
Densely Residual Network with Dual Attention for Hyperspectral Reconstruction from RGB Images


Abstract
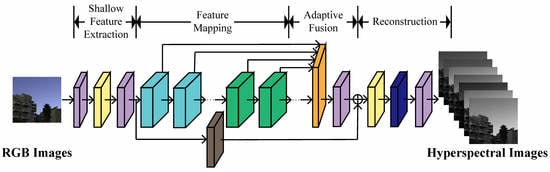
:
1. Introduction
- We propose a novel model, named densely residual network with dual attention (DRN-DA), which enhances the representation ability of feature learning for hyperspectral reconstruction.
- We propose a lightweight dense skip connection, where each layer is connected to the next layer rather than all the subsequent layers. Although this block is different from the classic DenseNet [34], it also reuses features and eliminates gradient vanishing.
- We propose a simple but effective non-local block named dual downsampling spatial attention (DDSA) to decrease the computation and memory consumption of the standard non-local block, which makes it feasible to insert multiple non-local blocks in the network for enhancing the performance.
- To further improve the learning ability of the network, we introduce an adaptive fusion block (AFB) to adaptively reuse the features from different intermediate layers.
2. Related Works
2.1. Hyperspectral Reconstruction with Deep Learning Methods
2.2. Attention Mechanism
2.3. Adaptive Fusion Block
3. Methodology
3.1. Network Architecture of DRN-DA
3.2. Densely Residual Attention Block
3.2.1. Multi-Scale Residual Block
3.2.2. Channel Attention
3.2.3. Dual Downsampling Spatial Attention
3.3. Adaptive Fusion Block
3.4. Adaptive Multi-Scale Block
4. Experiments
4.1. Settings
4.1.1. Data Sets
4.1.2. Experimental Configuration
4.1.3. Quantitative Metrics
4.2. Comparisons with State-of-the-Art Methods
4.2.1. Quantitative Evaluation
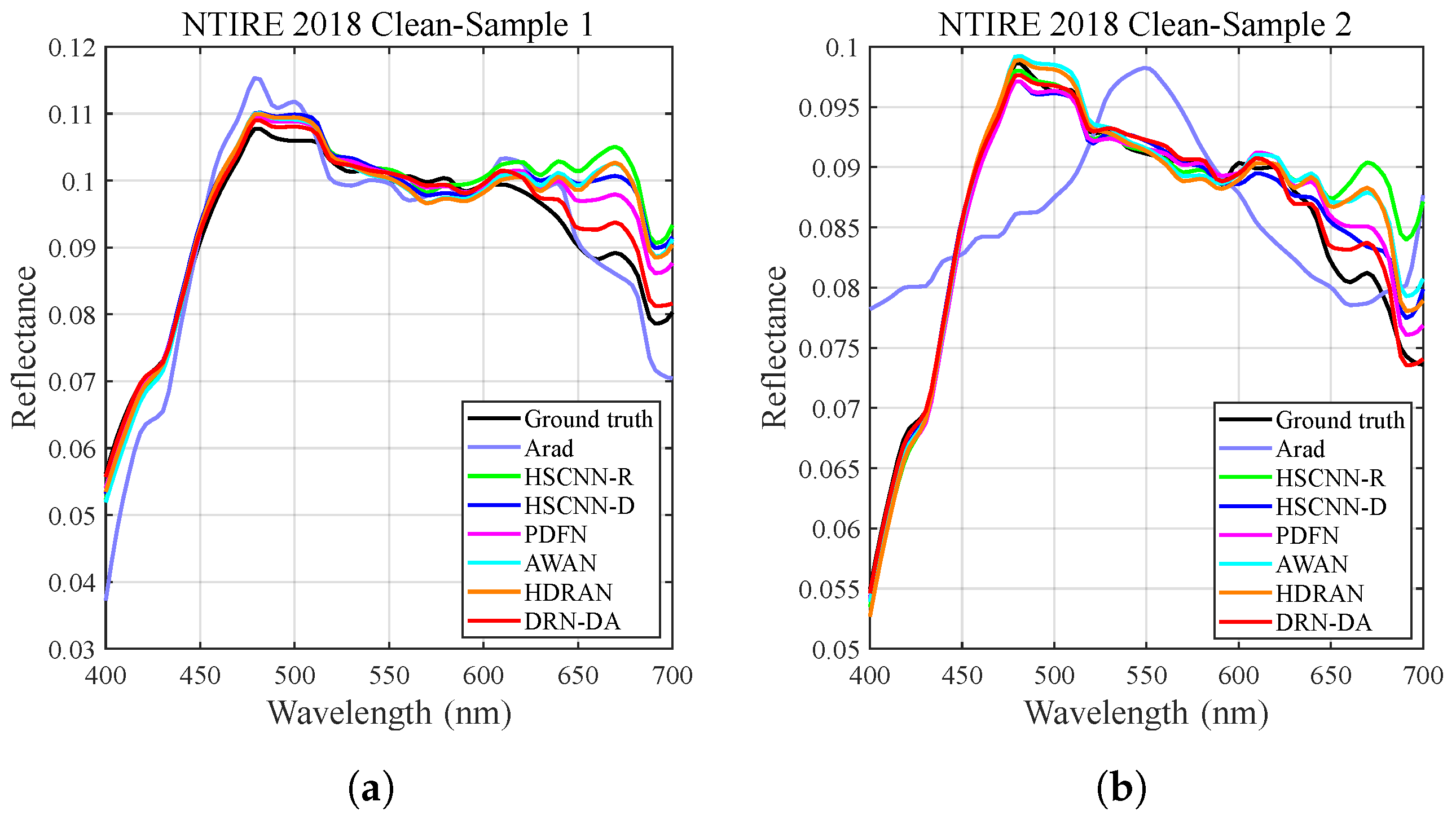
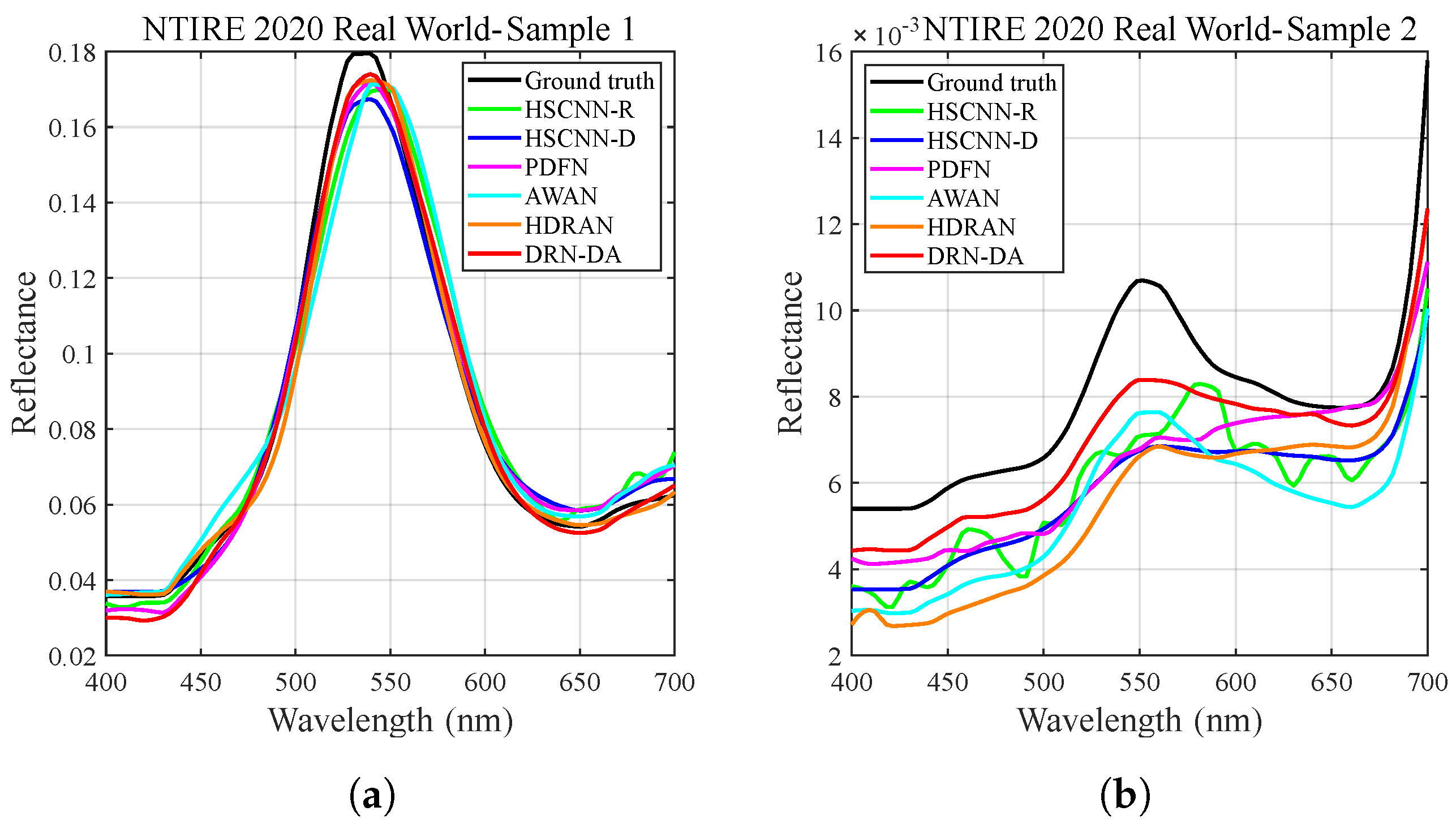
4.2.2. Visual Evaluation
4.3. Ablation Study for Different Modules
4.4. Effectiveness of Multi-Scale Convolution Scheme
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pelagotti, A.; Del Mastio, A.; De Rosa, A.; Piva, A. Multispectral imaging of paintings. IEEE Signal Process. Mag. 2008, 25, 27–36. [Google Scholar] [CrossRef]
- Chane, C.S.; Mansouri, A.; Marzani, F.S.; Boochs, F. Integration of 3D and multispectral data for cultural heritage applications: Survey and perspectives. Image Vis. Comput. 2013, 31, 91–102. [Google Scholar] [CrossRef] [Green Version]
- Nishidate, I.; Maeda, T.; Niizeki, K.; Aizu, Y. Estimation of melanin and hemoglobin using spectral reflectance images reconstructed from a digital RGB image by the Wiener estimation method. Sensors 2013, 13, 7902–7915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuen, P.W.; Richardson, M. An introduction to hyperspectral imaging and its application for security, surveillance and target acquisition. Imaging Sci. J. 2010, 58, 241–253. [Google Scholar] [CrossRef]
- Chao, K.; Yang, C.C.; Chen, Y.; Kim, M.; Chan, D. Hyperspectral-multispectral line-scan imaging system for automated poultry carcass inspection applications for food safety. Poult. Sci. 2007, 86, 2450–2460. [Google Scholar] [CrossRef]
- Valero, E.M.; Hu, Y.; Hernández-Andrés, J.; Eckhard, T.; Nieves, J.L.; Romero, J.; Schnitzlein, M.; Nowack, D. Comparative performance analysis of spectral estimation algorithms and computational optimization of a multispectral imaging system for print inspection. Color Res. Appl. 2014, 39, 16–27. [Google Scholar] [CrossRef]
- Pan, Z.; Healey, G.; Prasad, M.; Tromberg, B. Face recognition in hyperspectral images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1552–1560. [Google Scholar]
- Van Nguyen, H.; Banerjee, A.; Chellappa, R. Tracking via object reflectance using a hyperspectral video camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 44–51. [Google Scholar]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral image classification with imbalanced data based on orthogonal complement subspace projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Wu, F.; Duan, J.; Chen, S.; Ye, Y.; Ai, P.; Yang, Z. Multi-target recognition of bananas and automatic positioning for the inflorescence axis cutting point. Front. Plant Sci. 2021, 12, 705021. [Google Scholar] [CrossRef]
- Tang, Y.; Zhu, M.; Chen, Z.; Wu, C.; Chen, B.; Li, C.; Li, L. Seismic performance evaluation of recycled aggregate concrete-filled steel tubular columns with field strain detected via a novel mark-free vision method. Structures 2022, 37, 426–441. [Google Scholar] [CrossRef]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Hearn, D.; Digenis, C.; Lencioni, D.; Mendenhall, J.; Evans, J.; Welsh, R. EO-1 advanced land imager overview and spatial performance. In Proceedings of the IGARSS 2001, Scanning the Present and Resolving the Future, IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No. 01CH37217), Sydney, Australia, 9–13 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 2, pp. 897–900. [Google Scholar]
- Hagen, N.A.; Gao, L.S.; Tkaczyk, T.S.; Kester, R.T. Snapshot advantage: A review of the light collection improvement for parallel high-dimensional measurement systems. Opt. Eng. 2012, 51, 111702. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; He, X.; Wang, Y.; Liu, H.; Xu, D.; Guo, F. Review of spectral imaging technology in biomedical engineering: Achievements and challenges. J. Biomed. Opt. 2013, 18, 100901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, H.L.; Cai, P.Q.; Shao, S.J.; Xin, J.H. Reflectance reconstruction for multispectral imaging by adaptive Wiener estimation. Opt. Express 2007, 15, 15545–15554. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, W.F.; Tang, G.; Dai, D.Q.; Nehorai, A. Estimation of reflectance from camera responses by the regularized local linear model. Opt. Lett. 2011, 36, 3933–3935. [Google Scholar] [CrossRef]
- Wang, L.; Wan, X.; Xiao, G.; Liang, J. Sequential adaptive estimation for spectral reflectance based on camera responses. Opt. Express 2020, 28, 25830–25842. [Google Scholar] [CrossRef]
- Nguyen, R.M.; Prasad, D.K.; Brown, M.S. Training-based spectral reconstruction from a single RGB image. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 186–201. [Google Scholar]
- Aeschbacher, J.; Wu, J.; Timofte, R. In defense of shallow learned spectral reconstruction from rgb images. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Robles-Kelly, A. Single image spectral reconstruction for multimedia applications. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 251–260. [Google Scholar]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 19–34. [Google Scholar]
- Jia, Y.; Zheng, Y.; Gu, L.; Subpa-Asa, A.; Lam, A.; Sato, Y.; Sato, I. From RGB to spectrum for natural scenes via manifold-based mapping. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4705–4713. [Google Scholar]
- Xiong, Z.; Shi, Z.; Li, H.; Wang, L.; Liu, D.; Wu, F. Hscnn: Cnn-based hyperspectral image recovery from spectrally undersampled projections. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 518–525. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F.H. Advanced cnn-based hyperspectral recovery from rgb images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 18–22. [Google Scholar]
- Zhang, J.; Sun, Y.; Chen, J.; Yang, D.; Liang, R. Deep-learning-based hyperspectral recovery from a single RGB image. Opt. Lett. 2020, 45, 5676–5679. [Google Scholar] [CrossRef]
- Zhao, Y.; Po, L.M.; Yan, Q.; Liu, W.; Lin, T. Hierarchical regression network for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 422–423. [Google Scholar]
- Zhang, L.; Lang, Z.; Wang, P.; Wei, W.; Liao, S.; Shao, L.; Zhang, Y. Pixel-aware deep function-mixture network for spectral super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12821–12828. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Liu, F. Adaptive weighted attention network with camera spectral sensitivity prior for spectral reconstruction from RGB images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 462–463. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Xie, W.; Ge, C.; Li, B.; Li, Y. Hybrid 2-D–3-D Deep Residual Attentional Network With Structure Tensor Constraints for Spectral Super-Resolution of RGB Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2321–2335. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, D.; Chen, J.; Sun, Y.; Yang, D.; Liang, R. Unsupervised learning for hyperspectral recovery based on a single RGB image. Opt. Lett. 2021, 46, 3977–3980. [Google Scholar] [CrossRef]
- Lore, K.G.; Reddy, K.K.; Giering, M.; Bernal, E.A. Generative adversarial networks for spectral super-resolution and bidirectional rgb-to-multispectral mapping. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 926–933. [Google Scholar]
- Liu, P.; Zhao, H. Adversarial Networks for Scale Feature-Attention Spectral Image Reconstruction from a Single RGB. Sensors 2020, 20, 2426. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Arad, B.; Ben-Shahar, O.; Timofte, R. Ntire 2018 challenge on spectral reconstruction from rgb images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 929–938. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Arad, B.; Timofte, R.; Ben-Shahar, O.; Lin, Y.T.; Finlayson, G.D. Ntire 2020 challenge on spectral reconstruction from an rgb image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 446–447. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Anwar, S.; Barnes, N. Densely residual laplacian super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1192–1204. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Li, Z.; Shi, J. Lightweight image super-resolution with adaptive weighted learning network. arXiv 2019, arXiv:1904.02358. [Google Scholar]
- Chen, L.; Yang, X.; Jeon, G.; Anisetti, M.; Liu, K. A trusted medical image super-resolution method based on feedback adaptive weighted dense network. Artif. Intell. Med. 2020, 106, 101857. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Mi, L.; Chen, Z. AFNet: Adaptive fusion network for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7871–7886. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Z.; Xu, F. Adaptive spectral-spatial feature fusion network for hyperspectral image classification using limited training samples. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102687. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-adaptive remote sensing image super-resolution using a multiscale attention network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J. Hierarchical dense recursive network for image super-resolution. Pattern Recognit. 2020, 107, 107475. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Yuhas, R.H.; Boardman, J.W.; Goetz, A.F. Determination of semi-arid landscape endmembers and seasonal trends using convex geometry spectral unmixing techniques. In Proceedings of the JPL, Summaries of the 4th Annual JPL Airborne Geoscience Workshop, Washington, DC, USA, 25–29 October 1993; Volume 1. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NTIRE 2018 | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Real World | |||||||
| MRAE | PSNR | SAM | SSIM | MRAE | PSNR | SAM | SSIM | |
| Arad | 0.0746 | 34.4848 | 4.8086 | 0.9507 | - | - | - | - |
| HSCNN-R | 0.0140 | 49.9568 | 1.0432 | 0.9988 | 0.0303 | 45.2228 | 1.6176 | 0.9952 |
| HSCNN-D | 0.0135 | 50.4873 | 0.9929 | 0.9988 | 0.0293 | 45.3876 | 1.5944 | 0.9953 |
| PDFN | 0.0124 | 51.5143 | 0.9013 | 0.9990 | 0.0288 | 45.7187 | 1.5197 | 0.9956 |
| AWAN | 0.0115 | 52.2588 | 0.8022 | 0.9993 | 0.0287 | 45.7325 | 1.5035 | 0.9956 |
| HDRAN | 0.0113 | 52.1924 | 0.8038 | 0.9992 | 0.0279 | 45.8122 | 1.4578 | 0.9957 |
| DRN-DA | 0.0106 | 52.9249 | 0.7478 | 0.9994 | 0.0275 | 45.9295 | 1.4501 | 0.9957 |
| Method | NTIRE 2020 | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Real World | |||||||
| MRAE | PSNR | SAM | SSIM | MRAE | PSNR | SAM | SSIM | |
| Arad | 0.0886 | 30.0583 | 6.3112 | 0.9366 | - | - | - | - |
| HSCNN-R | 0.0389 | 38.4837 | 2.6834 | 0.9905 | 0.0687 | 35.8132 | 3.5955 | 0.9777 |
| HSCNN-D | 0.0383 | 39.0426 | 2.6330 | 0.9915 | 0.0702 | 35.8528 | 3.5633 | 0.9760 |
| PDFN | 0.0362 | 40.2493 | 2.4051 | 0.9936 | 0.0674 | 35.9353 | 3.4106 | 0.9781 |
| AWAN | 0.0321 | 40.7767 | 2.2108 | 0.9940 | 0.0666 | 36.2859 | 3.3793 | 0.9793 |
| HDRAN | 0.0338 | 40.3583 | 2.2706 | 0.9941 | 0.0660 | 36.2287 | 3.2887 | 0.9777 |
| DRN-DA | 0.0299 | 41.3852 | 2.0516 | 0.9952 | 0.0625 | 36.8841 | 3.0945 | 0.9814 |
| Method | NTIRE 2018 | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Real World | |||||||
| MRAE | PSNR | SAM | SSIM | MRAE | PSNR | SAM | SSIM | |
| HSCNN-R+ | 0.0135 | 50.4526 | 0.9919 | 0.9989 | 0.0297 | 45.3689 | 1.5889 | 0.9953 |
| HSCNN-D+ | 0.0132 | 50.6399 | 0.9829 | 0.9988 | 0.0287 | 45.5924 | 1.5469 | 0.9955 |
| PDMN+ | 0.0120 | 51.6619 | 0.8742 | 0.9991 | 0.0283 | 45.8206 | 1.5066 | 0.9956 |
| AWAN+ | 0.0112 | 52.4566 | 0.7823 | 0.9993 | 0.0282 | 45.8196 | 1.4788 | 0.9957 |
| HDRAN+ | 0.0109 | 52.4758 | 0.7712 | 0.9993 | 0.0277 | 45.9015 | 1.4481 | 0.9958 |
| DRN-DA+ | 0.0104 | 53.0600 | 0.7358 | 0.9994 | 0.0272 | 45.9864 | 1.4311 | 0.9958 |
| Method | NTIRE 2020 | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Real World | |||||||
| MRAE | PSNR | SAM | SSIM | MRAE | PSNR | SAM | SSIM | |
| HSCNN-R+ | 0.0372 | 39.2337 | 2.5544 | 0.9920 | 0.0673 | 36.0495 | 3.4131 | 0.9785 |
| HSCNN-D+ | 0.0377 | 39.1697 | 2.6012 | 0.9918 | 0.0696 | 36.0132 | 3.5028 | 0.9767 |
| PDMN+ | 0.0331 | 40.4981 | 2.2144 | 0.9985 | 0.0660 | 36.1770 | 3.3103 | 0.9789 |
| AWAN+ | 0.0312 | 40.9987 | 2.1552 | 0.9943 | 0.0646 | 36.2757 | 3.2328 | 0.9795 |
| HDRAN+ | 0.0337 | 40.4786 | 2.2611 | 0.9937 | 0.0640 | 36.4580 | 3.2030 | 0.9793 |
| DRN-DA+ | 0.0296 | 41.4652 | 2.0279 | 0.9954 | 0.0614 | 36.8029 | 3.0351 | 0.9811 |
| CA | ✗ | ✔ | ✔ | ✔ | ✔ |
| DDSA | ✗ | ✗ | ✔ | ✔ | ✔ |
| AMB | ✗ | ✗ | ✗ | ✔ | ✔ |
| AFB | ✗ | ✗ | ✗ | ✗ | ✔ |
| Clean | 0.0371 | 0.0348 | 0.0343 | 0.0338 | 0.0299 |
| Real World | 0.0670 | 0.0652 | 0.0649 | 0.0637 | 0.0625 |
| Multi-scale convolutions | ✗ | ✔ |
| Clean | 0.0311 | 0.0299 |
| Real World | 0.0652 | 0.0625 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Sole, A.; Hardeberg, J.Y. Densely Residual Network with Dual Attention for Hyperspectral Reconstruction from RGB Images. Remote Sens. 2022, 14, 3128. https://doi.org/10.3390/rs14133128
Wang L, Sole A, Hardeberg JY. Densely Residual Network with Dual Attention for Hyperspectral Reconstruction from RGB Images. Remote Sensing. 2022; 14(13):3128. https://doi.org/10.3390/rs14133128
Chicago/Turabian StyleWang, Lixia, Aditya Sole, and Jon Yngve Hardeberg. 2022. "Densely Residual Network with Dual Attention for Hyperspectral Reconstruction from RGB Images" Remote Sensing 14, no. 13: 3128. https://doi.org/10.3390/rs14133128
APA StyleWang, L., Sole, A., & Hardeberg, J. Y. (2022). Densely Residual Network with Dual Attention for Hyperspectral Reconstruction from RGB Images. Remote Sensing, 14(13), 3128. https://doi.org/10.3390/rs14133128