Author Contributions
Conceptualization, L.Z. and B.L.; methodology, L.Z., B.L., S.Z. and J.L.; validation, H.Z.; formal analysis, H.Z.; investigation, B.L. and S.Z.; resources, J.L.; data curation, L.Z.; writing—original draft preparation, B.L.; writing—review and editing, L.Z. and H.Z.; funding acquisition, H.Z. and J.L. All authors have read and agreed to the published version of the manuscript.
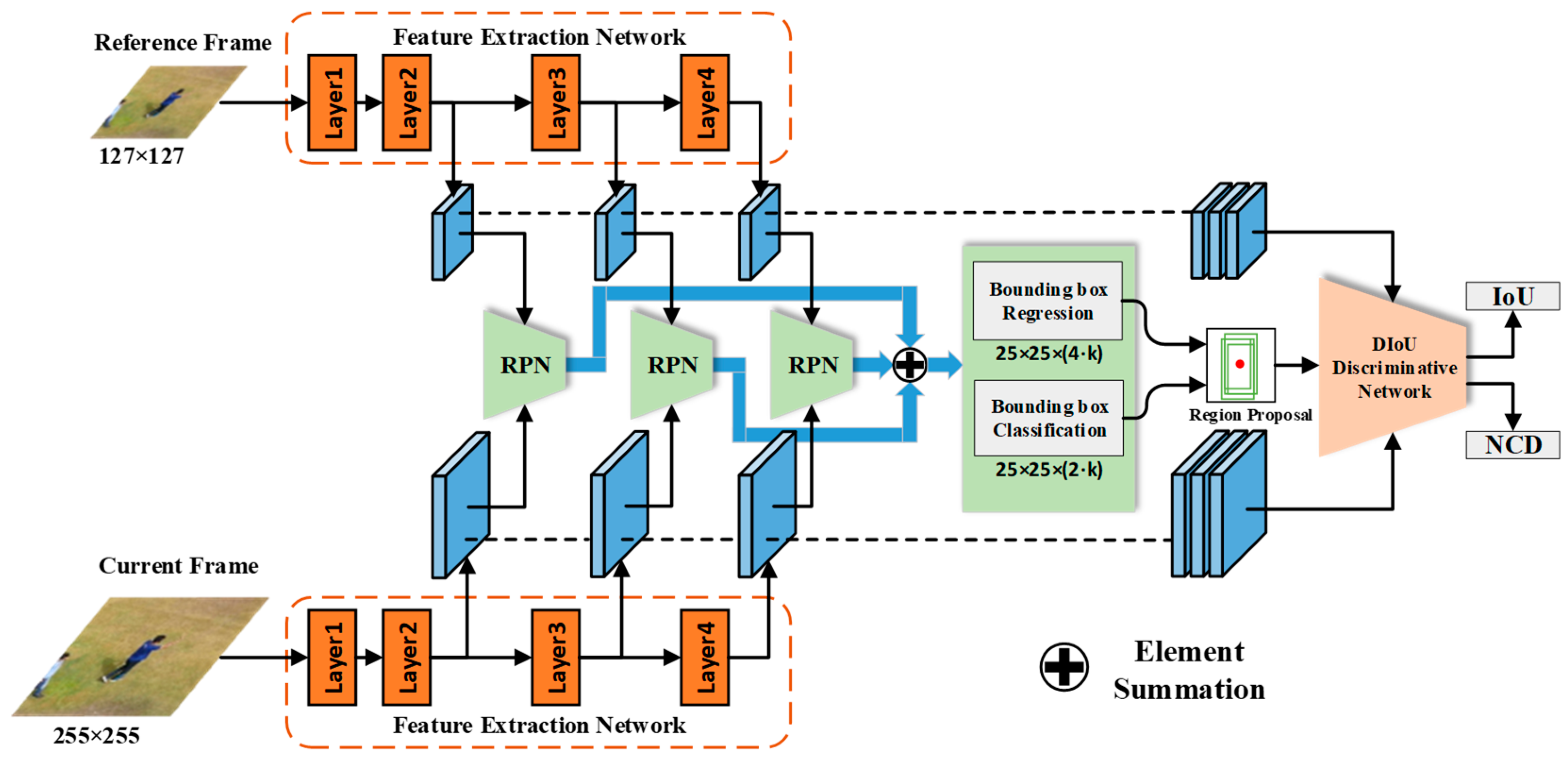
Figure 1.
Target tracking framework combining multiple RPNs and DIoU discriminative network. The multiple RPNs are used to determine high-quality candidate regions, and the DIoU discriminative network performs the correction of the candidate regions, and then outputs the final result.
Figure 1.
Target tracking framework combining multiple RPNs and DIoU discriminative network. The multiple RPNs are used to determine high-quality candidate regions, and the DIoU discriminative network performs the correction of the candidate regions, and then outputs the final result.
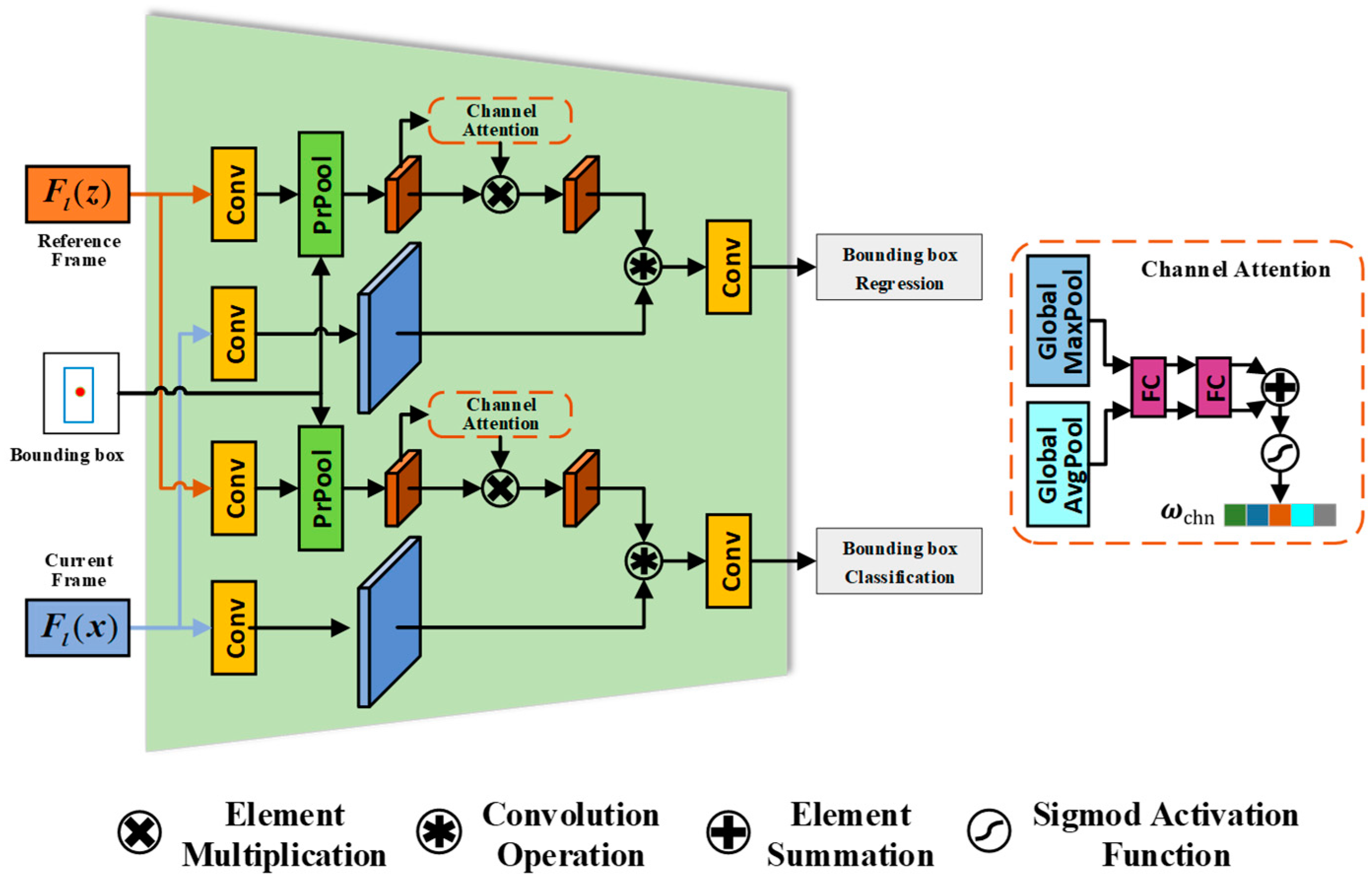
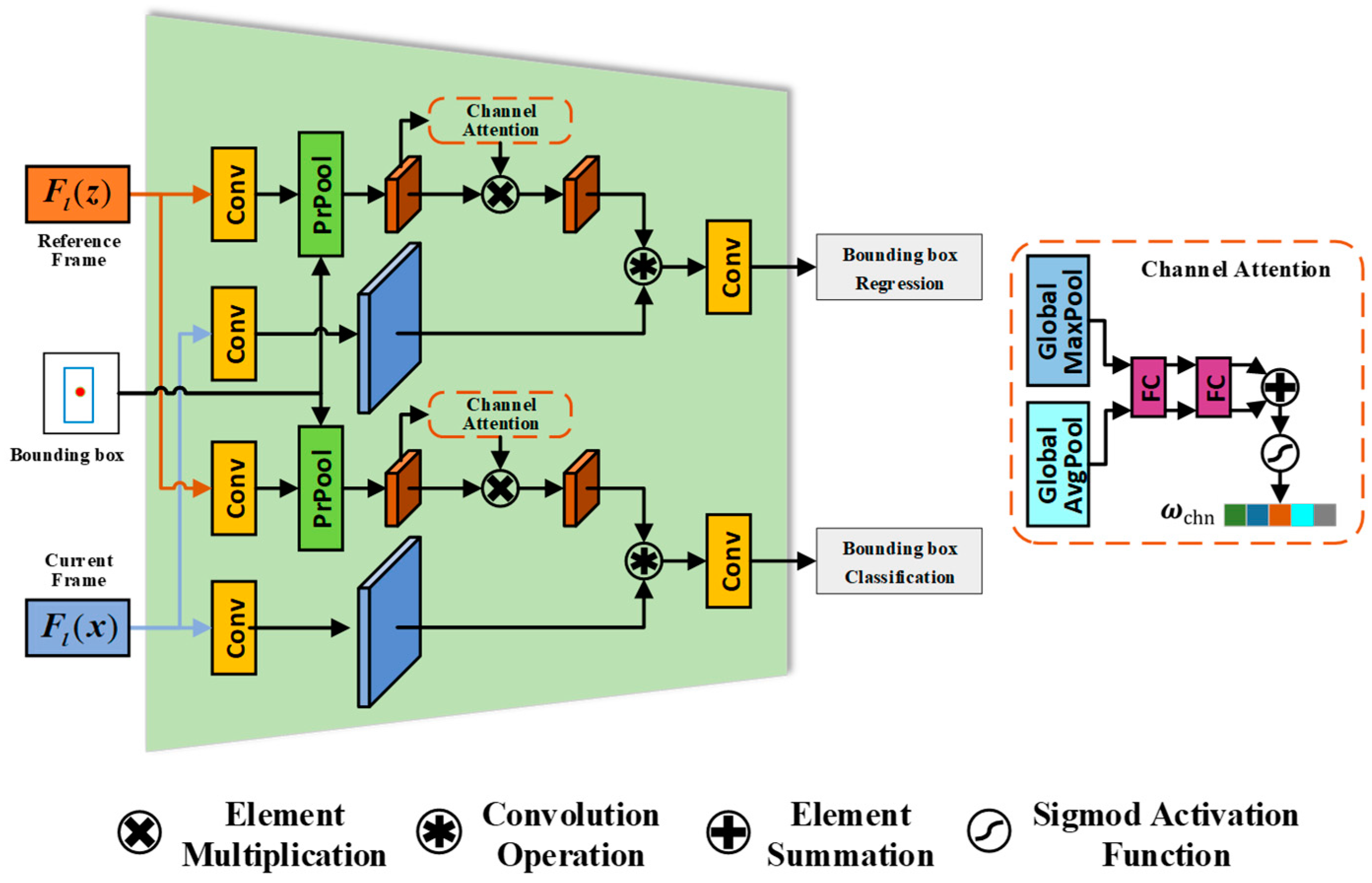
Figure 2.
SNN-based RPN structure with channel attention mechanism. The structure includes the branches of bounding box regression and classification. The input is the features of the l-th layer of the reference frame and the current frame. The bounding box regression branch obtains the regression output of the bounding box coordinates, while the bounding box classification branch obtains the classification scores of the target and the background.
Figure 2.
SNN-based RPN structure with channel attention mechanism. The structure includes the branches of bounding box regression and classification. The input is the features of the l-th layer of the reference frame and the current frame. The bounding box regression branch obtains the regression output of the bounding box coordinates, while the bounding box classification branch obtains the classification scores of the target and the background.
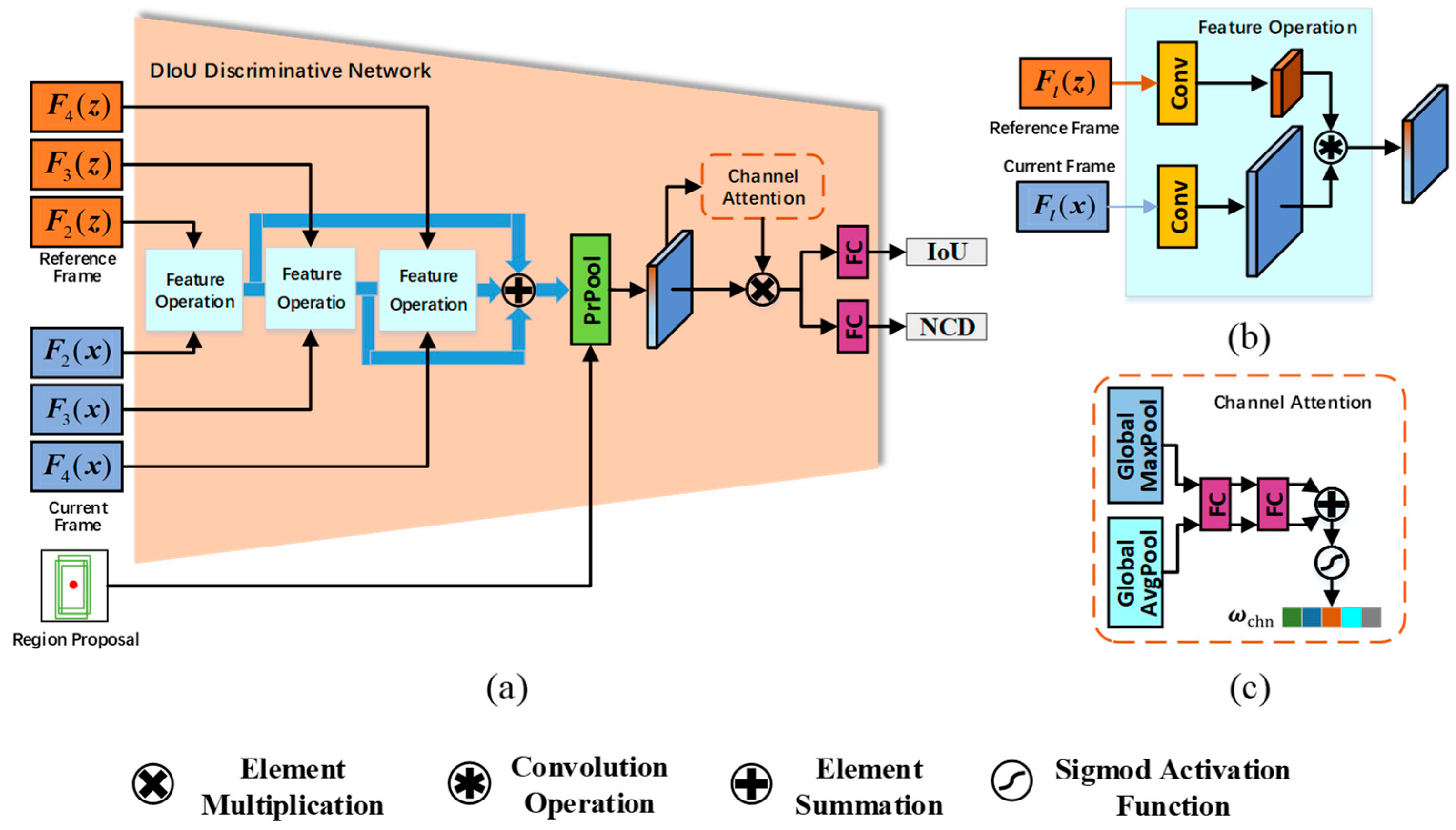
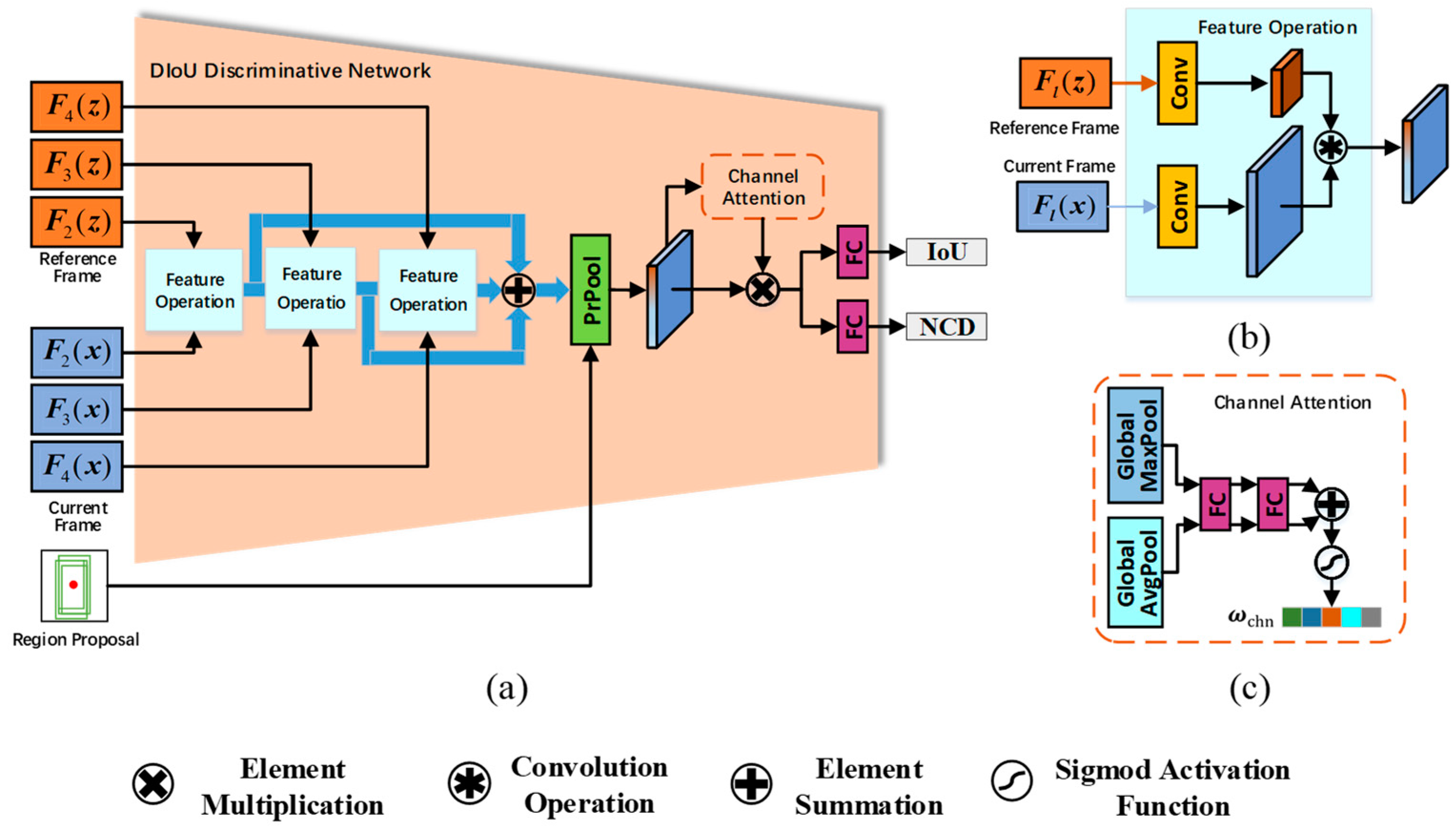
Figure 3.
DIoU discriminative network with Multi-layer feature fusion. DIoU discriminative network fuses the extracted convolutional features of multiple layers, and finally obtains the DIoU score of the region proposal through PrPool operation and channel attention operation.
Figure 3.
DIoU discriminative network with Multi-layer feature fusion. DIoU discriminative network fuses the extracted convolutional features of multiple layers, and finally obtains the DIoU score of the region proposal through PrPool operation and channel attention operation.
Figure 4.
Tracking results of the proposed tracker and other state-of-art trackers on the UAV20L dataset. From top to down and left to right are the screenshots of the tracking results on the videos of car9, group3, uav1, car9, and person7 respectively. The video sequences in (a), (b) and (c) mainly involve FOC and POC, FM and SV, FM and OV, respectively.
Figure 4.
Tracking results of the proposed tracker and other state-of-art trackers on the UAV20L dataset. From top to down and left to right are the screenshots of the tracking results on the videos of car9, group3, uav1, car9, and person7 respectively. The video sequences in (a), (b) and (c) mainly involve FOC and POC, FM and SV, FM and OV, respectively.
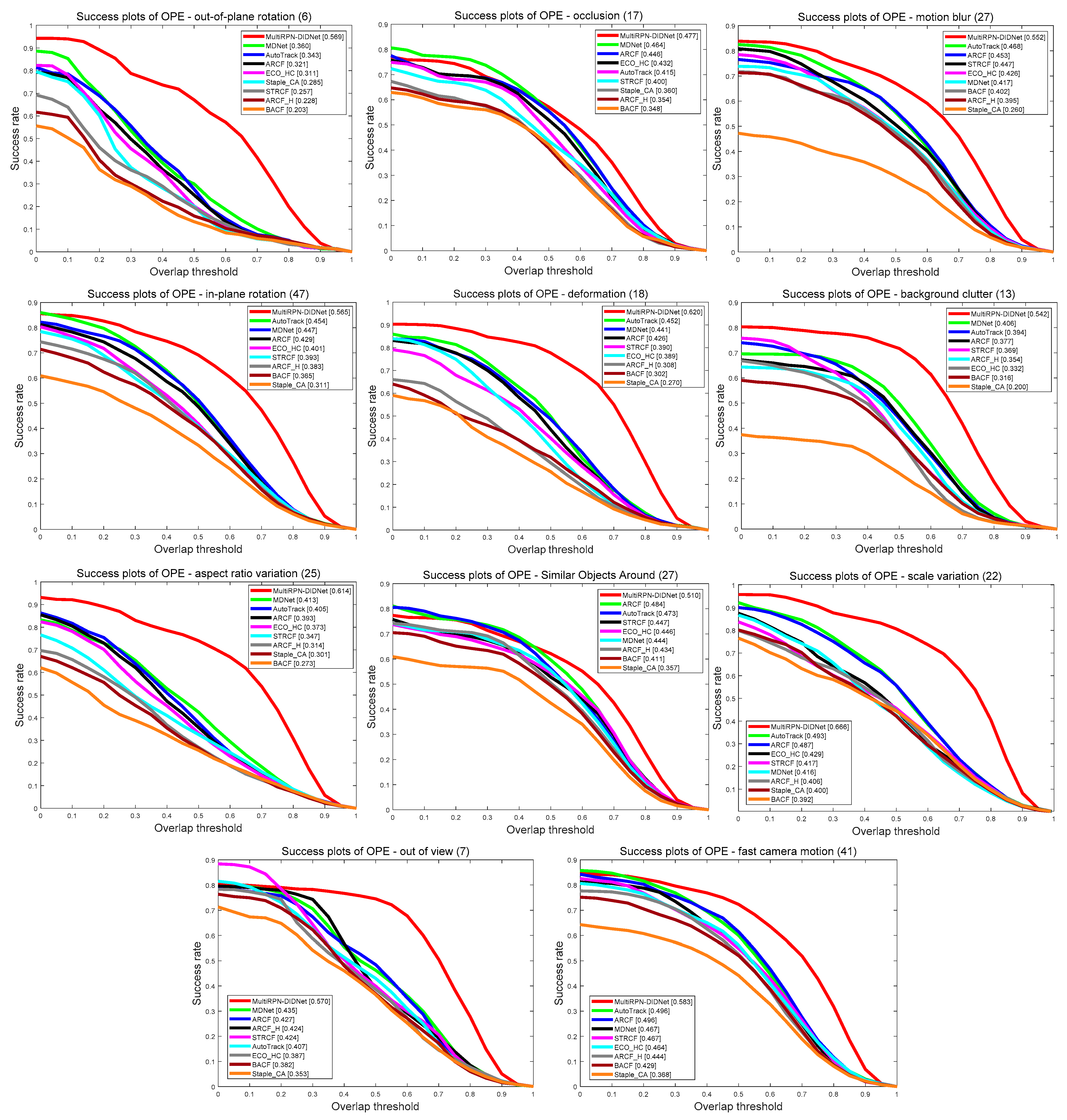
Figure 5.
AUC comparison results of several state-of-the-art trackers on the DTB70 dataset. From left to right and top to down are the success rate plots under OPR, OCC, MB, IPR, DEF, BC, ARV, SOA, SV, OV and FCM video attributes.
Figure 5.
AUC comparison results of several state-of-the-art trackers on the DTB70 dataset. From left to right and top to down are the success rate plots under OPR, OCC, MB, IPR, DEF, BC, ARV, SOA, SV, OV and FCM video attributes.
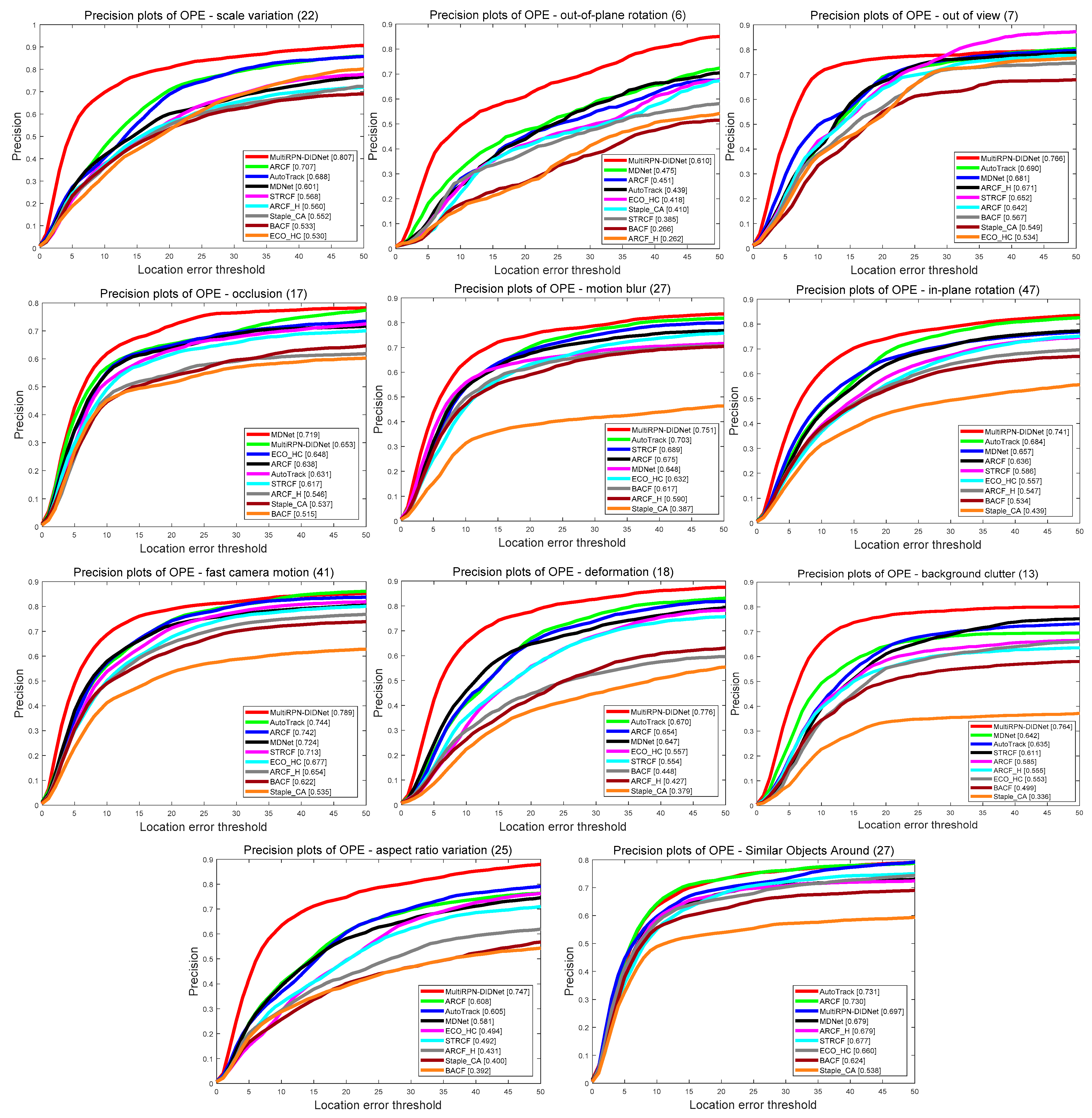
Figure 6.
Precision comparison results of several state-of-the-art trackers on the DTB70 dataset. From left to right and top to down are the precision plots of SV, OPR, OV, OCC, MB, IPR, FCM, DEF, BC, ARV, and SOA video attributes.
Figure 6.
Precision comparison results of several state-of-the-art trackers on the DTB70 dataset. From left to right and top to down are the precision plots of SV, OPR, OV, OCC, MB, IPR, FCM, DEF, BC, ARV, and SOA video attributes.
Figure 7.
Tracking results of the proposed tracker and other state-of-art trackers on the DTB70 dataset. From top to down and left to right are the screenshots of the tracking results on the videos of BMX3, BMX5, Hours1, Yatch4, RcCar4, and GULL1. The video sequences in (a), (b) and (c) mainly involve SV, ARV and IPR, OCC and SOA, MB, BA and FCM, respectively.
Figure 7.
Tracking results of the proposed tracker and other state-of-art trackers on the DTB70 dataset. From top to down and left to right are the screenshots of the tracking results on the videos of BMX3, BMX5, Hours1, Yatch4, RcCar4, and GULL1. The video sequences in (a), (b) and (c) mainly involve SV, ARV and IPR, OCC and SOA, MB, BA and FCM, respectively.
Table 1.
Comparison of the spatial resolution of the output feature map of ResNet50 before and after modification.
Table 1.
Comparison of the spatial resolution of the output feature map of ResNet50 before and after modification.
| Conv 1 | Block 1 | Block 2 | Block 3 | Block 4 |
|---|
| Original ResNet-50 | 128 × 128 | 64 × 64 | 32 × 32 | 16 × 16 | 8 × 8 |
| Modified ResNet-50 | 128 × 128 | 64 × 64 | 32 × 32 | 32 × 32 | 32 × 32 |
Table 2.
Parameter settings of RPN1.
Table 2.
Parameter settings of RPN1.
| Layers | Kernel Size | Stride | Output Size |
|---|
| Conv-1_1r | 3 × 3 | 1 | 32 × 32 × 256 |
| PrPool-1r | 7 × 7 | - | 7 × 7 × 256 |
| MaxPool-1r | 7 × 7 | 1 | 1 × 1 × 256 |
| AvgPool-1r | 7 × 7 | 1 | 1 × 1 × 256 |
| FC-1_1r | 256 × 16 | - | 1 × 16 |
| FC-1_2r | 16 × 256 | - | 1 × 256 |
| Conv-1_1t | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-Reg | 1 × 1 | 1 | 25 × 25 × (4 × 5) |
| Conv-2_1r | 3 × 3 | 1 | 32 × 32 × 256 |
| PrPool-2r | 7 × 7 | - | 7 × 7 × 256 |
| MaxPool-2r | 7 × 7 | 1 | 1 × 1 × 256 |
| AvgPool-2r | 7 × 7 | 1 | 1 × 1 × 256 |
| FC-2_1r | 256 × 16 | - | 1 × 16 |
| FC-2_2r | 16 × 256 | - | 1 × 256 |
| Conv-1_1t | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-Cls | 1 × 1 | 1 | 25 × 25 × (2 × 5) |
Table 3.
Parameter settings of DIoU discriminative network.
Table 3.
Parameter settings of DIoU discriminative network.
| Layers | Kernel Size | Stride | Output Size |
|---|
| Conv-1_1r | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-1_2r | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-1_3r | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-1_1r | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-1_2r | 3 × 3 | 1 | 32 × 32 × 256 |
| Conv-1_3r | 3 × 3 | 1 | 32 × 32 × 256 |
| PrPool | 5 × 5 | - | 5 × 5 × 256 |
| MaxPool | 5 × 5 | 1 | 1 × 1 × 256 |
| AvgPool | 5 × 5 | 1 | 1 × 1 × 256 |
| FC-1_1 | 256 × 16 | - | 1 × 16 |
| FC-1_2 | 16 × 256 | - | 1 × 256 |
| FC-IoU | 6400 × 1 | - | 1 × 1 |
| FC-NCD | 6400 × 1 | - | 1 × 1 |
Table 4.
Comparison results of the AUC score and DP score by using the proposed method and eleven state-of-the-art trackers on the UAV20L dataset.
Table 4.
Comparison results of the AUC score and DP score by using the proposed method and eleven state-of-the-art trackers on the UAV20L dataset.
| Tracker | Venue | AUC | DP |
|---|
| Ours | - | 54.1 | 72.8 |
| MS-Faster R-CNN [24] | Remote sens.2021 | 40.3 | 58.7 |
| SiamFCpp_googlenet [43] | AAAI2020 | 53.5 | 71.5 |
| AutoTrack [26] | CVPR2020 | 34.9 | 51.2 |
| SiamRPN++ [12] | CVPR2019 | 53.0 | 69.5 |
| ARCF [25] | ICCV2019 | 38.1 | 54.4 |
| ARCF_H [25] | ICCV2019 | 38.6 | 55.7 |
| STRCF [41] | CVPR2018 | 41.0 | 57.5 |
| KCC [38] | AAAI2018 | 32.4 | 48.3 |
| ECO_HC [40] | CVPR2017 | 37.7 | 49.8 |
| CSRDCF [39] | CVPR2017 | 35.0 | 50.1 |
| BACF [42] | ICCV2017 | 41.5 | 58.4 |
| MDNet [21] | CVPR2016 | 45.2 | 60.1 |
| SRDCF [4] | ICCV2015 | 34.3 | 50.7 |
Table 5.
AUC comparison results of the state-of-the-art trackers on the UAV20L dataset.
Table 5.
AUC comparison results of the state-of-the-art trackers on the UAV20L dataset.
| Tracker | SV | ARC | CM | FOC | IV | FM | LR | SOB | OV | POC | BC | VC |
|---|
| ours | 53.6 | 49.0 | 52.7 | 29.8 | 52.2 | 50.2 | 36.5 | 57.1 | 53.1 | 51.4 | 28.9 | 51.0 |
| SiamFCpp_googlenet [43] | 52.8 | 48.1 | 52.0 | 33.7 | 49.5 | 46.9 | 34.9 | 54.3 | 57.9 | 50.7 | 26.0 | 55.8 |
| AutoTrack [26] | 33.0 | 27.7 | 32.9 | 19.8 | 32.1 | 23.4 | 23.8 | 35.3 | 32.5 | 31.9 | 21.9 | 30.3 |
| ARCF [25] | 36.6 | 32.0 | 37.2 | 20.5 | 38.0 | 24.3 | 27.3 | 41.5 | 36.2 | 36.5 | 22.9 | 33.9 |
| ARCF_H [25] | 36.8 | 31.9 | 37.8 | 19.9 | 38.5 | 20.1 | 24.0 | 44.1 | 37.7 | 37.3 | 21.0 | 33.4 |
| STRCF [41] | 39.3 | 33.1 | 39.2 | 21.7 | 34.4 | 24.3 | 29.3 | 43.9 | 37.5 | 40.1 | 22.7 | 33.2 |
| KCC [38] | 30.8 | 24.9 | 30.8 | 15.9 | 29.4 | 19.5 | 21.9 | 35.1 | 30.6 | 29.8 | 16.0 | 27.9 |
| ECO_HC [40] | 36.0 | 28.9 | 35.7 | 16.3 | 33.3 | 21.9 | 26.0 | 44.5 | 37.3 | 34.9 | 13.3 | 35.3 |
| CSRDCF [39] | 33.4 | 29.4 | 33.6 | 21.1 | 35.8 | 19.3 | 23.4 | 38.4 | 31.0 | 32.8 | 22.7 | 30.9 |
| BACF [42] | 39.9 | 34.5 | 40.4 | 20.0 | 41.0 | 23.4 | 27.0 | 46.6 | 40.2 | 39.9 | 20.9 | 37.3 |
| MDNet [21] | 43.8 | 37.6 | 43.5 | 24.1 | 43.9 | 28.2 | 31.5 | 47.5 | 44.9 | 43.6 | 26.3 | 41.9 |
| SRDCF [4] | 33.2 | 27.0 | 32.7 | 17.0 | 29.5 | 19.7 | 22.8 | 39.7 | 32.9 | 32.0 | 15.6 | 30.3 |
Table 6.
Precision comparison results of the state-of-the-art trackers on the UAV20L dataset.
Table 6.
Precision comparison results of the state-of-the-art trackers on the UAV20L dataset.
| Tracker | SV | ARC | CM | FOC | IV | FM | LR | SOB | OV | POC | BC | VC |
|---|
| ours | 71.4 | 66.1 | 71.4 | 49.4 | 70.3 | 71.4 | 54.6 | 73.4 | 71.1 | 70.0 | 45.9 | 64.4 |
| SiamFCpp_googlenet [43] | 70.1 | 64.5 | 70.0 | 52.1 | 65.6 | 66.1 | 50.9 | 69.5 | 77.4 | 68.7 | 39.5 | 69.9 |
| AutoTrack [26] | 48.7 | 41.8 | 48.7 | 40.3 | 44.3 | 41.9 | 42.5 | 44.9 | 50.6 | 49.0 | 37.4 | 42.0 |
| ARCF [25] | 52.2 | 47.6 | 54.4 | 40.1 | 54.2 | 43.9 | 48.1 | 54.3 | 53.1 | 54.2 | 37.1 | 45.7 |
| ARCF_H [25] | 53.4 | 45.4 | 53.4 | 37.8 | 48.8 | 35.4 | 44.0 | 55.8 | 53.8 | 54.3 | 32.9 | 46.5 |
| STRCF [41] | 55.3 | 47.2 | 55.3 | 40.6 | 42.9 | 50.6 | 51.3 | 54.7 | 52.5 | 56.4 | 33.0 | 44.1 |
| KCC [38] | 45.6 | 35.6 | 45.6 | 32.6 | 33.8 | 35.3 | 42.4 | 46.6 | 45.9 | 45.8 | 24.7 | 37.5 |
| ECO_HC [40] | 47.1 | 37.5 | 47.1 | 33.9 | 39.1 | 35.9 | 43.6 | 51.8 | 49.5 | 47.6 | 23.5 | 42.3 |
| CSRDCF [39] | 48.6 | 43.0 | 47.5 | 40.3 | 51.4 | 37.7 | 41.5 | 49.5 | 43.5 | 46.3 | 37.7 | 43.5 |
| BACF [42] | 56.2 | 48.2 | 56.2 | 37.8 | 52.4 | 40.8 | 46.4 | 58.1 | 56.8 | 56.6 | 32.9 | 50.0 |
| MDNet [21] | 58.0 | 50.8 | 58.0 | 43.0 | 54.8 | 48.1 | 52.5 | 56.5 | 58.8 | 58.7 | 41.1 | 52.7 |
| SRDCF [4] | 48.1 | 38.9 | 48.2 | 33.1 | 41.1 | 32.7 | 42.9 | 52.2 | 52.5 | 49.1 | 25.2 | 41.4 |
Table 7.
Comparison results of the AUC score and the DP score between the proposed method and eight state-of-the-art trackers on the DTB70 dataset.
Table 7.
Comparison results of the AUC score and the DP score between the proposed method and eight state-of-the-art trackers on the DTB70 dataset.
| Tracker | Venue | AUC | DP |
|---|
| ours | - | 59.5 | 78.2 |
| AutoTrack [26] | CVPR2020 | 47.8 | 71.6 |
| ARCF [25] | ICCV2019 | 47.2 | 69.4 |
| ARCF_H [25] | ICCV2019 | 41.6 | 60.7 |
| STRCF [41] | CVPR2018 | 43.7 | 64.9 |
| ECO_HC [40] | CVPR2017 | 44.8 | 63.5 |
| Staple_CA [44] | CVPR2017 | 35.1 | 50.4 |
| BACF [42] | ICCV2017 | 39.8 | 58.1 |
| MDNet [21] | CVPR2016 | 45.6 | 69.0 |
Table 8.
Comparison of processing speed between the proposed method and other state-of-art object tracking methods on the UAV20L dataset.
Table 8.
Comparison of processing speed between the proposed method and other state-of-art object tracking methods on the UAV20L dataset.
| Ours | KCC | SRDCF | AutoTrack | CSRDCF | ECO_HC | ARCF_H | STRCF | BACF |
|---|
| FPS | 33.9 | 29.2 | 7.5 | 44.8 | 9.53 | 51.83 | 31.8 | 17.4 | 32.0 |
Table 9.
Comparison of processing speed between the proposed method and other state-of-art object tracking methods on the DTB70 dataset.
Table 9.
Comparison of processing speed between the proposed method and other state-of-art object tracking methods on the DTB70 dataset.
| Ours | STRCF | AutoTrack | ECO_HC | ARCF_H | BACF | Staple_CA |
|---|
| FPS | 33.0 | 21.9 | 48.6 | 51.9 | 37.1 | 37.7 | 50.66 |
Table 10.
Inner module ablation study by comparing the proposed method and the variants of our method on the UAVDT dataset.
Table 10.
Inner module ablation study by comparing the proposed method and the variants of our method on the UAVDT dataset.
| AUC | DP | BC | CR | OR | SO | IV | OB | SV | LO |
|---|
| Single RPN | 38.5 | 69.4 | 35.2 | 38.6 | 34.3 | 38.7 | 38.0 | 38.5 | 35.5 | 37.5 |
| Multiple RPNs | 60.4 | 81.4 | 53.0 | 55.5 | 58.6 | 55.7 | 62.6 | 62.7 | 61.6 | 52.2 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}