Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data


Abstract
1. Introduction
- Assess the Mask R-CNN DL algorithm for mapping VFFs using LiDAR-derived digital elevation data.
- Investigate model performance and generalization by applying the model to LiDAR-derived data in new geographic regions and acquired with differing LiDAR sensors and acquisition parameters, as well as a photogrammetrically-derived digital terrain dataset.
1.1. LiDAR and Digital Terrain Mapping
1.2. Deep Learning
1.3. Mountaintop Removal Coal Mining and Valley Fills
2. Methods
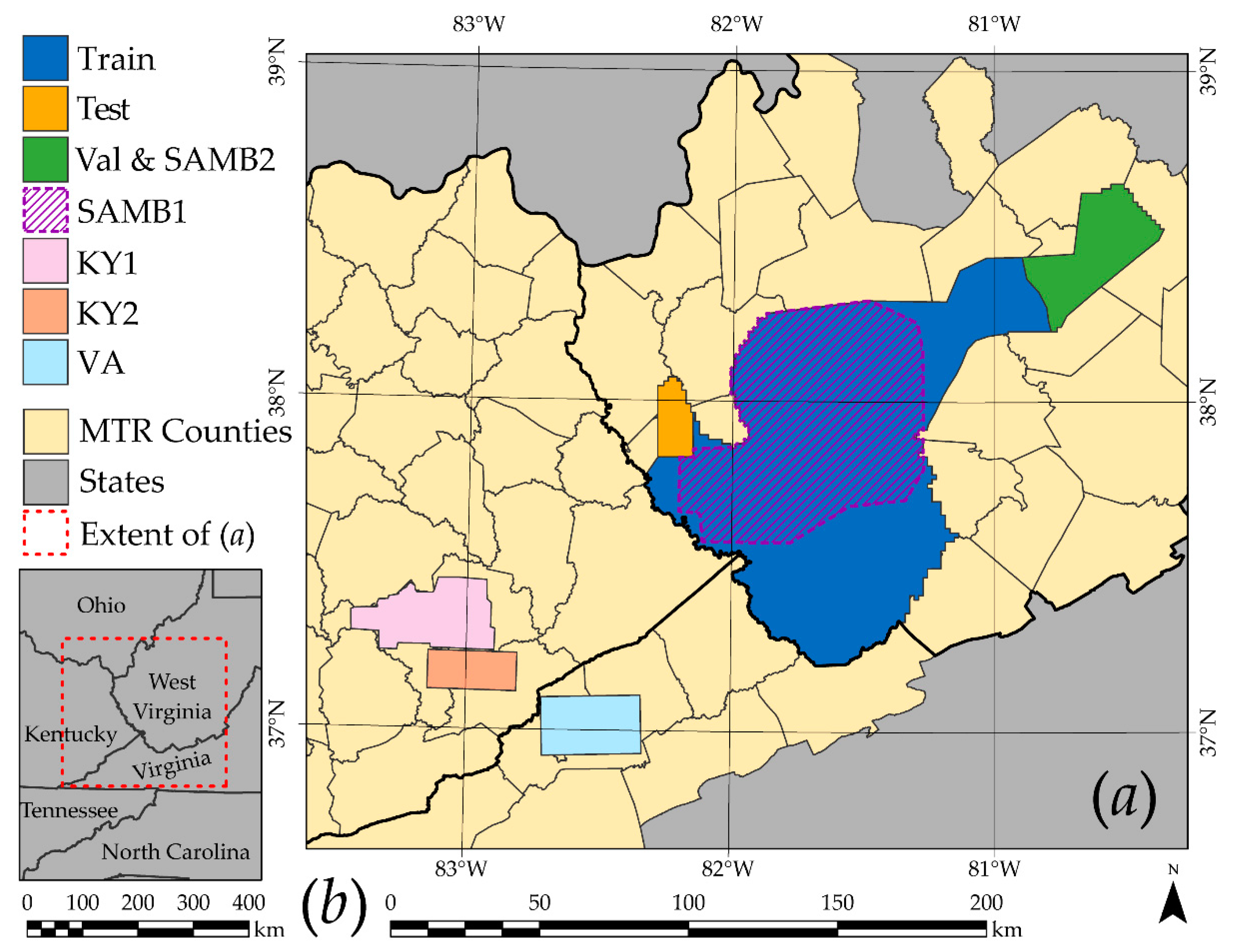
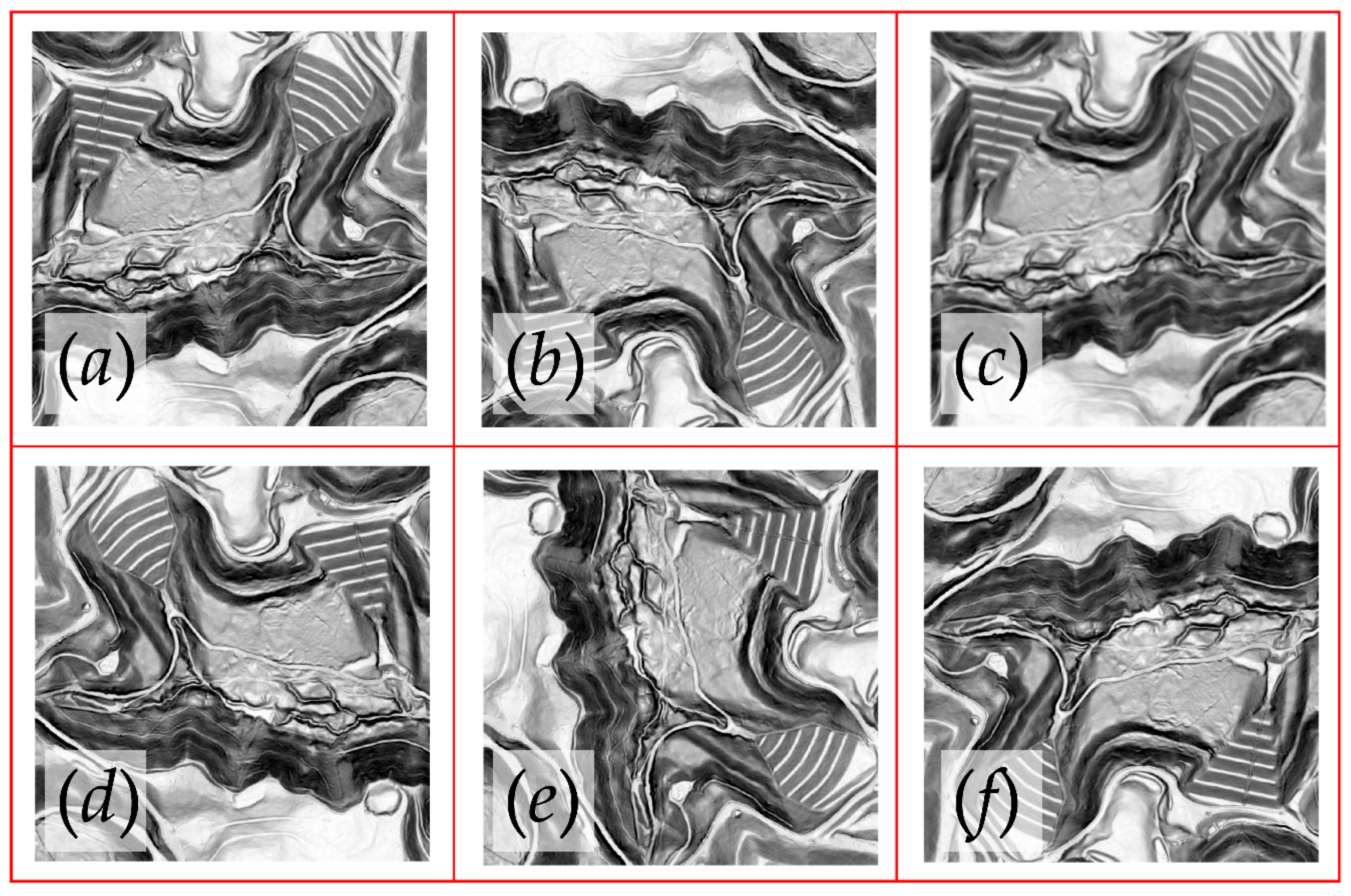
2.1. Study Area and Training Data Digitizing
2.2. Input Terrain Data and Pre-Processing
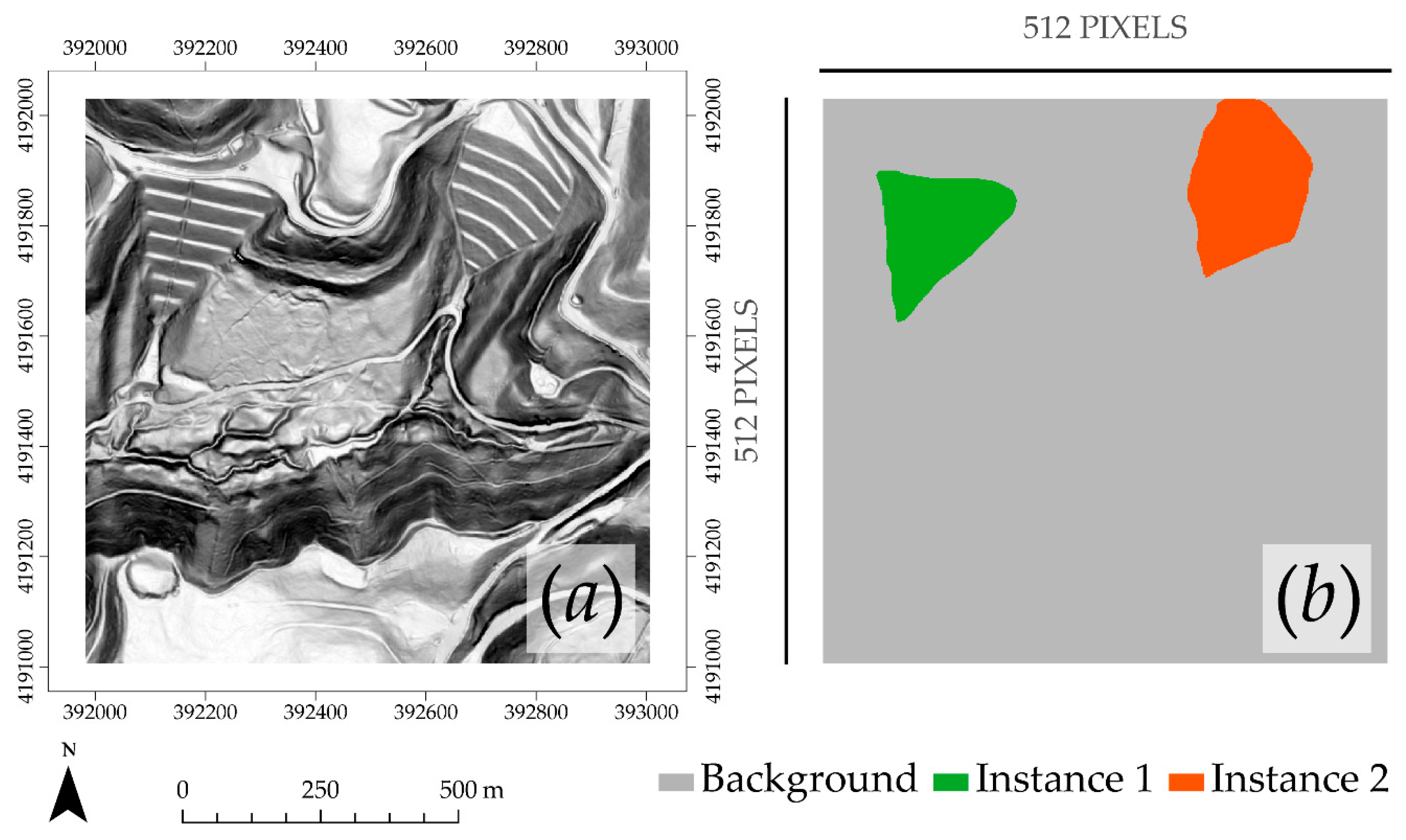
2.3. Image Chip Generation
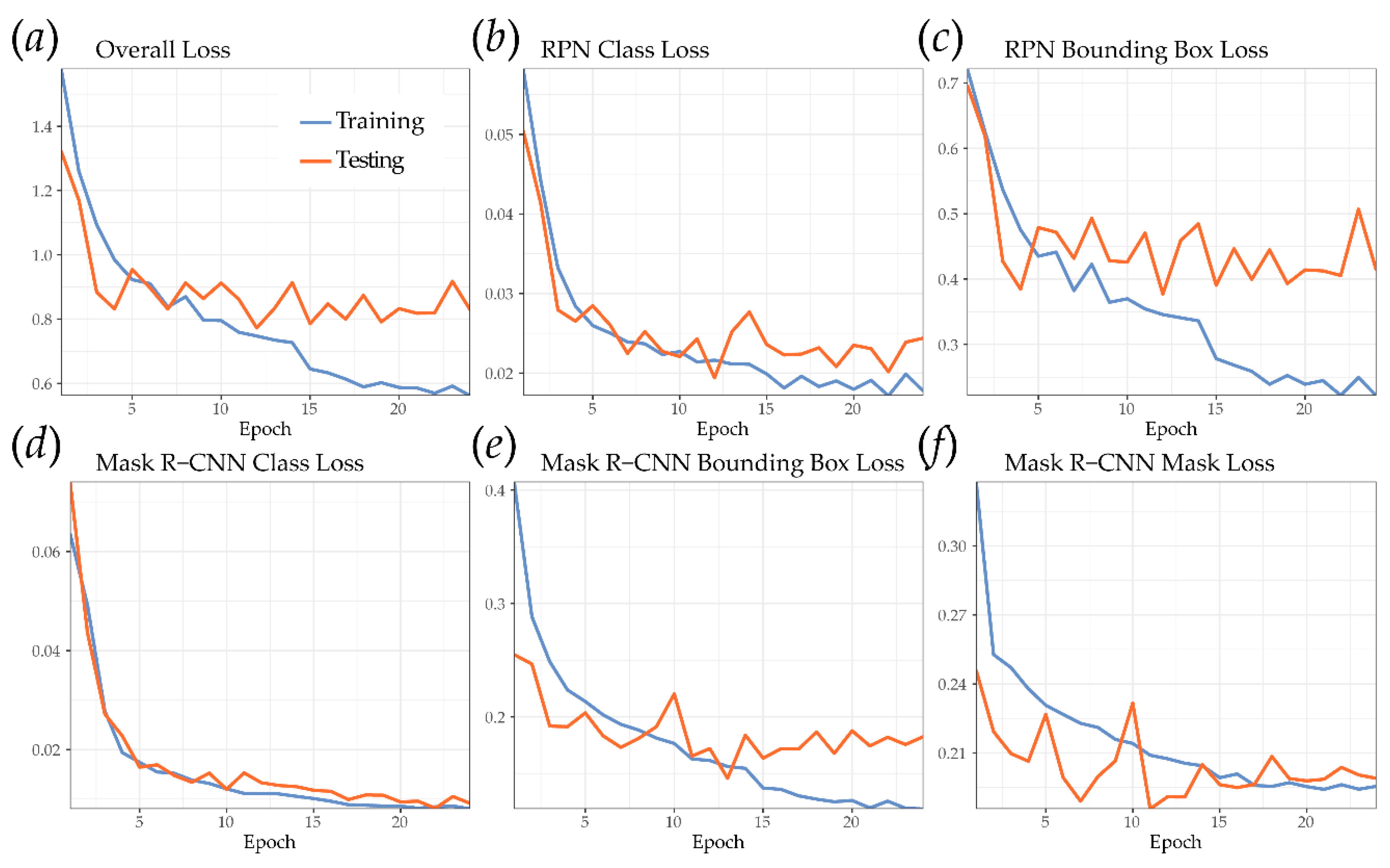
2.4. Mask R-CNN Implementation
2.5. Prediction and Post-Processing
2.6. Accuarcy Assessment
3. Results
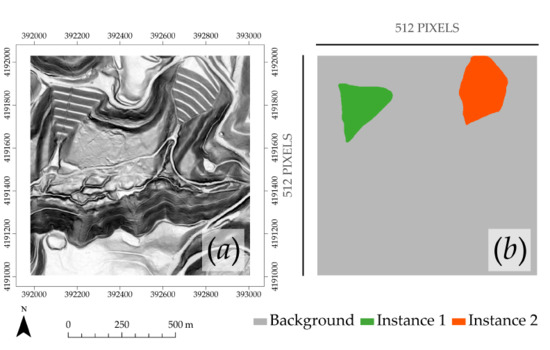
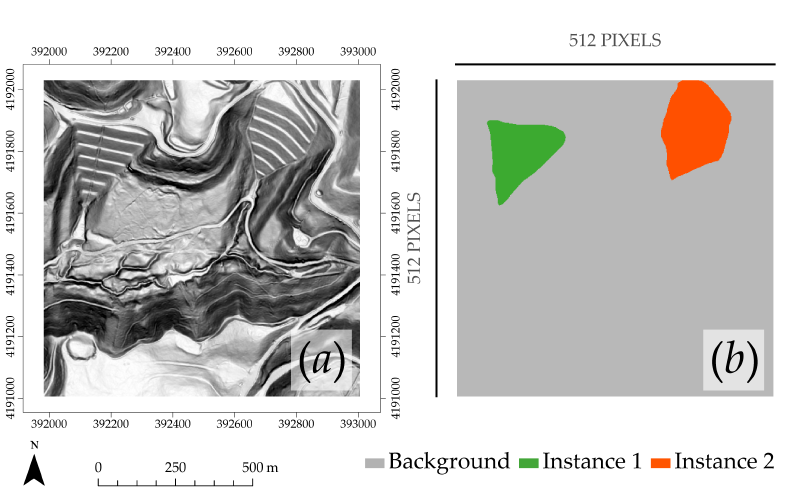
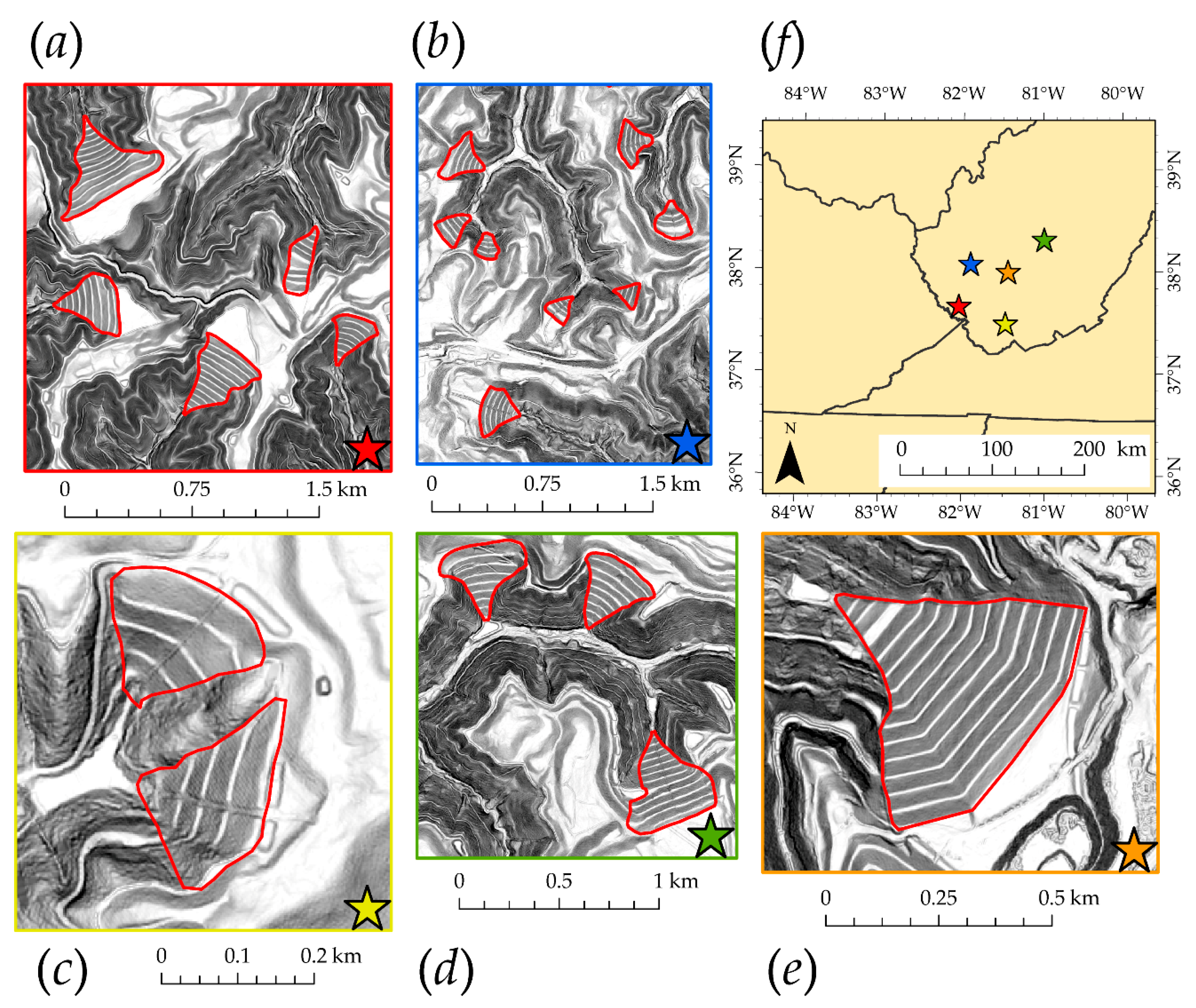
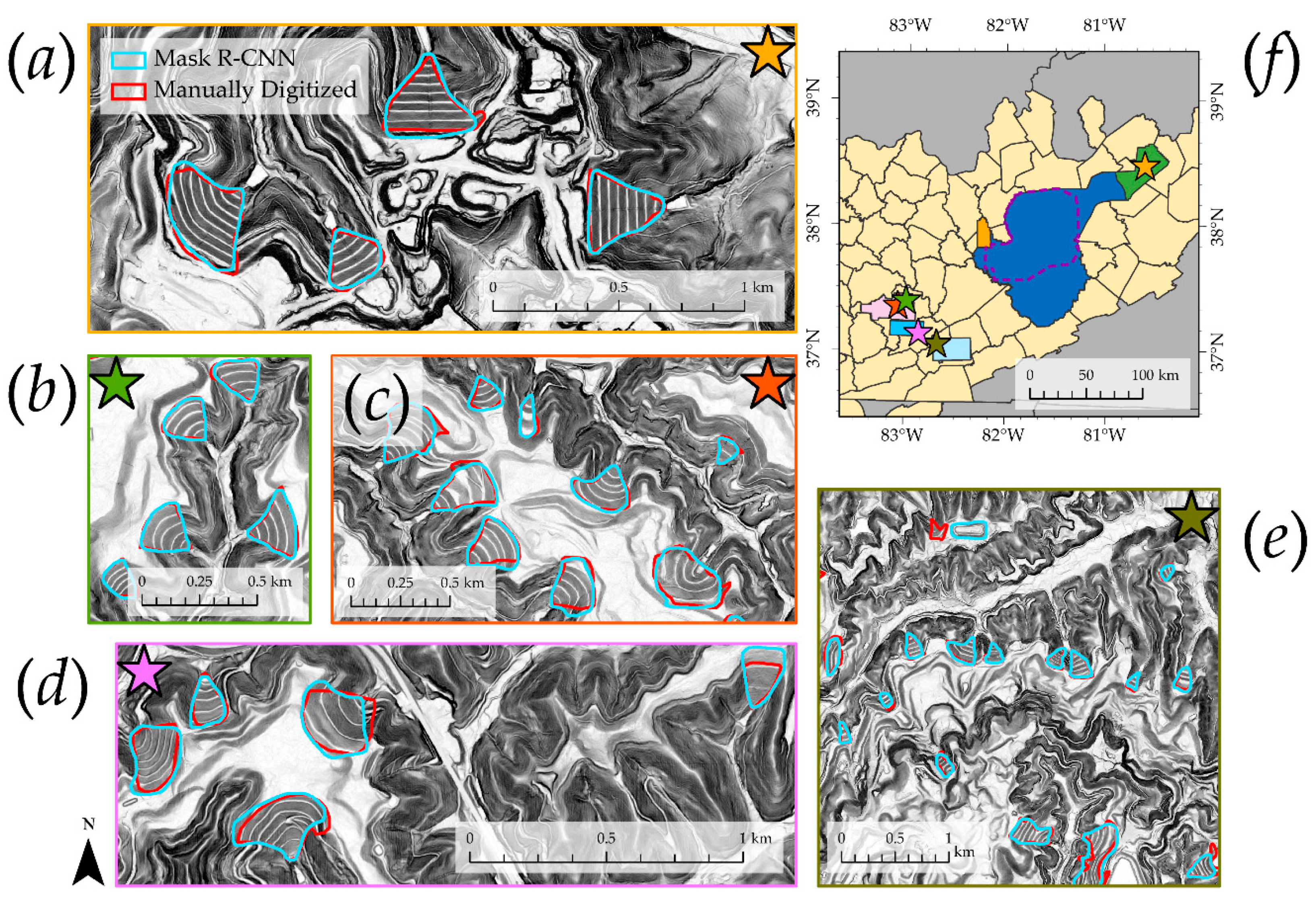
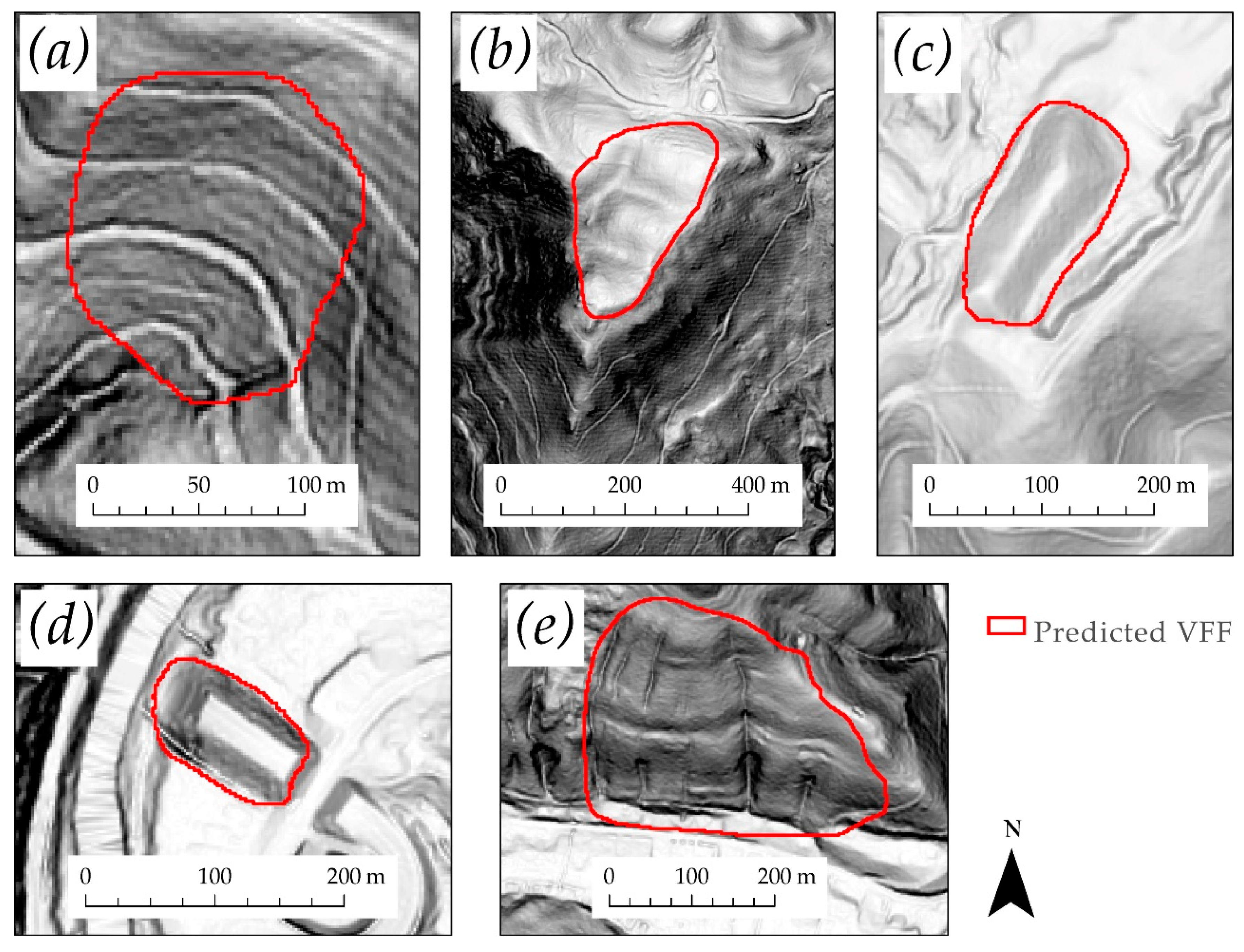
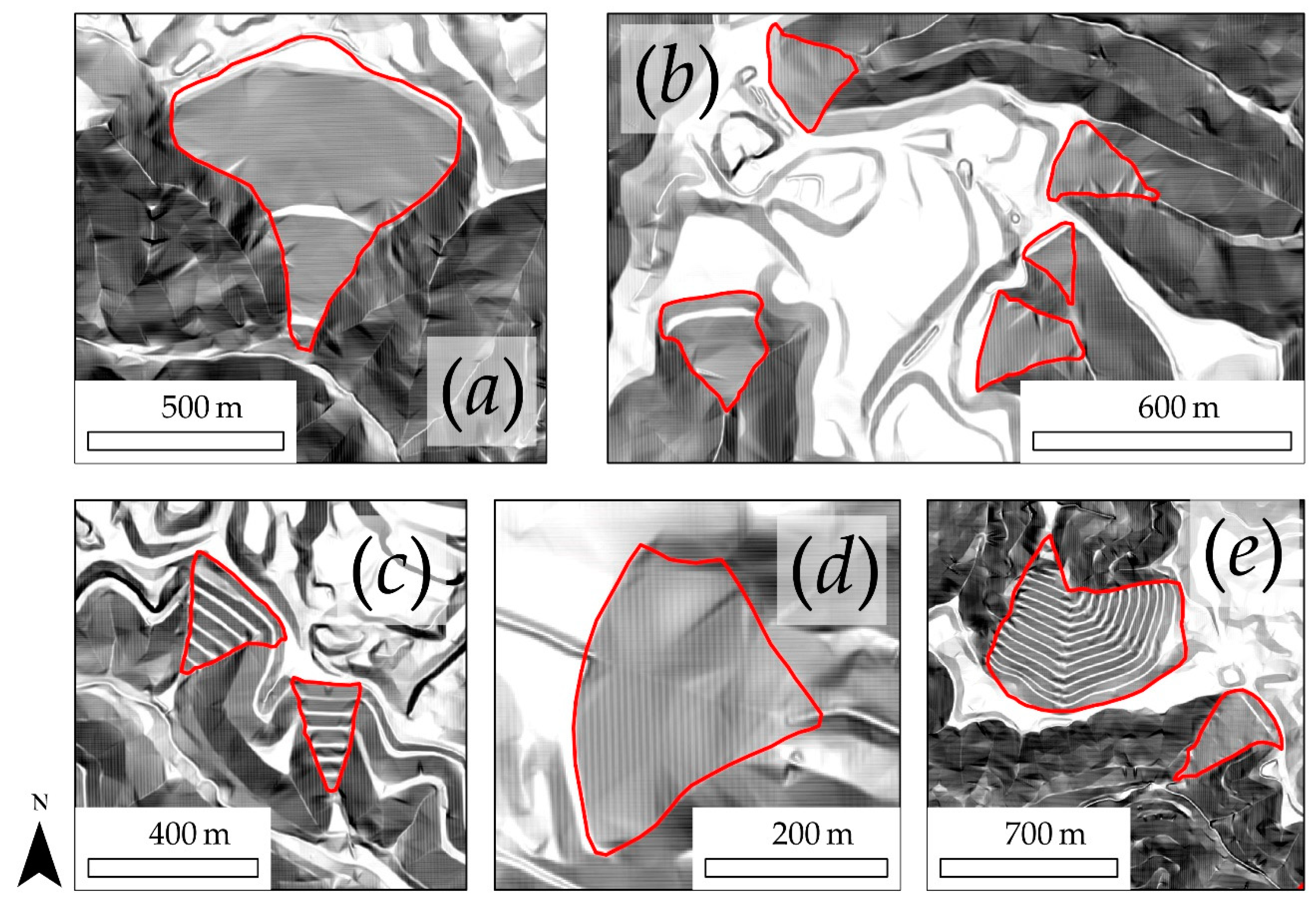
3.1. Mask R-CNN Model and Visual Assessment
3.2. Validation
4. Discussion
4.1. Study Findings
4.2. Limitations and Recommendations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.-H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef]
- Chase, A.F.; Chase, D.Z.; Fisher, C.T.; Leisz, S.J.; Weishampel, J.F. Geospatial revolution and remote sensing LiDAR in Mesoamerican archaeology. Proc. Natl. Acad. Sci. USA 2012, 109, 12916–12921. [Google Scholar] [CrossRef] [PubMed]
- Arundel, S.T.; Phillips, L.A.; Lowe, A.J.; Bobinmyer, J.; Mantey, K.S.; Dunn, C.A.; Constance, E.W.; Usery, E.L. Preparing The National Map for the 3D Elevation Program–products, process and research. Cartogr. Geogr. Inf. Sci. 2015, 42, 40–53. [Google Scholar] [CrossRef]
- The Earth Archive. Available online: https://www.theeartharchive.com (accessed on 28 October 2019).
- Passalacqua, P.; Tarolli, P.; Foufoula-Georgiou, E. Testing space-scale methodologies for automatic geomorphic feature extraction from lidar in a complex mountainous landscape. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Cowley, D.C.; Waldeland, A.U. Using deep neural networks on airborne laser scanning data: Results from a case study of semi-automatic mapping of archaeological topography on Arran, Scotland. Archaeol. Prospect. 2019, 26, 165–175. [Google Scholar] [CrossRef]
- Trier, Ø.D.; Zortea, M.; Tonning, C. Automatic detection of mound structures in airborne laser scanning data. J. Archaeol. Sci. Rep. 2015, 2, 69–79. [Google Scholar] [CrossRef]
- Eeckhaut, M.V.D.; Poesen, J.; Verstraeten, G.; Vanacker, V.; Nyssen, J.; Moeyersons, J.; Beek, L.P.H.; van Vandekerckhove, L. Use of LIDAR-derived images for mapping old landslides under forest. Earth Surf. Process. Landf. 2007, 32, 754–769. [Google Scholar] [CrossRef]
- Verhagen, P.; Drăguţ, L. Object-based landform delineation and classification from DEMs for archaeological predictive mapping. J. Archaeol. Sci. 2012, 39, 698–703. [Google Scholar] [CrossRef]
- Remote Sensing and Image Interpretation, 7th Edition Wiley. Available online: https://www.wiley.com/en-us/Remote+Sensing+and+Image+Interpretation%2C+7th+Edition-p-9781118343289 (accessed on 28 October 2019).
- Ardizzone, F.; Cardinali, M.; Galli, M.; Guzzetti, F.; Reichenbach, P. Identification and mapping of recent rainfall-induced landslides using elevation data collected by airborne Lidar. Nat. Hazards Earth Syst. Sci. 2007, 7, 637–650. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; Wang, Y.; Chen, G.; Liu, S. Forested landslide detection using LiDAR data and the random forest algorithm: A case study of the Three Gorges, China. Remote Sens. Environ. 2014, 152, 291–301. [Google Scholar] [CrossRef]
- Van Den Eeckhaut, M.; Kerle, N.; Poesen, J.; Hervás, J. Object-oriented identification of forested landslides with derivatives of single pulse LiDAR data. Geomorphology 2012, 173–174, 30–42. [Google Scholar] [CrossRef]
- Abdulwahid, W.M.; Pradhan, B. Landslide vulnerability and risk assessment for multi-hazard scenarios using airborne laser scanning data (LiDAR). Landslides 2017, 14, 1057–1076. [Google Scholar] [CrossRef]
- Haneberg, W.C.; Cole, W.F.; Kasali, G. High-resolution lidar-based landslide hazard mapping and modeling, UCSF Parnassus Campus, San Francisco, USA. Bull. Eng. Geol. Environ. 2009, 68, 263–276. [Google Scholar] [CrossRef]
- Latif, Z.A.; Aman, S.N.A.; Pradhan, B. Landslide susceptibility mapping using LiDAR derived factors and frequency ratio model: Ulu Klang area, Malaysia. In Proceedings of the 2012 IEEE 8th International Colloquium on Signal Processing and Its Applications, Malacca, Malaysia, 23 March 2012. [Google Scholar]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A. Differentiating Mine-Reclaimed Grasslands from Spectrally Similar Land Cover using Terrain Variables and Object-Based Machine Learning Classification. Int. J. Remote Sens. 2015, 36, 4384–4410. [Google Scholar] [CrossRef]
- DeWitt, J.D.; Warner, T.A.; Conley, J.F. Comparison of DEMS derived from USGS DLG, SRTM, a Statewide Photogrammetry Program, ASTER GDEM and LiDAR: Implications for Change Detection. GISci. Remote Sens. 2015, 52, 179–197. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic object-based image analysis (GEOBIA): Emerging trends and future opportunities. Gisci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Kim, M.; Madden, M.; Warner, T.A. Forest Type Mapping Using Object-Specific Texture Measures from Multispectral Ikonos Imagery. Photogramm. Eng. Remote Sens. 2009, 75, 819–829. [Google Scholar] [CrossRef]
- Kim, M.; Warner, T.A.; Madden, M.; Atkinson, D.S. Multi-scale GEOBIA with very high spatial resolution digital aerial imagery: Scale, texture and image objects. Int. J. Remote Sens. 2011, 32, 2825–2850. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Sr, C.S.C. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. JARS 2017, 11, 042609. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Fully convolutional neural networks for remote sensing image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. Gisci. Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D Convolutional Neural Networks for Crop Classification with Multi-Temporal Remote Sensing Images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef]
- Rizaldy, A.; Persello, C.; Gevaert, C.M.; Oude Elberink, S.J. Fully Convolutional Networks for Ground Classification from LiDAR Point Clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV–2, 231–238. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hofmann, F.; D’Anastasi, M.; et al. Automatic Liver and Lesion Segmentation in CT Using Cascaded Fully Convolutional Neural Networks and 3D Conditional Random Fields. Available online: https://arxiv.org/abs/1610.02177 (accessed on 5 February 2020).
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Yang, Y.; Niu, H.; Wang, D.; Chen, Y. Comparing U-Net convolutional network with mask R-CNN in the performances of pomegranate tree canopy segmentation. In Proceedings of the Multispectral, Hyperspectral, and Ultraspectral Remote Sensing Technology, Techniques and Applications VII. Int. Soc. Opt. Photonics 2018, 10780, 107801J. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. Available online: https://arxiv.org/abs/1703.06870 (accessed on 5 February 2020).
- Microsoft/USBuildingFootprints; Microsoft. Available online: https://github.com/microsoft/USBuildingFootprints (accessed on 5 February 2020).
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef]
- Janssens-Coron, E.; Guilbert, E. Ground Point Filtering from Airborne LiDAR Point Clouds using Deep Learning: A Preliminary Study. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W13, 1559–1565. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. Available online: https://www.semanticscholar.org/paper/Semantic3D.net%3A-A-new-Large-scale-Point-Cloud-Hackel-Savinov/5d9b36e296e6f61177c2f1739a6ca8c553303c09 (accessed on 5 February 2020).
- Hu, X.; Yuan, Y. Deep-Learning-Based Classification for DTM Extraction from ALS Point Cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree Classification in Complex Forest Point Clouds Based on Deep Learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Guan, H.; Yu, Y.; Ji, Z.; Li, J.; Zhang, Q. Deep learning-based tree classification using mobile LiDAR data. Remote Sens. Lett. 2015, 6, 864–873. [Google Scholar] [CrossRef]
- Liu, F.; Li, S.; Zhang, L.; Zhou, C.; Ye, R.; Wang, Y.; Lu, J. 3DCNN-DQN-RNN: A Deep Reinforcement Learning Framework for Semantic Parsing of Large-Scale 3D Point Clouds. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Behrens, T. Multi-scale digital soil mapping with deep learning. Sci. Rep. 2018, 8, 1–9. [Google Scholar] [CrossRef]
- Li, W.; Zhou, B.; Hsu, C.-Y.; Li, Y.; Ren, F. Recognizing terrain features on terrestrial surface using a deep learning model: An example with crater detection. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery-GeoAI 17, Los Angeles, CA, USA, 7–10 November 2017. [Google Scholar]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef]
- Zhang, W.; Witharana, C.; Liljedahl, A.K.; Kanevskiy, M. Deep Convolutional Neural Networks for Automated Characterization of Arctic Ice-Wedge Polygons in Very High Spatial Resolution Aerial Imagery. Remote Sens. 2018, 10, 1487. [Google Scholar] [CrossRef]
- Stewart, E.L.; Wiesner-Hanks, T.; Kaczmar, N.; DeChant, C.; Wu, H.; Lipson, H.; Nelson, R.J.; Gore, M.A. Quantitative Phenotyping of Northern Leaf Blight in UAV Images Using Deep Learning. Remote Sens. 2019, 11, 2209. [Google Scholar] [CrossRef]
- Bernhardt, E.S.; Palmer, M.A. The environmental costs of mountaintop mining valley fill operations for aquatic ecosystems of the Central Appalachians. Ann. N. Y. Acad. Sci. 2011, 1223, 39–57. [Google Scholar] [CrossRef] [PubMed]
- Griffith, M.B.; Norton, S.B.; Alexander, L.C.; Pollard, A.I.; LeDuc, S.D. The effects of mountaintop mines and valley fills on the physicochemical quality of stream ecosystems in the central Appalachians: A review. Sci. Total Environ. 2012, 417–418, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Fritz, K.M.; Fulton, S.; Johnson, B.R.; Barton, C.D.; Jack, J.D.; Word, D.A.; Burke, R.A. Structural and functional characteristics of natural and constructed channels draining a reclaimed mountaintop removal and valley fill coal mine. J. N. Am. Benthol. Soc. 2010, 29, 673–689. [Google Scholar] [CrossRef]
- Hartman, K.J.; Kaller, M.D.; Howell, J.W.; Sweka, J.A. How much do valley fills influence headwater streams? Hydrobiologia 2005, 532, 91–102. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P. Assessing landform alterations induced by mountaintop mining. Nat. Sci. 2013, 5, 229–237. [Google Scholar] [CrossRef]
- Miller, A.J.; Zégre, N.P. Mountaintop Removal Mining and Catchment Hydrology. Water 2014, 6, 472. [Google Scholar] [CrossRef]
- Ross, M.R.V.; McGlynn, B.L.; Bernhardt, E.S. Deep Impact: Effects of Mountaintop Mining on Surface Topography, Bedrock Structure, and Downstream Waters. Environ. Sci. Technol. 2016, 50, 2064–2074. [Google Scholar] [CrossRef]
- Wickham, J.; Wood, P.B.; Nicholson, M.C.; Jenkins, W.; Druckenbrod, D.; Suter, G.W.; Strager, M.P.; Mazzarella, C.; Galloway, W.; Amos, J. The Overlooked Terrestrial Impacts of Mountaintop Mining. BioScience 2013, 63, 335–348. [Google Scholar] [CrossRef]
- Wood, P.B.; Williams, J.M. Impact of Valley Fills on Streamside Salamanders in Southern West Virginia. J. Herpetol. 2013, 47, 119–125. [Google Scholar] [CrossRef]
- Zullig, K.J.; Hendryx, M. Health-Related Quality of Life among Central Appalachian Residents in Mountaintop Mining Counties. Am. J. Public Health 2011, 101, 848–853. [Google Scholar] [CrossRef] [PubMed]
- Wickham, J.D.; Riitters, K.H.; Wade, T.G.; Coan, M.; Homer, C. The effect of Appalachian mountaintop mining on interior forest. Landsc. Ecol. 2007, 22, 179–187. [Google Scholar] [CrossRef]
- Miller, A.J.; Zégre, N. Landscape-Scale Disturbance: Insights into the Complexity of Catchment Hydrology in the Mountaintop Removal Mining Region of the Eastern United States. Land 2016, 5, 22. [Google Scholar] [CrossRef]
- WVGISTC. Resources. Available online: http://www.wvgis.wvu.edu/resources/resources.php?page=dataProductDevelopment/SAMBElevation (accessed on 29 October 2019).
- ArcGIS Pro 2.2, ESRI, 2018. Available online: https://www.esri.com/arcgis-blog/products/arcgis-pro/uncategorized/arcgis-pro-2-2-now-available/ (accessed on 5 February 2020).
- Li, Z.; Zhu, Q.; Gold, C.M. Digital Terrain Modeling-Principles and Methodology; CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Reed, M. How Will Anthropogenic Valley Fills in Appalachian Headwaters Erode; West Virginia University Libraries: Morgantown, WV, USA, 2018. [Google Scholar]
- Gold, R.D.; Stephenson, W.J.; Odum, J.K.; Briggs, R.W.; Crone, A.J.; Angster, S.J. Concealed Quaternary strike-slip fault resolved with airborne lidar and seismic reflection: The Grizzly Valley fault system, northern Walker Lane, California. J. Geophys. Res. Solid Earth 2013, 118, 3753–3766. [Google Scholar] [CrossRef]
- Kweon, I.S.; Kanade, T. Extracting Topographic Terrain Features from Elevation Maps. CVGIP. Image Underst. 1994, 59, 171–182. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf (accessed on 5 February 2020).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. Available online: https://arxiv.org/abs/1405.0312 (accessed on 5 February 2020).
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Kawaguchi, K.; Kaelbling, L.P.; Bengio, Y. Generalization in Deep Learning. Available online: https://arxiv.org/abs/1710.05468 (accessed on 5 February 2020).
- Penatti, O.A.B.; Nogueira, K. Do Deep Features Generalize from Everyday Objects to Remote Sensing and Aerial Scenes Domains. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Imgaug—Imgaug 0.3.0 Documentation. Available online: https://imgaug.readthedocs.io/en/latest/ (accessed on 30 October 2019).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Computer Vision–ACCV 2016; Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation. In Proceedings of the Advances in Information Retrieval; Losada, D.E., Fernández-Luna, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Stehman, S.V. Comparison of Systematic and Random Sampling for Estimating the Accuracy of Maps Generated from Remotely Sensed Data. Photogramm. Eng. 1992, 58, 1343–1350. [Google Scholar]
- Stehman, S.V. Estimating area from an accuracy assessment error matrix. Remote Sens. Environ. 2013, 132, 202–211. [Google Scholar] [CrossRef]
- Stehman, S.V. Thematic map accuracy assessment from the perspective of finite population sampling. Int. J. Remote Sens. 1995, 16, 589–593. [Google Scholar] [CrossRef]
- Brandtberg, T.; Warner, T.A.; Landenberger, R.E.; McGraw, J.B. Detection and analysis of individual leaf-off tree crowns in small footprint, high sampling density lidar data from the eastern deciduous forest in North America. Remote Sens. Environ. 2003, 85, 290–303. [Google Scholar] [CrossRef]
- Zhang, Y.; You, Y.; Wang, R.; Liu, F.; Liu, J. Nearshore vessel detection based on Scene-mask R-CNN in remote sensing image. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018. [Google Scholar]
- You, Y.; Cao, J.; Zhang, Y.; Liu, F.; Zhou, W. Nearshore Ship Detection on High-Resolution Remote Sensing Image via Scene-Mask R-CNN. IEEE Access 2019, 7, 128431–128444. [Google Scholar] [CrossRef]
- ImageNet. Available online: http://www.image-net.org/ (accessed on 4 November 2019).
- Stereńczak, K.; Ciesielski, M.; Balazy, R.; Zawiła-Niedźwiecki, T. Comparison of various algorithms for DTM interpolation from LIDAR data in dense mountain forests. Eur. J. Remote Sens. 2016, 49, 599–621. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Total Area | Number of Image Chips with Valley Fills | Number of Image Chips to Predict To | Number of Valley Fills |
|---|---|---|---|---|
| Train | 9019.6 km2 | 4863 | - | 1105 |
| Test | 279.5 km2 | 282 | - | 118 |
| Val | 921.0 km2 | - | 3111 | 182 |
| KY1 | 773.4 km2 | - | 2650 | 540 |
| KY2 | 338.9 km2 | - | 1138 | 149 |
| VA | 599.3 km2 | - | 2093 | 143 |
| SAMB1 | 4661.8 km2 | - | 17,106 | 581 |
| SAMB2 | 921.0 km2 | - | 3110 | 108 |
| LiDAR Dataset | |||
|---|---|---|---|
| Specification | West Virginia | Kentucky | Virginia |
| Collection Dates | 4-9-2010 to 12-31-2011 | 11-8-2011 to 1-19-2013 | 11-3-2016 to 4-17-2017 |
| Phenology | Leaf-off | Leaf-off | Leaf-off |
| Sensor | Optech ALTM-3100 | Leica ALS70 and Optech Gemini | Riegel 780/680i |
| Average Post Spacing | 1 ppsm | 1 ppsm | 1.746 ppsm |
| Flight Height | 1524 m AGL | 1828 m AGL | 1800 m AGL |
| Approximate Flight Speed | 135 knots | 116 knots | 100 knots |
| Scanner Pulse Rate | 70 kHz | 50 kHz | 280 kHz |
| Scan Frequency | 35 Hz | 30.1 Hz | 68 Hz |
| Maximum Scan Angle | 36° | 25.6° | 60° |
| Start (IoU) | End (IoU) | mAP |
|---|---|---|
| 0.50 | 0.95 | 0.389 |
| 0.50 | 0.90 | 0.433 |
| 0.50 | 0.85 | 0.475 |
| 0.50 | 0.80 | 0.475 |
| 0.50 | 0.75 | 0.535 |
| 0.50 | 0.70 | 0.557 |
| 0.50 | 0.65 | 0.557 |
| 0.50 | 0.60 | 0.596 |
| 0.50 | 0.55 | 0.596 |
| Study Area | |||||||
|---|---|---|---|---|---|---|---|
| Measure | Val | KY1 | KY2 | VA | All LiDAR | SAMB1 | SAMB2 |
| No. Mapped VFFs | 182 | 540 | 149 | 143 | 1014 | 581 | 108 |
| No. Mask R-CNN VFFs | 200 | 546 | 143 | 149 | 1038 | 1735 | 321 |
| TP | 170 | 495 | 129 | 117 | 911 | 346 | 39 |
| FP | 30 | 51 | 14 | 32 | 127 | 1389 | 282 |
| FN | 13 | 59 | 37 | 42 | 151 | 239 | 69 |
| Precision | 0.850 | 0.907 | 0.902 | 0.785 | 0.878 | 0.199 | 0.121 |
| Recall | 0.929 | 0.894 | 0.777 | 0.736 | 0.858 | 0.591 | 0.361 |
| F1-Score | 0.888 | 0.9 | 0.835 | 0.76 | 0.868 | 0.278 | 0.181 |
| No. Mask R-CNN VFFs (>1 ha) | 123 | 463 | 129 | 111 | 826 | 527 | 77 |
| TP (>1 ha) | 118 | 418 | 105 | 89 | 730 | 315 | 35 |
| FN (>1 ha) | 5 | 48 | 2 | 25 | 80 | 217 | 42 |
| Recall (>1 ha) | 0.959 | 0.897 | 0.809 | 0.781 | 0.900 | 0.592 | 0.455 |
| Study Area | |||||||
|---|---|---|---|---|---|---|---|
| Measure | Val | KY1 | KY2 | VA | All LiDAR | SAMB1 | SAMB2 |
| Producer’s Accuracy (Area) | 0.787 | 0.797 | 0.831 | 0.735 | 0.793 | 0.129 | 0.263 |
| User’s Accuracy (Area) | 0.841 | 0.741 | 0.78 | 0.603 | 0.744 | 0.388 | 0.043 |
| Fuzzy Producer’s Accuracy (Center-Weighted) | 0.851 | 0.866 | 0.899 | 0.802 | 0.860 | 0.137 | 0.046 |
| Fuzzy User’s Accuracy (Center -Weighted) | 0.909 | 0.944 | 0.964 | 0.689 | 0.903 | 0.169 | 0.053 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maxwell, A.E.; Pourmohammadi, P.; Poyner, J.D. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sens. 2020, 12, 547. https://doi.org/10.3390/rs12030547
Maxwell AE, Pourmohammadi P, Poyner JD. Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sensing. 2020; 12(3):547. https://doi.org/10.3390/rs12030547
Chicago/Turabian StyleMaxwell, Aaron E., Pariya Pourmohammadi, and Joey D. Poyner. 2020. "Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data" Remote Sensing 12, no. 3: 547. https://doi.org/10.3390/rs12030547
APA StyleMaxwell, A. E., Pourmohammadi, P., & Poyner, J. D. (2020). Mapping the Topographic Features of Mining-Related Valley Fills Using Mask R-CNN Deep Learning and Digital Elevation Data. Remote Sensing, 12(3), 547. https://doi.org/10.3390/rs12030547