
Automatic, Multiview, Coplanar Extraction for CityGML Building Model Texture Mapping

 , ,
, ,
Abstract
:
1. Introduction
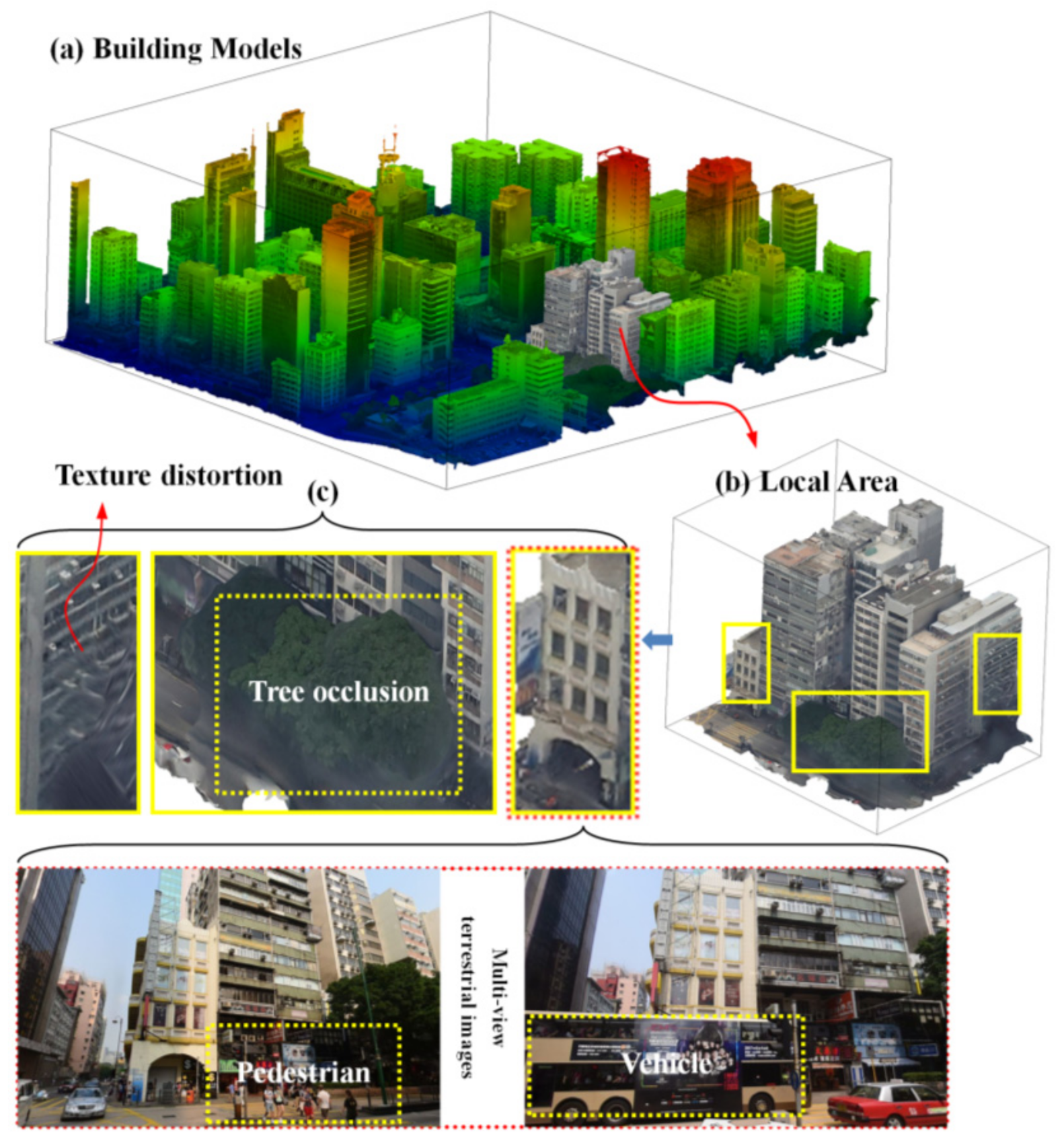
1.1. Background
1.2. Related Work
1.2.1. Texture Mapping Based on Photogrammetric Data and LiDAR Point Cloud Data
1.2.2. Texture Mapping Based on Crowd-Sourced Data
1.3. Research Objectives
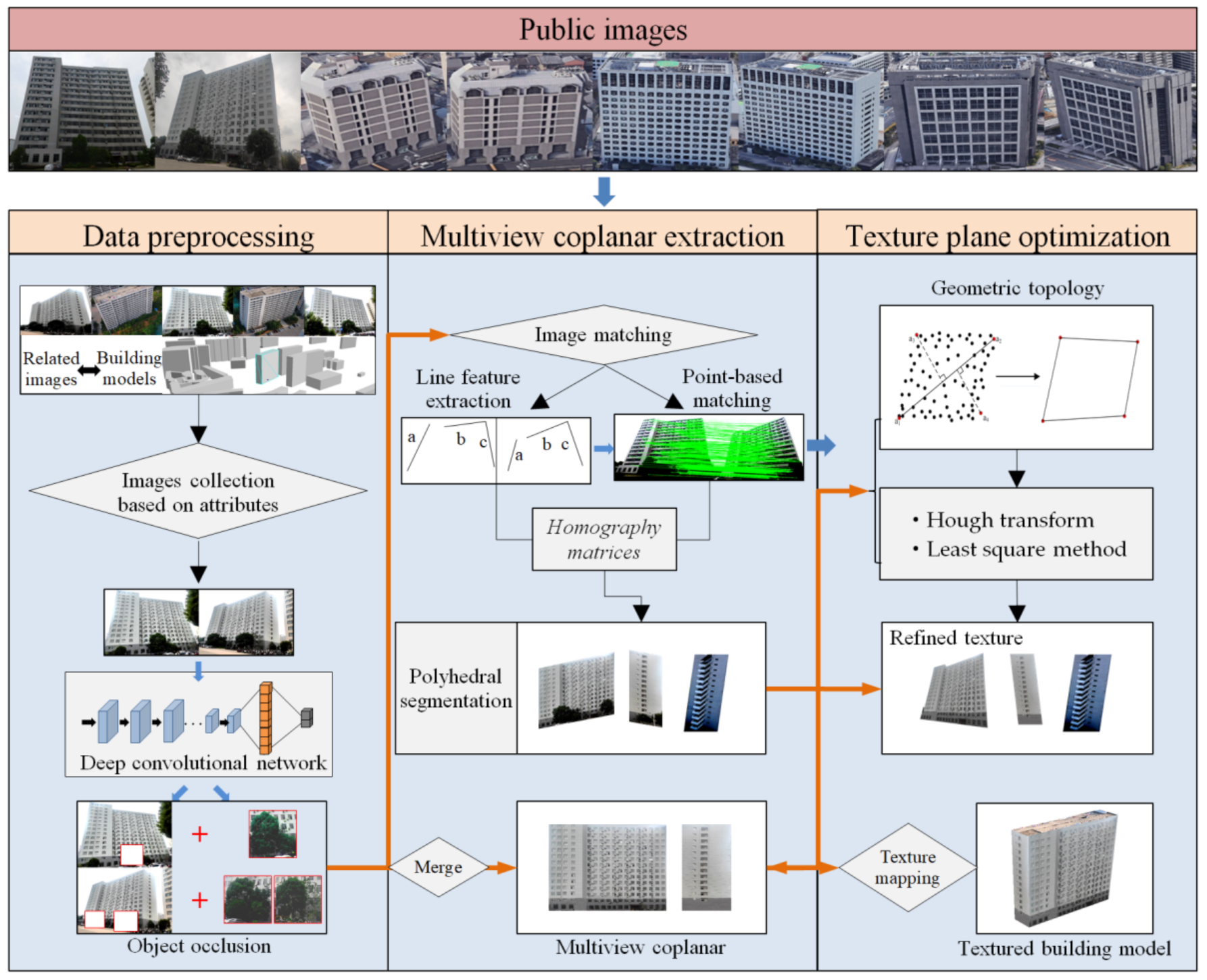
2. Methods
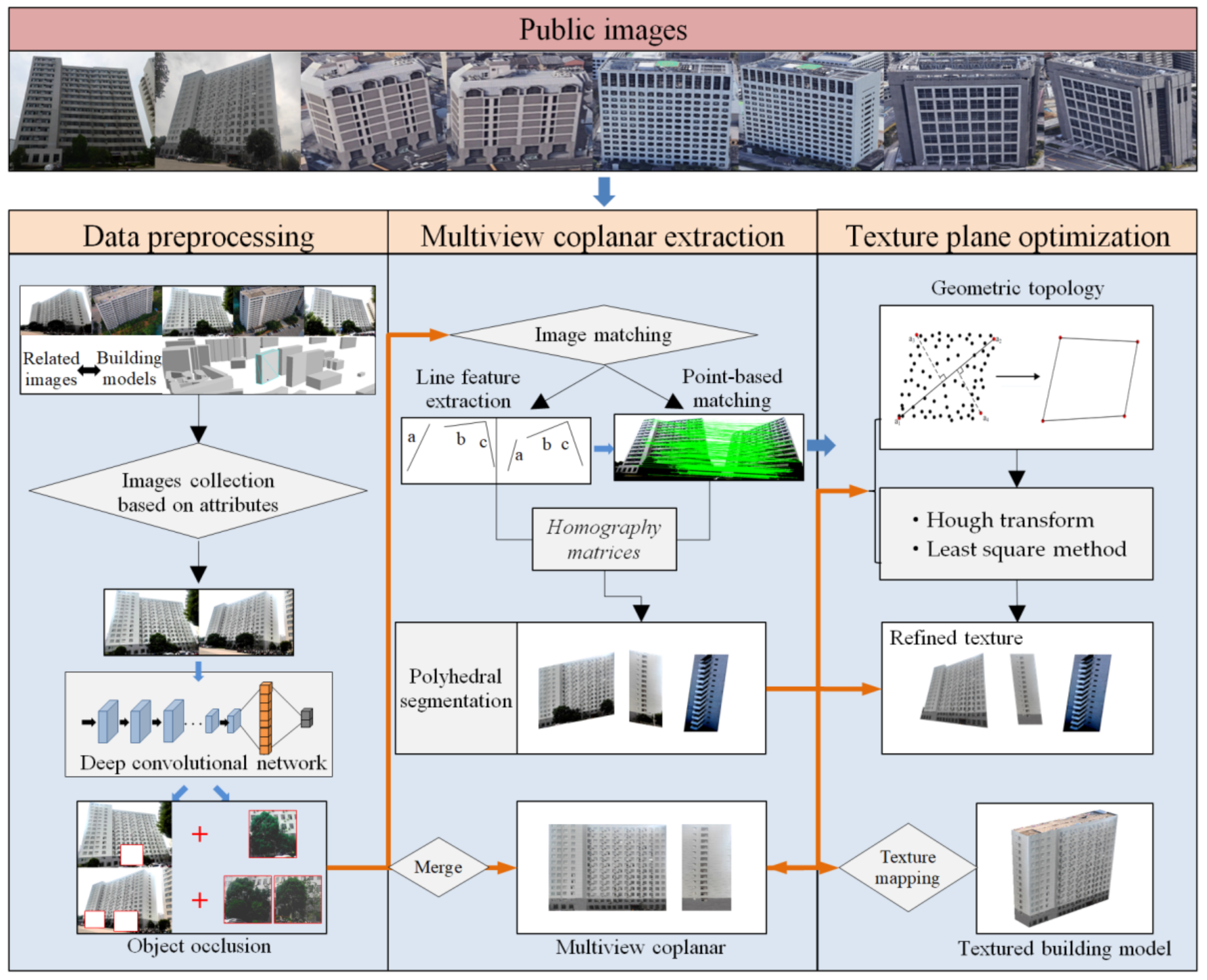
2.1. Overview of the Proposed Approach
2.2. Relevant Terrestrial Image Collection Based on Attributes
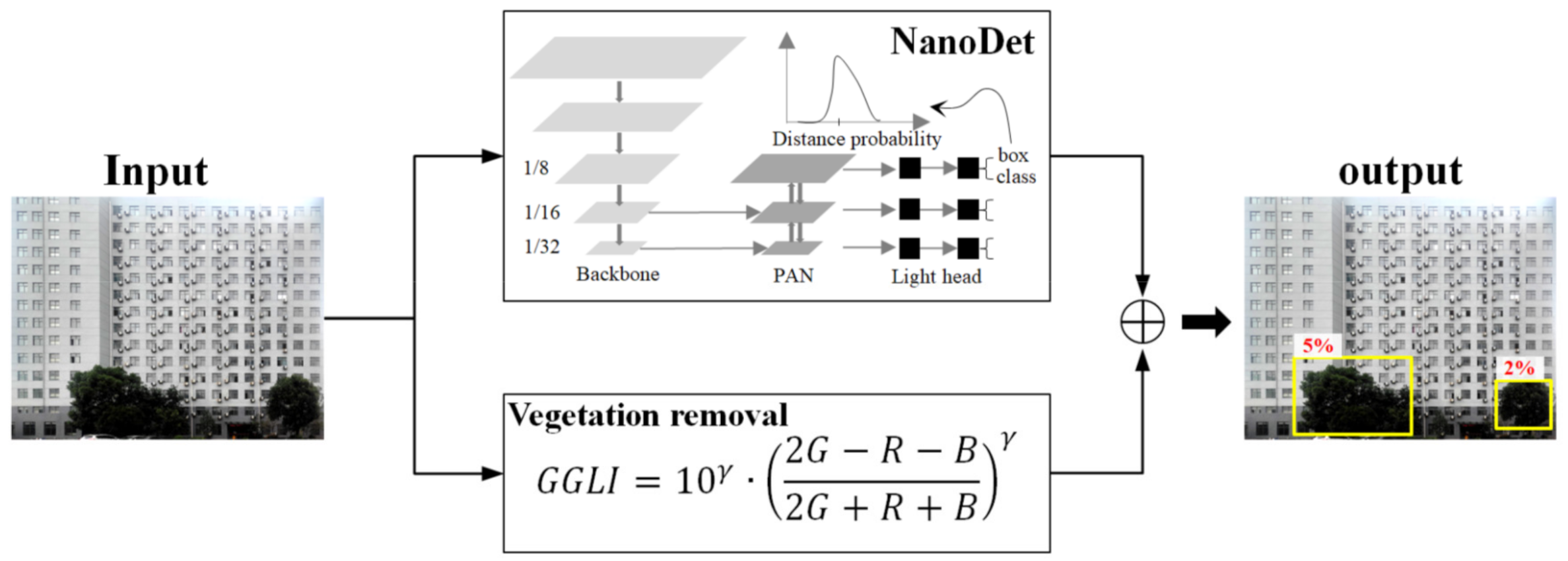
2.3. Object-Occlusion Detection Based on Deep Learning
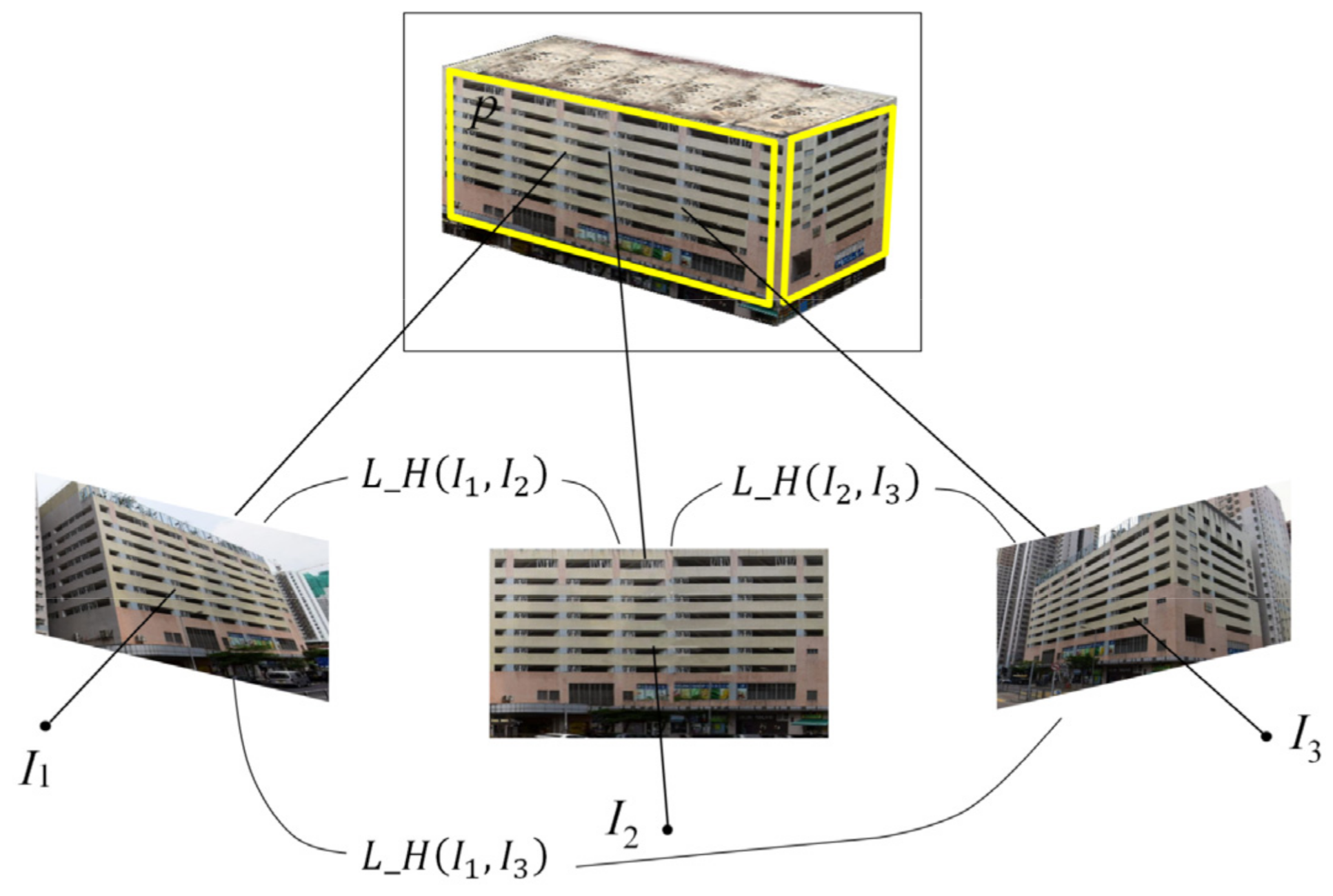
2.4. Multiview Coplanar Extraction
2.5. Texture-Plane Quadrilateral Definition Based on Geometric Topology
- (1)
- Along the straight lines, ,,, and , point sets ,,, and with the closest vertical distance to the corresponding straight lines are found.
- (2)
- Hough-transform algorithm is conducted to derive the mathematical formulas (i.e., , where denote slope and intercept of lines ,,, and from ,,, and, respectively.
- (3)
- Iterative weighted least-squares method [44] is explored to optimize each mathematical formula of lines ,,, and, and the error correction, , is expressed as follows:
2.6. Sub-Image Mosaic for Object-Occlusion Filling
| Algorithm 1: Texture extraction based on sub-image mosaic |
| Input: is the set of candidate terrestrial images for one façade, is the size of , is the coplanar point, and is the texture set. Parameters: Gamma-transform green leaf index, , multiple local homography matrices, . are the coefficients of a line. Output: Texture, , of the façade 1: for to do 2: Perform object detection using NanoDet 3: Compute 4: Remove area of object occlusion 5: end for 6: for to do 7: for to do 8: Perform feature extraction and matching based on sub-Harris operator 9: Compute 10: Define initial quadrilateral 11: Compute based on Hough transform 12: Compute based on least square method 13: Update 14: Refine and 15: Repeat steps from 12 to 14 until error convergence or the maximum iteration number is reached 16: Add into 17: end for 18: end for 19: Merge into |
3. Experiment Results and Analysis
3.1. Data Description
3.2. Qualitative Performance Evaluation
3.3. Performance Evaluation of Object-Occlusion Detection
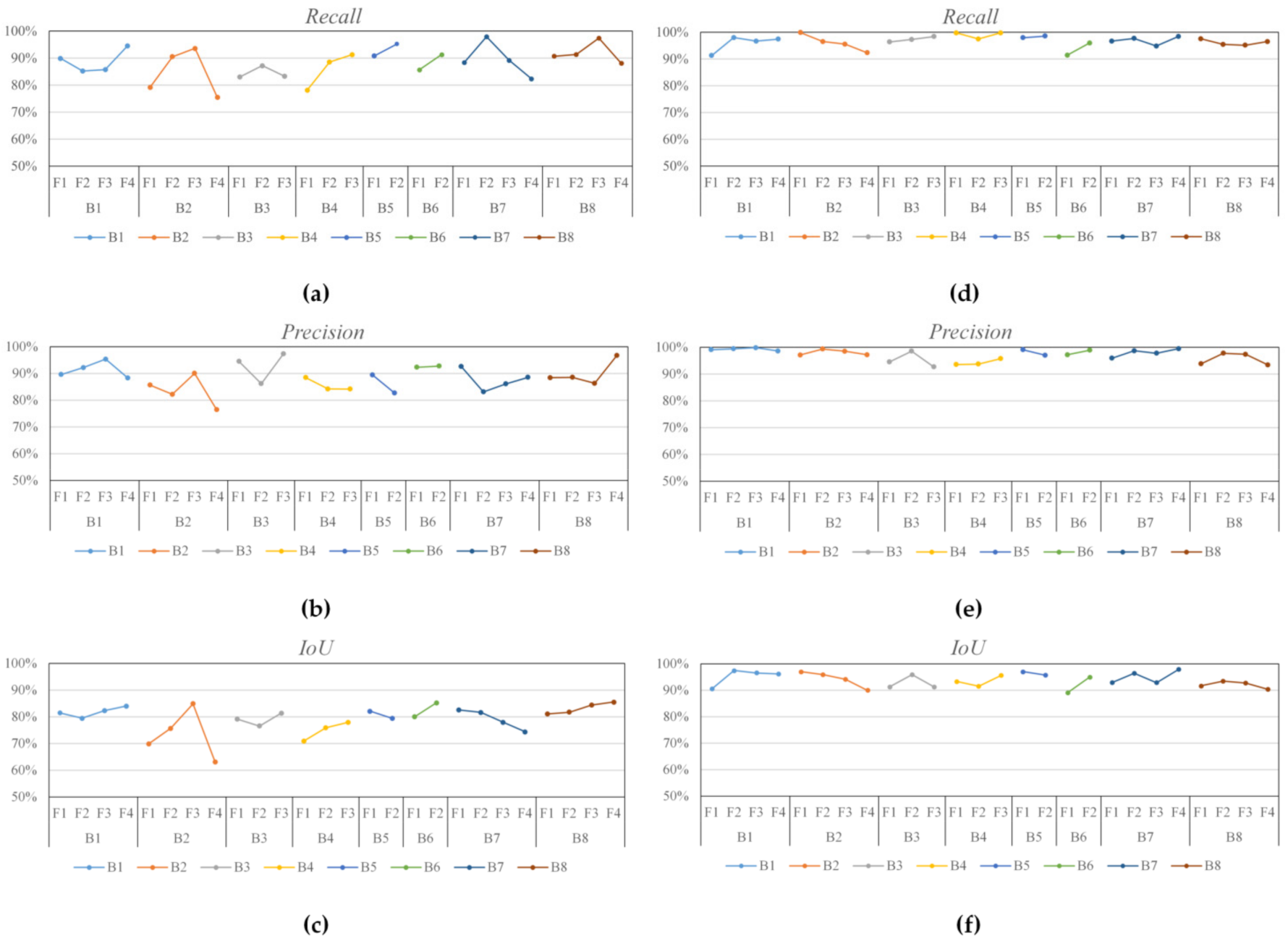
3.4. Performance Evaluation of Multiview Coplanar Extraction
3.5. Quality Evaluation of Updated Texture
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shan, J.; Li, Z.X.; Zhang, W.Y. Recent progress in large-scale 3D city modeling. Acta Geod. Cartogr. Sin. 2019, 48, 1523–1541. [Google Scholar]
- Gröger, G.; Kolbe, T.H.; Nagel, C.; Häfele, K.H. OGC City Geography Markup Language (CityGML) Encoding Standard; Open Geospatial Consortium: Rockville, MD, USA, 2012. [Google Scholar]
- Kolbe, T.H. Representing and Exchanging 3D City Models with CityGML. In 3D Geo-Information Sciences; Springer: New York, NY, USA, 2009. [Google Scholar]
- Kutzner, T.; Chaturvedi, K.; Kolbe, T.H. CityGML 3.0: New Functions Open Up New Applications. PFG—J. Photogramm. Remote Sens. Geoinf. Sci. 2020, 88, 43–61. [Google Scholar] [CrossRef] [Green Version]
- Eriksson, H.; Harrie, L. Versioning of 3D City Models for Municipality Applications: Needs, Obstacles and Recommendations. ISPRS Int. J. Geo-Inf. 2021, 10, 55. [Google Scholar] [CrossRef]
- Pepe, M.; Costantino, D.; Alfio, V.S.; Vozza, G.; Cartellino, E. A Novel Method Based on Deep Learning, GIS and Geomatics Software for Building a 3D City Model from VHR Satellite Stereo Imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 697. [Google Scholar] [CrossRef]
- Hensel, S.; Goebbels, S.; Kada, M. Facade reconstruction for textured Lod2 Citygml models based on deep learning and mixed integer linear programming. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W5, 37–44. [Google Scholar] [CrossRef] [Green Version]
- Li, D. 3D visualization of geospatial information: Graphics based or imagery based. Acta Geod. Cartogr. Sin. 2010, 39, 111–114. [Google Scholar]
- Yalcin, G.; Selcuk, O. 3D City Modelling with Oblique Photogrammetry Method. Procedia Technol. 2015, 19, 424–431. [Google Scholar] [CrossRef] [Green Version]
- Abayowa, B.O.; Yilmaz, A.; Hardie, R.C. Automatic registration of optical aerial imagery to a LiDAR point cloud for generation of city models. SPRS J. Photogramm. Remote Sens. 2015, 106, 68–81. [Google Scholar] [CrossRef]
- Heo, J.; Jeong, S.; Park, H.K.; Jung, J.; Han, S.; Hong, S.; Sohn, H.-G. Productive high-complexity 3D city modeling with point clouds collected from terrestrial LiDAR. Comput. Environ. Urban. Syst. 2013, 41, 26–38. [Google Scholar] [CrossRef]
- Wang, Q.D.; Ai, H.B.; Zhang, L. Rapid city modeling based on oblique photography and 3ds Max technique. Sci. Surv. Mapp. 2014, 39, 74–78. [Google Scholar] [CrossRef]
- Zhang, C.S.; Zhang, W.L.; Guo, B.X.; Liu, J.C.; Li, M. Rapidly 3D Texture Reconstruction Based on Oblique Photography. Acta Geod. Cartogr. Sin. 2015, 44, 782–790. [Google Scholar]
- Lari, Z.; El-Sheimy, N.; Habib, A. A new approach for realistic 3D reconstruction of planar surfaces from laser scanning data and imagery collected onboard modern low-cost aerial mapping systems. Remote Sens. 2017, 9, 212. [Google Scholar] [CrossRef] [Green Version]
- Khairnar, S. An Approach of Automatic Reconstruction of Building Models for Virtual Cities from Open Resources. Master’s Thesis, University of Windsor, Windsor, ON, Canada, 2019. [Google Scholar]
- Girindran, R.; Boyd, D.S.; Rosser, J.; Vijayan, D.; Long, G.; Robinson, D. On the Reliable Generation of 3D City Models from Open Data. Urban Sci. 2020, 4, 47. [Google Scholar] [CrossRef]
- Gong, J.Y.; Cui, T.T.; Shan, J.; Ji, S.P.; Huang, Y.C. A Survey on Façade Modeling Using LiDAR Point Clouds and Image Sequences Collected by Mobile Mapping Systems. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 1137–1143. [Google Scholar]
- Li, M.; Zhang, W.L.; Fan, D.Y. Automatic Texture Optimization for 3D Urban Reconstruction. Acta Geod. Cartogr. Sin. 2017, 46, 338–345. [Google Scholar]
- Deng, Y.; Cheng, J.C.; Anumba, C. Mapping between BIM and 3D GIS in different levels of detail using schema mediation and instance comparison. Autom. Constr. 2016, 67, 1–21. [Google Scholar] [CrossRef]
- Fan, H.; Meng, L. A three-step approach of simplifying 3D buildings modeled by CityGML. Int. J. Geogr. Inf. Sci. 2012, 26, 1091–1107. [Google Scholar] [CrossRef]
- Kang, T.W.; Hong, C.H. IFC-CityGML LOD mapping automation using multiprocessing-based screen-buffer scanning including mapping rule. KSCE J. Civ. Eng. 2017, 22, 373–383. [Google Scholar] [CrossRef]
- NanoDet. Super Fast and Light Weight Anchor-Free Object Detection Model: Real-Time on Mobile Devices. Available online: https://github.com/RangiLyu/nanodet (accessed on 14 November 2021).
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Al Dayil, R.; Al Ajlan, N. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Simultaneous Object Detection and Segmentation by Boosting Local shape Feature Based classifier. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition—CVPR’07, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Wu, B.; Nevatia, R. Detection and Segmentation of Multiple, Partially Occluded Objects by Grouping, Merging, Assigning Part Detection Responses. Int. J. Comput. Vis. 2008, 82, 185–204. [Google Scholar] [CrossRef] [Green Version]
- Pena, M.G. A Comparative Study of Three Image Matching Algorithms: SIFT, SURF, and FAST. Master’s Thesis, Utah State University, Logan, UT, USA, 2011. [Google Scholar]
- Druzhkov, P.N.; Kustikova, V.D. A survey of deep learning methods and software tools for image classification and object detection. Pattern Recognit. Image Anal. 2016, 26, 9–15. [Google Scholar] [CrossRef]
- Pritt, M.; Chern, G. Satellite Image Classification with Deep Learning. In Proceedings of the 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 10–12 October 2017; pp. 1–7. [Google Scholar]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Kauderer-Abrams, E. Quantifying translation-invariance in convolutional neural networks. arXiv 2017, arXiv:1801.01450. Available online: https://arxiv.fenshishang.com/pdf/1801.01450.pdf (accessed on 14 November 2021).
- Rodríguez, M.; Facciolo, G.; Von Gioi, R.G.; Musé, P.; Morel, J.-M.; Delon, J. Sift-Aid: Boosting Sift with an Affine Invariant Descriptor Based on Convolutional Neural Networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4225–4229. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.fenshishang.com/pdf/1409.1556.pdf(2014.pdf (accessed on 14 November 2021).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Geirhos, R.; Janssen, D.H.J.; Schütt, H.H.; Rauber, J.; Bethge, M.; Wichmann, F.A. Comparing deep neural networks against humans: Object recognition when the signal gets weaker. arXiv 2017, arXiv:1706.06969. Available online: https://arxiv.fenshishang.com/pdf/1706.06969.pdf (accessed on 14 November 2021).
- Afzal, M.Z.; Kölsch, A.; Ahmed, S.; Liwicki, M. Cutting the Error by Half: Investigation of Very Deep Cnn and Advanced Training Strategies for Document Image Classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 883–888. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.fenshishang.com/pdf/1804.02767.pdf (accessed on 14 November 2021).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.fenshishang.com/pdf/2004.10934.pdf (accessed on 14 November 2021).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling Cross Stage Partial Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- He, H.; Zhou, J.; Chen, M.; Chen, T.; Li, D.; Cheng, P. Building Extraction from UAV Images Jointly Using 6D-SLIC and Multiscale Siamese Convolutional Networks. Remote Sens. 2019, 11, 1040. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhao, L.; Huang, S.; Yan, L.; Dissanayake, G. Line matching based on planar homography for stereo aerial images. ISPRS J. Photogramm. Remote Sens. 2015, 104, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-I.; Kim, T. Comparison of Computer Vision and Photogrammetric Approaches for Epipolar Resampling of Image Sequence. Sensors 2016, 16, 412. [Google Scholar] [CrossRef] [Green Version]
- Vincent, E.; Laganiére, R. Detecting Planar Homographies in an Image Pair. In Proceedings of the 2nd International Symposium on Image and Signal Processing and Analysis (ISPA 2001) in Conjunction with 23rd International Conference on Information Technology Interfaces, Pula, Croatia, 19–21 June 2001; pp. 182–187. [Google Scholar]
- Ai, D.-N.; Han, X.-H.; Ruan, X.; Chen, Y.-W. Color Independent Components Based SIFT Descriptors for Object/Scene Classification. IEICE Trans. Inf. Syst. 2010, E93-D, 2577–2586. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yang, L.; Lin, H.; Liao, M. Automatic relative radiometric normalization using iteratively weighted least square regression. Int. J. Remote Sens. 2008, 29, 459–470. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-Cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Bah, M.D.; Hafiane, A.; Canals, R. CRowNet: Deep network for crop row detection in UAV images. IEEE Access 2019, 8, 5189–5200. [Google Scholar] [CrossRef]
- Hu, S.; Li, Z.; Wang, S.; Ai, M.; Hu, Q.A. A Texture Selection Approach for Cultural Artifact 3D Reconstruction Considering Both Geometry and Radiation Quality. Remote Sens. 2020, 12, 2521. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | R-CNN | Faster-R-CNN | YOLO | NanoDet | NanoDet + GGLI |
|---|---|---|---|---|---|
| Dataset1 | 66.0 | 66.9 | 71.6 | 71.2 | 92.9 |
| Dataset2 | 53.3 | 56.9 | 70.4 | 67.2 | 88.3 |
| Dataset3 | 61.6 | 68.3 | 74.1 | 64.7 | 85.9 |
| Dataset4 | 86.1 | 95.9 | 96.0 | 98.9 | 99.6 |
| Dataset5 | 50.4 | 57.9 | 68.4 | 59.6 | 87.6 |
| Dataset6 | 57.7 | 59.1 | 63.6 | 74.9 | 92.6 |
| Dataset7 | 43.3 | 48.9 | 50.1 | 78.7 | 87.8 |
| Dataset8 | 73.7 | 81.1 | 83.2 | 87.9 | 92.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, H.; Yu, J.; Cheng, P.; Wang, Y.; Zhu, Y.; Lin, T.; Dai, G. Automatic, Multiview, Coplanar Extraction for CityGML Building Model Texture Mapping. Remote Sens. 2022, 14, 50. https://doi.org/10.3390/rs14010050
He H, Yu J, Cheng P, Wang Y, Zhu Y, Lin T, Dai G. Automatic, Multiview, Coplanar Extraction for CityGML Building Model Texture Mapping. Remote Sensing. 2022; 14(1):50. https://doi.org/10.3390/rs14010050
Chicago/Turabian StyleHe, Haiqing, Jing Yu, Penggen Cheng, Yuqian Wang, Yufeng Zhu, Taiqing Lin, and Guoqiang Dai. 2022. "Automatic, Multiview, Coplanar Extraction for CityGML Building Model Texture Mapping" Remote Sensing 14, no. 1: 50. https://doi.org/10.3390/rs14010050
APA StyleHe, H., Yu, J., Cheng, P., Wang, Y., Zhu, Y., Lin, T., & Dai, G. (2022). Automatic, Multiview, Coplanar Extraction for CityGML Building Model Texture Mapping. Remote Sensing, 14(1), 50. https://doi.org/10.3390/rs14010050