
Hyperspectral Image Super-Resolution Based on Spatial Correlation-Regularized Unmixing Convolutional Neural Network





Abstract
:1. Introduction
- A CNN-based single HS image SR framework is proposed, which incorporates the linear spectral mixture model to fully exploit the intrinsic properties of HS images, thereby improving the spatial resolution of HS images, without auxiliary sources.
- The correlation between the high- and low-resolution HS images is characterized by the spatial spread transform function, which helps to preserve the spectra of the super-resolved image.
- A loss function regarding the spectral mixture models and spatial correlation regularization is defined to effectively train the proposed network.
2. Methodology
2.1. Observation Models
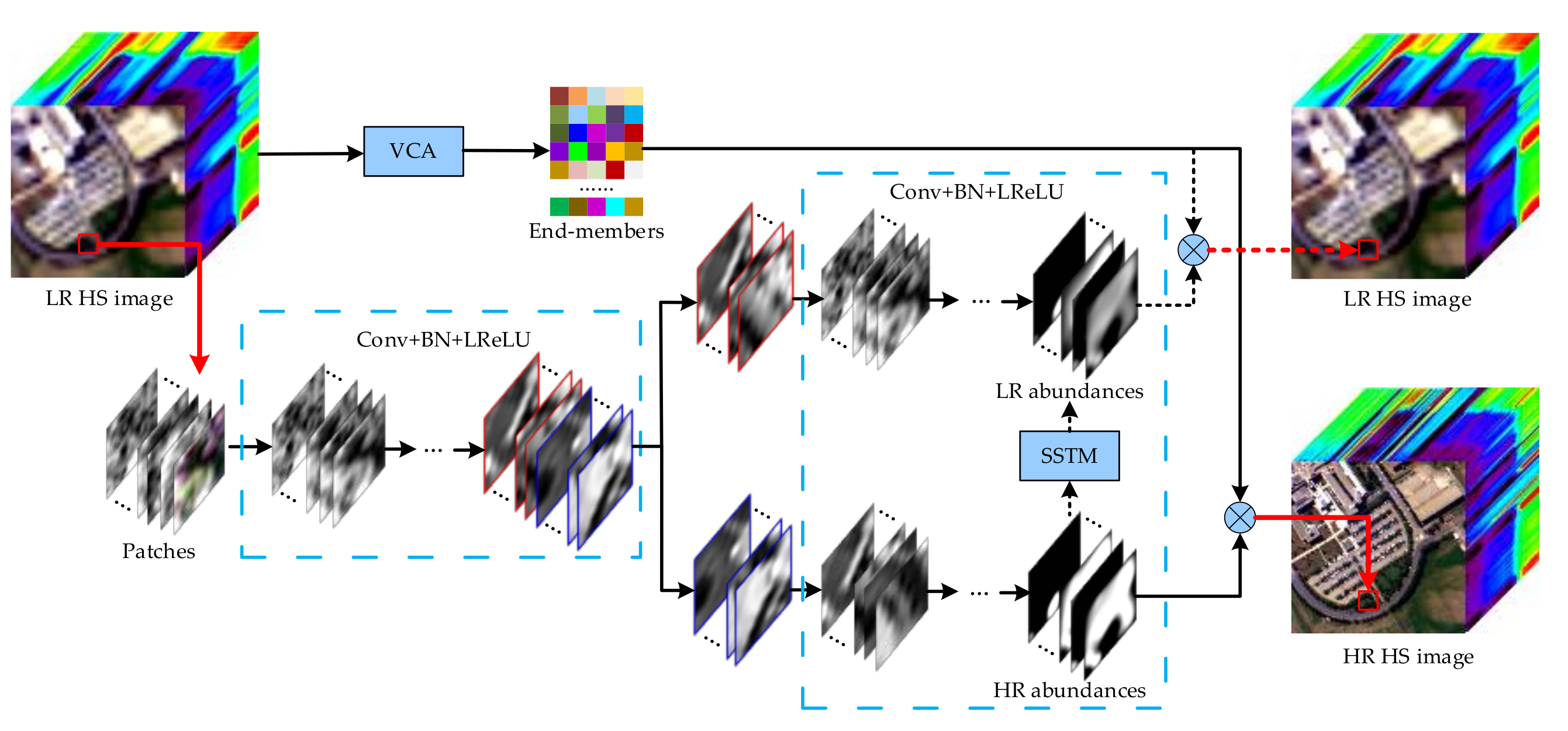
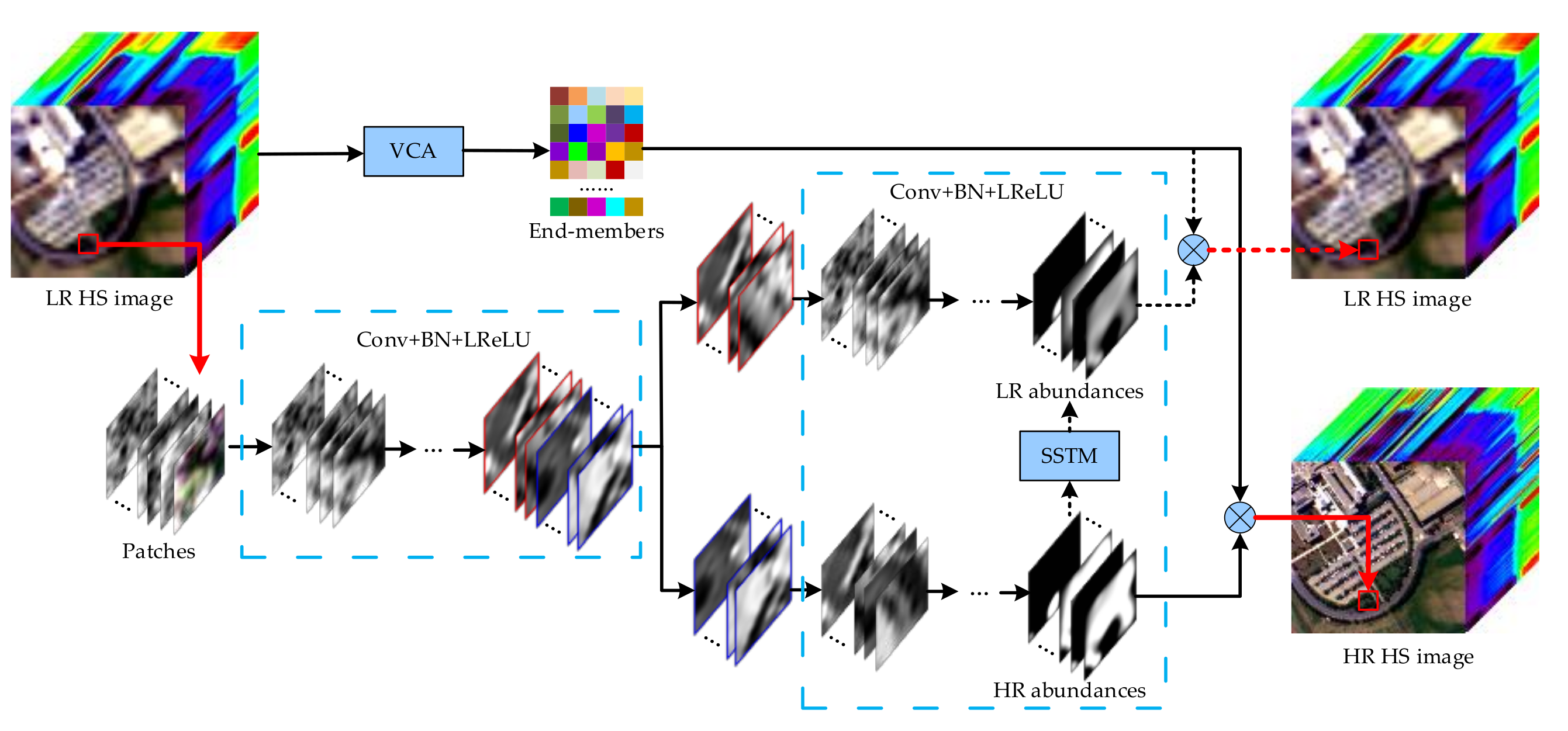
2.2. HS Image Super-Resolution via UCNN
3. Experimental Data Sets and Results
3.1. Experimental Setup
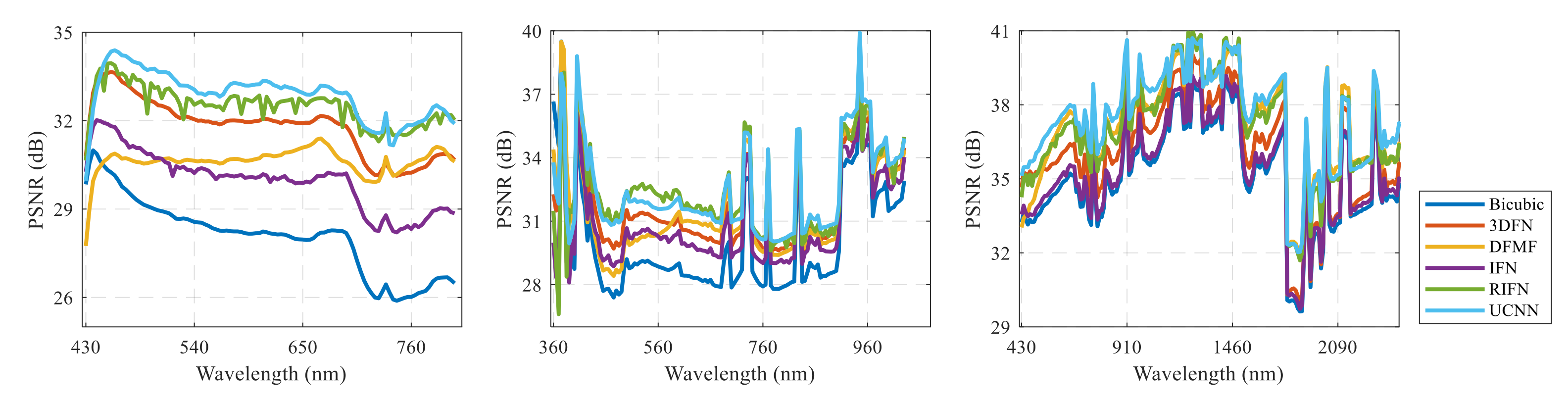
3.2. Results and Analyses
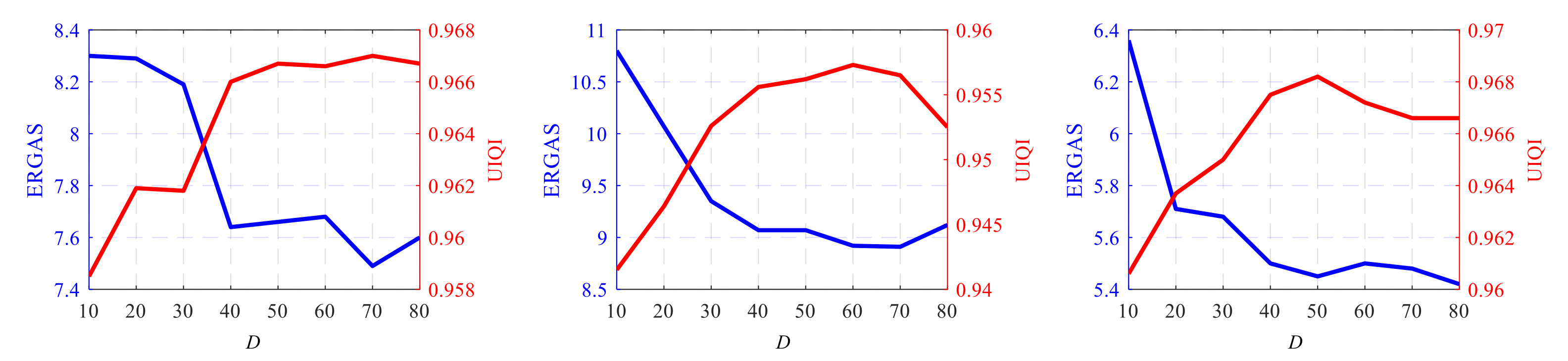
3.3. Discussion of Parameter and Ablation Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Selva, M.; Aiazzi, B.; Butera, F.; Chiarantini, L.; Baronti, S. Hyper-sharpening: A first approach on sim-ga data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3008–3024. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, J.; Li, T.; Zhang, Y. Pan-sharpening by multilevel interband structure modeling. IEEE Geosci. Remote Sens. Lett. 2016, 13, 892–896. [Google Scholar] [CrossRef]
- Li, X.; Yuan, Y.; Wang, Q. Hyperspectral and multispectral image fusion based on band simulation. IEEE Geosci. Remote Sens. Lett. 2020, 17, 479–483. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, J.R.; Ulfarsson, M.O.; Benediktsson, J.A. Model-based fusion of multi- and hyperspectral images using pca and wavelets. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2652–2663. [Google Scholar] [CrossRef]
- Wei, Q.; Dobigeon, N.; Tourneret, J.; Bioucas-Dias, J.; Godsill, S. R-fuse: Robust fast fusion of multiband images based on solving a sylvester equation. IEEE Signal Process Lett. 2016, 23, 1632–1636. [Google Scholar] [CrossRef] [Green Version]
- Yokoya, N.; Yairi, T.; Iwasaki, A. Coupled nonnegative matrix factorization unmixing for hyperspectral and multispectral data fusion. IEEE Trans. Geosci. Remote Sens. 2012, 50, 528–537. [Google Scholar] [CrossRef]
- Karoui, M.S.; Deville, Y.; Benhalouche, F.Z.; Boukerch, I. Hypersharpening by joint-criterion nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1660–1670. [Google Scholar] [CrossRef]
- Li, S.; Dian, R.; Fang, L.; Bioucas-Dias, J.M. Fusing hyperspectral and multispectral images via coupled sparse tensor factorization. IEEE Trans. Image Process. 2018, 27, 4118–4130. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Fang, L. Learning a low tensor-train rank representation for hyperspectral image super-resolution. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2672–2683. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Guo, A.; Fang, L. Deep hyperspectral image sharpening. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5345–5355. [Google Scholar] [CrossRef] [PubMed]
- Qi, X.; Zhou, M.; Zhao, Q.; Meng, D.; Zuo, W.; Xu, Z. Multispectral and Hyperspectral Image Fusion by MS/HS Fusion Net. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Amira, O.; Liu, J.; Zhang, C.; Zhang, J.; Li, G. Ham-mfn: Hyperspectral and multispectral image multiscale fusion network with rap loss. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4618–4628. [Google Scholar] [CrossRef]
- Zheng, K.; Gao, L.; Liao, W.; Hong, D.; Zhang, B.; Cui, X.; Chanussot, J. Coupled convolutional neural network with adaptive response function learning for unsupervised hyperspectral super resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2487–2502. [Google Scholar] [CrossRef]
- Simões, M.; Bioucas-Dias, J.; Almeida, L.B.; Chanussot, J. A convex formulation for hyperspectral image superresolution via subspace-based regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3373–3388. [Google Scholar] [CrossRef] [Green Version]
- Nezhad, Z.H.; Karami, A.; Heylen, R.; Scheunders, P. Fusion of hyperspectral and multispectral images using spectral unmixing and sparse coding. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2377–2389. [Google Scholar] [CrossRef]
- Xing, C.; Wang, M.; Dong, C.; Duan, C.; Wang, Z. Joint sparse-collaborative representation to fuse hyperspectral and multispectral images. Signal Process. 2020, 173, 107585. [Google Scholar] [CrossRef]
- Loncan, L.; De Almeida, L.B.; Bioucas-Dias, J.M.; Briottet, X.; Chanussot, J.; Dobigeon, N.; Fabre, S.; Liao, W.; Licciardi, G.A.; Simões, M.; et al. Hyperspectral pansharpening: A review. IEEE Geosci. Remote Sens. Mag. 2015, 3, 27–46. [Google Scholar] [CrossRef] [Green Version]
- Yokoya, N.; Grohnfeldt, C.; Chanussot, J. Hyperspectral and multispectral data fusion: A comparative review of the recent literature. IEEE Geosci. Remote Sens. Mag. 2017, 5, 29–56. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Sun, B.; Guo, A. Recent advances and new guidelines on hyperspectral and multispectral image fusion. Inf. Fusion 2021, 69, 40–51. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, J.; Yu, X.; Tang, W.; Li, T.; Zhang, Y. Hyper-sharpening based on spectral modulation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1534–1548. [Google Scholar] [CrossRef]
- Borsoi, R.A.; Imbiriba, T.; Bermudez, J.C.M. Super-resolution for hyperspectral and multispectral image fusion accounting for seasonal spectral variability. IEEE Trans. Image Process. 2020, 29, 116–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.; Huang, Z.; Gong, Y.; Pan, C. Ensemble based deep networks for image super-resolution. Pattern Recognit. 2017, 68, 191–198. [Google Scholar] [CrossRef]
- Akgun, T.; Altunbasak, Y.; Mersereau, R.M. Super-resolution reconstruction of hyperspectral images. IEEE Trans. Image Process. 2005, 14, 1860–1875. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.C.; Joshi, M.V. Super-resolution of hyperspectral images: Use of optimum wavelet filter coefficients and sparsity regularization. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1728–1736. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Q.; Shen, H.; Meng, X.; Zhang, L. Hyperspectral image super-resolution by spectral mixture analysis and spatial–spectral group sparsity. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1250–1254. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Cao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral image super-resolution via non-negative structured sparse representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef] [PubMed]
- Irmak, H.; Akar, G.B.; Yuksel, S.E. A map-based approach for hyperspectral imagery super-resolution. IEEE Trans. Image Process. 2018, 27, 2942–2951. [Google Scholar] [CrossRef]
- Hong, D.; He, W.; Yokoya, N.; Yao, J.; Gao, L.; Zhang, L.; Chanussot, J.; Zhu, X. Interpretable hyperspectral artificial intelligence: When nonconvex modeling meets hyperspectral remote sensing. IEEE Geosci. Remote Sens. Mag. 2021, 9, 52–87. [Google Scholar] [CrossRef]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Deep Laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar] [CrossRef] [Green Version]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Fast and accurate image super-resolution with deep Laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, J.; Li, Y.; Xie, W. Hyperspectral image super-resolution by spectral difference learning and spatial error correction. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1825–1829. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral image spatial super-resolution via 3d full convolutional neural network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef] [Green Version]
- Arun, P.V.; Buddhiraju, K.M.; Porwal, A.; Chanussot, J. Cnn-based super-resolution of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6106–6121. [Google Scholar] [CrossRef]
- Hu, J.; Tang, Y.; Fan, S. Hyperspectral image super resolution based on multiscale feature fusion and aggregation network with 3-d convolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5180–5193. [Google Scholar] [CrossRef]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral image super-resolution using deep feature matrix factorization. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6055–6067. [Google Scholar] [CrossRef]
- Zou, C.; Huang, X. Hyperspectral image super-resolution combining with deep learning and spectral unmixing. Signal Process. Image Commun. 2020, 84, 115833. [Google Scholar] [CrossRef]
- Li, J.; Cui, R.; Li, B.; Song, R.; Li, Y.; Dai, Y.; Du, Q. Hyperspectral image super-resolution by band attention through adversarial learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4304–4318. [Google Scholar] [CrossRef]
- Hu, J.; Jia, X.; Li, Y.; He, G.; Zhao, M. Hyperspectral image super-resolution via intrafusion network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7459–7471. [Google Scholar] [CrossRef]
- Hu, J.; Zhao, M.; Li, Y. Hyperspectral image super-resolution by deep spatial-spectral exploitation. Remote Sens. 2019, 11, 1229. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Sun, H.; Liu, X.; Ma, J. Learning spatial-spectral prior for super-resolution of hyperspectral imagery. IEEE Trans. Comput. Imaging 2020, 6, 1082–1096. [Google Scholar] [CrossRef]
- Fu, Y.; Liang, Z.; You, S. Bidirectional 3d quasi-recurrent neural network for hyperspectral image super-resolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2674–2688. [Google Scholar] [CrossRef]
- Shi, Q.; Tang, X.; Yang, T.; Liu, R.; Zhang, L. Hyperspectral image denoising using a 3-D attention denoising network. IEEE Trans. Geosci. Remote Sens. 2021, 1–16. [Google Scholar] [CrossRef]
- Dou, X.; Li, C.; Shi, Q.; Liu, M. Super-resolution for hyperspectral remote sensing images based on the 3D attention-SRGAN network. Remote Sens. 2020, 12, 1204. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Shi, Q.; Marinori, A.; He, D.; Liu, X.; Zhang, L. Super-resolution-based change detection network with stacked attention module for images with different resolutions. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Li, K.; Yang, S.H.; Dong, R.T.; Wang, X.Y.; Huang, J.Q. Survey of single image super-resolution reconstruction. IET Image Process 2020, 14, 2273–2290. [Google Scholar] [CrossRef]
- Lu, X.; Li, T.; Zhang, J.; Jia, F. A novel unmixing-based hypersharpening method via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2021, 1–14. [Google Scholar] [CrossRef]
- Zhu, X.; Kang, Y.; Liu, J. Estimation of the number of endmembers via thresholding ridge ratio criterion. IEEE Trans. Geosci. Remote Sens. 2020, 58, 637–649. [Google Scholar] [CrossRef]
- Prades, J.; Safont, G.; Salazar, A.; Vergara, L. Estimation of the number of endmembers in hyperspectral images using agglomerative clustering. Remote Sens. 2020, 12, 3585. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Cui, C.; Zhang, L.; Xu, Y. Autonomous endmember detection via an abundance anomaly guided saliency prior for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2336–2351. [Google Scholar] [CrossRef]
- Liu, D.; Li, J.; Yuan, Q. A spectral grouping and attention-driven residual dense network for hyperspectral image super-resolution. IEEE Trans. Geosci. Remote Sens. 2020, 1–15. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, J.; Yang, D.; Xu, L.; Jia, F. Cascaded convolutional neural network-based hyperspectral image resolution enhancement via an auxiliary panchromatic image. IEEE Trans. Image Process. 2021, 30, 6815–6828. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Parameters (M) |
|---|---|
| 3DFN | 0.08 |
| DFMF | 0.16 |
| IFN | 3.71 |
| RIFN | 4.72 |
| UCNN | 0.95 |
| Dataset | Method | SAM | ERGAS | PSNR (dB) | UIQI | SSIM | Time (s) (Training/Testing) |
|---|---|---|---|---|---|---|---|
| University of Pavia | Bicubic | 4.84 | 12.60 | 28.06 | 0.8969 | 0.8904 | -/0.0101 |
| 3DFN | 4.12 | 8.33 | 31.79 | 0.9611 | 0.9260 | 45,938.5/2492.9 | |
| DFMF | 4.99 | 10.05 | 30.62 | 0.9430 | 0.9249 | 1351.7/21.8 | |
| IFN | 4.35 | 10.24 | 29.97 | 0.9346 | 0.9189 | 1439.1/97.2 | |
| RIFN | 3.84 | 7.84 | 32.50 | 0.9651 | 0.9386 | 10,385.8/622.7 | |
| UCNN | 3.80 | 7.64 | 32.74 | 0.9660 | 0.9465 | 2944.5/104.4 | |
| University of Houston | Bicubic | 6.01 | 11.90 | 30.69 | 0.9323 | 0.9157 | -/0.0150 |
| 3DFN | 6.17 | 9.86 | 32.17 | 0.9538 | 0.9271 | 66,296.3/3637.2 | |
| DFMF | 5.87 | 9.88 | 32.20 | 0.9518 | 0.9274 | 1225.7/33.5 | |
| IFN | 6.13 | 11.04 | 31.26 | 0.9372 | 0.9272 | 1744.8/113.1 | |
| RIFN | 5.45 | 9.47 | 32.67 | 0.9481 | 0.9309 | 10,740.5/592.2 | |
| UCNN | 4.83 | 9.07 | 32.85 | 0.9556 | 0.9444 | 2979.4/110.3 | |
| San Diego | Bicubic | 1.96 | 7.00 | 35.21 | 0.9426 | 0.9760 | -/0.0143 |
| 3DFN | 2.34 | 6.25 | 36.16 | 0.9525 | 0.9811 | 61,342.4/3172.3 | |
| DFMF | 2.38 | 5.62 | 37.17 | 0.9643 | 0.9823 | 891.7/24.6 | |
| IFN | 2.07 | 6.81 | 35.46 | 0.9467 | 0.9767 | 1408.6/109.2 | |
| RIFN | 2.42 | 5.62 | 37.13 | 0.9656 | 0.9827 | 7665.0/447.1 | |
| UCNN | 2.58 | 5.50 | 37.33 | 0.9675 | 0.9849 | 2446.6/81.3 |
| Dataset | Method | SAM | ERGAS | PSNR (dB) | UIQI | SSIM | Time (s) (Training/Testing) |
|---|---|---|---|---|---|---|---|
| University of Pavia | Bicubic | 6.48 | 8.29 | 25.64 | 0.7998 | 0.8412 | -/0.0089 |
| 3DFN | 6.28 | 7.26 | 26.81 | 0.8673 | 0.8629 | 44,057.7/2394.0 | |
| DFMF | 6.77 | 7.69 | 26.43 | 0.8448 | 0.8603 | 1138.0/21.4 | |
| IFN | 6.07 | 7.66 | 26.38 | 0.8376 | 0.8563 | 1469.3/100.3 | |
| RIFN | 5.72 | 7.32 | 26.76 | 0.8649 | 0.8650 | 10,387.5/563.0 | |
| UCNN | 5.57 | 6.95 | 27.25 | 0.8815 | 0.8772 | 2976.3/107.7 | |
| University of Houston | Bicubic | 8.31 | 7.87 | 28.34 | 0.8759 | 0.8851 | -/0.0125 |
| 3DFN | 9.16 | 7.87 | 28.28 | 0.8998 | 0.8794 | 66,506.2/3413.2 | |
| DFMF | 8.05 | 7.28 | 28.92 | 0.8901 | 0.8972 | 1186.0/21.8 | |
| IFN | 8.55 | 7.84 | 28.38 | 0.8796 | 0.8870 | 1771.4/116.6 | |
| RIFN | 7.87 | 7.52 | 28.86 | 0.8974 | 0.8987 | 10,715.7/577.6 | |
| UCNN | 7.21 | 6.84 | 29.37 | 0.9042 | 0.9071 | 2964.8/112.8 | |
| San Diego | Bicubic | 2.59 | 4.57 | 32.91 | 0.8974 | 0.9652 | -/0.0118 |
| 3DFN | 3.33 | 4.42 | 33.18 | 0.9132 | 0.9673 | 61,124.9/3191.6 | |
| DFMF | 2.90 | 4.37 | 33.29 | 0.9119 | 0.9666 | 818.5/15.2 | |
| IFN | 2.79 | 4.45 | 33.14 | 0.9037 | 0.9660 | 1413.4/109.6 | |
| RIFN | 2.76 | 4.30 | 33.45 | 0.9146 | 0.9676 | 7688.1/477.3 | |
| UCNN | 3.10 | 4.23 | 33.58 | 0.9230 | 0.9703 | 2387.0/80.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Yang, D.; Zhang, J.; Jia, F. Hyperspectral Image Super-Resolution Based on Spatial Correlation-Regularized Unmixing Convolutional Neural Network. Remote Sens. 2021, 13, 4074. https://doi.org/10.3390/rs13204074
Lu X, Yang D, Zhang J, Jia F. Hyperspectral Image Super-Resolution Based on Spatial Correlation-Regularized Unmixing Convolutional Neural Network. Remote Sensing. 2021; 13(20):4074. https://doi.org/10.3390/rs13204074
Chicago/Turabian StyleLu, Xiaochen, Dezheng Yang, Junping Zhang, and Fengde Jia. 2021. "Hyperspectral Image Super-Resolution Based on Spatial Correlation-Regularized Unmixing Convolutional Neural Network" Remote Sensing 13, no. 20: 4074. https://doi.org/10.3390/rs13204074
APA StyleLu, X., Yang, D., Zhang, J., & Jia, F. (2021). Hyperspectral Image Super-Resolution Based on Spatial Correlation-Regularized Unmixing Convolutional Neural Network. Remote Sensing, 13(20), 4074. https://doi.org/10.3390/rs13204074