
KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching



Abstract
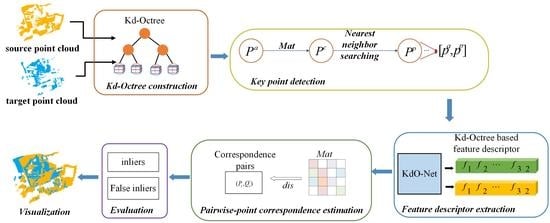
:
1. Introduction
2. Related Works
2.1. Network Architecture
2.2. Comparisons among the State-of-the-Arts
3. Our Approach
3.1. Kd–Octree Based Voxelization Descriptor
3.1.1. Kd–Octree Construction
3.1.2. Nearest Neighbor Searching Strategy
| Algorithm 1: Nearest Neighbor Searching Strategy |
|
3.2. Feature Descriptor Extraction
3.2.1. KdO-Net Architecture
3.2.2. Network Training
3.3. Pairwise-Point Correspondence Establishment
3.4. Pairwise-Point Feature Matching
4. Results
4.1. Implementation
4.2. Evaluation Metrics
4.2.1. Nearest Neighbor Searching and Network Training
4.2.2. Feature Matching Metrics
4.3. Evaluation
4.3.1. Evaluation on the Indoor 3DMatch Dataset
4.3.2. Generalization from BundleFusion to ETH Dataset
5. Discussion
5.1. Application
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, R.; Ye, Z.; Boerner, R.; Yao, W.; Xu, Y.; Stilla, U. Fast pairwise coarse registration between point clouds of construction sites using 2D projection based phase correlation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1015–1020. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Yang, B.; Liang, F.; Huang, R.; Scherer, S. Hierarchical registration of unordered TLS point clouds based on binary shape context descriptor. ISPRS J. Photogramm. Remote Sens. 2018, 144, 61–79. [Google Scholar] [CrossRef]
- Montuori, A.; Luzi, G.; Stramondo, S.; Casula, G.; Bignami, C.; Bonali, E.; Bianchi, M.G.; Crosetto, M. Combined use of ground-based systems for Cultural Heritage conservation monitoring. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4086–4089. [Google Scholar]
- Davis, A.; Belton, D.; Helmholz, P.; Bourke, P.; McDonald, J. Pilbara rock art: Laser scanning, photogrammetry and 3D photographic reconstruction as heritage management tools. Herit. Sci. 2017, 5, 25. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Liang, F.; Yang, B.; Xu, Y.; Zang, Y.; Li, J.; Wang, Y.; Dai, W.; Fan, H.; Hyyppä, J. Registration of large-scale terrestrial laser scanner point clouds: A review and benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 163, 327–342. [Google Scholar] [CrossRef]
- Xu, Y.; Boerner, R.; Yao, W.; Hoegner, L.; Uwe, S. Pairwise coarse registration of point clouds in urban scenes using voxel-based 4-planes congruent sets. ISPRS J. Photogramm. Remote Sens. 2019, 151, 106–123. [Google Scholar] [CrossRef]
- Guo, Y.; Sohel, F.; Bennamoun, M.; Wan, J.; Lu, M. An Accurate and Robust Range Image Registration Algorithm for 3D Object Modeling. IEEE Trans. Multimed. 2014, 16, 1377–1390. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Ao, S.; Hu, Q.; Yang, B.; Markham, A.; Guo, Y. SpinNet: Learning a General Surface Descriptor for 3D Point Cloud Registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11753–11762. [Google Scholar]
- Bai, X.; Luo, Z.; Zhou, L.; Fu, H.; Quan, L.; Tai, C.L. D3feat: Joint learning of dense detection and description of 3d local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6359–6367. [Google Scholar]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Wieser, A. The perfect match: 3d point cloud matching with smoothed densities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5545–5554. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1802–1811. [Google Scholar]
- Aoki, Y.; Goforth, H.; Srivatsan, R.A.; Lucey, S. Pointnetlk: Robust & efficient point cloud registration using pointnet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7163–7172. [Google Scholar]
- Fang, Y.; Xie, J.; Dai, G.; Wang, M.; Zhu, F.; Xu, T.; Wong, E. 3d deep shape descriptor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2319–2328. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppf-foldnet: Unsupervised learning of rotation invariant 3d local descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 602–618. [Google Scholar]
- Elbaz, G.; Avraham, T.; Fischer, A. 3D point cloud registration for localization using a deep neural network auto-encoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4631–4640. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. Ppfnet: Global context aware local features for robust 3d point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 195–205. [Google Scholar]
- Poiesi, F.; Boscaini, D. Generalisable and distinctive 3D local deep descriptors for point cloud registration. arXiv 2021, arXiv:2105.10382. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Li, J.; Chen, B.; Yuan, M.; Zhao, Q.; Luo, L.; Gao, X. Matching Algorithm for 3D Point Cloud Recognition and Registration Based on Multi-Statistics Histogram Descriptors. Sensors 2022, 22, 417. [Google Scholar] [CrossRef]
- Yue, X.; Liu, Z.; Zhu, J.; Gao, X.; Yang, B.; Tian, Y. Coarse-fine point cloud registration based on local point-pair features and the iterative closest point algorithm. Appl. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, Z.; Zhong, R.; Chen, D.; Zhang, L.; Zhu, L.; Wang, Q.; Wangb, G.; Zou, J.; Wangc, Y. A Weakly Supervised Graph Deep Learning Framework for Point Cloud Registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5702012. [Google Scholar] [CrossRef]
- Hana, X.F.; Jin, J.S.; Xie, J.; Wang, M.J.; Jiang, W. A comprehensive review of 3D point cloud descriptors. arXiv 2018, arXiv:1802.02297. [Google Scholar]
- Poiesi, F.; Boscaini, D. Distinctive 3D local deep descriptors. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021. [Google Scholar]
- Spezialetti, R.; Salti, S.; Stefano, L.D. Learning an effective equivariant 3d descriptor without supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6401–6410. [Google Scholar]
- Tian, Y.; Fan, B.; Wu, F. L2-net: Deep learning of discriminative patch descriptor in euclidean space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 661–669. [Google Scholar]
- Yew, Z.J.; Lee, G.H. 3dfeat-net: Weakly supervised local 3d features for point cloud registration. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 607–623. [Google Scholar]
- Choy, C.; Dong, W.; Koltun, V. Deep global registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2514–2523. [Google Scholar]
- Lu, W.; Wan, G.; Zhou, Y.; Fu, X.; Yuan, P.; Song, S. DeepICP: An end-to-end deep neural network for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 12–21. [Google Scholar]
- Feng, M.; Hu, S.; Ang, M.H.; Lee, G.H. 2d3d-matchnet: Learning to match keypoints across 2d image and 3d point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4790–4796. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3d object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; IEEE: Piscataway, NJ, USA; pp. 689–696. [Google Scholar]
- Li, L.; Zhu, S.; Fu, H.; Tan, P.; Tai, C.L. End-to-end learning local multi-view descriptors for 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1919–1928. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application toStereo Vision. In Proceedings of the 7th International Joint Conference on ArtificialIntelligence, Nagoya, Japan, 23–29 August 1997. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; Volume 2017, pp. 77–85. [Google Scholar]
- Li, J.; Lee, G.H. DeepI2P: Image-to-Point Cloud Registration via Deep Classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15960–15969. [Google Scholar]
- El Banani, M.; Gao, L.; Johnson, J. Unsupervised R & R: Unsupervised point cloud registration via differentiable rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7129–7139. [Google Scholar]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Guibas, L.J.; Birdal, T. Learning multiview 3d point cloud registration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1759–1769. [Google Scholar]
- Choy, C.; Park, J.; Koltun, V. Fully Convolutional Geometric Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Zhu, L.; Guan, H.; Lin, C.; Han, R. Neighborhood-aware Geometric Encoding Network for Point Cloud Registration. arXiv 2022, arXiv:2201.12094. [Google Scholar]
- Li, D.; He, K.; Wang, L.; Zhang, D. Local feature extraction network with high correspondences for 3d point cloud registration. Appl. Intell. 2022, 2022, 1–12. [Google Scholar] [CrossRef]
- Joung, S.; Kim, S.; Kim, H.; Kim, M.; Kim, I.J.; Cho, J.; Sohn, K. Cylindrical convolutional networks for joint object detection and viewpoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14163–14172. [Google Scholar]
- Kadam, P.; Zhang, M.; Liu, S.; Kuo, C.C.J. R-PointHop: A Green, Accurate, and Unsupervised Point Cloud Registration Method. IEEE Trans. Image Process. 2022, 31, 2710–2725. [Google Scholar] [CrossRef]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Wang, P.S.; Liu, Y.; Guo, Y.X.; Sun, C.Y.; Tong, X. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Souza Neto, P.; Marques Soares, J.; Pereira Thé, G.A. Uniaxial Partitioning Strategy for Efficient Point Cloud Registration. Sensors 2022, 22, 2887. [Google Scholar] [CrossRef]
- Li, J.; Zhan, J.; Zhou, T.; Bento, V.A.; Wang, Q. Point cloud registration and localization based on voxel plane features. ISPRS J. Photogramm. Remote Sens. 2022, 188, 363–379. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Trans. Graph. 2017, 36, 1. [Google Scholar] [CrossRef]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 2–8 December 2013; pp. 1625–1632. [Google Scholar]
- Shotton, J.; Glocker, B.; Zach, C.; Izadi, S.; Criminisi, A.; Fitzgibbon, A. Scene coordinate regression forests for camera relocalization in RGB-D images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2930–2937. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zhang, R.; Li, G.; Li, M.; Wang, L. Fusion of images and point clouds for the semantic segmentation of large-scale 3D scenes based on deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 143, 85–96. [Google Scholar] [CrossRef]
- Zhang, Z.; Sun, J.; Dai, Y.; Zhou, D.; Song, X.; He, M. Self-supervised Rigid Transformation Equivariance for Accurate 3D Point Cloud Registration. Pattern Recognit. 2022, 130, 108784. [Google Scholar] [CrossRef]
- Vkb, G.; Carneiro, G.; Reid, I. Learning Local Image Descriptors with Deep Siamese and Triplet Convolutional Networks by Minimising Global Loss Functions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Pomerleau, F.; Liu, M.; Colas, F.; Siegwart, R. Challenging data sets for point cloud registration algorithms. Int. J. Robot. Res. 2012, 31, 1705–1711. [Google Scholar] [CrossRef] [Green Version]
- Lai, K.; Bo, L.; Fox, D. Unsupervised feature learning for 3d scene labeling. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3050–3057. [Google Scholar]
- Valentin, J.; Dai, A.; Nießner, M.; Kohli, P.; Torr, P.; Izadi, S.; Keskin, C. Learning to navigate the energy landscape. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 323–332. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Apt0 | Apt1 | Apt2 | Copyroom | Office0 | Office1 | Office2 | Office3 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| 3DSmoothNet | 1.09 | 1.01 | 1.24 | 0.94 | 1.08 | 1.11 | 1.06 | 1.07 | 1.07 |
| KdO-Net | 0.37 | 0.36 | 0.44 | 0.32 | 0.36 | 0.39 | 0.36 | 0.37 | 0.37 |
| Model | Kitchen | Home1 | Home2 | Hotel1 | Hotel2 | Hotel3 | Study | MIT Lab | Avg |
|---|---|---|---|---|---|---|---|---|---|
| 3DSmoothNet | 0.99 | 1.12 | 1.04 | 1.31 | 1.26 | 1.30 | 1.70 | 1.58 | 1.29 |
| KdO-Net | 0.34 | 0.37 | 0.34 | 0.42 | 0.41 | 0.40 | 0.51 | 0.47 | 0.37 |
| Model | Convolution-Based Network | Feature Matching | ||||||
|---|---|---|---|---|---|---|---|---|
| Batch Size | Training Accuracy | Validation Accuracy | Loss | mR | STD_mR | mPR | STD_mPR | |
| 3DSmoothNet | 128 | 67.2 | 60.14 | 0.57 | 93.22 | 3.60 | 96.23 | 2.49 |
| D3Feat(pred) | 1 | 47.13 | 40.1 | 1.18 | 90.33 | 5.71 | 94.25 | 4.03 |
| SpinNet | 14 | 74.48 | – | 1.29 | 86.2 | 5.92 | 97.25 | 1.30 |
| KdO-Net | 128 | 78.4 | 63.08 | 0.49 | 91.66 | 5.46 | 97.63 | 1.30 |
| Scene | 3DSmoothNet | D3Feat(pred) | SpinNet | KdO-Net |
|---|---|---|---|---|
| Kitchen | 96.99 | 97.56 | 97.49 | 97.34 |
| Home1 | 96.77 | 93.24 | 96.53 | 96.67 |
| Home2 | 95.36 | 93.57 | 96.02 | 96.2 |
| Hotel1 | 98.19 | 97.26 | 99.05 | 98.63 |
| Hotel2 | 98.94 | 98.91 | 98.91 | 98.96 |
| Hotel3 | 98.15 | 96.23 | 98.11 | 100 |
| Study | 94.77 | 91.67 | 95.14 | 96.51 |
| MIT Lab | 90.67 | 85.54 | 96.77 | 96.77 |
| mPR | 96.23 | 94.25 | 97.25 | 97.63 |
| STD_mPR | 2.49 | 4.03 | 1.30 | 1.30 |
| Model | Gazebo | Wood | mR | STD_mR | mPR | ||
|---|---|---|---|---|---|---|---|
| Summer | Winter | Summer | Winter | ||||
| 3DSmoothNet | 82.61 | 64.36 | 57.39 | 63.2 | 66.89 | 9.45 | 100 |
| KdO-Net | 84.24 | 70.93 | 62.61 | 68.0 | 71.45 | 7.96 | 100 |
| Component | Training Accuracy | Loss | mR | mPR |
|---|---|---|---|---|
| w/o SGDR | 10.96 | 0.50 | 3.89 | - |
| w/o HCE | 71.89 | −0.26 | 94.07 | 95.61 |
| w/o compressor | 73.05 | −0.26 | 90.53 | 97.40 |
| simplify SCS-Net | 67.06 | 0.50 | 87.28 | 97.50 |
| w/o Kd–Octree | 71.09 | 0.49 | 89.82 | 97.63 |
| the full method | 78.4 | 0.49 | 90.23 | 97.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, R.; Li, G.; Wiedemann, W.; Holst, C. KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching. Remote Sens. 2022, 14, 2883. https://doi.org/10.3390/rs14122883
Zhang R, Li G, Wiedemann W, Holst C. KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching. Remote Sensing. 2022; 14(12):2883. https://doi.org/10.3390/rs14122883
Chicago/Turabian StyleZhang, Rui, Guangyun Li, Wolfgang Wiedemann, and Christoph Holst. 2022. "KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching" Remote Sensing 14, no. 12: 2883. https://doi.org/10.3390/rs14122883
APA StyleZhang, R., Li, G., Wiedemann, W., & Holst, C. (2022). KdO-Net: Towards Improving the Efficiency of Deep Convolutional Neural Networks Applied in the 3D Pairwise Point Feature Matching. Remote Sensing, 14(12), 2883. https://doi.org/10.3390/rs14122883