
Robust Classification Technique for Hyperspectral Images Based on 3D-Discrete Wavelet Transform



Abstract
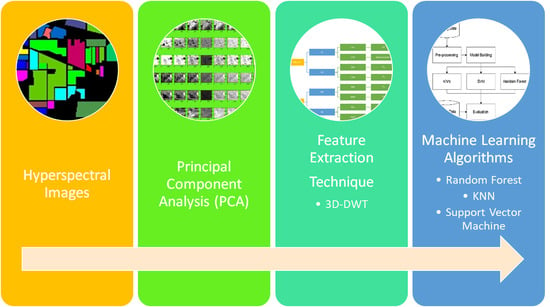
1. Introduction
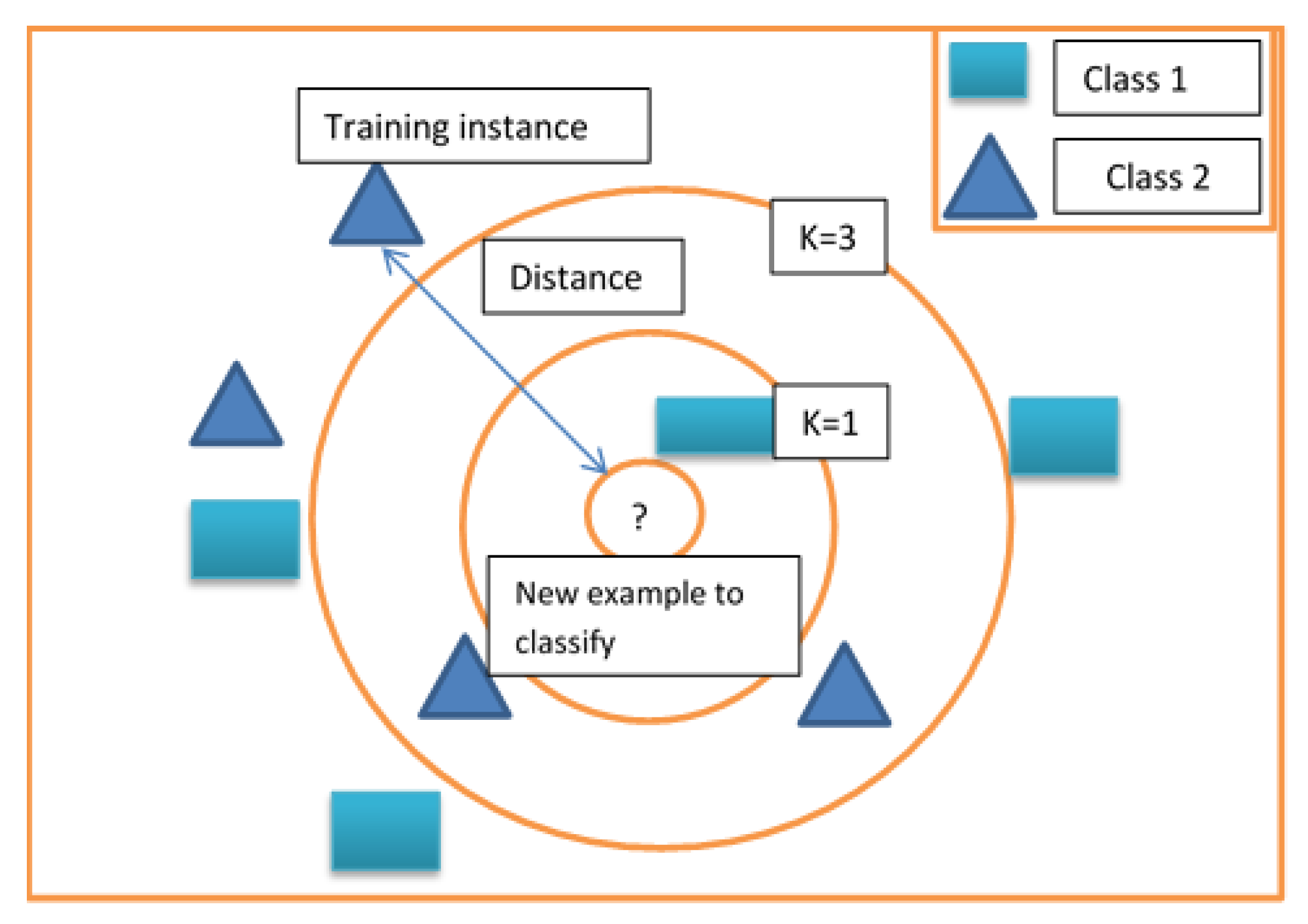
2. Related Work
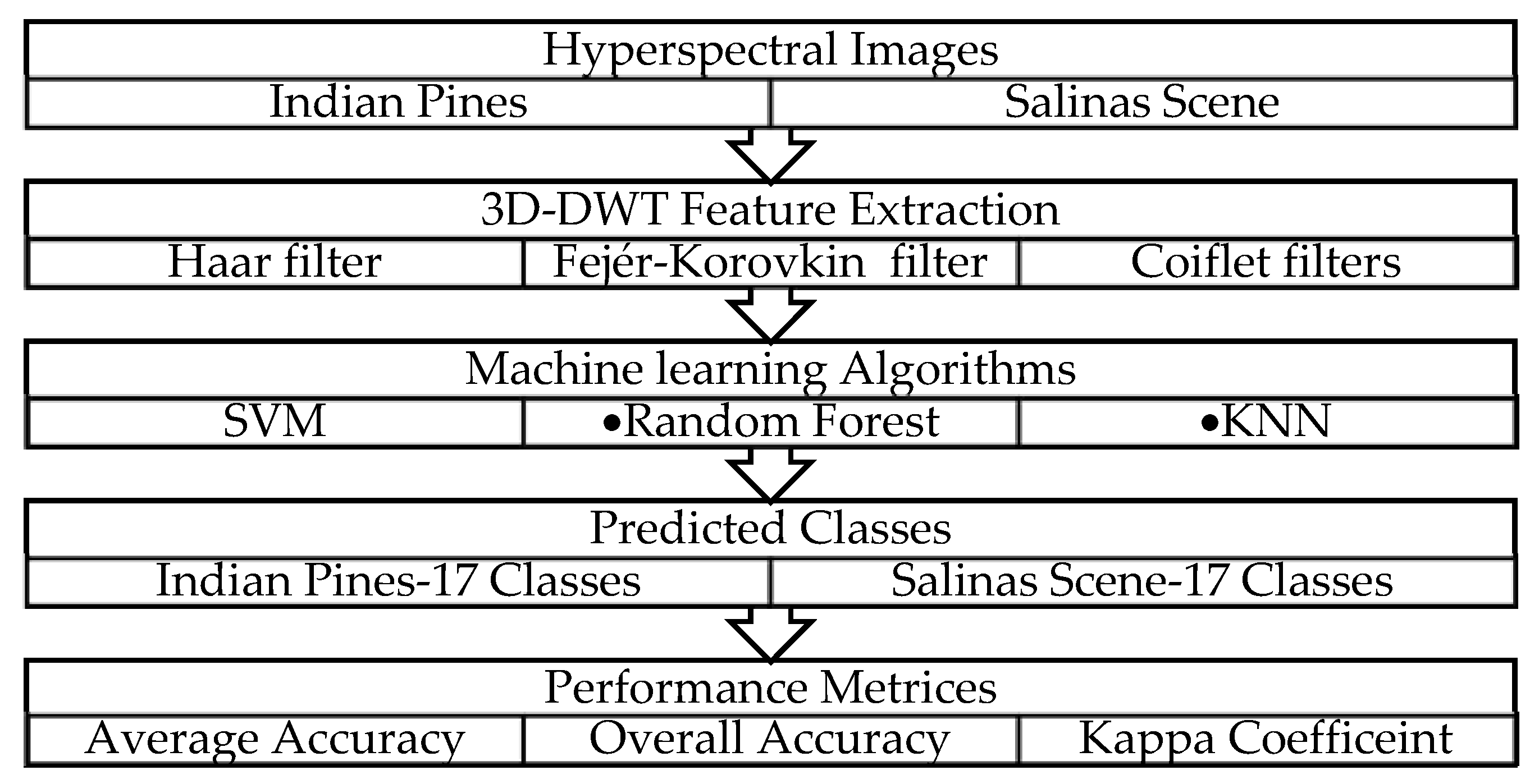
3. Methodology
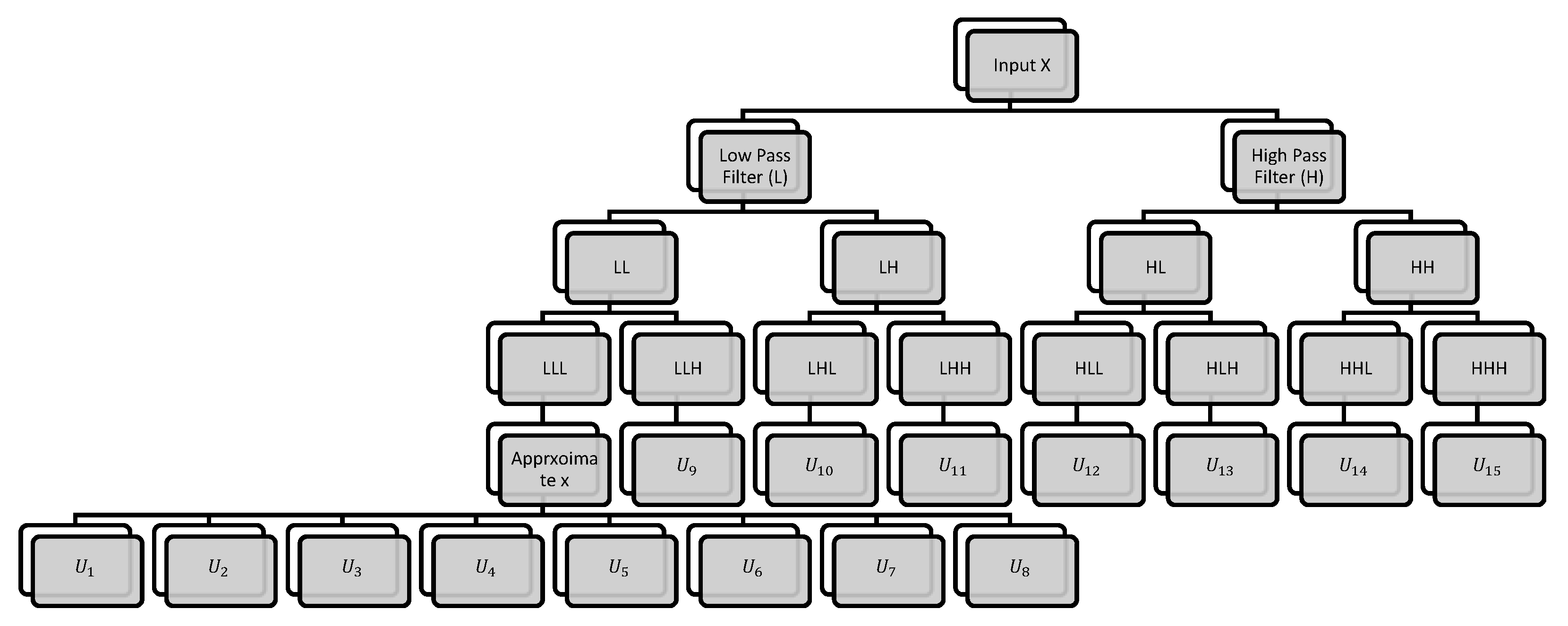
3.1. Overview of DWT
3.2. Hyperspectral Image Classification Using 3D-DWT Feature Extraction
| Algorithm 1: 3D-DWT-based feature extraction for hyperspectral image classifications |
| Input: Airborne hyperspectral image data X∈R^(w*h*λ), K is the number of classes. Output: Predicted labels y.
|
4. Results and Discussions
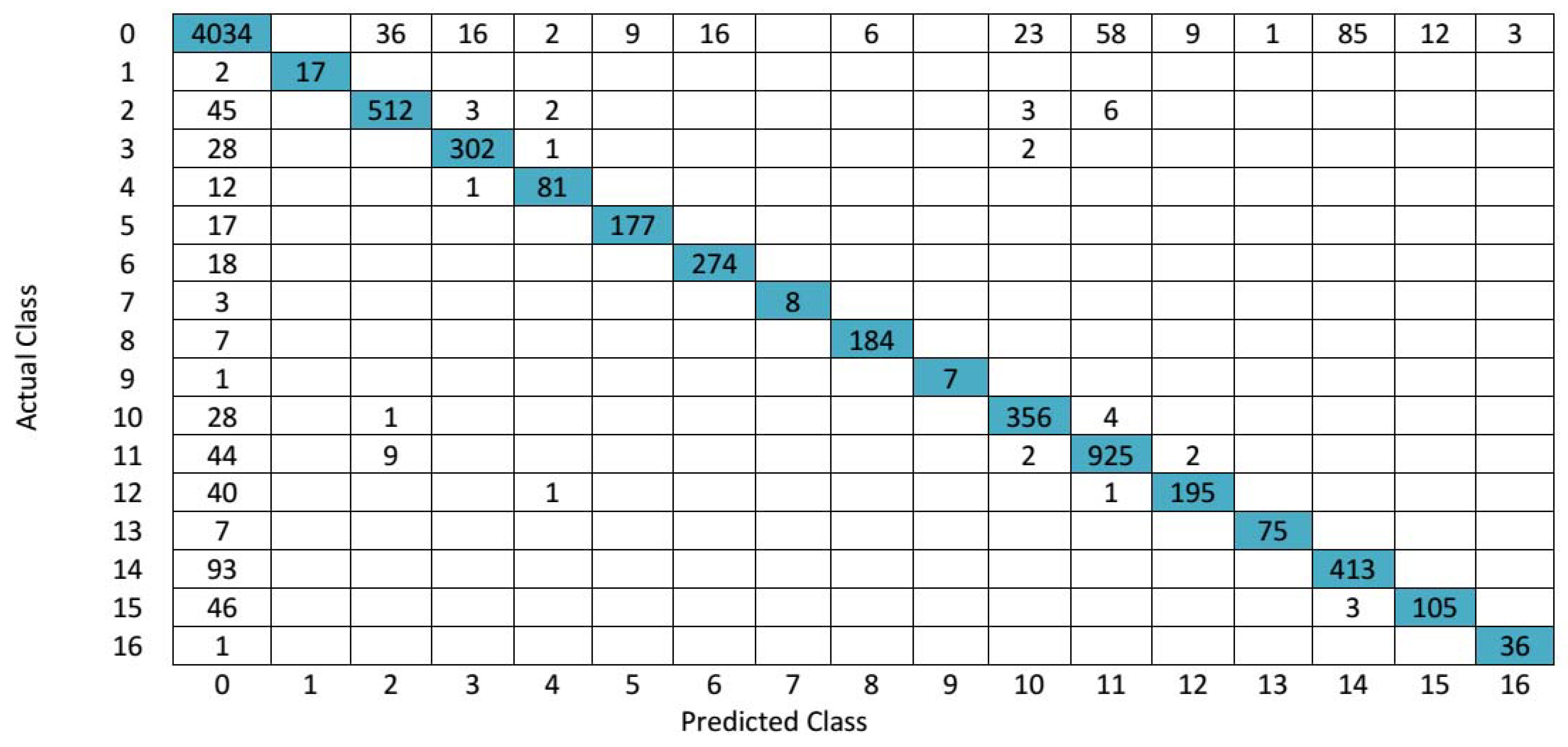
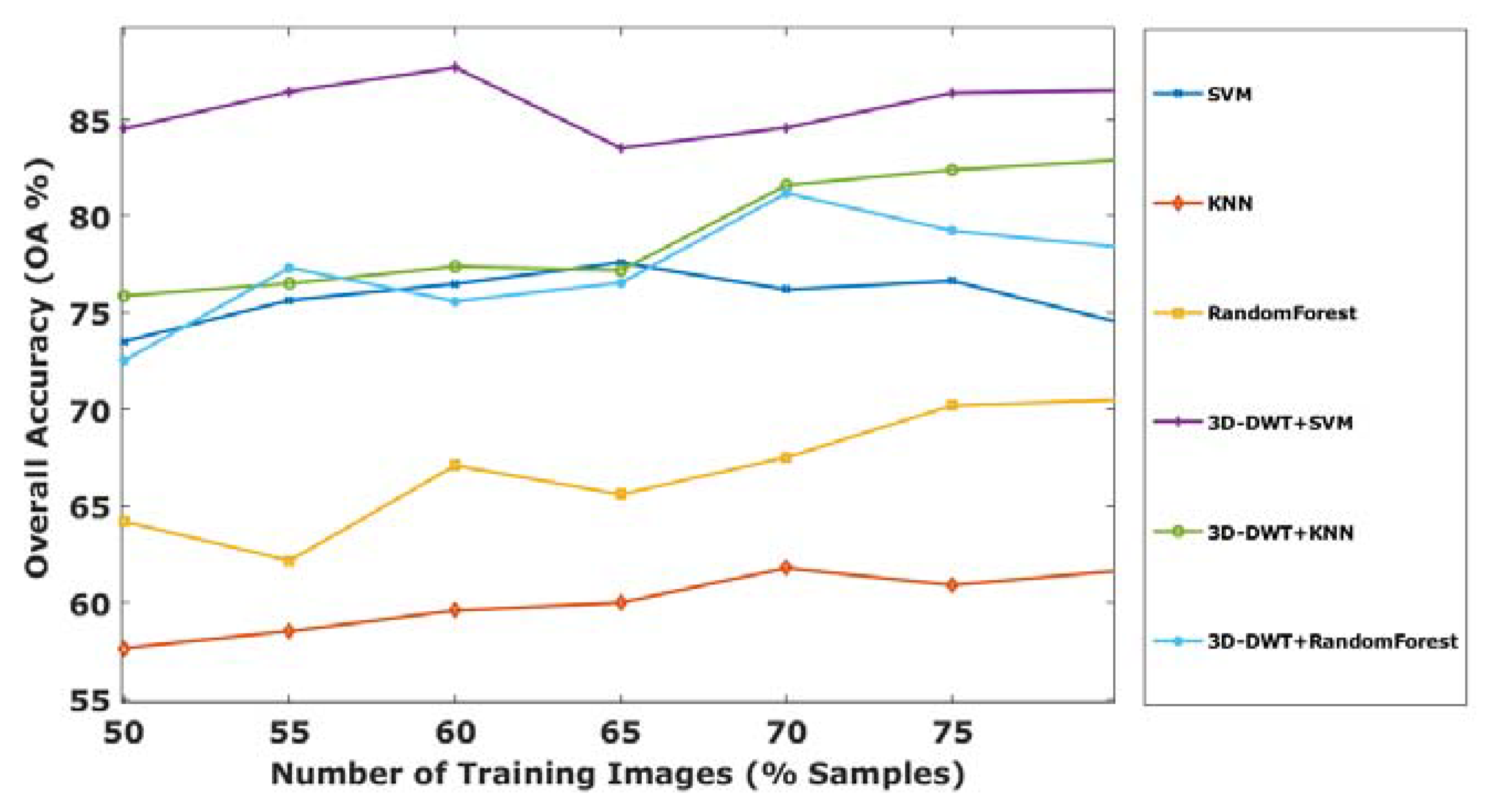
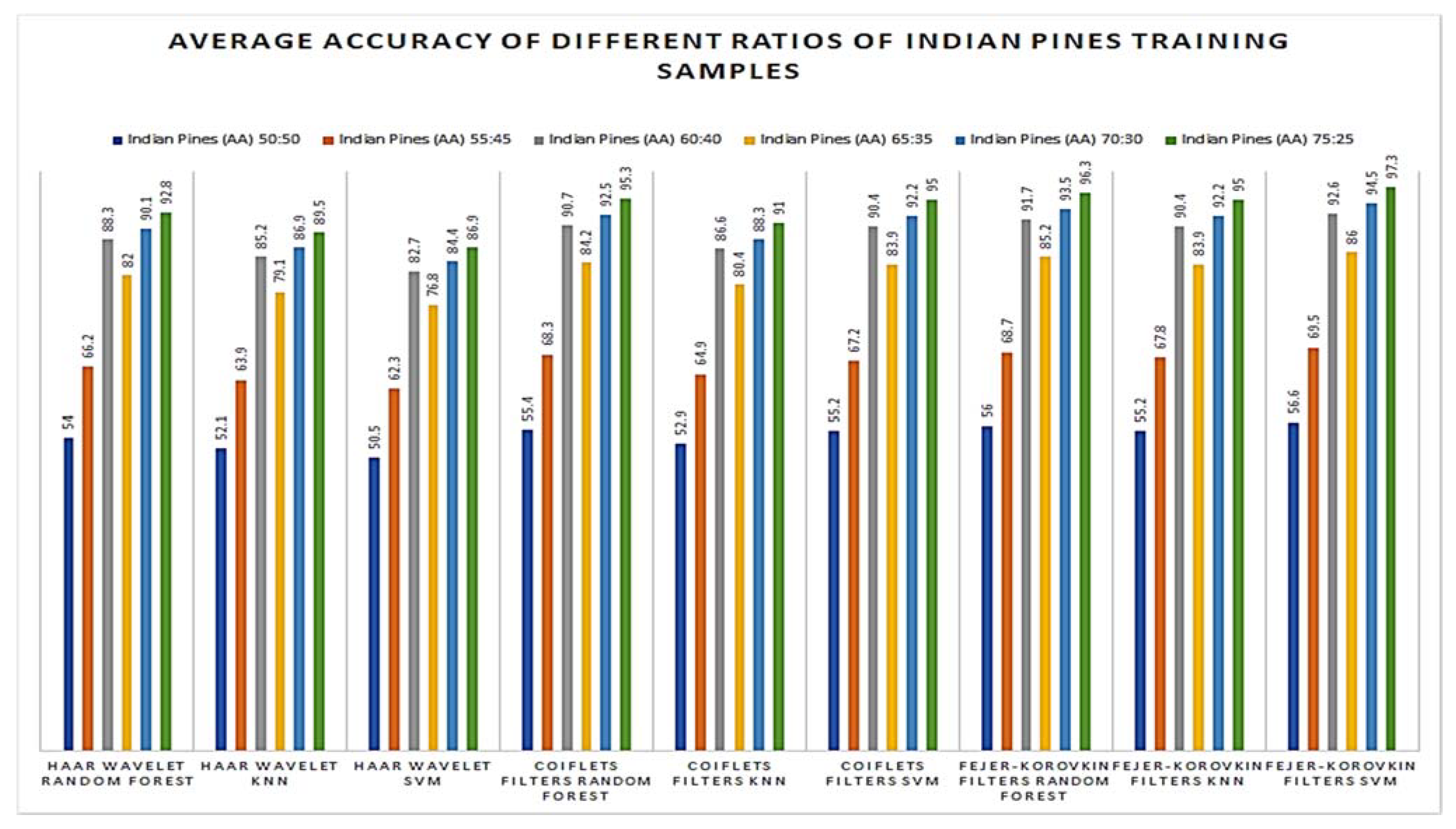
4.1. 3D-DWT-Based Hyperspectral Image Classification Using Indian Pines Data
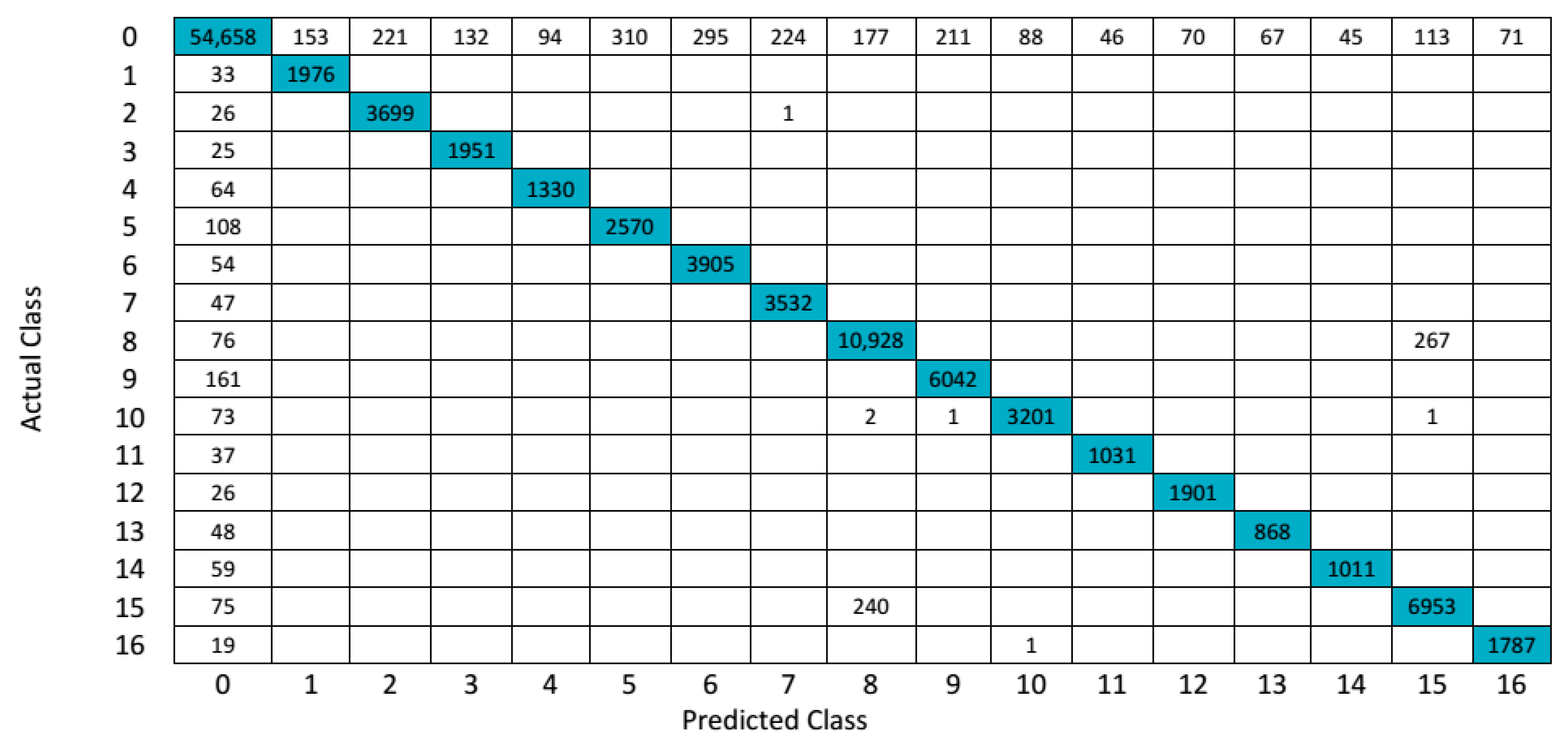
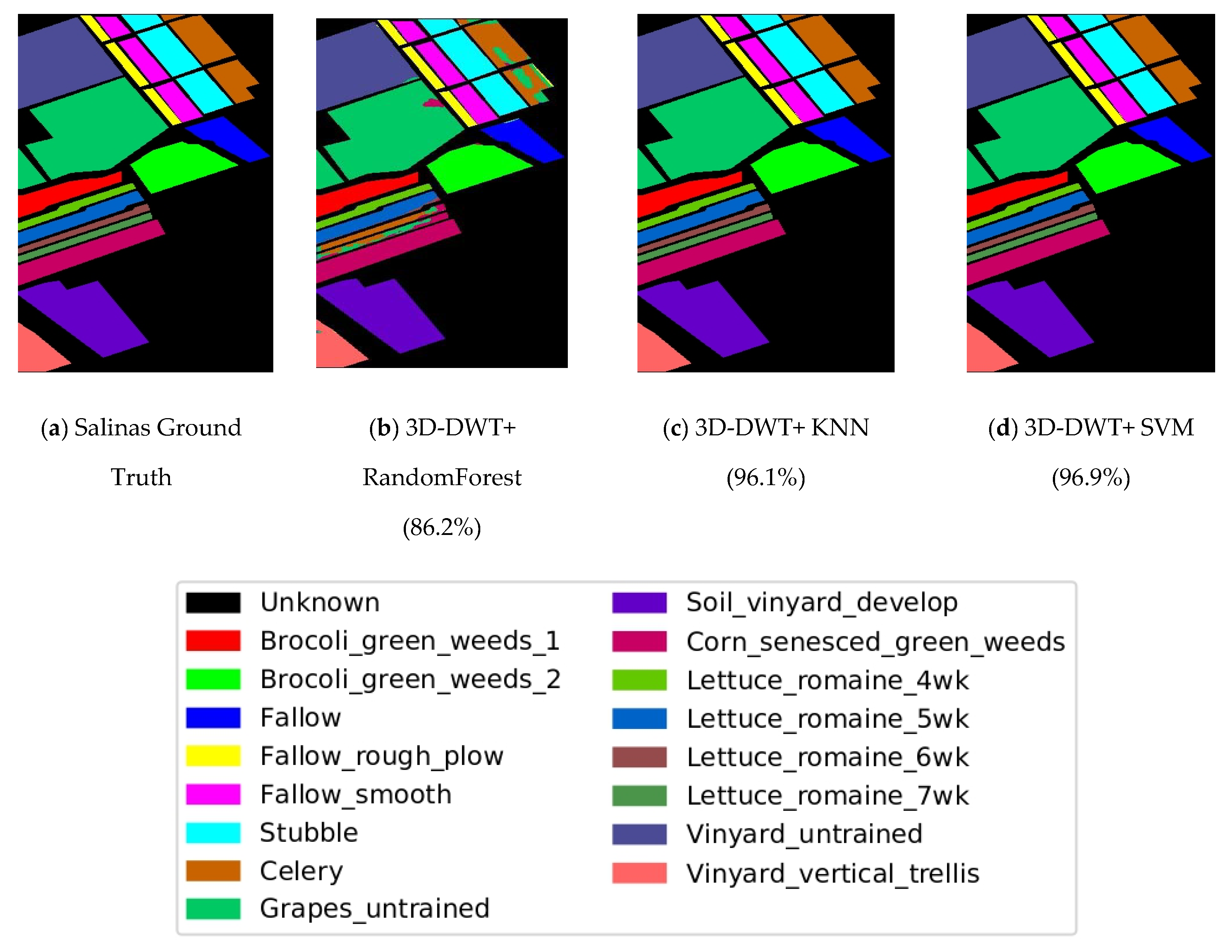
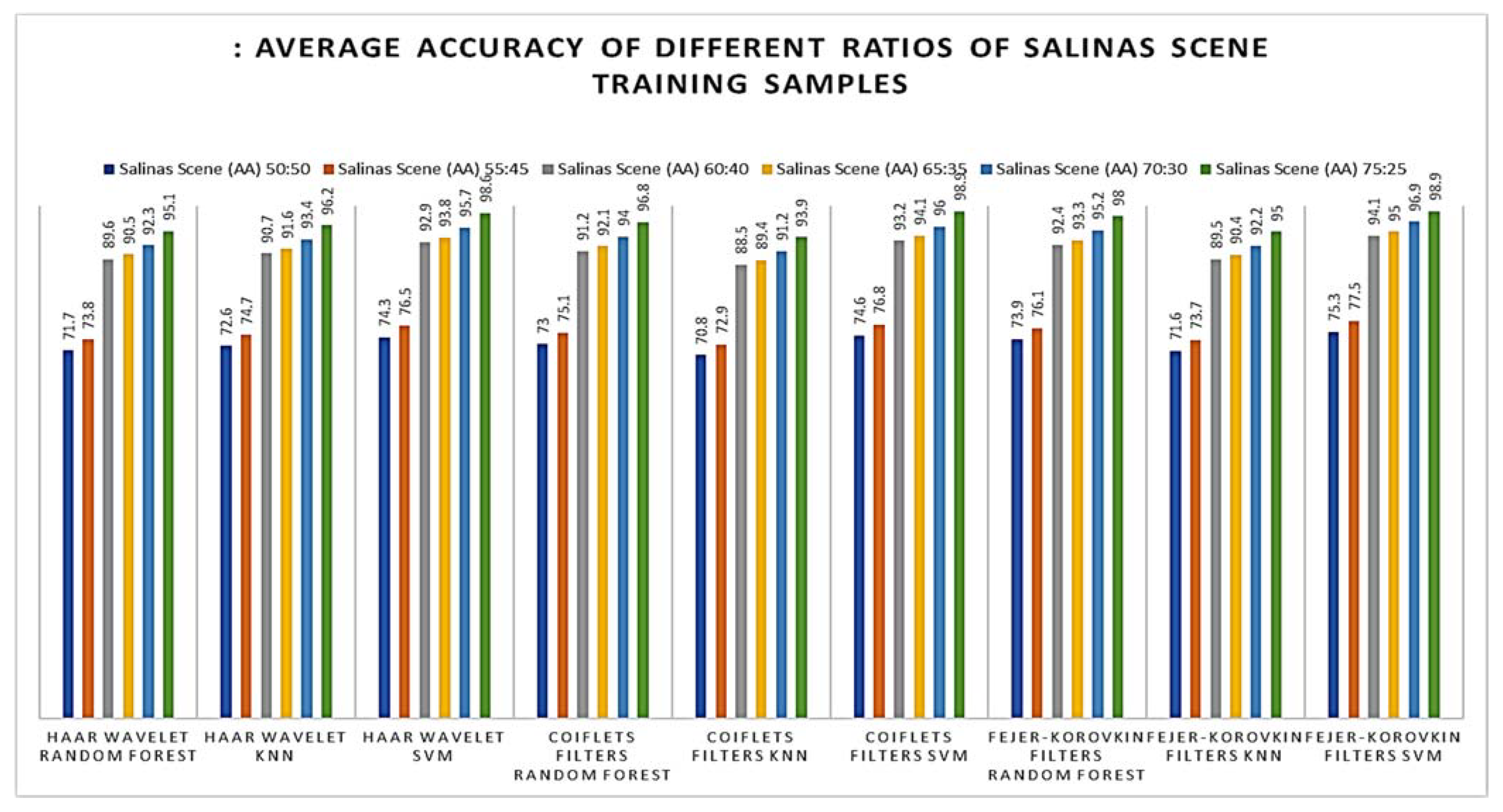
4.2. 3D-DWT-Based Hyperspectral Image Classification Using Salinas Scene Hyperspectral Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Elmasry, G.; Sun, D.-W. Principles of hyperspectral imaging technology. In Hyperspectral Imaging for Food Quality Analysis and Control; Academic Press: Cambridge, MA, USA, 2010; pp. 3–43. [Google Scholar]
- Gupta, N.; Voloshinov, V. Hyperspectral imager, from ultraviolet to visible, with a KDP acousto-optic tunable filter. Appl. Opt. 2004, 43, 2752–2759. [Google Scholar] [CrossRef]
- Vainshtein, L.A. Electromagnetic Waves; Izdatel’stvo Radio i Sviaz’: Moscow, Russian, 1988; 440 p. (In Russian) [Google Scholar]
- Engel, J.M.; Chakravarthy, B.L.N.; Rothwell, D.; Chavan, A. SEEQ™ MCT wearable sensor performance correlated to skin irritation and temperature. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 2030–2033. [Google Scholar]
- Shen, S.C. Comparison and competition between MCT and QW structure material for use in IR detectors. Microelectron. J. 1994, 25, 713–739. [Google Scholar] [CrossRef]
- Bowker, D.E. Spectral Reflectances of Natural Targets for Use in Remote Sensing Studies; NASA: Washington, DC, USA, 1985; Volume 1139.
- Chang, C.-I. Hyperspectral Imaging: Techniques for Spectral Detection and Classification; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 1. [Google Scholar]
- Martin, M.E.; Wabuyele, M.B.; Chen, K.; Kasili, P.; Panjehpour, M.; Phan, M.; Overholt, B.; Cunningham, G.; Wilson, D.; Denovo, R.C.; et al. Development of an advanced hyperspectral imaging (HSI) system with applications for cancer detection. Ann. Biomed. Eng. 2006, 34, 1061–1068. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Lamb, D.W.; Niu, Z.; Zhang, Y.; Liu, L.; Wang, J. Identification of yellow rust in wheat using in-situ spectral reflectance measurements and airborne hyperspectral imaging. Precis. Agric. 2007, 8, 187–197. [Google Scholar] [CrossRef]
- Wang, Y.; Duan, H. Classification of hyperspectral images by SVM using a composite kernel by employing spectral, spatial and hierarchical structure information. Remote. Sens. 2018, 10, 441. [Google Scholar] [CrossRef]
- Marconcini, M.; Camps-Valls, G.; Bruzzone, L. A composite semi supervised SVM for classification of hyperspectral images. IEEE Geosci. Remote. Sens. Lett. 2009, 6, 234–238. [Google Scholar] [CrossRef]
- Jian, Y.; Chu, D.; Zhang, L.; Xu, Y.; Yang, J. Sparse representation classifier steered discriminative projection with applications to face recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1023–1035. [Google Scholar]
- Li, Z.; Zhou, W.-D.; Chang, P.-C.; Liu, J.; Yan, Z.; Wang, T.; Li, F. Kernel sparse representation-based classifier. IEEE Trans. Signal Process. 2011, 60, 1684–1695. [Google Scholar] [CrossRef]
- Hongyan, Z.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 2056–2065. [Google Scholar] [CrossRef]
- Xiangyong, C.; Xu, L.; Meng, D.; Zhao, Q.; Xu, Z. Integration of 3-dimensional discrete wavelet transform and Markov random field for hyperspectral image classification. Neurocomputing 2017, 226, 90–100. [Google Scholar]
- Jun, L.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2011, 50, 809–823. [Google Scholar]
- Youngmin, P.; Yang, H.S. Convolutional neural network based on an extreme learning machine for image classification. Neurocomputing 2019, 339, 66–76. [Google Scholar]
- Zhuyun, C.; Gryllias, K.; Li, W. Mechanical fault diagnosis using convolutional neural networks and extreme learning machine. Mech. Syst. Signal Process. 2019, 133, 106272. [Google Scholar]
- Zhenyu, Y.; Gao, F.; Xiong, Q.; Wang, J.; Huang, T.; Yang, E.; Zhou, H. A novel semi-supervised convolutional neural network method for synthetic aperture radar image recognition. Cogn. Comput. 2019, 1–12. [Google Scholar] [CrossRef]
- Zhengxia, Z.; Shi, Z. Hierarchical suppression method for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2015, 54, 330–342. [Google Scholar]
- Xudong, K.; Li, S.; Benediktsson, J.A. Spectral–spatial hyperspectral image classification with edge-preserving filtering. IEEE Trans. Geosci. Remote Sens. 2013, 52, 2666–2677. [Google Scholar]
- Akrem, S.; Abbes, A.B.; Barra, V.; Farah, I.R. Fused 3-D spectral-spatial deep neural networks and spectral clustering for hyperspectral image classification. Pattern Recognit. Lett. 2020, 138, 594–600. [Google Scholar]
- Zhang, X. Wavelet-Domain Hyperspectral Soil Texture Classification. Ph.D. Thesis, Mississippi State University, Starkvale, MS, USA, 2020. [Google Scholar]
- Wang, H.; Ye, G.; Tang, Z.; Tan, S.H.; Huang, S.; Fang, D.; Feng, Y.; Bian, L.; Wang, Z. Combining Graph-based Learning with Automated Data Collection for Code Vulnerability Detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 1943–1958. [Google Scholar] [CrossRef]
- Mubarakali, A.; Marina, N.; Hadzieva, E. Analysis of Feature Extraction Algorithm Using Two Dimensional Discrete Wavelet Transforms in Mammograms to Detect Microcalcifications. In Computational Vision and Bio-Inspired Computing: ICCVBIC 2019; Springer International Publishing: Cham, Switzerland, 2020; Volume 1108, p. 26. [Google Scholar]
- Shi, G.; Huang, H.; Wang, L. Unsupervised dimensionality reduction for hyperspectral imagery via local geometric structure feature learning. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1425–1429. [Google Scholar] [CrossRef]
- Lei, J.; Fang, S.; Xie, W.; Li, Y.; Chang, C.I. Discriminative Reconstruction for Hyperspectral Anomaly Detection with Spectral Learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7406–7417. [Google Scholar] [CrossRef]
- Luo, F.; Du, B.; Zhang, L.; Zhang, L.; Tao, D. Feature learning using spatial-spectral hypergraph discriminant analysis for hyperspectral image. IEEE Trans. Cybern. 2018, 49, 2406–2419. [Google Scholar] [CrossRef] [PubMed]
- Nagtode, S.A.; Bhakti, B.P.; Morey, P. Two dimensional discrete Wavelet transform and Probabilistic neural network used for brain tumor detection and classification. In Proceedings of the 2016 Fifth International Conference on Eco-friendly Computing and Communication Systems (ICECCS), Manipal, India, 8–9 December 2016; pp. 20–26. [Google Scholar]
- Aman, G.; Demirel, H. 3D discrete wavelet transform-based feature extraction for hyperspectral face recognition. IET Biom. 2017, 7, 49–55. [Google Scholar]
- Pedram, G.; Chen, Y.; Zhu, X.X. A self-improving convolution neural network for the classification of hyperspectral data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1537–1541. [Google Scholar]
- Gao, H.; Lin, S.; Yang, Y.; Li, C.; Yang, M. Convolution neural network based on two-dimensional spectrum for hyperspectral image classification. J. Sens. 2018, 2018, 1–13. [Google Scholar] [CrossRef]
- Slimani, I.; Zaarane, A.; Hamdoun, A.; Issam, A. Traffic surveillance system for vehicle detection using discrete wavelet transform. Transform, detection using discrete wavelet. J. Theor. Appl. Inf. Technol. 2018, 96, 5905–5917. [Google Scholar]
- Alickovic, E.; Kevric, J.; Subasi, A. Performance evaluation of empirical mode decomposition, discrete wavelet transform, and wavelet packed decomposition for automated epileptic seizure detection and prediction. Biomed. Signal Process. Control. 2018, 39, 94–102. [Google Scholar] [CrossRef]
- Bhushan, D.B.; Sowmya, V.; Manikandan, M.S.; Soman, K.P. An effective pre-processing algorithm for detecting noisy spectral bands in hyperspectral imagery. In Proceedings of the 2011 International symposium on ocean electronics, Kochi, India, 16–18 November 2011; pp. 34–39. [Google Scholar]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P.; Akarsh, S.; Elhoseny, M. Improved DGA domain names detection and categorization using deep learning architectures with classical machine learning algorithms. In Cybersecurity and Secure Information Systems; Springer: Cham, Switzerland, 2019; pp. 161–192. [Google Scholar]
- Anand, R.; Veni, S.; Aravinth, J. Big data challenges in airborne hyperspectral image for urban landuse classification. In Proceedings of the 2017 International Conference on Advances in Computing, Communications, and Informatics (ICACCI), Manipal, India, 13–16 September 2017; pp. 1808–1814. [Google Scholar]
- Prabhakar, T.N.; Xavier, G.; Geetha, P.; Soman, K.P. Spatial preprocessing based multinomial logistic regression for hyperspectral image classification. Proc. Comput. Sci. 2015, 46, 1817–1826. [Google Scholar] [CrossRef]
- Morais, C.L.M.; Martin-Hirsch, P.L.; Martin, F.L. A three-dimensional principal component analysis approach for exploratory analysis of hyperspectral data: Identification of ovarian cancer samples based on Raman micro spectroscopy imaging of blood plasma. Analyst 2019, 144, 2312–2319. [Google Scholar] [CrossRef]
- Liang, H.; Bao, W.; Shen, X. Adaptive Weighting Feature Fusion Approach Based on Generative Adversarial Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 198. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Du, B.; Zhang, L. Dimensionality reduction with enhanced hybrid-graph discriminant learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5336–5353. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indian Pines Classes | Training Dataset | Testing Dataset |
|---|---|---|
| Label 0 Background | 6465 | 4310 |
| Label 1 Alfalfa | 27 | 19 |
| Label 2 Corn-no till | 857 | 571 |
| Label 3 Corn-min till | 486 | 333 |
| Label 4 Corn | 142 | 94 |
| Label 5 Grass-pasture | 290 | 194 |
| Label 6 Grass-trees | 438 | 292 |
| Label 7 Grass-pasture-mowed | 17 | 11 |
| Label 8 Hay-windrowed | 287 | 191 |
| Label 9 Oats | 12 | 8 |
| Label 10 Soybean-no till | 583 | 389 |
| Label 11 Soybean-min till | 1473 | 982 |
| Label 12 Soybean-clean | 356 | 237 |
| Label 13 Wheat | 123 | 82 |
| Label 14 Woods | 759 | 506 |
| Label 15 Buildings-Grass-Trees-Drives | 232 | 154 |
| Label 16 Stone-Steel-Towers | 56 | 37 |
| Total | 12,602 | 8411 |
| Class | Random Forest | KNN | SVM | AWFF-GAN | 3D-DWT+ Random Forest | 3D-DWT+KNN | 3D-DWT+SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | |||||
| 0 | 79.7 | 79.6 | 93.6 | 100 | 85.4 | 86.0 | 86.1 | 91.6 | 92.1 | 92.2 | 91.1 | 91.6 | 91.2 |
| 1 | 93.8 | 66.7 | 89.5 | 98.00 | 100 | 100 | 100 | 94.4 | 84.2 | 100 | 100 | 68.4 | 93.3 |
| 2 | 70.9 | 56.6 | 89.6 | 90.17 | 90.6 | 89.6 | 92.0 | 87.9 | 86.2 | 90.2 | 91.8 | 91.4 | 93.1 |
| 3 | 78.4 | 63.4 | 90.7 | 94.1 | 91.2 | 91.1 | 91.0 | 90.3 | 88.6 | 90.9 | 93.8 | 89.0 | 94.5 |
| 4 | 62.1 | 55.9 | 86.2 | 92.6 | 92.5 | 92.5 | 90.5 | 88.9 | 88.2 | 84.7 | 93.1 | 95.2 | 96.6 |
| 5 | 91.3 | 86.7 | 91.2 | 92.4 | 92.7 | 96.8 | 97.0 | 94.6 | 94.5 | 97.8 | 95.2 | 95.1 | 97.3 |
| 6 | 85.0 | 70.3 | 93.8 | 93.7 | 96.9 | 95.1 | 97.6 | 93.4 | 91.3 | 93.9 | 94.5 | 93.1 | 98.6 |
| 7 | 87.5 | 71.4 | 71.4 | 98.6 | 100 | 85.7 | 90.0 | 90.9 | 81.8 | 90.9 | 100 | 63.6 | 100 |
| 8 | 89.5 | 77.6 | 96.2 | 96.9 | 91.4 | 95.2 | 93.4 | 94.0 | 94.5 | 92.7 | 96.8 | 97.3 | 96.9 |
| 9 | 100 | 92.2 | 87.5 | 88.1 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| 10 | 73.8 | 58.9 | 91.6 | 94.5 | 88.1 | 91.5 | 89.9 | 86.6 | 86.8 | 84.5 | 92.2 | 93.8 | 91.3 |
| 11 | 76.8 | 69.3 | 94.2 | 92.6 | 92.1 | 90.3 | 91.9 | 91.0 | 90.3 | 90.2 | 93.1 | 93.1 | 93.0 |
| 12 | 74.9 | 66.8 | 82.2 | 94.5 | 90.8 | 88.9 | 90.7 | 88.0 | 86.2 | 92.2 | 94.7 | 91.9 | 96.3 |
| 13 | 91.5 | 78.8 | 91.5 | 97.9 | 96.1 | 97.2 | 96.2 | 97.4 | 97.4 | 94.0 | 98.7 | 98.8 | 96.4 |
| 14 | 62.3 | 58.0 | 81.6 | 91.4 | 87.6 | 97.8 | 85.4 | 82.6 | 82.8 | 82.5 | 82.4 | 83.3 | 92.0 |
| 15 | 50.0 | 51.1 | 68.0 | 88.1 | 97.8 | 97.4 | 91.4 | 91.5 | 91.0 | 85.4 | 89.7 | 83.8 | 91.2 |
| 16 | 78.2 | 74.3 | 96.8 | 92.6 | 91.4 | 85.4 | 79.1 | 91.2 | 84.2 | 78.6 | 92.3 | 87.8 | 84.6 |
| Class | Random Forest | KNN | SVM | AWFF-GAN | 3D-DWT+Random Forest | 3D-DWT+KNN | 3D-DWT+SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | |||||
| Overall Accuracy (OA) | 67.7 | 60.2 | 77.1 | 87.5 | 76.2 | 74.1 | 78.4 | 79.4 | 78.2 | 78.6 | 88.3 | 86.2 | 90.4 |
| Average Accuracy (AA) | 72.1 | 66.4 | 89.6 | 90.8 | 88.3 | 85.2 | 82.7 | 90.7 | 86.6 | 90.4 | 91.7 | 90.4 | 92.6 |
| Kappa Coefficient | 6.92 | 5.83 | 6.24 | 8.11 | 7.76 | 7.54 | 7.24 | 7.94 | 7.83 | 7.81 | 8.14 | 8.01 | 8.36 |
| Salinas Scene Classes | Training Dataset | Testing Dataset |
|---|---|---|
| Label 0 Background | 85,463 | 56,975 |
| Label 1 Brocoli green weeds 1 | 3014 | 2009 |
| Label 2 Brocoli green weeds 2 | 5588 | 3725 |
| Label 3 Fallow | 2964 | 1976 |
| Label 4 Fallow rough plow | 2091 | 1394 |
| Label 5 Fallow smooth | 4017 | 2678 |
| Label 6 Stubble | 5939 | 3959 |
| Label 7 Celery | 5369 | 3579 |
| Label 8 Grapes untrained | 16,907 | 11,271 |
| Label 9 Soil Vinyard develop | 9305 | 6203 |
| Label 10 Corn senesced green weeds | 4917 | 3278 |
| Label 11 Lettuce romaine 4wk | 1602 | 1068 |
| Label 12 Lettuce romaine 5wk | 2891 | 1927 |
| Label 13 Lettuce romaine 6wk | 1374 | 916 |
| Label 14 Lettuce romaine 7wk | 1605 | 1070 |
| Label 15 Vinyard untrained | 10,902 | 7268 |
| Label 16 Vinyard vertical trellis | 2711 | 1807 |
| 166,655 | 111,103 |
| Class | Random Forest | KNN | SVM | 3D-DWT+Random Forest | 3D-DWT+KNN | 3D-DWT+SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | ||||
| 0 | 83.1 | 88.2 | 96.2 | 95.0 | 84.1 | 88.3 | 98.2 | 92.1 | 95.2 | 97.3 | 92.2 | 95.9 |
| 1 | 46.2 | 90.2 | 86.4 | 96.7 | 100 | 92.2 | 95.3 | 92.1 | 100 | 92.8 | 92.1 | 98.4 |
| 2 | 88.4 | 83.7 | 82.4 | 90.2 | 87.6 | 94.2 | 95.4 | 88.2 | 94.4 | 94.4 | 89.2 | 99.3 |
| 3 | 87.9 | 68.4 | 91.3 | 67.0 | 68.1 | 92.4 | 92.5 | 89.7 | 93.5 | 93.1 | 90.3 | 98.7 |
| 4 | 70.3 | 82.4 | 89.4 | 72.6 | 84.5 | 92.7 | 91.6 | 86.5 | 92.6 | 83.4 | 85.6 | 95.4 |
| 5 | 81.2 | 80.2 | 86.2 | 93.1 | 94.8 | 84.8 | 92.3 | 96.2 | 92.3 | 89.2 | 97.0 | 96.0 |
| 6 | 91.2 | 72.2 | 93.1 | 83.9 | 85.4 | 92.8 | 94.1 | 92.6 | 94.1 | 93.0 | 93.3 | 98.6 |
| 7 | 88.4 | 86.5 | 91.4 | 89.5 | 85.7 | 92.2 | 94.8 | 86.4 | 94.8 | 94.0 | 88.6 | 98.7 |
| 8 | 84.5 | 90.7 | 90.2 | 76.2 | 95.2 | 95.6 | 92.9 | 93.6 | 95.9 | 96.3 | 93.2 | 97.0 |
| 9 | 84.5 | 92.6 | 92.7 | 89.2 | 100 | 100 | 97.9 | 100 | 94.9 | 96.6 | 100 | 97.4 |
| 10 | 87.5 | 90.2 | 92.6 | 52.8 | 62.3 | 72.1 | 96.8 | 85.65 | 93.8 | 96.3 | 85.1 | 97.7 |
| 11 | 83.3 | 87.5 | 88.5 | 95.6 | 92.1 | 90.7 | 93.7 | 90.3 | 92.7 | 90.7 | 90.2 | 96.5 |
| 12 | 75.6 | 88.6 | 82.7 | 85.7 | 88.9 | 92.9 | 92.7 | 89.2 | 92.7 | 86.4 | 90.7 | 98.7 |
| 13 | 82.2 | 86.2 | 88.6 | 97.8 | 96.9 | 98.4 | 92.0 | 95.7 | 92.4 | 92.8 | 94.9 | 94.8 |
| 14 | 84.5 | 88.4 | 92.4 | 92.8 | 93.8 | 87.6 | 91.5 | 82.7 | 93.5 | 90.7 | 82.6 | 94.5 |
| 15 | 86.5 | 85.2 | 90.2 | 89.7 | 90.2 | 93.6 | 91.4 | 88.2 | 92.4 | 89.8 | 86.8 | 95.7 |
| 16 | 81.5 | 89.1 | 92.3 | 96.6 | 93.4 | 78.2 | 96.7 | 81.4 | 89.7 | 96.2 | 80.0 | 98.9 |
| Class | Random Forest | KNN | SVM | 3D-DWT+Random Forest | 3D-DWT+KNN | 3D-DWT+SVM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | Haar Filters | Coiflets Filters | Fejer-Korovkin Filters | ||||
| Overall Accuracy (OA) | 84.2 | 88.2 | 90.1 | 86.2 | 88.7 | 86.2 | 96.1 | 78.4 | 96.1 | 91.9 | 88.5 | 96.7 |
| Average Accuracy (AA) | 86.6 | 90.2 | 92.4 | 89.6 | 90.7 | 92.9 | 91.2 | 88.5 | 93.2 | 92.4 | 89.5 | 97.1 |
| Kappa Coefficient | 6.92 | 5.83 | 6.24 | 8.13 | 7.88 | 7.67 | 8.42 | 7.82 | 7.86 | 8.42 | 8.51 | 8.62 |
| Algorithms | Indian Pines | Salinas Scene | |||
|---|---|---|---|---|---|
| Training Time (Sec) | Object Prediction Speed (Sec) | Training Time | Object Prediction Speed (Sec) | ||
| Haar Wavelet | Random Forest | 91.6 | 8000 | 98.3 | 8000 |
| KNN | 85.58 | 4100 | 93.5 | 4100 | |
| SVM | 107.26 | 5000 | 130.42 | 5000 | |
| Coiflets filters | Random Forest | 88.03 | 5900 | 95.42 | 5900 |
| KNN | 86.3 | 4200 | 92.66 | 4200 | |
| SVM | 104.85 | 4800 | 110.35 | 4800 | |
| Fejer-Korovkin filters | Random Forest | 103.45 | 8900 | 113.54 | 8900 |
| KNN | 82.82 | 4200 | 101.23 | 4200 | |
| SVM | 118.88 | 5000 | 142.47 | 5000 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anand, R.; Veni, S.; Aravinth, J. Robust Classification Technique for Hyperspectral Images Based on 3D-Discrete Wavelet Transform. Remote Sens. 2021, 13, 1255. https://doi.org/10.3390/rs13071255
Anand R, Veni S, Aravinth J. Robust Classification Technique for Hyperspectral Images Based on 3D-Discrete Wavelet Transform. Remote Sensing. 2021; 13(7):1255. https://doi.org/10.3390/rs13071255
Chicago/Turabian StyleAnand, R, S Veni, and J Aravinth. 2021. "Robust Classification Technique for Hyperspectral Images Based on 3D-Discrete Wavelet Transform" Remote Sensing 13, no. 7: 1255. https://doi.org/10.3390/rs13071255
APA StyleAnand, R., Veni, S., & Aravinth, J. (2021). Robust Classification Technique for Hyperspectral Images Based on 3D-Discrete Wavelet Transform. Remote Sensing, 13(7), 1255. https://doi.org/10.3390/rs13071255