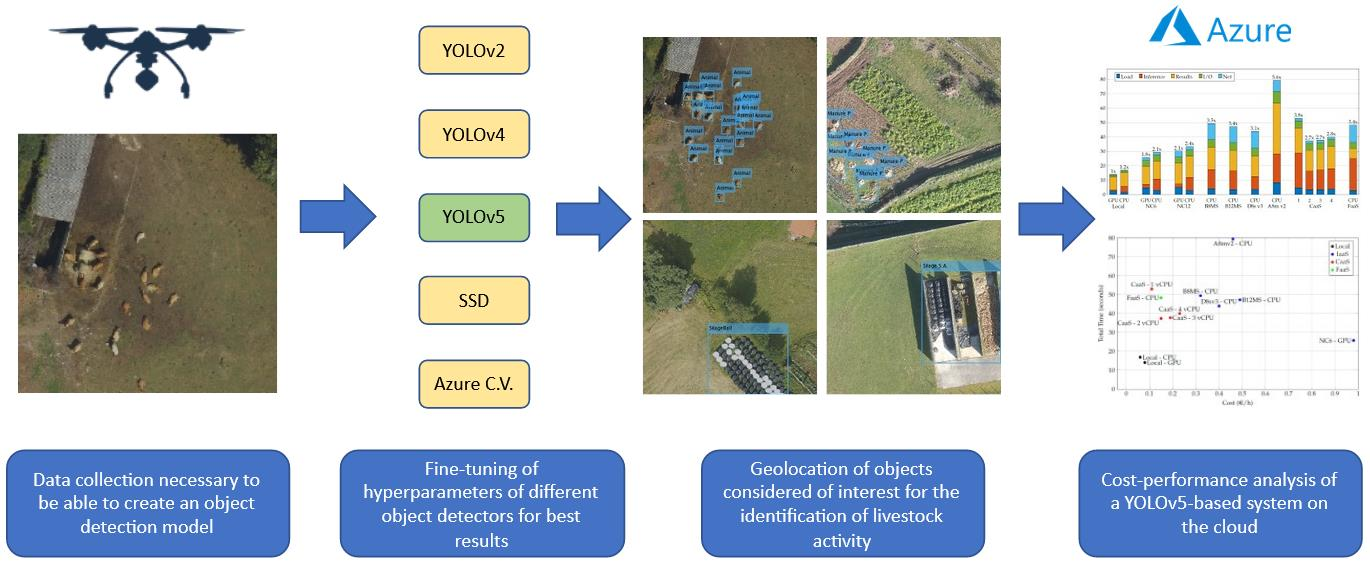
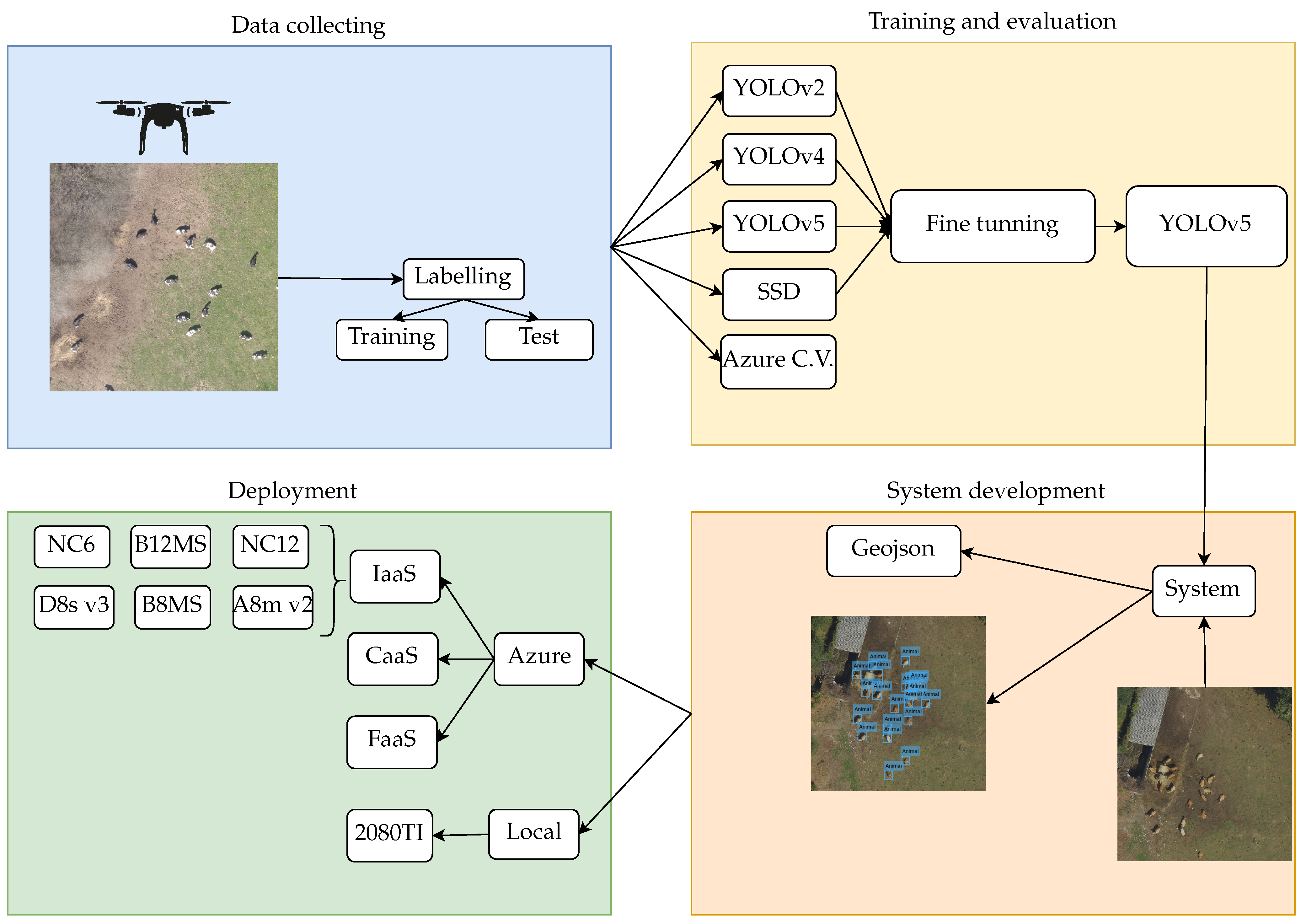
The objective of this work is the creation of a service to document the presence of livestock activity on a given piece of land. To achieve this, it is necessary to select the best model from the evaluated object detector algorithms, and the best deployment infrastructure.
3.1. Evaluation Metrics
In order to evaluate the accuracy performance of an object detector, it is necessary to define the most commonly used metrics. All of these metrics are based on:
True Positives or TPs: number of objects detected correctly.
False Positives or FPs: number of objects detected incorrectly.
False Negatives or FNs: number of undetected objects.
In the object detection context, True Negatives or TNs are not taken into account because there are infinite bounding boxes that should not be detected in any image. To classify a detection as TP or FP, it is important to define what a correct detection is. If a detection does not match 100% with its respective ground truth, it does not necessarily mean that the detection is not correct. To resolve this issue, intersection over union (IOU) is used. IOU is defined as (
1), and it is used to compare two regions: the bounding box produced by the detection (D) and the ground truth bounding box (G). If the IOU calculated is over a predefined threshold (the most common value in the literature is 0.5), the detection is correct (TP); otherwise, it is incorrect (FP). After computing all the TPs, FPs, and FNs, it is possible to calculate Precision and Recall. Precision, shown in (
2), measures how reliable the detections are and is calculated as the percentage of correct detections (TPs) over all the detections made (
). Recall, shown in (
3), measures the probability of ground truth objects being correctly detected and is calculated as the percentage of correct detection (TPs) over all the objects annotated in the ground truth (
):
A detection provided by a trained model is composed of the bounding box coordinates and a confidence score. The confidence score is used to determine how secure the model is regarding each specific detection. By using this confidence score, the detections can be sorted in descending order and the precision–recall curves for each class can be calculated.
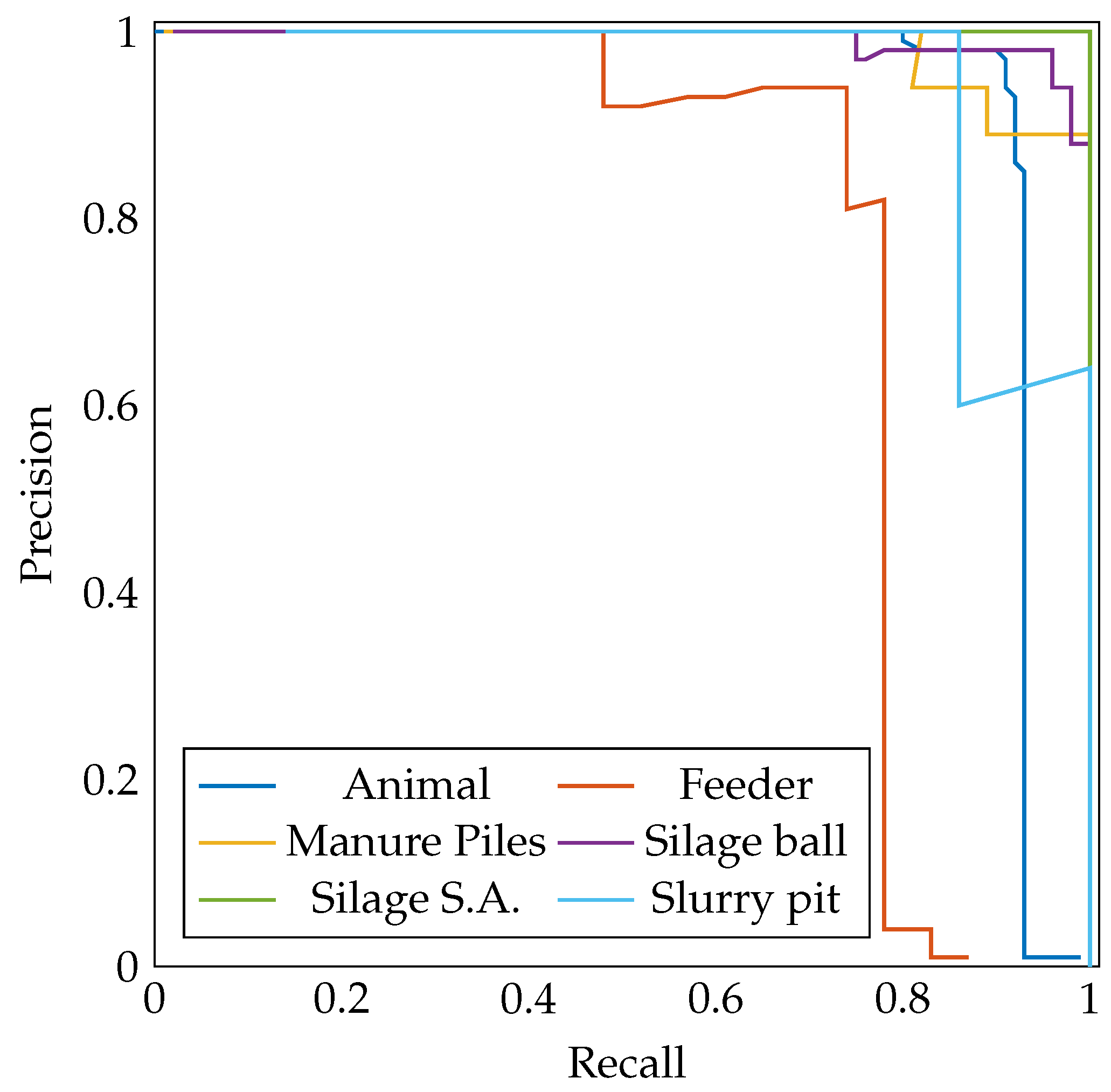
Figure 4 shows the precision–recall curve for each class obtained with YOLOv5. From these curves, the average precision, AP, can be calculated. The AP, which is represented with a number between 0 and 1, summarizes the precision–recall curve by averaging precision across different recall values. Conceptually, it represents the area under the precision–recall curve. If there is a large number of classes, it may be difficult to compare several object detectors, as there is an AP value for each class. In this case, the mean average precision (mAP) is used. The mean average precision, which is defined in (
4), is the result of averaging the AP for each class. AP and mAP has several forms of calculation [
31]:
AP(
): AP with
is used in PASCAL VOC [
32] and measures the area under the precision–recall curve by using the all-point interpolation method.
AP@.5 or AP@.75: are common metrics used in COCO [
11] that are measured using an interpolation with 101 recall points. The difference between AP@.5 and AP@.75 is the IOU threshold used.
AP@[.5:.05:.95]: uses the same interpolation method as AP@.5 and AP@.75, but averages the APs obtained from using ten different IOU thresholds (0.5, 0.55, …, 0.95).
AP Across Scales: applies AP@[.5:.05:.95] taking into consideration the size of the ground truth objects. computes AP@[.5:.05:.95] with small ground truth bounding boxes (), computes AP@[.5:.05:.95] with medium ground truth bounding boxes () and computes AP@[.5:.05:.95] with large ground truth bounding boxes ().
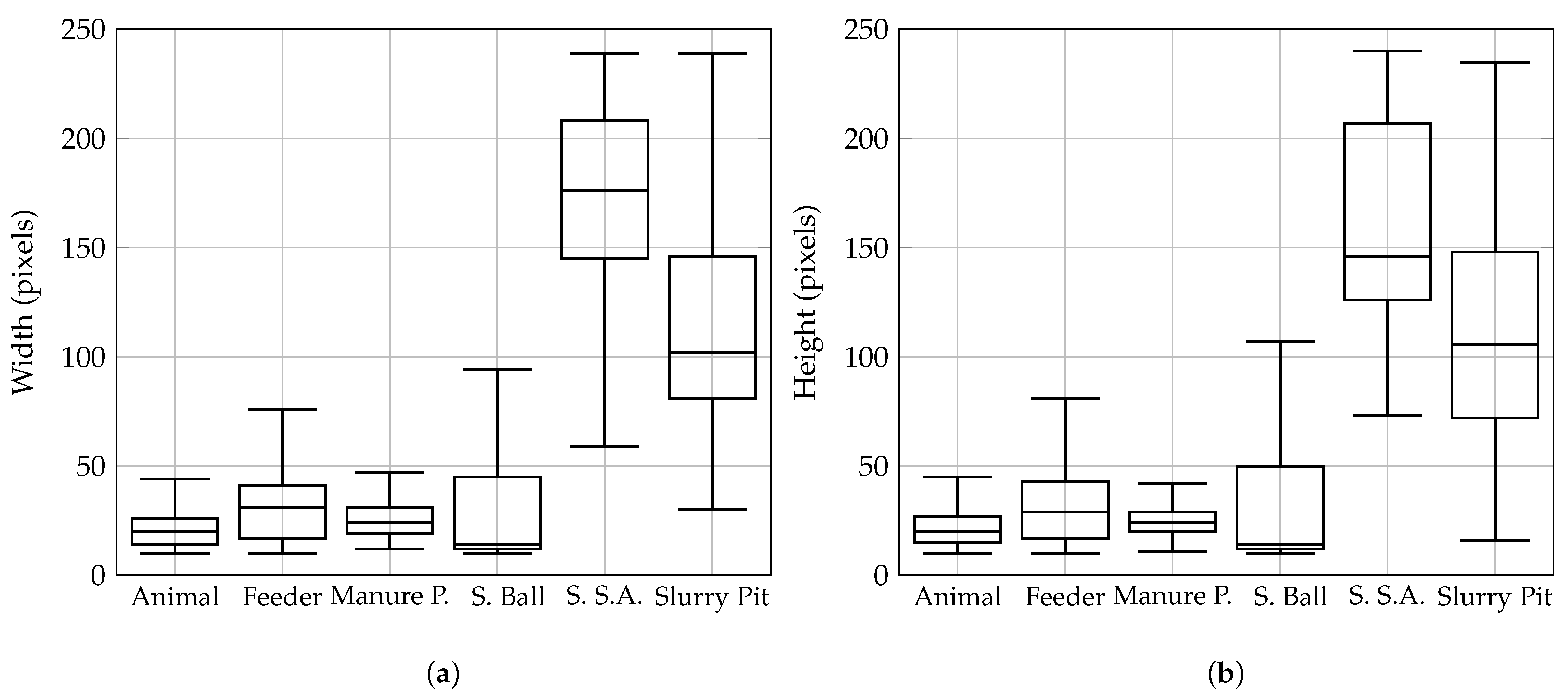
AP Across scales is useful when the dataset has different object sizes and aspect ratios, but as can be seen in
Figure 3a,b, there is little intra-class size variability. AP@[.5:.05:.95] is a robust metric but cannot be configured to work with a fixed IOU threshold. For these reasons, in this work, AP@.5 is used to compare several object detectors. After several experiments in which hyperparameters were tuned manually, the best configurations are:
YOLOv2:
- -
Anchor boxes: five are used: ((36, 36), (152, 146), (21, 18), (68, 70), (13, 17)).
- -
Backbone: Resnet50.
- -
Epochs: 30.
- -
Batch size: 16.
- -
Learning rate: 0.0001.
- -
Weight decay: 0.0001.
- -
Solver: Adam.
- -
Data augmentation: image color (contrast, hue, saturation brightness), flips and scale changes.
YOLOv4:
- -
Anchor boxes: nine are used: ((13, 13), (14, 25), (22, 18), (23, 33), (40, 37), (130, 19), (61, 64), (61, 94), (123, 84)).
- -
Backbone: CSPDarknet-53.
- -
Epochs: 500.
- -
Batch size: 32.
- -
Learning rate: 0.001.
- -
Weight decay: 0.0005.
- -
Solver: SGD with momentum 0.937.
- -
Data augmentation: image color (contrast, hue, saturation brightness), flips, scale changes and mosaic data augmentation.
YOLOv5:
- -
Anchor boxes: nine are used: ((13, 13), (14, 25), (22, 18), (23, 33), (40, 37), (130, 19), (61, 64), (61, 94), (123, 84)).
- -
Backbone: CSPDarknet-53.
- -
Model: S. YOLOv5 offers four models: small (S), medium (M), large (L), and extra-large (X). The larger the model, the more accurate it is, but the speed of inference is lost. In the dataset used, no improvement in accuracy is obtained by using the larger models, so small (S) is used.
- -
Epochs: 500.
- -
Batch size: 32.
- -
Learning rate: 0.001.
- -
Weight decay: 0.0005.
- -
Solver: Adam.
- -
Data augmentation: image color (contrast, hue, saturation brightness), flips, scale changes, and mosaic data augmentation.
SSD:
- -
Backbone: Resnet18.
- -
Epochs: 40.
- -
Batch size: 32.
- -
Learning rate: 0.001.
- -
Weight decay: 0.0005.
- -
Solver: SGD with momentum 0.9.
- -
Data augmentation: original SSD augmentation [
8].
With these configurations, the APs per class are shown in
Table 5. YOLOv5 clearly outperforms YOLOv2, SSD, and Azure Custom Vision and slightly outperforms YOLOv4; therefore, the service developed uses this object detection algorithm. It is important to highlight that the number of silage storage areas and slurry pits in the test set is too low, as can be seen in
Table 4; thus, the APs obtained for these classes may not be accurate. Except for the feeder class, with YOLOv5, the AP of each class exceeds 0.90. Regarding the rest of the object detection algorithms, in the animal and manure pile class, there are no major differences between YOLOv2, SSD, and Azure Custom Vision, YOLOv2 being 2% better in the case of the animal class. With respect to the manure pile class, significant differences are obtained, Azure Custom Vision being the best performer, approaching YOLOv4 and YOLOv5 with an AP of 0.95 and followed by YOLOv2 with 0.78. SSD produces poor results for this class. The results for silage balls are similar with all detectors, although Azure Custom Vision offers the worst results with an AP of 0.79. SSD produces the best results for the silage storage area and slurry pit classes, with the exception of YOLOv4 and YOLOv5.
Figure 5 shows a visual comparison among the different algorithms evaluated. Since the objective is to find the detector that generates the best overall results, it is important to analyze the mAP. Among YOLOv2, SSD, and Azure Custom Vision, there are no significant differences, although Azure Custom Vision obtains a higher mAP than YOLOv2 and SSD. As there are not major differences between YOLOv4 and YOLOv5, the decision is given by the difference in training time, since, with YOLOv5, the training takes one hour, while, with YOLOv4, it takes three hours. In addition, the weights generated with YOLOv5 (model S) take 14 MB, while those with YOLOv4 take 421 MB. Due to this difference, which may influence the deployment, it is decided to select YOLOv5 as the object detector to carry out the livestock activity recognition service. To ensure that the partitioning of the dataset (training and testing) does not affect the results, cross testing was carried out using four subsets. The results obtained are equivalent to those shown in
Table 5.
Figure 6 shows some detections over the test set performed with YOLOv5.
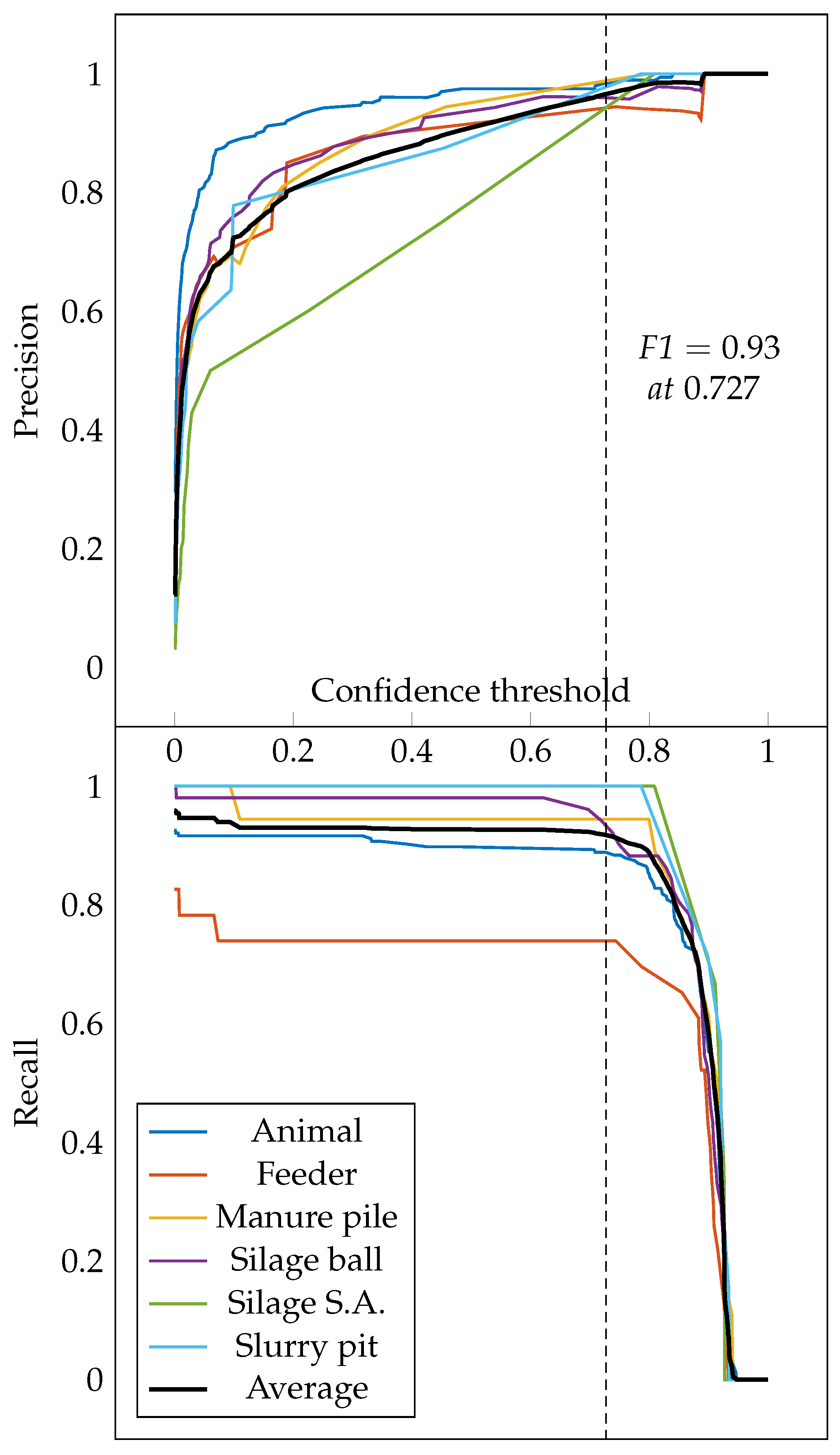
The AP (and all its variants) is a good metric to compare different models, since it computes the area under the precision–recall curve regardless of the confidence obtained. However, once the model is in production, it is necessary to perform the appropriate detections using a certain confidence level. To determine the confidence threshold, it is common to use the metric known as F-Score (F1) (the harmonic mean of precision and recall) defined as (
5). F1 combines precision (P) and recall (R) over a single confidence threshold. As shown in
Figure 7, as confidence increases, precision increases and recall decreases. The objective is to find the confidence threshold that maximizes F1 at all classes. In this case, with a confidence of 0.727, a precision of 0.96 and a recall of 0.91 are obtained; therefore, the F1 value is 0.93. For these reasons, a confidence threshold of 0.727 is established in the tests performed. When the objective is to minimize the number of FPs, the confidence threshold should be increased. When the aim is to detect all possible objects, and the generation of PFs is not important, the confidence threshold can be lowered. It is common for an object detector to produce more than one bounding box per object; therefore, non-maximal suppression (NMS) is used to remove all redundant bounding boxes. During the NMS process, it is necessary to establish a threshold, and, in the case that the IOU among two or more predicted bounding boxes is greater than this NMS threshold, the bounding boxes with less confidence must be removed. In the dataset used, this fact is not a problem, since, as can be seen in
Figure 6, object overlapping is not a problem. For this reason, the NMS threshold used is 0.5.
3.2. Service Deployment
In terms of deployment infrastructure, it is necessary to analyze the system under test (SUT). The SUT is evaluated in terms of the time elapsed between the client sending a request to the server, and the client receiving the response from the server. In order to simulate the actual operation of a service, two scenarios are tested. In the first one, a batch of one hundred images is used, and, in the second, one single 10,000 × 10,000 image. A local client and server are used to evaluate the SUT under same conditions as in training. This local environment is composed of two computers (client and server) with the following hardware: an Intel Core i7 9700 K CPU, 64 GB of RAM and a GeForce RTX 2080 Ti Turbo GPU. Apart from evaluating a local infrastructure, several cloud infrastructures are also evaluated for which purpose an Azure Virtual Machine is set up in the eastern US as a client and several servers in western Europe. The infrastructures evaluated in Azure as servers are classified into three types:
IaaS: Infrastructure as a Service is a type of service where the provider rents the infrastructure and gives almost all control to the customer, making it possible to install and run a wide range of software. Normally, the cost is calculated per hour. The virtual machines evaluated are: NC6, NC12, B8MS, B12MS, D8s v3, and A8m v2.
CaaS: Container as a Service is a form of container-based virtualization. All the set up and orchestration is given to users as a service. Azure offers GPU-based CaaS, but its support is currently limited to CUDA 9. In this case, CUDA 11 is being used, so the CaaS infrastructure has been evaluated using the full range of available CPUs (1–4) and 16 GB of RAM.
FaaS: Function as a Service is a type of service where ephemeral containers are created. In addition, known as serverless computing, FaaS supports the development of microservices-based architectures. The cost is calculated per use.
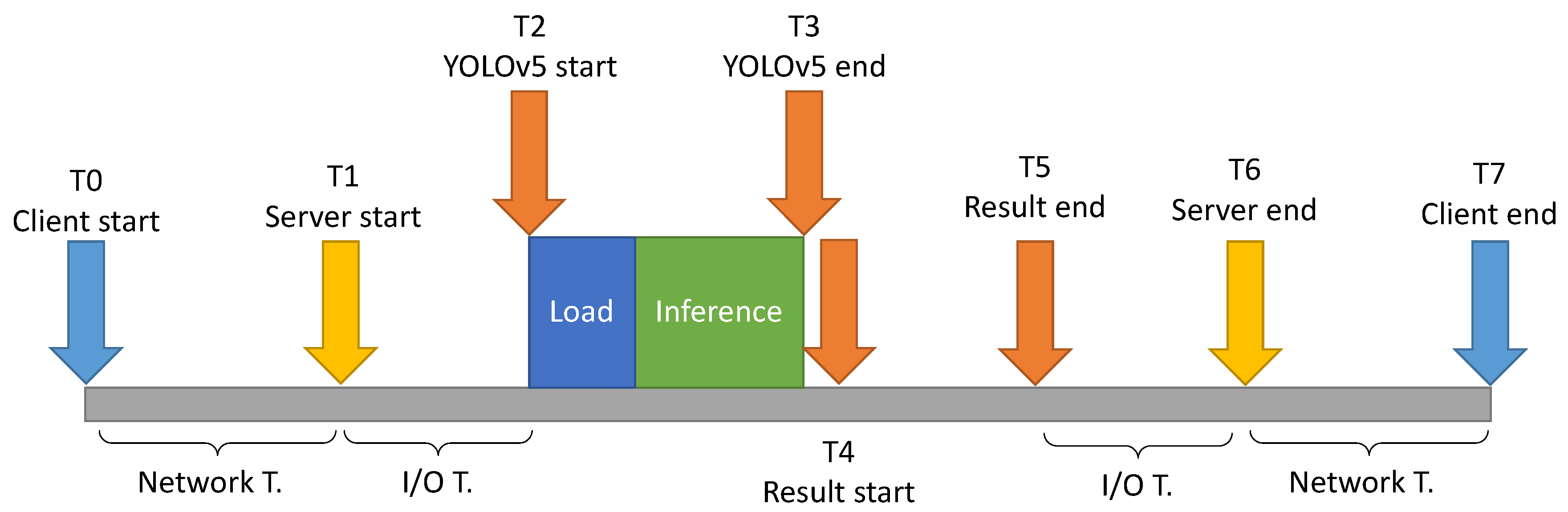
Figure 8 shows the times taken in the different stages to carry out the service:
Load time: Before starting inference, it is necessary to load the images into memory, either on CPU or GPU. This is called load time and is calculated as follows: .
Inference time: This is the time needed to process the images in search of objects, to verify the presence of livestock activity. This time is calculated from running the detect script of YOLOv5.
Results time: In order to confirm livestock activity, it is not enough to obtain the bounding boxes in pixels. These pixels must be translated into coordinates by creating a geojson file for each image. This translation is possible if georeferenced images are used. The time needed to do this translation is called the results time and is calculated as follows: .
Input/output time: Before starting with an inference, it is necessary to save the images. Before sending the response to the client, it is necessary to zip the images with their corresponding geojsons. The sum of the two times is called input/output time and is calculated as follows: .
Network time: The client and the server are in different locations so there is a communication time between the client and the server and vice-versa. This time is called network time and is calculated as follows: .
Total time: The whole time elapsed from when the client sends a request until the server processes it and sends a response back is called the total time. It is calculated as follows: .
Table 6 shows the results obtained with each of the infrastructures evaluated for the first scenario (a batch of one hundred
images). Since some infrastructures do not have GPU, they were evaluated using CPU. Each infrastructure was evaluated ten times, and the different times obtained were averaged. For this reason, the standard deviation of the total time is given. For the rest of the time, the standard deviation is very small.
Figure 9 shows a comparison of the different infrastructures. On top of each stacked bar is the latency ratio of each experiment calculated as (
6). The latency ratio expresses the difference in time between each experiment and the fastest one.
In this first scenario, the local infrastructure has the shortest total time, see
Figure 9 and
Table 6. This is the expected performance as the Geforce RTX 2080 TI GPU is better than that used in Azure infrastructures (Tesla K80). It should also be borne in mind that network times have little influence on a local infrastructure. The NC6 and NC12 infrastructures have one and two GPUs, respectively. Despite having GPUs, they have also been evaluated using the CPU in order to compare them with the rest of the infrastructures. Clearly, the use of two GPUs in the case of the NC12 does not improve the inference time, and, since it costs twice as much, it is not taken into account in the performance vs. cost comparison shown in
Figure 10. B8MS, B12MS, and D8s v3 have similar performance, the only difference being that the inference time in the case of D8s v3 is lower than that obtained with B8MS and B12MS. The A8m v2 is the worst infrastructure in terms of performance, offering the worst results in load, inference, results generation, and I/O times. In the case of CaaS infrastructures, a significant improvement is obtained by moving from one CPU to two. This improvement is not obtained when replacing two CPUs with three or four because the system does not scale up. The last infrastructure evaluated is FaaS. This infrastructure obtains the best result generation time of all, but its inference time is very high. For IaaS and CaaS, the model is preloaded in the memory, so it does not affect the total service time. In the case of FaaS, it is not possible to perform this preloading because it is serverless, so this time does affect the total time. The network time is not constant, as it varies in the different infrastructures.
Performance is not the only factor to be taken into account when deploying a service: it is also important to know the cost of the infrastructure. The costs of the infrastructures used in Azure were obtained from official documentation [
33,
34,
35], assuming constant requests for one hour. In the case of local infrastructure, the cost of purchasing equipment and electricity consumption are taken into account, but other costs such as maintenance, room cooling, etc. are not. The initial investment made (amortized over five years) was €3216.66 in the case of using GPU and €2020.66 in the case of not using it. The hourly electricity consumption is
kW with a cost of €0.14 per kWh. This implies that the cost per hour with GPU is €0.08 and €0.06 without.
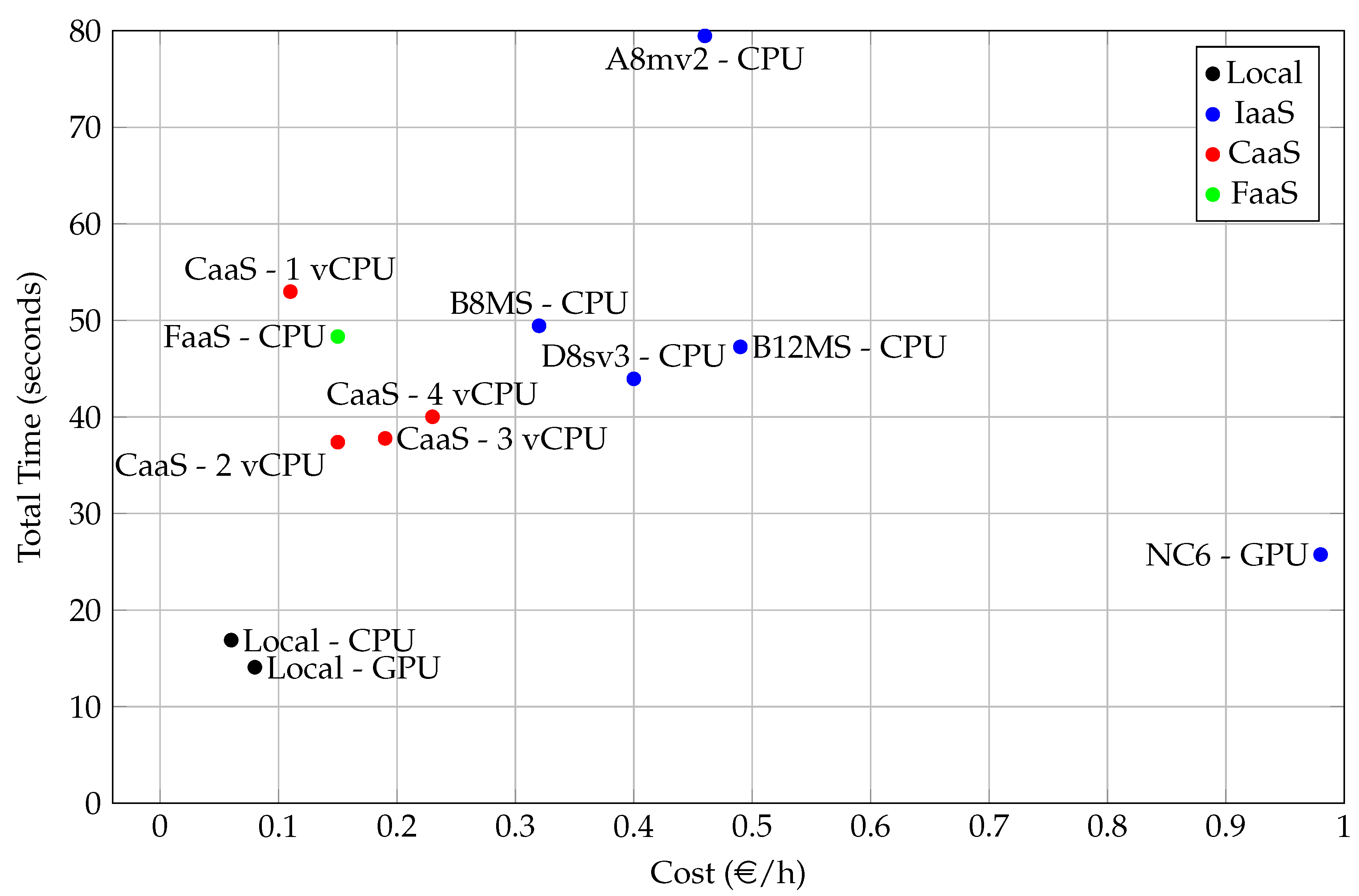
Figure 10 shows a comparison of performance (total time) and cost (€/h). Clearly, local infrastructures offer the best performance/cost ratio as they are the closest to the optimal point (0, 0). The NC6 is the best performing cloud infrastructure, but, due to its high price, it does not have the best performance/cost ratio. The CaaS 2vCPU is the infrastructure that offers the best ratio due to its low cost.
In the second scenario, where a single 10,000 × 10,000 image is used for the SUT evaluation, the results are different. The local infrastructure still offers the best performance (taking into account the negligible influence of network times in local infrastructures), but, in this case, CaaS infrastructures offer lower performance than IaaS, as can be seen in
Table 7 and
Figure 11. The NC6 and NC12 infrastructures offer the best cloud performance, but the B8MS and B12MS also deliver good results. D8s v3 and A8m v2 infrastructures have lower performance than other IaaS. In this scenario, the FaaS infrastructure could not be evaluated, as the current maximum file size that can be received per network is 100 MB, and the image used is 400 MB. In cloud infrastructures, with the exception of the A8m v2, the load, output, I/O, and network times are similar. The most influential time is inference time, due to the size of the images to be processed. As can be seen in
Table 7 and
Figure 11, the result times are lower than those obtained in the first scenario (see
Table 6 and
Figure 9). This is due to the fact that, in the 10,000 × 10,000 image used in this scenario, 151 objects were detected (129 animals, 8 feeders, 7 silage balls and 7 slurry pits), while, in the
image used in the previous scenario, only 19 animals were detected. Taking into account that a batch of one hundred images (always the same image) is used, a total of 1900 animals were detected, which means that the result time is longer in the first scenario than in the second.
Figure 12 shows a comparison between performance (total time) and cost (/h) for the second scenario. Local infrastructures still offer the best performance. The B8MS and B12MS have similar results, although they are inferior in terms of performance to the NC6, and lower in cost. The A8m v2 and D8s v3 offer better performance than the B8MS at a higher cost. Finally, CaaS infrastructures offer the lowest cost, considering their limited performance.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
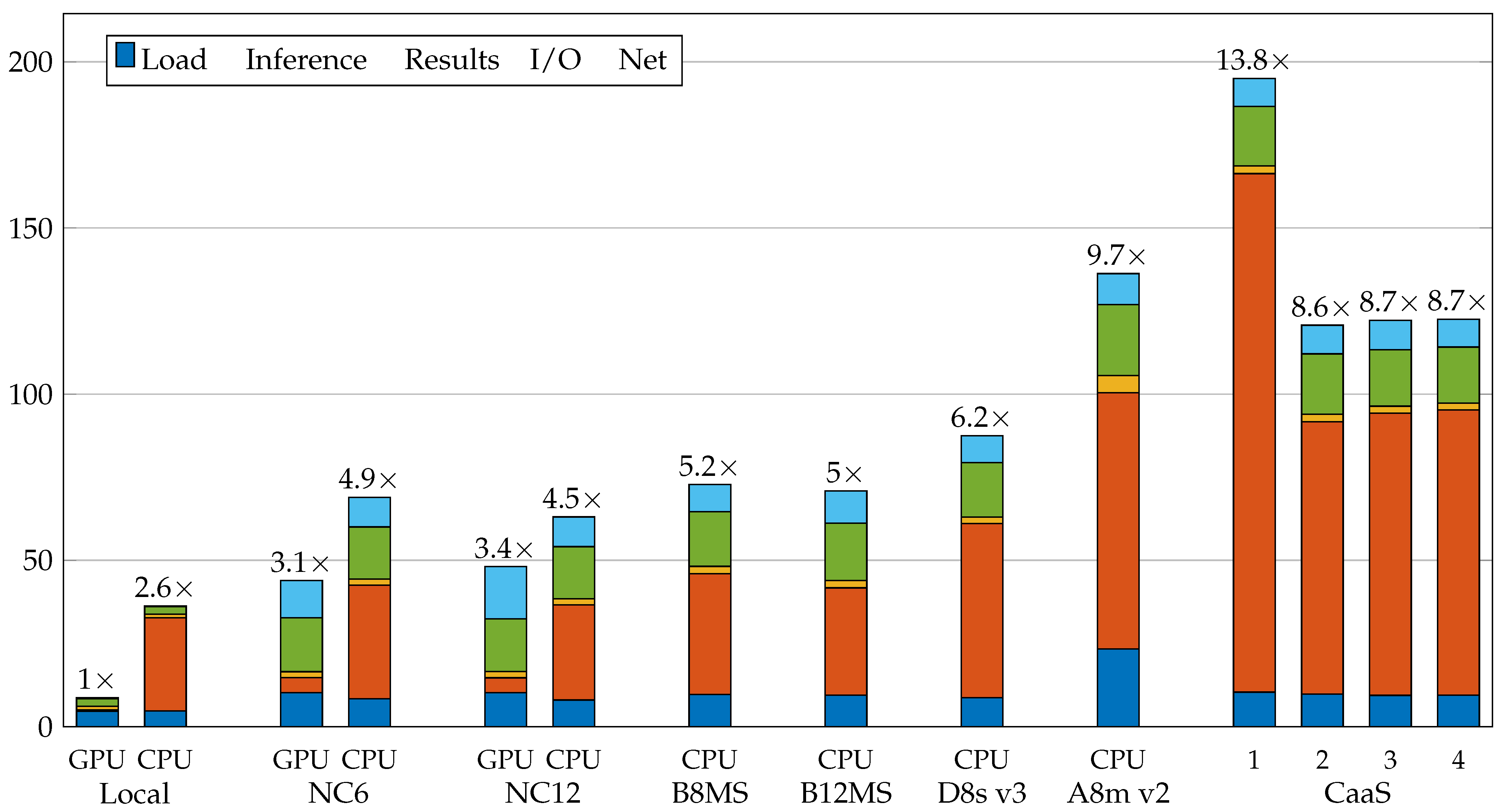{kind=link}
{kind=link}