1. Introduction
With the rapid progress and development of modern aerospace technology, remote sensing images have been widely used in military and civil fields, including agriculture and forestry inspection, military reconnaissance, and urban planning. However, due to hardware limitations and the large detection distance, there is still room for improvement in the resolution and clarity of remote sensing images. Considering the high research cost and long hardware iteration development cycle required to physically improve imaging sensors, it is increasingly important to improve the algorithms used for super-resolution (SR) reconstruction [
1] of remote sensing images.
Single-image super-resolution (SISR) technology aims to reconstruct a high-resolution (HR) image from a corresponding low-resolution (LR) image. For aerial remote sensing images, SISR technology can provide richer spatial details by increasing the resolution of LR images. In the past few decades, numerous SISR approaches based on machine learning have been proposed, and these techniques include methods based on neighbor embedding [
2], sparse representation [
3,
4], and local linear regression [
5,
6]. However, most of these methods use the low-level features of images for SR reconstruction, and the level of ability to represent these features greatly limits the reconstruction effect that is achievable.
With the rapid progress and development of big data and graphics processing unit (GPU) computing capacity, deep convolutional neural networks (DCNNs) have become the dominant approach for achieving success in image processing [
7,
8,
9]. Methods based on DCNNs have shown powerful abilities in the automatic extraction of high-level features from data, providing a highly feasible way to increase the effectiveness of resolution restoration. The basic principle of DCNN-based SR reconstruction methods is to train a model using a dataset that includes both HR images and their corresponding LR counterparts. The model then takes LR images as the input and outputs SR images.
Dong et al. [
10] proposed an SR convolutional neural network (SRCNN) that constructs three convolution layers to learn the nonlinear mapping from an LR image to its corresponding HR image. Soon after this, Faster-SRCNN was proposed to accelerate the speed of SRCNN [
11]. Shi et al. [
12] proposed an efficient sub-pixel convolutional network, which extracts feature information directly from LR images and efficiently reconstructs HR images. Ledig et al. [
13] introduced a generative adversarial network (GAN) into the field of SR image reconstruction and produced a super-resolution GAN (SRGAN). In the SRGAN, the input of the generator is an LR image and the output is an HR image, and the discriminator seeks to predict whether the input image is a real HR image or a generated image.
Recently, with the residual network [
7] proposed by He et al., many visual recognition tasks have tended to adopt a residual learning strategy for better performance. Kim et al. [
14] proposed a very deep SR convolutional neural network (VDSR), which uses residual learning to speed up the convergence of the network while preventing the gradient from disappearing. Soon after this, Kim et al. [
15] constructed a deeply recursive convolutional network (DRCN) using recursive modules, which achieves a better reconstruction effect with fewer model parameters. On the basis of DRCN, Tai et al. [
16] developed a deep recursive residual network, which combines the residual structure with the recursive module, and this effectively reduces the training difficulty of the deep network. Lim et al. [
17] built an enhanced deep SR network (EDSR), and their results showed that increasing the depth of the representation can enhance the high-frequency details of LR images. Zhang et al. [
18] proposed a deep residual dense network (RDN), which combines residual learning with dense network connections for SR image reconstruction tasks. Zhang et al. [
19] produced a deep residual channel attention network (RCAN), in which a channel attention [
20] module is designed to enhance the representation ability of the high-frequency information channel.
With regard to the SR reconstruction of remote sensing images, Lei et al. [
21] proposed a new algorithm named local–global combined networks (LGCNet) to learn multilevel representations of remote sensing images, and Dong et al. [
22] developed a dense-sampling network to explore the large-scale SR reconstruction of remote sensing images. Inspired by the channel attention mechanism, Gu et al. [
23] proposed a residual squeeze and excitation block as a building block for SR reconstruction networks. Furthermore, Wang et al. [
24] developed an adaptive multi-scale feature fusion network, in which the squeeze-and-excitation and feature gating unit mechanisms are adopted to enhance the extraction of feature information. These approaches have achieved promising improvements in SR reconstruction of remote sensing images; nonetheless, they still have some deficiencies.
Firstly, as the depth of a CNN increases, the feature information obtained in the different convolutional layers will be hierarchical with different receptive fields. However, most methods only use the features output from the last convolutional layer to realize feature mapping, which neglects the hierarchical features and wastes part of the available information. Secondly, most existing CNN-based methods treat different spatial areas equally, which leads to areas with low-frequency information (smooth areas) being easy to recover while areas with high-frequency details (edges and contours) are more difficult to recover. Moreover, equalization causes the network to use a large amount of computing resources on unimportant features. Thirdly, due to the complex content and richly detailed information contained within remote sensing images, local and global feature information should be considered in the design of the model, and this can lead to learning of multi-level features and improve the reconstruction effect.
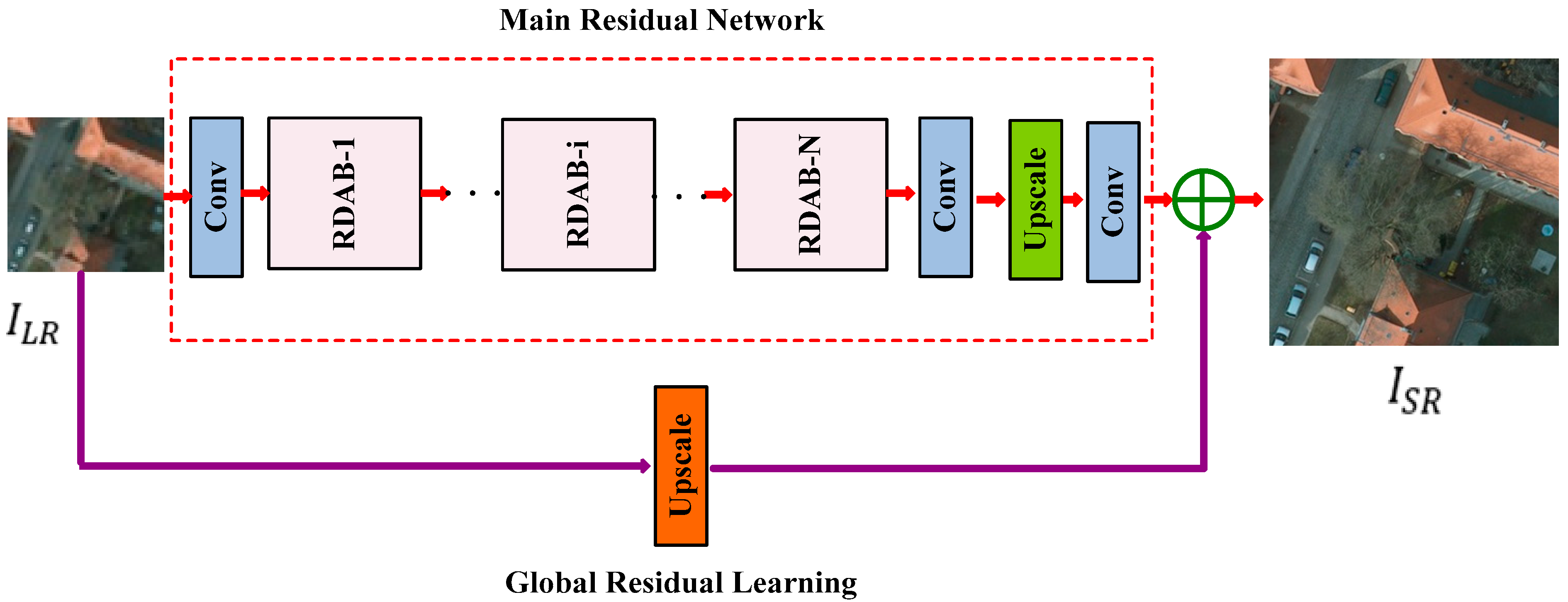
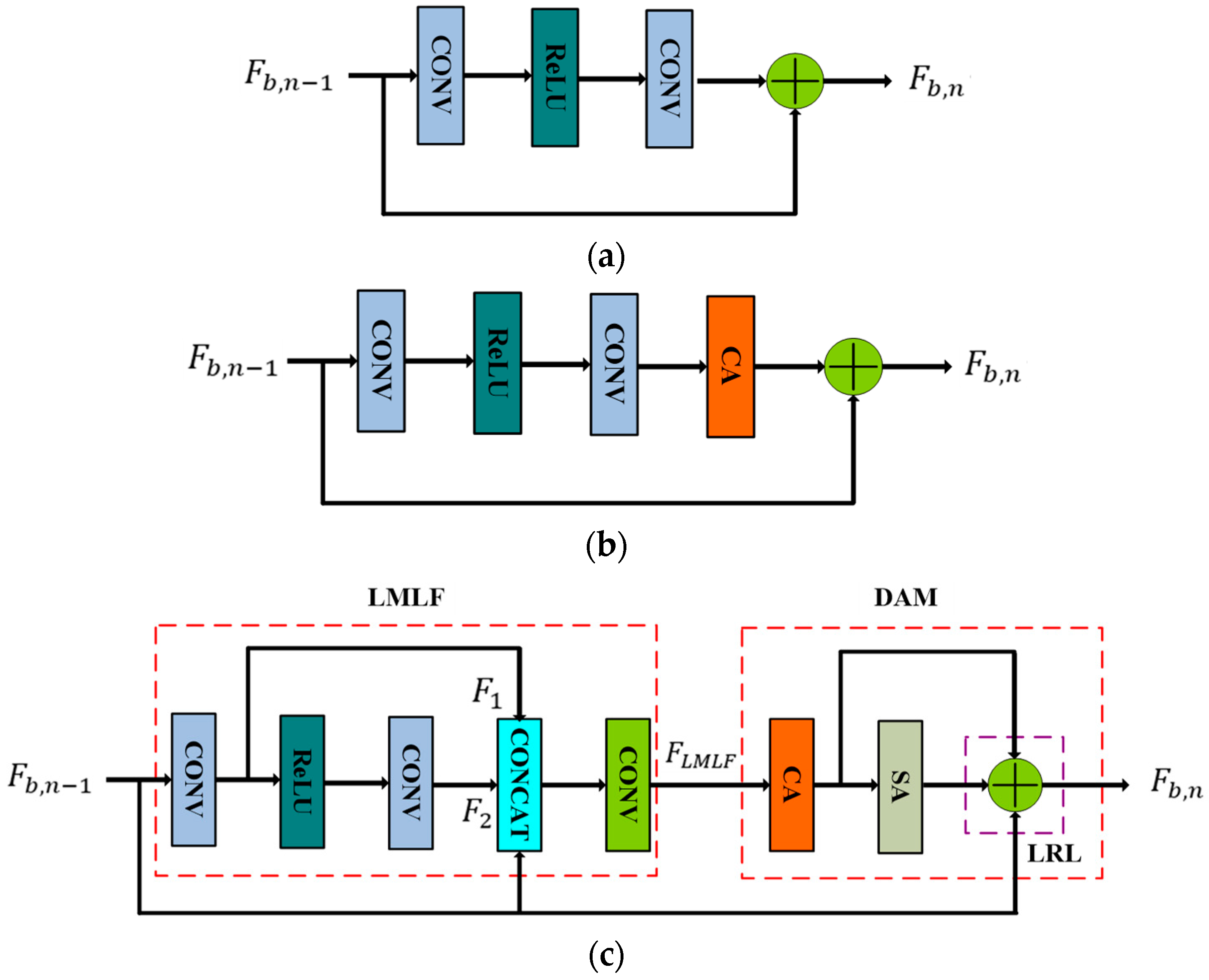
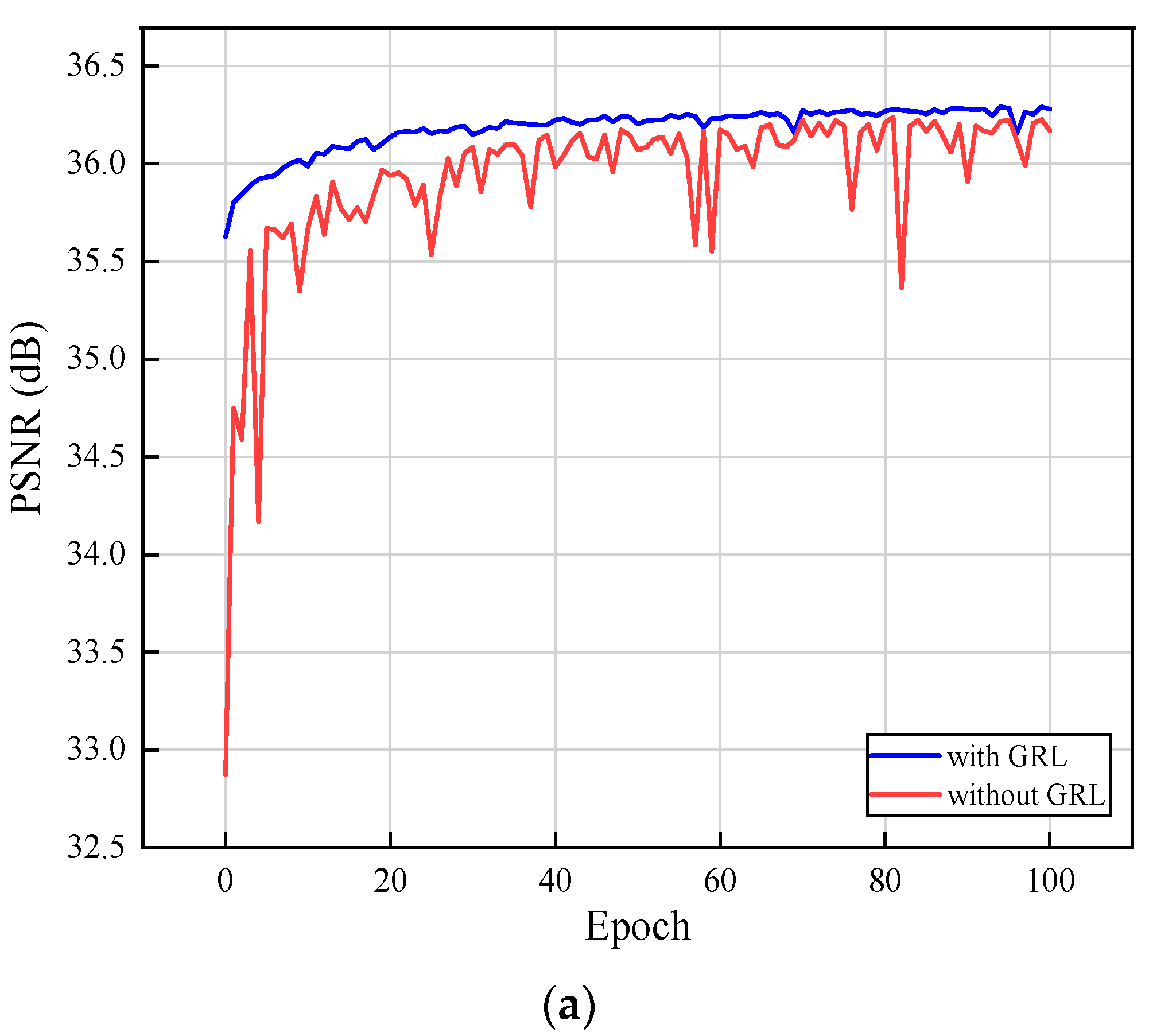
Aiming to tackle these issues, this paper proposes a novel aerial remote sensing SR image reconstruction network called a deep residual dual-attention network (DRDAN). This consists of two parts: a global residual learning (GRL) branch and a main residual network (MRN) branch. The GRL branch adopts an upsampling operation to generate the HR counterpart of an LR image directly, which allows the network to avoid learning the complex transformation from one complete image to another. The core of the MRN branch is formed from a stack of basic components called residual dual-attention blocks (RDABs). This network shows superior reconstruction ability and high feature utilization.
The main contributions of this work are as follows:
- (1)
We propose a novel approach to SR reconstruction of remote sensing images, DRDAN. This achieves a convenient and effective end-to-end training strategy.
- (2)
DRDAN achieves the fusion of global and local residual information, which facilitates the propagation and utilization of image features, providing more feature information for the final reconstruction.
- (3)
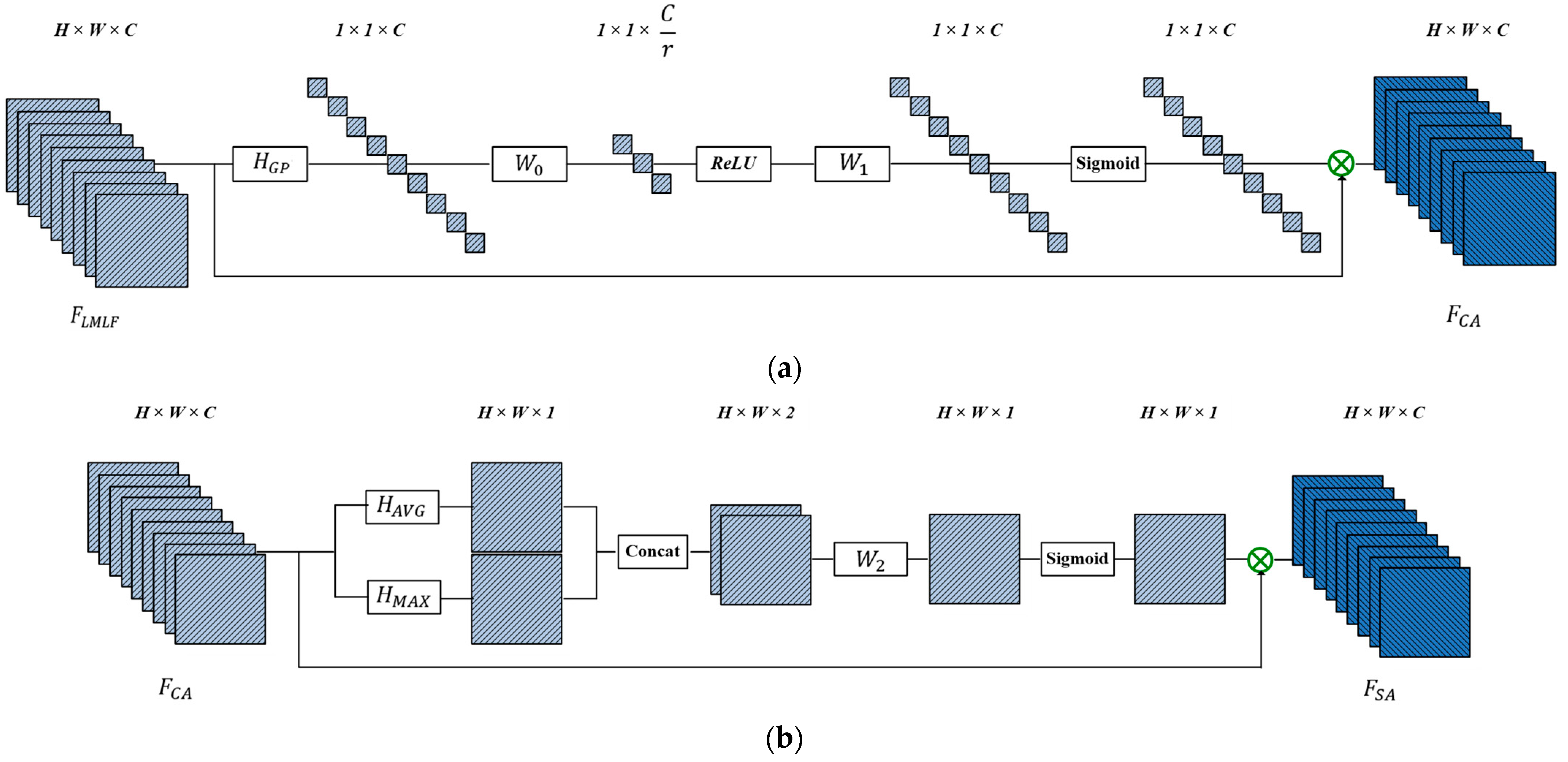
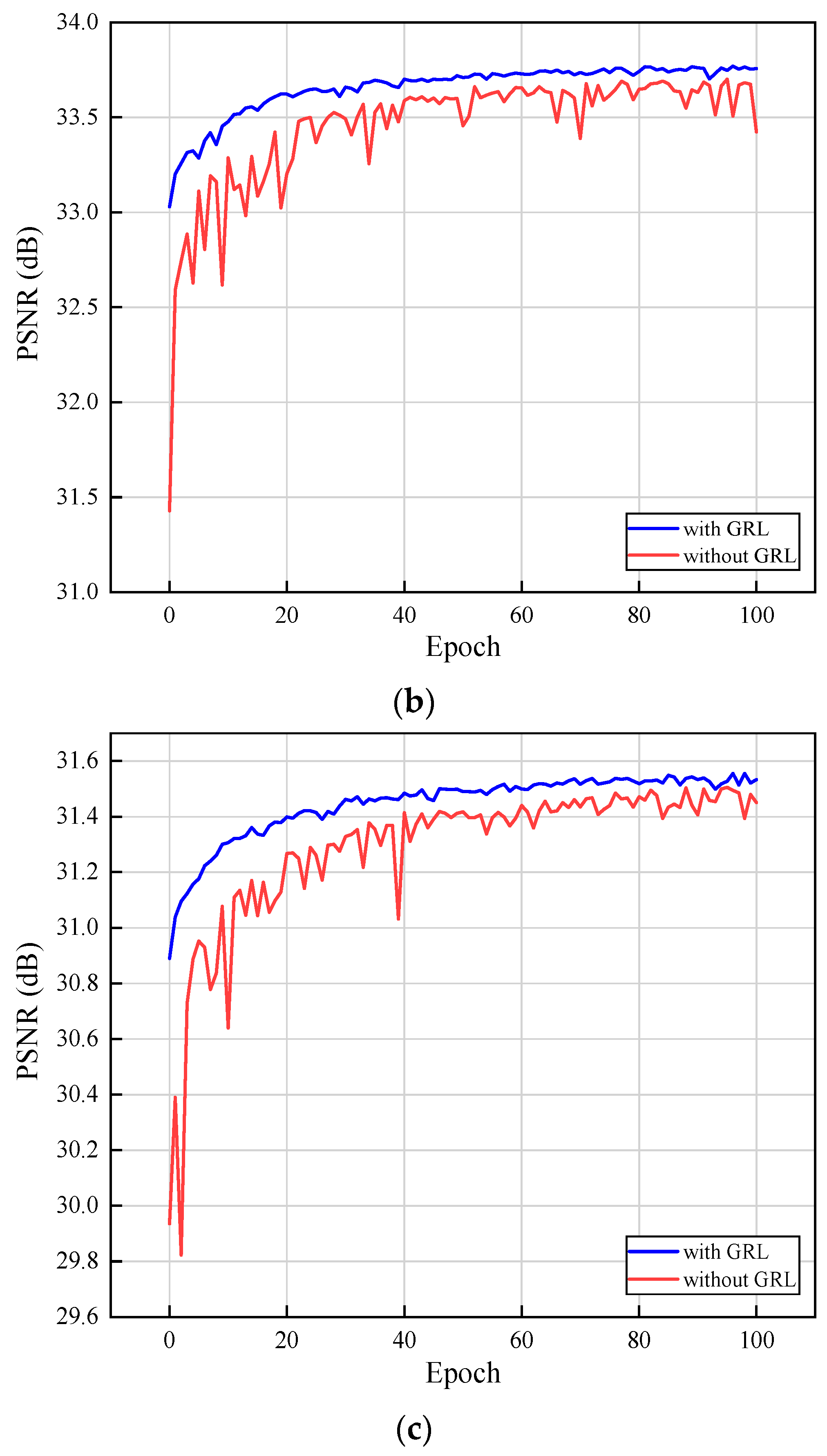
We propose a modified residual block named RDAB, which contains a local multi-level fusion (LMLF) module and dual-attention mechanism (DAM) module. The LMLF module fuses different level features with the input in the current RDAB. In the DAM module, the channel attention mechanism (CAM) submodule exploits the interdependencies among feature channels and adaptively obtains the weighting information of different channels; the spatial attention mechanism (SAM) submodule pays attention to the areas carrying high-frequency information and encodes which regions to emphasize or suppress; a local residual learning (LRL) strategy is used to alleviate the model-degradation problem due to the deepening of the work, and this improves the learning ability.
- (4)
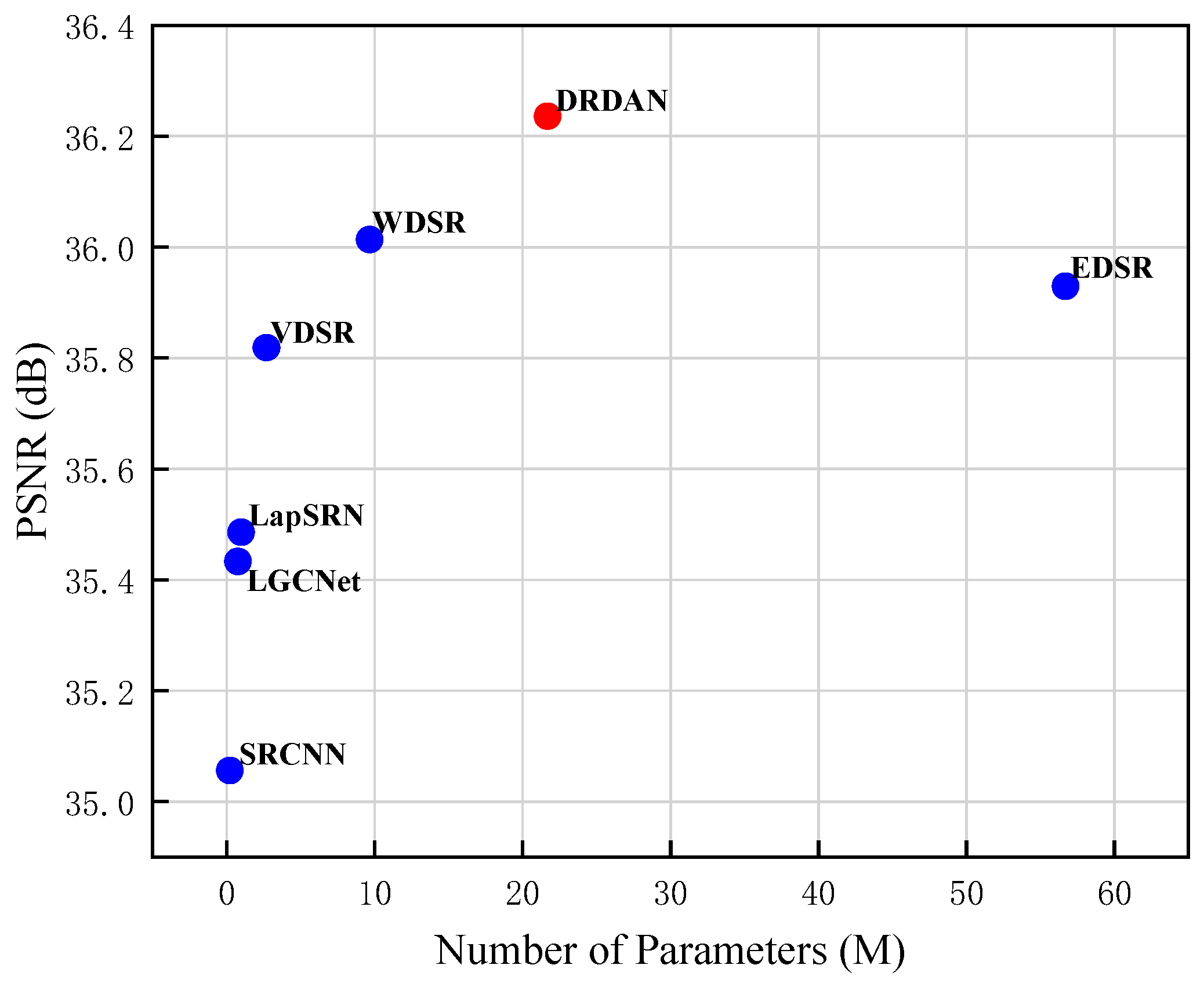
Through comparative experiments with remote sensing datasets, it is clear that, compared with other SISR algorithms, DRDAN shows better performance, both numerically and qualitatively.
The remainder of this paper is organized as follows:
Section 2 presents a detailed description of DRDAN,
Section 3 verifies its effectiveness by experimental comparisons, and
Section 4 draws some conclusions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}