
Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture



Abstract
:1. Introduction
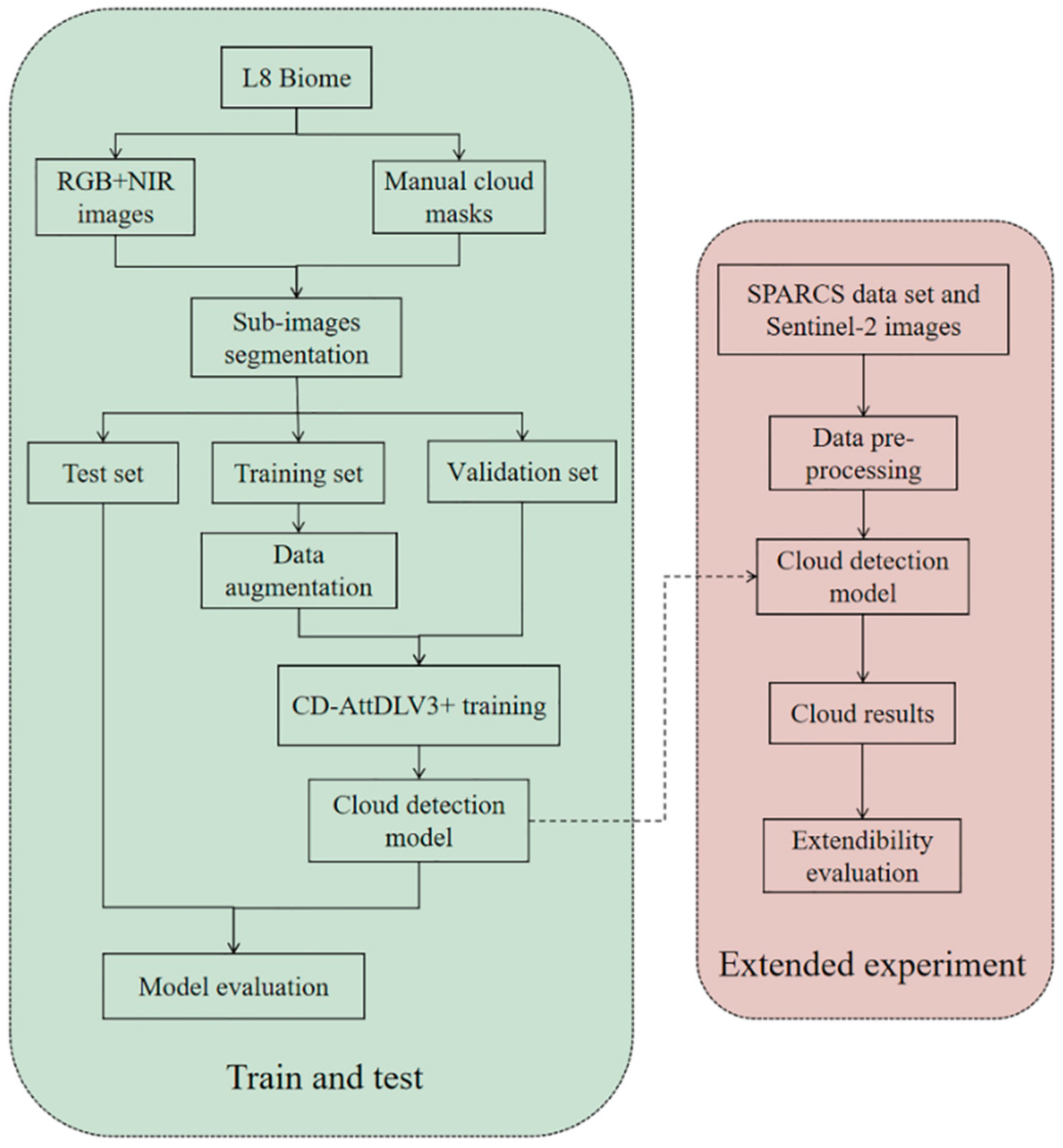
2. Dataset Description and Pre-Processing
2.1. Dataset Description
2.2. Data Pre-Processing
3. Methodology
| Algorithm 1 The CD-AttDLV3+ training and verification |
| Input:dataSet is data of L8 Biome; SPARCSimg and Sentinel2imgare the images for extended experiment; net is initial network; lr is learning rate; bs is batch size; algorithm SGD is named sgd; fl is focal loss function; iter is the number of iterations; maxiter is the maximum number of iterations Output: subimage set: subimageSet; trainSet, trainSetaug, testSet and valSet; trained model: modeliter; best trained model: modelbest; evaluation index: PRval, PRtest, RRtest, F1test, FWIoUtest; cloud detection results: testpredict, SPARCSpredict and Sentinel2predict 1: subimageSet ← cut images in dataSet with uniform size 2: (trainSet, testSet, valSet) ← split(subimageSet) 3: trainSetaug ← augment trainSet by flipping, rotating, and scaling 4: {Si|k = 1, 2,…, n} ← (split trainSet according to bs) 5: while iter < maxiter do 6: netiter ← update net parameters with Si, lr, sgd, fl 7: if iter%100 == 0 then 8: PRval ← netiter evaluate valSet 9: modeliter ← netiter 10: end if 11: end while 12: modelbest ← choose the best model in modeliter using PRval 13: (testimg, testlabel) ← testSet 14: testpredict ← cloud detection for testimg using modelbest 15: PRtest, RRtest, F1test, FWIoUtest ← comparison of testpredict and testlabel 16: (SPARCSpredict, Sentinel2predict) ← cloud detection for SPARCSimg and Sentinel2imgusing modelbest |
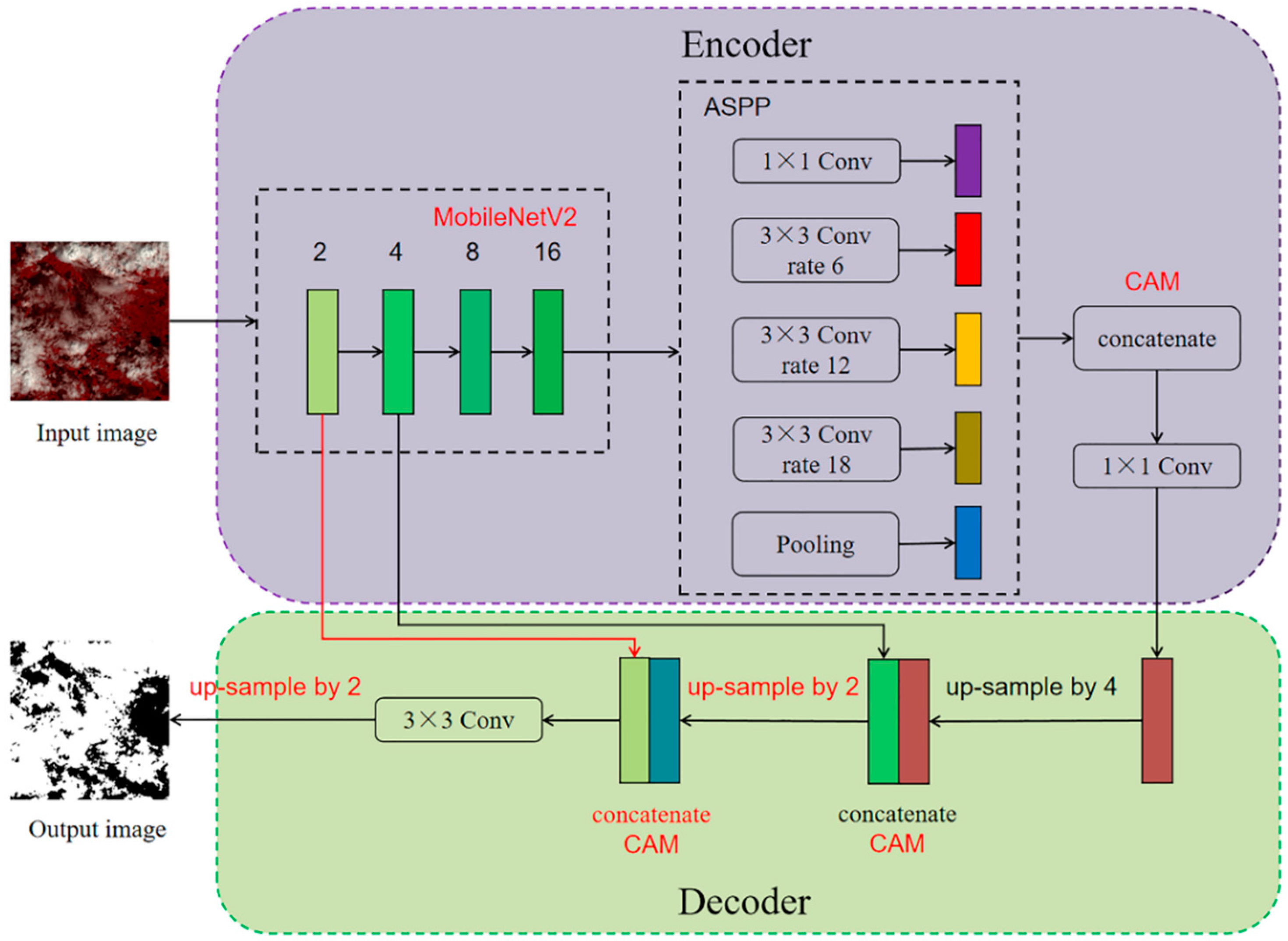
3.1. CD-AttDLV3+ Architecture
3.1.1. Light-Weight Backbone Network
3.1.2. Channel Attention Module
3.2. Improved Loss Function
4. Experimental Results
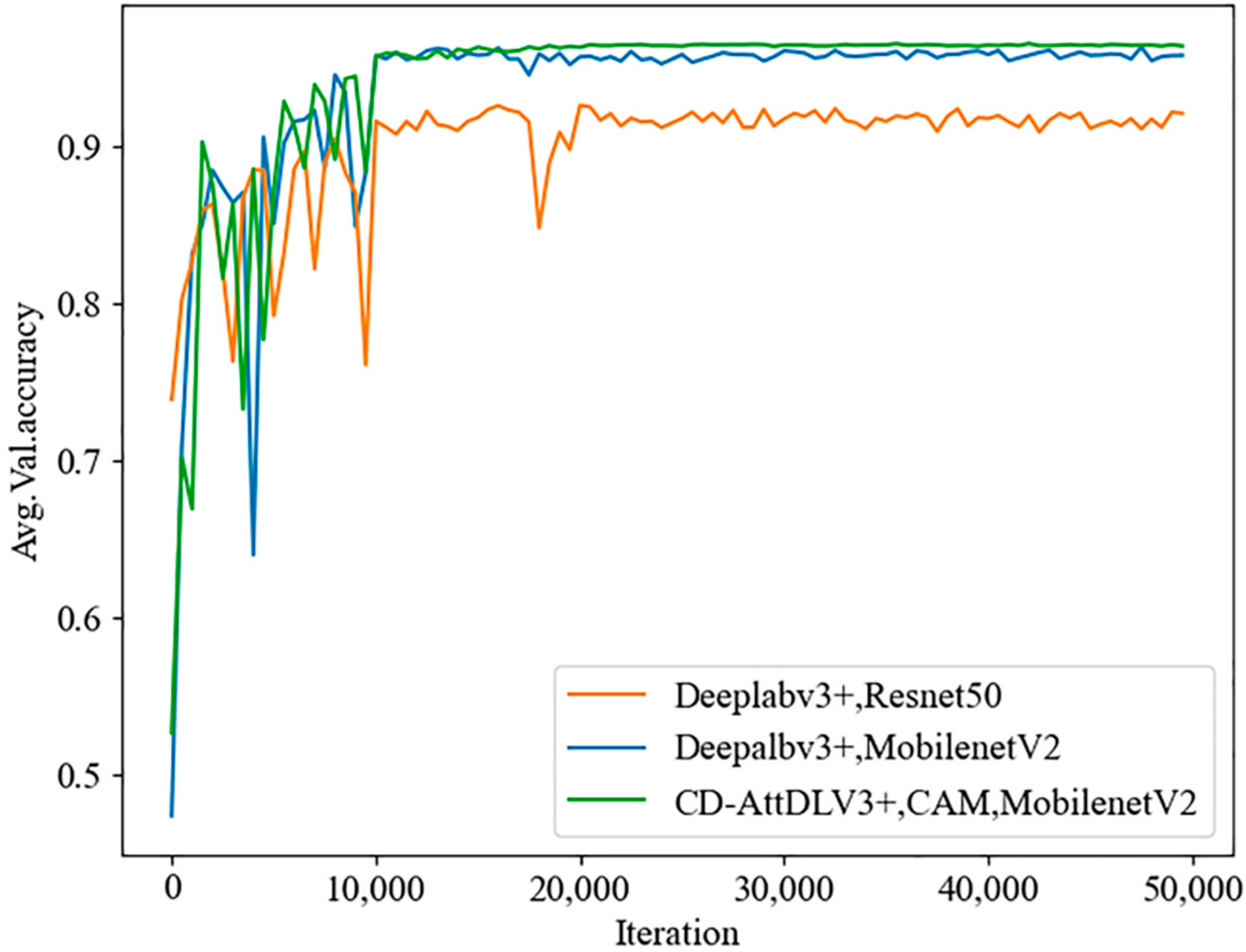
4.1. Network Architecture Validation
4.2. Qualitative Evaluation
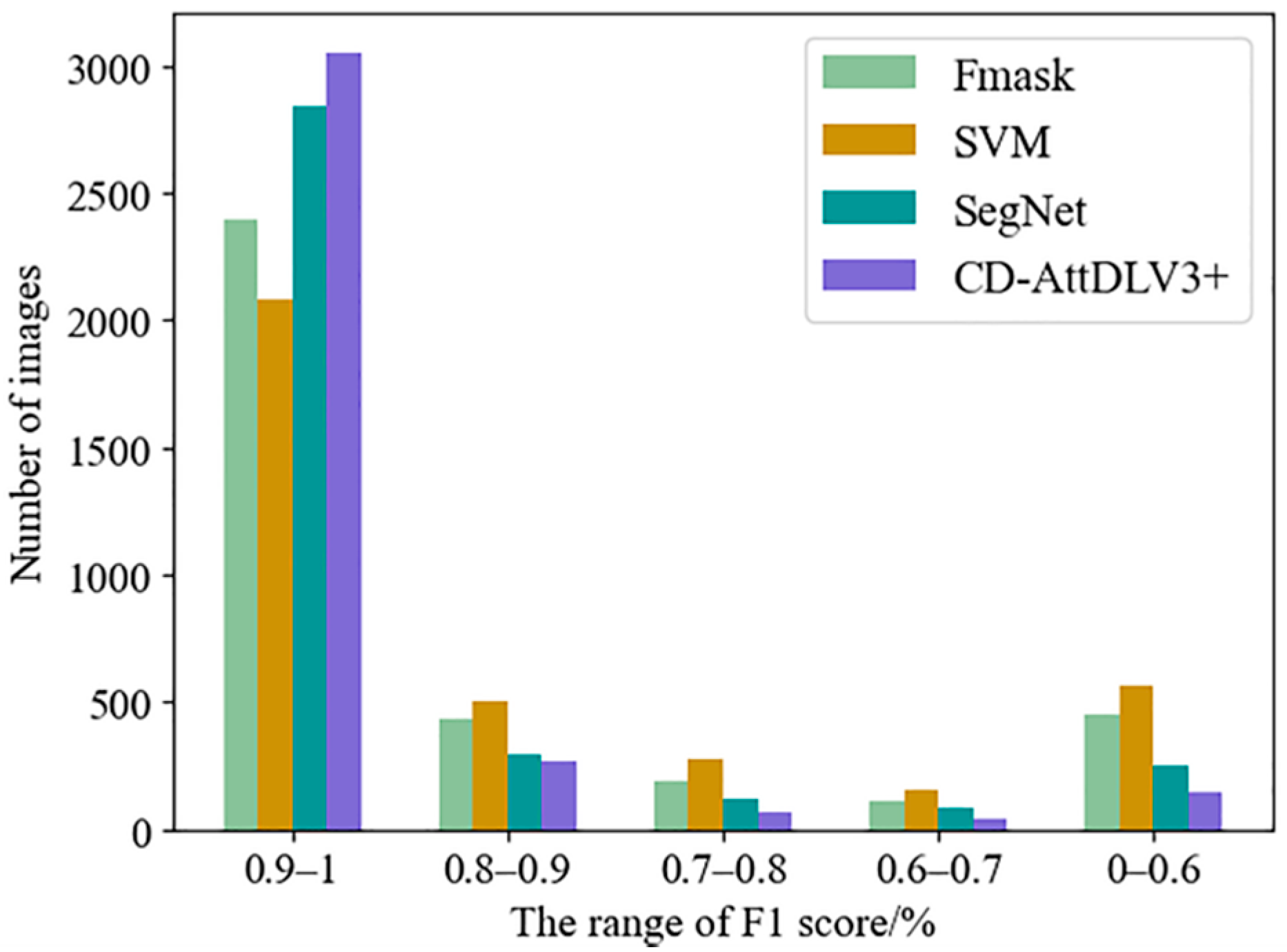
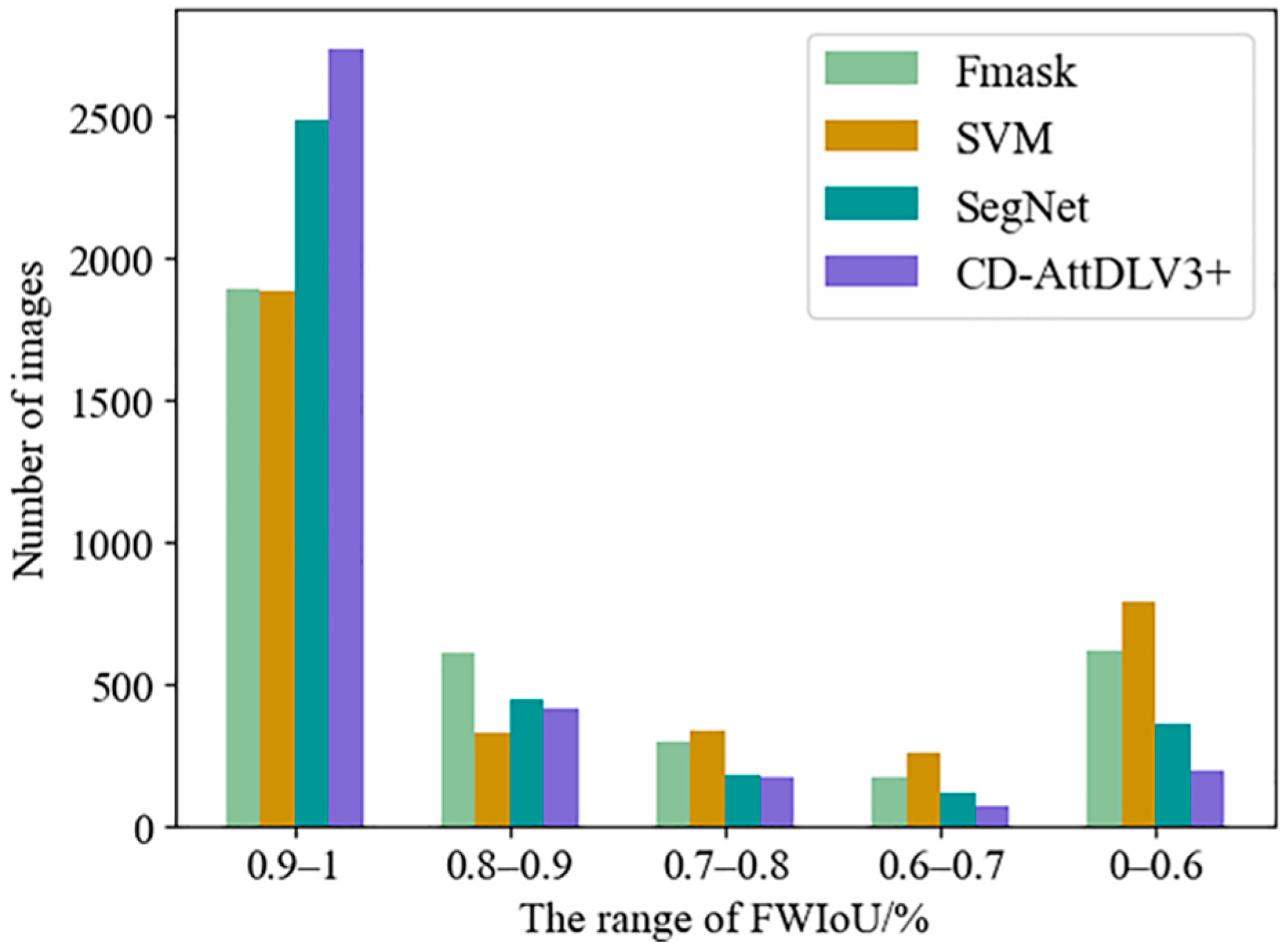
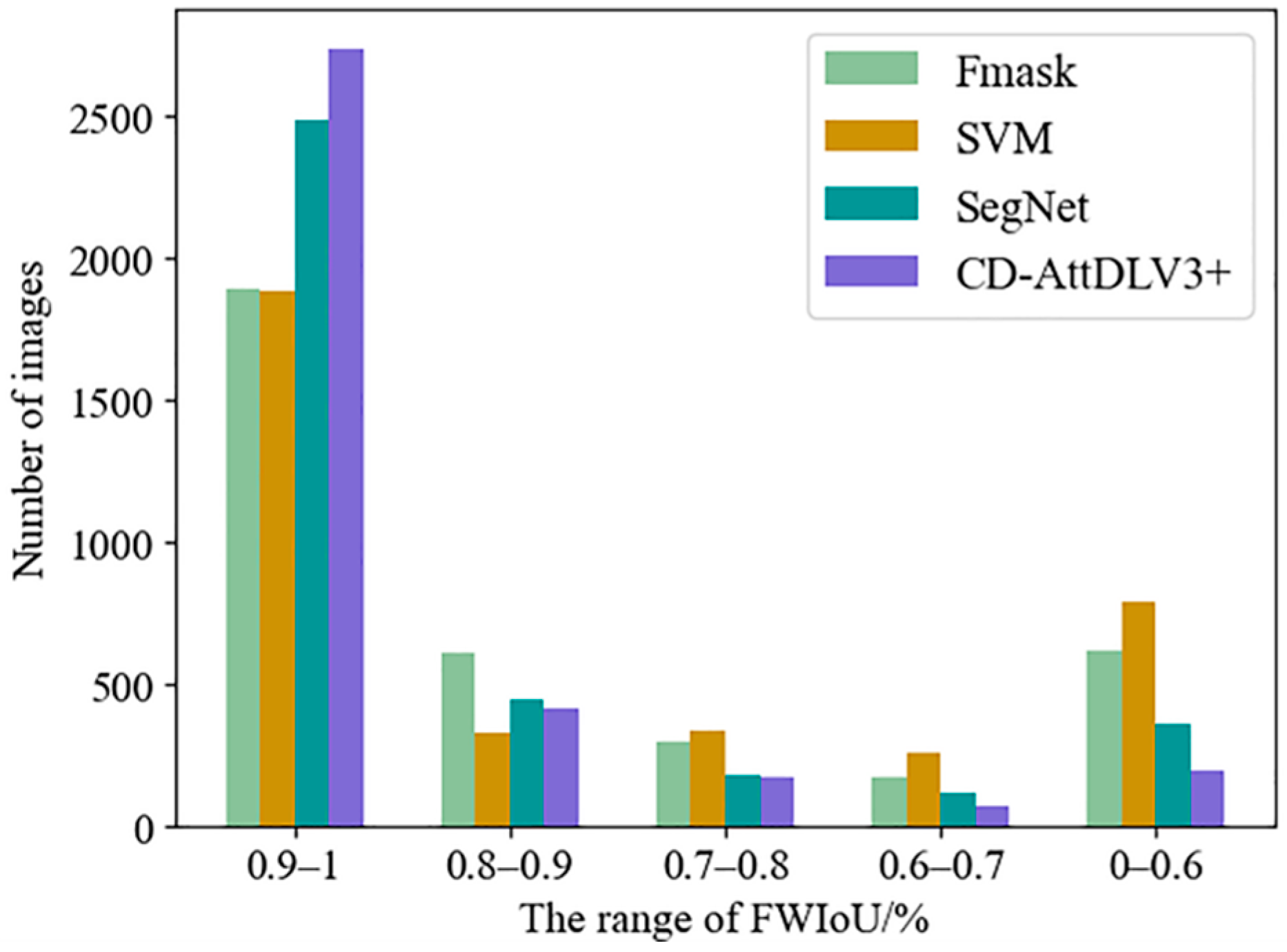
4.3. Quantitative Evaluation
4.4. Extended Experiment
4.4.1. The SPARCS Set Cloud Detection
4.4.2. Sentinel-2 Cloud Detection
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ju, J.; Roy, D.P. The availability of cloud-free Landsat ETM+ data over the conterminous United States and globally. Remote Sens. Environ. 2008, 112, 1196–1211. [Google Scholar] [CrossRef]
- Hou, S.W.; Sun, W.F.; Zheng, X.S. Overview of cloud detection methods in remote sensing images. Space Electron. Technol. 2014, 11, 68–76. [Google Scholar] [CrossRef]
- Irish, R.R. Landsat 7 automatic cloud cover assessment. Algorithms for Multispectral, Hyperspectral, and Ultraspectral Imagery VI. Int. Soc. Opt. Photonics 2000, 4049, 348–355. [Google Scholar] [CrossRef]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef]
- Wu, X.; Cheng, Q. Study on methods of cloud identification and data recovery for MODIS data. Remote Sensing of Clouds and the Atmosphere XII. Int. Soc. Opt. Photonics 2007, 6745, 67450P. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Sun, L.; Wei, J.; Wang, J.; Mi, X.; Guo, Y.; Lv, Y.; Yang, Y.; Gan, P.; Zhou, X.; Jia, C.; et al. A universal dynamic threshold cloud detection algorithm (UDTCDA) supported by a prior surface reflectance database. J. Geophys. Res. Atmos. 2016, 121, 7172–7196. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud detection in remote sensing images based on multiscale features-convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Shan, N.; Zheng, T.; Wang, Z. High-speed and high-accuracy algorithm for cloud detection and its application. J. Remote Sens. 2009, 13, 1138–1146. [Google Scholar]
- Zhang, Q.; Xiao, C. Cloud detection of RGB color aerial photographs by progressive refinement scheme. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7264–7275. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Wang, M.; Li, D.; Wang, Y.; Zhang, Z. Cloud Detection Method for High Resolution Remote Sensing Imagery Based on the Spectrum and Texture of Superpixels. Photogramm. Eng. Remote Sens. 2019, 85, 257–268. [Google Scholar] [CrossRef]
- Ishida, H.; Oishi, Y.; Morita, K.; Moriwaki, K.; Nakajima, T. Development of a support vector machine based cloud detection method for MODIS with the adjustability to various conditions. Remote Sens. Environ. 2018, 205, 390–407. [Google Scholar] [CrossRef]
- Sui, Y.; He, B.; Fu, T. Energy-based cloud detection in multispectral images based on the SVM technique. Int. J. Remote Sens. 2019, 40, 5530–5543. [Google Scholar] [CrossRef]
- Hualian, F.; Jie, F.; Jun, L.; Jun, L. Cloud detection method of FY-2G satellite images based on random forest. Bull. Surv. Mapp. 2019, 61-66. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Cilli, R.; Monaco, A.; Amoroso, N.; Tateo, A.; Tangaro, S.; Bellotti, R. Machine learning for cloud detection of globally distributed Sentinel-2 images. Remote Sens. 2020, 12, 2355. [Google Scholar] [CrossRef]
- Chai, Y.; Fu, K.; Sun, X.; Diao, W.; Yan, Z.; Feng, Y.; Wang, L. Compact cloud detection with bidirectional self-attention knowledge distillation. Remote Sens. 2020, 12, 2770. [Google Scholar] [CrossRef]
- Yu, J.; Li, Y.; Zheng, X.; Zhong, Y.; He, P. An effective cloud detection method for Gaofen-5 Images via deep learning. Remote Sens. 2020, 12, 2106. [Google Scholar] [CrossRef]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud detection of remote sensing images by deep learning. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Wang, J.; Lu, W.; Zhu, H.; Chu, Q. Cloud detection of ZY-3 satellite remote sensing images based on deep learning. Acta Opt. Sin. 2018, 38, 1–6. [Google Scholar] [CrossRef]
- Mateo-García, G.; Laparra, V.; Gómez-Chova, L. Domain adaptation of Landsat-8 and Proba-V data using generative adversarial networks for cloud detection. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, L.; Kan, Z.; Latif, A.; Yang, X.; Bilal, M.; Li, Q. Cloud and cloud shadow detection based on multiscale 3D-CNN for high resolution multispectral imagery. IEEE Access 2020, 8, 16505–16516. [Google Scholar] [CrossRef]
- Sun, H.; Li, L.; Xu, M.; Li, Q.; Huang, Z. Using Minimum Component and CNN for Satellite Remote Sensing Image Cloud Detection. IEEE Geosci. Remote. Sens. Lett. 2020, in press. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Q.; Wang, H.; Li, Y. Cloud Detection Using Gabor Filters and Attention-Based Convolutional Neural Network for Remote Sensing Images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2256–2259. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Shi, C.; Zhou, Y.; Qiu, B.; Li, M. CloudU-Net: A Deep Convolutional Neural Network Architecture for Daytime and Nighttime Cloud Images’ Segmentation. IEEE Geosci. Remote. Sens. Lett. 2020, in press. [Google Scholar] [CrossRef]
- López-Puigdollers, D.; Mateo-García, G.; Gómez-Chova, L. Benchmarking Deep Learning Models for Cloud Detection in Landsat-8 and Sentinel-2 Images. Remote Sens. 2021, 13, 992. [Google Scholar] [CrossRef]
- Dev, S.; Nautiyal, A.; Lee, Y.H.; Winkler, S. Cloudsegnet: A deep network for nychthemeron cloud image segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1814–1818. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. CDnet: CNN-based cloud detection for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Guo, Y.; Cao, X.; Liu, B.; Gao, M. Cloud detection for satellite imagery using attention-based U-Net convolutional neural network. Symmetry 2020, 12, 1056. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Li, Q.; Min, M.; Yao, Z. DCNet: A Deformable Convolutional Cloud Detection Network for Remote Sensing Imagery. IEEE Geosci. Remote. Sens. Lett. 2021, in press. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Hartwig, A. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- U.S. Geological Survey. L8 Biome Cloud Validation Masks; U.S. Geological Survey, Data Release; USGS: Reston, VA, USA, 2016. [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 5122 × 3 | conv2d | - | 32 | 1 | 2 |
| 2562 × 32 | bottleneck | 1 | 16 | 1 | 1 |
| 2562 × 16 | bottleneck | 6 | 24 | 2 | 2 |
| 1282 × 24 | bottleneck | 6 | 32 | 3 | 2 |
| 1282 × 32 | bottleneck | 6 | 64 | 4 | 2 |
| 642 × 64 | bottleneck | 6 | 96 | 3 | 1 |
| 642 × 96 | bottleneck | 6 | 160 | 3 | 1 |
| 642 × 160 | bottleneck | 6 | 320 | 1 | 1 |
| Model Architecture | Backbone Network | Parameter Quantity | Accuracy |
|---|---|---|---|
| DeeplabV3+ | Resnet50 | 3.98 × 107 | 0.9172 |
| DeeplabV3+ | MobilenetV2 | 5.22 × 106 | 0.9582 |
| CD-AttDLV3+ | MobilenetV2 | 5.56 × 106 | 0.9644 |
| Methods | PR | RR | F1 | FWIoU |
|---|---|---|---|---|
| Fmask | 0.9348 | 0.8245 | 0.8762 | 0.7967 |
| SVM | 0.8828 | 0.8054 | 0.8424 | 0.7670 |
| SegNet | 0.9499 | 0.9011 | 0.9249 | 0.8742 |
| CD-AttDLV3+ | 0.9586 | 0.9414 | 0.9499 | 0.9151 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, X.; Guo, Q.; Li, A. Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture. Remote Sens. 2021, 13, 3617. https://doi.org/10.3390/rs13183617
Yao X, Guo Q, Li A. Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture. Remote Sensing. 2021; 13(18):3617. https://doi.org/10.3390/rs13183617
Chicago/Turabian StyleYao, Xudong, Qing Guo, and An Li. 2021. "Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture" Remote Sensing 13, no. 18: 3617. https://doi.org/10.3390/rs13183617
APA StyleYao, X., Guo, Q., & Li, A. (2021). Light-Weight Cloud Detection Network for Optical Remote Sensing Images with Attention-Based DeeplabV3+ Architecture. Remote Sensing, 13(18), 3617. https://doi.org/10.3390/rs13183617