Abstract
Cloud segmentation is a fundamental step in accurately acquiring cloud cover. However, due to the nonrigid structures of clouds, traditional cloud segmentation methods perform worse than expected. In this paper, a novel deep convolutional neural network (CNN) named MA-SegCloud is proposed for segmenting cloud images based on a multibranch asymmetric convolution module (MACM) and an attention mechanism. The MACM is composed of asymmetric convolution, depth-separable convolution, and a squeeze-and-excitation module (SEM). The MACM not only enables the network to capture more contextual information in a larger area but can also adaptively adjust the feature channel weights. The attention mechanisms SEM and convolutional block attention module (CBAM) in the network can strengthen useful features for cloud image segmentation. As a result, MA-SegCloud achieves a 96.9% accuracy, 97.0% precision, 97.0% recall, 97.0% F-score, 3.1% error rate, and 94.0% mean intersection-over-union (MIoU) on the Singapore Whole-sky Nychthemeron Image Segmentation (SWINySEG) dataset. Extensive evaluations demonstrate that MA-SegCloud performs favorably against state-of-the-art cloud image segmentation methods.
1. Introduction
As an important meteorological element, clouds play fundamental roles in the Earth’s energy balance and water cycle [1,2]. Clouds not only reflect the current atmospheric movement, stability, and water vapor changes but can also be used to predict weather trends in a certain period of time in the future [3], and their generation and consumption process is also a redistribution process of water and energy. The automatic processing of cloud images is not only critical for site selection in academic research but also remains an essential daily link in follow-up observations [4]. This is because real-time cloud image processing results represent the weather conditions at the time of image acquisition and thus play an important role in telescope observation correction. Because whole-sky cameras have high temporal and spatial resolutions and can accurately reflect the local cloud coverage characteristics and changes, these cameras have become the main tool for capturing ground-based cloud images [5,6,7]. Segmenting cloud and noncloud regions to calculate cloud cover is the basis of cloud image analysis.
Traditional cloud image segmentation methods are generally based on threshold methods. Because clouds are white while the sky is blue in the daytime, Long et al. [8] used the red-to-blue ratio (R/B = 0.6) value to identify cloud and noncloud regions, and Heinle et al. [9] modified the criterion and considered the difference R-B (R-B = 30) instead of the ratio R/B. Moreover, Krauz et al. [10] presented a modified k-means++ color-based segmentation method for ground-based cloud image detection. However, as these methods are affected by the specifications of the utilized camera and the light and weather conditions, the accuracy of threshold-based segmentation algorithms is often unsatisfactory [11]. Therefore, superpixel segmentation algorithms have been proposed to overcome the drawbacks of threshold-based algorithms. Liu et al. [12] proposed the superpixel approach, in which the local threshold of each superpixel is first calculated to determine the threshold matrix of the entire image, and clouds are ultimately detected through comparisons using the obtained threshold matrix. Subsequently, Dev et al. [13] proposed a threshold-free superpixel approach to nighttime sky/cloud image segmentation.
In recent years, deep convolutional neural network approaches have gradually become the mainstream technology used in cloud image segmentation research due to their powerful feature extraction capabilities. Drönner et al. [14] proposed a fast cloud image segmentation method named CS-CNN that requires only 25 ms computation time for segmentation of images with 508 × 508 pixels. Dev et al. [15] designed a lightweight deep learning algorithm called CloudSegNet for both daytime and nighttime cloud image segmentation tasks. Moreover, Shi et al. [16] proposed an enhancement fully convolutional network (EFCN), an automatic cloud segmentation architecture to segment cloud pixels from nychthemeron all-sky camera images. Later, Shi et al. optimized the U-shaped network (U-Net) and proposed CloudU-Net [17] and CloudU-Netv2 [18] to segment daytime and nighttime cloud images. CloudU-Netv2 uses bilinear upsampling, position, and channel attention modules to optimize the performance of CloudU-Net. Additionally, Xie et al. [19] proposed a U-shaped network named SegCloud to achieve segmentation of sky, cloud, and sun regions.
Although cloud image segmentation research is continuously progressing, the results of cloud image segmentation are worse than expected due to the following two points: differences in color exist between daytime and nighttime cloud images, and the boundaries of clouds are difficult to define due to blurriness. The lightweight network CloudSegNet does not sufficiently extract cloud features and cannot obtain deep semantic features of daytime and nighttime cloud images, resulting in an unsatisfactory segmentation effect. The cloud image segmentation network based on the U-Net architecture restores the lost features through simple skip connections, which do not fully utilize the diverse features, resulting in incorrect cloud boundary segmentation. MA-SegCloud overcomes the problem of color differences between daytime cloud images and nighttime cloud images by extracting high-level features of cloud images because their colors differ but their high-level features are the same. MA-SegCloud has a strong feature extraction ability that is implemented by first using the convolution and identity blocks to extract features. Then, it uses the multibranch asymmetric convolution module (MACM) to continue to extract features of different scales and finally performs feature fusion of different levels. The MACM not only enables the network to capture more contextual information in a larger area but can also adaptively adjust the feature channel weights. In addition, MA-SegCloud uses the squeeze-and-excitation module (SEM) and the convolutional block attention module (CBAM) as attention mechanisms to optimize the performance of the network so that the network focuses on the cloud edge information and reasonably divides the cloud boundaries.
In summary, the main contributions of this work are as follows:
- The CBAM and SEM are used in the MA-SegCloud, and ablation experiments confirm that these two attention modules can improve the performance of this model [20,21];
- The MACM is first proposed to improve the ability of the network to capture more contextual information in a larger area and adaptively adjust the feature channel weights;
- MA-SegCloud performs favorably against state-of-the-art cloud image segmentation methods.
The remainder of the paper is organized as follows. Section 2 describes the architecture of the network. Section 3 introduces the Singapore Whole-sky Nychthemeron Image Segmentation (SWINySEG) dataset, implementation details, evaluation metrics, and a comparison of the experimental results. Finally, the discussions and conclusions are presented in Section 4 and Section 5, respectively.
2. Methods
2.1. Overall Architecture of MA-SegCloud
MA-SegCloud is composed of an encoder and a decoder network, as shown in Figure 1. The code of MA-SegCloud including model, training, prediction, and evaluation algorithms in this paper is available online at https://github.com/LiwenZhang1/MA-SegCloudv1-.git, 1 October 2021.
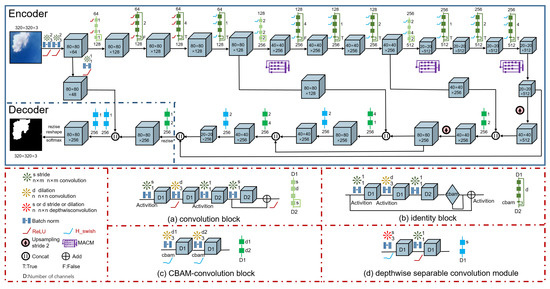
Figure 1.
Depiction of the proposed MA-SegCloud architecture. The green, yellow, and red asterisk-shaped symbols indicate standard convolution, atrous convolution, and depth-separable convolution, respectively. Concat and Add represent feature channel concatenation and feature elementwise addition, respectively. H_swish was first proposed in MobileNetv3 and can prevent numerical precision losses when quantizing [22].
The encoder network performs feature extraction and merges the target features from different scales. In the first step, the deep residual structure is adopted to extract the target features. This structure consists of a convolution block and an identity block. In contrast to the standard deep residual structure [23], atrous convolution is used in the second convolutional layer to increase the receptive field without requiring additional calculations [24]. In addition, CBAM is added to the identity block to strengthen the useful features for cloud segmentation.
In the second step, the MACM is proposed to further extract the features of different stages extracted by the deep residual structure. This module not only improves the ability of the network to extract cloud features but also adaptively adjusts the weights of feature channels by applying the SEM. The different scale features are fused because multiscale feature fusion can overcome the drawbacks of the U-Net and effectively improve the performance of the segmentation network.
The decoder network corresponds to the part outlined by the blue dashed lines in Figure 1. It is responsible for restoring the feature map to the original image size. Clouds have rich low-dimensional features such as color and texture features. To make use of these features, the high- and low-dimensional features output by the encoder are fused. Finally, the feature map is restored to the same size as the input image, and predictions can be made.
2.2. Convolutional Block Attention Module (CBAM)
The CBAM is applied to the identity block and CBAM-convolution block, as illustrated in Figure 2. The module first performs maximum pooling and average pooling on the input feature maps to reduce the dimensionality of the feature maps into two vectors and then sends the maps to the multilayer perceptron (MLP) for learning. These two vectors share one group weight value. The vector output in the perceptron is then added and sent to the sigmoid function for activation. Later, the features are subjected to average pooling, maximum pooling, convolution, and sigmoid function procedures to concentrate even more on the cloud pixel characteristics. Finally, the convolutional features are multiplied by the original features to obtain the final features of the cloud image.
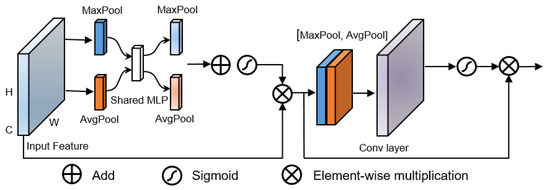
Figure 2.
Convolutional block attention module (CBAM) architecture.
2.3. Squeeze-and-Excitation Module (SEM)
SEM is applied to the MACM, as illustrated in Figure 3. The input feature map is considered a combination of channels . First, the squeeze process is implemented by global average pooling to obtain the global spatial information in vector with its element [21]
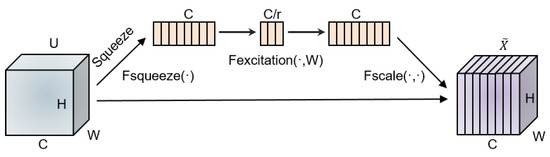
Figure 3.
Squeeze-and-excitation module (SEM) architecture.
Second, this vector is transformed to [21]
where and are the parameters of the two fully connected layers and and are the H_swish [22] and ReLU6 [25] activation functions, respectively. Two fully connected layers with parameter r are added before the ReLU6 and H_swish activation functions to limit the complexity of the model and aid generalization. The parameter r indicates the channel excitation, which encodes the channelwise dependencies. The best performance is obtained by r = 4. Finally, the output feature is obtained by multiplying s and the input [21]
2.4. Multibranch Asymmetric Convolution Module (MACM)
The MACM can be divided into three components: asymmetric convolution, depthwise separable convolution with different dilation rates, and SEM, as shown in Figure 4. In Inceptionv3 [26], the asymmetric convolution layer replaces the n×n convolution with 1 × n and n × 1 convolution layers, which can reduce the number of computations. Borrowing from Inceptionv3, the 5 × 5 and 7 × 7 convolutions are replaced with asymmetric convolutions. The basic intent of depthwise separable convolutions with different dilation rates is to generate high-dimensional feature maps that capture more contextual information in larger areas while maintaining the same number of parameters, which is beneficial for the segmenting of smaller clouds. The dilation rates of the four branches are set to 1, 3, 5, and 7. Each branch utilizes SEM to increase the weight of useful channels for cloud segmentation. Finally, each branch is concatenated and added to the input.
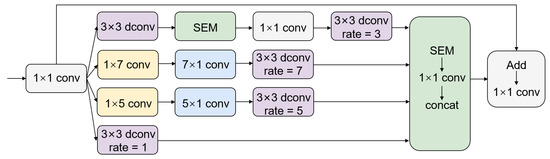
Figure 4.
Multibranch asymmetric convolution module (MACM) architecture. Depthwise separable convolution is represented by dconv.
3. Results
3.1. Dataset
In this study, the SWINySEG dataset is used to train and test the cloud image segmentation model [15]. All cloud images in the SWINySEG dataset are sourced from two publicly available sky/cloud image segmentation datasets: the Singapore Whole Sky IMaging SEGmentation (SWIMSEG) dataset and Singapore Whole sky Nighttime Image SEGmentation (SWINSEG) dataset. These whole sky images were taken at Nangyang Technological University Singapore with a calibrated all-sky camera. The SWINySEG dataset contains 6078 daytime and 690 nighttime cloud images, along with corresponding labels that were annotated after consultations with experts from Singapore Meteorological Services. Each cloud image and its corresponding label image are resized to 320 × 320. Details about these cloud images are shown in Figure 5. We randomly select 90% of the images as a training set for training and 10% of the images as a validation set to verify the effectiveness of the model.

Figure 5.
Daytime and nighttime cloud images and their corresponding ground-truth information in the SWINySEG dataset. Clouds and sky are shown in white and black colors, respectively. (a) Daytime. (b) Nighttime.
3.2. Implementation
In this work, experiments are performed on an NVIDIA GeForce RTX 2080ti graphics processing unit (GPU) with 11 GB of memory. The Keras 2.1.5 framework and Python 3.6 version are used to construct the MA-SegCloud and seven different state-of-the-art cloud image segmentation methods, CloudSegNet [15], U-Net [27], PSPNet [28], SegCloud [19], CloudU-Netv2 [18], DeeplabV3+ [29], and CloudU-Net [17] architecture. The seven different state-of-the-art cloud image segmentation approaches are retrained, and the models are built according to the structure given in the corresponding papers. Since cloud segmentation is a binary pixel-level classification problem, the loss function of all algorithms chooses the binary cross-entropy loss function. The batch size of all algorithms is set to 8. The CloudSegNet, CloudU-netv2, SegCloud, and CloudU-Net adopt the hyperparameters applied in their papers, with the exception of batch size. The detailed hyperparameter settings are shown in Table 1, where SegCloud applied the momentum parameter with a decay of 0.9. For U-Net, PSPNet, and DeepLabV3+, we did not finely adjust the learning rate, tried only the values 0.01, 0.001, and 0.0001, and discovered that the model with the learning rate set to 0.001 works best.

Table 1.
The detailed hyperparameter settings of MA-SegCloud and the other seven cloud image segmentation methods.
The MA-SegCloud is trained in 300 epochs using the Adam optimizer and the binary cross-entropy loss function. The binary cross-entropy loss function is calculated as follows:
where N is the batch size, y is the true label (1 represents cloud elements and 0 represents sky elements), and p(y) is the predicted probability that the pixel belongs to the y label. The sum in Formula (4) is over all the pixels in all the images in one batch. We first load the training set data for training, and after the training, load the validation set data to calculate the validation set Loss. Finally, the training epoch with the lowest validation loss was chosen to evaluate the performance of the model.
3.3. Evaluation Metrics
To evaluate the performance of MA-SegCloud, the receiver operating curve (ROC) and visualization segmentation results are applied to qualitatively describe the performance of the proposed model. We convert the probabilistic map to a binary map using the optimal segmentation threshold determined by ROC. Then, we compare the predicted image and the corresponding label image for each pixel to determine whether each pixel is correctly predicted, and quantitatively analyze the performance of the network using evaluation indicators such as precision, recall, F1-score, error rate, and mean intersection over union (MIoU).
3.4. Comparison of the Experimental Results
The MA-SegCloud output represents a probability mask. Because the cloud image ground-truth maps are binary, probabilities obtained using thresholds are required to convert the outputs to binary maps for comparison. The ROC technique is applied to the daytime + nighttime validation dataset to explore the impacts of the selected thresholds on MA-SegCloud and seven other algorithms. We increased the threshold from 0 to 1 in increments of 0.01 and calculated the true positive rate (TPR) and false positive rate (FPR) to draw the receiver operating curve. The larger the area enclosed by the curve and horizontal axis is, the better the performance of the cloud segmentation method. Figure 6 indicates that MA-SegCloud has the best performance. The best threshold for all algorithms, 0.5, is chosen to convert the probability maps into binary maps.
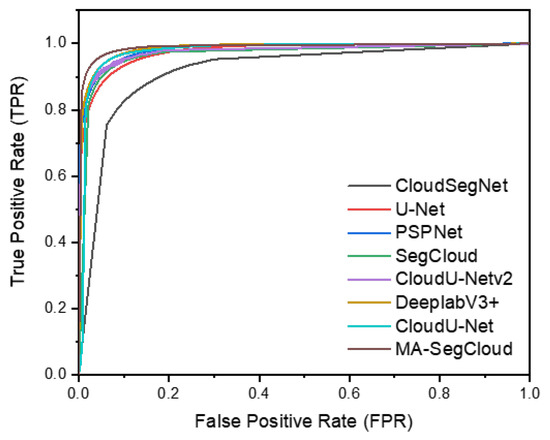
Figure 6.
ROC curve of MA-SegCloud and seven other algorithms.
Figure 7 shows the cloud mask outputs obtained from MA-SegCloud and the other seven cloud image segmentation methods. The segmentation results clearly show that MA-SegCloud has the best performance for daytime and nighttime cloud image segmentation. In addition, the figure shows that MA-SegCloud is superior to the other seven algorithms in segmenting the boundaries of clouds and small clouds. As shown by the red box at the bottom of the nighttime cloud chart, only MA-SegCloud successfully segmented long and narrow-shaped clouds.

Figure 7.
Visualization results on SWINySEG dataset. (a1,a2) Input images, (b1,b2) ground truth, (c1,c2) CloudSegNet, (d1,d2) U-Net, (e1,e2) PSPNet, (f1,f2) SegCloud, (g1,g2) CloudU-Netv2, (h1,h2) DeepLabV3+, (i1,i2) CloudU-Net, and (j1,j2) MA-SegCloud.
Table 2 shows the quantitative segmentation results obtained using MA-SegCloud and the other seven algorithms. Notably, MA-SegCloud and the other seven cloud image segmentation methods are trained only once on the daytime + nighttime datasets and then separately evaluated with daytime images, nighttime images, and daytime + nighttime images. The table shows that MA-SegCloud outperforms the state-of-the-art cloud image segmentation method CloudU-Net in the daytime and daytime + nighttime datasets. In the nighttime dataset, the segmentation recall of MA-SegCloud is lower than that of CloudU-Net, but the other indicators are better than CloudU-Net. In the daytime + nighttime dataset, compared to CloudU-Net, MA-SegCloud obtains a 0.015 increase in accuracy, 0.016 in precision, 0.012 in recall, 0.014 in F1-score, and 0.027 in MIoU, along with a decrease of 0.015 in error rate. The higher the values of accuracy, precision, recall, F1-score, and MIoU are, the better the cloud segmentation results of the model are; the opposite is true for the error rate. These evaluation metrics are mutually corroborated with the ROC and visualization output results, indicating that MA-SegCloud performs favorably against state-of-the-art cloud image segmentation methods.
Table 2.
Performance comparison between MA-SegCloud and other seven cloud image segmentation algorithms.
To verify the performance improvement of MA-SegCloud by the CBAM, SEM, and MACM, we perform an extensive ablation study. Note that the SEM is applied to the MACM. Figure 8 shows the visual output of the effect on the segmentation by adding different modules. Comparing Figure 8(g1,h1), the findings indicate that the absence of SEM and CBAM modules makes the cloud boundary inaccurate. Comparison of Figure 8(d1,h1) shows that without MACM, the network produces false detections, including false detections of small target clouds. Table 3 shows that the CBAM, SEM, and MACM can improve the performance of MA-SegCloud. After adding the SEM and CBAM, the accuracy, precision, recall, F1-score, and MIoU values of the model were improved by 0.021, 0.020, 0.021, 0.020, and 0.039, respectively. The SEM and CBAM improve the performance of the cloud image segmentation network by approximately equal margins. The addition of the MACM increased the accuracy, precision, recall, and F1 and MIoU values by 0.020, 0.029, 0.009, 0.019, and 0.038, respectively. The MACM has the greatest impact on the network segmentation performance because it not only enables the network to capture more contextual information in a larger area but can also adaptively adjust the feature channel weights. The experimental results indicate that the SEM, CBAM, and MACM all improve the performance of the cloud image segmentation network to varying degrees.

Figure 8.
Visual output of ablation experiments on the SWINySEG dataset. (a1,a2) Input images, (b1,b2) ground truth, (c1,c2) without MACM and CBAM, (d1,d2) without MACM, (e1,e2) without SEM, (f1,f2) without CBAM, (g1,g2) without SEM and CBAM, and (h1,h2) MA-SegCloud.
Table 3.
Ablation experiments of the CBAM, SEM and MACM.
The parameters, floating point operations (FLOPs), training time, and testing time of MA-SegCloud and the other seven algorithms are shown in Table 4. The parameters and FLOPs represent the number of operations to process an image at a particular resolution. The training time represents the time it takes to train the model to achieve convergence. The test time refers to the time taken to complete the prediction of 676 cloud images. The state-of-the-art cloud image segmentation method CloudU-Net has a comparable training time to MA-SegCloud, but the parameters, FLOPs, and test time are much larger than those of MA-SegCloud. Compared with the cloud image segmentation method based on the U-Net architecture, MA-SegCloud has a smaller number of parameters and FLOPs. Therefore, MA-SegCloud has more advantages in practical applications.
Table 4.
Parameters, FLOPs, Training Time, and Testing Time of Each Model.
4. Discussion
Ground-based cloud image segmentation is the basis for the realization of ground-based meteorological cloud observations. By segmenting the cloud pixels in ground-based cloud images, it is not only possible to complete local cloud amount statistics and realize observatory site selections but also to explain natural phenomena, such as weather changes, climate phenomena, and atmospheric movements, which has far-reaching research significance.
The encoder of the CloudSegNet network only consists of three convolution layers and max-pooling layers, which cannot fully extract the deep semantic features of daytime and nighttime cloud images, resulting in low segmentation accuracy of the network. The continuous and simple downsampling of the cloud image segmentation network based on the U-Net architecture easily leads to information loss and cannot accurately segment the cloud area. MA-SegCloud overcomes the above problems by building an encoder with a strong feature extraction capability. The encoder network of MA-SegCloud consists of a convolution block, identity block, MACM, and feature fusion part. The residual modules, convolution block, and identity block can deepen the network and fully extract cloud features. Using the CBAM attention mechanism in the identity block allows the network to continuously obtain spatial and channel information during the downsampling process. The findings reported in Table 3 prove that using CBAM can effectively improve the accuracy of cloud image segmentation.
In ground-based cloud images, the shapes and sizes of clouds vary. Therefore, extracting multiscale features of images helps to reduce the loss of spatial information and can effectively improve the accuracy of cloud segmentation. The MACM is used in MA-SegCloud to fuse cloud features of different scales and improve the ability of the model to extract multiscale information. In addition, the MACM can also adjust the weights of different channels to make the network focus more attention on the useful features for cloud image segmentation. Figure 8 shows that the use of MACM can overcome the missed detections of small target clouds by the network and improve the network segmentation effect on small target clouds. Compared with the cloud image segmentation network based on the U-Net architecture that adopts simple feature fusion, the feature fusion of MA-SegCloud is denser, which enables fully utilizing different feature levels and improves the performance of the network. If a more diverse cloud image dataset is applied to our model, it is bound to achieve better segmentation results than other methods.
The powerful feature extraction capability obtained by MA-SegCloud is not achieved at the expense of the loss of model parameters and computation. Because a large number of depthwise separable convolutions are used in the model, the amount of parameters and the amount of computation can be effectively reduced. Table 4 shows that the parameters and FLOPs of MA-SegCloud are lower than all U-Net-based cloud image segmentation methods. Therefore, under the condition of ensuring segmentation accuracy, MA-SegCloud consumes less memory and computing resources.
The above results indicate that compared with the best cloud image segmentation methods, MA-SegCloud has significant advantages in cloud image segmentation accuracy, model parameters, and computation. However, we did not consider the effect of different kinds of clouds on the segmentation network. In addition, the model needs to be further lightened to reduce the overhead in practical applications.
5. Conclusions
In this paper, a novel deep neural convolutional network architecture called MA-SegCloud was proposed for accurate cloud image segmentation. It has a powerful cloud recognition capability and can automatically segment ground-based cloud images. The model is composed of the deep residual structure, MACM, CBAM, and SEM. When the CBAM and SEM are added to the network, ablation experiments confirm that these two attention modules can improve the performance of the cloud image segmentation model. The MACM is proposed to improve the ability of the network to capture more contextual information in a larger area and adaptively adjust the feature channel weights. Extensive evaluations demonstrate that MA-SegCloud has powerful cloud segmentation capabilities compared with the state-of-the-art methods and prove that the CBAM, SEM, and MACM can effectively improve the performance of the cloud image segmentation network. Furthermore, compared with the state-of-the-art cloud image segmentation method CloudU-Net, MA-SegCloud has a smaller number of parameters and FLOPs, which is more conducive to practical applications. In future work, the performance of the model must be further optimized and a more efficient model is needed to complete real-time cloud image segmentation. In addition, it may be necessary to explore the segmentation effects of different types of clouds. Generally, segmentation is before classification, but if we can have some type of information and relevant cloud images in advance, by taking them as a training dataset, we may find another machine learning method for improving the segmentation process.
Author Contributions
Methodology, L.Z.; software, W.W.; validation, B.Q. and A.L.; formal analysis, M.Z. and X.L.; data curation, L.Z.; writing—original draft preparation, L.Z.; writing—review and editing, B.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Joint Research Fund in Astronomy through a cooperative agreement between the National Science Foundation of China (NSFC) and the Chinese Academy of Sciences (CAS) under Grant U1931134.
Data Availability Statement
The SWINySEG dataset used in this work belong to open source dataset available in their corresponding references within this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Calbo, J.; Long, C.N.; Gonzalez, J.A.; Augustine, J.; McComiskey, A. The thin border between cloud and aerosol: Sensitivity of several ground based observation techniques. Atmos. Res. 2017, 196, 248–260. [Google Scholar] [CrossRef]
- Klebe, D.I.; Blatherwick, R.D.; Morris, V.R. Ground-based all-sky mid-infrared and visible imagery for purposes of characterizing cloud properties. Atmos. Meas. Tech. 2014, 7, 637–645. [Google Scholar] [CrossRef]
- Schneider, S.H. Cloudiness as a global climatic feedback mechanism: The effects on the radiation balance and surface temperature of variations in cloudiness. J. Atmos. Sci. 1972, 29, 1413–1422. [Google Scholar] [CrossRef]
- Hudson, K.; Simstad, T. The Share Astronomy Guide to Observatory Site Selection; Neal Street Design Inc.: San Diego, CA, USA, 2010; Volume 1. [Google Scholar]
- Wang, G.; Kurtz, B.; Kleissl, J. Cloud base height from sky imager and cloud speed sensor. Sol. Energy 2016, 131, 208–221. [Google Scholar] [CrossRef]
- Kuji, M.; Murasaki, A.; Hori, M.; Shiobara, M. Cloud fractions estimated from shipboard whole-sky camera and ceilometer observations between East Asia and Antarctica. J. Meteorol. Soc. Jpn. Ser. II 2018, 96, 201–214. [Google Scholar] [CrossRef]
- Aebi, C.; Gröbner, J.; Kämpfer, N. Cloud fraction determined by thermal infrared and visible all-sky cameras. Atmos. Meas. Tech. 2018, 11, 5549–5563. [Google Scholar] [CrossRef]
- Long, C.; Sabburg, J.; Calbo, J.; Pages, D. Retrieving cloud characteristics from ground-based daytime color all-sky images. J. Atmos. Ocean. Technol. 2006, 23, 633–652. [Google Scholar] [CrossRef]
- Heinle, A.; Macke, A.; Srivastav, A. Automatic cloud classification of whole sky images. Atmos. Meas. Tech. 2010, 3, 557–567. [Google Scholar] [CrossRef]
- Krauz, L.; Janout, P.; Blažek, M.; Páta, P. Assessing Cloud Segmentation in the Chromacity Diagram of All-Sky Images. Remote Sens. 2020, 12, 1902. [Google Scholar] [CrossRef]
- Long, C.N. Correcting for circumsolar and near-horizon errors in sky cover retrievals from sky images. Open Atmos. Sci. J. 2010, 4, 45–52. [Google Scholar] [CrossRef][Green Version]
- Liu, S.; Zhang, L.; Zhang, Z.; Wang, C.; Xiao, B. Automatic Cloud Detection for All-Sky Images Using Superpixel Segmentation. IEEE Geosci. Remote Sens. Lett. 2015, 12, 354–358. [Google Scholar]
- Dev, S.; Savoy, F.M.; Lee, Y.H.; Winkler, S. Nighttime Sky/Cloud Image Segmentation. In Proceedings of the 2017 24th IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 345–349. [Google Scholar]
- Drönner, J.; Korfhage, N.; Egli, S.; Mühling, M.; Thies, B.; Bendix, J.; Freisleben, B.; Seeger, B. Fast Cloud Segmentation Using Convolutional Neural Networks. Remote Sens. 2018, 10, 1782. [Google Scholar] [CrossRef]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. Cloudsegnet: A deep network for nychthemeron cloud image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef]
- Shi, C.; Zhou, Y.; Qiu, B.; He, J.; Ding, M.; Wei, S. Diurnal and nocturnal cloud segmentation of all-sky imager (ASI) images using enhancement fully convolutional networks. Atmos. Meas. Tech. 2019, 12, 4713–4724. [Google Scholar] [CrossRef]
- Shi, C.; Zhou, Y.; Qiu, B.; Guo, D.; Li, M. CloudU-Net: A Deep Convolutional Neural Network Architecture for Daytime and Nighttime Cloud Images’ Segmentation. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1688–1692. [Google Scholar] [CrossRef]
- Shi, C.; Zhou, Y.; Qiu, B. CloudU-Netv2: A Cloud Segmentation Method for Ground-Based Cloud Images Based on Deep Learning. Neural Process. Lett. 2021, 53, 2715–2728. [Google Scholar] [CrossRef]
- Xie, W.; Liu, D.; Yang, M.; Chen, S.; Wang, B.; Wang, Z.; Xia, Y.; Liu, Y.; Wang, Y.; Zhang, C. SegCloud: A novel cloud image segmentation model using a deep convolutional neural network for ground-based all-sky-view camera observation. Atmos. Meas. Tech. 2020, 13, 1953–1961. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).