
BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images

 , , ,
, , ,
Abstract
:
1. Introduction
- (1)
- We propose a new unsupervised bidirectional domain adaptation method, coined BiFDANet, for semantic segmentation of remote sensing images, which conducts bidirectional image translation to minimize the domain shift and optimizes the classifiers in two opposite directions to take full advantage of the information from both domains. At test stage, we employ a linear combination method to take full advantage of the two complementary predicted labels which further enhances the performance of our BiFDANet. As far as we know, BiFDANet is the first work on unsupervised bidirectional domain adaptation for semantic segmentation of remote sensing images.
- (2)
- We propose a new bidirectional semantic consistency loss which effectively supervises the generators to maintain the semantic consistency in both source-to-target and target-to-source directions. We analyze the bidirectional semantic consistency loss by comparing it with two semantic consistency losses used in the existing approaches.
- (3)
- We perform our proposed framework on two datasets, one consisting of satellite images from two different satellites and the other is composed of aerial images from different cities. The results indicate that our method can improve the performance of the cross-domain semantic segmentation and minimize the domain gap effectively. In addition, the effect of each component is discussed.
2. Related Work
2.1. Domain Adaptation
2.2. Bidirectional Learning
3. Materials and Methods
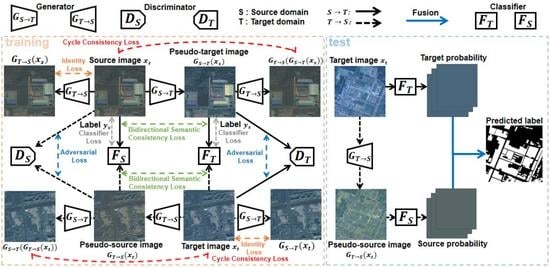
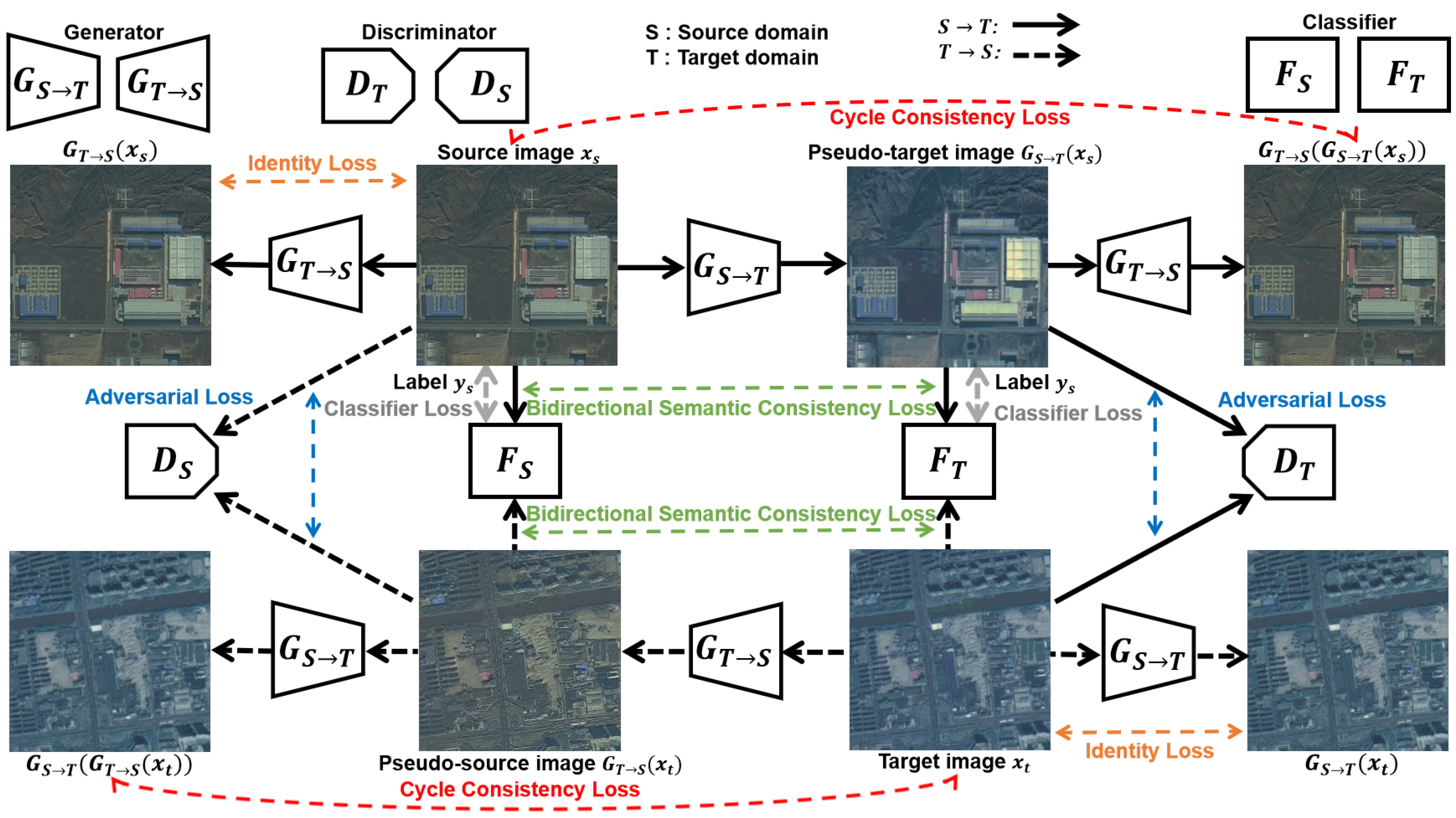
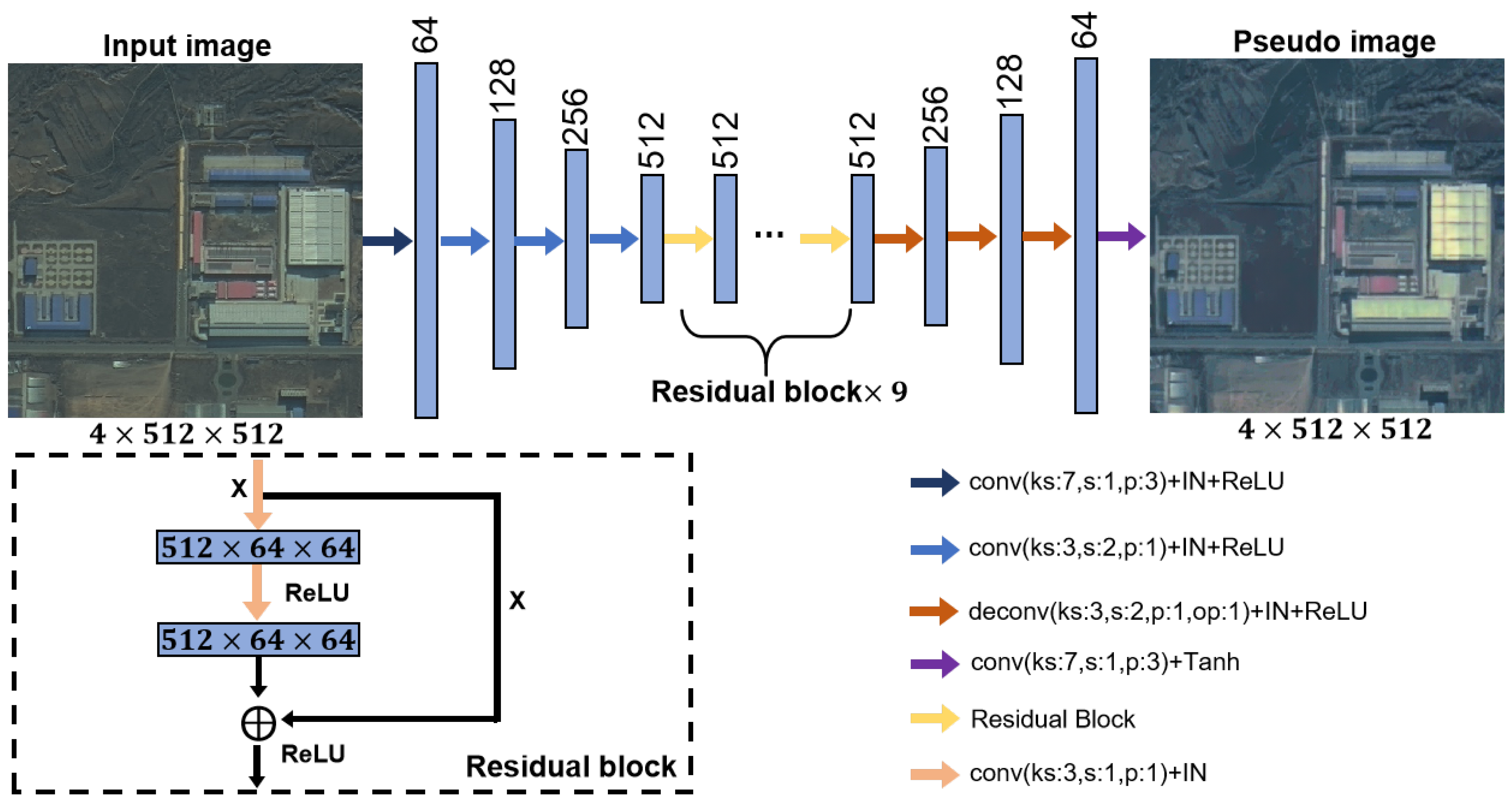
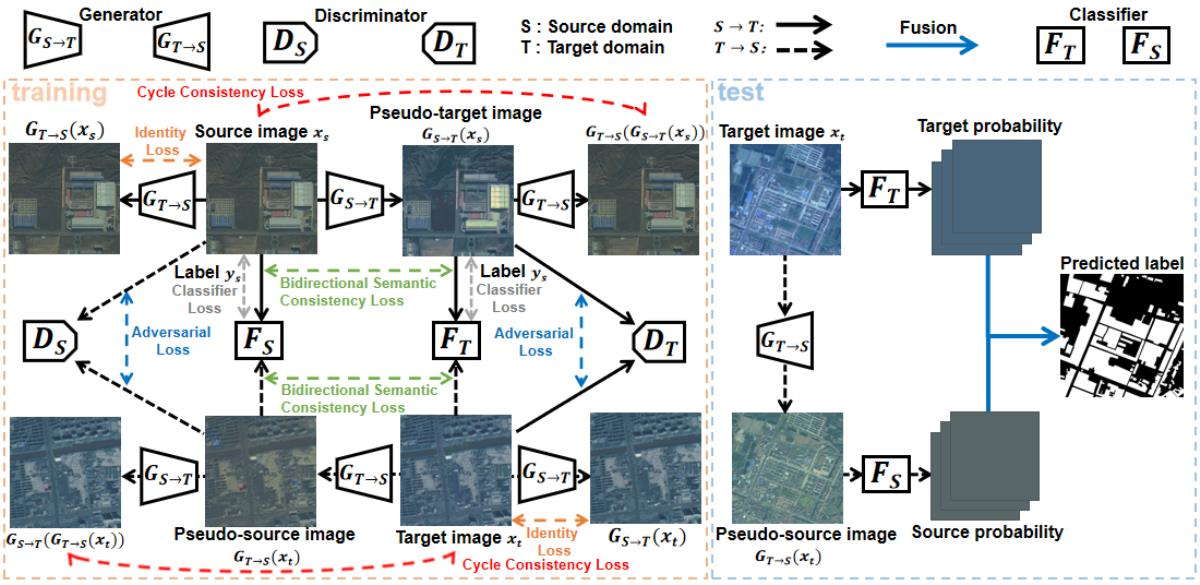
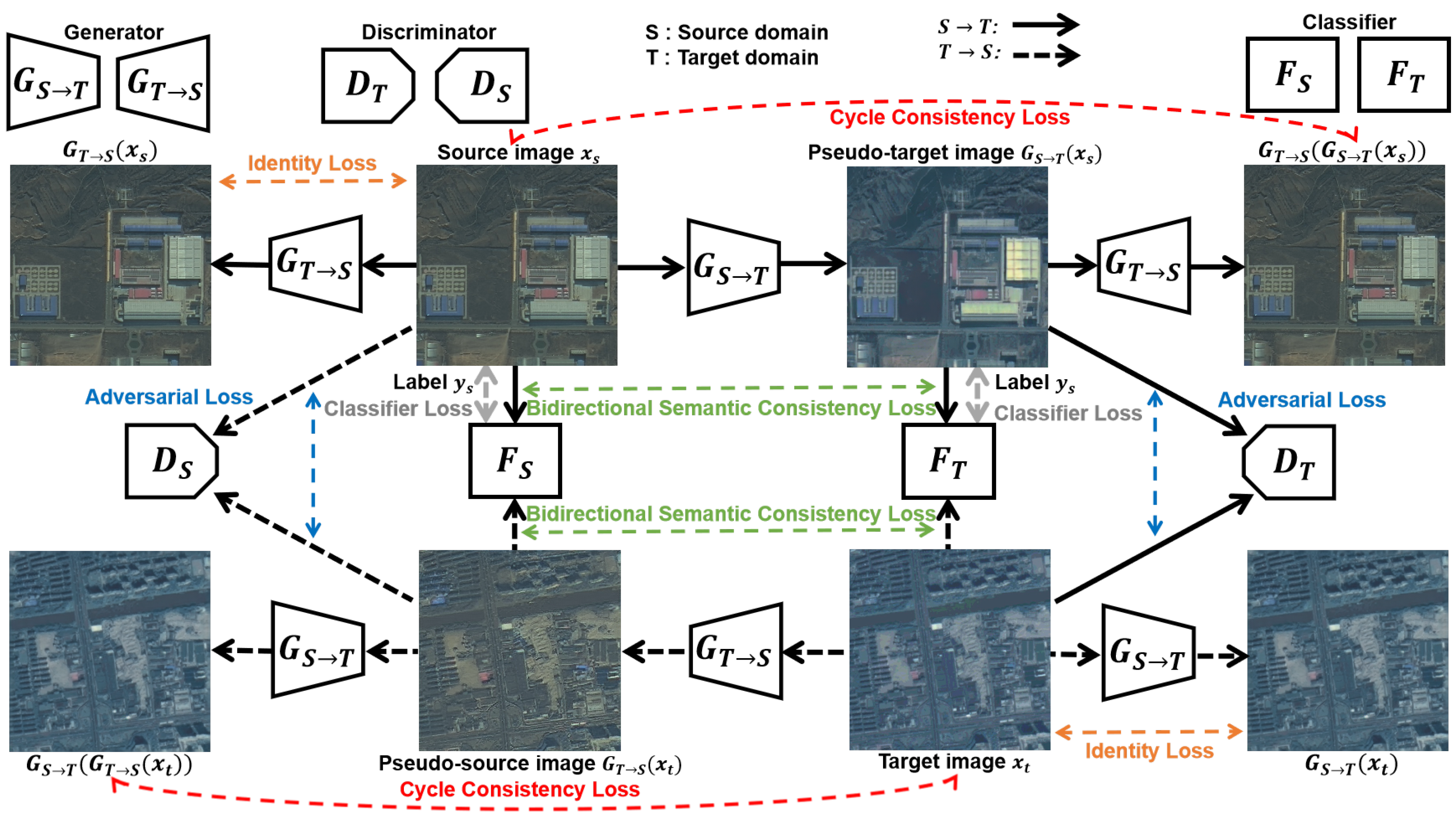
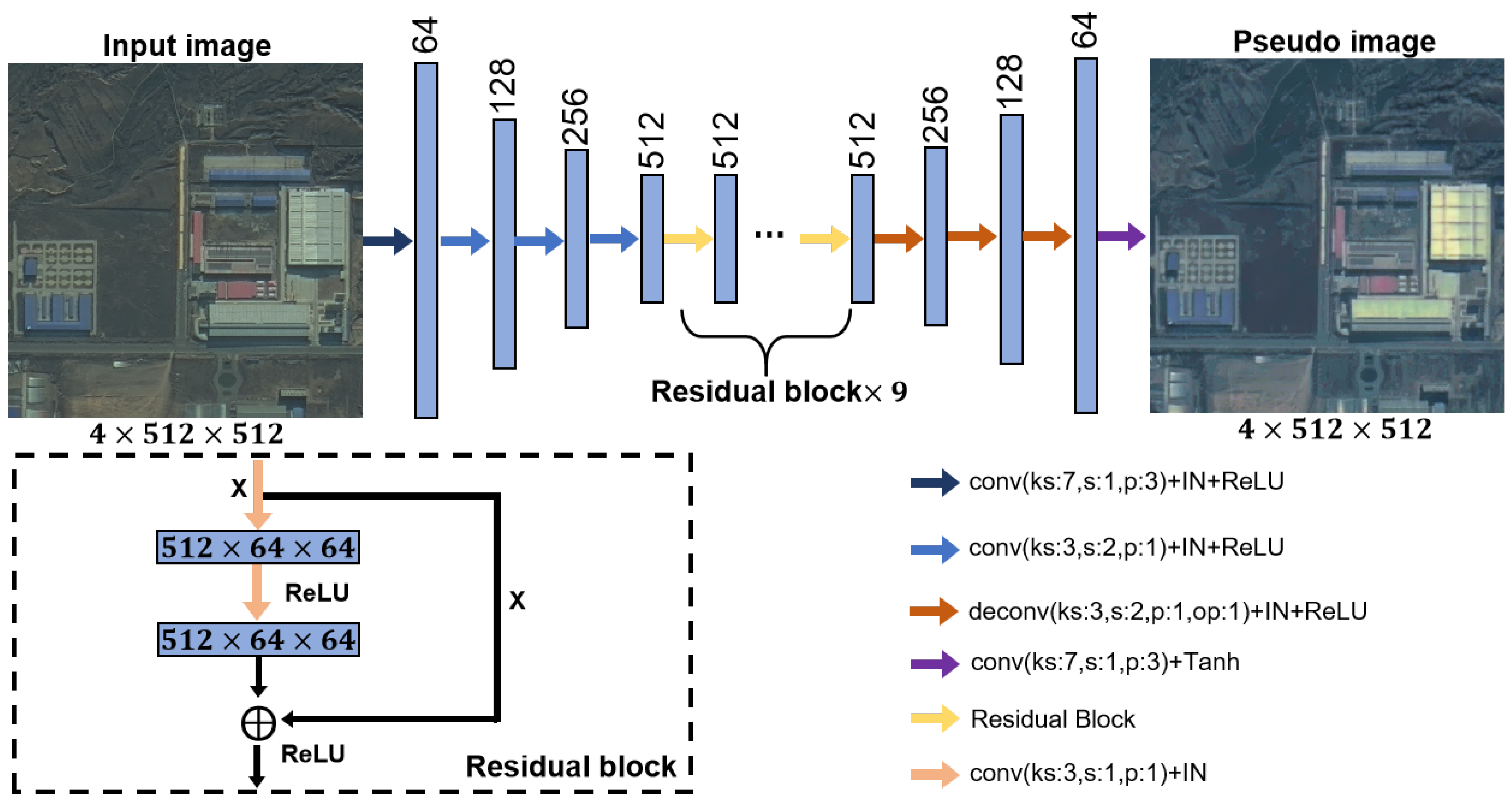
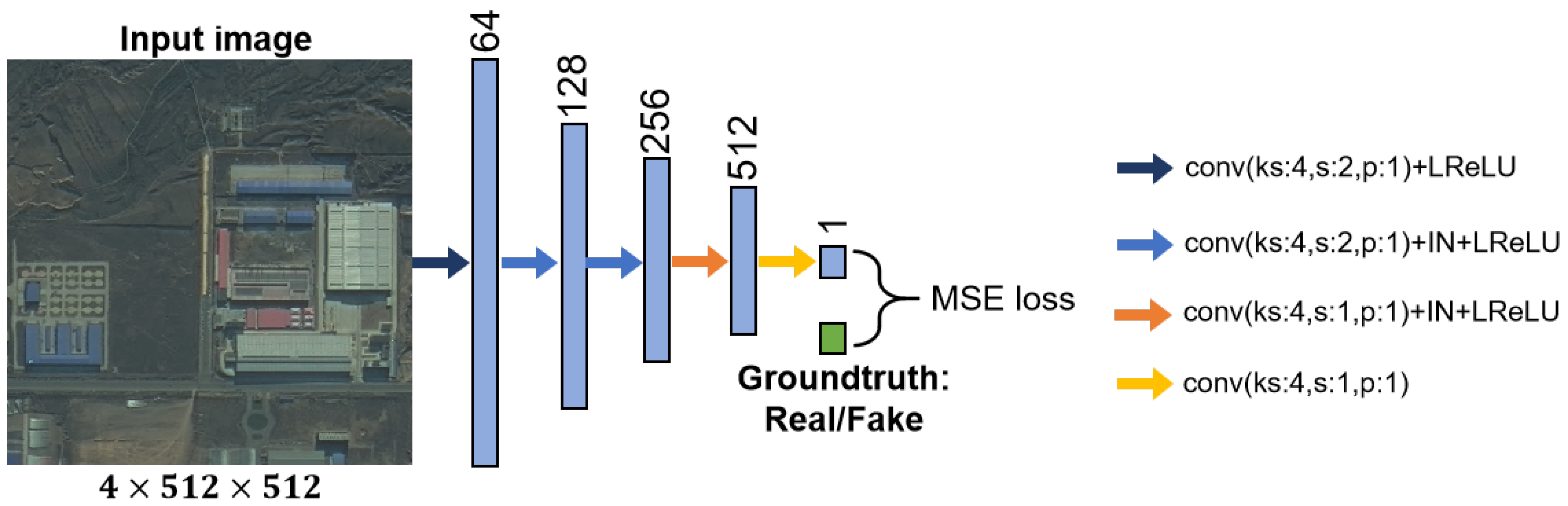
3.1. Bidirectional Image Translation
3.2. Bidirectional Segmentation Adaptation
3.2.1. Source-to-Target Adaptation
3.2.2. Target-to-Source Adaptation
3.3. Bidirectional Domain Adaptation
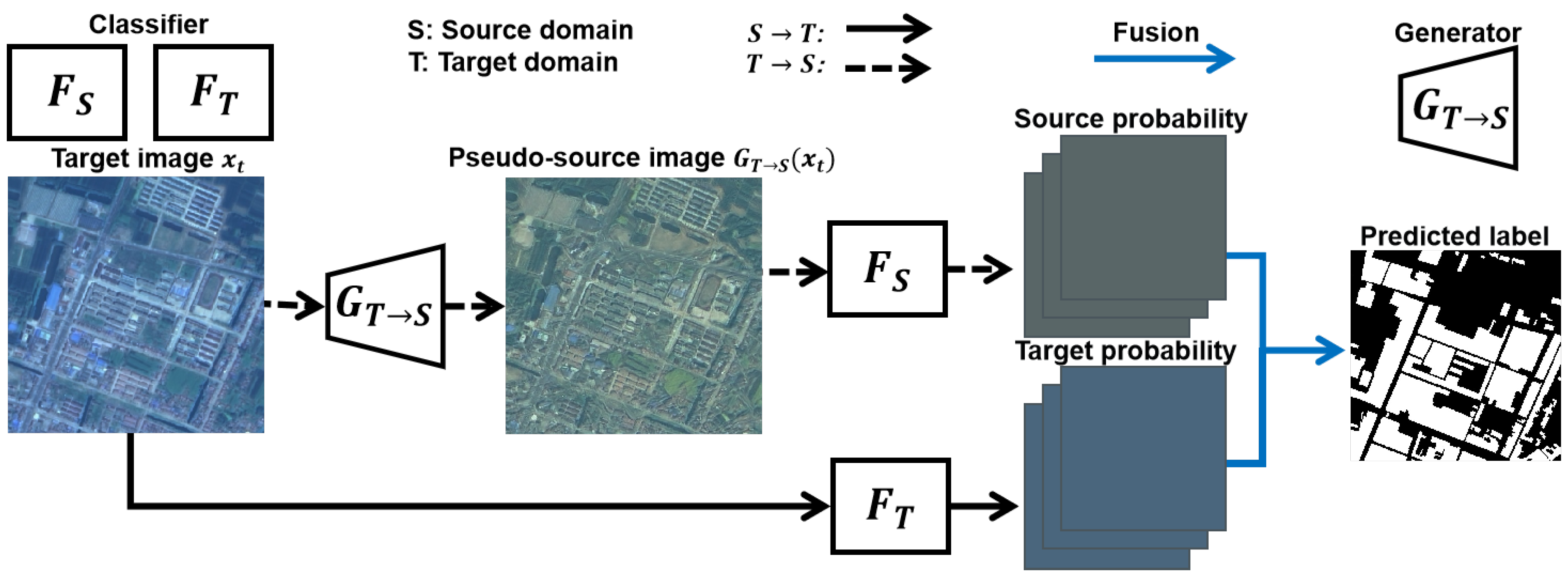
3.4. Linear Combination Method
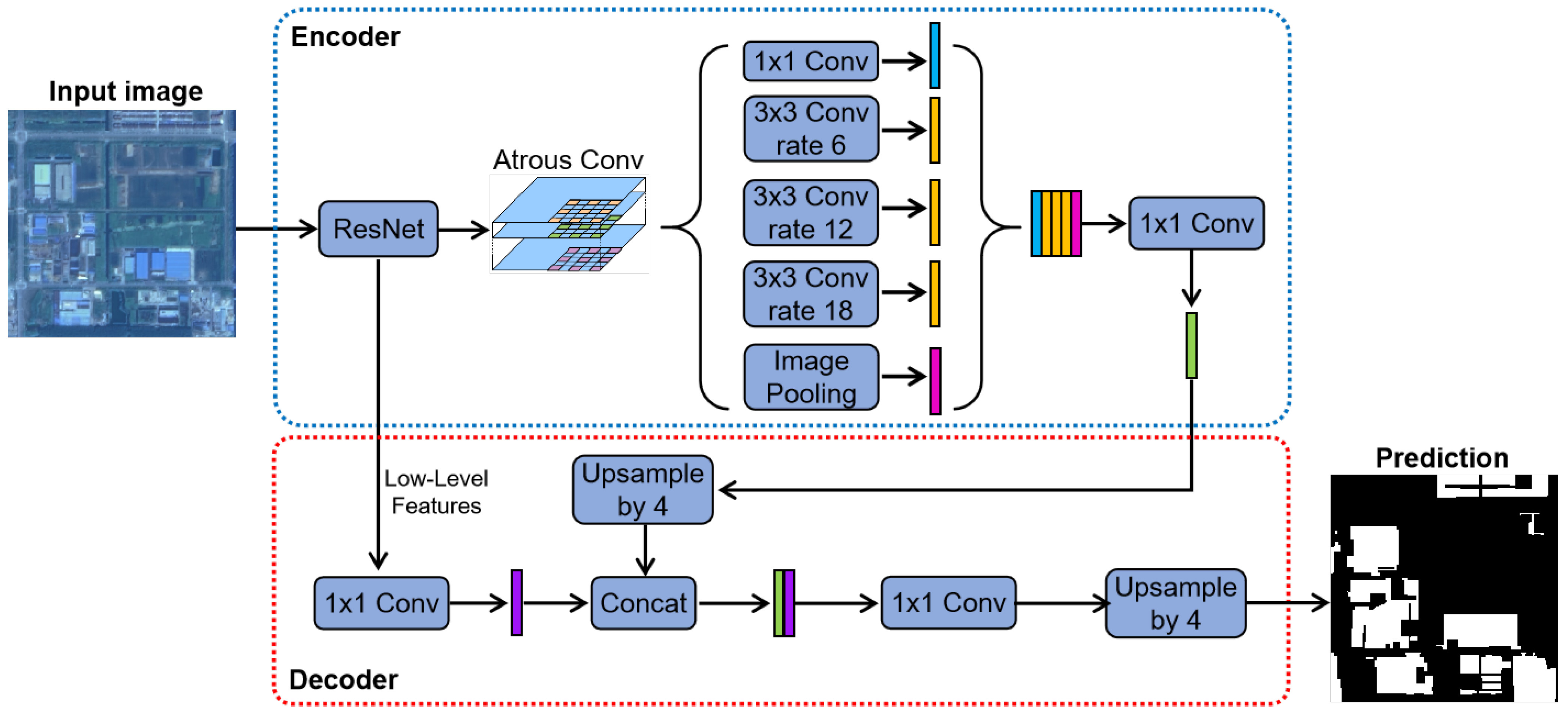
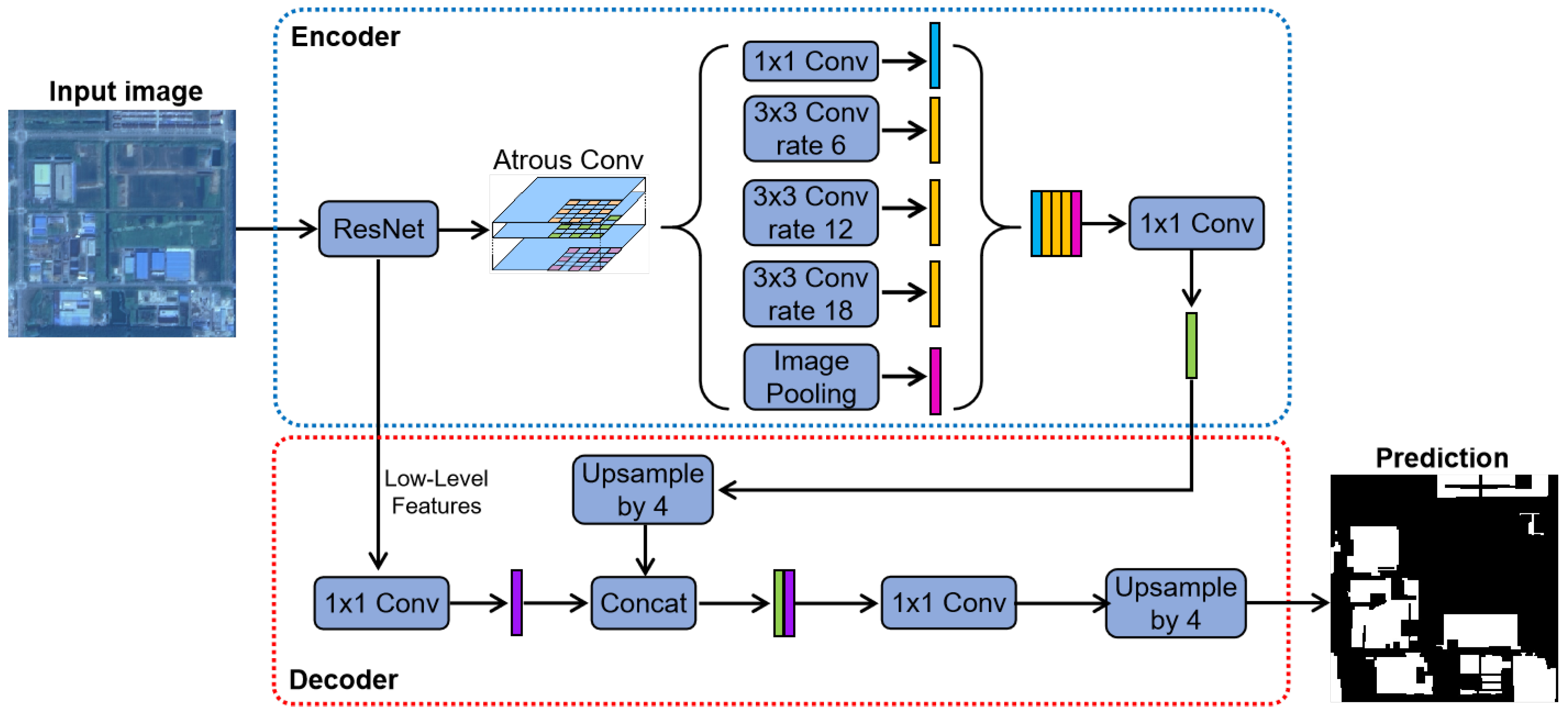
3.5. Network Architecture
4. Results
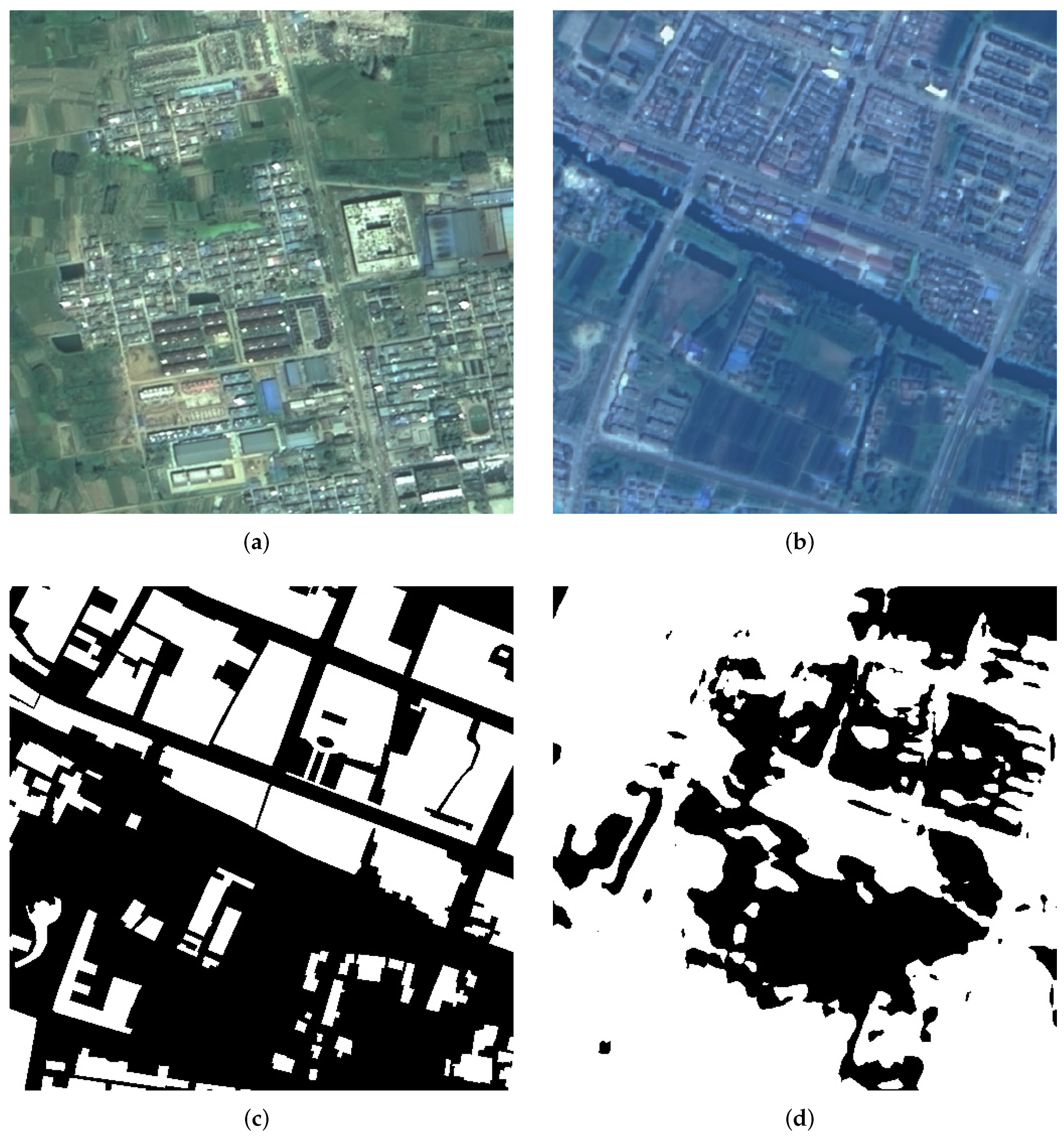
4.1. Data Set
4.1.1. Gaofen Data Set
4.1.2. ISPRS Data Set
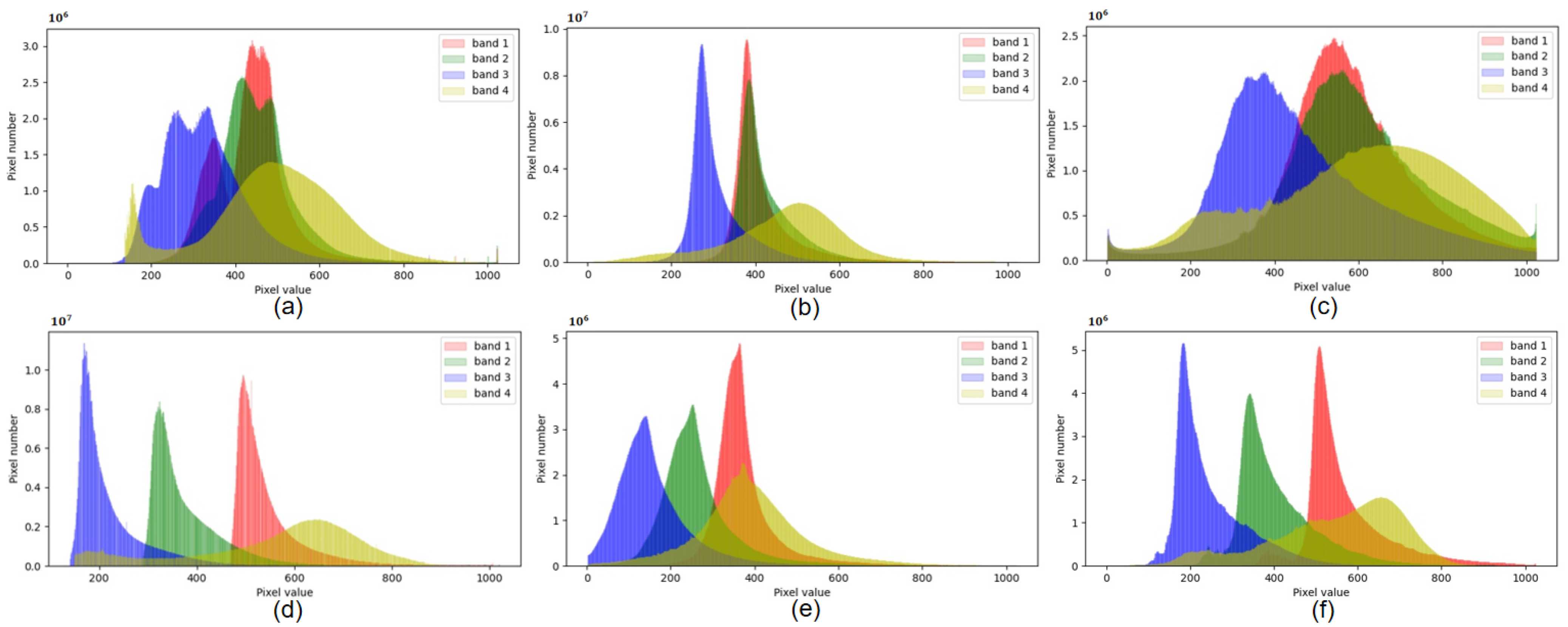
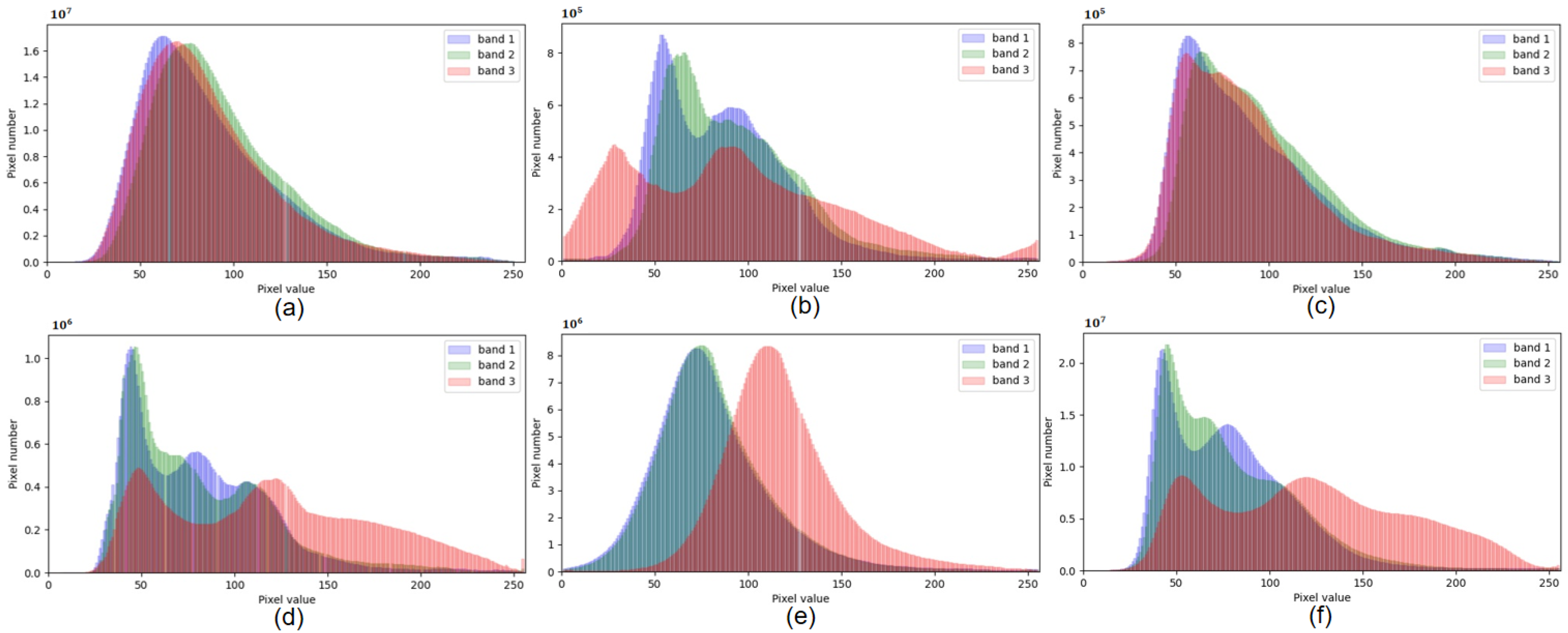
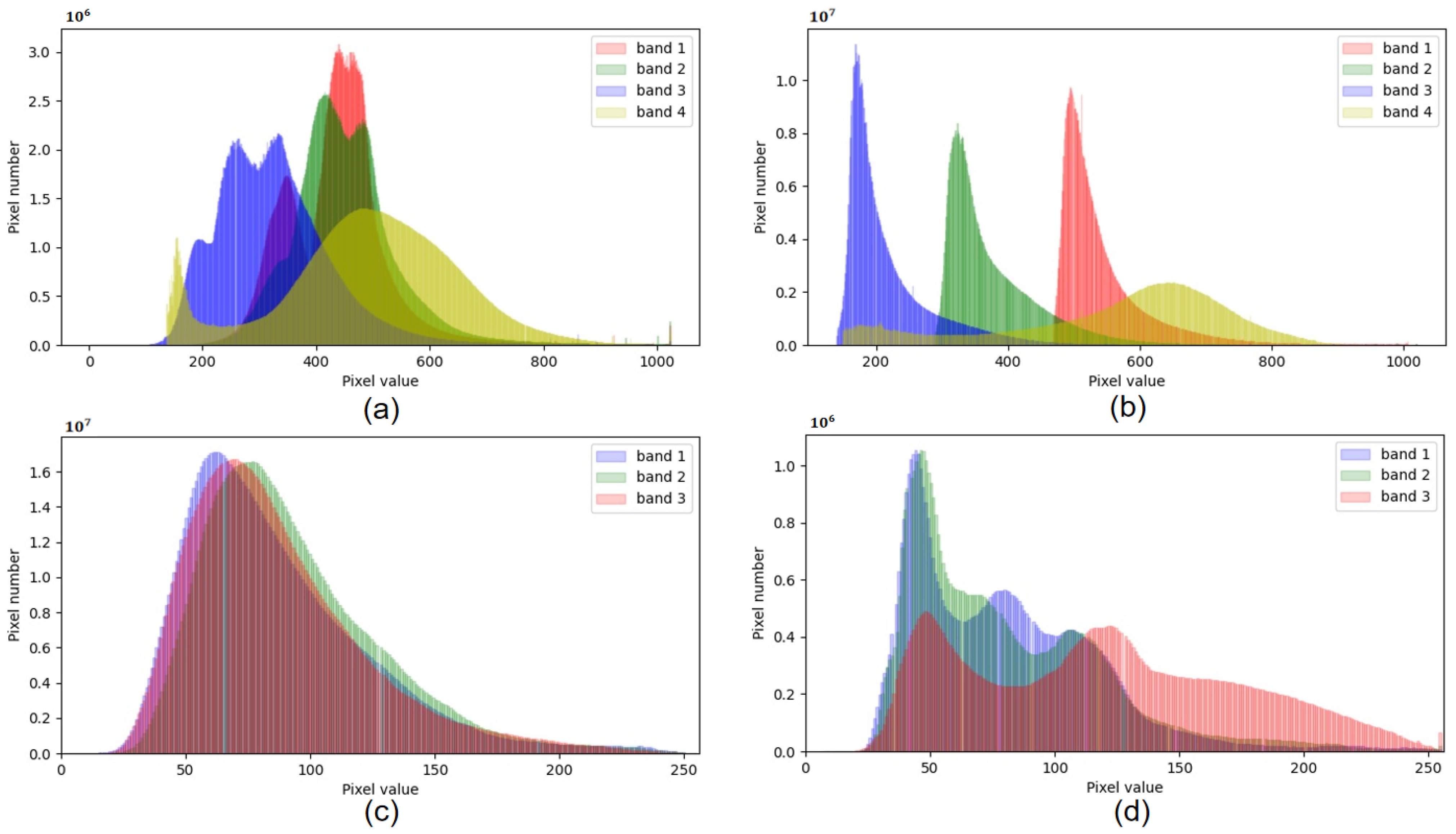
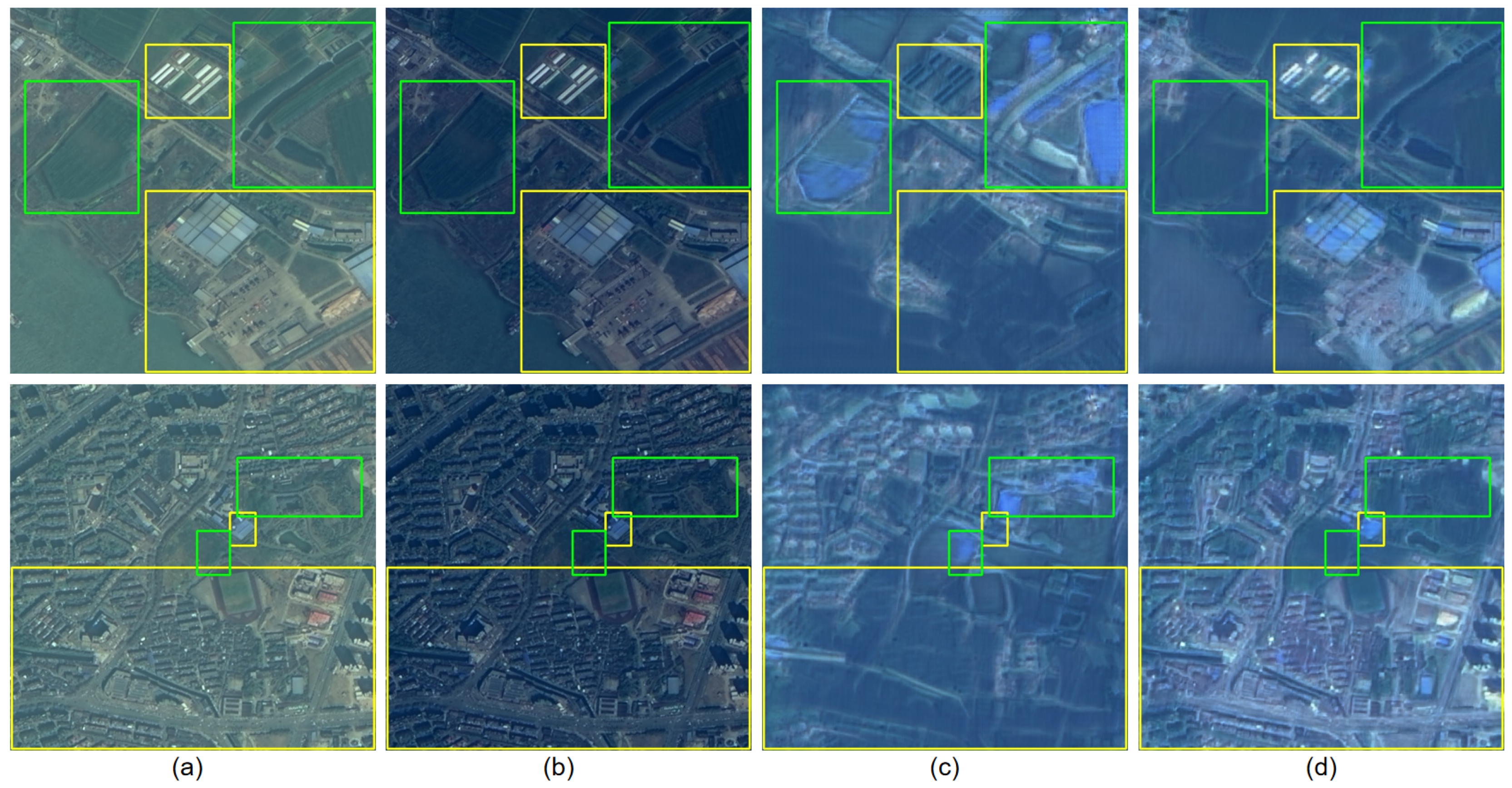
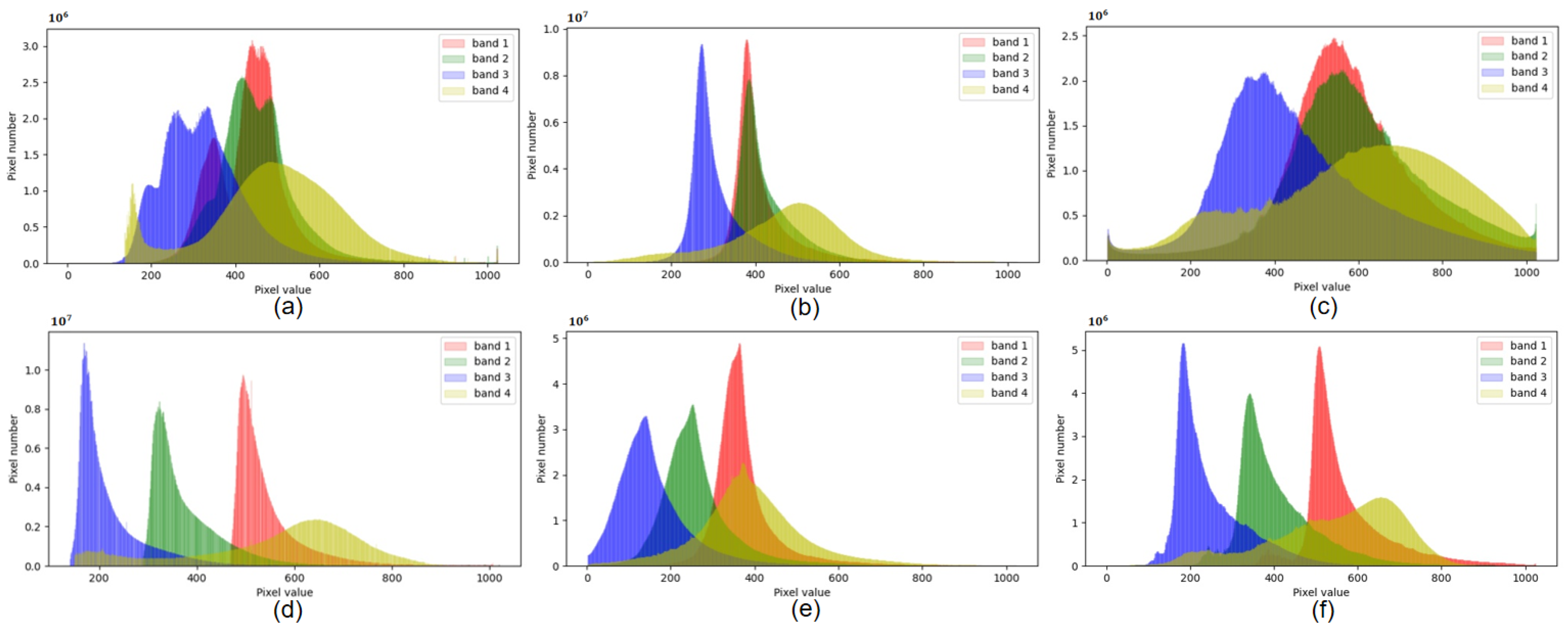
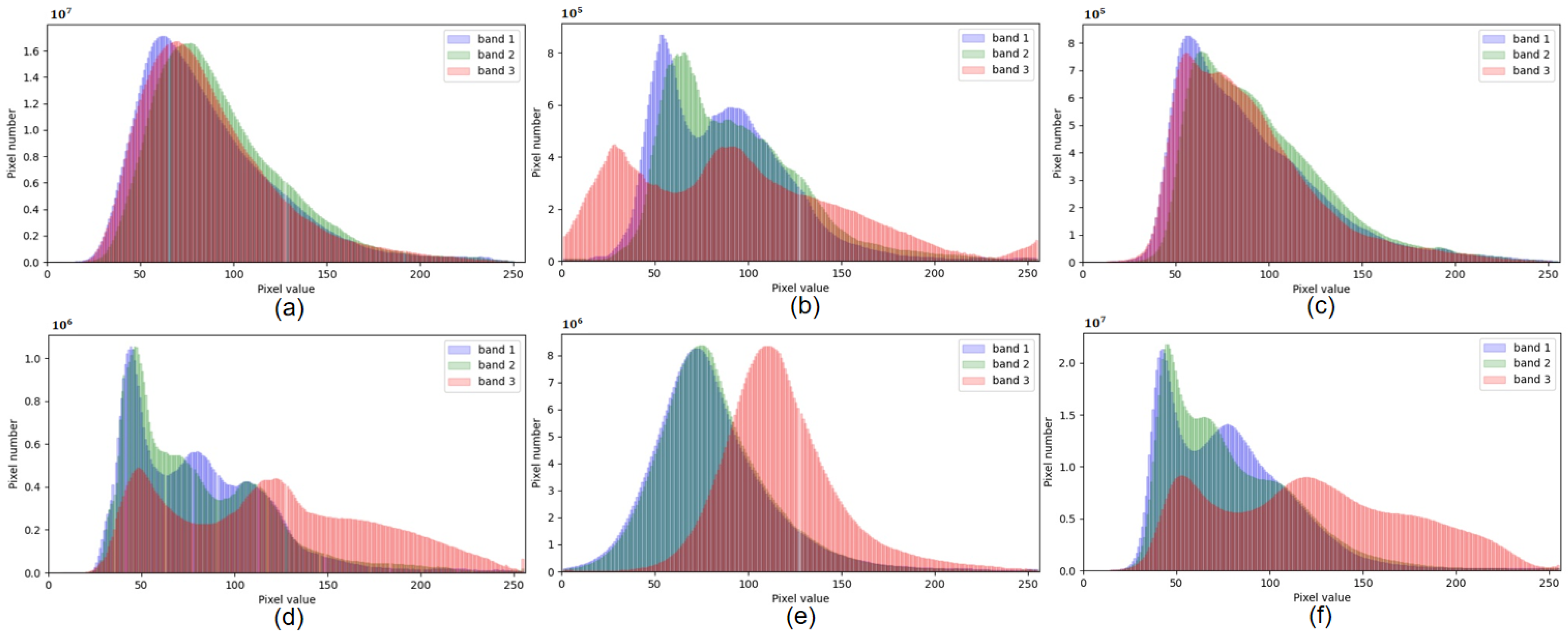
4.1.3. Domain Gap Analysis
4.2. Experimental Settings
4.3. Methods Used for Comparison
4.4. Evaluation Metrics
4.5. Quantitative Results
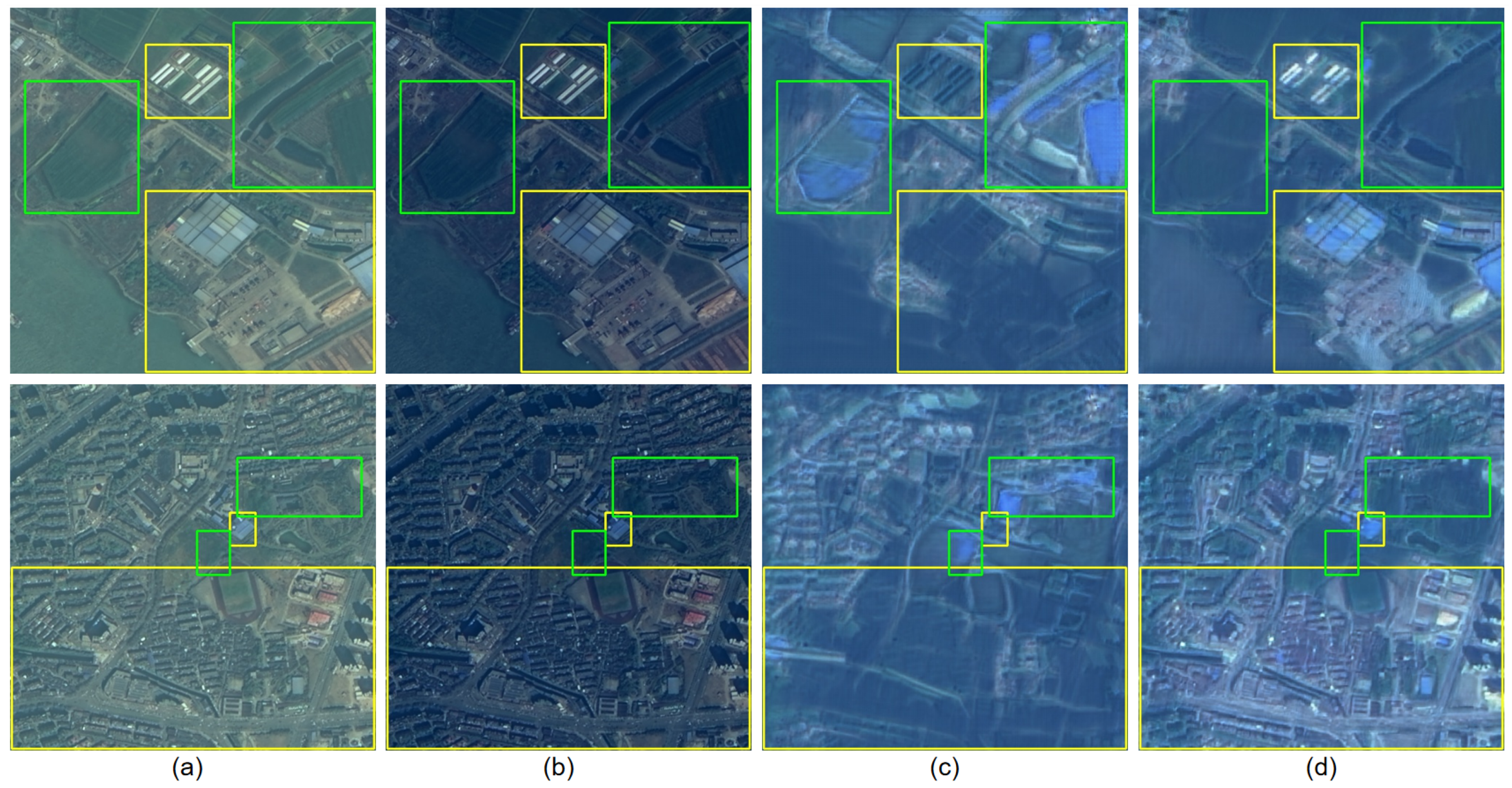
4.6. Visualization Results
5. Discussion
5.1. Comparisons with Other Methods
5.1.1. BiFDANet versus DeeplabV3+
5.1.2. BiFDANet versus CycleGAN
5.1.3. BiFDANet versus Color Matching
5.1.4. Linear Combination Method versus Intersection and Union
5.2. Bidirectional Semantic Consistency Loss
5.3. Loss Functions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Li, D.; Fan, W.; Guan, H.; Wang, C.; Li, J. Self-Attention in Reconstruction Bias U-Net for Semantic Segmentation of Building Rooftops in Optical Remote Sensing Images. Remote Sens. 2021, 13, 2524. [Google Scholar] [CrossRef]
- Kou, R.; Fang, B.; Chen, G.; Wang, L. Progressive Domain Adaptation for Change Detection Using Season-Varying Remote Sensing Images. Remote Sens. 2020, 12, 3815. [Google Scholar] [CrossRef]
- Ma, C.; Sha, D.; Mu, X. Unsupervised Adversarial Domain Adaptation with Error-Correcting Boundaries and Feature Adaption Metric for Remote-Sensing Scene Classification. Remote Sens. 2021, 13, 1270. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain Adaptation for the Classification of Remote Sensing Data: An Overview of Recent Advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Informatic 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Stark, J.A. Adaptive Image Contrast Enhancement Using Generalizations of Histogram Equalization. IEEE Trans. Image Process. 2000, 9, 889–896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient Contrast Enhancement Using Adaptive Gamma Correction With Weighting Distribution. IEEE Trans. Image Process. 2013, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Unsupervised Domain Adaptation for Semantic Segmentation with GANs. arXiv 2017, arXiv:1711.06969. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Rida, I.; Al-Maadeed, N.; Al-Maadeed, S.; Bakshi, S. A comprehensive overview of feature representation for biometric recognition. Multimed. Tools Appl. 2020, 79, 4867–4890. [Google Scholar] [CrossRef]
- Bruzzone, L.; Persello, C. A Novel Approach to the Selection of Spatially Invariant Features for the Classification of Hyperspectral Images With Improved Generalization Capability. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3180–3191. [Google Scholar] [CrossRef] [Green Version]
- Persello, C.; Bruzzone, L. Kernel-Based Domain-Invariant Feature Selection in Hyperspectral Images for Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2615–2626. [Google Scholar] [CrossRef]
- Rida, I.; Al Maadeed, S.; Bouridane, A. Unsupervised feature selection method for improved human gait recognition. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 1128–1132. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to Adapt Structured Output Space for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7472–7481. [Google Scholar]
- Zhang, Y.; David, P.; Gong, B. Curriculum Domain Adaptation for Semantic Segmentation of Urban Scenes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2020–2030. [Google Scholar]
- Zhang, Y.; Qiu, Z.; Yao, T.; Liu, D.; Mei, T. Fully Convolutional Adaptation Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6810–6818. [Google Scholar]
- Bruzzone, L.; Prieto, D.F. Unsupervised Retraining of a Maximum Likelihood Classifier for the Analysis of Multitemporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef] [Green Version]
- Bruzzone, L.; Cossu, R. A Multiple-Cascade-Classifier System for a Robust and Partially Unsupervised Updating of Land-Cover Maps. IEEE Trans. Geosci. Remote Sens. 2002, 40, 1984–1996. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Van Gool, L. ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7892–7901. [Google Scholar]
- Tasar, O.; Tarabalka, Y.; Giros, A.; Alliez, P.; Clerc, S. StandardGAN: Multi-source Domain Adaptation for Semantic Segmentation of Very High Resolution Satellite Images by Data Standardization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 192–193. [Google Scholar]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. Sparse Transfer Manifold Embedding for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1030–1043. [Google Scholar] [CrossRef]
- Yang, H.L.; Crawford, M.M. Spectral and Spatial Proximity-Based Manifold Alignment for Multitemporal Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 51–64. [Google Scholar] [CrossRef]
- Huang, H.; Huang, Q.; Krahenbuhl, P. Domain Transfer Through Deep Activation Matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 590–605. [Google Scholar]
- Demir, B.; Minello, L.; Bruzzone, L. Definition of Effective Training Sets for Supervised Classification of Remote Sensing Images by a Novel Cost-Sensitive Active Learning Method. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1272–1284. [Google Scholar] [CrossRef]
- Ghassemi, S.; Fiandrotti, A.; Francini, G.; Magli, E. Learning and Adapting Robust Features for Satellite Image Segmentation on Heterogeneous Data Sets. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6517–6529. [Google Scholar] [CrossRef]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 700–708. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal Unsupervised Image-to-Image Translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Lee, H.Y.; Tseng, H.Y.; Huang, J.B.; Singh, M.; Yang, M.H. Diverse Image-to-Image Translation via Disentangled Representations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 35–51. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V.S. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; p. 4. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from Simulated and Unsupervised Images through Adversarial Training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Murez, Z.; Kolouri, S.; Kriegman, D.; Ramamoorthi, R.; Kim, K. Image to Image Translation for Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4500–4509. [Google Scholar]
- Taigman, Y.; Polyak, A.; Wolf, L. Unsupervised Cross-Domain Image Generation. arXiv 2016, arXiv:1611.02200. [Google Scholar]
- Zhao, S.; Li, B.; Yue, X.; Gu, Y.; Xu, P.; Hu, R.; Chai, H.; Keutzer, K. Multi-source Domain Adaptation for Semantic Segmentation. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Tuia, D.; Munoz-Mari, J.; Gomez-Chova, L.; Malo, J. Graph Matching for Adaptation in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 329–341. [Google Scholar] [CrossRef] [Green Version]
- Rakwatin, P.; Takeuchi, W.; Yasuoka, Y. Restoration of Aqua MODIS Band 6 Using Histogram Matching and Local Least Squares Fitting. IEEE Trans. Geosci. Remote Sens. 2009, 47, 613–627. [Google Scholar] [CrossRef]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef] [Green Version]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. SEMI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1837–1840. [Google Scholar]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, Multisource, Multitarget, and Life-Long Domain Adaptation for Semantic Segmentation of Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1067–1081. [Google Scholar] [CrossRef]
- He, D.; Xia, Y.; Qin, T.; Wang, L.; Yu, N.; Liu, T.Y.; Ma, W.Y. Dual Learning for Machine Translation. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 820–828. [Google Scholar]
- Niu, X.; Denkowski, M.; Carpuat, M. Bi-Directional Neural Machine Translation with Synthetic Parallel Data. In Proceedings of the 2nd Workshop on Neural Machine Translation and Generation, Melbourne, Australia, 20 July 2018; pp. 84–91. [Google Scholar]
- Li, Y.; Yuan, L.; Vasconcelos, N. Bidirectional Learning for Domain Adaptation of Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6936–6945. [Google Scholar]
- Chen, C.; Dou, Q.; Chen, H.; Qin, J.; Heng, P.A. Unsupervised Bidirectional Cross-Modality Adaptation via Deeply Synergistic Image and Feature Alignment for Medical Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 2494–2505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Nie, S.; Liang, S.; Liu, W. Bidirectional Adversarial Domain Adaptation with Semantic Consistency. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xi’an, China, 8–11 November 2019; pp. 184–198. [Google Scholar]
- Yang, G.; Xia, H.; Ding, M.; Ding, Z. Bi-Directional Generation for Unsupervised Domain Adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 6615–6622. [Google Scholar]
- Jiang, P.; Wu, A.; Han, Y.; Shao, Y.; Qi, M.; Li, B. Bidirectional Adversarial Training for Semi-Supervised Domain Adaptation. In Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI), Yokohama, Japan, 11–17 July 2020; pp. 934–940. [Google Scholar]
- Russo, P.; Carlucci, F.M.; Tommasi, T.; Caputo, B. From Source to Target and Back: Symmetric Bi-Directional Adaptive GAN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8099–8108. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); ResearcheGate: Berlin, Germany, 2014. [Google Scholar]
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling Contest-Potsdam. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 20 November 2021).
- International Society for Photogrammetry and Remote Sensing. 2D Semantic Labeling-Vaihingen Data. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 20 November 2021).
- Kingma, D.P.; Ba, J. A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–13. [Google Scholar]
- Csurka, G.; Larlus, D.; Perronnin, F.; Meylan, F. What is a good evaluation measure for semantic segmentation? In Proceedings of the British Machine Vision Conference (BMVC), Bristol, UK, 9–13 September 2013. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | # of Patches | Patch Size | Class Percentages |
|---|---|---|---|
| GF-1 | 2039 | 512 × 512 | 12.6% |
| GF-1B | 4221 | 512 × 512 | 5.4% |
| Potsdam | 4598 | 512 × 512 | 28.1% |
| Vaihingen | 459 | 512 × 512 | 26.8% |
| Method | Source: GF-1, Target: GF-1B | Source: GF-1B, Target: GF-1 | ||||||
|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | F1 (%) | IoU (%) | Recall (%) | Precision (%) | F1 (%) | IoU (%) | |
| DeeplabV3+ | 74.78 | 16.60 | 27.16 | 15.72 | 2.14 | 70.07 | 4.17 | 2.13 |
| Color matching | 53.82 | 55.65 | 54.72 | 37.66 | 49.00 | 83.64 | 61.80 | 44.71 |
| CycleGAN | 54.72 | 67.31 | 60.37 | 43.24 | 60.74 | 75.12 | 67.17 | 50.57 |
| BiFDANet | 58.56 | 69.34 | 63.50 | 46.52 | 71.65 | 72.21 | 71.93 | 56.17 |
| BiFDANet | 61.82 | 67.00 | 64.31 | 47.39 | 71.81 | 73.69 | 72.74 | 57.16 |
| 57.12 | 70.99 | 63.31 | 46.31 | 67.90 | 75.77 | 71.62 | 55.79 | |
| 60.92 | 68.11 | 64.32 | 47.40 | 71.94 | 73.88 | 72.90 | 57.36 | |
| BiFDANet | 63.31 | 65.70 | 64.48 | 47.58 | 75.57 | 70.58 | 72.99 | 57.47 |
| Method | Source: Vaihingen, Target: Potsdam | Source: Potsdam, Target: Vaihingen | ||||||
|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | F1 (%) | IoU (%) | Recall (%) | Precision (%) | F1 (%) | IoU (%) | |
| DeeplabV3+ | 30.10 | 17.81 | 22.37 | 12.59 | 29.64 | 33.16 | 31.30 | 18.55 |
| Color matching | 39.27 | 54.28 | 45.57 | 29.51 | 42.61 | 36.13 | 39.11 | 24.30 |
| CycleGAN | 61.13 | 55.86 | 58.38 | 41.22 | 49.75 | 66.44 | 56.90 | 39.76 |
| BiFDANet | 68.82 | 61.62 | 65.02 | 48.17 | 59.00 | 75.39 | 66.20 | 49.47 |
| BiFDANet | 56.90 | 62.39 | 59.52 | 42.37 | 60.44 | 76.70 | 67.60 | 51.06 |
| 52.35 | 69.27 | 59.63 | 42.48 | 53.60 | 79.67 | 64.09 | 47.15 | |
| 73.37 | 57.63 | 64.55 | 47.66 | 59.95 | 77.12 | 67.46 | 50.90 | |
| BiFDANet | 66.37 | 64.03 | 65.18 | 48.35 | 65.83 | 73.33 | 69.38 | 53.12 |
| Method | Source: GF-1, Target: GF-1B | Source: GF-1B, Target: GF-1 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | F1 (%) | IoU (%) | Recall (%) | Precision (%) | F1 (%) | IoU (%) | ||
| BiFDANet w/o | 55.68 | 62.07 | 58.70 | 41.55 | 65.36 | 67.21 | 66.27 | 49.68 | |
| 52.97 | 70.69 | 60.56 | 43.43 | 65.80 | 70.63 | 68.13 | 51.53 | ||
| BiFDANet | 54.83 | 68.83 | 61.04 | 43.92 | 67.10 | 69.86 | 68.45 | 51.87 | |
| BiFDANet w/SC | 50.84 | 73.68 | 60.16 | 43.02 | 69.43 | 68.36 | 68.89 | 52.33 | |
| 57.76 | 68.39 | 62.63 | 45.59 | 65.28 | 74.48 | 69.58 | 53.35 | ||
| BiFDANet | 56.10 | 71.21 | 62.76 | 45.73 | 66.67 | 73.20 | 69.78 | 53.59 | |
| BiFDANet w/DSC | 53.66 | 69.36 | 60.51 | 43.38 | 68.14 | 70.36 | 69.23 | 52.84 | |
| 59.90 | 66.69 | 63.11 | 46.11 | 70.44 | 73.24 | 71.81 | 56.02 | ||
| BiFDANet | 58.47 | 70.23 | 63.81 | 46.86 | 72.34 | 71.93 | 72.13 | 56.41 | |
| BiFDANet w/BSC | 58.56 | 69.34 | 63.50 | 46.52 | 71.65 | 72.21 | 71.93 | 56.17 | |
| 61.82 | 67.00 | 64.31 | 47.39 | 71.81 | 73.69 | 72.74 | 57.16 | ||
| BiFDANet | 63.31 | 65.70 | 64.48 | 47.58 | 75.57 | 70.58 | 72.99 | 57.47 | |
| Method | Source: Vaihingen, Target: Potsdam | Source: Potsdam, Target: Vaihingen | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Recall (%) | Precision (%) | F1 (%) | IoU (%) | Recall (%) | Precision (%) | F1 (%) | IoU (%) | ||
| BiFDANet w/o | 49.37 | 72.12 | 58.62 | 41.46 | 45.81 | 71.71 | 55.91 | 38.80 | |
| 44.60 | 73.89 | 55.63 | 38.53 | 47.30 | 72.32 | 57.19 | 40.05 | ||
| BiFDANet | 51.39 | 68.75 | 58.81 | 41.66 | 48.41 | 72.67 | 58.11 | 40.96 | |
| BiFDANet w/SC | 52.72 | 72.96 | 61.21 | 44.10 | 53.69 | 69.82 | 60.70 | 43.58 | |
| 49.71 | 72.20 | 58.88 | 41.73 | 56.05 | 72.89 | 63.37 | 46.38 | ||
| BiFDANet | 53.83 | 71.97 | 61.59 | 44.50 | 60.35 | 67.40 | 63.68 | 46.71 | |
| BiFDANet w/DSC | 58.93 | 67.35 | 62.86 | 45.84 | 58.01 | 68.30 | 62.74 | 45.70 | |
| 50.66 | 70.76 | 59.05 | 41.89 | 60.53 | 74.44 | 66.77 | 50.11 | ||
| BiFDANet | 53.03 | 77.84 | 63.08 | 46.07 | 62.75 | 73.13 | 67.54 | 50.99 | |
| BiFDANet w/BSC | 68.82 | 61.62 | 65.02 | 48.17 | 59.00 | 75.39 | 66.20 | 49.47 | |
| 56.90 | 62.39 | 59.52 | 42.37 | 60.44 | 76.70 | 67.60 | 51.06 | ||
| BiFDANet | 66.37 | 64.03 | 65.18 | 48.35 | 65.83 | 73.33 | 69.38 | 53.12 | |
| Source: Vaihingen, Target: Potsdam | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 (%) | IoU (%) | ||||||||||
| ✓ | ✓ | 35.67 | 18.65 | ||||||||
| ✓ | ✓ | 39.84 | 23.63 | ||||||||
| ✓ | ✓ | ✓ | ✓ | 40.17 | 24.08 | ||||||
| ✓ | ✓ | ✓ | 55.24 | 38.16 | |||||||
| ✓ | ✓ | ✓ | 56.73 | 39.64 | |||||||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 57.04 | 40.06 | ||||
| ✓ | ✓ | ✓ | ✓ | 54.36 | 37.83 | ||||||
| ✓ | ✓ | ✓ | ✓ | 57.74 | 40.12 | ||||||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 58.81 | 41.66 | ||
| ✓ | ✓ | ✓ | ✓ | ✓ | 58.44 | 41.54 | |||||
| ✓ | ✓ | ✓ | ✓ | ✓ | 63.96 | 47.08 | |||||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 65.18 | 48.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Y.; Yang, Y.; Zheng, Q.; Shen, Z.; Shang, Y.; Yin, J.; Shi, Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 190. https://doi.org/10.3390/rs14010190
Cai Y, Yang Y, Zheng Q, Shen Z, Shang Y, Yin J, Shi Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sensing. 2022; 14(1):190. https://doi.org/10.3390/rs14010190
Chicago/Turabian StyleCai, Yuxiang, Yingchun Yang, Qiyi Zheng, Zhengwei Shen, Yongheng Shang, Jianwei Yin, and Zhongtian Shi. 2022. "BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images" Remote Sensing 14, no. 1: 190. https://doi.org/10.3390/rs14010190
APA StyleCai, Y., Yang, Y., Zheng, Q., Shen, Z., Shang, Y., Yin, J., & Shi, Z. (2022). BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sensing, 14(1), 190. https://doi.org/10.3390/rs14010190