Big Data Geospatial Processing for Massive Aerial LiDAR Datasets


Abstract
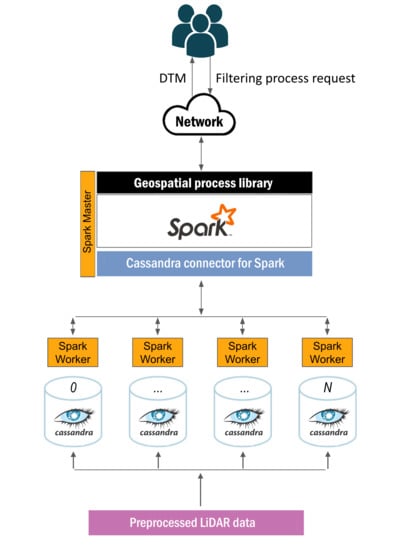
1. Introduction
2. A Scalable Big Data Approach on Geospatial Processing
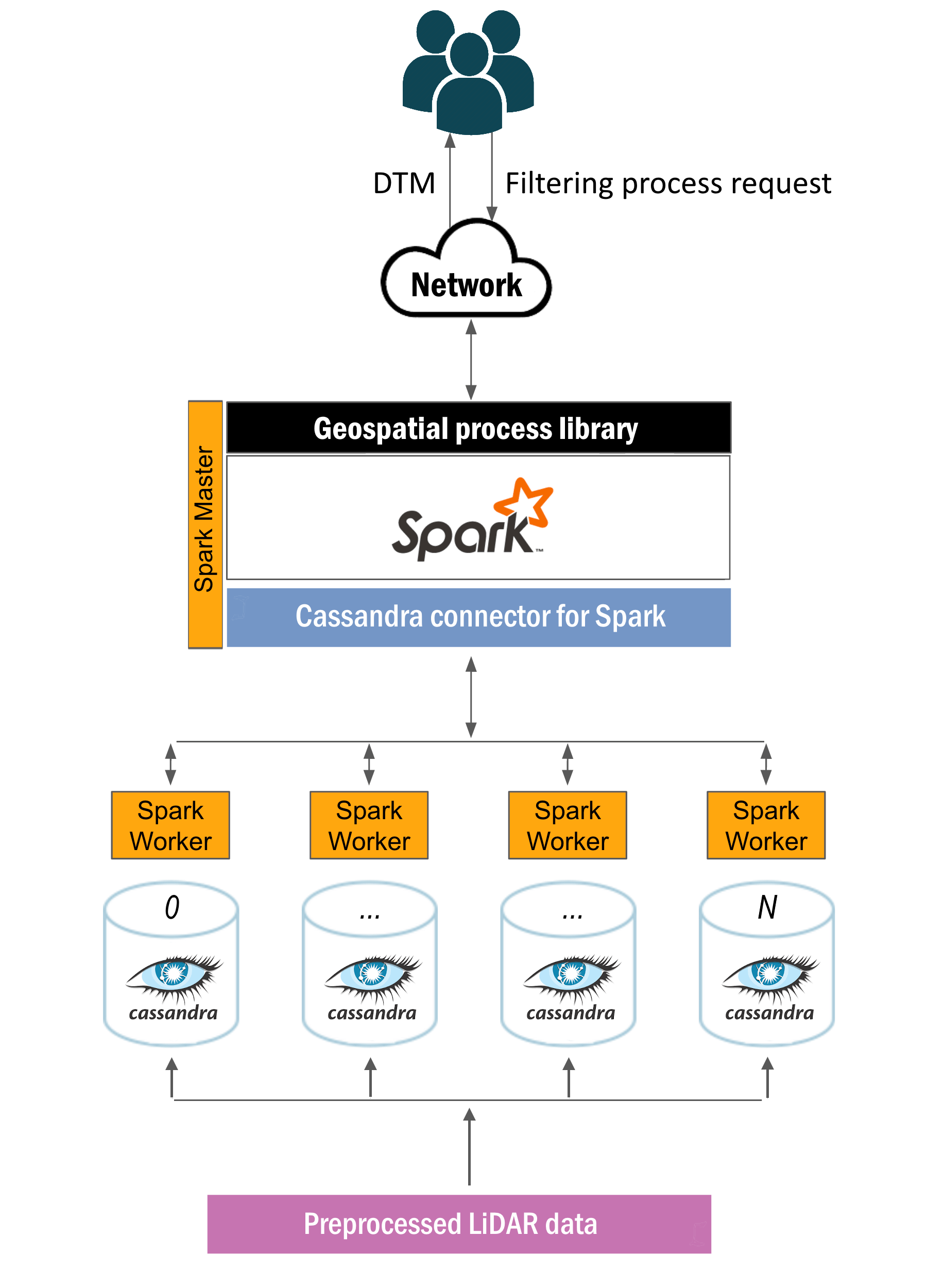
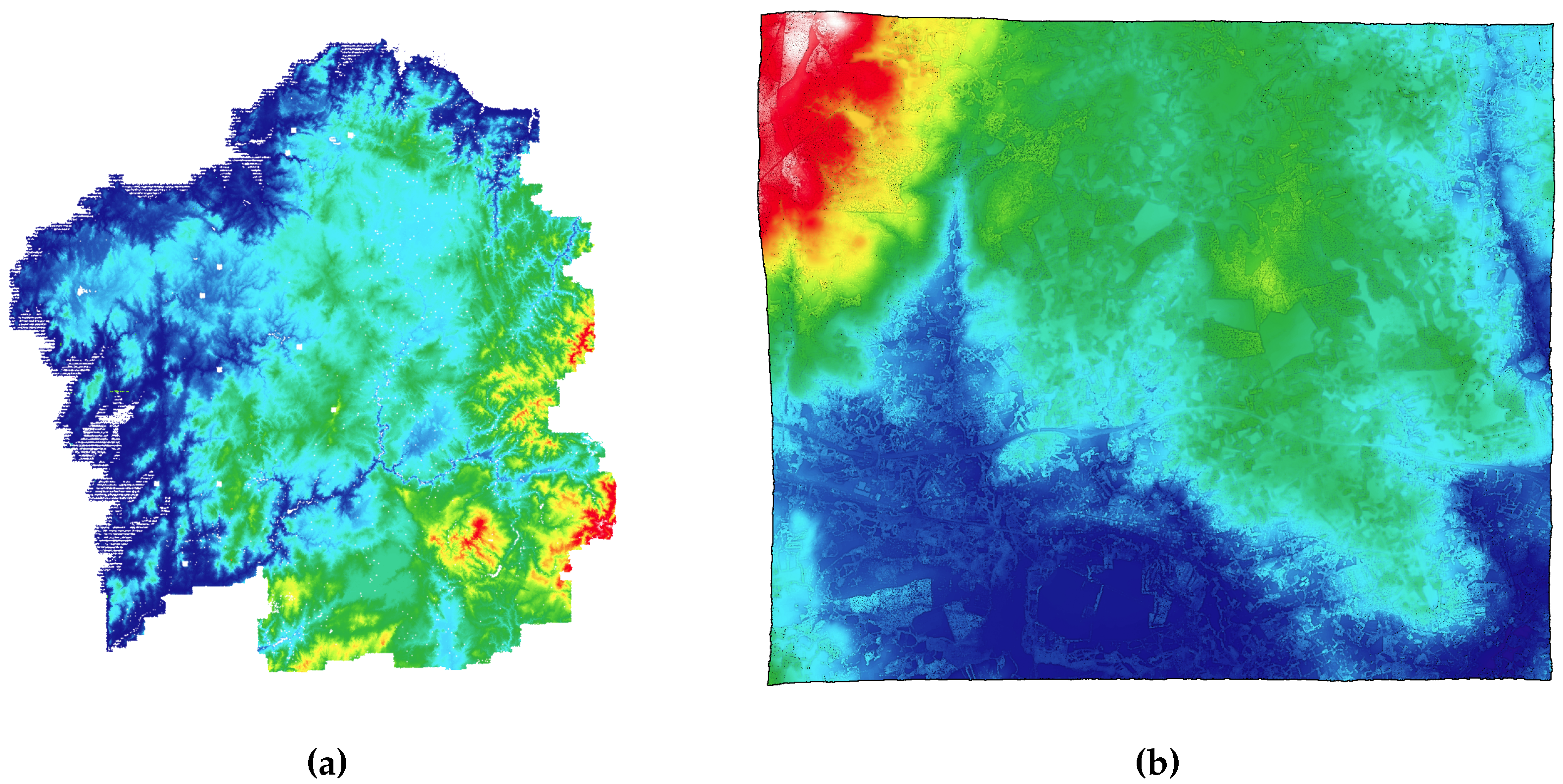
2.1. Geospatial Processing: Fast DTM Obtention
2.2. Distributed Storage: Cassandra
2.3. Distributed Computing: Spark
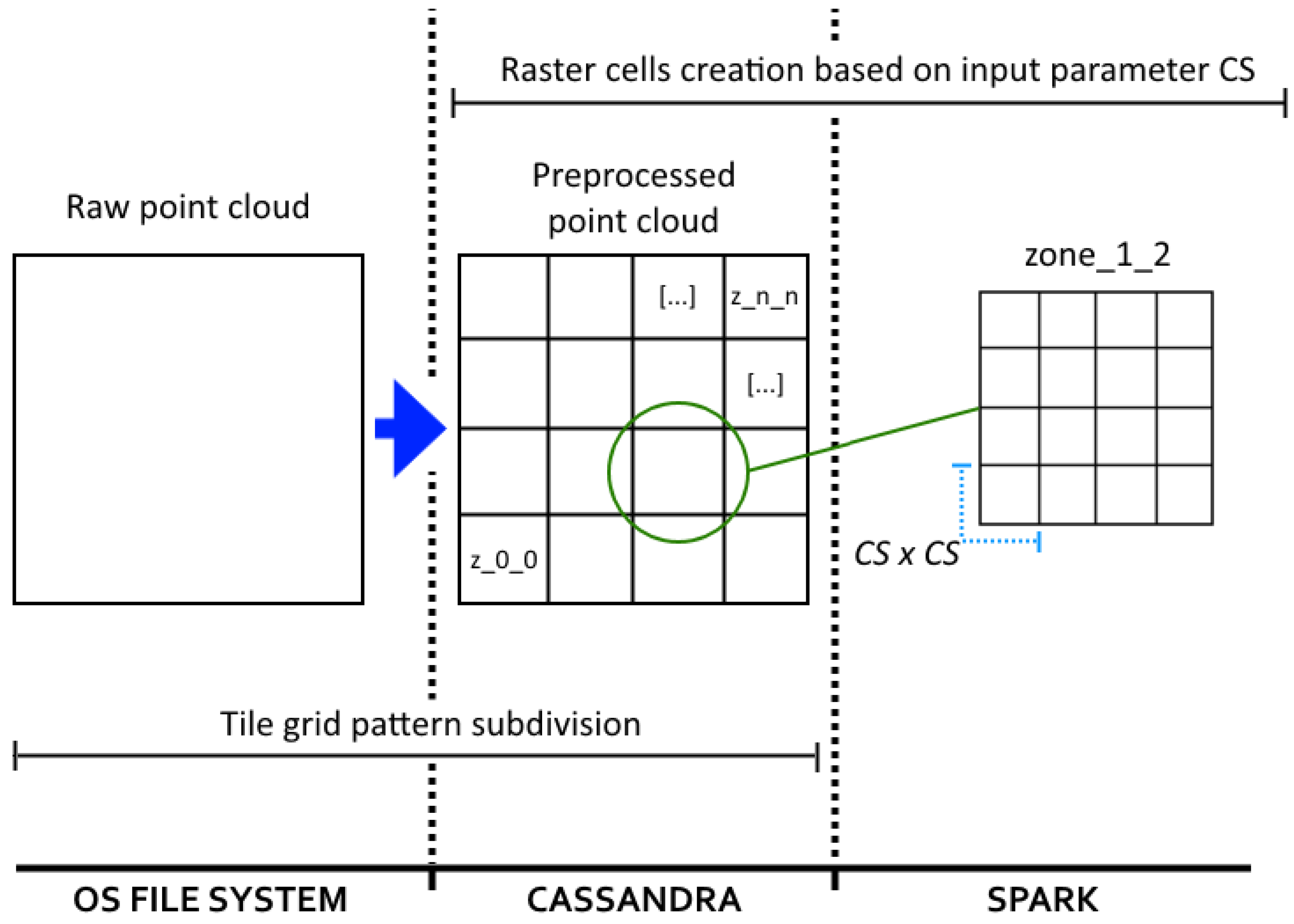
3. Automated Boundary Error Correction
3.1. Creation of the Correction Patches
3.2. Filtering of the LiDAR Zones and Error Correction
- If both points are labeled with the same class, the ZRP is considered as correctly classified, as was confirmed by the results of the patch.
- If a ZRP is classified as ground, but the CPP is classified as non-ground, the ZRP is considered as correctly classified. The overlapping rasters have their own boundary errors; if this scenario were considered as a classification error, the final results would display gaps that would match with the boundaries of the correction patches, thus, instead of correcting errors, new ones would be introduced.
- If a ZRP is classified as non-ground, but the CPP is classified as ground, the ZRP is considered as misclassified and ZRP should be labeled as ground. Additionally, following the same logic described in Section 2.1 for the selection of raster points, if the Z coordinate of ZRP is higher than the Z from CPP, the ZRP is replaced entirely by the CPP.
4. Results and Discussion
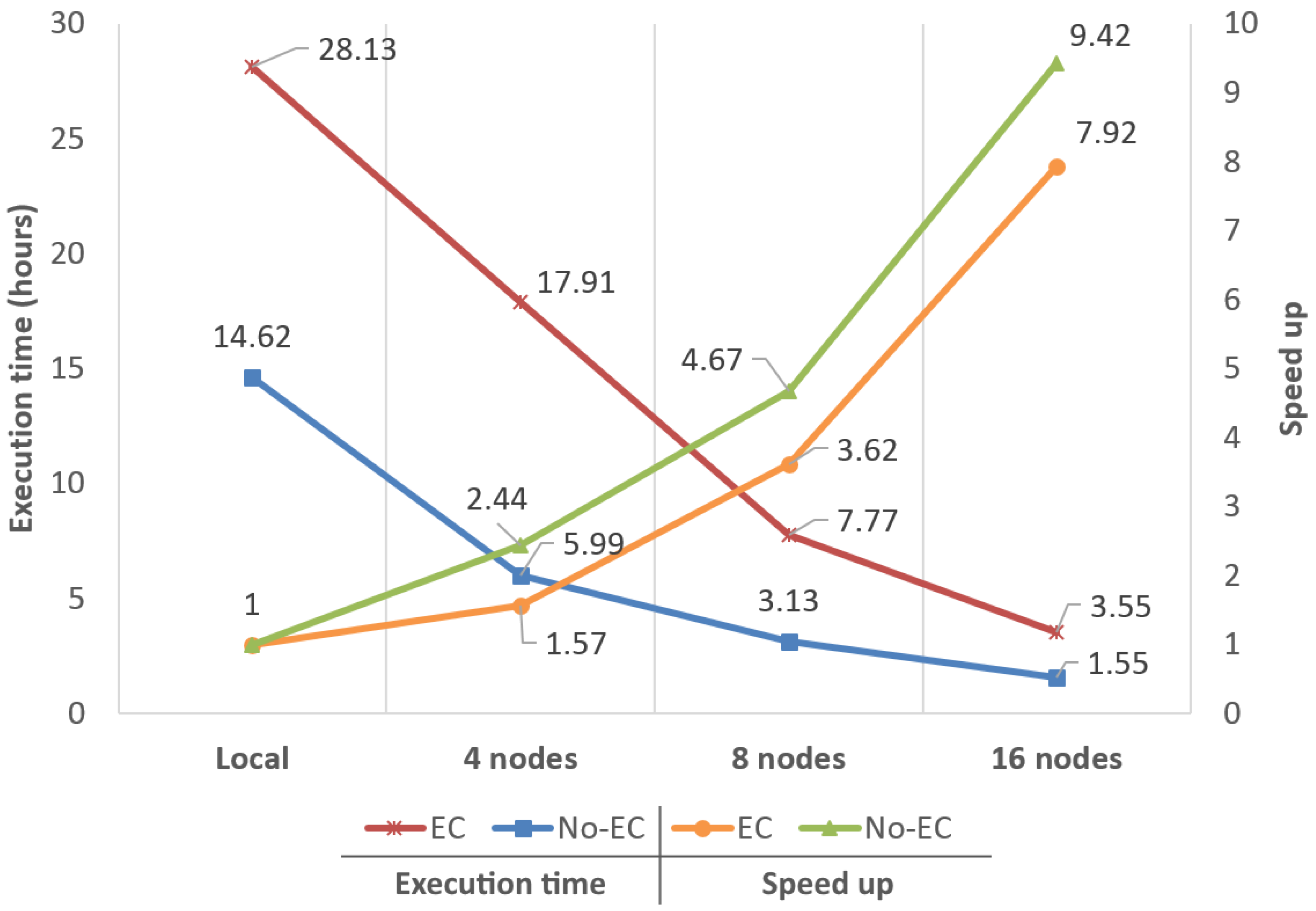
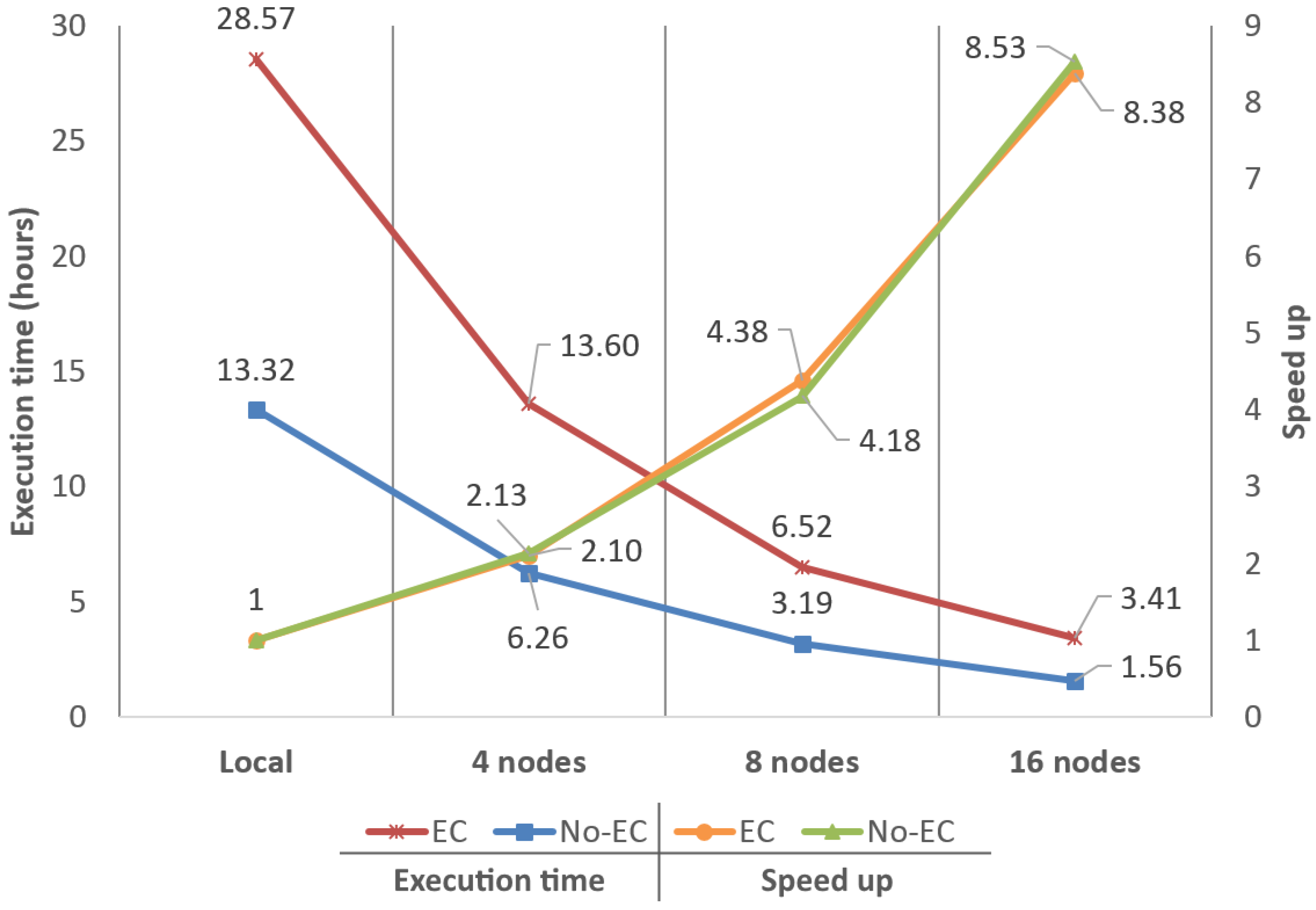
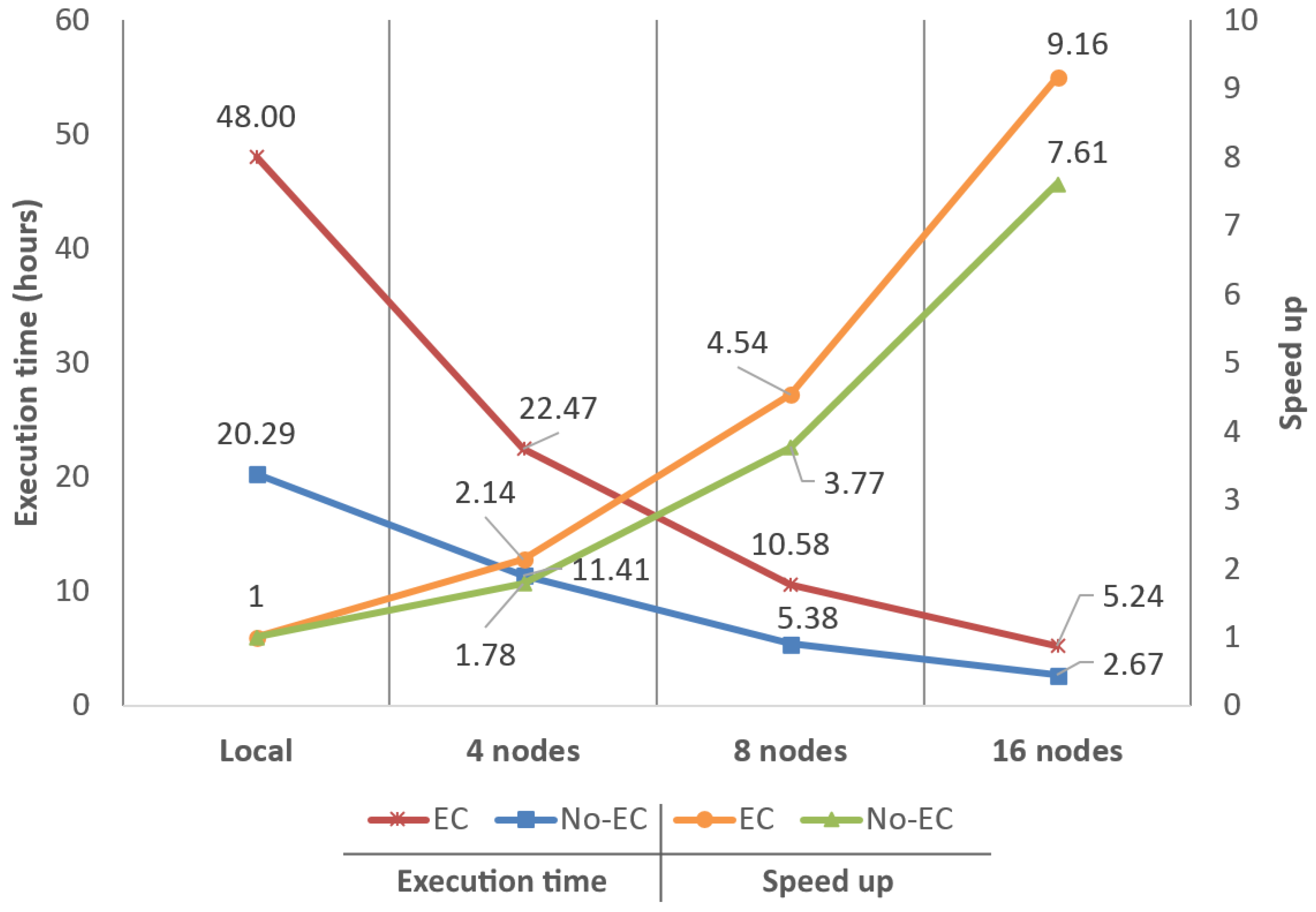
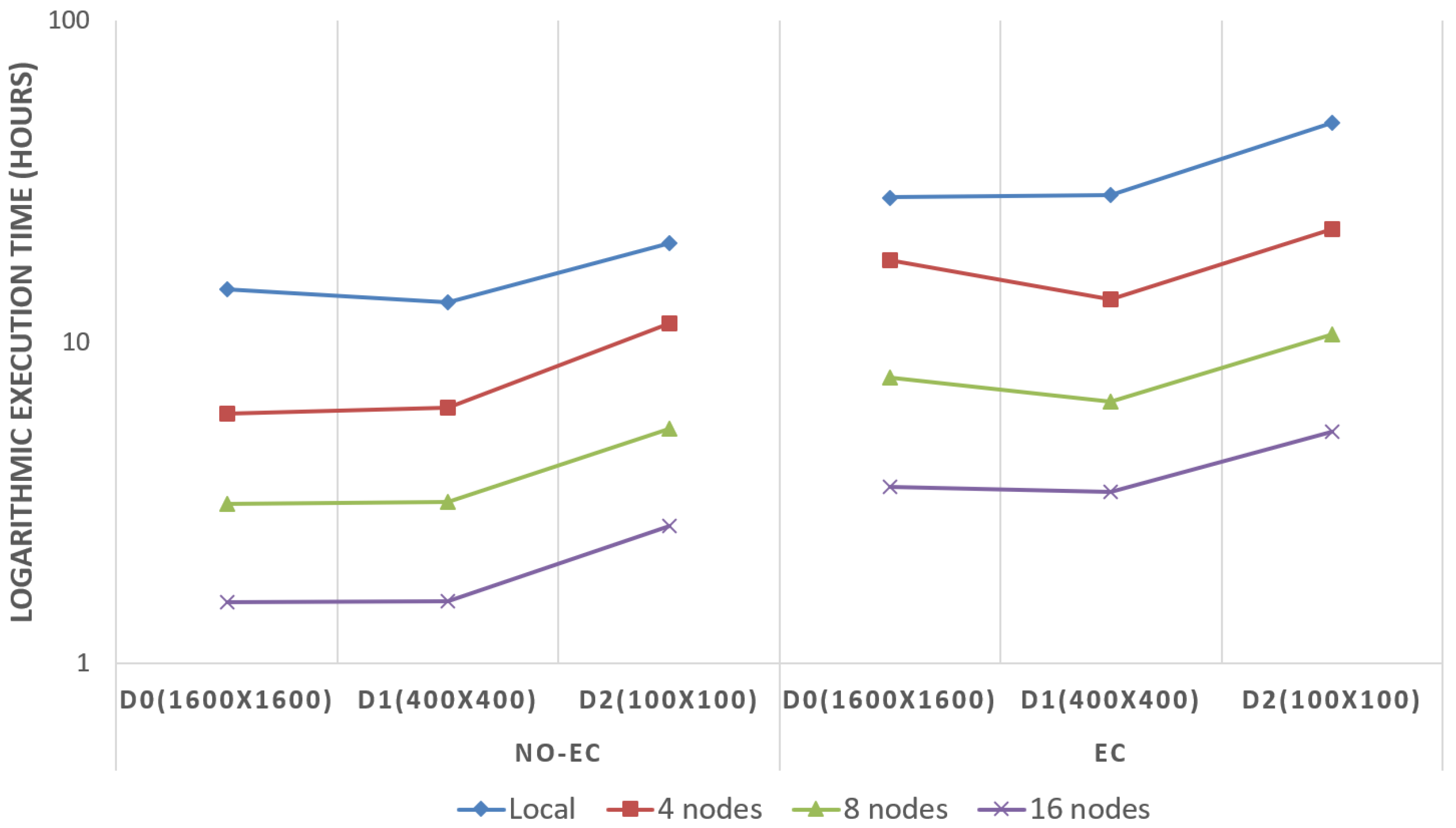
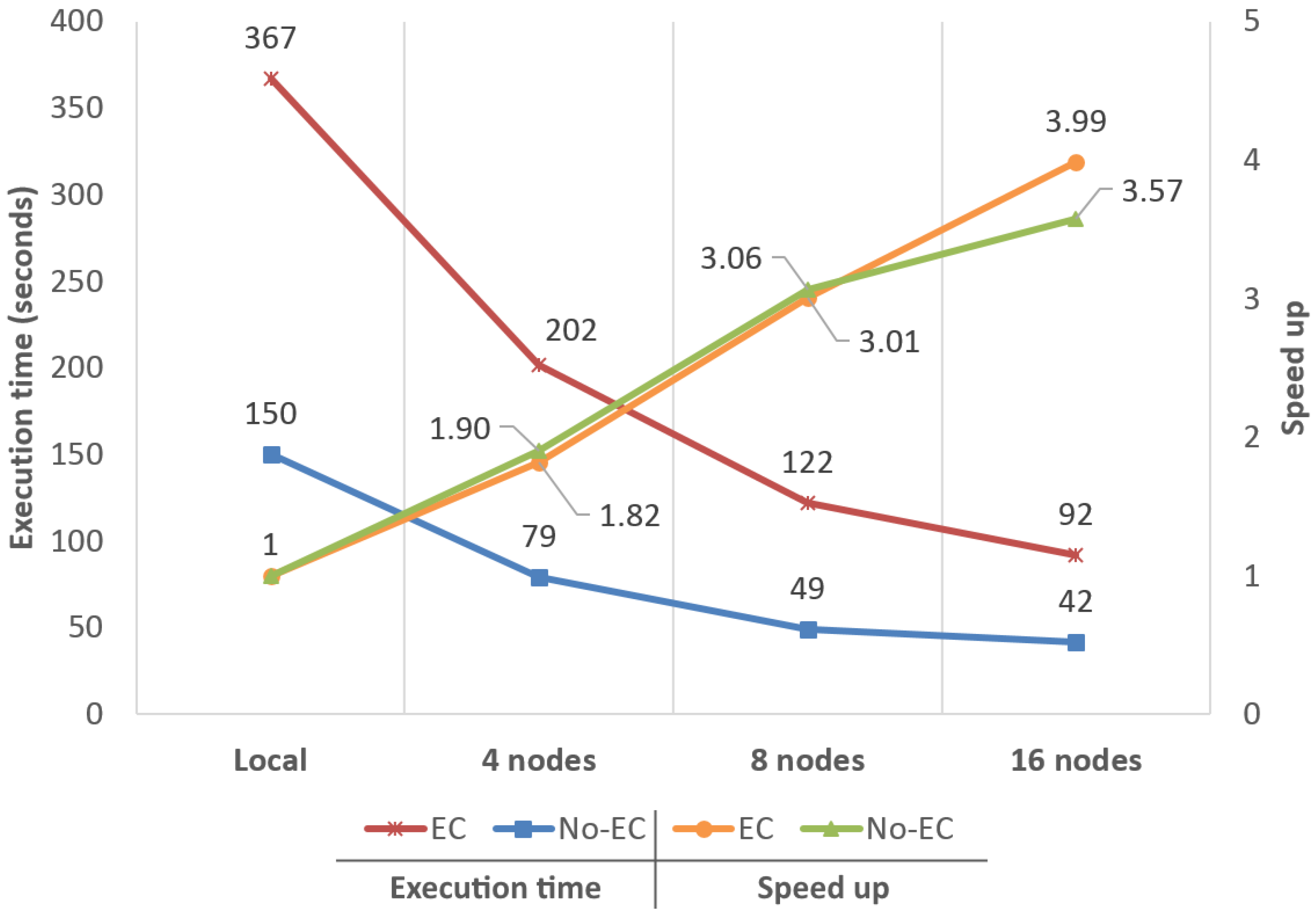
4.1. Performance in Terms of Execution Times
4.2. Boundary Error Correction Quality
4.3. The Importance of an Adequate Point Cloud Preprocessing
4.4. Full Point Classification
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
- Guitiriz was provided by Laboratorio do Territorio (LaboraTe) [36].
- PNOA: Files from the LiDAR-PNOA data repository, region of Galicia, were provided by ©Instituto Geográfico Nacional de España [37].
- ISPRS Filter Test dataset: Datasets from the International Society for Photogrammetry and Remote Sensing were provided by the University of Twente [32].
Conflicts of Interest
Abbreviations
| LiDAR | Light Detection and Ranging |
| DTM | Digital terrain model |
| DSM | Digital surface model |
| GIS | Geographic information science |
| IWS | Initial window size |
| MWS | Maximum window size |
| IET | Initial elevation threshold |
| MED | Maximum elevation difference |
| CS | Cell size |
| HT | Height threshold |
| HDFS | Hadoop Distributed File System |
| SQL | Structured Query Language |
| CPU | Central processing unit |
| CCP | Correction patch point |
| ZRP | Zone raster point |
| #P | Number of points |
| #F | Number of files |
| FE | File extent |
| FS | File size |
| TS | Total point cloud size |
| #Z | Number of zones |
| ZE | Zone extent |
| ZS | Zone size |
| TS | Total dataset size |
| EC | Error correction |
| NO-EC | No error correction |
| RAM | Random Access Memory |
| DDR | Double Data Rate |
| ISPRS | International Society for Photogrammetry and Remote Sensing |
| #GP | Number of ground points |
| #MP | Number of misclassified points |
Appendix A. Spark and Cassandra Configuration
- Several performance differences among Java 8, 9, 10 and 11 were found during our research, with Java 11 being the version that offers best performance results. Hence, the big data version of the filtering algorithm was compiled using JDK11 and both the Spark Master and the Spark workers are launched using JRE11 as well. However, the latest Java version supported by Cassandra is Java 8, thus it is launched using JRE8.
- Spark’s documentation defines spark.locality.wait as how long Spark must wait to launch a data-local task before giving up and launching it on a less-local node. The same wait is used to step through multiple locality levels (process-local, node-local, rack-local and then any). After several tests, it was determined that a value of 0 s (default is 3 s) offers the best results. This configuration implies that, as soon as a node becomes idle, data are moved from another node and a task is assigned to the idle node. This improves performance as, in most cases, the time penalty for moving data between nodes is lower than the time penalty for having a node idle.
- Due to the volumes of data handled by the system, the JVM parameters -Xms and -Xmx configured in Cassandra must be raised as needed. For the analysis presented here and considering the amount of memory presented on each node, -Xms and -Xmx were set to 24 GB. Memory configuration ends up with 32 GB for Spark, 24 GB for Cassandra and 8 GB for the OS. Additionally, some parameters such as native_transport_max_frame_size_in_mb and commitlog_segment_size_in_mb were also raised as needed when handling D0 and D3, the two datasets with the largest byte size per zone.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting | Value |
|---|---|
| Java Runtime Environment (JRE) | 11 |
| spark.locality.wait | 0 |
| spark.serializer | DEFAULT |
| spark.driver.memory | 5 GB |
| spark.executor.instances | 4, 8, 16 |
| spark.executor.cores | 16 |
| spark.executor.memory | 32 GB |
| Setting | Value |
|---|---|
| Java Runtime Environment (JRE) | 8 |
| Heap size | 24 GB |
| Garbage collector | G1 |
| Read/Write/Request timeouts | 10–120 s |
| native_transport_max_frame_size_in_mb | 256–1024 |
| commitlog_segment_size_in_mb | 32–128 |
| disk_optimization_strategy | spinning |
| concurrent_reads | 16 |
| concurrent_writes | 128 |
| concurrent_counter_writes | 16 |
| concurrent_materialized_view_writes | 16 |
References
- González-Ferreiro, E.; Miranda, D.; Barreiro-Fernández, L.; Buján, S.; García-Gutiérrez, J.; Diéguez-Aranda, U. Modelling stand biomass fractions in Galician Eucalyptus globulus plantations by use of different LiDAR pulse densities. For. Syst. 2013, 22, 510–525. [Google Scholar] [CrossRef]
- Ventura, G.; Vilardo, G.; Terranova, C.; Sessa, E.B. Tracking and evolution of complex active landslides by multi-temporal airborne LiDAR data: The Montaguto landslide (Southern Italy). Remote Sens. Environ. 2011, 115, 3237–3248. [Google Scholar] [CrossRef]
- Deibe, D.; Amor, M.; Doallo, R. Supporting multi-resolution out-of-core rendering of massive LiDAR point clouds through non-redundant data structures. Int. J. Geogr. Inf. Sci. 2019, 33, 593–617. [Google Scholar] [CrossRef]
- Rodríguez, M.B.; Gobbetti, E.; Marton, F.; Tinti, A. Coarse-grained Multiresolution Structures for Mobile Exploration of Gigantic Surface Models. In Proceedings of the SIGGRAPH Asia 2013 Symposium on Mobile Graphics and Interactive Applications, Hong Kong, China, 19–22 November 2013. [Google Scholar]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of big data on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Yang, C.; Yu, M.; Hu, F.; Jiang, Y.; Li, Y. Utilizing Cloud Computing to address big geospatial data challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A.; et al. Geospatial big data handling theory and methods: A review and research challenges. Isprs J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Wang, L.; Ma, Y.; Yan, J.; Chang, V.; Zomaya, A.Y. pipsCloud: High performance cloud computing for remote sensing big data management and processing. Future Gener. Comput. Syst. 2018, 78, 353–368. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Boehm, J. File-centric Organization of large LiDAR Point Clouds in a Big Data context. In Proceedings of the IQmulus First Workshop on Processing Large Geospatial Data, Cardiff, UK, 8 July 2014; pp. 69–76. [Google Scholar]
- Brédif, M.; Vallet, B.; Ferrand, B. Distributed Dimensonality-Based Rendering of Lidar Point Clouds. Isprs - Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-3/W3, 559–564. [Google Scholar]
- Deibe, D.; Amor, M.; Doallo, R. Big data storage technologies: A case study for web-based LiDAR visualization. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3831–3840. [Google Scholar]
- Persson, H.; Wallerman, J.; Olsson, H.; Fransson, J.E. Estimating forest biomass and height using optical stereo satellite data and a DTM from laser scanning data. Can. J. Remote Sens. 2013, 39, 251–262. [Google Scholar] [CrossRef]
- Zhou, X.; Li, W.; Arundel, S.T. A spatio-contextual probabilistic model for extracting linear features in hilly terrains from high-resolution DEM data. Int. J. Geogr. Inf. Sci. 2019, 33, 666–686. [Google Scholar] [CrossRef]
- Deibe, D.; Amor, M.; Doallo, R.; Miranda, D.; Cordero, M. GVLiDAR: An Interactive Web-based Visualization Framework to Support Geospatial Measures on Lidar Data. Int. J. Remote Sens. 2017, 38, 827–849. [Google Scholar] [CrossRef]
- The Apache Software Foundation. Apache Cassandra. Available online: http://cassandra.apache.org/ (accessed on 8 January 2018).
- The Apache Software Foundation. Apache Spark. Available online: http://spark.apache.org/ (accessed on 22 January 2019).
- Buyya, R.; Dastjerdi, A.; Calheiros, R. Big Data Principles and Paradigms; Elsevier Science: Amsterdam, The Netherlands, 2016; pp. 39–58. [Google Scholar]
- Zhang, K.; Chen, S.C.; Whitman, D.; Shyu, M.L.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef]
- Crecente, R.; González, E.; Arias, D.; Miranda, D.; Suárez, M. LIDAR2MDTPlus Generación de Modelos Digitales de Terreno de Pendiente Variable a Partir de datos LIDAR Mediante Filtro Morfológico Adaptativo y Computación Paralela Sobre Procesadores Multinúcleo, 2012. Software registration: Universidade de Santiago, Spain. SC-091-12 03/28/2012. Available online: http://www.ibader.gal/seccion/378/Outras-actividades.html (accessed on 21 February 2020).
- USDA Forest Service. FUSION/LDV LIDAR Analysis and Visualization Software. Available online: http://forsys.cfr.washington.edu/fusion/fusion_overview.html (accessed on 22 January 2019).
- Recarey, V.C.; Barrós, D.M.; Prado, D.A.A. Optimización de los Parámteros del Algoritmo de Filtrado LiDAR2MDTPlus, Para la Obtención de Modelos Digitales del Terreno con LiDAR. Ph.D. Thesis, Higher Polytechnic Engineering School, University of Santiago de Compostela (USC), Santiago de Compostela, Spain, September 2014. [Google Scholar]
- The Apache Software Foundation. Apache Hadoop 3.0.0—HDFS Architecture. Available online: http://hadoop.apache.org/docs/r3.0.0/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html (accessed on 8 January 2018).
- MongoDB, Inc. MongoDB. Available online: http://www.mongodb.com/ (accessed on 8 January 2018).
- Redis Labs. Redis. Available online: http://redis.io/ (accessed on 8 January 2018).
- solid IT. DB-Engines Ranking—Popularity Ranking of Database Management Systems. Available online: http://db-engines.com/en/ranking (accessed on 8 January 2018).
- Datastax. GitHub—Datastax/spark-Cassandra-Connector: DataStax Spark Cassandra Connector. Available online: https://github.com/datastax/spark-cassandra-connector (accessed on 22 January 2019).
- The Apache Software Foundation. Apache Storm. Available online: http://storm.apache.org/ (accessed on 11 March 2019).
- The Apache Software Foundation. Apache Flink: Stateful Computations over Data Streams. Available online: https://flink.apache.org/ (accessed on 11 March 2019).
- The Apache Software Foundation. Apache Hadoop. Available online: http://hadoop.apache.org/ (accessed on 11 March 2019).
- Lin, S.; Chen, H.; Hu, F. A Workload-Driven Approach to Dynamic Data Balancing in MongoDB. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 786–791. [Google Scholar]
- University of Twente. ISPRS Test Sites. Available online: https://www.itc.nl/isprs/wgIII-3/filtertest/downloadsites (accessed on 27 April 2019).
- Blue Marble Geographics. Global Mapper—All-in-one GIS Software. Available online: https://www.bluemarblegeo.com/products/global-mapper.php (accessed on 10 May 2019).
- GmbH, R. LAStools. Available online: https://rapidlasso.com/lastools/ (accessed on 15 May 2019).
- Rizaldi, A.; Persello, C.; Gevaert, C.; Oude Elberink, S. Fully Convolutional Networks for Ground Classification from LiDAR Point Clouds. Isprs Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 231–238. [Google Scholar] [CrossRef]
- Universidade de Santiago de Compostela (USC). Laboratorio do Territorio (Laborate). Available online: http://laborate.usc.es/index.html (accessed on 23 October 2018).
- Infraestructura de Datos Espaciales de España (IDEE). Geoportal IDEE. Available online: http://www.idee.es/ (accessed on 8 March 2019).












| Point Cloud | #P | #F | FE | FS | TS |
|---|---|---|---|---|---|
| PNOA (Region) | 28 | 8697 | 2000 × 2000 | 96,731 | 802 |
| Guitiriz (Village) | 1 | 304 | 500 × 500 | 126,194 | 37 |
| Dataset | Source | #Z | ZE | ZS | TS |
|---|---|---|---|---|---|
| D0 | PNOA | 11,662 | 1600 × 1600 | 8925 | 99 |
| D1 | PNOA | 181,823 | 400 × 400 | 563 | 99 |
| D2 | PNOA | 2,875,097 | 100 × 100 | 39 | 108 |
| D3 | Guitiriz | 304 | 500 × 500 | 29,696 | 9 |
| Datasets | Type I Error (%) | ||
|---|---|---|---|
| Undivided | Divided in 4 (NO-EC) | Divided in 4 (EC) | |
| Sample 11 | 45.99 | 50.18 | 44.97 |
| Sample 22 | 39.71 | 40.59 | 39.44 |
| Sample 52 | 10.79 | 13.43 | 10.54 |
| Sample 53 | 14.87 | 15.71 | 14.25 |
| Sample 54 | 6.80 | 7.22 | 6.47 |
| Sample 61 | 8.03 | 8.44 | 7.76 |
| Datasets info. | Rasters info. | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Undivided | Divided in 4 (NO-EC) | Divided in 4 (EC) | |||||||
| Name | #GP | #GP | #MP | #GP | #MP | (%) | #GP | #MP | (%) |
| Sample 11 | 21,781 | 12,218 | 453 | 11,416 | 414 | 93.51 | 12,599 | 566 | 102.28 |
| Sample 22 | 22,498 | 13,843 | 280 | 13,769 | 400 | 98.57 | 14,101 | 468 | 100.52 |
| Sample 52 | 20,112 | 18,119 | 177 | 17,532 | 180 | 96.71 | 18,104 | 186 | 99.87 |
| Sample 53 | 32,989 | 28,208 | 124 | 27,875 | 124 | 98.81 | 28,349 | 124 | 100.50 |
| Sample 54 | 3983 | 3866 | 154 | 3845 | 154 | 99.43 | 3877 | 160 | 100.13 |
| Sample 61 | 33,854 | 31,195 | 59 | 31,045 | 57 | 99.52 | 31,284 | 60 | 100.28 |
| Datasets | Total Error (%) | Type I Error (%) | Type II Error (%) | |||
|---|---|---|---|---|---|---|
| Our Approach | LAStools | Our Approach | LAStools | Our Approach | LAStools | |
| Sample 11 | 17.05 | 17.67 | 27.06 | 26.94 | 3.61 | 5.18 |
| Sample 12 | 5.28 | 6.97 | 8.25 | 12.87 | 2.16 | 0.77 |
| Sample 21 | 1.79 | 6.66 | 1.42 | 7.98 | 3.09 | 1.87 |
| Sample 53 | 14.33 | 14.37 | 14.55 | 14.84 | 8.92 | 3.24 |
| Sample 61 | 7.29 | 17.24 | 7.38 | 17.85 | 4.89 | 0.40 |
| Average | 9.15 | 12.58 | 11.732 | 16.10 | 4.53 | 2.29 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deibe, D.; Amor, M.; Doallo, R. Big Data Geospatial Processing for Massive Aerial LiDAR Datasets. Remote Sens. 2020, 12, 719. https://doi.org/10.3390/rs12040719
Deibe D, Amor M, Doallo R. Big Data Geospatial Processing for Massive Aerial LiDAR Datasets. Remote Sensing. 2020; 12(4):719. https://doi.org/10.3390/rs12040719
Chicago/Turabian StyleDeibe, David, Margarita Amor, and Ramón Doallo. 2020. "Big Data Geospatial Processing for Massive Aerial LiDAR Datasets" Remote Sensing 12, no. 4: 719. https://doi.org/10.3390/rs12040719
APA StyleDeibe, D., Amor, M., & Doallo, R. (2020). Big Data Geospatial Processing for Massive Aerial LiDAR Datasets. Remote Sensing, 12(4), 719. https://doi.org/10.3390/rs12040719