
MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning





Abstract
:1. Introduction
1.1. Previous Work
2. Materials and Methods
2.1. The MADNet 1.0 System and Summary of Existing Issues
- (a)
- Degraded (or weakened) topographic variation/feature at the intermediate scale between the scales of the input image and reference DTM. This is due to the fact that large-scale (relative to the input image) topographic cues cannot be perceived by the trained model using the small-sized (512 × 512 pixels) tiled input. This missing information may also not be recoverable from the reference DTM if it is not large enough in scale for the lower-resolution reference DTM. This is generally not an issue if we use a reference DTM that has a spatial resolution close to (≤3 times) the resolution of the input image. However, if there is a large resolution gap between the input image and reference DTM, intermediate-scale topographic information of the MADNet 1.0 result is likely to be missing or inaccurate.
- (b)
- Inherited large-scale (relative to the input image) topographic errors or artefacts. Although we should always use a high-quality or pre-corrected DTM as the lower-resolution reference, some small-scale (relative to the reference DTM) errors are inevitable, and consequently, small-scale errors on the lower-resolution reference DTM can potentially become large-scale errors in the higher-resolution output DTM. Building and refining the MADNet 1.0 DTMs progressively using multi-resolution cascaded inputs could minimise the impact of the inherited photogrammetric errors and artefacts [7], but the issue cannot be fully eliminated, and the issue could become more obvious alongside enlarged resolution gap between the input image and reference DTM.
- (c)
- Inconsistent performance (mainly found for high-frequency features) on the DTM inference processes of different tiles of the full-scene input. The effect of this issue is that some of the resultant DTM tiles are sharper and some of the resultant DTM tiles are smoother, and consequently, all these resultant DTM tiles cannot be seamlessly mosaiced together without producing obvious artefacts. Even the smoother ones may still appear to be sharper in comparison to any photogrammetric results, and such issues will still cause discontinuities for local topographic features. Moreover, if there are large and frequent differences in sharpness of adjacent DTM tiles, this creates a patterned gridding artefact on the final DTM result.
- (d)
- Tiling artefacts caused by incorrect or inconsistent inference of large-scale slopes of neighbouring tiles. Due to the memory constraint of a graphics processing unit, the size of the tiled input for inference is limited, and consequently, a large image (e.g., HiRISE) needs to be divided into tens of thousands of tiles. As there are not enough “global height cues” within each input image tile, the predicted large-scale topographic information (e.g., a global slope) is highly likely to be incorrect or inaccurate. 3D fitting and overlapped blending were used in [7] to correct the large-scale error and minimise the impact of the inconsistent large-scale topography of adjacent tiles. However, minor height variations (typically being of the order of ~10 cm) still exist at the joints of neighbouring tiles on steep slopes.
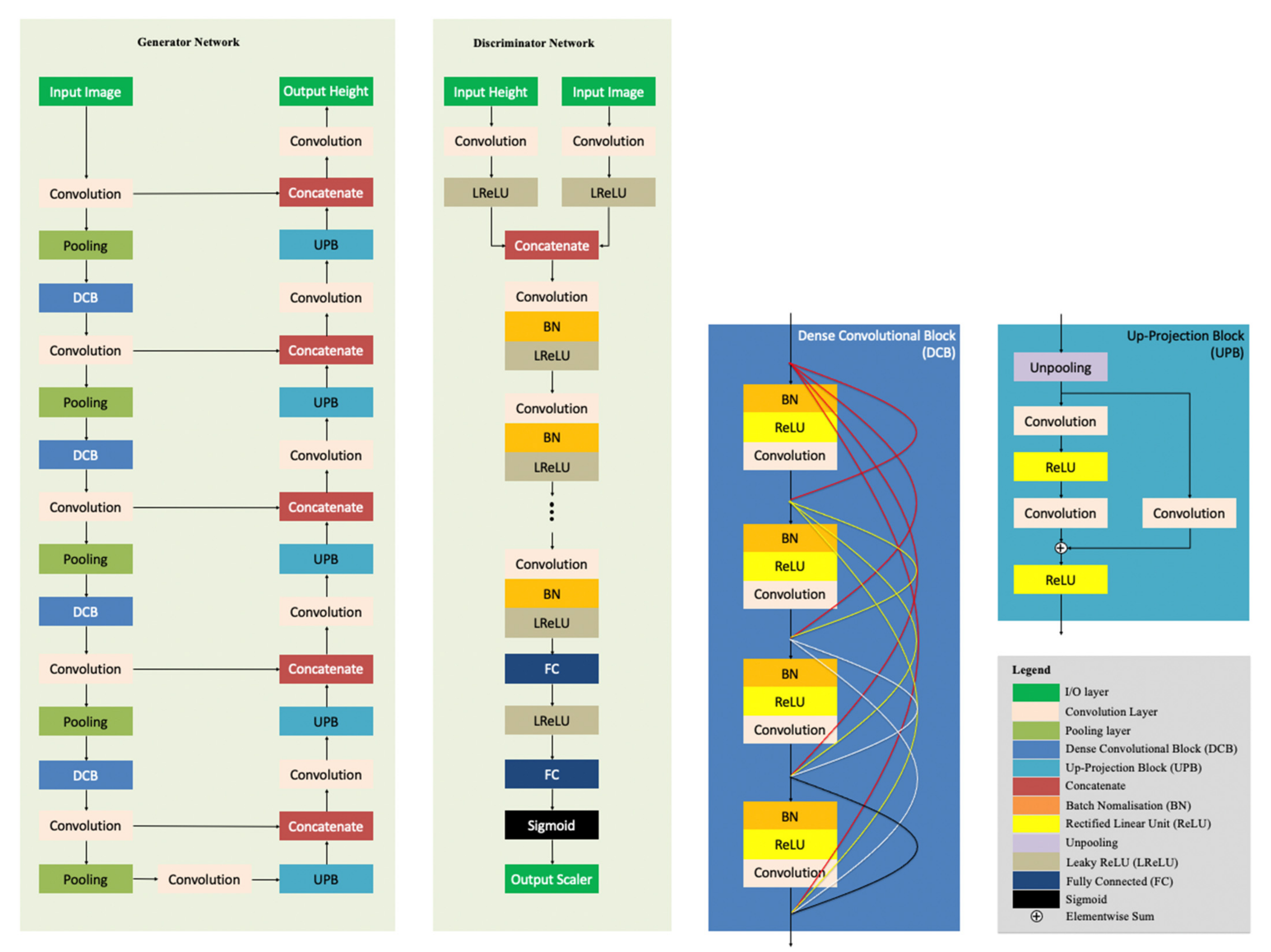
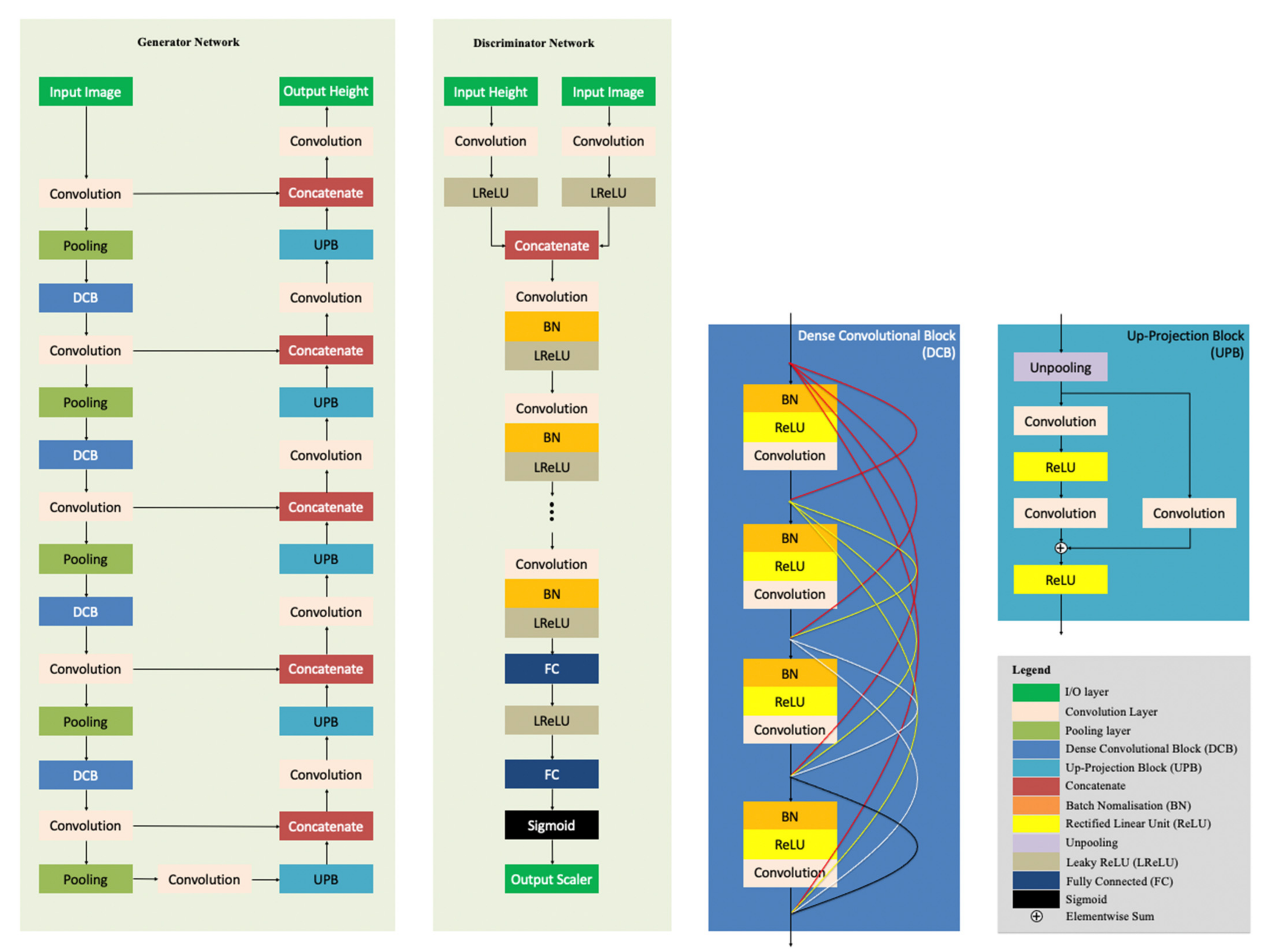
2.2. The Proposed MADNet 2.0 System
- (a)
- The coarse-scale and intermediate-scale U-nets of the MADNet 1.0 generator are removed in MADNet 2.0.
- (b)
- The fine-scale U-net of the MADNet 1.0 generator is optimised, adding an extra block of UPB [27] with concatenation operation at the decoder end, and using the output of each convolution layer (before the pooling layer) of the encoder, instead of using the output of each pooling layer of the encoder, for concatenation with the corresponding output of each UPB of the decoder.
- (c)
- A coarse-to-fine multi-scale reconstruction process is implemented on top of the DTM estimation network.
2.3. Network Training
- (a)
- Firstly, we batch hill-shade the HiRISE and CTX DTMs using the same illumination parameters as the image, resample the ORIs, DTMs, and hill-shaded relief images (into 4 m/pixel and 2 m/pixel sets for HiRISE and 36 m/pixel set for CTX), spatially slice them into 512 × 512 pixel crops, and then rescale all the DTM crops into relative heights of [0, 1].
- (b)
- Secondly, large-scale height variations (e.g., global slopes) are removed from all DTM crops by subtracting each of the DTM crops with a heavily smoothed version (1/20 downsampled and then bicubically interpolated) of the DTM crop itself (considering this to be a strong low-pass filter), in order to minimise the information flow (during training) of the large-scale height variations that are not generally indicated within the small, corresponding ORI crop.
- (c)
- Thirdly, a bilateral-filtered set of the ORI crops is created, and the mean SSIM values between all corresponding filtered ORI crops and hill-shaded relief crops are calculated. Subsequently, the ORI and DTM samples are sorted in descending order of their mean SSIM values to assist the manual screening process.
- (d)
- Fourthly, we perform visual screening using the sorted hill-shaded relief samples, focusing on the training samples that have higher mean SSIM values (larger than 0.4). Subsequently, we form the filtered training dataset with 20,000 pairs of ORI and DTM crops, which are then visually checked that the various surface features contained in [6] are still sufficiently included.
- (e)
- Finally, we apply data augmentation (i.e., vertical and horizontal flipping) to form the final training dataset containing 60,000 pairs of ORI and DTM crops with identical size of 512 × 512 pixels but at various scales (i.e., 2 m/pixel, 4 m/pixel, and 36 m/pixel). N.B., we make this high-quality image-height training dataset openly available in the Supplementary Materials.
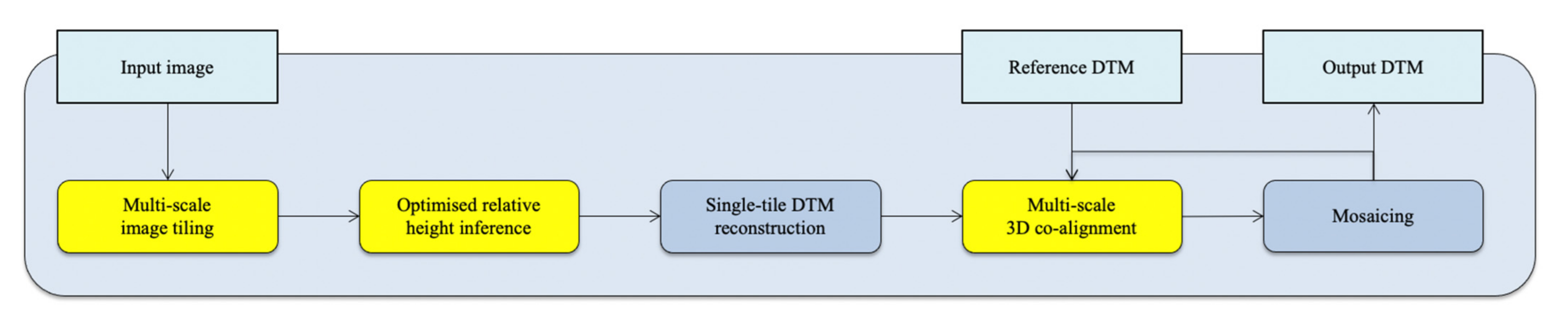
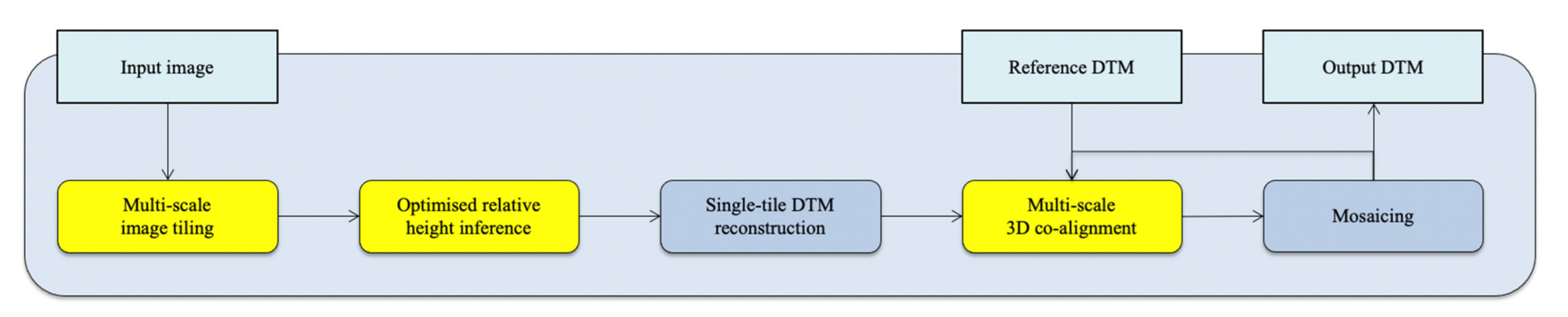
2.4. Datasets and Experiments Overview
- (a)
- Produce two downscaled versions of the input HiRISE image at 1 m/pixel and 4 m/pixel, respectively.
- (b)
- Spatially slice the 25 cm/pixel, 1 m/pixel, and 4 m/pixel HiRISE images and produce overlapping image tiles at the size of 512 × 512 pixels.
- (c)
- Perform batch relative height inference for all image tiles from (b) using the pre-trained MADNet 2.0 model to produce initial inference outputs at 25 cm/pixel, 1 m/pixel, and 4 m/pixel.
- (d)
- Perform height rescaling and 3D co-alignment for the 4 m/pixel inference outputs from (c) using the input CTX DTM mosaic as the reference.
- (e)
- Mosaic the co-aligned 4 m/pixel DTM tiles from (d).
- (f)
- Perform height rescaling and 3D co-alignment for the 1 m/pixel inference outputs from (c) using the mosaiced 4 m/pixel DTM from (e) as the reference.
- (g)
- Mosaic the co-aligned 1 m/pixel DTM tiles from (f).
- (h)
- Perform height rescaling and 3D co-alignment for the 25 cm/pixel inference outputs from (c) using the mosaiced 1 m/pixel DTM from (g) as the reference.
- (i)
- Mosaic the co-aligned 25 cm/pixel DTM tiles from (h) to produce the final 25 cm/pixel output HiRISE DTM.
3. Results
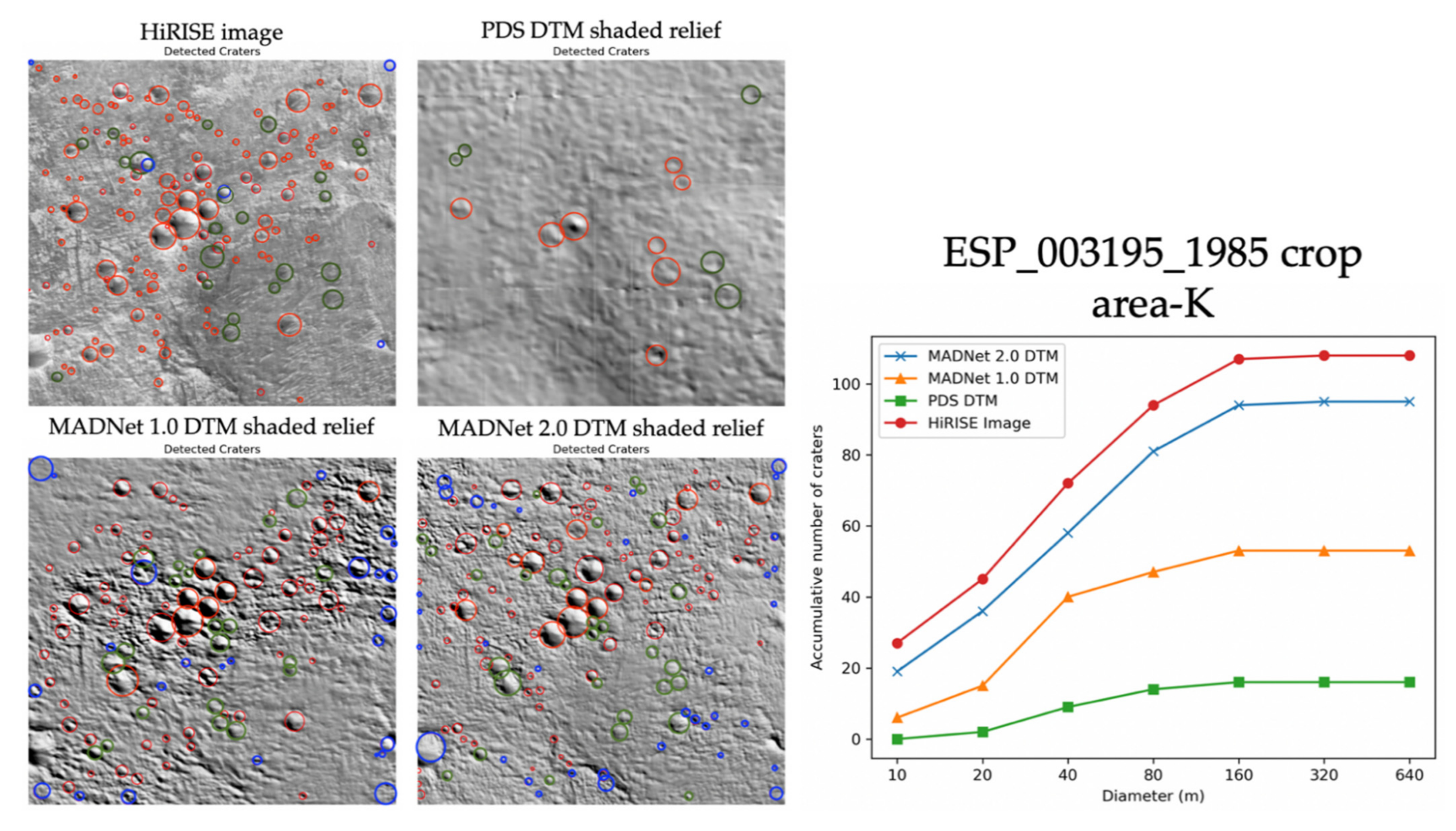
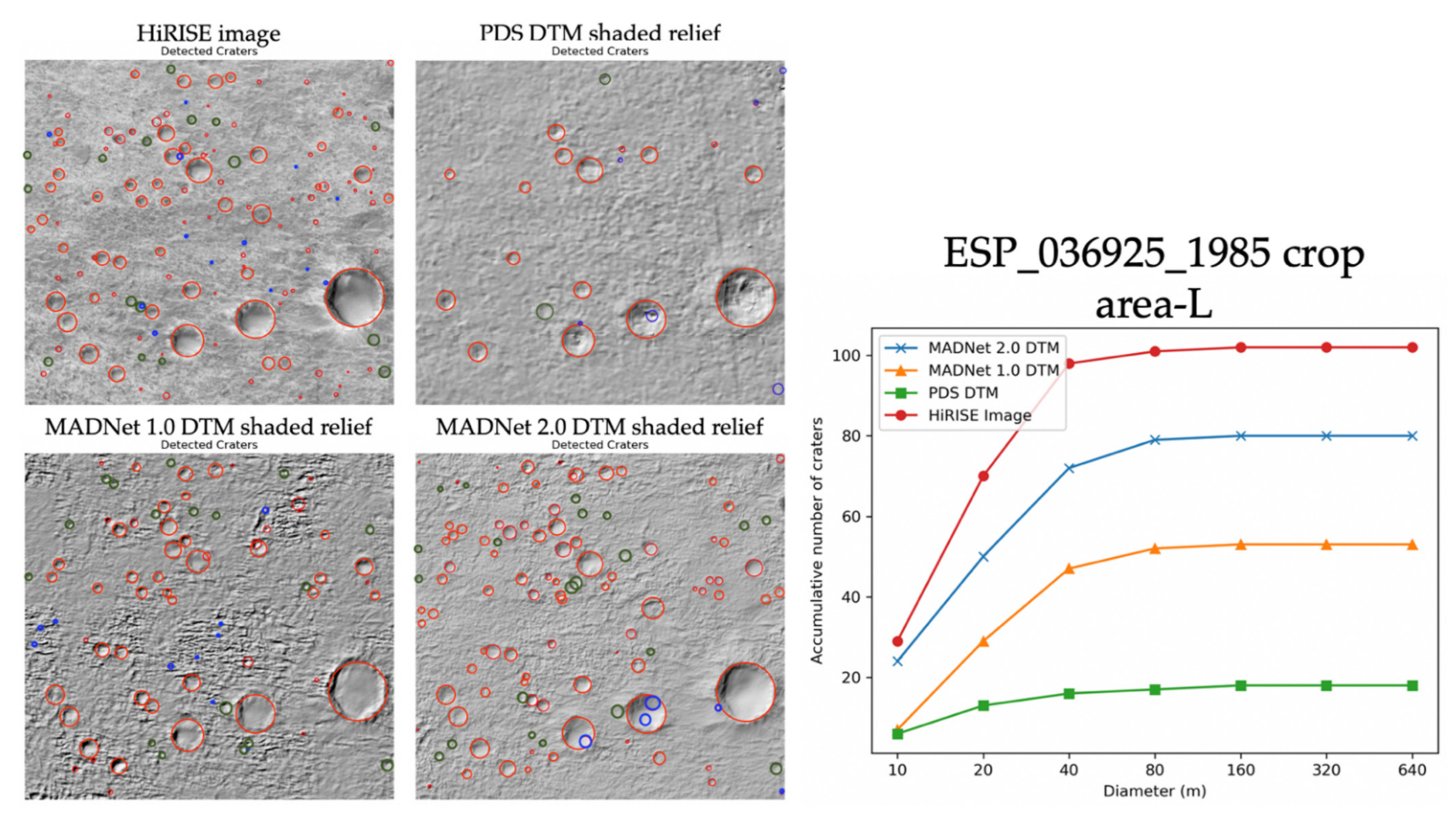
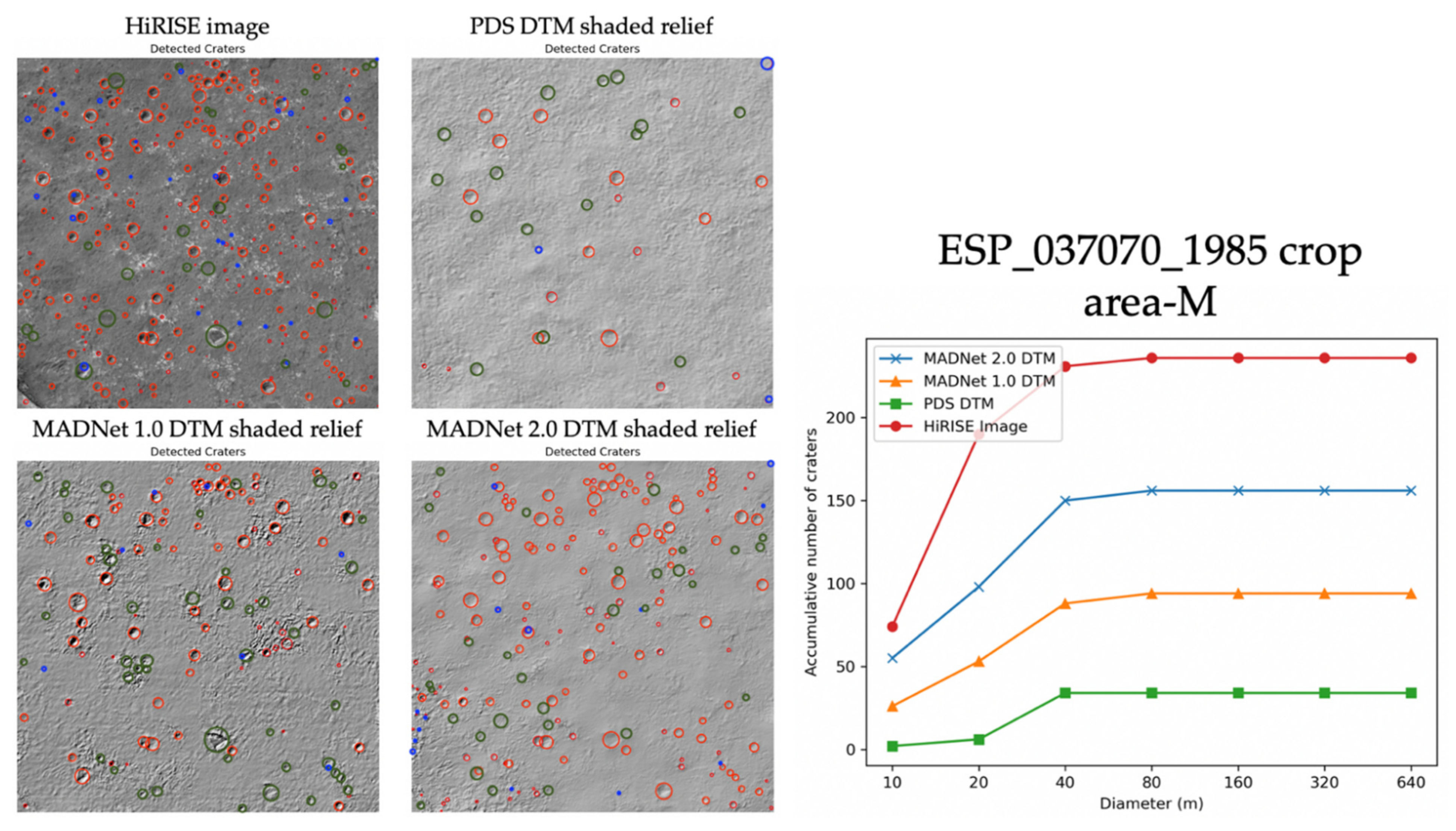
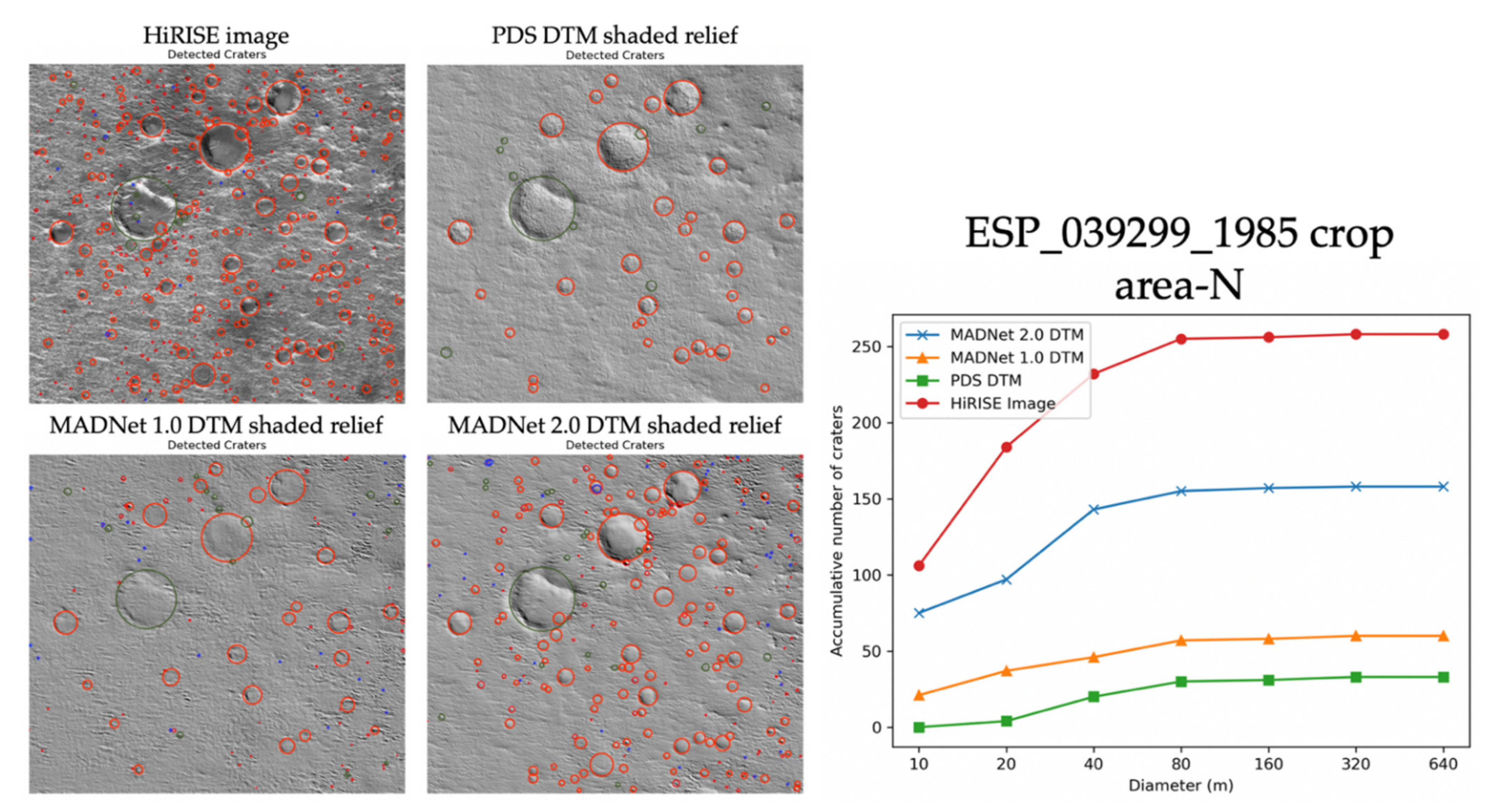
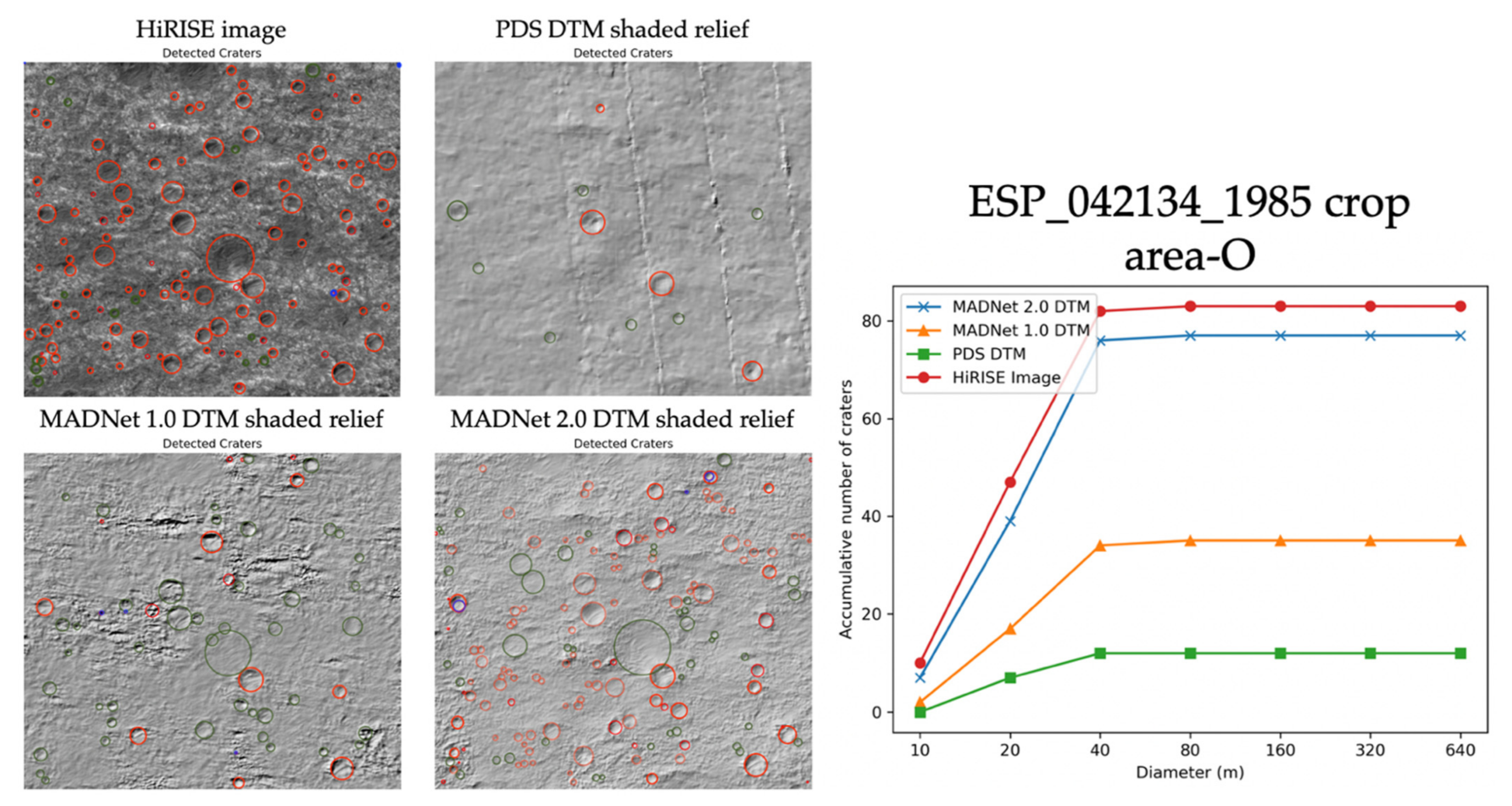
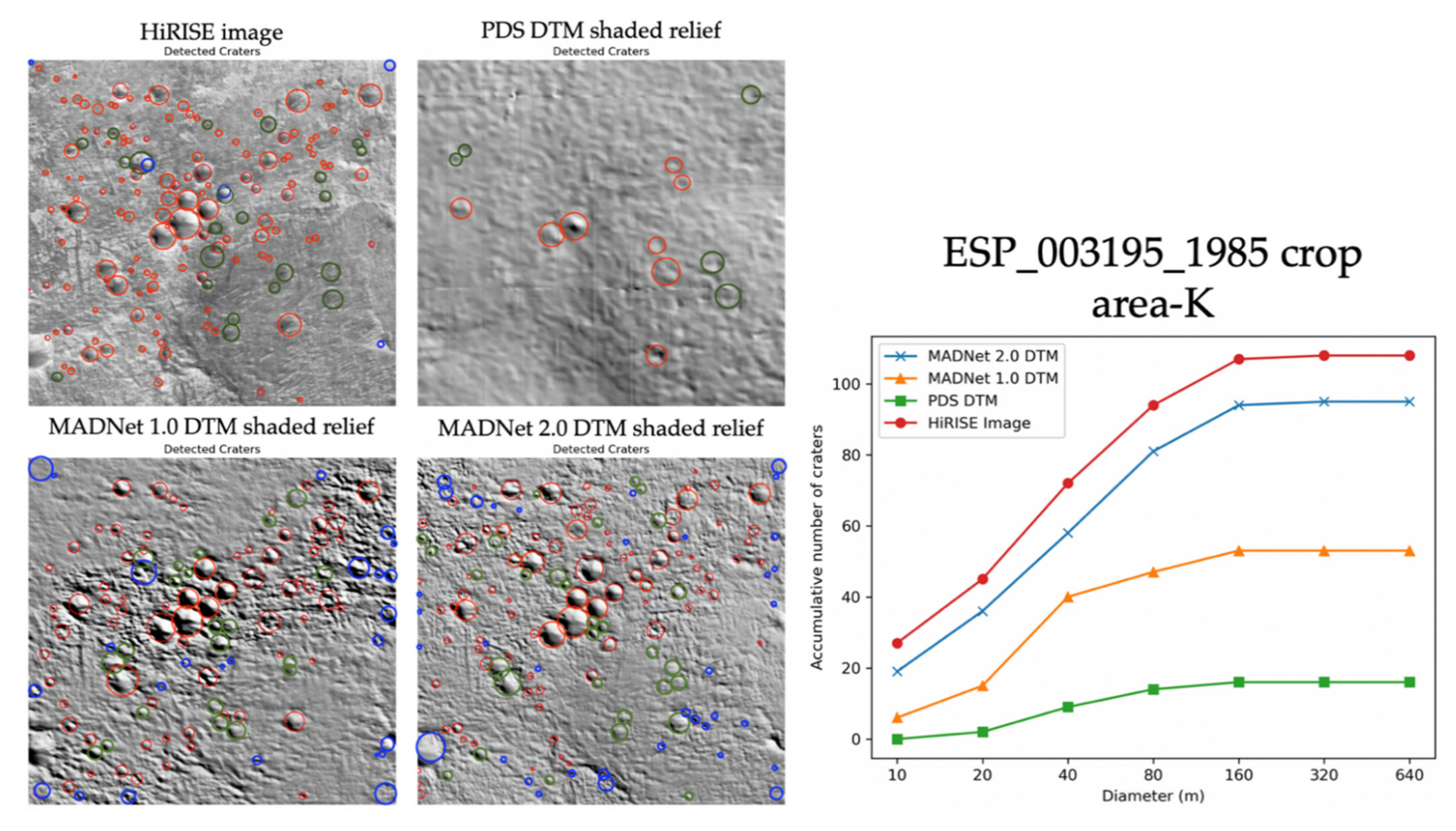
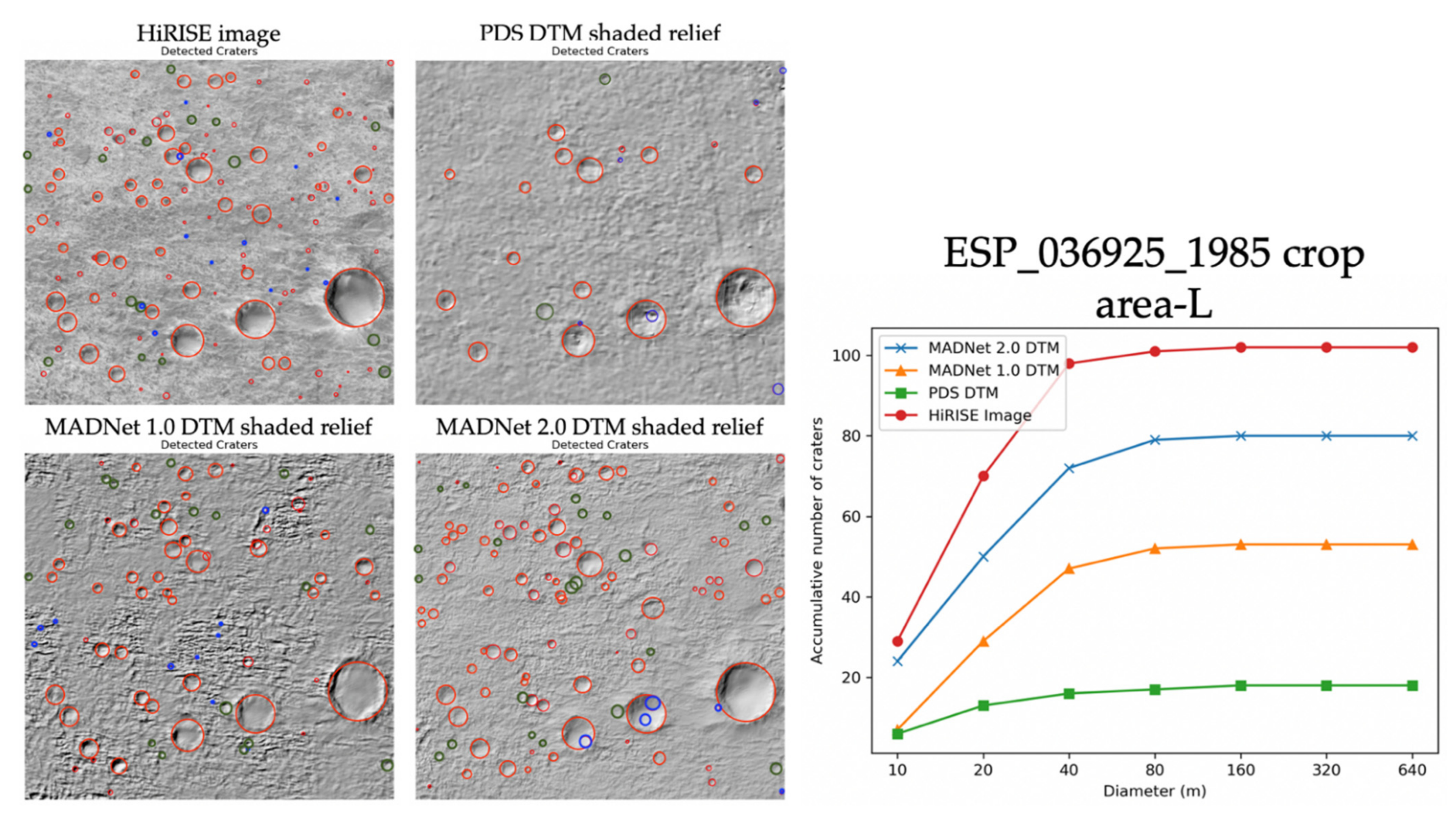
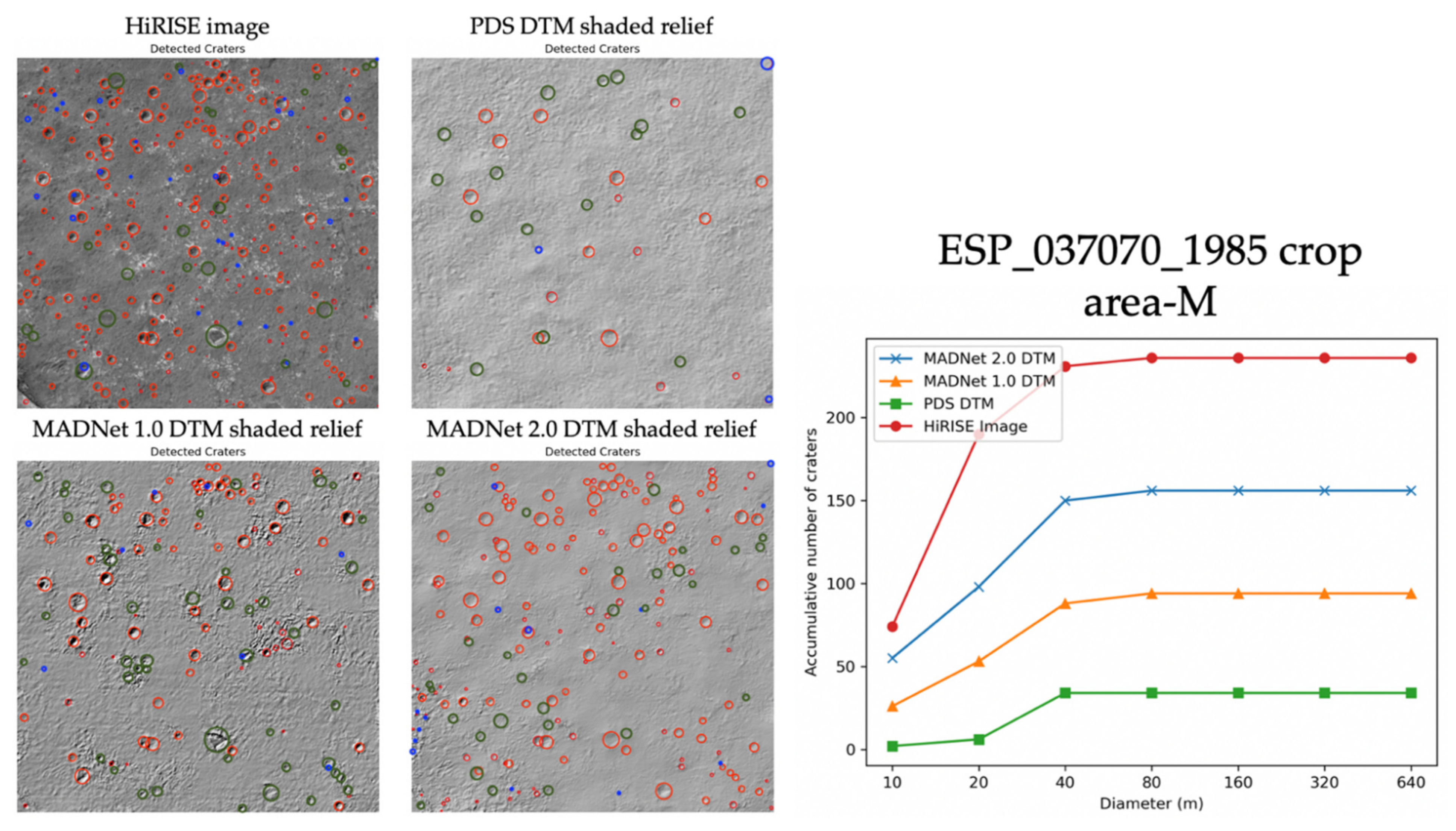
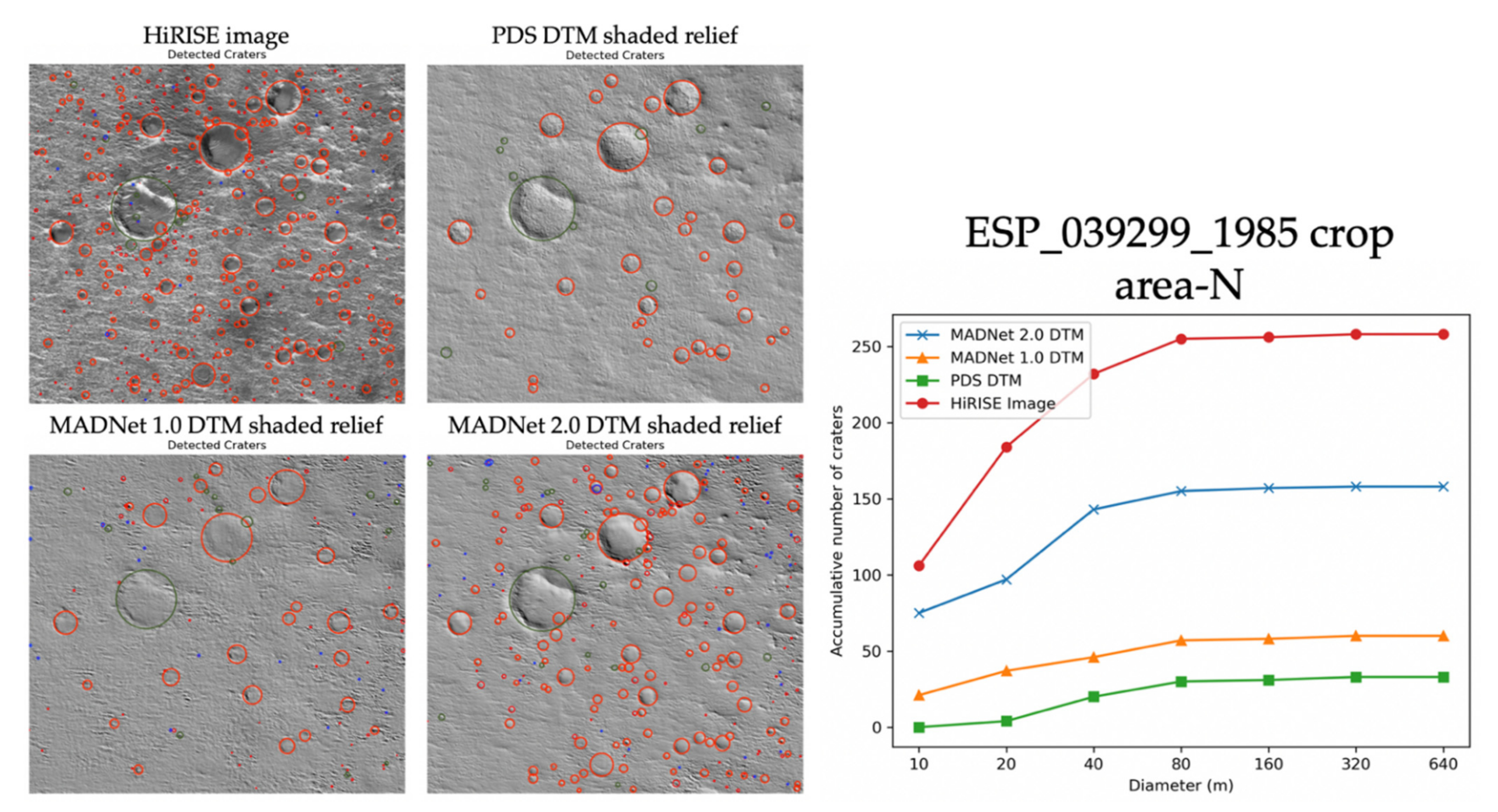
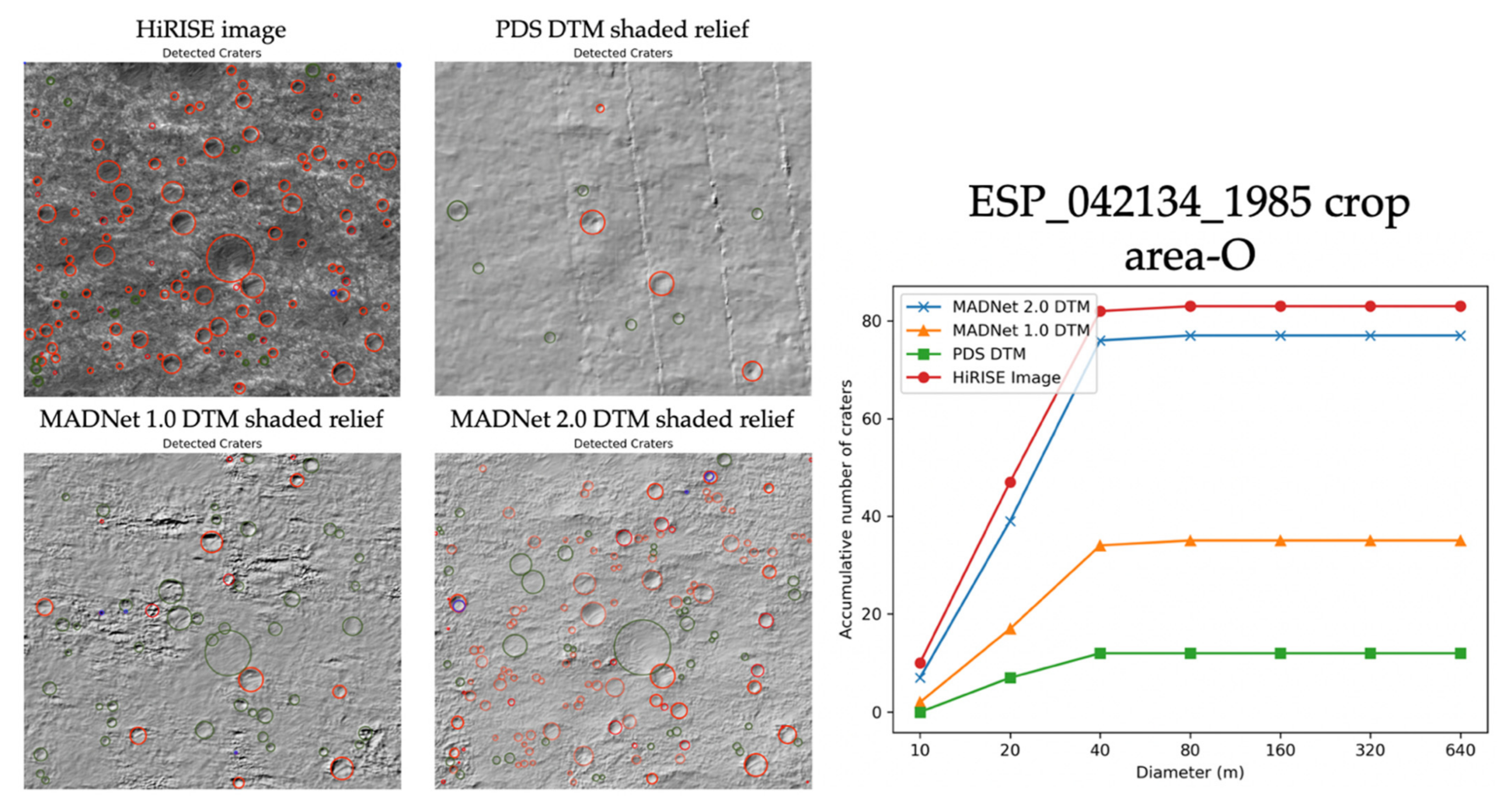
3.1. Qualitative Assessments
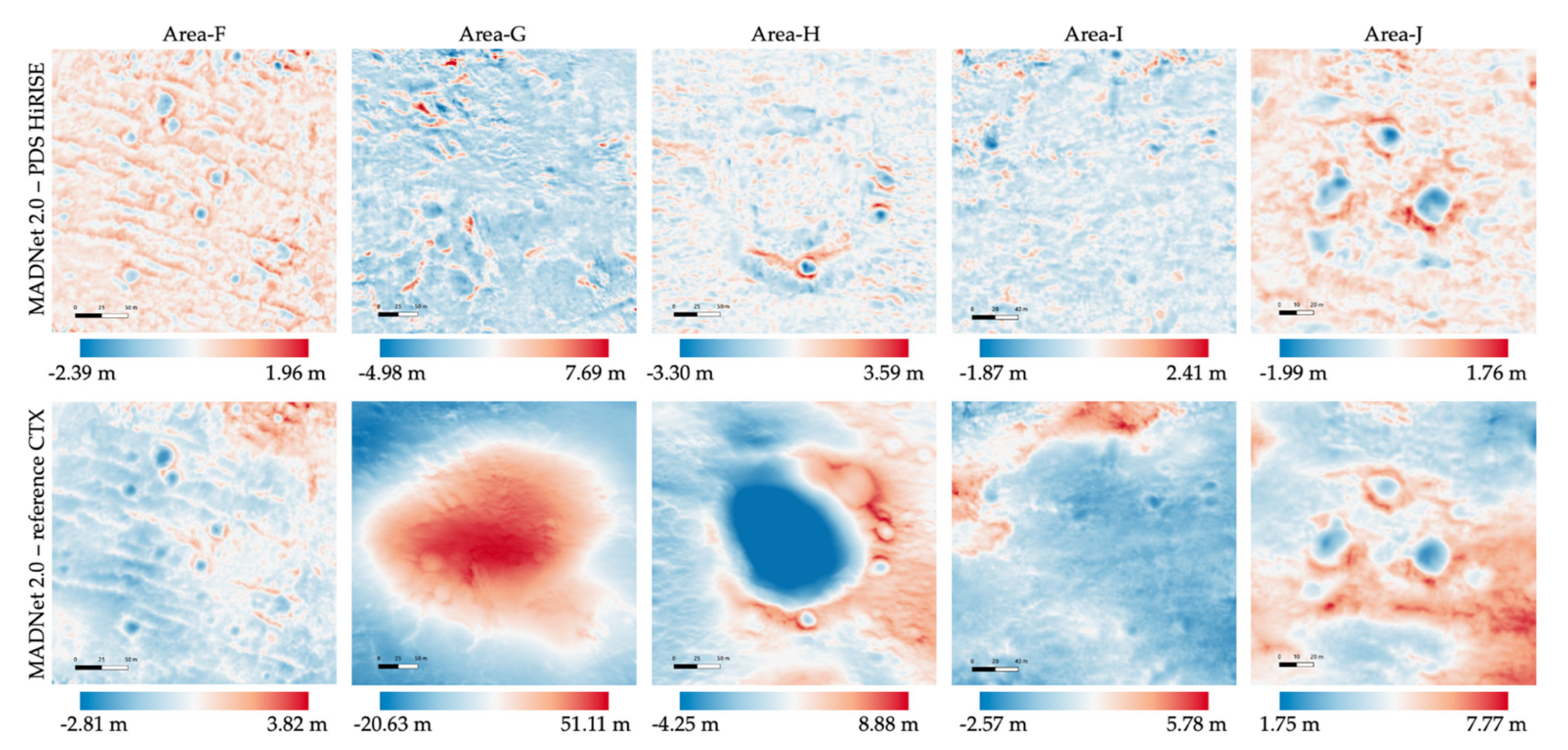
3.2. Quantitative Assessments
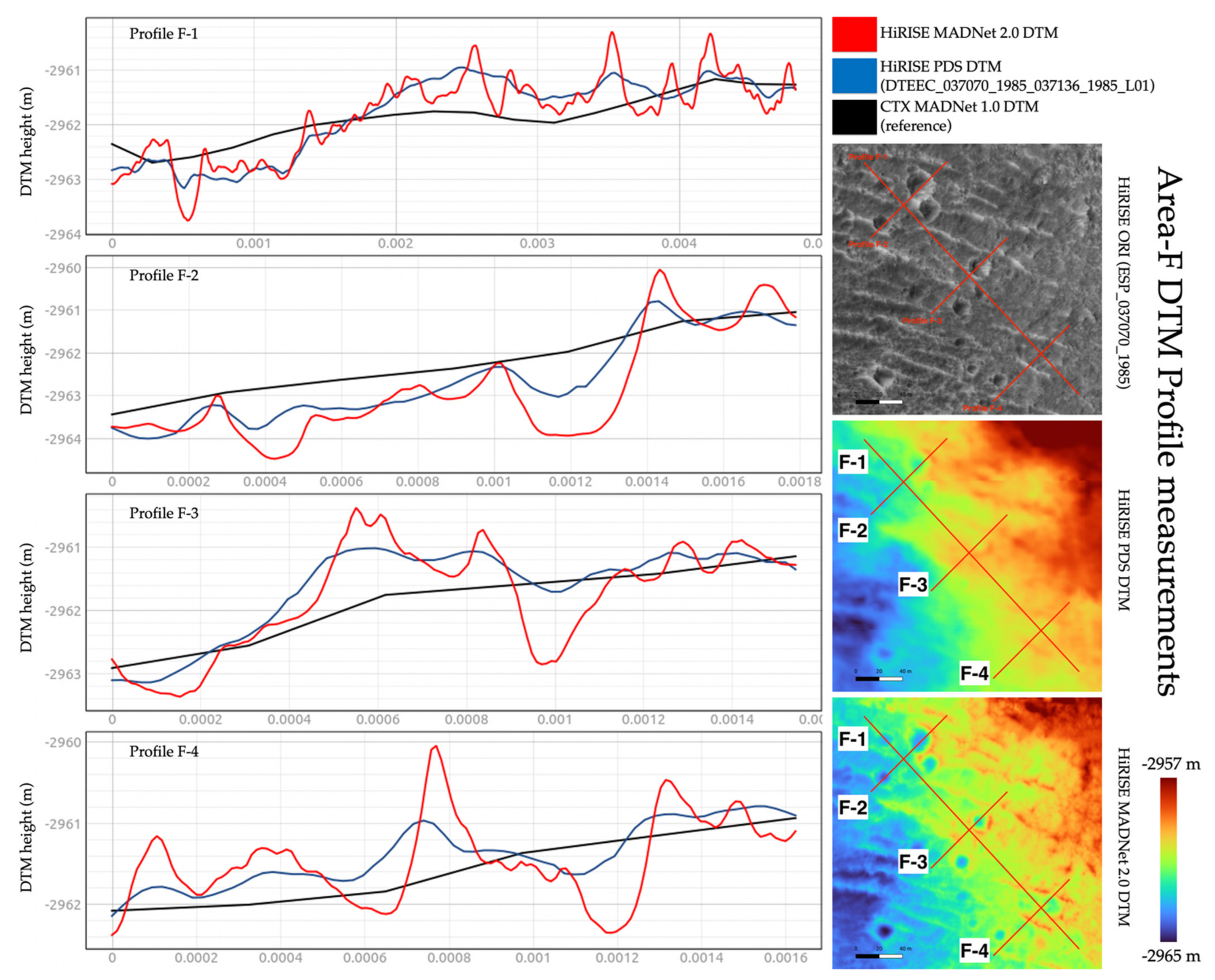
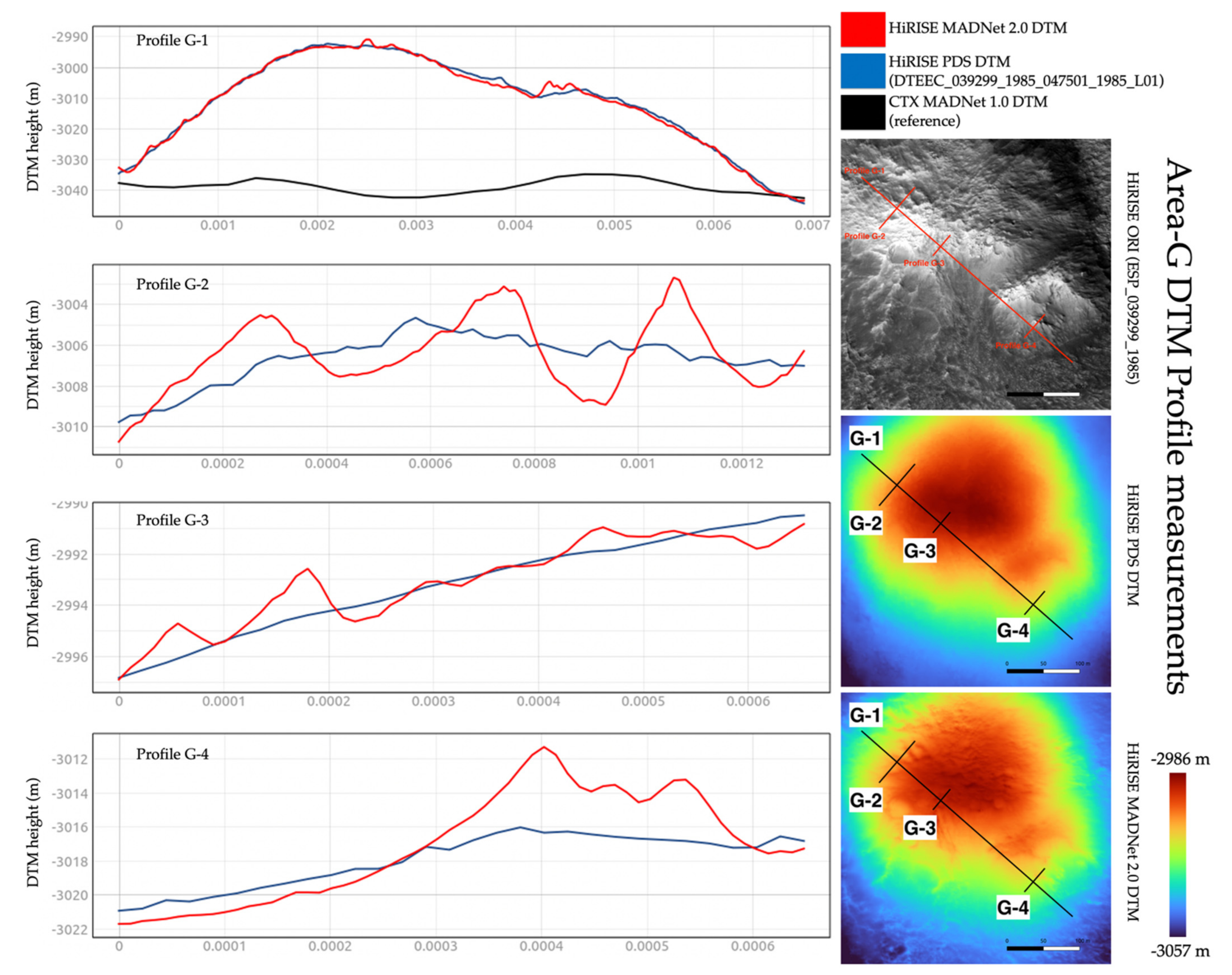
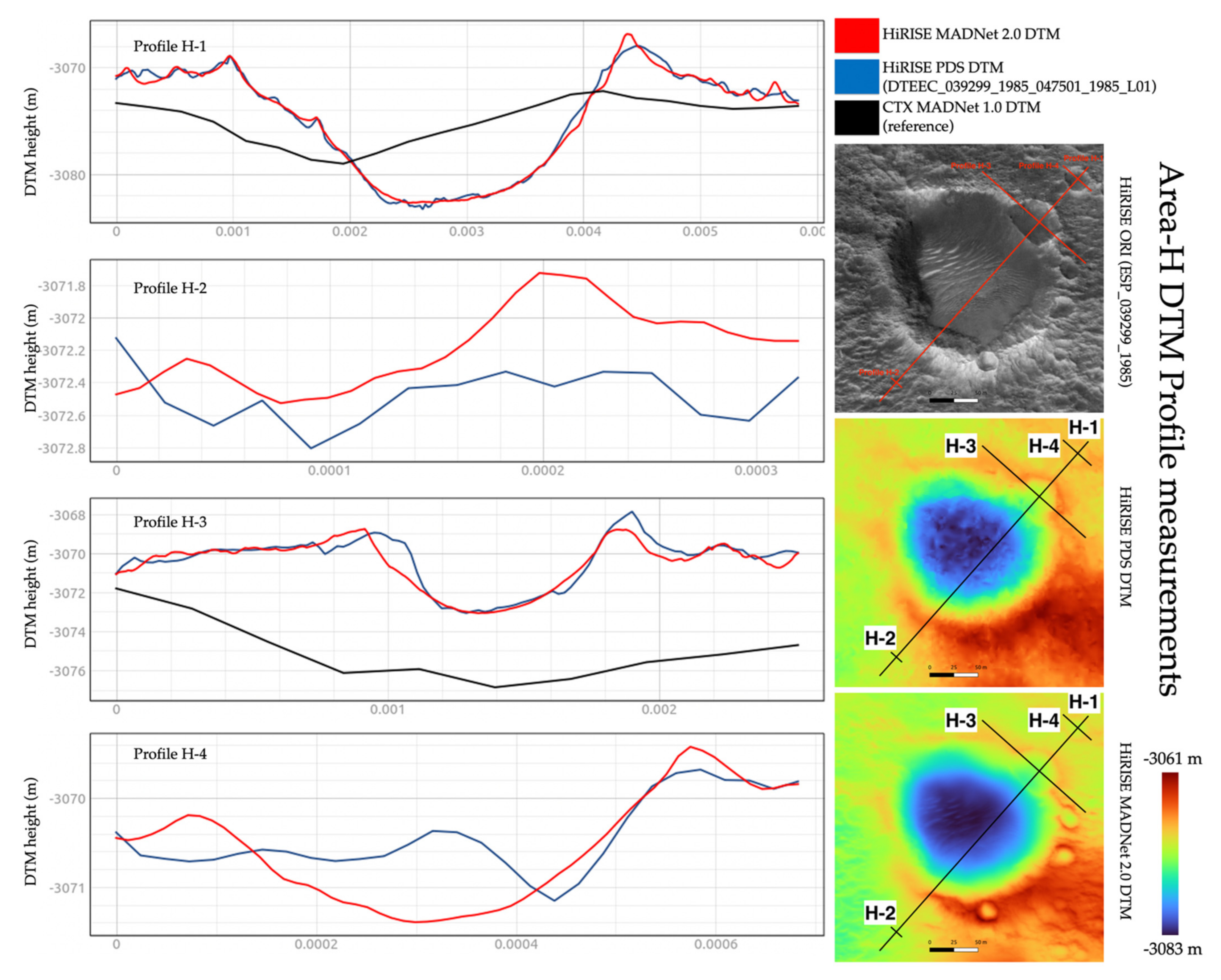
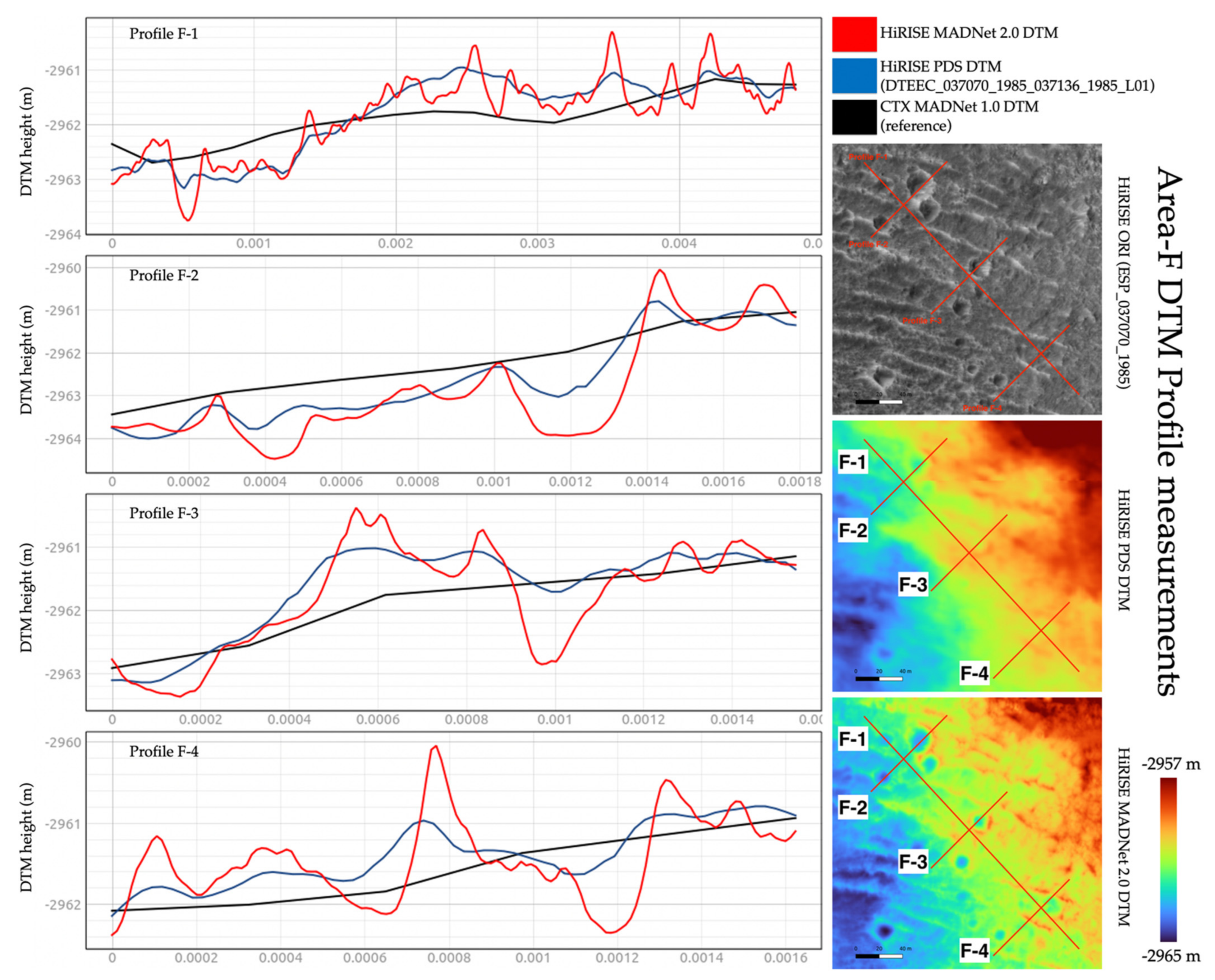
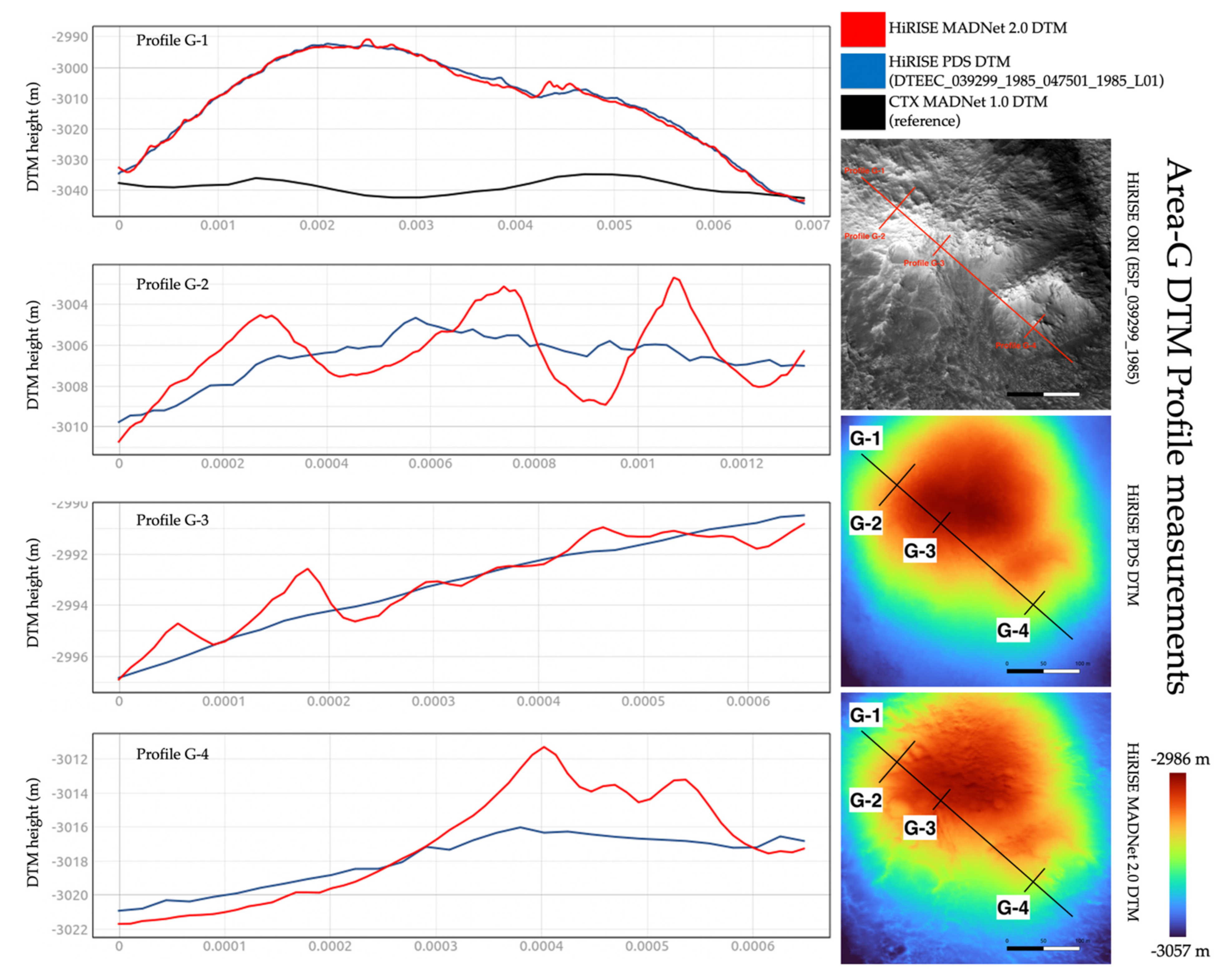
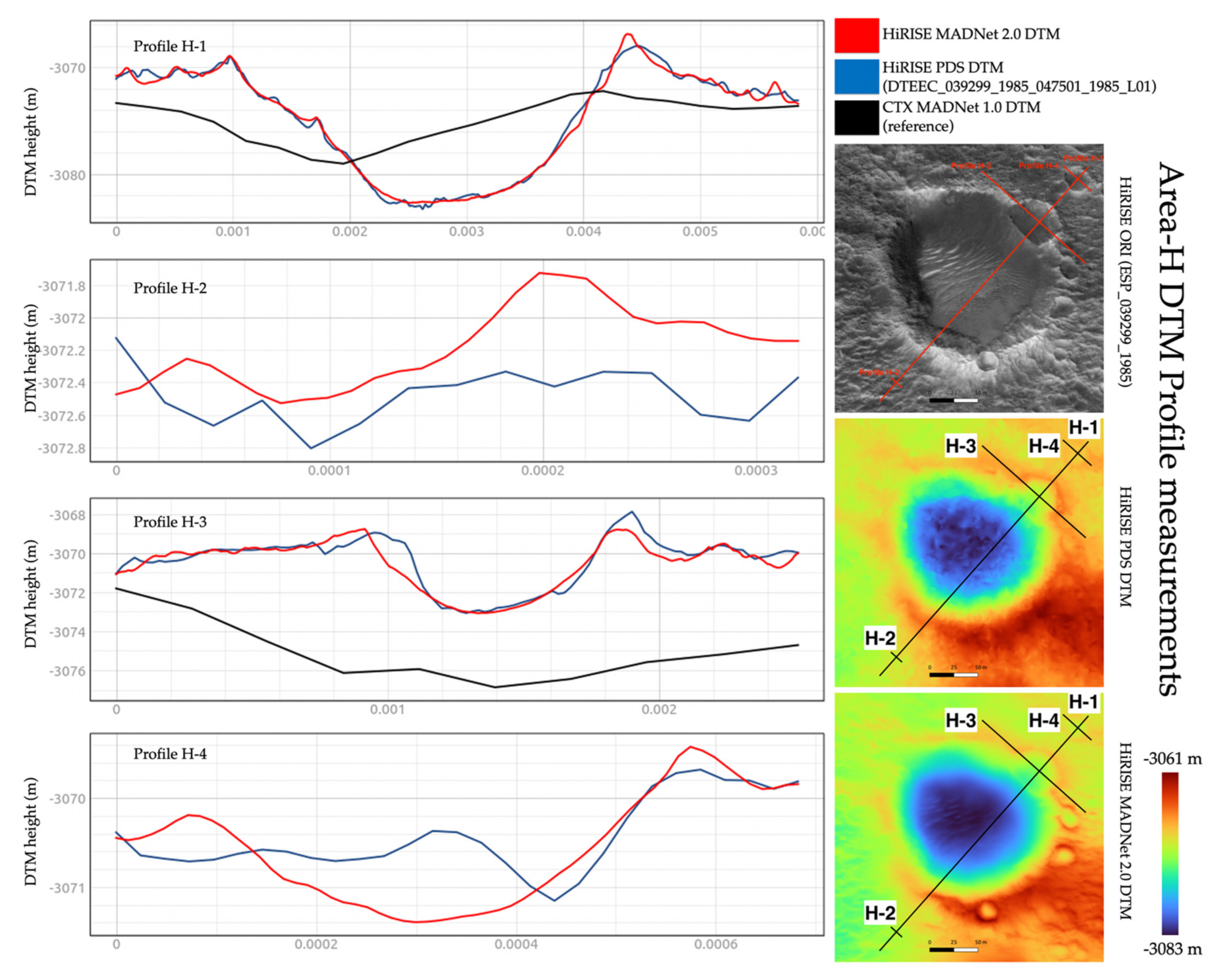
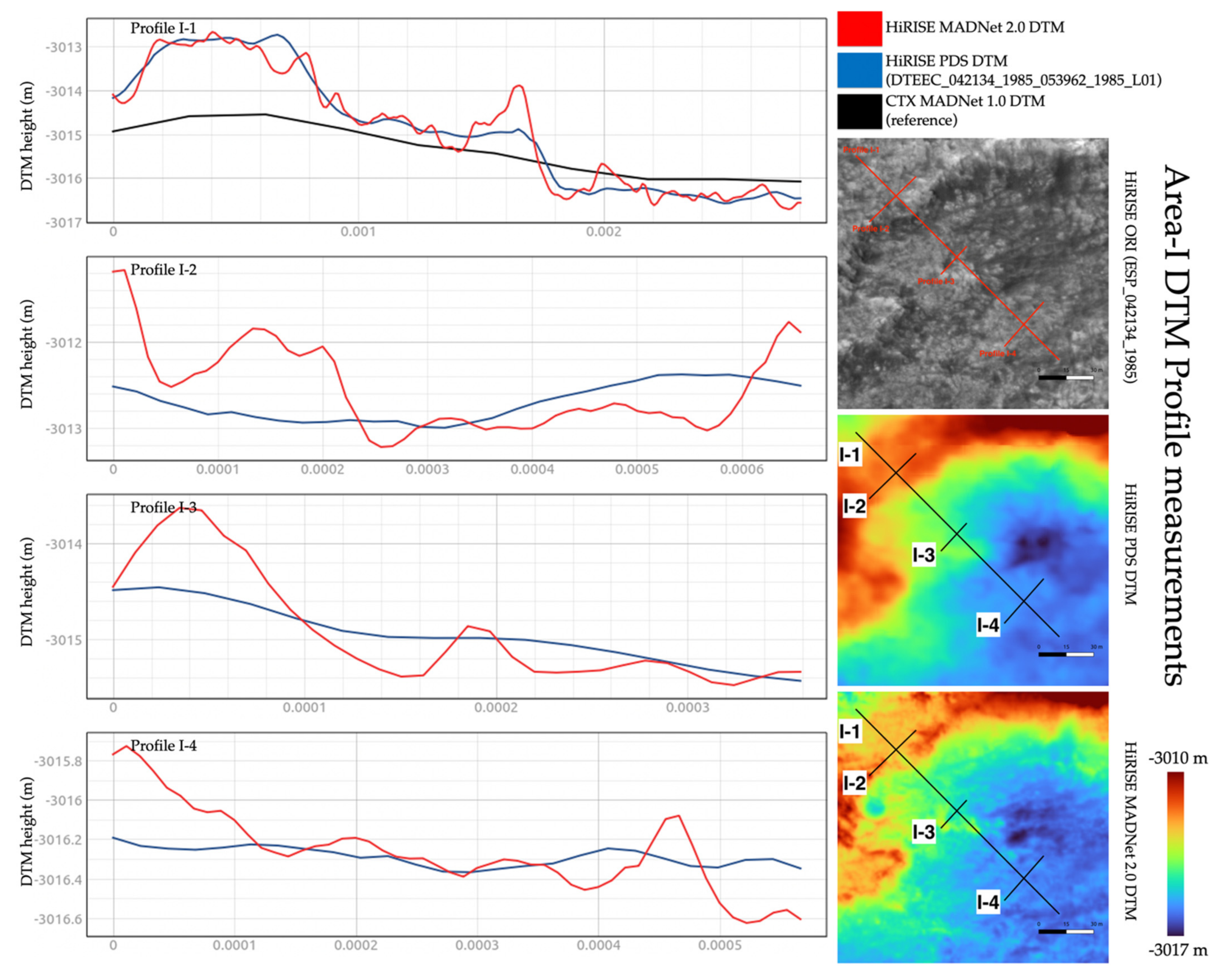
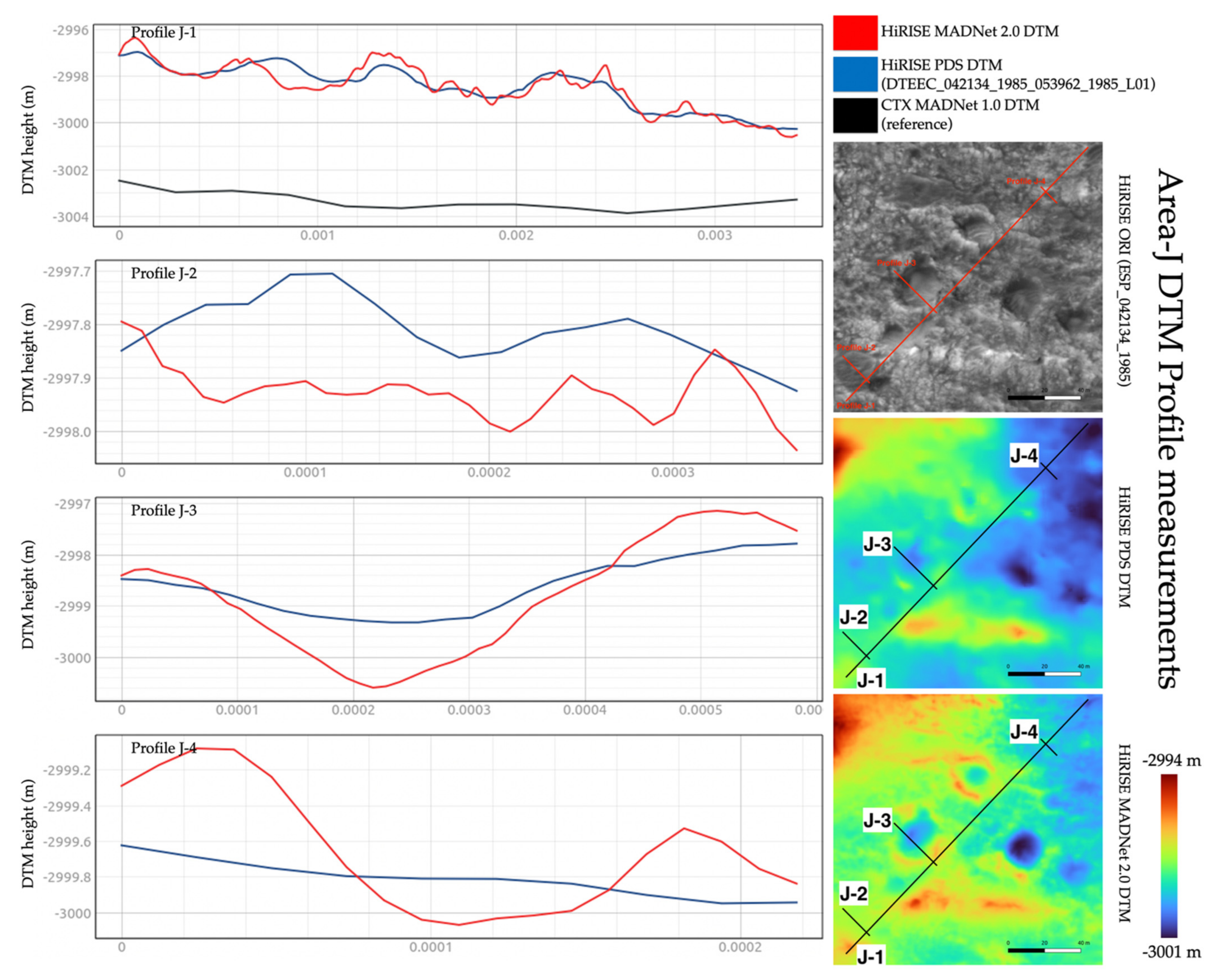
3.3. DTM Profile and Difference Measurements
4. Discussion
4.1. MADNet 2.0 without Photogrammetric Inputs
4.2. Limitations and Future Work
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neukum, G.; Jaumann, R. HRSC: The high resolution stereo camera of Mars Express. Sci. Payload 2004, 1240, 17–35. [Google Scholar]
- Malin, M.C.; Bell, J.F.; Cantor, B.A.; Caplinger, M.A.; Calvin, W.M.; Clancy, R.T.; Edgett, K.S.; Edwards, L.; Haberle, R.M.; James, P.B.; et al. Context camera investigation on board the Mars Reconnaissance Orbiter. J. Geophys. Res. Space Phys. 2007, 112, 112. [Google Scholar] [CrossRef] [Green Version]
- Thomas, N.; Cremonese, G.; Ziethe, R.; Gerber, M.; Brändli, M.; Bruno, G.; Erismann, M.; Gambicorti, L.; Gerber, T.; Ghose, K.; et al. The colour and stereo surface imaging system (CaSSIS) for the ExoMars trace gas orbiter. Space Sci. Rev. 2017, 212, 1897–1944. [Google Scholar] [CrossRef] [Green Version]
- McEwen, A.S.; Eliason, E.M.; Bergstrom, J.W.; Bridges, N.T.; Hansen, C.J.; Delamere, W.A.; Grant, J.A.; Gulick, V.C.; Herkenhoff, K.E.; Keszthelyi, L.; et al. Mars reconnaissance orbiter’s high resolution imaging science experiment (HiRISE). J. Geophys. Res. Space Phys. 2007, 112, E5. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wu, B.; Liu, W.C. Mars3DNet: CNN-Based High-Resolution 3D Reconstruction of the Martian Surface from Single Images. Remote Sens. 2021, 13, 839. [Google Scholar] [CrossRef]
- Tao, Y.; Xiong, S.; Conway, S.J.; Muller, J.-P.; Guimpier, A.; Fawdon, P.; Thomas, N.; Cremonese, G. Rapid Single Image-Based DTM Estimation from ExoMars TGO CaSSIS Images Using Generative Adversarial U-Nets. Remote Sens. 2021, 13, 2877. [Google Scholar] [CrossRef]
- Tao, Y.; Muller, J.-P.; Conway, S.J.; Xiong, S. Large Area High-Resolution 3D Mapping of Oxia Planum: The Landing Site for The ExoMars Rosalind Franklin Rover. Remote Sens. 2021, 13, 3270. [Google Scholar] [CrossRef]
- Tao, Y.; Muller, J.P.; Sidiropoulos, P.; Xiong, S.T.; Putri, A.R.D.; Walter, S.H.G.; Veitch-Michaelis, J.; Yershov, V. Massive stereo-based DTM production for Mars on cloud computers. Planet. Space Sci. 2018, 154, 30–58. [Google Scholar] [CrossRef]
- Masson, A.; De Marchi, G.; Merin, B.; Sarmiento, M.H.; Wenzel, D.L.; Martinez, B. Google dataset search and DOI for data in the ESA space science archives. Adv. Space Res. 2021, 67, 2504–2516. [Google Scholar] [CrossRef]
- Quantin-Nataf, C.; Carter, J.; Mandon, L.; Thollot, P.; Balme, M.; Volat, M.; Pan, L.; Loizeau, D.; Millot, C.; Breton, S.; et al. Oxia Planum: The Landing Site for the ExoMars “Rosalind Franklin” Rover Mission: Geological Context and Prelanding Interpretation. Astrobiology 2021, 21, 345–366. [Google Scholar] [CrossRef]
- Smith, D.E.; Zuber, M.T.; Frey, H.V.; Garvin, J.B.; Head, J.W.; Muhleman, D.O.; Pettengill, G.H.; Phillips, R.J.; Solomon, S.C.; Zwally, H.J.; et al. Mars Orbiter Laser Altimeter—Experiment summary after the first year of global mapping of Mars. J. Geophys. Res. 2001, 106, 23689–23722. [Google Scholar] [CrossRef]
- Neumann, G.A.; Rowlands, D.D.; Lemoine, F.G.; Smith, D.E.; Zuber, M.T. Crossover analysis of Mars Orbiter Laser Altimeter data. J. Geophys. Res. 2001, 106, 23753–23768. [Google Scholar] [CrossRef] [Green Version]
- Kirk, R.L.; Barrett, J.M.; Soderblom, L.A. Photoclinometry made simple. In Proceedings of the ISPRS Working Group IV/9 Workshop ‘Advances in Planetary Mapping’, Houston, TX, USA, 24–28 February 2003; p. 4. [Google Scholar]
- Lohse, V.; Heipke, C.; Kirk, R.L. Derivation of planetary topography using multi-image shape-from-shading. Planet. Space Sci. 2006, 54, 661–674. [Google Scholar] [CrossRef]
- Grumpe, A.; Belkhir, F.; Wöhler, C. Construction of lunar DEMs based on reflectance modelling. Adv. Space Res. 2014, 53, 1735–1767. [Google Scholar] [CrossRef]
- Bhoi, A. Monocular depth estimation: A survey. arXiv 2019, arXiv:1901.09402. [Google Scholar]
- Zhao, C.; Sun, Q.; Zhang, C.; Tang, Y.; Qian, F. Monocular depth estimation based on deep learning: An overview. Sci. China Technol. Sci. 2020, 63, 1612–1627. [Google Scholar] [CrossRef]
- Khan, F.; Salahuddin, S.; Javidnia, H. Deep Learning-Based Monocular Depth Estimation Methods—A State-of-the-Art Review. Sensors 2020, 20, 2272. [Google Scholar] [CrossRef] [Green Version]
- de Queiroz Mendes, R.; Ribeiro, E.G.; dos Santos Rosa, N.; Grassi, V., Jr. On deep learning techniques to boost monocular depth estimation for autonomous navigation. Robot. Auton. Syst. 2021, 136, 103701. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. arXiv 2014, arXiv:1406.2283. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting depth, surface normal and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Shelhamer, E.; Barron, J.T.; Darrell, T. Scene intrinsics and depth from a single image. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 37–44. [Google Scholar]
- Ma, X.; Geng, Z.; Bie, Z. Depth Estimation from Single Image Using CNN-Residual Network. SemanticScholar. 2017. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/203.pdf (accessed on 15 October 2021).
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Zwald, L.; Lambert-Lacroix, S. The berhu penalty and the grouped effect. arXiv 2012, arXiv:1207.6868. [Google Scholar]
- Li, B.; Shen, C.; Dai, Y.; Van Den Hengel, A.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical crfs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1119–1127. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A.L. Towards unified depth and semantic prediction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2800–2809. [Google Scholar]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint semantic segmentation and depth estimation with deep convolutional networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Jung, H.; Kim, Y.; Min, D.; Oh, C.; Sohn, K. Depth prediction from a single image with conditional adversarial networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1717–1721. [Google Scholar]
- Lore, K.G.; Reddy, K.; Giering, M.; Bernal, E.A. Generative adversarial networks for depth map estimation from RGB video. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1258–12588. [Google Scholar]
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2019, Prepr. arXiv:1907.10326. [Google Scholar]
- Wofk, D.; Ma, F.; Yang, T.J.; Karaman, S.; Sze, V. Fastdepth: Fast monocular depth estimation on embedded systems. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6101–6108. [Google Scholar]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured attention guided convolutional neural fields for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3917–3925. [Google Scholar]
- Chen, Y.; Zhao, H.; Hu, Z.; Peng, J. Attention-based context aggregation network for monocular depth estimation. Int. J. Mach. Learn. Cybern. 2021, 12, 1583–1596. [Google Scholar] [CrossRef]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised CNN for single view depth estimation: Geometry to the rescue. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 740–756. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Buenaposada, J.M.; Zhu, R.; Lucey, S. Learning depth from monocular videos using direct methods. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2022–2030. [Google Scholar]
- Luo, Y.; Ren, J.; Lin, M.; Pang, J.; Sun, W.; Li, H.; Lin, L. Single view stereo matching. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 155–163. [Google Scholar]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9799–9809. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Zou, Y.; Luo, Z.; Huang, J.B. Df-net: Unsupervised joint learning of depth and flow using cross-task consistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 36–53. [Google Scholar]
- Ranjan, A.; Jampani, V.; Balles, L.; Kim, K.; Sun, D.; Wulff, J.; Black, M.J. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation. In Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12240–12249. [Google Scholar]
- Pilzer, A.; Xu, D.; Puscas, M.; Ricci, E.; Sebe, N. Unsupervised adversarial depth estimation using cycled generative networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 587–595. [Google Scholar]
- Feng, T.; Gu, D. Sganvo: Unsupervised deep visual odometry and depth estimation with stacked generative adversarial networks. IEEE Robot. Autom. Lett. 2019, 4, 4431–4437. [Google Scholar] [CrossRef] [Green Version]
- Pnvr, K.; Zhou, H.; Jacobs, D. Sharin GAN: Combining Synthetic and Real Data for Unsupervised Geometry Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13974–13983. [Google Scholar]
- Shen, J.; Cheung, S.C.S. Layer depth denoising and completion for structured-light rgb-d cameras. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 1187–1194. [Google Scholar]
- Zhang, X.; Wu, R. Fast depth image denoising and enhancement using a deep convolutional network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2499–2503. [Google Scholar]
- Schneider, N.; Schneider, L.; Pinggera, P.; Franke, U.; Pollefeys, M.; Stiller, C. Semantically guided depth upsampling. In Proceedings of the German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2015; Springer: Cham, Switzerland, 2016; pp. 37–48. [Google Scholar]
- Ku, J.; Harakeh, A.; Waslander, S.L. In defense of classical image processing: Fast depth completion on the cpu. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 9–11 May 2018; pp. 16–22. [Google Scholar]
- Lu, J.; Forsyth, D. Sparse depth super resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2245–2253. [Google Scholar]
- Pillai, S.; Ambruş, R.; Gaidon, A.; Gaidon, A. Superdepth: Self-supervised, super-resolved monocular depth estimation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA); Montreal, QC, Canad, 20–24 May 2019, pp. 9250–9256.
- Zhou, L.; Ye, J.; Abello, M.; Wang, S.; Kaess, M. Unsupervised learning of monocular depth estimation with bundle adjustment, super-resolution and clip loss. arXiv 2018, Prepr. arXiv:1812.03368. [Google Scholar]
- Zhao, S.; Zhang, L.; Shen, Y.; Zhao, S.; Zhang, H. Super-resolution for monocular depth estimation with multi-scale sub-pixel convolutions and a smoothness constraint. IEEE Access 2019, 7, 16323–16335. [Google Scholar] [CrossRef]
- Li, S.; Shi, J.; Song, W.; Hao, A.; Qin, H. Hierarchical Object Relationship Constrained Monocular Depth Estimation. Pattern Recognit. 2021, 120, 108116. [Google Scholar] [CrossRef]
- Miangoleh, S.M.H.; Dille, S.; Mai, L.; Paris, S.; Aksoy, Y. Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 9685–9694. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Tao, Y.; Conway, S.J.; Muller, J.-P.; Putri, A.R.D.; Thomas, N.; Cremonese, G. Single Image Super-Resolution Restoration of TGO CaSSIS Colour Images: Demonstration with Perseverance Rover Landing Site and Mars Science Targets. Remote Sens. 2021, 13, 1777. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Donostia, Spain, 5–8 June 2017; pp. 4700–4708. [Google Scholar]
- Tao, Y.; Michael, G.; Muller, J.P.; Conway, S.J.; Putri, A.R. Seamless 3 D Image Mapping and Mosaicing of Valles Marineris on Mars Using Orbital HRSC Stereo and Panchromatic Images. Remote Sens. 2021, 13, 1385. [Google Scholar] [CrossRef]
- Tao, Y.; Xiong, S.; Song, R.; Muller, J.-P. Towards Streamlined Single-Image Super-Resolution: Demonstration with 10 m Sentinel-2 Colour and 10–60 m Multi-Spectral VNIR and SWIR Bands. Remote Sens. 2021, 13, 2614. [Google Scholar] [CrossRef]
- Gwinner, K.; Scholten, F.; Spiegel, M.; Schmidt, R.; Giese, B.; Oberst, J.; Jaumann, R.; Neukum, G. Derivation and Validation of High-Resolution Digital Terrain Models from Mars Express HRSC data. Photogramm. Eng. Remote Sens. 2009, 75, 1127–1142. [Google Scholar] [CrossRef] [Green Version]
- Gwinner, K.; Jaumann, R.; Hauber, E.; Hoffmann, H.; Heipke, C.; Oberst, J.; Neukum, G.; Ansan, V.; Bostelmann, J.; Dumke, A.; et al. The High Resolution Stereo Camera (HRSC) of Mars Express and its approach to science analysis and mapping for Mars and its satellites. Planet. Space Sci. 2016, 126, 93–138. [Google Scholar] [CrossRef]
- Beyer, R.; Alexandrov, O.; McMichael, S. The Ames Stereo Pipeline: NASA’s Opensource Software for Deriving and Processing Terrain Data. Earth Space Sci. 2018, 5, 537–548. [Google Scholar] [CrossRef]
- O’Hara, R.; Barnes, D. A new shape from shading technique with application to Mars Express HRSC images. ISPRS J. Photogramm. Remote Sens. 2012, 67, 27–34. [Google Scholar] [CrossRef]
- Tyler, L.; Cook, T.; Barnes, D.; Parr, G.; Kirk, R. Merged shape from shading and shape from stereo for planetary topographic mapping. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 27 April–2 May 2014; p. 16110. [Google Scholar]
- Douté, S.; Jiang, C. Small-Scale Topographical Characterization of the Martian Surface with In-Orbit Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 447–460. [Google Scholar] [CrossRef]
- Hess, M. High Resolution Digital Terrain Model for the Landing Site of the Rosalind Franklin (ExoMars) Rover. Adv. Space Res. 2019, 53, 1735–1767. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test-1 | Test-2 | Test-3 | Test-4 | Test-5 | ||
|---|---|---|---|---|---|---|
| MADNet 1.0 | RMSE (m) | 1.0892 | 0.8920 | 1.3501 | 1.2575 | 1.1727 |
| Mean SSIM | 0.9169 | 0.9308 | 0.7222 | 0.8702 | 0.7823 | |
| MADNet 2.0 | RMSE (m) | 0.9985 | 0.9286 | 1.1526 | 1.0999 | 1.1580 |
| Mean SSIM | 0.9235 | 0.9391 | 0.9253 | 0.8971 | 0.7851 | |
| HiRISE ID | Test-1 | Test-2 | Test-3 | Test-4 | Avg. M-FWHM in Pixels | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Extracted Edges | M-FWHM | Extracted Edges | M-FWHM | Extracted Edges | M-FWHM | Extracted Edges | M-FWHM | |||
| ESP_003195_1985 | HiRISE Image | - | 2.98 | - | 4.35 | - | 3.10 | - | 2.36 | 3.20 |
| MADNet 1.0 shaded relief | 83 | 3.26 | 37 | 6.05 | 301 | 4.90 | 89 | 4.57 | 4.45 | |
| MADNet 2.0 shaded relief | 83 | 3.01 | 58 | 4.85 | 301 | 3.98 | 89 | 2.41 | 3.56 | |
| ESP_036925_1985 | HiRISE Image | - | 2.92 | - | 2.90 | - | 2.70 | - | 3.32 | 2.96 |
| MADNet 1.0 shaded relief | 117 | 3.46 | 395 | 4.17 | 162 | 3.79 | 216 | 4.22 | 3.91 | |
| MADNet 2.0 shaded relief | 117 | 3.22 | 395 | 3.01 | 162 | 2.92 | 216 | 3.35 | 3.13 | |
| ESP_037070_1985 | HiRISE Image | - | 3.74 | - | 3.67 | - | 3.13 | - | 3.91 | 3.61 |
| MADNet 1.0 shaded relief | 92 | 3.94 | 13 | 4.32 | 277 | 5.07 | 21 | 4.84 | 4.54 | |
| MADNet 2.0 shaded relief | 92 | 4.03 | 17 | 4.77 | 277 | 3.16 | 25 | 4.53 | 4.12 | |
| ESP_039299_1985 | HiRISE Image | - | 3.58 | - | 2.76 | - | 3.16 | - | 2.95 | 3.11 |
| MADNet 1.0 shaded relief | 122 | 6.48 | 22 | 4.70 | 80 | 5.95 | 52 | 3.58 | 5.18 | |
| MADNet 2.0 shaded relief | 122 | 6.21 | 22 | 2.84 | 84 | 6.12 | 54 | 3.46 | 4.66 | |
| ESP_042134_1985 | HiRISE Image | - | 2.94 | - | 2.83 | - | 3.38 | - | 3.10 | 3.06 |
| MADNet 1.0 shaded relief | 64 | 6.77 | 248 | 3.16 | 169 | 5.52 | 20 | 3.40 | 4.71 | |
| MADNet 2.0 shaded relief | 65 | 3.25 | 248 | 3.08 | 172 | 5.69 | 49 | 3.33 | 3.84 | |
| Area-F | Area-G | Area-H | Area-I | Area-J | ||
|---|---|---|---|---|---|---|
| MADNet 2.0 HiRISE DTM - PDS HiRISE DTM | Mean | 0.001 m | −0.013 m | −0.20 m | −0.005 m | −0.003 m |
| Standard Deviation | 0.289 m | 1.073 m | 0.435 m | 0.297 m | 0.304 m | |
| MADNet 2.0 HiRISE DTM - CTX reference DTM | Mean | 0.076 m | 6.059 m | 1.155 m | 0.292 m | 4.868 m |
| Standard Deviation | 0.601 m | 16.381 m | 2.804 m | 1.218 m | 0.886 m | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, Y.; Muller, J.-P.; Xiong, S.; Conway, S.J. MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning. Remote Sens. 2021, 13, 4220. https://doi.org/10.3390/rs13214220
Tao Y, Muller J-P, Xiong S, Conway SJ. MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning. Remote Sensing. 2021; 13(21):4220. https://doi.org/10.3390/rs13214220
Chicago/Turabian StyleTao, Yu, Jan-Peter Muller, Siting Xiong, and Susan J. Conway. 2021. "MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning" Remote Sensing 13, no. 21: 4220. https://doi.org/10.3390/rs13214220
APA StyleTao, Y., Muller, J.-P., Xiong, S., & Conway, S. J. (2021). MADNet 2.0: Pixel-Scale Topography Retrieval from Single-View Orbital Imagery of Mars Using Deep Learning. Remote Sensing, 13(21), 4220. https://doi.org/10.3390/rs13214220