
LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments

Abstract
:1. Introduction
2. Related Work
2.1. Point Cloud Semantic Segmentation
2.2. Semantic SLAM
2.3. SLAM for Dynamic Environments
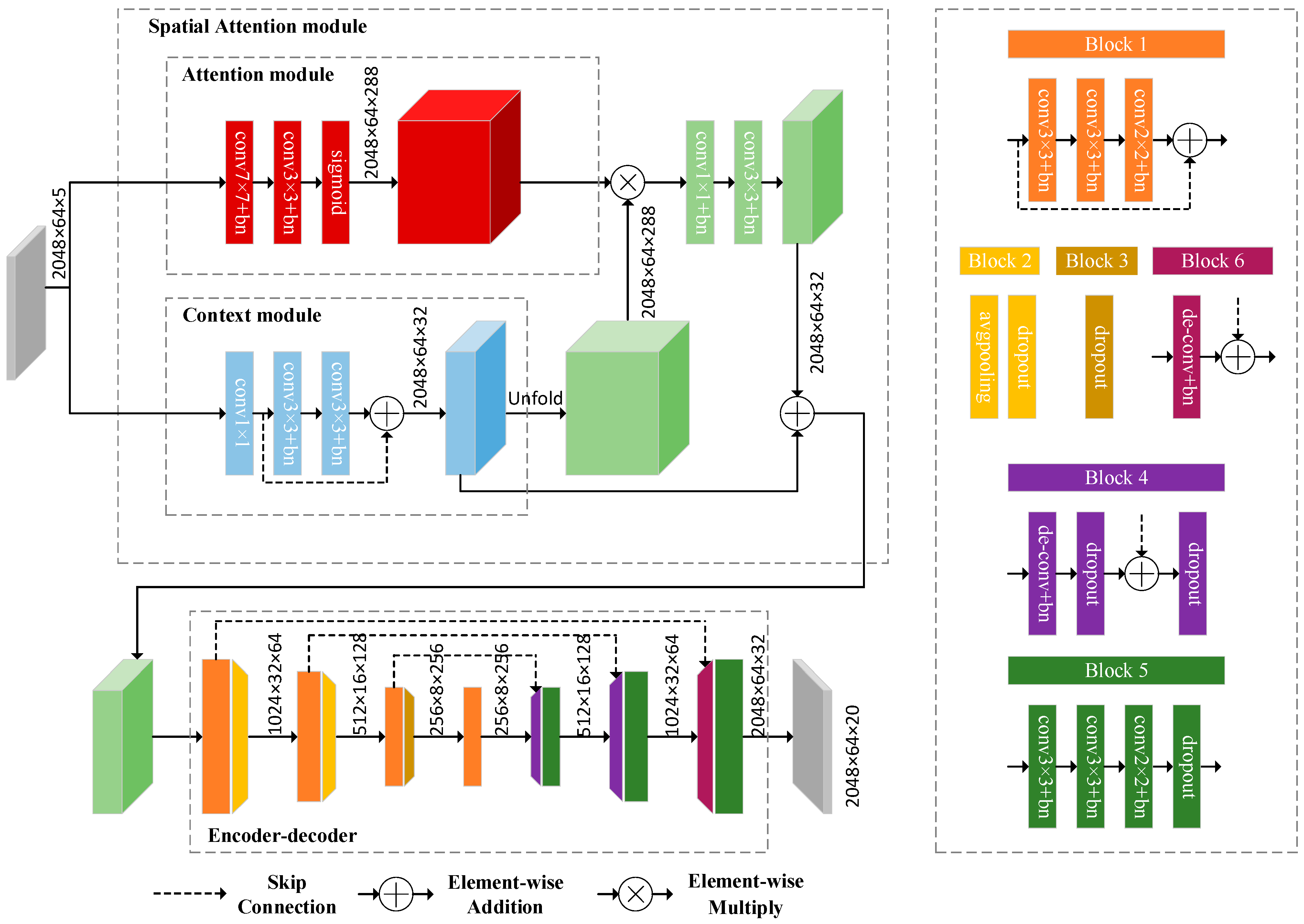
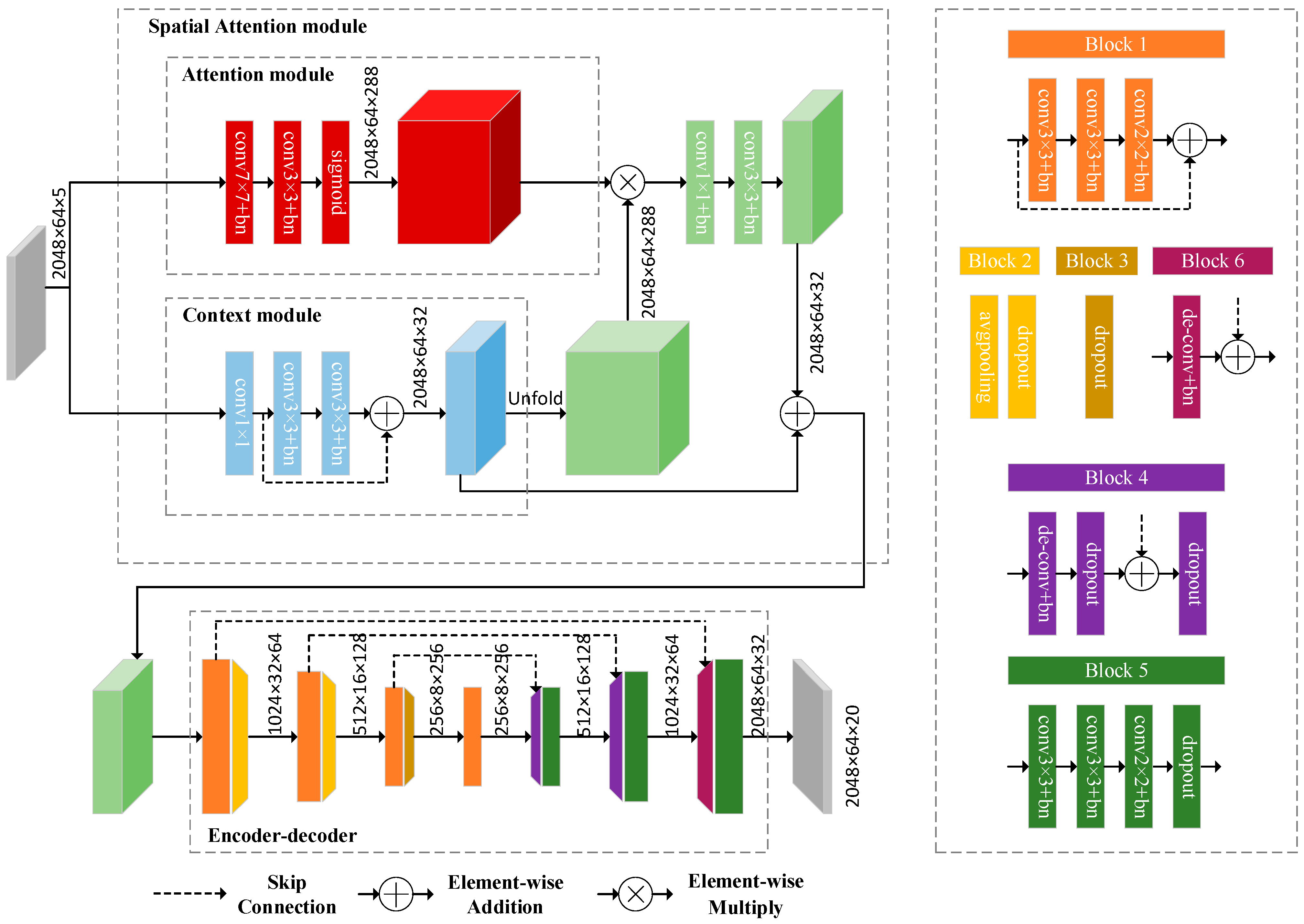
3. Method
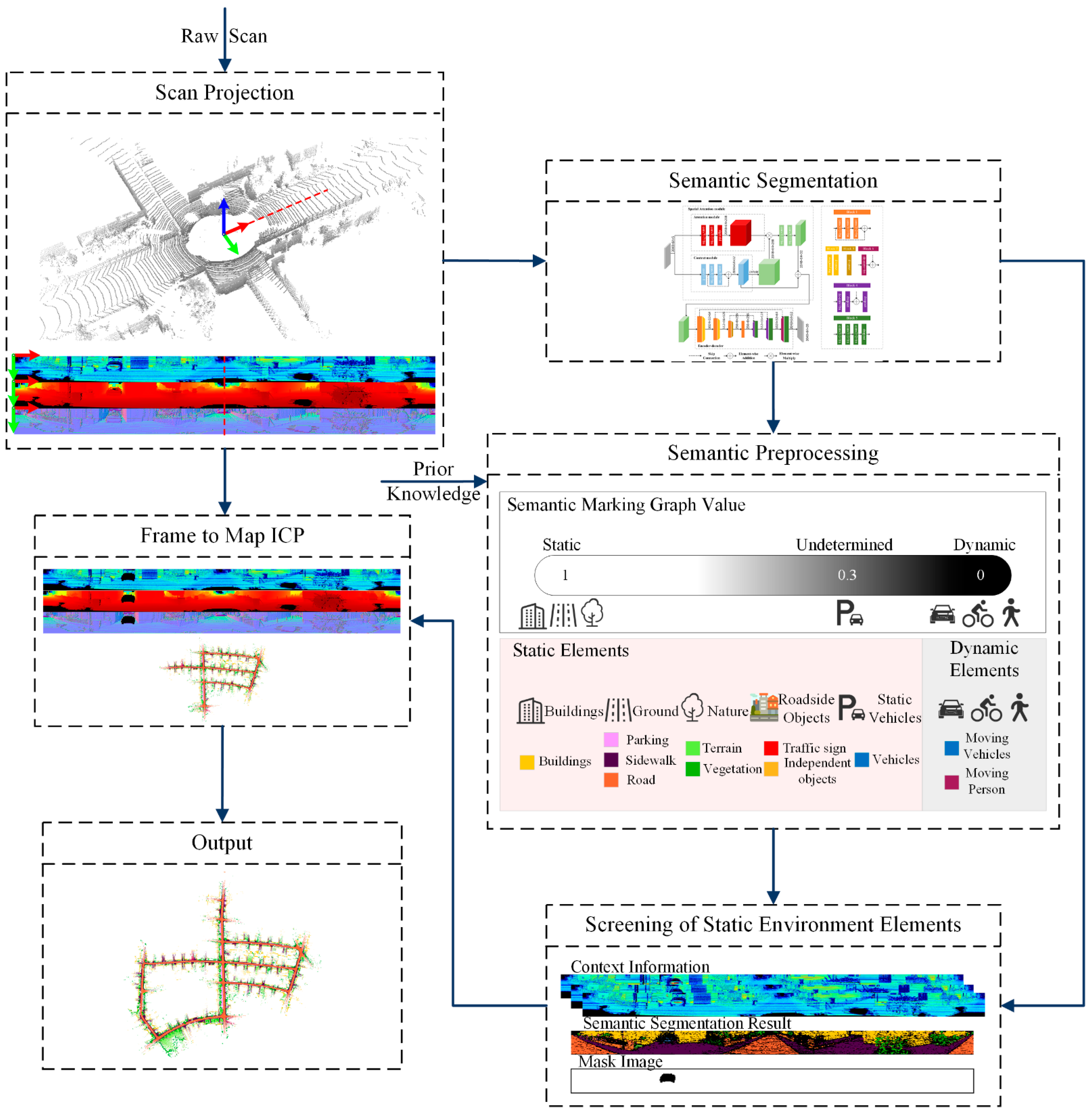
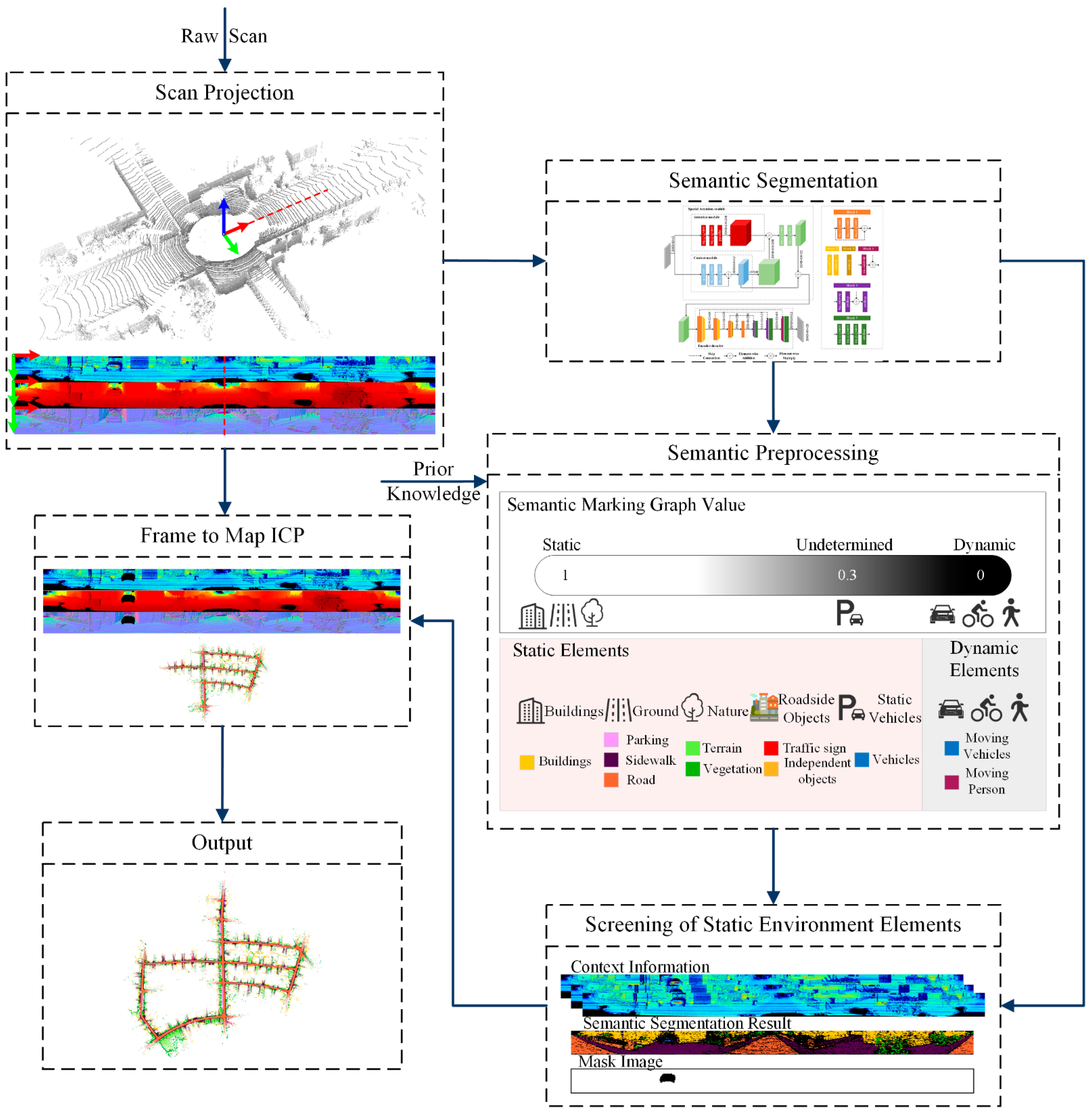
3.1. Overview of the Proposed Approach
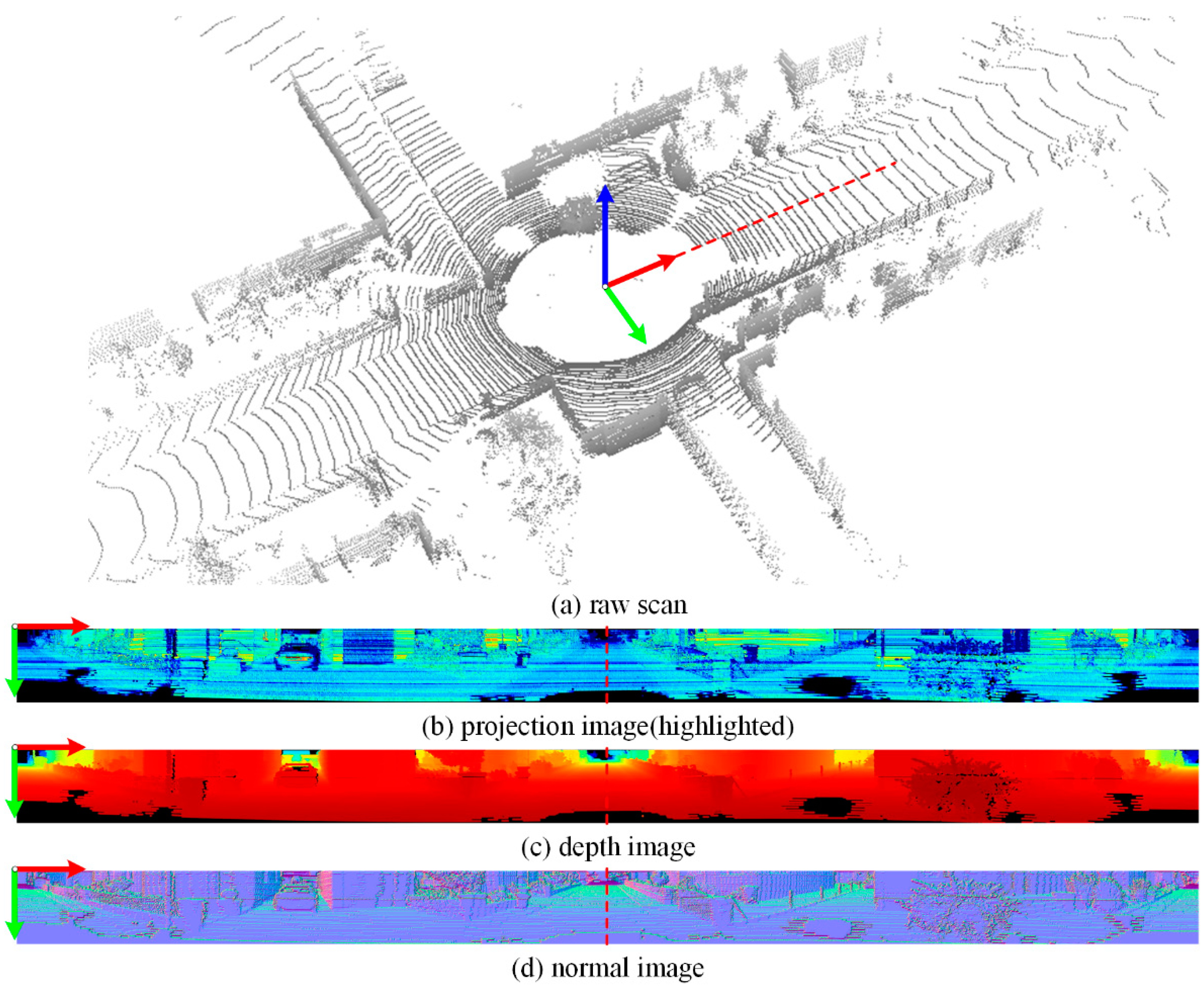
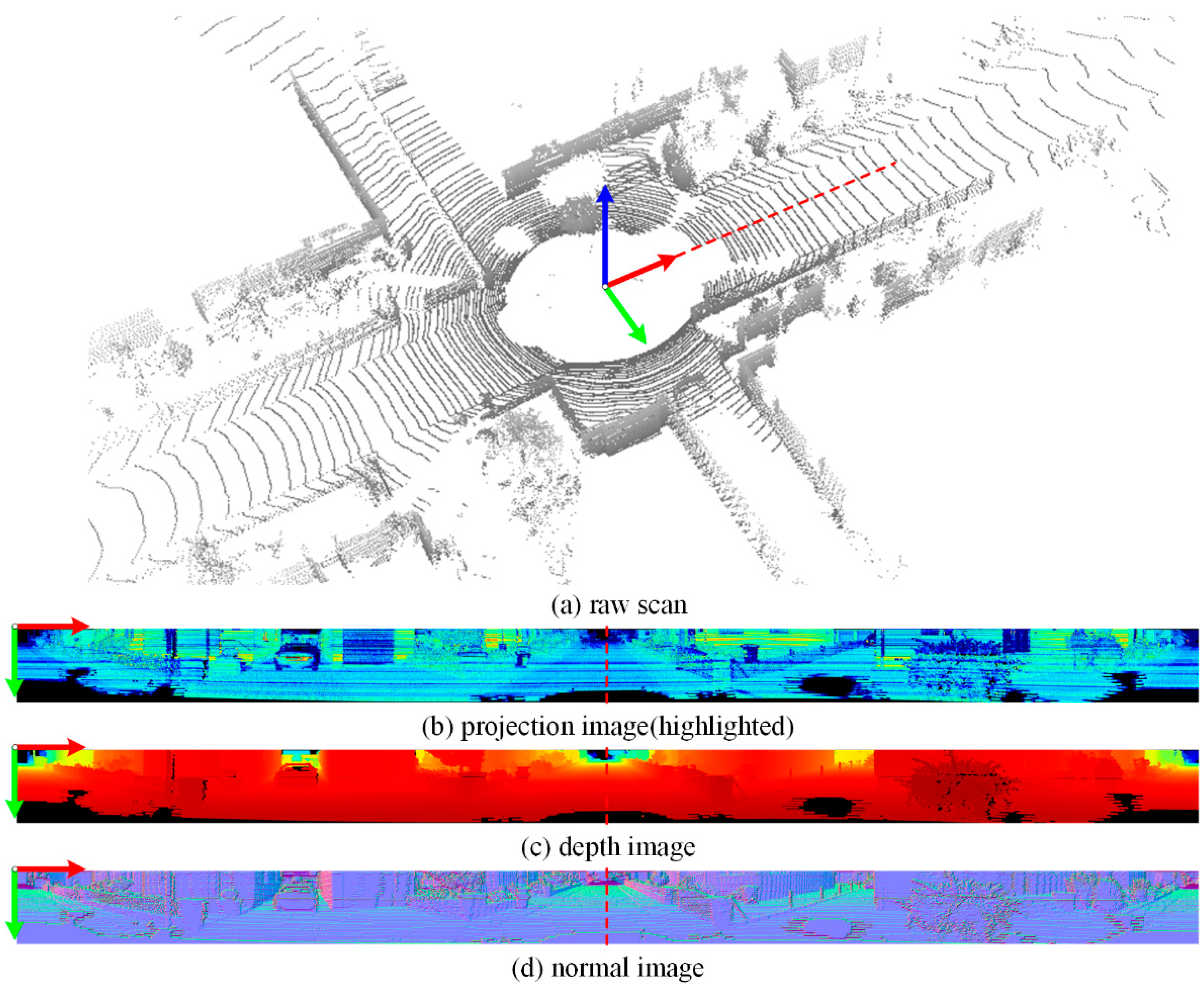
3.2. Semantic Segmentation
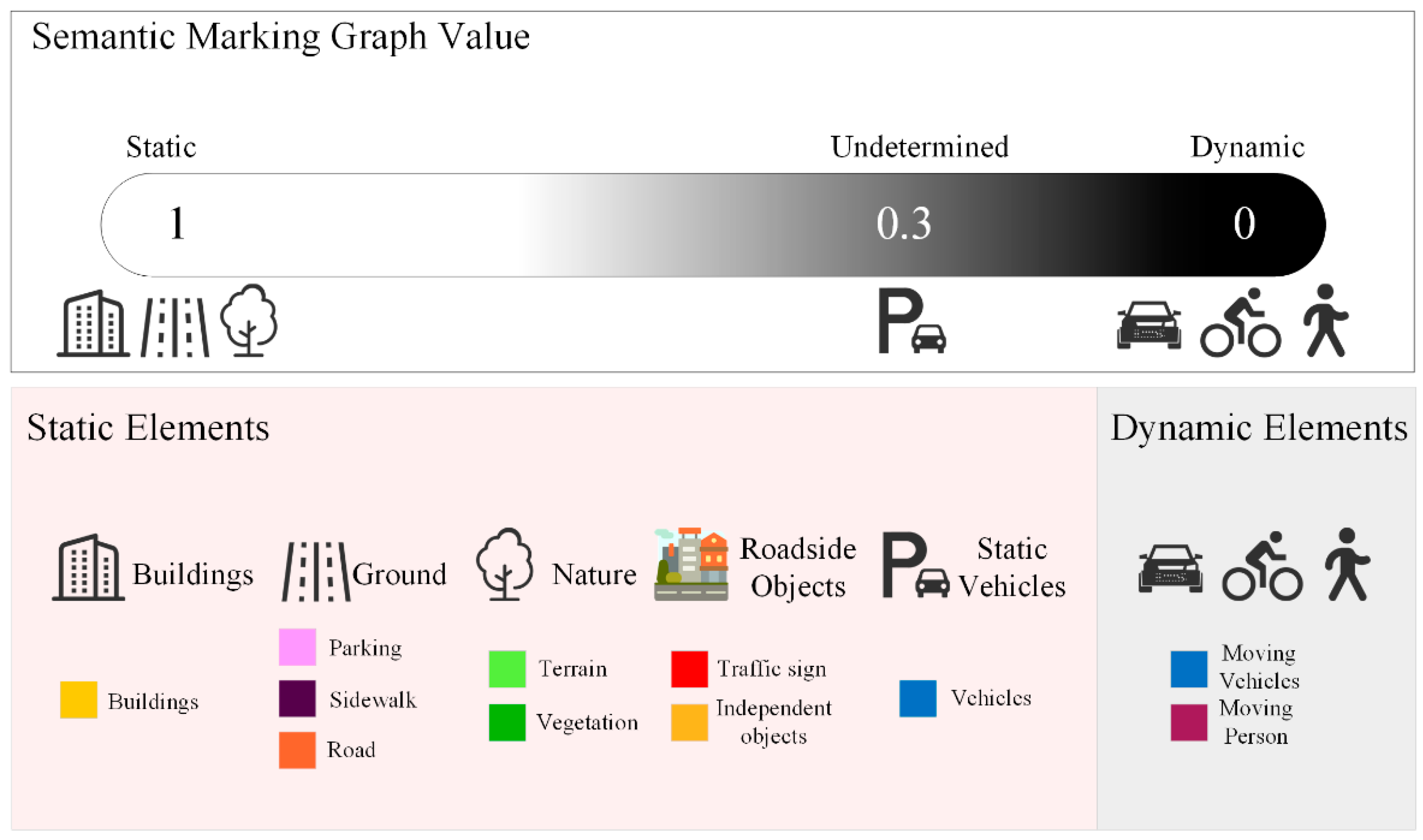
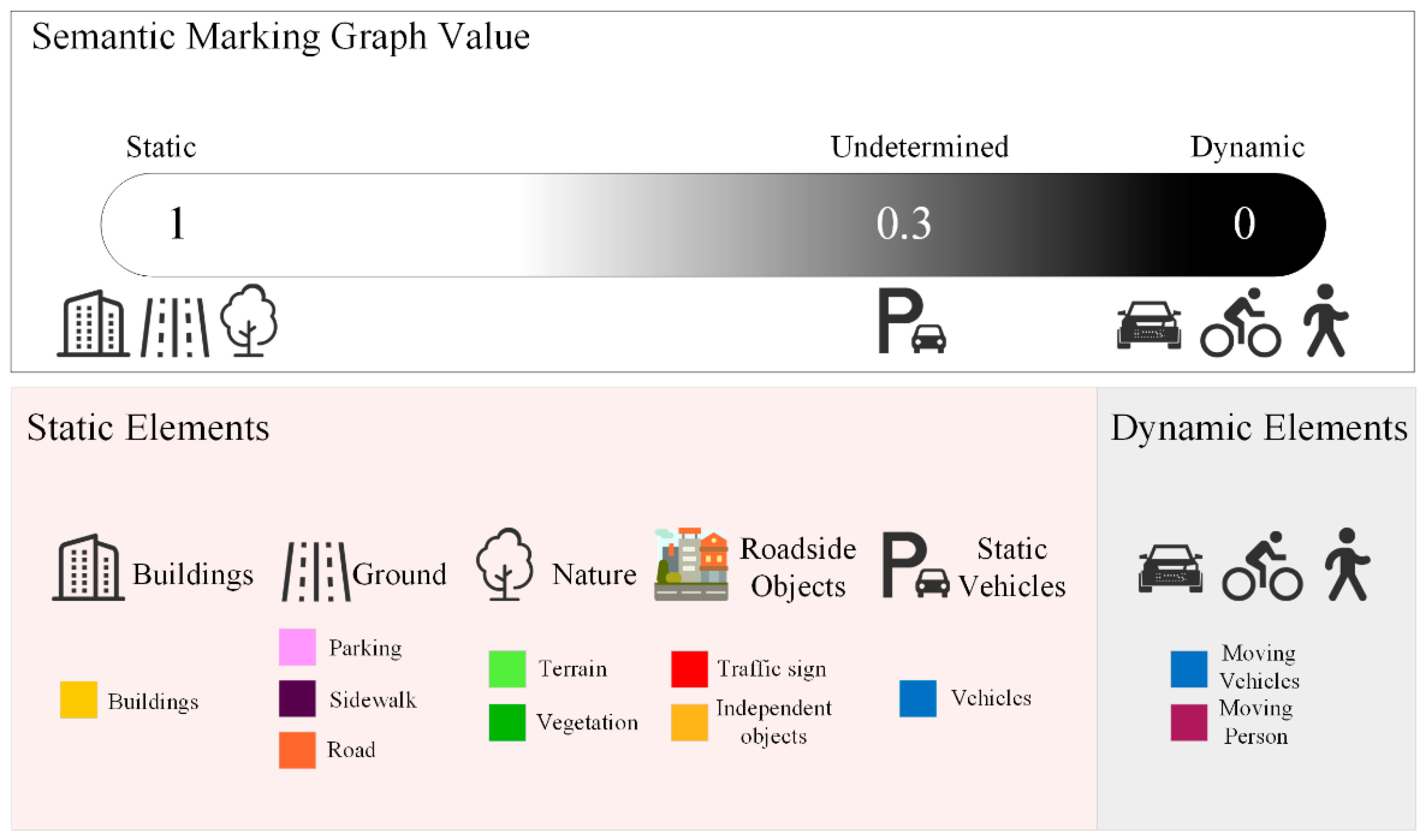
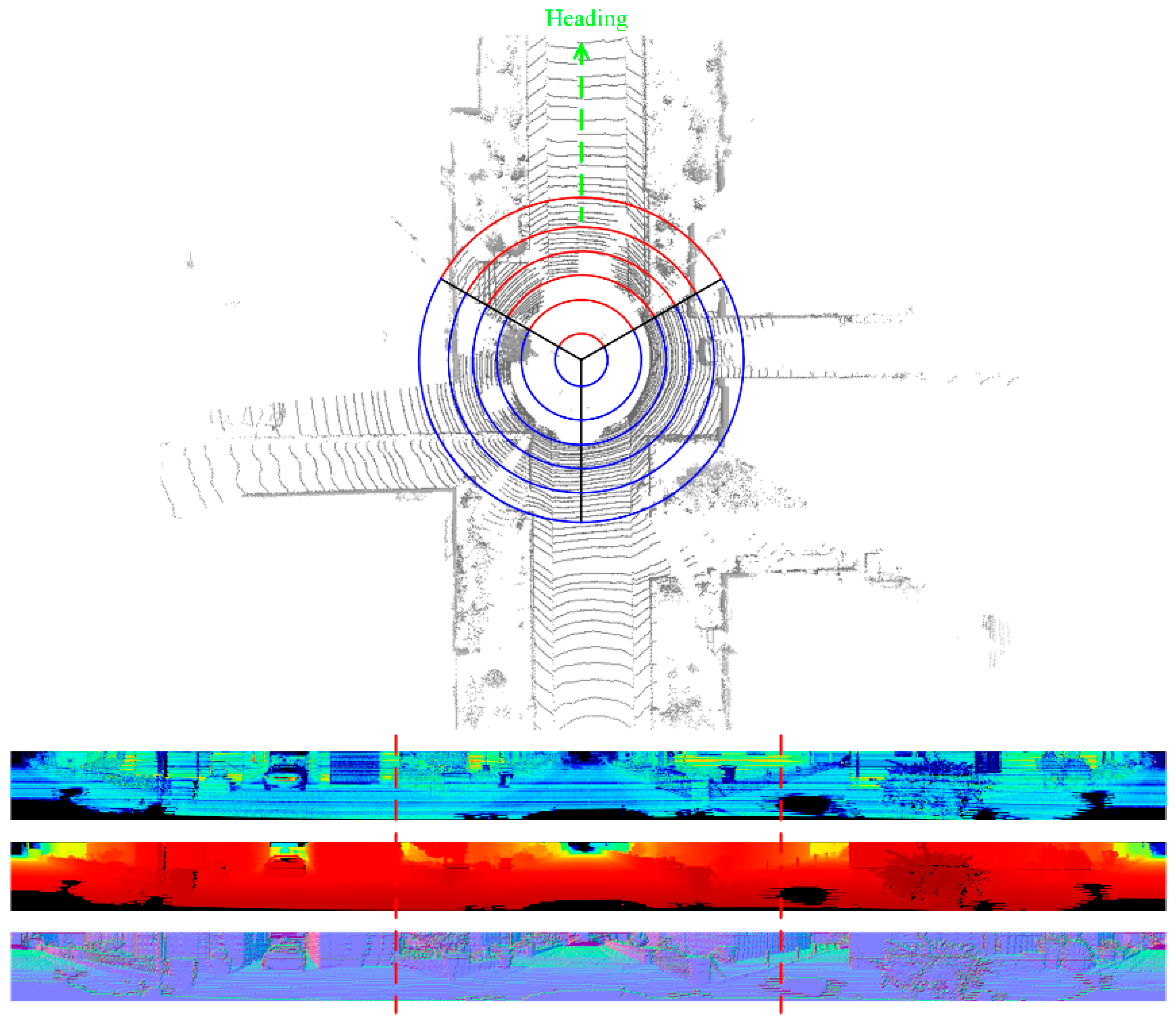
3.3. Dealing with Potential Dynamics
| Algorithm 1. Screening of static environment elements |
| Input: pose transformation matrix , semantic segmentation result |
| and semantic marking graph |
| Output: updated semantic marking Graph |
| Intermediate variable: average displacement and decision weight |
| Begins |
| for i in w, do |
| for j in h, do |
| calculate ; |
| end |
| end |
| for u in w, do |
| for v in h, do |
| if then |
| else |
| end |
| end |
3.4. Pose Estimation
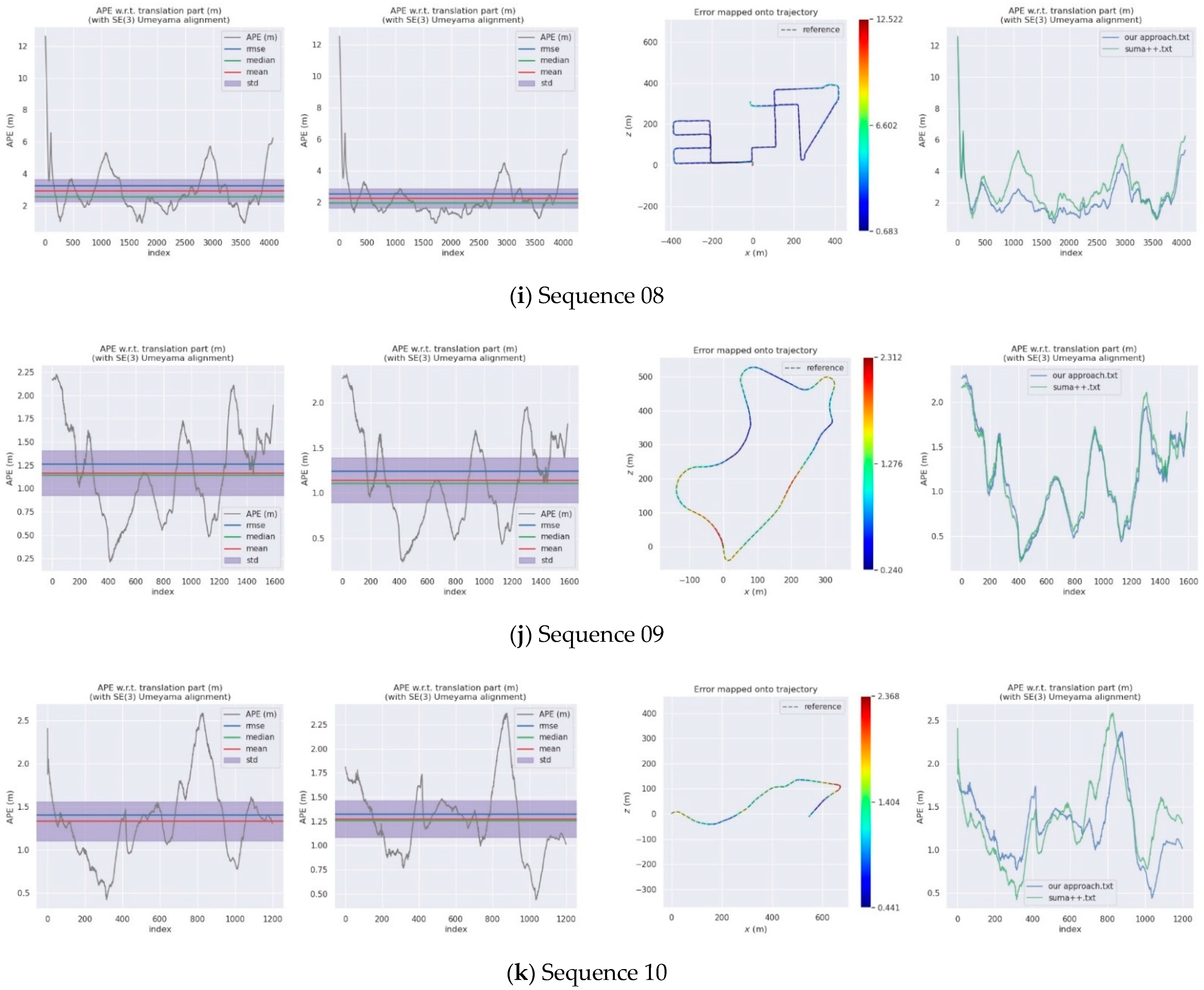
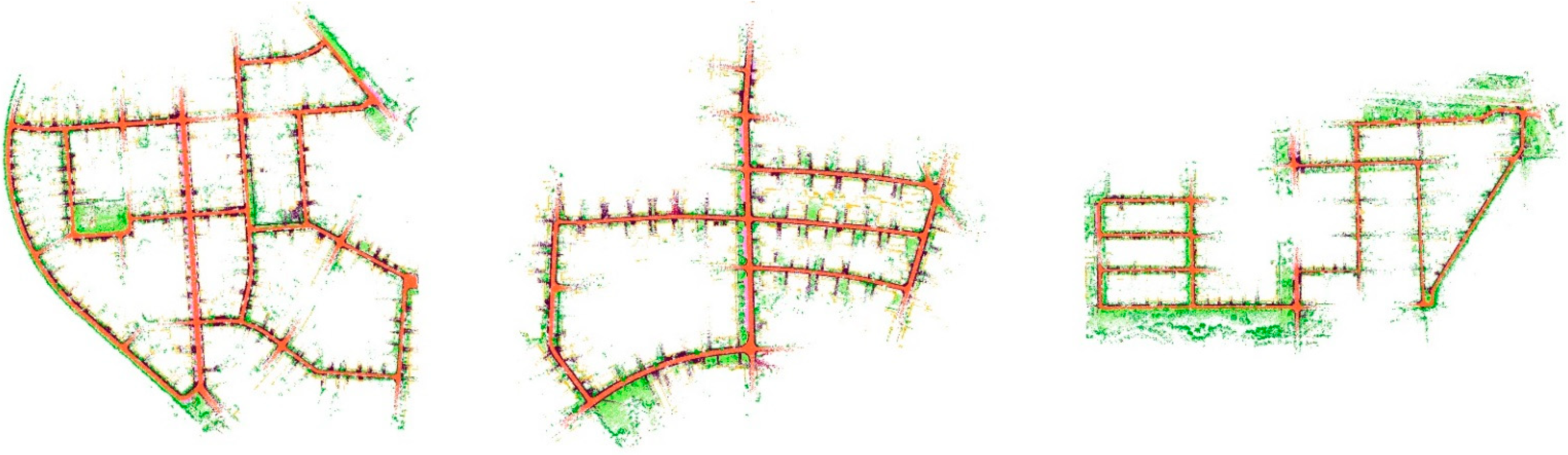
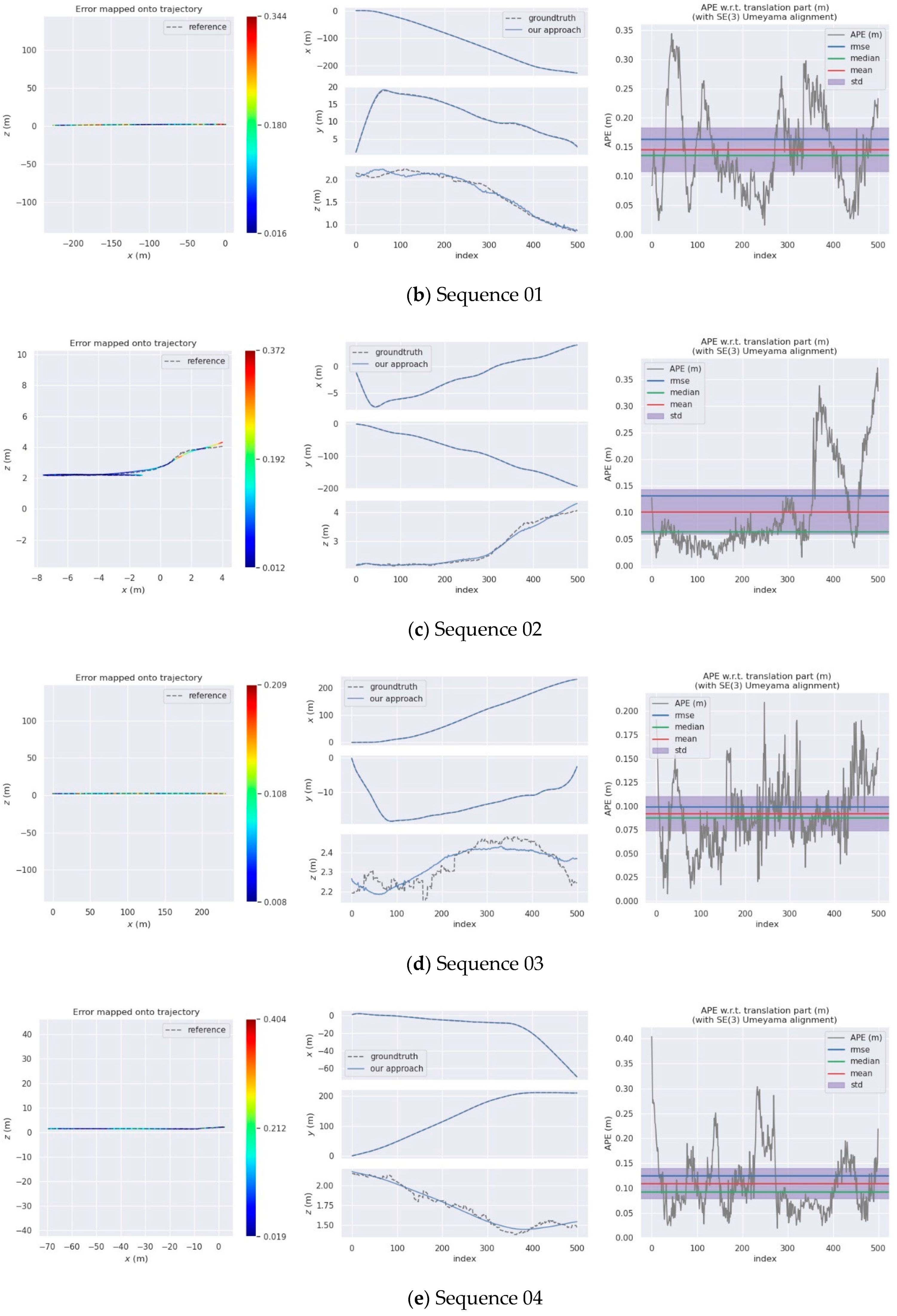
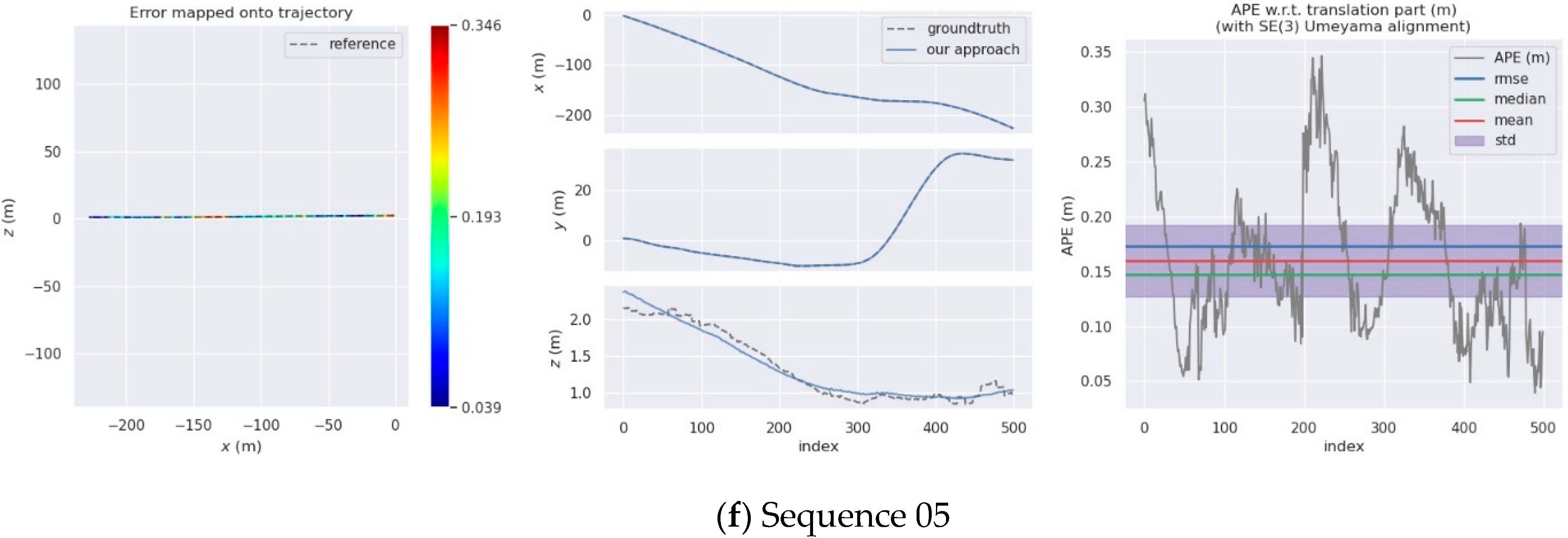
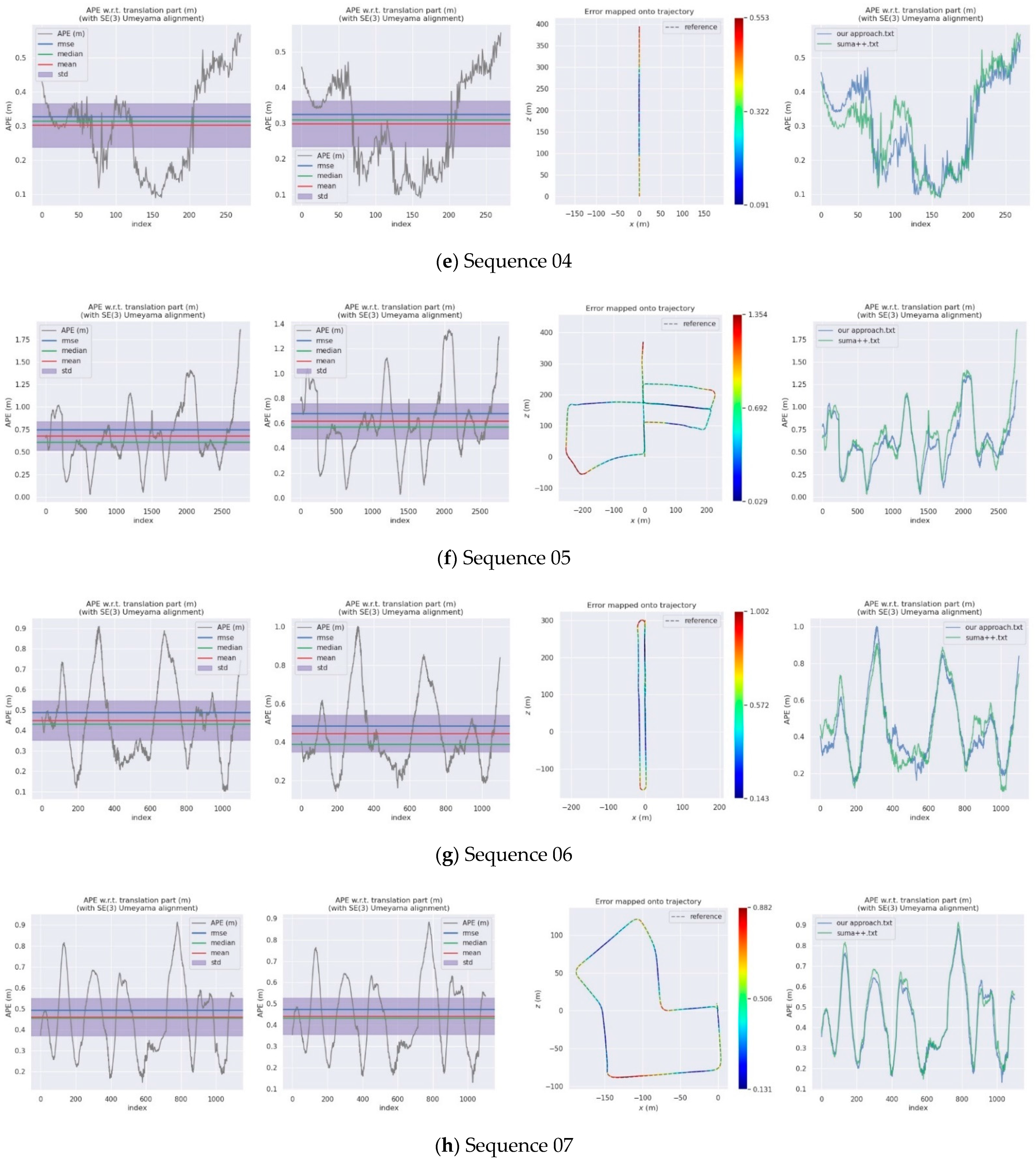
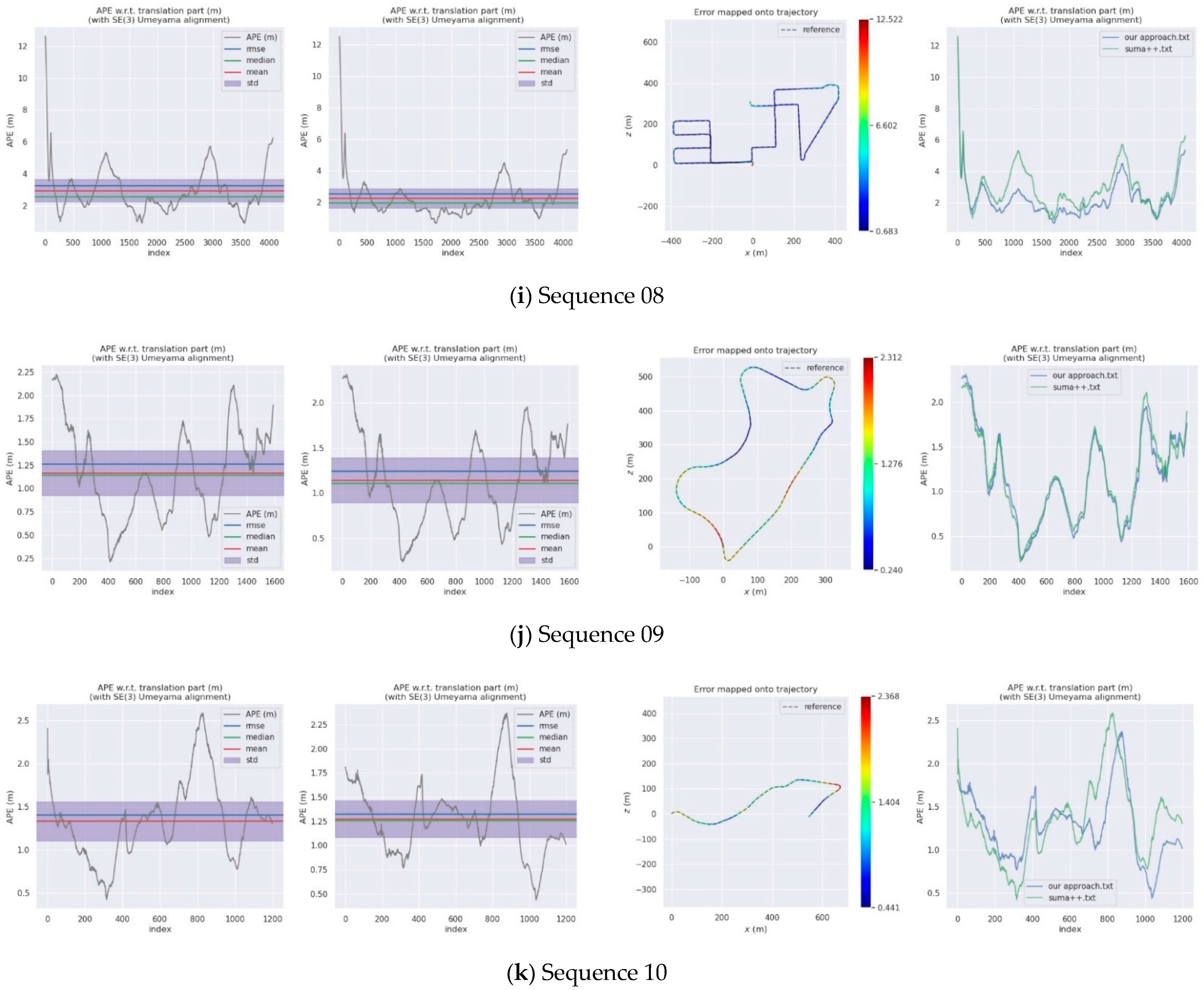
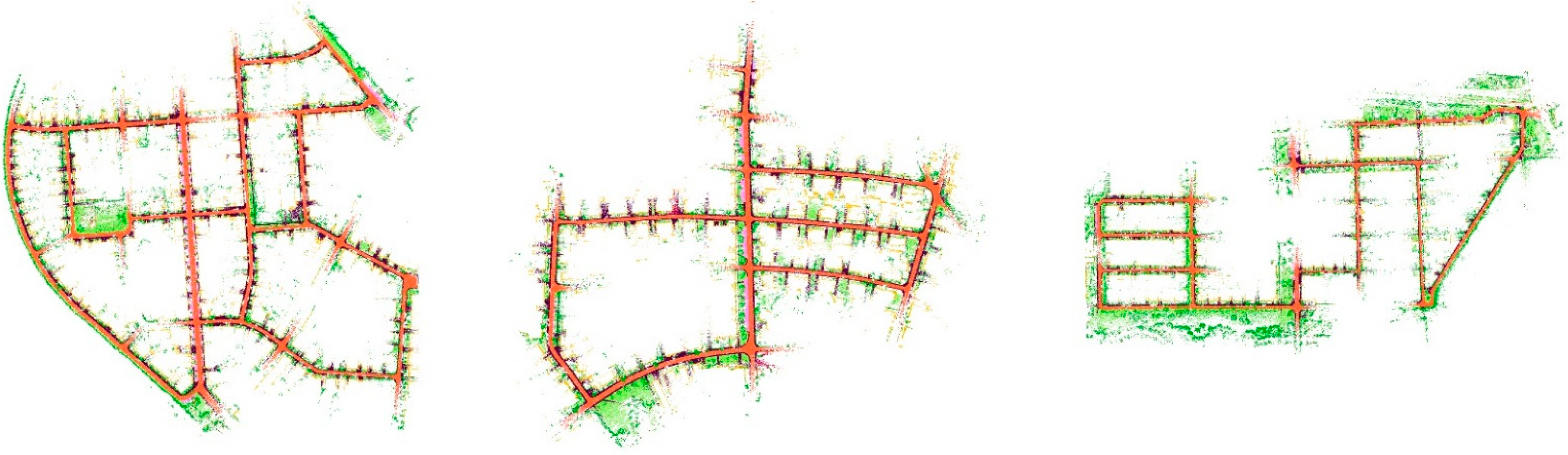
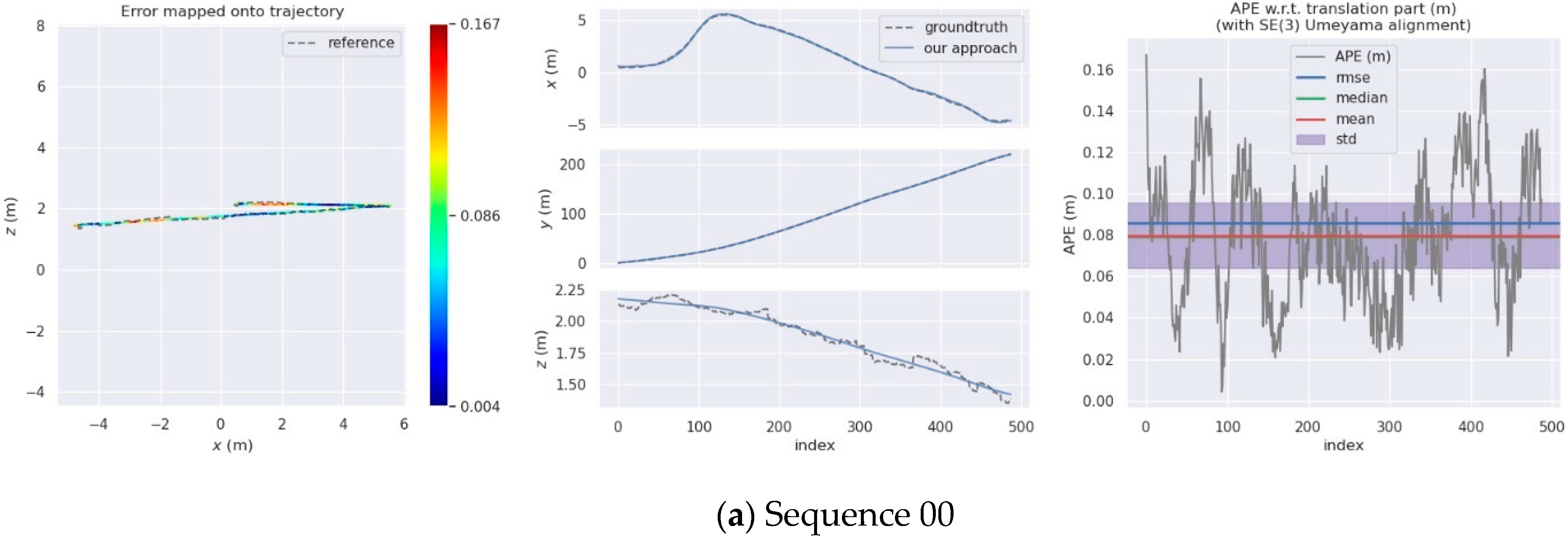
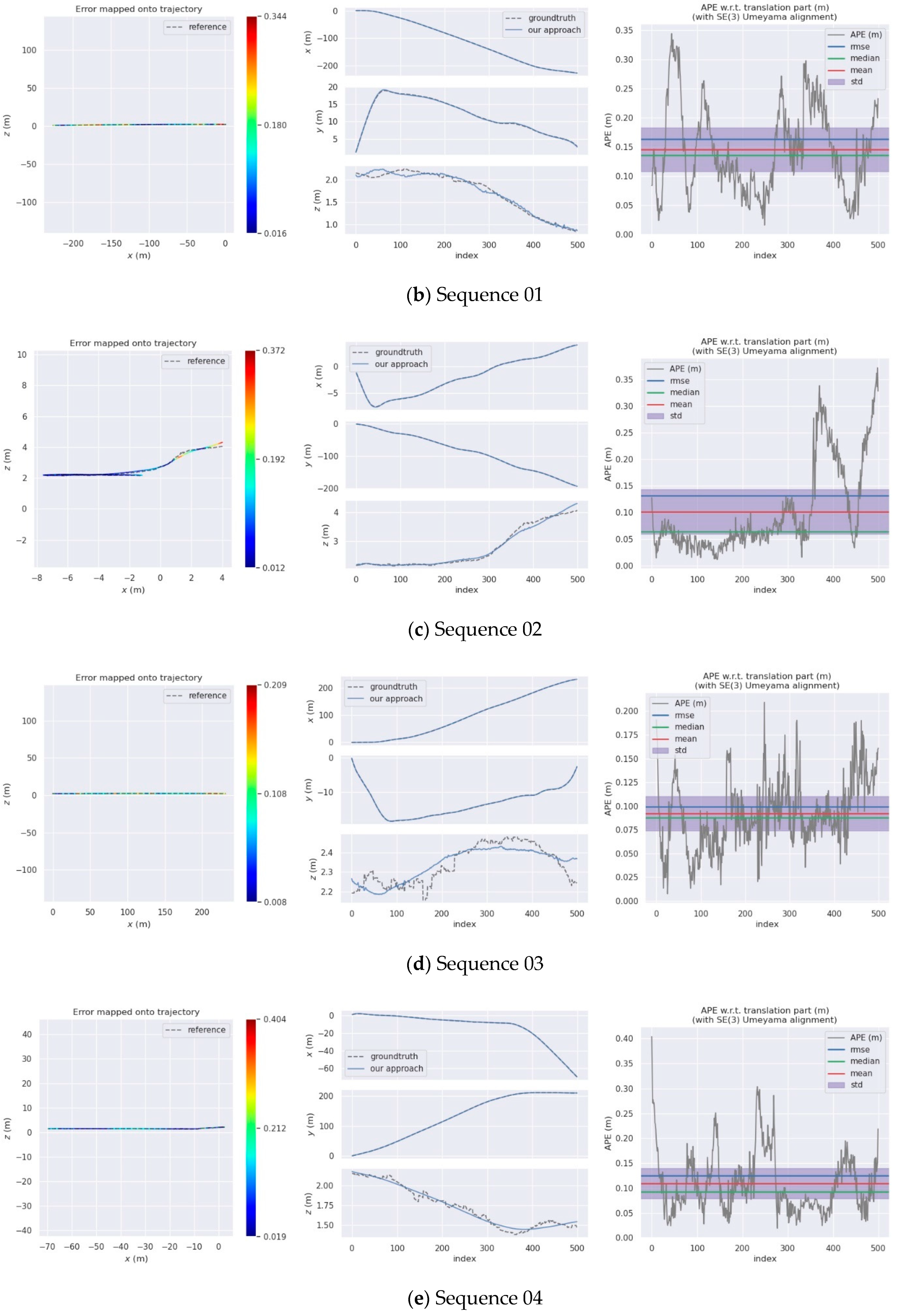
4. Experiments
4.1. Semantic Segmentation Experiments on the SemanticKITTI Dataset
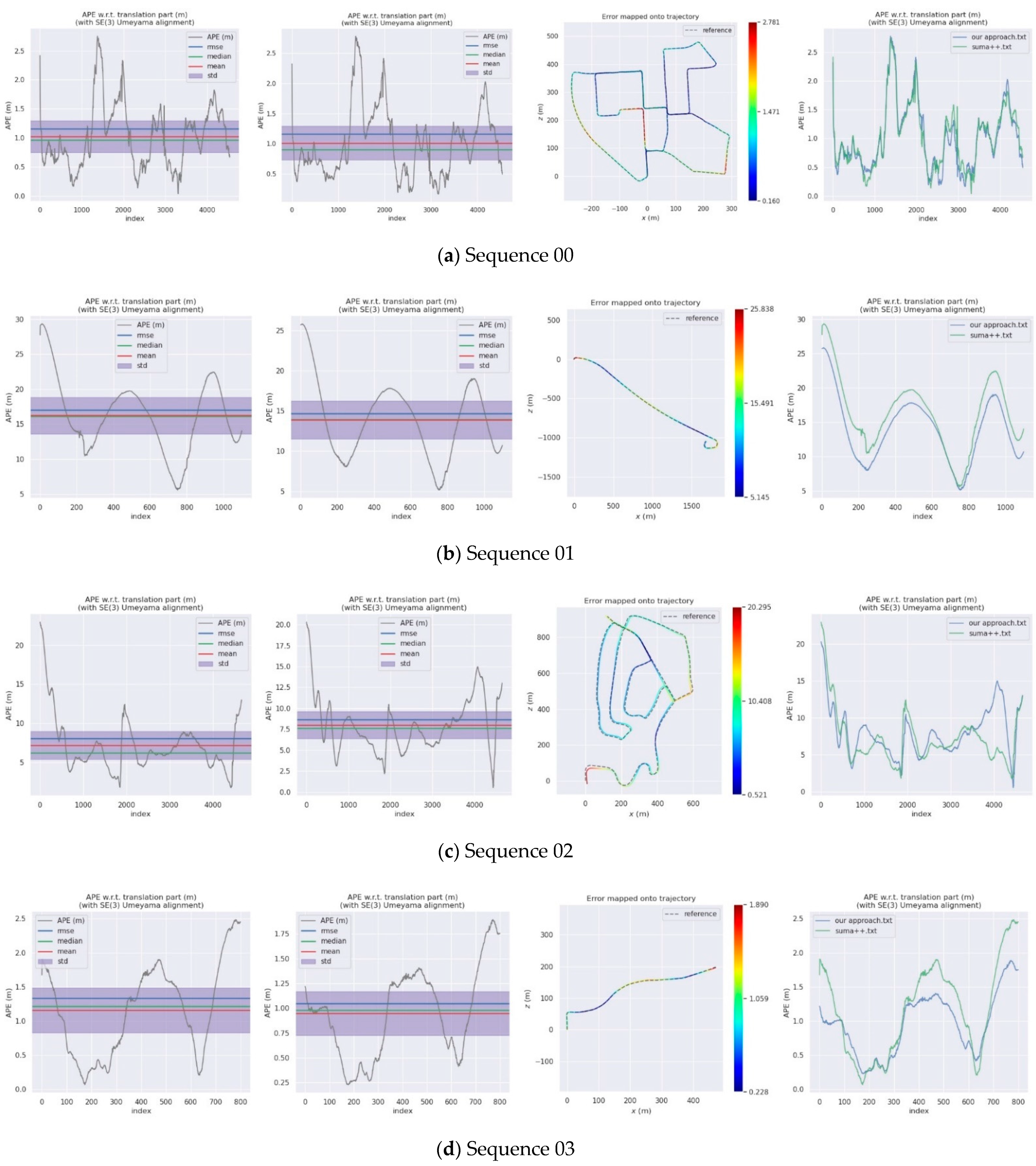
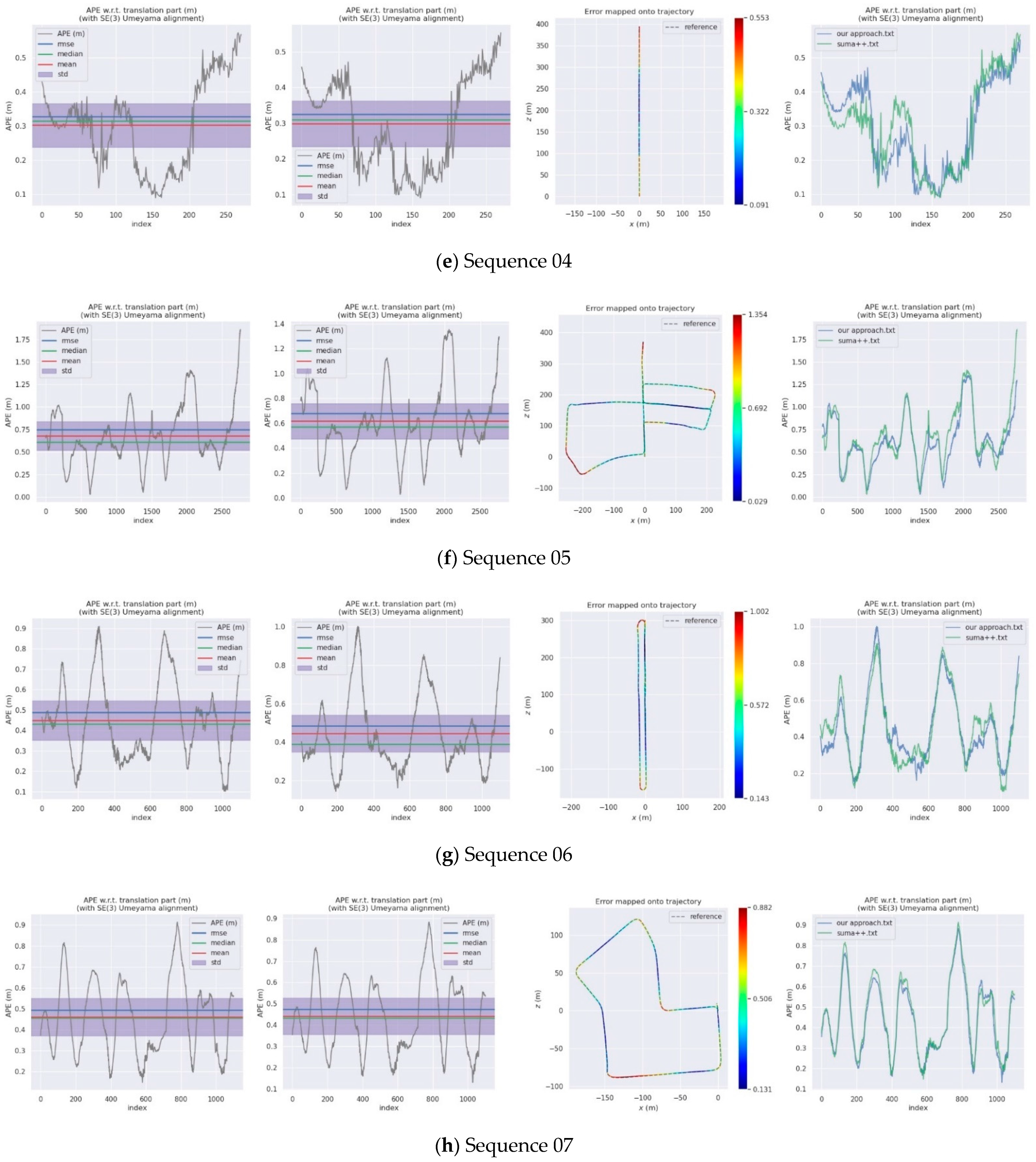
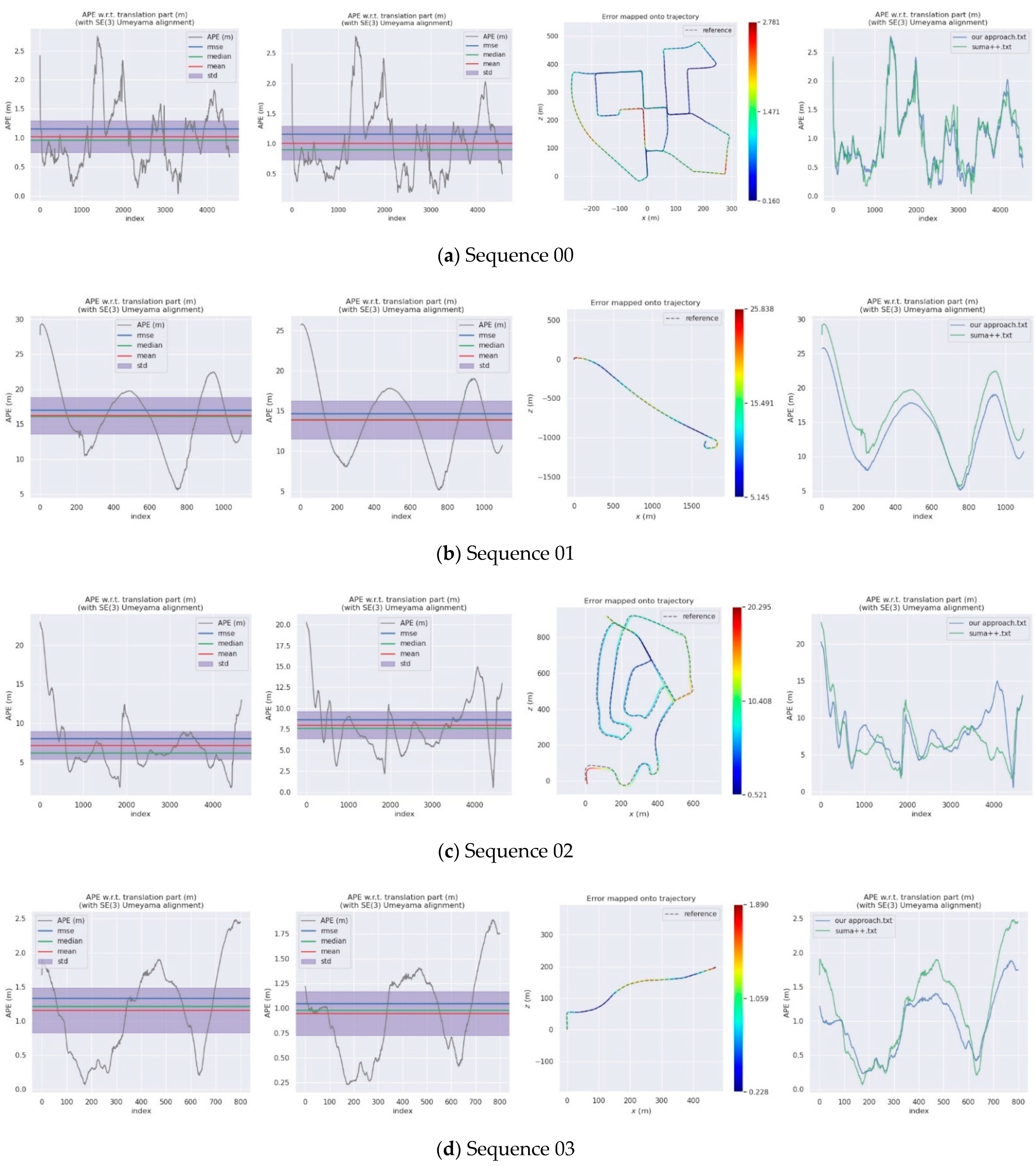
4.2. KITTI Dataset
4.3. SemanticPOSS Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- The Group of Strategic Research on Artificial Intelligence 2.0 in China. In Strategic Research on Artificial Intelligence 2.0 in China; Zhejiang University press: Zhejiang, China, 2018; pp. 1–10.
- Jun, G.A.O. The 60 Anniversary and Prospect of Acta Geodaetica et Cartographica Sinica. Acta Geod. Et Cartogr. Sin. 2017, 46, 1219–1225. [Google Scholar]
- Gao, B.; Pan, Y.; Li, C.; Geng, S.; Zhao, H. Are We Hungry for 3D LiDAR Data for Semantic Segmentation? A Survey of Datasets and Methods. IEEE Trans. Intell. Transp. Syst. 2021, 1–19. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++ deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; pp. 5105–5114. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Advances in neural information processing systems. Adv. Neural Inf. Process. Syst. 2018, 31, 820–830. [Google Scholar]
- Lawin, F.J.; Danelljan, M.; Tosteberg, P.; Bhat, G.; Khan, F.S.; Felsberg, M. Deep projective 3D semantic segmentation. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; Springer: Cham, The Netherlands, 2017; pp. 95–107. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the IEEE 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In European Conference on Computer Vision; Springer: Cham, The Netherlands, 2020; pp. 1–19. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4213–4220. [Google Scholar]
- Liu, F.; Li, S.; Zhang, L.; Zhou, C.; Ye, R.; Wang, Y.; Lu, J. 3DCNN-DQN-RNN: A deep reinforcement learning framework for semantic parsing of large-scale 3D point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5678–5687. [Google Scholar]
- Radi, H.; Ali, W. VolMap: A Real-time Model for Semantic Segmentation of a LiDAR surrounding view. arXiv 2019, arXiv:1906.11873. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Liu, Z.; Liu, X.-J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A Semantic Visual SLAM towards Dynamic Environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Zeng, Z.; Zhou, Y.; Jenkins, O.C.; Desingh, K. Semantic mapping with simultaneous object detection and localization. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 911–918. [Google Scholar]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5729–5736. [Google Scholar]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A. Visual representations for semantic target driven navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar]
- Ma, W.C.; Tartavull, I.; Bârsan, I.A.; Wang, S.; Bai, M.; Mattyus, G.; Homayounfar, N.; Lakshmikanth, S.K.; Pokrovsky, A.; Urtasun, R. Exploiting Sparse Semantic HD Maps for Self-Driving Vehicle Localization. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 5304–5311. [Google Scholar]
- Limketkai, B.; Liao, L.; Fox, D. Relational object maps for mobile robots. In Proceedings of the Nineteenth International Joint Conference on Artificial Intelligence (IJCAI), Edinburgh, Scotland, UK, 30 July–5 August 2005; pp. 1471–1476. [Google Scholar]
- Nüchter, A.; Hertzberg, J. Towards semantic maps for mobile robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Sengupta, S.; Sturgess, P.; Torr, P.H.S. Automatic dense visual semantic mapping from street-level imagery. In Proceedings of the 2012 IEEE/RSJ International Conference Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 857–862. [Google Scholar]
- Valentin, J.P.; Sengupta, S.; Warrell, J.; Shahrokni, A.; Torr, P.H. Mesh based semantic modelling for indoor and outdoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2067–2074. [Google Scholar]
- Sengupta, S.; Sturgess, P. Semantic octree: Unifying recognition, reconstruction and representation via an octree constrained higher order MRF. In Proceedings of the 2015 IEEE International Conference, Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2015; pp. 1874–1879. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Vasudevan, S.; Gächter, S.; Nguyen, V.; Siegwart, R. Cognitive maps for mobile robots—An object based approach. Robot. Auton. Syst. 2007, 55, 359–371. [Google Scholar] [CrossRef] [Green Version]
- Vasudevan, S.; Siegwart, R. Bayesian space conceptualization and place classification for semantic maps in mobile robotics. Robot. Auton. Syst. 2008, 56, 522–537. [Google Scholar] [CrossRef]
- Rituerto, A.; Murillo, A.C.; Guerrero, J.J. Semantic labeling for indoor topological mapping using a wearable catadioptric system. Robot. Auton. Syst. 2014, 62, 685–695. [Google Scholar] [CrossRef]
- Liu, M.; Colas, F.; Pomerleau, F.; Siegwart, R. A Markov semi-supervised clustering approach and its application in topological map extraction. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 4743–4748. [Google Scholar]
- Brunskill, E.; Kollar, T.; Roy, N. Topological mapping using spectral clustering and classification. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 3491–3496. [Google Scholar]
- Liu, M.; Colas, F.; Siegwart, R. Regional topological segmentation based on mutual information graphs. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation. IEEE, Shanghai, China, 9–13 May 2011; pp. 3269–3274. [Google Scholar]
- Liu, Z.; Chen, D.; von Wichert, G. Online semantic exploration of indoor maps. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 4361–4366. [Google Scholar]
- Pronobis, A.; Mozos, O.; Caputo, B.; Jensfelt, P. Multi-modal Semantic Place Classification. Int. J. Robot. Res. 2009, 29, 298–320. [Google Scholar] [CrossRef]
- Pronobis, A.; Jensfelt, P. Large-scale semantic mapping and reasoning with heterogeneous modalities. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3515–3522. [Google Scholar]
- Goeddel, R.; Olson, E. Learning semantic place labels from occupancy grids using CNNs. In Proceedings of the 2016 IEEE/RSJ international conference on intelligent robots and systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 3999–4004. [Google Scholar]
- Hiller, M.; Qiu, C.; Particke, F.; Hofmann, C.; Thielecke, J. Learning Topometric Semantic Maps from Occupancy Grids. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Bescos, B.; Facil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, Mapping, and Inpainting in Dynamic Scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. Suma++: Efficient lidar-based semantic slam. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 4530–4537. [Google Scholar]
- Zaganidis, A.; Sun, L.; Duckett, T.; Cielniak, G. Integrating Deep Semantic Segmentation Into 3-D Point Cloud Registration. IEEE Robot. Autom. Lett. 2018, 3, 2942–2949. [Google Scholar] [CrossRef] [Green Version]
- Dubé, R.; Cramariuc, A.; Dugas, D.; Nieto, J.; Siegwart, R.; Cadena, C. SegMap: 3D Segment Mapping using Data-Driven Descriptors. In Robotics: Science and Systems XIV; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle Detection from 3D Lidar Using Fully Convolutional Network. arXiv arXiv:1608.07916, 2016.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinzmann, T. Perception and Learning for Autonomous UAV Missions. Ph.D. Thesis, ETH Zurich, Zürich, Switzerland, 2020. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV); Institute of Electrical and Electronics Engineers (IEEE), Seoul, Korea, 27 October–3 October 2019; pp. 9296–9306. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Pan, Y.; Gao, B.; Mei, J.; Geng, S.; Li, C.; Zhao, H. SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 687–693. [Google Scholar]
- Aksoy, E.E.; Baci, S.; Cavdar, S. Salsanet: Fast road and vehicle segmentation in lidar point clouds for autonomous driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 926–932. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds. In International Symposium on Visual Computing; Springer: Cham, The Netherlands, 2020; pp. 207–222. [Google Scholar]
- Grupp, M. Evo: Python PackAge for the Evaluation of Odometry and Slam. Available online: https://github.com/MichaelGrupp/evo (accessed on 5 May 2021).
- Lu, X.; Wang, H.; Tang, S.; Huang, H.; Li, C. DM-SLAM: Monocular SLAM in dynamic environments. Appl. Sci. 2020, 10, 4252. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Car | Bicycle | Motorcycle | Truck | Other-vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic-sign | mIoU(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RangeNet | 91.4 | 25.7 | 34.4 | 25.7 | 23.0 | 38.3 | 38.8 | 4.8 | 91.8 | 65.0 | 75.2 | 27.8 | 87.4 | 58.6 | 80.5 | 55.1 | 64.6 | 47.9 | 55.9 | 52.2 |
| SquSegV3 | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | 89.0 | 59.4 | 82.0 | 58.7 | 65.4 | 49.6 | 58.9 | 55.9 |
| SalsaNet | 83.3 | 25.4 | 23.9 | 23.9 | 17.3 | 32.5 | 30.4 | 8.3 | 89.7 | 51.6 | 70.4 | 19.9 | 80.2 | 45.9 | 71.5 | 38.1 | 61.2 | 26.9 | 39.4 | 44.2 |
| SalsaNext | 90.9 | 36.4 | 29.5 | 21.7 | 19.9 | 52.0 | 52.7 | 16.0 | 90.9 | 58.1 | 74.0 | 27.8 | 87.9 | 58.2 | 81.8 | 61.7 | 66.3 | 51.7 | 58.0 | 54.5 |
| SANet | 92.5 | 49.7 | 37.9 | 38.7 | 32.4 | 57.5 | 52.0 | 33.5 | 91.4 | 64.0 | 75.1 | 28.8 | 88.6 | 59.6 | 81.0 | 62.5 | 65.4 | 53.2 | 61.6 | 59.2 |
| Sequences | SuMa++ | DynaSLAM | DM-SLAM | Our Approach | |||
|---|---|---|---|---|---|---|---|
| RMSE | RMSE | RMSE | RMSE | Mean | Median | Std. | |
| 00 | 1.16 | 1.4 | 1.4 | 1.15 | 1.00 | 0.90 | 0.56 |
| 01 | 17.05 | 9.4 | 9.1 | 14.65 | 13.88 | 13.95 | 4.69 |
| 02 | 8.02 | 6.7 | 4.6 | 8.62 | 7.99 | 7.63 | 3.24 |
| 03 | 1.34 | 0.6 | 0.6 | 1.04 | 0.95 | 0.98 | 0.45 |
| 04 | 0.33 | 0.2 | 0.2 | 0.32 | 0.29 | 0.30 | 0.13 |
| 05 | 0.75 | 0.8 | 0.7 | 0.67 | 0.61 | 0.57 | 0.28 |
| 06 | 0.49 | 0.8 | 0.8 | 0.48 | 0.44 | 0.38 | 0.19 |
| 07 | 0.50 | 0.5 | 0.6 | 0.47 | 0.44 | 0.43 | 0.17 |
| 08 | 3.25 | 3.5 | 3.3 | 2.56 | 2.26 | 1.99 | 1.21 |
| 09 | 1.26 | 1.6 | 1.7 | 1.24 | 1.14 | 1.11 | 0.49 |
| 10 | 1.41 | 1.2 | 1.1 | 1.32 | 1.27 | 1.26 | 0.38 |
| Frames | Points | Type | Average Instances per Frame | |||
|---|---|---|---|---|---|---|
| People | Rider | Car | ||||
| Cityscapes | 24,998 | 52,425 M | images | 6.16 | 0.68 | 9.51 |
| KITTI | 14,999 | 1799 M | point clouds | 0.63 | 0.22 | 4.38 |
| SemanticPOSS | 2988 | 216 M | point clouds | 8.29 | 2.57 | 15.02 |
| Sequences | Our Approach | |||
|---|---|---|---|---|
| RMSE | Mean | Median | Std. | |
| 00 | 0.09 | 0.08 | 0.08 | 0.03 |
| 01 | 0.16 | 0.15 | 0.13 | 0.07 |
| 02 | 0.13 | 0.10 | 0.06 | 0.08 |
| 03 | 0.10 | 0.10 | 0.09 | 0.04 |
| 04 | 0.13 | 0.11 | 0.10 | 0.06 |
| 05 | 0.17 | 0.16 | 0.15 | 0.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; You, X.; Zhang, X.; Chen, L.; Zhang, L.; Liu, X. LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments. Remote Sens. 2021, 13, 3651. https://doi.org/10.3390/rs13183651
Wang W, You X, Zhang X, Chen L, Zhang L, Liu X. LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments. Remote Sensing. 2021; 13(18):3651. https://doi.org/10.3390/rs13183651
Chicago/Turabian StyleWang, Weiqi, Xiong You, Xin Zhang, Lingyu Chen, Lantian Zhang, and Xu Liu. 2021. "LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments" Remote Sensing 13, no. 18: 3651. https://doi.org/10.3390/rs13183651
APA StyleWang, W., You, X., Zhang, X., Chen, L., Zhang, L., & Liu, X. (2021). LiDAR-Based SLAM under Semantic Constraints in Dynamic Environments. Remote Sensing, 13(18), 3651. https://doi.org/10.3390/rs13183651