
Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology



Abstract
1. Introduction
2. Materials and Methods
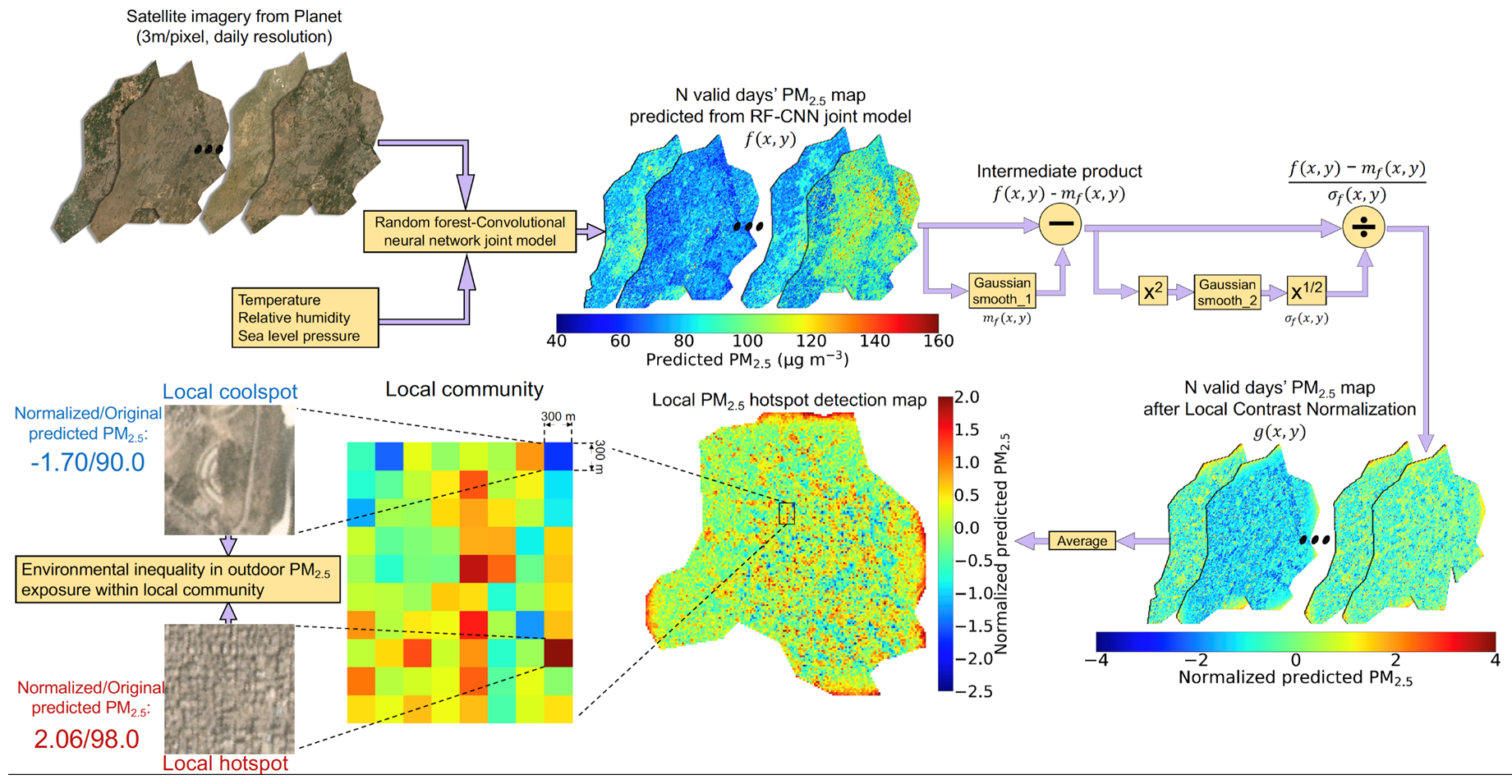
2.1. Ground-Level PM2.5 Data
2.2. Meteorological Data
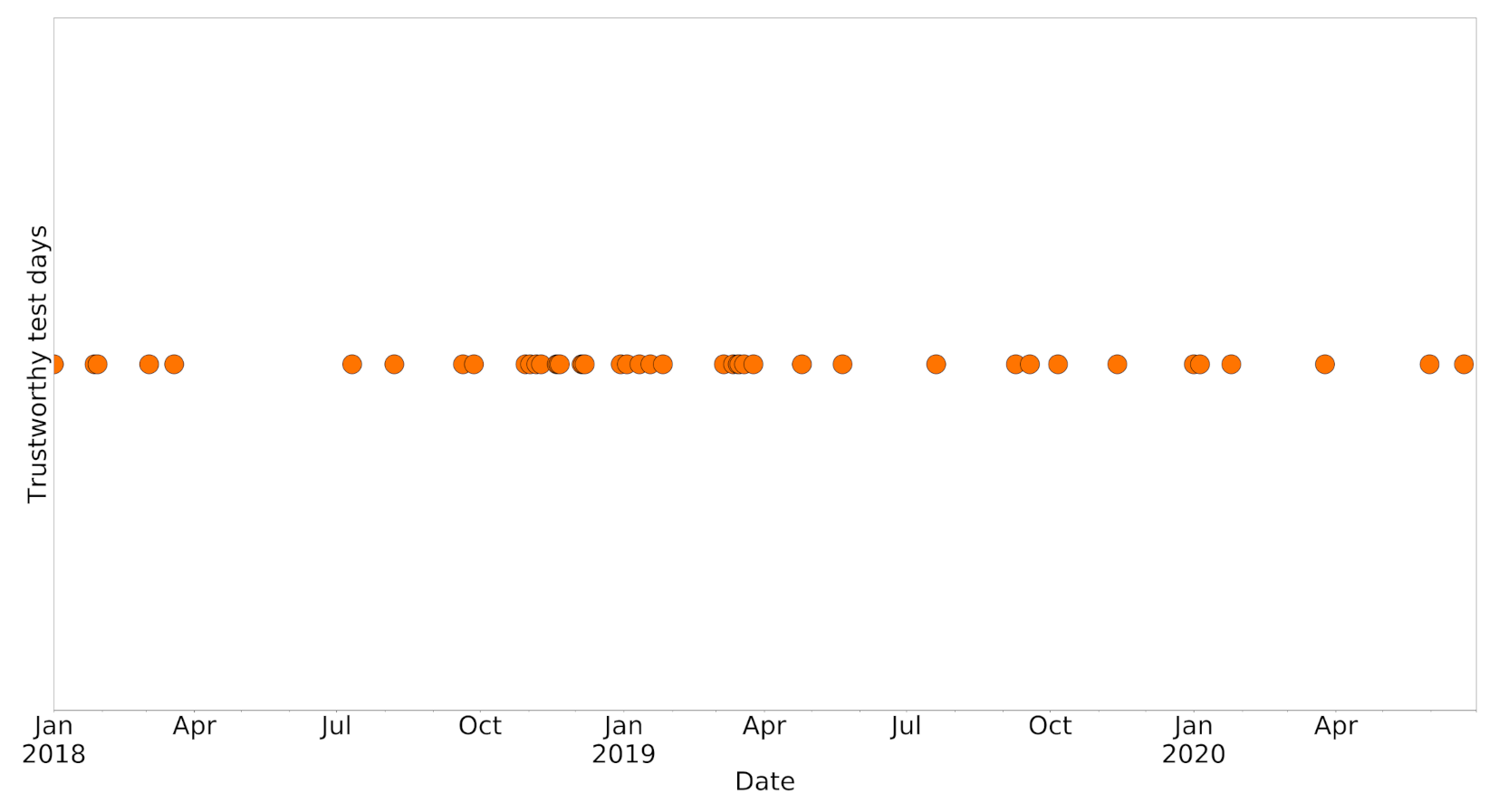
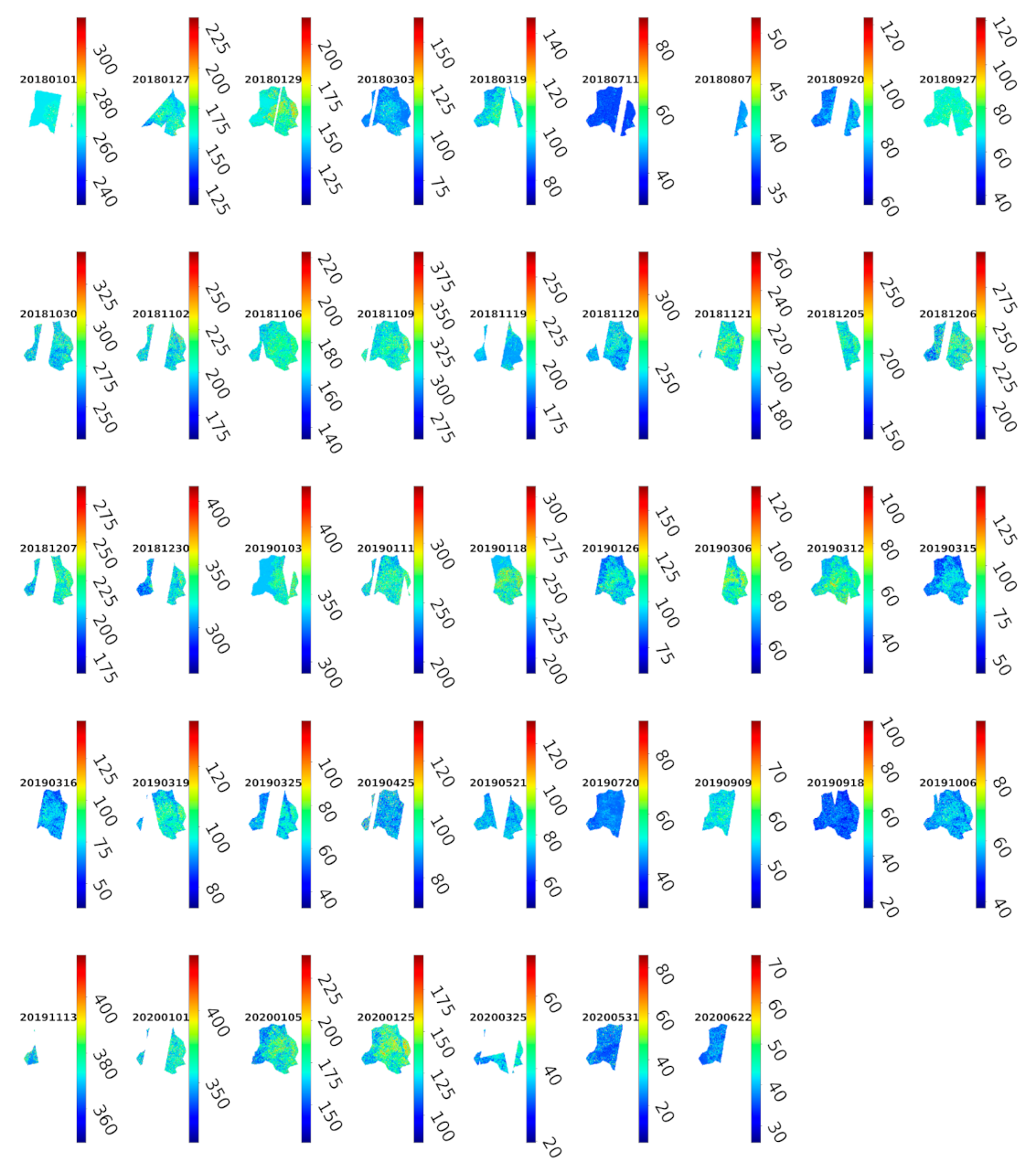
2.3. Satellite Imagery
2.4. RF–CNN Joint Model
2.4.1. RF Details
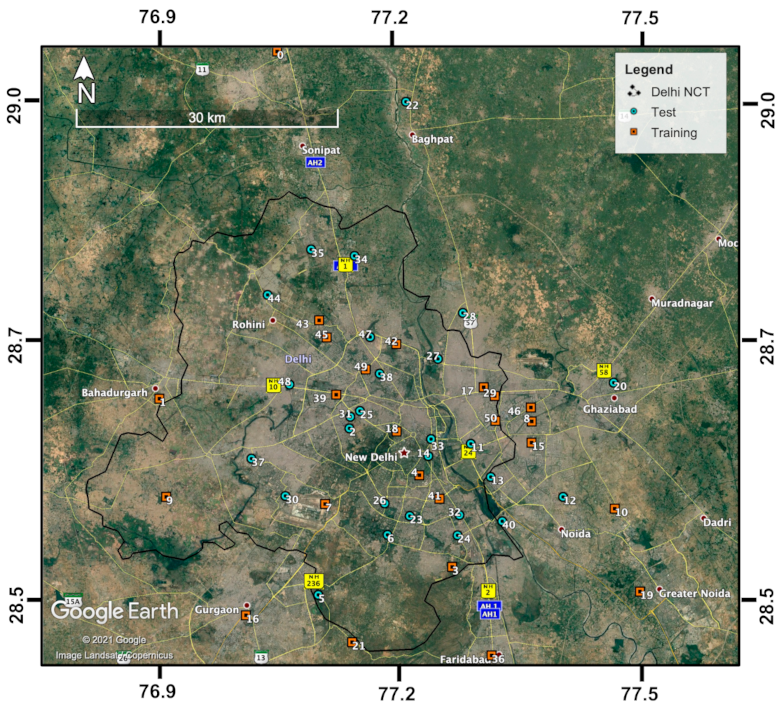
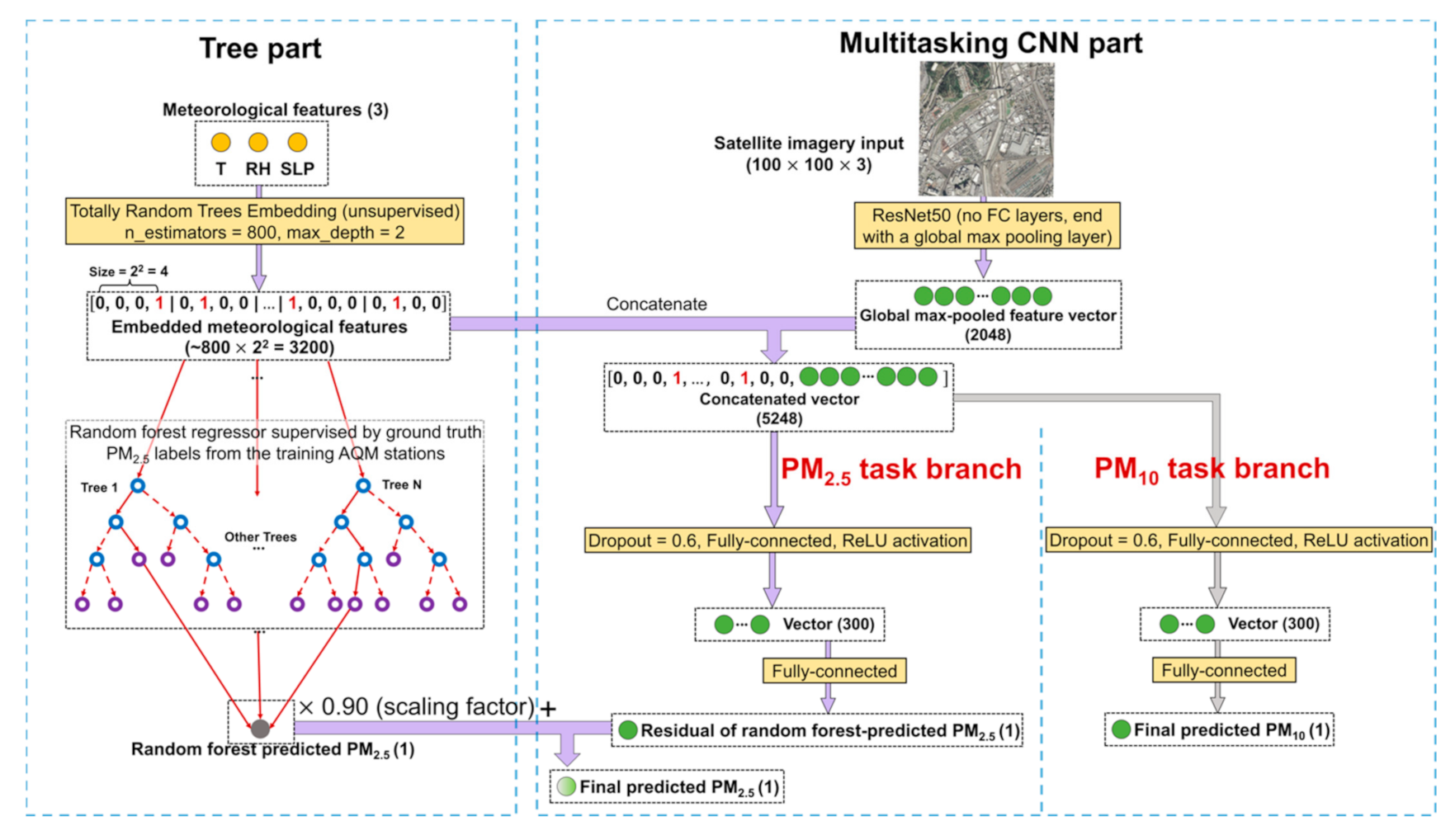
- Instead of directly using the T, RH and SLP meteorological features (as they are) for prediction by RF and CNN, they were first embedded in/mapped to a significantly higher dimension using an unsupervised algorithm called Totally Random Trees Embedding [43], as shown in Figure 2a. Totally Random Trees Embedding can be easily implemented in Scikit-Learn. The idea of this unsupervised algorithm is to first build an RF classifier (by fitting it to only all the meteorology datapoints that you have without using your associated PM2.5 labels) that aims to separate the original observed meteorology datapoints from the synthetic ones that are generated by sampling from a joint distribution of the observed T, RH and SLP values. Then, this RF classifier transforms each observed meteorology datapoint into the indices of leaf nodes which that datapoint ends up in, expressed in a one-hot encoding format (i.e., for K leaf nodes in each tree in the forest, only the leaf node which the datapoint is sorted into is encoded in 1, while the rest of the K-1 leaf nodes are all encoded in 0). For instance, in this paper, we embedded meteorological data using an RF classifier that consisted of 800 trees, each of which had a max depth of 2 or equivalently at most 22 = 4 leaf nodes. See Figure 2a for the example of a meteorology datapoint embedded by such an RF classifier with the dimension increasing from 3 to at most 3200 (800 trees at most 4 leaf nodes = 3200). Additionally, notice the sparse binary nature of the embedded meteorological feature vector; that is, for each tree in the forest, only one of the (at most) 4 leaf nodes is encoded in 1 and the rest all in 0. The intuition behind the high-dimensional embedded meteorological feature vectors is that two similar meteorology datapoints are more likely to lie within the same leaf node of a tree. Embedding meteorological features, however, is not so much to improve RF regressor’s PM2.5 prediction performance as to improve CNN’s. Embedding meteorological features to a high dimension that rivals the dimension of satellite image features helps CNN cope with the difficulty of combining and effectively using multi-modality data, thus improving its PM2.5 prediction performance.
- Unlike what is commonly seen in studies that explicitly train an RF using a 5-fold CV, this study only implicitly trained the RF regressor in the tree part (Figure 2a) together with explicitly training the entire CNN using back-propagation. This joint training strategy was possible because we made the tree part’s information flow into the CNN by adding the scaled RF-predicted PM2.5 to the CNN-predicted PM2.5 (i.e., the last solid green dot in Figure 2b). Scaling RF-predicted PM2.5 by a stabilizing factor of ~0.90−0.95 (0.95 was used in this study) is important in that it leaves reasonably more room for CNN to learn to predict PM2.5 (since RF alone using meteorological conditions can already yield low PM2.5 prediction errors, as mentioned in Section 2.4.). The optimal hyperparameters for the RF regressor in the tree part were determined to be ~600, 1 and for the number of trees in the forest (N); the minimum number of samples required to be at a leaf node (n); and the number of input features to consider when splitting data at a decision node (m), respectively. The optimal values of N and n (the most influential parameter of the three) are consistent with [26], indicating that the RF setting can be universal, regardless of the locations (i.e., hyperparameter tuning is not necessary for RF in the future), although m needs to be switched to for a joint model rather than for a sequential model.
- As discussed in Section 2.3, the meteorological data used in this study were determined to be daily measurements averaged from all available AQM stations on each day (i.e., all AQM stations that have any of the T, RH and SLP measurements on each day), meaning that all 51 AQM stations were matched with the same set of meteorological records on each individual day. The tree part of our prediction system can be thought of as using the same meteorological records to first generate a single homogeneous baseline map that has the same PM2.5 prediction across Delhi on each day, and the CNN part can be thought of as using the location-specific high-resolution satellite imagery information to then fill in the PM2.5 variation for each location (e.g., a 300 300 m grid) across Delhi on each day. Hence, in addition to thinking that CNN learns to predict the residual of PM2.5, readers can also think that it learns to predict the spatial variation of PM2.5. This also subtly explains why RF alone is not sufficient for detecting hotspots, even though RF alone using meteorological conditions can already yield low PM2.5 prediction errors. Regardless of how low the RF predictions are, all the RF prediction values on a day are the same, and this is where CNN with satellite imagery information is useful, as it breaks ties and reveals spatial patterns.
2.4.2. CNN Details
2.4.3. RF–CNN Joint Model Evaluation
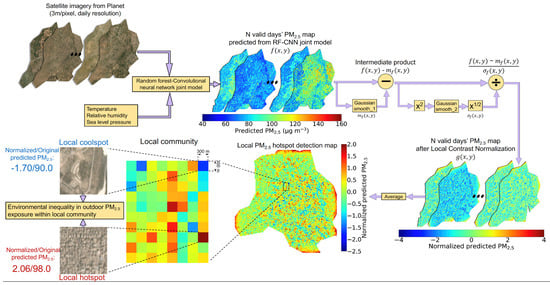
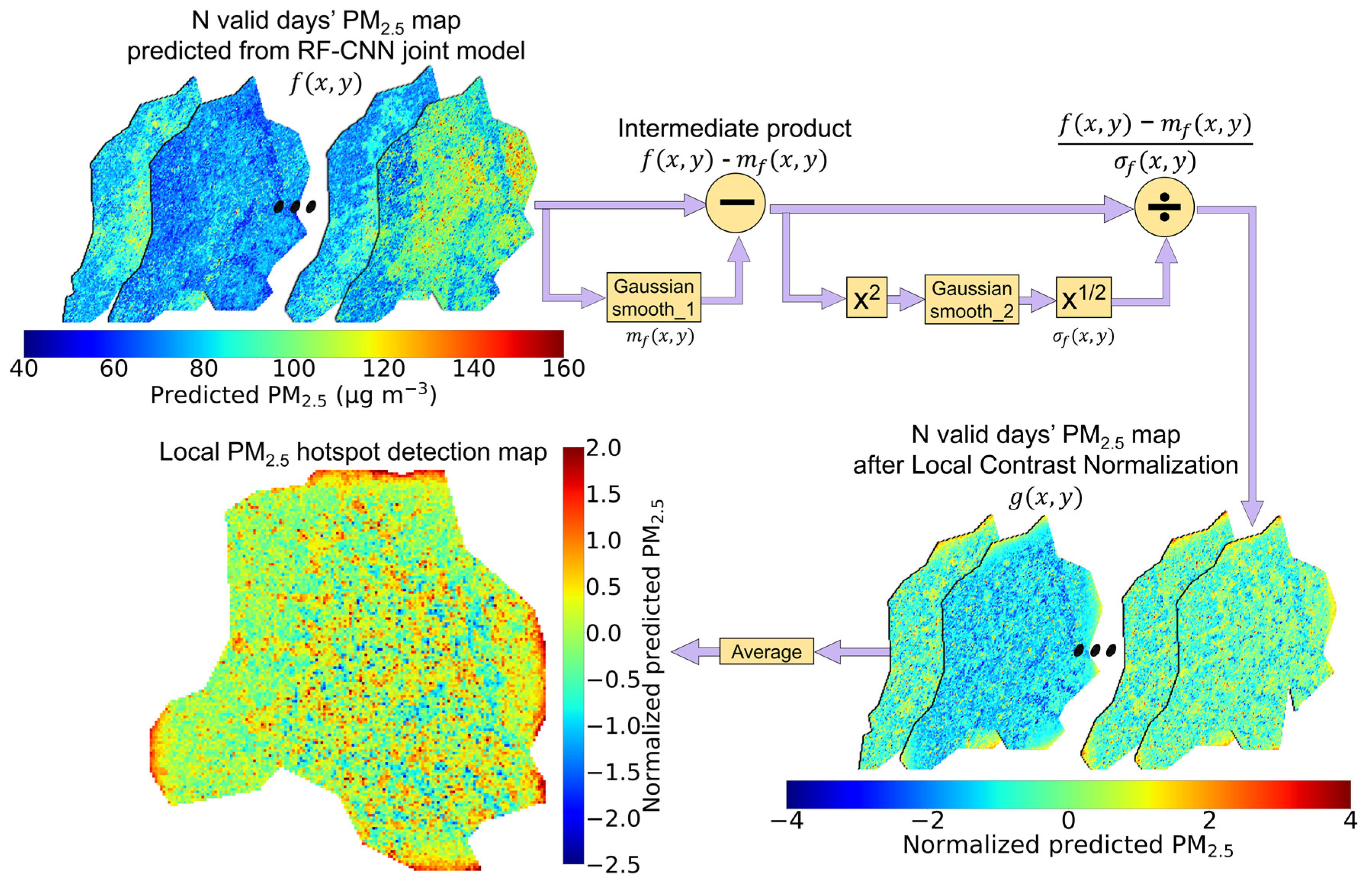
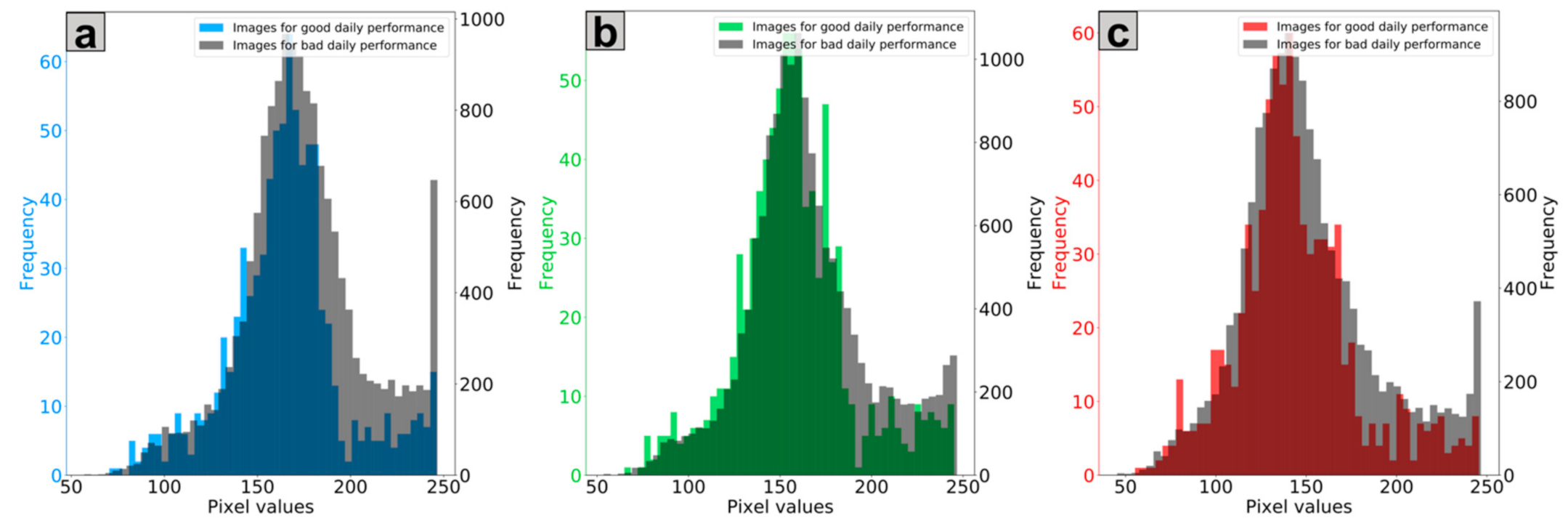
2.5. Local Contrast Normalization (LCN)
3. Results
3.1. RF–CNN Joint Model PM2.5 Prediction Performances
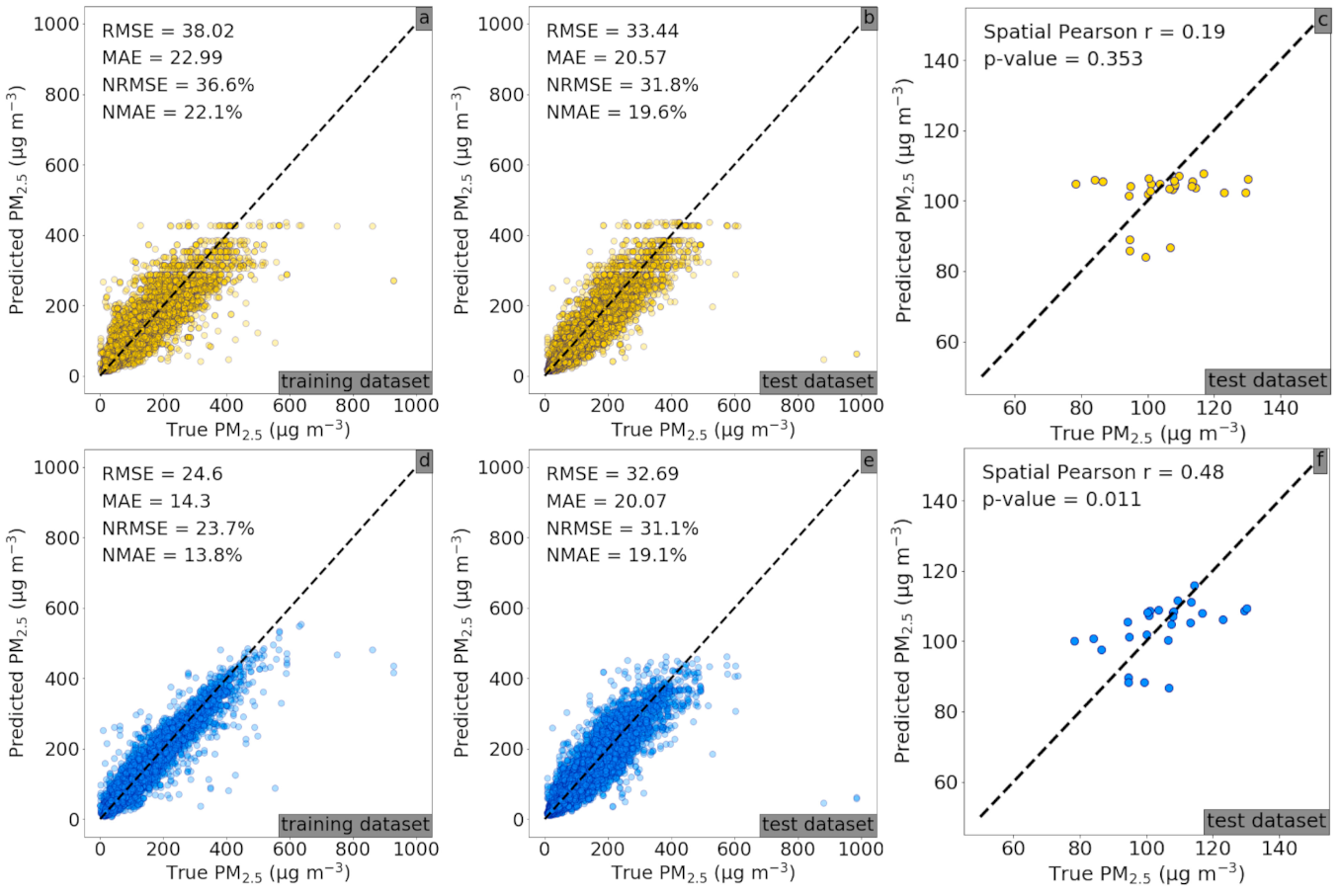
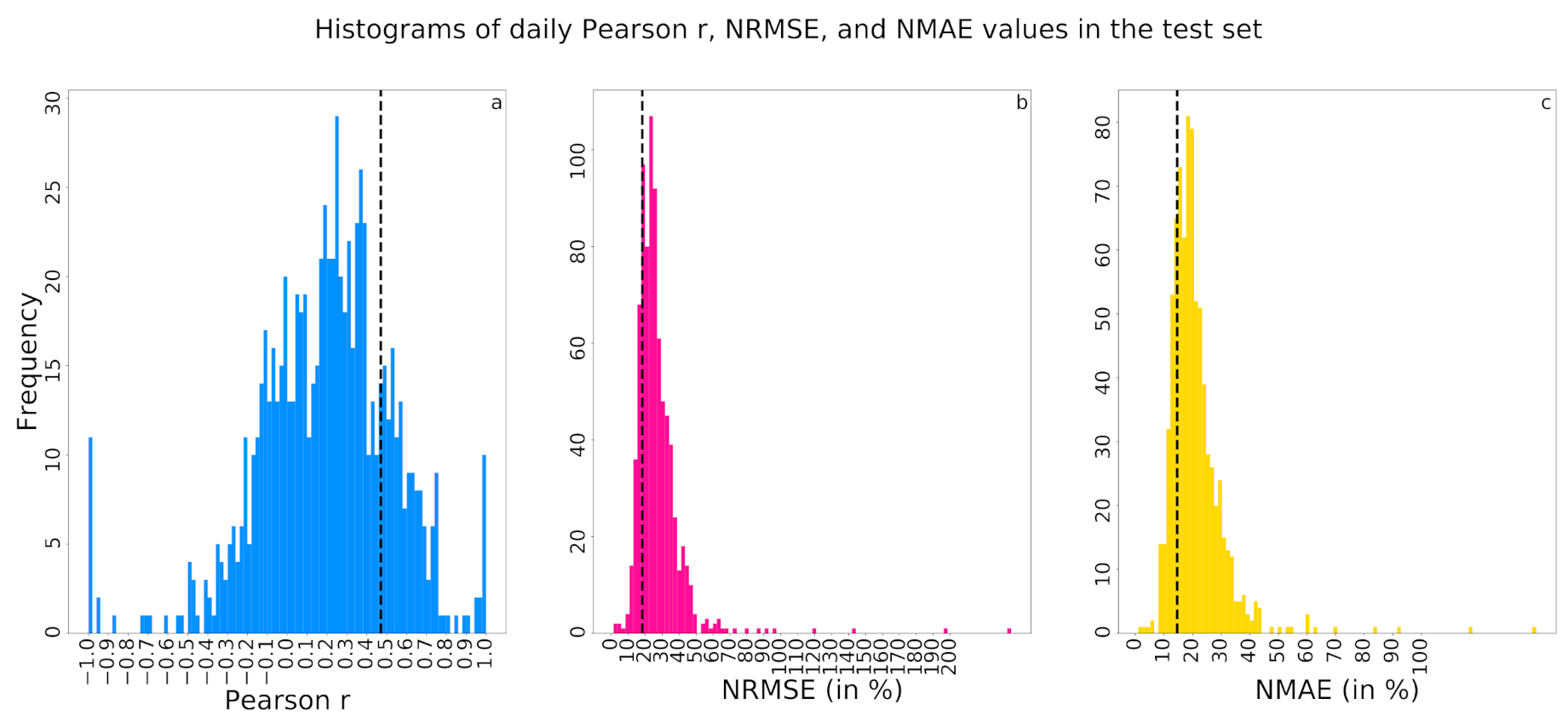
3.1.1. Delhi
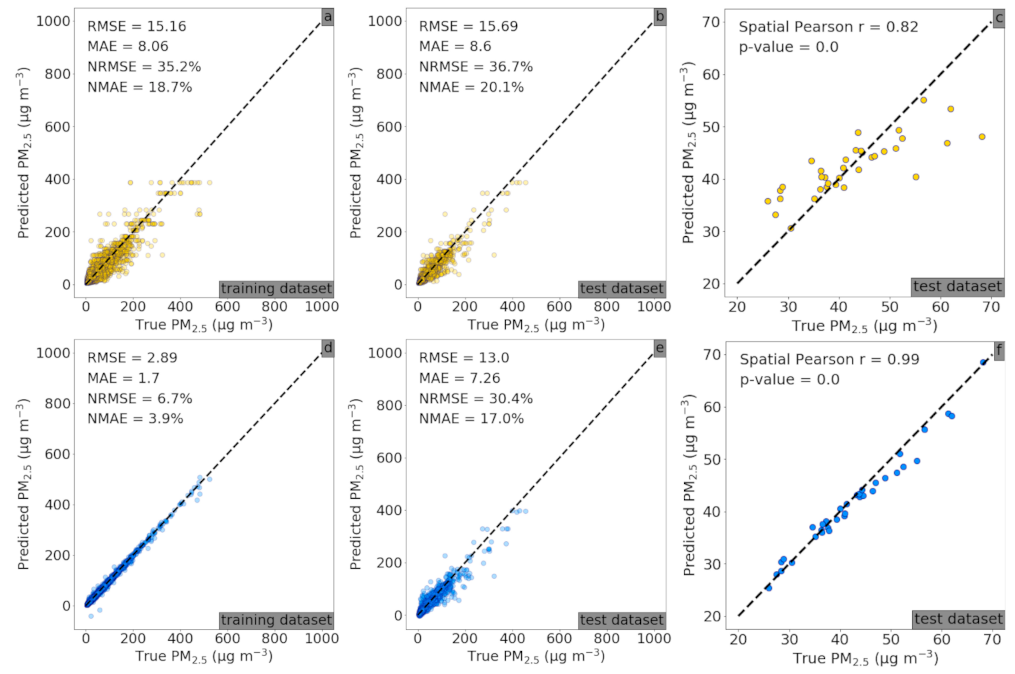
3.1.2. Beijing
3.1.3. Comparison between Delhi and Beijing
3.2. A Subsampling Strategy to Detect Hotspots in Delhi
3.3. Case Study: Hottest and Coolest 300 300 m Spots within Each of the 20 Sampled Neighborhoods in Delhi
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B

Appendix C

Appendix D

Appendix E

Appendix F

Appendix G

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case # | Hottest Spots | Coolest Spots | ||
|---|---|---|---|---|
| Lat | Lon | Lat | Lon | |
| 1 | 28.82872204 | 77.10700999 | 28.82350141 | 77.09460978 |
| 2 | 28.80949079 | 77.12506275 | 28.80422361 | 77.11573631 |
| 3 | 28.80213779 | 77.07574336 | 28.80470179 | 77.08501388 |
| 4 | 28.80554491 | 77.02971166 | 28.79971394 | 77.05725672 |
| 5 | 28.76531395 | 77.1794628 | 28.77087418 | 77.17036198 |
| 6 | 28.75227615 | 77.14847589 | 28.74135447 | 77.15439489 |
| 7 | 28.73269406 | 77.18799839 | 28.74647139 | 77.17292852 |
| 8 | 28.72336389 | 77.26150048 | 28.73153257 | 77.2586055 |
| 9 | 28.70975135 | 77.09847964 | 28.72869391 | 77.09885802 |
| 10 | 28.69026256 | 76.95380395 | 28.69554192 | 76.96311248 |
| 11 | 28.67827673 | 77.20528242 | 28.68353818 | 77.2146013 |
| 12 | 28.67442916 | 77.10698321 | 28.67960154 | 77.1224344 |
| 13 | 28.65632843 | 77.22323517 | 28.642799 | 77.22294971 |
| 14 | 28.6348702 | 77.03869029 | 28.64000433 | 77.05720023 |
| 15 | 28.62106102 | 77.05683072 | 28.60776183 | 77.041234 |
| 16 | 28.60307928 | 76.99206508 | 28.6087164 | 76.97683348 |
| 17 | 28.57328896 | 77.16935841 | 28.58150494 | 77.16339384 |
| 18 | 28.54486672 | 77.08293893 | 28.53641738 | 77.10423034 |
| 19 | 28.5227744 | 77.27865733 | 28.54186924 | 77.26987231 |
| 20 | 28.50720147 | 77.23848587 | 28.52062986 | 77.24489909 |
Appendix H

References
- Pope, C.A.; Dockery, D.W. Health effects of fine particulate air pollution: Lines that connect. J. Air Waste Manag. Assoc. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- Brook, R.D.; Rajagopalan, S.; Pope, C.A.; Brook, J.R.; Bhatnagar, A.; Diez-Roux, A.V.; Holguin, F.; Hong, Y.L.; Luepker, R.V.; Mittleman, M.A.; et al. Particulate Matter Air Pollution and Cardiovascular Disease An Update to the Scientific Statement From the American Heart Association. Circulation 2010, 121, 2331–2378. [Google Scholar] [CrossRef]
- Burnett, R.; Chen, H.; Szyszkowicz, M.; Fann, N.; Hubbell, B.; Pope, C.A.; Apte, J.S.; Brauer, M.; Cohen, A.; Weichenthal, S.; et al. Global estimates of mortality associated with long-term exposure to outdoor fine particulate matter. Proc. Natl. Acad. Sci. USA 2018, 115, 9592–9597. [Google Scholar] [CrossRef] [PubMed]
- Di, Q.; Dai, L.Z.; Wang, Y.; Zanobetti, A.; Choirat, C.; Schwartz, J.D.; Dominici, F. Association of Short-term Exposure to Air Pollution With Mortality in Older Adults. JAMA J. Am. Med Assoc. 2017, 318, 2446–2456. [Google Scholar] [CrossRef]
- Di, Q.; Wang, Y.; Zanobetti, A.; Wang, Y.; Koutrakis, P.; Choirat, C.; Dominici, F.; Schwartz, J.D. Air Pollution and Mortality in the Medicare Population. N. Engl. J. Med. 2017, 376, 2513–2522. [Google Scholar] [CrossRef]
- India State-Level Disease Burden Initiative Air Pollution Collaborators. The impact of air pollution on deaths, disease burden, and life expectancy across the states of India: The Global Burden of Disease Study 2017. Lancet Planet. Health 2019, 3, E26–E39. [Google Scholar] [CrossRef]
- Wu, X.; Nethery, R.C.; Sabath, M.B.; Braun, D.; Dominici, F. Air pollution and COVID-19 mortality in the United States: Strengths and limitations of an ecological regression analysis. Sci. Adv. 2020, 6. [Google Scholar] [CrossRef]
- Apte, J.; Messier, K.P.; Gani, S.; Brauer, M.; Kirchstetter, T.; Lunden, M.; Marshall, J.; Portier, C.; Vermeulen, R.; Hamburg, S. High-Resolution Air Pollution Mapping with Google Street View Cars: Exploiting Big Data. Environ. Sci. Technol. 2017, 51, 6999–7008. [Google Scholar] [CrossRef]
- Alexeeff, S.E.; Roy, A.; Shan, J.; Liu, X.; Messier, K.; Apte, J.S.; Portier, C.; Sidney, S.; Van Den Eeden, S.K. High-resolution mapping of traffic related air pollution with Google street view cars and incidence of cardiovascular events within neighborhoods in Oakland, CA. Environ. Health 2018, 17, 38. [Google Scholar] [CrossRef] [PubMed]
- Simon, M.C.; Patton, A.P.; Naumova, E.N.; Levy, J.I.; Kumar, P.; Brugge, D.; Durant, J.L. Combining Measurements from Mobile Monitoring and a Reference Site To Develop Models of Ambient Ultrafine Particle Number Concentration at Residences. Environ. Sci. Technol. 2018, 52, 6985–6995. [Google Scholar] [CrossRef]
- Li, H.Z.; Gu, P.; Ye, Q.; Zimmerman, N.; Robinson, E.S.; Subramanian, R.; Apte, J.S.; Robinson, A.L.; Presto, A.A. Spatially dense air pollutant sampling: Implications of spatial variability on the representativeness of stationary air pollutant monitors. Atmos. Environ. X 2019, 2, 100012. [Google Scholar] [CrossRef]
- Miller, D.J.; Actkinson, B.; Padilla, L.; Griffin, R.J.; Moore, K.; Lewis, P.G.T.; Gardner-Frolick, R.; Craft, E.; Portier, C.J.; Hamburg, S.P.; et al. Characterizing Elevated Urban Air Pollutant Spatial Patterns with Mobile Monitoring in Houston, Texas. Environ. Sci. Technol. 2020, 54, 2133–2142. [Google Scholar] [CrossRef]
- Tanzer, R.; Malings, C.; Hauryliuk, A.; Subramanian, R.; Presto, A.A. Demonstration of a Low-Cost Multi-Pollutant Network to Quantify Intra-Urban Spatial Variations in Air Pollutant Source Impacts and to Evaluate Environmental Justice. Int. J. Environ. Res. Public Health 2019, 16, 2523. [Google Scholar] [CrossRef] [PubMed]
- Xu, S.; Zou, B.; Lin, Y.; Zhao, X.; Li, S.; Hu, C. Strategies of method selection for fine-scale PM2.5 mapping in an intra-urban area using crowdsourced monitoring. Atmos. Meas. Tech. 2019, 12, 2933. [Google Scholar] [CrossRef]
- Bi, J.Z.; Wildani, A.; Chang, H.H.; Liu, Y. Incorporating Low-Cost Sensor Measurements into High-Resolution PM2.5 Modeling at a Large Spatial Scale. Environ. Sci. Technol. 2020, 54, 2152–2162. [Google Scholar] [CrossRef]
- Rose Eilenberg, S.; Subramanian, R.; Malings, C.; Hauryliuk, A.; Presto, A.A.; Robinson, A.L. Using a network of lower-cost monitors to identify the influence of modifiable factors driving spatial patterns in fine particulate matter concentrations in an urban environment. J. Expo. Sci. Environ. Epidemiol. 2020, 30, 949–961. [Google Scholar] [CrossRef] [PubMed]
- Bi, J.; Wallace, L.A.; Sarnat, J.A.; Liu, Y. Characterizing outdoor infiltration and indoor contribution of PM2.5 with citizen-based low-cost monitoring data. Environ. Pollut. 2021, 276, 116763. [Google Scholar] [CrossRef] [PubMed]
- Kelly, K.E.; Xing, W.W.; Sayahi, T.; Mitchell, L.; Becnel, T.; Gaillardon, P.-E.; Meyer, M.; Whitaker, R.T. Community-Based Measurements Reveal Unseen Differences during Air Pollution Episodes. Environ. Sci. Technol. 2021, 55, 120–128. [Google Scholar] [CrossRef]
- Bai, Y.; Wu, L.X.; Qin, K.; Zhang, Y.F.; Shen, Y.Y.; Zhou, Y. A Geographically and Temporally Weighted Regression Model for Ground-Level PM2.5 Estimation from Satellite-Derived 500 m Resolution AOD. Remote Sens. 2016, 8, 262. [Google Scholar] [CrossRef]
- Xie, Y.Y.; Wang, Y.X.; Bilal, M.; Dong, W.H. Mapping daily PM2.5 at 500 m resolution over Beijing with improved hazy day performance. Sci. Total Environ. 2019, 659, 410–418. [Google Scholar] [CrossRef]
- Yao, F.; Wu, J.S.; Li, W.F.; Peng, J. Estimating Daily PM2.5 Concentrations in Beijing Using 750-M VIIRS IP AOD Retrievals and a Nested Spatiotemporal Statistical Model. Remote Sens. 2019, 11, 841. [Google Scholar] [CrossRef]
- Di, Q.; Amini, H.; Shi, L.H.; Kloog, I.; Silvern, R.; Kelly, J.; Sabath, M.B.; Choirat, C.; Koutrakis, P.; Lyapustin, A.; et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 2019, 130. [Google Scholar] [CrossRef] [PubMed]
- Kloog, I.; Chudnovsky, A.A.; Just, A.C.; Nordio, F.; Koutrakis, P.; Coull, B.A.; Lyapustin, A.; Wang, Y.J.; Schwartz, J. A new hybrid spatio-temporal model for estimating daily multi-year PM2.5 concentrations across northeastern USA using high resolution aerosol optical depth data. Atmos. Environ. 2014, 95, 581–590. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.Q.; Yuan, Q.Q.; Yue, L.W.; Li, T.W.; Shen, H.F.; Zhang, L.P. Mapping PM2.5 concentration at a sub-km level resolution: A dual-scale retrieval approach. ISPRS J. Photogramm. Remote Sens. 2020, 165, 140–151. [Google Scholar] [CrossRef]
- Zhang, T.H.; Zhu, Z.M.; Gong, W.; Zhu, Z.R.; Sun, K.; Wang, L.C.; Huang, Y.S.; Mao, F.Y.; Shen, H.F.; Li, Z.W.; et al. Estimation of ultrahigh resolution PM2.5 concentrations in urban areas using 160 m Gaofen-1 AOD retrievals. Remote Sens. Environ. 2018, 216, 91–104. [Google Scholar] [CrossRef]
- Zheng, T.S.; Bergin, M.H.; Hu, S.J.; Miller, J.; Carlson, D.E. Estimating ground-level PM2.5 using micro-satellite images by a convolutional neural network and random forest approach. Atmos. Environ. 2020, 230. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Planet Team. Planet Application Program Interface: In Space for Life on Earth. Available online: https://api.planet.com (accessed on 13 November 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sage, D.; Unser, M. Teaching image-processing programming in Java. IEEE Signal Process. Mag. 2003, 20, 43–52. [Google Scholar] [CrossRef]
- WHO Global Urban Ambient Air Pollution Database (Update 2016). Available online: https://www.who.int/phe/health_topics/outdoorair/databases/cities/en/ (accessed on 1 December 2020).
- State of Global Air. A Special Report on Global Exposure to Air Pollution and its Health Impacts; State of Global Air: Boston, MA, USA, 2020. [Google Scholar]
- Mahato, S.; Pal, S.; Ghosh, K.G. Effect of lockdown amid COVID-19 pandemic on air quality of the megacity Delhi, India. Sci. Total Environ. 2020, 730. [Google Scholar] [CrossRef] [PubMed]
- Central Control Room for Air Quality Management–Delhi NCR. Available online: https://app.cpcbccr.com/ccr/#/caaqm-dashboard/caaqm-landing (accessed on 12 November 2020).
- Chowdhury, S.; Dey, S.; Di Girolamo, L.; Smith, K.R.; Pillarisetti, A.; Lyapustin, A. Tracking ambient PM2.5 build-up in Delhi national capital region during the dry season over 15 years using a high-resolution (1 km) satellite aerosol dataset. Atmos. Environ. 2019, 204, 142–150. [Google Scholar] [CrossRef]
- Gorai, A.K.; Tchounwou, P.B.; Biswal, S.S.; Tuluri, F. Spatio-Temporal Variation of Particulate Matter(PM2.5) Concentrations and Its Health Impacts in a Mega City, Delhi in India. Environ. Health Insights 2018, 12. [Google Scholar] [CrossRef]
- Tiwari, G. Urban transport priorities–Meeting the challenge of socio-economic diversity in cities, a case study of Delhi, India. Cities 2002, 19, 95–103. [Google Scholar] [CrossRef]
- Tiwari, S.; Hopke, P.K.; Pipal, A.S.; Srivastava, A.K.; Bisht, D.S.; Tiwari, S.; Singh, A.K.; Soni, V.K.; Attri, S.D. Intra-urban variability of particulate matter (PM2.5 and PM10) and its relationship with optical properties of aerosols over Delhi, India. Atmos. Res. 2015, 166, 223–232. [Google Scholar] [CrossRef]
- Zheng, T.S.; Bergin, M.H.; Sutaria, R.; Tripathi, S.N.; Caldow, R.; Carlson, D.E. Gaussian process regression model for dynamically calibrating and surveilling a wireless low-cost particulate matter sensor network in Delhi. Atmos. Meas. Tech. 2019, 12, 5161–5181. [Google Scholar] [CrossRef]
- Song, W.; Jia, H.; Huang, J.; Zhang, Y. A satellite-based geographically weighted regression model for regional PM2.5 estimation over the Pearl River Delta region in China. Remote Sens. Environ. 2014, 154, 1–7. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Malof, J.M.; Bradbury, K.; Collins, L.M.; Newell, R.G. Automatic detection of solar photovoltaic arrays in high resolution aerial imagery. Appl. Energy 2016, 183, 229–240. [Google Scholar] [CrossRef]
- Shi, T.; Horvath, S. Unsupervised Learning With Random Forest Predictors. J. Comput. Graph. Stat. 2006, 15, 118–138. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Kloog, I.; Koutrakis, P.; Coull, B.; Lee, H.J.; Schwartz, J. Assessing temporally and spatially resolved PM2.5 exposures for epidemiological studies using satellite aerosol optical depth measurements. Atmos. Environ. 2011, 45, 6267–6275. [Google Scholar] [CrossRef]
- Di, Q.; Kloog, I.; Koutrakis, P.; Lyapustin, A.; Wang, Y.; Schwartz, J. Assessing PM2.5 Exposures with High Spatiotemporal Resolution across the Continental United States. Environ. Sci. Technol. 2016, 50, 4712–4721. [Google Scholar] [CrossRef] [PubMed]
- Mandal, S.; Madhipatla, K.K.; Guttikunda, S.; Kloog, I.; Prabhakaran, D.; Schwartz, J.D.; GeoHlth Hub India Team. Ensemble averaging based assessment of spatiotemporal variations in ambient PM2.5 concentrations over Delhi, India, during 2010–2016. Atmos. Environ. 2020, 224. [Google Scholar] [CrossRef]
- Local Normalization. Available online: http://bigwww.epfl.ch/demo/ip/demos/local-normalization (accessed on 7 November 2020).
- Kumar, A.; Mishra, R.K.; Sarma, K. Mapping spatial distribution of traffic induced criteria pollutants and associated health risks using kriging interpolation tool in Delhi. J. Transp. Health 2020, 18. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]







| Number | Sites | Lat | Lon | Category | Mean of PM2.5 (μg m−3) | Weather Station Uptime (in %) | Number of Daily Image–Stationwide Mean Meteorology–PM2.5 Triplets |
|---|---|---|---|---|---|---|---|
| 0 | Murthal | 29.02721 | 77.06208 | train | 62.2 | 0 | 392 |
| 1 | Arya_Nagar | 28.67008 | 76.92541 | train | 68.8 | 96 | 387 |
| 2 | Pusa_IMD | 28.63965 | 77.14626 | test | 78.3 | 81 | 711 |
| 3 | Shooting_Range | 28.49857 | 77.26484 | train | 81.1 | 100 | 683 |
| 4 | Lodhi_Rd | 28.59182 | 77.22731 | train | 81.8 | 1 | 718 |
| 5 | Aya_Nagar | 28.47062 | 77.10993 | test | 84.1 | 3 | 740 |
| 6 | Sri_Aurobindo_Marg | 28.53132 | 77.19015 | test | 86.5 | 100 | 572 |
| 7 | IGI_Airport_T3 | 28.56278 | 77.11801 | train | 86.8 | 0 | 733 |
| 8 | Indirapuram | 28.64615 | 77.3581 | train | 88.9 | 97 | 361 |
| 9 | Najafgarh | 28.57012 | 76.93374 | train | 90.8 | 95 | 655 |
| 10 | Knowledge_ParkV | 28.55703 | 77.45365 | train | 91.7 | 100 | 240 |
| 11 | Patparganj | 28.62364 | 77.28717 | test | 94.3 | 99 | 706 |
| 12 | Sector116 | 28.56921 | 77.39384 | test | 94.5 | 100 | 224 |
| 13 | Sector1 | 28.5898 | 77.3101 | test | 94.6 | 100 | 247 |
| 14 | Major_Dhyan_Chand_National_Stadium | 28.61128 | 77.23773 | test | 94.9 | 100 | 720 |
| 15 | Sector62 | 28.62455 | 77.35771 | train | 95.1 | 3 | 729 |
| 16 | Vikas_Sadan | 28.45004 | 77.02634 | train | 95.1 | 99 | 671 |
| 17 | IHBAS | 28.68117 | 77.30252 | train | 96.2 | 100 | 722 |
| 18 | Mandir_Marg | 28.63643 | 77.20107 | train | 98.5 | 100 | 778 |
| 19 | Knowledge_ParkIII | 28.47273 | 77.48199 | train | 98.9 | 97 | 567 |
| 20 | Sanjay_Nagar | 28.68539 | 77.45383 | test | 99.3 | 96 | 339 |
| 21 | NISE_Gwal_Pahari | 28.42267 | 77.14893 | train | 99.6 | 0 | 530 |
| 22 | New_Collectorate | 28.97479 | 77.21335 | test | 100.1 | 71 | 269 |
| 23 | Sirifort | 28.55042 | 77.21594 | test | 100.3 | 97 | 694 |
| 24 | Okhla_Phase2 | 28.53072 | 77.27121 | test | 100.8 | 100 | 706 |
| 25 | North_Campus | 28.65738 | 77.15854 | test | 101.1 | 4 | 678 |
| 26 | R_K_Puram | 28.56326 | 77.18694 | test | 103.6 | 100 | 753 |
| 27 | Sonia_Vihar | 28.71032 | 77.24945 | test | 106.4 | 100 | 715 |
| 28 | Loni | 28.75728 | 77.27879 | test | 106.6 | 98 | 351 |
| 29 | Vivek_Vihar | 28.67229 | 77.31532 | train | 106.6 | 100 | 748 |
| 30 | Dwarka_Sector_8 | 28.57099 | 77.07193 | test | 107.4 | 100 | 744 |
| 31 | Shadipur | 28.65148 | 77.14731 | test | 107.9 | 99 | 714 |
| 32 | CRRI_MTR_Rd | 28.5512 | 77.27357 | test | 108.0 | 4 | 734 |
| 33 | ITO | 28.62855 | 77.24102 | test | 108.1 | 0 | 715 |
| 34 | Alipur | 28.81606 | 77.15266 | test | 109.4 | 97 | 429 |
| 35 | Narela | 28.8227 | 77.10191 | test | 113.2 | 98 | 708 |
| 36 | Sector16A | 28.40884 | 77.30988 | train | 113.3 | 99 | 723 |
| 37 | NSIT_Dwarka | 28.60902 | 77.03251 | test | 113.4 | 100 | 798 |
| 38 | Ashok_Vihar | 28.69538 | 77.18163 | test | 114.3 | 100 | 715 |
| 39 | Punjabi_Bagh | 28.67405 | 77.13102 | train | 115.1 | 99 | 719 |
| 40 | Sector125 | 28.54476 | 77.32313 | test | 116.9 | 98 | 703 |
| 41 | Nehru_Nagar | 28.56786 | 77.25046 | train | 117.9 | 100 | 714 |
| 42 | Burari_Crossing | 28.72556 | 77.20111 | train | 118.8 | 2 | 453 |
| 43 | DTU | 28.75005 | 77.11126 | train | 119.8 | 98 | 700 |
| 44 | Bawana | 28.77618 | 77.0511 | test | 123.1 | 99 | 557 |
| 45 | Rohini | 28.73251 | 77.11993 | train | 124.8 | 99 | 690 |
| 46 | Vasundhara | 28.66033 | 77.35726 | train | 125.3 | 99 | 735 |
| 47 | Jahangirpuri | 28.73278 | 77.17064 | test | 129.4 | 100 | 697 |
| 48 | Mundka | 28.68449 | 77.07668 | test | 130.3 | 100 | 584 |
| 49 | Wazirpur | 28.69972 | 77.1654 | train | 132.2 | 99 | 725 |
| 50 | Anand_Vihar | 28.6469 | 77.31592 | train | 136.0 | 91 | 672 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, T.; Bergin, M.; Wang, G.; Carlson, D. Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology. Remote Sens. 2021, 13, 1356. https://doi.org/10.3390/rs13071356
Zheng T, Bergin M, Wang G, Carlson D. Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology. Remote Sensing. 2021; 13(7):1356. https://doi.org/10.3390/rs13071356
Chicago/Turabian StyleZheng, Tongshu, Michael Bergin, Guoyin Wang, and David Carlson. 2021. "Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology" Remote Sensing 13, no. 7: 1356. https://doi.org/10.3390/rs13071356
APA StyleZheng, T., Bergin, M., Wang, G., & Carlson, D. (2021). Local PM2.5 Hotspot Detector at 300 m Resolution: A Random Forest–Convolutional Neural Network Joint Model Jointly Trained on Satellite Images and Meteorology. Remote Sensing, 13(7), 1356. https://doi.org/10.3390/rs13071356