
Real-Time Identification of Rice Weeds by UAV Low-Altitude Remote Sensing Based on Improved Semantic Segmentation Model



 and
and
Abstract
:1. Introduction
2. Materials and Methods
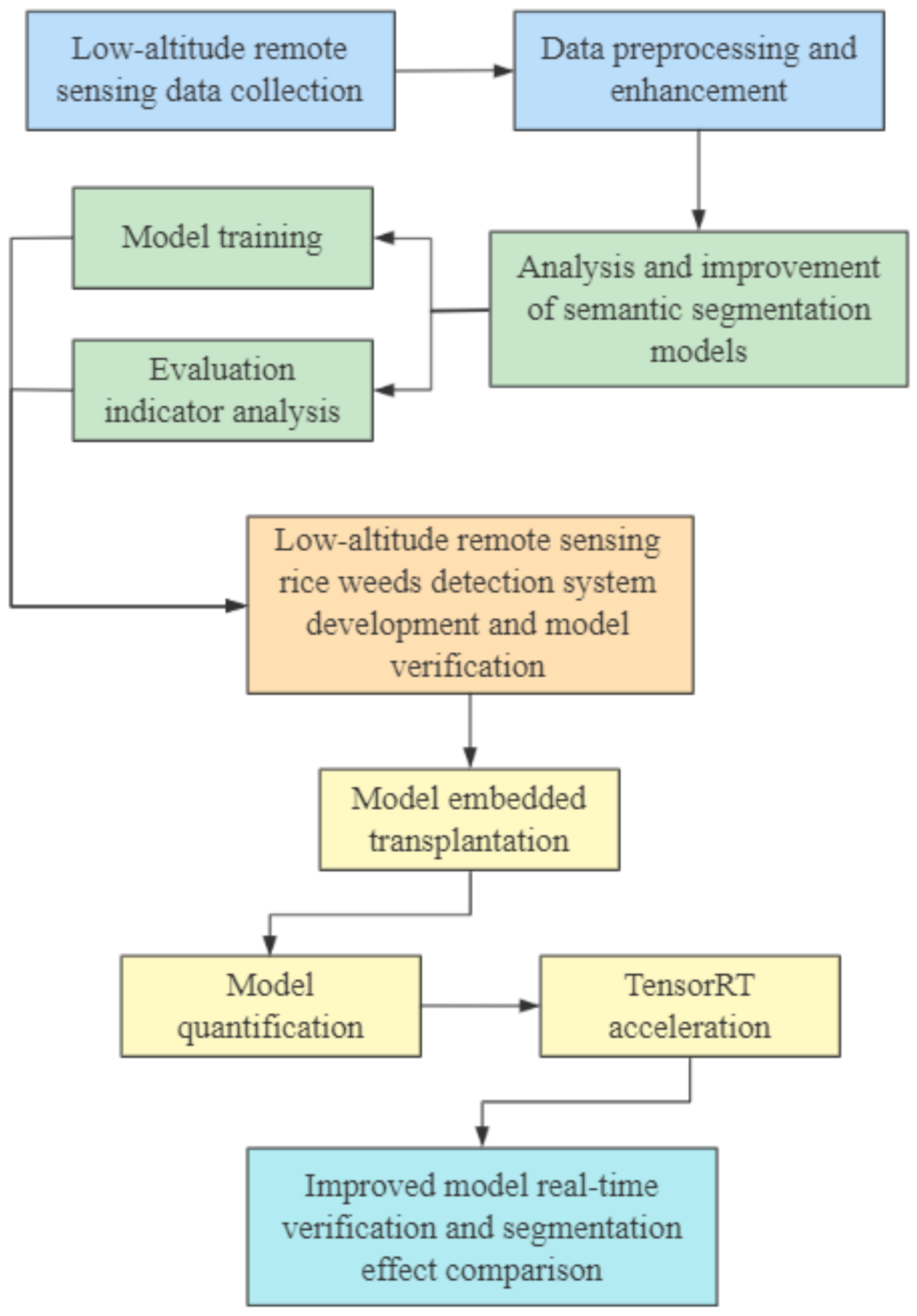
2.1. The Technical Route of the Study
- The UAV equipped with an RGB camera was used to collect low-altitude remote sensing visible image data of rice fields, and then the data preprocessing and enhancement methods in Section 2.2.2 was used to process the remote sensing data. Further, the training set and validation set were divided for the training of the semantic segmentation models.
- The deep learning semantic segmentation networks U-Net and BiSeNetV2 and their improved structures MobileNetV2-UNet and FFB-BiSeNetV2 were used to identify and analyze rice weeds in UAV remote sensing images. The training set and validation set data was used to train the semantic segmentation models. Further, through the evaluating indicators analysis, the original models and the improved models were compared the segmentation accuracy, operation efficiency, and segmentation effect in the UAV low-altitude remote sensing rice weeds images, and the optimal rice weeds segmentation model that meets the actual identification accuracy and real-time performance requirements was selected for further verification.
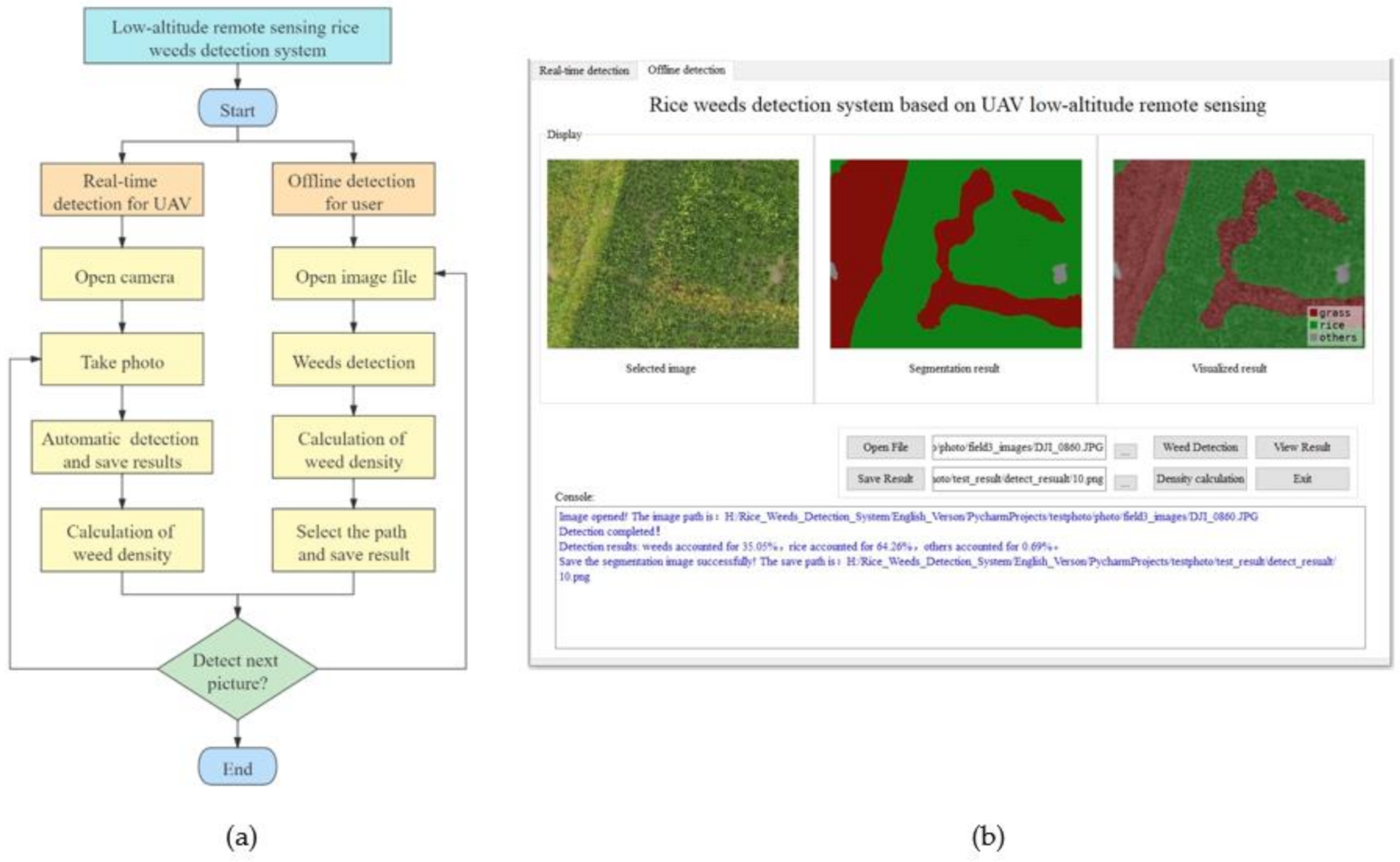
- A low-altitude remote sensing rice weed recognition system was developed to verify the practicality of the optimal rice weeds segmentation model.
- The improved semantic segmentation models were transplanted to the high-performance embedded device, the models structure was optimized through model quantization and the TensorTR [37] acceleration tool to improve inference speed of the models.
- The collected rice field video data were used to verify the real-time recognition performance and compare the segmentation effect of the improved models, which will provide a technical basis for further airborne real-time identification of rice weeds.
2.2. Image Acquisition and Preprocessing
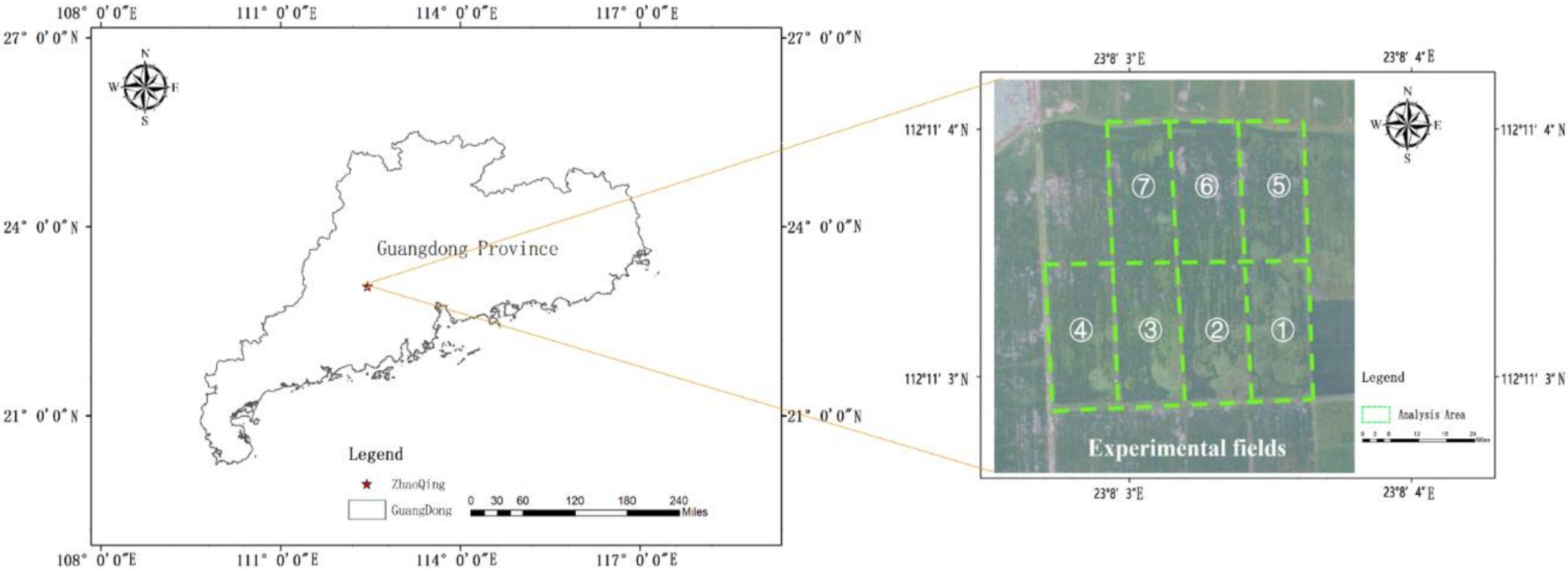
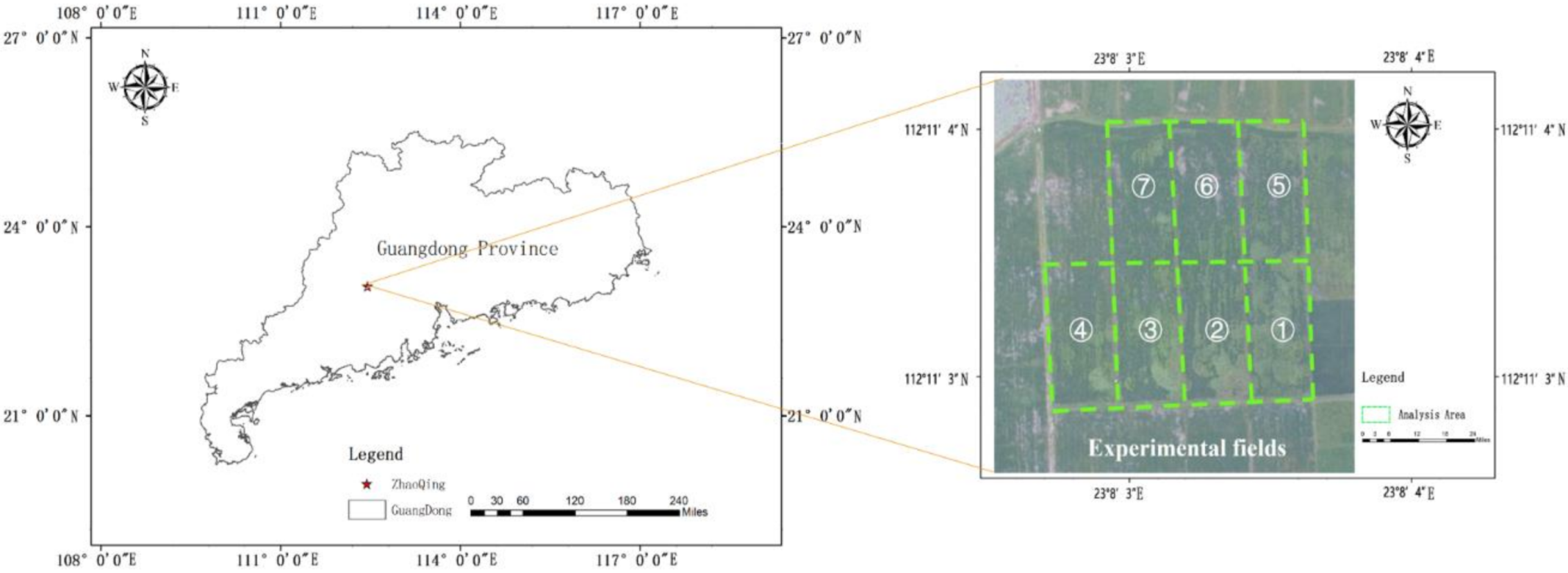
2.2.1. Image Acquisition
2.2.2. Image Data Preprocessing
2.3. Construction of Rice Weeds Identification Model
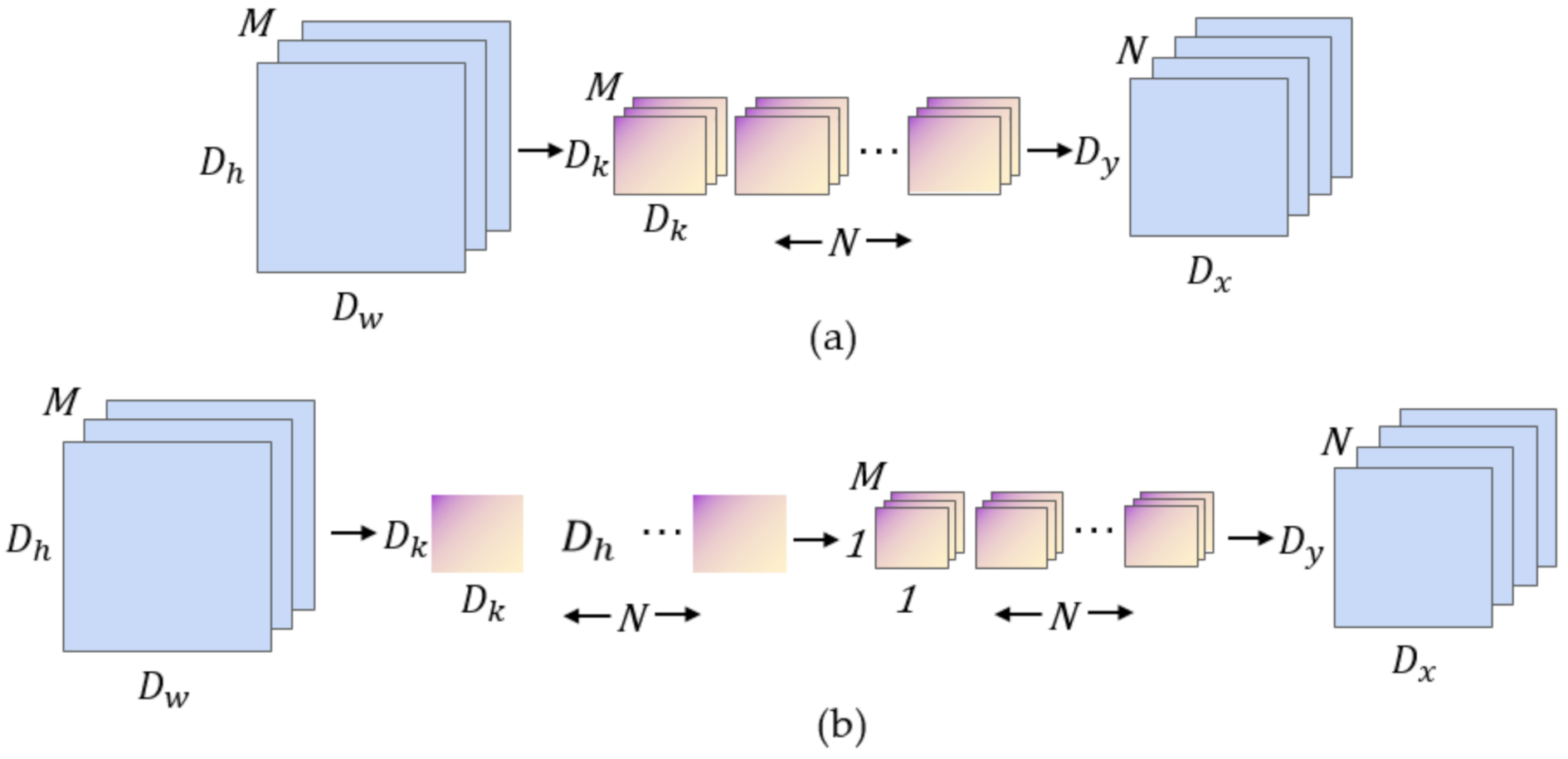
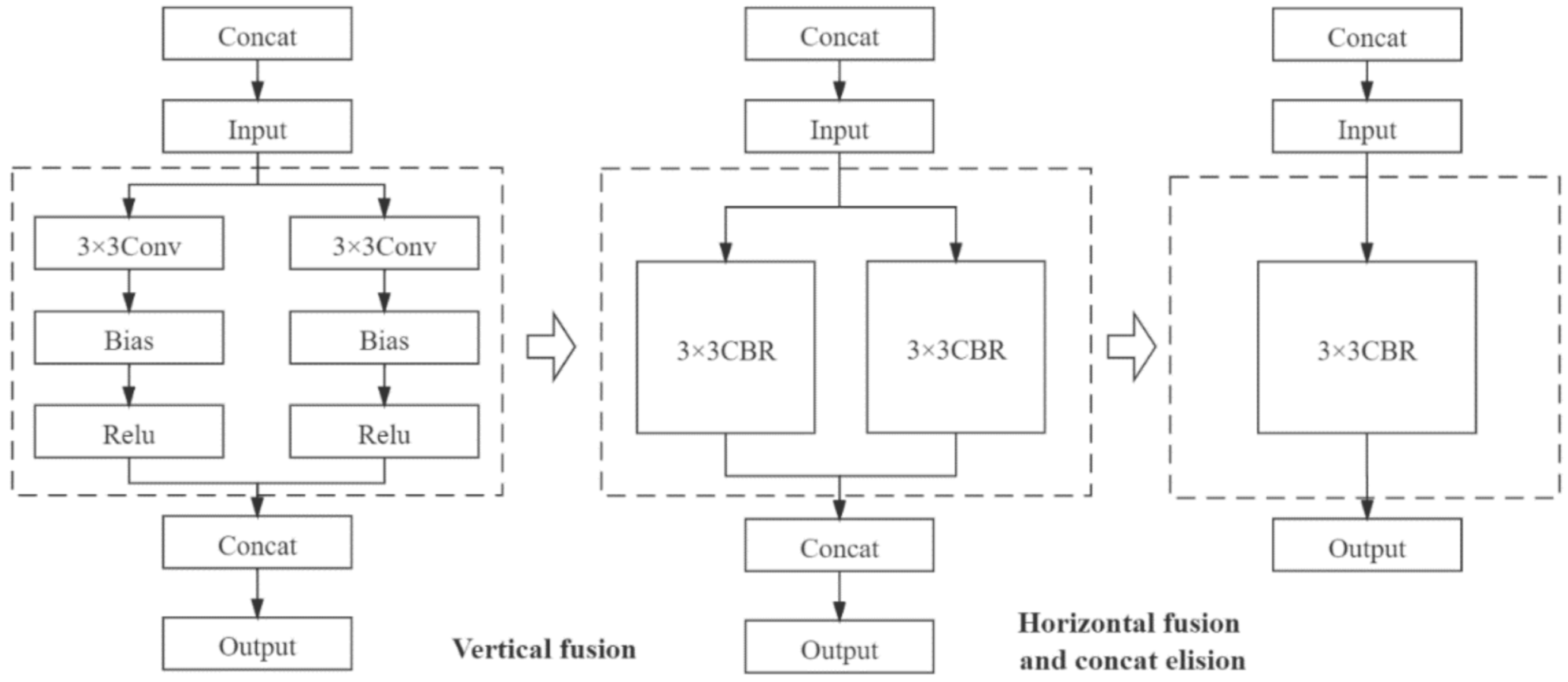
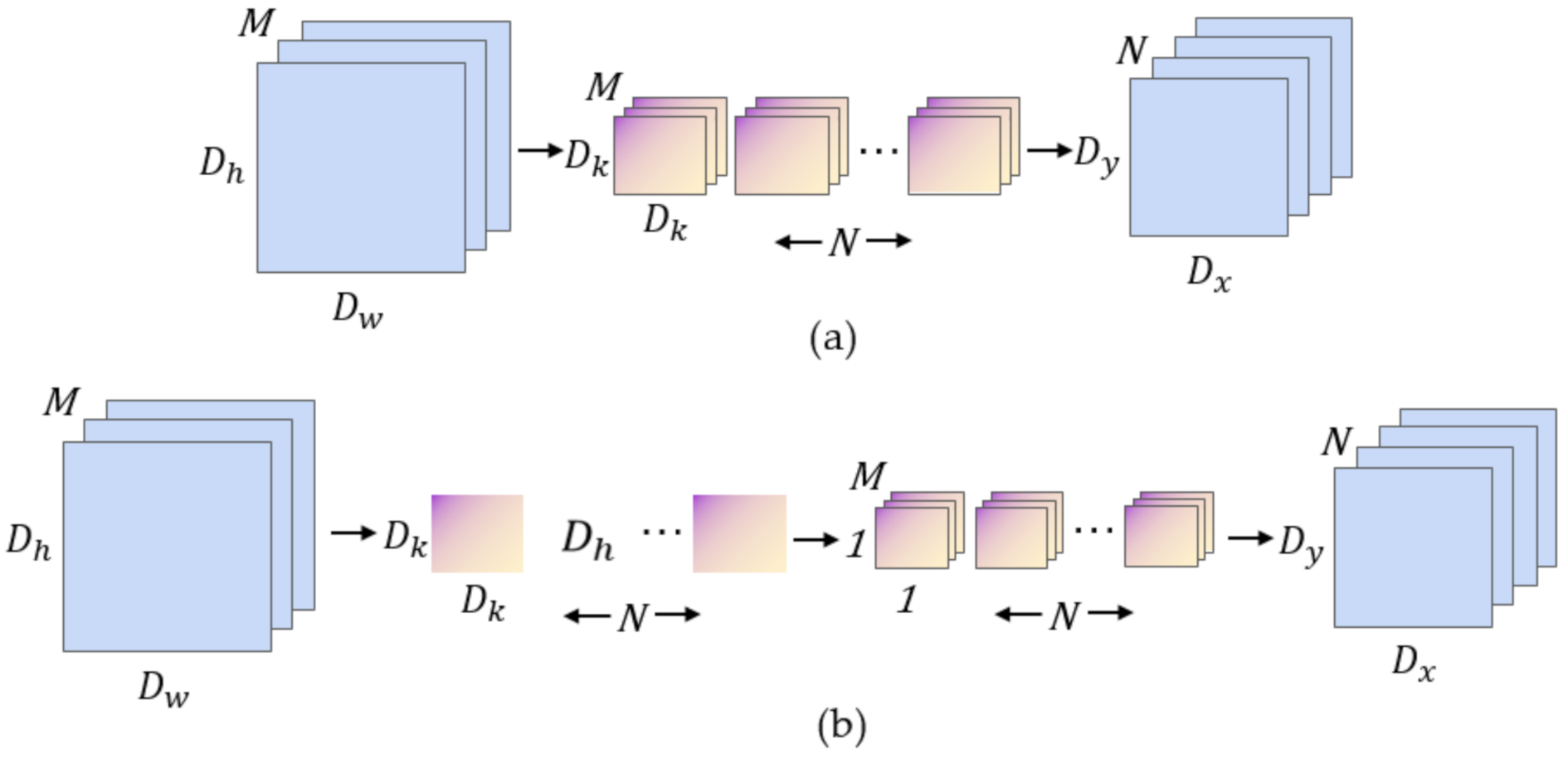
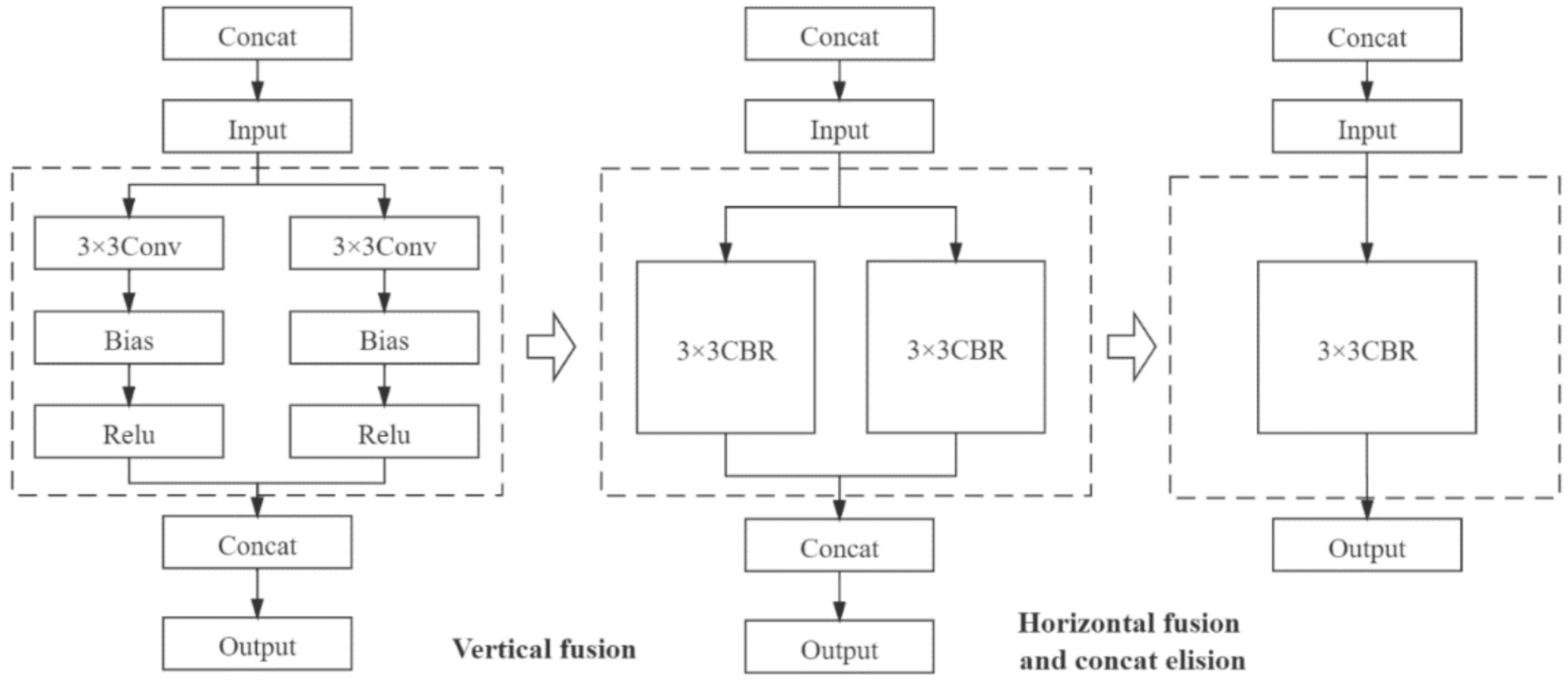
2.3.1. Depth-wise Separable Convolution
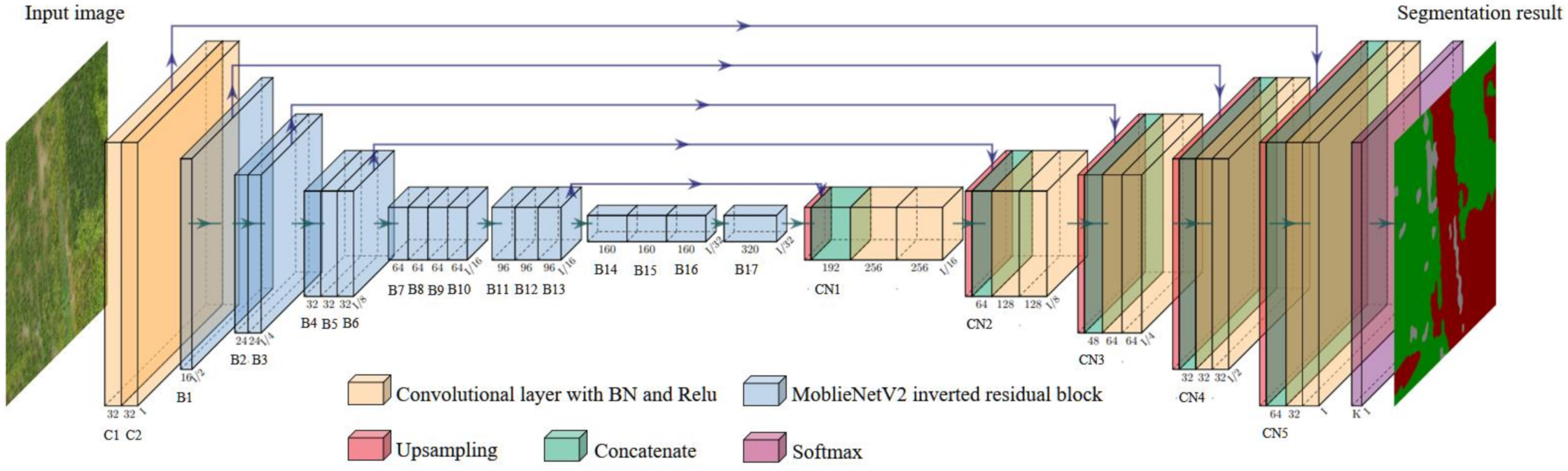
2.3.2. The MobileNetV2-UNet Semantic Segmentation Model Structure
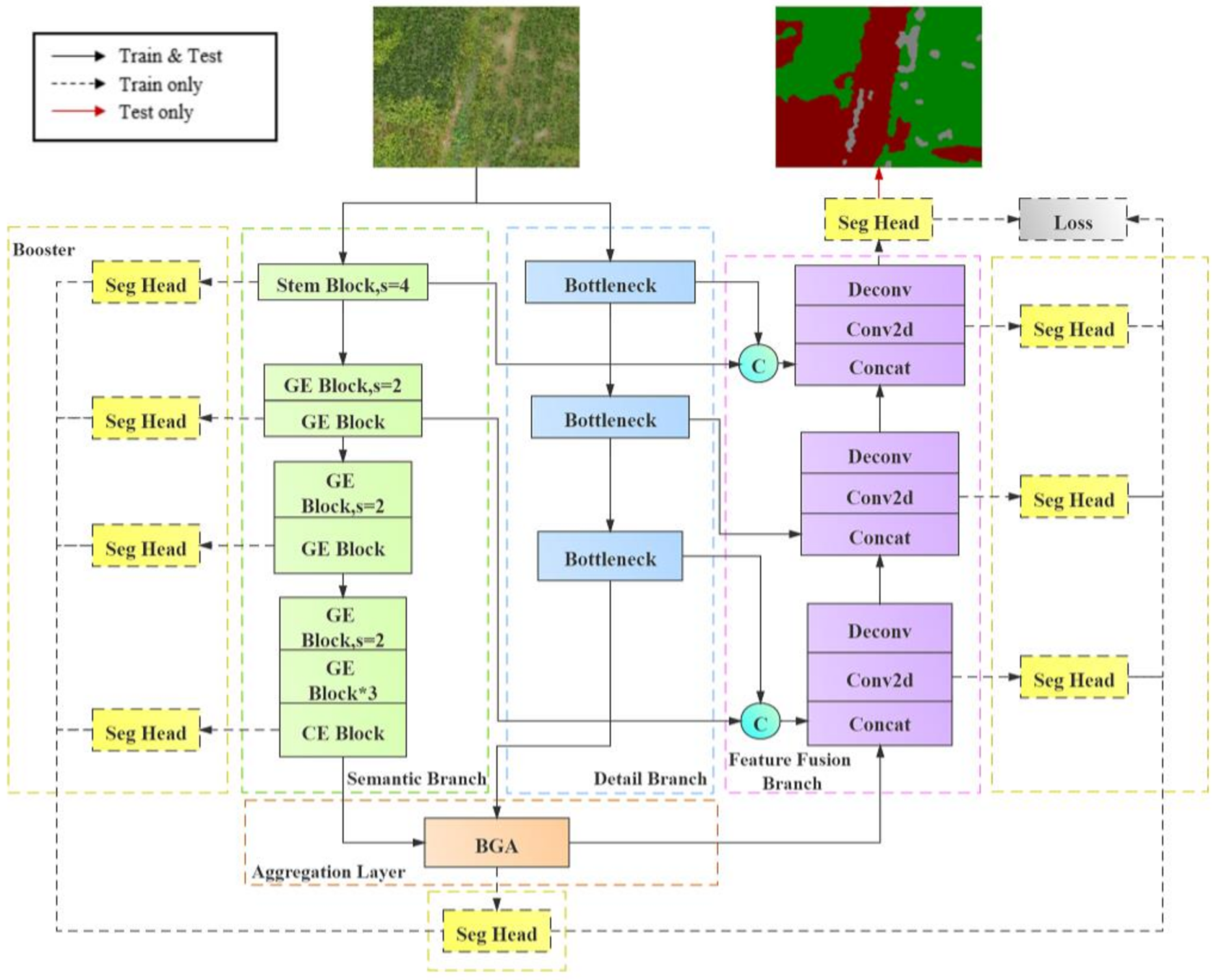
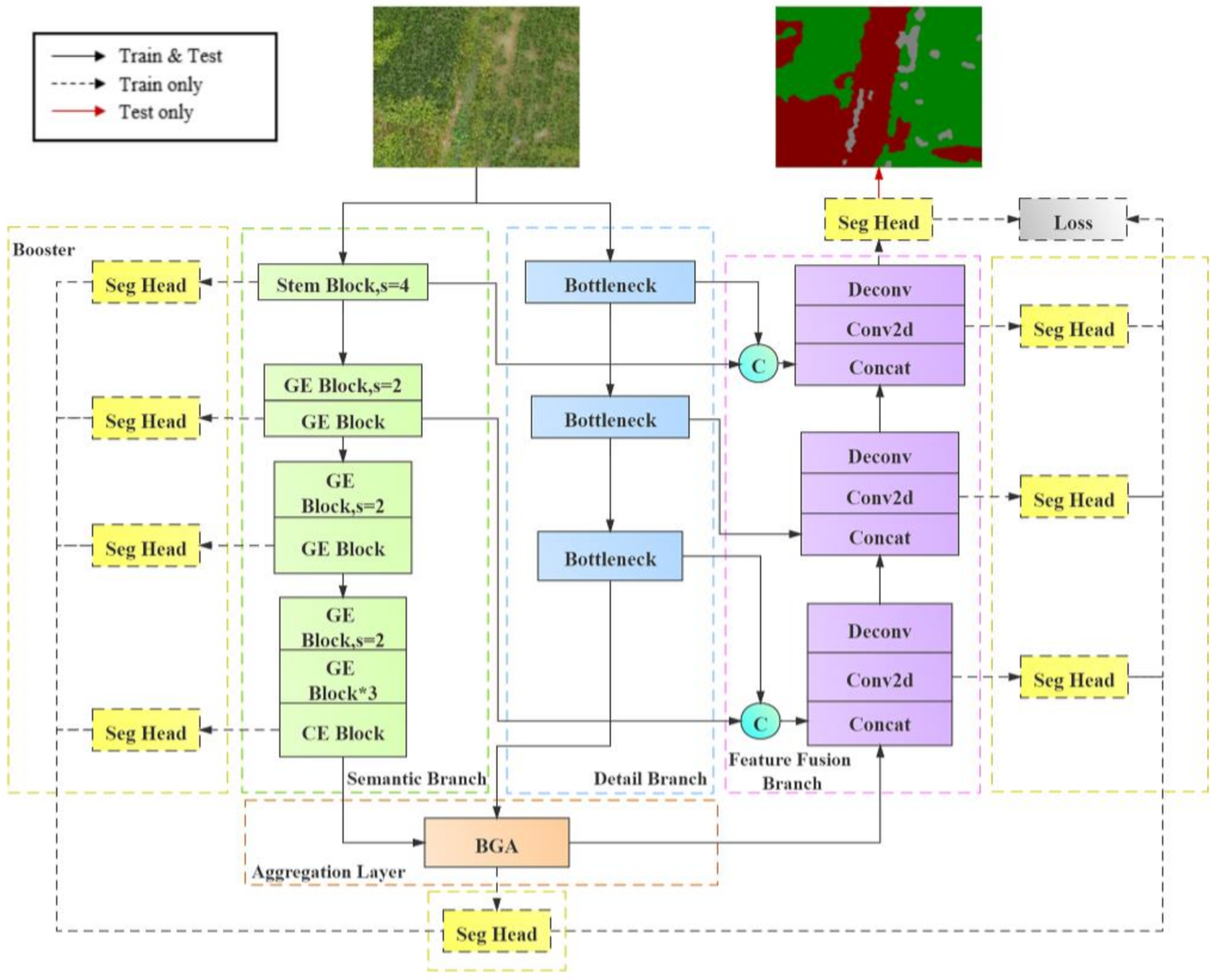
2.3.3. The FFB-BiSeNetV2 Semantic Segmentation Model Structure
- Introduce a module with depthwise separable convolution in the detail branch to realize the lightweight of the branch structure.
- Introduce the Feature Fusion Branch, and integrate the output results from the aggregation layer with the feature information from different scales of semantic branch and detail branch through concatenate operations.
- Add the convolution output of the feature fusion branch to the boost training strategy to optimize the calculation of the loss function, so that make the overall segmentation result of the network more accurate.
- Improvements in the detail branch
- 2.
- Introduction of the feature fusion branch
- 3.
- The loss function
2.4. The Computer Platform and the Embedded Hardware Platform of Experiments
2.5. Models Training Strategy
2.6. Experimental Evaluation
2.7. Models Training Parameters
2.8. Model Optimization and Inference Acceleration
3. Results
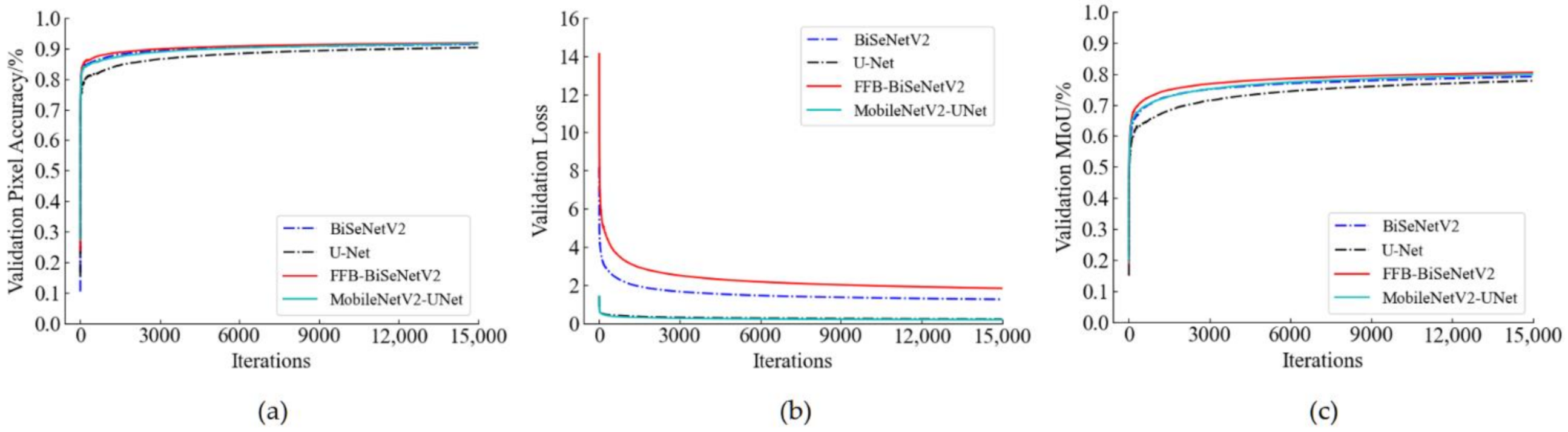
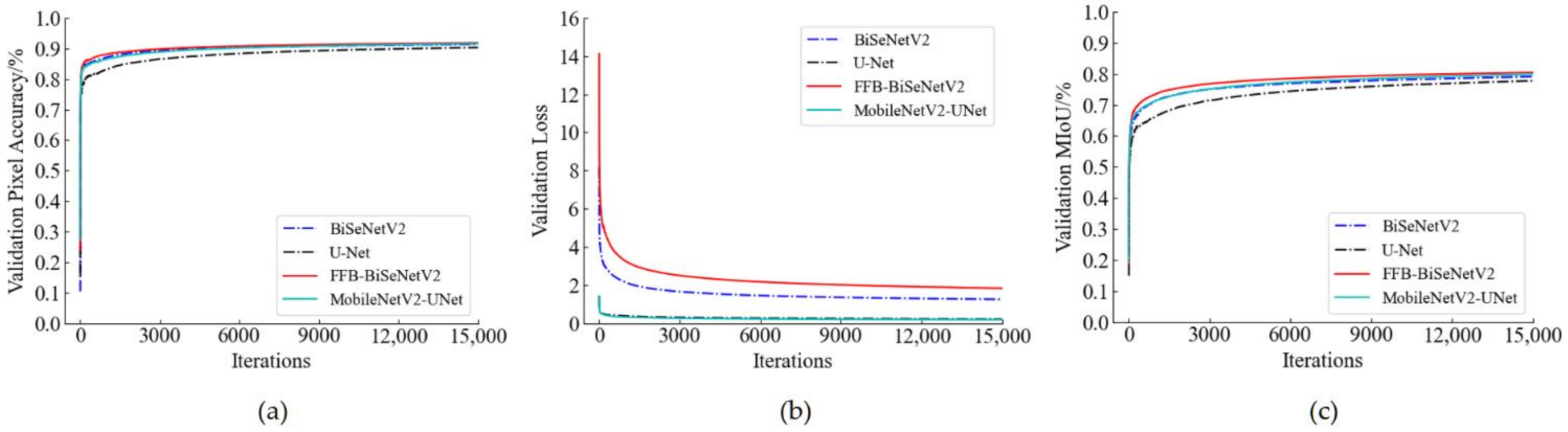
3.1. Analysis of Training Process of the Semantic Models
3.2. Recognition Results and Analysis of Rice Weeds
3.2.1. Comparison of Segmentation Accuracy of Different Models
3.2.2. Comparison of Model Parameters and Operating Efficiency
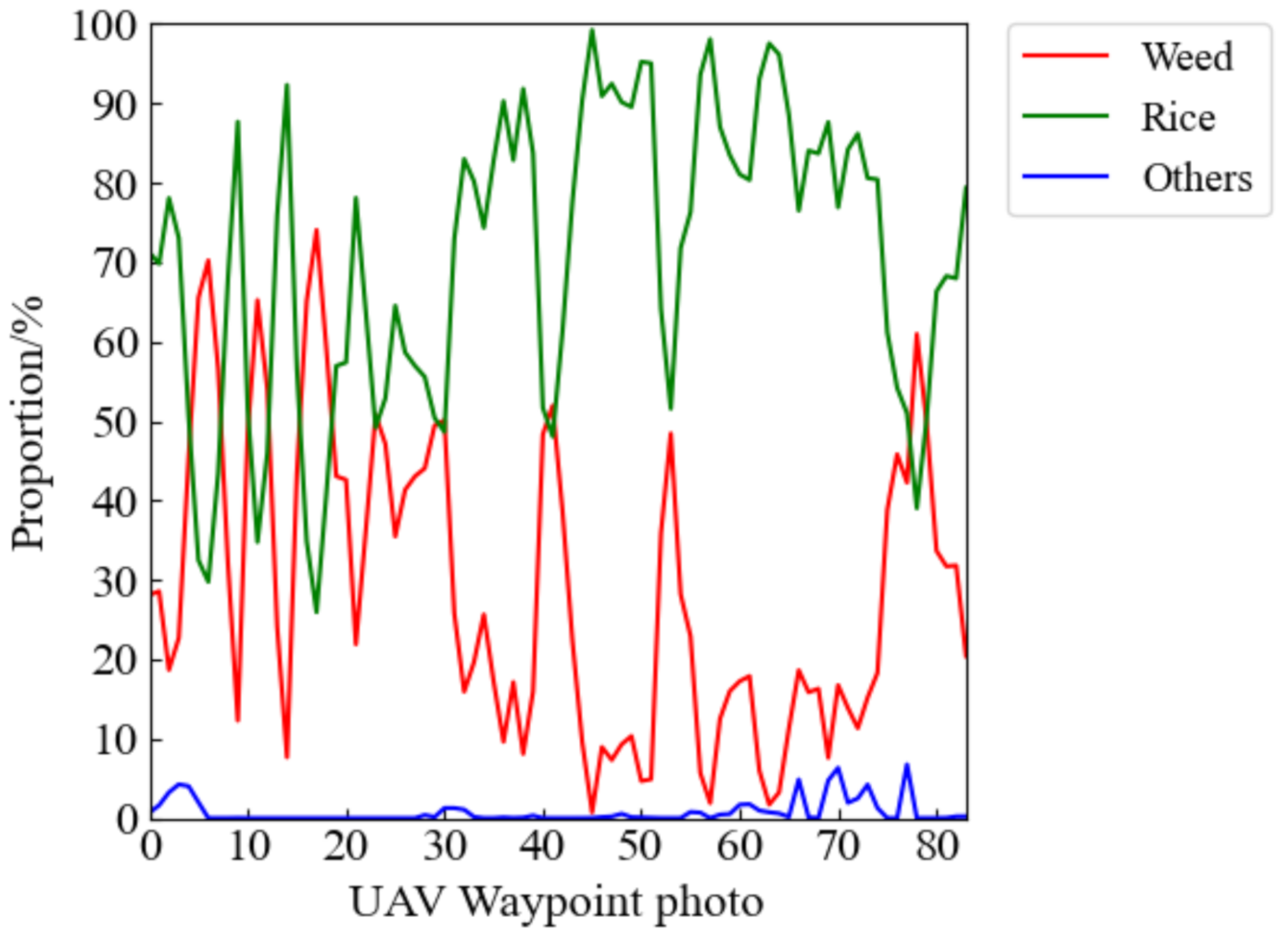
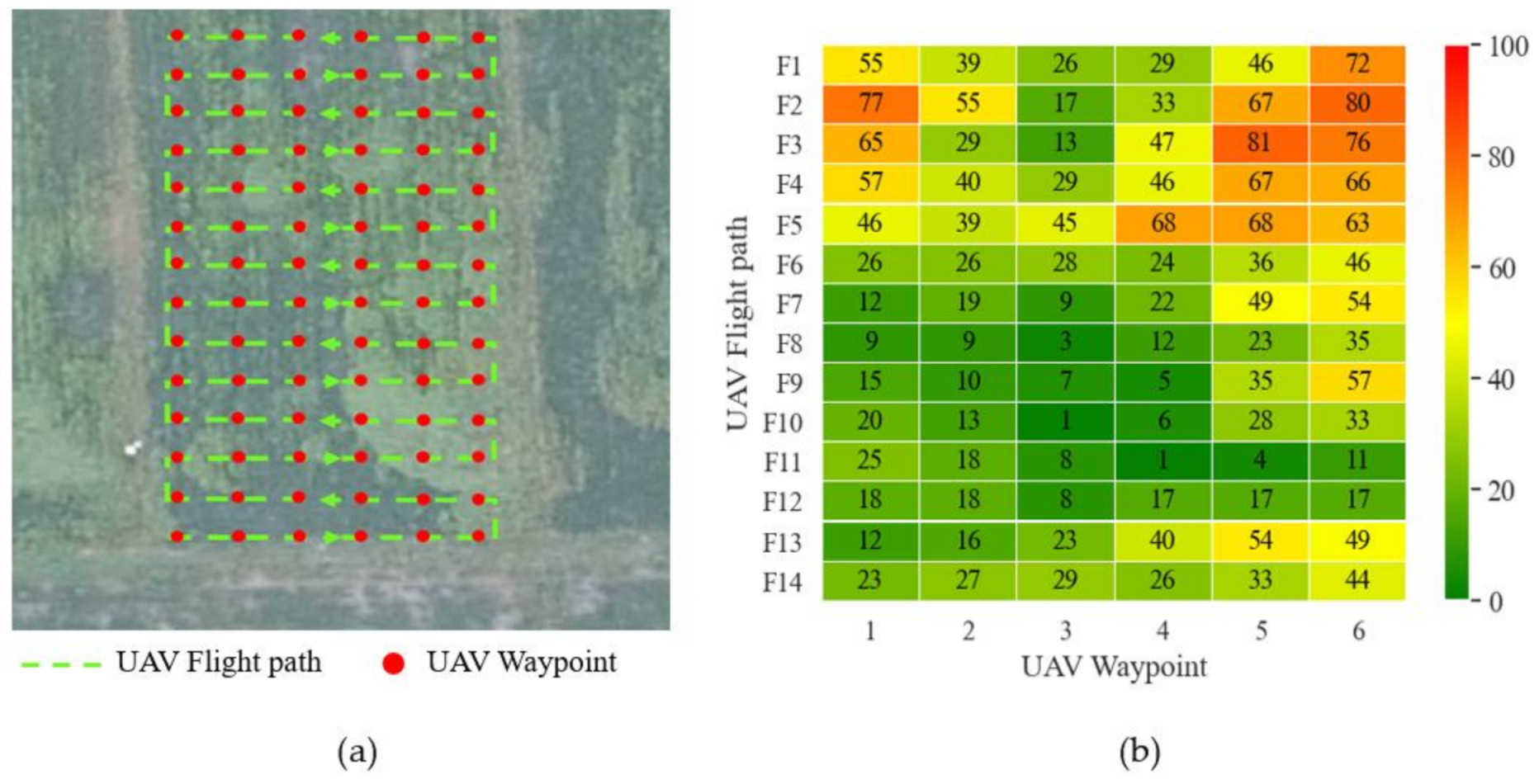
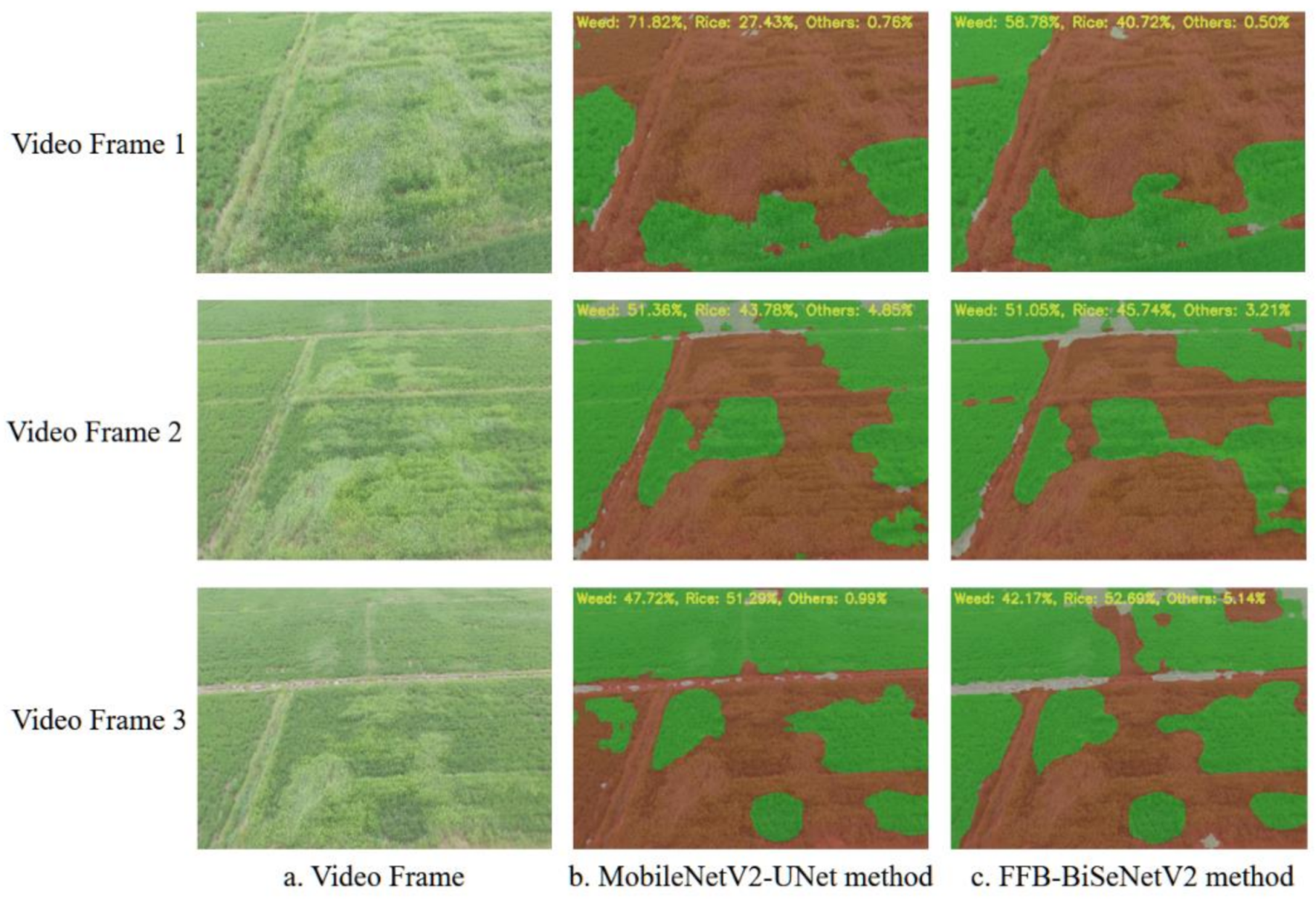
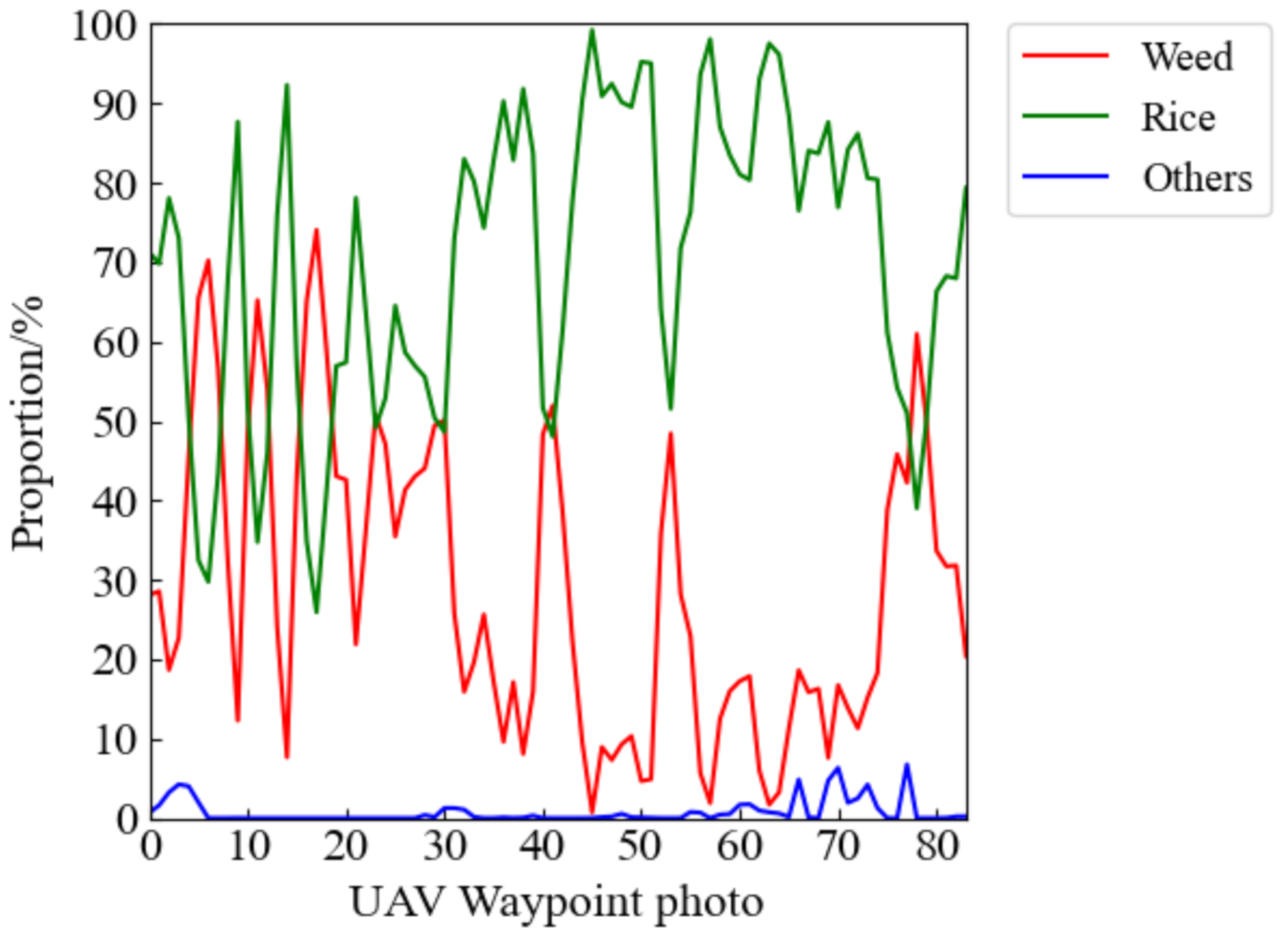
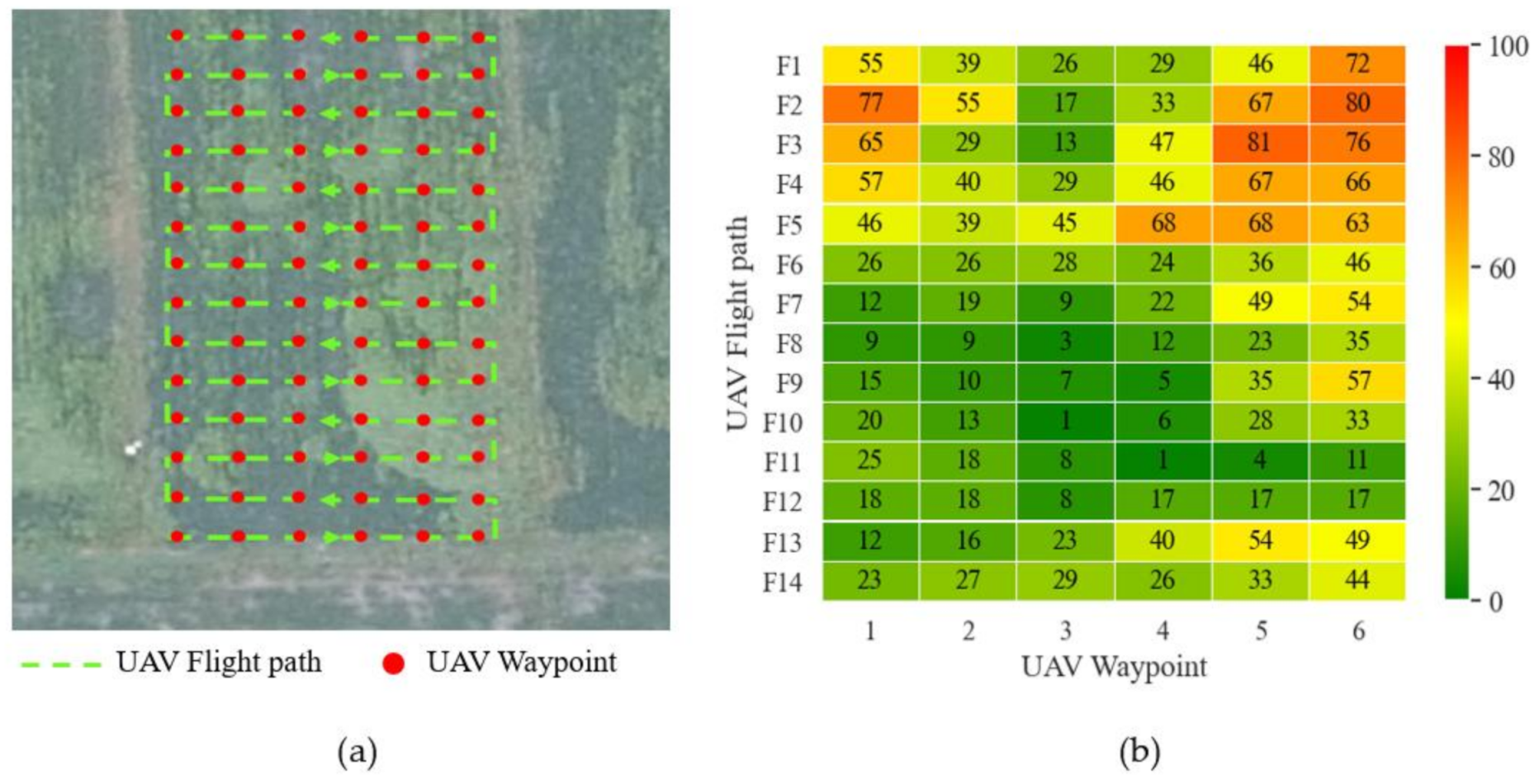
3.2.3. Segmentation Results of UAV Remote Sensing Image of Rice Weeds
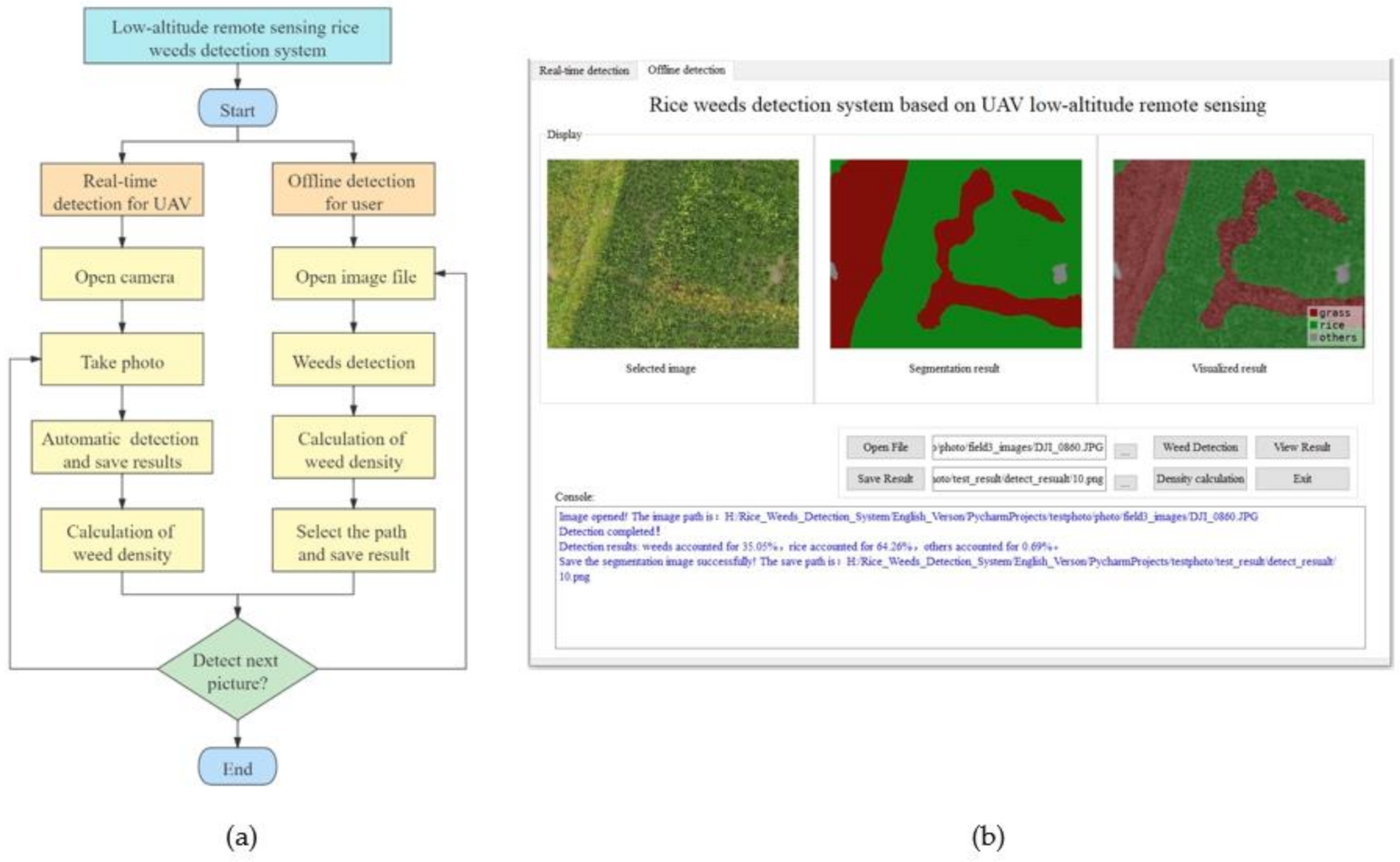
3.3. Semantic Segmentation Model Validation
3.4. Embedded Transplantation and Real-Time Verification Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lan, Y.B.; Chen, S.D.; Fritz, B.K. Current status and future trends of precision agricultural aviation technologies. Int. J. Agric. Biol. Eng. 2017, 10, 1–17. [Google Scholar]
- Stroppiana, D.; Villa, P.; Sona, G.; Ronchetti, G.; Candiani, G.; Pepe, M.; Busetto, L.; Migliazzi, M.; Boschetti, M. Early season weed mapping in rice crops using multi-spectral UAV data. Int. J. Remote Sens. 2018, 39, 5432–5452. [Google Scholar] [CrossRef]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A Review on UAV-Based Applications for Precision Agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Mao, H.P.; Hu, B.; Zhang, Y.C.; Qian, D.; Chen, S.R. Optimization of color index and threshold segmentation in weed recognition. Trans. Chin. Soc. Aric. Eng. 2007, 23, 154–158. (In Chinese) [Google Scholar]
- Kazmi, W.; Garcia-Ruiz, F.; Nielsen, J.; Rasmussen, J.; Andersen, H.J. Exploiting affine invariant regions and leaf edge shapes for weed detection. Comput. Electron. Agric. 2015, 118, 290–299. [Google Scholar] [CrossRef]
- Pflanz, M.; Nordmeyer, H.; Schirrmann, M. Weed Mapping with UAS Imagery and a Bag of Visual Words Based Image Classifier. Remote Sens. 2018, 10, 1530. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.S.; Wang, S.; Zhang, H.; Wen, C.J. Soybean field weed recognition based on light sum-product networks and UAV remote sensing images. Trans. Chin. Soc. Aric. Eng. 2019, 35, 81–89. (In Chinese) [Google Scholar]
- Sun, J.; Tan, W.J.; Wu, X.H.; Shen, J.F.; Lu, B.; Dai, C.X. Real-time recognition of sugar beet and weeds in complex backgrounds using multi-channel depth-wise separable convolution model. Trans. Chin. Soc. Aric. Eng. 2019, 35, 184–190. (In Chinese) [Google Scholar]
- Yang, M.-D.; Tseng, H.-H.; Hsu, Y.-C.; Yang, C.-Y.; Lai, M.-H.; Wu, D.-H. A UAV Open Dataset of Rice Paddies for Deep Learning Practice. Remote Sens. 2021, 13, 1358. [Google Scholar] [CrossRef]
- Yang, M.-D.; Boubin, J.G.; Tsai, H.P.; Tseng, H.-H.; Hsu, Y.-C.; Stewart, C.C. Adaptive autonomous UAV scouting for rice lodging assessment using edge computing with deep learning EDANet. Comput. Electron. Agric. 2020, 179, 105817. [Google Scholar] [CrossRef]
- Qiao, M.; He, X.; Cheng, X.; Li, P.; Luo, H.; Zhang, L.; Tian, Z. Crop yield prediction from multi-spectral, multi-temporal remotely sensed imagery using recurrent 3D convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102436. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; Lopez-Granados, F.; De Castro, A.I.; Peña-Barragan, J.M. Configuration and Specifications of an Unmanned Aerial Vehicle (UAV) for Early Site Specific Weed Management. PLoS ONE 2013, 8, e58210. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Zhang, L. A fully convolutional network for weed mapping of unmanned aerial vehicle (UAV) imagery. PLoS ONE 2018, 13, e0196302. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Deng, J.; Lan, Y.; Yang, A.; Deng, X.; Wen, S.; Zhang, H.; Zhang, Y. Accurate Weed Mapping and Prescription Map Generation Based on Fully Convolutional Networks Using UAV Imagery. Sensors 2018, 18, 3299. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Lan, Y.; Deng, J.; Yang, A.; Deng, X.; Zhang, L.; Wen, S. A Semantic Labeling Approach for Accurate Weed Mapping of High Resolution UAV Imagery. Sensors 2018, 18, 2113. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Deng, J.Z.; Zhang, Y.L.; Yang, C.; Yan, Z.W.; Xie, Y.Q. Study on distribution map of weeds in rice field based on UAV remote sensing. J. South China Agric. Univ. 2020, 41, 67–74. (In Chinese) [Google Scholar]
- Chen, J.S.; Ran, X.K. Deep Learning With Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Boubin, J.G.; Chumley, J.; Stewart, C.; Khanal, S. Autonomic computing challenges in fully autonomous precision agriculture. In Proceedings of the 2019 IEEE International Conference on Autonomic Computing (ICAC), Umea, Sweden, 16–20 June 2019; pp. 11–17. [Google Scholar] [CrossRef]
- AlKameli, A.; Hammad, M. Automatic Learning in Agriculture: A Survey. Int. J. Comput. Digit. Syst. 2021, in press. Available online: http://journal.uob.edu.bh/handle/123456789/4427 (accessed on 1 June 2021).
- Boubin, J.G.; Babu, N.T.R.; Stewart, C.; Chumley, J.; Zhang, S.Q. Managing edge resources for fully autonomous aerial systems. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Arlington, VA, USA, 7–9 November 2019; pp. 74–87. [Google Scholar] [CrossRef]
- Guillén, M.A.; Llanes, A.; Imbernón, B.; Martínez-España, R.; Bueno-Crespo, A.; Cano, J.-C.; Cecilia, J.M. Performance evaluation of edge-computing platforms for the prediction of low temperatures in agriculture using deep learning. J. Supercomput. 2021, 77, 818–840. [Google Scholar] [CrossRef]
- Hu, J.; Bruno, A.; Ritchken, B.; Jackson, B.; Espinoza, M.; Shah, A.; Delimitrou, C. HiveMind: A Scalable and Serverless Coordination Control Platform for UAV Swarms. arXiv 2020, arXiv:2002.01419. [Google Scholar]
- Hadidi, R.; Asgari, B.; Jijina, S.; Amyette, A.; Shoghi, N.; Kim, H. Quantifying the design-space tradeoffs in autonomous drones. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Online, 19–23 April 2021; pp. 661–673. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. Computer Vision and Pattern Recognition. Available online: https://arxiv.org/abs/1602.07360 (accessed on 1 June 2021).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weiyand, T.; Andreetto, M.; Hartwing, A. MobileNets: Efficient convolutional neural networks for mobile vision applications. Computer Vision and Pattern Recognition. Available online: https://arxiv.org/abs/1704.04861 (accessed on 1 June 2021).
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Shin, J.; Chang, Y.K.; Heung, B.; Nguyen-Quang, T.; Price, G.W.; Al-Mallahi, A. A deep learning approach for RGB image-based powdery mildew disease detection on strawberry leaves. Comput. Electron. Agric. 2021, 183, 106042. [Google Scholar] [CrossRef]
- Rançon, F.; Bombrun, L.; Keresztes, B.; Germain, C. Comparison of SIFT Encoded and Deep Learning Features for the Classification and Detection of Esca Disease in Bordeaux Vineyards. Remote Sens. 2019, 11, 1. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; Yang, J.; Li, Z.; Qi, F. Grape disease image classification based on lightweight convolution neural networks and channelwise attention. Comput. Electron. Agric. 2020, 178, 105735. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015 18th International Conference, Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2015; Volume 9351. Available online: https://doi.org/10.1007/978-3-319-24574-4_28 (accessed on 1 June 2021).
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation. arXiv 2020, arXiv:2004.02147. [Google Scholar]
- NVIDIA. TensorRT. Available online: https://developer.nvidia.com/tensorrt (accessed on 1 June 2021).
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNet V2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Jang, J.; Cho, H.; Kim, J.; Lee, J.; Yang, S. Deep neural networks with a set of node-wise varying activation functions. Neural Networks 2020, 126, 118–131. [Google Scholar] [CrossRef] [PubMed]
- Yao, C.; Liu, W.; Tang, W.; Guo, J.; Hu, S.; Lu, Y.; Jiang, W. Evaluating and analyzing the energy efficiency of CNN inference on high-performance GPU. Concurr. Comput. Pract. Exp. 2021, 33, e6064. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Pixel Accuracy/% | Intersection over Union/% | |||
|---|---|---|---|---|---|
| Mean Intersection over Union Ratio/% | Weed | Rice | Others | ||
| U-Net | 92.01 | 76.52 | 87.19 | 87.41 | 54.94 |
| MobileNetV2-UNet | 92.58 | 78.77 | 88.02 | 88.08 | 60.19 |
| BiSeNetV2 | 92.28 | 77.92 | 87.26 | 87.78 | 58.73 |
| FFB-BiSeNetV2 | 93.09 | 80.28 | 88.02 | 88.46 | 64.38 |
| Methods | Number of Parameters | Before Freezing | After Freezing | ||||
|---|---|---|---|---|---|---|---|
| Size of Model/MB | Floating Points of Operations/GFLOPs | Speed of Inference/FPS | Size of Model/MB | Floating Points of Operations/GFLOPs | Speed of Inference/FPS | ||
| U-Net | 93,140,046 | 357 | 248.68 | 31.5 | 118 | 248.53 | 32.26 |
| MobileNetV2-UNet | 10,129,614 | 49.4 | 18.41 | 78.31 | 13 | 18.4 | 89.28 |
| BiSeNetV2 | 16,065,682 | 98.8 | 33.84 | 100.2 | 9.64 | 11.1 | 149.25 |
| FFB-BiSeNetV2 | 17,394,450 | 111 | 40.51 | 83.19 | 8.64 | 10.7 | 104.17 |
| Methods | Before TRT Optimization/FPS | After TRT Optimization//FPS | |
|---|---|---|---|
| FP32 | FP16 | ||
| MobileNetV2-UNet | 14.33 | 25.13 | 45.05 |
| FFB-BiSeNetV2 | 19.42 | 25.58 | 40.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, Y.; Huang, K.; Yang, C.; Lei, L.; Ye, J.; Zhang, J.; Zeng, W.; Zhang, Y.; Deng, J. Real-Time Identification of Rice Weeds by UAV Low-Altitude Remote Sensing Based on Improved Semantic Segmentation Model. Remote Sens. 2021, 13, 4370. https://doi.org/10.3390/rs13214370
Lan Y, Huang K, Yang C, Lei L, Ye J, Zhang J, Zeng W, Zhang Y, Deng J. Real-Time Identification of Rice Weeds by UAV Low-Altitude Remote Sensing Based on Improved Semantic Segmentation Model. Remote Sensing. 2021; 13(21):4370. https://doi.org/10.3390/rs13214370
Chicago/Turabian StyleLan, Yubin, Kanghua Huang, Chang Yang, Luocheng Lei, Jiahang Ye, Jianling Zhang, Wen Zeng, Yali Zhang, and Jizhong Deng. 2021. "Real-Time Identification of Rice Weeds by UAV Low-Altitude Remote Sensing Based on Improved Semantic Segmentation Model" Remote Sensing 13, no. 21: 4370. https://doi.org/10.3390/rs13214370
APA StyleLan, Y., Huang, K., Yang, C., Lei, L., Ye, J., Zhang, J., Zeng, W., Zhang, Y., & Deng, J. (2021). Real-Time Identification of Rice Weeds by UAV Low-Altitude Remote Sensing Based on Improved Semantic Segmentation Model. Remote Sensing, 13(21), 4370. https://doi.org/10.3390/rs13214370