
LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment

Abstract
:
1. Introduction
1.1. Classification of SLAM Methods Based on Registration
1.2. LOAM and Its Variants
- Moving objects removal. Dynamic objects, such as pedestrians and vehicles, in the environment will lead to false corresponding points, which can cause large errors. To this end, semantic information can be used to remove dynamic objects [34].
- Semantic mapping. The constructed semantic map helps to carry out further path planning and obstacle avoidance tasks [37].
1.3. Semantic-Assisted LiDAR SLAM Method
- Point cloud with point-wise semantic labels is used to coarsely remove dynamic objects and outliers. The proposed filtering method largely preserves the static parts of all movable classes while removing dynamic objects and outliers.
- We use point-wise semantic labels instead of the smoothness of the local surface to extract edge and plane features. Semantic labels are first used to establish candidate feature points. Then, some down-sampling and culling strategies are presented to select feature points from these candidate feature points.
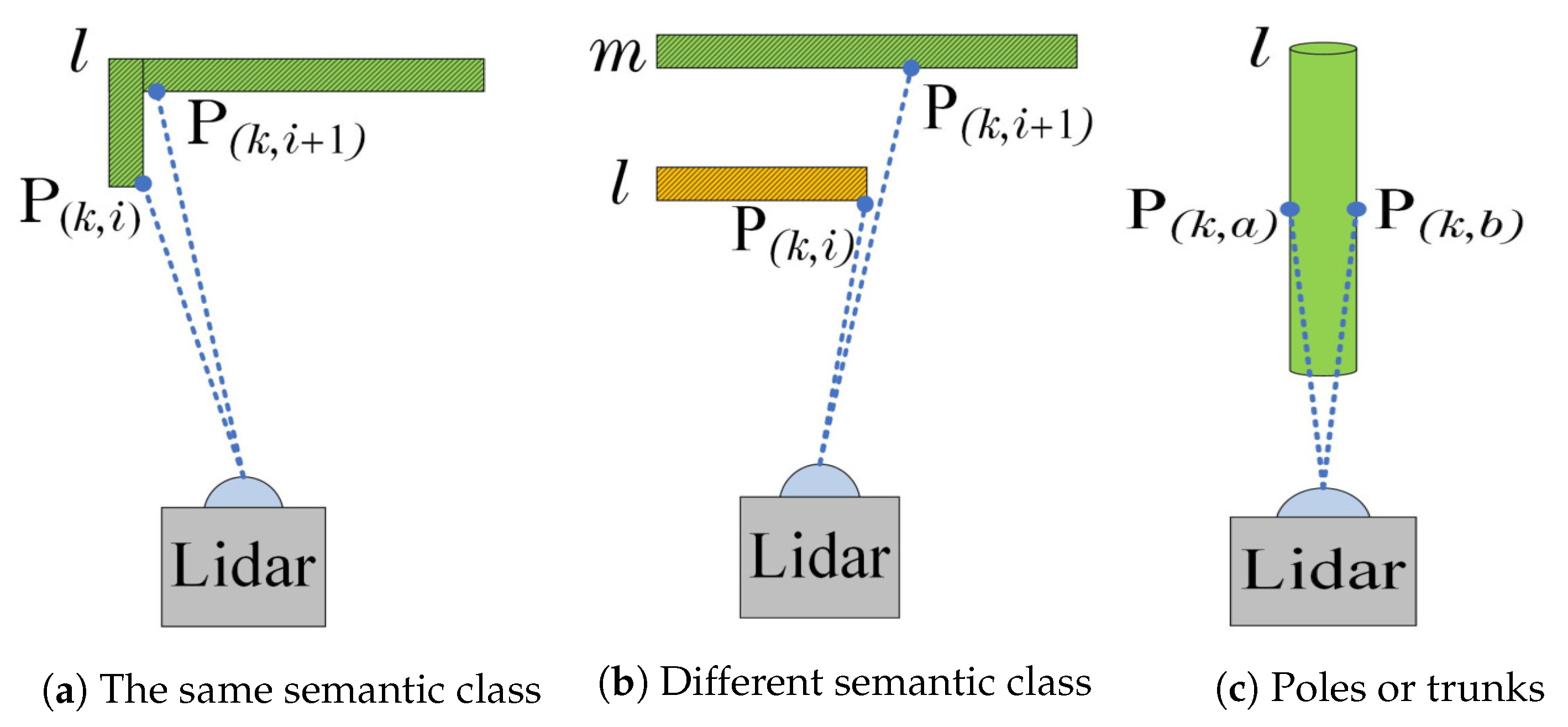
- In the LiDAR odometry and mapping module, we constrain the corresponding points of frame-to-frame or frame-to-map to the same semantic label. Besides, a second dynamic objects filtering strategy is also presented in the mapping module.
- To verify the proposed solution, extensive experiments have been carried out in several scenarios, including the urban, the country and highway, based on the semanticKITTI dataset [33]. Experimental results show that the proposed methods can achieve high-precision positioning and mapping results compared with the state-of-the-art SLAM methods.
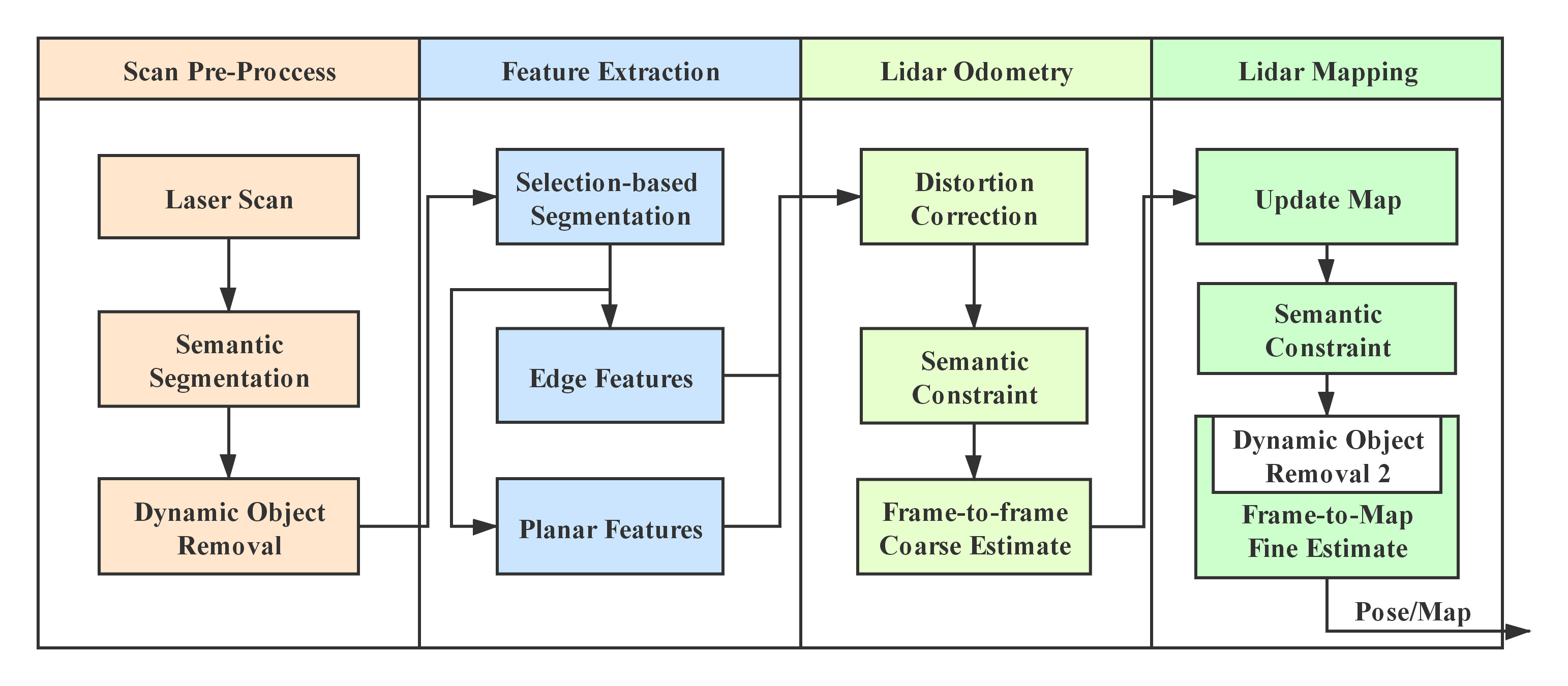
2. Materials and Methods
2.1. Scan Pre-Processing
2.2. Feature Extraction
2.3. LiDAR Odometry
2.3.1. Deformation Correction
2.3.2. LiDAR Odometry
2.4. Lidar Mapping
| Algorithm 1 LiDAR Mapping. |
|
3. Results
3.1. Experimental Platform and Evaluation Method
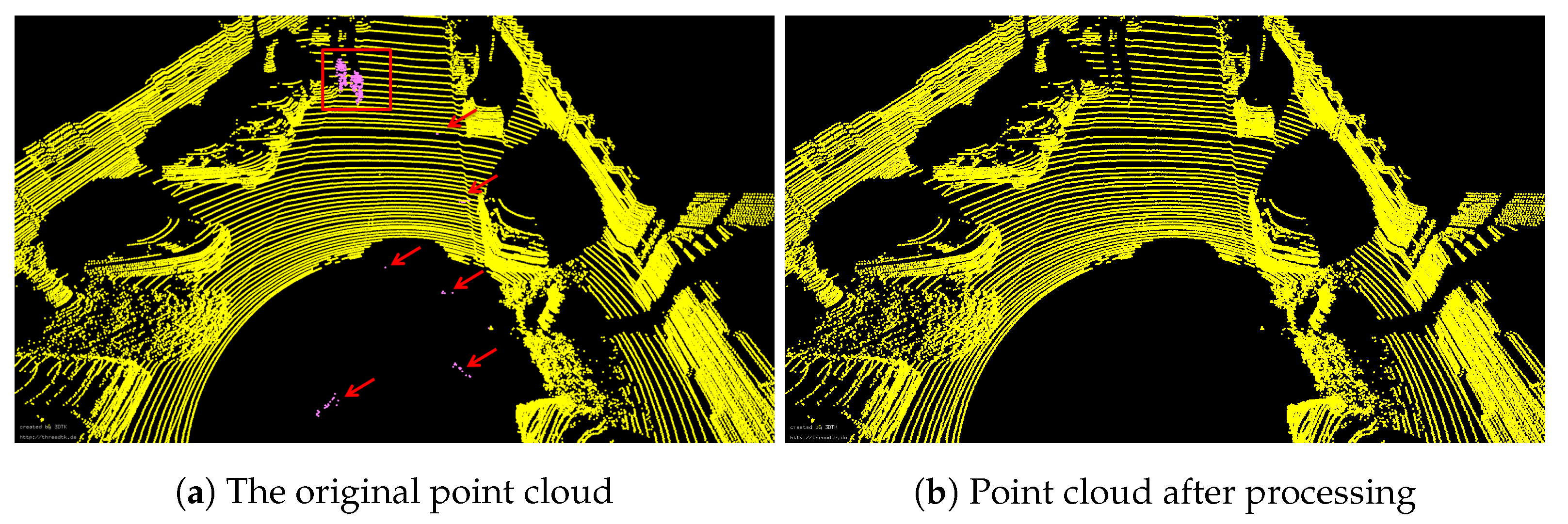
3.2. Dynamic Object Removal
3.3. Feature Extraction Results
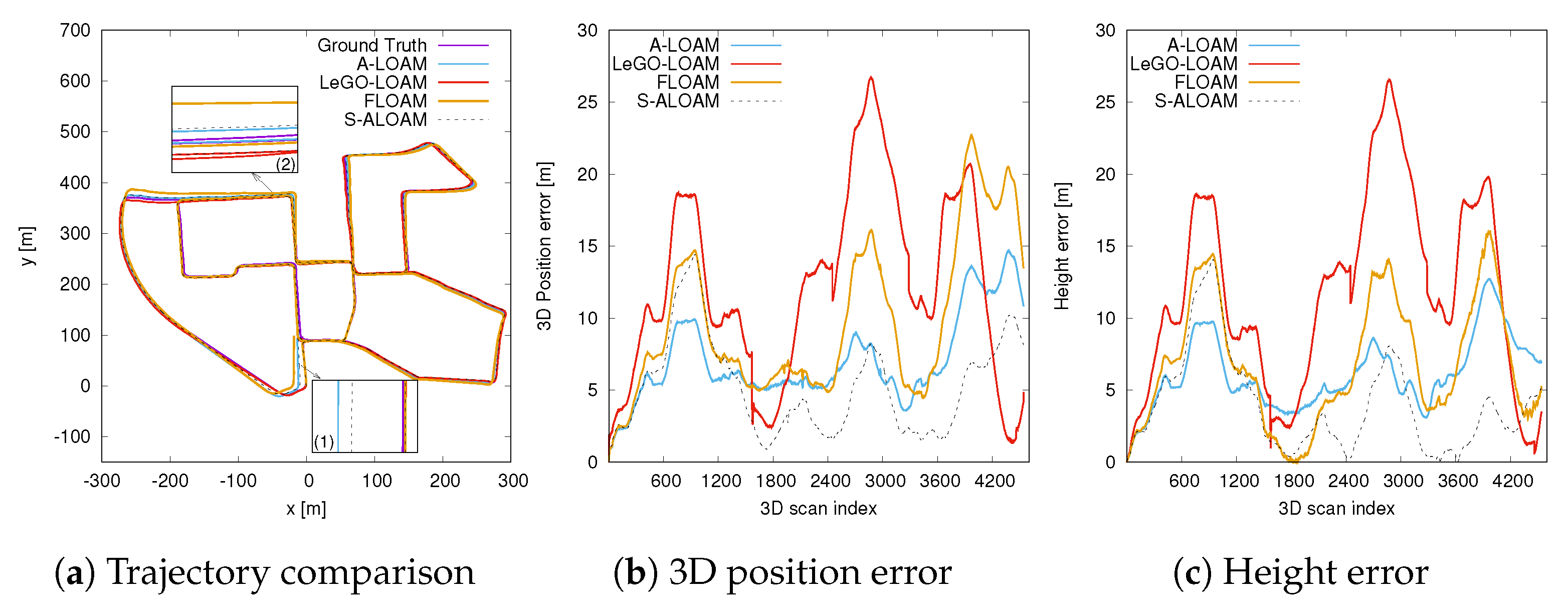
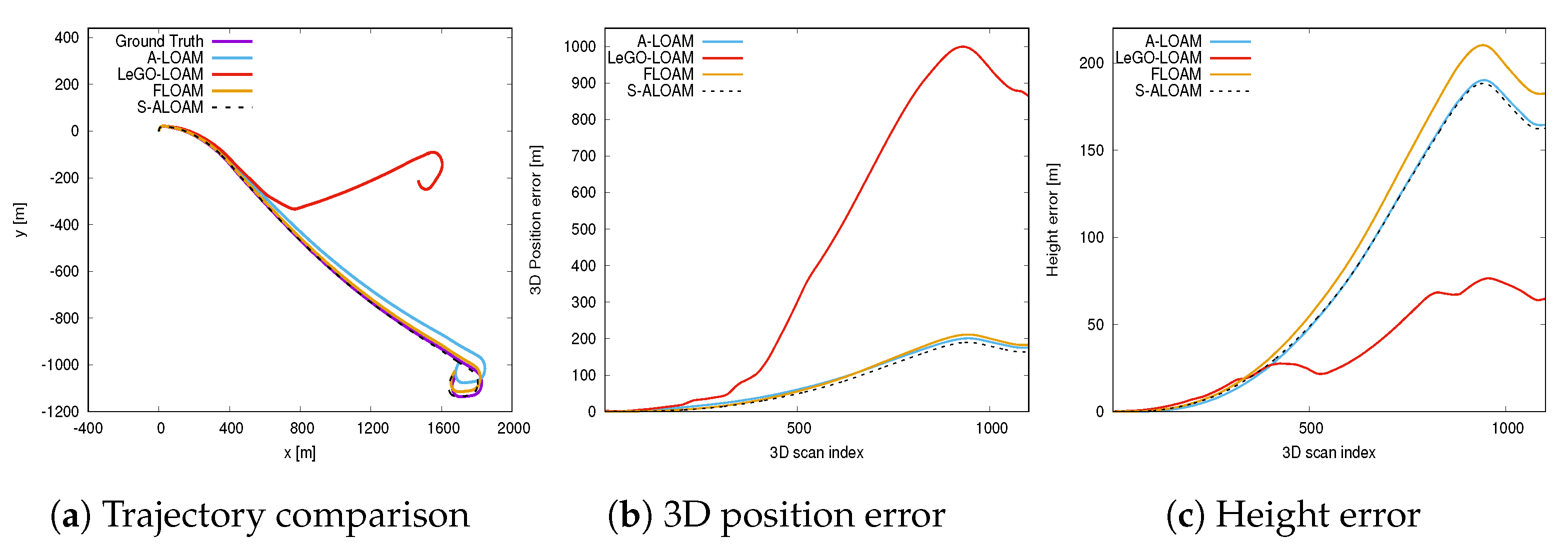
3.4. Pose Estimation Comparison
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Grisetti, G.; Kümmerle, R.; Stachniss, C.; Burgard, W. A Tutorial on Graph-Based SLAM. IEEE Intell. Transp. Syst. Mag. 2010, 2, 31–43. [Google Scholar] [CrossRef]
- Bârsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust dense mapping for large-scale dynamic environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7510–7517. [Google Scholar]
- Xu, C.; Liu, Z.; Li, Z. Robust visual-inertial navigation system for low precision sensors under indoor and outdoor environments. Remote Sens. 2021, 13, 772. [Google Scholar] [CrossRef]
- Ji, K.; Chen, H.; Di, H.; Gong, J.; Xiong, G.; Qi, J.; Yi, T. CPFG-SLAM: A robust simultaneous localization and mapping based on LIDAR in off-road environment. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 650–655. [Google Scholar]
- Zhang, J.; Singh, S. Laser-visual-inertial odometry and mapping with high robustness and low drift. J. Field Robot. 2018, 35, 1242–1264. [Google Scholar] [CrossRef]
- Lin, Y.; Gao, F.; Qin, T.; Gao, W.; Liu, T.; Wu, W.; Yang, Z.; Shen, S. Autonomous aerial navigation using monocular visual-inertial fusion. J. Field Robot. 2018, 35, 23–51. [Google Scholar] [CrossRef]
- Fu, D.; Xia, H.; Qiao, Y. Monocular visual-inertial navigation for dynamic environment. Remote Sens. 2021, 13, 1610. [Google Scholar] [CrossRef]
- Horaud, R.; Hansard, M.; Evangelidis, G.; Menier, C. An overview of depth cameras and range scanners based on time-of-flight technologies. Mach. Vis. Appl. 2016, 27, 1005–1020. [Google Scholar] [CrossRef] [Green Version]
- Shan, T.; Englot, B. LeGO-LOAM: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Hall, D.; Velodyne Lidar. HDL-64E High Definition Real-Time 3D LiDAR. 2021. Available online: https://velodynelidar.com/products/hdl-64e/ (accessed on 16 June 2021).
- Elhousni, M.; Huang, X. A survey on 3D LiDAR localization for autonomous vehicles. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las, Vegas, NV, USA, 23–26 June 2020; pp. 1879–1884. [Google Scholar]
- Magnusson, M.; Vaskevicius, N.; Stoyanov, T.; Pathak, K.; Birk, A. Beyond points: Evaluating recent 3D scan-matching algorithms. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 3631–3637. [Google Scholar]
- Li, X.; Du, S.; Li, G.; Li, H. Integrate point-cloud segmentation with 3D LiDAR scan-matching for mobile robot localization and mapping. Sensors 2020, 20, 237–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Besl, P.; McKay, N. A method for registration of 3D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Censi, A. An ICP variant using a point-to-line metric. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 19–25. [Google Scholar]
- Low, K. Linear least-squares optimization for point-to-plane ICP surface registration. Chapel Hill 2004, 4, 1–3. [Google Scholar]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-ICP. In Proceedings of the Robotics Science and Systems V (RSS), University of Washington, Seattle, WA, USA, 1–28 July 2009; pp. 1–8. [Google Scholar]
- Borrmann, D.; Elseberg, J.; Lingemann, K.; Nuechter, A.; Hertzberg, J. Globally consistent 3D mapping with scan matching. Robot. Auton. Syst. 2008, 56, 130–142. [Google Scholar] [CrossRef] [Green Version]
- Elseberg, J.; Borrmann, D.; Nuechter, A. Algorithmic solutions for computing precise maximum likelihood 3D point clouds from mobile laser scanning platforms. Remote Sens. 2013, 5, 5871–5906. [Google Scholar] [CrossRef] [Green Version]
- Lauterbach, H.A.; Borrmann, D.; Heß, R.; Eck, D.; Schilling, K.; Nüchter, A. Evaluation of a backpack-mounted 3D mobile scanning system. Remote Sens. 2015, 7, 13753–13781. [Google Scholar] [CrossRef] [Green Version]
- Moosmann, F.; Stiller, C. Velodyne slam. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden, Germany, 5–9 June 2011; pp. 393–398. [Google Scholar]
- Magnusson, M.; Lilienthal, A.; Ducket, T. Scan registration for autonomous mining vehicles using 3D-NDT. J. Field Robot. 2007, 24, 803–827. [Google Scholar] [CrossRef] [Green Version]
- Stoyanov, T.; Magnusson, M.; Lilientha, A.J. Point set registration through minimization of the L2 distance between 3D-NDT models. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 5196–5201. [Google Scholar]
- Koide, K.; Miura, J.; Menegatti, E. A portable three-dimensional LIDAR-based system for long-term and wide-area people behavior measurement. Int. J. Adv. Robot. Syst. 2019, 16, 1–16. [Google Scholar] [CrossRef]
- Pathak, K.; Birk, A.; Vaskevicius, N.; Pfingsthorn, M.; Schwertfeger, S.; Poppinga, J. Online three-dimensional slam by registration of large planar surface segments and closed-form pose-graph relaxation. J. Field Robot. 2010, 27, 52–84. [Google Scholar] [CrossRef]
- Zhou, Q.Y.; Park, J.; Koltun, V. Fast global registration. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 766–782. [Google Scholar]
- Zaganidis, A.; Sun, L.; Duckett, T.; Cielniak, G. Integrating deep semantic segmentation into 3-D point cloud registration. IEEE Robot. Autom. Lett. 2018, 3, 2942–2949. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Singh, S. Low-drift and real-time lidar odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Park, Y.S.; Jang, H.; Kim, A. I-LOAM: Intensity Enhanced LiDAR Odometry and Mapping. In Proceedings of the 2020 17th International Conference on Ubiquitous Robots (UR), Kyoto, Japan, 22–26 June 2020; pp. 455–458. [Google Scholar]
- Rufus, N.; Nair, U.K.R.; Kumar, A.V.S.S.B.; Madiraju, V.; Krishna, K.M. SROM: Simple Real-time Odometry and Mapping using LiDAR data for Autonomous Vehicles. arXiv 2020, arXiv:2005.02042. [Google Scholar]
- Zhou, B.; He, Y.; Qian, K.; Ma, X.; Li, X. S4-SLAM: A real-time 3D LIDAR SLAM system for ground/watersurface multi-scene outdoor applications. Auton. Robot. 2021, 45, 77–98. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A dataset for semantic scene understanding of LiDAR sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar]
- Zhao, Z.; Zhang, W.; Gu, J.; Yang, J.; Huang, K. Lidar mapping optimization based on lightweight semantic segmentation. IEEE Trans. Intell. Veh. 2019, 4, 353–362. [Google Scholar] [CrossRef]
- Wang, F.; Wang, Z.; Yan, F.; Gu, H.; Zhuang, Y. A novel real-time semantic-assisted Lidar odometry and mapping system. In Proceedings of the 10th International Conference on Intelligent Control and Information Processing (ICICIP), Marrakesh, Morocco, 11–16 December 2019. [Google Scholar]
- Zaganidis, A.; Zerntev, A.; Duckett, T.; Cielniak, G. Semantically assisted loop closure in SLAM using NDT histograms. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4562–4568. [Google Scholar]
- Zhao, Z.; Mao, Y.; Ding, Y.; Ren, P.; Zheng, N. Visual-based semantic SLAM with landmarks for large-scale outdoor environment. In Proceedings of the 2019 2nd China Symposium on Cognitive Computing and Hybrid Intelligence (CCHI), Xi’an, China, 21–22 September 2019; pp. 149–154. [Google Scholar]
- Nuechter, A.; Wulf, O.; Lingemann, K.; Hertzberg, J.; Wagner, B. 3D mapping with semantic knowledge. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2005; pp. 335–346. [Google Scholar]
- Zaganidis, A.; Magnusson, M.; Duckett, T.; Cielniak, G. Semantic-assisted 3D normal distributions transform for scan registration in environments with limited structure. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A precise and robust segmentation-based lidar localization system for automated urban driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, D.; Boehm, J. A review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on point sets for 3D classification and segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Hua, B.S.; Tran, M.K.; Yeung, S.K. Pointwise convolutional neural networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 984–993. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11105–11114. [Google Scholar]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. SuMa++: Efficient LiDAR-based semantic SLAM. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4530–4537. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Chen, S.W.; Nardari, G.V.; Lee, E.S.; Qu, C.; Liu, X.; Romero, R.A.F.; Kumar, V. SLOAM: Semantic Lidar odometry and mapping for forest inventory. IEEE Robot. Autom. Lett. 2020, 5, 612–619. [Google Scholar] [CrossRef] [Green Version]
- Qin, T.; Cao, S. Advanced Implementation of LOAM. 2019. Available online: https://github.com/HKUST-Aerial-Robotics/A-LOAM (accessed on 16 June 2019).
- Lin, J.; Zhang, F. Loam livox: A fast, robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 Jannuary 2021; pp. 3126–3131. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- May, S.; Droeschel, D.; Holz, D.; Fuchs, S.; Malis, E.; Nuechter, A. Three dimensional mapping with time of flight cameras. J. Field Robot. 2009, 26, 934–965. [Google Scholar] [CrossRef]
- Wang, H. Fast Lidar Odometry and Mapping. 2020. Available online: https://github.com/bill4u/floam (accessed on 16 June 2020).
- Grupp, M. evo: Python Package for the Evaluation of Odometry and SLAM. 2017. Available online: https://github.com/MichaelGrupp/evo (accessed on 16 June 2017).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Number of Scans | Distance (m) | Environment |
|---|---|---|---|
| 00 | 4541 | 3714 | Urban |
| 01 | 1101 | 2453 | Highway |
| 02 | 4661 | 5067 | Urban + Country |
| 04 | 271 | 394 | Country |
| 07 | 1101 | 694 | Urban |
| 08 | 4071 | 3223 | Urban + Country |
| Sequence | A-LOAM | LeGO-LOAM | FLOAM | S-ALOAM | ||||
|---|---|---|---|---|---|---|---|---|
| (m) | (deg) | (m) | (deg) | (m) | (deg) | (m) | (deg) | |
| 00 | 7.6741 | 13.8302 | n.a. | 2.9859 | 1.9447 | |||
| 01 | 114.8519 | 586.9212 | n.a. | 7.6786 | 7.0901 | |||
| 02 | 157.2780 | 32.4780 | 88.3942 | n.a. | ||||
| 04 | 4.9123 | n.a. | 2.8831 | 1.1383 | 2.9541 | 1.1444 | ||
| 07 | 1.0154 | 2.0474 | n.a. | 0.8264 | 0.9361 | |||
| 08 | 21.0646 | n.a. | 20.9252 | 3.7745 | 17.9965 | 3.6825 | ||
| Sequence | A-LOAM | FLOAM | S-ALOAM | |||
|---|---|---|---|---|---|---|
| (m) | (m) | (m) | ||||
| 00 | 1.1639 | 0.0205 | 1.0536 | 0.0206 | ||
| 01 | 1.0312 | 1.0533 | 0.0140 | 0.0142 | ||
| 02 | 55.7849 | 32.4780 | 1.0397 | 0.0194 | ||
| 04 | 0.5970 | 0.0123 | 0.6677 | 0.0143 | ||
| 07 | 0.5590 | 0.5478 | 0.0154 | |||
| 08 | 0.0143 | 1.3818 | 0.0154 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Li, Y.; Li, X.; Wu, M. LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment. Remote Sens. 2021, 13, 2864. https://doi.org/10.3390/rs13152864
Du S, Li Y, Li X, Wu M. LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment. Remote Sensing. 2021; 13(15):2864. https://doi.org/10.3390/rs13152864
Chicago/Turabian StyleDu, Shitong, Yifan Li, Xuyou Li, and Menghao Wu. 2021. "LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment" Remote Sensing 13, no. 15: 2864. https://doi.org/10.3390/rs13152864
APA StyleDu, S., Li, Y., Li, X., & Wu, M. (2021). LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment. Remote Sensing, 13(15), 2864. https://doi.org/10.3390/rs13152864