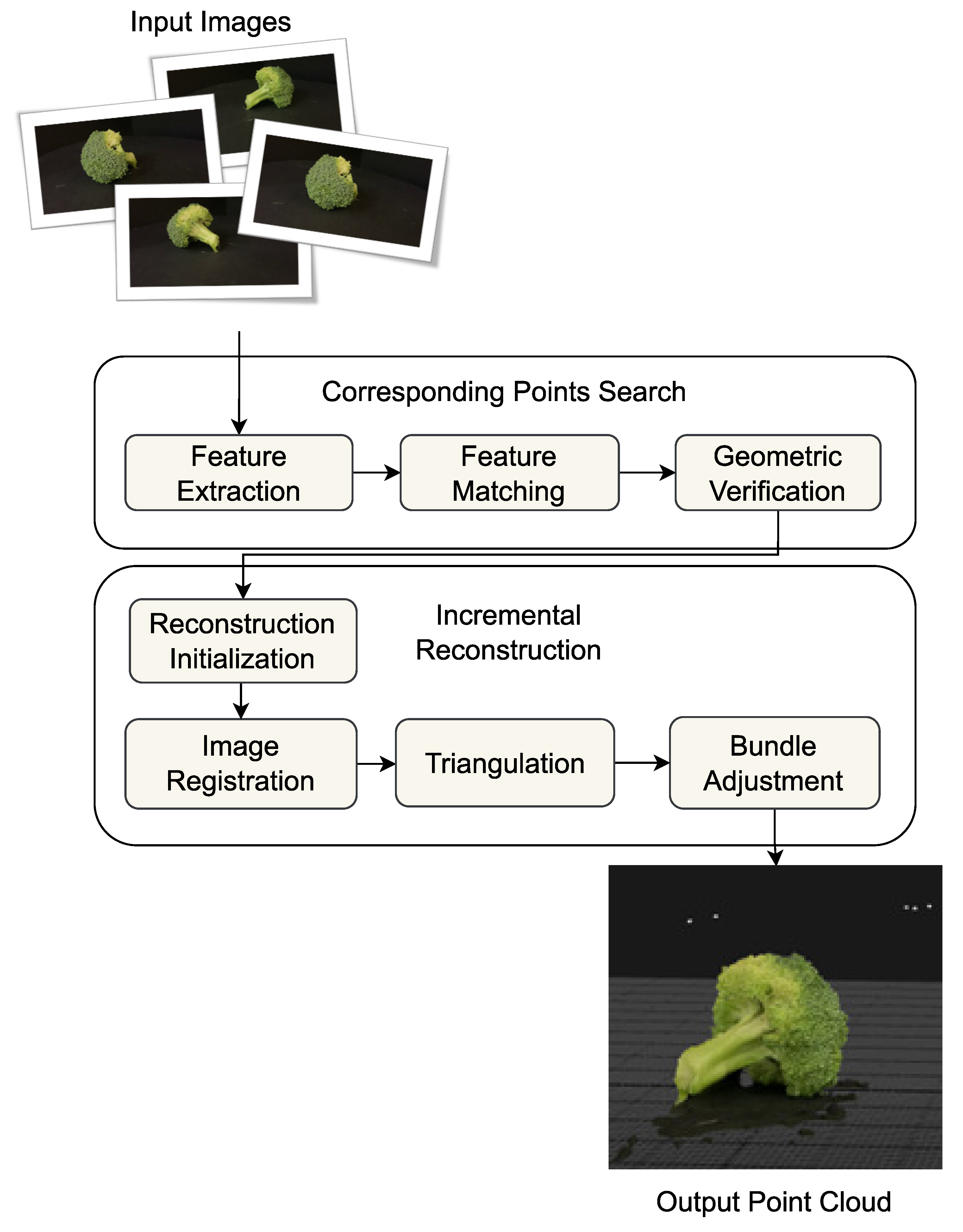
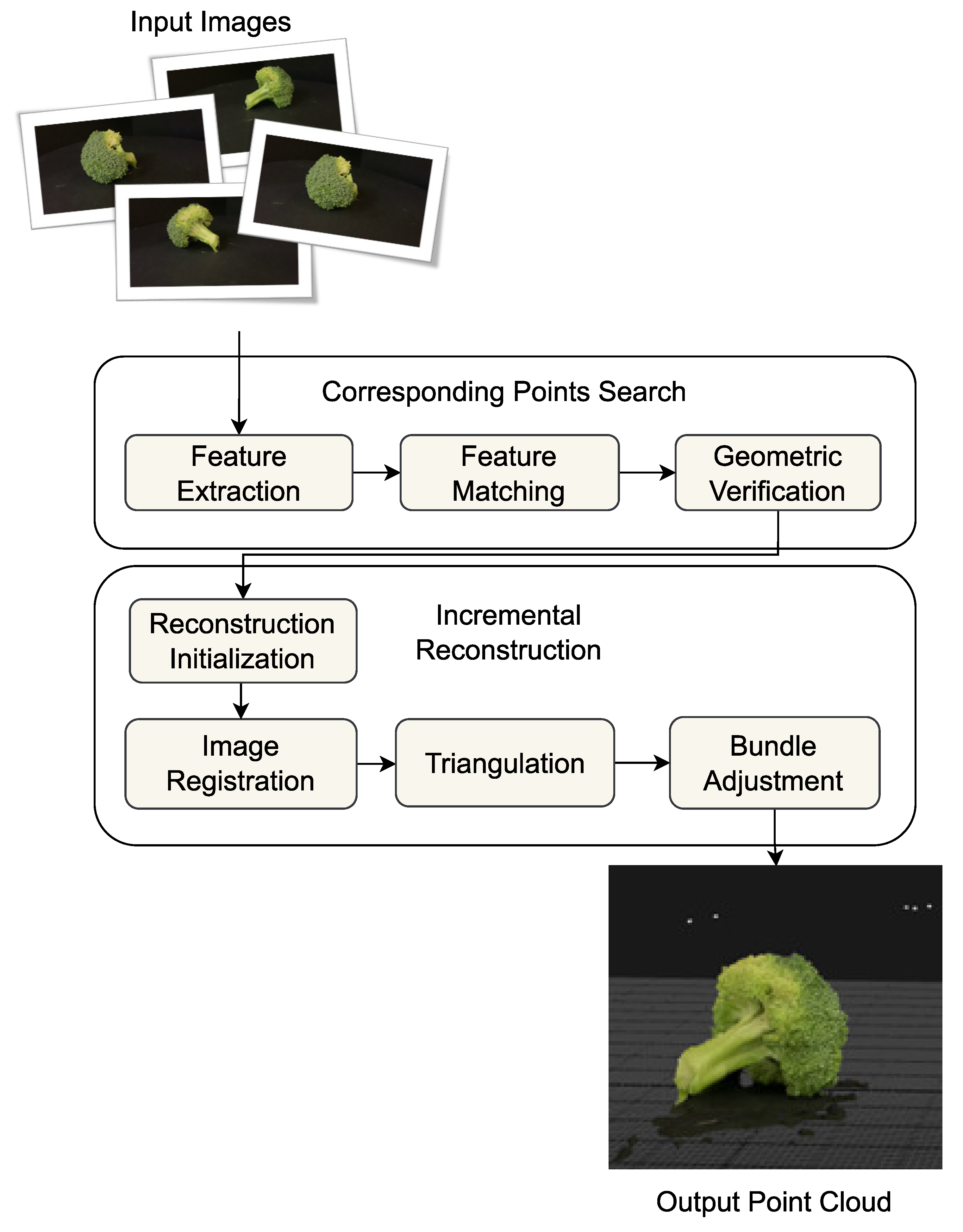
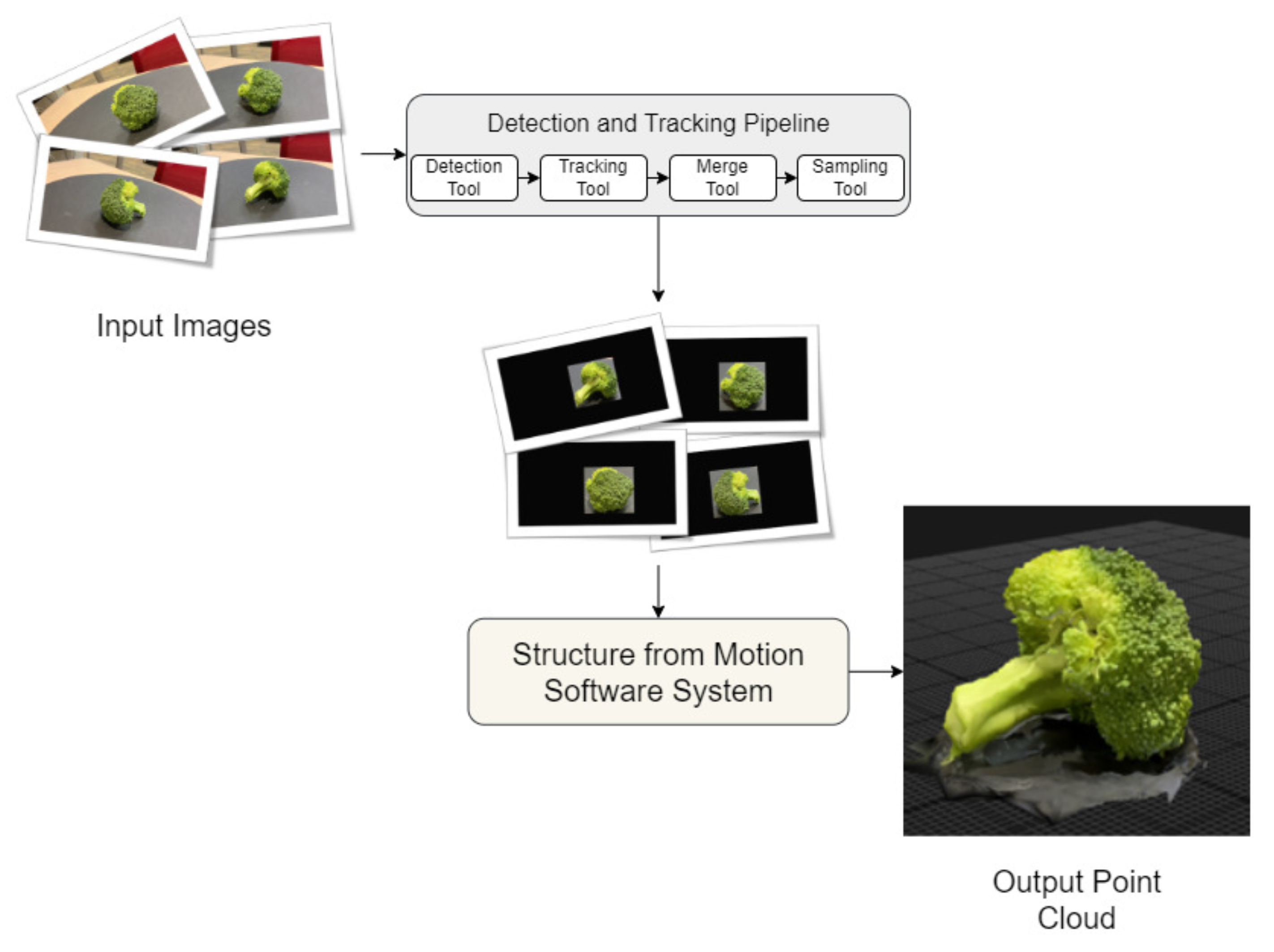
The detection and tracking pipeline and Structure from Motion software present a framework to utilize existing tools and technologies to recover or reconstruct partial regions of a scene based on the objects present in the scene. The pipeline incorporates a correction mechanism to merge incorrectly reidentified objects during tracking to maintain the object tracking for a longer time. The framework introduces a strategy to decompose a dynamic scene, which may not be reconstructed using SfM software only, into multiple static only sub-scenes by detecting and tracking objects, separating them from the main scene, then feeding them to SfM software and recovering the point clouds.
We designed experiments to evaluate the reconstruction quality of SfM software systems with and without the proposed pipeline. First, we determine the reconstruction accuracy of a point cloud using a controlled SfM setup (turntable with black background) by comparing measurements on the point cloud to measurements obtained from the actual object. Then we compare the reconstruction integrity or deformation with and without the pipeline against the controlled SfM reconstruction.
4.2. Evaluation
SfM utilities are powerful tools to reconstruct geometry or measure distances accurately. Our research is more concerned with the reconstruction of geometry for an arbitrary scene since measurement tools such as scaling markers or control points may not be available. In other words, we evaluate the reconstruction of an arbitrary video of an object and measure how it would be aligned with and without the detection and tracking pipeline as if it was recorded in a controlled environment. The experimental setup produces four different point clouds for each object, a raw point cloud, a masked point cloud, a controlled point cloud, and a reference point cloud. The raw point cloud (uncontrolled environment) results from feeding 200 frames to the SfM software. The masked point cloud results from preprocessing the frames with our pipeline and then feeding the processed frames to the SfM software. The controlled point cloud results from feeding 200 frames from the controlled environment to the SfM software. The reference point cloud is a manually cleaned version of the output of the SfM software of the frames from the controlled environment. The reference point cloud is used to evaluate the quality of the other two point clouds.
Additionally, we use three different state-of-the-art SfM software (Agisoft metashape, Pix4d, and RealityCapture) with their default reconstruction settings to evaluate the effect of our pipeline on each software. Since each software system has their own proprietary algorithms to reconstruct the point cloud it will be challenging to define a common reference point cloud for all software systems. Instead, we evaluate the reconstruction quality of the masked and raw point clouds with respect to the software being used. For example, we generate the reference, masked, and raw point clouds for each software system.
Furthermore, we determine the reconstruction quality using two methods for each software system. First, we compare the measurements of reference point clouds with the actual measurements from the objects (truck, car, and airplane) used in the experiments. Second, we measure the alignment or the deformation of the masked and raw point clouds against the reference point clouds. Since the alignment process between masked and raw point clouds with the reference point cloud contains only rigid transformations, then the alignment quality would directly indicate the masked and raw point cloud quality.
Figure 6,
Figure 7 and
Figure 8 show sample views of the different point clouds (masked, raw, and reference) per object. We use the short names Ctrl, Ref, Msk, Unctrl to refer to a controlled environment, reference, masked, and uncontrolled point clouds, respectively. It is clear that the SfM software was able to generate point clouds for a partial scene when using our pipeline, and it achieves accurate results compared to its corresponding raw point cloud where a large portion of the points are part of the background. Furthermore, the front of the yellow truck reconstruction using Agisoft, Pix4d, and RealityCapture is deformed without using our pipeline. For example, Agisoft constructed multiple portions of its front multiple times and skipped the rear part due to scene complexity, and in some cases, the raw point cloud is not usable.
However, the visual representation is not sufficient to quantify the reconstruction quality. As a point cloud consists of a list of 3D points where the number of points and the positions are used to compare and evaluate the reconstruction quality compared to the reference point cloud. We consider the number of points to be indicative of the signal-to-noise ratio or object points to scene points. As the ratio gets closer to 1, the generated points are more likely to be relevant to the target object.
Table 2 shows the number of points for the reference objects before and after background (noise points) removal for each software. For instance, the yellow truck scene recorded 455.8 K points, but only 133 K points belong to the truck, roughly 1/4 of the scene points belong to the yellow truck, and the remaining points are irrelevant. SfM software adds additional background points, and that behavior is consistent between the different software and their scenes as shown in
Table 2. The second metric is the average distance and standard deviation between two point clouds. Given two registered point clouds, registration is the process of transforming (scale, translate, or rotate) a target point cloud (scene) to align with a reference point cloud (object), and a distance measure can be computed to evaluate the geometrical (structural) quality of the target point cloud. Cloudcompare [
53] uses a version of Hausdorff [
54] distance between two sets of corresponding points. The modified version models the local surface near the points instead of computing the distances directly between the corresponding points of the reference and target point cloud to obtain reliable results. For instance, if the two point clouds are exactly the same, then the average distance and standard deviation should be 0, and both start to increase as one set of points deviate from its corresponding set of points, indicating the point cloud shape deformation.
However, the average distance and standard deviation are limited measures because during the reconstruction process we have no camera information (both intrinsic and extrinsic parameters) and we do not require any scaling markers. Hence each software system defines an arbitrary coordinate system to measure distances between points. The average distance and standard deviation, in this case, can show the deformation differences between the masked and raw point clouds only if the same reference point cloud is used. However, it may not translate to other point clouds of the same object because each software system uses an arbitrary unit in its internal coordinate system.
In order to fix this issue, we converted all of the units to millimeters and then compare results across systems. This allows us to use the average distance and standard deviation to evaluate the deformation of the point clouds independent of the software used. To convert to millimeters, we physically measure the distance between two points on an object in millimeters and then find the corresponding points in the point cloud and calculate a scale factor to transform the point cloud units to millimeters. We apply the scaling and then verify the scale using another set of points. This process ensures the measurement units are unified to IS units between all point clouds.
Table 3 shows the manual measurements (MM) of three objects (truck, car, and airplane) of three different dimensions (Length, Width, and Height) against the measurements of the same dimensions (DIMS) using the point cloud for the Agisoft (AG), Pix4d (PX), and RealityCatpure (RC) software systems. The scaling operations are applied to all reference point clouds but only three point clouds (the truck, the car, and the airplane) are used to evaluate measurement accuracy due to the challenge of getting accurate physical measurements of the other objects. Even though the camera calibration information and turntable control or scale points are never used during the reconstruction,
Table 3 shows the measurements can be as accurate as the manual measurements in the case of the truck length using Agisoft and many other instances as well. Even with relatively high error values, such as the airplane width at almost 12 mm, the scaled point clouds achieve roughly between 2 and 3 mm accuracy as shown in
Table 4 independent of the software. The measurements indicate high quality as they can be used to obtain measures or reproduce parts with high fidelity.
Table 3 and
Table 4 show a controlled (turntable) setup would produce high quality reconstruction but a dynamic scene with two or more motion systems may fail to generate a point cloud or generate a significantly deformed point cloud [
9]. The second step of the quality evaluation is to measure the number of points of the masked and raw point clouds, their ratio with respect to the reference point cloud and the alignment between the masked and raw point clouds with the scaled version of the reference point cloud.
Table 5,
Table 6 and
Table 7 show multiple quantitative traits, number of points (Np), number of reference object points to scene points (O2S), average distance between object point cloud and the registered scene (Mean) and its standard deviation (SD) to measure the quality differences between the masked and raw with respect to the reference point cloud and the SfM software. The mean distance and the standard deviation between the registered point clouds are measured in millimeters.
Table 5 shows the reconstruction quality using Agisoft for the different objects. First, the number of points of the masked point cloud is significantly lower than its corresponding raw point cloud. The masked points are likely to be more relevant to the target object because the masked imagery contained the target object only as shown in
Figure 5. The masked point cloud is also more computationally friendly since it has a lower number of points. For example, the raw point cloud of the yellow truck has 2+ million extra points than its corresponding masked point cloud which needs more computation to process the extra points. The raw point cloud is susceptible to generating noise due to the existence of irrelevant points and their potential deformation. The object-to-scene relation shows the impact of the reference signal with respect to the scene; the number of points the reference yellow truck represents is
of the masked scene, which is less than twice the reference object points while it is only
on the raw point cloud or 17 times the size of the reference object point cloud. For all objects, Agisoft produced a significantly lower number of points and a higher object-to-scene ratio as well. The number of points and the object-to-scene ratio is reflected on alignment measures between the masked and raw point cloud with the corresponding reference object. As shown in
Table 5, the raw point clouds have a higher average distance and standard deviation with respect to the corresponding reference object, meaning that the raw point cloud is structurally deviated from the reference object due to the noise points and deformation. On the other hand, the masked point clouds are closer to the reference point cloud and have significantly lower average distance and standard deviation from the reference point cloud. For instance, the masked broccoli scene has a
mm average distance and
mm standard deviation compared to the raw scene with a
mm average distance and
standard deviation which is 20 times uncertain compared to the masked scene.
In addition to quantitative measurements,
Figure 6 shows the qualitative traits of Agisoft 3D point cloud reconstructions for the controlled, reference, masked, and raw point clouds. The raw point cloud of the double winged airplane appears to be the most deformed object. Furthermore, the raw point cloud of the yellow truck shows additional artifacts (points) or duplicate points of the front of the truck. Furthermore, the car object has deformation in the front and the wheels, manifested as a duplication of points. The duplication and overlapping of points deform the shape of the object and it is challenging to fix and more likely to require rescanning the object. On the other hand, the masked point clouds appear to produce the correct shape with minimal noise and no observable deformation. Furthermore, the masked point clouds are similar to the cleaned version of the controlled environment and most of the noise in the masked objects is due to the turntable surface that appears in the imagery.
Table 6 shows the same evaluation criteria for the same objects using Pix4d SfM software. It is safe to say that the masked point clouds have a better reconstruction quality compared to the raw point clouds, which confirms the observations of Agisoft.
Table 6 shows a lower number of points compared to the raw point clouds and it is more relevant to the object due to background removal. Masked point clouds are also better aligned with the reference objects since they have a lower average distance and standard deviation compared to the raw point cloud. However, the quantitative approach only applies to the yellow truck and banana objects, the other objects (car, airplane, and broccoli) have significantly lower numbers of points compared to the masked point clouds and even lower than the reference objects. For example, the masked airplane scene has 160.3 K points and the reference object has 337.3 K compared to only 14.4 K points in the raw point cloud. The significant reduction of the number of points in the raw point clouds is mainly because Pix4d failed to reconstruct those target objects (car, airplane, broccoli, and banana), shown in
Figure 7. Pix4d recovered mainly the background points of the car and the airplane, and the points were scattered over a large space. The average distance and standard deviation of the two objects are not available because the registration of the raw and reference point clouds failed due to the serious deformation of the raw point clouds. Moreover, Pix4d failed to recover any points for the broccoli and the banana objects because it could not find an appropriate camera calibration. It is worth noting that Pix4d tends to drop points in rich scenes. For example, the raw point cloud of the yellow truck is missing many points in front of the car, likely because of the transformation consistency between the points. In contrast, the masked imagery successfully reconstructed all objects as shown in
Figure 7 and it is almost as dense as the reference point cloud (no missing points). The background removal improved transformation consistency by removing noise and inconsistent features.
Table 7 shows the RealityCapture reconstruction results. RealityCapture recorded more or an equal number of points for the masked point clouds compared to the corresponding raw point clouds except for the banana object. Furthermore, the object-to-scene ratio shows the number of points can be as much as twice the number of points in the reference object point clouds. However, the extra number of points in the masked point cloud does not imply noise points in this case because the average distance and standard deviation from the reference point clouds are significantly lower than the corresponding raw point cloud and it also falls within the same ranges as Agisoft and Pix4d. The results suggest that RealityCapture sampled significantly more points of the objects from the masked imagery. The results also imply that RealityCapture could extract more details compared to the controlled environment. RealityCapture examples presented in
Figure 8 demonstrate the generation of high-quality point clouds using the masked imagery.
Figure 8 shows that most of the noise is from the points recovered from the turntable surface. The noise points do not have a significant negative impact on the recovered point cloud because it follows the same motion as the object. Furthermore, the noise points occupy a small portion of the scene which implies that most of the points in the masked point cloud belong to the object. However, sampling more points was not effective in the raw scene. For example, the airplane object is highly deformed, and the airplane structure barely appears in the point cloud. Similarly, the yellow truck is also deformed and one side of it and the car has some deformation as well. However, the broccoli and banana objects are well reconstructed except for extra background points.
In addition,
Figure 9 shows the visual traits of the reconstruction when multiple objects are present in the scene. The video is processed with no additional configuration to the pipeline, and it reconstructs the two vehicles and separates them into two different point clouds. However, pix4d reconstructions are deformed, more likely because the software was not able to find appropriate camera positions and orientations to recover the correct shape of the vehicles. It is more likely because of the lower frame resolution and feature ambiguity.
Table 8 shows the quantitative results of the scene where the number of extracted points is significantly lower than in previous experiments. For example, the truck is only 12.5 K points using Agisoft which is 0.09% of the reference point cloud. However, RealityCapture was able to generate more points compared to Agisoft and Pix4d. However, the number of points did not affect the reconstruction quality. Most of the objects aligned correctly with their reference point cloud with minor changes to average distance and standard deviation except for the Pix4d car reconstruction which has serious deformation and consequently it has significantly higher average distance and standard deviation from the reference point cloud.
Figure 10a shows the detection and tracking profiles of the different objects in the scene;
Figure 10a shows that the pipeline identifies 12 unique objects even though there are only two vehicles present in the scene. Some objects only appear for a short period of time, like objects 15 and 16.
Figure 10a shows the potential issues for detection and tracking algorithms. For example, the detection network can generate multiple detections (bounding boxes) for a single object which is shown for objects 2 and 3, where they refer to the same vehicle (car object). Furthermore, the tracking algorithm may reidentify an object due to visual or motion changes (depending on similarity criterion) and lack of detection. For instance,
Figure 10a shows object 1 is being tracked through about half of the video, but it then appears immediately with a different ID (12) for the rest of the video. Reidentification or track losses of objects may have a significant impact on the reconstruction quality of the objects because the loss of different views creates gaps in the resulting point clouds. So, the correction mechanism is intended to reduce the impact of track losses and object re-identification.
Figure 10b shows the effect of the correction mechanism. It reduces the overall number of tracked objects from 12 to 7.
Table 9 shows the two vehicles and their corresponding IDs throughout the video and the merged IDs. The correction mechanism successfully merges the IDs of the same objects. IDs 17 and 19 are not merged because the overlap is not large enough and IDs 15 and 16 are missed due to temporal distance between frames. However, there were enough IDs to track the two vehicles correctly throughout the video, as shown in
Figure 10b under the objects 1 and 2. The algorithm performance is controlled by setting the overlap and the distance between frames and the performance using a set of parameters is scene-dependent.
The results show that the pipeline is a robust mechanism where the resulting point cloud is structurally correct without deformation similar to the controlled environment, and it can be as reliable as a controlled environment for generating high-quality 3D point clouds of objects with reduced noise and artifacts. The pipeline is also independent of the SfM software, and it can improve the reconstruction quality. For example, RealityCapture sampled more points of many objects compared to the reference object point cloud which may add more fine details to the generated point cloud.
Furthermore, the experiments show that the most contributing factor in the reconstruction process is the extracted features (points) and their motion system. For example, the SfM software are able to generate a 3D point cloud from the raw imagery for all the scenes, but the yellow truck, the car, and the airplane are generally deformed and it is challenging to correct the resulting point clouds. Object deformation is common among the different software used because of their small size and rich background. The small size affected the number of features that can be extracted, and the rich background features interfered with the object motion system and reconstructed the scene incorrectly. These objects are more likely to require another scan in a controlled environment. On the other hand, the broccoli and banana objects have a rich texture that increased the number of extracted features that dominated the motion system of the scene allowing the to be reconstructed correctly in the raw scene. However, it did not prevent the additional noise in the scene from the background. The pipeline separated the different motion systems mainly the object and the background, but it is not based on clustering features based on their motion but instead based on their visual traits for both detection and tracking which elevated the need for camera information such as the focal length and radial distortion. It is important to note that blocking features such as using black background is as equally important as the extracted reconstruction features where blocking features prevents the interference between the different motion systems in the scene. It is also notable that the pipeline is scalable where it can track multiple objects at the same time and separate them from the scene. The pipeline works by removing interfering features from the scene and preserving the target region for reconstruction.
Table 10 shows the estimated camera parameters in the controlled environment for Agisoft, Pix4d, and RealityCapture, respectively. F[mm] is the estimated focal length in millimeters and F[pix] is the estimated focal length in pixels. C
x and C
y are the calibrated principal points offsets measured in pixels while the Ks and Ps are the radial and tangential distortion coefficients. The three software systems each give different camera calibration information using the same imagery of the same object. For instance, the Agisoft estimated negative values for the principal points offsets while Pix4d estimated them near the image center and RealityCapture estimated the principal points offsets is roughly 0, 0 of the image coordinates. Furthermore, the three estimated camera parameters are different from the calibrated one in
Table 1. In addition to camera intrinsic parameters, the SfM software estimates the extrinsic parameters of the camera position and orientation.
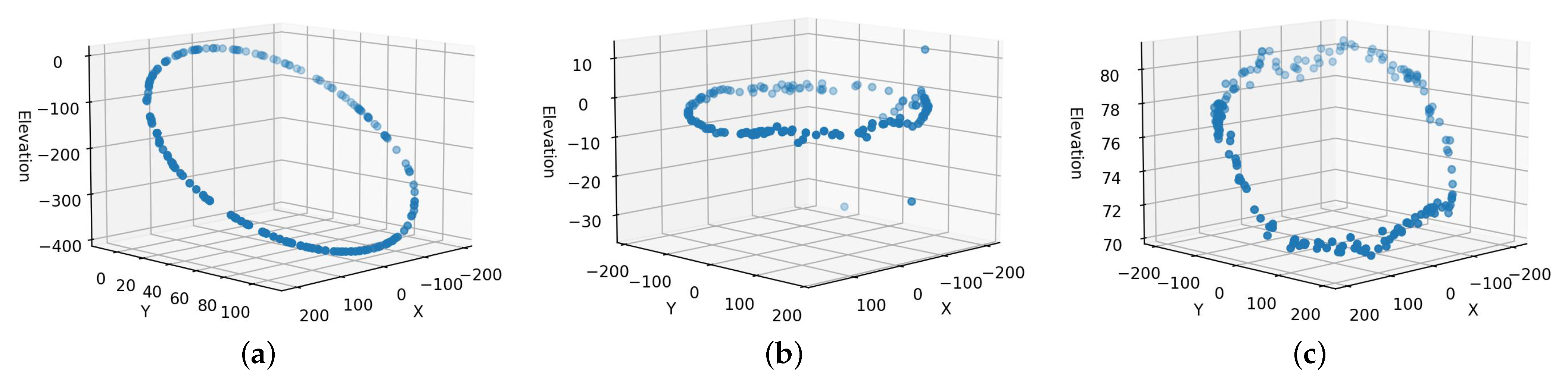
Figure 11 shows the camera positions for the same experiments (the controlled environment reconstruction of the truck using Agisoft, Pix4d, and RealityCapture, after applying the same scaling factor for the same scenes in the controlled environment. The exact camera positions are not necessarily correct but the relative positions or the circular shape of the cameras are more likely to conform to the turntable movements. For example,
Figure 11b shows almost a perfect circle of the camera positions around the object generated by Pix4d that is similar to the turntable’s actual setup. On the other hand, the Agisoft and RealityCapture camera positions shown in
Figure 11a,c are elliptical which may introduce a shape deformation. Furthermore, the positions in
Figure 11a,c show that the turntable setup is tilted. Moreover,
Figure 11 suggests that the camera is rotating around the objects, but it is, in fact, stationary. These results show that accurate camera calibration is actually not necessary to reconstruct the scenes.
Furthermore, it is worth noting that the exact intrinsic and extrinsic are more likely to impact the scale of the object than the reconstruction quality. In other words, the lack of intrinsic and extrinsic camera information does not have a significant impact on the reconstruction quality (object’s shape) if it has strong distinctive features to estimate the relative camera positions and their orientation correctly. The intrinsic and extrinsic configurations that are automatically computed show the power and flexibility of the SfM to find a camera configuration to reconstruct the correct object structure even though the calibrations are highly variable. As for the scale or the accurate measurements, it can be mitigated using our scale technique to acquire measurements from the point cloud.













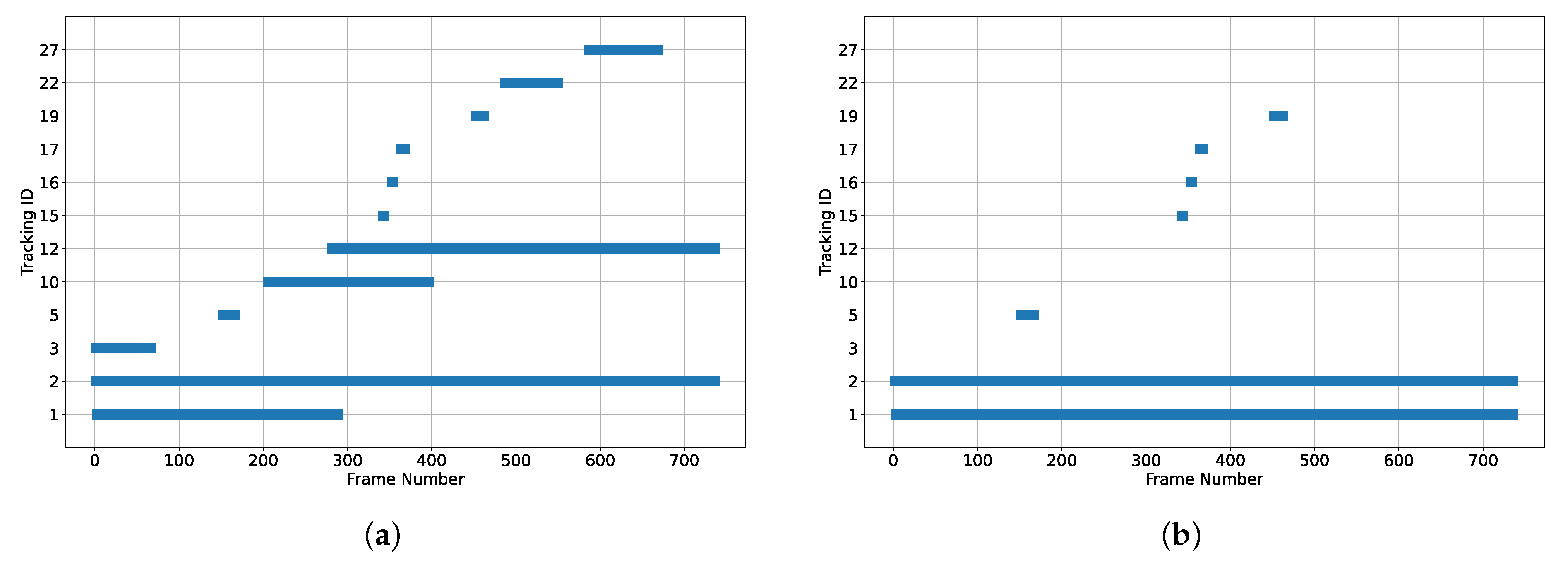


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
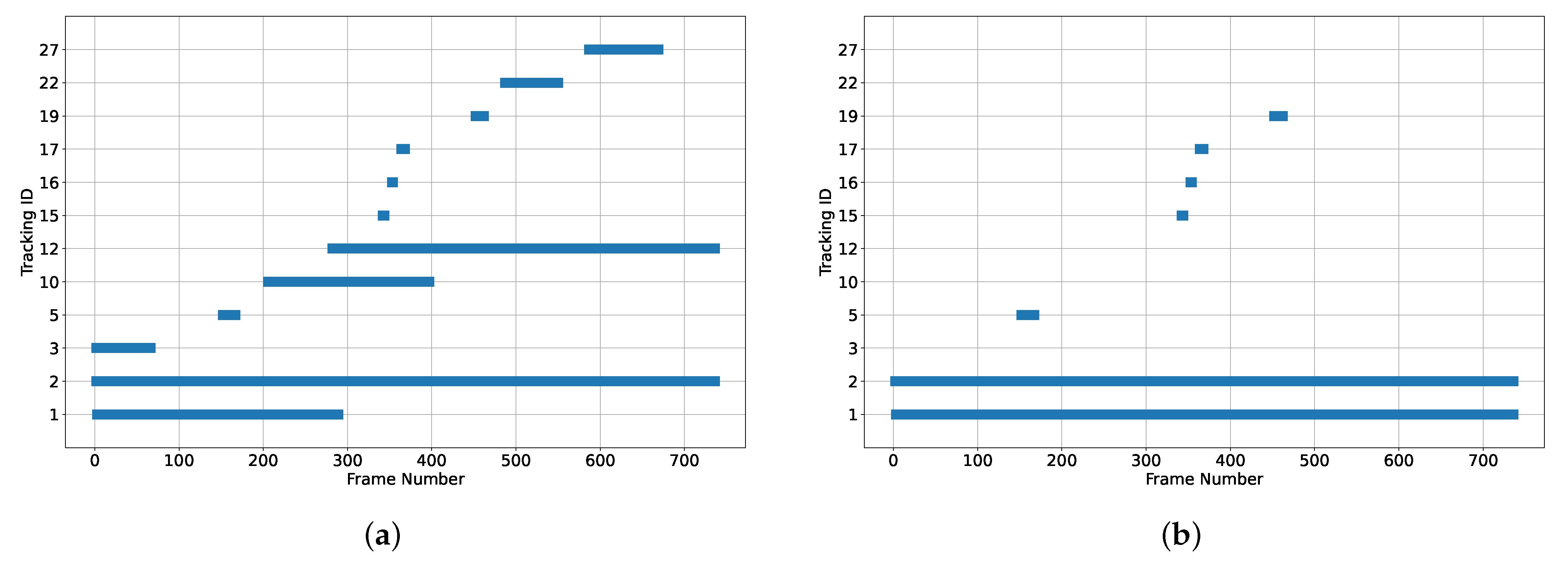{kind=link}
{kind=link}