1. Introduction
In the past decade, deep learning methods have achieved milestones in various fields. For object recognition and scene understanding in aerial images, significant achievements have been made as a result of deep-learning-based algorithms. However, deep learning algorithms require a large amount of data for training and testing, and the scale of the data determines the upper limit of the model and the final results. For generic object recognition, it is relatively easy to obtain a large amount of data from the real world to constitute a sufficiently large dataset, such as VOC [
1], COCO [
2], OID [
3], Objects365 [
4], and other datasets, which usually contain tens of thousands or even millions of images, and dozens or even hundreds of categories of instance examples. These large-scale datasets have greatly promoted the development of computer vision algorithms and related applications.
However, aerial image datasets are usually more difficult to collect due to their distinctive perspectives and relatively rare sources. Existing aerial image datasets include VEDAI [
5], COWC [
6], HRSC2016 [
7], DOTA [
8], DIOR [
9], and LEVIR [
10], and these datasets are relatively small in scale. Furthermore, the individual datasets for each direction and application of aerial imagery will be much smaller than generic datasets. In addition, compared with generic object recognition datasets, aerial image datasets will have higher resolution over thousands or tens of thousands of pixels, whereas the scales of their example objects are much smaller and the proportion of small objects is higher. The characteristics of these aerial image datasets make it more difficult and often more expensive to accurately label their example objects. Additionally, because of their different data sources, viewpoints, acquisition heights, and environmental scenes, the differences between aerial image datasets are usually very large. Even data from a single source can have the problem of regional differences, thus it is also difficult to mix or reuse different aerial image object recognition datasets. This results in even greater data shortage problems for the already relatively scarce aerial image datasets.
One of the solutions to the data shortage is the use of synthetic data, and realistic game engines or 3D video engines are often used to create the data needed. Finding ways to use these tools to acquire data and rapidly and automatically complete annotation tasks quickly is a very active area of research. Some recent works have provided much inspiration in this field, and these have included the validation and testing of autonomous driving in a virtual environment [
11,
12,
13,
14] and the use of reinforcement learning to accomplish tasks in a virtual environment [
15]. In the area of computer vision, recent works have considered the construction of synthetic data for detection [
16], segmentation [
17,
18], pedestrian re-identification [
19,
20] or vehicle re-identification [
21] with the help of virtual engines, and the study of synthetic data for tasks such as action recognition using 3D models [
22]. The excellent results of these works fully demonstrate that it is possible and indeed achievable to implement and improve existing tasks using synthetic data. In a 3D virtual environment, a large amount of data can be easily generated from different scenes, different environments, and different objects, and the locations of their objects and the instances can be easily obtained and labeled, simultaneously solving the problems of difficult access to datasets and the difficulties encountered in labeling.
Based on previous works, this work used Unity, a 3D engine tool, to create a synthetic dataset for ship recognition in aerial images, called UnityShip. This is the first large-scale synthetic dataset for ship recognition in aerial images. UnityShip dataset consists of 79 ship models in ten categories and six virtual scenes, and it contains over 100,000 images and 194,054 instance objects. Each instance object has horizontal bounding box annotation, oriented bounding boxes annotation, fine-grained categories, and specific instance ID and scene information for tasks such as horizontal object detection, rotated object detection, fine-grained object recognition, ship re-identification, and scene understanding.
To generate a large-scale, realistic, and generalized dataset, it is necessary to take into account the variations in the spatial resolutions of sensors and their observation angles, the time of day for collection, object shadows, and the variation of lighting environments caused by the position of the sun relative to the sensor. Additionally, gravity, collision, and other effects need to be implemented by the physics engine. Therefore, we designed two weather environments (with or without clouds), four time periods (morning, noon, afternoon, and night) and their corresponding four light intensities, as well as shooting at different altitudes to obtain a rich and diverse synthetic dataset. This method can be used not only for the generation of ship object datasets in aerial images but also for the generation of other aerial image objects such as vehicles and buildings, bringing new inspiration for object recognition and dataset collection in aerial images.
To validate the application and effectiveness of the synthetic data in specific recognition tasks, we divided the created synthetic dataset into UnityShip-100k and UnityShip-10k. UnityShip-100k was used to validate the synthetic data for model pre-training, and UnityShip-10k was used to validate the synthetic data for data augmentation. We collected six real-world aerial image datasets containing ship objects for validating the synthetic datasets: AirBus-Ship [
23], DIOR [
9], DOTA [
8], HRSC2016 [
7], LEVIR [
10], and TGRS-HRRSD [
24]. The details of these datasets are given in
Section 4.1. Three representative object detection algorithms, the two-stage object detection algorithm Faster RCNN [
25], the single-stage object detection algorithm RetinaNet [
26], and the anchor-free object detection algorithm FCOS [
27], were used to comprehensively validate the effects of the synthetic data on model pre-training and data augmentation for real-world data. The specific setup and results of the experiments are presented in
Section 4.
The main contributions of the paper can be summarized as follows:
The first large-scale synthetic dataset for ship object recognition and analysis in aerial images, UnityShips, was created. This dataset contains over 100,000 images and 194,054 example objects collected from 79 ship models in ten categories and six large virtual scenes with different weather, time of day, light intensity, and altitude settings. This dataset exceeds existing real-world ship recognition datasets in terms of the number of images and instances.
UnityShip contains horizontal bounding boxes, oriented bounding boxes, fine-grained category information, instance ID information, and scene information. It can be used for tasks such as horizontal object detection, rotated object detection, fine-grained recognition, re-identification, scene recognition, and other computer vision tasks.
Along with six existing real-world datasets, we have validated the role of synthetic data in model pre-training and data augmentation. The results of our experiments conducted on three prevalent object detection algorithms show that the inclusion of synthetic data provides greater improvements for small-sized and medium-sized datasets.
3. UnityShip Dataset
In
Section 3.1, we describe the collection and annotation processes used to create the UnityShip dataset and give a detailed description of the scene resources, ship models, and environmental information. In
Section 3.2, we provide statistics regarding the detailed attributes of the UnityShip dataset, including the location distribution, density distribution, scale distribution, and category distribution of the instance objects, as well as the scene statistics for each different attribute. In
Section 3.3, we give visual examples of the UnityShip synthetic dataset compared with the real-world aerial images from the ship object detection datasets.
3.1. Collection of UnityShip Dataset
We used the Unity engine as a tool for creating 3D virtual environments. Unity (
https://unity.com, accessed on 6 December 2021) is a platform for creating 3D content, and it provides authoring tools to freely build the terrain and models needed for a scene using real-time rendering technology. The Unity engine can use components such as cameras to constantly acquire photos of a scene and output them in layers according to where the content is located for easy image processing. It has a rich application programming interface (API) interface that can be used for scripting programs to control the components within a scene.
Using the Unity 3D engine, it is possible to build scenes and objects that are comparable to those encountered in real applications and to obtain a large number of composite images. However, to create a large, sufficiently realistic, and generalized synthetic dataset, one must take into account the factors including variation in sensor spatial resolutions and viewing angles, the time of collecting, object shadows, and changes in lighting due to the position of the sun relative to the sensor, and environmental changes. In this work, random individual attributes, including multiple parameters such as weather, collection time, sunlight intensity, viewing angle, model, and distribution density, were adjusted to create a diverse and heterogeneous dataset. A total of 79 ship models from ten categories were included, each with different sizes and types of ships, as shown in
Figure 1. There were six large virtual scenes, including sea, harbor, island, river, and beach. Two weather environments (with or without clouds), four time periods (morning, noon, afternoon, night) with their corresponding four light intensities were used in each virtual scene, as well as different altitudes. This approach allowed rich and varied virtual data to be obtained. Examples of images at the same location with different random attribute settings are shown in
Figure 2.
We used the built-in Unity API to control the generation of virtual cameras, ships, clouds, and other items in the virtual engine; two types of the shooting were used: spot shooting and scanning shooting at certain spatial intervals. The specific component-generation methods and settings were as follows.
Camera model. In the Unity virtual environment, we used the camera component to generate the camera model. To simulate the perspective of aerial images, the camera mode was set to top-down with the horizontal field of view set to 60 degrees, and images with a resolution of 2000 × 1600 were captured. To generate more images of multi-scale ship objects as possible, we randomly placed the camera at a specific and reasonable altitude during each capture.
Ship model. We generated the number of ships according to the height of the camera. The number of ships was increased with the height. Before each acquisition, a certain number of ships were randomly selected from the 79 pre-imported ships, and the coordinates and rotation angles of the ships were randomly obtained within the camera’s range. As the terrain in the scene is hollow, to prevent ships from spawning inside the terrain or crossing with other objects and causing the shot to fail, we added collision-body components to all ship models and set collision triggers for them so that the models and data were automatically cleared when the ship hit another collision body. A transparent geometric collision body exactly filling the land was used to detect collisions, preventing ship models from being generated on land.
Environment model. We randomly generated direct sunlight using a range of variables, including the position of the sun, the angle of direct sunlight, and the intensity of the light, to characterize the local time and season in a physical sense. In addition, we used random values to determine whether the clouds should be generated and their concentration. To reduce the amount of computer rendering effort required and the time taken to generate the scenes, the fog was only generated within a range that the camera could capture.
While constructing various models for generating virtual composite images, we used the component layering function in Unity to extract ship information from the object layer and obtain image annotation information through threshold segmentation and image morphology operations; each ship was accurately annotated with a horizontal bounding box and an oriented bounding box. Moreover, for additional research purposes, we also annotated each ship’s subdivision category, instance ID, scene information, and other annotations, building a foundation for subsequent tasks such as fine-grained object recognition, re-identification, and scene analysis.
3.2. Statistics of the UnityShip Dataset
Through the above method, a dataset of 105,086 synthetic images was generated for ship recognition in aerial images. As noted, the ship objects in each image are annotated with horizontal and rotated bounding boxes, along with the subclasses and inter-class ID of the ships, as shown in
Figure 3, in which the red boxes represent rotated box annotations, and the green boxes represent horizontal box annotations.
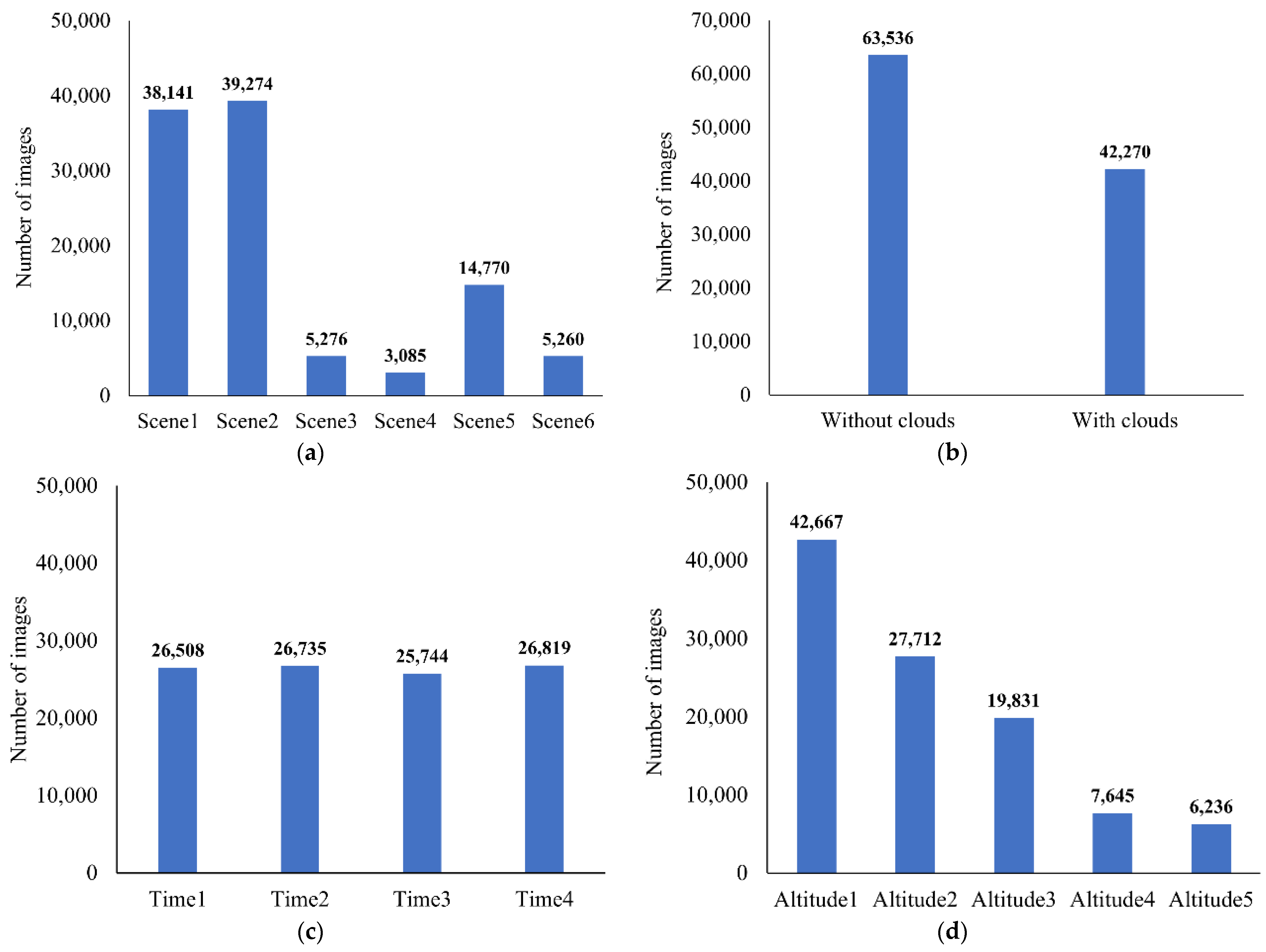
We placed ship models in six large virtual scenes with different environmental parameters, including the presence or absence of clouds, different capture altitudes, and capture times. The statistical results of the scenario information are shown in
Figure 4. Among all six scenes, the first and second were used for the majority of the images because they were larger in scale and had a greater range of ocean scenes available for capture. The remaining images were mainly collected from restricted-range sections such as islands and rivers and were less numerous. The number of images containing clouds constitutes around 40% of the total, far exceeding the proportion of natural scenes that contain clouds, providing research data for ship recognition in complex and extreme environments. Analysis in terms of the acquisition altitudes of the data shows a higher proportion of ships with higher altitudes. In terms of the acquisition time, a random selection from a set period of time was made before each image acquisition so that the distribution of times was even.
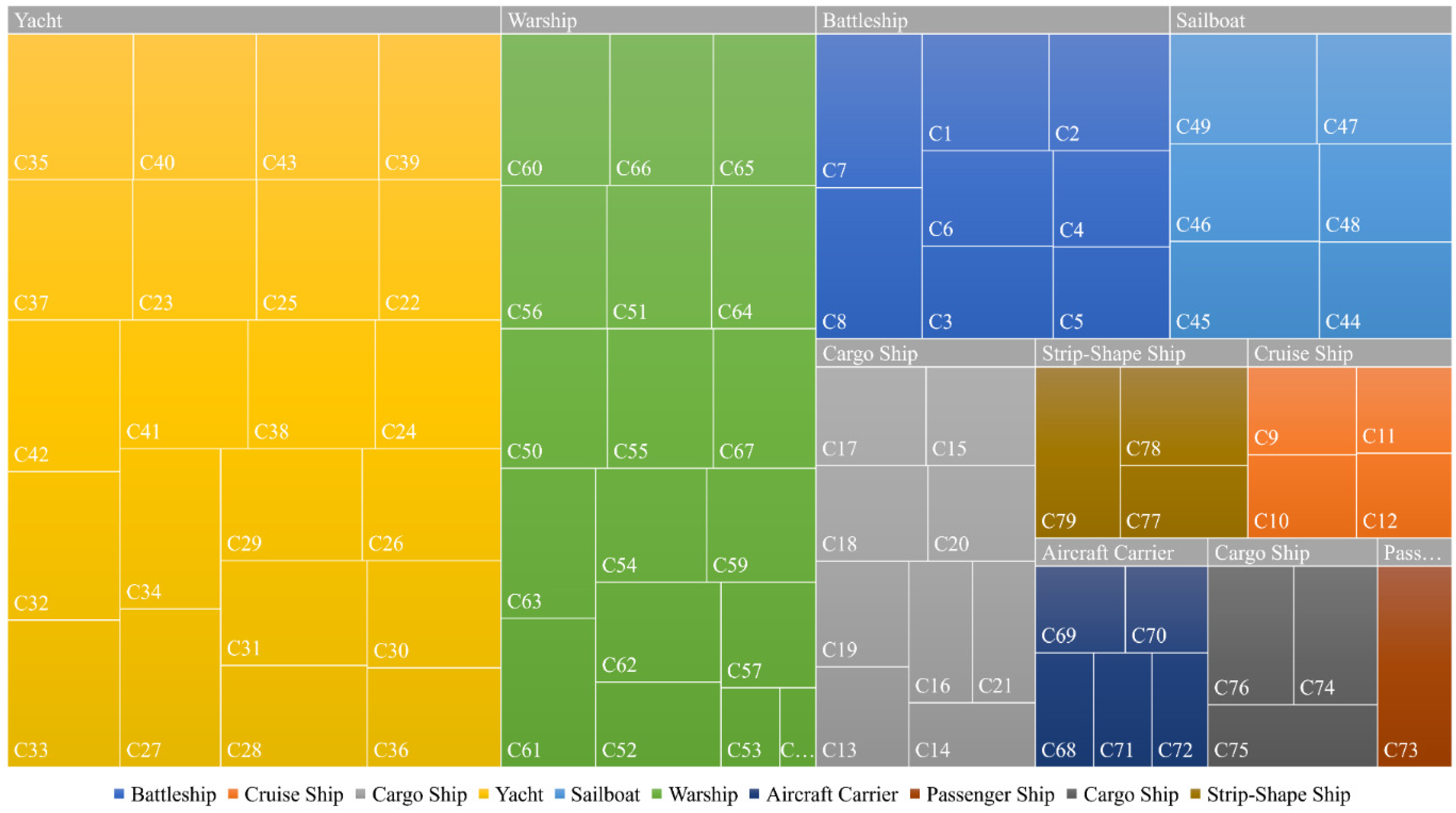
The most significant feature of the UnityShip dataset, as well as its most prominent advantage over real-world datasets, is the availability of accurate and detailed ship categories and specific instance ID, which can be used for tasks such as fine-grained ship detection and ship re-identification. As shown in
Figure 5, UnityShip contains ten specific categories (Battleship, Cruise Ship, Cargo Ship, Yacht, Sailship, Warship, Aircraft Carrier, Passenger Ship, Cargo Ship, and Strip-Shape Ship), and a total of 79 different instances of ship objects, with the specific distribution shown in
Figure 5a; the distribution of the number of instances of ships in each category is shown in
Figure 5b. The number of instances is proportional to the number of categories, as each placement was randomly selected from the 79 ships. We also counted the distribution of ship instances in the subcategories, as shown in
Figure 6.
For the instance-level objects, we also calculated statistics regarding the attributes of the dataset, including the location distribution, scale distribution, and density distribution of the ship instances. As shown in
Figure 7, the distribution of ship objects in the images is relatively even, as we have randomly placed them in suitable locations. We also counted the distribution of all instances, and it is clear that the vast majority of the images contain fewer than four ships In addition, we counted the distribution of relative width (ratio of instance width to image width), relative height (ratio of instance height to image height) and relative area (ratio of instance area to image area) of all ship instances. The results indicate that most of the ships have a relative width and relative height distribution below 0.1, and similarly a relative area distribution below 0.02, as shown in
Figure 8.
3.3. Comparison with Real-World Datasets
We took two existing real-world datasets for ship object detection in aerial images (AirBus-Ship [
23] and HRSC2016 [
7]) and four datasets containing ship categories in aerial images (DOTA [
8], DIOR [
9], LEVIR [
10], and TGRS-HRRSD [
24]) and extracted parts of those datasets containing ship objects. The extremely large images of the DOTA [
8] dataset were cropped to smaller images of 1000×1000 pixels on average; the datasets are described and divided in detail in
Section 4.1.
Table 3 shows a comparison of the properties of these six datasets with the synthetic dataset in
Table 3. It is observed that our synthetic dataset has the largest size in terms of the number of images and the largest number of ships. Another significant difference is the average number of instances per image, with the UnityShip dataset having an example density distribution closer to the AirBus-Ship, HRSC2016, LEVIR, and TGRS-HRRSD datasets, whereas the DOTA and DIOR dataset have a higher density of ship distribution. We selected some representative images from these six datasets, as shown in
Figure 9 and
Figure 10; it is clear that the reason for the difference in the instance density distribution is that the ship objects in the DOTA and DIOR datasets are mainly distributed in near-coast and port locations, where a large number of ships often gather. We also selected some images from UnityShip, and visually, this synthetic dataset is most similar to the AirBus-Ship, LEVIR, and TGRS-HRRSD datasets.
4. Experiments and Results
To explore the use of synthetic datasets and the results of the augmentation of existing datasets, we used the synthetic dataset UnityShip and six existing real-world datasets to complete separate model pre-training experiments using UnityShip100k (containing all synthetic images) and UnityShip10k (containing 10,000 synthetic images) as additional data experiments for data augmentation.
Section 4.1 details the dataset partitioning and gives other details of these six real-world datasets and the synthetic dataset.
Section 4.2 explains the environment and detailed settings of the experiments.
Section 4.3 and
Section 4.4 mainly show the results of model pre-training and data augmentation;
Section 4.5 summarizes and discusses the experimental results.
4.1. Dataset Partitioning
AirBus Ship. The AirBus Ship dataset was released in 2019 and is used for the Kaggle data competition “AirBus Ship Detection Challenge”; it is one of the largest datasets publicly available for ship detection in aerial images. The original dataset is labeled in mask form for instance segmentation task. In this experiment, we transformed this labeling into horizontal bounding box. The original training dataset (the test dataset and labels are not available) has a total of 192,556 images, containing 150,000 negative samples that do not contain any ships. We selected only positive samples for the experiment, resulting in 42,556 images and 81,011 instances. We randomly divided the dataset in the ratio 6:2:2 for the training, validation, and testing sets, respectively.
DIOR. The DIOR dataset is a large-scale object detection dataset for object detection in optical remote sensing images. The dataset contains a total of 20 categories, and these are large in scale with respect to the number of object classes, images, and instances. We extracted ship data totaling 2702 images and 61,371 example objects. Most of the ship objects are located in ports and near coasts with a dense distribution. Again, we randomly divide the dataset into training, validation, and testing sets in the ratio 6:2:2.
DOTA. DOTA is a large-scale dataset containing 15 categories for object recognition in aerial images. In this work, we extracted images containing ship categories and cropped them to 1000 × 1000 pixels with an overlap rate of 0.5, creating a total of 2704 images and 80,164 ship objects. Once more, these were randomly divided into training, validation, and testing sets in the ratio 6:2:2.
HRSC2016. HRSC2016 is a dataset collected from Google Earth for ship detection in aerial imagery; it contains 1070 images and 2971 ship objects. All images in the dataset are from six well-known ports, with image resolutions between 2 m and 0.4 m and image sizes ranging from 300 to about 1500 pixels. The training, validation, and testing sets contain 436, 181, and 444 images, respectively. All annotations contain horizontal and rotated frames and have detailed annotations of geographic locations as well as ship attributes.
LEVIR. LEVIR is mainly used for aerial remote sensing object detection; it includes aircraft, ships (including offshore and surface ships), and oil tanks. The LEVIR dataset consists of a large number of Google Earth images with ground resolutions of 0.2 to 1.0 m; it also contains common human habitats and environments, including countryside, mountains, and oceans. We extracted the fraction containing ships, resulting in 1494 images and 2961 ship objects. This was divided into training, validation, and testing sets in the ratio 6:2:2.
TGRS-HRRSD. TGRS-HRRSD is a large-scale dataset for remote sensing image object detection; all images are from Baidu Maps and Google Maps, with ground resolutions from 0.15 to about 1.2 m, and it includes 13 categories of objects. The sample size is relatively balanced among the categories, and each category has about 4000 samples. We extracted those images containing ships from them, creating a total of 2165 images and 3954 ship objects. These were again divided into training, validation, and testing sets in the ratio 6:2:2.
4.2. Implementation
The experiments described in this section were implemented by PyTorch and MMDetection [
60]. By convention, all images in this paper were scaled to a size of 600 to 800 pixels without changing their aspect ratio. SGD was used as the default optimizer, and four NVIDIA GeForce 2080 Ti were used to train the model. The initial learning rate was set to 0.01 (two images on each GPU) or 0.05 (one image on each GPU) for Faster RCNN [
25], and 0.05 (two images on each GPU) or 0.0025 (one image on each GPU) for RetinaNet [
26] and FCOS [
27]. The models in this paper were trained using the backbone ResNet50 [
61], and used the feature fusion structure FPN [
62] by default. If not explicitly stated, all hyperparameters and structures follow the default settings in MMDetection.
All reported results follow the COCO [
2] metrics, including AP, which represents the average precision for the IoU interval from 0.5 to 0.95 at 0.05 intervals, and AP
50, which represents the average precision when the IoU takes the value of 0.5. The average recall (AR), which represents the average recall obtained for the representative IoU interval from 0.5 to 0.95 at 0.05 intervals, was also calculated.
4.3. Model Pre-Training Experiments
To verify the utility of the synthetic dataset presented here for model pre-training in a detailed and comprehensive manner, the following experiments were conducted on six datasets using Faster RCNN, RetinaNet, and FCOS, including: (1) training the object detection algorithm from scratch using GN [
63] in both the detection head and the feature extraction backbone network, with a training schedule using 72 and 144 epochs, respectively; (2) using the default ImageNet pre-training model ResNet50 according to the default settings in MMDetection with a training schedule using 12 and 24 epochs, respectively; (3) using the synthetic dataset UnityShip100k to obtain pre-trained models, then use the same settings in (2) and train 12 and 24 epochs.
The results of the model pre-training experiments are shown in
Table 4 and
Table 5. Compared with pre-training the backbone network with ImageNet, training from scratch can achieve better results on larger datasets, and pre-training with the UnityShip dataset achieved better results in small- to medium-sized datasets. To be specific, compared with pre-training with ImageNet: (1) in the experiments on the large AirBus-Ship and DOTA datasets, training from scratch achieved more significant improvements in all three algorithms, and pre-training with the UnityShip dataset achieved similar results in all three algorithms; (2) in the experiments on the medium- or small-sized datasets DIOR, HRSC2016, LEVIR and TGRS-HRRSD, pre-training with the UnityShip dataset brought more significant improvements. We compare the values of mAP under different settings for each dataset in detail in
Table 4.
4.4. Data Augmentation Experiments
In the experiments on data augmentation, we used the training-set portion of Unity-Ship 10k (containing 6000 images) as additional data and added this to the existing six real-world datasets to verify the role of synthetic data for data augmentation. The results of these experiments are shown in
Table 6 and
Table 7, in which the results with and without data augmentation are compared, respectively.
Similar to the results presented in
Section 4.2, compared with the results without data augmentation, using UnityShip synthetic data as additional data achieved comparable results with large datasets (AirBus-Ship, DOTA), whereas more significant improvements were seen with small- and medium-sized datasets (DIOR, HRSC2016, LEVIR, and TGRS-HRRSD).
4.5. Discussion
The larger datasets (AirBus-Ship and DOTA) are better and more stable when using the scratch training method, and a more significant improvement is obtained in the smaller datasets (HRSC2016, LEVIR, and TGRS-HRRSD) by using the UnityShip pre-training. The reason for this may be that the larger datasets have enough samples to train from scratch and obtain a sufficiently accurate and generalized model without relying on the initialization of the detector structure parameters, whereas the smaller datasets rely more on a good parameter initialization method due to their relative lack of samples. In addition, similar results were obtained using ImageNet pre-training, and pre-training with the UnityShip dataset yielded bigger boosts on the single-stage algorithms (RetinaNet and FCOS) than on the two-stage algorithm (Faster RCNN). One possible reason for this is that the accuracy of two-stage algorithms is usually higher, decreasing the pre-training gain when compared with single-stage algorithms. Another possible reason is that, in contrast to single-stage algorithms, two-stage algorithms have the region proposal network, making the training process smoother and more balanced, and the gains from pre-training are thus not as obvious.
In the data augmentation experiments, a larger improvement was obtained for small datasets, and a larger improvement was obtained on the single-stage algorithms (FCOS and RetinaNet) algorithms than the two-stage algorithm (Faster RCNN). In the larger dataset, the additional data represent a relatively small proportion in terms of the number of images and instances, and they thus bring limited improvements. In addition, there are still large differences between the synthetic dataset and the real-world datasets; using the synthetic data directly and simply as additional data for data augmentation thus does not take full advantage of its potential.
Overall, this paper’s results demonstrate the beneficial impact of using larger-scale synthetic data for relatively small-scale real-world tasks. For model pre-training, some existing work has demonstrated that pretraining on large datasets and then transfer learning and fine-tuning will be valid for improving downstream tasks. However, for the object recognition task in aerial images, the significant difference between natural and aerial images is unfavorable for classifying and localizing small and dense objects. UnityShip has similar features and distributions as the ship objects in aerial images, so using the UnityShip for pretraining will be more beneficial both for the classification and localization of ship objects in aerial images. Similarly, using the synthetic dataset as additional data for data augmentation with a large number of images in various environments and scenes will effectively complement the problems posed by the sparse number of aerial images to acquire a more generalizable model.
5. Conclusions
In this paper, we present the first synthetic dataset for ship identification in aerial images, UnityShip, captured and annotated using the Unity virtual engine; this comprises over 100,000 synthetic images and 194,054 ship instances. The annotation information includes environmental information, instance-level horizontal bounding boxes, oriented bounding boxes, and the category and ID of each ship, providing the basis for object detection, rotating object detection, fine-grained recognition, scene recognition, and other tasks.
To investigate the use of the synthetic dataset, we validated the synthetic data for model pre-training and data augmentation using three different object detection algorithms. The results of our experiments indicate that for small- and medium-sized real-world datasets, the synthetic dataset provides a large improvement in model pre-training and data augmentation, demonstrating the value and application potential of synthetic data in aerial images.
However, there are some limitations to this work that also deserve consideration and improvement. First, although the UnityShip dataset exceeds existing real datasets in terms of the numbers of images and instances, it still has a lack of scene diversity and generalization, as well insufficient ship distribution in scenes such as ports and near coasts, along with differences from the details and textures of real-world images. Due to time and space constraints, this paper does not explore other possible uses of synthetic datasets, such as ship re-identification tasks in aerial images, fine-grained recognition of ships, or exploring ship recognition under different weather conditions and against different backgrounds. In addition, among the experiments that have been completed, only the relatively simple dataset pre-training and data augmentation parts have been considered in this paper; studies of topics such as dataset bias, domain bias, and domain adaption have not been carried out. In general, there are still relatively few studies on synthetic datasets in aerial images at this stage, and more in-depth research and studies on the use and research of synthetic datasets are needed.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}