
Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data


Abstract
:1. Introduction
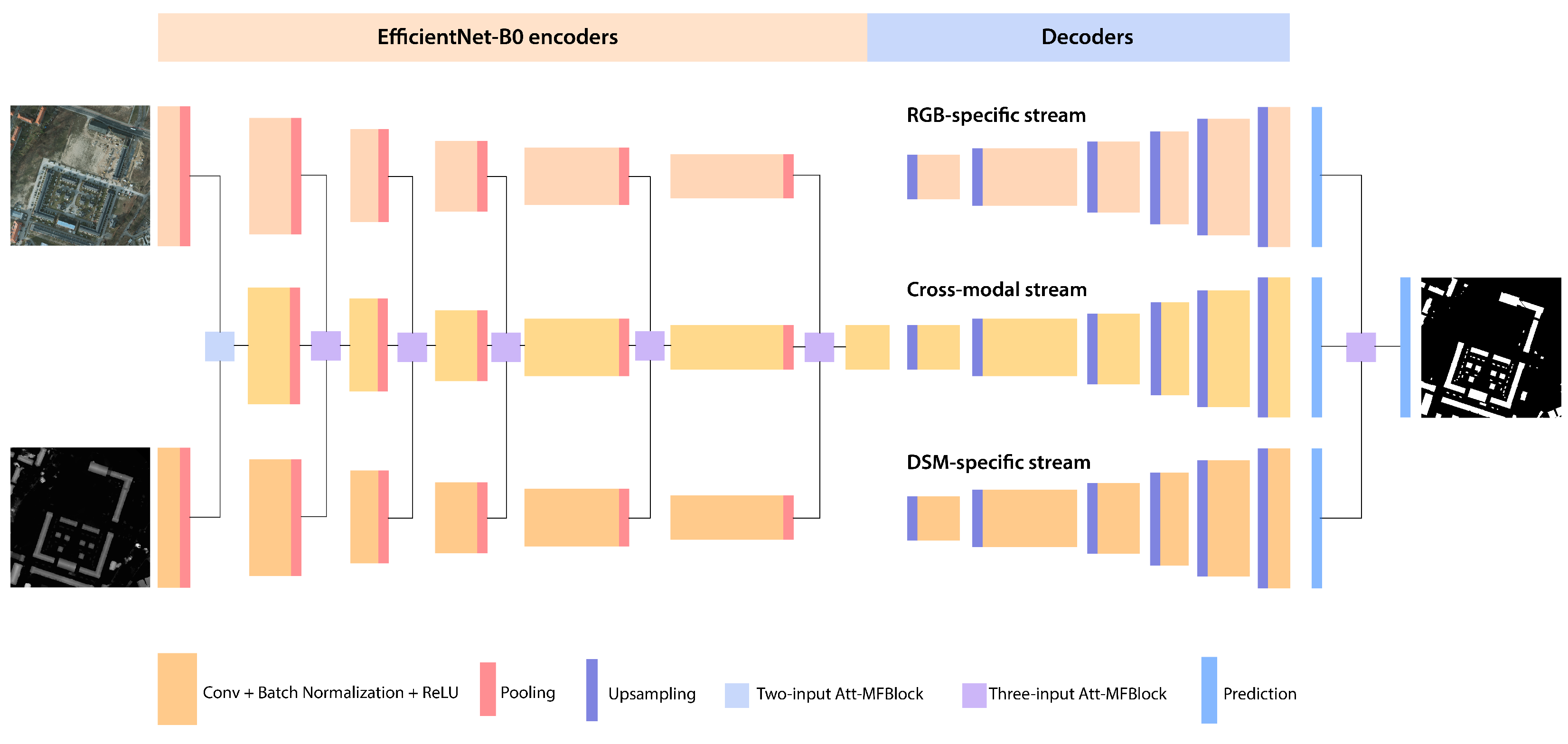
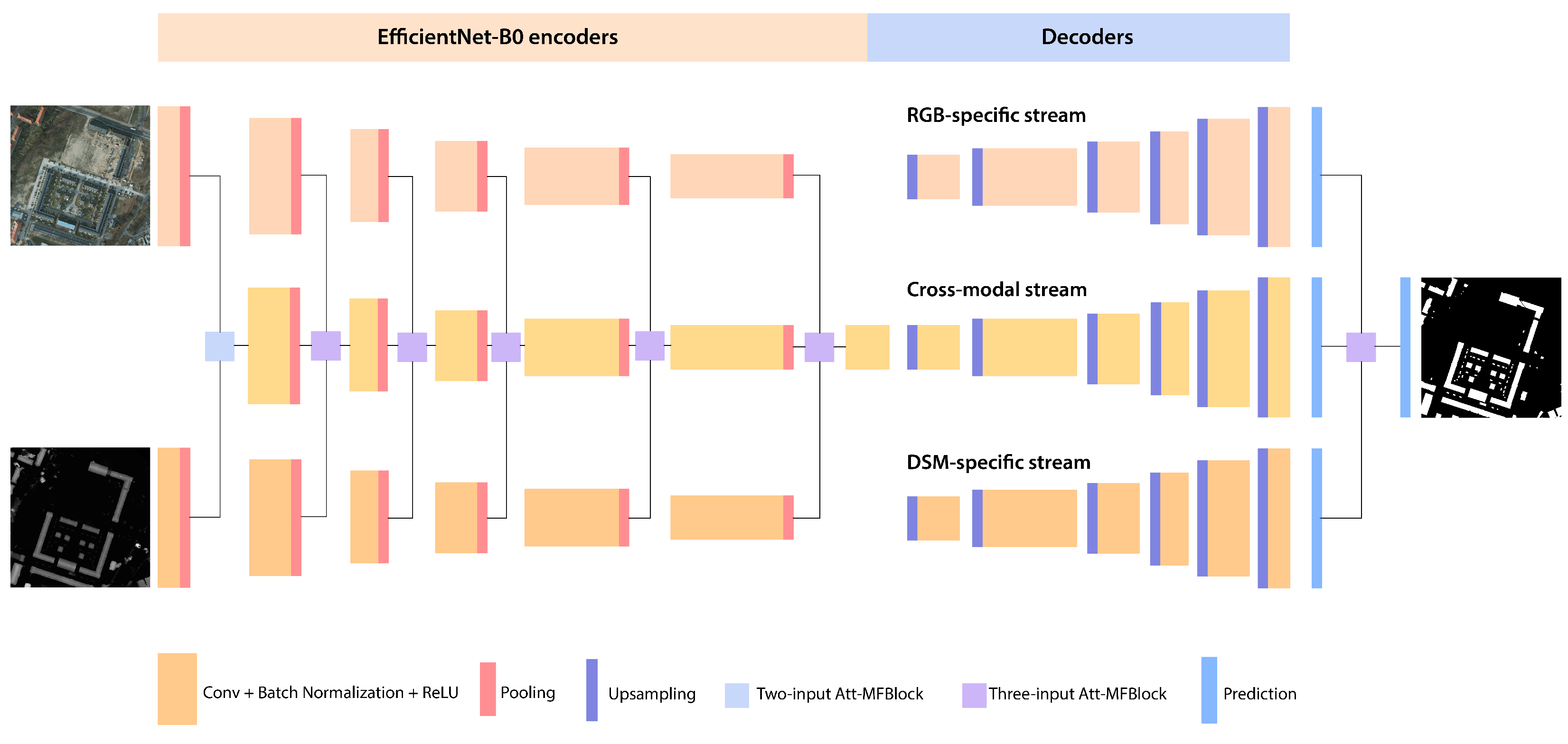
2. Building Blocks
2.1. EfficientNet
2.2. Attention-Aware Multi-Modal Fusion Block
3. HAFNet and HAFNetE
4. Experiment Design
4.1. Dataset
4.2. Model Performance Metrics
4.3. Training Procedure
4.3.1. Data Processing
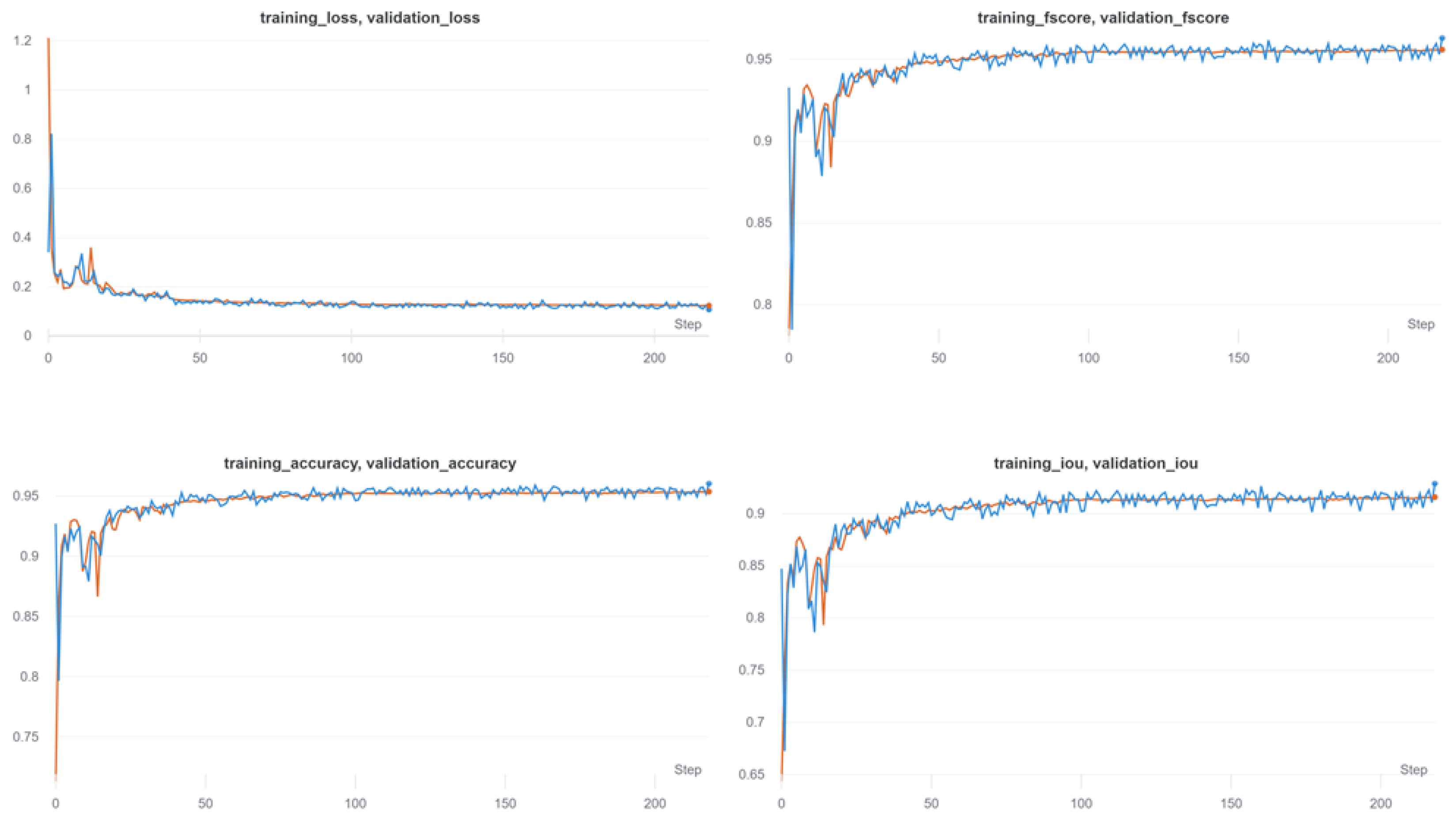
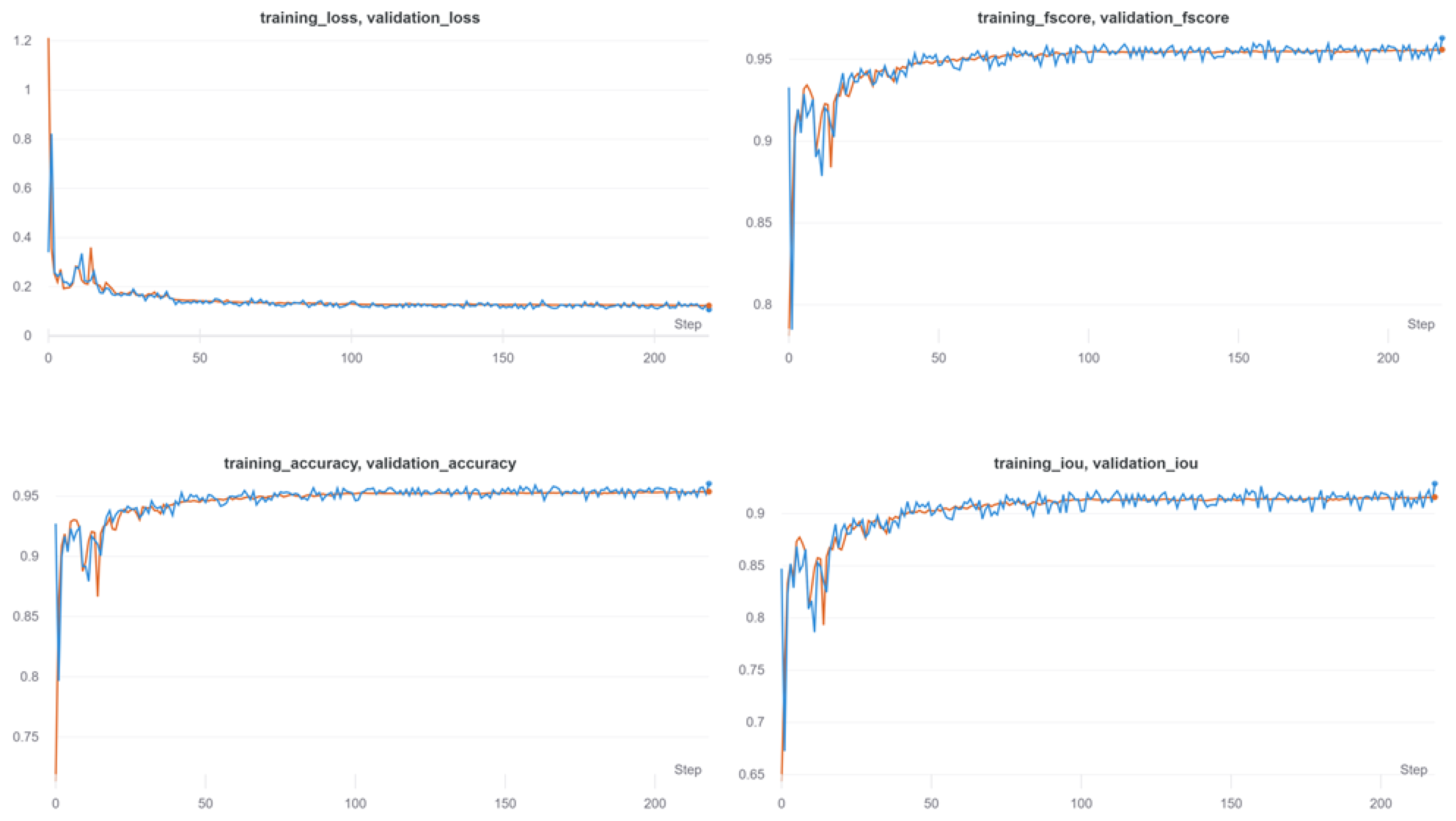
4.3.2. Model Training
5. Discussion of Results
5.1. Segmentation Performance Assessment
- the pre-trained encoders already providing good basic encoding power, plus
- the reduced overall model size speeding up training.
5.2. Novelties Introduced
5.2.1. Application Level
5.2.2. Resource Level
- Reduction of training time: the number of weights in a network is directly correlated with the number of gradients updates that the GPU needs to operate to optimize the loss function. A 92% parameters reduction coupled with an extra pre-trained stream translates to a 80% reduction in training time to reach the same model performance.
- Reduction of inference time
- Reduction of memory footprint: the model weights are encoded as 32-bit floating point variables. To further speed up the inference procedure and limit the overall model size, weights are usually converted to 16-bit floating point. This conversion can sometimes affect the model performance, but, in most cases, the impact is negligible. Under these assumptions, we can estimate the final model size:vs.The used memory can be further compressed to a 8-bit fixed point systolic array in order to make the model directly deployable to dedicated AI platforms, such as Intel’s Myriad 2 or Google’s Google Coral 28-nm Tensor Processing Unit (TPU) that features 8 MB of on board memory. The memory footprint of the proposed model is much smaller than that of the reference one. Moreover, its computational and power demand are small; all these factors make it suitable for on-board processing in spaceborne Earth observation platforms.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| Att-MFBlock | Attention-Aware Multi-modal Fusion Block |
| CNN | convolutional neural network |
| DSM | Digital Surface Model |
| EO | Earth Observation |
| GT | Ground Truth |
| HAFNet | Hybrid Attention-aware Fusion Network |
| HAFNetE | HAFNet with EfficientNet |
| HRI | High-resolution Remote sensing Imagery |
| IoU | Intersection over Union |
| SGD | Stochastic Gradient Descent |
| LiDAR | Light Detection and Ranging |
| OA | overall accuracy |
| SMP | Segmentation Models PyTorch, |
References
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Multi-source remote sensing data classification via fully convolutional networks and post-classification processing. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3852–3855. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. Fusenet: Incorporating depth into semantic segmentation via fusion-based cnn architecture. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 213–228. [Google Scholar]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. Effective fusion of multi-modal remote sensing data in a fully convolutional network for semantic labeling. Remote Sens. 2018, 10, 52. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Marcos, D.; Hamid, R.; Tuia, D. Geospatial correspondences for multimodal registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5091–5100. [Google Scholar]
- Zhang, P.; Du, P.; Lin, C.; Wang, X.; Li, E.; Xue, Z.; Bai, X. A Hybrid Attention-Aware Fusion Network (HAFNet) for Building Extraction from High-Resolution Imagery and LiDAR Data. Remote Sens. 2020, 12, 3764. [Google Scholar] [CrossRef]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.O.; et al. Towards the Use of Artificial Intelligence on the Edge in Space Systems: Challenges and Opportunities. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 44–56. [Google Scholar] [CrossRef]
- Kothari, V.; Liberis, E.; Lane, N.D. The final frontier: Deep learning in space. In Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3–4 March 2020; pp. 45–49. [Google Scholar]
- Mateo-Garcia, G.; Veitch-Michaelis, J.; Smith, L.; Oprea, S.V.; Schumann, G.; Gal, Y.; Baydin, A.G.; Backes, D. Towards global flood mapping onboard low cost satellites with machine learning. Sci. Rep. 2021, 11, 7249. [Google Scholar] [CrossRef]
- Giuffrida, G.; Diana, L.; de Gioia, F.; Benelli, G.; Meoni, G.; Donati, M.; Fanucci, L. CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images. Remote Sens. 2020, 12, 2205. [Google Scholar] [CrossRef]
- Maskey, A.; Cho, M. CubeSatNet: Ultralight Convolutional Neural Network designed for on-orbit binary image classification on a 1U CubeSat. Eng. Appl. Artif. Intell. 2020, 96, 103952. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple Yet Effective Fine-Tuning of Deep CNNs Using an Auxiliary Classification Loss for Remote Sensing Scene Classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef] [Green Version]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of Remote Sensing Images Using EfficientNet-B3 CNN Model With Attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Lasloum, T.; Alhichri, H.; Bazi, Y.; Alajlan, N. SSDAN: Multi-Source Semi-Supervised Domain Adaptation Network for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 3861. [Google Scholar] [CrossRef]
- Salas, J.; Vera, P.; Zea-Ortiz, M.; Villaseñor, E.A.; Pulido, D.; Figueroa, A. Fine-Grained Large-Scale Vulnerable Communities Mapping via Satellite Imagery and Population Census Using Deep Learning. Remote Sens. 2021, 13, 3603. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Zhao, Y.; Dong, R.; Yu, L. Cross-regional oil palm tree counting and detection via a multi-level attention domain adaptation network. ISPRS J. Photogramm. Remote Sens. 2020, 167, 154–177. [Google Scholar] [CrossRef]
- Cai, W.; Wei, Z. Remote Sensing Image Classification Based on a Cross-Attention Mechanism and Graph Convolution. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-Shot Object Detection on Remote Sensing Images via Shared Attention Module and Balanced Fine-Tuning Strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Shi, H.; Fan, J.; Wang, Y.; Chen, L. Dual Attention Feature Fusion and Adaptive Context for Accurate Segmentation of Very High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 3715. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y. Three-stream attention-aware network for RGB-D salient object detection. IEEE Trans. Image Process. 2019, 28, 2825–2835. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- ImageNet. Available online: https://image-net.org/index.php (accessed on 10 May 2021).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- ISPRS 2D Semantic Labeling Contest. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/semantic-labeling/ (accessed on 10 May 2021).
- Xia, X.; Lu, Q.; Gu, X. Exploring An Easy Way for Imbalanced Data Sets in Semantic Image Segmentation. J. Phys. Conf. Ser. 2019, 1213, 022003. [Google Scholar] [CrossRef]
- Yakubovskiy, P. Segmentation Models Pytorch. 2020. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 10 May 2021).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale adaptive feature fusion network for semantic segmentation in remote sensing images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef] [Green Version]
- Cao, Z.; Fu, K.; Lu, X.; Diao, W.; Sun, H.; Yan, M.; Yu, H.; Sun, X. End-to-end DSM fusion networks for semantic segmentation in high-resolution aerial images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1766–1770. [Google Scholar] [CrossRef]
- Peng, C.; Li, Y.; Jiao, L.; Chen, Y.; Shang, R. Densely based multi-scale and multi-modal fully convolutional networks for high-resolution remote-sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2612–2626. [Google Scholar] [CrossRef]
- Liu, C.; Zeng, D.; Wu, H.; Wang, Y.; Jia, S.; Xin, L. Urban land cover classification of high-resolution aerial imagery using a relation-enhanced multiscale convolutional network. Remote Sens. 2020, 12, 311. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.; Li, L.; Lv, Z.; Zhu, M.; Du, X.; Nandi, A.K. Multi-Modality and Multi-Scale Attention Fusion Network for Land Cover Classification from VHR Remote Sensing Images. Remote Sens. 2021, 13, 3771. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. Efficientnetv2: Smaller models and faster training. arXiv 2021, arXiv:2104.00298. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Top-5 Acc | #Params | #FLOPs |
|---|---|---|---|
| EfficientNet-B0 [16] | 93.3% | 5.3 M | 0.39 B |
| EfficientNet-B2 [16] | 94.9% | 9.2 M | 1.0 B |
| EfficientNet-B4 [16] | 96.4% | 19 M | 4.2 B |
| VGG-16 [30] | 91.9% | 138 M | 19.6 B |
| ResNet-50 [28] | 93.0% | 26 M | 4.1 B |
| SENet [21] | 96.2% | 146 M | 42 B |
| Optimizer | Validation IoU | Validation F1-Score | Validation Accuracy |
|---|---|---|---|
| SGD | 85.56% | 92.15% | 92.07% |
| Adagrad | 89.76% | 90.32% | 91.98% |
| Adam | 91.58% | 95.59% | 96.41% |
| Training Mode | Validation IoU | Validation F1-Score | Validation Accuracy |
|---|---|---|---|
| Main training | 91.58% | 95.59% | 96.41% |
| Fine-tuning | 93.64% | 96.68% | 97.55% |
| Method | F1 Score |
|---|---|
| DeepLab v3 + [35] | 95.8% |
| MANet [36] | 95.91% |
| DSMFNet [37] | 96.0% |
| DP-DCN [38] | 95.36% |
| REMSNet [39] | 96.17% |
| MMAFNet [40] | 96.26% |
| HAFNetE | 96.68% |
| Model | IoU | F1-Score | Accuracy |
|---|---|---|---|
| HAFNet [8] | 90.10% | 98.78% | 97.96% |
| HAFNetE | 93.64% | 96.68% | 97.55% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferrari, L.; Dell’Acqua, F.; Zhang, P.; Du, P. Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data. Remote Sens. 2021, 13, 4361. https://doi.org/10.3390/rs13214361
Ferrari L, Dell’Acqua F, Zhang P, Du P. Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data. Remote Sensing. 2021; 13(21):4361. https://doi.org/10.3390/rs13214361
Chicago/Turabian StyleFerrari, Luca, Fabio Dell’Acqua, Peng Zhang, and Peijun Du. 2021. "Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data" Remote Sensing 13, no. 21: 4361. https://doi.org/10.3390/rs13214361
APA StyleFerrari, L., Dell’Acqua, F., Zhang, P., & Du, P. (2021). Integrating EfficientNet into an HAFNet Structure for Building Mapping in High-Resolution Optical Earth Observation Data. Remote Sensing, 13(21), 4361. https://doi.org/10.3390/rs13214361