1. Introduction
The traditional pattern of obtaining useful information from remote sensing satellites contains three major steps: on-board data generation, data downloading, and on-ground data processing. On the one hand, with the growth in the spatial resolution, spectral resolution, and temporal resolution of modern remote sensing satellites, the data generation rate is increasing rapidly. This situation brings massive stress to data downloading and processing systems, and the information acquisition delay is also becoming longer. On the other hand, users are increasingly demanding the timeliness of information acquisition from remote sensing satellites. A shorter delay or instant response is required in many high-timeliness applications, such as disaster prevention and mitigation, earthquake early warning, and rescue guidance. Thus, task-driven on-board processing is provided to solve this contradiction.
To relieve the stress of data downloading and processing systems, it is important to deploy on-board edge computing on satellites. Ideally, with on-board data picking, processing, and downloading, a massive amount of raw data has been concentrated into little useful information that can be downloaded and delivered immediately [
1,
2]. Several achievements have been made in this area; for example, the Coastal Ocean Imaging Spectrometer (COIS) in the Naval Earth Map Observer (NEMO) satellite is used to characterize the littoral region environment. COIS uses the Optical Real-time Adaptive Spectral Identification System (ORASIS) to accomplish spectral filtering and spatial filtering, before finally generating battlefield environmental information and a direct downlink [
3]. The Australian satellite, FedSat, carried a demonstration device for the feasibility of reconfigurable computing technology in space called High Performance Computing (HPC-I). Using this device in conjunction with an optical sensor, the system could detect and monitor natural disasters and would be capable of producing useful information that could be broadcast directly within rapid timeframes [
4]. The Yet Another Mission (YAM-3) satellite launched by the US Space Development Agency carried an edge computing system called Prototype on-Orbit Experimental Testbed (POET) based on SpaceCube v3.0 [
5] technology, which can perform autonomous data fusion and processing on board and is used by the US military to detect and track a target on the ground or in the sea or air. Furthermore, several Field Programmable Gate Array (FPGA)-based methods have been presented for on-board processing, such as image ortho-rectification [
6], feature point detection and matching [
7], object detection [
8,
9], and image classification [
10,
11].
In fact, in the harsh space environment, the design of the on-board processing system will always be limited. The natural radiation from stable low-flux Galactic Cosmic Rays (GCR) and infrequent high-flux Solar Particle Events (SPE) can have an impact on on-board devices [
12]. Depending on the radiation environment in which the on-board device is located, ionizing radiation can produce radiation effects including Single Event Effect (SEE) [
13], Displacement Damage (DD), and Total Ionizing Dose (TID) [
14]. The general approach to mitigating SEE is redundancy techniques which are based on hardware, software, and information redundancy [
15], but this will cause a lot of resource consumption. To solve this problem, Jacobs proposed a Reconfigurable Fault Tolerance (RFT) framework to dynamically adjust a system’s level of redundancy and fault mitigation [
16]. Glein proposed an Adaptive Single Event Effect Mitigation (ASEEM) method for FPGA-based processing systems, which dynamically adjusts the state of the processing system according to different space radiation conditions to save system resources [
17]. Sabogal proposed Hybrid, Adaptive Reconfigurable Fault Tolerance (HARFT), a reconfigurable framework for environmentally adaptive resilience in hybrid space systems [
18]. As hybrid processors become a trend and high-performance commercial devices are used for on-board computing [
19], the related research is also underway. The Science Data Processing Branch at National Aeronautics and Space Administration (NASA) Goddard Space Flight Center (GSFC) has pioneered a hybrid-processing approach that combines radiation-hardened and commercial components while emphasizing a novel architecture harmonizing the best capabilities of Central Processing Units (CPUs), Digital Signal Processing (DSPs), and FPGAs [
20]. Müller refined the methodology for assessing the Fault Detection, Isolation, and Recovery (FDIR) design of on-board computers in space systems by introducing a library of FDIR routines [
21].
Although DSPs and FPGAs are used in most on-board embedded systems, Graphics Processing Units (GPUs) are another feasible option. GPUs have already been implemented on board for anomaly detection of hyperspectral images [
22] and spaceborne Synthetic Aperture Radar (SAR) processing [
23]. Considering that GPUs are implemented in many remote sensing fields, such as hyperspectral image compression, classification, unmixing, and detection, they have already substantially enhanced the efficiency of the algorithms. Additionally, GPUs are also widely used in intelligent remote sensing applications, such as object detection, semantic segmentation, and change detection. It is predictable that using GPU and CPU on board will make the processing system more efficient and expandable.
In previous work, embedded GPUs have been used to implement on-board stream computing for sensor correction processing [
24]. Through the strategy of multimodule cooperation, scene-by-scene standard image product processing for flow-in data is realized. To achieve this goal, the data generation rate, processing time consumption, and computability need to be strictly matched. Predictably, once a different time-consuming application is deployed, it is nearly impossible to maintain a strict balance in such a strategy.
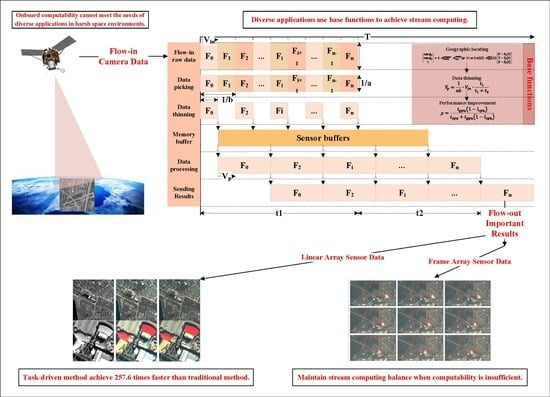
The basic truth is that in the harsh space environment, limited by the volume, weight, and power consumption, it is impossible to deploy as many computing devices on board as every application needs. Moreover, another truth is that only a small part of the data contains useful and important information on most occasions; other unimportant data are disposable. Therefore, to build an expandable on-board processing system for the deployment of various intelligent applications, first, the accurate geographic position of the data must be calculated in time to locate the ROI. Second, a multi-buffer strategy must be introduced to balance the difference between data generation and data processing for applications, such as fusion, georectification, ROI extraction, cloud-cover detection, target recognition, and change detection.
This manuscript proposes an expandable on-board edge computing architecture that can not only provide autonomy for the computing performance of heterogeneous hardware but also meet the needs of different intelligent applications as much as possible while balancing the difference in data generation and data processing speed. In
Section 2, an instant geographic locating algorithm is proposed as the key base function of the architecture to assist on-board applications to quickly obtain the geographic position of the current imaging data and extract ROI data while the data continuously flow-in, to ensure that precious computability is used for important data. In
Section 3, based on the SoC hardware of Luojia3, an on-board edge computing architecture is proposed, which provides a standard application template, base functions, and optimization strategies for developers in realizing on-board stream computing for various applications.
3. Edge Computing Architecture
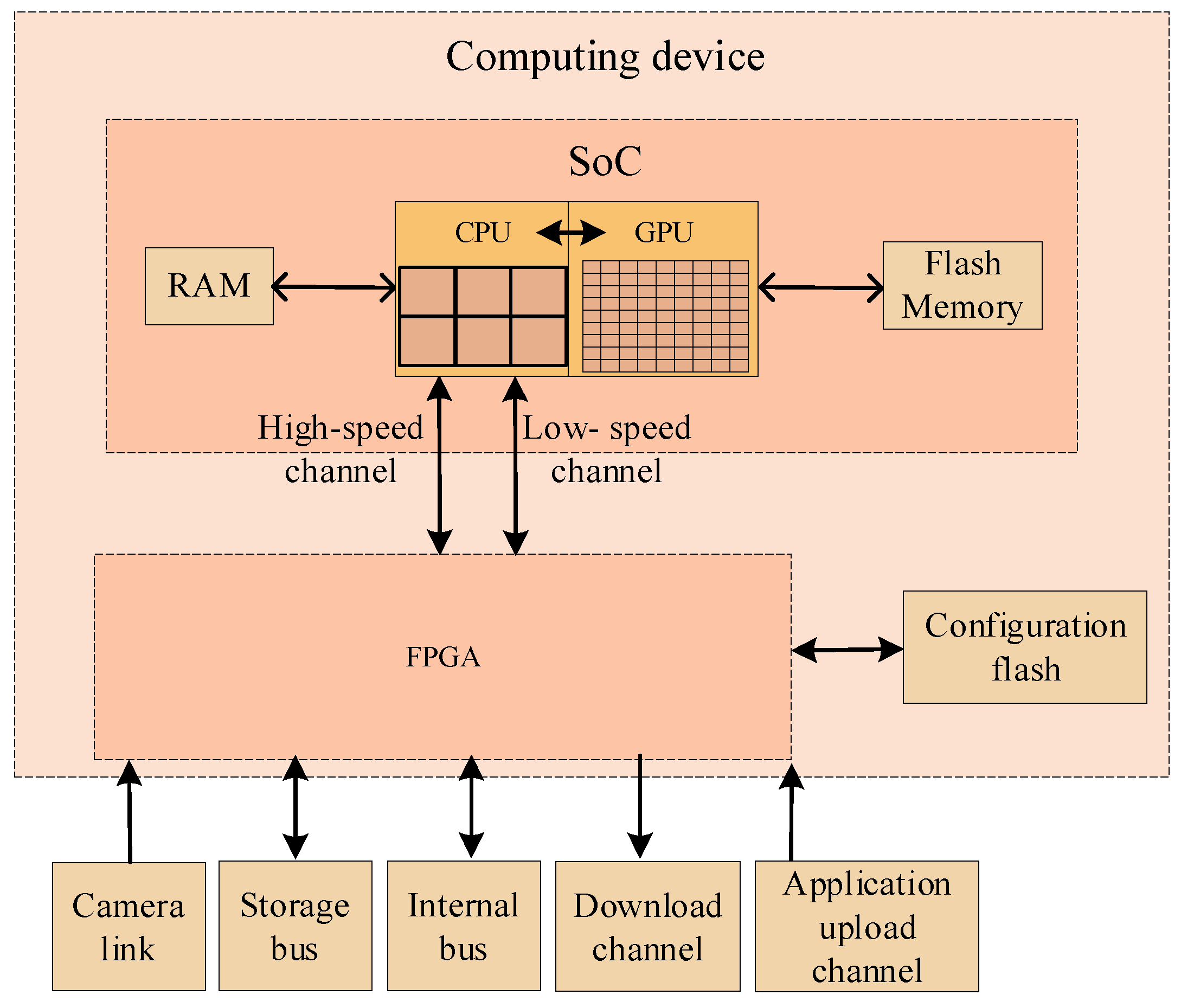
The on-board computing device of the Luojia3 satellite is mainly composed of SoC and FPGA. The SoC includes 8 GB Random Access Memory (RAM) for loading the operating system and running applications, 32 GB Flash Memory for storing applications, basic data, and configuration, and 6-core ARM64 CPU and 256-core GPU processing units, which are responsible for executing different intelligent applications. It uses Peripheral Component Interconnect Express (PCIE) and Serial Peripheral Interface (SPI) to communicate with FPGA. The FPGA is responsible for assisting the SoC with camera interaction, external storage devices, system buses, and the application upload channel. The SoC high-speed channel (PCIE) is connected to the FPGA, receives massive camera data through the FPGA, and the low-speed channel (SPI) is used to receive the platform auxiliary data and the uploaded data from the ground. The on-board computing device has the ability to dynamically deploy new applications during the lifecycle. The concept of the hardware architecture of the on-board computing device can be described in
Figure 3.
The on-board processing data sources are mainly high-resolution optical cameras. On the one hand, to ensure data integrity, the hardware designer confirms that the data transfer bandwidth between the camera and the SoC meets the requirements; that is, the data generated by the camera can be in real-time and can be completely sent to the SoC. On the other hand, different on-board applications have various time consumptions, and the SoC with a limited processing ability needs to realize stream computing for a continuous influx of large amounts of data under the premise of mainly in-memory computation. This poses great challenges to the design of the expandable on-board real-time edge computing architecture. The core issues are as follows:
Selecting important data in real-time while the data flow in to ensure that precious computability is used for important data;
Shortening the execution time of a single application as much as possible;
When the computing is slower than the data flow-in, we ensure that continuous data can be processed in time to confirm that the processing results are synchronized with the flow-in data;
In the above situation, making full use of on-board transfer, storage, and computing resources to maximize the efficiency of streaming computing so that as much important data as possible can be processed.
Considering the above issues and challenges, this manuscript presents an edge computing architecture with base functions. First, as
Section 2 describes, an instant geographic locating function is provided for applications to select the important data from the enormous raw data in time. Second, using the stream computing balance model, applications with different time consumptions could balance the difference between data flow-in speed and processing speed to ensure that as much important data as possible can be processed. Third, following a heterogeneous parallel processing strategy, applications can adjust their algorithms as needed to fully use on-board computability, thereby minimizing the time consumption. The details are discussed in this section.
3.1. Multilayer Structure
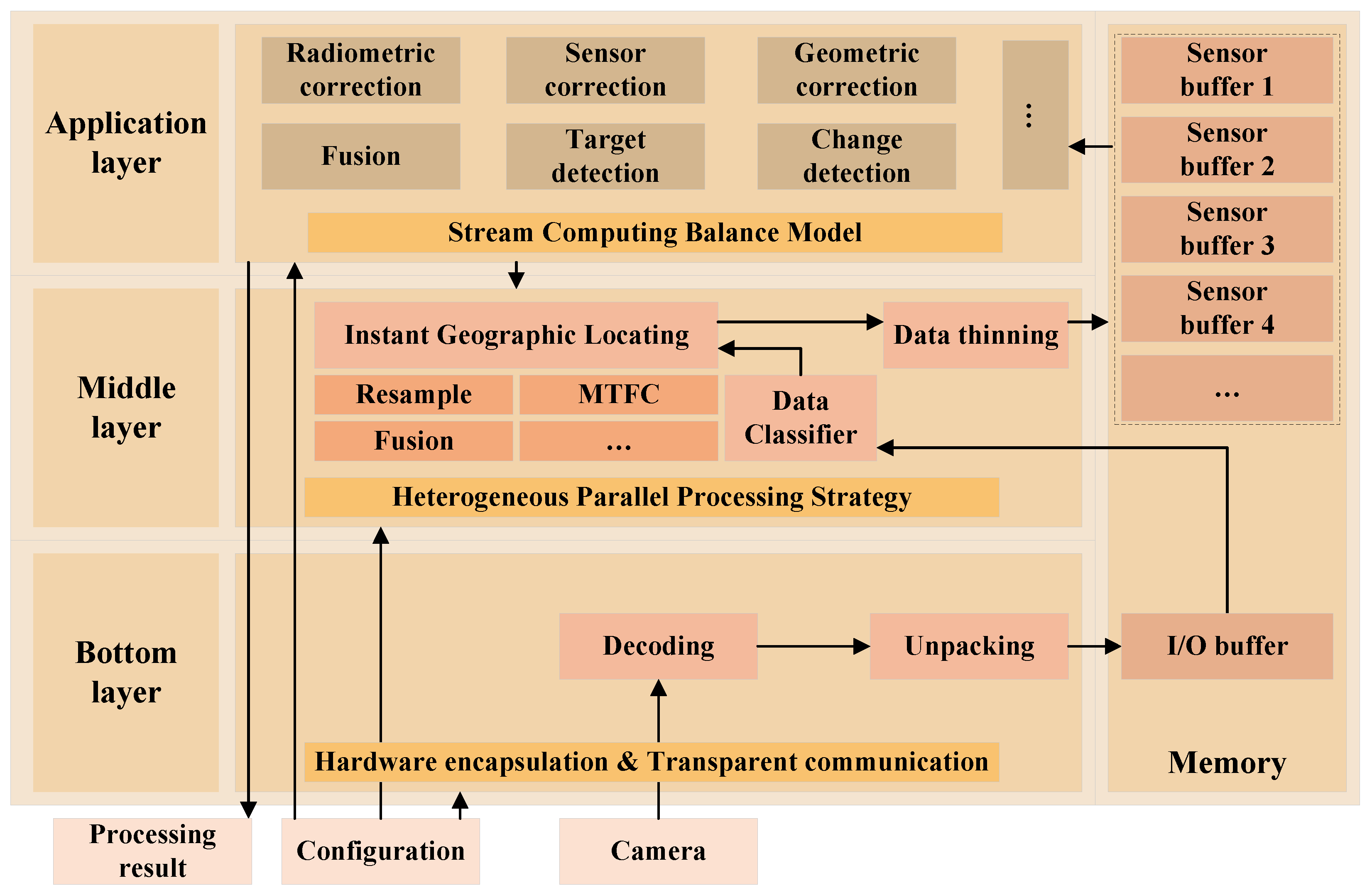
To better organize the base structure of the on-board edge computing architecture and make it convenient for applications to focus on algorithm logic, execution efficiency, and stream computing balance, this manuscript proposes a layered platform architecture, which mainly includes three layers:
The bottom layer is responsible for hardware communications and I/O works while maintaining a buffer to store image data for upper levels temporarily. On the one hand, by maintaining a small circular memory buffer space shared with the upper layer where the actual size can be configured as needed, the flow-in data are stored synchronously with the camera. On the other hand, by ensuring data integrity and consistency in the process of sending and receiving, a data transfer interface is provided to the upper layer to ensure that upper-layer applications do not need to involve hardware and data transfer details.
The middle layer obtains data from the circular memory buffer space shared with the bottom layer, completes the instant geographic locating and ROI locating calculation for the data, and provides the position information to the application layer. During this procedure, the data classification, which is by camera type and sensor number, is processed at the same time. The selected important data are stored in an independent memory buffer shared with the application layer. In addition, deeply optimized base functions, such as radiometric correction, geometric resampling, and other base functions, are also provided for the application layer.
The application layer is an expandable layer that supports the deployment of multiple applications, including radiometric correction, sensor correction, geometric correction, fusion, target detection, and change detection. A standard template is provided in this layer for all on-board applications. The template includes the following elements: program initialization and configuration reading, buffer initialization at all levels, bottom layer function initialization, middle layer function initialization, application logic, and processing results feedback. Among them, the application logic part is implemented by different applications, and the rest is completed by a template or by calling base functions.
The structure of the edge computing architecture is displayed in
Figure 4.
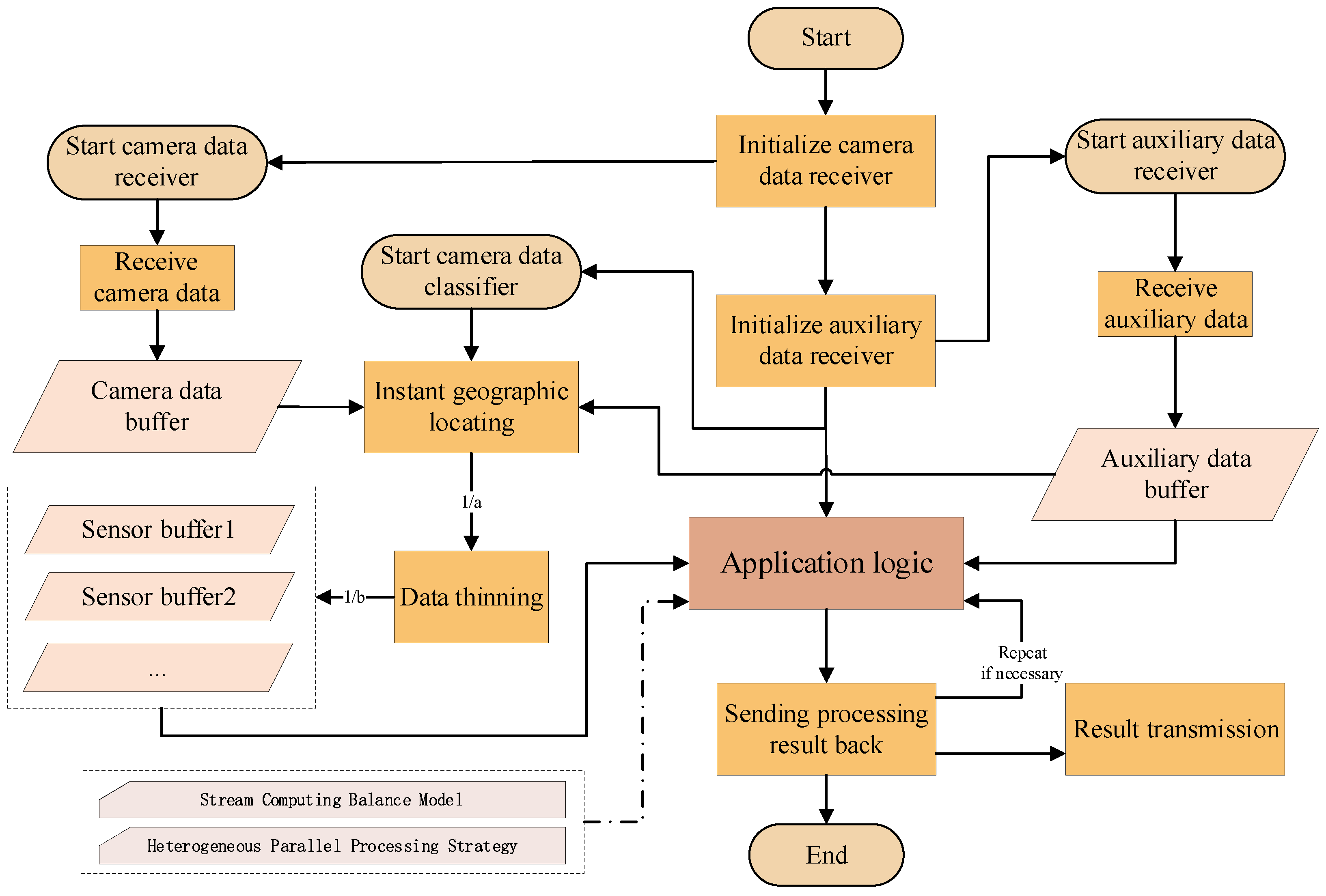
The flowchart of a typical application using a standard template is displayed in
Figure 5, in which the “Application logic” should be implemented by different applications. As
Figure 5 shows, after the application is started, the camera data receiver is initialized first, then the auxiliary data receiver is initialized, and then the camera data classifier is started. All these three run as independent threads, executing concurrently with the main thread. Among them, the camera data receiver exclusively occupies the high-speed channel of the SoC and receives raw camera data into the “Camera data buffer”; the auxiliary data receiver monitors the low-speed interface of the SoC and receives auxiliary data into the “Auxiliary data buffer”; the camera data classifier monitors these two buffers while extracting the ROI data through “Instant geographic locating”, then performs “Data thinning” according to the configurations, and stores the classified data into the “Sensor buffer” for “Application logic”. After processing, the “Application logic” uses a base function to pass the processing result out of the SoC.
3.2. Stream Computing Balance Model
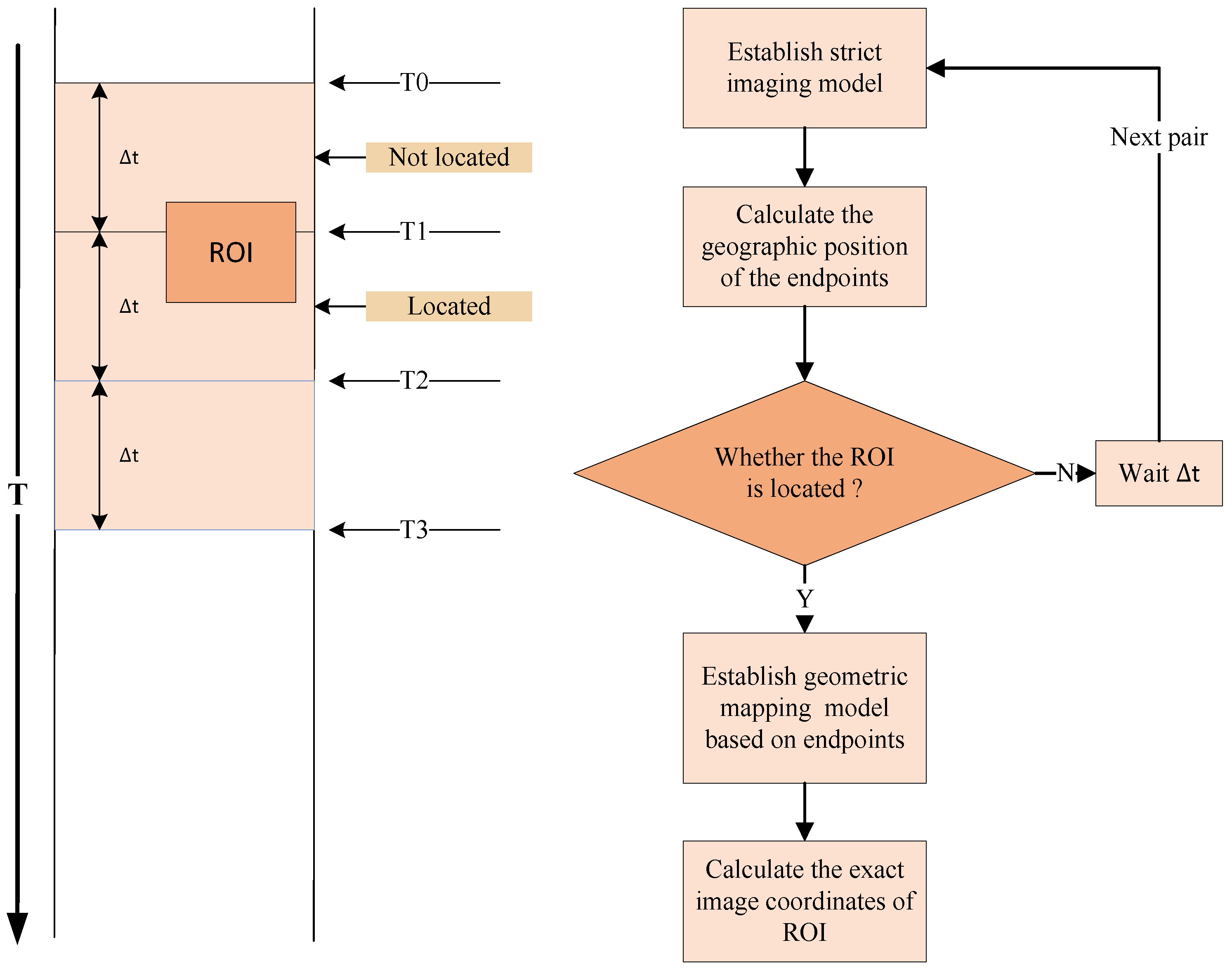
Due to the contradiction between the limited on-board computability and storability and the large amounts of flow-in data, it is almost impossible to complete on-board processing for all data in real-time. Therefore, selecting important data and ensuring that precious computability is used for important data is the main duty of the on-board edge computing architecture. Based on the above architecture, after the application is correctly initialized, it can obtain the geographic location of the current imaging position in real-time based on the API provided by the middle layer and select important data for processing to efficiently use the limited on-board computability.
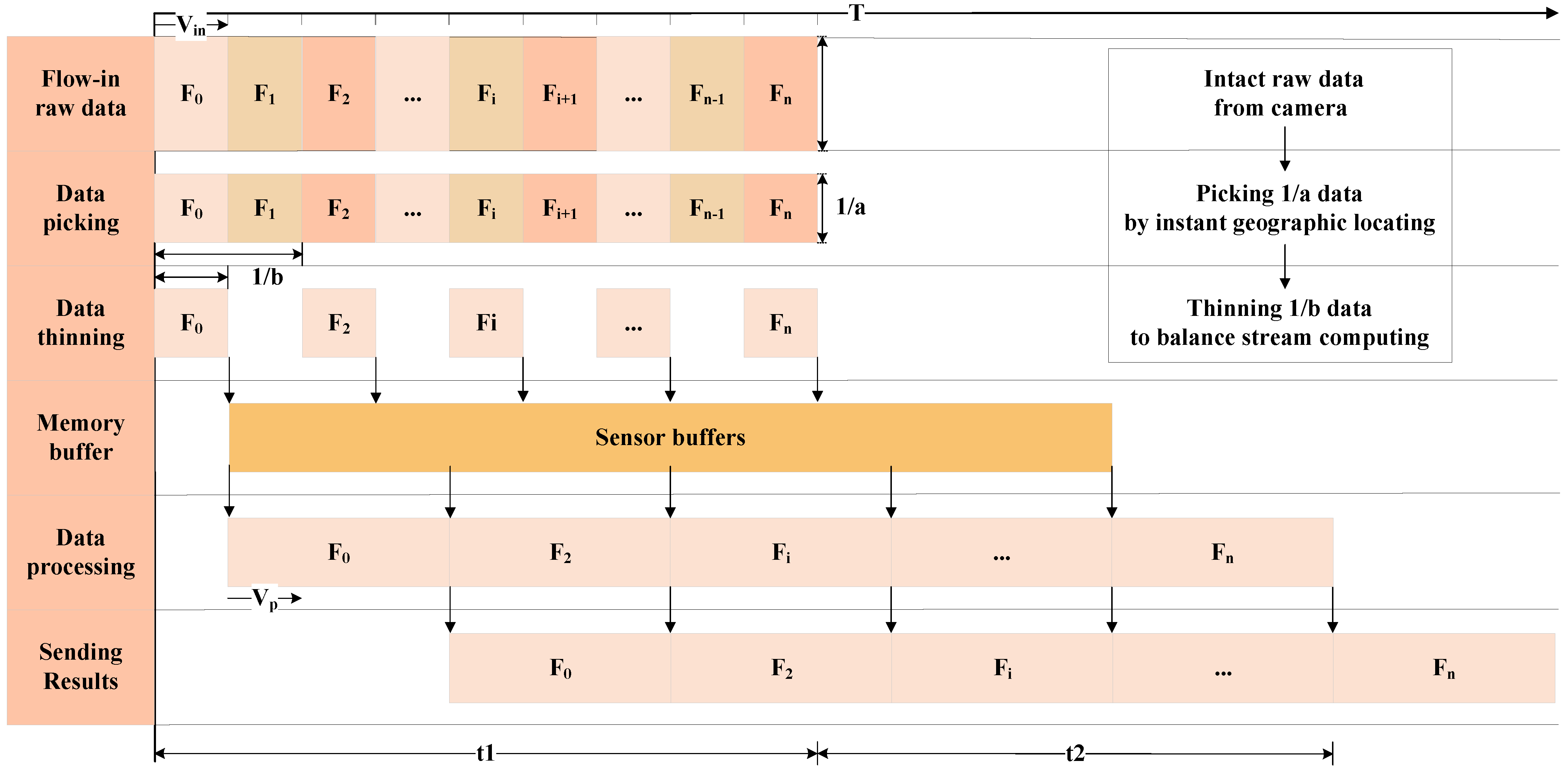
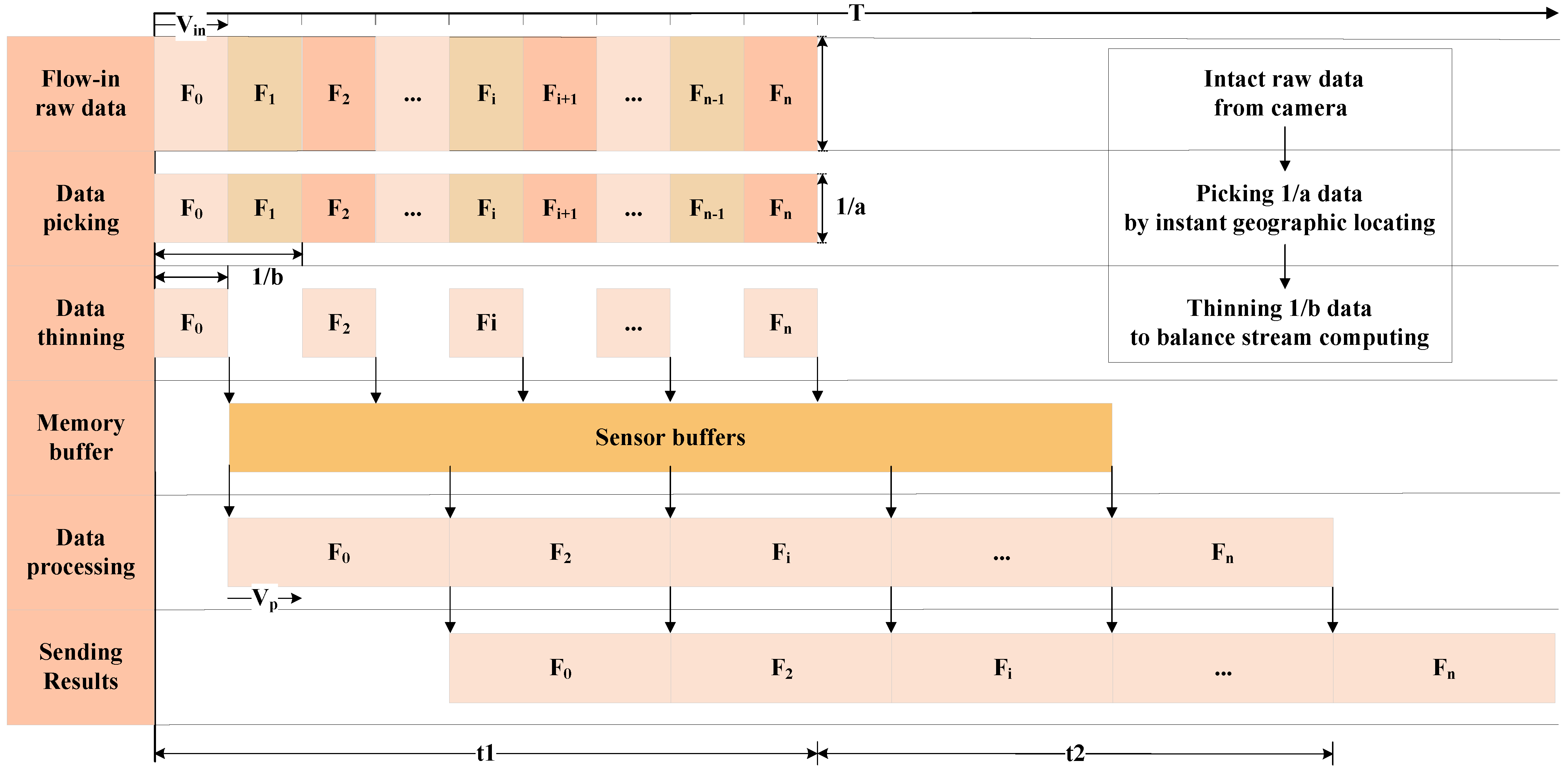
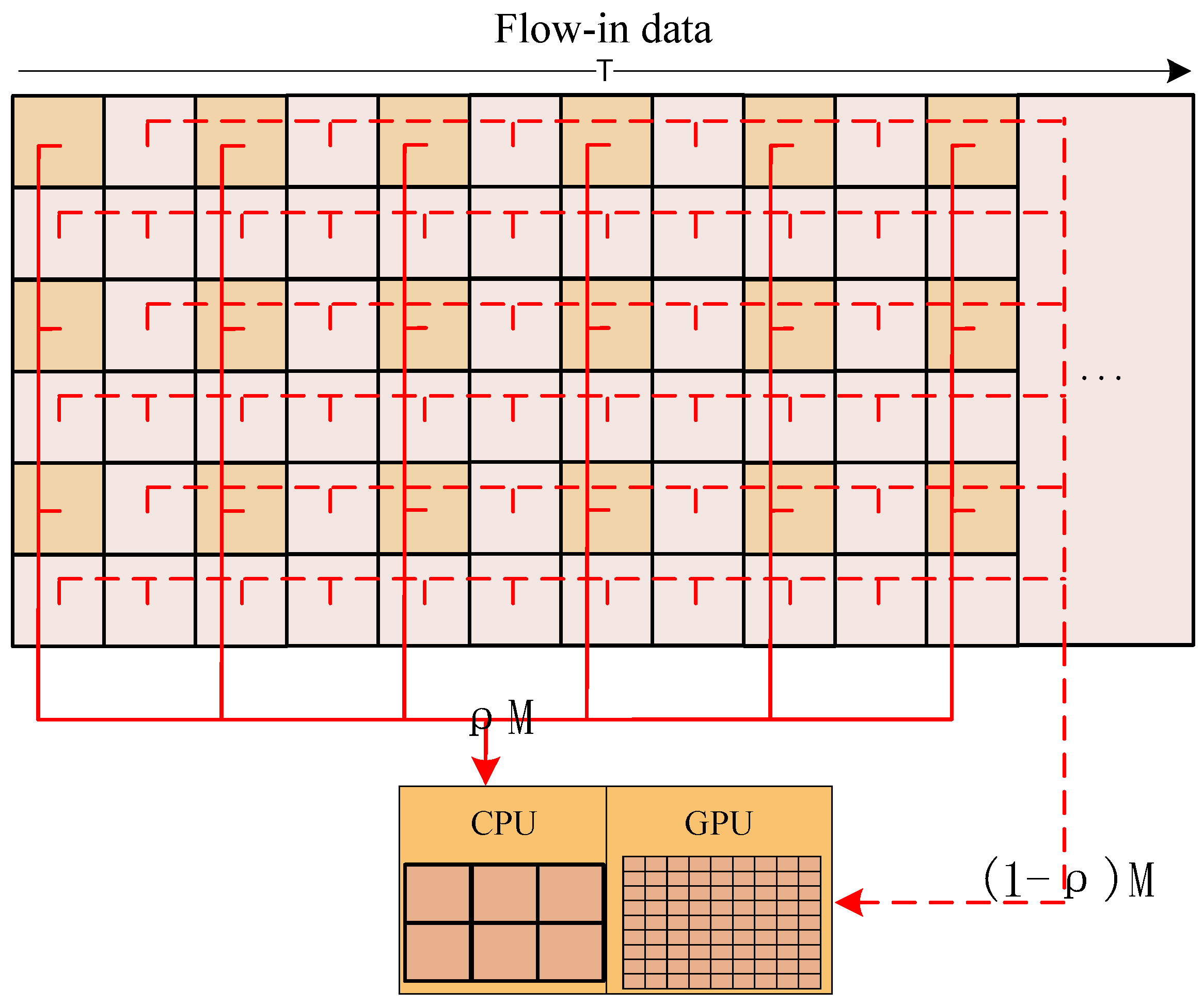
Second, when the computing is still slower than the data flow-in, the balance of stream computing is broken, and part of the data must be discarded. The traditional strategy is to complete the processing of the flow-in data as much as possible and store the data that cannot be processed in the buffer if feasible, and once the buffer is full, the new data is discarded. Another more reasonable strategy is to maintain a buffer with an appropriate size as configured by the architecture and periodically discard part of the flow-in data to balance the flow-in and computing. The traditional strategy leads to the situation where only the beginning part of the data is processed, and the later data is discarded. In contrast, the second strategy can periodically process the data according to the configured frequency, and all the processing results are distributed evenly in the time dimension. In addition, considering the relative position between the satellite and Earth, to ensure that the ground station can obtain the on-board processing results in time, the time window for on-board processing is usually not very long. When the camera starts imaging, the application on the SoC starts running synchronously. Usually, the result must be given within tens of seconds after the camera imaging is completed. Therefore, the second strategy is more adaptable and suitable than the traditional one. The processing timeline of this strategy is shown in
Figure 6.
To quantitatively describe the above process, a stream computing balance model is built. Let represent the data flow-in speed, represent the computing speed, represent the maximum size of memory occupation during processing, including the occupation of the operating system, represent the memory buffer size, represent the total memory size, represent the imaging time, represent the processing time after imaging, represent the data picking coefficient, which is numerically equal to the raw data size divided by the picked data size by instant geographic locating theoretically, and represent the data thinning coefficient when computing is slower than the flow-in.
Ideally, when the memory buffer is sufficient and the computing speed meets the following conditions, the stream computing state is steady.
For most intelligent applications,
does not satisfy Equation (5a), which means that stream computing cannot be naturally realized. In this case, after applying instant geographic locating, the equivalent data flow-in speed is reduced to
; furthermore, when the data thinning coefficient
is greater than 1, the equivalent data flow-in speed is reduced to
. Then, the stream computing conditions can be described as follows:
can be calculated as follows:
It is important to note that the memory buffer size also needs to meet Equation (5b).
The data flow-in speed depends on the camera, which can be considered a fixed value for a certain satellite. When introducing a new application, the computing speed and the memory occupation size of this application should be determined first. Then, the imaging time and the processing time after imaging are determined according to the task requirements.
Substituting the above values into Equation (5c) can determine whether the memory buffer size
meets the requirements. If the memory is sufficient, we determine the
and
values that make the minimum
value according to the specific requirements. Then, we set the
,
and
values to the application configuration to leverage the architectural foundational capabilities to realize stream computing of new applications. When the memory is insufficient, which means that
, then the stream computing conditions can be described as follows:
can be calculated as follows:
Clearly, the data thinning coefficient needs to be further increased.
When an application starts, the platform reads the configurations and then sets parameters through the API to ensure that the stream computing of this specific application can work optimally per on-board hardware ability limitations.
3.3. Heterogeneous Parallel Processing Strategy
Any algorithm that can be implemented by a computer system can be divided into serial component
and parallel component
. The well-known Amdahl′s Law [
27] is given as follows:
where
is the number of parallel cores and
is the speedup ratio of parallel computing. Theoretically, when
, the upper limit of the speedup ratio is
. This means that the theoretical maximum speedup ratio of the algorithm depends on the ratio of the parallel component to the serial component of the algorithm itself. In an actual parallel system, the number of parallel cores
is limited. Due to the limitations of the chip architecture and memory access performance, it is almost impossible to achieve the upper limit of the theoretical speedup ratio. However, the analysis of the algorithm’s characteristics itself can always help developers achieve efficient optimization of the algorithm.
The classical Flynn taxonomy [
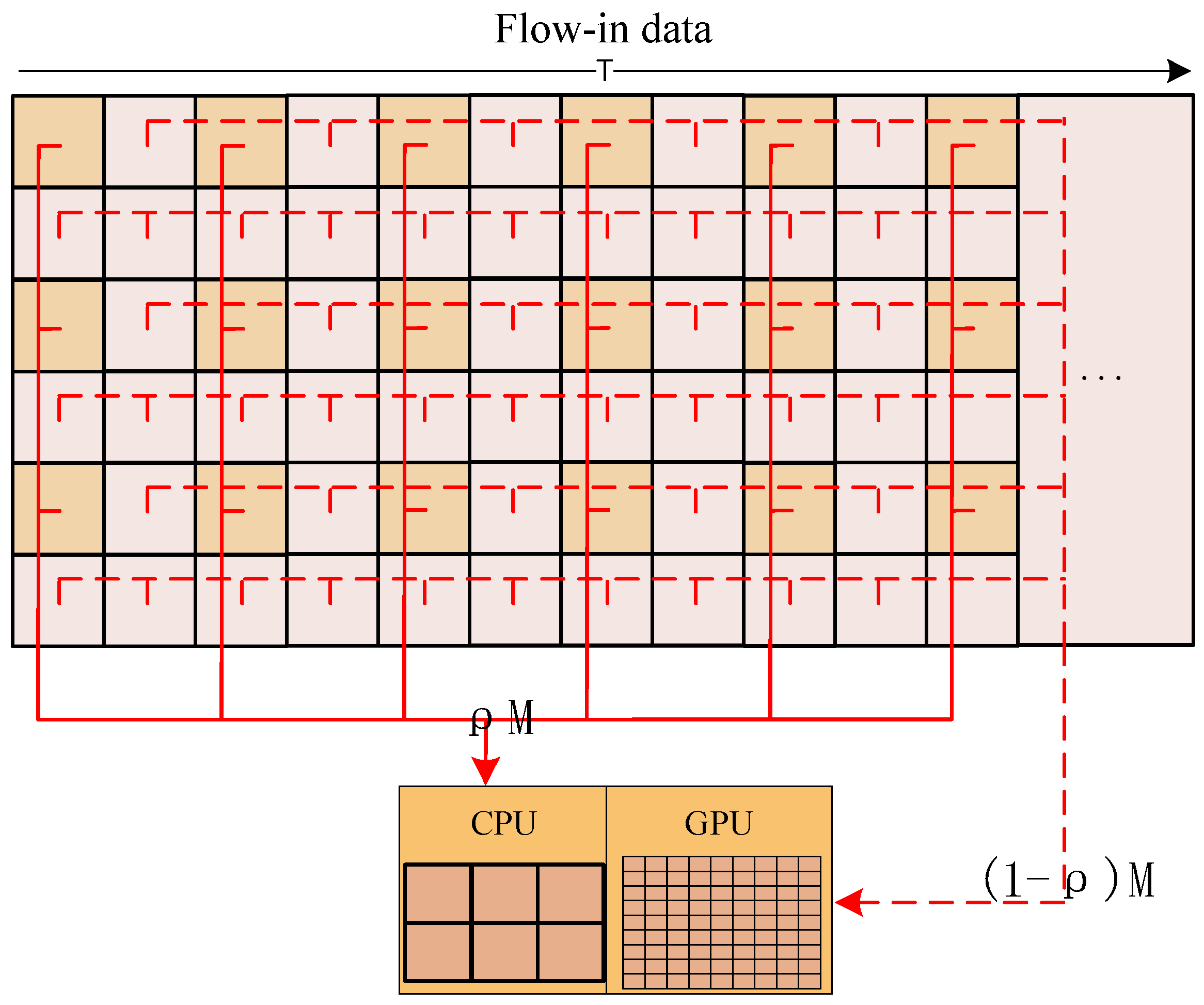
28] divides computing platforms into four categories according to the instruction flow and the data flow of the computing platform, namely, Single Instruction Single Data (SISD), Single Instruction Multiple Data (SIMD), Multiple Instruction Single Data (MISD), and Multiple Instruction Multiple Data (MIMD). Presently, the majority of mainstream hardware adopts the hardware architecture combining SISD and SIMD. The serial component of the algorithm is often executed on an SISD processor such as a CPU, and the parallel component is often executed on an SIMD processor such as a GPU to realize efficient processing. Ideally, when the performance of the GPU is sufficient to meet the needs, the algorithm can be fully parallelized. However, under the limitation of on-board computing, the performance of the GPU is usually insufficient on most occasions. Fortunately, most of the current mainstream CPUs have multiple cores, which can take part in the parallel component computing work under the premise of meeting the requirements of serial component computing, thereby shortening the overall computing time. The optimal heterogeneous parallel processing strategy can be described as follows.
Let
represent the proportion of the parallel component allocated to the CPU,
represent the total computing amount,
represent the total CPU load for computing the serial component,
represent the processing performance when the algorithm occupies multiple CPU cores for execution, and
represent the processing performance when the algorithm uses a GPU to execute. The relationship between these variables can be described by Equation (11).
can be calculated as follows:
The time consumption of heterogeneous parallel processing
can be calculated as follows:
The flowchart of the heterogeneous parallel processing strategy is shown in
Figure 7.
According to Equations (11) and (12), the values of and can be determined through experiments. The specific value of is more difficult to determine because too many factors affect its value, in actual use, one or two CPU cores can be reserved for . Therefore, usually, a region of value could be estimated for . It is worth noting that when , the CPU multicore parallelism does not work well for this algorithm. At this time, the value of is very small, which means that the CPU multicore parallelism does not suit this algorithm, and the heterogeneous parallelism is unworthy.
When applying heterogeneous parallel optimization to an algorithm, we first measure and and estimate the value; then, we substitute them with Equation (12) to obtain the optimal division of parallel components. During image processing, the data to be processed are divided into blocks and sent to the CPU and GPU according to the above division to realize the performance optimization of the algorithm. It can be seen that the optimization scheme of the specific algorithm is highly related to the specific hardware composition, ability, algorithm characteristics, etc., and the optimization cost is high. The developers of different applications can determine whether to apply this strategy according to specific situations.
5. Discussion
Most of the previous on-board processing research was guided by specific applications. In the satellite design stage, the on-board applications to be implemented were first determined, and then a large amount of testing and optimization work was done for these applications. For applications with a large amount of computation and high timeliness requirements, to ensure the balance of stream processing, it is necessary to provide enough on-board computing resources. What follows is a substantial increase in the volume, power consumption, heat dissipation, weight, manufacturing costs, and launch costs. Although this method can ensure that the specific application functions work well, its cost is high, and the openness and expandability are poor. This method does not conform to the development trend of agility, intelligence, miniaturization, low cost, and expandable functions of the next generation of remote sensing satellites.
Combined with the development procedure of the Luojia3 satellite, aiming at the core issue that the low computability and storability of on-board devices cannot meet the real-time computing needs of different applications, this manuscript discusses building an expandable on-board real-time edge computing architecture based on limited on-board hardware. Through a layered architecture, the applications from the hardware and the communication details are isolated so that the applications can focus on the logic and performance of the algorithm. Through instant geographic locating calculations, applications are provided with the base function of data picking, which helps applications concentrate precious computability to process key data. Establishing a stream computing balance model helps application developers analyze and set key parameters according to baseline performance test results, and they realize stream computing of various applications. Establishing a heterogeneous parallel processing strategy helps application developers optimize the performance of algorithms based on on-board hardware.
During the joint testing and commissioning of the Luojia3 satellite, application developers carried out various extended applications, including high-precision cloud detection, target detection, change detection, and high magnification compression, based on the architecture of this manuscript, which validates the adaptability and expandability of this architecture.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}