Accounting for Training Data Error in Machine Learning Applied to Earth Observations

 , , , ,
, , , ,  ,
, 
Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- The “big data” era vastly increases the demand for TD.
- ML-generated map products rely heavily on human-generated TD, which in most cases contain error, particularly when developed through image interpretation.
- TD errors may propagate to downstream products in surprising and potentially harmful ways (e.g., leading to bad decisions) and can occur without the map producer and/or map user’s knowledge. This problem is particularly relevant in the common case where TD and reference data are collected using the same methods, and/or in cases where map reference data error is not known or accounted for, which is still common [57].
1.1. Current Trends in Training Data (TD) Collection
1.2. Characterizing Training Data Error
1.2.1. Map Accuracy Assessment Procedures
1.2.2. Current Approaches for Assessing and Accounting for Training Data Error
2. Sources and Impacts of Training Data Error
2.1. Sources of Training Data Error
2.1.1. Design-Related Errors
2.1.2. Collection-Related Errors
2.2. Impacts of Training Data Error
3. Case Studies
3.1. Infrastructure Mapping
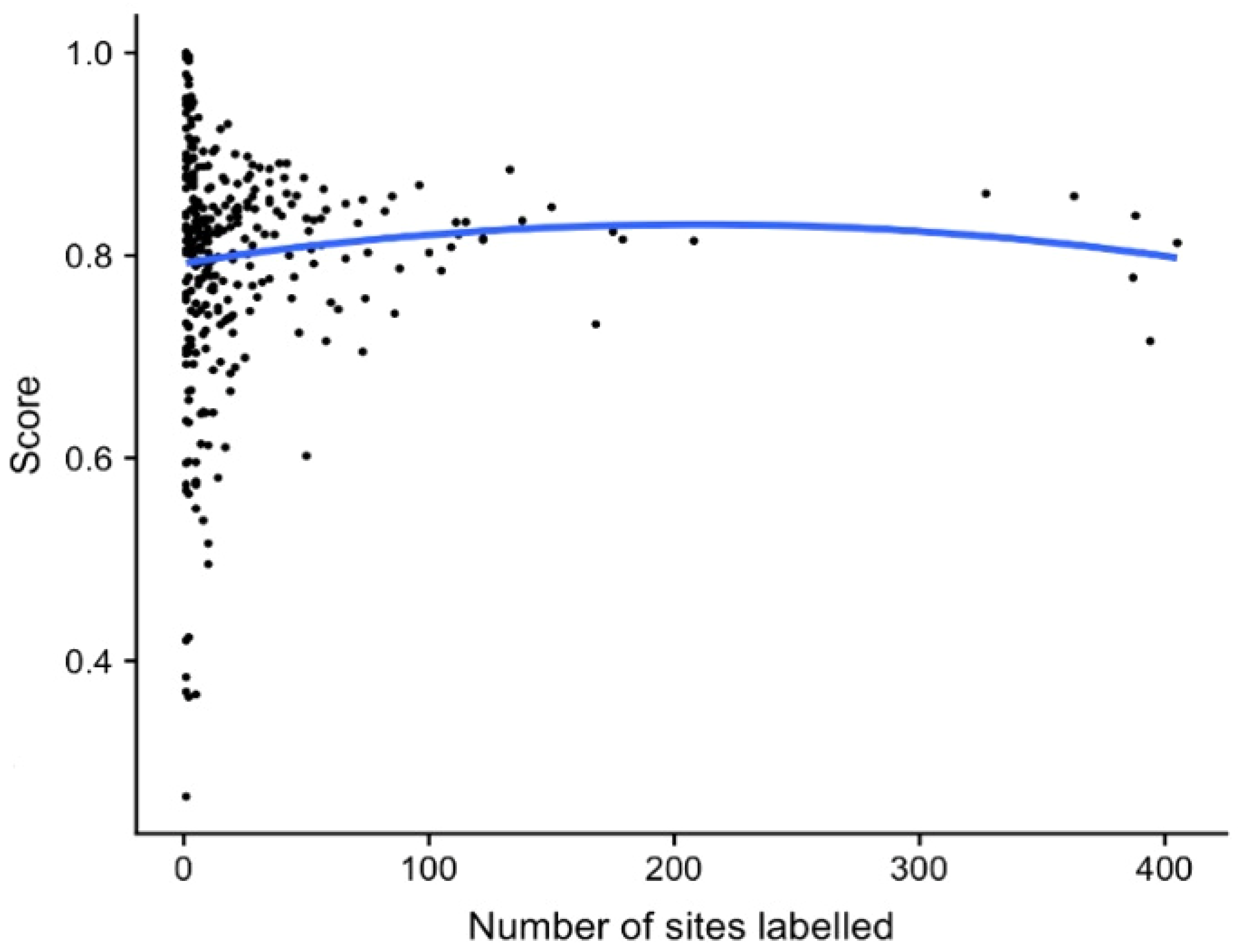
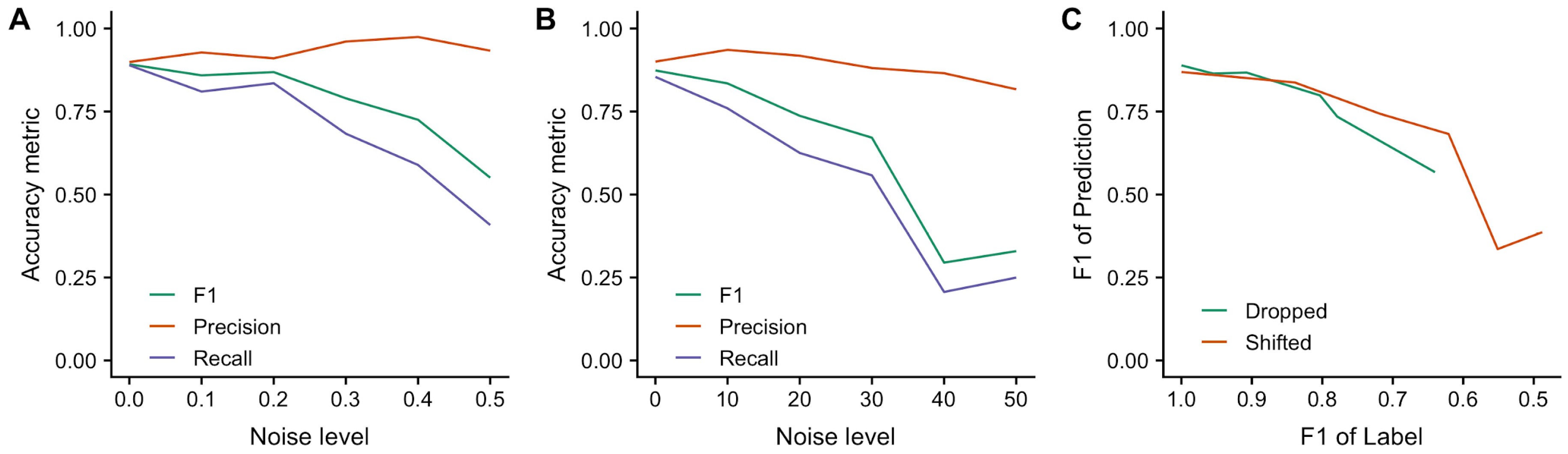
3.1.1. Incorporating Noisy Training Label Data
3.1.2. Detecting Roads from Satellite Imagery
3.2. Global Surface Flux Estimates
3.3. Agricultural Monitoring
4. Guidelines and Recommendations
4.1. Step 1: Define Acceptable Level of Accuracy and Choose Appropriate Metric
4.2. Step 2: Minimize Design-Related Errors
4.2.1. Sample Design
4.2.2. Training Data Sources
4.2.3. Legend Design
4.3. Step 3: Minimize Collection-Related Errors
4.4. Step 4. Assess Error in Training Data Error
4.5. Step 5. Evaluate and Communicate the Impact of Training Data Error
4.5.1. TD Treatment Tiers
4.5.2. Communicating Error
4.5.3. Towards an Open Training Data Repository
5. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global Land Cover Mapping at 30 m Resolution: A POK-Based Operational Approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Song, X.-P.; Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Tyukavina, A.; Vermote, E.F.; Townshend, J.R. Global land change from 1982 to 2016. Nature 2018, 560, 639–643. [Google Scholar] [CrossRef] [PubMed]
- Mohanty, B.P.; Cosh, M.H.; Lakshmi, V.; Montzka, C. Soil Moisture Remote Sensing: State-of-the-Science. Vadose Zone J. 2017, 16. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Guided Anisotropic Diffusion and Iterative Learning for Weakly Supervised Change Detection. arXiv 2019. [Google Scholar]
- Hecht, R.; Meinel, G.; Buchroithner, M. Automatic identification of building types based on topographic databases—A comparison of different data sources. Int. J. Cartogr. 2015, 1, 18–31. [Google Scholar] [CrossRef]
- Zhang, X.; Jayavelu, S.; Liu, L.; Friedl, M.A.; Henebry, G.M.; Liu, Y.; Schaaf, C.B.; Richardson, A.D.; Gray, J. Evaluation of land surface phenology from VIIRS data using time series of PhenoCam imagery. Agric. For. Meteorol. 2018, 256–257, 137–149. [Google Scholar] [CrossRef]
- Tan, B.; Morisette, J.T.; Wolfe, R.E.; Gao, F.; Ederer, G.A.; Nightingale, J.; Pedelty, J.A. An Enhanced TIMESAT Algorithm for Estimating Vegetation Phenology Metrics From MODIS Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 361–371. [Google Scholar] [CrossRef]
- Zhang, X.; Friedl, M.A.; Schaaf, C.B. Global vegetation phenology from Moderate Resolution Imaging Spectroradiometer (MODIS): Evaluation of global patterns and comparison with in situ measurements: GLOBAL PHENOLOGY FROM MODIS. J. Geophys. Res. 2006, 111, 981. [Google Scholar] [CrossRef]
- Schaaf, C.B.; Gao, F.; Strahler, A.H.; Lucht, W.; Li, X.; Tsang, T.; Strugnell, N.C.; Zhang, X.; Jin, Y.; Muller, J.-P.; et al. First operational BRDF, albedo nadir reflectance products from MODIS. Remote Sens. Environ. 2002, 83, 135–148. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Sun, Q.; Erb, A.M.; Li, Z.; Schaaf, C.B.; Zhang, X.; Román, M.O.; Scott, R.L.; Zhang, Q.; et al. Evaluation of the VIIRS BRDF, Albedo and NBAR products suite and an assessment of continuity with the long term MODIS record. Remote Sens. Environ. 2017, 201, 256–274. [Google Scholar] [CrossRef]
- Wang, Z.; Schaaf, C.B.; Sun, Q.; Shuai, Y.; Román, M.O. Capturing rapid land surface dynamics with Collection V006 MODIS BRDF/NBAR/Albedo (MCD43) products. Remote Sens. Environ. 2018, 207, 50–64. [Google Scholar] [CrossRef]
- Wan, Z. New refinements and validation of the MODIS Land-Surface Temperature/Emissivity products. Remote Sens. Environ. 2008, 112, 59–74. [Google Scholar] [CrossRef]
- Jiménez-Muñoz, J.C.; Sobrino, J.A.; Skoković, D.; Mattar, C.; Cristóbal, J. Land Surface Temperature Retrieval Methods From Landsat-8 Thermal Infrared Sensor Data. IEEE Geoscie. Remote Sens. Lett. 2014, 11, 1840–1843. [Google Scholar] [CrossRef]
- Jean, N.; Burke, M.; Xie, M.; Davis, W.M.; Lobell, D.B.; Ermon, S. Combining satellite imagery and machine learning to predict poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [PubMed]
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.; Tyukavina, A. Comment on “Tropical forests are a net carbon source based on aboveground measurements of gain and loss”. Science 2019, 363. [Google Scholar] [CrossRef]
- Gutierrez-Velez, V.H.; Pontius, R.G. Influence of carbon mapping and land change modelling on the prediction of carbon emissions from deforestation. Environ. Conserv. 2012, 39, 325–336. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens 2019, 1–10. [Google Scholar] [CrossRef]
- Liu, Q.; Hang, R.; Song, H.; Li, Z. Learning Multiscale Deep Features for High-Resolution Satellite Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 117–126. [Google Scholar] [CrossRef]
- Laso Bayas, J.C.; Lesiv, M.; Waldner, F.; Schucknecht, A.; Duerauer, M.; See, L.; Fritz, S.; Fraisl, D.; Moorthy, I.; McCallum, I.; et al. A global reference database of crowdsourced cropland data collected using the Geo-Wiki platform. Sci. Data 2017, 4, 170136. [Google Scholar] [CrossRef] [PubMed]
- Lary, D.J.; Zewdie, G.K.; Liu, X.; Wu, D.; Levetin, E.; Allee, R.J.; Malakar, N.; Walker, A.; Mussa, H.; Mannino, A.; et al. Machine Learning Applications for Earth Observation. In Earth Observation Open Science and Innovation; Mathieu, P.-P., Aubrecht, C., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 165–218. ISBN 9783319656335. [Google Scholar]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Gray, J.M.; Abercrombie, S.P.; Friedl, M.A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sens. Environ. 2019, 222, 183–194. [Google Scholar] [CrossRef]
- Fortier, J.; Rogan, J.; Woodcock, C.E.; Runfola, D.M. Utilizing Temporally Invariant Calibration Sites to Classify Multiple Dates and Types of Satellite Imagery. Photogramm. Eng. Remote Sens. 2011, 77, 181–189. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Graves, S.J.; Asner, G.P.; Martin, R.E.; Anderson, C.B.; Colgan, M.S.; Kalantari, L.; Bohlman, S.A. Tree Species Abundance Predictions in a Tropical Agricultural Landscape with a Supervised Classification Model and Imbalanced Data. Remote Sens. 2016, 8, 161. [Google Scholar] [CrossRef]
- Foody, G.; Pal, M.; Rocchini, D.; Garzon-Lopez, C. The sensitivity of mapping methods to reference data quality: Training supervised image classifications with imperfect reference data. Int. J. Geo-Inf. 2016, 5, 199. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: an applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Estes, L.; Chen, P.; Debats, S.; Evans, T.; Ferreira, S.; Kuemmerle, T.; Ragazzo, G.; Sheffield, J.; Wolf, A.; Wood, E.; et al. A large-area, spatially continuous assessment of land cover map error and its impact on downstream analyses. Glob. Chang. Biol. 2018, 24, 322–337. [Google Scholar] [CrossRef] [PubMed]
- Pengra, B.W.; Stehman, S.V.; Horton, J.A.; Dockter, D.J.; Schroeder, T.A.; Yang, Z.; Cohen, W.B.; Healey, S.P.; Loveland, T.R. Quality control and assessment of interpreter consistency of annual land cover reference data in an operational national monitoring program. Remote Sens. Environ. 2019, 111261. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the accuracy of land cover change with imperfect ground reference data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Monmonier, M. Cartography: Uncertainty, interventions, and dynamic display. Prog. Hum. Geogr. 2006, 30, 373–381. [Google Scholar] [CrossRef]
- MacEachren, A.M. Visualizing Uncertain Information. Cartogr. Perspect. 1992, 1, 10–19. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Gopal, S. The Accuracy of Spatial Databases; CRC Press: Boca Raton, FL, USA, 1989; ISBN 9780203490235. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Stehman, S.V.; Liknes, G.C.; Næsset, E.; Sannier, C.; Walters, B.F. The effects of imperfect reference data on remote sensing-assisted estimators of land cover class proportions. ISPRS J. Photogramm. Remote Sens. 2018, 142, 292–300. [Google Scholar] [CrossRef]
- Carlotto, M.J. Effect of errors in ground truth on classification accuracy. Int. J. Remote Sens. 2009, 30, 4831–4849. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Swan, B.; Laverdiere, M.; Yang, H.L. How Good is Good Enough?: Quantifying the Effects of Training Set Quality. In Proceedings of the 2Nd ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Seattle, WA, USA, 6 November 2018; ACM: New York, NY, USA, 2018; pp. 47–51. [Google Scholar]
- Ghimire, B.; Rogan, J.; Galiano, V.R.; Panday, P.; Neeti, N. An Evaluation of Bagging, Boosting, and Random Forests for Land-Cover Classification in Cape Cod, Massachusetts, USA. GISci. Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Bruzzone, L.; Persello, C. A Novel Context-Sensitive Semisupervised SVM Classifier Robust to Mislabeled Training Samples. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2142–2154. [Google Scholar] [CrossRef]
- Cracknell, M.J.; Reading, A.M. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar] [CrossRef]
- Mellor, A.; Boukir, S. Exploring diversity in ensemble classification: Applications in large area land cover mapping. ISPRS J. Photogramm. Remote Sens. 2017, 129, 151–161. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Tilton, J.C.; Gumma, M.K.; Teluguntla, P.; Oliphant, A.; Congalton, R.G.; Yadav, K.; Gorelick, N. Nominal 30-m Cropland Extent Map of Continental Africa by Integrating Pixel-Based and Object-Based Algorithms Using Sentinel-2 and Landsat-8 Data on Google Earth Engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef]
- Bey, A.; Jetimane, J.; Lisboa, S.N.; Ribeiro, N.; Sitoe, A.; Meyfroidt, P. Mapping smallholder and large-scale cropland dynamics with a flexible classification system and pixel-based composites in an emerging frontier of Mozambique. Remote Sens. Environ. 2020, 239, 111611. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Z. Object-based Vegetation Mapping in the Kissimmee River Watershed Using HyMap Data and Machine Learning Techniques. Wetlands 2013, 33, 233–244. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping land-cover modifications over large areas: A comparison of machine learning algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Copass, C.; Antonova, N.; Kennedy, R. Comparison of Office and Field Techniques for Validating Landscape Change Classification in Pacific Northwest National Parks. Remote Sens. 2018, 11, 3. [Google Scholar] [CrossRef]
- Lesiv, M.; See, L.; Laso Bayas, J.C.; Sturn, T.; Schepaschenko, D.; Karner, M.; Moorthy, I.; McCallum, I.; Fritz, S. Characterizing the Spatial and Temporal Availability of Very High Resolution Satellite Imagery in Google Earth and Microsoft Bing Maps as a Source of Reference Data. Land 2018, 7, 118. [Google Scholar] [CrossRef]
- Biradar, C.M.; Thenkabail, P.S.; Noojipady, P.; Li, Y.; Dheeravath, V.; Turral, H.; Velpuri, M.; Gumma, M.K.; Gangalakunta, O.R.P.; Cai, X.L.; et al. A global map of rainfed cropland areas (GMRCA) at the end of last millennium using remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 114–129. [Google Scholar] [CrossRef]
- Mallinis, G.; Emmanoloudis, D.; Giannakopoulos, V.; Maris, F.; Koutsias, N. Mapping and interpreting historical land cover/land use changes in a Natura 2000 site using earth observational data: The case of Nestos delta, Greece. Appl. Geogr. 2011, 31, 312–320. [Google Scholar] [CrossRef]
- Jawak, S.D.; Luis, A.J. Improved land cover mapping using high resolution multiangle 8-band WorldView-2 satellite remote sensing data. JARS 2013, 7, 073573. [Google Scholar] [CrossRef]
- Ye, S.; Pontius, R.G.; Rakshit, R. A review of accuracy assessment for object-based image analysis: From per-pixel to per-polygon approaches. ISPRS J. Photogramm. Remote Sens. 2018, 141, 137–147. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Perger, C.; McCallum, I.; Schill, C.; Schepaschenko, D.; Duerauer, M.; Karner, M.; Dresel, C.; Laso-Bayas, J.-C.; et al. A global dataset of crowdsourced land cover and land use reference data. Sci. Data 2017, 4, 170075. [Google Scholar] [CrossRef] [PubMed]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Brodrick, P.G.; Davies, A.B.; Asner, G.P. Uncovering Ecological Patterns with Convolutional Neural Networks. Trends Ecol. Evol. 2019, 34, 734–745. [Google Scholar] [CrossRef] [PubMed]
- Xiao, T.; Xia, T.; Yang, Y.; Huang, C.; Wang, X. Learning from massive noisy labeled data for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2691–2699. [Google Scholar]
- Frénay, B.; Verleysen, M. Classification in the presence of label noise: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar]
- Brodley, C.E.; Friedl, M.A. Identifying Mislabeled Training Data. J. Artif. Intell. Res. 1999, 11, 131–167. [Google Scholar] [CrossRef]
- Van Etten, A.; Lindenbaum, D.; Bacastow, T.M. SpaceNet: A Remote Sensing Dataset and Challenge Series. arXiv 2018. [Google Scholar]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. BigEarthNet: A Large-Scale Benchmark Archive For Remote Sensing Image Understanding. arXiv 2019. [Google Scholar]
- Lesiv, M.; Laso Bayas, J.C.; See, L.; Duerauer, M.; Dahlia, D.; Durando, N.; Hazarika, R.; Kumar Sahariah, P.; Vakolyuk, M.; Blyshchyk, V.; et al. Estimating the global distribution of field size using crowdsourcing. Glob. Chang. Biol. 2019, 25, 174–186. [Google Scholar] [CrossRef]
- Fritz, S.; McCallum, I.; Schill, C.; Perger, C.; See, L.; Schepaschenko, D.; van der Velde, M.; Kraxner, F.; Obersteiner, M. Geo-Wiki: An Online Platform for Improving Global Land Cover. Environ. Model. Softw. 2012, 31, 110–123. [Google Scholar]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the IJCAI, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Catal, C. Performance evaluation metrics for software fault prediction studies. Acta Polytech. Hung. 2012, 9, 193–206. [Google Scholar]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing Imbalanced Data--Recommendations for the Use of Performance Metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar]
- Kuzera, K.; Pontius, R.G. Importance of Matrix Construction for Multiple-Resolution Categorical Map Comparison. GISci. Remote Sens. 2008, 45, 249–274. [Google Scholar] [CrossRef]
- Pontius, R.G.; Thontteh, O.; Chen, H. Components of information for multiple resolution comparison between maps that share a real variable. Environ. Ecol. Stat. 2008, 15, 111–142. [Google Scholar] [CrossRef]
- Pontius, R.G.; Parmentier, B. Recommendations for using the relative operating characteristic (ROC). Landsc. Ecol. 2014, 29, 367–382. [Google Scholar] [CrossRef]
- Pontius, R.G. Component intensities to relate difference by category with difference overall. Int. J. Appl. Earth Obs. Geoinf. 2019, 77, 94–99. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Connors, J. Range of Categorical Associations for Comparison of Maps with Mixed Pixels. Photogramm. Eng. Remote Sens. 2009, 75, 963–969. [Google Scholar] [CrossRef]
- Aldwaik, S.Z.; Pontius, R.G., Jr. Intensity analysis to unify measurements of size and stationarity of land changes by interval, category, and transition. Landsc. Urban Plan. 2012, 106, 103–114. [Google Scholar] [CrossRef]
- Pontius, R.G.; Gao, Y.; Giner, N.M.; Kohyama, T.; Osaki, M.; Hirose, K. Design and Interpretation of Intensity Analysis Illustrated by Land Change in Central Kalimantan, Indonesia. Land 2013, 2, 351–369. [Google Scholar] [CrossRef]
- Foody, G.M. Harshness in image classification accuracy assessment. Int. J. Remote Sens. 2008, 29, 3137–3158. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Allouche, O.; Tsoar, A.; Kadmon, R. Assessing the Accuracy of Species Distribution Models: Prevalence, Kappa and the True Skill Statistic (TSS). J. Appl. Ecol. 2006, 43, 1223–1232. [Google Scholar] [CrossRef]
- Foody, G.M. Explaining the unsuitability of the kappa coefficient in the assessment and comparison of the accuracy of thematic maps obtained by image classification. Remote Sens. Environ. 2020, 239, 111630. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. On the use of dimensioned measures of error to evaluate the performance of spatial interpolators. Int. J. Geogr. Inf. Sci. 2006, 20, 89–102. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K.; Robeson, S.M. Ambiguities inherent in sums-of-squares-based error statistics. Atmos. Environ. 2009, 43, 749–752. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Si, K. The total operating characteristic to measure diagnostic ability for multiple thresholds. Int. J. Geogr. Inf. Sci. 2014, 28, 570–583. [Google Scholar] [CrossRef]
- Fielding, A.H.; Bell, J.F. A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ. Conserv. 1997, 24, 38–49. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Costa, H.; Foody, G.M.; Boyd, D.S. Supervised methods of image segmentation accuracy assessment in land cover mapping. Remote Sens. Environ. 2018, 205, 338–351. [Google Scholar] [CrossRef]
- Powell, R.L.; Matzke, N.; de Souza, C.; Clark, M.; Numata, I.; Hess, L.L.; Roberts, D.A. Sources of error in accuracy assessment of thematic land-cover maps in the Brazilian Amazon. Remote Sens. Environ. 2004, 90, 221–234. [Google Scholar] [CrossRef]
- Zhong, B.; Ma, P.; Nie, A.; Yang, A.; Yao, Y.; Lü, W.; Zhang, H.; Liu, Q. Land cover mapping using time series HJ-1/CCD data. Sci. China Earth Sci. 2014, 57, 1790–1799. [Google Scholar] [CrossRef]
- Pacifici, F.; Chini, M.; Emery, W.J. A neural network approach using multi-scale textural metrics from very high-resolution panchromatic imagery for urban land-use classification. Remote Sens. Environ. 2009, 113, 1276–1292. [Google Scholar] [CrossRef]
- Abbas, I.I.; Muazu, K.M.; Ukoje, J.A. Mapping land use-land cover and change detection in Kafur local government, Katsina, Nigeria (1995-2008) using remote sensing and GIS. Res. J. Environ. Earth Sci. 2010, 2, 6–12. [Google Scholar]
- Sano, E.E.; Rosa, R.; Brito, J.L.S.; Ferreira, L.G. Land cover mapping of the tropical savanna region in Brazil. Environ. Monit. Assess. 2010, 166, 113–124. [Google Scholar] [CrossRef]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping Urban Land Use by Using Landsat Images and Open Social Data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Galletti, C.S.; Myint, S.W. Land-Use Mapping in a Mixed Urban-Agricultural Arid Landscape Using Object-Based Image Analysis: A Case Study from Maricopa, Arizona. Remote Sens. 2014, 6, 6089–6110. [Google Scholar] [CrossRef]
- Hu, Q.; Wu, W.; Xia, T.; Yu, Q.; Yang, P.; Li, Z.; Song, Q. Exploring the Use of Google Earth Imagery and Object-Based Methods in Land Use/Cover Mapping. Remote Sens. 2013, 5, 6026–6042. [Google Scholar] [CrossRef]
- Al-Bakri, J.T.; Ajlouni, M.; Abu-Zanat, M. Incorporating Land Use Mapping and Participation in Jordan: An Approach to Sustainable Management of Two Mountainous Areas. Mt. Res. Dev. 2008, 28, 49–57. [Google Scholar] [CrossRef]
- Liu, J.; Kuang, W.; Zhang, Z.; Xu, X.; Qin, Y.; Ning, J.; Zhou, W.; Zhang, S.; Li, R.; Yan, C.; et al. Spatiotemporal characteristics, patterns, and causes of land-use changes in China since the late 1980s. J. Geogr. Sci. 2014, 24, 195–210. [Google Scholar] [CrossRef]
- Yadav, P.K.; Kapoor, M.; Sarma, K. Land Use Land Cover Mapping, Change Detection and Conflict Analysis of Nagzira-Navegaon Corridor, Central India Using Geospatial Technology. Int. J. Remote Sens. GIS 2012, 1. [Google Scholar]
- da Costa Freitas, C.; de Souza Soler, L.; Sant’Anna, S.J.S.; Dutra, L.V.; dos Santos, J.R.; Mura, J.C.; Correia, A.H. Land Use and Land Cover Mapping in the Brazilian Amazon Using Polarimetric Airborne P-Band SAR Data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2956–2970. [Google Scholar] [CrossRef]
- Dewan, A.M.; Yamaguchi, Y. Land use and land cover change in Greater Dhaka, Bangladesh: Using remote sensing to promote sustainable urbanization. Appl. Geogr. 2009, 29, 390–401. [Google Scholar] [CrossRef]
- Castañeda, C.; Ducrot, D. Land cover mapping of wetland areas in an agricultural landscape using SAR and Landsat imagery. J. Environ. Manag. 2009, 90, 2270–2277. [Google Scholar] [CrossRef] [PubMed]
- Griffiths, P.; van der Linden, S.; Kuemmerle, T.; Hostert, P. A Pixel-Based Landsat Compositing Algorithm for Large Area Land Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2088–2101. [Google Scholar] [CrossRef]
- Ge, Y. Sub-pixel land-cover mapping with improved fraction images upon multiple-point simulation. Int. J. Appl. Earth Obs. Geoinf. 2013, 22, 115–126. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Ghorbani, A.; Pakravan, M. Land use mapping using visual vs. digital image interpretation of TM and Google earth derived imagery in Shrivan-Darasi watershed (Northwest of Iran). Eur. J. Exp. Biol. 2013, 3, 576–582. [Google Scholar]
- Deng, J.S.; Wang, K.; Hong, Y.; Qi, J.G. Spatio-temporal dynamics and evolution of land use change and landscape pattern in response to rapid urbanization. Landsc. Urban Plan. 2009, 92, 187–198. [Google Scholar] [CrossRef]
- Otukei, J.R.; Blaschke, T. Land cover change assessment using decision trees, support vector machines and maximum likelihood classification algorithms. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, S27–S31. [Google Scholar] [CrossRef]
- Malinverni, E.S.; Tassetti, A.N.; Mancini, A.; Zingaretti, P.; Frontoni, E.; Bernardini, A. Hybrid object-based approach for land use/land cover mapping using high spatial resolution imagery. Int. J. Geogr. Inf. Sci. 2011, 25, 1025–1043. [Google Scholar] [CrossRef]
- Rozenstein, O.; Karnieli, A. Comparison of methods for land-use classification incorporating remote sensing and GIS inputs. Appl. Geogr. 2011, 31, 533–544. [Google Scholar] [CrossRef]
- Ran, Y.H.; Li, X.; Lu, L.; Li, Z.Y. Large-scale land cover mapping with the integration of multi-source information based on the Dempster–Shafer theory. Int. J. Geogr. Inf. Sci. 2012, 26, 169–191. [Google Scholar] [CrossRef]
- Clark, M.L.; Aide, T.M.; Grau, H.R.; Riner, G. A scalable approach to mapping annual land cover at 250 m using MODIS time series data: A case study in the Dry Chaco ecoregion of South America. Remote Sens. Environ. 2010, 114, 2816–2832. [Google Scholar] [CrossRef]
- Berberoglu, S.; Akin, A. Assessing different remote sensing techniques to detect land use/cover changes in the eastern Mediterranean. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 46–53. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G.G.; Frescino, T.S. Evaluating effectiveness of down-sampling for stratified designs and unbalanced prevalence in Random Forest models of tree species distributions in Nevada. Ecol. Modell. 2012, 233, 1–10. [Google Scholar] [CrossRef]
- Townshend, J.R.; Masek, J.G.; Huang, C.; Vermote, E.F.; Gao, F.; Channan, S.; Sexton, J.O.; Feng, M.; Narasimhan, R.; Kim, D.; et al. Global characterization and monitoring of forest cover using Landsat data: Opportunities and challenges. Int. J. Digit. Earth 2012, 5, 373–397. [Google Scholar] [CrossRef]
- Shao, Y.; Lunetta, R.S. Comparison of support vector machine, neural network, and CART algorithms for the land-cover classification using limited training data points. ISPRS J. Photogramm. Remote Sens. 2012, 70, 78–87. [Google Scholar] [CrossRef]
- Planet Team Planet Application Program Interface. In Space for Life on Earth; Planet Labs, Inc.: San Francisco, CA, USA, 2017.
- Manfreda, S.; McCabe, M.F.; Miller, P.E.; Lucas, R.; Pajuelo Madrigal, V.; Mallinis, G.; Ben Dor, E.; Helman, D.; Estes, L.; Ciraolo, G.; et al. On the Use of Unmanned Aerial Systems for Environmental Monitoring. Remote Sens. 2018, 10, 641. [Google Scholar] [CrossRef]
- Toutin, T. Geometric processing of IKONOS Geo images with DEM. In Proceedings of the ISPRS Joint Workshop “High Resolution Mapping from Space” 2001, Hanover, Germany, 19–21 September 2001; pp. 19–21. [Google Scholar]
- Reinartz, P.; Müller, R.; Schwind, P.; Suri, S.; Bamler, R. Orthorectification of VHR optical satellite data exploiting the geometric accuracy of TerraSAR-X data. ISPRS J. Photogramm. Remote Sens. 2011, 66, 124–132. [Google Scholar] [CrossRef]
- Aguilar, M.A.; del M. Saldaña, M.; Aguilar, F.J. Assessing geometric accuracy of the orthorectification process from GeoEye-1 and WorldView-2 panchromatic images. Int. J. Appl. Earth Obs. Geoinf. 2013, 21, 427–435. [Google Scholar] [CrossRef]
- Chen, J.; Zipf, A. DeepVGI: Deep Learning with Volunteered Geographic Information. In Proceedings of the Proceedings of the 26th International Conference on World Wide Web Companion; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 771–772. [Google Scholar]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation From Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Joint learning from earth observation and openstreetmap data to get faster better semantic maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 67–75. [Google Scholar]
- Strahler, A.H.; Woodcock, C.E.; Smith, J.A. On the nature of models in remote sensing. Remote Sens. Environ. 1986, 20, 121–139. [Google Scholar] [CrossRef]
- Foody, G.M. Relating the land-cover composition of mixed pixels to artificial neural network classification output. Photogramm. Eng. Remote Sens. 1996, 62, 491–498. [Google Scholar]
- Moody, A.; Gopal, S.; Strahler, A.H. Artificial neural network response to mixed pixels in coarse-resolution satellite data. Remote Sens. Environ. 1996, 58, 329–343. [Google Scholar] [CrossRef]
- De Fries, R.S.; Hansen, M.; Townshend, J.R.G.; Sohlberg, R. Global land cover classifications at 8 km spatial resolution: The use of training data derived from Landsat imagery in decision tree classifiers. Int. J. Remote Sens. 1998, 19, 3141–3168. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Kennedy, R.E.; Yang, Z.; Cohen, W.B. Detecting trends in forest disturbance and recovery using yearly Landsat time series: 1. LandTrendr—Temporal segmentation algorithms. Remote Sens. Environ. 2010, 114, 2897–2910. [Google Scholar] [CrossRef]
- Oppenshaw, S.; Taylor, P. A million or so correlation coefficients. In Statistical Methods in the Spatial Sciences; Pion: London, UK, 1979. [Google Scholar]
- Jelinski, D.E.; Wu, J. The modifiable areal unit problem and implications for landscape ecology. Landsc. Ecol. 1996, 11, 129–140. [Google Scholar] [CrossRef]
- Weiss, M.; de Beaufort, L.; Baret, F.; Allard, D.; Bruguier, N.; Marloie, O. Mapping leaf area index measurements at different scales for the validation of large swath satellite sensors: First results of the VALERI project. In Proceedings of the 8th International Symposium in Physical Measurements and Remote Sensing, Aussois, France, 8–12 January 2001; pp. 125–130. [Google Scholar]
- Tian, Y.; Woodcock, C.E.; Wang, Y.; Privette, J.L.; Shabanov, N.V.; Zhou, L.; Zhang, Y.; Buermann, W.; Dong, J.; Veikkanen, B.; et al. Multiscale analysis and validation of the MODIS LAI product: I. Uncertainty assessment. Remote Sens. Environ. 2002, 83, 414–430. [Google Scholar] [CrossRef]
- Masuoka, E.; Roy, D.; Wolfe, R.; Morisette, J.; Sinno, S.; Teague, M.; Saleous, N.; Devadiga, S.; Justice, C.O.; Nickeson, J. MODIS Land Data Products: Generation, Quality Assurance and Validation. In Land Remote Sensing and Global Environmental Change: NASA’s Earth Observing System and the Science of ASTER and MODIS; Ramachandran, B., Justice, C.O., Abrams, M.J., Eds.; Springer New York: New York, NY, USA, 2011; pp. 509–531. ISBN 9781441967497. [Google Scholar]
- Cohen, W.B.; Justice, C.O. Validating MODIS terrestrial ecology products: linking in situ and satellite measurements. Remote Sens. Environ. 1999, 70, 1–3. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; McCallum, I.; You, L.; Bun, A.; Moltchanova, E.; Duerauer, M.; Albrecht, F.; Schill, C.; Perger, C.; et al. Mapping global cropland and field size. Glob. Chang. Biol. 2015, 21, 1980–1992. [Google Scholar] [CrossRef] [PubMed]
- Debats, S.R.; Estes, L.D.; Thompson, D.R.; Caylor, K.K. Integrating Active Learning and Crowdsourcing into Large-Scale Supervised Landcover Mapping Algorithms. PeerJ 2017. preprints. [Google Scholar]
- Estes, L.D.; McRitchie, D.; Choi, J.; Debats, S.; Evans, T.; Guthe, W.; Luo, D.; Ragazzo, G.; Zempleni, R.; Caylor, K.K. A Platform for Crowdsourcing the Creation of Representative, Accurate Landcover Maps. Environ. Model. Softw. 2016, 80, 41–53. [Google Scholar] [CrossRef]
- Waldner, F.; Schucknecht, A.; Lesiv, M.; Gallego, J.; See, L.; Pérez-Hoyos, A.; d’Andrimont, R.; de Maet, T.; Bayas, J.C.L.; Fritz, S.; et al. Conflation of expert and crowd reference data to validate global binary thematic maps. Remote Sens. Environ. 2019, 221, 235–246. [Google Scholar] [CrossRef]
- Bey, A.; Sánchez-Paus Díaz, A.; Maniatis, D.; Marchi, G.; Mollicone, D.; Ricci, S.; Bastin, J.-F.; Moore, R.; Federici, S.; Rezende, M.; et al. Collect Earth: Land Use and Land Cover Assessment through Augmented Visual Interpretation. Remote Sens. 2016, 8, 807. [Google Scholar] [CrossRef]
- Fritz, S.; Sturn, T.; Karner, M.; Moorthy, I.; See, L.; Laso Bayas, J.C.; Fraisl, D. FotoQuest Go: A Citizen Science Approach to the Collection of In-Situ Land Cover and Land Use Data for Calibration and Validation. In Proceedings of the Digital Earth Observation, Salzburg, Austria, 1–4 July 2019. [Google Scholar]
- Tuia, D.; Pasolli, E.; Emery, W.J. Using active learning to adapt remote sensing image classifiers. Remote Sens. Environ. 2011, 115, 2232–2242. [Google Scholar] [CrossRef]
- Van Coillie, F.M.B.; Gardin, S.; Anseel, F.; Duyck, W.; Verbeke, L.P.C.; De Wulf, R.R. Variability of operator performance in remote-sensing image interpretation: the importance of human and external factors. Int. J. Remote Sens. 2014, 35, 754–778. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsat time-series imagery for rapid land use/land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Neigh, C.S.R.; Carroll, M.L.; Wooten, M.R.; McCarty, J.L.; Powell, B.F.; Husak, G.J.; Enenkel, M.; Hain, C.R. Smallholder crop area mapped with wall-to-wall WorldView sub-meter panchromatic image texture: A test case for Tigray, Ethiopia. Remote Sens. Environ. 2018, 212, 8–20. [Google Scholar] [CrossRef]
- Clark, M.L.; Aide, T.M.; Riner, G. Land change for all municipalities in Latin America and the Caribbean assessed from 250-m MODIS imagery (2001–2010). Remote Sens. Environ. 2012, 126, 84–103. [Google Scholar] [CrossRef]
- Comber, A.; Fisher, P.; Wadsworth, R. What is land cover? Environ. Plan. 2005, 32, 199–209. [Google Scholar] [CrossRef]
- Kohli, D.; Sliuzas, R.; Kerle, N.; Stein, A. An ontology of slums for image-based classification. Comput. Environ. Urban Syst. 2012, 36, 154–163. [Google Scholar] [CrossRef]
- Verburg, P.H.; Neumann, K.; Nol, L. Challenges in using land use and land cover data for global change studies. Glob. Chang. Biol. 2011, 17, 974–989. [Google Scholar] [CrossRef]
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ. 2012, 117, 34–49. [Google Scholar] [CrossRef]
- Kohli, D.; Stein, A.; Sliuzas, R. Uncertainty analysis for image interpretations of urban slums. Comput. Environ. Urban Syst. 2016, 60, 37–49. [Google Scholar] [CrossRef]
- Rocchini, D. While Boolean sets non-gently rip: A theoretical framework on fuzzy sets for mapping landscape patterns. Ecol. Complex. 2010, 7, 125–129. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Gopal, S. Fuzzy set theory and thematic maps: Accuracy assessment and area estimation. Int. J. Geogr. Inf. Sci. 2000, 14, 153–172. [Google Scholar] [CrossRef]
- Rocchini, D.; Foody, G.M.; Nagendra, H.; Ricotta, C.; Anand, M.; He, K.S.; Amici, V.; Kleinschmit, B.; Förster, M.; Schmidtlein, S.; et al. Uncertainty in ecosystem mapping by remote sensing. Comput. Geosci. 2013, 50, 128–135. [Google Scholar] [CrossRef]
- Zhang, J.; Foody, G.M. A fuzzy classification of sub-urban land cover from remotely sensed imagery. Int. J. Remote Sens. 1998, 19, 2721–2738. [Google Scholar] [CrossRef]
- Woodcock, C.E.; Strahler, A.H. The factor of scale in remote sensing. Remote Sens. Environ. 1987, 21, 311–332. [Google Scholar] [CrossRef]
- Cracknell, A.P. Review article Synergy in remote sensing-what’s in a pixel? Int. J. Remote Sens. 1998, 19, 2025–2047. [Google Scholar] [CrossRef]
- Pontius, R.G.; Cheuk, M.L. A generalized cross-tabulation matrix to compare soft-classified maps at multiple resolutions. Int. J. Geogr. Inf. Sci. 2006, 20, 1–30. [Google Scholar] [CrossRef]
- Silván-Cárdenas, J.L.; Wang, L. Sub-pixel confusion–uncertainty matrix for assessing soft classifications. Remote Sens. Environ. 2008, 112, 1081–1095. [Google Scholar] [CrossRef]
- Foody, G.M. The continuum of classification fuzziness in thematic mapping. Photogramm. Eng. Remote Sens. 1999, 65, 443–452. [Google Scholar]
- Foody, G.M. Fully fuzzy supervised classification of land cover from remotely sensed imagery with an artificial neural network. Neural Comput. Appl. 1997, 5, 238–247. [Google Scholar] [CrossRef]
- Laso Bayas, J.C.; See, L.; Fritz, S.; Sturn, T.; Perger, C.; Dürauer, M.; Karner, M.; Moorthy, I.; Schepaschenko, D.; Domian, D.; et al. Crowdsourcing In-Situ Data on Land Cover and Land Use Using Gamification and Mobile Technology. Remote Sens. 2016, 8, 905. [Google Scholar] [CrossRef]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef]
- Stehman, S.V.; Fonte, C.C.; Foody, G.M.; See, L. Using volunteered geographic information (VGI) in design-based statistical inference for area estimation and accuracy assessment of land cover. Remote Sens. Environ. 2018, 212, 47–59. [Google Scholar] [CrossRef]
- Thompson, I.D.; Maher, S.C.; Rouillard, D.P.; Fryxell, J.M.; Baker, J.A. Accuracy of forest inventory mapping: Some implications for boreal forest management. For. Ecol. Manag. 2007, 252, 208–221. [Google Scholar] [CrossRef]
- Bland, M.J.; Altman, D.G. Statistics notes: Measurement error. BMJ 1996, 312, 1654. [Google Scholar] [CrossRef] [PubMed]
- Martin, D. An Introduction to “The Guide to the Expression of Uncertainty in Measurement”. In Evaluation of Measurement Data—Guide to the Expression of Uncertainty in Measurement; JCGM: Geneva, Switzerland, 2008; pp. 1–10. [Google Scholar]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2017, 18. [Google Scholar] [CrossRef] [PubMed]
- Song, K. Tackling Uncertainties and Errors in the Satellite Monitoring of Forest Cover Change. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2010. [Google Scholar]
- Foody, G.M. The impact of imperfect ground reference data on the accuracy of land cover change estimation. Int. J. Remote Sens. 2009, 30, 3275–3281. [Google Scholar] [CrossRef]
- Foody, G.M. Ground reference data error and the mis-estimation of the area of land cover change as a function of its abundance. Remote Sens. Lett. 2013, 4, 783–792. [Google Scholar] [CrossRef]
- Homer, C.G.; Fry, J.A.; Barnes, C.A.; National land cover dataset (NLCD). The National Land Cover Database; U.S. Geological Survey: Reston, VA, USA, 2012.
- Menon, S.; Akbari, H.; Mahanama, S.; Sednev, I.; Levinson, R. Radiative forcing and temperature response to changes in urban albedos and associated CO2 offsets. Environ. Res. Lett. 2010, 5, 014005. [Google Scholar] [CrossRef]
- Hutyra, L.R.; Yoon, B.; Hepinstall-Cymerman, J.; Alberti, M. Carbon consequences of land cover change and expansion of urban lands: A case study in the Seattle metropolitan region. Landsc. Urban Plan. 2011, 103, 83–93. [Google Scholar] [CrossRef]
- Reinmann, A.B.; Hutyra, L.R.; Trlica, A.; Olofsson, P. Assessing the global warming potential of human settlement expansion in a mesic temperate landscape from 2005 to 2050. Sci. Total Environ. 2016, 545-546, 512–524. [Google Scholar] [CrossRef]
- Hardiman, B.S.; Wang, J.A.; Hutyra, L.R.; Gately, C.K.; Getson, J.M.; Friedl, M.A. Accounting for urban biogenic fluxes in regional carbon budgets. Sci. Total Environ. 2017, 592, 366–372. [Google Scholar] [CrossRef]
- Seto, K.C.; Güneralp, B.; Hutyra, L.R. Global forecasts of urban expansion to 2030 and direct impacts on biodiversity and carbon pools. Proc. Natl. Acad. Sci. USA 2012, 109, 16083–16088. [Google Scholar] [CrossRef]
- Angel, S.; Parent, J.; Civco, D.L.; Blei, A.; Potere, D. The dimensions of global urban expansion: Estimates and projections for all countries, 2000–2050. Prog. Plann. 2011, 75, 53–107. [Google Scholar] [CrossRef]
- Coulston, J.W.; Moisen, G.G.; Wilson, B.T.; Finco, M.V.; Cohen, W.B.; Brewer, C.K. Modeling percent tree canopy cover: A pilot study. Photogramm. Eng Remote Sens. 2012, 78, 715–727. [Google Scholar] [CrossRef]
- Reinmann, A.B.; Hutyra, L.R. Edge effects enhance carbon uptake and its vulnerability to climate change in temperate broadleaf forests. Proc. Natl. Acad. Sci. USA 2017, 114, 107–112. [Google Scholar] [CrossRef] [PubMed]
- Rolnick, D.; Veit, A.; Belongie, S.; Shavit, N. Deep Learning is Robust to Massive Label Noise. arXiv 2017. [Google Scholar]
- Nachmany, Y.; Alemohammad, H. Detecting Roads from Satellite Imagery in the Developing World. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 83–89. [Google Scholar]
- The SpaceNet Catalog SpaceNet on Amazon Web Services (AWS). “Datasets.” The SpaceNet Catalog. Last modified 30 April 2018. Available online: https://spacenetchallenge.github.io/datasets/datasetHomePage.html (accessed on 15 November 2019).
- Alemohammad, S.H.; Fang, B.; Konings, A.G.; Aires, F.; Green, J.K.; Kolassa, J.; Miralles, D.; Prigent, C.; Gentine, P. Water, Energy, and Carbon with Artificial Neural Networks (WECANN): A statistically-based estimate of global surface turbulent fluxes and gross primary productivity using solar-induced fluorescence. Biogeosciences 2017, 14, 4101–4124. [Google Scholar] [CrossRef] [PubMed]
- McColl, K.A.; Vogelzang, J.; Konings, A.G.; Entekhabi, D.; Piles, M.; Stoffelen, A. Extended triple collocation: Estimating errors and correlation coefficients with respect to an unknown target. Geophys. Res. Lett. 2014, 41, 6229–6236. [Google Scholar] [CrossRef]
- Debats, S.R.; Luo, D.; Estes, L.D.; Fuchs, T.J.; Caylor, K.K. A Generalized Computer Vision Approach to Mapping Crop Fields in Heterogeneous Agricultural Landscapes. Remote Sens. Environ. 2016, 179, 210–221. [Google Scholar] [CrossRef]
- Estes, L.D.; Ye, S.; Song, L.; Avery, R.B.; McRitchie, D.; Eastman, J.R.; Debats, S.R. Improving Maps of Smallholder-Dominated Croplands through Tight Integration of Human and Machine Intelligence; American Geophysical Union: Washington, DC, USA, 2019. [Google Scholar]
- Jain, M.; Balwinder-Singh; Rao, P.; Srivastava, A.K.; Poonia, S.; Blesh, J.; Azzari, G.; McDonald, A.J.; Lobell, D.B. The impact of agricultural interventions can be doubled by using satellite data. Nat. Sustain. 2019, 2, 931–934. [Google Scholar] [CrossRef]
- Pontius, R.G. Criteria to Confirm Models that Simulate Deforestation and Carbon Disturbance. Land 2018, 7, 105. [Google Scholar] [CrossRef]
- Schennach, S.M. Recent Advances in the Measurement Error Literature. Annu. Rev. Econom. 2016, 8, 341–377. [Google Scholar] [CrossRef]
- Waldner, F.; De Abelleyra, D.; Verón, S.R.; Zhang, M.; Wu, B.; Plotnikov, D.; Bartalev, S.; Lavreniuk, M.; Skakun, S.; Kussul, N.; et al. Towards a set of agrosystem-specific cropland mapping methods to address the global cropland diversity. Int. J. Remote Sens. 2016, 37, 3196–3231. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. arXiv 2015. [Google Scholar]
- Azevedo, T., Sr.; Souza, C.M., Jr.; Shimbo, J.; Alencar, A. MapBiomas Initiative: Mapping Annual Land Cover and Land Use Changes in Brazil from 1985 to 2017; American Geophysical Union: Washington, DC, USA, 2018; Volume 2018. [Google Scholar]
- Brown, J.F.; Tollerud, H.J.; Barber, C.P.; Zhou, Q.; Dwyer, J.L.; Vogelmann, J.E.; Loveland, T.R.; Woodcock, C.E.; Stehman, S.V.; Zhu, Z.; et al. Lessons learned implementing an operational continuous United States national land change monitoring capability: The Land Change Monitoring, Assessment, and Projection (LCMAP) approach. Remote Sens. Environ. 2019, 111356. [Google Scholar] [CrossRef]
- Estes, L.; Elsen, P.R.; Treuer, T.; Ahmed, L.; Caylor, K.; Chang, J.; Choi, J.J.; Ellis, E.C. The spatial and temporal domains of modern ecology. Nat. Ecol. Evol. 2018, 2, 819–826. [Google Scholar] [CrossRef] [PubMed]
- Jensen, J.R.; Cowen, D.C. Remote sensing of urban/suburban infrastructure and socio-economic attributes. Photogramm. Eng. Remote Sens. 1999, 65, 611–622. [Google Scholar]
- Dorais, A.; Cardille, J. Strategies for Incorporating High-Resolution Google Earth Databases to Guide and Validate Classifications: Understanding Deforestation in Borneo. Remote Sens. 2011, 3, 1157–1176. [Google Scholar] [CrossRef]
- Sexton, J.O.; Urban, D.L.; Donohue, M.J.; Song, C. Long-term land cover dynamics by multi-temporal classification across the Landsat-5 record. Remote Sens. Environ. 2013, 128, 246–258. [Google Scholar] [CrossRef]
- Reis, M.S.; Escada, M.I.S.; Dutra, L.V.; Sant’Anna, S.J.S.; Vogt, N.D. Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies. Land 2018, 7, 65. [Google Scholar] [CrossRef]
- Anderson, J.R. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; U.S. Government Printing Office: Washington, DC, USA, 1976.
- Herold, M.; Woodcock, C.E.; di Gregorio, A.; Mayaux, P.; Belward, A.S.; Latham, J.; Schmullius, C.C. A joint initiative for harmonization and validation of land cover datasets. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1719–1727. [Google Scholar] [CrossRef]
- Carletto, C.; Gourlay, S.; Winters, P. From Guesstimates to GPStimates: Land Area Measurement and Implications for Agricultural Analysis. J. Afr. Econ. 2015, 24, 593–628. [Google Scholar] [CrossRef]
- See, L.; Comber, A.; Salk, C.; Fritz, S.; van der Velde, M.; Perger, C.; Schill, C.; McCallum, I.; Kraxner, F.; Obersteiner, M. Comparing the quality of crowdsourced data contributed by expert and non-experts. PLoS ONE 2013, 8, e69958. [Google Scholar] [CrossRef]
- Phinn, S.R. A framework for selecting appropriate remotely sensed data dimensions for environmental monitoring and management. Int. J. Remote Sens. 1998, 19, 3457–3463. [Google Scholar] [CrossRef]
- Phinn, S.R.; Menges, C.; Hill, G.J.E.; Stanford, M. Optimizing Remotely Sensed Solutions for Monitoring, Modeling, and Managing Coastal Environments. Remote Sens. Environ. 2000, 73, 117–132. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Cingolani, A.M.; Renison, D.; Zak, M.R.; Cabido, M.R. Mapping vegetation in a heterogeneous mountain rangeland using landsat data: An alternative method to define and classify land-cover units. Remote Sens. Environ. 2004, 92, 84–97. [Google Scholar] [CrossRef]
- Burke, M.; Lobell, D.B. Satellite-based assessment of yield variation and its determinants in smallholder African systems. Proc. Natl. Acad. Sci. USA 2017. [Google Scholar] [CrossRef] [PubMed]
- Jin, Z.; Azzari, G.; You, C.; Di Tommaso, S.; Aston, S.; Burke, M.; Lobell, D.B. Smallholder maize area and yield mapping at national scales with Google Earth Engine. Remote Sens. Environ. 2019, 228, 115–128. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A Scalable Satellite-Based Crop Yield Mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Grassini, P.; van Bussel, L.G.J.; Van Wart, J.; Wolf, J.; Claessens, L.; Yang, H.; Boogaard, H.; de Groot, H.; van Ittersum, M.K.; Cassman, K.G. How Good Is Good Enough? Data Requirements for Reliable Crop Yield Simulations and Yield-Gap Analysis. Field Crops Res. 2015, 177, 49–63. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Fu, X.; McCane, B.; Mills, S.; Albert, M. NOKMeans: Non-Orthogonal K-means Hashing. In Computer Vision—ACCV 2014; Cremers, D., Reid, I., Saito, H., Yang, M.-H., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9003, pp. 162–177. ISBN 9783319168647. [Google Scholar]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; DiBiano, R.; Karki, M.; Nemani, R. DeepSat: A Learning Framework for Satellite Imagery. In Proceedings of the Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; ACM: New York, NY, USA, 2015; pp. 37:1–37:10. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2 November 2010. [Google Scholar]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]












© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elmes, A.; Alemohammad, H.; Avery, R.; Caylor, K.; Eastman, J.R.; Fishgold, L.; Friedl, M.A.; Jain, M.; Kohli, D.; Laso Bayas, J.C.; et al. Accounting for Training Data Error in Machine Learning Applied to Earth Observations. Remote Sens. 2020, 12, 1034. https://doi.org/10.3390/rs12061034
Elmes A, Alemohammad H, Avery R, Caylor K, Eastman JR, Fishgold L, Friedl MA, Jain M, Kohli D, Laso Bayas JC, et al. Accounting for Training Data Error in Machine Learning Applied to Earth Observations. Remote Sensing. 2020; 12(6):1034. https://doi.org/10.3390/rs12061034
Chicago/Turabian StyleElmes, Arthur, Hamed Alemohammad, Ryan Avery, Kelly Caylor, J. Ronald Eastman, Lewis Fishgold, Mark A. Friedl, Meha Jain, Divyani Kohli, Juan Carlos Laso Bayas, and et al. 2020. "Accounting for Training Data Error in Machine Learning Applied to Earth Observations" Remote Sensing 12, no. 6: 1034. https://doi.org/10.3390/rs12061034
APA StyleElmes, A., Alemohammad, H., Avery, R., Caylor, K., Eastman, J. R., Fishgold, L., Friedl, M. A., Jain, M., Kohli, D., Laso Bayas, J. C., Lunga, D., McCarty, J. L., Pontius, R. G., Reinmann, A. B., Rogan, J., Song, L., Stoynova, H., Ye, S., Yi, Z.-F., & Estes, L. (2020). Accounting for Training Data Error in Machine Learning Applied to Earth Observations. Remote Sensing, 12(6), 1034. https://doi.org/10.3390/rs12061034