
Deep Learning with Adaptive Attention for Seismic Velocity Inversion

 ,
,
Abstract
:1. Introduction
2. Methodology
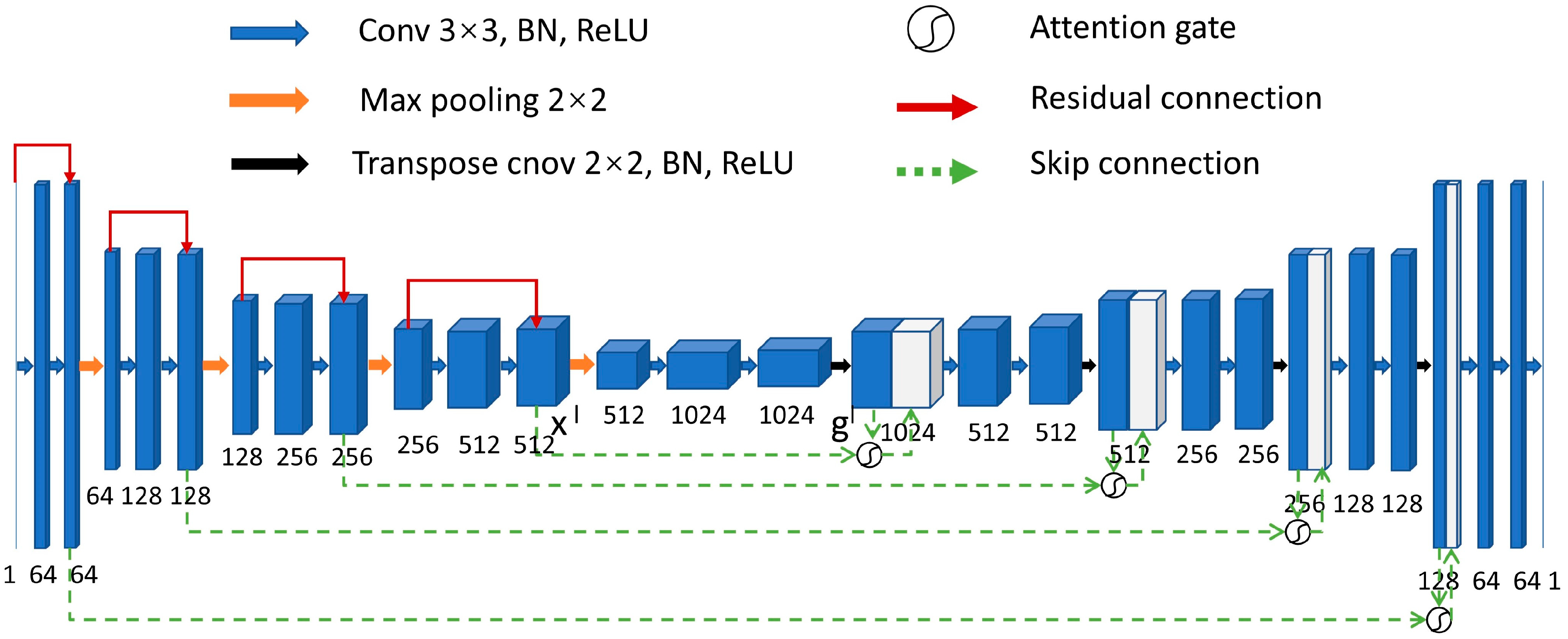
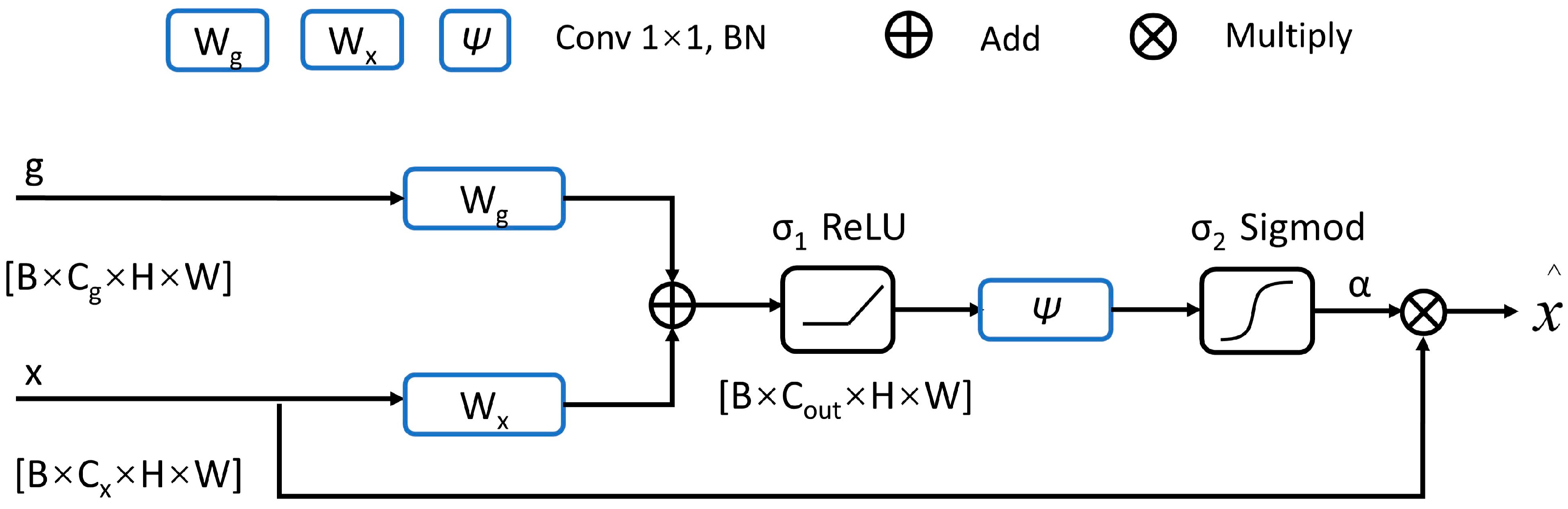
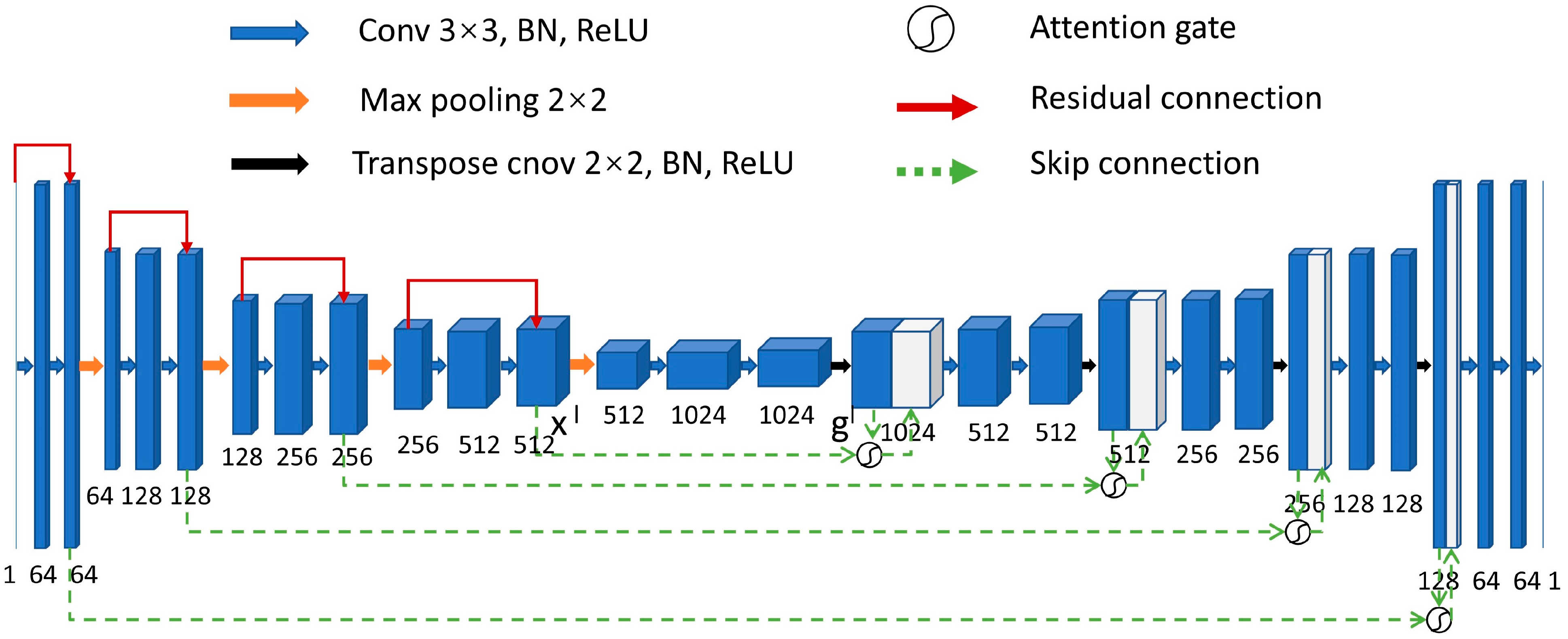
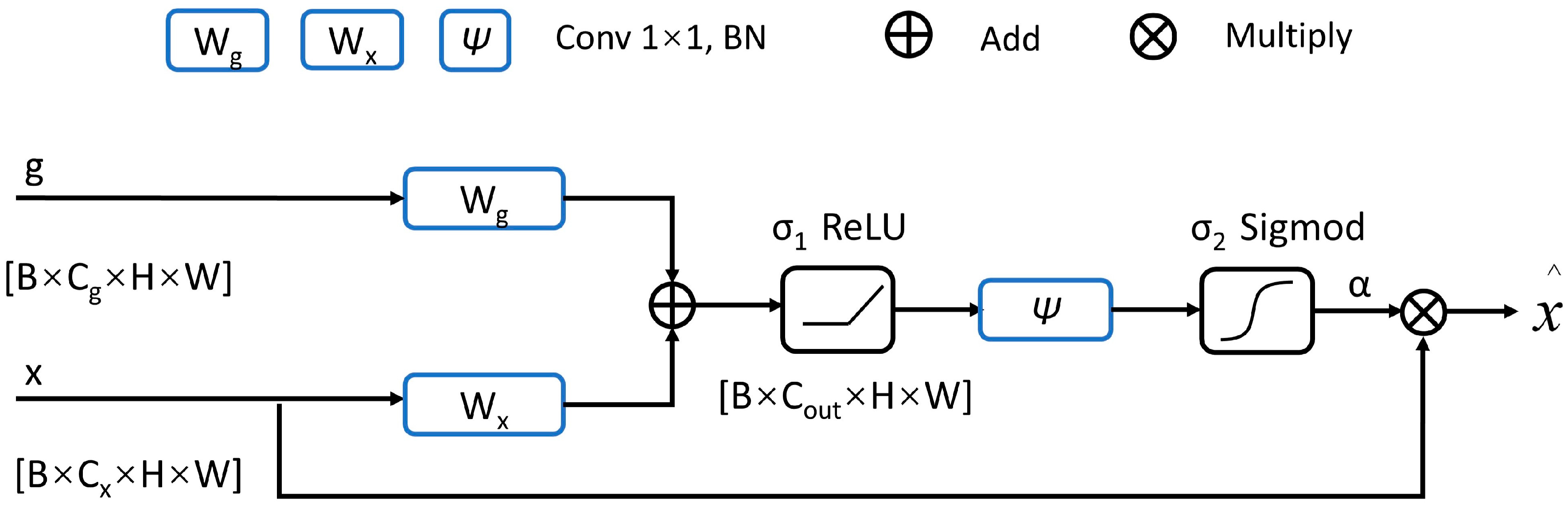
2.1. Network Architecture
2.2. Loss Function
2.3. Quantitative Metrics
3. Experiments
3.1. Data Preparation
3.2. Implementation Details
4. Results
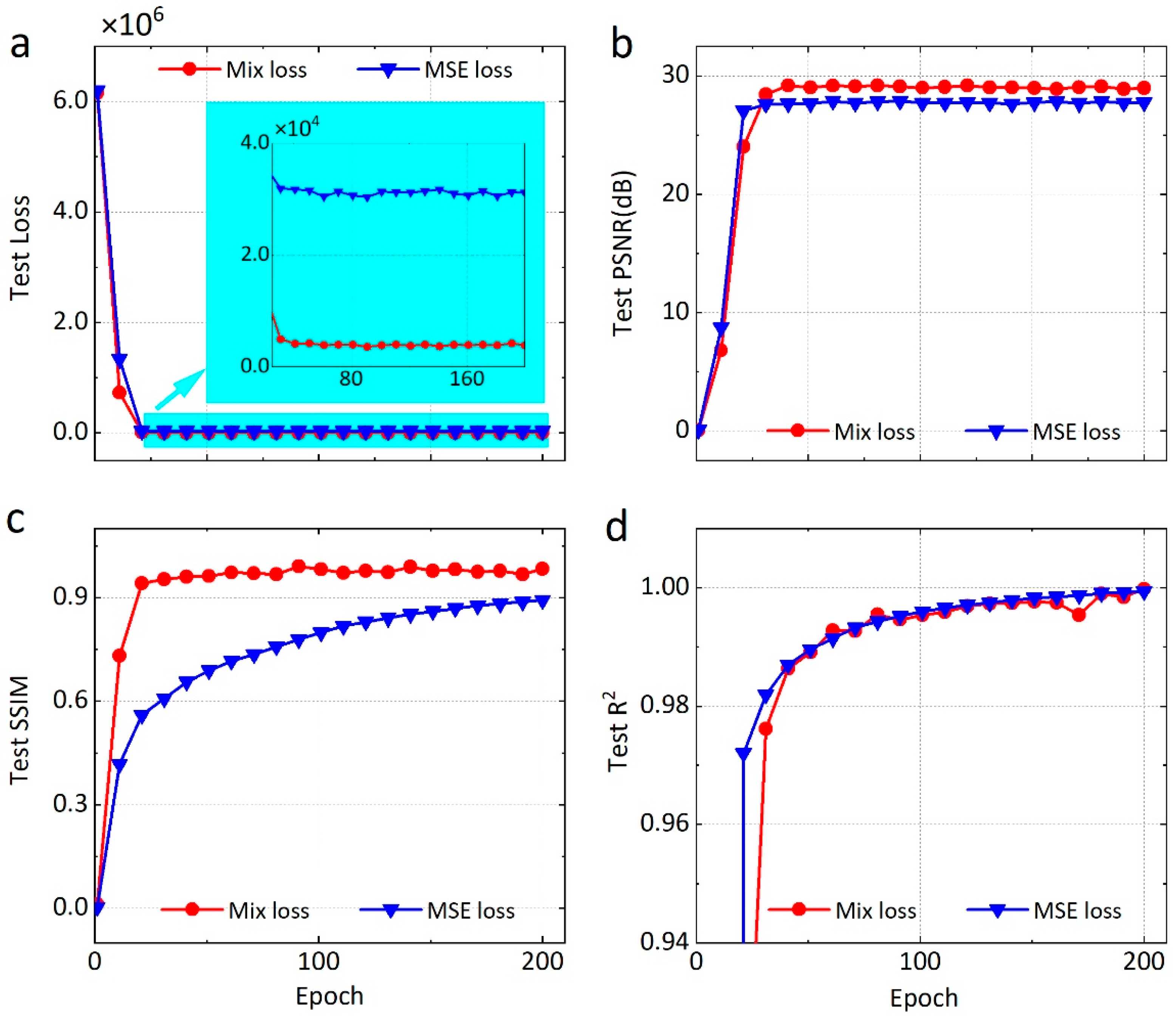
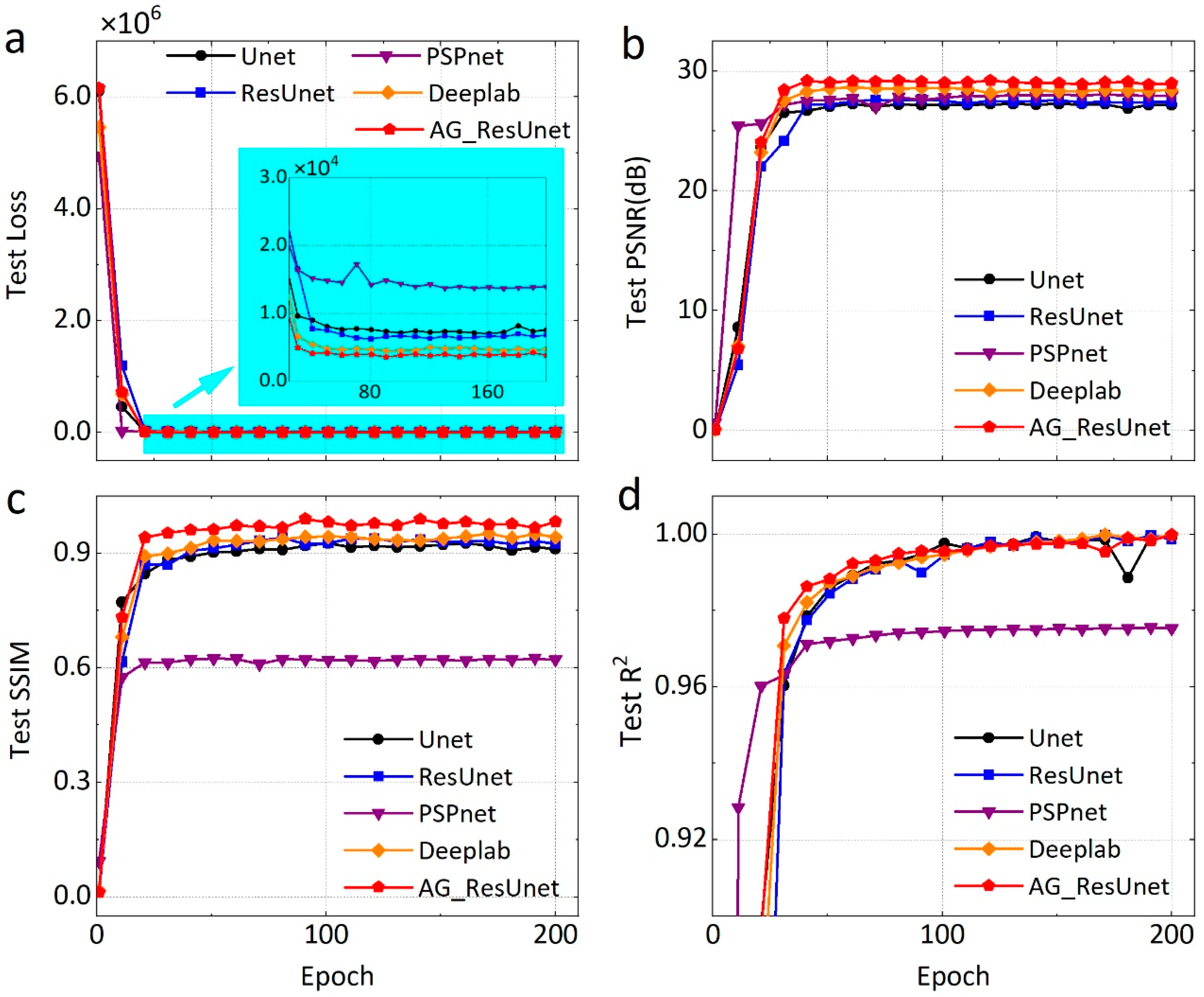
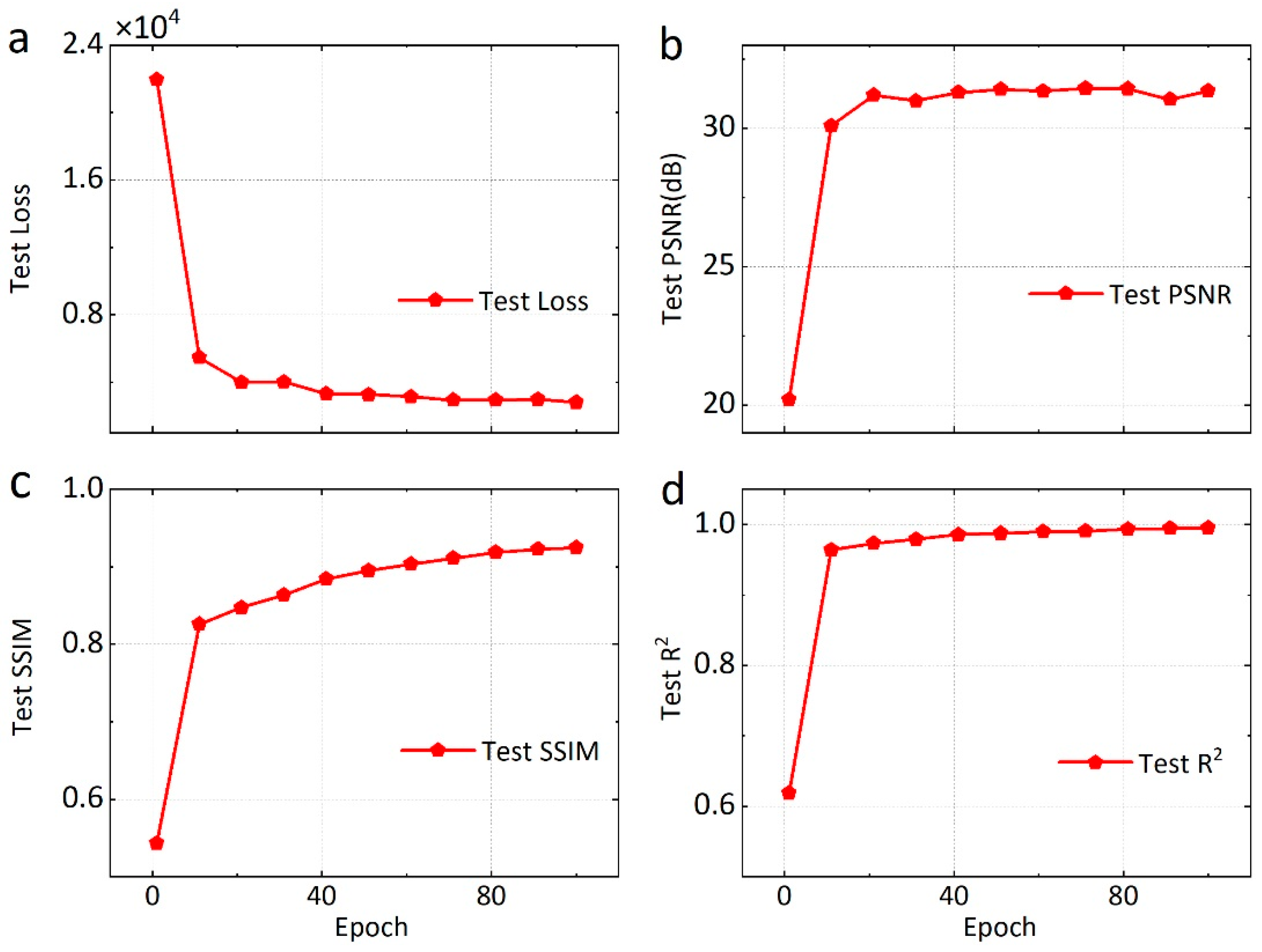
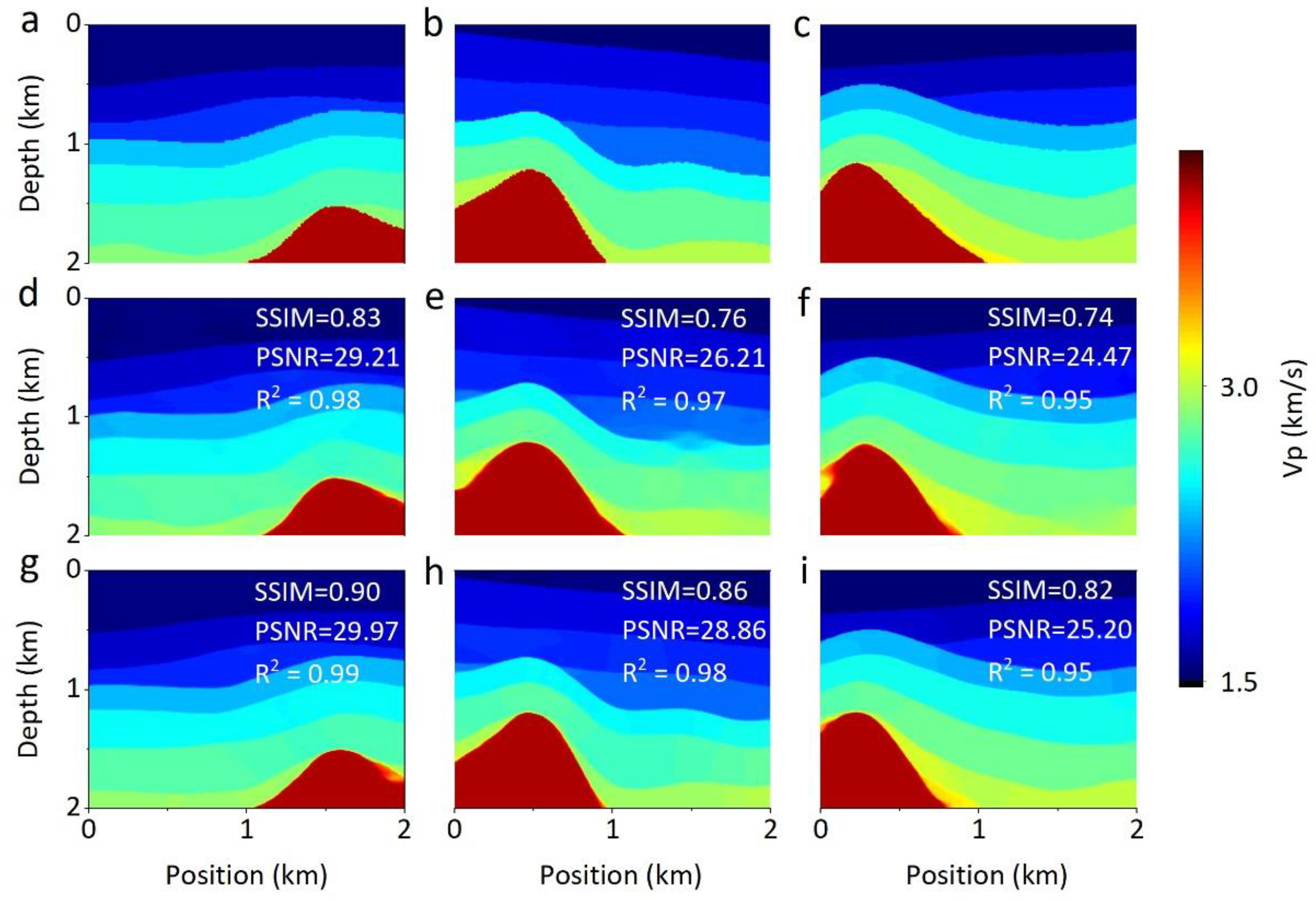
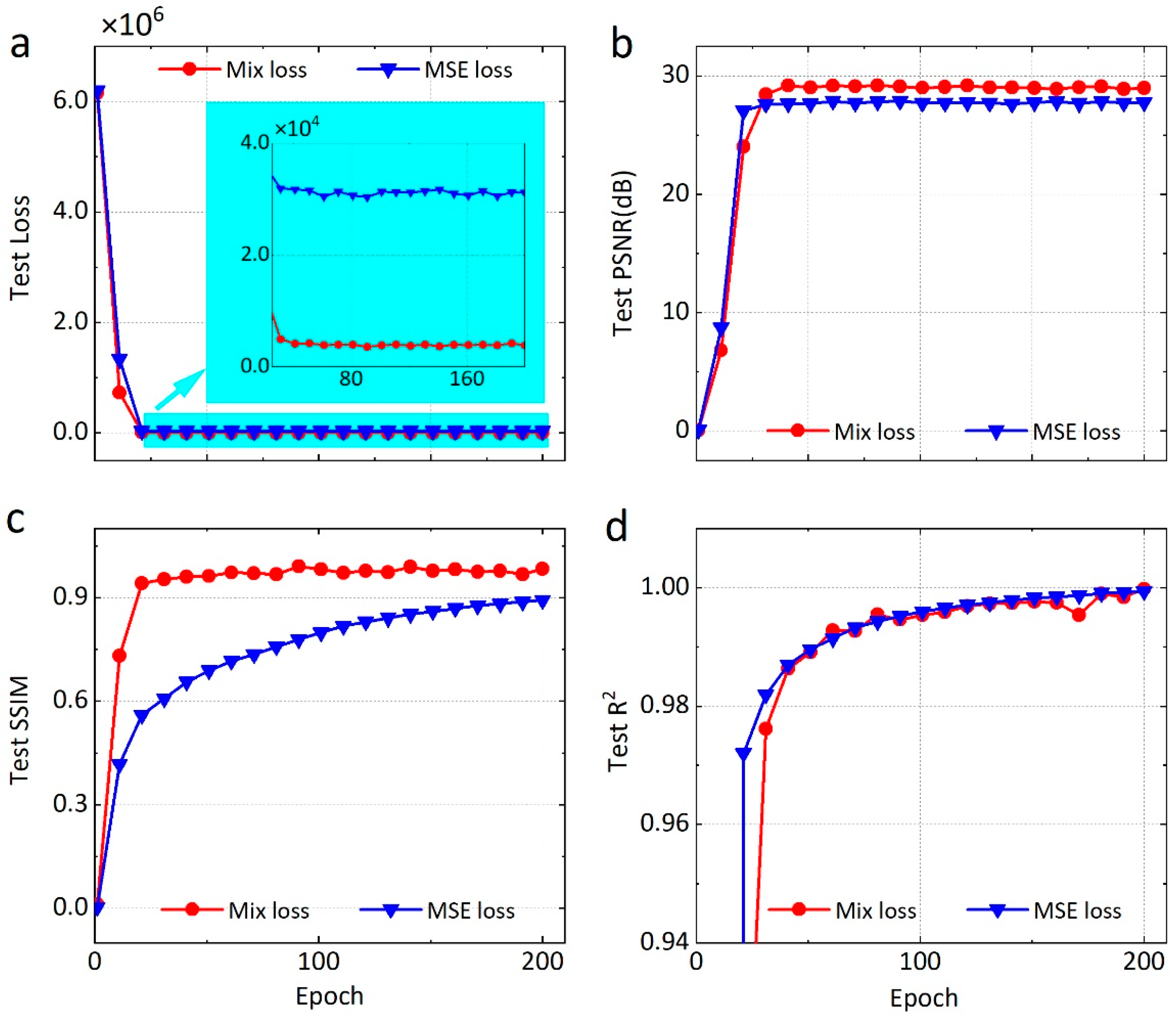
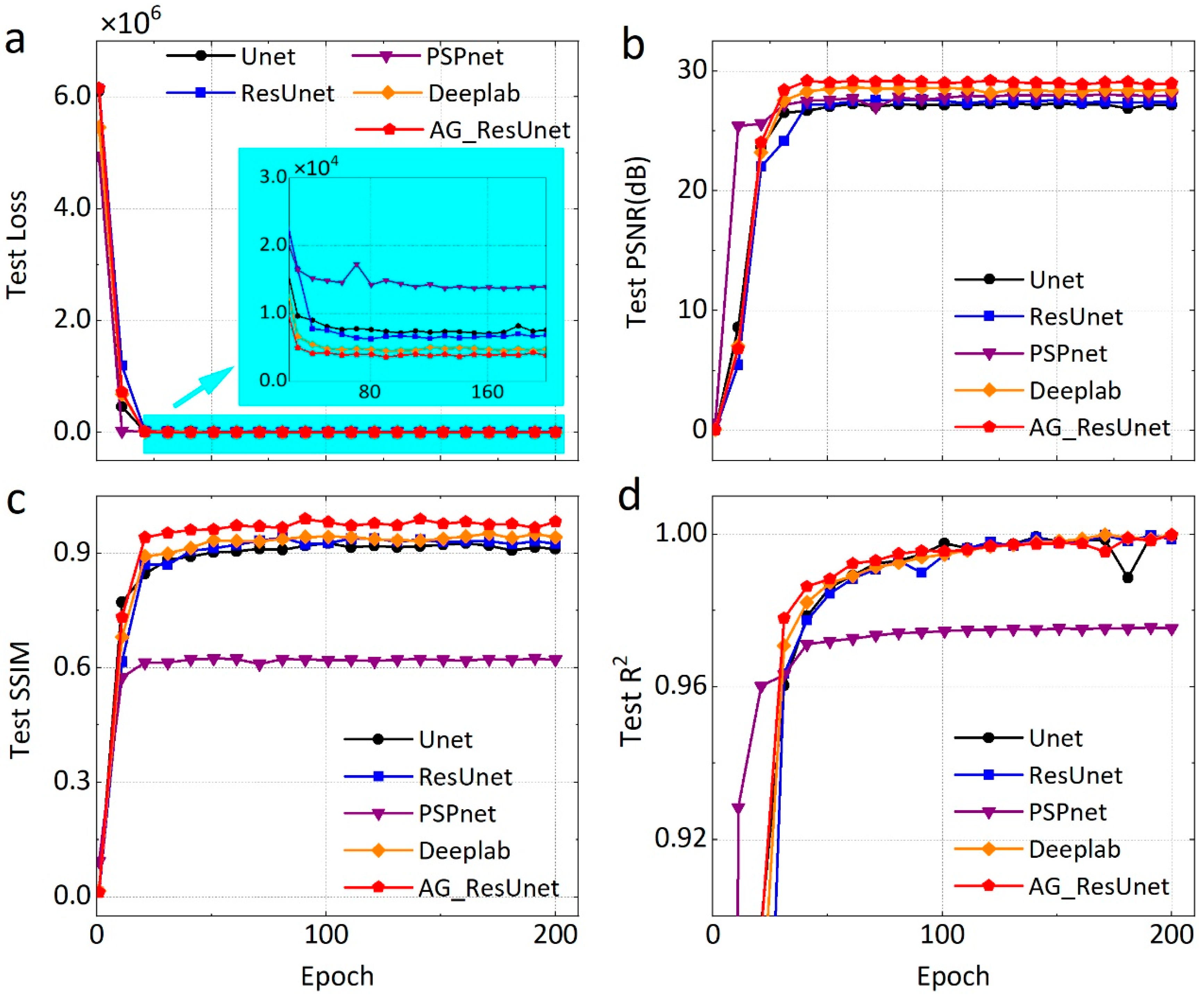
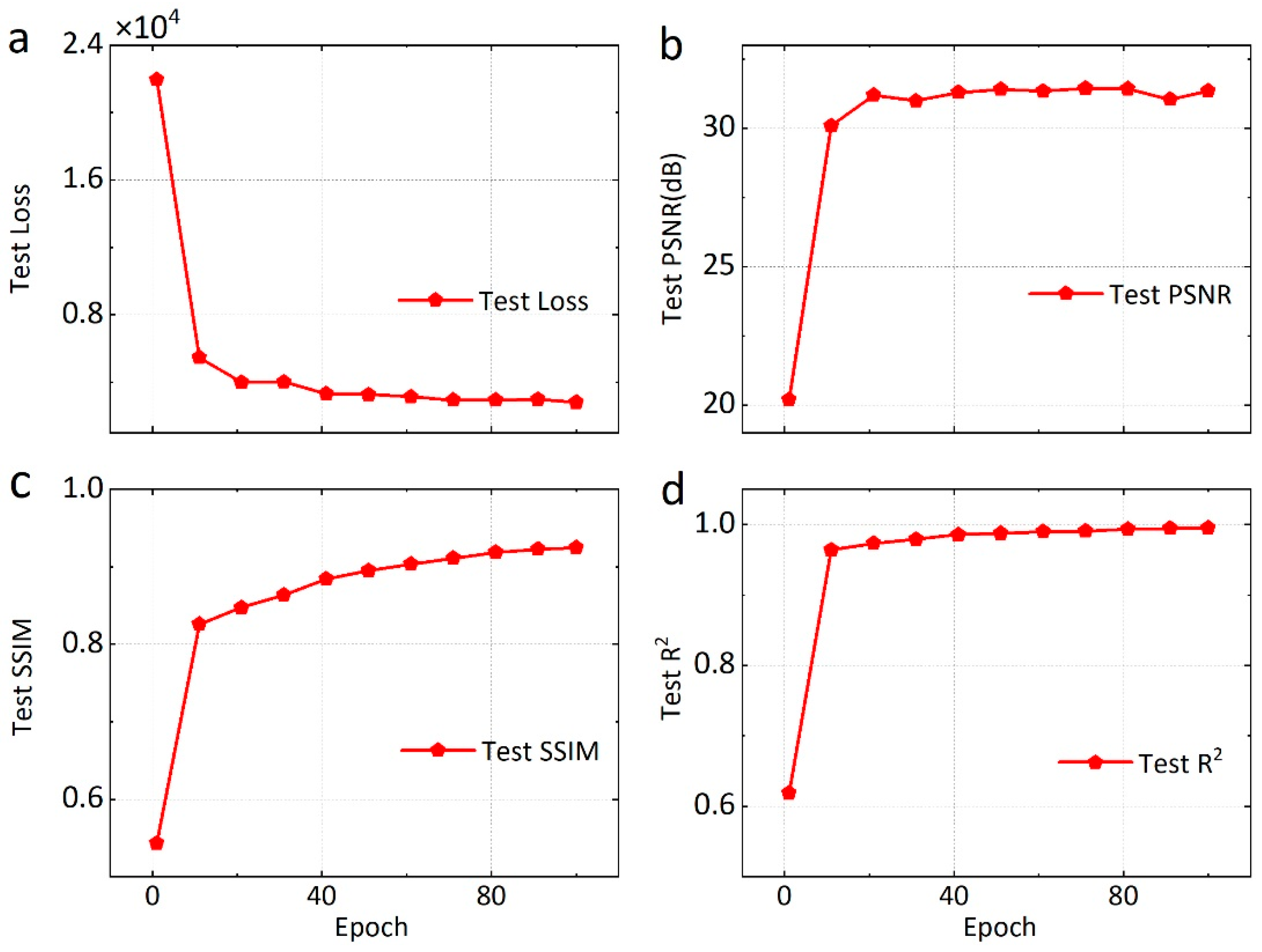
4.1. Optimized Performance of Loss Function
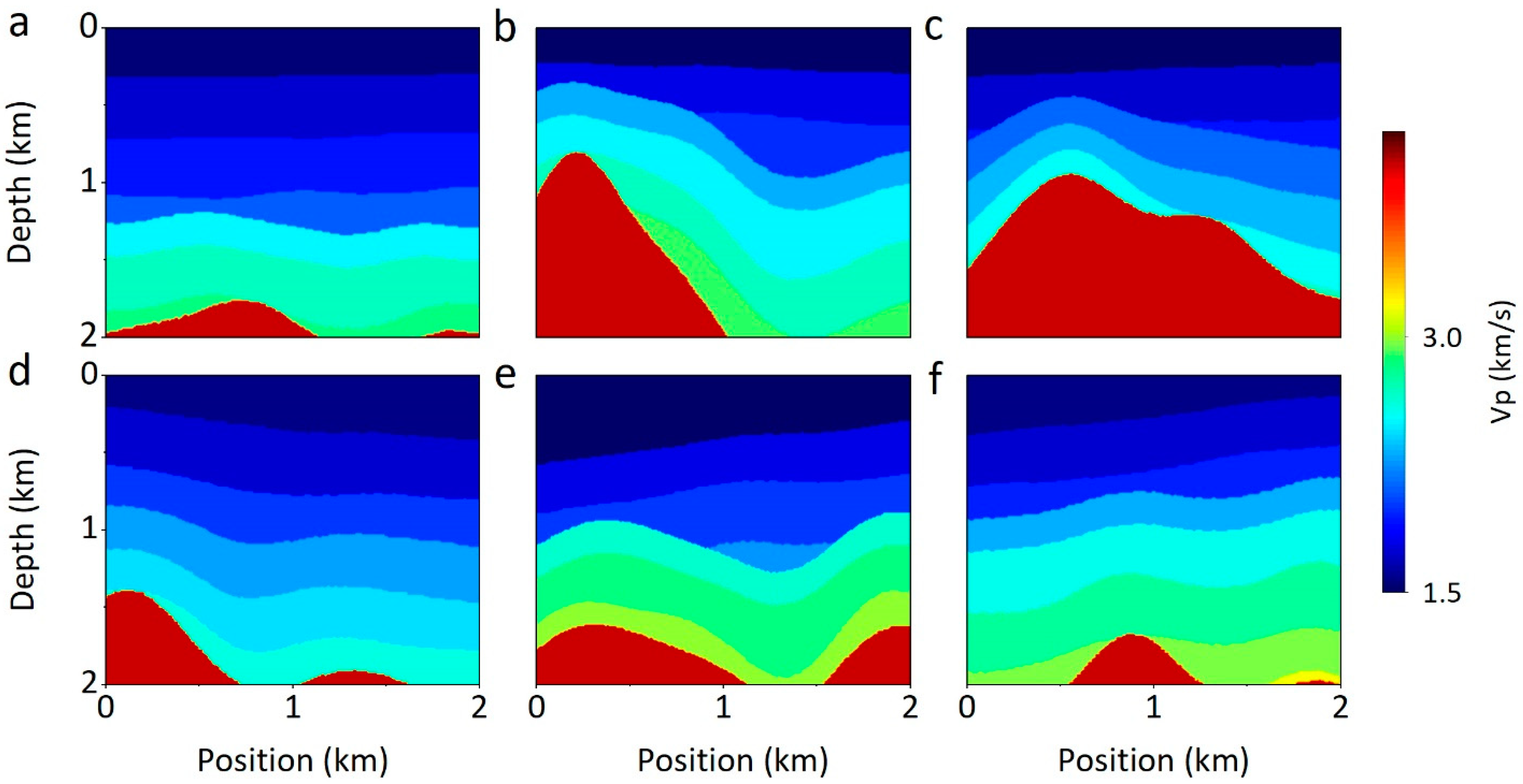
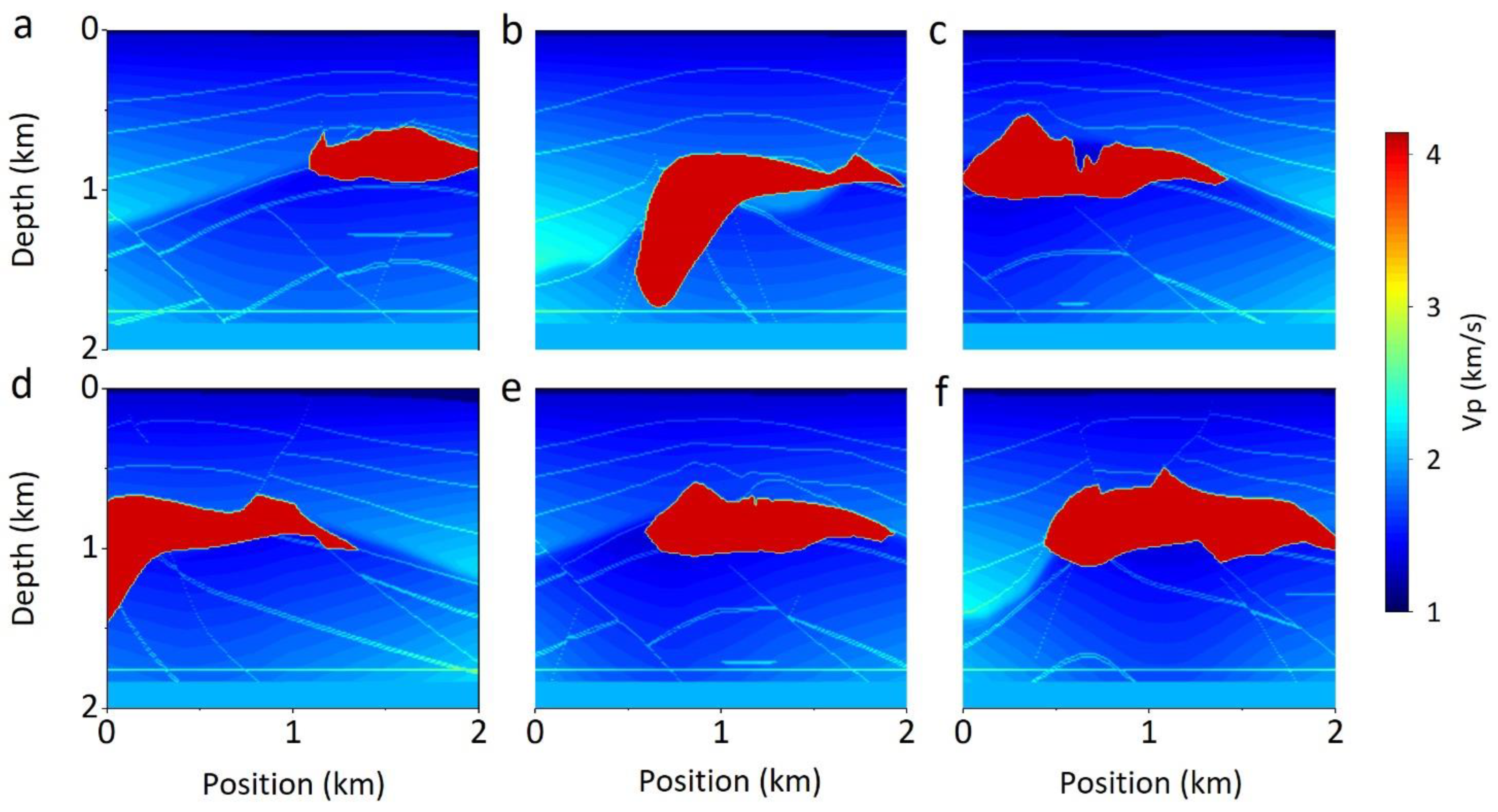
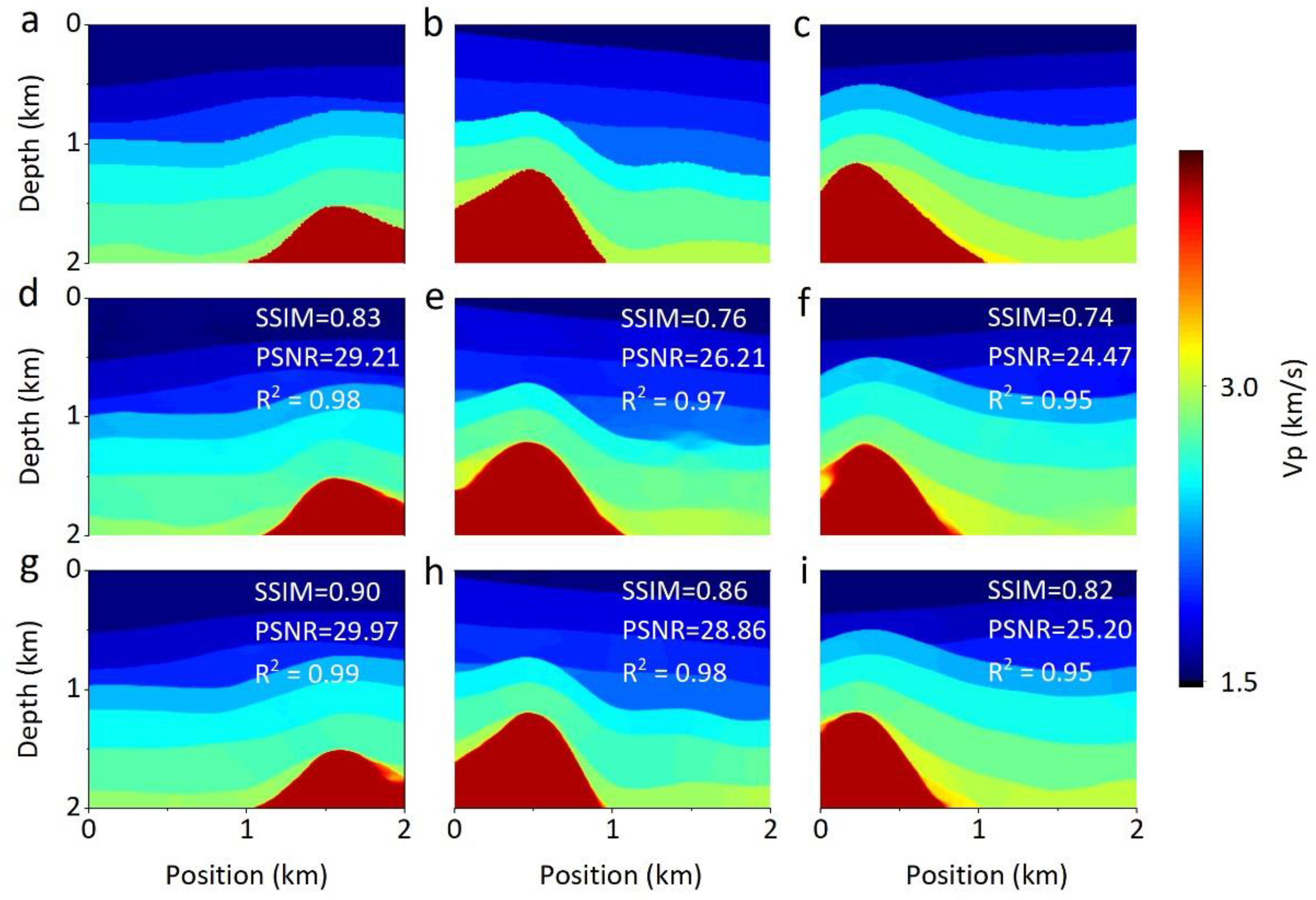
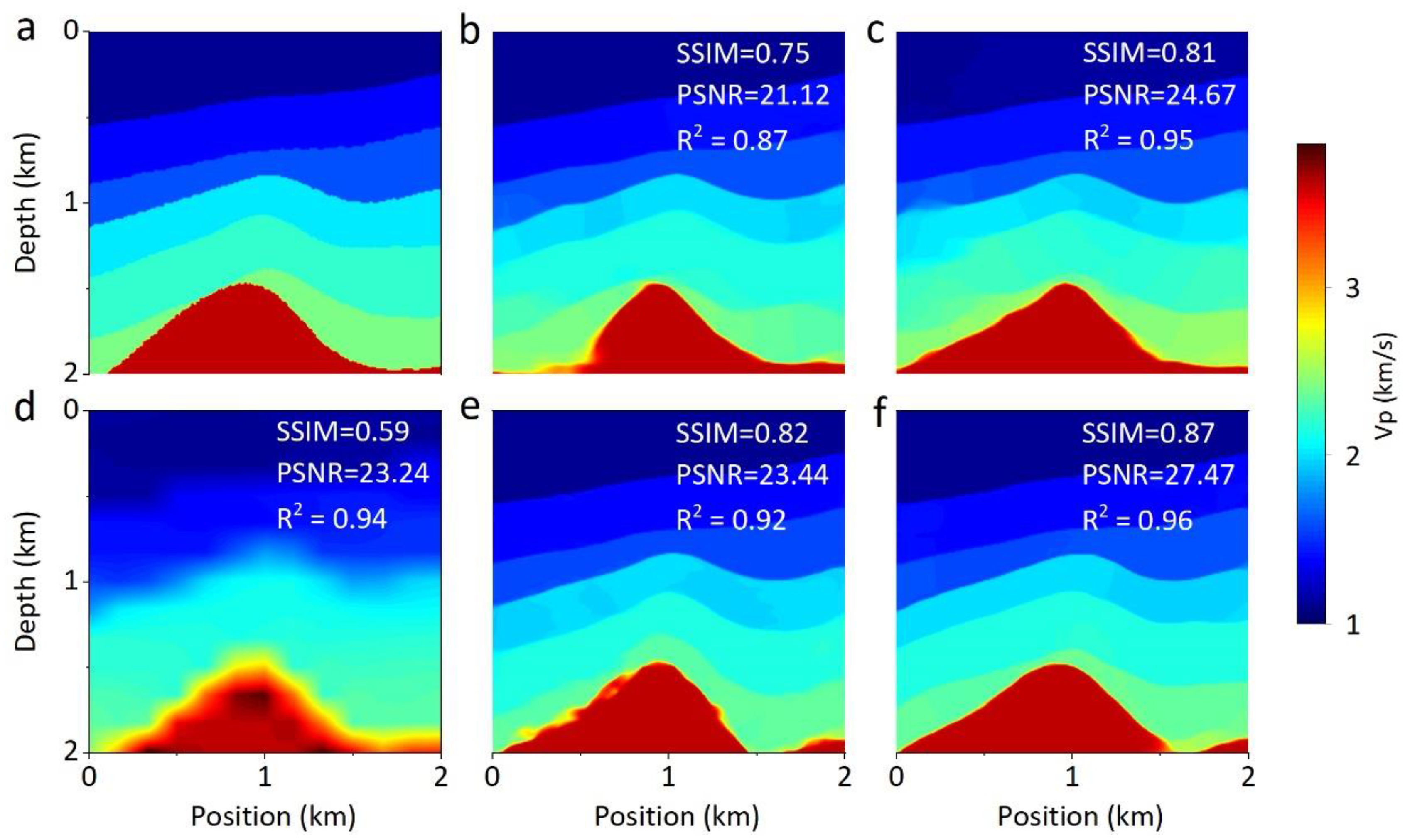
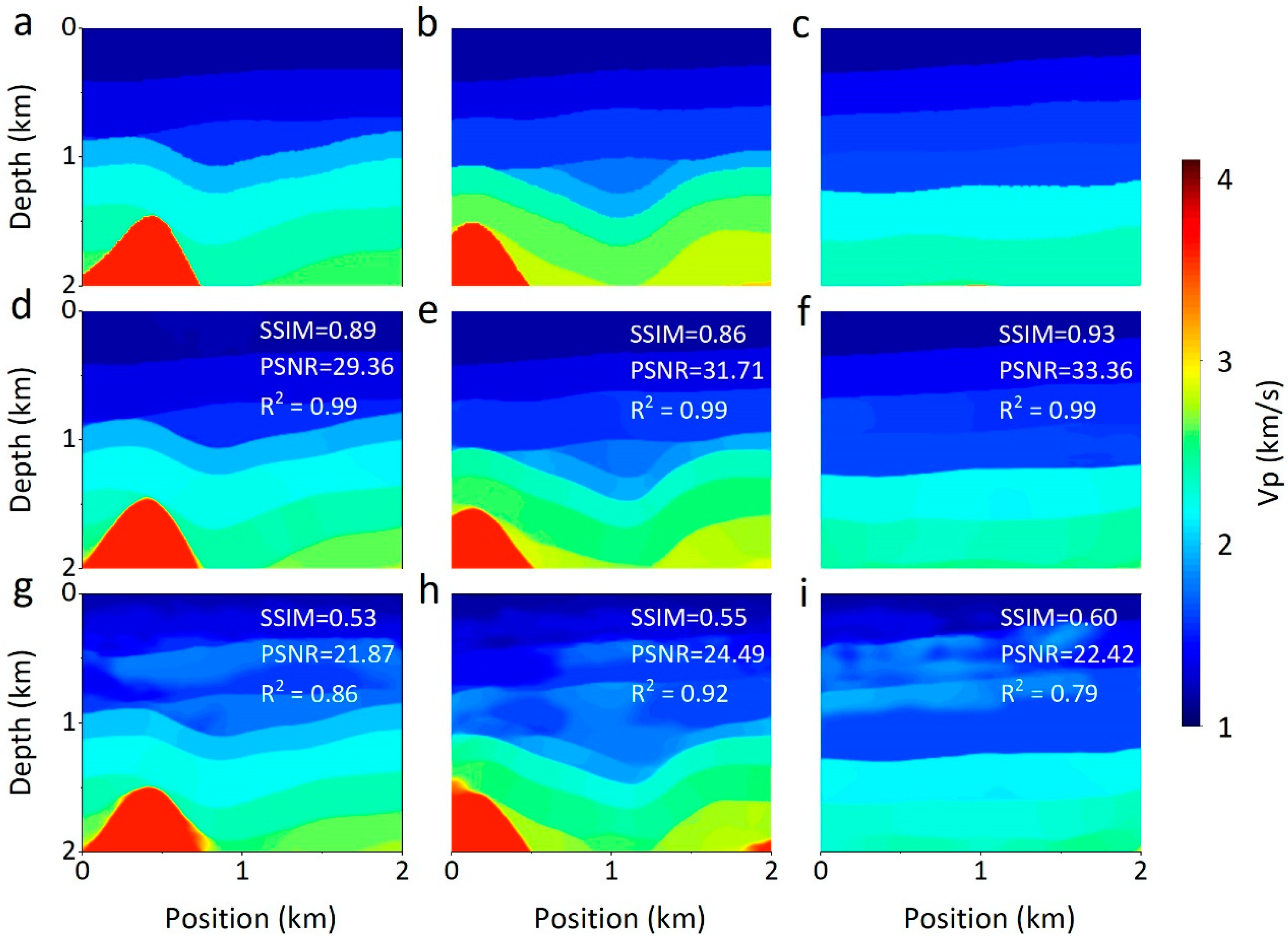
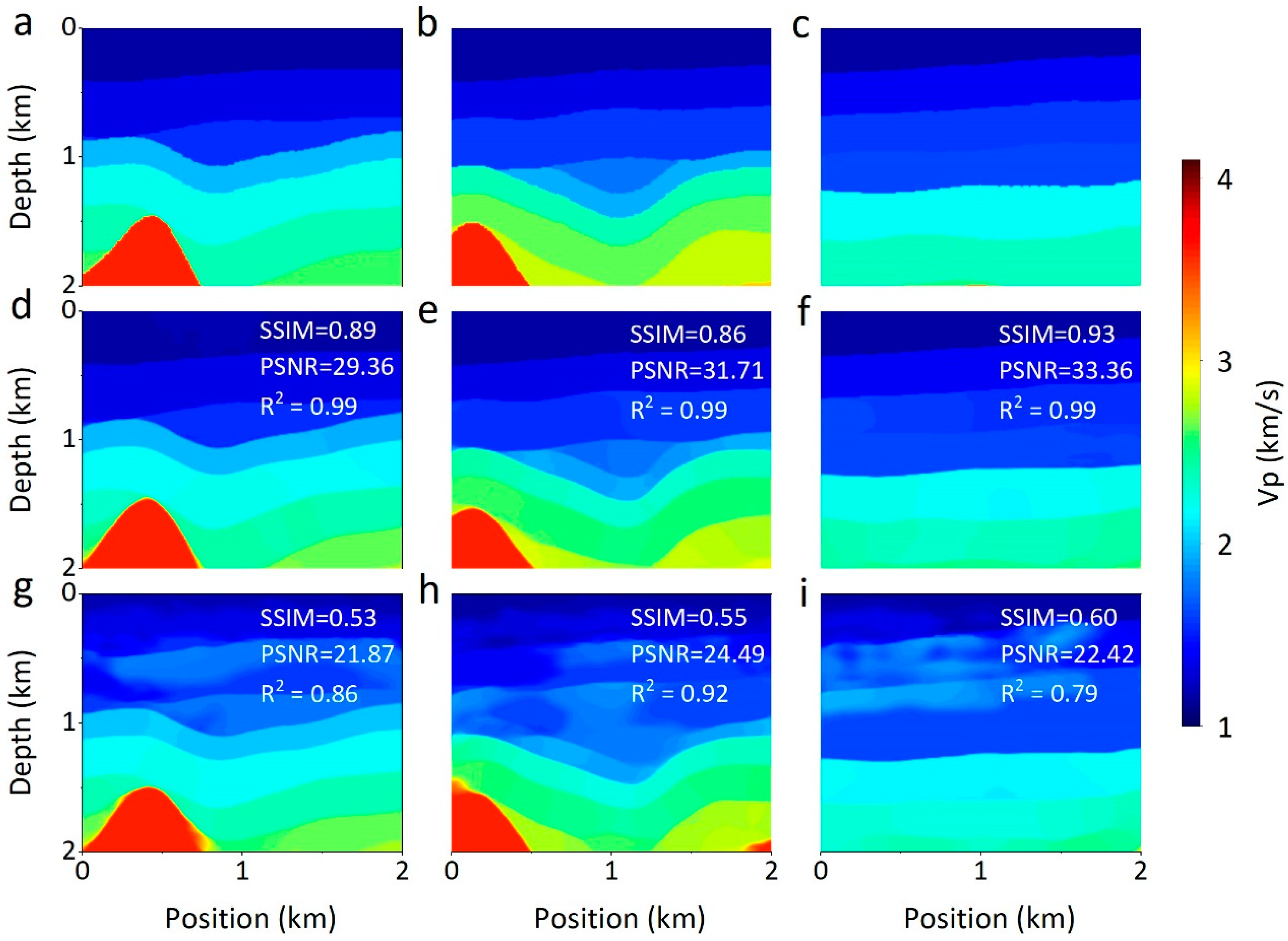
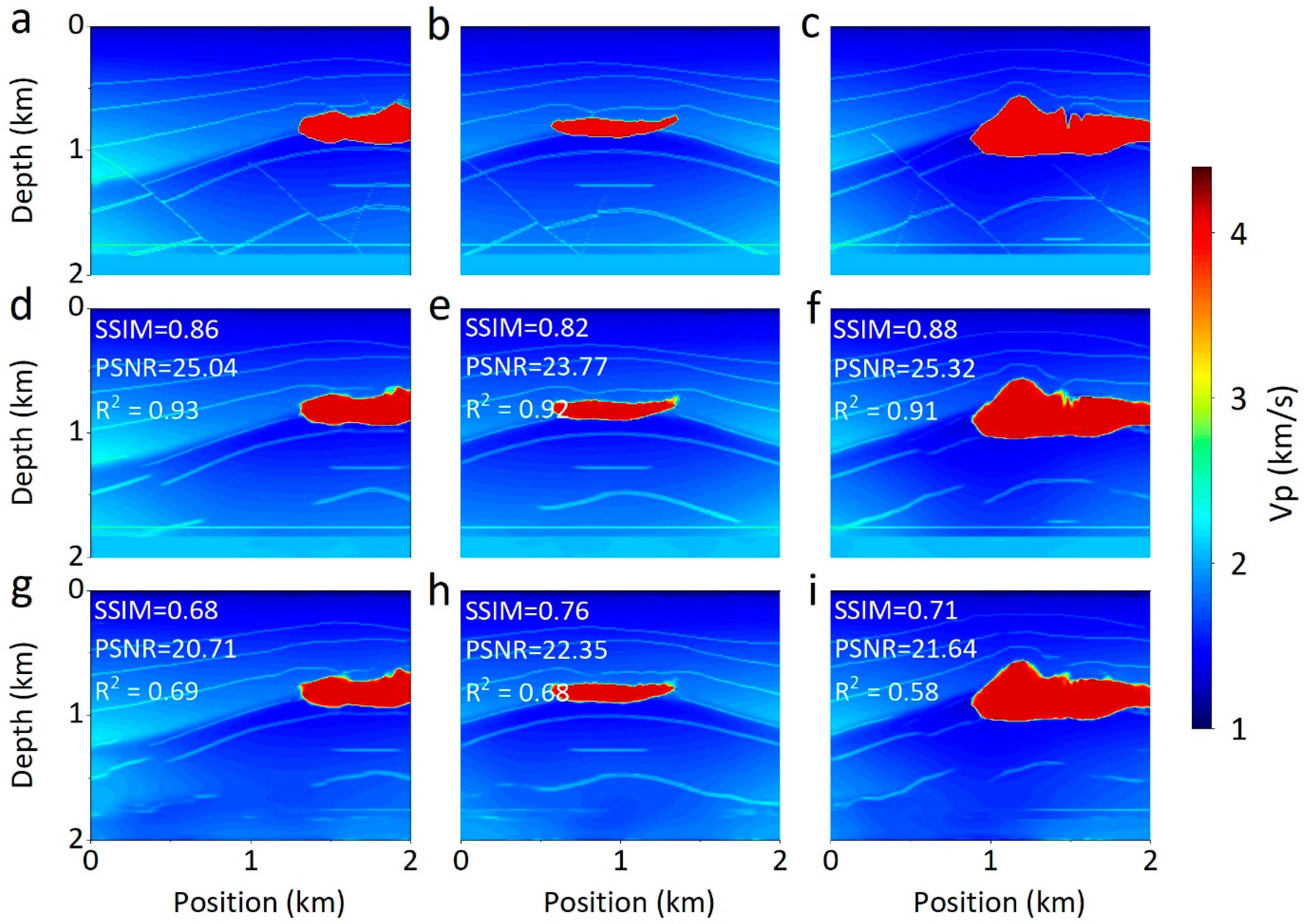
4.2. Qualitative Comparison
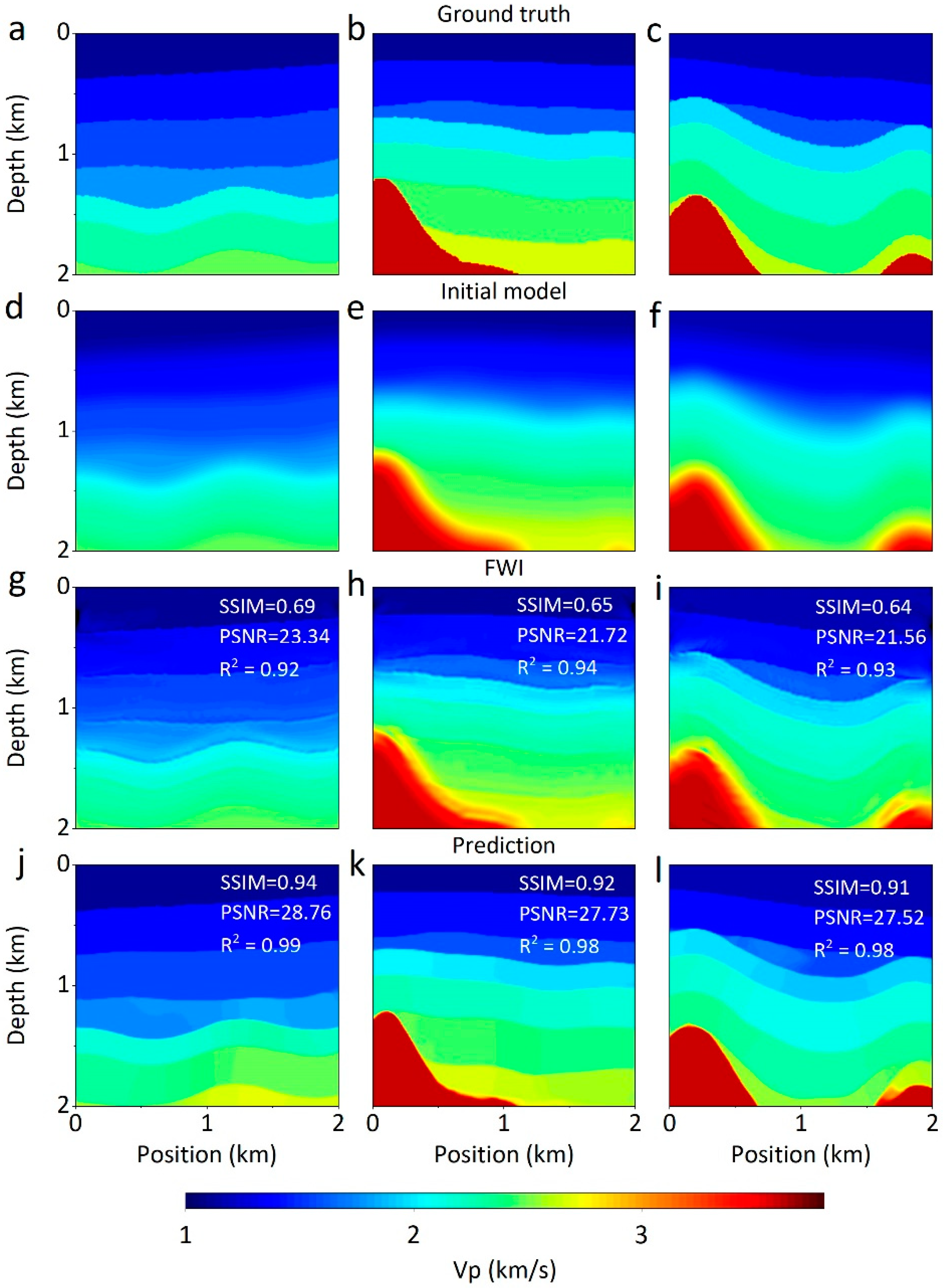
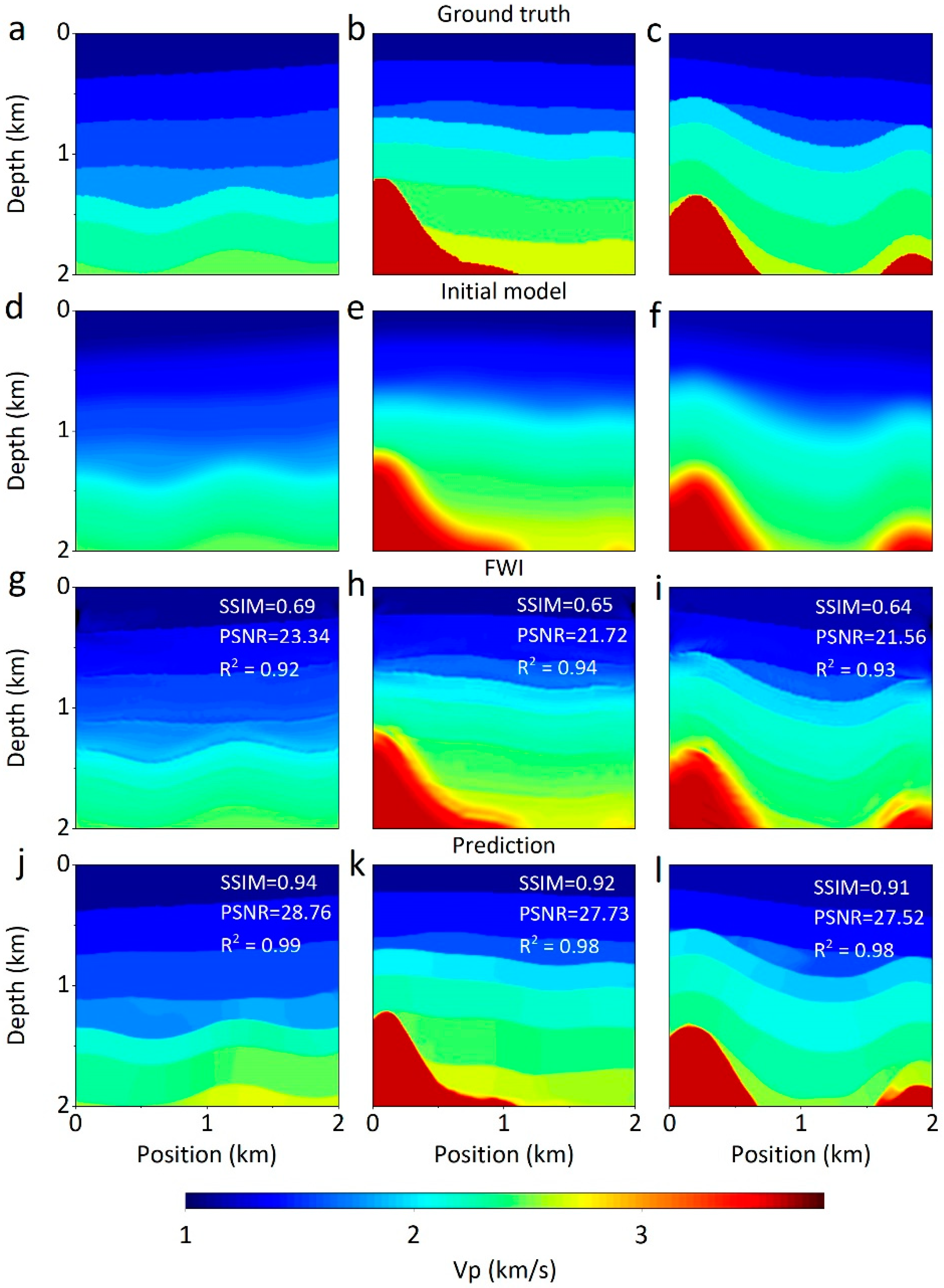
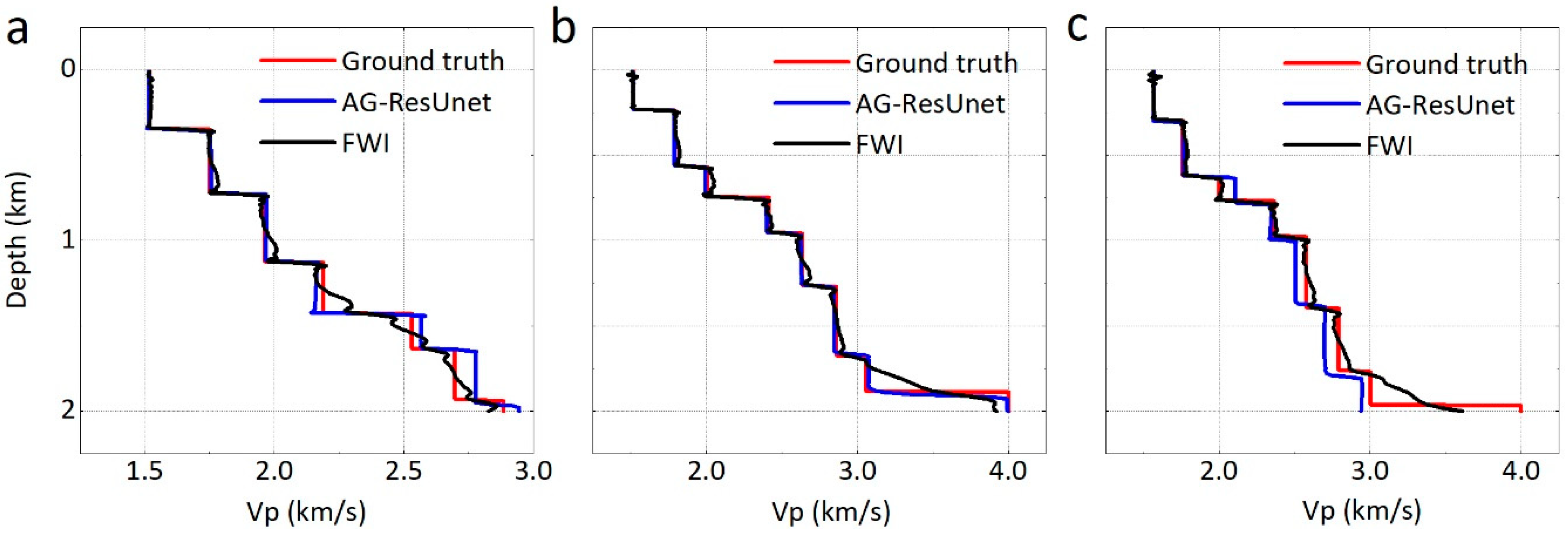
4.2.1. Comparison with Time-Domian FWI
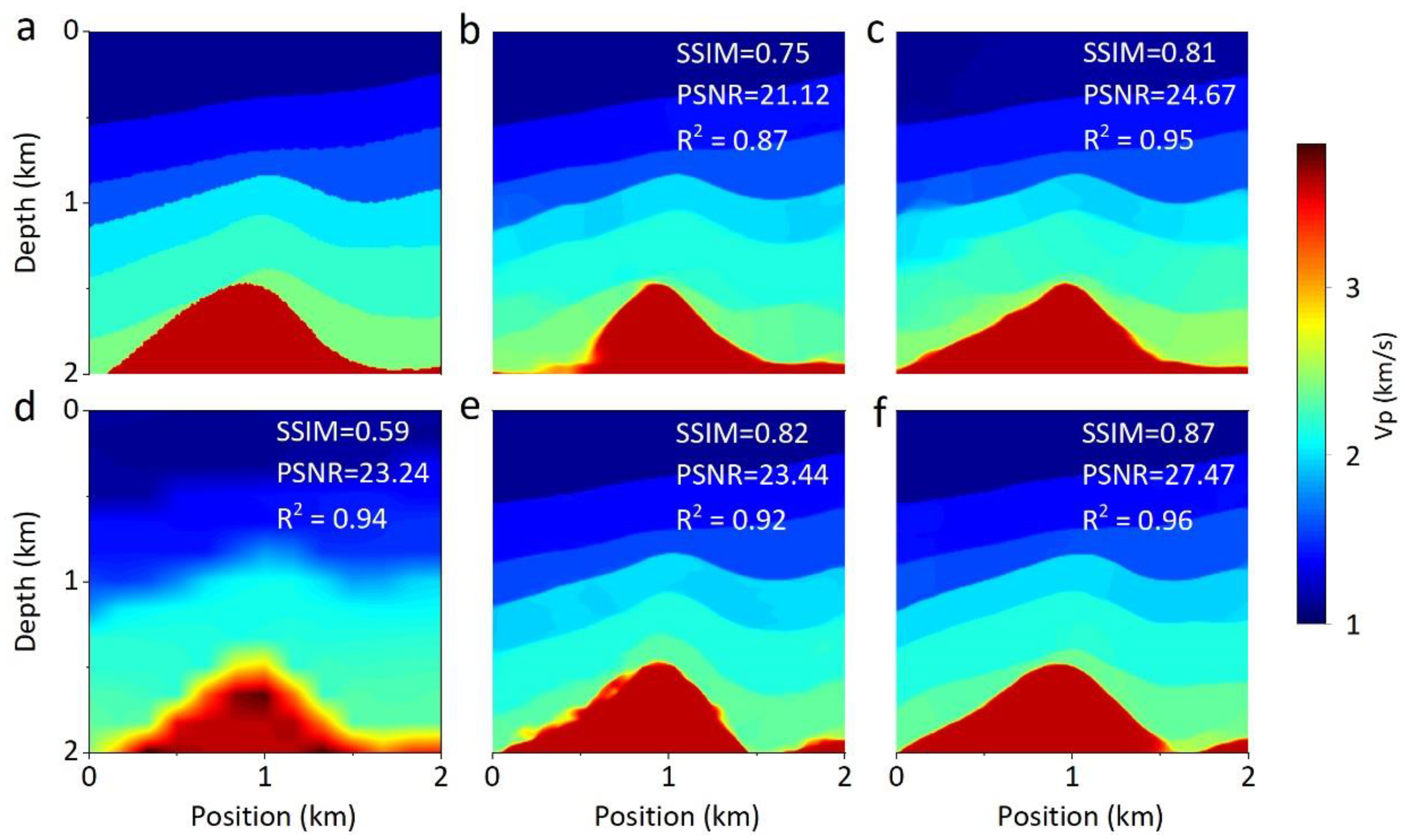
4.2.2. Comparison with Other Networks
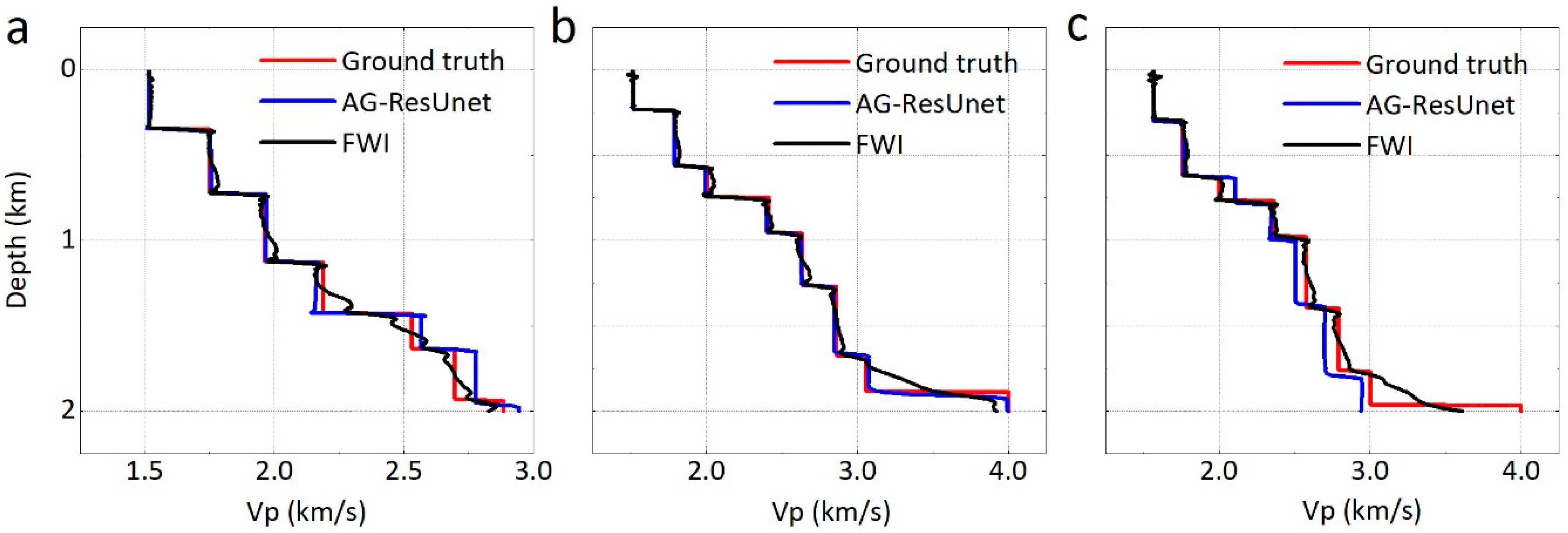
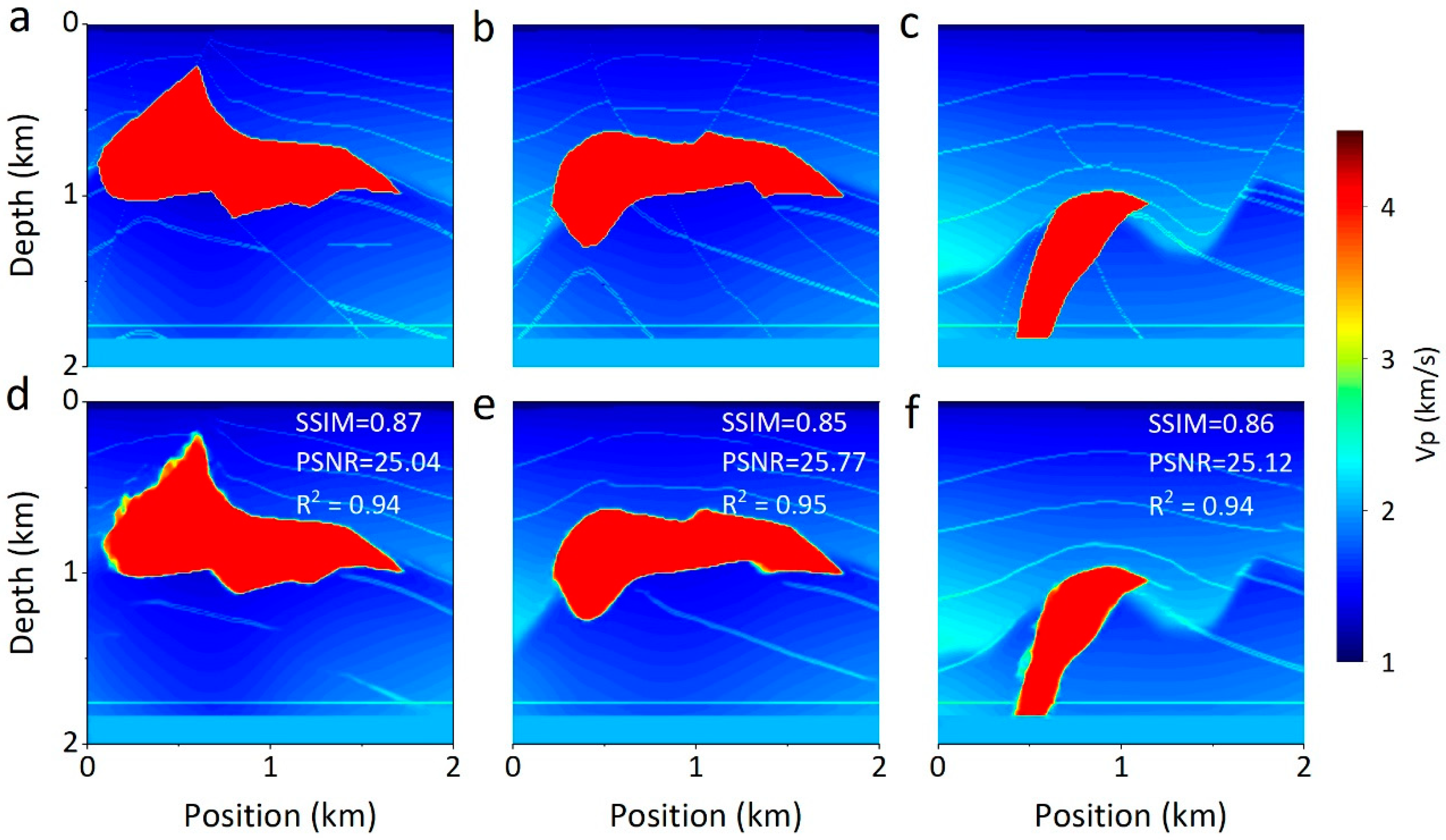
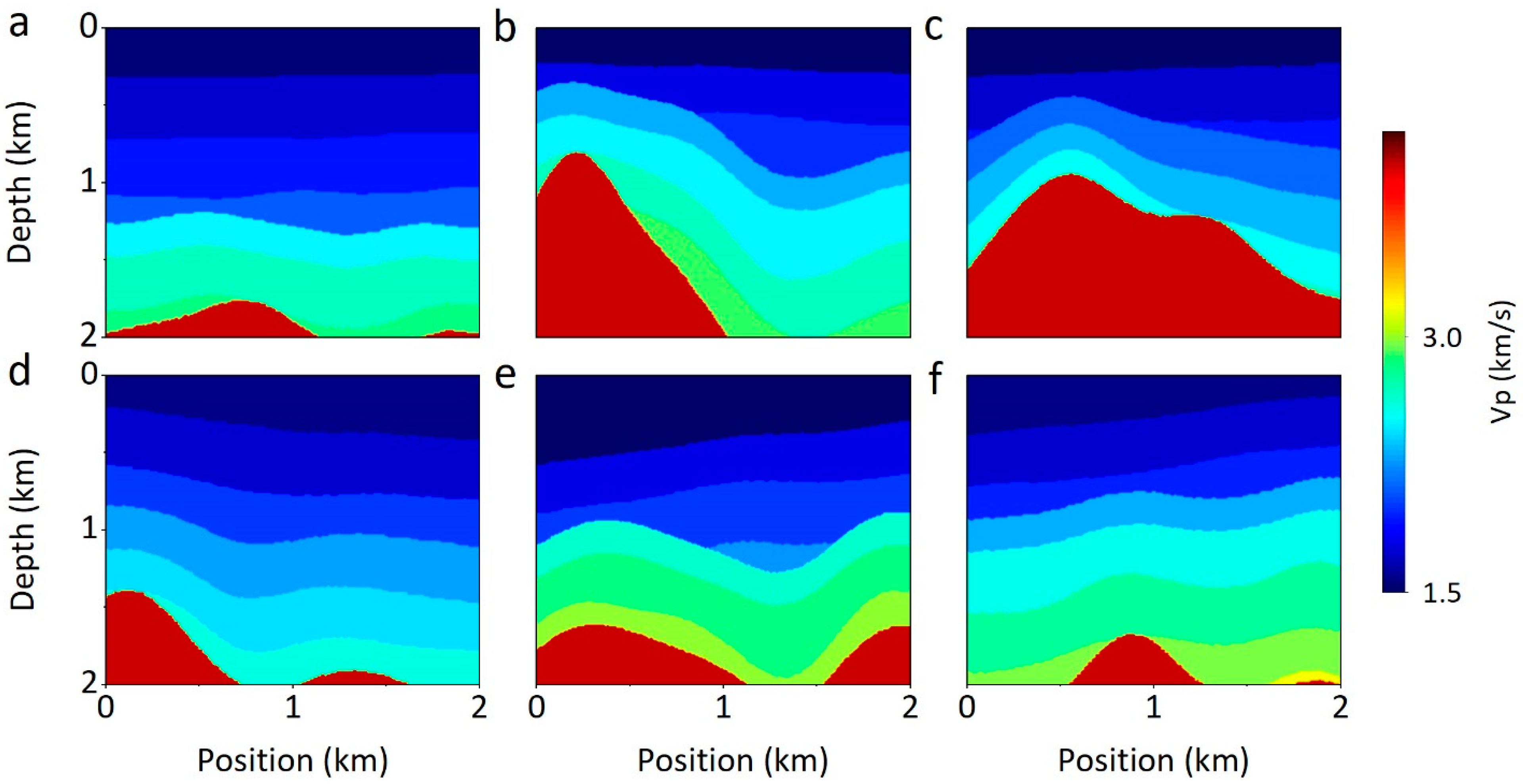
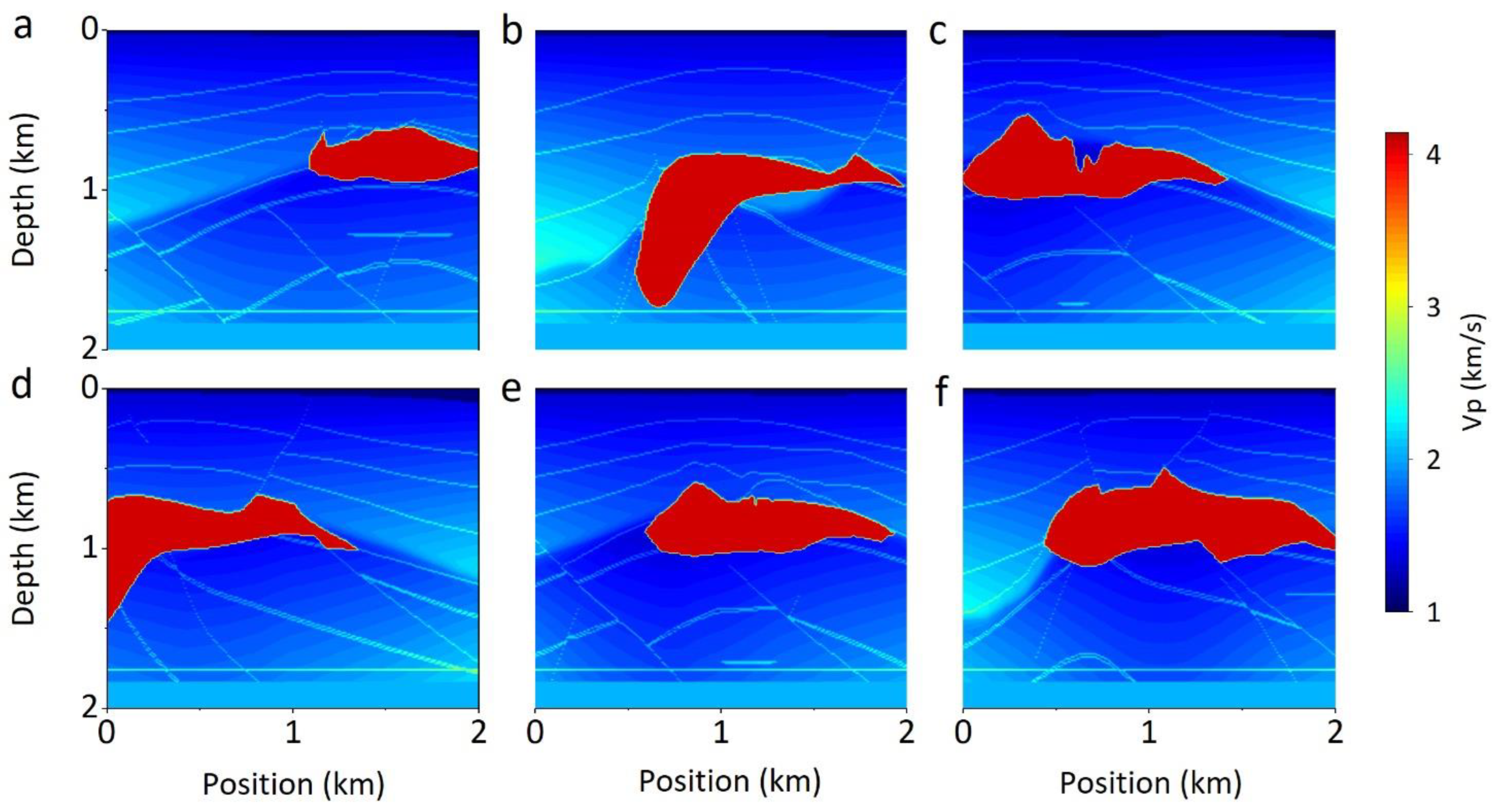
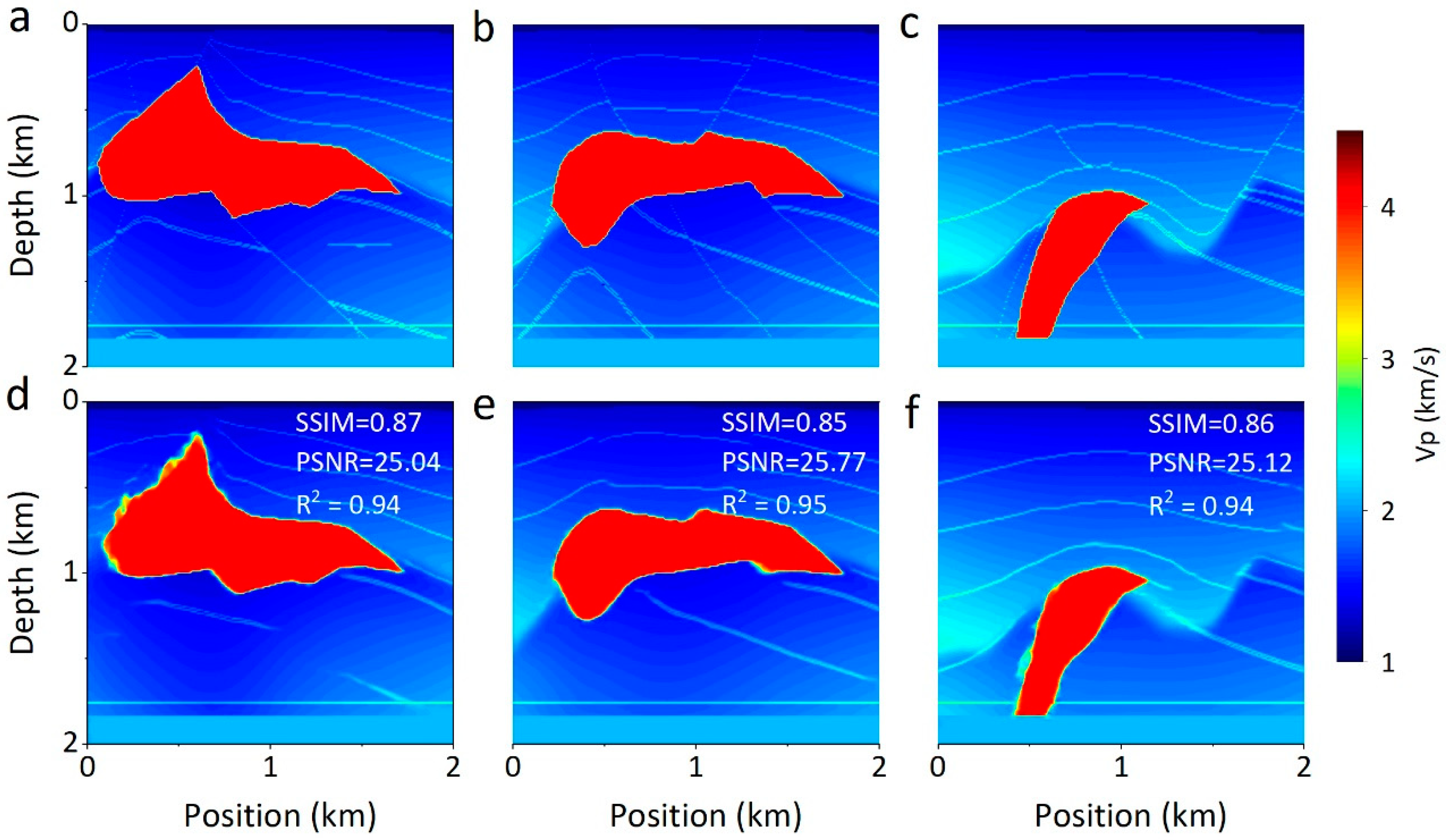
4.3. Network Generalization
4.4. Network Stability
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pan, X.; Zhang, P.; Zhang, G.; Guo, Z.; Liu, J. Seismic characterization of fractured reservoirs with elastic impedance difference versus angle and azimuth: A low-frequency poroelasticity perspective. Geophysics 2021, 86, M123–M139. [Google Scholar] [CrossRef]
- Pan, X.; Li, L.; Zhang, G. Multiscale frequency-domain seismic inversion for fracture weakness. J. Pet. Sci. Eng. 2020, 195, 107845. [Google Scholar] [CrossRef]
- Pan, X.; Zhang, G.; Yin, X. Azimuthally anisotropic elastic impedance parameterisation and inversion for anisotropy in weakly orthorhombic media. Explor. Geophys. 2019, 50, 376–395. [Google Scholar] [CrossRef]
- Pan, X.; Zhang, G. Bayesian seismic inversion for estimating fluid content and fracture parameters in a gas-saturated fractured porous reservoir. Sci. China Earth Sci. 2019, 62, 798–811. [Google Scholar] [CrossRef]
- Nguyen, P.K.T.; Nam, M.J.; Park, C. A review on time-lapse seismic data processing and interpretation. Geosci. J. 2015, 19, 375–392. [Google Scholar] [CrossRef]
- Yilmaz, Ö. Seismic Data Analysis: Processing, Inversion, and Interpretation of Seismic Data; Society of Exploration Geophysicists: Houston, TX, USA, 2001. [Google Scholar]
- Russell, B.; Hampson, D. Comparison of poststack seismic inversion methods. In SEG Technical Program Expanded Abstracts 1991; Society of Exploration Geophysicists: Houston, TX, USA, 1991; pp. 876–878. [Google Scholar]
- Garotta, R.; Michon, D. Continuous analysis of the velocity function and of the move out corrections. Geophys. Prospect. 1967, 15, 584. [Google Scholar] [CrossRef]
- Al-Yahya, K. Velocity analysis by iterative profile migration. Geophysics 1989, 54, 718–729. [Google Scholar] [CrossRef]
- Dines, K.A.; Lytle, R.J. Computerized geophysical tomography. Proc. IEEE 1979, 67, 1065–1073. [Google Scholar] [CrossRef]
- Tarantola, A. Inversion of seismic reflection data in the acoustic approximation. Geophysics 1984, 49, 1259–1266. [Google Scholar] [CrossRef]
- Biondi, B.; Almomin, A. Simultaneous inversion of full data bandwidth by tomographic full-waveform inversion. Geophysics 2014, 79, WA129–WA140. [Google Scholar] [CrossRef]
- Wu, Z.; Alkhalifah, T. Simultaneous inversion of the background velocity and the perturbation in full-waveform inversion. Geophysics 2015, 80, R317–R329. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Wang, X.; Yong, X.; Chen, Q. The review of seismic Full waveform inversion method. Prog. Geophys. 2013, 28, 766–776. [Google Scholar] [CrossRef]
- Virieux, J.; Operto, S. An overview of full-waveform inversion in exploration geophysics. Geophysics 2009, 74, WCC1–WCC26. [Google Scholar] [CrossRef]
- Sun, M.; Jin, S. Multiparameter Elastic Full Waveform Inversion of Ocean Bottom Seismic Four-Component Data Based on A Modified Acoustic-Elastic Coupled Equation. Remote Sens. 2020, 12, 2816. [Google Scholar] [CrossRef]
- Tarantola, A. Linearized inversion of seismic reflection data. Geophys. Prospect. 1984, 32, 998–1015. [Google Scholar] [CrossRef]
- Sen, M.K.; Stoffa, P.L. Nonlinear one-dimensional seismic waveform inversion using simulated annealing. Geophysics 1991, 56, 1624–1638. [Google Scholar] [CrossRef]
- Jin, S.; Madariaga, R. Background velocity inversion with a genetic algorithm. Geophys. Res. Lett. 1993, 20, 93–96. [Google Scholar] [CrossRef]
- Jin, S.; Madariaga, R. Nonlinear velocity inversion by a two-step Monte Carlo method. Geophysics 1994, 59, 577–590. [Google Scholar] [CrossRef]
- Pratt, R.G.; Shin, C.; Hick, G. Gauss–Newton and full Newton methods in frequency–space seismic waveform inversion. Geophys. J. Int. 1998, 133, 341–362. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, F. Full waveform inversion based on reverse time propagation. In SEG Technical Program Expanded Abstracts 2008; Society of Exploration Geophysicists: Houston, TX, USA, 2008; pp. 1950–1955. [Google Scholar]
- Xu, W.; Wang, T.; Cheng, J. Elastic model low-to intermediate-wavenumber inversion using reflection traveltime and waveform of multicomponent seismic dataElastic reflection inversion. Geophysics 2019, 84, R123–R137. [Google Scholar] [CrossRef]
- Wang, T.; Cheng, J.; Geng, J. Reflection Full Waveform Inversion With Second-Order Optimization Using the Adjoint-State Method. J. Geophys. Res. Solid Earth 2021, 126, e2021JB022135. [Google Scholar] [CrossRef]
- Sirgue, L.; Pratt, R.G. Efficient waveform inversion and imaging: A strategy for selecting temporal frequencies. Geophysics 2004, 69, 231–248. [Google Scholar] [CrossRef] [Green Version]
- Ko, S.; Cho, H.; Min, D.J.; Shin, C.; Cha, Y.H. A comparative study of cascaded frequency-selection strategies for 2D frequency-domain acoustic waveform inversion. In Proceedings of the 2008 SEG Annual Meeting, Las Vegas, NV, USA, 9–14 November 2008. [Google Scholar]
- Bunks, C.; Saleck, F.M.; Zaleski, S.; Chavent, G. Multiscale seismic waveform inversion. Geophysics 1995, 60, 1457–1473. [Google Scholar] [CrossRef]
- Shin, C.; Ha, W. A comparison between the behavior of objective functions for waveform inversion in the frequency and Laplace domains. Geophysics 2008, 73, VE119–VE133. [Google Scholar] [CrossRef]
- Chung, W.; Shin, C.; Pyun, S. 2D elastic waveform inversion in the Laplace domain. Bull. Seismol. Soc. Am. 2010, 100, 3239–3249. [Google Scholar] [CrossRef]
- Ha, W.; Kang, S.-G.; Shin, C. 3D Laplace-domain waveform inversion using a low-frequency time-domain modeling algorithm. Geophysics 2015, 80, R1–R13. [Google Scholar] [CrossRef]
- Shin, C.; Ha, W.; Kim, Y. Subsurface model estimation using Laplace-domain inversion methods. Lead. Edge 2013, 32, 1094–1099. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 628–644. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image. Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [Green Version]
- Meng, F.; Fan, Q.; Li, Y. Self-Supervised Learning for Seismic Data Reconstruction and Denoising. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Dong, X.; Li, Y. Denoising the optical fiber seismic data by using convolutional adversarial network based on loss balance. IEEE Trans. Geosci. Remote Sens. 2020, 59, 10544–10554. [Google Scholar] [CrossRef]
- Zhong, T.; Cheng, M.; Dong, X.; Li, Y. Seismic random noise suppression by using adaptive fractal conservation law method based on stationarity testing. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3588–3600. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, N.; Lu, W.; Wang, J. Deep-learning-based seismic data interpolation: A preliminary result. Geophysics 2019, 84, V11–V20. [Google Scholar] [CrossRef]
- Ovcharenko, O.; Kazei, V.; Kalita, M.; Peter, D.; Alkhalifah, T. Deep learning for low-frequency extrapolation from multioffset seismic data. Geophysics 2019, 84, R989–R1001. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Wang, T.; Cheng, J.; Xiong, Y.; Wang, C.; Geng, J. Self-Supervised Deep Learning to Reconstruct Seismic Data With Consecutively Missing Traces. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Pham, N.; Fomel, S.; Dunlap, D. Automatic channel detection using deep learning. Interpretation 2019, 7, SE43–SE50. [Google Scholar] [CrossRef]
- Wu, X.; Liang, L.; Shi, Y.; Fomel, S. FaultSeg3D: Using synthetic data sets to train an end-to-end convolutional neural network for 3D seismic fault segmentation. Geophysics 2019, 84, IM35–IM45. [Google Scholar] [CrossRef]
- Das, V.; Mukerji, T. Petrophysical properties prediction from prestack seismic data using convolutional neural networks. Geophysics 2020, 85, N41–N55. [Google Scholar] [CrossRef]
- Lewis, W.; Vigh, D. Deep learning prior models from seismic images for full-waveform inversion. In SEG Technical Program Expanded Abstracts 2017; Society of Exploration Geophysicists: Houston, TX, USA, 2017; pp. 1512–1517. [Google Scholar]
- Araya-Polo, M.; Jennings, J.; Adler, A.; Dahlke, T. Deep-learning tomography. Lead. Edge 2018, 37, 58–66. [Google Scholar] [CrossRef]
- Mosser, L.; Kimman, W.; Dramsch, J.; Purves, S.; De la Fuente Briceño, A.; Ganssle, G. Rapid seismic domain transfer: Seismic velocity inversion and modeling using deep generative neural networks. In Proceedings of the 80th Eage Conference and Exhibition 2018, Copenhagen, Denmark, 11–14 June 2018; pp. 1–5. [Google Scholar]
- Wu, B.; Meng, D.; Zhao, H. Semi-supervised learning for seismic impedance inversion using generative adversarial networks. Remote Sens. 2021, 13, 909. [Google Scholar] [CrossRef]
- Yang, F.; Ma, J. Deep-learning inversion: A next-generation seismic velocity model building method. Geophysics 2019, 84, R583–R599. [Google Scholar] [CrossRef] [Green Version]
- Takam Takougang, E.M.; Bouzidi, Y. Imaging high-resolution velocity and attenuation structures from walkaway vertical seismic profile data in a carbonate reservoir using visco-acoustic waveform inversion. Geophysics 2018, 83, B323–B337. [Google Scholar] [CrossRef]
- De Landro, G.; Serlenga, V.; Russo, G.; Amoroso, O.; Festa, G.; Bruno, P.P.; Gresse, M.; Vandemeulebrouck, J.; Zollo, A. 3D ultra-high resolution seismic imaging of shallow Solfatara crater in Campi Flegrei (Italy): New insights on deep hydrothermal fluid circulation processes. Sci. Rep. 2017, 7, 3412. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Liu, B.; Ren, Y.; Chen, Y.; Yang, S.; Wang, Y.; Jiang, P. Deep-Learning Inversion of Seismic Data. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2135–2149. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Yang, S.; Ren, Y.; Xu, X.; Jiang, P.; Chen, Y. Deep-learning seismic full-waveform inversion for realistic structural models. Geophysics 2021, 86, R31–R44. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lin, Y. InversionNet: An efficient and accurate data-driven full waveform inversion. IEEE Trans. Comput. Imaging 2019, 6, 419–433. [Google Scholar] [CrossRef]
- Geng, Z.; Zhao, Z.; Shi, Y.; Wu, X.; Fomel, S.; Sen, M. Deep learning for velocity model building with common-image gather volumes. Geophys. J. Int. 2022, 228, 1054–1070. [Google Scholar] [CrossRef]
- Araya-Polo, M.; Adler, A.; Farris, S.; Jennings, J. Fast and accurate seismic tomography via deep learning. In Deep Learning: Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–156. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar] [CrossRef]
- Lecomte, J.; Campbell, E.; Letouzey, J. Building the SEG/EAEG overthrust velocity macro model. In Proceedings of the EAEG/SEG Summer Workshop-Construction of 3-D Macro Velocity-Depth Models, Noordwijkerhout, The Netherlands, 24–27 July 1994; p. cp-96-00024. [Google Scholar]
- Wu, X.; Geng, Z.; Shi, Y.; Pham, N.; Fomel, S.; Caumon, G. Building realistic structure models to train convolutional neural networks for seismic structural interpretation. Geophysics 2020, 85, WA27–WA39. [Google Scholar] [CrossRef]
- Ren, Y.; Nie, L.; Yang, S.; Jiang, P.; Chen, Y. Building complex seismic velocity models for deep learning inversion. IEEE Access 2021, 9, 63767–63778. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Qamar, S.; Jin, H.; Zheng, R.; Ahmad, P.; Usama, M. A variant form of 3D-UNet for infant brain segmentation. Future Gener. Comput. Syst. 2020, 108, 613–623. [Google Scholar] [CrossRef]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted res-unet for high-quality retina vessel segmentation. In Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Yan, L.; Liu, D.; Xiang, Q.; Luo, Y.; Wang, T.; Wu, D.; Chen, H.; Zhang, Y.; Li, Q. PSP net-based automatic segmentation network model for prostate magnetic resonance imaging. Comput. Methods Programs Biomed. 2021, 207, 106211. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, X. Medical image recognition and segmentation of pathological slices of gastric cancer based on Deeplab v3+ neural network. Comput. Methods Programs Biomed. 2021, 207, 106210. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Li, J.; Wu, X.; Hu, Z. Deep learning for simultaneous seismic image super-resolution and denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Sun, J.; Innanen, K.A.; Huang, C. Physics-guided deep learning for seismic inversion with hybrid training and uncertainty analysis. Geophysics 2021, 86, R303–R317. [Google Scholar] [CrossRef]
- Puzyrev, V. Deep learning electromagnetic inversion with convolutional neural networks. Geophys. J. Int. 2019, 218, 817–832. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Niu, Z.; Innanen, K.A.; Li, J.; Trad, D.O. A theory-guided deep-learning formulation and optimization of seismic waveform inversion. Geophysics 2020, 85, R87–R99. [Google Scholar] [CrossRef]
- Alkhalifah, T.; Song, C.; bin Waheed, U.; Hao, Q. Wavefield solutions from machine learned functions constrained by the Helmholtz equation. Artif. Intell. Geosci. 2021, 2, 11–19. [Google Scholar] [CrossRef]
- Rasht-Behesht, M.; Huber, C.; Shukla, K.; Karniadakis, G.E. Physics-Informed Neural Networks (PINNs) for Wave Propagation and Full Waveform Inversions. J. Geophys. Res. Solid Earth 2022, 127, e2021JB023120. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Receiver Interval | Time Interval | Maximum Travel Time | Dominant Frequency | Source Points | Source Interval | Boundary Condition |
|---|---|---|---|---|---|---|---|
| FDM | 10 m | 0.003 s | 3 s | 25 Hz | 6 | 28.5 m | PML |
| Optimizer | GPU | Learning Rate | Weight Decay | Batch Size | Epoch |
|---|---|---|---|---|---|
| Adam | Tesla V100 | 1 × 10−3 | 1 × 10−4 | 8 | 200 |
| Dataset | Loss Function | Loss | PSNR | SSIM | R2 | Time |
|---|---|---|---|---|---|---|
| Test | LMSE | 29528.22 | 28.00 | 0.8636 | 0.9994 | 299 m 17 s |
| LMix | 3577.75 | 29.31 | 0.9903 | 0.9999 | 308 m 13 s |
| Dateset | Process | AG-ResUnet | FWI |
|---|---|---|---|
| Synthetic | Training | 308 min 13 s | N/A |
| Inversion | 1.8 s | 272 min 54 s |
| Dataset | Network | Loss | PSNR | SSIM | R2 | Time |
|---|---|---|---|---|---|---|
| Test | Unet | 7046.72 | 27.30 | 0.9265 | 0.9994 | 208 min 56 s |
| ResUnet | 6045.29 | 28.05 | 0.9490 | 0.9998 | 295 min 26 s | |
| PSPnet | 13662.38 | 28.03 | 0.6249 | 0.9756 | 157 min 48 s | |
| Deeplab v3+ | 4290.33 | 28.76 | 0.9545 | 0.9996 | 247 min 38 s | |
| AG-ResUnet | 3577.75 | 29.31 | 0.9903 | 0.9999 | 308 min 13 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Guo, Z.; Pan, X.; Liu, J.; Wang, Y.; Gao, D. Deep Learning with Adaptive Attention for Seismic Velocity Inversion. Remote Sens. 2022, 14, 3810. https://doi.org/10.3390/rs14153810
Li F, Guo Z, Pan X, Liu J, Wang Y, Gao D. Deep Learning with Adaptive Attention for Seismic Velocity Inversion. Remote Sensing. 2022; 14(15):3810. https://doi.org/10.3390/rs14153810
Chicago/Turabian StyleLi, Fangda, Zhenwei Guo, Xinpeng Pan, Jianxin Liu, Yanyi Wang, and Dawei Gao. 2022. "Deep Learning with Adaptive Attention for Seismic Velocity Inversion" Remote Sensing 14, no. 15: 3810. https://doi.org/10.3390/rs14153810
APA StyleLi, F., Guo, Z., Pan, X., Liu, J., Wang, Y., & Gao, D. (2022). Deep Learning with Adaptive Attention for Seismic Velocity Inversion. Remote Sensing, 14(15), 3810. https://doi.org/10.3390/rs14153810