
iVS Dataset and ezLabel: A Dataset and a Data Annotation Tool for Deep Learning Based ADAS Applications


Abstract
:1. Introduction
2. Data Description
2.1. Data Introduction
2.2. Data Annotation
- Vehicle: Four-wheeled machines with an engine, particularly utilized for moving humans or goods by road on land are defined as “Vehicle”, namely hatchbacks, vans, sedans, buses and trucks.
- Pedestrian: The “Pedestrian” class is categorized based as the people on the road excluding those riding the two-wheeled vehicles such as motorbikes, scooters, and bikes.
- Scooter: The third class “scooter” is considered as a combined set of the compact bounding boxes for scooters and motorbikes.
- Bikes: The last class “bikes” is defined as objects with two bigger wheels, but no rearview mirrors and license plates.
ezLabel: An Open-to-Free-Use Data Annotation Tool
2.3. Training Data
3. iVS Dataset Applications
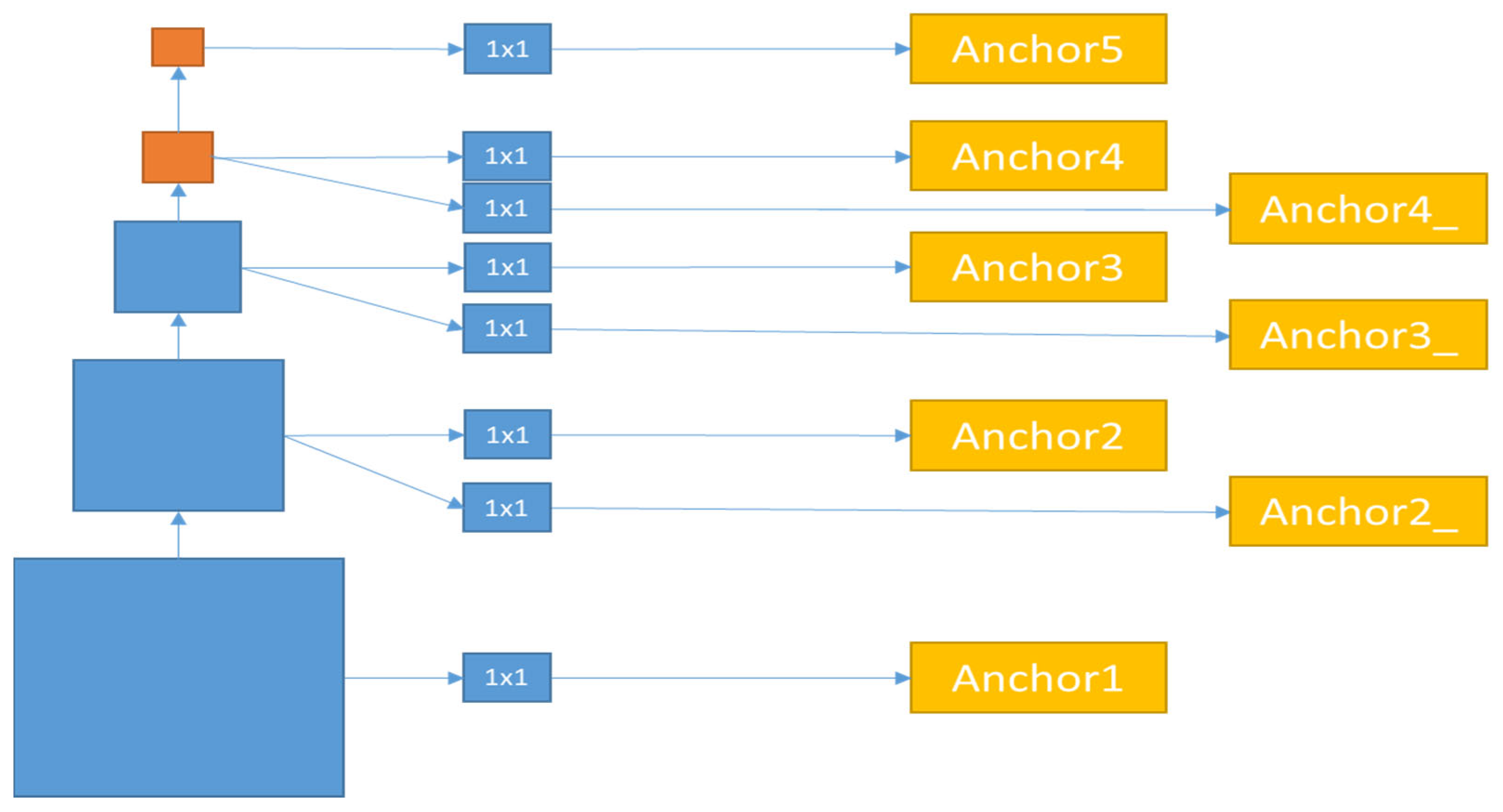
3.1. Demonstration of the CSP-Jacinto-SSD CNN Model
3.2. Task Specific Bounding Box Regressors (TSBRRs)
3.3. Competitions Based on the iVS Dataset
3.3.1. IEEE MMSP-2019 PAIR Competition
3.3.2. IEEE ICME-2020 GC PAIR Competition
3.3.3. ACM ICMR-2021 GC PAIR Competition
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS) 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yang, M.-D.; Tseng, H.-H.; Hsu, Y.-C.; Tsai, H.P. Semantic Segmentation Using Deep Learning with Vegetation Indices for Rice Lodging Identification in Multi-date UAV Visible Images. Remote Sens. 2020, 12, 633. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Everingham, K.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Computer Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Wang, C.; Liao, H.M.; Wu, Y.; Chen, P.; Hsieh, J.; Yeh, I. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Mathew, M.; Desappan, K.; Swami, P.K.; Nagori, S. Sparse, Quantized, Full Frame CNN for Low Power Embedded Devices. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 328–336. [Google Scholar]
- Lai, C.Y.; Wu, B.X.; Lee, T.H.; Shivanna, V.M.; Guo, J.I. A Light Weight Multi-Head SSD Model for ADAS Applications. In Proceedings of the 2020 International Conference on Pervasive Artificial Intelligence (ICPAI), Taipei, Taiwan, 3–5 December 2020; pp. 1–6. [Google Scholar]
- Salton, G.; McGill, M.J. Introduction to Modern Information Retrieval; McGraw-Hill: New York, NY, USA, 1986. [Google Scholar]
- Lin, G.-T.; Malligere Shivanna, V.; Guo, J.-I. A Deep-Learning Model with Task-Specific Bounding Box Regressors and Conditional Back-Propagation for Moving Object Detection in ADAS Applications. Sensors 2020, 20, 5269. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Guo, J.-I.; Tsai, C.-C.; Yang, Y.-H.; Lin, H.-W.; Wu, B.-X.; Kuo, T.-T.; Wang, L.-J. Summary Embedded Deep Learning Object Detection Model Competition. In Proceedings of the IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tsai, C.-C.; Yang, Y.-H.; Lin, H.-W.; Wu, B.-X.; Chang, E.-C.; Liu, H.-Y.; Lai, J.-S.; Chen, P.-Y.; Lin, J.-J.; Chang, J.-S.; et al. The 2020 Embedded Deep Learning Object Detection Model Compression Competition for Traffic in Asian Countries. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ni, Y.-S.; Tsai, C.-C.; Guo, J.-I.; Hwang, J.-N.; Wu, B.-X.; Hu, P.-C.; Kuo, T.-T.; Chen, P.-Y.; Kuo, H.-K. Summary on the 2021 Embedded Deep Learning Object Detection Model Compression Competition for Traffic in Asian Countries. In Proceedings of the 2021 ACM International Conference on Multimedia Retrieval (ICMR2021), Taipei, Taiwan, 21–24 August 2021. [Google Scholar]
- MediaTek Dimensity 1000+, Flagship 5 G Experiences, Incredible Performance, Supreme AI-Cameras. Available online: https://i.mediatek.com/dimensity-1000-plus (accessed on 5 January 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annotated Training Images | 89,002 |
| Annotated Validation/Testing Images | 6400 |
| Resolution | 1920 × 1080 |
| Total object in the iVS dataset | 733,108 |
| Pedestrians | 74,805 |
| Vehicles | 497,685 |
| Scooters | 153,928 |
| Bikes | 9690 |
| Base Size | |
|---|---|
| Original SSD | 16, 32, 64, 100, 300 |
| Proposed SSD | 16, 32, 64, 128, 256 |
| Input Size | 256 × 256 |
| Number of parameters | 2.78 M |
| Model complexity (Flops) | 1.08 G |
| Speed on GPU (1080Ti) | 138 fps |
| Speed on embedded platform (TI TDA2X) | 30 fps |
| YOLOv5 | CSP-Jacinto-SSD | |
|---|---|---|
| Number of parameters | 46.5 M | 2.78 M |
| Model Complexity (Flops) | 68.57 G | 1.08 G |
| Speed on GPU (1080Ti) | 50 fps | 138 fps |
| mAP(iVS dataset Test set) | 32.4 % | 23.8 % |
| Model | Vehicle AP(%) | Pedestrian AP(%) | Bikes AP(%) | Scooter AP(%) | Total mAP(%) |
|---|---|---|---|---|---|
| YOLOv5 | 51.3 | 37.4 | 13.4 | 27.5 | 32.4 |
| CSP-Jacinto-SSD | 40.7 | 27.9 | 10.8 | 15.8 | 23.8 |
| Name of the Competition | Number of Registered Contestants |
|---|---|
| IEEE MMSP-2019 PAIR Competition | 87 |
| IEEE ICME-2020 GC PAIR Competition | 128 |
| ACM ICMR-2021 GC PAIR Competition | 308 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, Y.-S.; Shivanna, V.M.; Guo, J.-I. iVS Dataset and ezLabel: A Dataset and a Data Annotation Tool for Deep Learning Based ADAS Applications. Remote Sens. 2022, 14, 833. https://doi.org/10.3390/rs14040833
Ni Y-S, Shivanna VM, Guo J-I. iVS Dataset and ezLabel: A Dataset and a Data Annotation Tool for Deep Learning Based ADAS Applications. Remote Sensing. 2022; 14(4):833. https://doi.org/10.3390/rs14040833
Chicago/Turabian StyleNi, Yu-Shu, Vinay M. Shivanna, and Jiun-In Guo. 2022. "iVS Dataset and ezLabel: A Dataset and a Data Annotation Tool for Deep Learning Based ADAS Applications" Remote Sensing 14, no. 4: 833. https://doi.org/10.3390/rs14040833
APA StyleNi, Y.-S., Shivanna, V. M., & Guo, J.-I. (2022). iVS Dataset and ezLabel: A Dataset and a Data Annotation Tool for Deep Learning Based ADAS Applications. Remote Sensing, 14(4), 833. https://doi.org/10.3390/rs14040833