
Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism

Abstract
:1. Introduction
2. Related Work
2.1. Single Image Super Resolution (SISR) with Deep Learning
- Standard Convolutional Neural Networks (CNNs): The first CNN-based SISR was the very well-known Super-Resolution Convolutional Neural Network (SRCNN) proposed by Dong et al. [8,9]. This network demonstrated great superiority over other methods and gained great success. However, it presented some issues principally related to the use of the LR version upscaled with bicubic interpolation [1] and the use of loss function, which inspired the search for more effective solutions. The problem with the loss function came from its inability to focus on the perceptual aspects of the images [10].
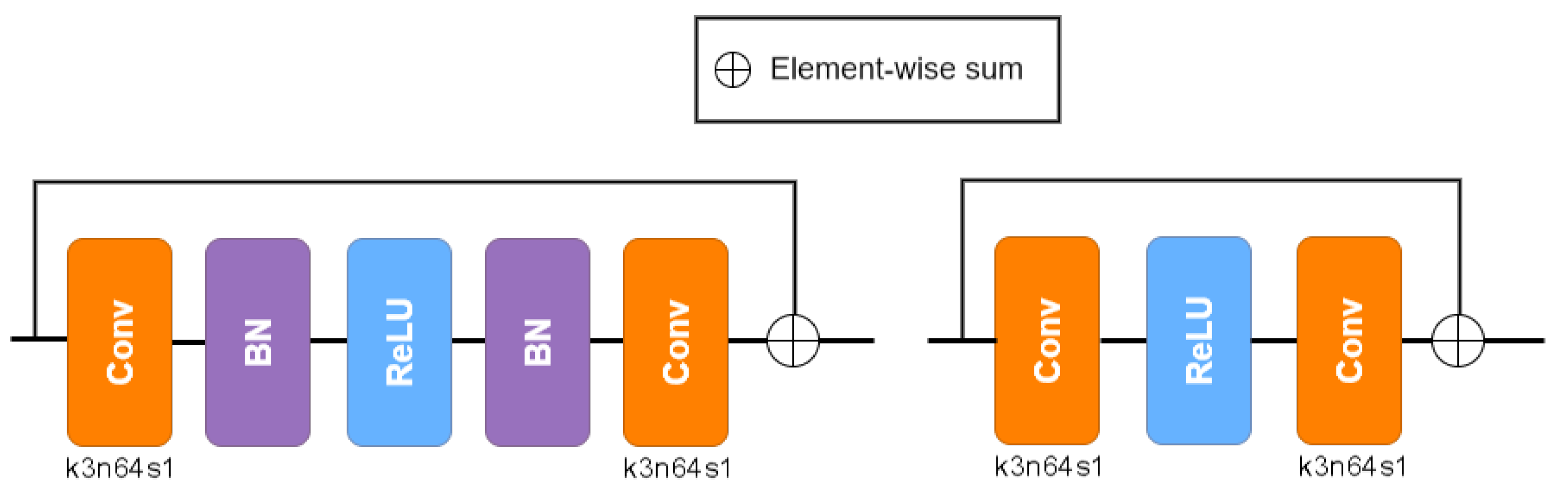
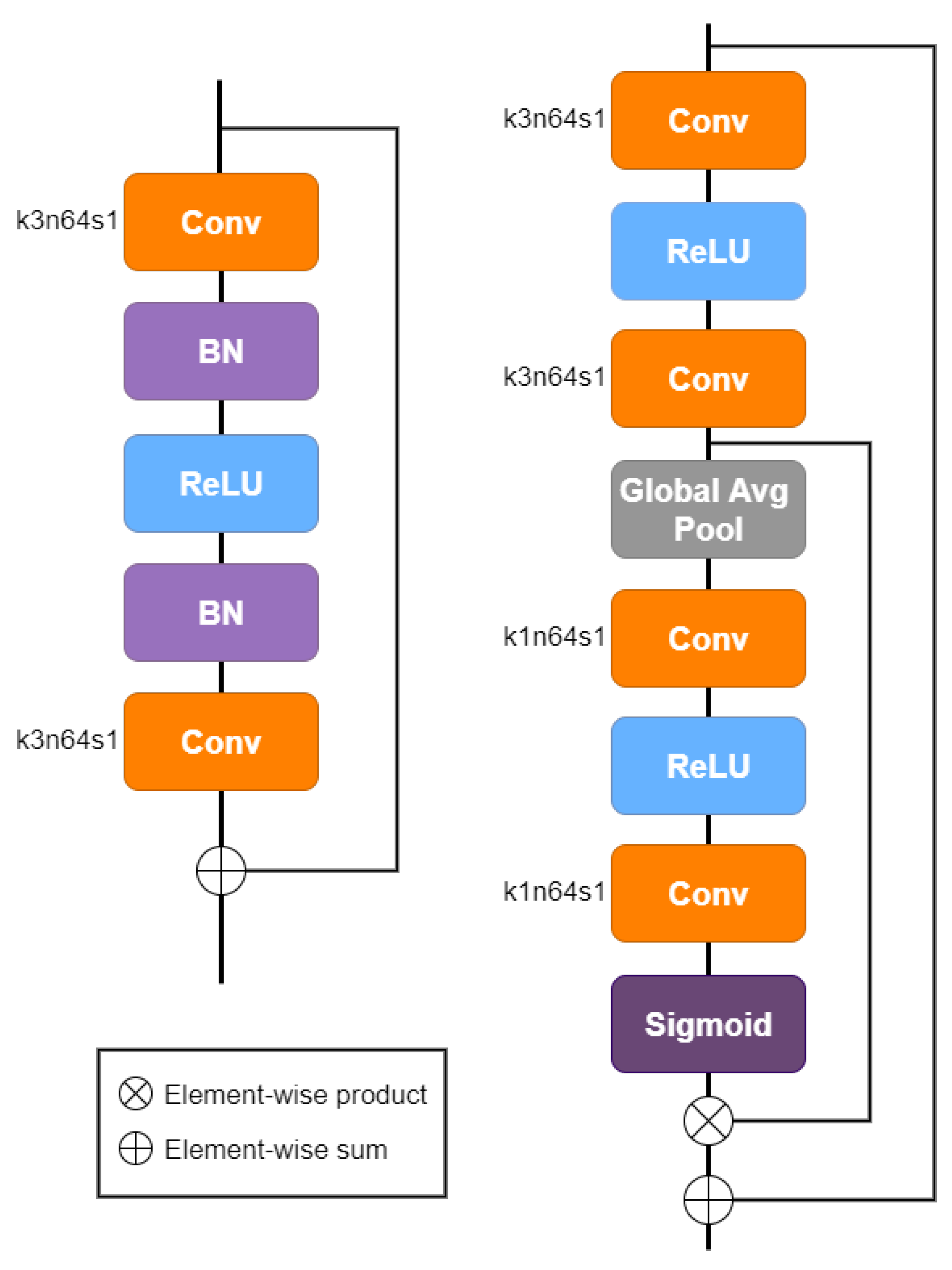
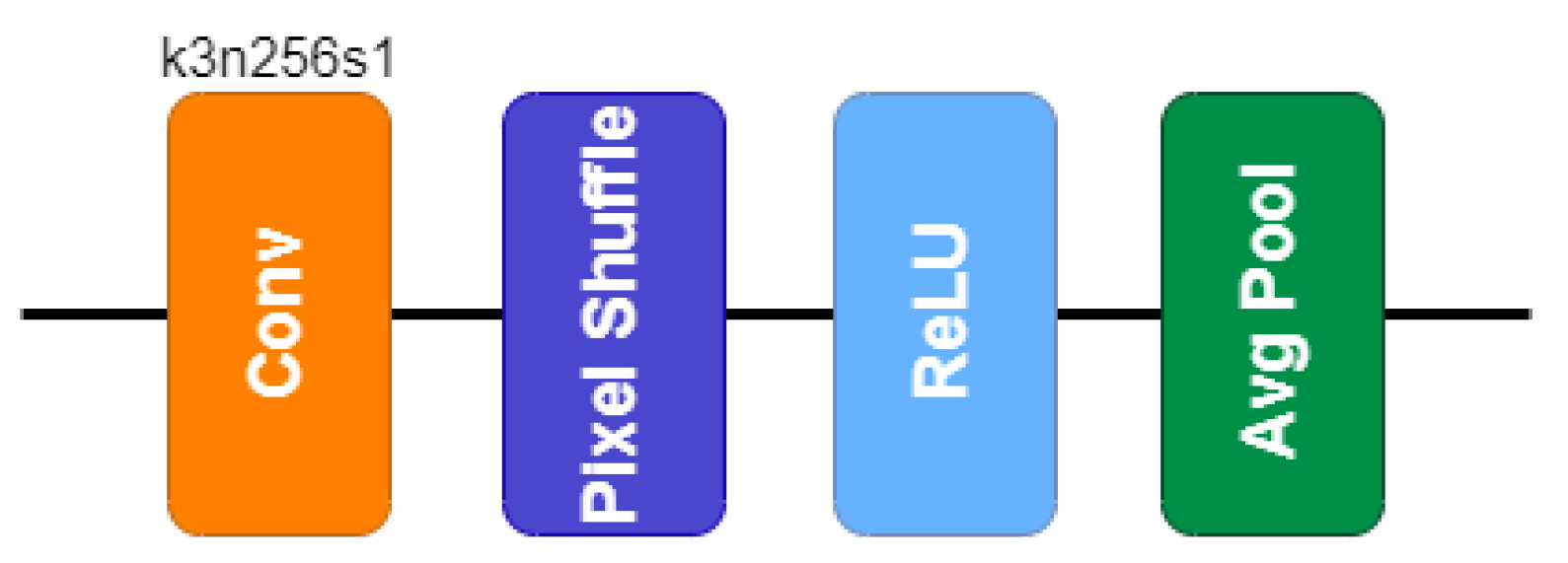
- Residual Networks: The next big contribution was provided by the residual learning presented in [11]. Very Deep Super-Resolution (VDSR) was the first very deep model used for SISR (with 20 layers) and the first one introducing residual learning. It was inspired by the SRCNN model and was based on the VGG network [12]. The authors demonstrated that this learning improves performance and accelerates convergence, but the network uses an interpolated low-resolution image as input. To overcome this problem, Shi et al. [13] proposed the Efficient Sub-Pixel Convolutional Neural Network (ESPCN), an efficient subpixel convolution layer known as the Pixel Shuffle layer. This method carries out the upsampling process in the last layers of the architecture, instead of resampling the image prior to the network. Then, in [14] the authors introduced Super-Resolution Residual Network (SRResNet), a network with 16 residual blocks [15]. Based on this model, Lim et al [16] presented a model called Enhanced Deep Super-Resolution (EDSR), which has made different improvements on the overall frame. The main ones consist of removing the Batch Normalization layers to make the network more flexible and employing a residual scaling factor to facilitate the training. More recently, Zhang et al. [17] defined a network for super-resolution formed by some residual blocks called Residual Channel Attention Block (RCAB), which introduced a channel attention mechanism to study channel interdependencies.
- Autoencoder and Generative Adversarial Networks (GANs): Autoencoders and GANs have attracted much attention in the past few years because of their great performance in most computer vision tasks. An example is given by the encoder-decoder residual architecture in [18] for information restoration and noise reduction called Encoder-Decoder Residual Network (EDRN). The authors prove that this super-resolution network offers much better results compared to the state-of-the-art methods for SISR. On the other hand, Ledig et al. [14] proposed the very well-known Super-Resolution Generative Adversarial Network (SRGAN), a generative adversarial network for single image super-resolution that mainly consists of residual blocks for features extraction.
2.2. SRResNet
3. Materials and Methods
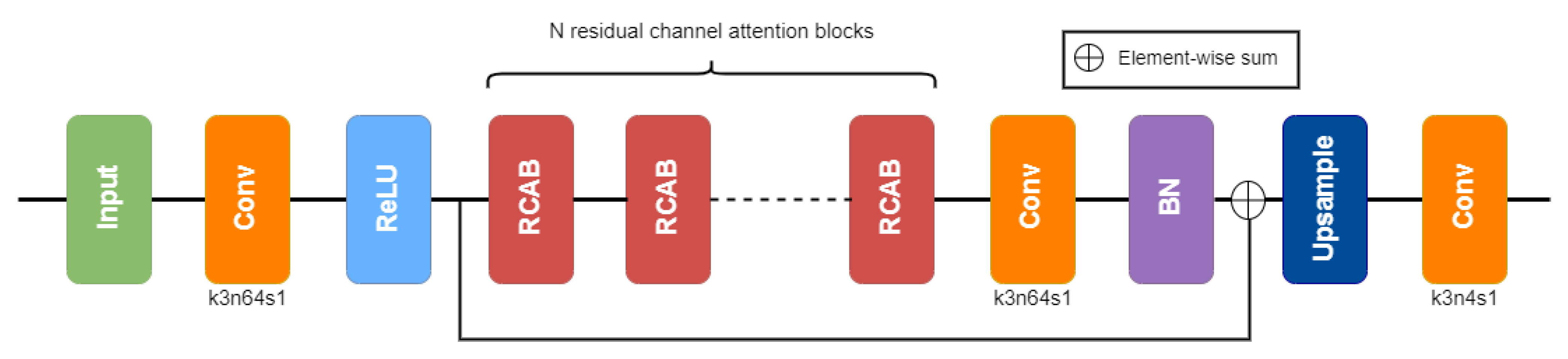
3.1. Proposal
3.2. Satellite Images
3.3. Dataset
3.4. Image Pre-Processing
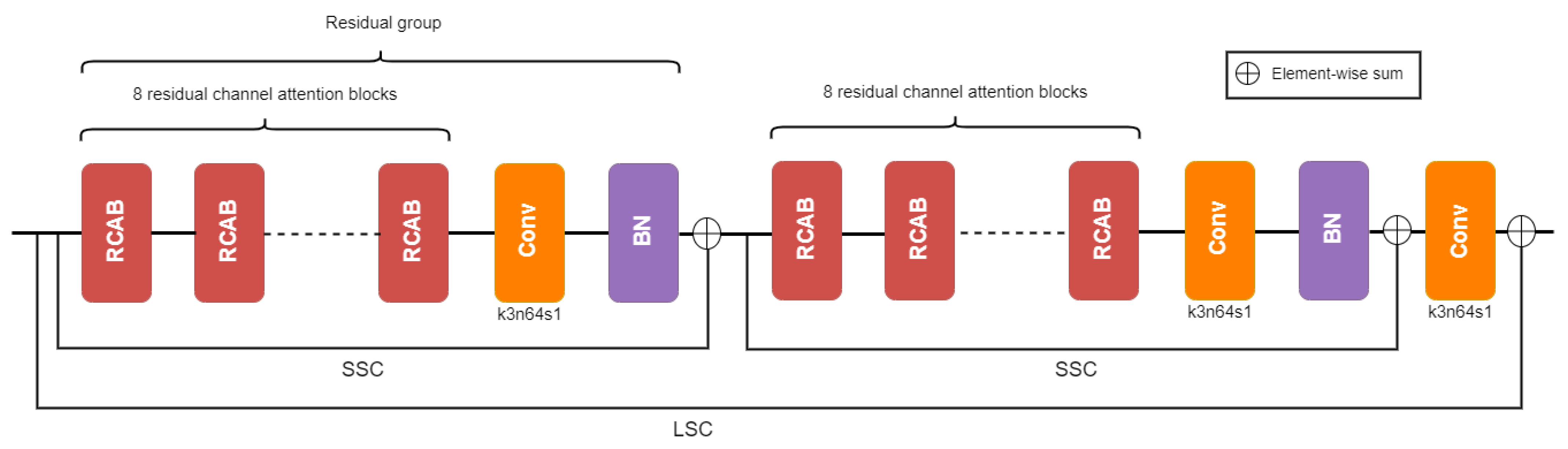
3.5. Network Architecture
3.6. Loss Function
- Pixel loss (): The pixel loss, also known as Mean Absolute Error (MAE), is defined as the sum of the absolute differences between the pixel values of the true image Y and predicted image :Here, is the size of the images and C the number of channels.
- Feature loss [10]: Instead of matching predicted image pixels with target image pixels, the feature loss (also known as content loss) encourages them to have similar feature representations. These features are usually extracted with a pre-trained VGG network. Let be the feature map of size of the jth convolutional layer of the VGG network when processing the image X. This loss computes the mean absolute error between the feature maps of each target image Y and predicted image :
- Style loss [10]: The style loss focuses on making the styles of the target and predicted image as similar as possible, penalizing differences in colors, textures, etc. As for feature loss, let be the feature map of size of the jth convolutional layer of the VGG network when processing the image X. The Gram Matrix is defined as a matrix whose elements are given by:Then, the style loss is defined as:where denotes the Frobenius norm.
- Total variation Regularization () [10,37]: The authors of [10] justified the use of this regularizer in super-resolution tasks to favour spatial smoothness in the predicted image. However, this loss does not consider the spectral correlation between bands of multispectral and hyperspectral images. To overcome this issue, Aggarwal et al. [37] proposed a spatial–spectral total regularization. In order to reduce noise in the output images, we follow the same idea.
3.7. Evaluation Metrics
- Peak Signal to Noise Ratio (PSNR): PSNR is one of the most used metrics for quality evaluation of a reconstructed image. The term is used to define the relationship between the maximum possible energy of a signal and the noise that affects its faithful representation. In Equation (6), corresponds to the maximum pixel value of the original image, and is the Mean Squared Error between the original image Y and the reconstructed image :The error is the amount by which the values of the original image differ from the degraded image. Generally, the higher the PSNR, the better the quality of the reconstructed image.
- Structural Similarity (SSIM): SSIM is a metric that measures the similarity between two images considering the luminance, contrast and structure. It is closer to the idea that humans have of similarity. The range of the metric values is [−1,1], where 1 means that the images are identical. If Y is the original image and the reconstructed image, the structural similarity between them is defined as follows:where and are the average of Y and , is the covariance of Y and , and are the variances of Y and and and are constants introduced to avoid instability. The latter are defined as and , where L is the images maximum pixel value and and are usually set to 0.01 and 0.03, respectively.
3.8. Training Details
4. Results
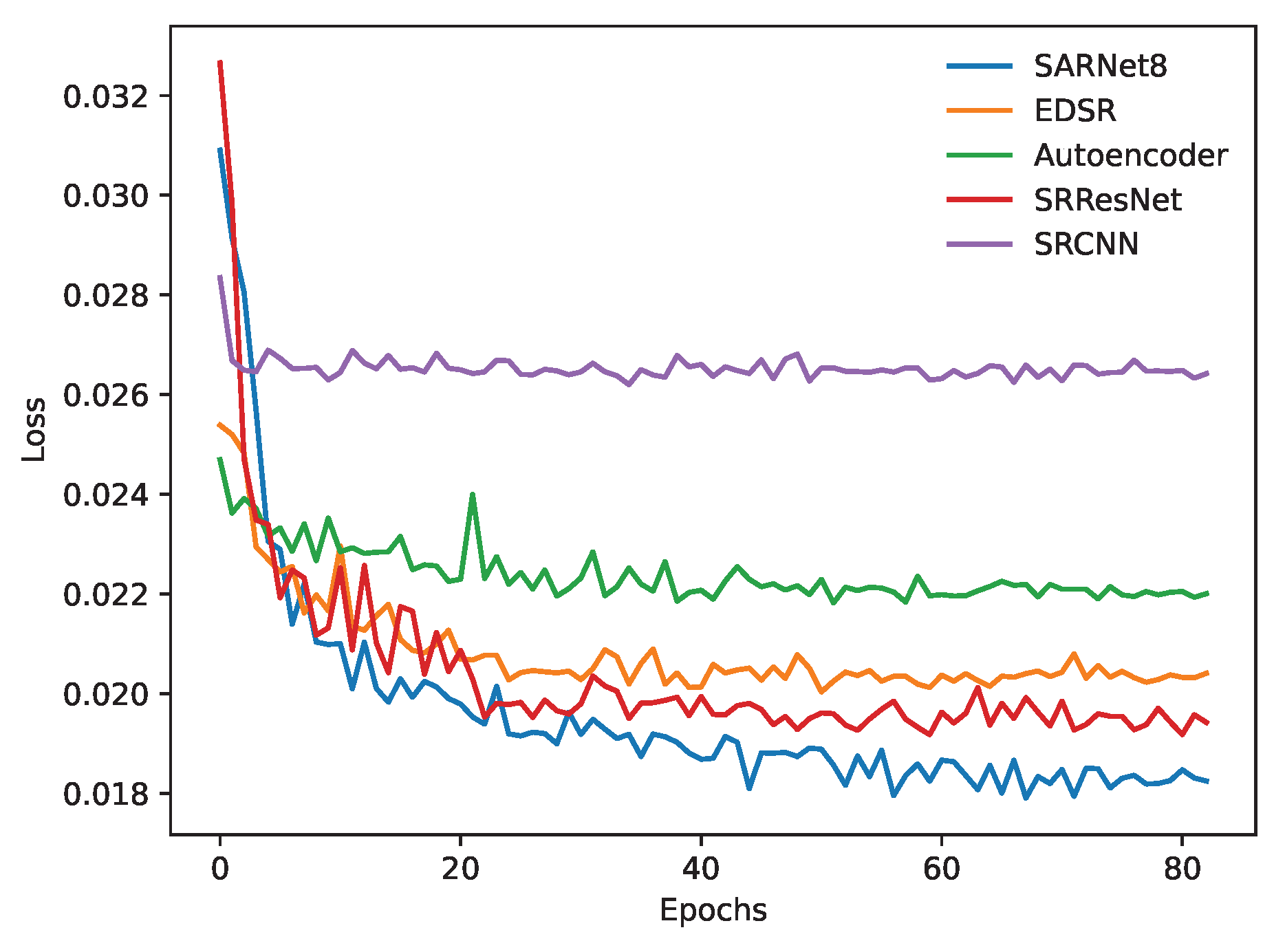
4.1. Loss Functions
4.2. Depth of the Network
4.3. Comparison with Existing Models
4.4. Spectral Validation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BOA | Bottom of Atmosphere. |
| CNN | Convolutional Neural Network. |
| ECMWF | European Centre for Medium Range Weather Forecasts. |
| ESA | European Space Agency. |
| EUMETSAT | European Organization for the Exploitation of Meteorological Satellites. |
| GAN | Generative Adversarial Network. |
| HM | Histogram Matching. |
| HR | High-resolution image. |
| LR | Low-resolution image. |
| LSC | Long Skip Connection. |
| MAE | Mean Absolute Error. |
| MSE | Mean Square Error. |
| PSNR | Peak Signal to Noise Ratio. |
| RCAB | Residual Channel Attention Block. |
| RGB | Red-Green-Blue. |
| SISR | Single Image Super Resolution. |
| SSC | Short Skip Connection. |
| SSIM | Structural Similarity. |
| std | Standard Deviation. |
| TOA | Top of Atmosphere. |
Appendix A. Visual Comparison of Super-Resolved Sentinel-2 Images


References
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.-Y.; Ma, C.; Yang, M.-H. Single-Image Super-Resolution: A Benchmark. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 372–386. [Google Scholar]
- Sentinel Hub. Available online: https://www.sentinel-hub.com/explore/industries-and-showcases/agriculture/ (accessed on 25 February 2022).
- The Sentinel Missions. The European Space Agency. Available online: https://sentinel.esa.int/web/sentinel/missions (accessed on 1 October 2021).
- Planet’s Website. Available online: https://www.planet.com/ (accessed on 9 February 2022).
- Keys, R. Cubic Convolution Interpolation for Digital Image Processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; He, X.; Wu, Y.; Ren, C.; Zhu, C. Real-World Single Image Super-Resolution: A Brief Review. Inf. Fusion. 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics): Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, J.; Alahi, A.; Li, F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Zhang, Y.; Li, L.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Resolution Using Very Deep Residual Channel Attention Networks. arXiv 2018, arXiv:1807.02758. [Google Scholar]
- Cheng, G.; Matsune, A.; Li, Q.; Zhu, L.; Zang, H.; Zhan, S. Encoder-Decoder Residual Network for Real Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 2169–2178. [Google Scholar] [CrossRef]
- Galar, M.; Sesma, R.; Ayala, C.; Albizua, L.; Aranda, C. Super-Resolution of Sentinel-2 Images Using Convolutional Neural Networks and Real Ground Truth Data. Remote Sens. 2020, 12, 2941. [Google Scholar] [CrossRef]
- Galar, M.; Sesma, R.; Ayala, C.; Aranda, C. Super-Resolution for Sentinel-2 Images. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W16, 95–102. [Google Scholar] [CrossRef] [Green Version]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a Globally Applicable Deep Neural Network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- Gargiulo, M. Advances on CNN-Based Super-Resolution of Sentinel-2 Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Saint Petersburg, Russia, 1–4 July 2019. [Google Scholar]
- Pouliot, D.; Latifovic, R.; Pasher, J.; Duffe, J. Landsat Super-Resolution Enhancement Using Convolution Neural Networks and Sentinel-2 for Training. Remote Sens. 2018, 10, 394. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.U.; Ekhtiari, N.; Almeida, R.M.; Rieke, C. Super-Resolution of Multispectral Satellite Images Using Convolutional Neural Networks. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Nice, France, 14–20 June 2020. [Google Scholar]
- Salgueiro Romero, L.; Marcello, J.; Vilaplana, V. Super-Resolution of Sentinel-2 Imagery Using Generative Adversarial Networks. Remote Sens. 2020, 12, 2424. [Google Scholar] [CrossRef]
- Beaulieu, M.; Foucher, S.; Haberman, D.; Stewart, C. Deep Image-To-Image Transfer Applied to Resolution enhancement of sentinel-2 images. Int. Geosci. Remote Sens. Symp. (IGARSS) 2018, 2018, 2611–2614. [Google Scholar]
- The Copernicus Program. Available online: https://www.copernicus.eu/es (accessed on 1 October 2021).
- Copernicus Open Acces Hub. Available online: https://scihub.copernicus.eu/dhus/#/home (accessed on 21 November 2021).
- Wagner, L.; Liebel, L.; Körner, M. Deep Residual Learning for Single-Image Super-Resolution of Multi-Spectral Satellite Imagery. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W7, 189–196. [Google Scholar] [CrossRef] [Green Version]
- Liebel, L.; Körner, M. Single-Image Super Resolution for Multispectral Remote Sensing Data Using Convolutional Neural Networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 41, 883–890. [Google Scholar] [CrossRef] [Green Version]
- Eduaction and Research Program. Planet. Available online: https://www.planet.com/markets/education-and-research/ (accessed on 21 November 2021).
- Scheffler, D.; Hollstein, A.; Diedrich, H.; Segl, K.; Hostert, P. AROSICS: An Automated and Robust Open-Source Image Co-Registration Software for Multi-Sensor Satellite Data. Remote Sens. 2017, 9, 676. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Sugawara, Y.; Shiota, S.; Kiya, H. Super-Resolution Using Convolutional Neural Networks Without Any Checkerboard Artifacts. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 66–70. [Google Scholar]
- Aitken, A.; Ledig, C.; Theis, L.; Caballero, J.; Wang, Z.; Shi, W. Checkerboard Artifact Free Sub-Pixel Convolution: A Note on Sub-Pixel Convolution, Resize Convolution and Convolution Resize. arXiv 2017, arXiv:1707.02937. [Google Scholar]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral Image Denoising Using Spatio-Spectral Total Variation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 442–446. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ghaffar, M.; Mckinstry, A.; Maul, T.; Vu, T.-T. Data Augmentation Approaches for Satellite Image Super-Resolution. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W7, 47–54. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spectral Bands | Sentinel-2A | Sentinel-2B | ||
|---|---|---|---|---|
| Wavelength (nm) | Spatial Resolution (m) | Wavelength (nm) | Spatial Resolution (m) | |
| B1—Coastal Aerosol | 442.7 | 60 | 442.3 | 60 |
| B2—Blue | 492.4 | 10 | 492.1 | 10 |
| B3—Green | 559.8 | 10 | 559.0 | 10 |
| B4—Red | 664.6 | 10 | 665.0 | 10 |
| B5—Red-edge 1 | 704.1 | 20 | 703.8 | 20 |
| B6—Red-edge 2 | 740.5 | 20 | 739.1 | 20 |
| B7—Red-edge 3 | 782.8 | 20 | 779.7 | 20 |
| B8—NIR 1 | 832.8 | 10 | 833.0 | 10 |
| B8A—NIR 2 | 864.7 | 20 | 864.0 | 20 |
| B9—Water Vapor | 945.1 | 60 | 943.2 | 60 |
| B10—SWIR/Cirrus | 1373.5 | 60 | 1376.9 | 60 |
| B11—SWIR 1 | 1613.7 | 20 | 1610.4 | 20 |
| B12—SWIR 2 | 2202.4 | 20 | 2185.7 | 20 |
| Location | Date | Hour | Set | Number of Patches | Number of Patches | |
|---|---|---|---|---|---|---|
| Sentinel-2 | PlanetScope | |||||
| NE | 06-08-2020 | 10:56:19 | 11:06:14 | Train | 1651 | 1651 |
| 06-08-2020 | 10:56:19 | 11:06:13 | Train | 1180 | 1200 | |
| 06-08-2020 | 10:56:19 | 11:06:10 | Train | 1136 | 1131 | |
| 06-08-2020 | 10:56:19 | 11:06:10 | Train | 1717 | 1736 | |
| 06-08-2020 | 10:56:19 | 11:06:06 | Test | 2259 | 2273 | |
| 21-11-2020 | 10:53:49 | 11:00:13 | Train | 1407 | 1407 | |
| 21-11-2020 | 10:53:49 | 11:00:13 | Train | 2535 | 2538 | |
| 21-11-2020 | 10:53:49 | 11:00:08 | Train | 2676 | 2675 | |
| 07-10-2021 | 10:48:29 | 10:50:47 | Train | 1106 | 1106 | |
| 07-10-2021 | 10:48:29 | 10:50:47 | Train | 2698 | 2662 | |
| 07-10-2021 | 10:48:29 | 10:50:43 | Test | 2704 | 2650 | |
| 07-10-2021 | 10:48:29 | 10:50:40 | Train | 2654 | 2631 | |
| 07-10-2021 | 10:48:29 | 10:53:53 | Validation | 1763 | 1762 | |
| 07-10-2021 | 10:48:29 | 10:53:51 | Train | 2306 | 2280 | |
| 07-10-2021 | 10:48:29 | 10:53:49 | Test | 1244 | 1244 | |
| 07-10-2021 | 10:48:29 | 10:53:49 | Train | 2691 | 2693 | |
| 23-01-2022 | 11:09:16 | 11:31:20 | Train | 1259 | 1279 | |
| 23-01-2022 | 11:09:16 | 11:31:17 | Test | 842 | 842 | |
| NW | 30-10-2020 | 11:02:11 | 11:13:25 | Train | 2534 | 2501 |
| 30-10-2020 | 11:02:11 | 11:13:21 | Validation | 1994 | 1993 | |
| 30-10-2020 | 11:02:11 | 11:13:21 | Test | 722 | 743 | |
| 30-10-2020 | 11:02:11 | 11:13:18 | Test | 1286 | 1300 | |
| 05-09-2021 | 10:56:21 | 10:57:15 | Train | 2652 | 2704 | |
| 05-09-2021 | 10:56:21 | 10:57:15 | Test | 998 | 988 | |
| SW | 22-07-2021 | 10:56:21 | 10:34:19 | Validation | 2469 | 2487 |
| 22-07-2021 | 10:56:21 | 10:34:16 | Train | 2480 | 2459 | |
| 16-08-2021 | 10:56:21 | 10:40:59 | Train | 1678 | 1697 | |
| 18-04-2021 | 10:56:11 | 10:58:49 | Test | 1144 | 1144 | |
| SE | 19-11-2021 | 11:09:28 | 10:52:06 | Test | 1506 | 1502 |
| 19-11-2021 | 11:09:28 | 10:52:06 | Train | 2537 | 2552 | |
| 19-11-2021 | 11:09:28 | 10:52:06 | Validation | 993 | 993 | |
| Model | Loss Function | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | ||||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | ||
| SARNet8 | 33.103 | 1.728 | 0.989 | 0.018 | 33.533 | 1.837 | 0.989 | 0.030 | |
| SARNet8 | 33.350 | 1.877 | 0.987 | 0.035 | 33.578 | 1.864 | 0.990 | 0.026 | |
| Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| SARNet8 | 33.350 | 1.877 | 0.987 | 0.035 | 33.578 | 1.864 | 0.990 | 0.026 |
| SARNet16 | 33.493 | 1.931 | 0.987 | 0.034 | 33.718 | 1.998 | 0.991 | 0.022 |
| SARNet16-RG | 33.560 | 1.910 | 0.987 | 0.043 | 33.740 | 1.947 | 0.990 | 0.027 |
| Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |||||
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| Bicubic | 31.218 | 1.510 | 0.979 | 0.018 | 29.471 | 1.320 | 0.936 | 0.046 |
| SRCNN | 31.798 | 1.550 | 0.987 | 0.012 | 31.824 | 1.527 | 0.987 | 0.012 |
| Autoencoder | 32.497 | 1.620 | 0.990 | 0.010 | 32.415 | 1.587 | 0.990 | 0.010 |
| EDSR | 32.791 | 1.661 | 0.985 | 0.036 | 32.881 | 1.650 | 0.987 | 0.034 |
| SRResNet | 33.001 | 1.706 | 0.985 | 0.040 | 33.197 | 1.741 | 0.989 | 0.024 |
| SARNet8 | 33.350 | 1.877 | 0.987 | 0.035 | 33.578 | 1.864 | 0.990 | 0.026 |
| SARNet16 | 33.493 | 1.931 | 0.987 | 0.034 | 33.718 | 1.998 | 0.991 | 0.022 |
| SARNet16-RG | 33.560 | 1.910 | 0.987 | 0.043 | 33.740 | 1.947 | 0.990 | 0.027 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zabalza, M.; Bernardini, A. Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism. Remote Sens. 2022, 14, 2890. https://doi.org/10.3390/rs14122890
Zabalza M, Bernardini A. Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism. Remote Sensing. 2022; 14(12):2890. https://doi.org/10.3390/rs14122890
Chicago/Turabian StyleZabalza, Maialen, and Angela Bernardini. 2022. "Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism" Remote Sensing 14, no. 12: 2890. https://doi.org/10.3390/rs14122890
APA StyleZabalza, M., & Bernardini, A. (2022). Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism. Remote Sensing, 14(12), 2890. https://doi.org/10.3390/rs14122890