
High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module



Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset and Pre-Processing
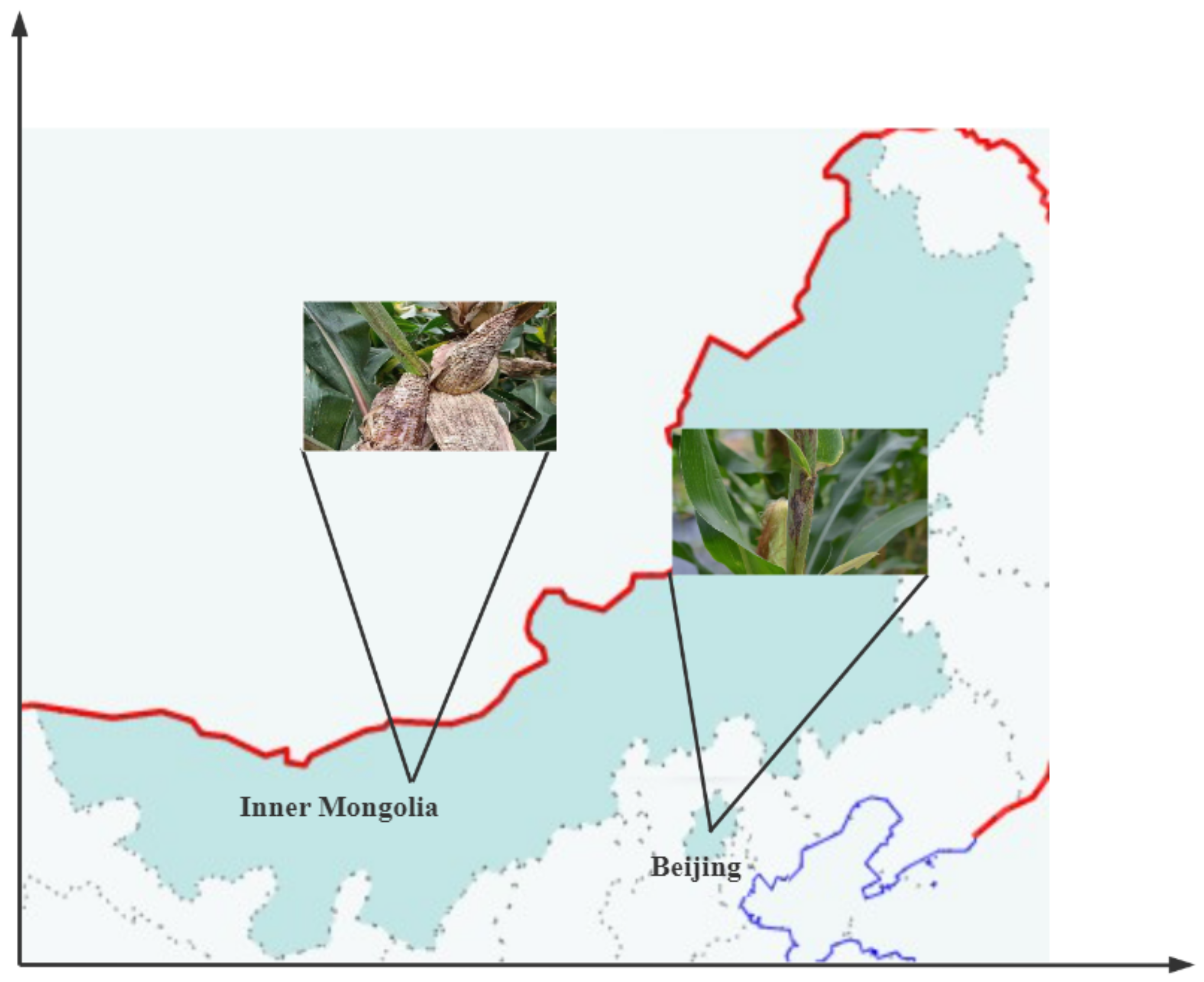
2.1.1. Dataset
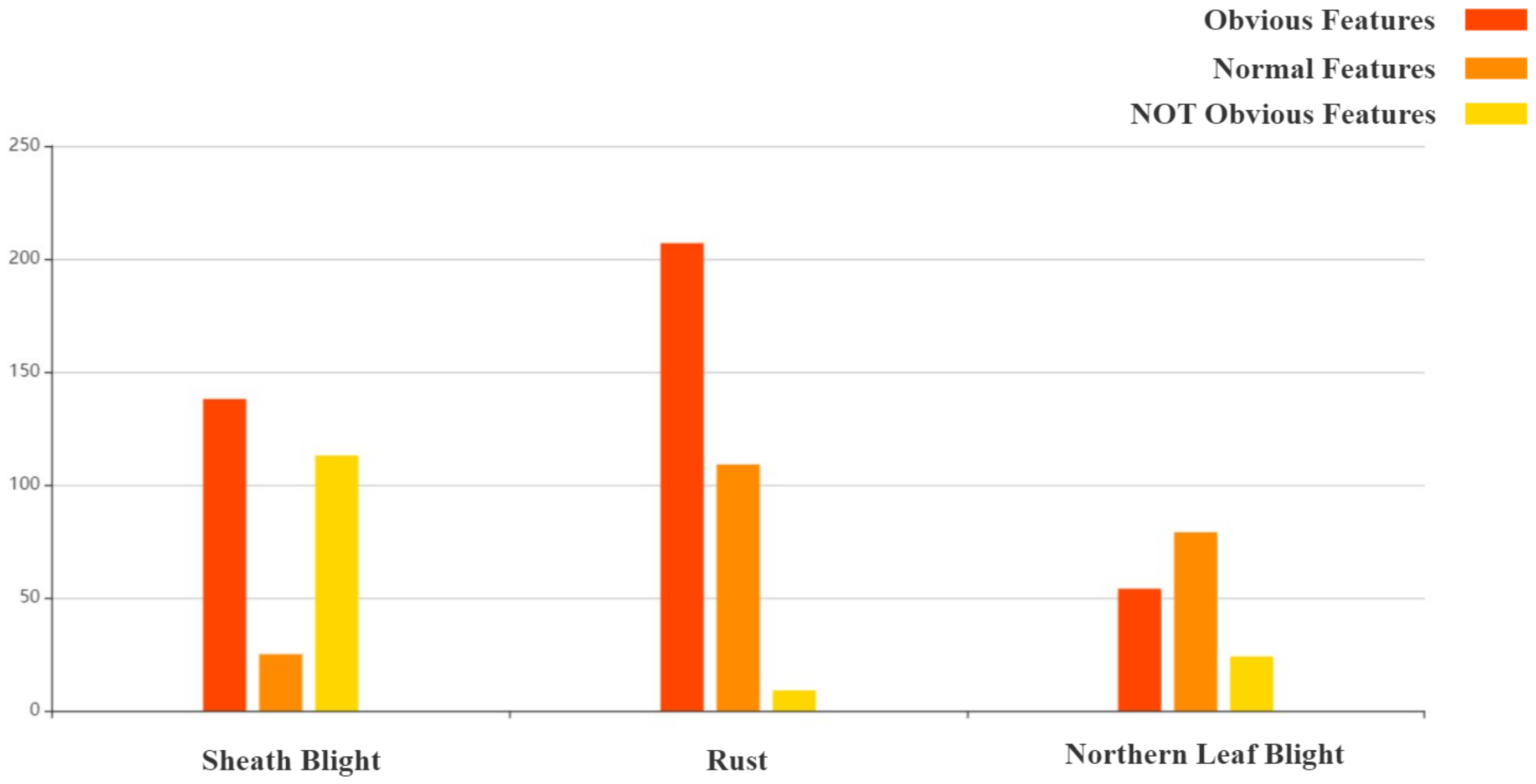
2.1.2. Dataset Analysis
2.1.3. Data Augmentation
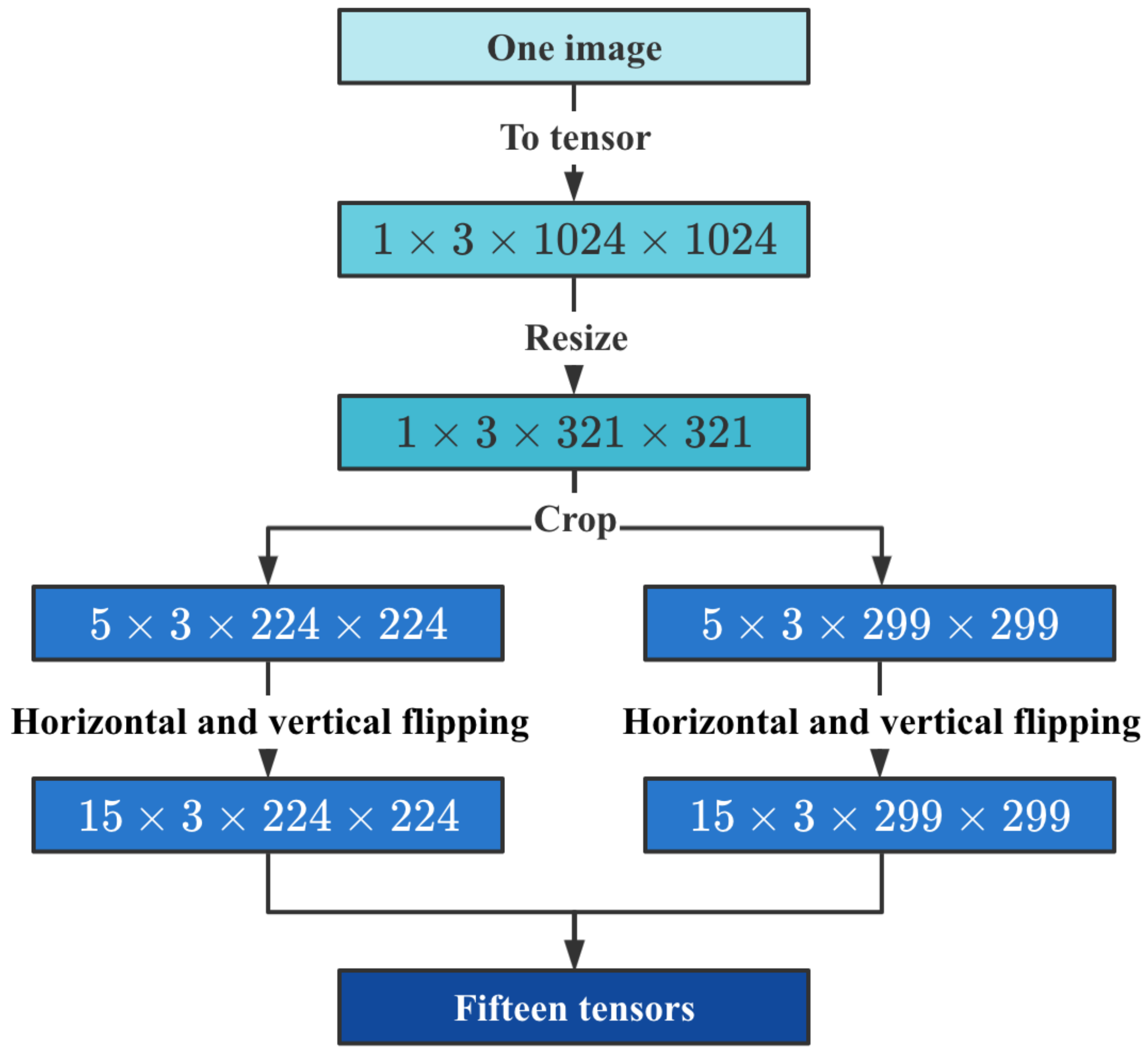
- Simple amplification. We use the traditional image geometry transform, including image translation, rotation, cutting, and other operations. In this study, the method proposed by Alex et al. [8] was explicitly adopted. First, images were cut, the original image was cut into five subgraphs, and then the five subgraphs were flipped horizontally and vertically. Outsourcing frames counted the trimmed training set image to prevent the part of outsourcing frames from being cut out. In this way, each original image will eventually generate 15 extended images and the procedure of data augmentation is illustrated in Figure 4 and Figure 5.
- Image graying. The gray-scale processing is a necessary step to preprocess the image, which helps conduct later higher-level operations, such as image segmentation, image recognition, and image analysis [9]In this paper, the images involved are expressed in RGB color mode, of which the three RGB components are processed separately in the image procession. However, in disease detection, RGB can only blend colors from the principle of optics but fails to reveal the morphological features of the images.Since the visual features of the disease can be retained after gray-scale processing, the number of parameters of the model will be lessened, which can accelerate the training and inferencing process. Specifically, the RGB three-channel images were grayed in the first step. Then the number of parameters in the first convolutional layer of the model was successfully reduced to one third of the original one. Therefore, the training time of the model decreased as a result.
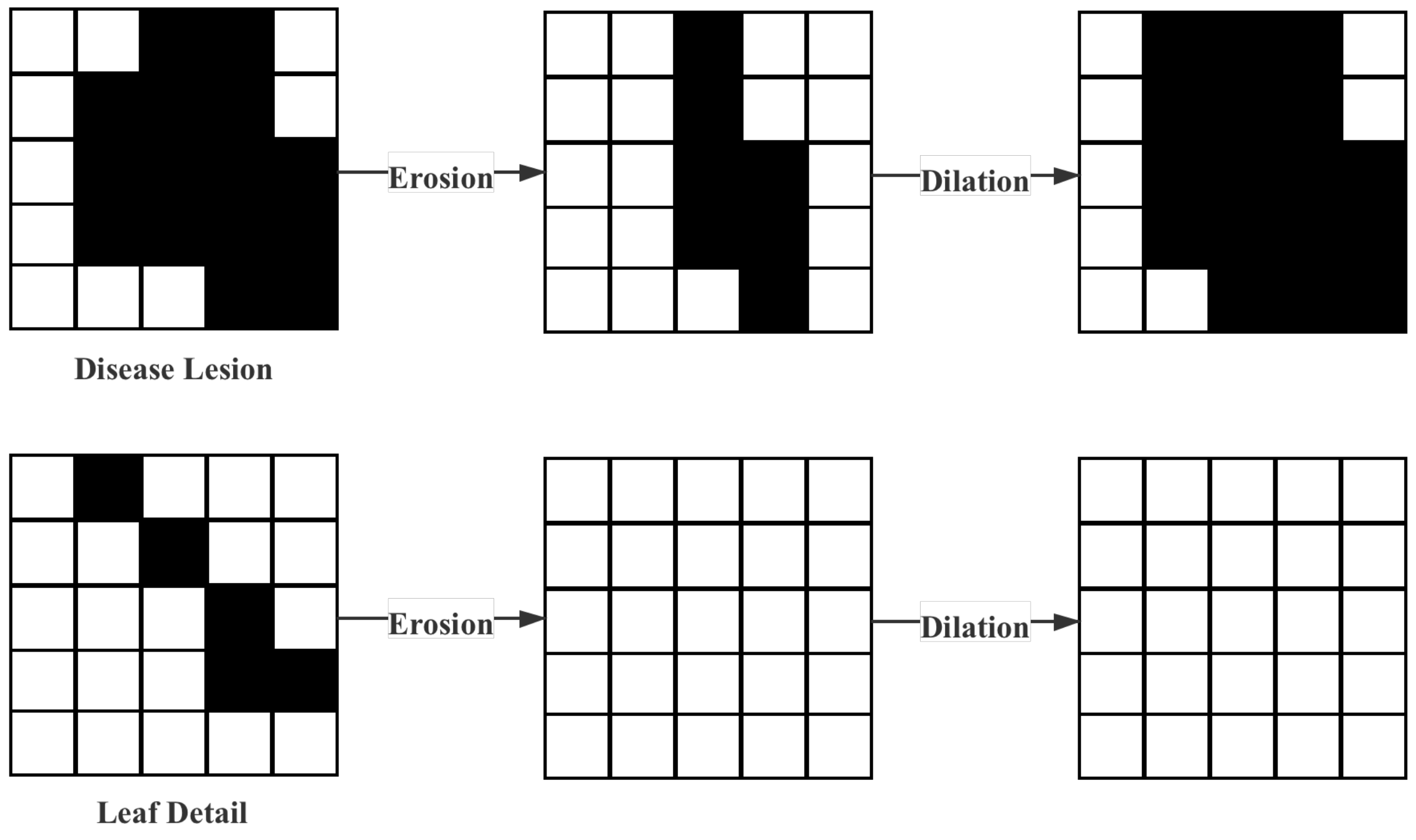
- Removal of interferential leaf details. Given the dataset’s characteristics in this paper, many details in the maize leaf images will interfere with the model, so erosion and dilation [10] were used to preprocess the data. First, the erosion operation is performed. The logical operation process is shown in Equation (1). The leaf details can be removed through the erosion operation, but this operation would also change the characteristics of the lesion. Therefore, the dilation process was necessary, and the logical operation process is shown in Equation (2). In Equations (1) and (2), A represents the original image, and B represents the operator. The original characteristics of the lesion can be restored through the expansion process. The operation process above is shown in Figure 6.
- Snapmix and Mosaic. Currently, popular data amplification methods in deep learning research include Snapmix [11] and Mosaic [12]. In this study, these two methods were used for further data amplification based on 59,778 training samples. Different amplification methods were used to evaluate the comparative experimental results. The Snapmix method randomly cuts out some areas in the sample and fills them with a particular patch from other images stochastically and the classification label remains unchanged. The mosaic method could use multiple pictures at once, and its most significant advantage lies in the fact that it could enrich the background of the detected objects.
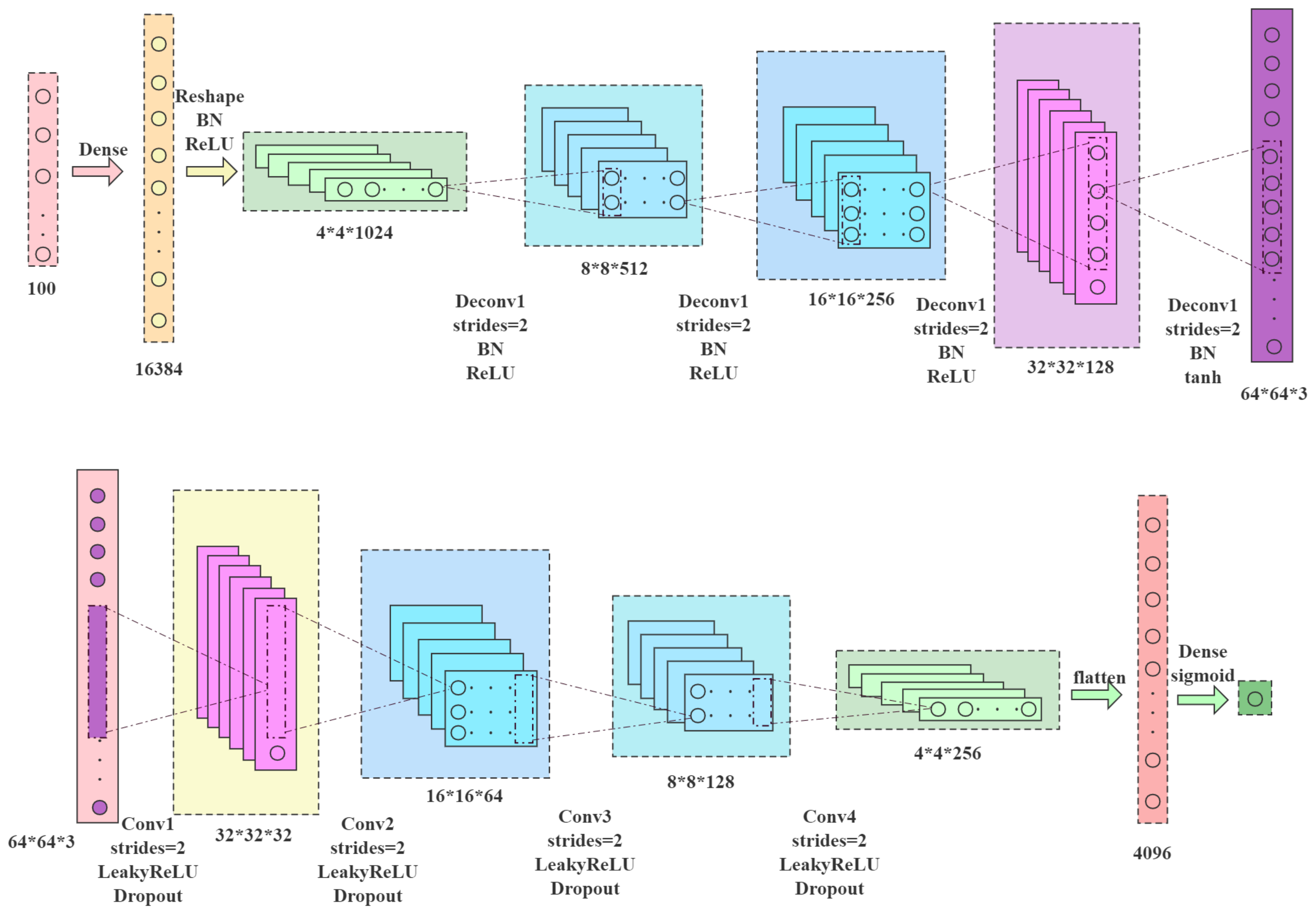
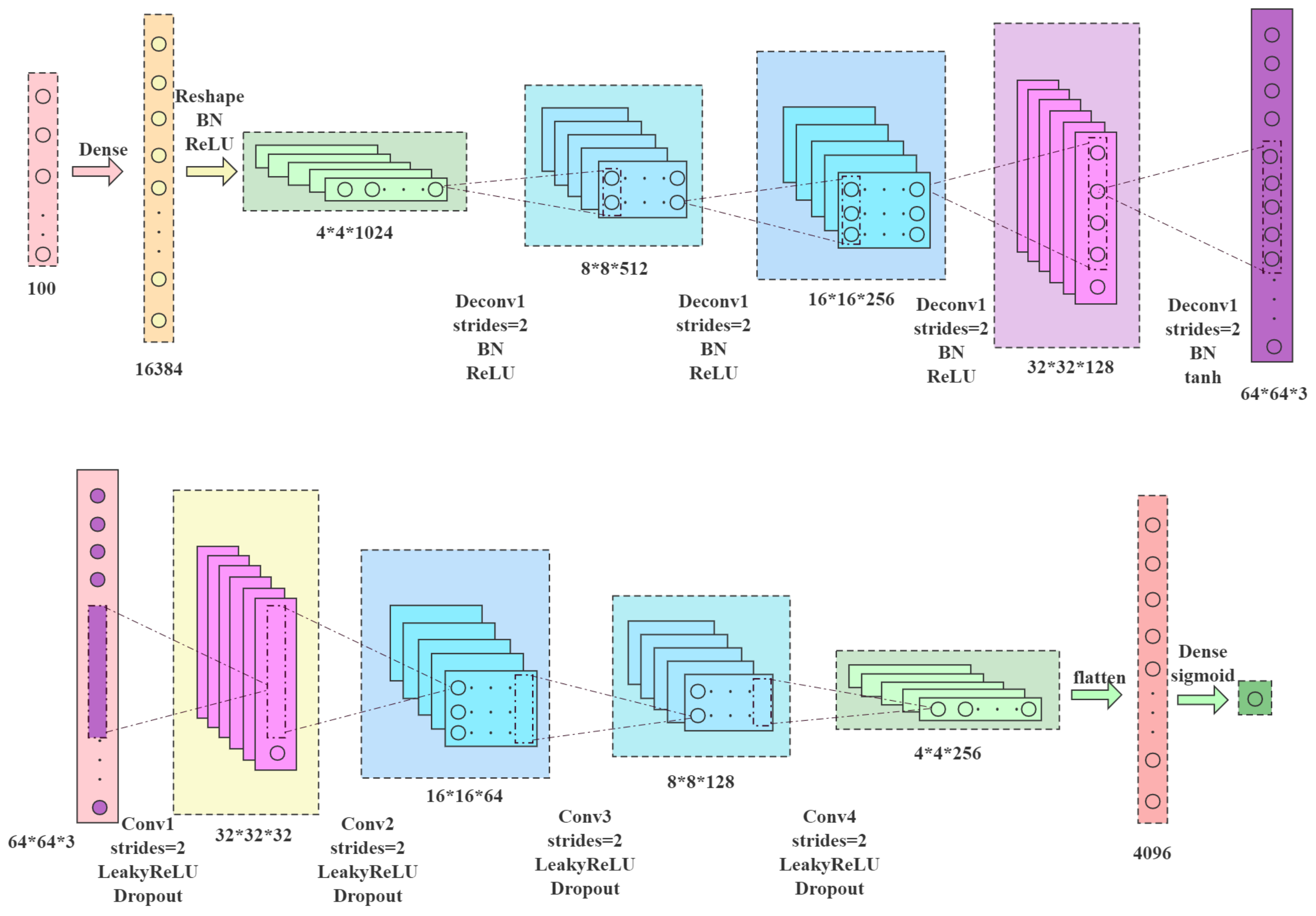
- In this paper, the generation of synthetic data plays a vital role in model training. As for the missing data, many measures have been proposed to tackle these problems. Suppose there is a limitation on the training data. In that case, it is necessary to generate three kinds of data, i.e., three disease images of maize leave sick with sheath blight, rust, and northern leaf blight. A Gaussian-based sampling method will be adopted to generate imagers based on available images. The two required parameters include the mean and standard deviation. The probability density distribution of the Gaussian distribution is displayed as Equation (3):The x is the eigenvector. After varying the mean and standard deviation, the desired eigenvectors of disease images will be generated based on the samples from the normal Gaussian distribution.Given the available eigenvectors which correspond to the normal and diseased leaves, a synthetic data generator based on DCGAN [13] is established. The generator plays the role of generating much more available feature vectors of normal and diseased leaves, and in turn, enriching the training step in reinforcement learning. In the DCGAN, there are two participants: the generator G and the discriminator D. Let denote the distribution of feature vectors extracted from them. The aim of the generator model G lies in generating probability distribution on the feature vector data. Commonly, two deep neural networks are designed to represent the generator and discriminator. The optimized objective of the DCGAN model can be mathematically expressed in Equation (4):The structure of DCGAN is shown in Figure 7.
2.1.4. Image Quality Assessment
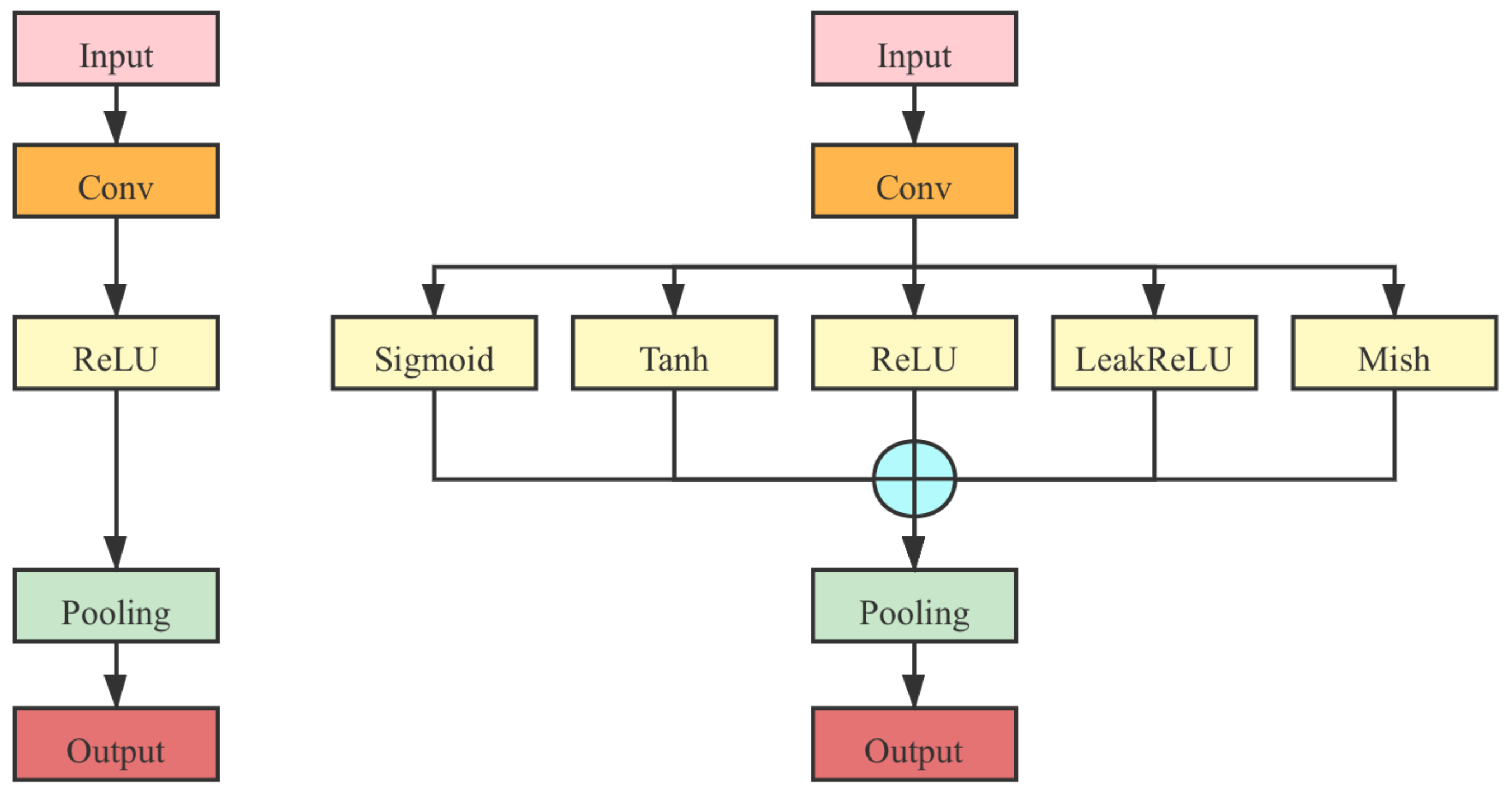
2.2. Multi-Activation Function Module
2.2.1. Combination of Different Activation Functions
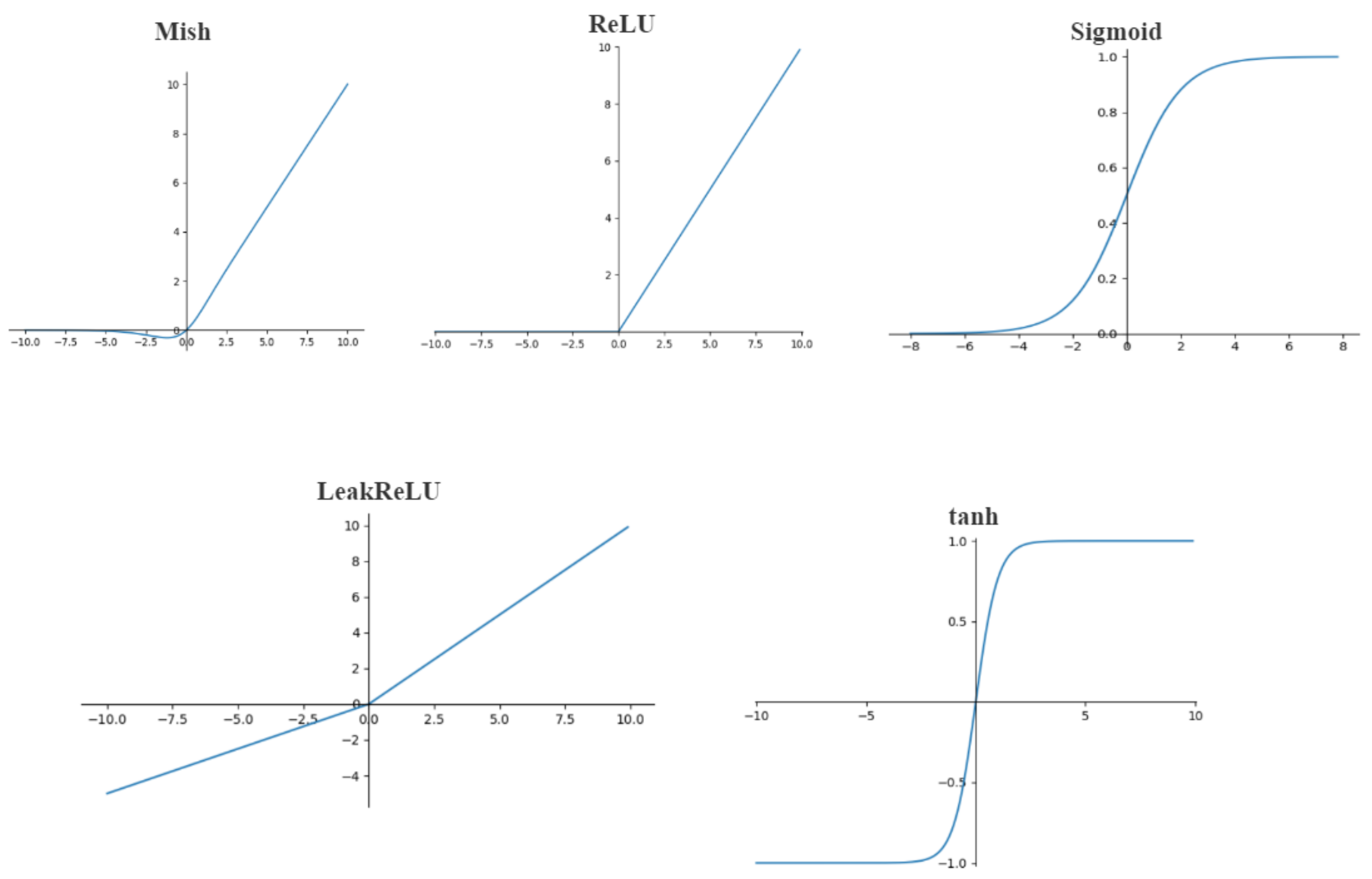
2.2.2. Base Activation Functions
- ReLU function is adopted by the activation function used in many of the backbone networks mentioned above by default, and was first applied to the AlexNet.
- LeakReLU is an activation function, where the leak is a tiny constant so that some values of the negative axis are preserved, and not all information of the negative axis is lost.
- Tanh is one of the hyperbolic functions. In mathematics, the hyperbolic tangent is derived from the hyperbolic sine and hyperbolic cosine of the fundamental hyperbolic function. Its mathematical expression is .
- Sigmoid is a smooth step function that can be derived. Sigmoid can convert any value to probability and is mainly used in binary classification problems. The mathematical expression is .
2.2.3. Apply MAF Module to Different CNNs
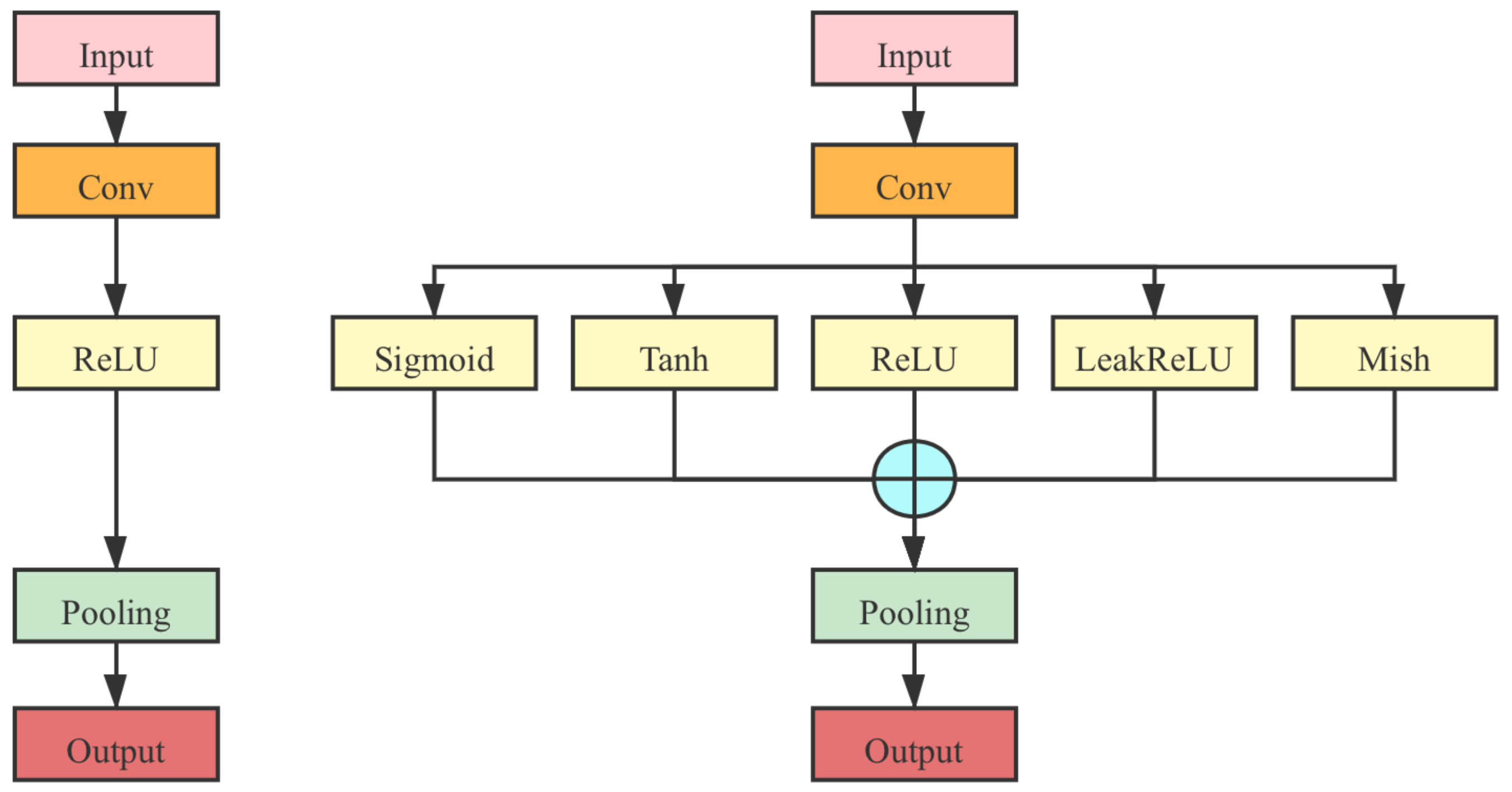
- In the AlexNet and VGG series, as shown in Figure 9, the activation function layer is directly replaced with the MAF module in the original networks.
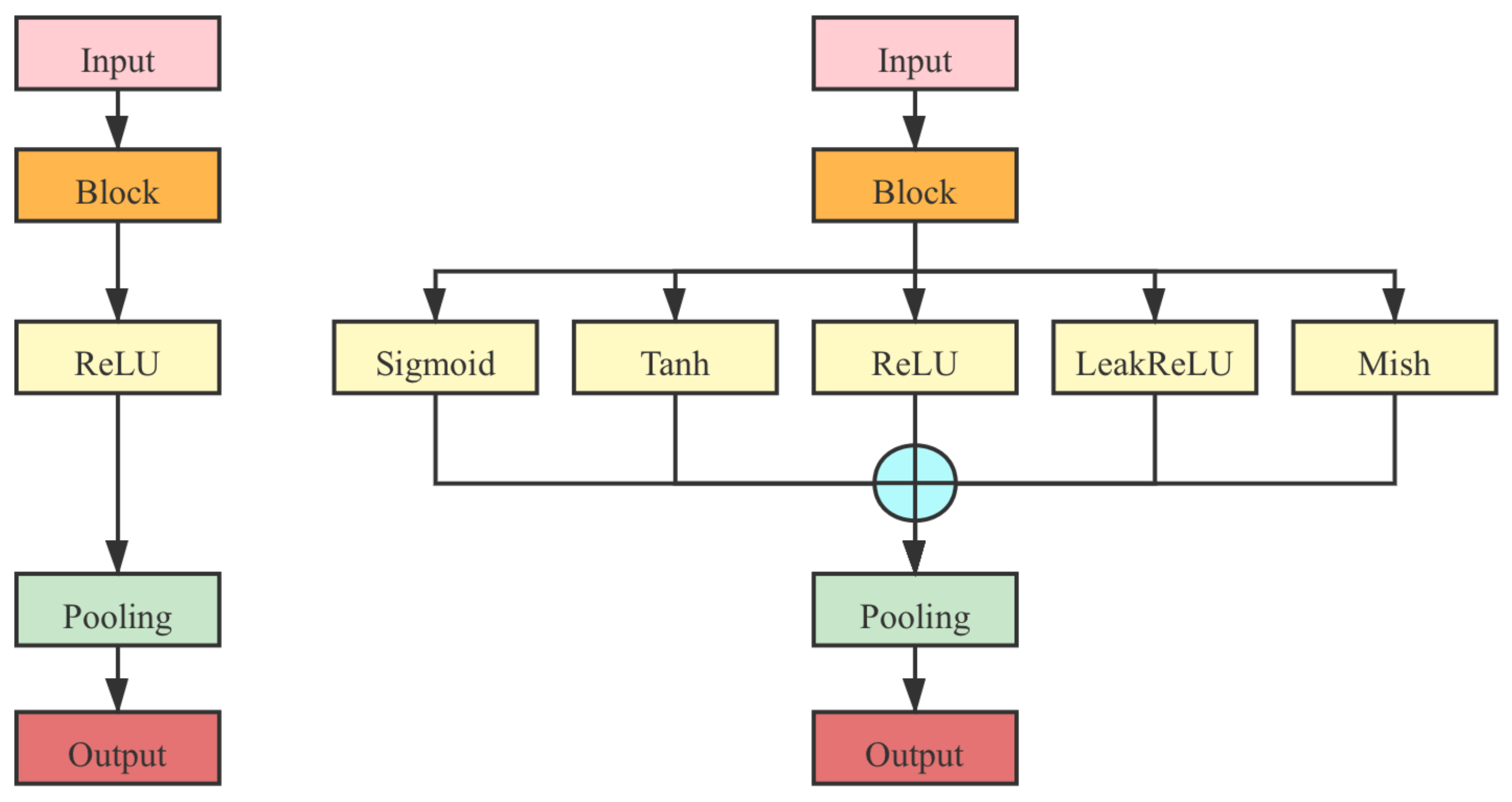
- In the ResNet series, as shown in Figure 10, the ReLU activation function layer is replaced between the block with an MAF module.
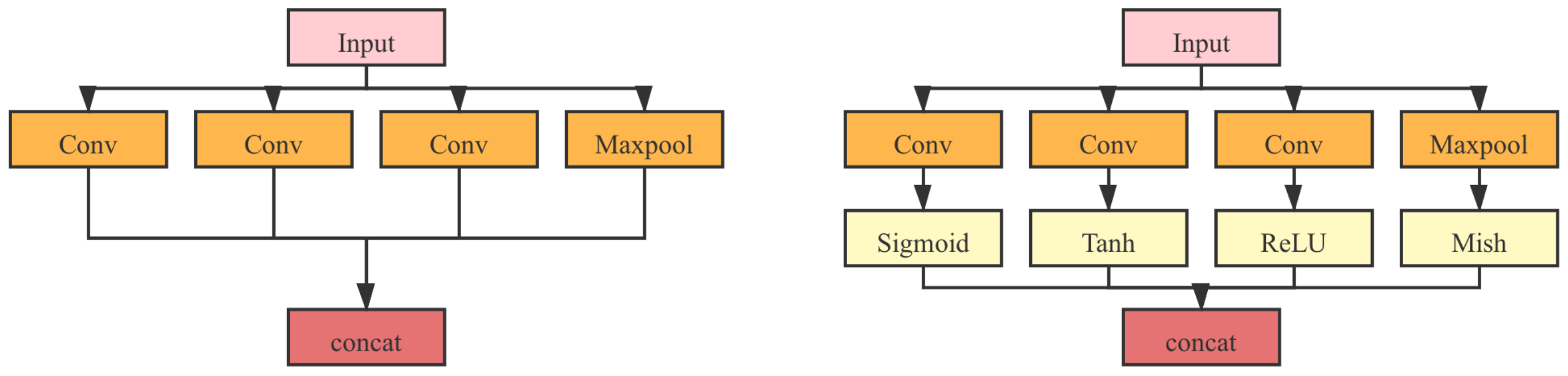
- In the GoogLeNet, as shown in Figure 11, an MAF module was applied inside the inception module. Diverse activation functions were applied to the branches inside the inception accordingly.
3. Results
3.1. Experiment
3.1.1. Training Strategy
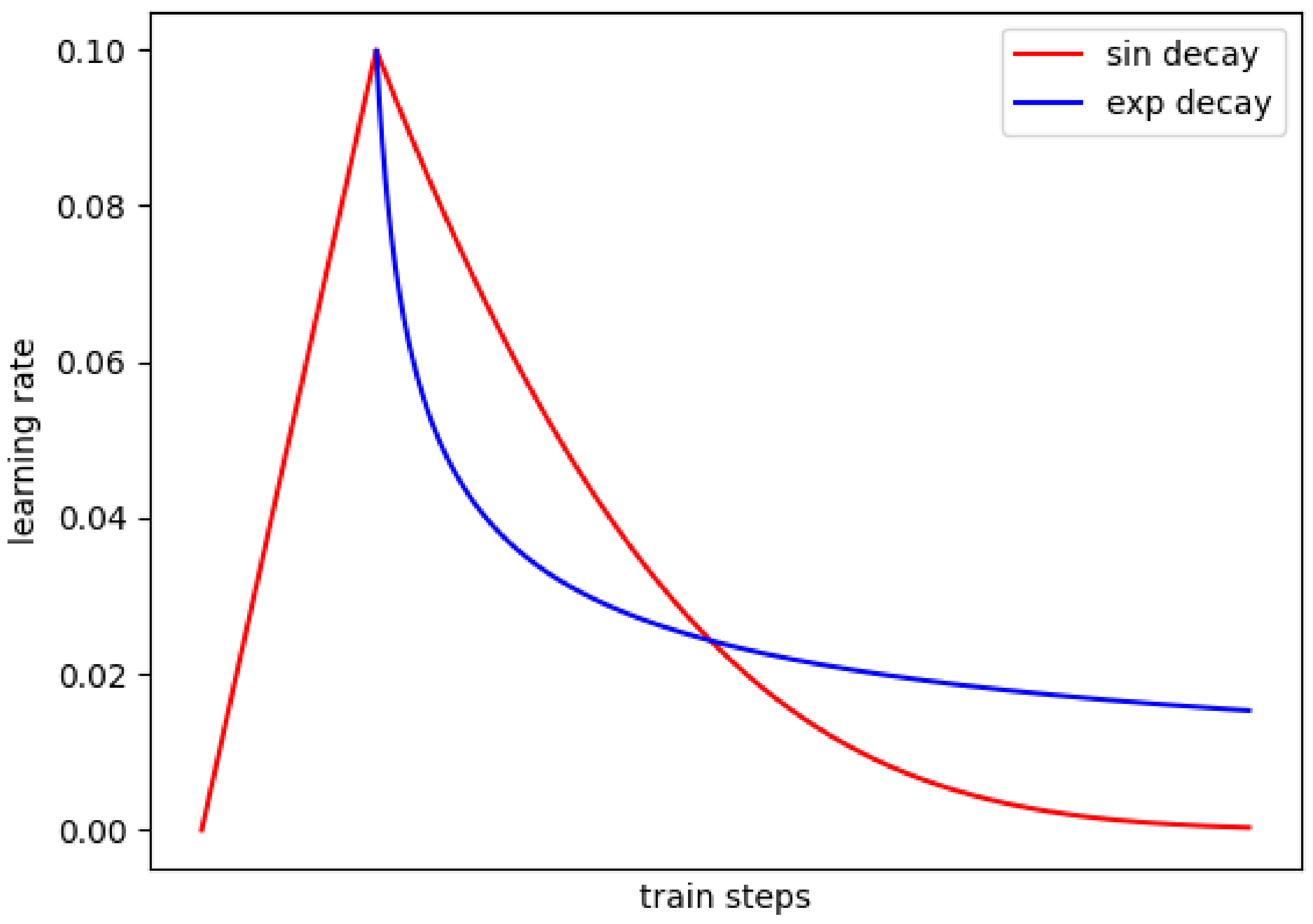
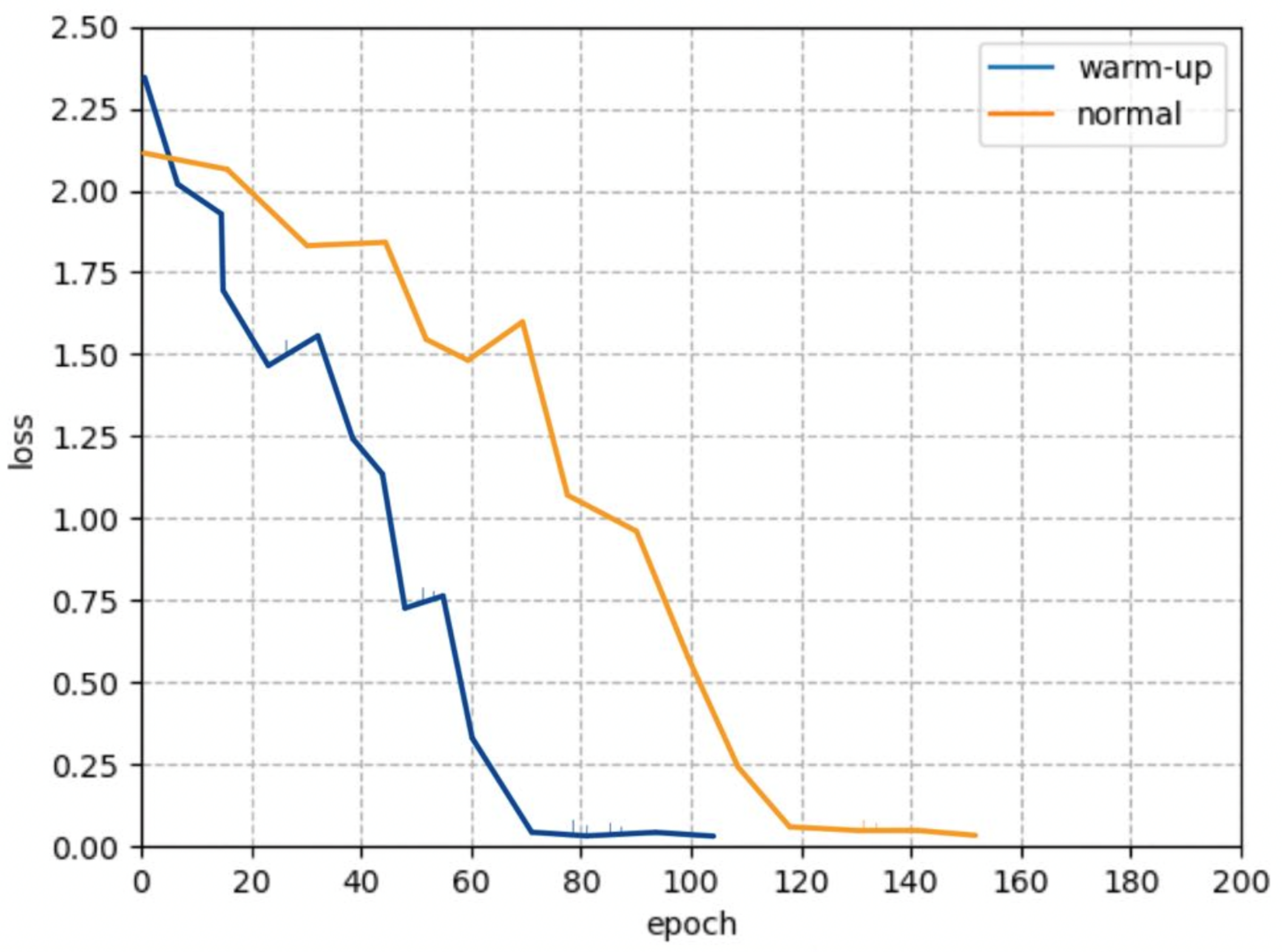
3.1.2. Warm-Up
3.1.3. Label-Smoothing
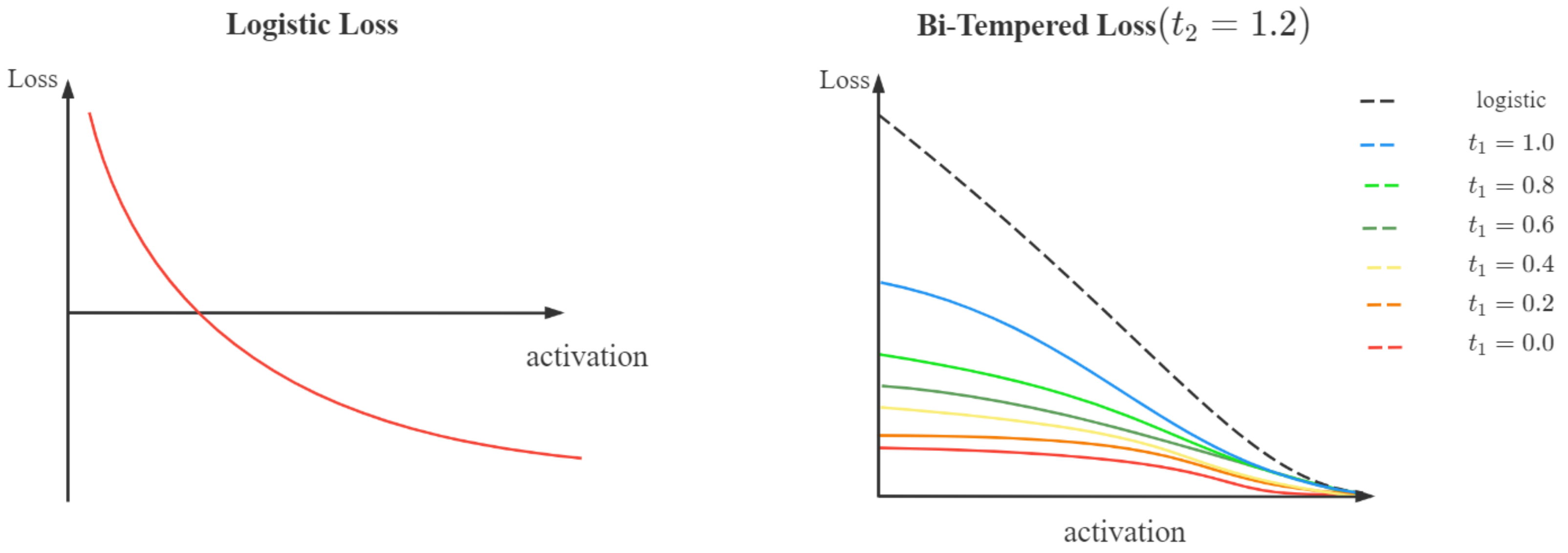
3.1.4. Bi-Tempered Logistic Loss
- In the left-side part, close to the origin, the curve was steep, and there was no upper bound. The label samples that were incorrectly marked would often be close to the left y-axis. The loss value would become very large under this circumstance, which leads to an abnormally large error value that stretches the decision boundary. In turn, it adversely affects the training result, and sacrifices the contribution of other correct samples as well. That was, far-away outliers would dominate the overall loss.
- As for the classification problem, , which expressed the activation value as the probability of each class, was adopted. If the output value were close to 0, it would decay quickly. Ultimately the tail of the final loss function would also exponentially decline. The unobvious wrong label sample would be close to this point. Meanwhile, the decision boundary would be close to the wrong sample because the contribution of the positive sample was tiny, and the wrong sample was used to make up for it. That was, the influence of the wrong label would extend to the boundary of the classification.
3.2. Experiment Results
3.2.1. Ablation Experiments to Verify the Effectiveness of Warm-Up
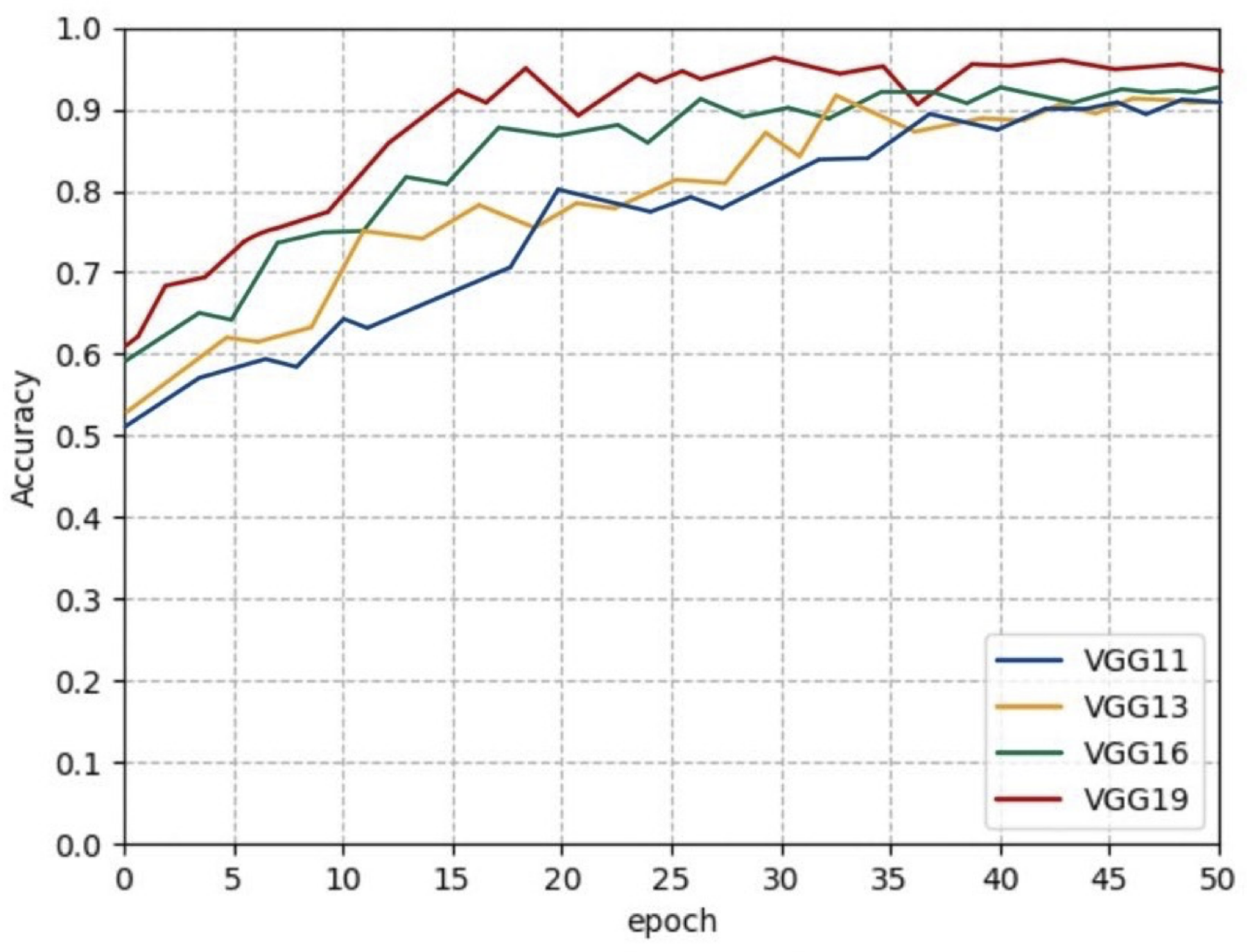
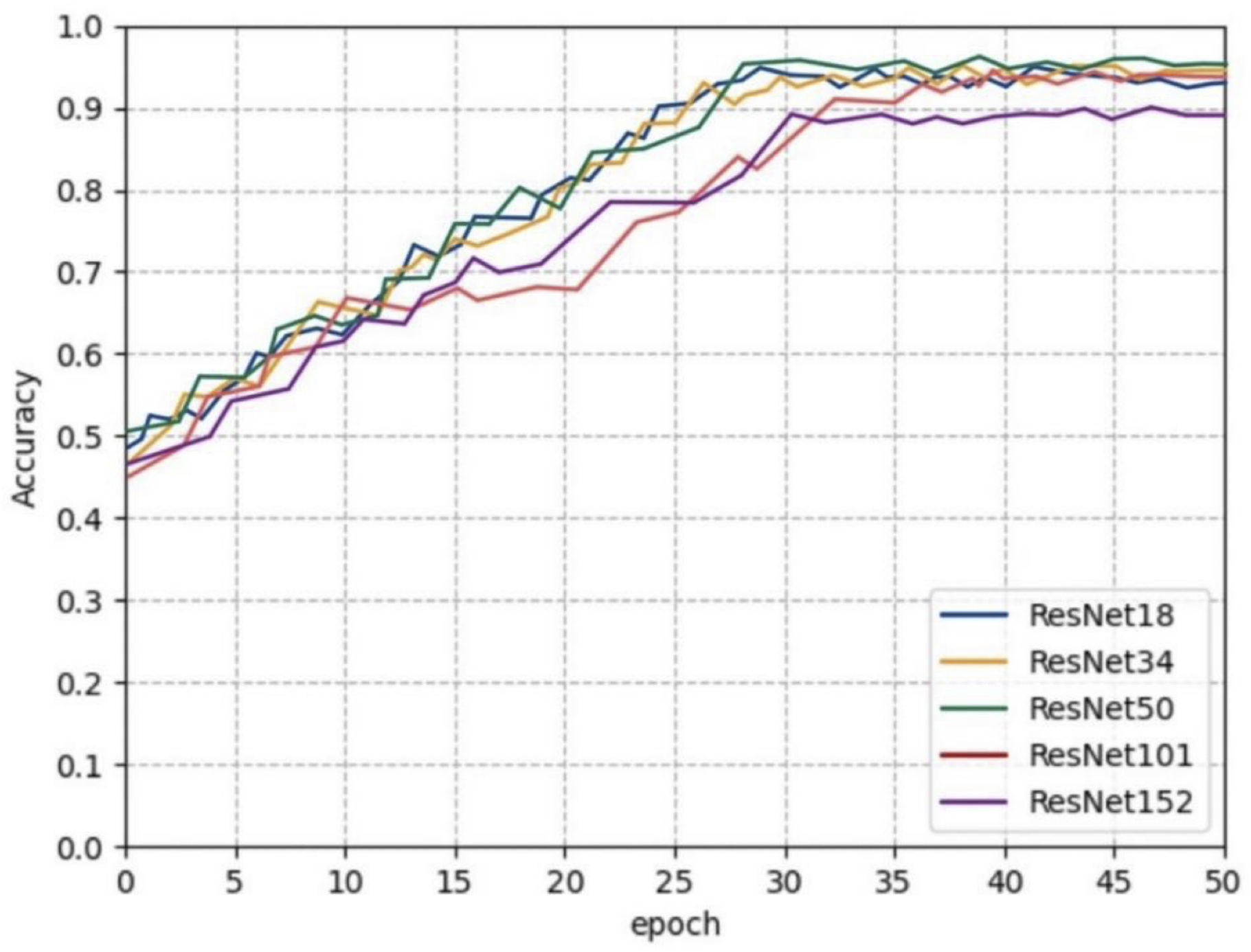
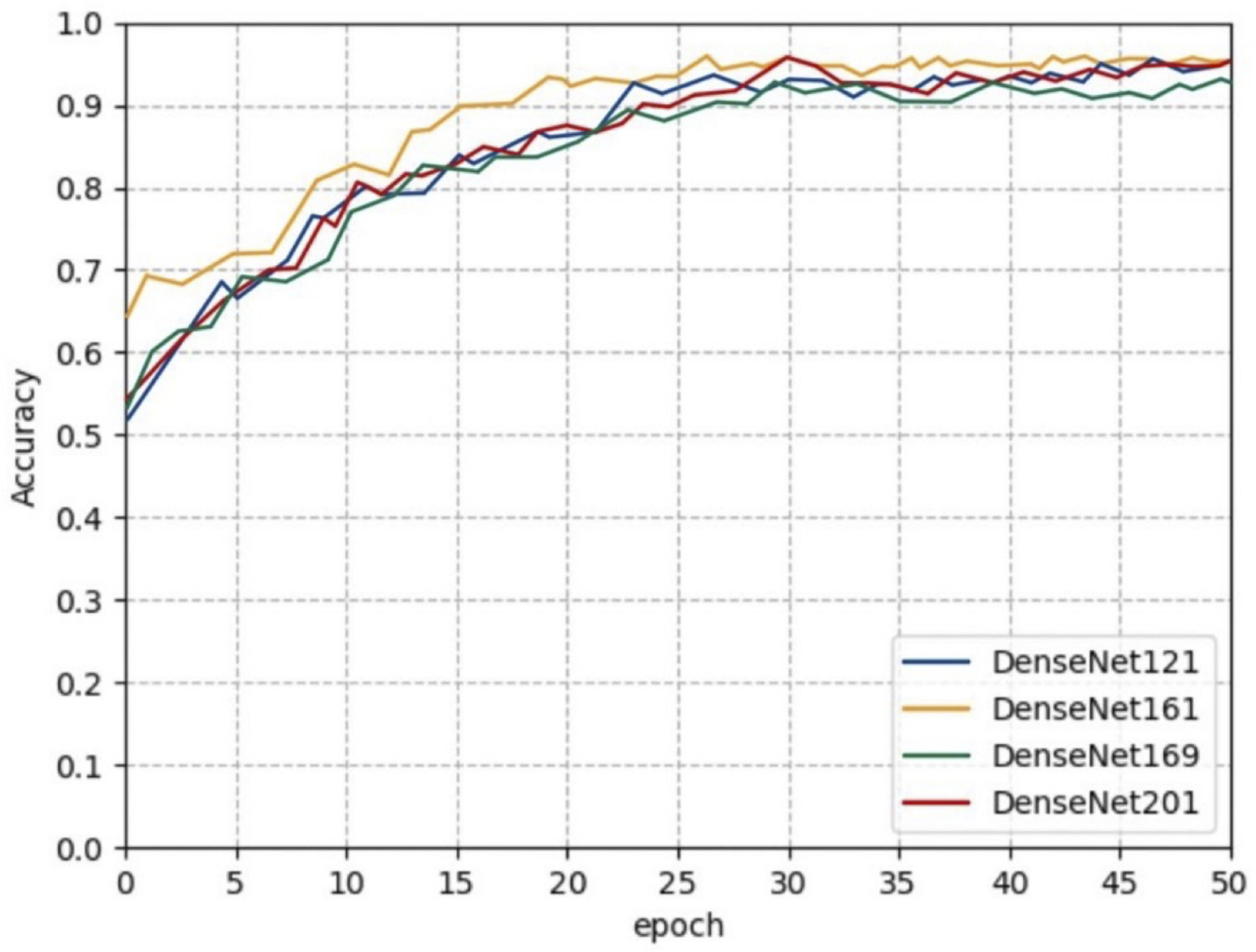
3.2.2. Ablation Experiments
4. Discussion
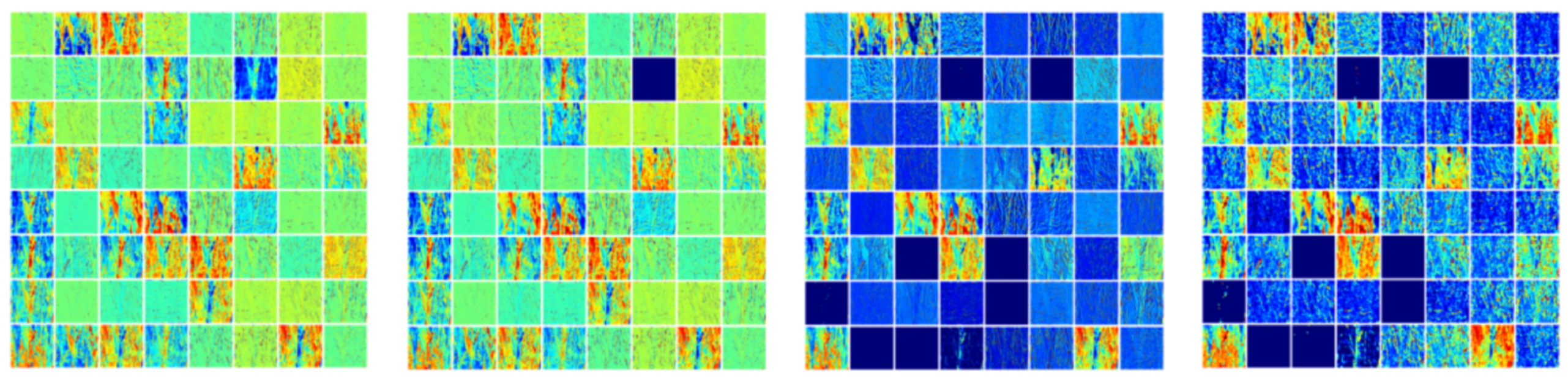
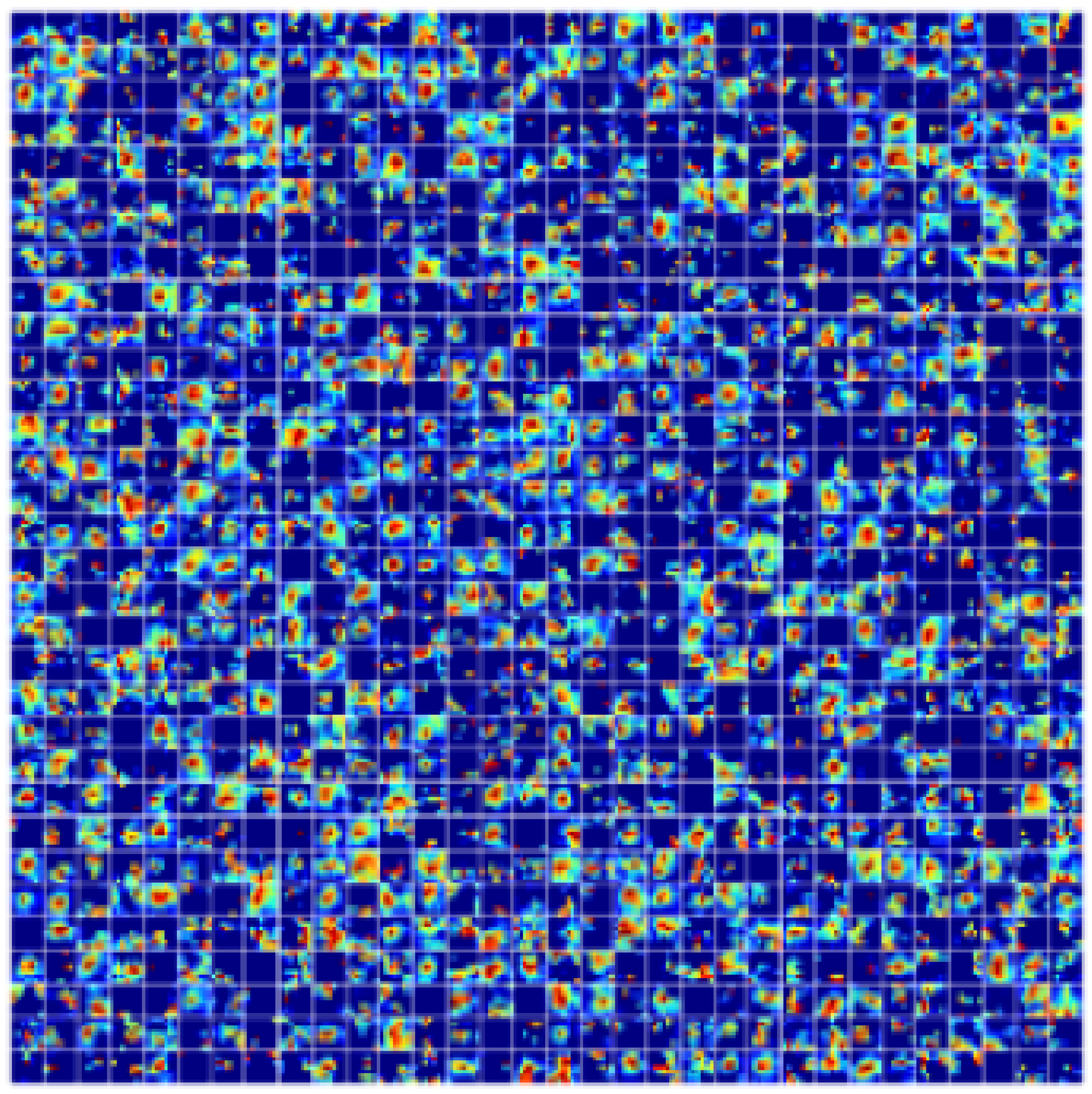
4.1. Visualization of Feature Maps
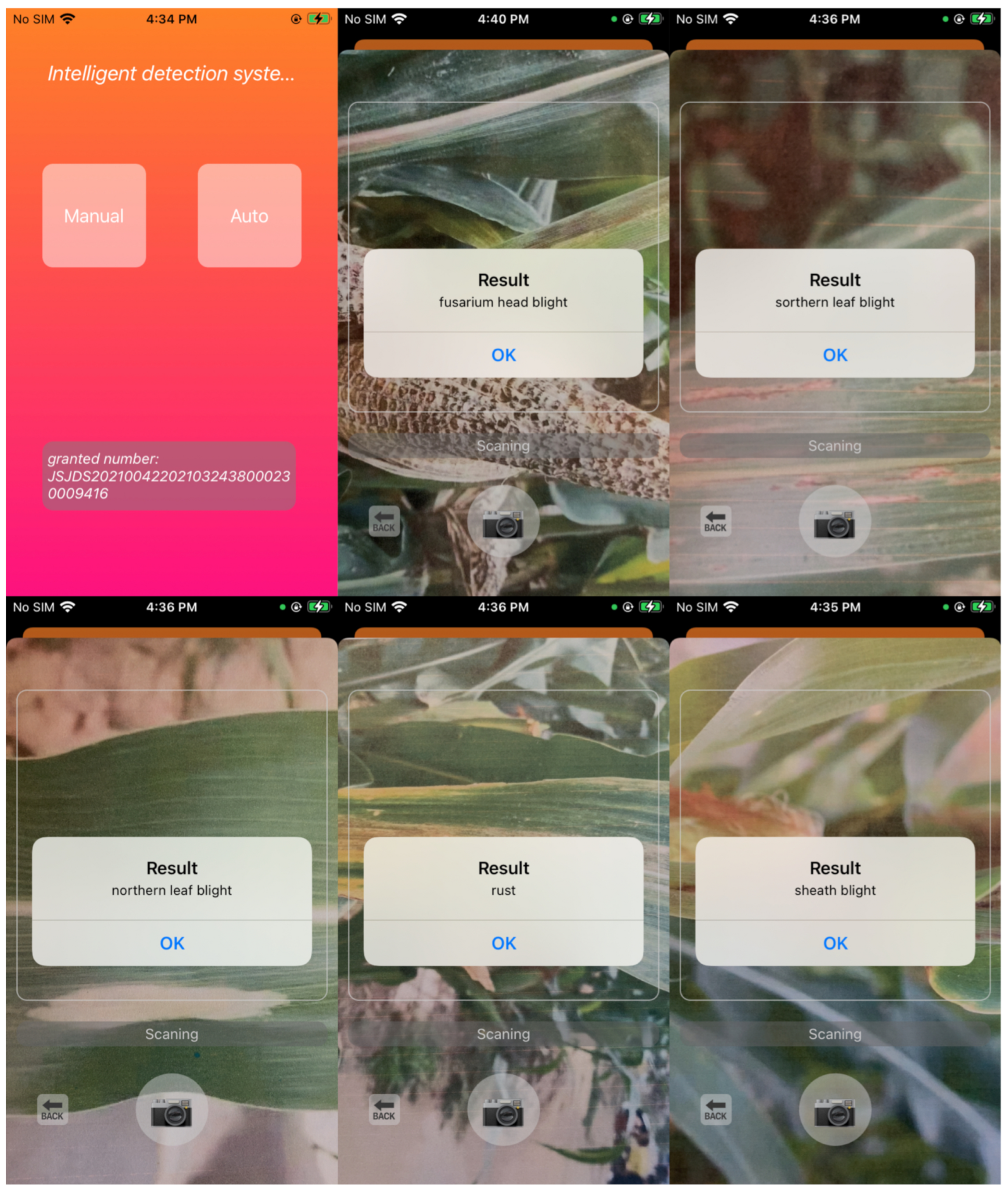
4.2. Intelligent Detection System for Maize Diseases
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, J.; Wang, J.; Leblon, B. Evaluation of Soil Properties, Topographic Metrics, Plant Height, and Unmanned Aerial Vehicle Multispectral Imagery Using Machine Learning Methods to Estimate Canopy Nitrogen Weight in Corn. Remote Sens. 2021, 13, 3105. [Google Scholar] [CrossRef]
- Xie, Q.; Wang, J.; Lopez-Sanchez, J.M.; Peng, X.; Liao, C.; Shang, J.; Zhu, J.; Fu, H.; Ballester-Berman, J.D. Crop height estimation of corn from multi-year RADARSAT-2 polarimetric observables using machine learning. Remote Sens. 2021, 13, 392. [Google Scholar] [CrossRef]
- Lee, H.; Wang, J.; Leblon, B. Using linear regression, Random Forests, and Support Vector Machine with unmanned aerial vehicle multispectral images to predict canopy nitrogen weight in corn. Remote Sens. 2020, 12, 2071. [Google Scholar] [CrossRef]
- Kayad, A.; Sozzi, M.; Gatto, S.; Marinello, F.; Pirotti, F. Monitoring within-field variability of corn yield using Sentinel-2 and machine learning techniques. Remote Sens. 2019, 11, 2873. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Pound, M.P.; Atkinson, J.A.; Wells, D.M.; Pridmore, T.P.; French, A.P. Deep learning for multi-task plant phenotyping. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2055–2063. [Google Scholar]
- Nazki, H.; Yoon, S.; Fuentes, A.; Park, D.S. Unsupervised image translation using adversarial networks for improved plant disease recognition. Comput. Electron. Agric. 2020, 168, 105117. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Jinhe, Z.; Futang, P. A Method of Selective Image Graying. Comput. Eng. 2006, 20, 198–200. [Google Scholar]
- Chen, S.; Haralick, R.M. Recursive erosion, dilation, opening, and closing transforms. IEEE TRansactions Image Process. 1995, 4, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.; Wang, X.; Tao, D. SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data. arXiv 2020, arXiv:2012.04846. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Laurens, V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? arXiv 2019, arXiv:1906.02629. [Google Scholar]
- Amid, E.; Warmuth, M.K.; Anil, R.; Koren, T. Robust bi-tempered logistic loss based on bregman divergences. arXiv 2019, arXiv:1906.03361. [Google Scholar]
- Hearst, M.; Dumais, S.; Osman, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Normal | Sheath Blight | Rust | Northern Leaf Blight | Total | |
|---|---|---|---|---|---|
| Original data set | 2735 | 521 | 459 | 713 | 4428 |
| After data augmentation | 41,025 | 17,815 | 16,885 | 13,695 | 89,420 |
| Training set | 36,923 | 16,034 | 15,197 | 12,326 | 80,478 |
| Validation set | 4102 | 1781 | 1688 | 1369 | 8942 |
| Index | DCGAN | Snapmix | Mosaic |
|---|---|---|---|
| PSNR | 27.9 dB | 16.8 dB | 15.3 dB |
| SSIM | 0.818 | 0.438 | 0.411 |
| Model | Tanh | ReLU | LeakyReLU | Sigmoid | Mish | Accuracy |
|---|---|---|---|---|---|---|
| SVM | 83.18% | |||||
| RF | 87.13% | |||||
| baseline | 92.82% | |||||
| 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 93.11% | |
| MAF-AlexNet | 🗸 | 🗸 | 🗸 | 93.49% | ||
| 🗸 | 🗸 | 🗸 | 92.80% | |||
| baseline | 93.92% | |||||
| 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 94.93% | |
| MAF-VGG19 | 🗸 | 🗸 | 🗸 | 95.30% | ||
| 🗸 | 🗸 | 🗸 | 95.18% | |||
| baseline | 95.08% | |||||
| 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 95.93% | |
| MAF-ResNet50 | 🗸 | 🗸 | 🗸 | 97.41% | ||
| 🗸 | 🗸 | 🗸 | 96.18% | |||
| baseline | 96.18% | |||||
| 🗸 | 🗸 | 🗸 | 95.90% | |||
| MAF-DenseNet161 | 🗸 | 🗸 | 🗸 | 96.75% | ||
| 🗸 | 🗸 | 🗸 | 97.01% | |||
| baseline | 94.27% | |||||
| MAF-GoogLeNet | 🗸 | 🗸 | 🗸 | 🗸 | 🗸 | 95.01% |
| 🗸 | 🗸 | 🗸 | 95.09% | |||
| 🗸 | 🗸 | 🗸 | 94.27% |
| Removal of Details | Gray-Scale | Snapmix | Mosaic | Accuracy | |
|---|---|---|---|---|---|
| baseline | 95.08% | ||||
| MAF-ResNet50 | 🗸 | 🗸 | 🗸 | 🗸 | 97.41% |
| 🗸 | 🗸 | 🗸 | 96.29% | ||
| 🗸 | 🗸 | 🗸 | 95.82% | ||
| 🗸 | 🗸 | 🗸 | 93.17% | ||
| 🗸 | 🗸 | 🗸 | 94.39% |
| DCGAN | Label-Smoothing | Bi-Tempered Loss | Accuracy | |
|---|---|---|---|---|
| baseline | 95.08% | |||
| MAF-ResNet50 | 🗸 | 🗸 | 🗸 | 96.53% |
| 🗸 | 🗸 | 97.41% | ||
| 🗸 | 🗸 | 95.77% | ||
| 🗸 | 🗸 | 97.22% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. https://doi.org/10.3390/rs13214218
Zhang Y, Wa S, Liu Y, Zhou X, Sun P, Ma Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sensing. 2021; 13(21):4218. https://doi.org/10.3390/rs13214218
Chicago/Turabian StyleZhang, Yan, Shiyun Wa, Yutong Liu, Xiaoya Zhou, Pengshuo Sun, and Qin Ma. 2021. "High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module" Remote Sensing 13, no. 21: 4218. https://doi.org/10.3390/rs13214218
APA StyleZhang, Y., Wa, S., Liu, Y., Zhou, X., Sun, P., & Ma, Q. (2021). High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sensing, 13(21), 4218. https://doi.org/10.3390/rs13214218