
DP-MVS: Detail Preserving Multi-View Surface Reconstruction of Large-Scale Scenes

 , , , ,
, , , ,
Abstract
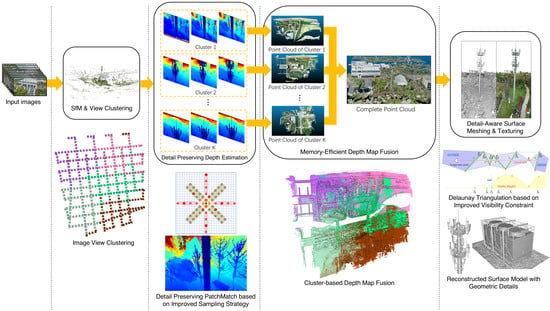
:
1. Introduction
- We propose a detail preserving PatchMatch approach to ensure an accurate dense depth map estimation with geometric details for each image view.
- Considering that high resolution depth map fusion is usually memory consuming, we propose a memory-efficient depth map fusion approach for handling extremely high resolution depth map fusion, to ensure accurate point cloud reconstruction of large-scale scenes without out-of-memory issues.
- We propose a novel detail-aware Delaunay meshing to preserve fine surface details for complicated scene structures.
2. Related Work
2.1. Voxel Based Methods
2.2. Surface Evolution Based Methods
2.3. Feature Growing Based Methods
2.4. Depth-Map Merging Based Methods
3. Materials and Methods
3.1. System Overview
3.2. Detail Preserving Depth Map Estimation
3.3. Memory-Efficient Depth Map Fusion
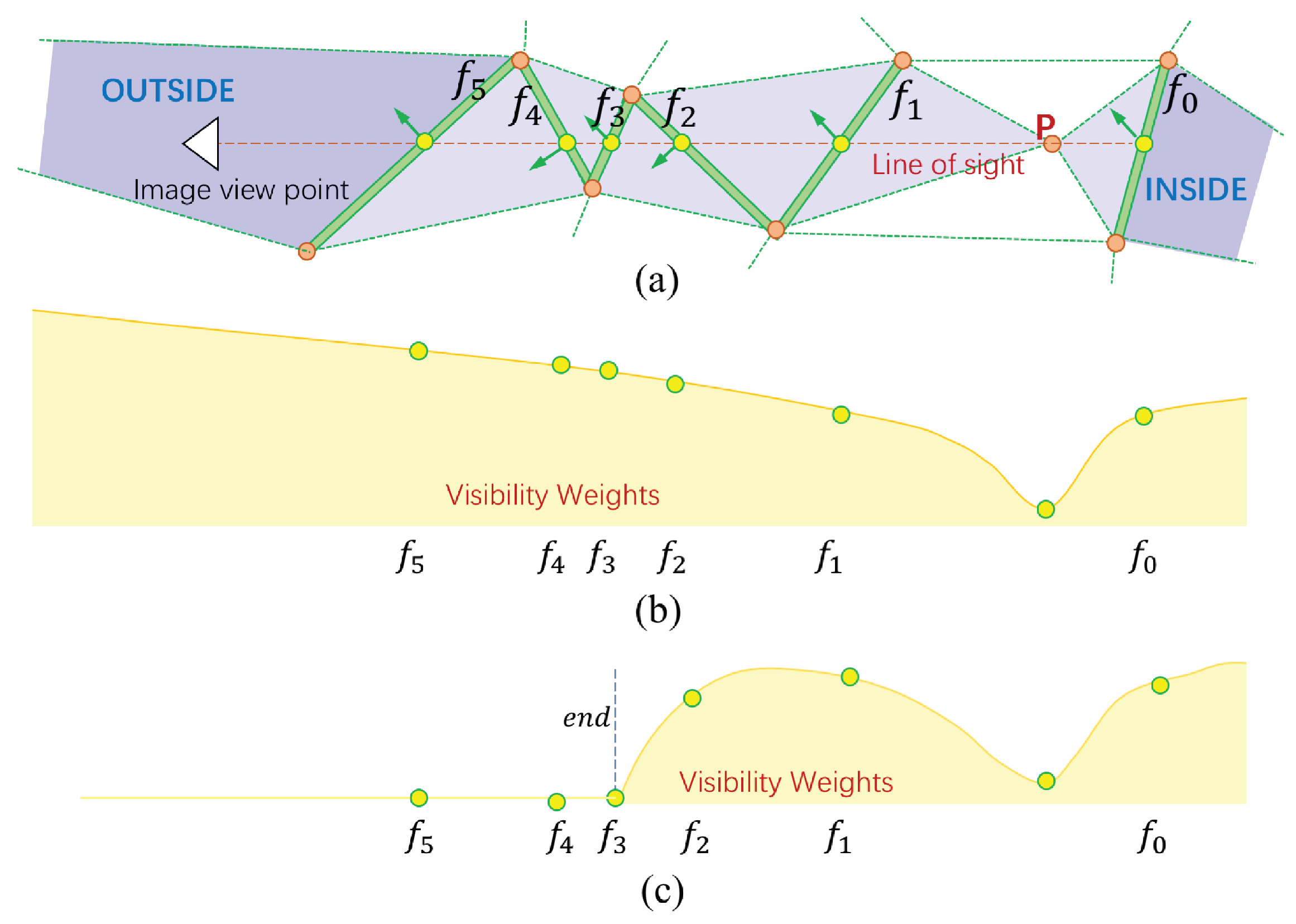
3.4. Detail-Aware Surface Meshing
4. Results
4.1. Qualitative Evaluation
4.2. Quantitative Evaluation
4.3. Time Statistics
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar]
- Seitz, S.M.; Dyer, C.R. Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vis. 1999, 35, 151–173. [Google Scholar] [CrossRef]
- Vogiatzis, G.; Esteban, C.H.; Torr, P.H.; Cipolla, R. Multiview stereo via volumetric graph-cuts and occlusion robust photo-consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2241–2246. [Google Scholar] [CrossRef] [Green Version]
- Sinha, S.N.; Mordohai, P.; Pollefeys, M. Multi-view stereo via graph cuts on the dual of an adaptive tetrahedral mesh. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Faugeras, O.; Keriven, R. Variational Principles, Surface Evolution, PDE’s, Level Set Methods and the Stereo Problem. IEEE Trans. Image Process. 1998, 7, 336–344. [Google Scholar] [CrossRef] [PubMed]
- Esteban, C.H.; Schmitt, F. Silhouette and stereo fusion for 3D object modeling. Comput. Vis. Image Underst. 2004, 96, 367–392. [Google Scholar] [CrossRef] [Green Version]
- Hiep, V.H.; Keriven, R.; Labatut, P.; Pons, J.P. Towards high-resolution large-scale multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1430–1437. [Google Scholar]
- Li, S.; Siu, S.Y.; Fang, T.; Quan, L. Efficient multi-view surface refinement with adaptive resolution control. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 349–364. [Google Scholar]
- Romanoni, A.; Matteucci, M. Mesh-based camera pairs selection and occlusion-aware masking for mesh refinement. Pattern Recognit. Lett. 2019, 125, 364–372. [Google Scholar] [CrossRef] [Green Version]
- Cremers, D.; Kolev, K. Multiview stereo and silhouette consistency via convex functionals over convex domains. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1161–1174. [Google Scholar] [CrossRef] [Green Version]
- Lhuillier, M.; Quan, L. A quasi-dense approach to surface reconstruction from uncalibrated images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 418–433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goesele, M.; Snavely, N.; Curless, B.; Hoppe, H.; Seitz, S.M. Multi-view Stereo for Community Photo Collections. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.P.; Yeung, S.K.; Jia, J.; Tang, C.K. Quasi-dense 3D reconstruction using tensor-based multiview stereo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1482–1489. [Google Scholar]
- Furukawa, Y.; Curless, B.; Seitz, S.M.; Szeliski, R. Towards internet-scale multi-view stereo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1434–1441. [Google Scholar]
- Strecha, C.; Fransens, R.; Van Gool, L. Combined depth and outlier estimation in multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2394–2401. [Google Scholar]
- Goesele, M.; Curless, B.; Seitz, S.M. Multi-view stereo revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2402–2409. [Google Scholar]
- Merrell, P.; Akbarzadeh, A.; Liang, W.; Mordohai, P.; Frahm, J.M.; Yang, R.; Nister, D.; Pollefeys, M. Real-time Visibility-Based Fusion of Depth Maps. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A globally optimal algorithm for robust TV-L1 range image integration. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Kuhn, A.; Mayer, H.; Hirschmüller, H.; Scharstein, D. A TV prior for high-quality local multi-view stereo reconstruction. In Proceedings of the International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; Volume 1, pp. 65–72. [Google Scholar]
- Liu, Y.; Cao, X.; Dai, Q.; Xu, W. Continuous depth estimation for multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2121–2128. [Google Scholar]
- Li, Z.; Zuo, W.; Wang, Z.; Zhang, L. Confidence-Based Large-Scale Dense Multi-View Stereo. IEEE Trans. Image Process. 2020, 29, 7176–7191. [Google Scholar] [CrossRef]
- Bradley, D.; Boubekeur, T.; Heidrich, W. Accurate multi-view reconstruction using robust binocular stereo and surface meshing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Campbell, N.D.; Vogiatzis, G.; Hernández, C.; Cipolla, R. Using multiple hypotheses to improve depth-maps for multi-view stereo. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Springer: Cham, Switzerland, 2008; pp. 766–779. [Google Scholar]
- Schönberger, J.L.; Zheng, E.; Pollefeys, M.; Frahm, J.M. Pixelwise View Selection for Unstructured Multi-View Stereo. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 501–518. [Google Scholar]
- Shen, S. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef]
- Tola, E.; Strecha, C.; Fua, P. Efficient large-scale multi-view stereo for ultra high-resolution image sets. Mach. Vis. Appl. 2012, 23, 903–920. [Google Scholar] [CrossRef]
- Tola, E.; Lepetit, V.; Fua, P. DAISY: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 815–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Li, E.; Chen, Y.; Xu, L.; Zhang, Y. Bundled depth-map merging for multi-view stereo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2769–2776. [Google Scholar]
- Xue, J.; Chen, X.; Hui, Y. Efficient Multi-View 3D Dense Matching for Large-Scale Aerial Images Using a Divide-and-Conquer Scheme. In Proceedings of the Chinese Automation Congress, Xi’an, China, 30 November–2 December 2018; pp. 2610–2615. [Google Scholar]
- Mostegel, C.; Fraundorfer, F.; Bischof, H. Prioritized multi-view stereo depth map generation using confidence prediction. ISPRS J. Photogramm. Remote Sens. 2018, 143, 167–180. [Google Scholar] [CrossRef] [Green Version]
- Wei, M.; Yan, Q.; Luo, F.; Song, C.; Xiao, C. Joint bilateral propagation upsampling for unstructured multi-view stereo. Vis. Comput. 2019, 35, 797–809. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Guan, T.; Chen, Z.; Luo, Y.; Luo, K.; Ju, L. Mesh-Guided Multi-View Stereo With Pyramid Architecture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2039–2048. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth Inference for Unstructured Multi-view Stereo. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar]
- Chen, R.; Han, S.; Xu, J.; Su, H. Point-based multi-view stereo network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1538–1547. [Google Scholar]
- Luo, K.; Guan, T.; Ju, L.; Huang, H.; Luo, Y. P-MVSNet: Learning patch-wise matching confidence aggregation for multi-view stereo. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10452–10461. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2495–2504. [Google Scholar]
- Kuhn, A.; Sormann, C.; Rossi, M.; Erdler, O.; Fraundorfer, F. DeepC-MVS: Deep confidence prediction for multi-view stereo reconstruction. In Proceedings of the International Conference on 3D Vision, Fukuoka, Japan, 25–28 November 2020; pp. 404–413. [Google Scholar]
- Yang, X.; Zhou, L.; Jiang, H.; Tang, Z.; Wang, Y.; Bao, H.; Zhang, G. Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone. IEEE Trans. Vis. Comput. Graph. 2020, 26, 3446–3456. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Jiang, G. A Practical 3D Reconstruction Method for Weak Texture Scenes. Remote Sens. 2021, 13, 3103. [Google Scholar] [CrossRef]
- Stathopoulou, E.K.; Battisti, R.; Cernea, D.; Remondino, F.; Georgopoulos, A. Semantically Derived Geometric Constraints for MVS Reconstruction of Textureless Areas. Remote Sens. 2021, 13, 1053. [Google Scholar] [CrossRef]
- Yan, F.; Xia, E.; Li, Z.; Zhou, Z. Sampling-Based Path Planning for High-Quality Aerial 3D Reconstruction of Urban Scenes. Remote Sens. 2021, 13, 989. [Google Scholar] [CrossRef]
- Liu, Y.; Cui, R.; Xie, K.; Gong, M.; Huang, H. Aerial Path Planning for Online Real-Time Exploration and Offline High-Quality Reconstruction of Large-Scale Urban Scenes. ACM Trans. Graph. 2021, 40, 226:1–226:16. [Google Scholar]
- Pepe, M.; Fregonese, L.; Crocetto, N. Use of SfM-MVS approach to nadir and oblique images generated throught aerial cameras to build 2.5 D map and 3D models in urban areas. Geocarto Int. 2019. [Google Scholar] [CrossRef]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28, 24. [Google Scholar] [CrossRef]
- Zheng, E.; Dunn, E.; Jojic, V.; Frahm, J.M. Patchmatch based joint view selection and depthmap estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1510–1517. [Google Scholar]
- Galliani, S.; Lasinger, K.; Schindler, K. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 873–881. [Google Scholar]
- Xu, Q.; Tao, W. Multi-scale geometric consistency guided multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5483–5492. [Google Scholar]
- Xu, Q.; Tao, W. Multi-view stereo with asymmetric checkerboard propagation and multi-hypothesis joint view selection. arXiv 2018, arXiv:1805.07920. [Google Scholar]
- Xu, Q.; Tao, W. Planar prior assisted patchmatch multi-view stereo. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12516–12523. [Google Scholar] [CrossRef]
- Romanoni, A.; Matteucci, M. TAPA-MVS: Textureless-aware patchmatch multi-view stereo. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10413–10422. [Google Scholar]
- Xu, Z.; Liu, Y.; Shi, X.; Wang, Y.; Zheng, Y. MARMVS: Matching Ambiguity Reduced Multiple View Stereo for Efficient Large Scale Scene Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5981–5990. [Google Scholar]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Cernea, D. OpenMVS: Multi-View Stereo Reconstruction Library. Available online: https://cdcseacave.github.io/openMVS (accessed on 3 September 2021).
- Li, S.; Yao, Y.; Fang, T.; Quan, L. Reconstructing thin structures of manifold surfaces by integrating spatial curves. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2887–2896. [Google Scholar]
- Labatut, P.; Pons, J.P.; Keriven, R. Robust and efficient surface reconstruction from range data. Comput. Graph. Forum 2009, 28, 2275–2290. [Google Scholar] [CrossRef] [Green Version]
- Vu, H.H.; Labatut, P.; Pons, J.P.; Keriven, R. High accuracy and visibility-consistent dense multiview stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 889–901. [Google Scholar] [CrossRef] [PubMed]
- Waechter, M.; Moehrle, N.; Goesele, M. Let there be color! Large-scale texturing of 3D reconstructions. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 836–850. [Google Scholar]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3260–3269. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Measures [cm] | OpenMVS | COLMAP | DP-MVS |
|---|---|---|---|---|
| ZJU CCE | RMSE/MAE | 4.337/2.084 | 4.476/2.275 | 3.698/1.859 |
| Dataset | Error | Measure | ACMM | OpenMVS | COLMAP | DP-MVS |
|---|---|---|---|---|---|---|
| Training dataset | 2 cm | F1-score | 78.86 | 76.15 | 67.66 | 80.11 |
| accuracy | 90.67 | 78.44 | 91.85 | 83.56 | ||
| completeness | 70.42 | 74.92 | 55.13 | 77.56 | ||
| 10 cm | F1-score | 91.70 | 92.51 | 87.61 | 94.77 | |
| accuracy | 98.12 | 95.75 | 98.75 | 95.95 | ||
| completeness | 86.40 | 89.84 | 79.47 | 93.72 | ||
| Test dataset | 2 cm | F1-score | 80.78 | 79.77 | 73.01 | 83.11 |
| accuracy | 90.65 | 81.98 | 91.97 | 84.05 | ||
| completeness | 74.34 | 78.54 | 62.98 | 82.73 | ||
| 10 cm | F1-score | 92.96 | 92.86 | 90.40 | 95.68 | |
| accuracy | 98.05 | 95.48 | 98.25 | 95.55 | ||
| completeness | 88.77 | 90.75 | 84.54 | 95.85 |
| Case | #Images | Stages | OpenMVS | COLMAP | DP-MVS |
|---|---|---|---|---|---|
| B5 Tower | 1163 | Depth Estimation | 757.57 | 135.795 | 54.207 |
| Fusion | 99.55 | 1810.244 | 48.139 | ||
| Meshing | 132.65 | 125.49 | 158.803 | ||
| Total | 989.77 | 2071.529 | 261.149 | ||
| B5 West | 513 | Depth Estimation | 312.56 | 148.484 | 26.833 |
| Fusion | 47.53 | 214.713 | 8.413 | ||
| Meshing | 163.62 | 64.92 | 63.191 | ||
| Total | 523.71 | 428.117 | 98.437 | ||
| Qiaoxi Street | 305 | Depth Estimation | 168.87 | 69.313 | 11.318 |
| Fusion | 18.33 | 42.538 | 3.862 | ||
| Meshing | 156 | 54.1 | 56.227 | ||
| Total | 343.2 | 165.951 | 71.407 | ||
| B5 Wire | 1251 | Depth Estimation | 728.58 | 224.183 | 40.826 |
| Fusion | 99.57 | 1168.048 | 56.312 | ||
| Meshing | 220.62 | 165.4 | 130.764 | ||
| Total | 1048.77 | 1557.631 | 227.902 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, L.; Zhang, Z.; Jiang, H.; Sun, H.; Bao, H.; Zhang, G. DP-MVS: Detail Preserving Multi-View Surface Reconstruction of Large-Scale Scenes. Remote Sens. 2021, 13, 4569. https://doi.org/10.3390/rs13224569
Zhou L, Zhang Z, Jiang H, Sun H, Bao H, Zhang G. DP-MVS: Detail Preserving Multi-View Surface Reconstruction of Large-Scale Scenes. Remote Sensing. 2021; 13(22):4569. https://doi.org/10.3390/rs13224569
Chicago/Turabian StyleZhou, Liyang, Zhuang Zhang, Hanqing Jiang, Han Sun, Hujun Bao, and Guofeng Zhang. 2021. "DP-MVS: Detail Preserving Multi-View Surface Reconstruction of Large-Scale Scenes" Remote Sensing 13, no. 22: 4569. https://doi.org/10.3390/rs13224569
APA StyleZhou, L., Zhang, Z., Jiang, H., Sun, H., Bao, H., & Zhang, G. (2021). DP-MVS: Detail Preserving Multi-View Surface Reconstruction of Large-Scale Scenes. Remote Sensing, 13(22), 4569. https://doi.org/10.3390/rs13224569