
Wildfire Segmentation Using Deep Vision Transformers



Abstract
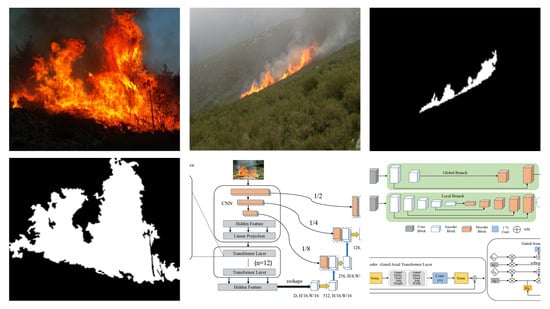
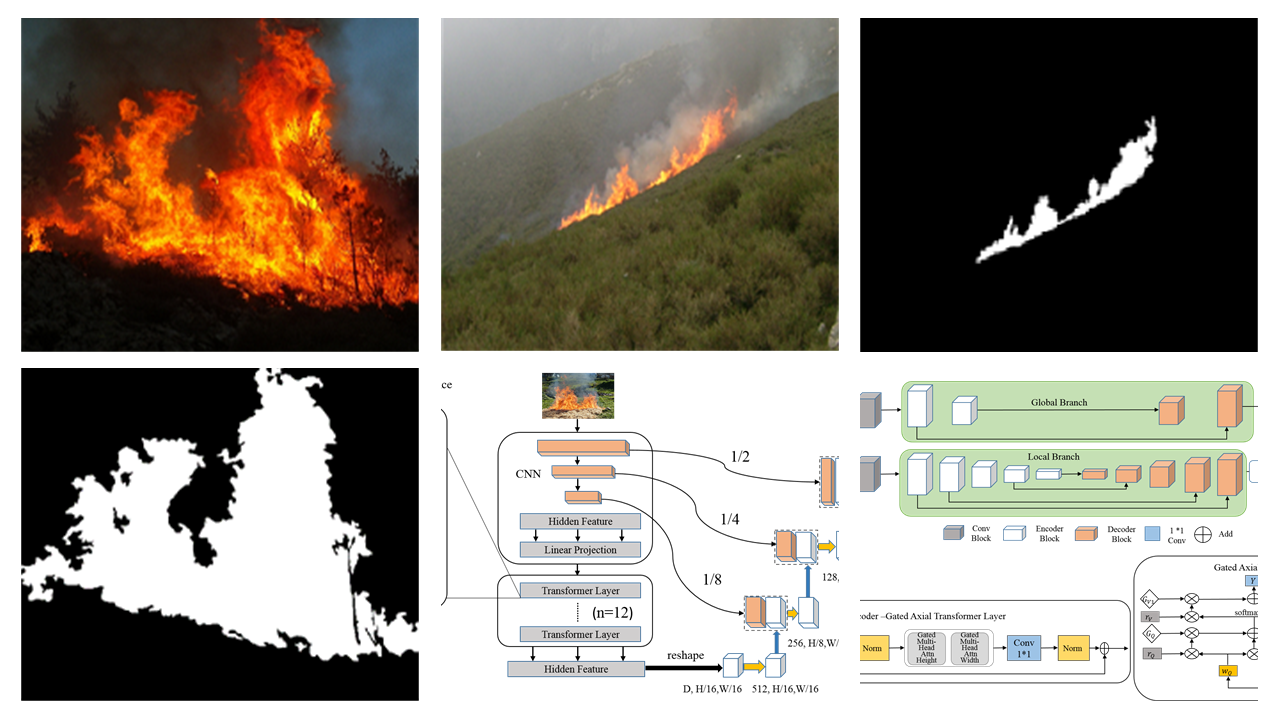
:
1. Introduction
2. Related Work
2.1. Feature-Based Fire Detection and Segmentation Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Methodology | Object Segmented | Dataset | Results |
|---|---|---|---|---|
| [25] | HSI color | Flame | Private: 7 videos | Det. accuracy = 96.97% |
| [26] | YCbCr color | Flame | Private: 751 images | Flame Det. rate = 99% |
| [29] | YCbCr color, LBP, KNN, Naive-Bayes | Flame | BowFire: 226 images | Det. precision = 80%, Det. recall = 65% |
| [38] | AlexNet, simple CNN | Flame | Private: 560 images | Seg. accuracy = 94.76%, Seg. F1-score = 90.31% |
| [35] | YCbCr color, 2D DWT, 3D DWT, ELM classifier | Flame | VisiFire, VisionFire: 85 videos | Det. accuracy = 95.65% |
| [21] | U-Net | Flame | CorsicanFire: 419 images | Seg. accuracy = 97.09%, Seg. F1-score = 91% |
| [22] | RGB, HSV, HSL, HWB color | Flame | CorsicanFire: 500 images | Det. accuracy = 93%, Det. F1-score = 79% |
| [39] | RGB, YCbCr, optical flow | Flame | Private: 30 videos | Det. accuracy = 96.09% |
| [37] | SIFT Flow, optical flow, GMM, K-means, MRF, GMRF | Flame, smoke | Private: 10 IR videos | Seg. accuracy = 95.39% |
| [40] | Lightweight CNN based on the SqueezeNet | Flame | BowFire, MIVIA: 68457 images | Det. accuracy = 94.50%, Det. F1-score = 91% |
| [31] | HSV color, LBP-TOP | Flame | Firesense: 27 videos | Det. accuracy = 98.5% |
| [34] | YUV color, LKT optical flow | Flame | Zenodo, Mivia, web | Det. accuracy = 97.2% |
| [41] | DeepLab V3 | Flame | FlickFire, Firesense, Visifire, private: 7561 images | Seg. accuracy = 98.78%, Seg. mean IoU = 70.51% |
| [42] | DeepLab V3+ | Flame | CorsicanFire: 1775 images | Seg. accuracy = 97.67%, Seg. mean IoU = 89.64% |
| [43] | wUUNet | Flame | Private: 6250 images | Seg. accuracy = 95.34% |
| [44] | Yolov3, R-FCN, Faster R-CNN, SSD | Flame, smoke | Public smoke/fire: 29180 images | Det. accuracy = 83.7% |
| [45] | Yolov5, efficientDet, efficientNet | Flame | BowFire, VisiFire, FD, ForestryImages: 10581 images | Det. accuracy = 99.4% |
2.2. Deep Learning Based Fire Detection and Segmentation Methods
2.3. Methods Based on Transformers
2.4. Post-Fire Mapping Based Satellite Remote Sensing Imagery
3. Methods
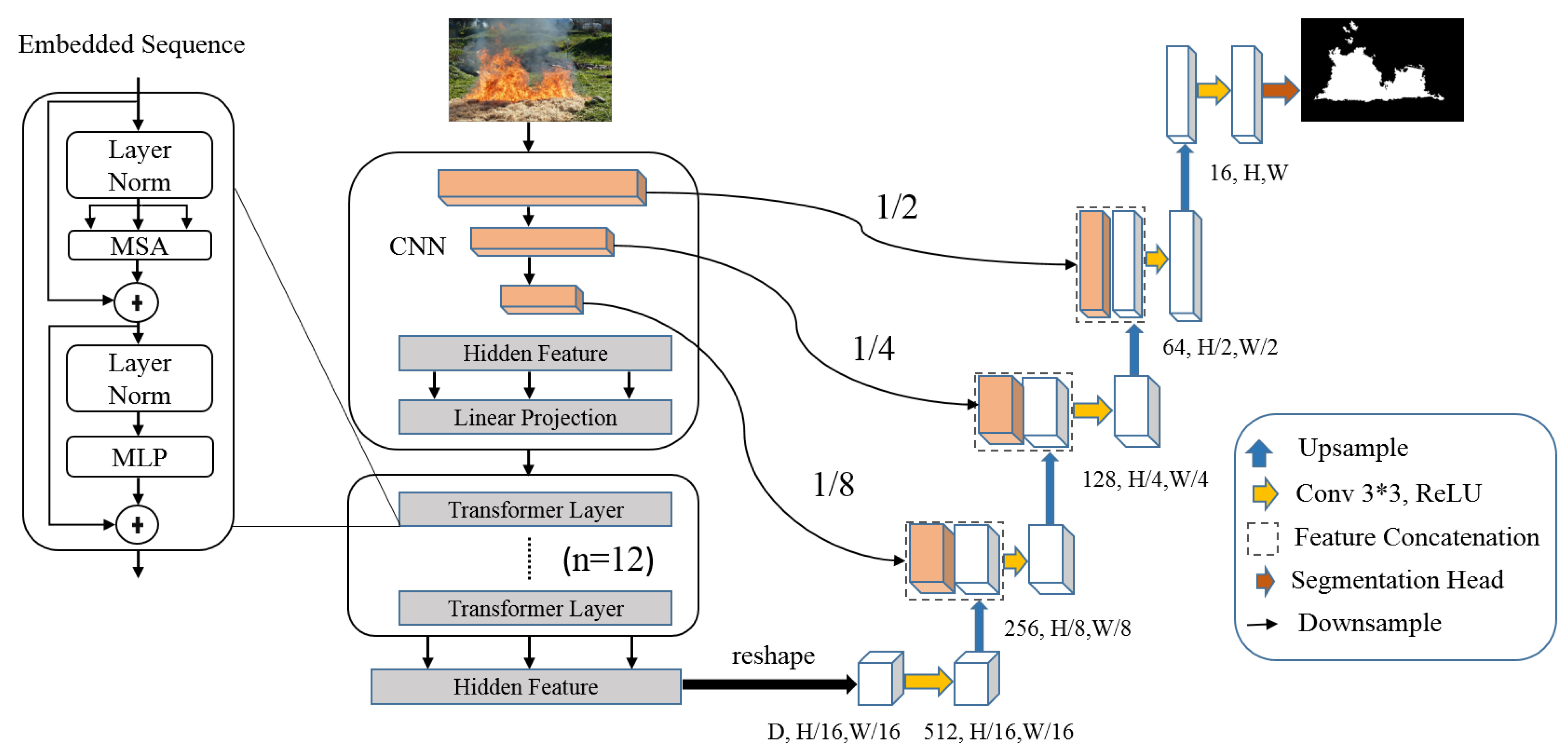
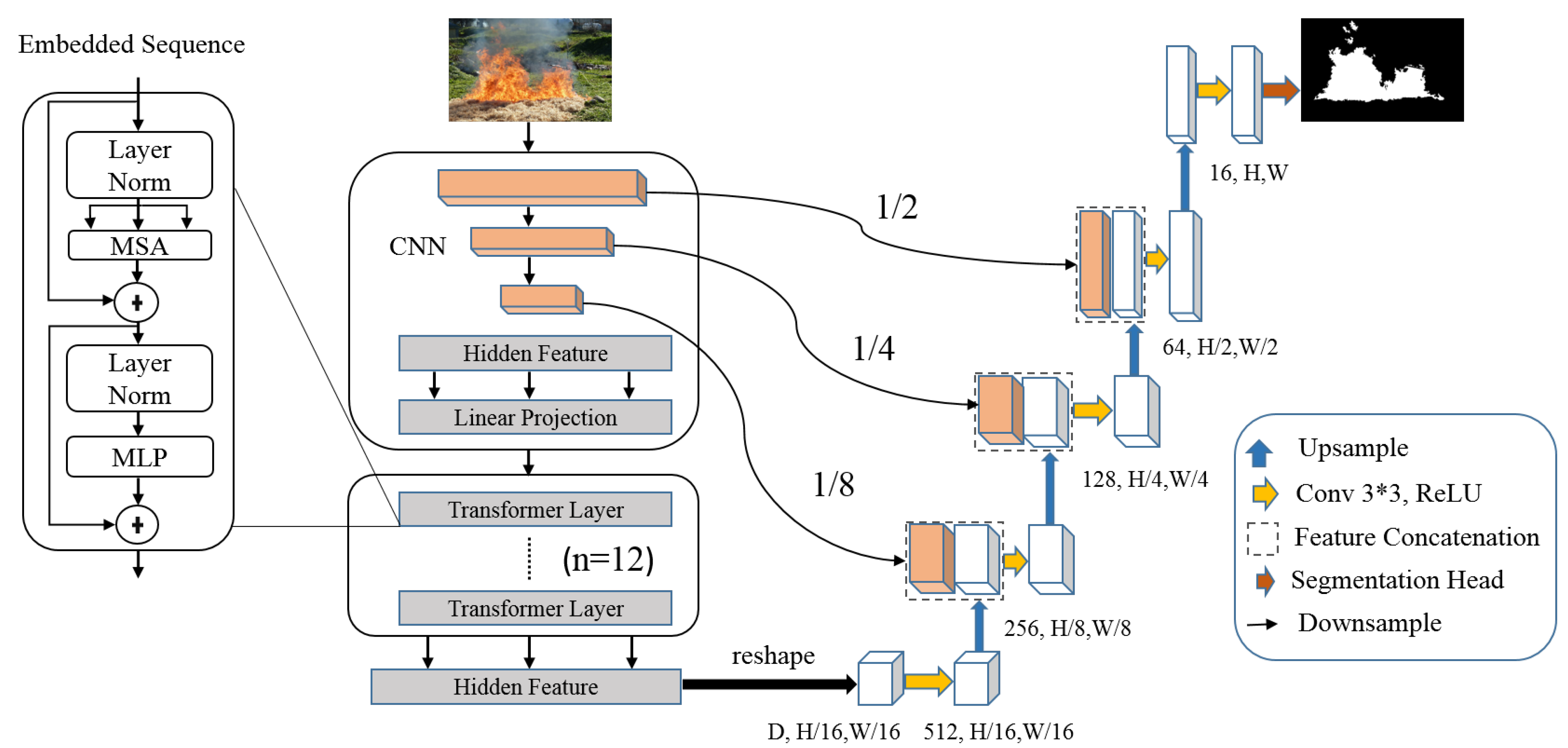
3.1. TransUNet
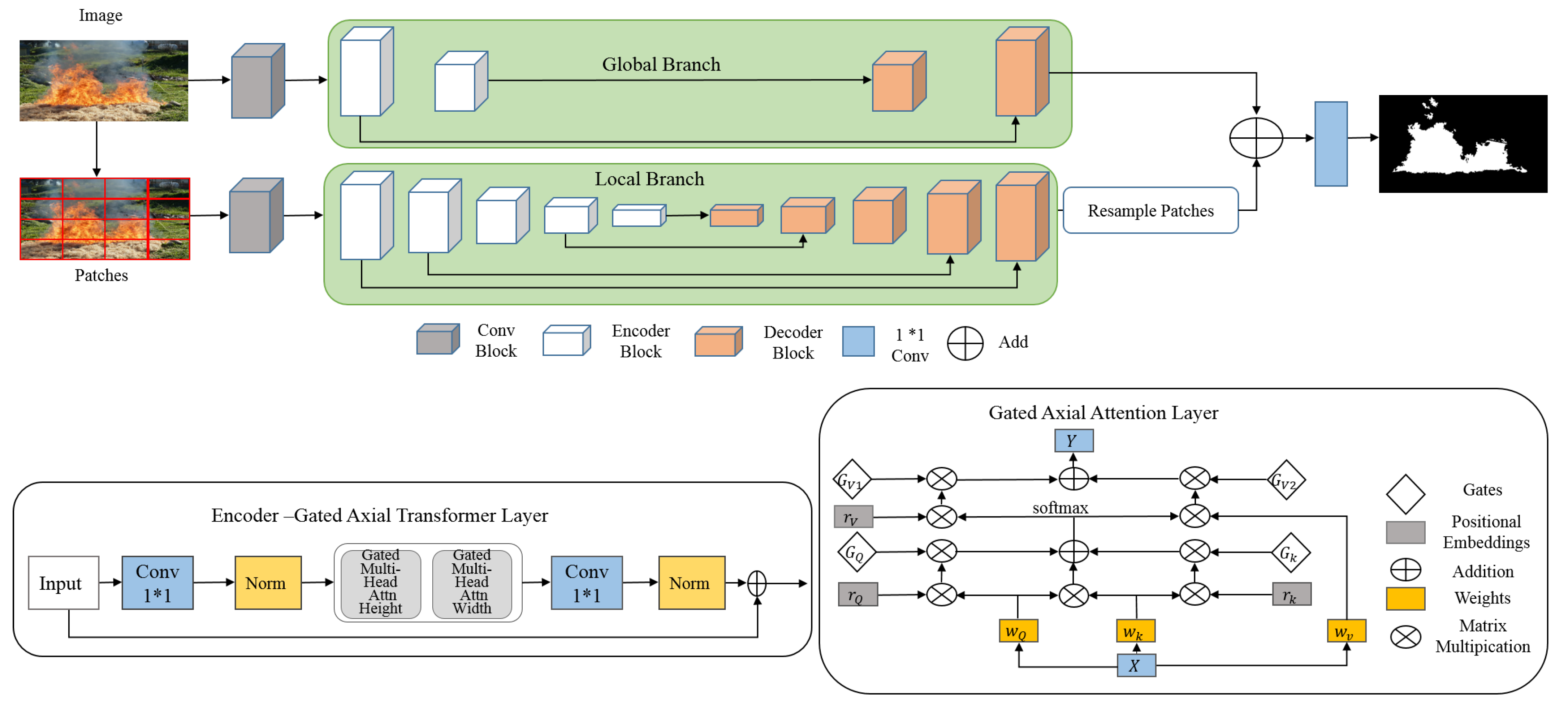
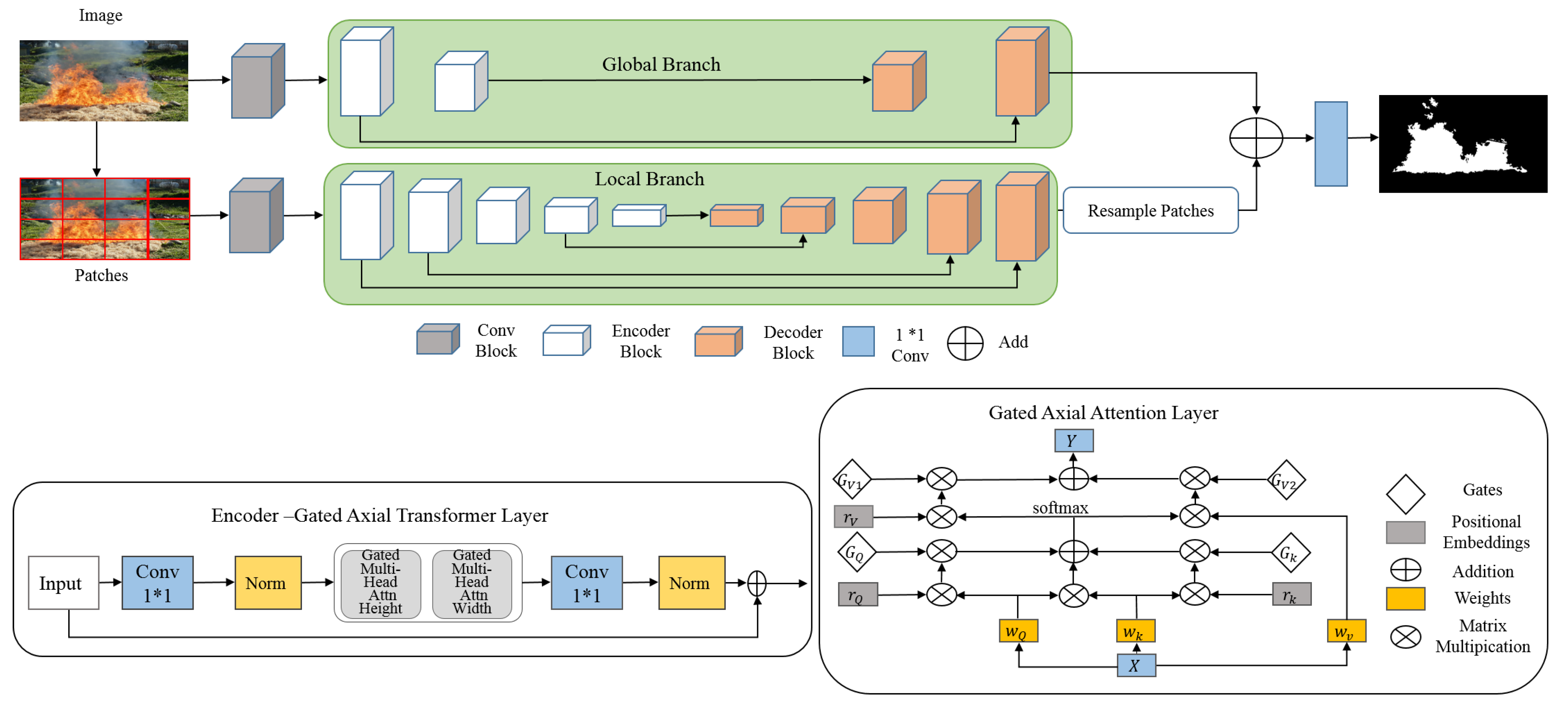
3.2. Medical Transformer (MedT)
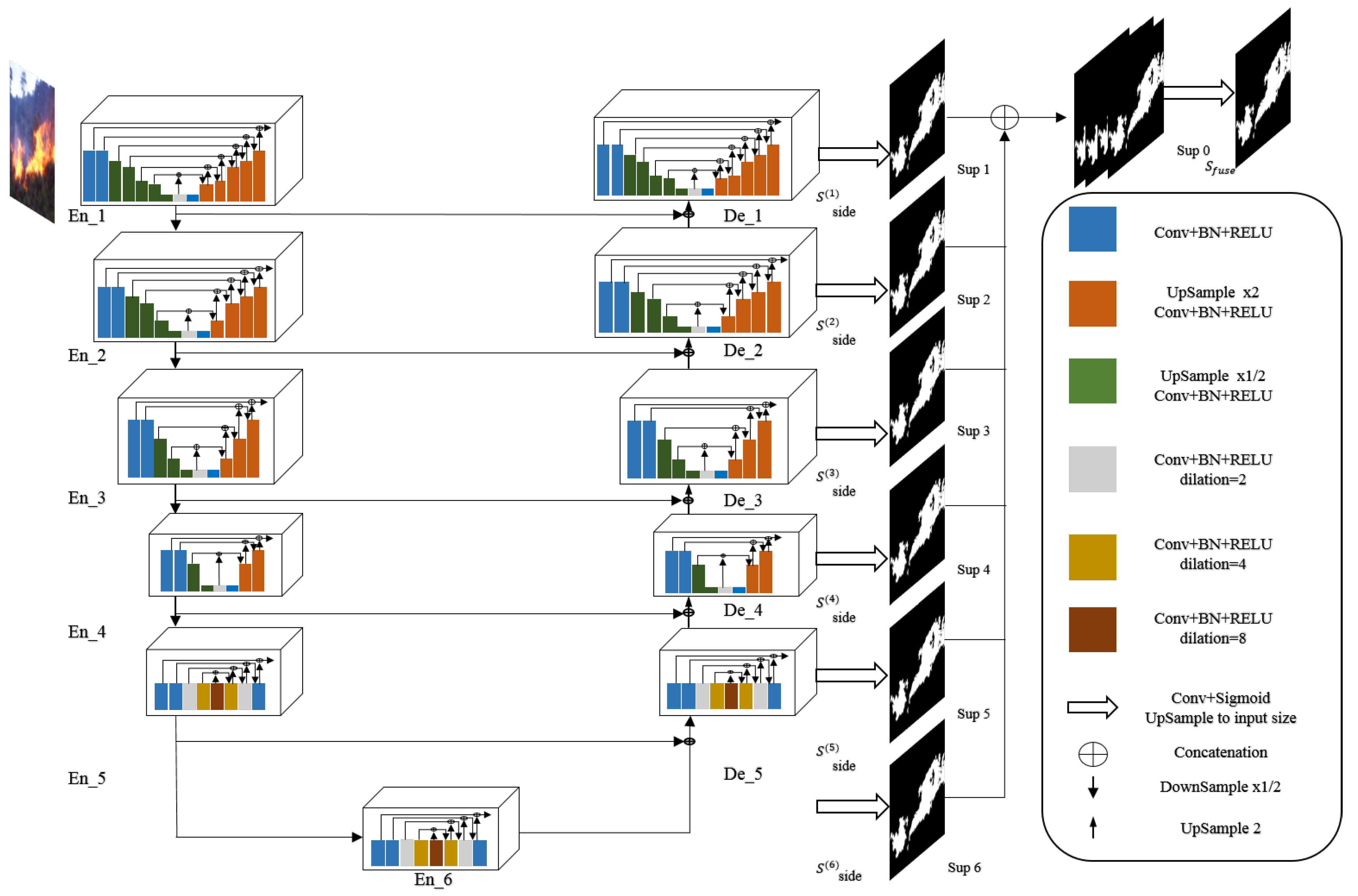
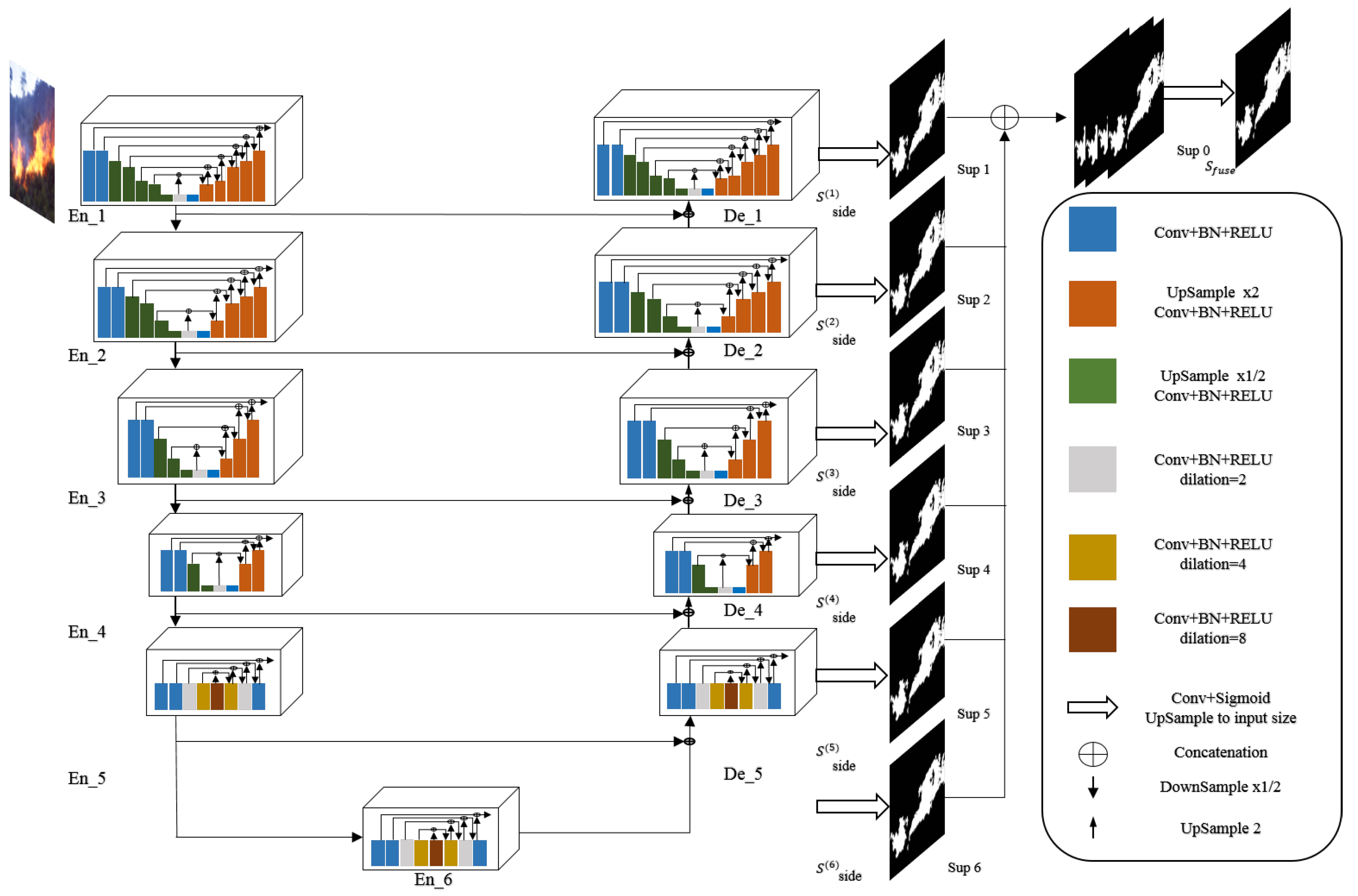
3.3. UNet Architecture
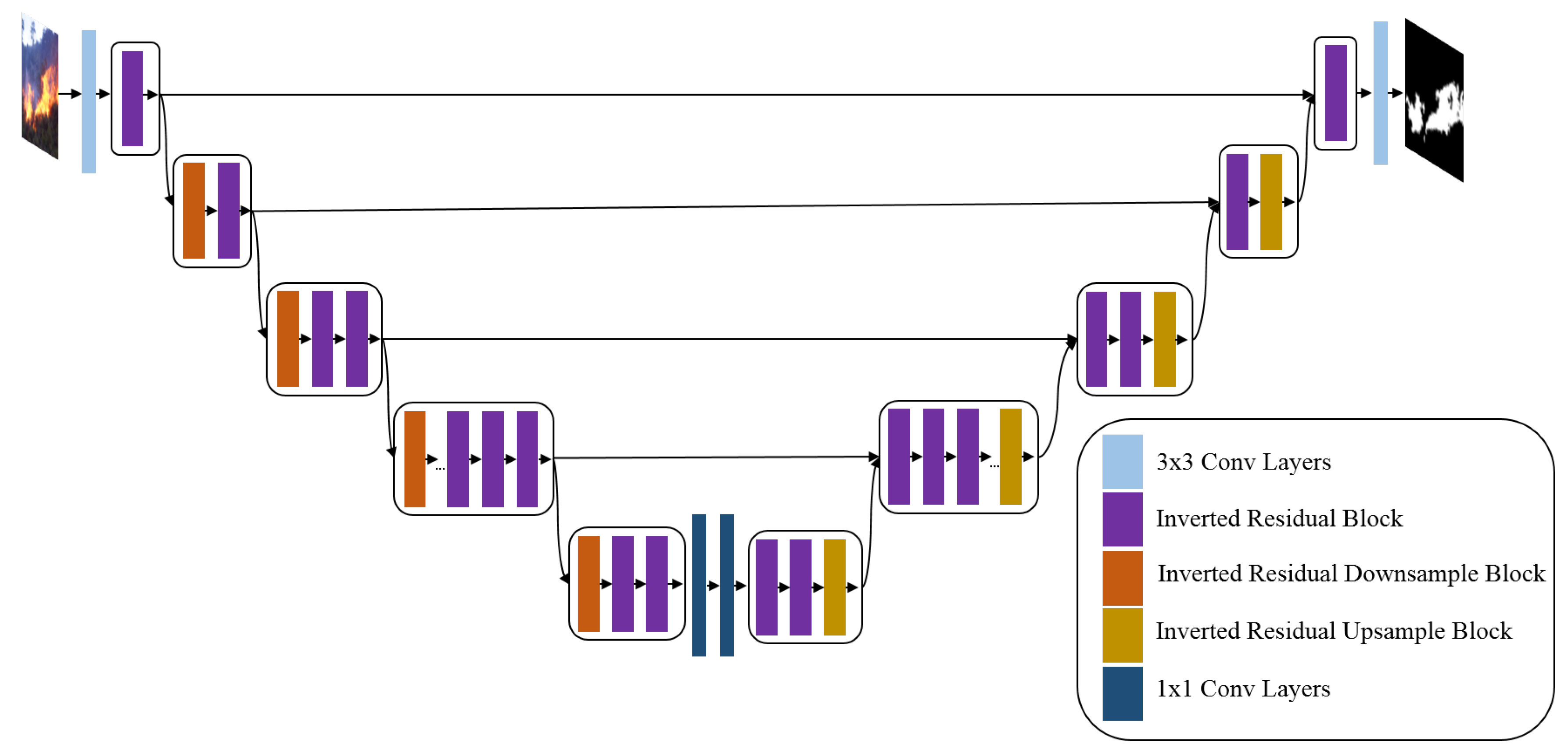
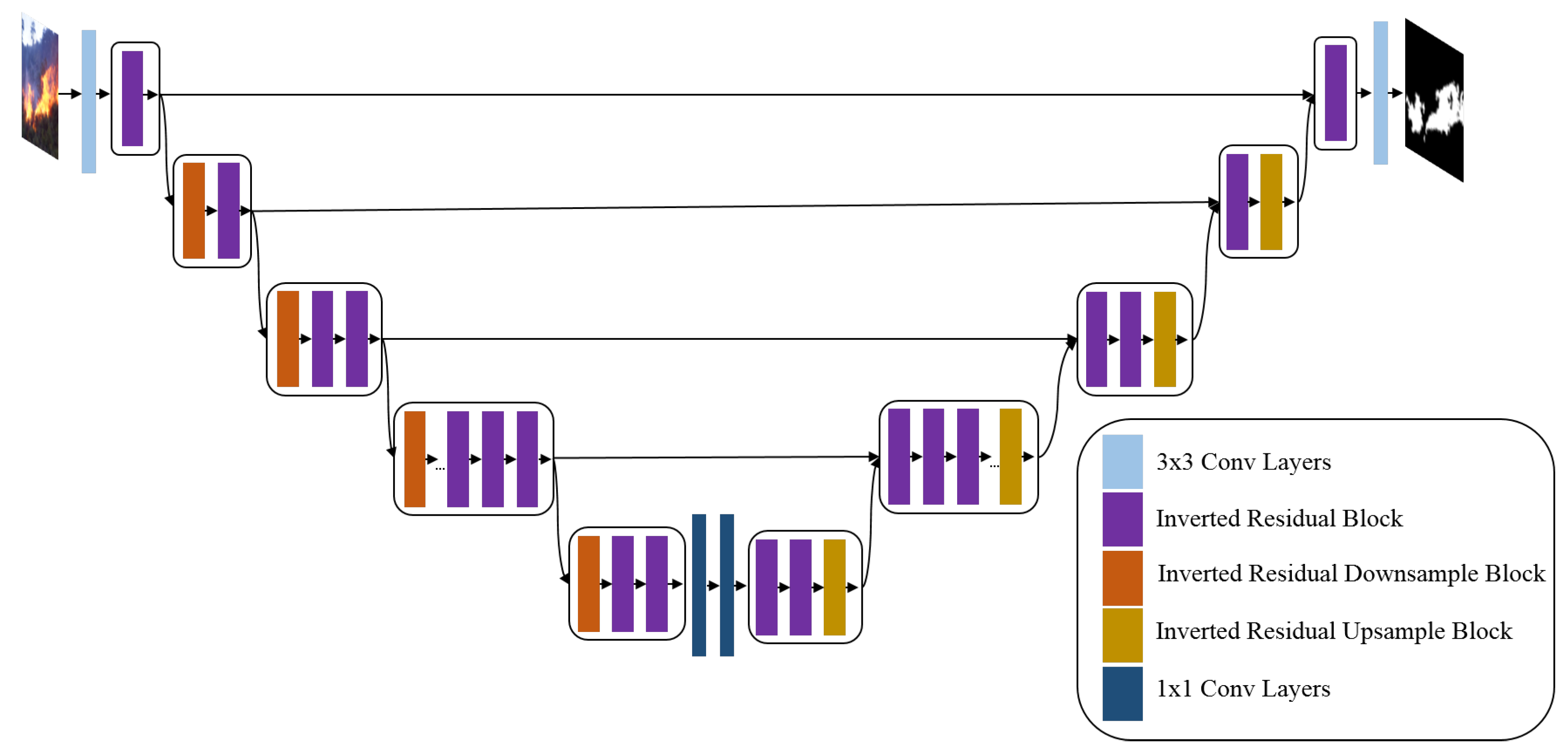
3.4. EfficientSeg
3.5. Dataset
3.6. Evaluation Metrics
- F1-score combines recall and precision metrics to calculate the performance of the model (as given by Equation (1)).where is the false negative rate, is the false positive rate, and is the true positive rate.
- Inference time is defined as the average segmentation’s time using our test data.
4. Experiments and Results
4.1. Experimental Results
4.1.1. Quantitative Results
4.1.2. Qualitative Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dimitropoulos, S. Fighting fire with science. Nature 2019, 576, 328–329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire Sensing Technologies: A Review. IEEE Sens. J. 2019, 19, 3191–3202. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A Survey of Deep Learning Applications to Autonomous Vehicle Control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 712–733. [Google Scholar] [CrossRef]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Deep Learning Strong Parts for Pedestrian Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1904–1912. [Google Scholar]
- Pérez-Hernández, F.; Tabik, S.; Lamas, A.; Olmos, R.; Fujita, H.; Herrera, F. Object Detection Binary Classifiers methodology based on deep learning to identify small objects handled similarly: Application in video surveillance. Knowl.-Based Syst. 2020, 194, 105590. [Google Scholar] [CrossRef]
- Nawaratne, R.; Alahakoon, D.; De Silva, D.; Yu, X. Spatiotemporal Anomaly Detection Using Deep Learning for Real-Time Video Surveillance. IEEE Trans. Ind. Inform. 2020, 16, 393–402. [Google Scholar] [CrossRef]
- Gaur, A.; Singh, A.; Kumar, A.; Kumar, A.; Kapoor, K. Video flame and smoke based fire detection algorithms: A literature review. Fire Technol. 2020, 56, 1943–1980. [Google Scholar] [CrossRef]
- Ghali, R.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Recent Advances in Fire Detection and Monitoring Systems: A Review. In Proceedings of the 18th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT’18), Genoa, Italy, 20–22 December 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 1, pp. 332–340. [Google Scholar]
- Ott, M.; Edunov, S.; Grangier, D.; Auli, M. Scaling Neural Machine Translation. arXiv 2018, arXiv:1806.00187. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Visual Transformer. arXiv 2020, arXiv:2012.12556. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. arXiv 2021, arXiv:2105.13290. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning Texture Transformer Network for Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5791–5800. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical Transformer: Gated Axial-Attention for Medical Image Segmentation. arXiv 2021, arXiv:2102.10662. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. arXiv 2021, arXiv:2101.01169. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhloufi, M.A. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef] [Green Version]
- Akhloufi, M.A.; Tokime, R.B.; Elassady, H. Wildland fires detection and segmentation using deep learning. Pattern recognition and tracking xxix. Int. Soc. Opt. Photonics Proc. SPIE 2018, 10649, 106490B. [Google Scholar] [CrossRef]
- Dzigal, D.; Akagic, A.; Buza, E.; Brdjanin, A.; Dardagan, N. Forest Fire Detection based on Color Spaces Combination. In Proceedings of the 11th International Conference on Electrical and Electronics Engineering (ELECO), Bursa, Turkey, 28–30 November 2019; pp. 595–599. [Google Scholar] [CrossRef]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Yesilkaynak, V.B.; Sahin, Y.H.; Unal, G.B. EfficientSeg: An Efficient Semantic Segmentation Network. arXiv 2020, arXiv:2009.06469. [Google Scholar]
- Horng, W.B.; Peng, J.W.; Chen, C.Y. A new image-based real-time flame detection method using color analysis. In Proceedings of the IEEE Networking, Sensing and Control, Tucson, AZ, USA, 19–22 March 2005; pp. 100–105. [Google Scholar] [CrossRef]
- Çelik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the International Conference on Image Processing, Singapore, 24–27 October 2004; Volume 3, pp. 1707–1710. [Google Scholar] [CrossRef]
- Collumeau, J.F.; Laurent, H.; Hafiane, A.; Chetehouna, K. Fire scene segmentations for forest fire characterization: A comparative study. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2973–2976. [Google Scholar] [CrossRef]
- Chino, D.Y.T.; Avalhais, L.P.S.; Rodrigues, J.F.; Traina, A.J.M. BoWFire: Detection of Fire in Still Images by Integrating Pixel Color and Texture Analysis. In Proceedings of the 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 6–29 August 2015; pp. 95–102. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; He, Y.; Wang, J. Multi-feature fusion based fast video flame detection. Build. Environ. 2010, 45, 1113–1122. [Google Scholar] [CrossRef]
- Jamali, M.; Karimi, N.; Samavi, S. Saliency Based Fire Detection Using Texture and Color Features. In Proceedings of the 28th Iranian Conference on Electrical Engineering (ICEE), Tabriz, Iran, 4–6 August 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Ko, B.C.; Cheong, K.H.; Nam, J.Y. Fire detection based on vision sensor and support vector machines. Fire Saf. J. 2009, 44, 322–329. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Vento, M. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Khondaker, A.; Khandaker, A.; Uddin, J. Computer Vision-based Early Fire Detection Using Enhanced Chromatic Segmentation and Optical Flow Analysis Technique. Int. Arab. J. Inf. Technol. (IAJIT) 2020, 17, 947–953. [Google Scholar]
- Emmy Prema, C.; Vinsley, S.S.; Suresh, S. Efficient Flame Detection Based on Static and Dynamic Texture Analysis in Forest Fire Detection. Fire Technol. 2018, 54, 255–288. [Google Scholar] [CrossRef]
- Wang, T.; Shi, L.; Yuan, P.; Bu, L.; Hou, X. A new fire detection method based on flame color dispersion and similarity in consecutive frames. In Proceedings of the Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 151–156. [Google Scholar] [CrossRef]
- Ajith, M.; Martínez-Ramón, M. Unsupervised Segmentation of Fire and Smoke From Infra-Red Videos. IEEE Access 2019, 7, 182381–182394. [Google Scholar] [CrossRef]
- Gonzalez, A.; Zuniga, M.D.; Nikulin, C.; Carvajal, G.; Cardenas, D.G.; Pedraza, M.A.; Fernandez, C.A.; Munoz, R.I.; Castro, N.A.; Rosales, B.F.; et al. Accurate fire detection through fully convolutional network. In Proceedings of the 7th Latin American Conference on Networked and Electronic Media (LACNEM), Valparaiso, Chile, 6–7 November 2017; pp. 1–6. [Google Scholar]
- Dang-Ngoc, H.; Nguyen-Trung, H. Evaluation of Forest Fire Detection Model using Video captured by UAVs. In Proceedings of the 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 513–518. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient Deep CNN-Based Fire Detection and Localization in Video Surveillance Applications. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 1419–1434. [Google Scholar] [CrossRef]
- Mlích, J.; Koplík, K.; Hradiš, M.; Zemčík, P. Fire segmentation in Still images. In International Conference on Advanced Concepts for Intelligent Vision Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 27–37. [Google Scholar]
- Harkat, H.; Nascimento, J.; Bernardino, A. Fire segmentation using a DeepLabv3+ architecture. Image and Signal Processing for Remote Sensing XXVI. Int. Soc. Opt. Photonics Proc. SPIE 2020, 11533, 134–145. [Google Scholar]
- Bochkov, V.S.; Kataeva, L.Y. wUUNet: Advanced Fully Convolutional Neural Network for Multiclass Fire Segmentation. Symmetry 2021, 13, 98. [Google Scholar] [CrossRef]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Khan, R.A.; Uddin, J.; Corraya, S. Real-time fire detection using enhanced color segmentation and novel foreground extraction. In Proceedings of the 4th International Conference on Advances in Electrical Engineering (ICAEE), Dhaka, Bangladesh, 28–30 September 2017; pp. 488–493. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. [Google Scholar] [CrossRef]
- Bragilevsky, L.; Bajić, I.V. Deep learning for Amazon satellite image analysis. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 21–23 August 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Bakator, M.; Radosav, D. Deep Learning and Medical Diagnosis: A Review of Literature. Multimodal Technol. Interact. 2018, 2, 47. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Xing, Y.; Zhong, L.; Zhong, X. An Encoder-Decoder Network Based FCN Architecture for Semantic Segmentation. Wirel. Commun. Mob. Comput. 2020, 2020, 8861886. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European conference on computer vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; Chanvichet, V.; Kwon, Y.; TaoXie, S.; Changyu, L.; Abhiram, V.; Skalski, P.; et al. Yolov5. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 August 2021).
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video Action Transformer Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 9–15 June 2019; pp. 244–253. [Google Scholar]
- Ye, L.; Rochan, M.; Liu, Z.; Wang, Y. Cross-Modal Self-Attention Network for Referring Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 9–15 June 2019; pp. 10502–10511. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2020, arXiv:2012.12877. [Google Scholar]
- Chuvieco, E.; Mouillot, F.; van der Werf, G.R.; San Miguel, J.; Tanase, M.; Koutsias, N.; García, M.; Yebra, M.; Padilla, M.; Gitas, I.; et al. Historical background and current developments for mapping burned area from satellite Earth observation. Remote Sens. Environ. 2019, 225, 45–64. [Google Scholar] [CrossRef]
- Van der Werf, G.R.; Randerson, J.T.; Giglio, L.; van Leeuwen, T.T.; Chen, Y.; Rogers, B.M.; Mu, M.; van Marle, M.J.E.; Morton, D.C.; Collatz, G.J.; et al. Global fire emissions estimates during 1997–2016. Earth Syst. Sci. Data 2017, 9, 697–720. [Google Scholar] [CrossRef] [Green Version]
- Giglio, L.; Boschetti, L.; Roy, D.P.; Humber, M.L.; Justice, C.O. The Collection 6 MODIS burned area mapping algorithm and product. Remote Sens. Environ. 2018, 217, 72–85. [Google Scholar] [CrossRef]
- Key, C.H.; Benson, N.C. Landscape assessment (LA). In FIREMON: Fire Effects Monitoring and Inventory System. Gen. Tech. Rep. RMRS-GTR-164-CD; Lutes, D.C., Keane, R.E., Caratti, J.F., Key, C.H., Benson, N.C., Sutherland, S., Gangi, L.J., Eds.; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; Volume 164, p. LA-1-55. [Google Scholar]
- Roy, D.; Boschetti, L.; Trigg, S. Remote sensing of fire severity: Assessing the performance of the normalized burn ratio. IEEE Geosci. Remote Sens. Lett. 2006, 3, 112–116. [Google Scholar] [CrossRef] [Green Version]
- Miller, J.D.; Thode, A.E. Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR). Remote Sens. Environ. 2007, 109, 66–80. [Google Scholar] [CrossRef]
- Frampton, W.J.; Dash, J.; Watmough, G.; Milton, E.J. Evaluating the capabilities of Sentinel-2 for quantitative estimation of biophysical variables in vegetation. ISPRS J. Photogramm. Remote Sens. 2013, 82, 83–92. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Wang, J.; Shan, B.; He, Y.; Liao, C.; Gao, Y.; Yang, S. A New Model for Transfer Learning-Based Mapping of Burn Severity. Remote Sens. 2020, 12, 708. [Google Scholar] [CrossRef] [Green Version]
- Rebecca, G.; Tim, D.; Warwick, H.; Luke, C. A remote sensing approach to mapping fire severity in south-eastern Australia using sentinel 2 and random forest. Remote Sens. Environ. 2020, 240, 111702. [Google Scholar] [CrossRef]
- Zanetti, M.; Marinelli, D.; Bertoluzza, M.; Saha, S.; Bovolo, F.; Bruzzone, L.; Magliozzi, M.L.; Zavagli, M.; Costantini, M. A high resolution burned area detector for Sentinel-2 and Landsat-8. In Proceedings of the 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yuan, Q.; Zeng, C.; Li, X.; Wei, Y. Missing Data Reconstruction in Remote Sensing Image With a Unified Spatial–Temporal–Spectral Deep Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4274–4288. [Google Scholar] [CrossRef] [Green Version]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 680–688. [Google Scholar]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Pinto, M.M.; Libonati, R.; Trigo, R.M.; Trigo, I.F.; DaCamara, C.C. A deep learning approach for mapping and dating burned areas using temporal sequences of satellite images. ISPRS J. Photogramm. Remote Sens. 2020, 160, 260–274. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Farasin, A.; Colomba, L.; Garza, P. Double-Step U-Net: A Deep Learning-Based Approach for the Estimation of Wildfire Damage Severity through Sentinel-2 Satellite Data. Appl. Sci. 2020, 10, 4332. [Google Scholar] [CrossRef]
- Rahmatov, N.; Paul, A.; Saeed, F.; Seo, H. Realtime fire detection using CNN and search space navigation. J. Real-Time Image Process. 2021, 18, 1331–1340. [Google Scholar] [CrossRef]
- Khennou, F.; Ghaoui, J.; Akhloufi, M.A. Forest fire spread prediction using deep learning. Geospatial Informatics XI. Int. Soc. Opt. Photonics Proc. SPIE 2021, 11733, 106–117. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]








| Model | Backbone | Input Resolution | F1-Score (%) |
|---|---|---|---|
| TransUNet | Res50-ViT | 224*224 | 97.5 |
| TransUNet | Res50-ViT | 512*512 | 97.7 |
| TransUNet | ViT | 224*224 | 94.1 |
| TransUNet | ViT | 512*512 | 94.8 |
| MedT | simple CNN-Transformer | 224*224 | 95.5 |
| MedT | simple CNN-Transformer | 256*256 | 96.0 |
| Model | Backbone | Learning Data | F1-Score (%) | Inference Time (s) |
|---|---|---|---|---|
| TransUNet | Res50-ViT | 1135 images | 97.5 | 1.20 |
| TransUNet | ViT | 1135 images | 94.1 | 0.13 |
| MedT | simple CNN-Transformer | 1135 images | 95.5 | 2.72 |
| U-Net [21] | —– | 419 images | 91.0 | — |
| Color fusion method [22] | —– | 500 images | 79.0 | — |
| U-Net | —– | 1135 images | 92.0 | 0.02 |
| U-Net | —– | 1135 images | 82.93 | 1.41 |
| EfficientSeg | —– | 1135 images | 94.27 | 2.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghali, R.; Akhloufi, M.A.; Jmal, M.; Souidene Mseddi, W.; Attia, R. Wildfire Segmentation Using Deep Vision Transformers. Remote Sens. 2021, 13, 3527. https://doi.org/10.3390/rs13173527
Ghali R, Akhloufi MA, Jmal M, Souidene Mseddi W, Attia R. Wildfire Segmentation Using Deep Vision Transformers. Remote Sensing. 2021; 13(17):3527. https://doi.org/10.3390/rs13173527
Chicago/Turabian StyleGhali, Rafik, Moulay A. Akhloufi, Marwa Jmal, Wided Souidene Mseddi, and Rabah Attia. 2021. "Wildfire Segmentation Using Deep Vision Transformers" Remote Sensing 13, no. 17: 3527. https://doi.org/10.3390/rs13173527
APA StyleGhali, R., Akhloufi, M. A., Jmal, M., Souidene Mseddi, W., & Attia, R. (2021). Wildfire Segmentation Using Deep Vision Transformers. Remote Sensing, 13(17), 3527. https://doi.org/10.3390/rs13173527