4.1. Datasets Description
To verify the effectiveness of the proposed DRIN, we conducted experiments on four hyperspectral benchmark datasets: the University of Pavia (UP), University of Houston (UH), Salinas Valley (SV), and HyRANK datasets.
(1) UP: It was collected by the ROSIS sensor and contains spectral samples with 103 bands. The spatial resolution is 1.3 m/pixel and the wavelength range of bands is between 0.43 and 0.86 m. The corresponding ground truth map consists of nine classes of land cover.
(2) UH: It was captured by the CASI sensor and has spectral samples with 144 bands. The spatial resolution is 2.5 m/pixel and the wavelength range of bands is between 0.38 and 1.05 m. The corresponding ground truth map consists of 15 classes of land cover.
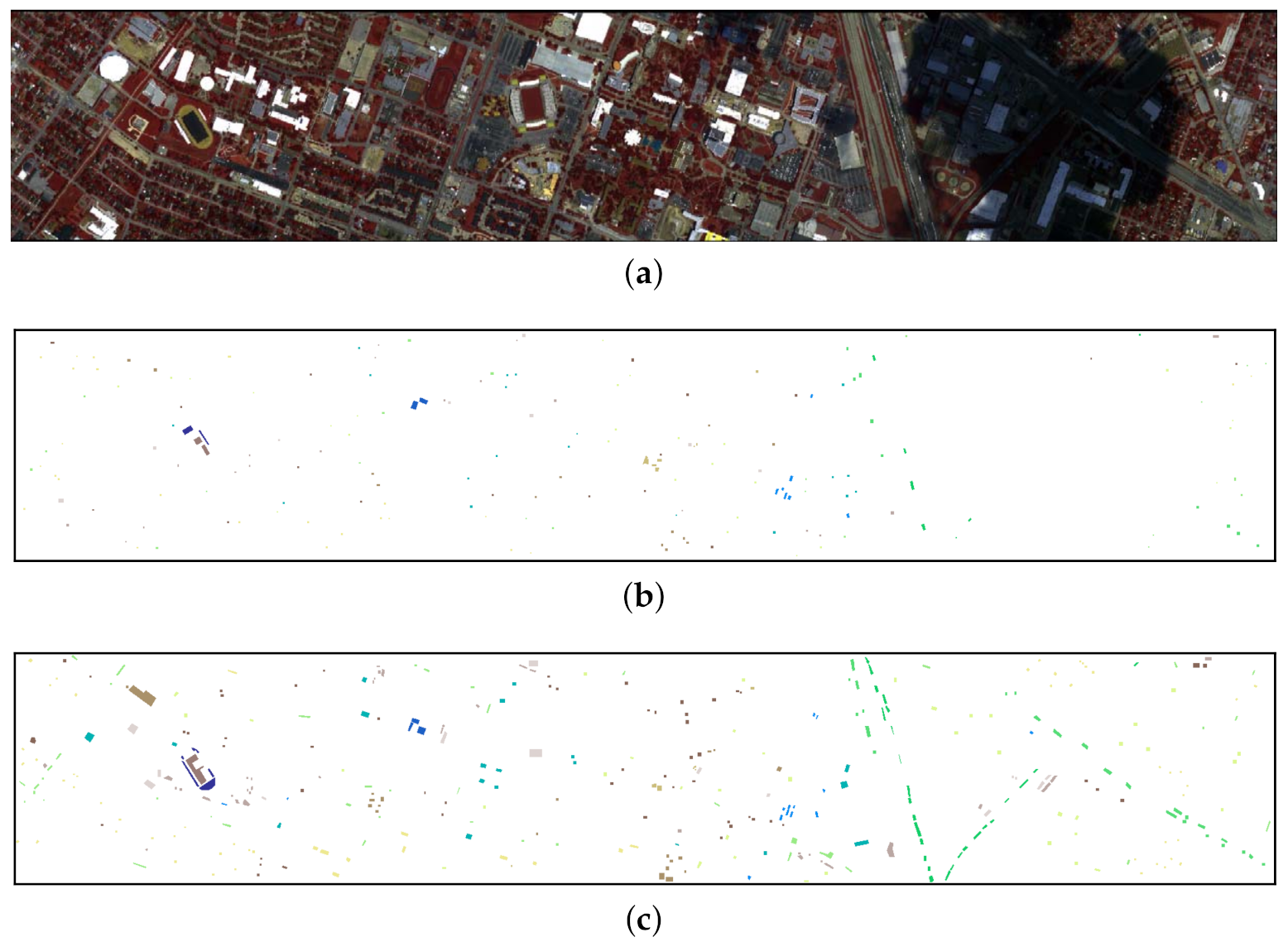
(3) SV: It was gathered by the AVIRIS sensor over Salinas Valley, CA, USA, containing pixels and 204 available spectral bands. The wavelength range is between 0.4 and 2.5 m. The spatial resolution is 3.7 m/pixel. The corresponding ground truth map consists of 16 different land-cover classes.
(4) HyRANK: The ISPRS HyRANK dataset is a recently released hyperspectral benchmark dataset. Different from the widely used hyperspectral benchmark datasets that consist of a single hyperspectral scene, the HyRANK dataset comprises two hyperspectral scenes, namely Dioni and Loukia. The available labeled samples in the Dioni scene are used for training, while those in the Loukia scene are used for test. The Dioni and Loukia scenes comprise and spectral samples, respectively, and they have the same number of spectral reflectance bands, i.e., 176.
Note that the widespread random sampling strategy overlooks the spatial dependence between training and test samples, which usually leads to information leakage (i.e., overlap between the training and test HSI patches) and overoptimistic results when performing spectral-spatial classification [
65]. To reduce the overlap and select spatially separated samples, researchers propose using spatially disjoint training and test sets to evaluate the HSI classification performance [
66,
67].
For the UP, UH, and HyRANK datasets, the official disjoint training and test sets were considered. The standard fixed training and test sets for the UP scene are available at:
http://dase.grss-ieee.org (accessed on 3 June 2021). The UH dataset is available at:
https://www.grss-ieee.org/resources/tutorials/data-fusion-tutorial-in-spanish/ (accessed on 3 June 2021). The HyRANK dataset is available at
https://www2.isprs.org/commissions/comm3/wg4/hyrank/ (accessed on 3 June 2021). Taking the HyRANK dataset as an example, the available labeled samples in the Dioni scene are used for training, while those in the Loukia scene are used for test. Therefore, there is no information leakage between the patches contained within the training and test sets. Since the spatial distribution of the training and test samples is fixed for these three datasets, we executed our experiments five times over the same split, in order to avoid the influence of random initialization of network parameters on its performance.
For the SV dataset, since it does not have official spatially disjoint training and test sets, we first randomly selected 30 samples from each class in the ground truth for network training, and the remaining were used for test.
Table 2,
Table 3,
Table 4 and
Table 5 summarize the detail information of each category in these four datasets.
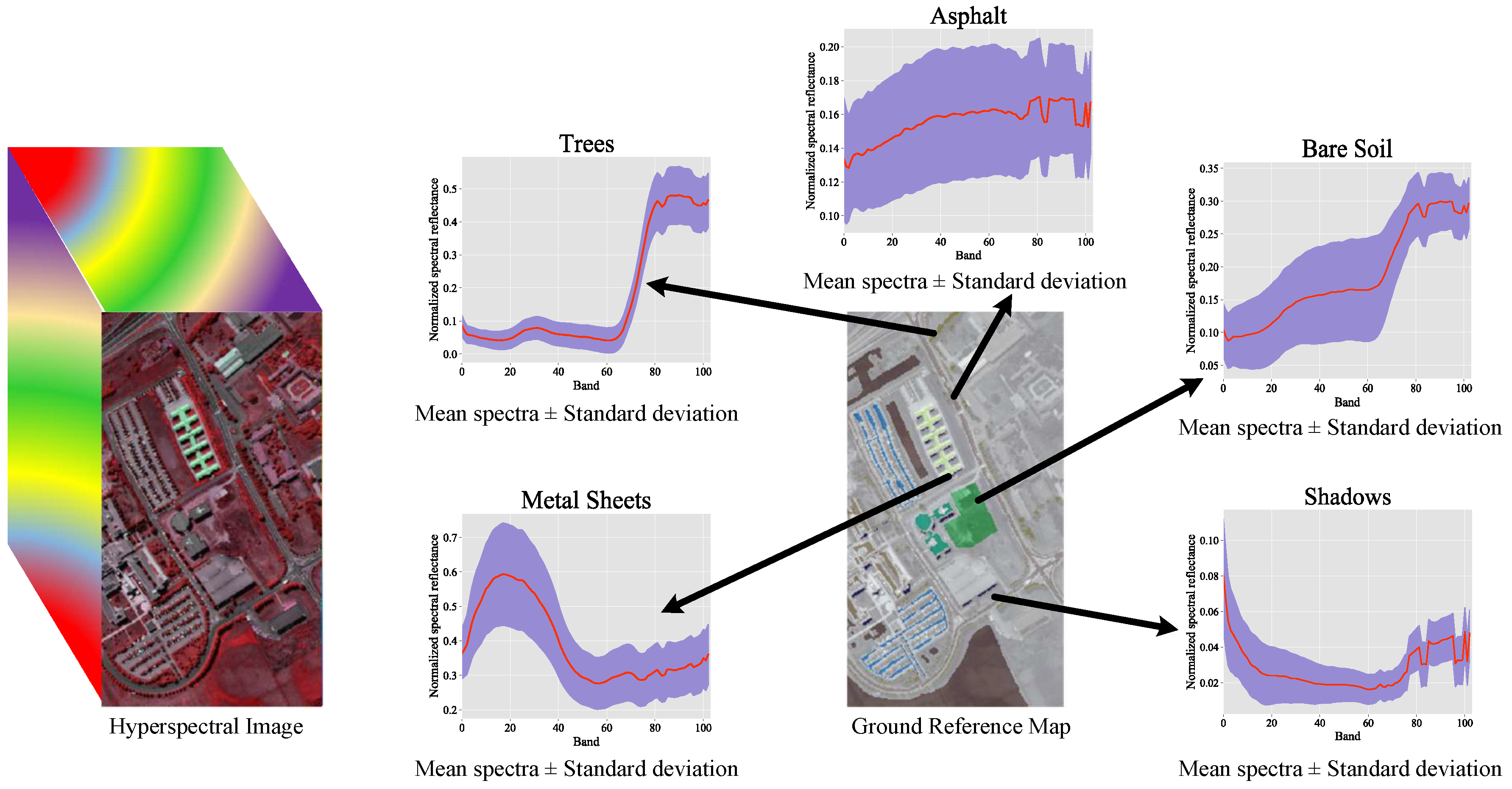
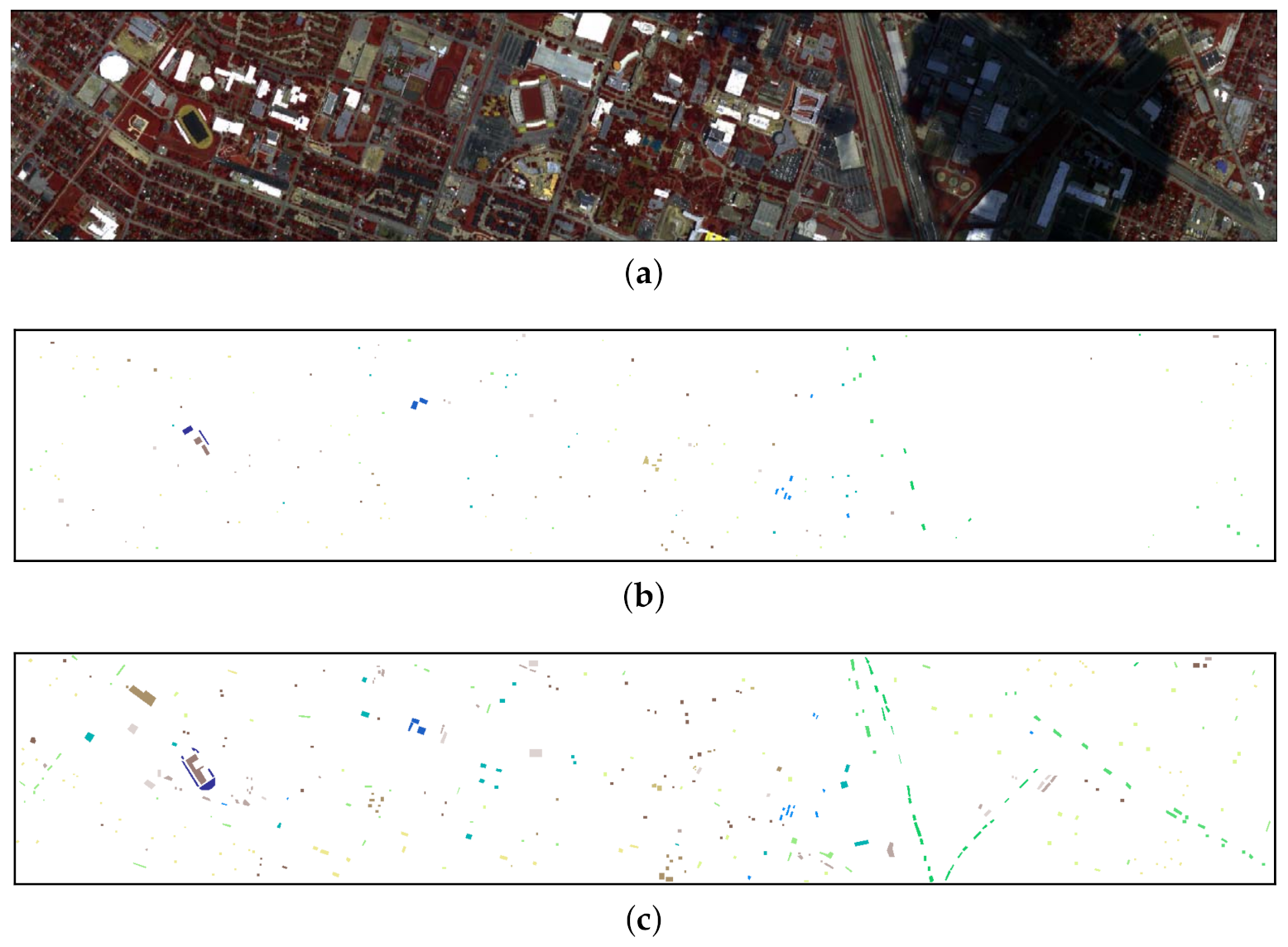
Figure 8,
Figure 9,
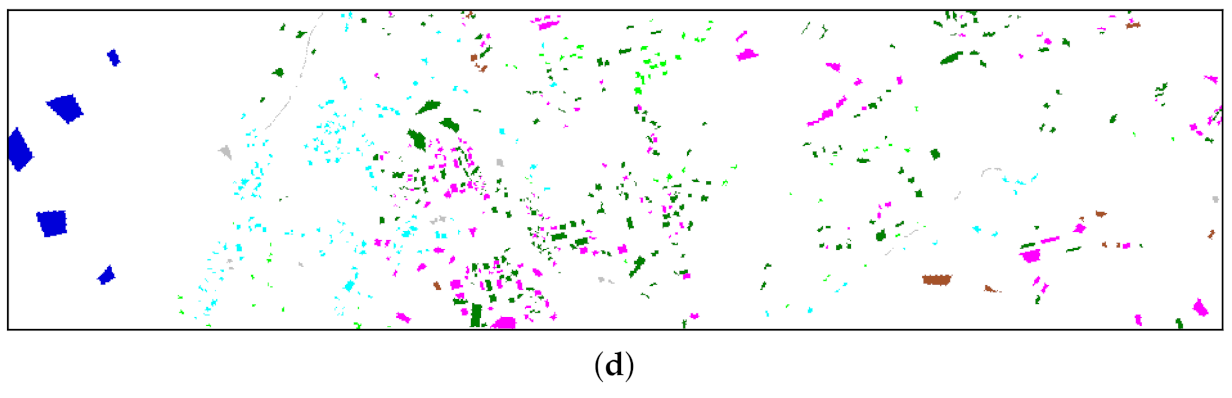
Figure 10 and
Figure 11 show the false color image and the distribution of available labeled samples of the four hyperspectral scenes.
The classification performance of all approaches was evaluated quantitatively with per-class classification accuracy, overall classification accuracy (OA), average classification accuracy (AA), and kappa coefficients ().
4.2. Parameters Analysis
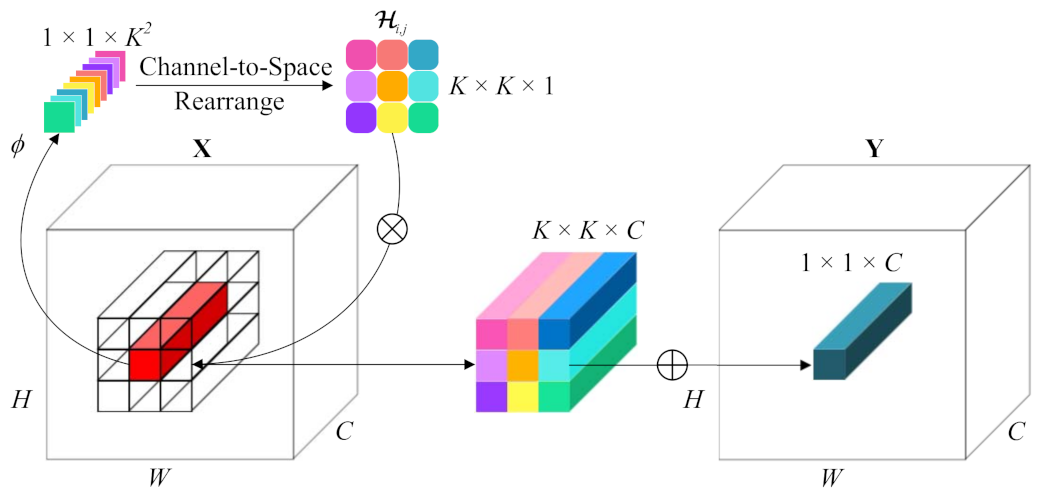
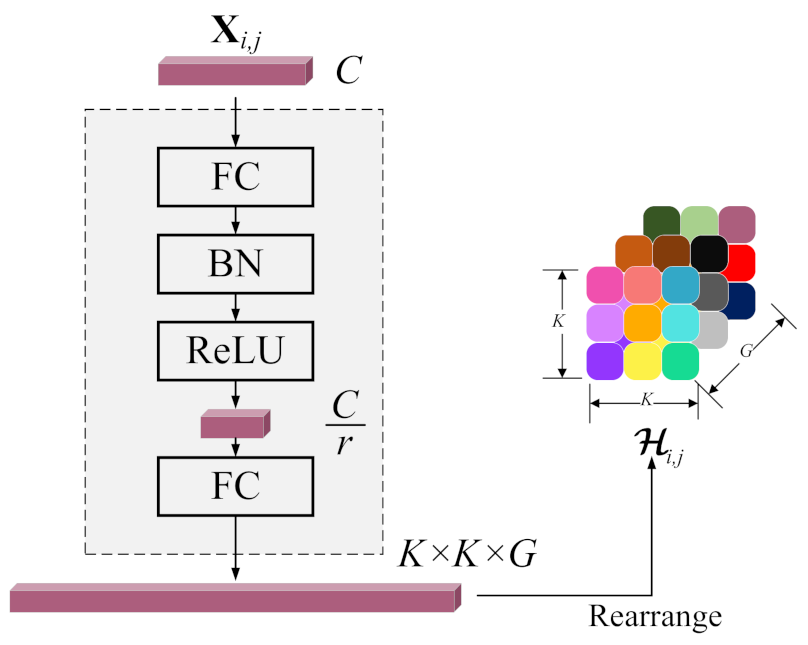
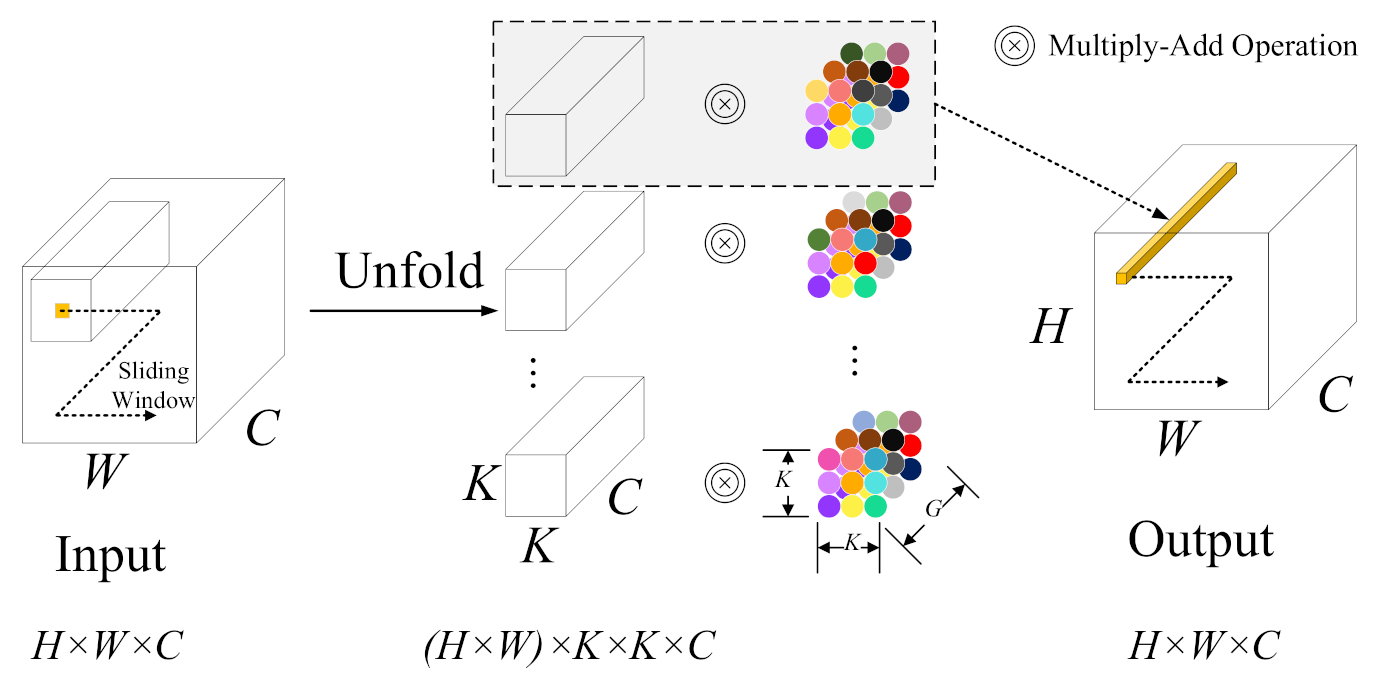
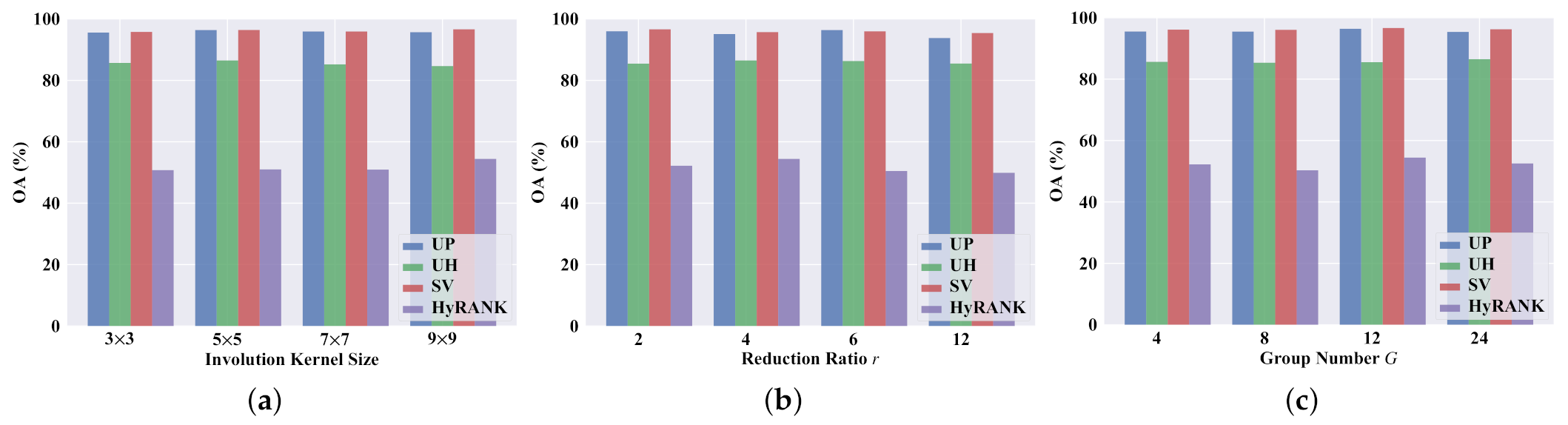
The classification performance of our DRIN is affected by the parameter selection to a certain extent. We therefore experimentally analyzed the influences of some main parameters involved in the proposed network for the optimal results, including the involution kernel size, the reduction ratio
r, and the group number
G.
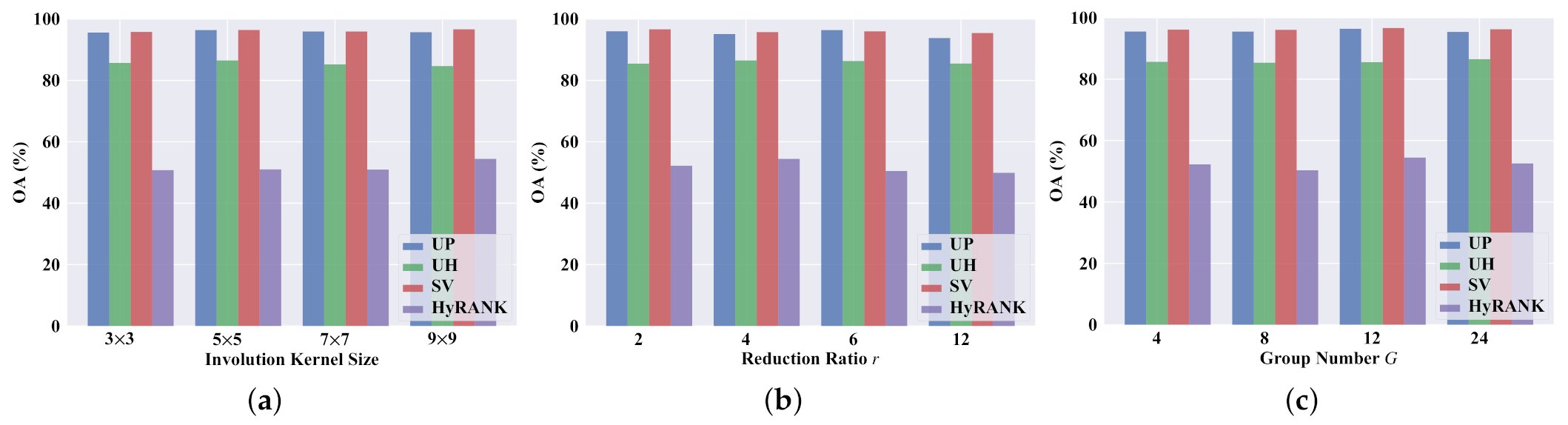
Figure 12 presents the resulting quantitative results (in terms of OA).
When employing a larger involution kernel, the proposed DRIN could utilize spatial context information in a wider spatial arrangement, capturing long-range spatial dependencies for correctly identifying the land cover type of each pixel. To prove this benefit, DRINs with different sizes of involution kernel (i.e.,
,
,
, and
) were implemented, and the obtained results are shown in
Figure 12a. As can be seen, the best OA values are achieved when the involution kernel size is set to
,
,
, and
for the UP, UH, SV, and HyRANK datasets, respectively, which suggests that utilizing a larger involution kernel is helpful for increasing the classification accuracy. Note that the UP and UH scenes have more detailed regions, thus considering too large spatial context could weaken the information of the target pixel. As for the SV and HyRANK scenes, since they have larger smooth regions, dynamically reasoning in an enlarged spatial range could capture long-range dependencies well and hence offer better classification performance.
Reduction ratio
r controls the intermediate channel dimension between the two linear transformations in the kernel generation function
. Specifically, appropriate parameter
r could reduce the parameter count and permit the usage of larger involution kernel size under the same budget.
Figure 12b illustrates the influence of different values of reduction ratio
r on the OA of the our DRIN. For different datasets, the degree of influence and the optimal value are different. Based on the classification outcomes, the optimum values of reduction ratio
r for the UP, UH, SV, and HyRANK datasets are 6, 4, 2, and 4, respectively.
Group number
G is also a crucial factor in feature representation of DRIN. The more groups there are, the more distinct involution kernels are involved for discriminative spatial feature extraction. We select the optimum group number
G from {4, 8, 12, 24} for each dataset. As shown in
Figure 12c, the proposed DRIN with
achieves the highest OA on the UP, SV, and HyRANK datasets, and the best performance is obtained when
on the UH dataset. As a result, to obtain the optimal results, the
G is set to 12, 24, 12, and 12 for the four datasets, respectively.
Taking the HyRANK dataset as an example, the influence of these three hyperparameters on the number of parameters and the computational complexity (in terms of the number of multiply-accumulate operations (MACs)) was further analyzed.
Table 6,
Table 7 and
Table 8 show the classification performance and the number of parameters and MACs of the proposed DRIN with different involution kernel sizes,
G, and
r on the HyRANK dataset, respectively. As can be seen in
Table 6, increasing involution kernel size can improve the classification accuracies. Note that the parameter count of convolution kernels increases quadratically with the increase of the kernel size. However, for the involution operation, we can harness large kernel while avoid introducing too many extra parameters. In addition, we adopt a bottleneck architecture to achieve efficient kernel generation. As shown in
Table 7, although aggressive channel reduction (
) significantly reduces the number of parameters and MACs, it harms the classification performance (i.e., the lowest OA score of 49.9% is obtained). As long as
r is set to an acceptable range, the proposed DRIN not only obtains good performance but also reduces the parameter count and computational cost. In addition, for the proposed DRIN, we share the involution kernels across different channels to reduce the parameter count and computational cost. The smaller is the
G, the more channels share the same involution kernels. As shown in
Table 8, the non-shared DRIN (
) incurs more parameters and MACs, while obtaining the second best OA score. The possible reason of this phenomenon is that the limited training samples in the HSI classification task are not enough to train networks with excessive parameters.
4.3. Classification Results
The proposed DRIN was compared with two traditional machine learning methods, namely, SVM [
11] and extended morphological profiles (EMP) [
8], and seven convolution-based networks, namely, deep&dense CNN (DenseNet) [
57], deep pyramidal residual network (DPRN) [
55], fully dense multiscale fusion network (FDMFN) [
58], multiscale residual network with mixed depthwise convolution (MSRN) [
32], lightweight spectral-spatial convolution module-based residual network (LWRN) [
34], spatial-spectral squeeze-and-excitation residual network (SSSERN) [
60], and deep residual network (DRN) [
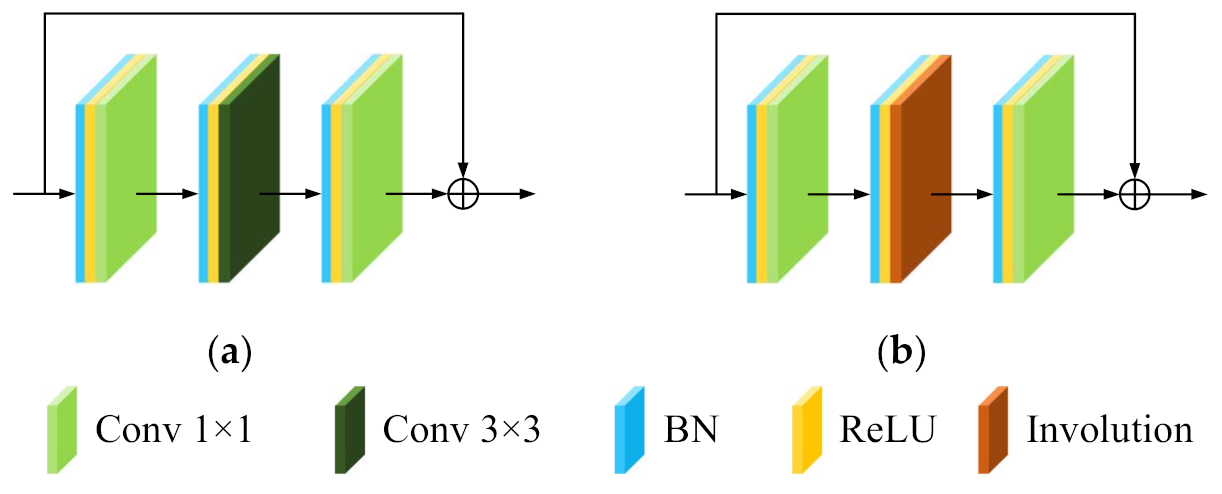
64].
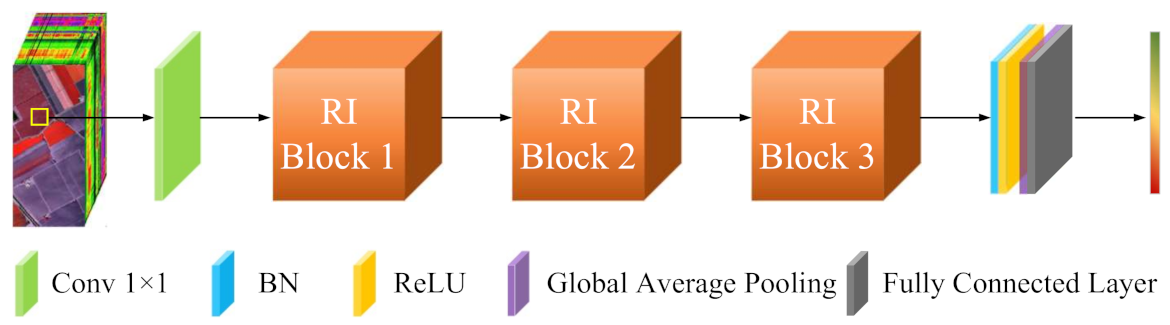
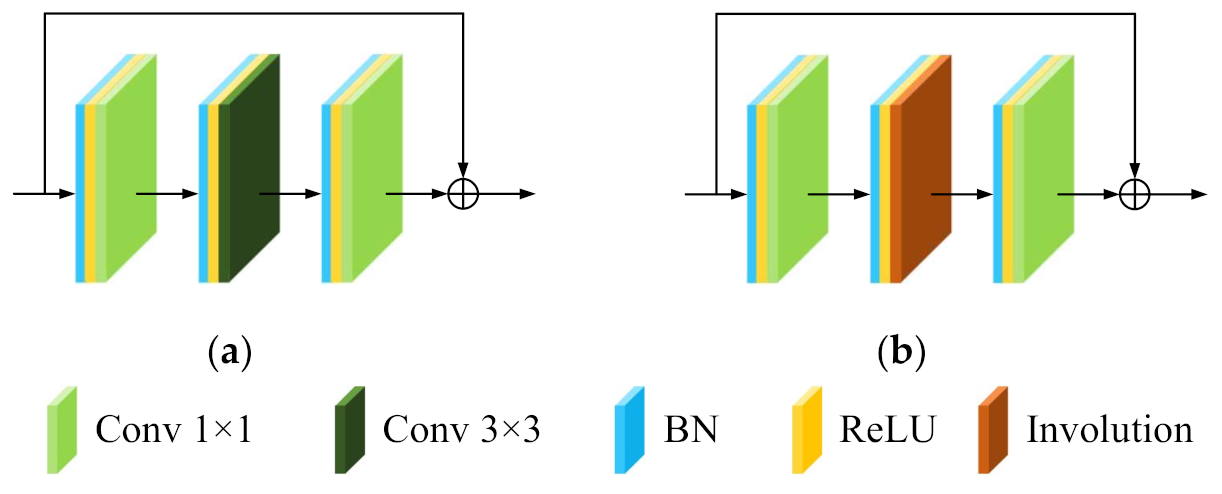
DRN and the proposed DRIN have a similar architecture. The DRN is regarded as a baseline model and can be obtained by replacing all involution layers in the DRIN with the standard Conv layer. For all network models, the input patch size was fixed to be to make a fair comparison. All the network models were implemented with the deep-learning framework of PyTorch and accelerated with an NVIDIA GeForce RTX 2080 GPU (with 8-GB GPU memory).
For the UP dataset, the proposed DRIN achieves the highest OA, as shown in
Table 9. To be specific, the OA obtained by our DRIN is 96.4%, which is higher than that of SVM (80.0%), EMP (83.2%), DenseNet (91.6%), DPRN (92.1%), FDMFN (92.8%), MSRN (90.6%), LWRN (93.4%), SSSERN (94.4%), and its convolution-based counterpart DRN (95.9%). In comparison with the traditional machine learning approaches, SVM and EMP, the proposed network significantly increases the OA by 16.4% and 13.2%, respectively. In addition, compared with the DenseNet, DPRN, FDMFN, MSRN, LWRN, SSSERN, and DRN, the improvements in
achieved by the proposed DRIN are 6.7%, 6.0%, 4.9%, 8.1%, 4.2%, 2.7%, and 0.6%, respectively.
Table 10 presents the classification results for the UH dataset. The proposed DRIN attains the highest overall metrics. Specifically, the OA, AA, and
values are 86.5%, 88.6%, and 85.4%, respectively. In comparison with the second best approach, i.e., the MSRN, the performance improvements for OA, AA, and
metrics are +0.6%, +0.5%, and +0.6%, respectively. The baseline model DRN is able to achieve satisfactory performance on this dataset. In comparison with it, the proposed involution-powered DRIN achieves higher OA, AA, and
values, proving the superiority of larger dynamic involution kernel over compact and static
convolution kernel. To be specific, our proposed model improves OA, AA, and
values from 85.2% to 86.5%, 87.5% to 88.6%, and 84.0% to 85.4%, respectively.
Table 11 reports the classification results for the SV dataset. SVM shows the worst performance and EMP is better than SVM. Thanks to the excellent nonlinear and hierarchical feature extraction ability, the other deep learning-based approaches, i.e., DenseNet, DPRN, FDMFN, MSRN, LWRN, SSSERN, DRN, and the proposed DRIN, outperform the SVM and EMP on the SV dataset. Specifically, compared to spectral classification approach SVM, DRIN significantly enhances OA and
by about 10%. Besides, the proposed DRIN achieves 96.7% OA, 98.6% AA, and 96.3%
, which are higher than those obtained by DRN. This again demonstrates the effectiveness and superiority of involution.
The classification accuracies of different approaches for the HyRANK dataset are summarized in
Table 12, and the proposed DRIN achieves the highest overall accuracy among all the compared approaches. In comparison with DRN, our DRIN significantly increases the OA by 2.3%. In addition, the AA and
values obtained by our DRIN are nearly 3% higher than those achieved by DRN. This experiment on the recently released HyRANK benchmark again verifies that the proposed involution-powered DRIN can achieve better classification performance than the convolutional baseline DRN.
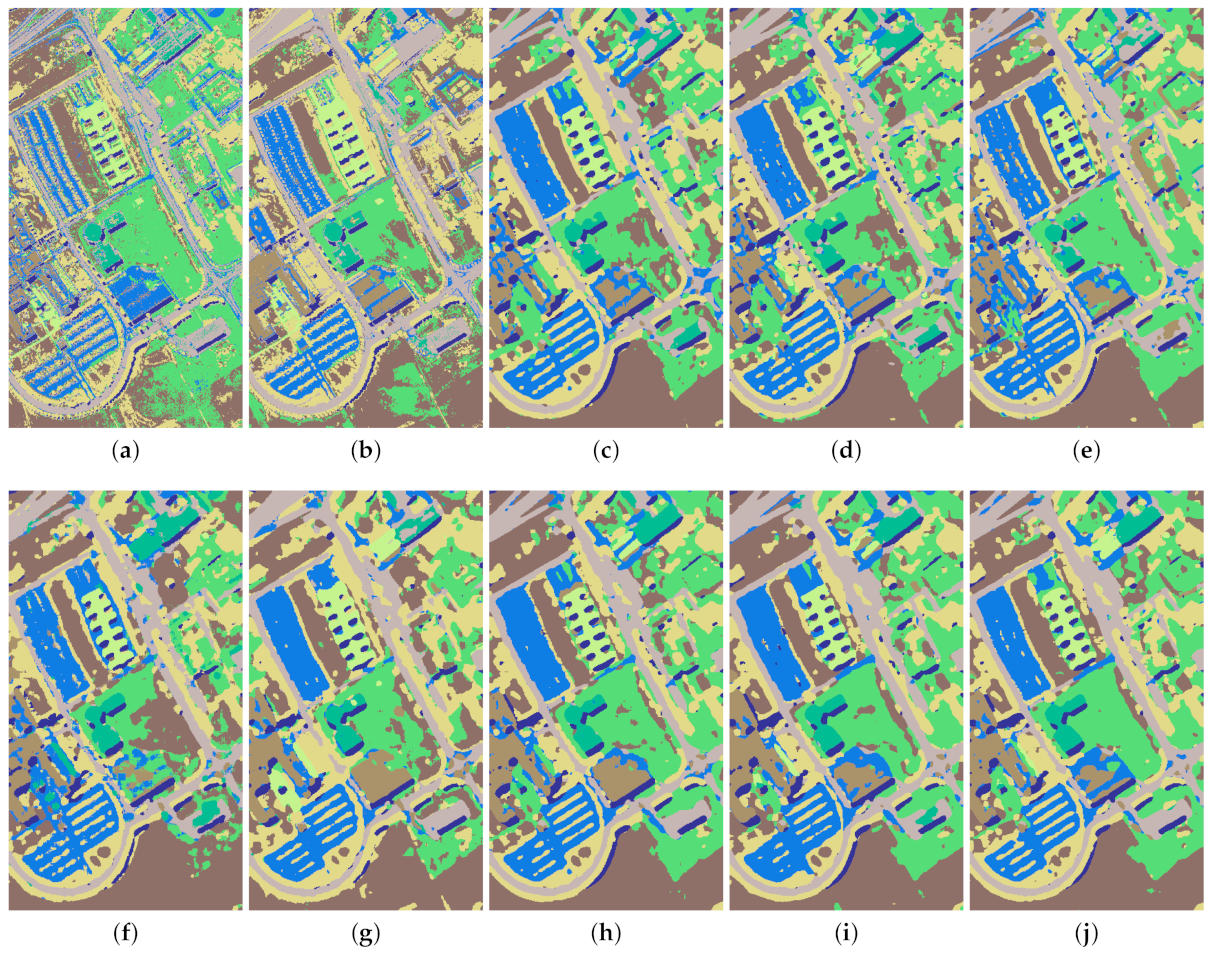
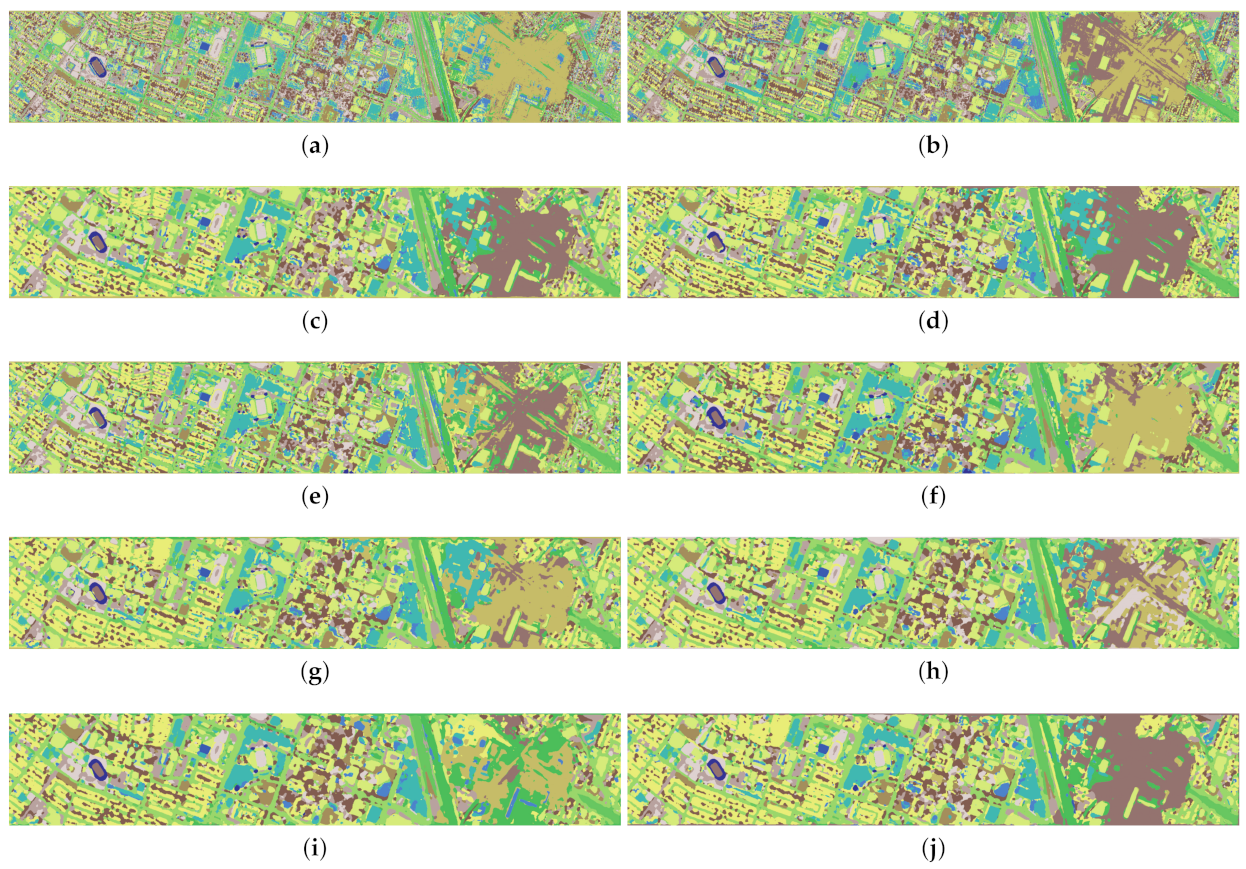
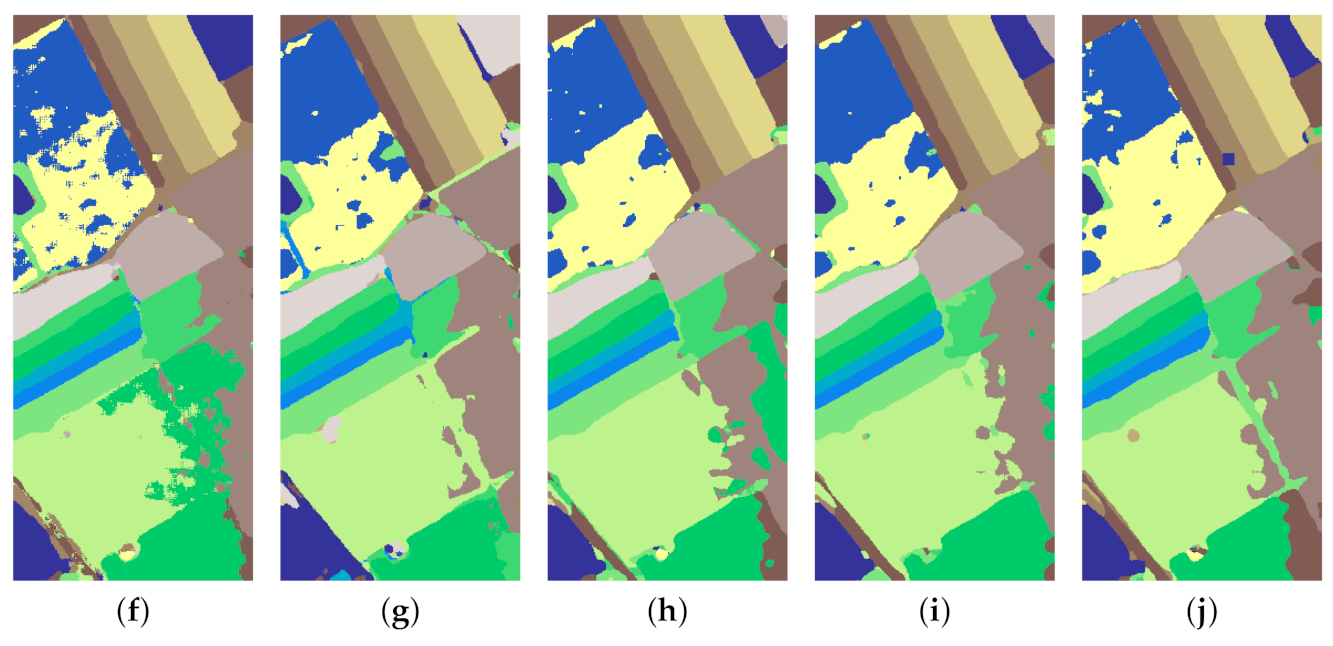
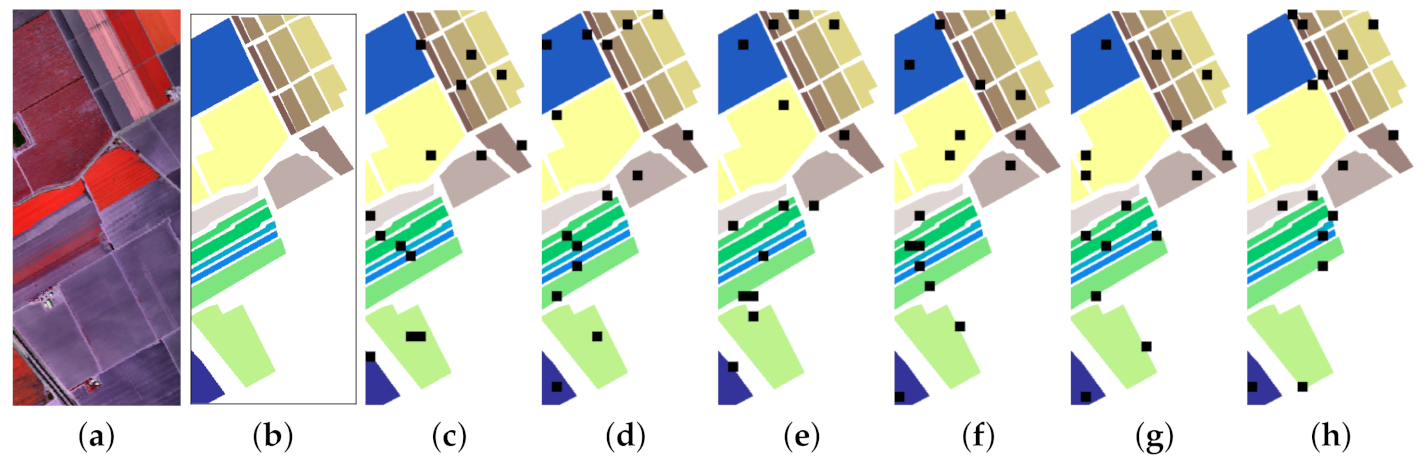
The classification maps of different approaches are illustrated in
Figure 13,
Figure 14,
Figure 15 and
Figure 16. Taking the SV dataset as an example, it is obvious that the classification maps generated by the SVM and EMP present many noisy scatter points, while the other deep learning-based methods mitigate this problem through the elimination of noisy scattered points of misclassification (see
Figure 15). Clearly, our DRIN’s classification map is close to the ground truth map (see
Figure 10b), especially in the region of grapes-untrained (Class 8). This is in consistent with the quantitative results reported in
Table 11, where our DRIN model achieves the highest classification accuracy of 88.7% for the grapes-untrained category.
Focusing on the obtained overall classification accuracies, the proposed involution-based DRIN model consistently outperforms its convolution-based counterpart DRN on the four datasets. Specifically, in comparison with DRN, the proposed network increases the OA by 0.5%, 1.3%, 0.4%, and 2.3% on the UP, UH, SV, and HyRANK datasets, respectively, demonstrating the effectiveness of our DRIN model.
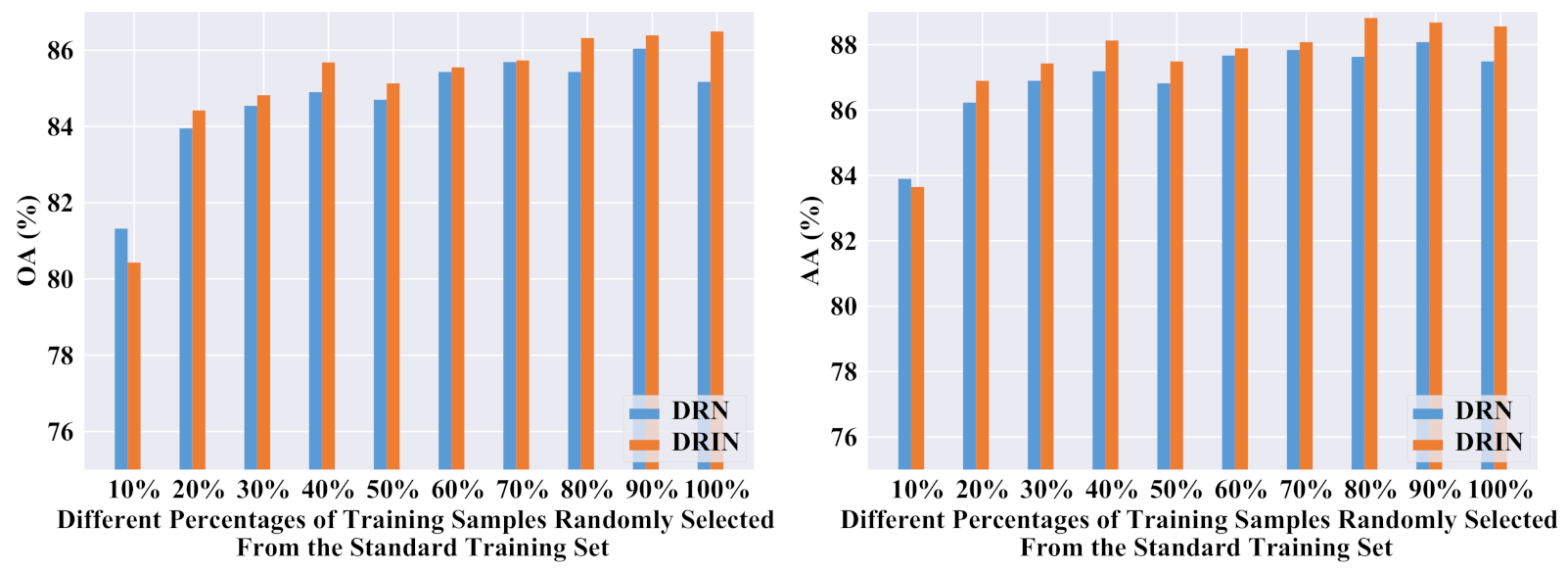
Figure 17 further shows the classification results when different number of samples are used for training on the UH dataset. It is apparent that DRIN is better than DRN in most cases.
In addition, our proposed DRIN could deliver enhanced performance at reduced parameter count compared to its counterpart DRN.
Table 13 gives information about the OA and the corresponding model parameters. Specifically, for the UP dataset, DRIN is able to achieve a margin of 0.5% higher OA over DRN, using 26.07% fewer parameters. For the UH dataset, the proposed DRIN significantly increases the OA by 1.3% as compared with the DRN model, while requiring fewer parameters. For the SV dataset, the proposed DRIN with
involution kernel (denoted as DRIN*) can also obtain higher OA than DRN, with 23.27% fewer parameters. As for the HyRANK dataset, the proposed DRIN* with 14,430 fewer parameters can obtain 1.0% gains in terms of OA as compared with DRN. Moreover, with only 5328 more parameters, the OA of the proposed DRIN is 2.3% better than that of DRN.
Regarding the runtimes, the proposed DRIN consumes more time than the DRN. Taking the UP data set as an example, the running time of the DRN is 119.54 s, while the proposed DRIN consumes 183.19 s. The reason behind this is that the convolution layer is trained more efficiently than involution layer on GPU. In the future, a customized CUDA kernel implementation of the involution operation will be explored, to efficiently utilize computational hardware (i.e., GPU) and reduce the time cost.
To understand the contributions of the proposed DRIN’s two core components, residual learning and involution operation, we further constructed a plain CNN model (without residual learning) for comparison, which is obtained by eliminating the skip connections from the DRN model. The classification results obtained by CNN, DRN, and DRIN are summarized in
Table 14. Note that, for a fair comparison, these three networks have the same number of layers and are trained under exactly the same experimental setting. As can be seen in
Table 14, in comparison with the CNN, the performance improvements (in term of OA) obtained by DRN are +2.1%, +3.0%, +0.4%, and +2.1% on the UP, UH, SV, and HyRANK datasets, respectively, which demonstrate that residual learning plays a positive role in enhancing the HSI classification performance. Compared with DRN, the proposed involution-powered DRIN model further increases the OA by +0.5%, +1.3%, +0.4%, and +2.3% on the four datasets, which shows that the involution operation is also useful to improve the HSI classification accuracy. As can be seen, the improvement achieved by residual learning technique outperforms that obtained by the involution operation on the UP and UH datasets. However, compared with DRN, the proposed involution-powered DRIN can significantly increase the OA by +1.3% and +2.3% on the UH and HyRANK datasets, respectively, which demonstrates the huge potential of designing involution-based networks. More importantly, our DRIN model using both techniques performs the best on all four HSI datasets, demonstrating its effectiveness for HSI classification.
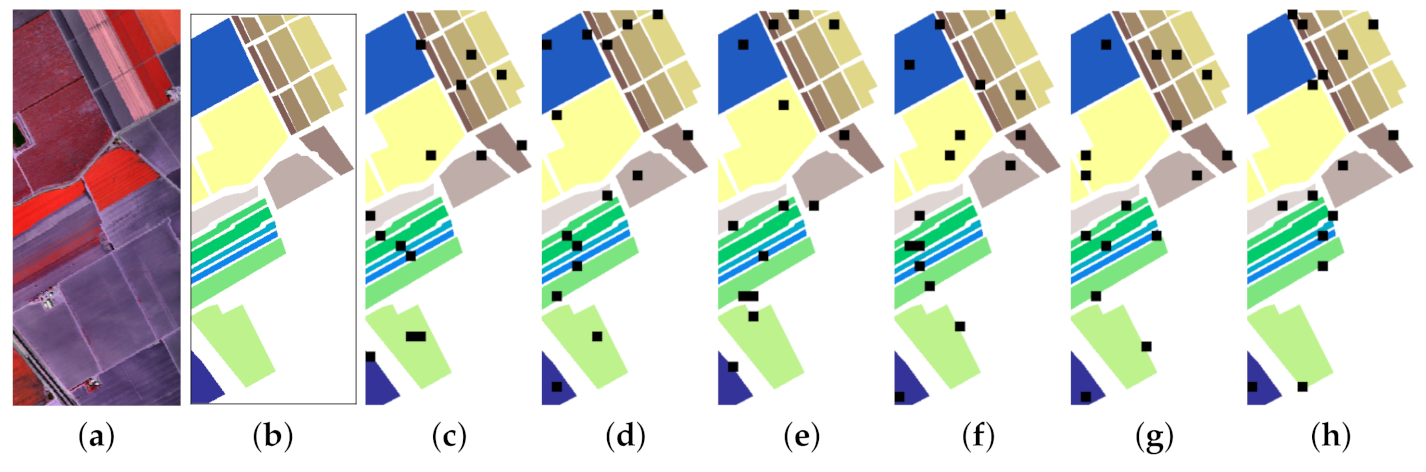
In addition, considering that the random sampling strategy usually leads to overoptimistic results, we further compared the proposed DRIN with other deep models on the SV dataset using spatially disjoint training and test samples. We used a novel sampling strategy [
65] to select training and test samples, which can avoid the overlap between the training and test sets and hence the information leakage. We extracted six-fold training–test splits for cross validation (see
Figure 18) and repeated the experiments five times for each fold. Therefore, we performed 30 independent Monte Carlo runs for the proposed DRIN and the overall classification accuracies are reported. In this experiment, the proportion of training samples in each fold is about 3%, and the training HSI patches can only be selected within the black area, as shown in
Figure 18. For more details of this sampling strategy, please refer to the work of Nalepa et al. [
65]. As shown in
Table 15, the proposed DRIN again achieves better performance over the other compared approaches. In addition, we further analyzed the influence of involution kernel size on the classification performance using these six non-overlapping training–test splits. The experimental results are summarized in
Table 16. We can easily observe that using a larger involution kernel could deliver improvements in accuracy.
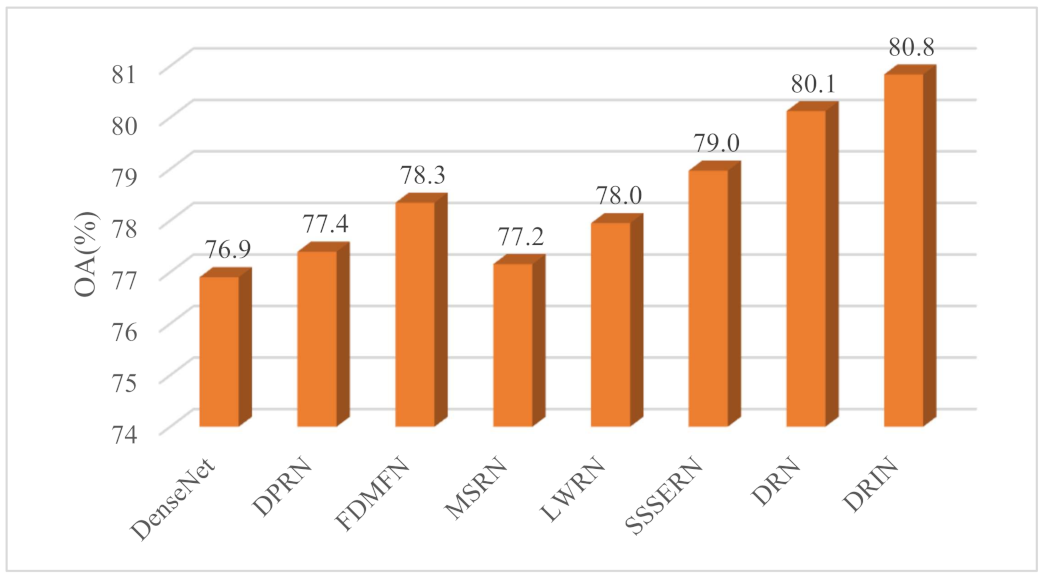
In summary, extensive experimental results on four benchmark datasets demonstrate that employing DRIN could deliver very promising results in terms of increasing classification accuracy and reducing model parameters. In addition, in order to present a global view of the classification performance of the compared deep models, the aggregated results across all four benchmarks are presented. Specifically, we average the OA scores obtained by different deep models on the four HSI datasets. As can be seen in
Figure 19, the proposed DRIN achieves the highest averaged OA score (i.e., 80.8%). Besides, to verify the importance of the differences across different CNN models, we executed Wilcoxon signed-rank tests over OA. As can be observed in
Table 17, the differences between the proposed DRIN and other models are statistically important. For instance, the proposed DRIN delivers significant improvements over DRN in accuracy, according to the Wilcoxon tests at
.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

























