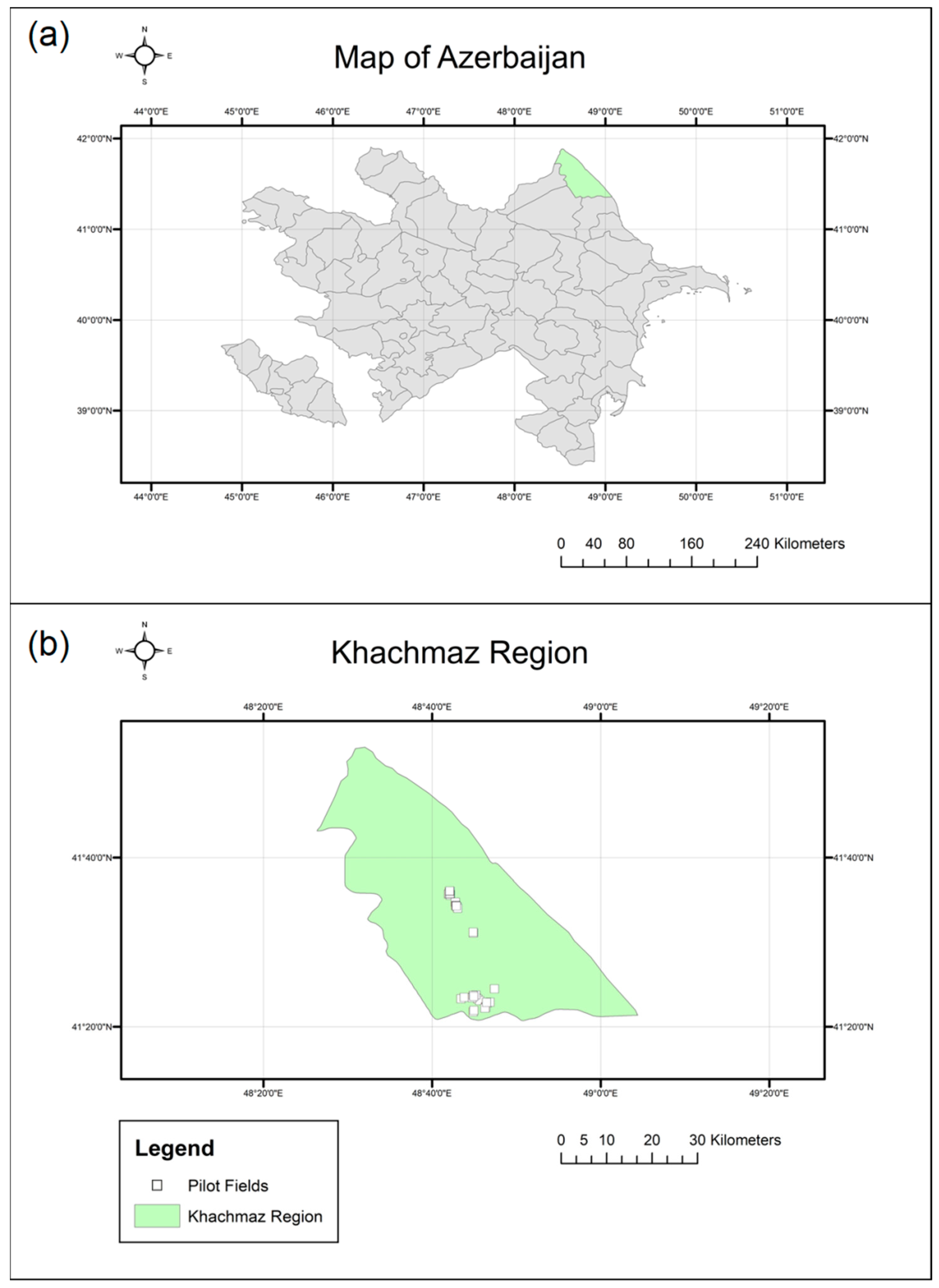
The study took place in the Khachmaz region of Azerbaijan, where 34 processing tomato fields with a total area of 128 ha (±SD = 5.75 ha) were selected as pilot fields for this study (extent of 41°21′40.2″ N 48°41′51.8″ E: 41°36′07.8″ N 48°47′24.8″). The planting date of the pilot fields ranged between the end of May and the beginning of June 2021, while harvesting was completed in all fields at the beginning of September. All pilot fields were irrigated and planted in rows with an average row spacing of 0.6–0.8 m, which corresponds to the extensive cropping system commonly used in the region. In addition, all fields were located in flat areas with a maximum slope of 10° within each field. The area of the study region is shown in
Figure 1.
2.2. Data Collection and Pre-Processing
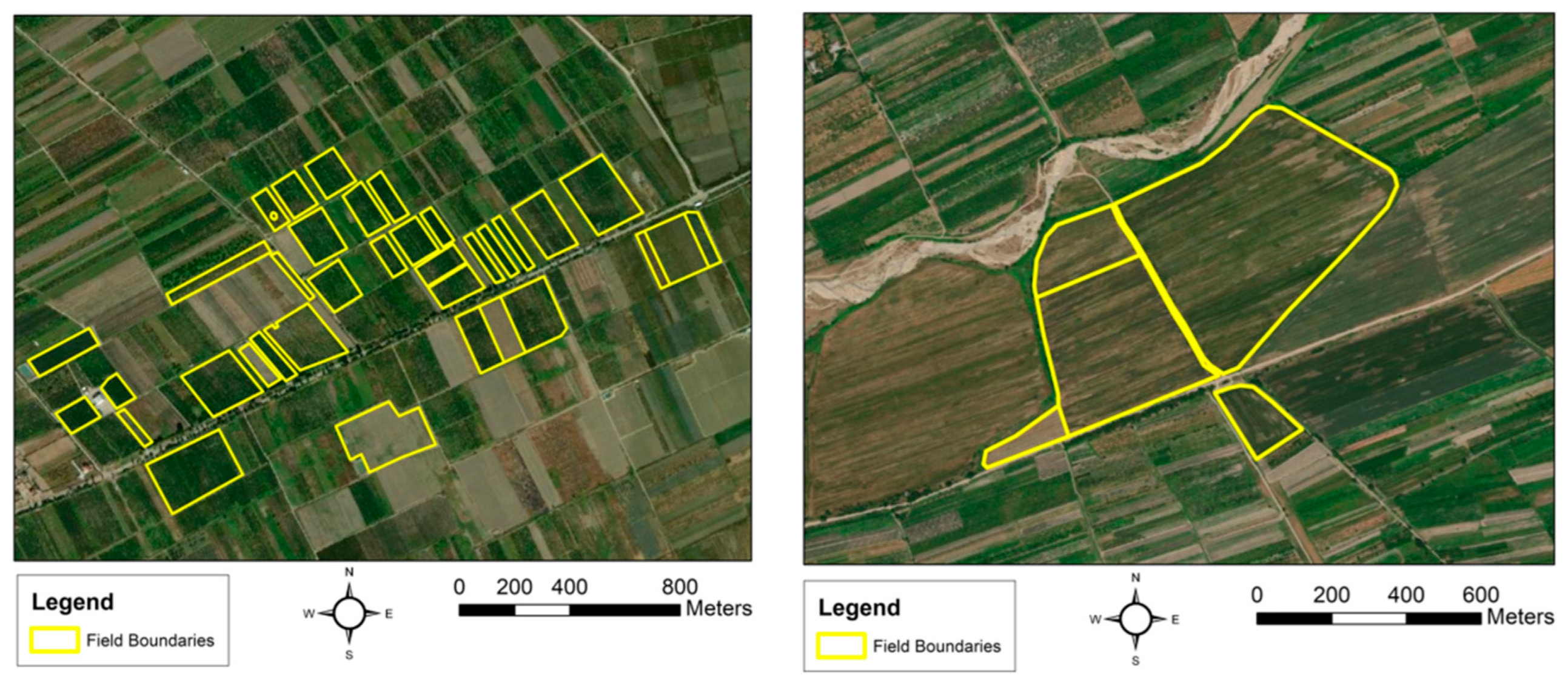
First, the pilot fields were digitised using topographic field data collected by agronomists of the Ministry of Agriculture (MOA) of the Republic of Azerbaijan in their respective regions using portable positioning systems in May 2021. These field measurements and the polygon boundary files generated were then checked and possibly fine-tuned using RGB components created from Azersky satellite imagery (SPOT-7) from the same period. An example of the vector layers of field boundaries acquired during these field measurements is presented in
Figure 2.
The remote sensing data used in this study are 10 × 10 m2 resolution multispectral images obtained from the Multi-Spectral Imager (MSI) sensor of ESA’s Sentinel-2 satellite platforms. The atmospherically corrected images (Level-2A, providing Bottom of Atmosphere reflectance values) from the Sentinel-2A satellite in cartographic geometry (UTM/WGS84 projection) were downloaded from the official Copernicus Open Access Hub (scihub.copernicus.eu, accessed on 30 September 2021). Since Khachmaz was heavily clouded throughout June, the first image mosaic that could be used was taken in early July (2021). In the event that heavy cloud cover occurred and the experimental fields of interest were not visible, the next available set of images was used instead. Satellite imagery data was collected at 10-day intervals, except for the first two measurements when heavy cloud cover over the study area required an increase in the interval to ensure the validity of the data. It was decided that the interval between two consecutive image captures should not be shorter than 10 days because (1) the field visits were necessary for the purposes of the project and had to be carried out in a timely manner and (2) no major fluctuations were to be expected at such short intervals.
For each data collection date, a total of four (4) images were downloaded to adequately cover the entire study area. The first step of data pre-processing involved the mosaicing of the individual images from each data collection date into orthoimages of the entire study area, using ArcGIS software (Environmental Systems Research Institute, Redlands, CA, USA). Once the total number of images was determined, an additional filtering step was applied to all regional images to ensure that each generated mosaic consisted exclusively of high-quality and cloud-free data from the pilot fields. This process was only carried out on the area covered by the vector layer containing the pilot fields, as an overall low cloud cover index for an image does not necessarily guarantee the visibility of the pilot fields and vice versa. In the event that high cloud cover occurred and the pilot fields were not visible, the next available set of images was used instead. The generated data cube consisted of five (5) cloud-free regional raster orthomosaics sampled at 10 × 10 m2 resolution.
The next step, which spanned the entire cropping season, was to use each generated multispectral orthomosaic of the Khachmaz region to create plant vigour variability maps for the study fields. For this study, NDVI [
24] was selected as the main vegetation index because of its ability to distinguish vigour patterns of foliage plants, its popularity in research, and its ease of replication for future implementations. Moreover, five additional widely used VIs, namely the Weighted Difference Vegetation Index (WDVI), Green Normalised Difference Vegetation (GNDVI), Soil-Adjusted Vegetation Index (SAVI), Modified Soil-Adjusted Vegetation Index (MSAVI) and Perpendicular Vegetation Index (PVI) were also used to assess their ability to describe crop status throughout the season and, naturally, the final yield. To this end, the VI orthomaps of the entire area were created by iterating the VI formulas over all satellite image pixels using the Raster Calculator tool of ArcGIS, resulting in the VI orthomaps of the study area. The Vis used in the present study and their respective equations are presented below (
Table 1):
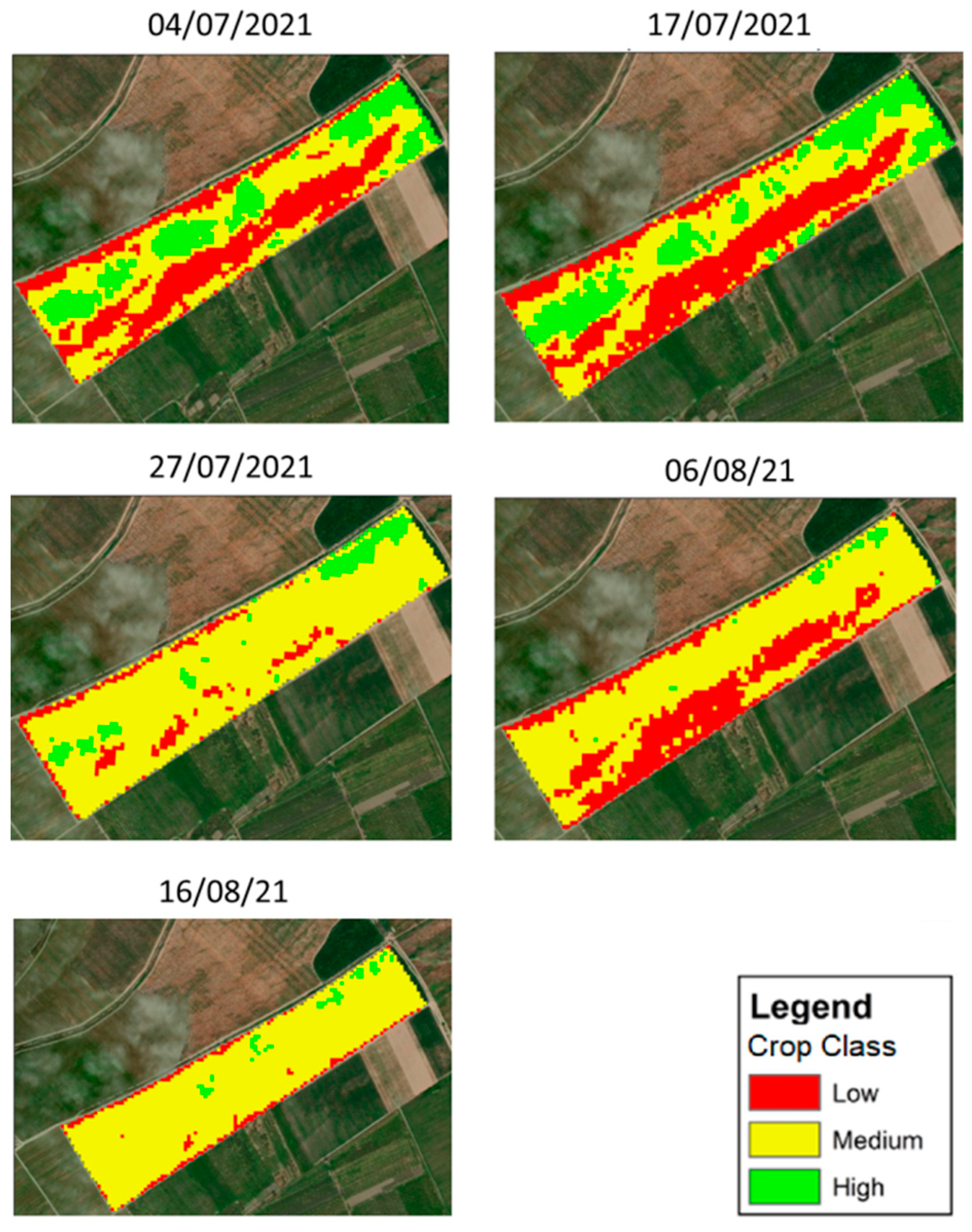
The VI maps served a dual purpose: (1) they are needed for the following steps of the methodology, as yield forecasts are essentially generated based on the cumulative values of each field throughout the season, but in addition (2) they can also serve as a valuable field management tool for farmers and agronomists during the cultivation season. These maps and the time series generated can provide information on which field segments need more attention and help to identify faulty areas easily and in a timely manner. Furthermore, as they were used to quantify the development of plant vigour in all pilot fields in near real time, they were also used to classify them based on their expected productivity. Therefore, once the original VI layers had been cropped using the field boundaries as a mask, for each selected date, all pixels in the new raster layer, were classified using a 3-class quantile classification to capture the overall picture of crop field performance in the region. This resulted in a new layer where each pilot field pixel was assigned a productivity class value based on the VI values recorded at the time of the last data collection, compared to all other pilot fields in the area. An example of the NDVI maps generated at a similar resolution to the original Sentinel-2 imagery (10 × 10 m
2) for each data collection date for this season is shown in
Figure 3.
Finally, for each field layer extracted using the pilot field boundaries as a “mask” on the regional orthomosaics, a mean VI value was extracted from each field. These values were finally integrated with their time interval (i.e., 10–13 days between each image) to produce the cumulative VI for each field in that season, or simply the area under the VI curve of each field.
2.3. In-Situ Data Collection Campaigns
To evaluate the accuracy of the VI maps produced, field visits were made to Khachmaz district on selected dates towards the end of the cultivation season (early August) to collect in situ samples from targeted pilot fields productivity zones. Sampling sites were selected based on the most recently produced NDVI maps to verify the accuracy of the classification against actual data from the pilot fields. The soil sampling carried out on the selected processing tomato fields, which resulted in a total of 12 sampling visits, consisted of production measurements (yield weighting) in 1 m
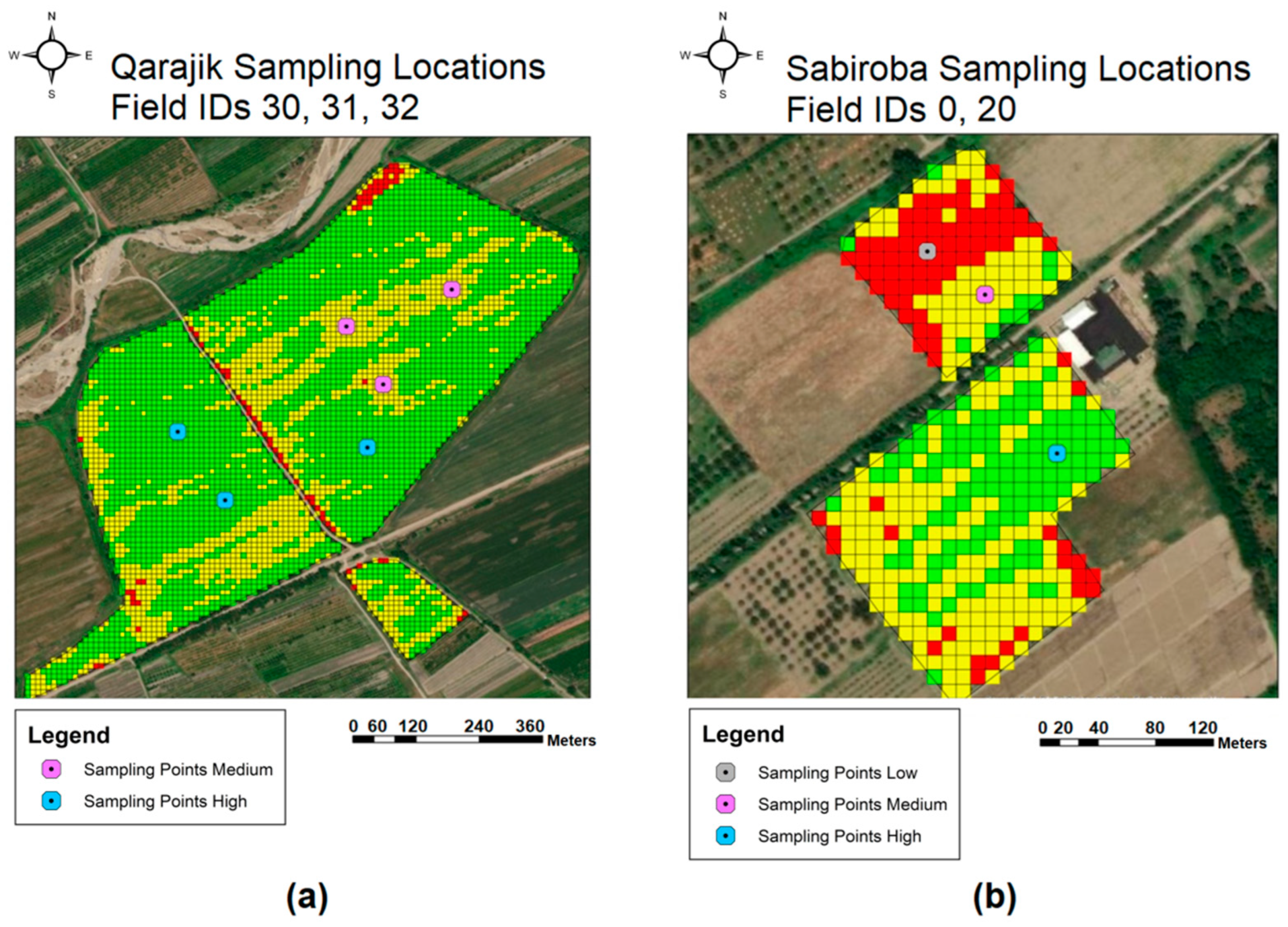
2 cells, so that they can evaluate the validity of the productivity class assigned to that pixel. The sample locations were selected using a Python script that first identified the “purest” cells of each field, i.e., the pixels that were located in the centre of their respective zone and were exclusively and completely surrounded by pixels belonging to their class. A list of 36 selected sampling locations (12 sampling locations per class across all pilot fields) was then selected based on the number of classes present in each field and its total area. An example of two (2) selective sampling maps over the productivity quantile class layer (NDVI) with an integrated supporting 10 × 10 m
2 grid aligned with the grid of the satellite imagery to assist in locating the selected sampling locations are presented in
Figure 4.
In addition to the targeted sampling at Khachmaz, field visits were conducted on several days throughout the cultivation season to assess zone classification and the overall accuracy of crop growth status maps. These visits, which were an additional validity check, were carried out in the presence of the farmers managing the respective fields or the agronomists in charge, and the main observations for each field visit were documented. Finally, at the end of the growing season, after the harvest was completed, the actual yields at field level were collected, expressed in t/ha. These data were needed to evaluate and update the crop-specific equation of the model, as it is expected to have the smallest possible error to these yield values. The actual yield of each pilot field was recorded directly by the farmers under the supervision of the MoA offices, and the respective total yield values were assigned to each pilot field. At the end of the season, a total of five (5) values for each of the six (6) VIs used and the recorded yield were assigned to each pilot field.
2.4. Statistical Analysis and Yield Estimation Equations
In this study, the first step of the selected yield forecasting method was to establish a baseline and a set of initial predictions by implementing a fitted equation following the approach of Kross et al., 2015 [
30] using a biomass conversion function and a harvest index (HI). This linear approach is simple to implement and can be easily calibrated once actual yield data become available to update the model and significantly increase its accuracy.
The predictions naturally inherit the linearity of the implemented VIs and crop growth and are also divided into 3-class quantiles to determine which fields in the pilot area are likely to perform better than others. For the first run of the system, the NDVI was selected along with a biomass transfer factor of 1.9 and a HI of 0.6 for tomatoes based on existing literature [
31,
32]. Once the actual yield data had been collected, the linear equation values that best described the yield were determined. This resulted in the new updated crop-specific yield estimation model, which is of course much more accurate than the arbitrary approach based on the literature, as it was directly regressed on the data collected in this particular region. Furthermore, it has the potential to become even more robust with further similar iterations in upcoming years. For the statistical analysis of the correlations between the yield and VI data, the correlation coefficient estimates and regression analysis were performed using Statgraphics 16 (StatPoint Technologies Inc., Warrenton, VA, USA). Pearson’s correlation coefficient (r) and regression analysis (r
2) were used to compare the spatial similarity between the different datasets by measuring the strength and direction of the linear relationship between the two variables. To determine the linear model that best describes the relationship between the VI data and the recorded yield, the “comparison of alternative models” function of Statgraphics was used. The linear regression model was selected based on the values of R squared, adjusted R squared, and Mean Absolute Error (MAE), since these are the most widely used evaluation metrics for regression models. Furthermore, an additional analysis was performed, to assess the cumulative capacity (data availability) of the satellite data, and how the cumulative VI approach performs when less data is used for the predictions.
4. Discussion
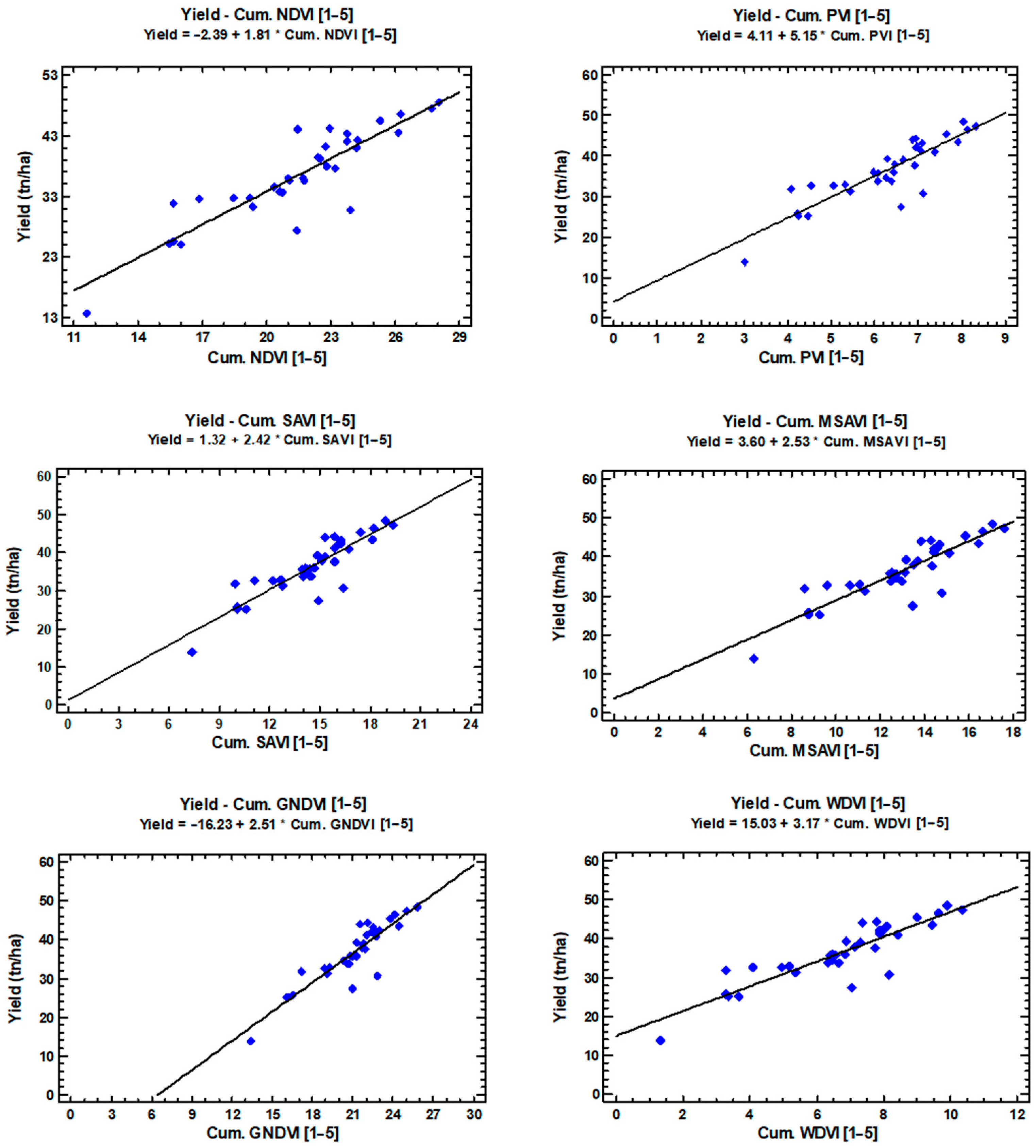
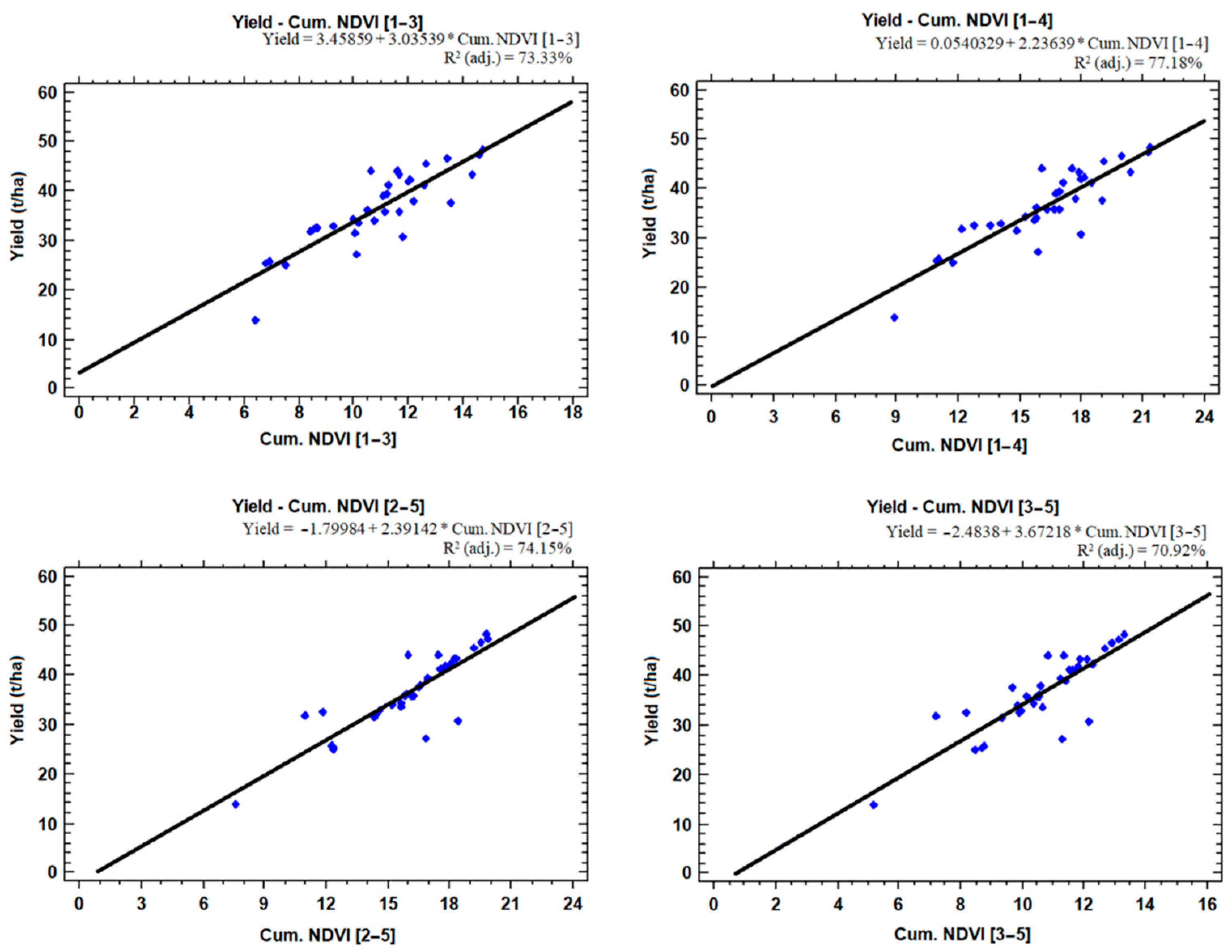
The results show that, across all of the experiments, the predictive capabilities of Sentinel-2 derived VI data are satisfactory. Specifically for NDVI, the performance of all cumulative NDVI models, regardless of cumulative range, was consistently above 0.84 correlations with the final recorded yield in all experimental fields in the Khachmaz region. The best performance for all VIs used in this study was obtained with the maximum cumulative range [1–5], which corresponds to the maximum data availability. The same pattern of “more data used, higher accuracy” was also found for the shorter cumulative ranges, as [1–4] and [2–5] outperformed [1–3] and [3–5] for most VIs. However, even the lower end of cumulative ranges achieved solid performances, considering the inherent limitations of only using three (3) images as predictive inputs.
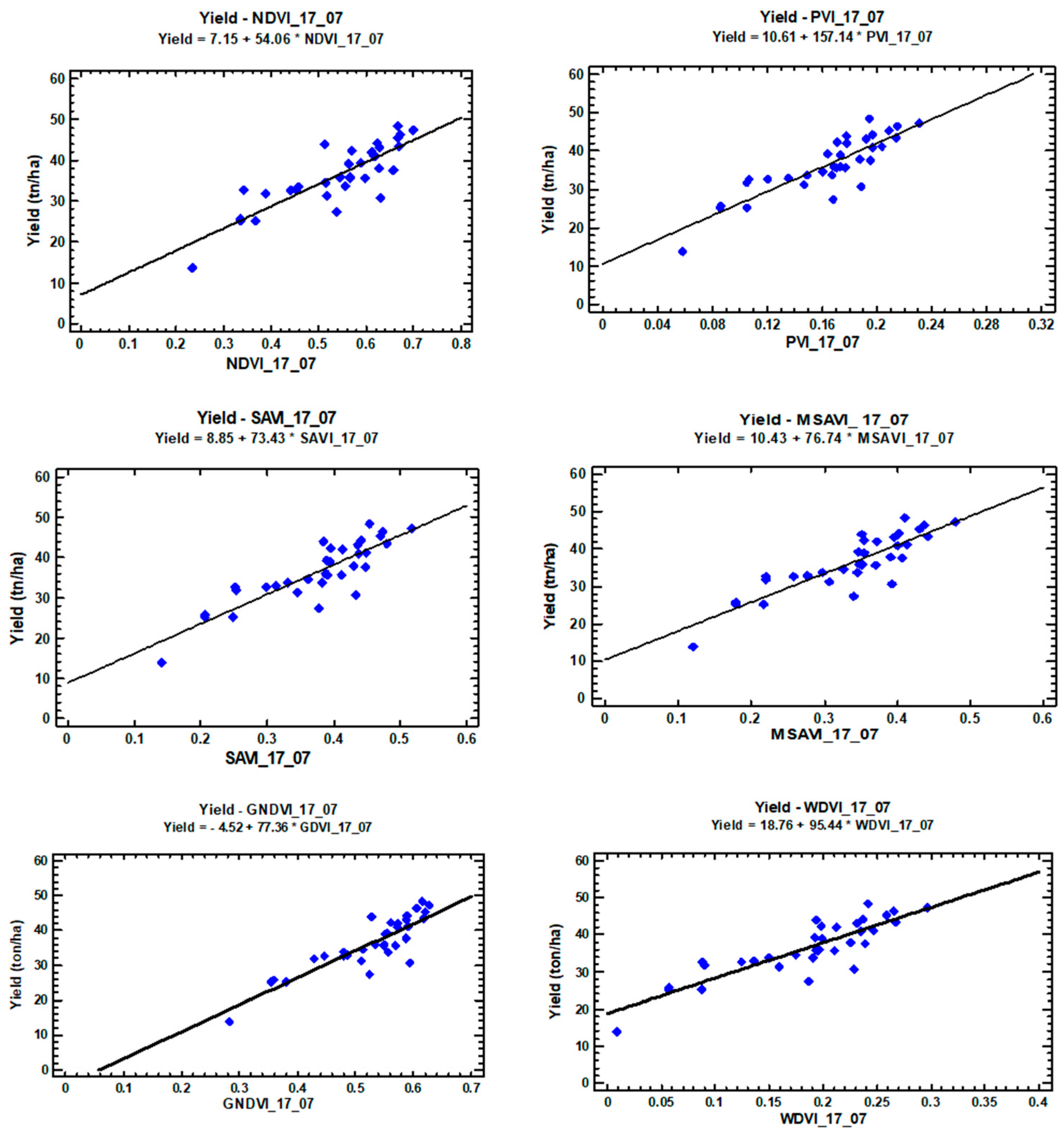
The VI that demonstrated the highest performance in the maximum cumulative range was GNDVI, with a correlation of over 90% with final yield, followed by NDVI with a correlation of over 89%. SAVI, MSAVI and WDVI all demonstrated similar results in maximum cumulative capacity, while the lowest correlation was observed with PVI. This was also the case across all cumulative ranges, with PVI consistently demonstrating the lowest correlation with yield, while also exhibiting the lowest correlation value across all VIs, for all single dates and cumulative ranges, barely exceeding 80% for the [3–5] range and 37% at the 1st measurement.
For the correlation between single dates and the final yield, poor prediction capability of NDVI and all VIs was generally observed at very early crop growth stages, when vegetation is sparse and bare soil covers a significant portion of the fields’ total area. Moreover, the 1st measurement is the one exhibiting the highest variation (36.77%). This variability is to be expected in plants with variable ground cover at different growth stages, since in the early growth stages most of the satellite sampling grids are bare soil. The percentage of ground cover increases towards the middle of the season when tomato plants reach their maximum vigour before they start transferring sugars to their fruits. However, it cannot be assumed that this process of canopy development is homogeneous and synchronous in several fields. The different planting dates are a logical explanation for the different vegetation cover during the planting period.
On the other hand, the primary canopy development stages (2nd measurement, 17_07) appeared to be strongly correlated with the final yield, possibly indicating a critical stage when processing tomato crops undergo changes that can be distinguishable through Sentinel-2 derived data. These results indicate a potential robust relationship between processing tomato yield and remote sensing VI datasets, displaying satisfactory linear correlation coefficients, and provide new insights into the monitoring of processing tomato fields at the Sentinel-2 resolution scale of 10 × 10 m2. The fact that the differences between the minimum and maximum yield values are 34.6 t/ha show that there is room for improvement through more efficient field management strategies and decisions.
Another interesting comparison can be made between SAVI and MSAVI, the latter being essentially the modified version of the former, to mitigate the effect of bare soil on its values. To this end, some degree of variation would logically be expected, especially in early development stages. This was confirmed by our results, with the MSAVI generally being a less variable index and the SAVI having 6 times higher Standard Deviation across the growing season. Despite the fact that the MSAVI was one of the least variable indices, while the SAVI was one of the most variable ones, both had very similar performance values in terms of correlation with final yield, for single dates and for different cumulative ranges.
Regarding the homogeneity of the mean cumulative NDVI data, the range of values within a single date is minimised towards the end of the season (5th measurement, 16_08), after remaining fairly constant during most of the cultivation season. Interestingly, the highest variability between the different cumulative ranges is encountered in the maximum cumulative range (all 5 dates), which had twice as much heterogeneity compared to the two lowest cumulative ranges ([1–3] and [3–5]). The method used in the paper initially extracted the mean NDVI values of each field from each measurement date, and then used to calculate the cumulative values. The reason this method was followed, is because yield measurements would be collected in a field-level, as sub-field yield mapping would not be sustainable when developing a similar model with multiple fields in this region as input data. In future research, however, it would be interesting to experiment with a higher resolution yield sampling approach, even in a lower number of fields, to assess the capacity and compare the results with cumulative NDVI in specific field segments instead of the entire field.
Finally, an interesting finding regarding the upscaling of the predictions at regional and national levels was that the prediction for the Khachmaz region was overestimated by the maximum range ([1–5]) cumulative model, while the national forecast was underestimated. Considering that Khachmaz is one of the largest tomato producers in the country, this observation would normally indicate that several problems occurred in 2021 significantly affected the production of the region. In fact, during the seasonal field visits across the experimental region, several farmers had expressed concerns related to issues with irrigation, especially during early July, when the majority of the fields demonstrated peak vigour (seasonal NDVI maxima). Moreover, shortly after this period, the NDVI values started decreasing, although this is not necessarily related to symptoms due to water stress, as it is common for crops with high sugar and water content fruits to exhibit this behaviour during late growth stages [
17,
22].


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}