The Use of Deep Machine Learning for the Automated Selection of Remote Sensing Data for the Determination of Areas of Arable Land Degradation Processes Distribution

Abstract
1. Introduction
- Land degradation can be identified based on the analysis of vegetation indices in the analysis mode of big satellite data.
- The selection of satellite imagery for analysis can be carried out by deep machine learning methods.
- Indicators of places of development of degradation may be areas of long-term occurrence of low values of vegetation indices.
- It is possible to verify the results of identifying areas of development of degradation by ground methods.
- The boundary conditions for the identification of areas of degradation can be set by retrospective monitoring of land use and soil cover.
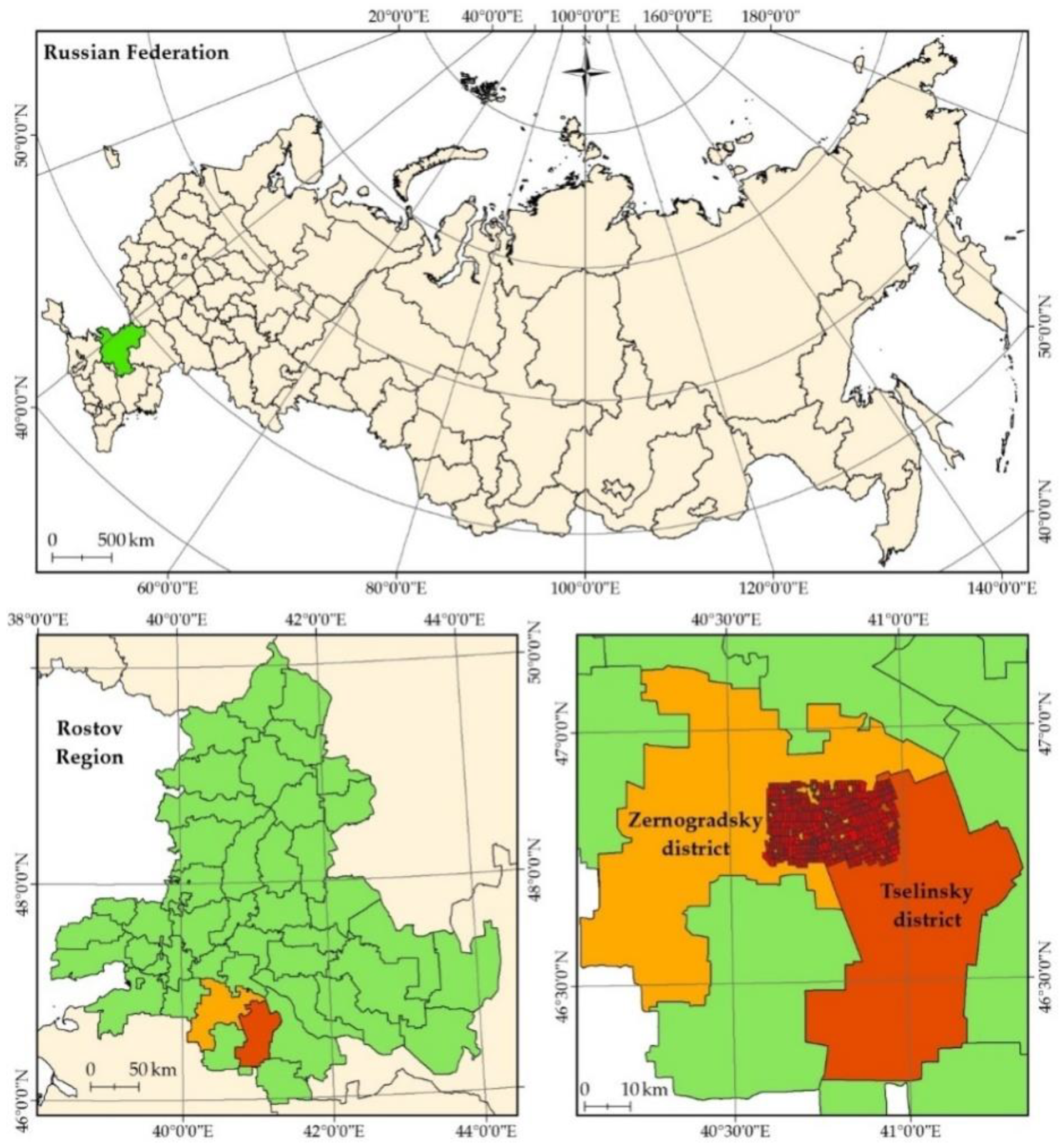
2. Materials and Methods
2.1. Setting Boundary Conditions for Interpretation
2.2. Formation of the Dataset
- Cloud cover.
- Cloud shadows.
- Areas of waterlogging.
- The open surface of the soil.
- Snow.
- Crop residues (straw).
- Burning of crop residues.
- Sowing of several crops or varieties of crops on one field.
- Traces and errors of agrotechnical processing.
- Ripening of crops.
- Weed vegetation.
- The defects or shift of remote sensing data.
2.3. Machine Learning Methods
2.3.1. Gradient Boosting on Decision Trees
- is a set of vertexes, is a root of the tree,
- is a predicate transition function to child nodes of a vertex ,
- is branching predicate for each ,
- Every is associated with one class label .
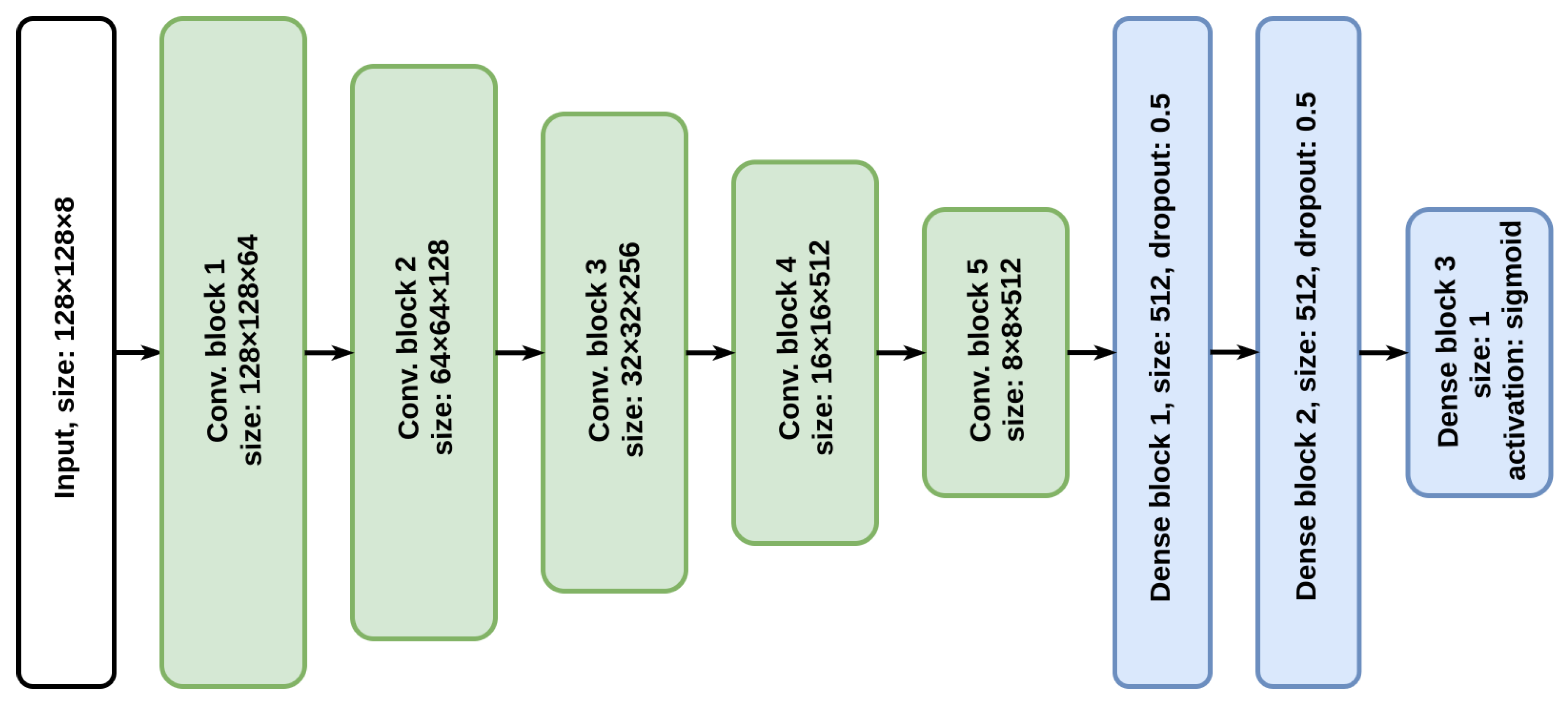
2.3.2. Convolutional Neural Network
2.4. Methods for Assessing the Quality of Machine Learning Algorithms
- Test sample. A set of objects not used in learning.
- Acceptance sample. A set of objects not used in development.
2.5. Machine Learning Experiments
2.5.1. Gradient Boosting
2.5.2. Convolutional Neural Network
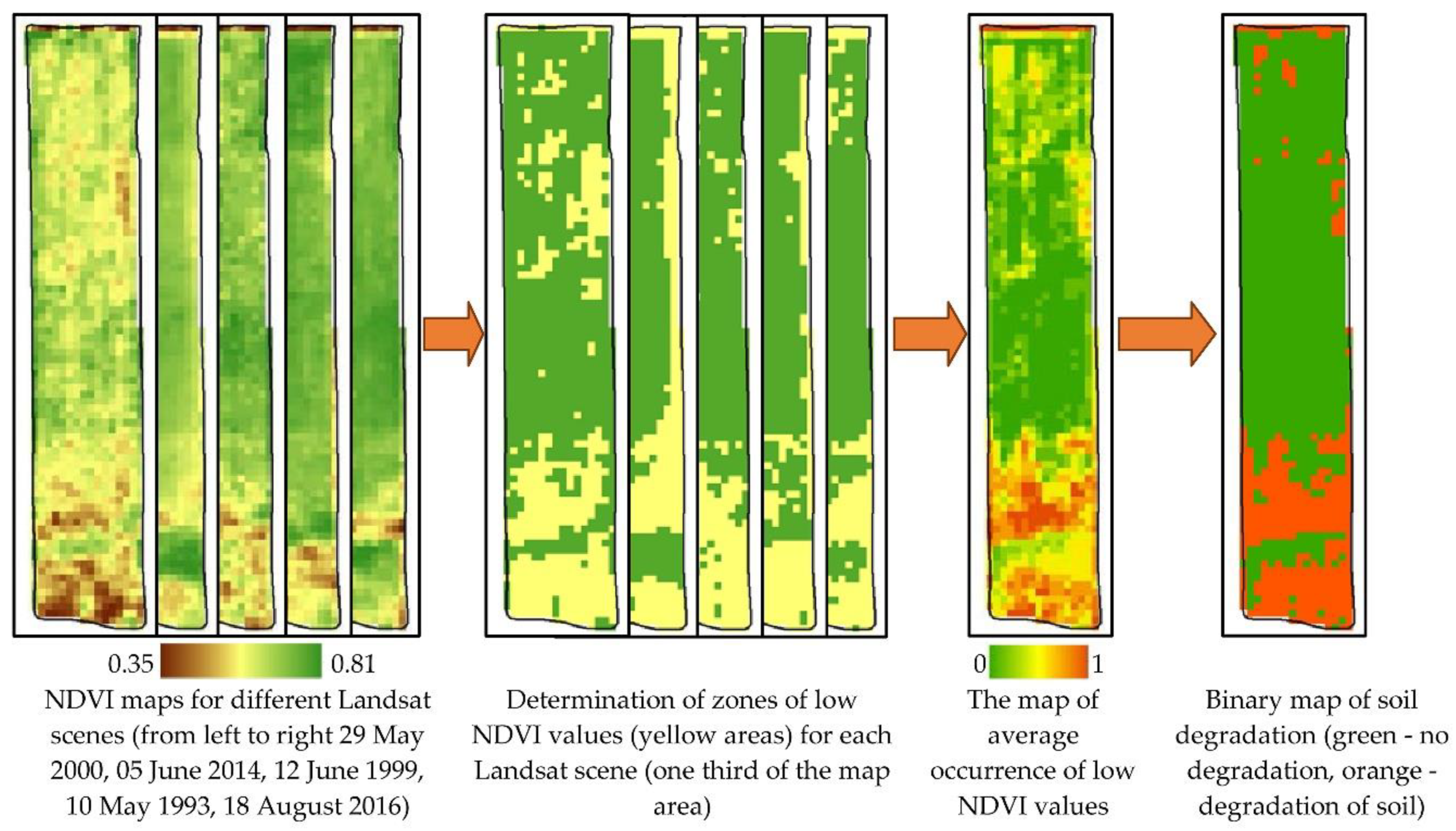
2.6. Calculation of Zones of Low NDVI Values (Zones of Reduced Fertility)
2.6.1. Calculation of the Zones of Low Values of NDVI (Zones of Reduced Fertility) Based on Data Selected by Machine Learning
- NIR is the infrared band value channel after atmospheric correction.
- Atmospheric correction was carried out using the ATCOR module of the ERDAS imagine software package [84].
- AOLNDVI—average occurrence of low NDVI values;
- LNDVIi—NDVI low zone indicator for the i-th Landsat scene;
- n—number of Landsat scenes selected for calculations.
2.6.2. Calculation of the Zones of Low NDVI Values (Zones of Reduced Fertility) Based on Manually Selected Data
2.7. Ground Verification
2.8. Cartographic Analysis
2.9. GIS Project
- Topographic map on a scale of 1:25,000.
- Aerial photography of 2012. Panchromatic orthophotomap with a spatial resolution of 0.6 m.
- Digital elevation model (SRTM), horizontal resolution is 1 arc second and vertical 1 m.
- Space survey of 1968 with a spatial resolution of 1.8 m. Panchromatic survey, satellite KH-4B, mission CORONA USA.
- Space survey of 1975 with a spatial resolution of 6 m. Panchromatic survey, satellite KH-9, mission CORONA USA.
- Remote sensing data Landsat 4, 5, 7 and 8 from 1984 to 2019 (1028 scenes).
- Remote sensing data Sentinel-2 2019 (7 tiles).
3. Results
3.1. Predicting the Suitability of Satellite Imagery Frames for Acceptance Sample
3.2. Addition to the GIS Project
- The scheme of agricultural fields (the boundaries of interpretation and recognition).
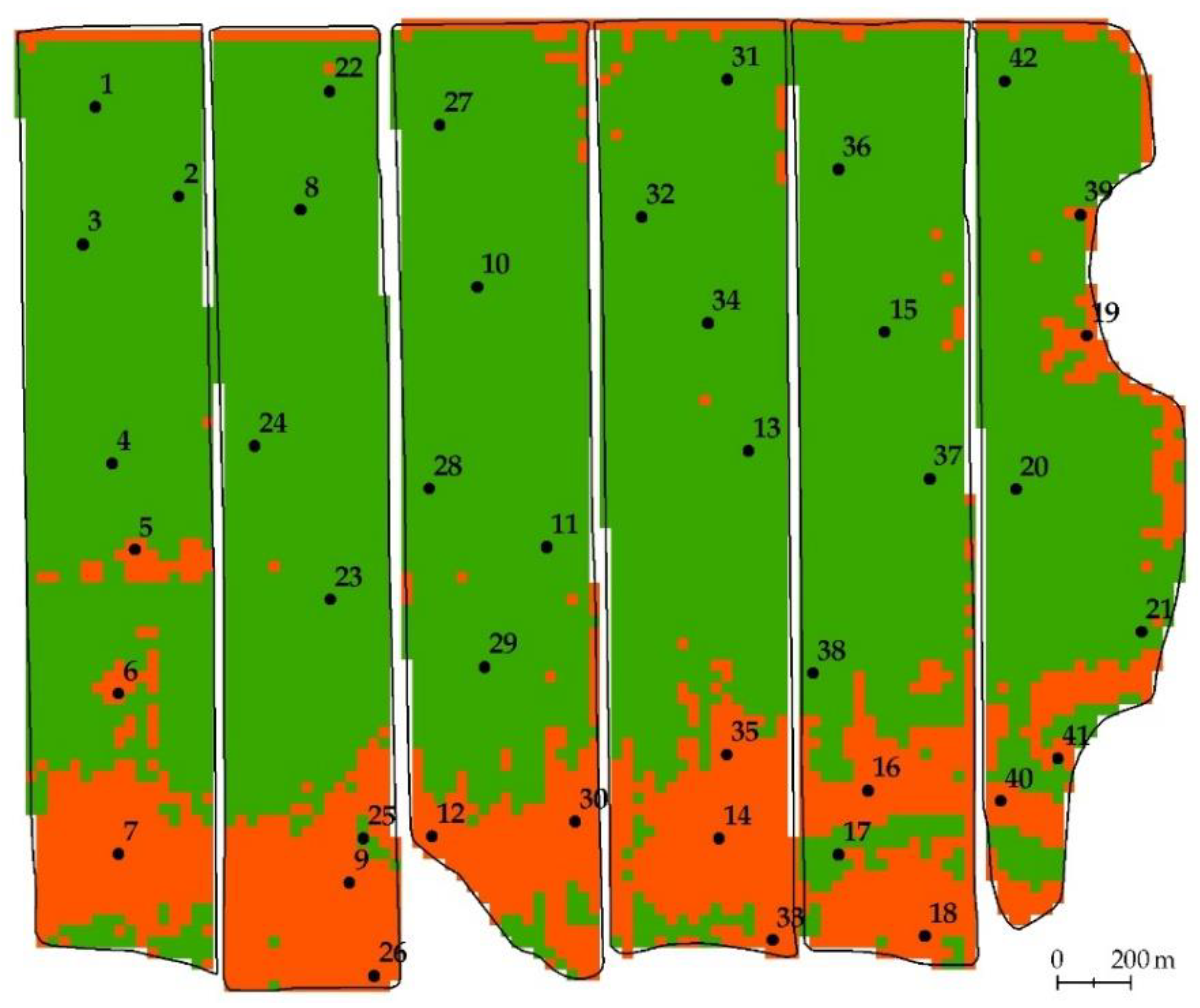
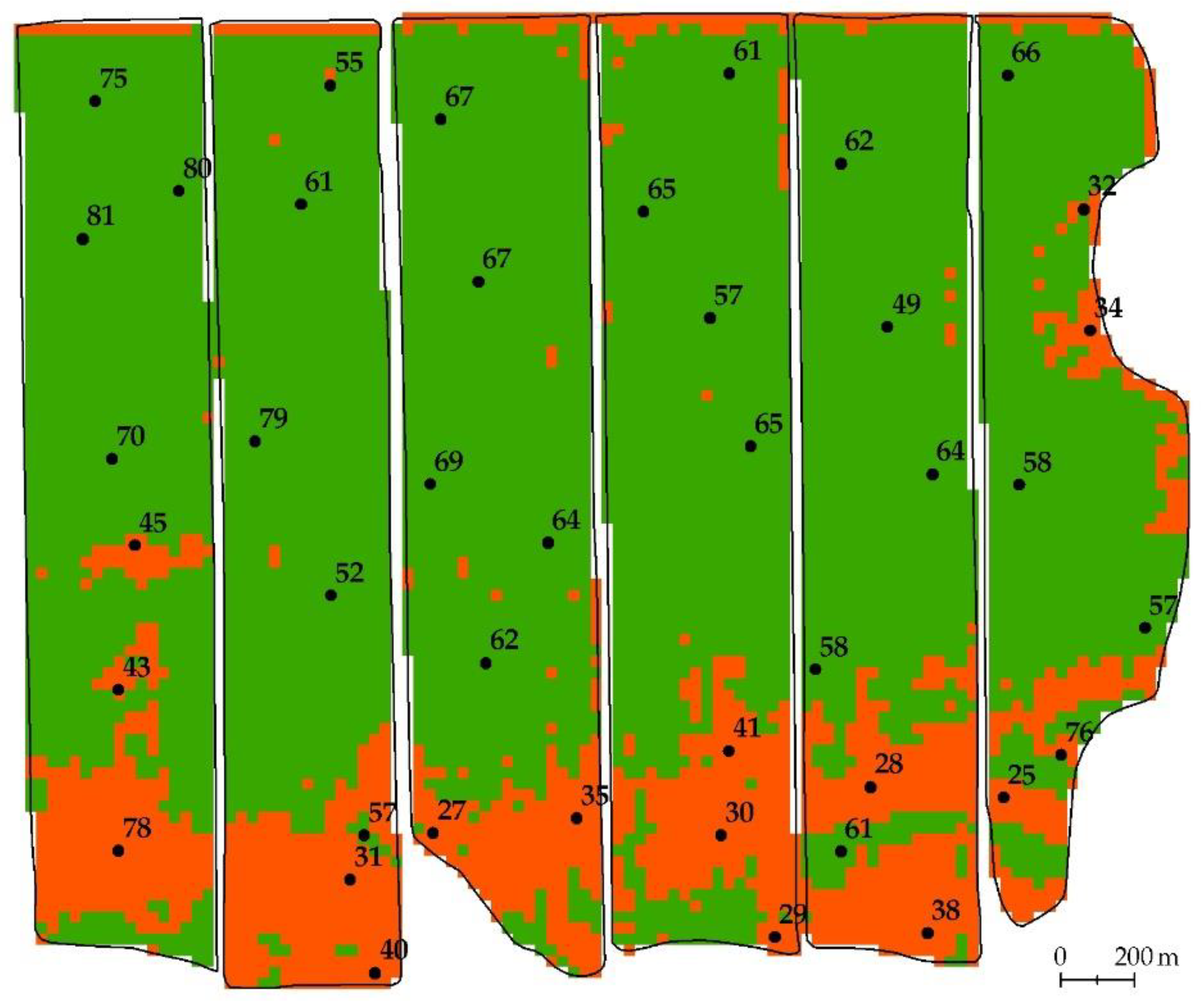
- Binary map of the degradation development calculated using Landsat data selected by a neural network (Figure 10).
- Binary map of the degradation development calculated using Landsat data selected by gradient boosting (Figure 11).
- Binary map of the degradation development calculated using Landsat data selected by visual viewing (Figure 12).
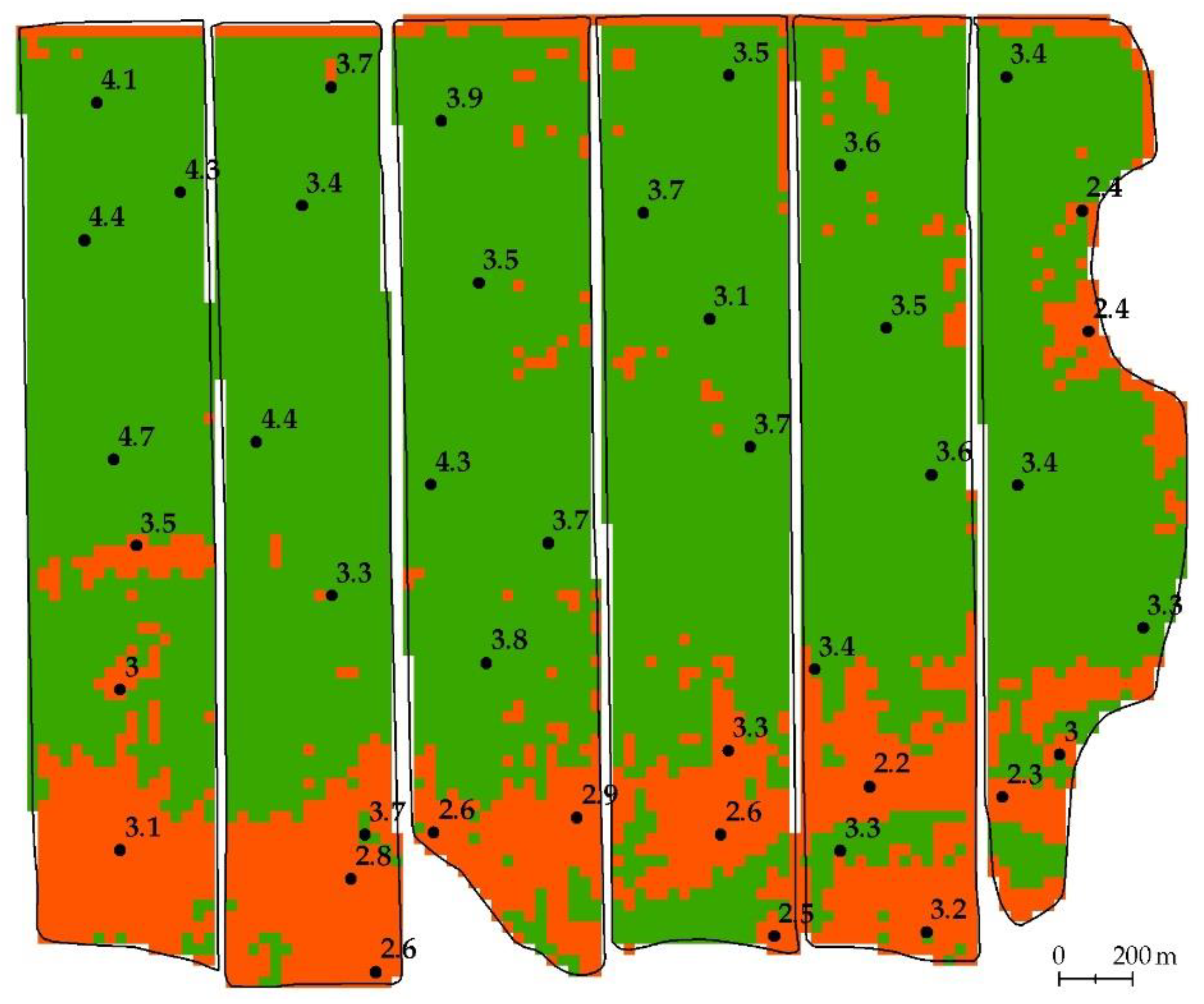
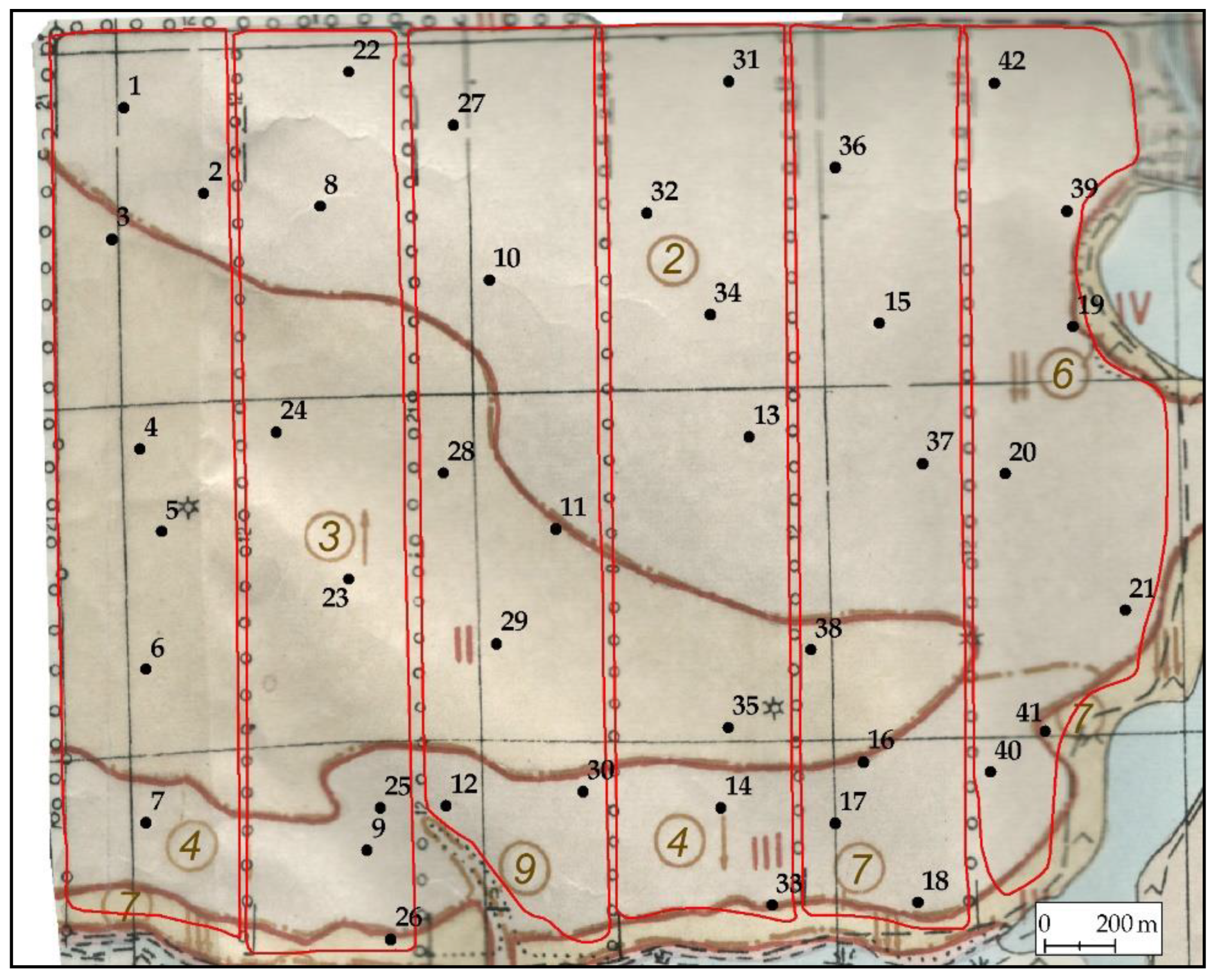
- Map of the location of the results of ground surveys (map of soil pits).
3.3. Comparison of Degradation Development Maps Obtained Using Different Methods of Satellite Imagery Selection
- for manual selection of Landsat scenes—156.5 hectares;
- for Landsat scenes selection using gradient boosting—145.7 hectares;
- for Landsat scenes selection using neural network—149.5 hectares.
3.4. Ground Verification of Degradation Maps
4. Discussion
4.1. Sources and Methods of Soil Erosion Detection
4.2. Analysis of the Causes of Errors
4.3. Analysis of Previously Created Maps of Soil Cover Degradation
4.4. Physical Interpretation of Work Technology
4.5. Promising Remote Sensing Data
5. Conclusions
- Setting the boundary conditions of the calculation.
- Neural network filtering of satellite images in predetermined boundary conditions.
- Calculation of low NDVI values from satellite images selected by the neural network.
- Calculation of average occurrence of low NDVI values over 35 years.
- Classification of average occurrence of low NDVI values to highlight areas of potential degradation.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- All-Union Instruction on Soil Surveys and the Compilation of Large-Scale Soil Land Use Maps; Ischenko, T.A., Ed.; Kolos: Moscow, Russia, 1973. (In Russian) [Google Scholar]
- Farifteh, J.; Van Der Meer, F.; Atzberger, C.; Carranza, E.J.M. Quantitative analysis of salt-affected soil reflectance spectra: A comparison of two adaptive methods (PLSR and ANN). Remote Sens. Environ. 2007, 110, 59–78. [Google Scholar] [CrossRef]
- Higginbottom, T.P.; Symeonakis, E. Assessing Land Degradation and Desertification Using Vegetation Index Data: Current Frameworks and Future Directions. Remote Sens. 2014, 6, 9552–9575. [Google Scholar] [CrossRef]
- Ibrahim, Y.Z.; Balzter, H.; Kaduk, J.; Tucker, C.J. Land degradation assessment using residual trend analysis of GIMMS NDVI3g, soil moisture and rainfall in sub-Saharan west Africa from 1982 to 2012. Remote Sens. 2015, 7, 5471–5494. [Google Scholar] [CrossRef]
- Mendonça-Santos, M.D.L.; Dart, R.O.; Santos, H.G.; Coelho, M.R.; Berbara, R.L.L.; Lumbreras, J.F. Digital Soil Mapping of Topsoil Organic Carbon Content of Rio de Janeiro State, Brazil. In Digital Soil Mapping; Boettinger, J.L., Howell, D.W., Moore, A.C., Hartemink, A.E., Kienast-Brown, S., Eds.; Springer: New York, NY, USA, 2010; pp. 255–266. [Google Scholar]
- Romanenkov, V.; Smith, J.; Smith, P.; Sirotenko, O.D.; Rukhovitch, D.I.; Romanenko, I.A. Soil organic carbon dynamics of croplands in European Russia: Estimates from the “model of humus balance”. Reg. Environ. Chang. 2007, 7, 93–104. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Koroleva, P.V.; Vilchevskaya, E.V.; Romanenkov, V.; Kolesnikova, L.G. Constructing a spatially-resolved database for modelling soil organic carbon stocks of croplands in European Russia. Reg. Environ. Chang. 2007, 7, 51–61. [Google Scholar] [CrossRef]
- Glazunov, G.P.; Gendugov, V.M. A full-scale model of wind erosion and its verification. Eurasian Soil Sci. 2003, 36, 216–226. [Google Scholar]
- Larionov, G.A.; Dobrovol’skaya, N.G.; Krasnov, S.F.; Liu, B.Y. The new equation for the relief factor in statistical models of water erosion. Eurasian Soil Sci. 2003, 36, 1105–1113. [Google Scholar]
- Maltsev, K.A.; Yermolaev, O.P. Potential Soil Loss from Erosion on Arable Lands in the European Part of Russia. Eurasian Soil Sci. 2019, 52, 1588–1597. [Google Scholar] [CrossRef]
- Sukhanovskii, Y.P. Rainfall erosion model. Eurasian Soil Sci. 2010, 43, 1036–1046. [Google Scholar] [CrossRef]
- A Shary, P.; Sharaya, L.S.; Mitusov, A.V. Fundamental quantitative methods of land surface analysis. Geoderma 2002, 107, 1–32. [Google Scholar] [CrossRef]
- SRTM. Available online: http://srtm.csi.cgiar.org (accessed on 20 July 2020).
- Koroleva, P.V.; Rukhovich, D.I.; Shapovalov, D.A.; Suleiman, G.A.; Dolinina, E.A. Retrospective Monitoring of Soil Waterlogging on Arable Land of Tambov Oblast in 2018–1968. Eurasian Soil Sci. 2019, 52, 834–852. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Simakova, M.S.; Kulyanitsa, A.L.; Bryzzhev, A.V.; Koroleva, P.V.; Kalinina, N.V.; Chernousenko, G.I.; Vil’Chevskaya, E.V.; Dolinina, E.A. The influence of soil salinization on land use changes in azov district of Rostov oblast. Eurasian Soil Sci. 2017, 50, 276–295. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Simakova, M.S.; Kulyanitsa, A.L.; Bryzzhev, A.V.; Koroleva, P.V.; Kalinina, N.V.; Chernousenko, G.I.; Vil’Chevskaya, E.V.; Dolinina, E.A.; Rukhovich, S.V. Methodology for Comparing Soil Maps of Different Dates with the Aim to Reveal and Describe Changes in the Soil Cover (by the Example of Soil Salinization Monitoring). Eurasian Soil Sci. 2016, 49, 145–162. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Simakova, M.S.; Kulyanitsa, A.L.; Bryzzhev, A.V.; Koroleva, P.V.; Kalinina, N.V.; Vil’Chveskaya, E.V.; Dolinina, E.A.; Rukhovich, S.V. Retrospective analysis of changes in land uses on vertic soils of closed mesodepressions on the Azov plain. Eurasian Soil Sci. 2015, 48, 1050–1075. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Simakova, M.S.; Kulyanitsa, A.L.; Bryzzhev, A.V.; Koroleva, P.V.; Kalinina, N.V.; Vil’Chevskaya, E.V.; Dolinina, E.A.; Rukhovich, S.V. Impact of shelterbelts on the fragmentation of erosional networks and local soil waterlogging. Eurasian Soil Sci. 2014, 47, 1086–1099. [Google Scholar] [CrossRef]
- Bryzzhev, A.V.; Rukhovich, D.I.; Koroleva, P.V.; Kalinina, N.V.; Vilchevskaya, E.V.; Dolinina, E.A.; Rukhovich, S.V. Organization of retrospective monitoring of the soil cover of Rostov oblast. Eurasian Soil Sci. 2015, 48, 1029–1049. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Simakova, M.S.; Kulyanitsa, A.L.; Bryzzhev, A.V.; Koroleva, P.V.; Kalinina, N.V.; Vilchevskaya, E.V.; Dolinina, E.A.; Rukhovich, S.V. Analysis of the use of soil maps in the system of retrospective monitoring of the state of lands and soil cover. Pochvovedeniye 2015, 5, 605–625. (In Russian) [Google Scholar]
- Shapovalov, D.A.; Koroleva, P.V.; Kalinina, N.V.; Rukhovich, D.I.; Suleiman, G.A.; Dolinina, E.A. Differences in Inventories of Waterlogged Territories in Soil Surveys of Different Years and in Land Management Documents. Eurasian Soil Sci. 2020, 53, 294–309. [Google Scholar] [CrossRef]
- Ayalew, D.A.; Deumlich, D.; Šarapatka, B.; Doktor, D. Quantifying the Sensitivity of NDVI-Based C Factor Estimation and Potential Soil Erosion Prediction using Spaceborne Earth Observation Data. Remote Sens. 2020, 12, 1136. [Google Scholar] [CrossRef]
- De Carvalho, D.F.; Durigon, V.L.; Antunes, M.A.H.; De Almeida, W.S.; Oliveira, P.T.S. Predicting soil erosion using Rusle and NDVI time series from TM Landsat 5. Pesqui. Agropecuária Bras. 2014, 49, 215–224. [Google Scholar] [CrossRef]
- Yengoh, G.T.; Dent, D.; Olsson, L.; Tengberg, A.E.; Tucker, C.J. Limits to the Use of NDVI in Land Degradation Assessment. In Use of the Normalized Difference Vegetation Index (NDVI) to Assess Land Degradation at Multiple Scales; Springer Briefs in Environmental Science; Springer: Cham, Switzerland, 2015; pp. 27–30. [Google Scholar]
- Xu, H.; Hu, X.; Guan, H.; Zhang, B.; Wang, M.; Chen, S.; Chen, M. A Remote Sensing Based Method to Detect Soil Erosion in Forests. Remote. Sens. 2019, 11, 513. [Google Scholar] [CrossRef]
- Phinzi, K.; Ngetar, N.S. Mapping soil erosion in a quaternary catchment in Eastern Cape using geographic information system and remote sensing. S. Afr. J. Geomat. 2017, 6, 11. [Google Scholar] [CrossRef]
- Eckert, S.; Hüsler, F.; Liniger, H.; Hodel, E. Trend analysis of MODIS NDVI time series for detecting land degradation and regeneration in Mongolia. J. Arid. Environ. 2015, 113, 16–28. [Google Scholar] [CrossRef]
- Farm Management. Satellite Big Data: How It Is Changing the Face of Precision Farming. Available online: http://www.farmmanagement.pro/satellite-big-data-how-it-is-changing-the-face-of-precision-farming/ (accessed on 20 July 2020).
- Huang, Y.; Chen, Z.-X.; Yu, T.; Huang, X.-Z.; Gu, X.-F. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Khitrov, N.B.; Rukhovich, D.I.; Koroleva, P.V.; Kalinina, N.V.; Trubnikov, A.V.; Petukhov, D.A.; Kulyanitsa, A.L. A study of the responsiveness of crops to fertilizers by zones of stable intra-field heterogeneity based on big satellite data analysis. Arch. Agron. Soil Sci. 2020, 66, 1963–1975. [Google Scholar] [CrossRef]
- EarthExplorer. Available online: http://earthexplorer.usgs.gov (accessed on 20 July 2020).
- Zi, Y.; Xie, F.; Jiang, Z. A Cloud Detection Method for Landsat 8 Images Based on PCANet. Remote Sens. 2018, 10, 877. [Google Scholar] [CrossRef]
- Zeng, X.; Yang, J.; Deng, X.; An, W.; Li, J. Cloud detection of remote sensing images on Landsat-8 by deep learning. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; p. 108064Y. [Google Scholar]
- Mateo-Garcia, G.; Gómez-Chova, L. Convolutional Neural Networks for Cloud Screening: Transfer Learning from Landsat-8 to Proba-V. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2103–2106. [Google Scholar]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud Detection in Remote Sensing Images Based on Multiscale Features-Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Openshaw, S. Geographical Data Mining: Key Design Issues. In Proceedings of the 4th International Conference on GeoComputation, Fredericksburg, VA, USA, 25–28 July 1999; Available online: http://www.geocomputation.org/1999/051/gc_051.htm (accessed on 20 July 2020).
- Hastie, T.J.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2008; 763p. [Google Scholar]
- Mo, H.; Sun, H.; Liu, J.; Wei, S. Developing window behavior models for residential buildings using XGBoost algorithm. Energy Build. 2019, 205, 109564. [Google Scholar] [CrossRef]
- Abdullah, A.Y.M.; Masrur, A.; Adnan, M.S.G.; Al Baky, A.; Hassan, Q.K.; Dewan, A. Spatio-temporal Patterns of Land Use/Land Cover Change in the Heterogeneous Coastal Region of Bangladesh between 1990 and 2017. Remote Sens. 2019, 11, 790. [Google Scholar] [CrossRef]
- Schneider dos Santos, R. Estimating spatio-temporal air temperature in London (UK) using machine learning and earth observation satellite data. Int. J. Appl. Earth Obs. 2020, 88, 102066. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2016, 9, 22. [Google Scholar] [CrossRef]
- Baeta, R.; Nogueira, K.; Menotti, D.; Dos Santos, J.A. Learning Deep Features on Multiple Scales for Coffee Crop Recognition. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017; pp. 262–268. [Google Scholar]
- Guirado, E.; Tabik, S.; Alcaraz-Segura, D.; Cabello, J.; Herrera, F. Deep-learning Versus OBIA for Scattered Shrub Detection with Google Earth Imagery: Ziziphus lotus as Case Study. Remote Sens. 2017, 9, 1220. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning for digital soil mapping. Soil 2019, 5, 79–89. [Google Scholar] [CrossRef]
- Meng, Q.; Zhang, L.; Xie, Q.; Yao, S.; Chen, X.; Zhang, Y. Combined Use of GF-3 and Landsat-8 Satellite Data for Soil Moisture Retrieval over Agricultural Areas Using Artificial Neural Network. Adv. Meteorol. 2018, 2018, 9315132. [Google Scholar] [CrossRef]
- Nijhawan, R.; Sharma, H.; Sahni, H.; Batra, A. A Deep Learning Hybrid CNN Framework Approach for Vegetation Cover Mapping Using Deep Features. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Niteroi, Brazil, 17–20 October 2017; pp. 192–196. [Google Scholar]
- Petropoulos, G.P.; Vadrevu, K.; Xanthopoulos, G.; Karantounias, G.; Scholze, M. A Comparison of Spectral Angle Mapper and Artificial Neural Network Classifiers Combined with Landsat TM Imagery Analysis for Obtaining Burnt Area Mapping. Sensors 2010, 10, 1967–1985. [Google Scholar] [CrossRef]
- Rai, A.K.; Mandal, N.; Singh, A.; Singh, K.K. Landsat 8 OLI Satellite Image Classification using Convolutional Neural Network. Procedia Comput. Sci. 2020, 167, 987–993. [Google Scholar] [CrossRef]
- Khan, M.S.; Semwal, M.; Sharma, A.; Verma, R.K. An artificial neural network model for estimating Mentha crop biomass yield using Landsat 8 OLI. Precis. Agric. 2020, 21, 18–33. [Google Scholar] [CrossRef]
- NEXT Farming: Smarte Lösungen für Landwirte. Available online: https://www.nextfarming.de/ (accessed on 20 July 2020).
- Shapovalov, D.A.; Koroleva, P.V.; Kalinina, N.V.; Vilchevskaya, E.V.; Kulyanitsa, A.L.; Rukhovich, D.I. ASF-index-a map of stable intra-field heterogeneity of soil cover fertility, based on big satellite data for precision agriculture tasks. Mejdunarodnyi Selskohozyaistvennyi J. 2020, 1, 9–15. [Google Scholar]
- ExactFarming. Available online: https://www.exactfarming.com/ru/ (accessed on 20 July 2020).
- Farmers Edge. Available online: https://www.farmersedge.ca/ru/ (accessed on 20 July 2020).
- Cropio. Available online: https://about.cropio.com/ru/ (accessed on 20 July 2020).
- Intterra. Available online: https://intterra.ru/ru (accessed on 20 July 2020).
- AGRO-SAT Consulting GmbH. Available online: http://agro-sat.de/ (accessed on 20 July 2020).
- Agronote. Available online: https://www.avgust.com/newspaper/topics/detail.php?ID=6860 (accessed on 20 July 2020).
- Unified Interdepartmental Information and Statistical System. State Statistics. Available online: https://fedstat.ru/indicator/31328 (accessed on 20 July 2020).
- Rukhovich, D.I.; Koroleva, P.V.; Vilchevskaya, E.V.; Kalinina, N.V. Digital thematic cartography as a change in the available primary sources and ways of using them. In Digital Soil Mapping: Theoretical and Experimental Studies; Ivanov, A.L., Sorokina, N.P., Savin, I., Eds.; Dokuchaev Soil Science Institute: Moscow, Russia, 2012; pp. 58–86. [Google Scholar]
- Development of a Software Package for the Selection of Satellite Images and Generation of Task Maps in Digital Agriculture using Computer Vision Technologies Based on Neural Networks (Research Work under the Grant). Available online: https://www.rosrid.ru/nioktr/OVY4GO11YV0GD8MARCDPM22O (accessed on 20 July 2020).
- USGS EROS Archive-Declassified Data-Declassified Satellite Imagery-1. Available online: https://www.usgs.gov/centers/eros/science/usgs-eros-archive-declassified-data-declassified-satellite-imagery-1?qt-science_center_objects=0#qt-science_center_objects (accessed on 20 July 2020).
- Zolfaghari, K.; Shang, J.; McNairn, H.; Li, J.; Homyouni, S.; Li, J. Using support vector machine (SVM) for agriculture land use mapping with SAR data: Preliminary results from western Canada. In Proceedings of the 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Fairfax, VA, USA, 12–16 August 2013; pp. 126–130. [Google Scholar]
- Lebrini, Y.; Boudhar, A.; Hadria, R.; Lionboui, H.; Elmansouri, L.; Arrach, R.; Ceccato, P.; Benabdelouahab, T. Identifying Agricultural Systems Using SVM Classification Approach Based on Phenological Metrics in a Semi-arid Region of Morocco. Earth Syst. Environ. 2019, 3, 277–288. [Google Scholar] [CrossRef]
- Akbarzadeh, S.; Paap, A.; Ahderom, S.; Apopei, B.; Alameh, K. Plant discrimination by Support Vector Machine classifier based on spectral reflectance. Comput. Electron. Agric. 2018, 148, 250–258. [Google Scholar] [CrossRef]
- Shi, L.; Duan, Q.; Ma, X.; Weng, M. The Research of Support Vector Machine in Agricultural Data Classification. In Computer and Computing Technologies in Agriculture V. CCTA 2011. IFIP Advances in Information and Communication Technology; Li, D., Chen, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 370, pp. 265–569. [Google Scholar]
- Maniyath, S.R.; Hebbar, R.; Akshatha, K.N.; Architha, L.S.; Subramoniam, S.R. Soil Color Detection Using Knn Classifier. In Proceedings of the 2018 International Conference on Design Innovations for 3Cs Compute Communicate Control (ICDI3C), Bangalore, India, 25–28 April 2018; pp. 52–55. [Google Scholar]
- Amato, G.; Falchi, F. KNN based image classification relying on local feature similarity. In Proceedings of the Third International Conference on Similarity Search and Applications (SISAP ’10), Istanbul, Turkey, 18–19 September 2010; pp. 101–108. [Google Scholar]
- Thamilselvan, P.; Sathiaseelan, J.G.R. An enhanced k nearest neighbor method to detecting and classifying MRI lung cancer images for large amount data. Int. J. Appl. Eng. Res. 2016, 11, 4223–4229. [Google Scholar]
- Imandoust, S.B.; Bolandraftar, M. Application of K-nearest neighbor (KNN) approach for predicting economic events theoretical background. Int. J. Eng. Res. Appl. 2013, 3, 605–610. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167v3. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence-Volume 2 (IJCAI’95), Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1143. [Google Scholar]
- Mullin, M.; Sukthankar, R. Complete Cross-Validation for Nearest Neighbor Classifiers. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML ’00), Stanford, CA, USA, 29 June–2 July 2000; pp. 639–646. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. Catboost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6638–6648. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the great plains with ERTS. In Proceedings of the Third ERTS Symposium, Washington, DC, USA, 10–14 December 1973; Scientific and Technical Information Office, NASA: Washington, DC, USA, 1974; Volume 1, pp. 309–317. [Google Scholar]
- Koroleva, P.; Dolinina, E.; Rukhovich, A. Comparative analysis of the yield map obtained from the John Deere combine and the ASF-index distribution map. In Proceedings of the 20th International Multidisciplinary Scientific GeoConference SGEM 2020, Albena, Bulgaria, 18–24 August 2020; Volume 20, pp. 191–198. [Google Scholar]
- Chavez, P.S. An improved dark-object subtraction technique for atmospheric scattering correction of multispectral data. Remote Sens. Environ. 1988, 24, 459–479. [Google Scholar] [CrossRef]
- Chavez, P.S., Jr. Radiometric Calibration of Landsat Thematic Mapper Multispectral Images. Photogramm. Eng. Remote Sens. 1989, 55, 1285–1294. [Google Scholar]
- Chavez, P.S., Jr. Image-based atmospheric corrections-revisited and revised. Photogramm. Eng. Remote Sens. 1996, 62, 1025–1036. [Google Scholar]
- Erdas Imagine. Available online: https://www.hexagongeospatial.com/products/power-portfolio/erdas-imagine (accessed on 20 July 2020).
- State Standard of the USSR 26213-91. Soils. Methods for Determination of Organic Matter. 1993. Available online: http://docs.cntd.ru/document/1200023481 (accessed on 20 July 2020).
- Walkley, A.J.; Black, I.A. Estimation of soil organic carbon by the chromic acid titration method. Soil Sci. 1934, 37, 29–38. [Google Scholar] [CrossRef]
- Soil Map of Experimental and Production Farm of North Caucasian MTS, Zernogradsky District, Rostov Region, Scale 1:25000; Roskomzem of the RSFSR, RosNIIZemproekt, Institute YUZHNIIGIPROZEM: Rostov-on-Don, Russia, 1983.
- ArcGIS. Available online: https://www.esri.com/ru-ru/arcgis/about-arcgis/overview (accessed on 20 July 2020).
- Unified State Register of Soil Resources of Russia. Available online: http://egrpr.soil.msu.ru/index.php (accessed on 20 July 2020).
- Soil Map of Zernogradsky District, Rostov Region, Scale 1:100,000; VISKHAGI Southern Branch: Novocherkassk, Russia, 1972.
- Li, P.; Wu, J.; Qian, H. Regulation of secondary soil salinization in semi-arid regions: A simulation research in the Nanshantaizi area along the Silk Road, northwest China. Environ. Earth Sci. 2016, 75, 1–12. [Google Scholar] [CrossRef]
- Nawar, S.; Buddenbaum, H.; Hill, J. Digital Mapping of Soil Properties Using Multivariate Statistical Analysis and ASTER Data in an Arid Region. Remote Sens. 2015, 7, 1181–1205. [Google Scholar] [CrossRef]
- Daliakopoulos, I.; Tsanis, I.; Koutroulis, A.; Kourgialas, N.; Varouchakis, A.; Karatzas, G.; Ritsema, C. The threat of soil salinity: A European scale review. Sci. Total Environ. 2016, 573, 727–739. [Google Scholar] [CrossRef]
- Cook, K.L. An evaluation of the effectiveness of low-cost UAVs and structure from motion for geomorphic change detection. Geomorphology 2017, 278, 195–208. [Google Scholar] [CrossRef]
- Rahmati, O.; Tahmasebipour, N.; Haghizadeh, A.; Pourghasemi, H.R.; Feizizadeh, B. Evaluation of different machine learning models for predicting and mapping the susceptibility of gully erosion. Geomorphology 2017, 298, 118–137. [Google Scholar] [CrossRef]
- Gong, C.; Lei, S.; Bian, Z.; Liu, Y.; Zhang, Z.; Cheng, W. Analysis of the Development of an Erosion Gully in an Open-Pit Coal Mine Dump During a Winter Freeze-Thaw Cycle by Using Low-Cost UAVs. Remote Sens. 2019, 11, 1356. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Gopp, N.V.; Nechaeva, T.V.; Savenkov, O.A.; Smirnova, N.V.; Smirnov, V.V. Indicative capacity of NDVI in predictive mapping of the properties of plow horizons of soils on slopes in the south of Western Siberia. Eurasian Soil Sci. 2017, 50, 1332–1343. [Google Scholar] [CrossRef]
- Gopp, N.V.; Savenkov, O.A. Relationships between the NDVI, Yield of Spring Wheat, and Properties of the Plow Horizon of Eluviated Clay-Illuvial Chernozems and Dark Gray Soils. Eurasian Soil Sci. 2019, 52, 339–347. [Google Scholar] [CrossRef]
- Koroleva, P.V.; Rukhovich, D.I.; Rukhovich, A.D.; Rukhovich, D.D.; Kulyanitsa, A.L.; Trubnikov, A.V.; Kalinina, N.V.; Simakova, M.S. Characterization of Soil Types and Subtypes in N-Dimensional Space of Multitemporal (Empirical) Soil Line. Eurasian Soil Sci. 2018, 51, 1021–1033. [Google Scholar] [CrossRef]
- Kulyanitsa, A.L.; Rukhovich, A.D.; Koroleva, P.V.; Simakova, M.S. The application of the piecewise linear approximation to the spectral neighborhood of soil line for the analysis of the quality of normalization of remote sensing materials. Eurasian Soil Sci. 2017, 50, 387–395. [Google Scholar] [CrossRef]
- Rukhovich, D.I.; Rukhovich, A.D.; Simakova, M.S.; Kulyanitsa, A.L.; Koroleva, P.V.; Rukhovich, D.D. Application of the Spectral Neighborhood of Soil Line Technique to Analyze the Intensity of Soil Use in 1985–2014 (by the Example of Three Districts of Tula Oblast). Eurasian Soil Sci. 2018, 51, 345–358. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AUC |
|---|---|
| Gradient Boosting | 98.51 |
| Neural Network | 98.56 |
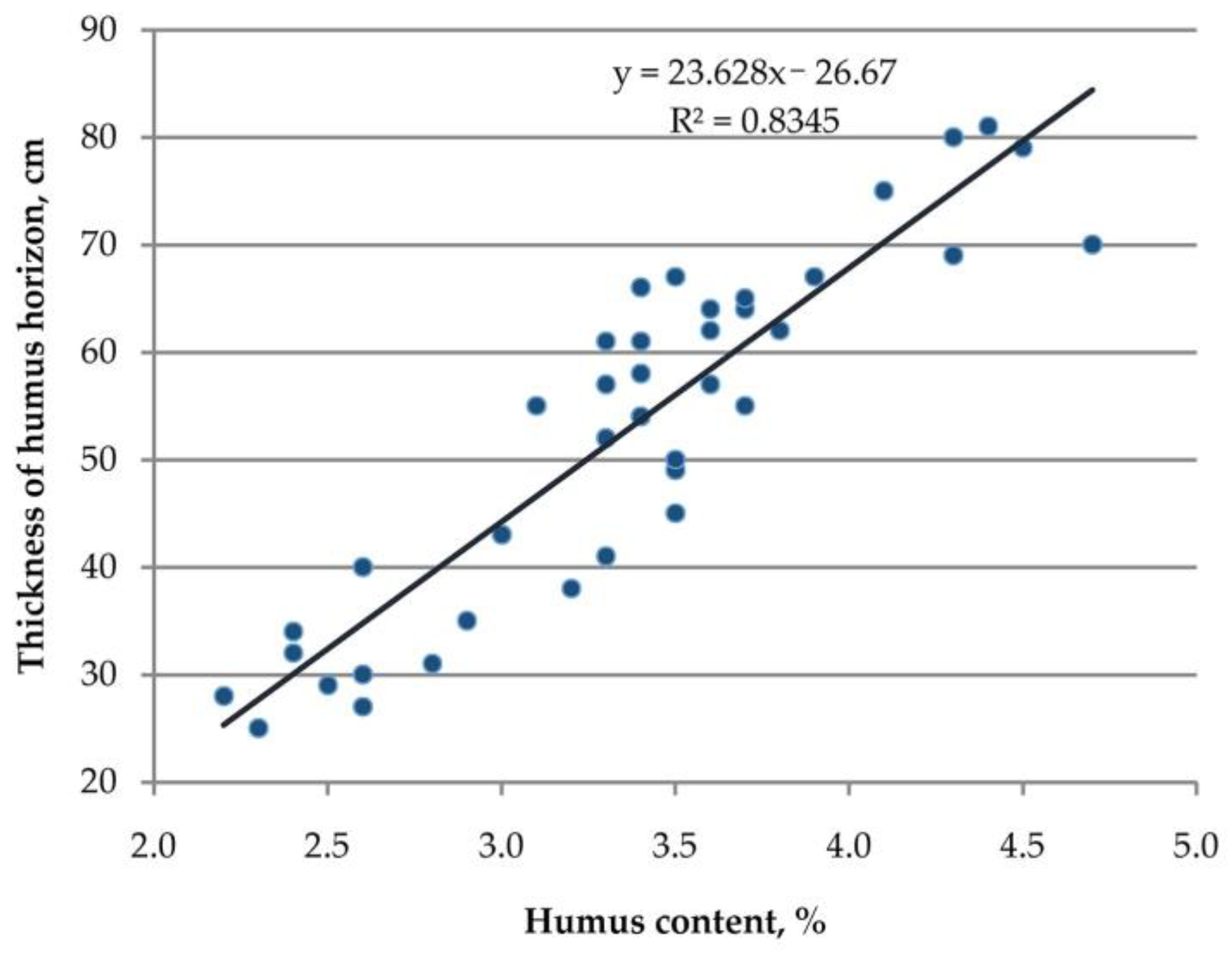
| Soil Pit | Thickness of Humus Horizon, cm | Humus Content in Plow Horizon, % | Presence of Degradation According to Ground Survey Based on: | Soil Pit Belongs to the Degradation Area Based on: | Degradation Type * | ||||
|---|---|---|---|---|---|---|---|---|---|
| Humus Horizon | Humus Content | Both Signs | Gradient Boosting | Neural Network | Manual Selection | ||||
| 1 | 75 | 4.1 | − | − | − | − | − | − | n |
| 2 | 80 | 4.3 | − | − | − | − | − | − | n |
| 3 | 81 | 4.4 | − | − | − | − | − | − | n |
| 4 | 70 | 4.7 | − | − | − | − | − | − | n |
| 5 | 45 | 3.5 | + | − | + | + | + | + | d |
| 6 | 43 | 3.0 | + | − | + | + | + | + | e |
| 7 | 78 | 3.1 | − | − | − | + | + | + | n |
| 8 | 61 | 3.4 | − | − | − | − | − | − | n |
| 9 | 31 | 2.8 | + | + | + | + | + | + | e |
| 10 | 67 | 3.5 | − | − | − | − | − | − | n |
| 11 | 64 | 3.7 | − | − | − | − | − | − | n |
| 12 | 27 | 2.6 | + | + | + | + | + | + | e |
| 13 | 65 | 3.7 | − | − | − | − | − | − | n |
| 14 | 30 | 2.6 | + | + | + | + | + | + | e |
| 15 | 49 | 3.5 | + | − | + | − | − | − | e |
| 16 | 28 | 2.2 | + | + | + | + | + | + | e |
| 17 | 61 | 3.3 | − | − | − | − | − | − | n |
| 18 | 38 | 3.2 | + | − | + | + | + | + | e |
| 19 | 34 | 2.4 | + | + | + | + | + | + | e |
| 20 | 58 | 3.4 | − | − | − | − | − | − | n |
| 21 | 57 | 3.3 | − | − | − | − | − | − | n |
| 22 | 55 | 3.7 | − | − | − | − | − | − | n |
| 23 | 52 | 3.3 | − | − | − | − | − | − | n |
| 24 | 79 | 4.5 | − | − | − | − | − | − | n |
| 25 | 57 | 3.6 | − | − | − | − | − | − | n |
| 26 | 40 | 2.6 | + | + | + | + | + | + | e |
| 27 | 67 | 3.9 | − | − | − | − | − | − | n |
| 28 | 69 | 4.3 | − | − | − | − | − | − | n |
| 29 | 62 | 3.8 | − | − | − | − | − | − | n |
| 30 | 35 | 2.9 | + | + | + | + | + | + | e |
| 31 | 50 | 3.5 | − | − | − | − | − | − | n |
| 32 | 65 | 3.7 | − | − | − | − | − | − | n |
| 33 | 29 | 2.5 | + | + | + | + | + | + | e |
| 34 | 55 | 3.1 | − | − | − | − | − | − | n |
| 35 | 41 | 3.3 | + | − | + | + | + | + | e |
| 36 | 62 | 3.6 | − | − | − | − | − | − | n |
| 37 | 64 | 3.6 | − | − | − | − | − | − | n |
| 38 | 54 | 3.4 | − | − | − | − | − | − | n |
| 39 | 32 | 2.4 | + | + | + | + | + | + | e |
| 40 | 25 | 2.3 | + | + | + | + | + | + | e |
| 41 | 76 | 3.0 | − | − | − | + | + | + | n |
| 42 | 66 | 3.4 | − | − | − | − | − | − | n |
| Selection Methods | Total Area, Hectares | Area of Identical Values, Hectares | Area of Different Values, Hectares | Area of Identical Values, % | Area of Different Values, % |
|---|---|---|---|---|---|
| Neural network and gradient boosting | 713.3 | 691.9 | 21.4 | 97.0 | 3.0 |
| Manual selection and gradient boosting | 713.3 | 675.4 | 38.0 | 94.7 | 5.3 |
| Manual selection and neural network | 713.3 | 673.4 | 40.0 | 94.4 | 5.6 |
| Sum of Squares | df | Mean Square | F | p-Value | F Crit | |
|---|---|---|---|---|---|---|
| Between groups | 8.830806 | 1 | 8.831 | 54.761 | 5.23093 × 10−9 | 4.085 |
| Within groups | 6.450385 | 40 | 0.161 | |||
| Total | 15.28119 | 41 |
| Sum of Squares | df | Mean Square | F | p-Value | F Crit | |
|---|---|---|---|---|---|---|
| Between groups | 5908.059 | 1 | 5908.059 | 43.603 | 6.71827 × 10−8 | 4.085 |
| Within groups | 5419.846 | 40 | 135.496 | |||
| Total | 11,327.905 | 41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rukhovich, D.I.; Koroleva, P.V.; Rukhovich, D.D.; Kalinina, N.V. The Use of Deep Machine Learning for the Automated Selection of Remote Sensing Data for the Determination of Areas of Arable Land Degradation Processes Distribution. Remote Sens. 2021, 13, 155. https://doi.org/10.3390/rs13010155
Rukhovich DI, Koroleva PV, Rukhovich DD, Kalinina NV. The Use of Deep Machine Learning for the Automated Selection of Remote Sensing Data for the Determination of Areas of Arable Land Degradation Processes Distribution. Remote Sensing. 2021; 13(1):155. https://doi.org/10.3390/rs13010155
Chicago/Turabian StyleRukhovich, Dmitry I., Polina V. Koroleva, Danila D. Rukhovich, and Natalia V. Kalinina. 2021. "The Use of Deep Machine Learning for the Automated Selection of Remote Sensing Data for the Determination of Areas of Arable Land Degradation Processes Distribution" Remote Sensing 13, no. 1: 155. https://doi.org/10.3390/rs13010155
APA StyleRukhovich, D. I., Koroleva, P. V., Rukhovich, D. D., & Kalinina, N. V. (2021). The Use of Deep Machine Learning for the Automated Selection of Remote Sensing Data for the Determination of Areas of Arable Land Degradation Processes Distribution. Remote Sensing, 13(1), 155. https://doi.org/10.3390/rs13010155