
A Multi-Task Network with Distance–Mask–Boundary Consistency Constraints for Building Extraction from Aerial Images


Abstract
:
1. Introduction
- (1)
- A multi-scale and multi-task network is proposed for building extraction, consisting of a primary task for building-mask segmentation and two auxiliary tasks for distance and boundary prediction. The proposed network has the advantage of compensating for the loss of shape information by capturing specific geometric features (i.e., distance and boundary information).
- (2)
- The consistency constraints crossing the three tasks (i.e., distance, mask, and boundary predictions) for building information are considered and constructed in the proposed multi-task network. Such consistency constraints exploit the duality between the mask prediction and two shape-related information predictions, and further improve the building segmentation performance.
- (3)
- Compared with existing methods, the proposed method achieves superior performance on both mask- and boundary-based accuracy metrics. Meanwhile, the constructed consistency constraint model can be readily plugged into existing basic segmentation networks.
2. Related Works
2.1. DCNN-Based Semantic Segmentation
2.2. Shape-Aware Segmentation
2.3. Building Extraction from Aerial Images
3. Methodology
3.1. Preliminaries
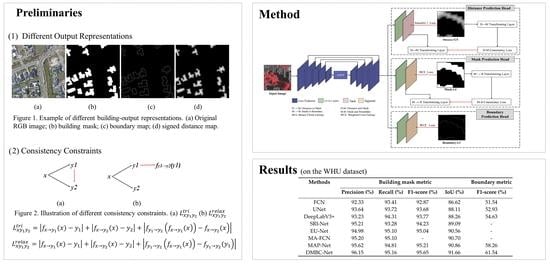
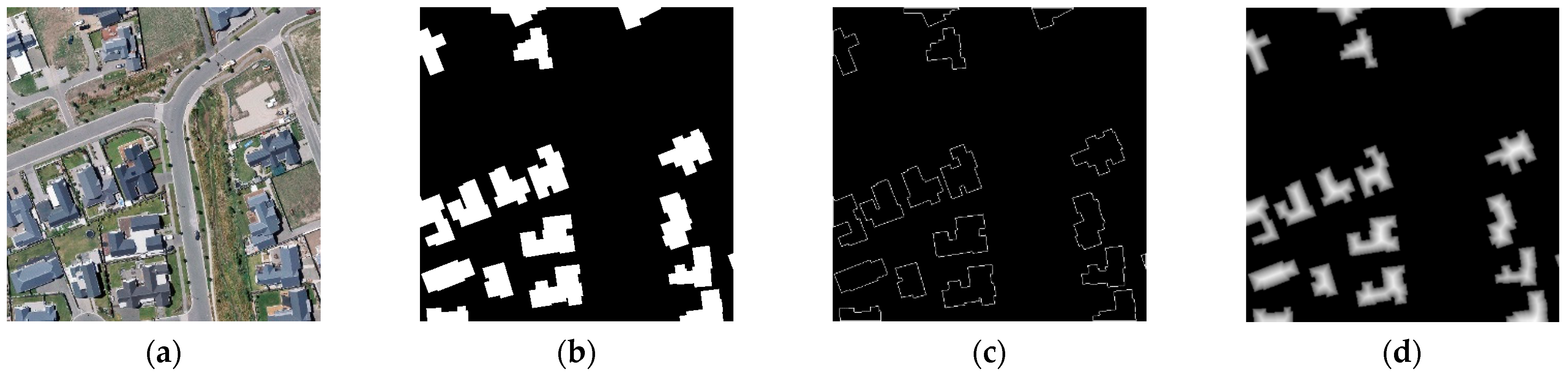
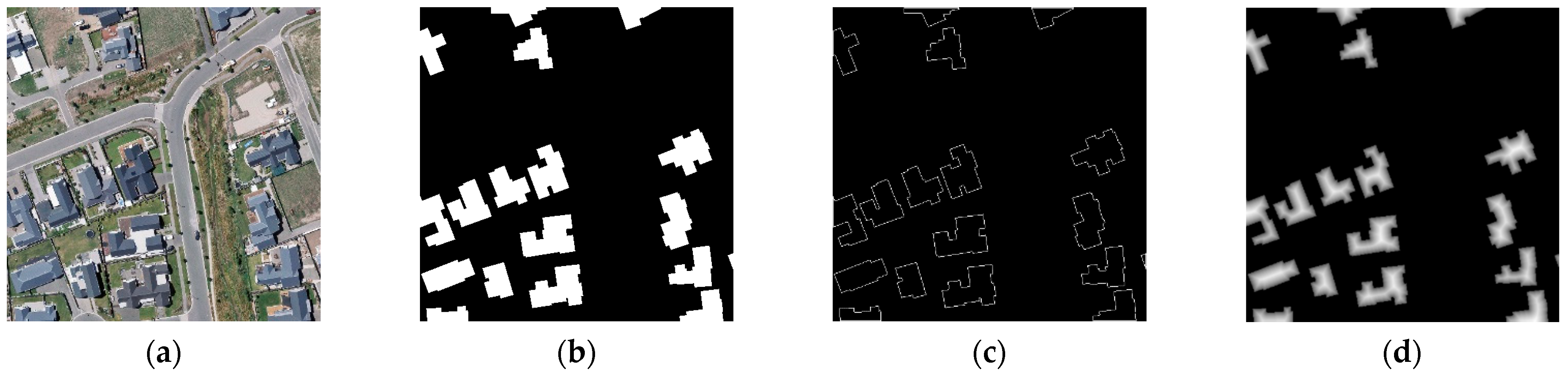
3.1.1. Different Output Representations
3.1.2. Consistency Constraints
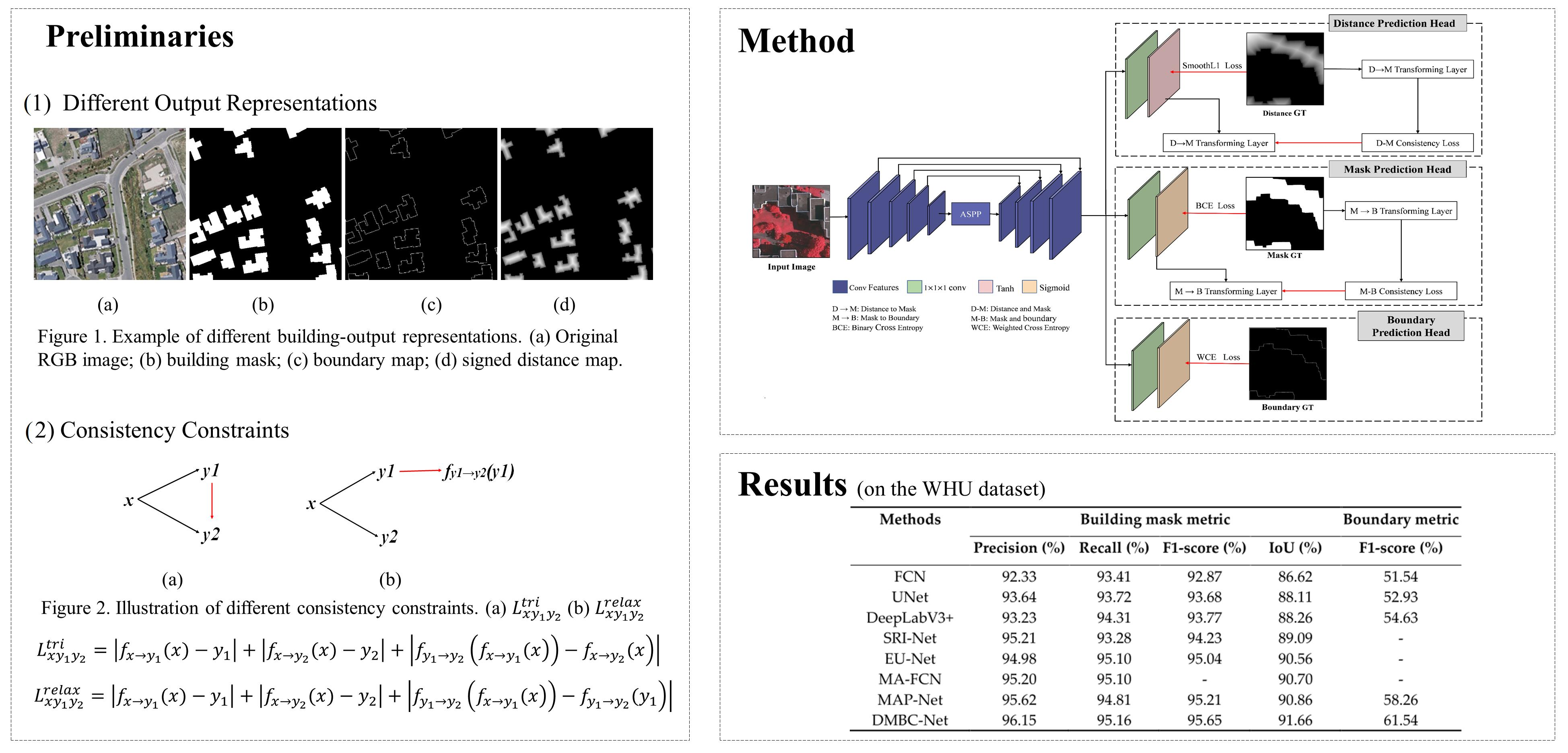
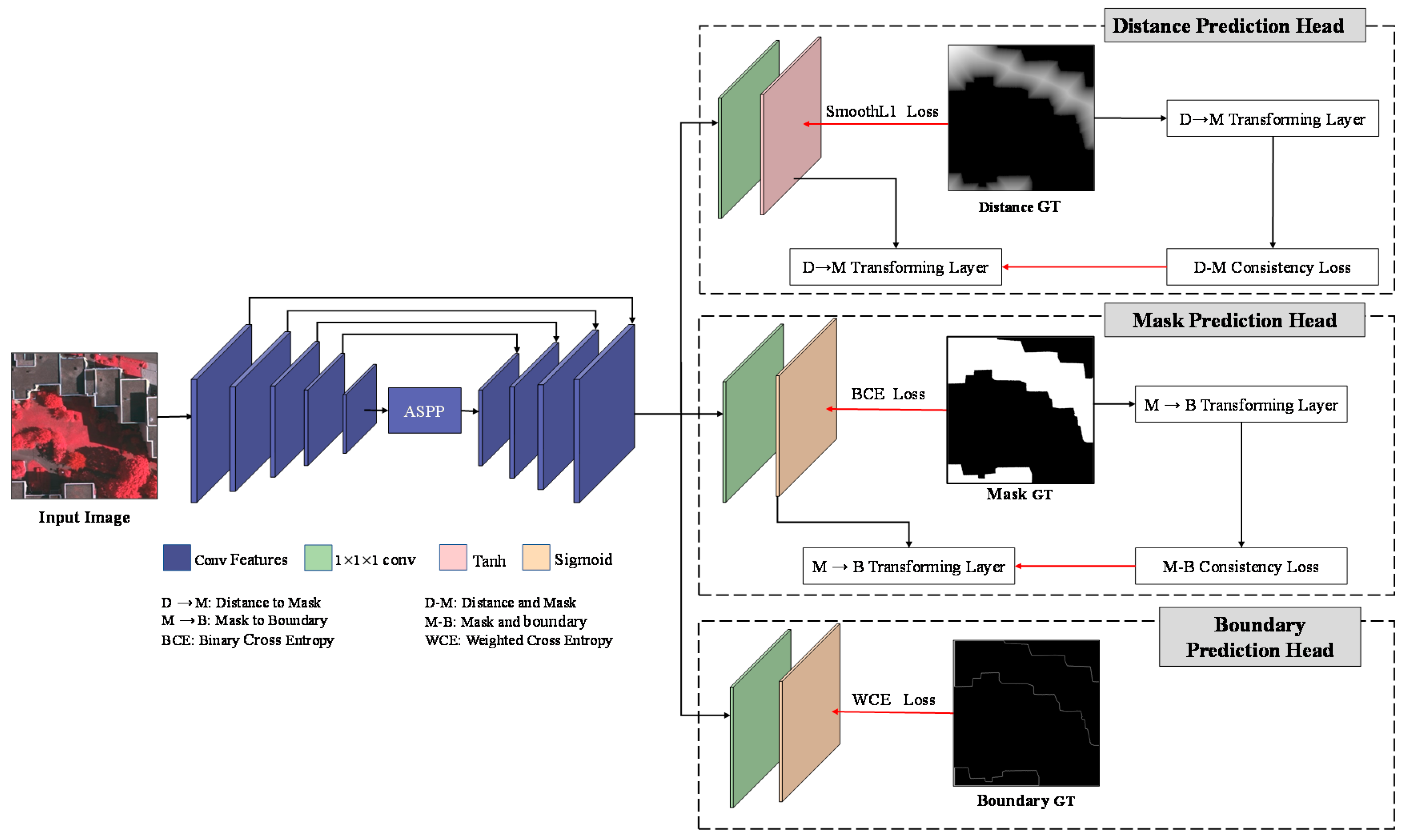
3.2. Overall Architecture
3.3. Distance–Mask Consistency Constraint
3.4. Mask–Boundary Consistency Constraint
3.5. Overall Training Loss Function
4. Experimental Results and Discussion
4.1. Datasets and Implementation Details
4.2. Evaluation Metrics
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Experiments for Inter-Task Consistency Constraints
- (1)
- Mask-Net: Only including the branch for building-mask-prediction task.
- (2)
- DMB-Net (Distance + Mask + Boundary): Including three branches for the distance-, mask-, and boundary-prediction tasks simultaneously.
- (3)
- DMBC-Net (Distance + Mask + Boundary + +): The proposed complete module with two inter-task consistency constraints.
4.5. Ablation Experiments for Different Base Networks
4.6. Efficiency Analysis
4.7. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jun, W.; Qiming, Q.; Xin, Y.; Jianhua, W.; Xuebin, Q.; Xiucheng, Y. A Survey of Building Extraction Methods from Optical High Resolution Remote Sensing Imagery. Remote Sens. Technol. Appl. 2016, 31, 653–662. [Google Scholar]
- Wang, X.; Li, P. Extraction of urban building damage using spectral, height and corner information from VHR satellite images and airborne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2020, 159, 322–336. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint Learning of Contour and Structure for Boundary-Preserved Building Extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Jin, Y.; Xu, W.; Zhang, C.; Luo, X.; Jia, H. Boundary-Aware Refined Network for Automatic Building Extraction in Very High-Resolution Urban Aerial Images. Remote Sens. 2021, 13, 692. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2018, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 519–534. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Lin, L.; Jian, L.; Min, W.; Haihong, Z. A Multiple-Feature Reuse Network to Extract Buildings from Remote Sensing Imagery. Remote Sens. 2018, 10, 1350. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2017, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Meng, G.; Xiang, S.; Pan, C. FusionNet: Edge aware deep convolutional networks for semantic segmentation of remote sensing harbor images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2017, 10, 5769–5783. [Google Scholar] [CrossRef]
- Liu, S.; Ding, W.; Liu, C.; Liu, Y.; Wang, Y.; Li, H. ERN: Edge loss reinforced semantic segmentation network for remote sensing images. Remote Sens. 2018, 10, 1339. [Google Scholar] [CrossRef] [Green Version]
- He, S.; Jiang, W. Boundary-Assisted Learning for Building Extraction from Optical Remote Sensing Imagery. Remote Sens. 2021, 13, 760. [Google Scholar] [CrossRef]
- Zheng, X.; Huan, L.; Xia, G.S.; Gong, J. Parsing very high resolution urban scene images by learning deep ConvNets with edge-aware loss. ISPRS J. Photogramm. Remote Sens. 2020, 170, 15–28. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Hui, J.; Du, M.; Ye, X.; Qin, Q.; Sui, J. Effective building extraction from high-resolution remote sensing images with multitask driven deep neural network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 786–790. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yang, J.; Price, B.; Cohen, S.; Lee, H.; Yang, M.H. Object contour detection with a fully convolutional encoder-decoder network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 193–202. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Bertasius, G.; Shi, J.; Torresani, L. Semantic segmentation with boundary neural fields. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3602–3610. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar] [CrossRef] [Green Version]
- Hatamizadeh, A.; Terzopoulos, D.; Myronenko, A. Edge-gated CNNs for volumetric semantic segmentation of medical images. arXiv 2020, arXiv:2002.04207. [Google Scholar]
- Zimmermann, R.S.; Siems, J.N. Faster training of Mask R-CNN by focusing on instance boundaries. Comput. Vis. Image Underst. 2019, 188, 102795. [Google Scholar] [CrossRef] [Green Version]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-Preserving Mask R-CNN. Trans. Petri Nets Other Models Concurr. XV 2020, 660–676. [Google Scholar] [CrossRef]
- Yuan, J. Learning building extraction in aerial scenes with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2793–2798. [Google Scholar] [CrossRef] [PubMed]
- Chai, D.; Newsam, S.; Huang, J. Aerial image semantic segmentation using DCNN predicted distance maps. ISPRS J. Photogramm. Remote Sens. 2020, 161, 309–322. [Google Scholar] [CrossRef]
- Hayder, Z.; He, X.; Salzmann, M. Boundary-aware instance segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5696–5704. [Google Scholar]
- Wang, Y.; Wei, X.; Liu, F.; Chen, J.; Zhou, Y.; Shen, W.; Fishman, E.K.; Yuille, A.L. Deep distance transform for tubular structure segmentation in CTscans. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3833–3842. [Google Scholar]
- Kim, T.; Muller, J.-P. Development of a graph-based approach for building detection. Image Vis. Comput. 1999, 17, 3–14. [Google Scholar] [CrossRef]
- Femiani, J.; Li, E.; Razdan, A.; Wonka, P. Shadow-based rooftop segmentation in visible band images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2014, 8, 2063–2077. [Google Scholar] [CrossRef]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust rooftop extraction from visible band images using higher order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Turker, M.; Koc-San, D. Building extraction from high-resolution optical spaceborne images using the integration of support vector machine (SVM) classification, Hough transformation and perceptual grouping. Int. J. Appl. Earth Obs. 2015, 34, 58–69. [Google Scholar] [CrossRef]
- Guo, Z.; Chen, Q.; Wu, G.; Xu, Y.; Shibasaki, R.; Shao, X. Village building identification based on ensemble convolutional neural networks. Sensors 2017, 17, 2487. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Z.; Shao, X.; Xu, Y.; Miyazaki, H.; Ohira, W.; Shibasaki, R. Identification of village building via Google Earth images and supervised machine learning methods. Remote Sens. 2016, 8, 271. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Wei, S.; Ji, S.; Lu, M. Toward automatic building footprint delineation from aerial images using CNN and regularization. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2178–2189. [Google Scholar] [CrossRef]
- Kang, W.; Xiang, Y.; Wang, F.; You, H. EU-net: An efficient fully convolutional network for building extraction from optical remote sensing images. Remote Sens. 2019, 11, 2813. [Google Scholar] [CrossRef] [Green Version]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple attending path neural network for building footprint extraction from remote sensed imagery. IEEE Trans. Geosci. Remote Sens. 2020. [Google Scholar] [CrossRef]
- Zamir, A.R.; Sax, A.; Cheerla, N.; Suri, R.; Cao, Z.; Malik, J.; Guibas, L.J. Robust Learning Through Cross-Task Consistency. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11194–11203. [Google Scholar] [CrossRef]
- ISPRS 2D Semantic Labeling Contest. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 7 July 2018).
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Xie, Y.; Zhu, J.; Cao, Y.; Feng, D.; Hu, M.; Li, W.; Zhang, Y.; Fu, L. Refined extraction of building outlines from high-resolution remote sensing imagery based on a multi feature convolutional neural network and morphological filtering. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 1842–1855. [Google Scholar] [CrossRef]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 724–732. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
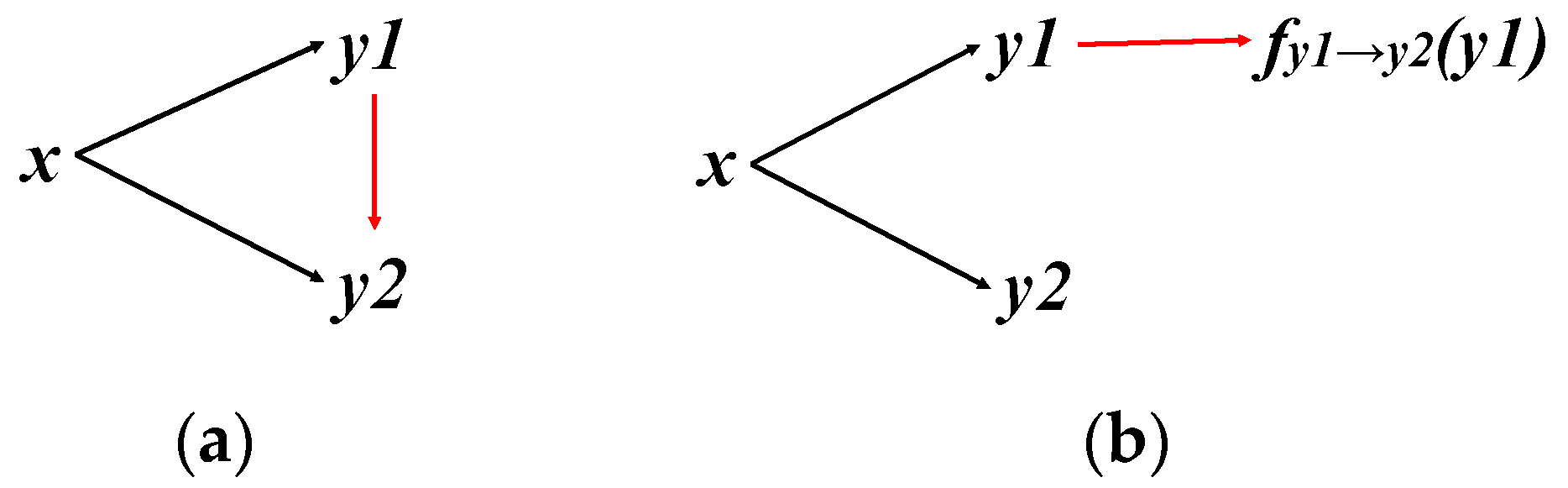










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Building-Mask Metric | Boundary Metric | |||
|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | F1-Score (%) | |
| FCN [21] | 92.33 | 93.41 | 92.87 | 86.62 | 51.54 |
| UNet [7] | 93.64 | 93.72 | 93.68 | 88.11 | 52.93 |
| DeepLabV3+ [24] | 93.23 | 94.31 | 93.77 | 88.26 | 54.63 |
| SRI-Net [57] | 95.21 | 93.28 | 94.23 | 89.09 | - |
| EU-Net [48] | 94.98 | 95.1 | 95.04 | 90.56 | - |
| MA-FCN [47] | 95.2 | 95.1 | - | 90.7 | - |
| MAP-Net [51] | 95.62 | 94.81 | 95.21 | 90.86 | 58.26 |
| DMBC-Net | 96.15 | 95.16 | 95.65 | 91.66 | 61.54 |
| Methods | Building-Mask Metric | Boundary Metric | |||
|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | F1-Score (%) | |
| FCN [21] | 93.57 | 89.43 | 91.45 | 84.26 | 44.41 |
| UNet [7] | 93.55 | 91.24 | 92.38 | 85.84 | 47.28 |
| DeepLabV3+ [24] | 93.86 | 91.83 | 92.83 | 86.63 | 48.86 |
| MAP-Net [51] | 94.01 | 92.98 | 93.49 | 87.78 | 49.82 |
| DMBC-Net | 94.78 | 93.91 | 94.34 | 89.28 | 51.43 |
| Methods | Building-Mask Metric | Boundary Metric | |||
|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | F1-Score (%) | |
| UNet [7] | 87.07 | 85.93 | 86.50 | 76.20 | 35.96 |
| DeepLabV3+ [24] | 88.23 | 85.83 | 87.01 | 77.02 | 37.04 |
| MCFNN [55] | 88.58 | 87.91 | 88.38 | 79.35 | - |
| EU-Net [48] | 90.28 | 88.14 | 89.20 | 80.50 | - |
| DMBC-Net | 89.94 | 88.77 | 89.35 | 80.74 | 39.05 |
| Network | Mask IoU (%) | Boundary F1-Score (%) | |||
|---|---|---|---|---|---|
| Distance Thresholds (Pixels) | |||||
| 1 | 3 | 5 | 7 | ||
| Mask-Net | 89.70 | 57.85 | 82.28 | 88.82 | 90.32 |
| DMB-Net | 90.77 | 60.09 | 84.27 | 89.36 | 91.01 |
| DMBC-Net | 91.66 | 61.54 | 85.83 | 90.56 | 92.05 |
| Base Network | Inter-Task Consistency Constraints | Building-Mask Metric | Boundary Metric | |||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | F1-Score (%) | ||
| FCN | 🗶 | 92.33 | 93.41 | 92.87 | 86.62 | 51.54 |
| 🗸 | 93.20 | 94.54 | 93.87 | 88.44 | 53.51 | |
| UNet | 🗶 | 93.64 | 93.72 | 93.68 | 88.11 | 52.93 |
| 🗸 | 94.75 | 94.84 | 94.79 | 90.10 | 58.25 | |
| DeepLabV3+ | 🗶 | 93.23 | 94.31 | 93.77 | 88.26 | 54.63 |
| 🗸 | 94.98 | 94.82 | 94.90 | 90.29 | 58.37 | |
| UNet + ASPP | 🗶 | 94.93 | 94.21 | 94.57 | 89.70 | 57.85 |
| 🗸 | 96.15 | 95.16 | 95.65 | 91.66 | 61.54 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, F.; Zhang, T. A Multi-Task Network with Distance–Mask–Boundary Consistency Constraints for Building Extraction from Aerial Images. Remote Sens. 2021, 13, 2656. https://doi.org/10.3390/rs13142656
Shi F, Zhang T. A Multi-Task Network with Distance–Mask–Boundary Consistency Constraints for Building Extraction from Aerial Images. Remote Sensing. 2021; 13(14):2656. https://doi.org/10.3390/rs13142656
Chicago/Turabian StyleShi, Furong, and Tong Zhang. 2021. "A Multi-Task Network with Distance–Mask–Boundary Consistency Constraints for Building Extraction from Aerial Images" Remote Sensing 13, no. 14: 2656. https://doi.org/10.3390/rs13142656
APA StyleShi, F., & Zhang, T. (2021). A Multi-Task Network with Distance–Mask–Boundary Consistency Constraints for Building Extraction from Aerial Images. Remote Sensing, 13(14), 2656. https://doi.org/10.3390/rs13142656