1. Introduction
With the fast development of science and technology, the automation in industry is being improved gradually. Big developments have been made in mobile robotics since it involves automation, computer science, artificial intelligence, and so on. Simultaneous Localization and Mapping (SLAM) has always been the focus of the robot navigation for many decades; SLAM is the basic and necessary factor for mobile robot to realize location and obstacle avoidance. It means that moving objects only depend on the sensors they carry to locate themselves in the process of motion and map the surrounding environment at the same time. Because cameras are cheaper, smaller, and more informative than laser sensors, vision-based SLAM (V-SLAM) technology has become a research hotspot [
1,
2].
However, relying only on monocular camera information to locate a mobile robot in navigation creates a problem of scale ambiguity, and the true length of the trajectory cannot be obtained. This is the scale ambiguity in monocular SLAM, which limits extensive application. RGB-D camera can obtain color image and depth image at the same time, but its measurement distance is limited and contains too much noise [
3]. A two-dimensional laser scanner is widely used in indoor positioning, but it contains too little information to perform complex tasks. Three-dimensional laser scanners are not widely used because of its high price. In order to solve this defect, more and more solutions tend to use the sensor fusion method, making use of the different characteristics of data acquired by sensors to complement each sensor’s advantages and achieve better results [
4,
5]. In different sensor modes, the combination of a monocular camera and an IMU has good robustness and low cost, so this combination is a potential solution.
SLAM technology, which combines vision and an IMU, is also called a Visual-Inertial Navigation System (VINS) [
6]. The camera provides abundant environmental information for motion recovery and the identification of visited sites. However, the IMU sensor provides its own motion state information, which can restore the scale information for monocular vision, estimate the gravity direction, and provide visual absolute pitch and rolling information. The complementary nature of the two components makes them obtain higher accuracy and better robustness for the system.
The representative work of vision-based SLAM includes Parallel Tracking and Mapping (PATM) [
7], Fast semi-direct monocular visual odometry (SVO) [
8], Large-Scale Direct monocular SLAM (LSD-SLAM) [
9], and ORB-SLAM [
10]. Liu et al. [
11,
12,
13,
14] gave a detailed overview of the existing work. This paper also summarizes the current classic visual SLAM scheme as shown in
Table 1. This work focuses on the research status of monocular vision and IMU fusion. The easiest way to combine monocular vision with an IMU is loose coupling [
15,
16], which treats an IMU as a separate module to assist in visually solving the results of structure from motion. The loosely coupled method is mainly produced with an Extended Kalman Filter (EKF) algorithm; that is, the IMU data are used for state estimation, and the pose calculated by the monocular vision is updated. The state estimation algorithms based on the tight coupling method are the EKF algorithm [
17,
18,
19] and the graph optimization algorithm [
20,
21,
22,
23]. The tight coupling method is a joint optimization of the raw data obtained by the IMU and the monocular camera. The Multi-State Constraint Kalman Filter (MSCKF) [
17] scheme is a better method based on the EKF method, which maintains several previous camera poses and uses the same feature points for multi-view projection to form a multi-constrained update. The optimal method based on bundle adjustment is used to optimize all the variables to obtain the optimal solution. Because an iterative solution to nonlinear systems requires a large amount of computing resources, it is difficult to achieve a real-time solution with a platform of limited computing resources. In order to ensure the consistency of the algorithm complexity of the pose estimation, sliding window filtering is usually used [
21,
22,
23].
In practice, the measurement frequency of an IMU is generally 100–1000 Hz, which is much higher than the camera shooting frequency. This can lead to more complicated state estimation problems. To this end, the most straightforward solution is to use the EKF method to estimate the state using IMU measurements [
15,
16] and then use the camera data to update the state prediction values.
Another method is the use of pre-integration theory, which appears in the framework of graph optimization, in order to avoid repeating the integration of IMU data and reducing the amount of calculation. This theory was first proposed by Lupton [
24], and it uses the Euler angle to parameterize the rotation error. An on-manifold rotation formulation for IMU-pre-integration was developed by Shen et al. [
20], who further derived the covariance propagation using continuous-time IMU error state dynamics. However, this formulation does not consider the random walk error in the IMU measurement process. Forster [
25] further completed the theory and increased the correction of the IMU random walk bias.
The integration of IMU into monocular SLAM will make a system more complicated, attracting many new problems, including different sensor time synchronization problems, initialization problems, data reception asynchronous problems, and nonlinear optimization. At present, the research on the positioning and navigation system based on monocular camera and IMU fusion has achieved some results, as shown in
Table 2.
Based on a monocular visual-inertial navigation system (VINS-mono), a state-of-the-art fusion performance of monocular vision and IMU, this paper designs a new initialization scheme that can calculate the acceleration bias as a variable during the initialization process so that it can be applied to low-cost IMU sensors. Besides, in order to obtain better initialization accuracy, visual matching positioning method based on feature point method is used to assist the initialization process. After the initialization process, it switches to optical flow tracking visual positioning mode to reduce the computational complexity. By using the above method, the advantages of feature point method and optical flow method can be fused, and this scheme has better performance in the comprehensive performance of positioning accuracy and robustness under the low-cost sensors. Through experiments and analysis with scenarios in the EuRoc dataset and campus environment, the results show that the initial values obtained through this process can efficiently be used to launch nonlinear visual-inertial state estimator and positioning accuracy of the improved VINS-mono has been improved by about 10% according to VINS-mono.
The rest of this study is organized as follows. In
Section 2, the improved VINS-mono system overall framework is given; then, the initialization process of the improved VINS-mono is described in
Section 3. Next, the local visual-inertial bundle adjustment with relocalization is presented in
Section 4. The experiment result and analysis are shown in
Section 5. Finally, a conclusion is drawn in
Section 6.
2. Improved VINS-Mono System Overall Framework
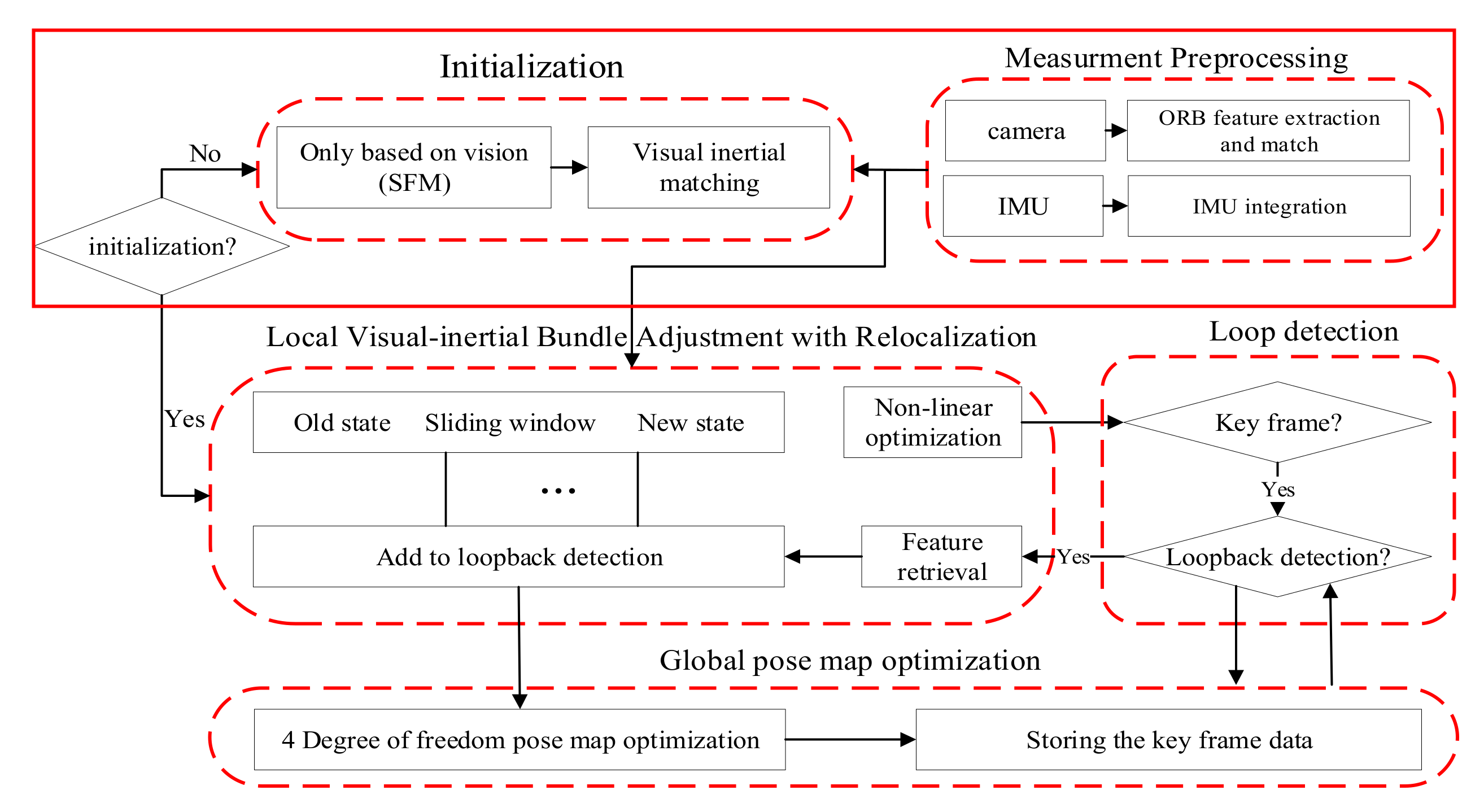
Both a monocular VINS and a visual SLAM essentially state estimation problems. Based on the VINS-mono project, this paper uses nonlinear optimization to couple IMU and camera data in a tightly coupled manner. The functional modules of the improved VINS-mono consist of five parts: data preprocessing, initialization, back-end nonlinear optimization, closed-loop detection, and closed-loop optimization. The code mainly opens four threads, including front-end image matching, back-end nonlinear optimization, closed-loop detection, and closed-loop optimization. The overall frame of the improved VINS-mono system is shown in
Figure 1, where the red solid line represents the improvement parts compared with the VINS-mono. The main functions of each functional module are as follows.
(1) Image and IMU preprocessing. The acquired image is processed with a pyramid presentation. The ORB feature points are extracted from each layer of the image. The adjacent frames are matched according to the feature points method. The outliers are removed by Random Sample Consensus (RANSAC) [
31]. Finally, the tracking feature points are pushed into the image queue, and a notification is sent to the back end for processing. The IMU data are integrated to obtain the position, velocity, and rotation (PVQ) of the current time, and the pre-integration increments of the adjacent frames, the Jacobian matrix, and the covariance terms of the pre-integration errors used in the back-end optimization are calculated.
(2) Initialization. Structure From Motion (SFM) [
32] is used for the pure visual estimation of the poses and 3D positions of all key frames in the sliding window. Then, the initial parameter calculation is performed by combining the IMU pre-integration results.
(3) Local visual-inertial bundle adjustment with relocalization. The visual constraints, IMU constraints, and closed-loop constraints are put into a large objective function for nonlinear optimization in order to solve the speed, position, attitude, and bias of all frames in the sliding window.
(4) Closed-loop detection and optimization. The Open-Source Library-Dictionary Bag-of-Words (DBoW3) is used for closed-loop detection. When the detection is successful, the relocation is performed, and finally the entire camera trajectory is closed-loop optimized.
3. The Initialization Process of the Improved VINS-Mono
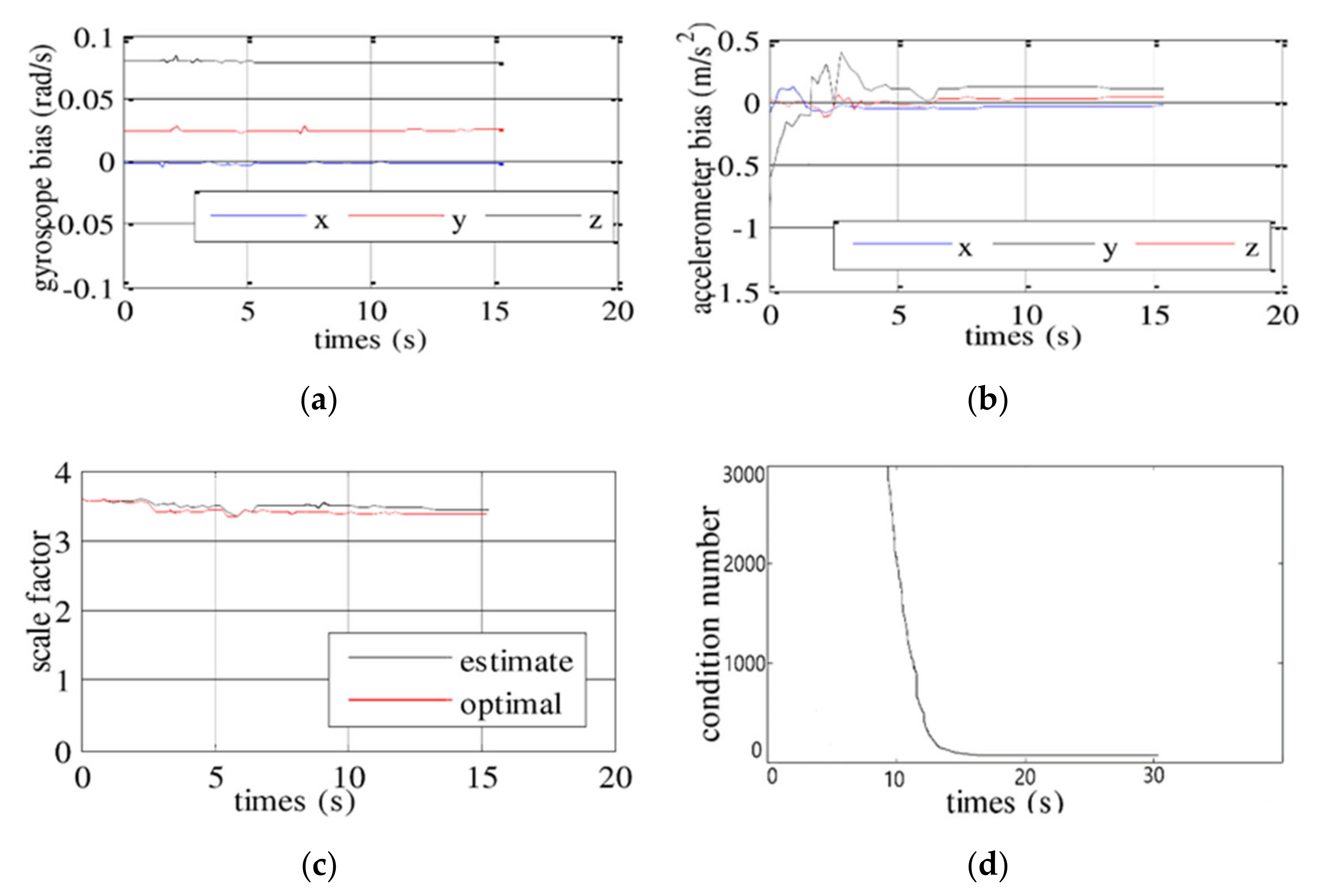
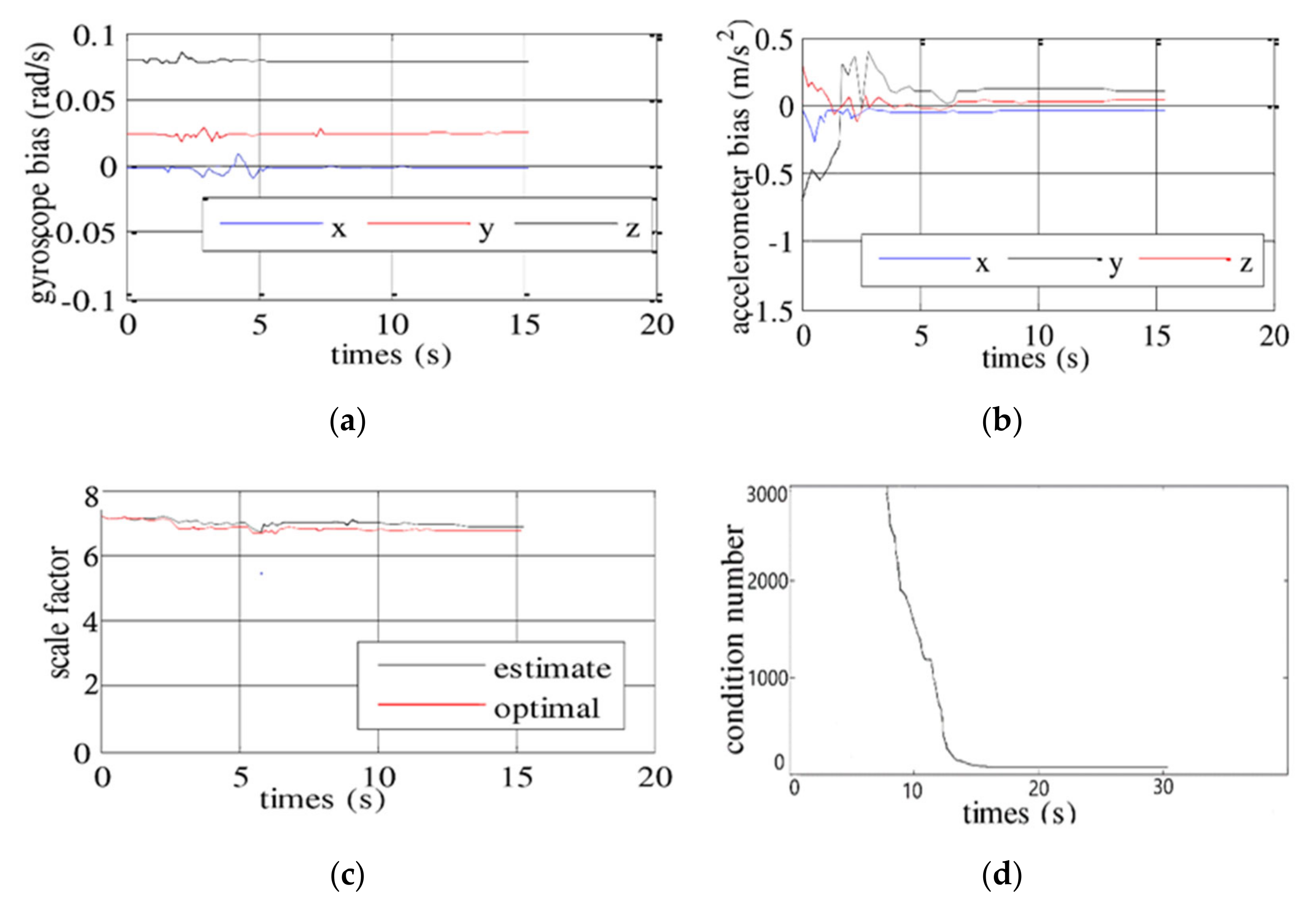
VINS-mono does not initialize acceleration bias which simply sets its initial value to zero, which is not applicable to low-precision IMUs. The initialization result directly affects the robustness and positioning accuracy of the entire tightly coupled system.
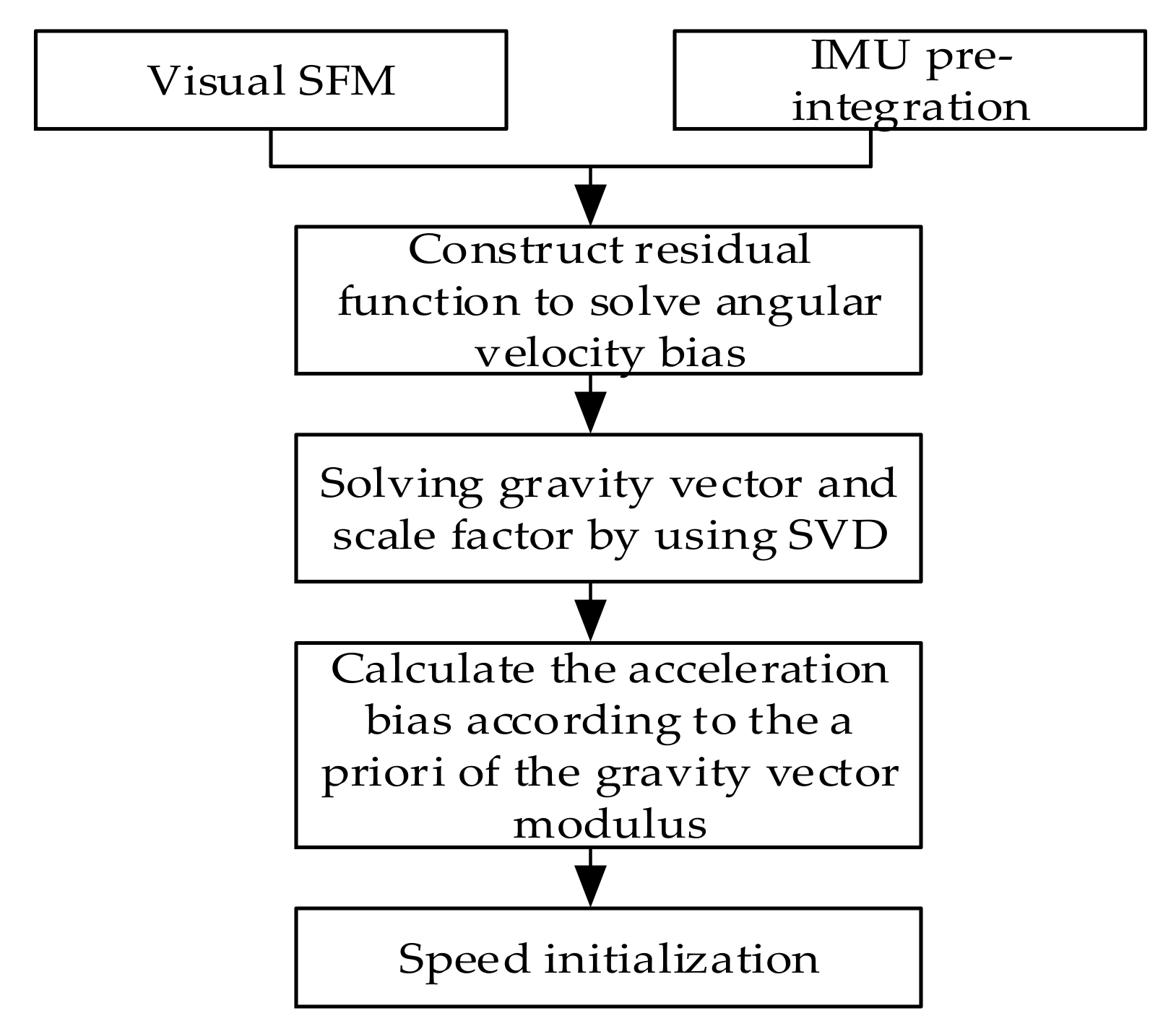
In this paper, a new initialization scheme is designed, which can calculate the acceleration bias during the initialization process so that it can be applied to low-cost IMU sensors. Besides, the ORB feature point method is used instead of optical flow method to make the initialization model more accurate and robust during the initialization process.
The VINS-mono visual processing uses the optical flow tracking method. The accuracy of the pose solved by the optical flow tracking is not as good as the feature point matching, which has a great influence on the accuracy of the initialization and is directly related to the accuracy of the subsequent motion estimation. In order to improve this situation, in this paper, the ORB feature point method is used for pose estimation in the initialization phase. The flow of the initialization is shown in
Figure 2.
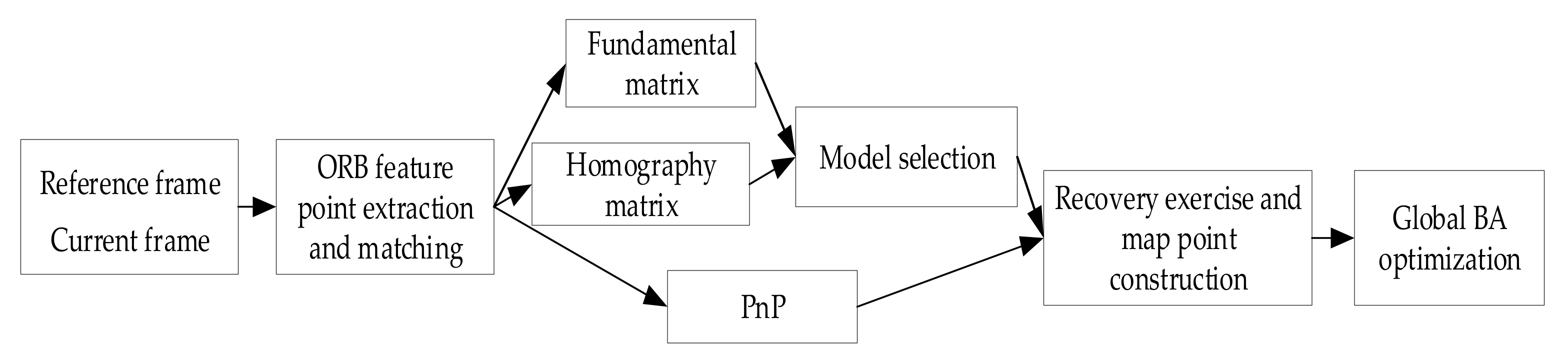
3.1. Visual SFM
The visual initialization uses the key frames image sequences in the initial time about 10 s to perform the pose calculation and triangulation as well as further global optimization. The selection of the image key frame is mainly based on the distance of the parallax, and when the parallax distance is greater than a certain threshold, it is selected as a key frame. The vision based SFM technique is used to obtain the more accurate pose and image point coordinates of the key frame sequence. This provides more accurate pose parameters for IMU initialization. In order to make the visual initialization independent of the scene, that is, to determine whether the initial scene is flat or non-planar, a relatively accurate initial value can be obtained. The two initial key frames images of the system adopt a parallel computing fundamental matrix and a homography matrix method and choose the right model according to a specific mechanism. The scene scale is fixed, and the triangle points are initialized according to the initial two key frames, then the Perspective-n-Point (PnP) algorithm is used to restore motion and continuously triangulate to restore the map point coordinates. After tracking a sequence, a Bundle Adjustment (BA) is constructed based on the projection error of the image coordinates for global optimization, and the optimized map points and poses are obtained, as shown in
Figure 3.
3.1.1. Two Parallel Computing Models and Model Selection
During the movement of the camera, the visual initialization may occur for the case of pure rotation or the distribution of feature points on the same plane. In this case, the degree of freedom of the fundamental matrix is degraded, and a unique solution cannot be obtained. Therefore, in order to make the initialization more robust, two models of parallel computing for the fundamental matrix and homography matrix are adopted. Finally, a model is chosen with a lower re-projection error, and the motion and map construction resume.
In practice, there are a large number of mismatches in feature matching. Using these points directly is inaccurate for solving the fundamental matrix and the homography matrix. Therefore, the RANSAC algorithm is used in the system to remove the mismatched pairs. Then, using the remaining pairs of points to solve the fundamental matrix and the homography matrix, the pose transformation under different models is further derived. Since the monocular vision has scale uncertainty, the scale needs to be normalized in the decomposition process. The initial map points can then be further triangulated by the two models.
Finally, the pose parameters recovered by the two models are used to calculate the re-projection error, and the model with a lower re-projection error is selected for motion recovery and map construction.
3.1.2. BA Optimization
In the system, after the visual initialization, there are already triangular map points, and the pose of remaining key frames can be solved with 3D-2D. In order to prevent the degradation of the map points in this process, it is necessary to continuously triangulate the map points and finally construct a Bundle Adjustment (BA) based on the key frame data. The position and pose of the camera and the coordinates of the map points are optimized, and the objective function of the optimization is as follows:
In the formula, represents the number of key frames, represents the number of map points visible in each frame, represents the re-projection error of the pixel coordinates, and represents the weight matrix.
3.2. Visual-inertial Alignment
The purpose of visual-inertial alignment is to use the results of the visual SFM to decouple the IMU and calculate its initial values separately. The initialization process can be decomposed into four small problems in order to solve:
- (1)
Estimation of the gyroscope bias
- (2)
Estimation of the scale and the gravitational acceleration
- (3)
Estimation of the acceleration bias and the optimization of the scale and gravity
- (4)
Speed estimation
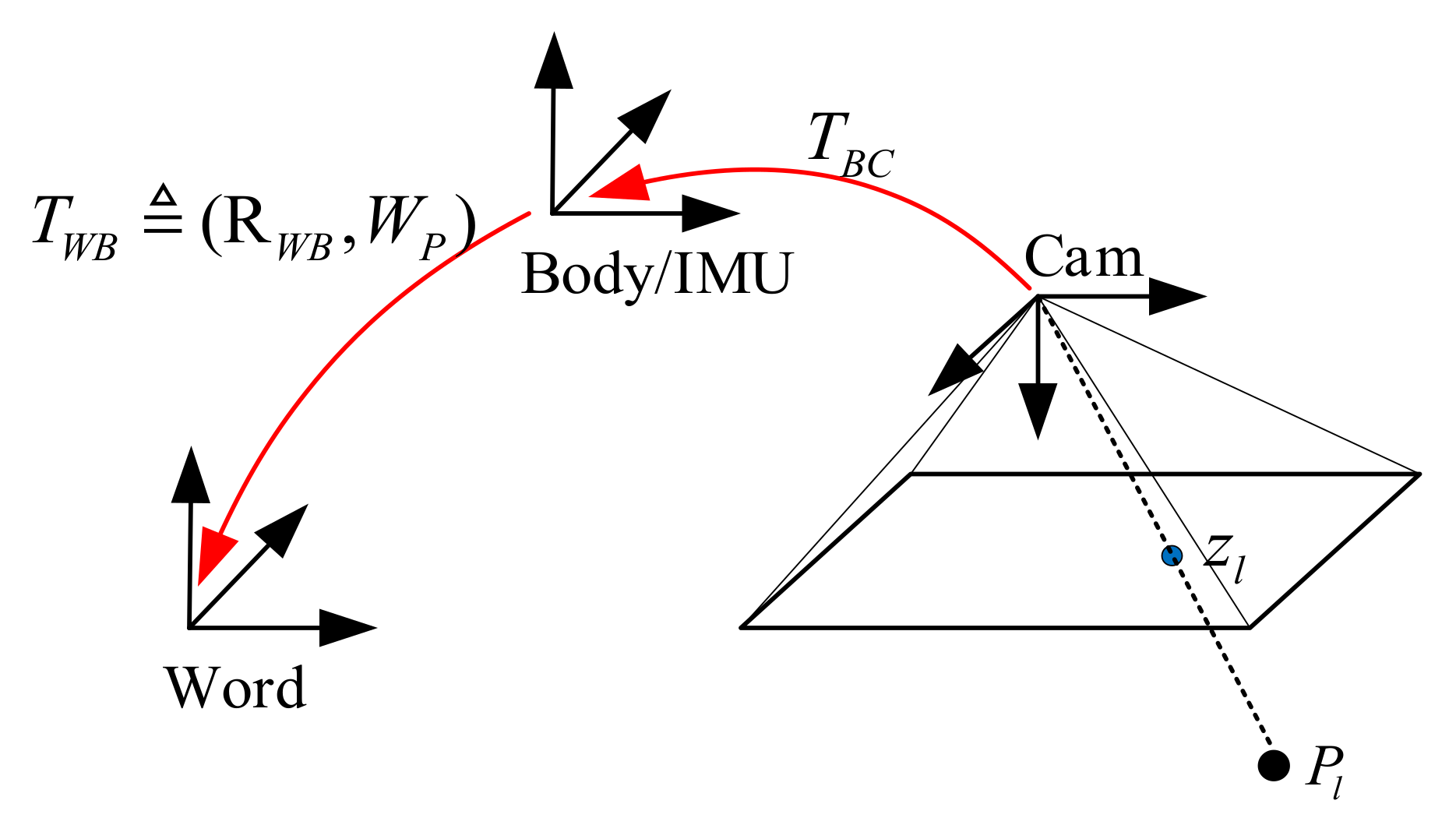
In order to describe the movement of the rigid body in three-dimensional space and the positional relationship between the camera and the IMU sensor mounted on the rigid body, the positional transformation relationship is defined as shown in
Figure 4. The IMU coordinate system and the rigid body coordinate system (body) are defined as coinciding.
represents the transformation of the coordinates in the camera coordinates to the IMU coordinate system, and it is composed of
and
.
denotes the transformation relationship between the rigid body coordinate system and the world coordinate system (
denotes the rotating part, and
denotes the translation part).
and
represent world coordinates and image plane coordinates, respectively.
3.2.1. Gyro Bias Estimation
The bias of the gyroscope can be decoupled from the result of the rotation calculated by the visual SFM and the result of the IMU pre-integration. During the initialization process, it can be assumed that is a constant and does not change over time. Throughout the initialization process, the rotation of the adjacent key frames can be solved by the visual SFM. The rotation between adjacent frames can also be obtained by the pre-integration of the IMU. Assuming that the rotation matrix obtained by visual SFM is accurate, the value of can be calculated indirectly using the difference between the two rotation matrices corresponding to Lie algebra. The exponential map (at the identity) Exp: so(3)→SO(3) associates an element of the Lie Algebra to a rotation and coincides with the standard matrix exponential (Rodrigues’ formula).
The calculation formula is as follows:
where the Jacobians
account for a first-order approximation of the effect of changing the gyroscope biases without explicitly recomputing the pre-integrations. Both pre-integrations and Jacobians can be efficiently computed iteratively as IMU measurements arrive [
28]. The above formula
,
represents the number of key frames, and
represents the integral value of the gyroscope between two adjacent key frames. The superscript
represents the time of the key frame.
can be obtained with visual SFM, and
is the rotation matrix of the IMU coordinate system in the camera coordinate system. Formula (2) can be solved with the Levenberg–Marquard algorithm based on nonlinear optimization, which is more robust than the Gauss–Newton method, and the value of
can be decoupled.
3.2.2. Scale and Gravity Estimation
is calculated, brought into the pre-integration formula again, and then the position, speed, and rotation between adjacent frames are recalculated. Because the position calculated by visual SFM does not have real scale, the conversion between the camera coordinate system and the IMU coordinate system includes a scale factor s. The transformation equation of the two coordinate systems is as follows [
26]:
It can be seen from the IMU pre-integration [
28] that the motion between the two consecutive key frames can be written as follows:
In the formula, represents the world coordinate system, and represents the IMU coordinate system or carrier coordinate system.
The accelerometer bias is relatively small to the gravitational acceleration, and therefore can then be neglected. When Formula (4) is introduced in Formula (3), the following formula is obtained:
The purpose of this formula is to solve for the scale factor s and the gravity vector. It can be seen that the above equation contains velocity variables. To reduce the computation and to eliminate the velocity variables, the following transformations are performed. Formula (5) is a three-dimensional linear equation. The data of the three key frames can be used to list the two sets of linear equations, and the velocity variables can be eliminated by using the speed relationship of Formula (4). We can write Formula (5) as a vector form:
To facilitate the description, three keyframe symbols,
,
, and
are written as 4, 5, and 6. The specific forms are as follows:
Formula (6) can be constructed as a linear system in the form of
. The scale factor and the gravity vector form a four-dimensional variable, so at least four frames of key frame data are needed for a Singular Value Decomposition (SVD) [
33] solution.
3.2.3. Estimation of the Acceleration Deviation and the Optimization of the Scale and Gravity
It can be seen from Formula (5) that the accelerometer bias is not considered in the process of solving for the gravity and the scale factor, because the biases of the acceleration and gravity are difficult to distinguish, but it is easy to form a pathological system without considering the bias of the accelerometer. In order to increase the observability of the system, some prior knowledge is introduced. It is known that the gravitational acceleration of the Earth
is 9.8
, and the direction points to the center of the earth. Under the inertial reference frame, the direction vector of gravity is considered to be
According to
, the direction
of gravity can be calculated, and the rotation matrix of the inertial coordinate system to the world coordinate system can be further calculated, as follows [
26]:
So, the gravity vector can be written as:
The z-axis of the world coordinate system is aligned with the gravity direction, so
only needs to parameterize and optimize the angle around the x-axis and the y-axis. The perturbation is used to optimize the rotation as follows:
The first-order approximation of Formula (10) is obtained as follows:
Formula (11) is introduced into Formula (3), then the bias of acceleration is taken into consideration, and the following formula is obtained:
Similar to Formula (6), in three consecutive key frames, speed variables can be eliminated, and the following forms can be obtained:
is the same as Formula (6).
,
, and
are written as follows:
In formula (14), the represents the first two columns of the matrix. According to the relationship between the consecutive key frames, a similar form of the linear system can be constructed according to Formula (13). This linear system has six variables and equations, so at least four keyframe datasets are needed to solve the linear system. The ratio of the maximum singular value to the minimum singular value is obtained by SVD decomposition to verify whether the problem is well solved. If the ratio is less than a certain threshold, Formula (12) can be re-linearized to solve the problem iteratively.
According to the above subsections, , ,
, and have been determined. So far, there are only variables related to velocity. At this time, the speed of each key frame can be calculated by substituting , , , and into Formula (12).
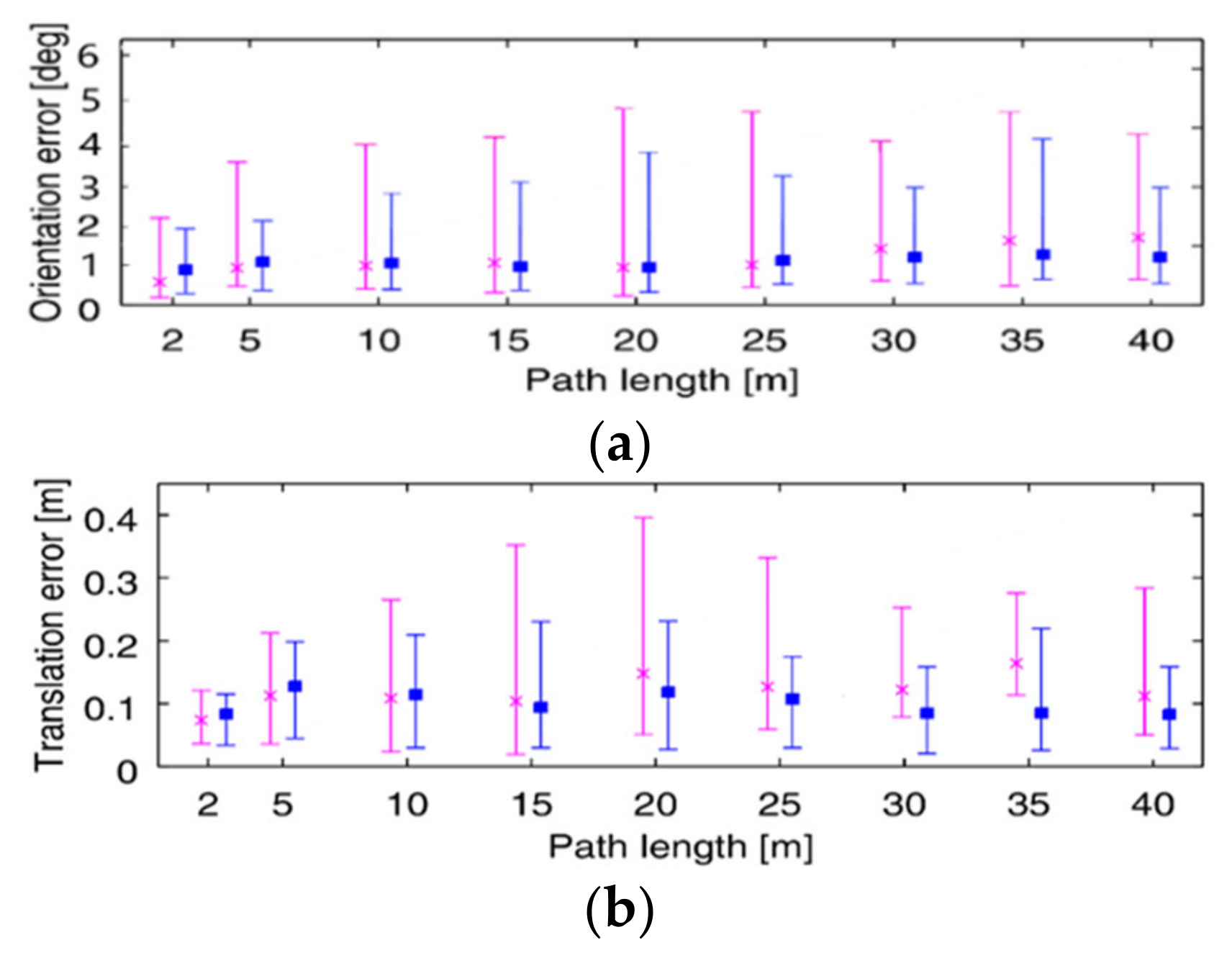
6. Conclusions
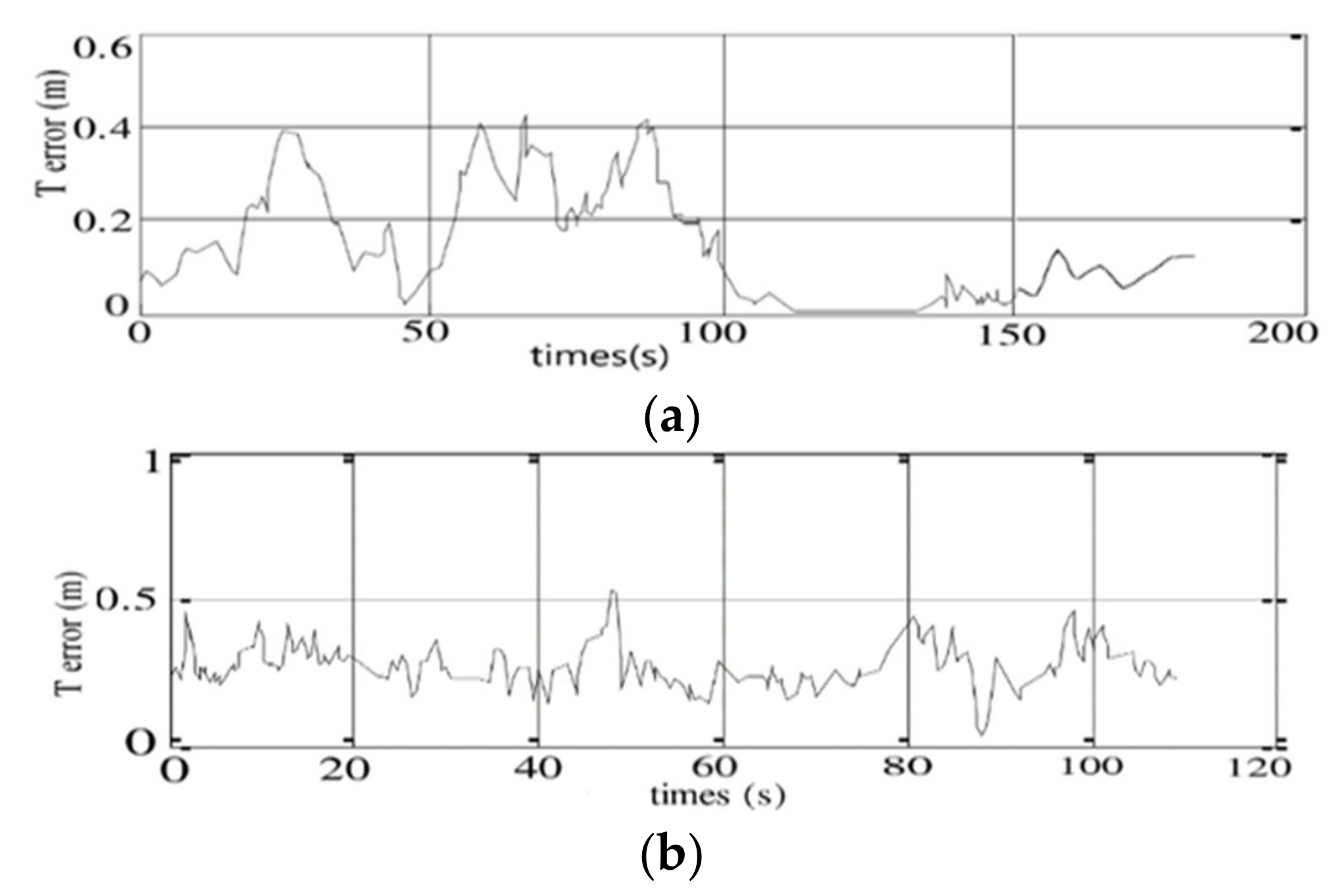
In this study, an initialization scheme was suggested to improve the accuracy and robustness of the visual-inertial navigation system. For this purpose, this paper designs a new initialization scheme which can calculate the acceleration bias as a variable during the initialization process so that it can be applied to low-cost IMU sensors. Besides, in order to obtain better initialization accuracy, a visual matching positioning method based on feature point method is used to assist the initialization process. After the initialization process, it switches to optical flow tracking visual positioning mode to reduce the calculation complexity. In the research, the improved VINS-mono was tested based on the unveiled dataset EuRoc and campus environment. The results show that the improved VINS-mono scheme completes the entire initialization process within approximately 10 s and can efficiently facilitate initialization with low-cost sensors. Due to the stricter initialization scheme to avoid the result from falling into the local minimum, the positioning accuracy is also improved.
The improved VINS-mono scheme still uses bag-of-word for loopback detection, but it can easily cause false results for loopback detection especially in an indoor environment that has many similar scenes. Therefore, further improvement of the robustness of the system loop detection is needed. Besides, this scheme can generate sparse point clouds information and it is necessary to generate dense 3D point clouds information of environment based on the video stream captured by camera real-time in the next work. In addition, it is necessary to fuse more sensor information to improve the positioning accuracy and robustness further in next step.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}