1. Introduction
Hyperspectral images (HSI) contain rich spectral information and spatial context, where the electromagnetic spectrum is approximately contiguous and covers the ultraviolet, visible, near-infrared, and even mid-to-long infrared regions. The abundant spectral-spatial information provides great opportunities for the fine identification of materials with subtle spectral discrepancies, and at the same time brings new challenges in discriminant feature learning, especially in mining the potential correlation of data with the high-dimensional nonlinear distribution.
Compared with the limitations of the shallow and handcrafted extractors in complex data representation, deep neural networks (DNNs) have proven to be more powerful in feature learning with their excellent power in layer-wise feedforward perception, and have become prevailing benchmarks in HSI classification tasks [
1,
2,
3], including multilayer perceptron (MLP) [
4], stacked autoencoders (SAEs) [
5], deep belief networks (DBNs) [
6], recurrent neural networks (RNNs) [
7,
8,
9], convolutional neural networks (CNNs) [
10,
11,
12], graph convolutional networks (GCNs) [
13], generative adversarial networks (GANs) [
14], and their variants. CNN has become populat popular due to its advantage in locally contextual perception and feature transformation with parameter sharing. To strengthen the contribution of the spectrum as spatial information dose in CNNs, multi-branch networks, 3-D-CNNs, and other more complex models are introduced to extract spectral-spatial features. Although they improve the model ability in feature representation, new issues will also arise, such as huge computing burdens, especially difficulty in model optimization. Thus, many lightweight deep models [
15,
16,
17] were proposed for HSI classification. Meanwhile, shortcut connections [
18] become an almost indispensable component to avoid model degradation.
CNN shares convolution kernels among different locations in each feature map and collects diverse information encoded in all of the channels. Although the kernel sharing and feature recombination enable CNN with great performance in translation equivalence and high-level feature learning, it passively focus attention on important regions, whether in spatial or in channel dimension, while this is just exactly common in human vision. Thus, the attention mechanism has raised much concern in remote sensing (RS) fields. This can be treated as a dynamic selection of features by adaptively weighting, while CNN is a static method. To focus more on significant channels for object recognition, a squeeze-and-excitation (SE) block in the SE network (SENet) [
19] calibrates the channel weights by spatial squeeze and channel excitation. Subsequently, many of its variations were presented for feature learning of HSI. For example, Zhao et al. [
20] replaced the excitation part with feature capture by two 1D convolution layers and aggregation by shortcut connections, namely CBW. Wang et al. [
21] performed SE on spatial and spectral dimension in parallel (namely, SSSRN), then recalibrated features by weighted summation of the two attention matrices. Convolutional block attention module (CBAM) [
22] refines the feature maps by two sub-modules, which squeeze respectively the spatial and channel information by global average pooling (GAP) and max pooling, and excites channel attention via a shared MLP and spatial attention by 2-D convolution. CBAM was then embedded into diverse deep networks for attention recalibration, such as double-branch 3-D convolution network (DBMA) [
23].
CNN specializes in local perception and enlarges the receptive field by a deep stack of the convolutional layers, which is relatively weak and inefficient in long-range interaction. Transformers with self-attention, which has emerged as the dominant paradigm in natural language processing (NLP) [
24], are thus designed to model long-range dependencies in computer vision fields [
25,
26]. For example, ViT [
27] and BEiT [
28] treat splitting patches in an image as words in one sentence, and perform non-local operations such as self-attention in a transformer [
24]. In feature learning of HSI, spatial pixels or spectral bands are usually regarded as tokens of words for long-range attention perception. For example, He et al. [
29] treated pixels in one input patch as tokens, and employed BRET [
30] (namely HSI-BRET) to learn the global relationships between pixel sequences by multiple Transformer layers. Sun et al. [
31] insert the spatial self-attention mechanism into a deep model with sequential spectral and spatial sub-modules (SSAN). To capture subtle discrepancies of the spectrum with sequence attributes, He et al. [
32] performed spectral feature embedding by a pre-trained deep CNN. It regarded one spectral band as a word, and modeled sequential spectra relationships by a modified dense transformer. Hong et al. [
33] instead applied band-wise self-attention with group-wise spectral embedding and proposed a SpectralFormer model. To capture semantic dependencies in both spatial and channel dimensions, dual attention network (DANet) [
26] sets, two corresponding self-attention sub-modules were used, and the outputs were combined to perform 3-D attention perception and feature calibration. This 3-D attention is appropriate to spectral-spatial feature learning of HSI. Thus, Tang et al. [
34] inserted a DANet like-wise attention block into a 3-D octave convolution network. Li et al. [
35] embedded the sub-modules of DANet respectively into a double-branch 3-D dense convolutional network (DBDA).
HSI contains a wealth of information in both the spatial and spectral dimension; thus, data representation will prefer 3-D attention from multiple perspectives. However, the difficulty faced by 3-D multi-head attention is the increased burden in parameter optimization, computation, and storage. As a result, the existing self-attention-based methods in HSI classification mainly insert a one-head spectral-spatial attention into a 3-D deep model. Self-attention can be seen as non-local filter [
25] that captures long-range dependencies by weighted aggregation of features at all positions, while Hu et al. [
36] verified that constraining the aggregation scope to a local neighborhood will be more reasonable for feature learning in visual recognition with less computation. Thus, in this paper, we focus on building a 3-D multi-head attention with local interaction and with the fewer possible parameters and lower computation cost. Beyond that, previous designs mainly capture attention by independent pairwise query-key interaction but ignore the contextual information among neighbor keys. Li et al. [
37] proposed a contextual transformer (CoT) that contextually encoded input keys and concatenated them with queries to learn dynamic attention, which is much more efficient at boosting visual representation. On this basis, we present a dual multi-head contextual attention mechanism (DMuCA) for multi-view spectral-spatial neighborhood perception.
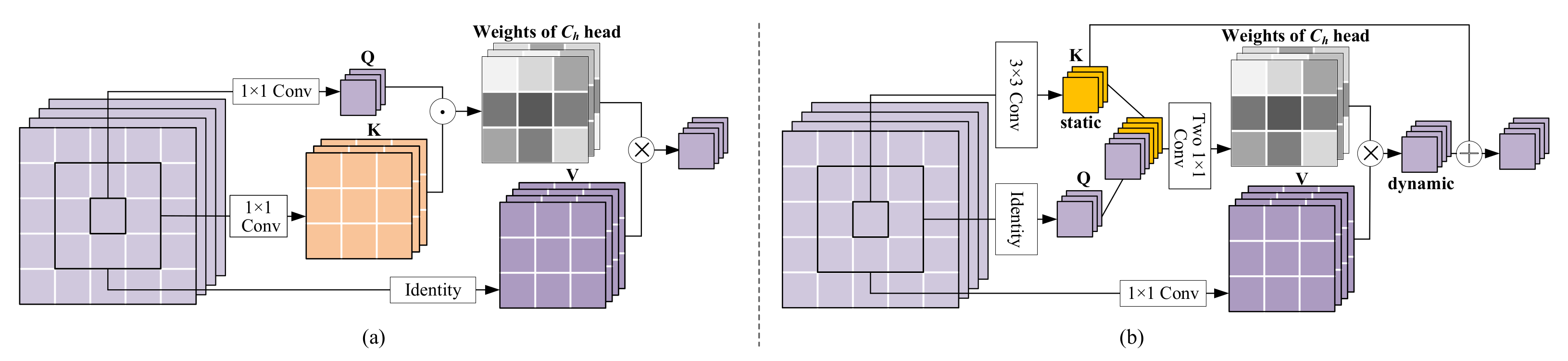
DMuCA decouples the spatial and spectral contextual attention into two sub-modules and builds multi-head attention on groups to control model complexity. In the spatial attention module (SaMCA), we treat pixels in the input as tokens and employ depth-wise convolution to contextualize the input keys in the pure spatial domain. Then, the keys are alternately concatenated with the queries and grouped to learn multiple neighborhood relationships. The learned multi-head local attention matrices are then broadcast across group channels to aggregate the neighborhood inputs. CoT [
37] can be seen as a special case of SaMCA when the number of groups is equal to 1. As for spectral attention (SeMCA), which treats each channel as a token, the feature representation of one channel involves a bidirectional dimension. Consequently, the parameters and computation for multi-head attention matrices will increase exponentially, especially when it is exposed to inputs with enlarged spatial resolution. With the neighborhood consistency assumption, we therefore group the spatial pixels by equal-interval sampling and create multi-head attention on each neighbor block, to reduce the number of the parameter and avoid the computation burden. The main contributions of this paper are summarized as follows.
By decoupling 3-D self-attention perception into two sub-modules, SaMCA and SeMCA, we build a dual contextual self-attention mechanism, DMuCA, for dynamic spatial and spectral attention calibration.
To avoid parameter and computation increase, we group the representation of each token by evenly sampling, and capture multi-head self-attention with an alternate concatenation of the queries and keys on each group.
Extensive experiments on three public HSIs demonstrate that our proposed DMuCA achieves excellent results over several state-of-the-art attention mechanisms with the same backbone.
The remainder of the paper is organized as follows.
Section 2 reviews the general form of self-attention mechanisms.
Section 3 details the proposed DMuCA with two well-designed sub-modules SaMCA and SeMCA for HSI classification. Extensive contrast and ablation experiments are conducted and discussed in
Section 4.
Section 5 draws conclusions and presents a brief outlook on future work.
3. Proposed Method
The proposed framework of DMuCA network is illustrated in
Figure 2. We build a plug-and-play 3-D attention block to guide a deep convolutional network focusing on spectral-spatial regions of interest. CoT [
37] integrates both neighborhood-enriched contextual information and self-attention to enhance feature learning with dynamic local perception. We inherit the advantage of CoT and decouple the spatial and spectral neighborhood interaction into two separate blocks, SaMCA (see
Figure 3) and SeMCA (see
Figure 4). The former allocates more attention to important spatial regions, while the latter acts as a weighted aggregation of neighborhood spectral bands or attention-based feature recombination. To take full advantage of the two contextual information from different dimensions, we place the two blocks parallel to one another, and fuse their results by element-wise weighting summation. Thus, the output of DMuCA can be defined as,
where
and
are the output of SeMCA and SaMCA, respectively.
is a weighting factor that can be learned when model training, with an initial value set as 0.5.
The integrated DMuCA can alternate any standard convolution filter. For HSI classification, we replace some convolutional layers in a ResNet backbone with our proposed DMuCA module, to strengthen the model with spectral-spatial contextual interdependencies and attention perception. As illustrated in
Figure 2, the backbone contains two residual blocks, and one of the convolution layers in each block is replaced by a DMuCA module. All of the other convolution layers are followed by batch normalization and ReLU activation layer. A global average pooling (GAP) and FC layer are performed to integrate the global spatial information and to project the learned feature into label space for probability prediction of classification.
Table 1 shows the detailed model structure of the DMuCA network, taking the IN dataset as an example.
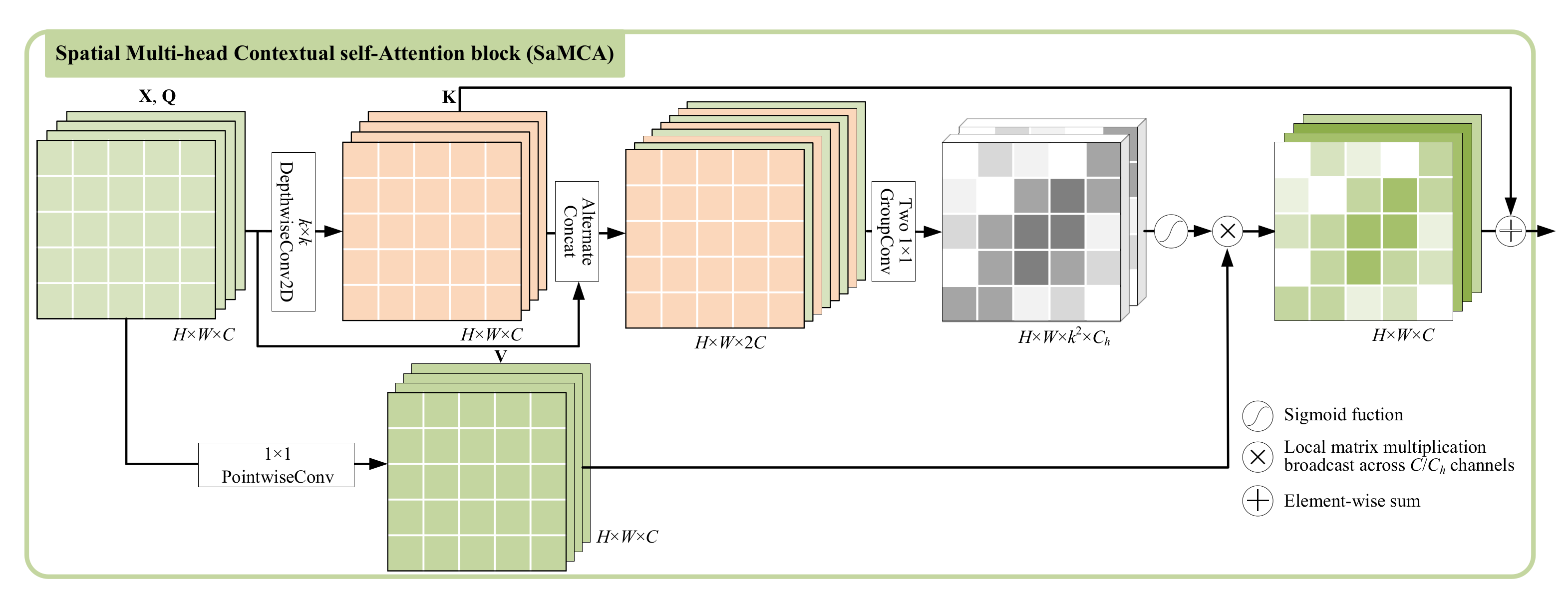
3.1. Spatial Multi-Head Contextual Self-Attention
The SaMCA block aims to assign appropriate weights to the spatial neighborhood pixels and aggregates them for presentation of the central pixel. Formally, given the input , where denotes the spatial dimension and C is the channel number. We treat each pixel as an independent token and transform into queries and values with kernel of size . For absolute mining of spatial relation with relatively few parameters, we transform into keys by depth-wise convolution with kernel of size , defined as .
In HSI, neighbor bands contain similar spatial distribution but certain noise interference. So in order to avoid weight allocation suffering from noise interference, we alternately concatenate the queries and keys, and then group them to capture the local relationships for multi-head attention. This processing can be defined as
where
and
denote the alternate concatenation and group convolution operation for short, respectively. Two consecutive group convolutions with kernel of size
and group number of
are set here to generate multi-head attention weights. Then, the spatial weights are normalized by Softmax function as
represents the attention weight of the
t-th head (
) for
with neighbor scope of
. The normalized attention weights
are then allocated to the corresponding elements of
in a
channel-sharing manner, and get the output feature map
with dynamic weighted aggregation
where ⊗ denotes local matrix multiplication broadcasting across
channels. The channel sharing here can reduce the number of model parameters and facilitate memory scheduling on the GPU for efficiency.
The keys
generated by depth-wise convolution, which shares weights in the spatial domain, can be seen as a static context, while pixel-wise self-attention is in a dynamic fashion. The former is adept at spatial translation invariance while the latter can adaptively capture aggregation weights. To combine both of the advantages, we fuse the static context from
into the dynamic contextual representation
and get the final output
of SaMCA, which focus more on rich spatial information,
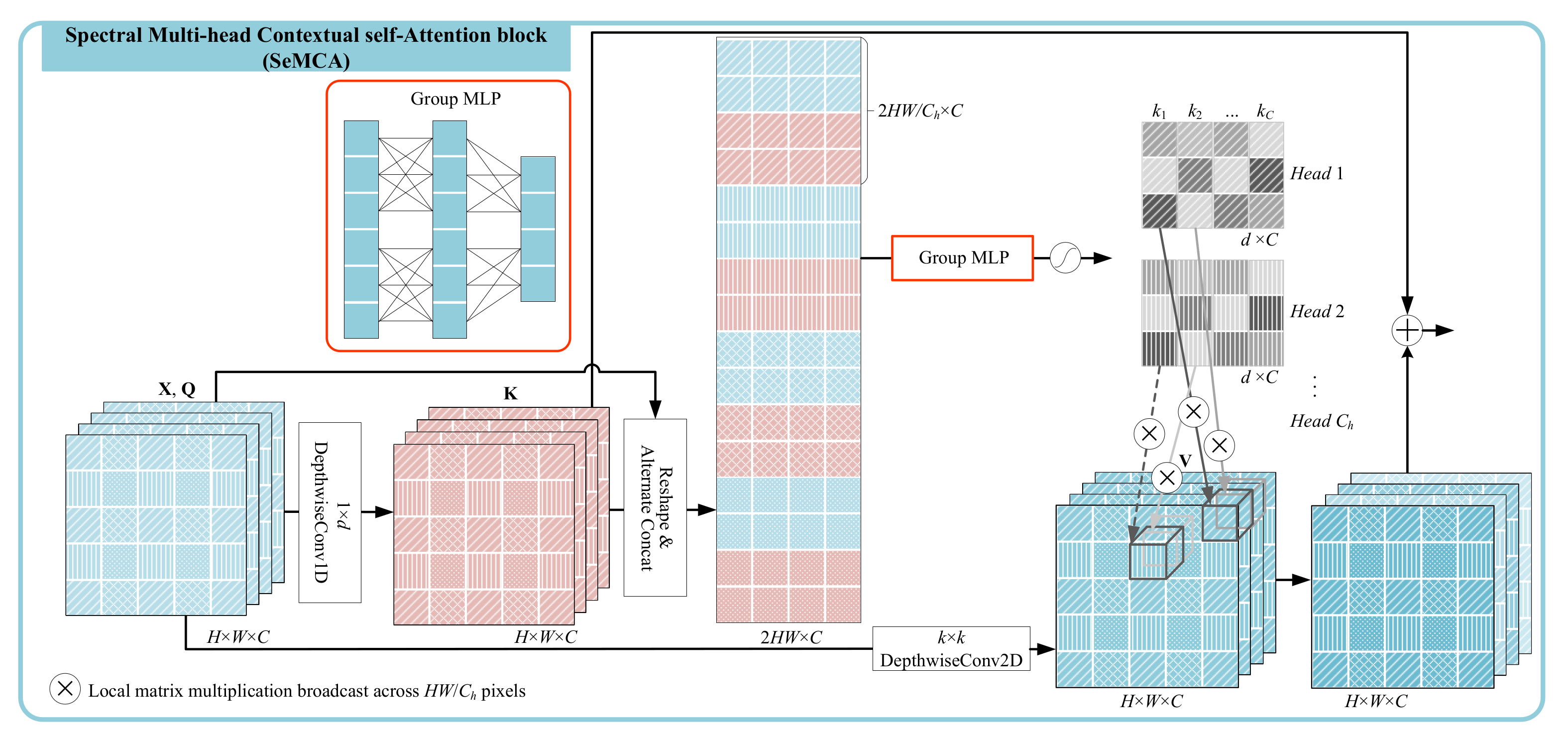
3.2. Spectral Multi-Head Contextual Self-Attention
The far abundant spectral information of pixels in HSI, compared with the color (RGB) dataset, brings a greater challenge to finer spectral neighborhood perception. Therefore, we design a SeMCA block (see
Figure 4) to mine spectral neighborhood information from multiple perspectives. Similarly, given the input feature map
as the same in SaMCA block, we treat each channel or band as a token. The queries (
), keys (
), and values (
) are defined respectively as
Specifically, 1-D depth-wise convolution with the kernel of size is introduced here to contextualize the keys. This means each pixel owns its convolution kernel, which helps prevent interference between groups of samples and provides diversity to the followed multi-head self-attention. is projected to values by a spatial transformation layer, a 2-D depth-wise convolution layer with a kernel of size .
In spectral attention, each token is featured from one two-dimensional feature map, which will sharply consume the memory if generating multi-head attention matrices by a regular convolution. Meanwhile, the parameters and computation cost will exponentially increase with the increase in spatial resolution. Fortunately, there is a fairly strong neighborhood consistency in the spatial domain. Thus, we evenly sample multiple groups of data (filled with different textures in
Figure 4) to represent each channel and generate multi-head attention on the sampling groups. More specifically, pixels sampled from both queries
and keys
in the same location are concatenated together to learn one head of attention weights by an MLP, which can be written as
where
refers to the
t-th set of sampling offsets. MLP with two fully connected (FC) layers are employed for relevance learning of neighborhood channels.
and
represent the corresponding embedding matrices of FC layers, where
d is the neighbor scope for channel aggregation. The final multi-head spectral attention weights
for all the channels can be defined as
where
denotes all of the sampling offsets stored in groups. GMLP denotes a grouped MLP where the group number equals
, the head number in self-attention. Note that the aggregation weights in each head are per channel normalized by the Softmax function.
In order to capture the spectral information from multiple perspectives without an increase in storage, we share the attention matrix in one head only to the corresponding spatial sampling set. This means that each head of attention weighted aggregate a specific set of neighborhood pixels. Thus, weighted aggregation of the neighbors of the
i-th channel on the sub-sampling set
can be formulated as
where
refers to a set which saved
d offsets of neighbors around the
i-th channel,
. Spatial samples in
share the same filter kernel
. The multi-head attention calibration in the spectral domain can be implemented on diverse sub-sampling sets, which are staggered in local space as different texture marks in
Figure 4.
Similar to the SaMCA block, we fuse the static spectral context
with the dynamic contextual representation
, and obtain the final spectral local perception
,










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}