1. Introduction
Scene classification is an important topic in the field of remote sensing. It aims at identifying the remote sensing image with a specific semantic category according to semantic information. Remote sensing image scene classification (RSISC) is a fundamental problem for understanding high-resolution remote sensing imagery, and has been widely applied in many remote sensing applications, such as natural disaster detection [
1,
2,
3], land use and land cover detection [
4,
5,
6], vegetation mapping [
7,
8], and so on.
With the increasing number of remote sensing images, understanding the semantic content of these images effectively is a difficult but important task [
9]. Traditional RSISC methods use handcrafted features to extract characteristics of scene images, such as color, texture, shape, and so on [
10,
11]. Scene images usually contain complex geographical environments, and handcrafted features cannot adaptively obtain features from different scenes as well as not be able to meet the increasing needs of classification accuracy. Therefore, the method based on unsupervised feature extraction has been developed [
5,
12,
13,
14,
15]. The unsupervised feature extraction method can learn the internal features of scene images adaptively and has achieved good results. However, features extracted by unsupervised methods such as BOVW [
5,
12] are usually shallow features, which cannot express the high-level semantic information and abstract features of remote sensing scene images. Recently, methods based on deep neural networks (DNN) have achieved the best results in RSISC. Many DNN models such as CNN [
16,
17] and LSTM [
18,
19] have been verified to be able to obtain the state-of-the-art results on most RSISC datasets such as UC-Merced [
12] and AID [
9].
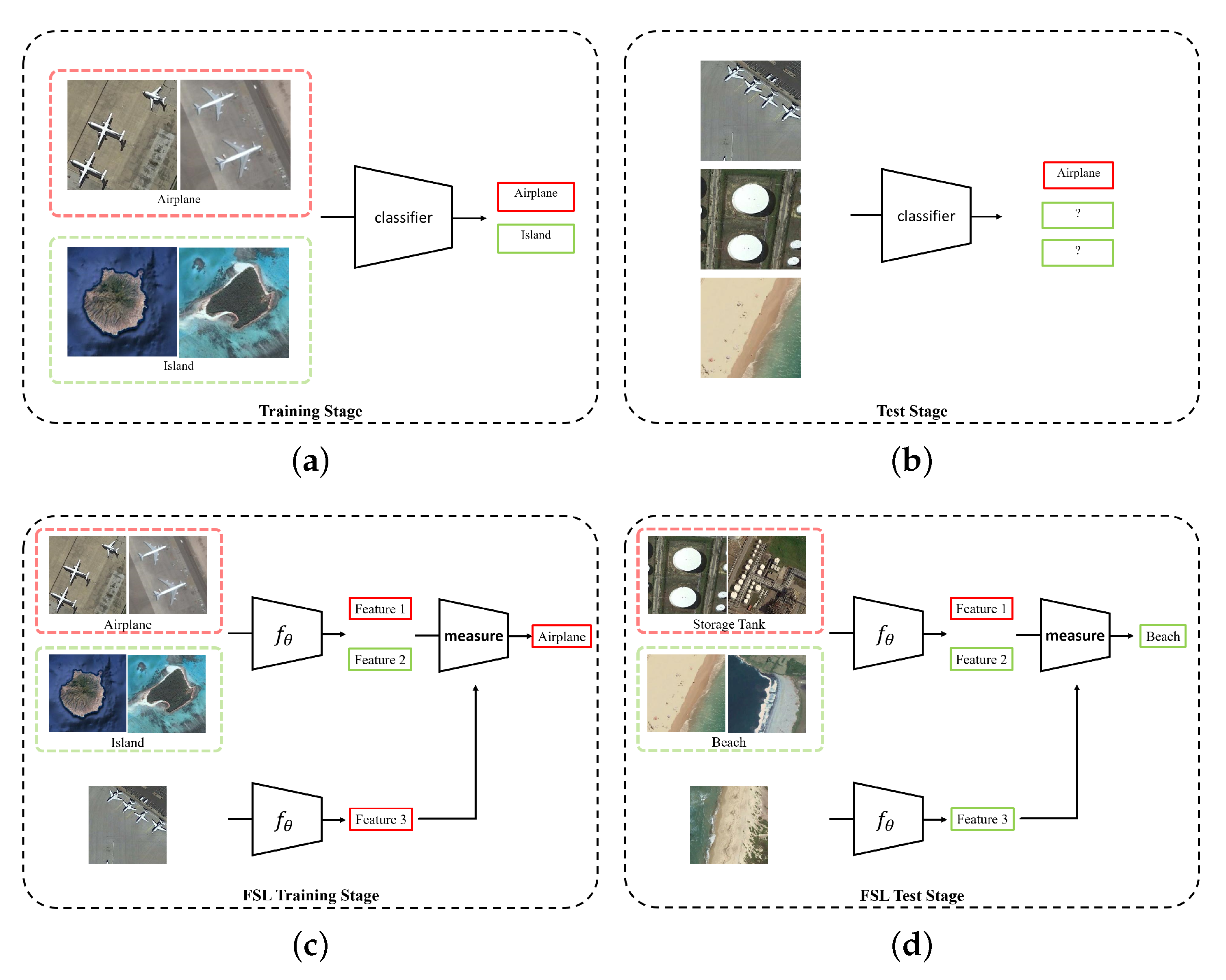
Although DNN-based methods have achieved better performance in the RSISC task, its limitations have drawn the attention of researchers. Firstly, data driven training strategy makes DNN a black box. It is difficult to understand DNNs’ internal dynamics [
20]; therefore, a large number of samples are required to train the model and achieve better performance. Secondly, Target categories of RSISC tasks are quite different from natural image classification tasks. Because of the particularity of remote sensing images, it is very difficult and time-consuming to obtain abundant manually annotated high-resolution remote sensing images [
21], especially for unusual scenes such as military installations. Therefore, the RSISC problem in the case of a few labeled samples has become an urgent and important task to be studied. Thirdly, most of the existing DNN-based classification methods can only classify the scenes which have been trained already, but they cannot classify the untrained scenes, as shown in
Figure 1. When recognizing an untrained scene by a DNN model, we need a large number of scene images to retrain the model, or fine-tune the model on new scene images. The problems mentioned above are essentially caused by the fact that deep learning methods severely rely on the training data. Due to the increasing number of remote sensing images worldwide, the highly complex geometrical structures and spatial patterns and the diversity of image features all pose a great challenge to the RSISC tasks. It is significant to find a way to learn the knowledge from just a few labeled scene images or even one image, which will greatly promote the use of remote sensing images in more fields.
In this paper, we propose a new framework to solve the one-shot RSISC problem inspired by few-shot learning (FSL) methods. The metric-based FSL method first extracts the features of labeled samples and unlabeled samples, and then classifies unlabeled samples by measuring the similarity of features. It adopts task-based methods [
22] to achieve the ability to perform classification tasks that only require a small number of labeled data, even for categories that have not appeared in the training stage. For an FSL task which contains
N categories of data, task-based learning does not care about the specific categories of labeled samples but focuses on the feature similarity of the unlabeled samples and classifying them to
N groups. This approach makes FSL more general for different types of samples. Thus, for images from unknown classes, the few-shot classification can also be realized.
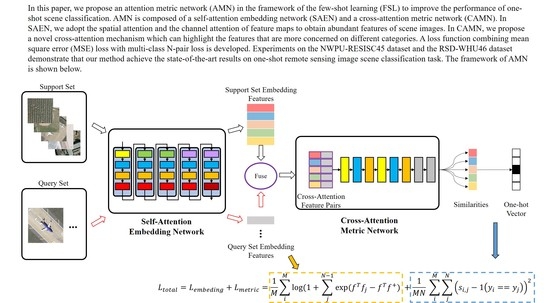
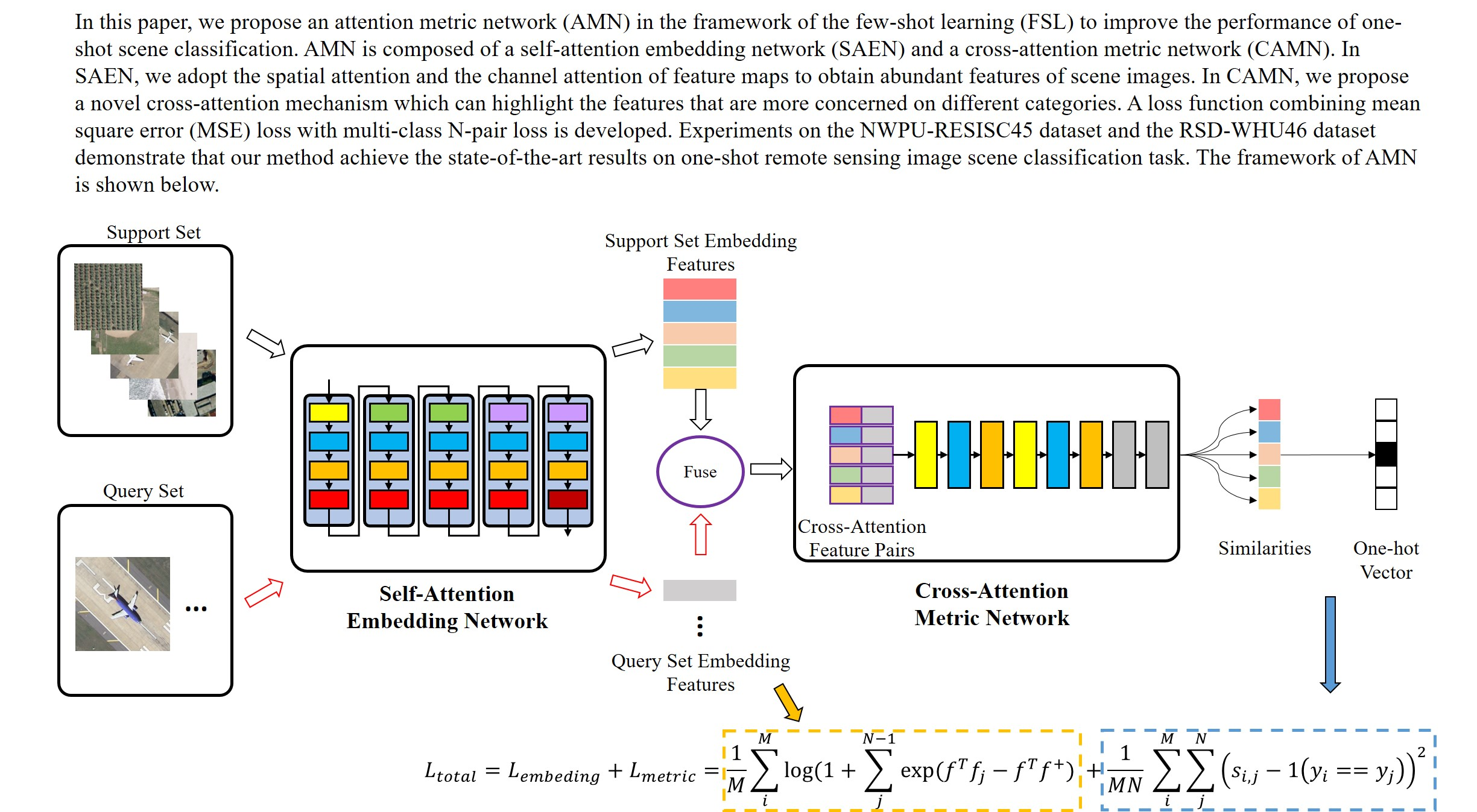
Although the FSL method has the ability of classification with only a few labeled samples, its accuracy is still far from satisfactory compared with the DNN-based method. In this paper, we design an Attention Metric Network (AMN) for one-shot RSISC to boost the performance of extracting discriminative features from a small number of labeled samples and measure the similarity of features. Specifically, we design a Self-Attention Embedding Network (SAEN) for feature extraction and a Cross-Attention Metric Network (CAMN) for similarity measurement. The SAEN applies spatial attention and channel attention to feature maps of different sizes and a different number of channels to enhance the feature extraction capabilities of different scene images. Motivated by the fact that the important features of the same category are similar, CAMN is carefully designed to extract the channel attention of the labeled embedding features and fuses with the unlabeled features. Then, CAMN measures the similarity between the fused embedding features of unlabeled samples and labeled samples to obtain the predicted class. Moreover, we use a loss function that fuses mean square error (MSE) and multi-class N-pair loss to enhance the effectiveness of AMN in one-shot scene classification tasks.
The contributions of this paper can be summarized as follows:
We propose a metric-based FSL method AMN to solve the one-shot RSISC task. We design the SAEN in feature extraction stage and the CAMN in the similarity measurement stage for the one-shot RSISC task. The SAEN adopts both spatial and channel attention, and is carefully designed to obtain distinctive features under small labeled sample settings. The CAMN contains a novel and effective cross-attention mechanism to enhance features of interest to different categories and suppress unimportant features.
Joint MSE loss and the multi-class N-pair loss have been developed for the one-shot RSISC task. The proposed loss function can promote the intra-class similarity and inter-class variance of embedding features and improve the accuracy of similarity metric results by the CAMN.
We conduct extensive experiments on two large-scale scene classification datasets NWPU-RESISC45 [
23] and RSD46-WHU [
24,
25]. Experimental results prove that our method can effectively promote the accuracy of the one-shot RSISC task than other state-of-the-art methods.
The rest of this paper is organized as follows. In
Section 2, methods related to this paper are introduced. Detailed descriptions of the proposed method are covered in
Section 3. Experiments and analysis are introduced in
Section 4. In
Section 5, we conduct ablation studies to prove that the contributions are all valid and further discuss the embedding features and the cross-attention mechanism. Finally, the conclusions are drawn in
Section 6.
3. Method Description
In this section, we introduce the architecture and settings of AMN for the one-shot RSISC task in detail.
3.1. Overall Architecture
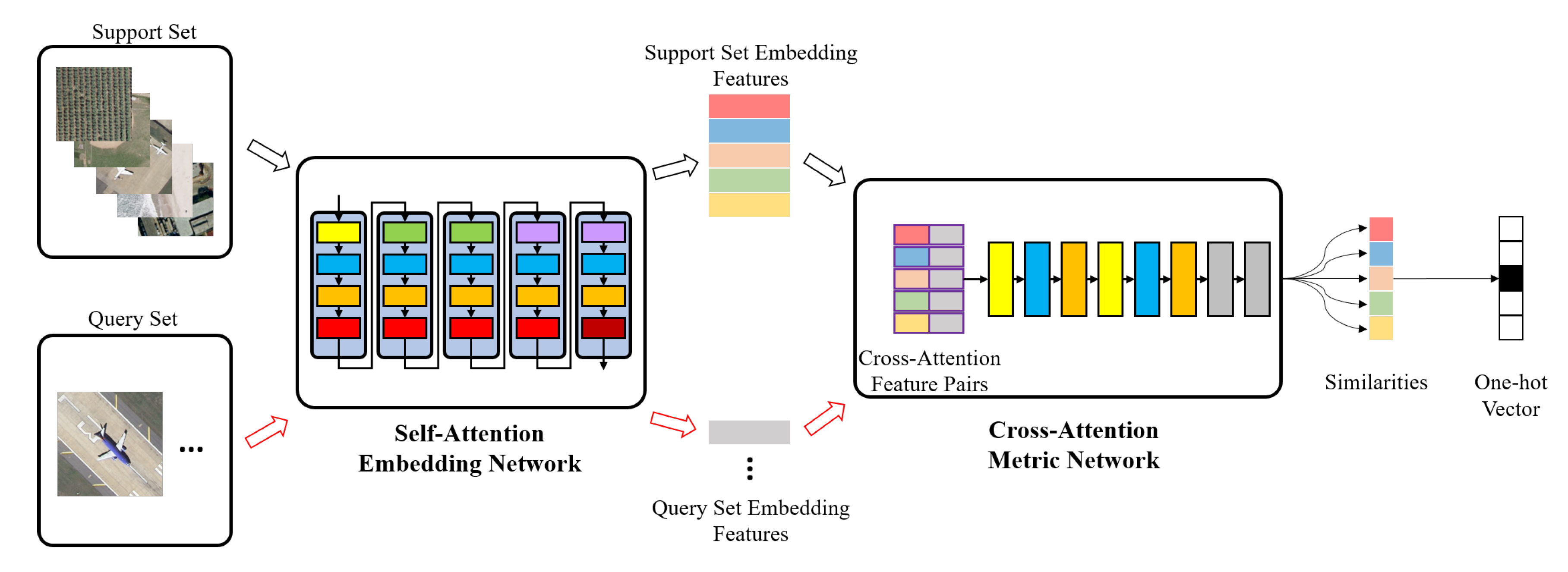
AMN is mainly composed of two parts: SAEN and CAMN. The overall framework of the AMN algorithm is shown in
Figure 2.
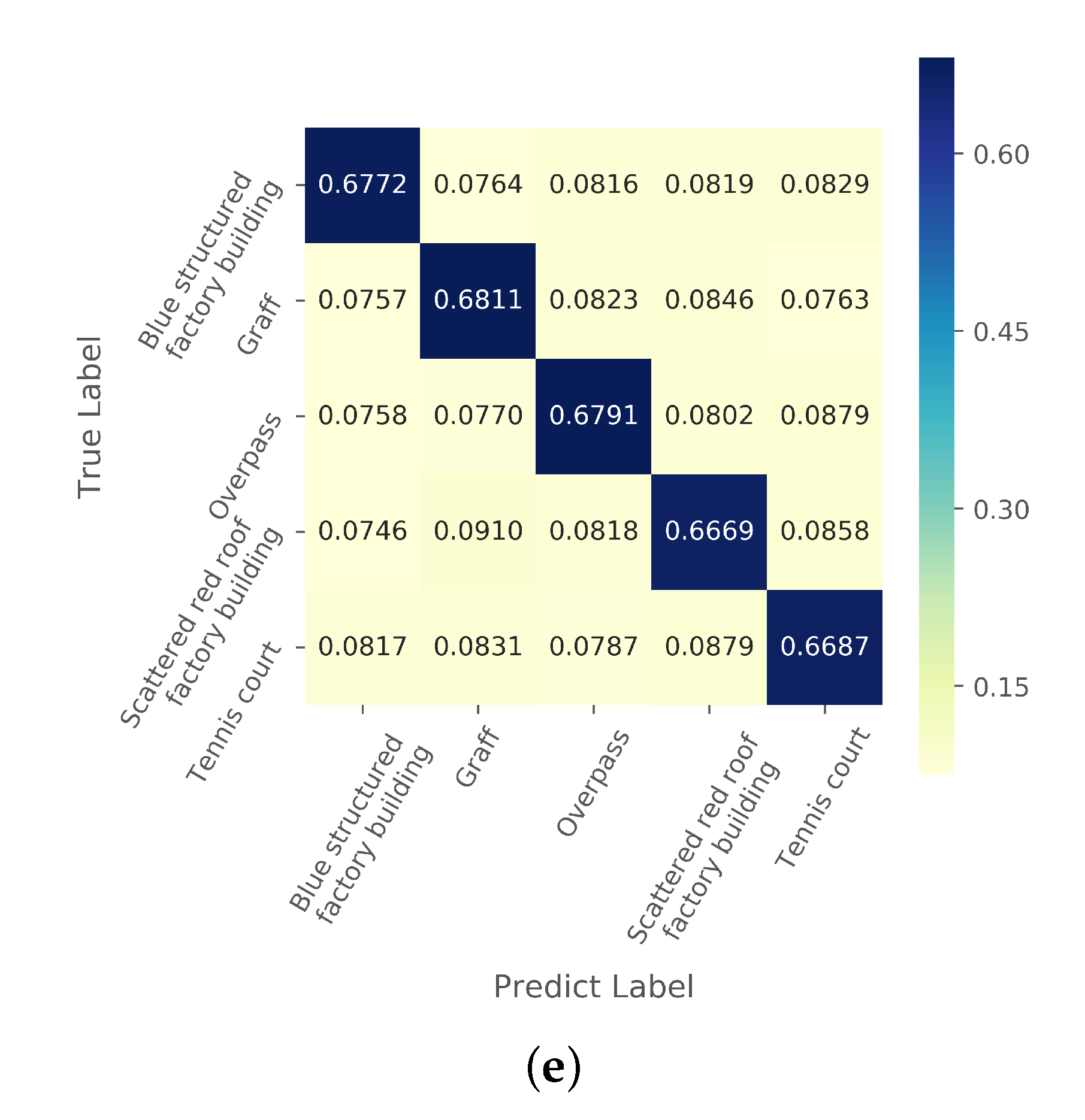
We apply AMN to the 5-way 1-shot scene classification task. During the training stage, we randomly select 5-way 1-shot tasks from the training data. Each task contains five categories of images, and each category includes one support set image and 15 query set images. The embedding features of five labeled samples (from support set) and 75 query samples (from query set) are calculated by SAEN. Then, CAMN is used to measure the similarities among 75 query set embedding features and five support set embedding features. Each query set image will get five similarity measurement results, and the class of the most similar support set image is the predicted label. In the testing phase, we randomly select tasks from the test data that differ from the scene categories in the training stage.
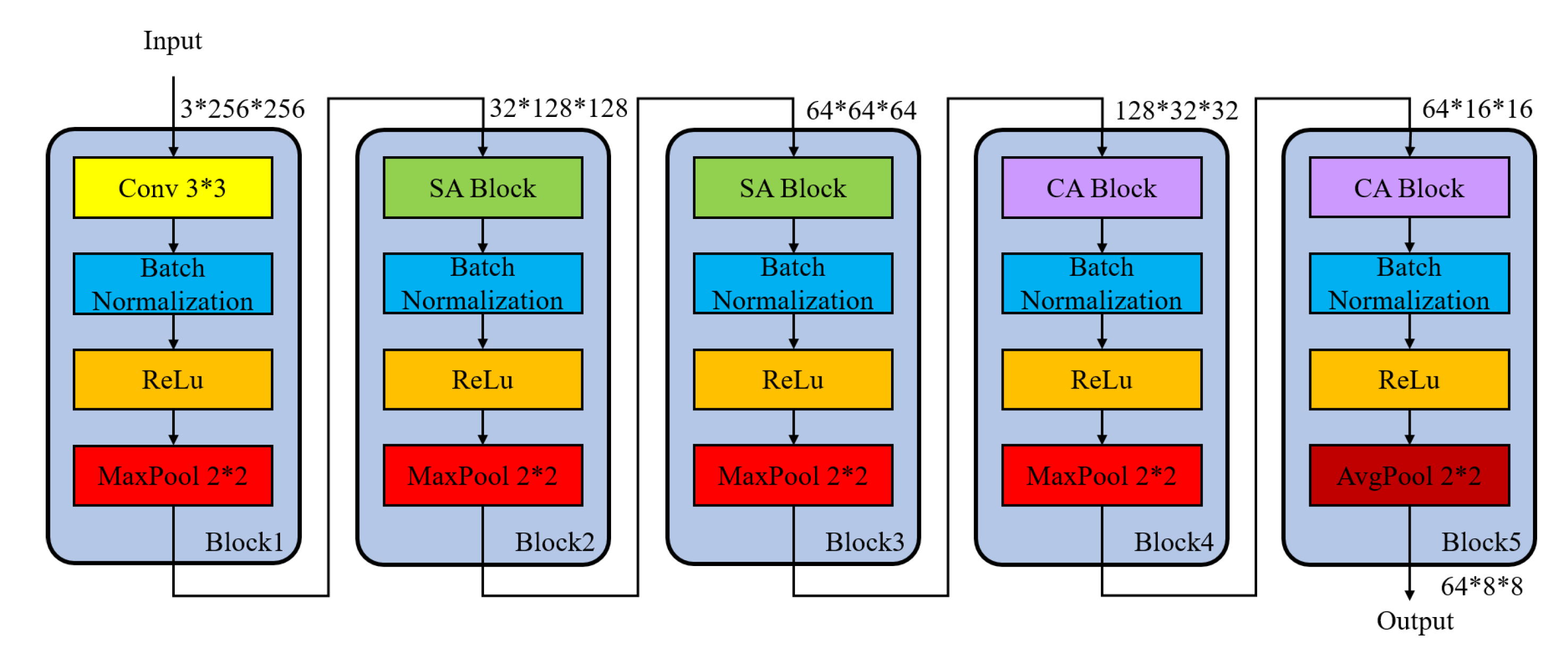
3.2. Self-Attention Embedding Network
The SAEN is composed of five blocks, which is shown in
Figure 3. The size of input image is
, and the shape of output embedding features of SAEN is
.
The spatial attention is applied in the second and third block of SAEN due to the large scale of feature map. In addition, the channel attention is adopted in the fourth and fifth blocks of SAEN for the rich information of channel dimensions.
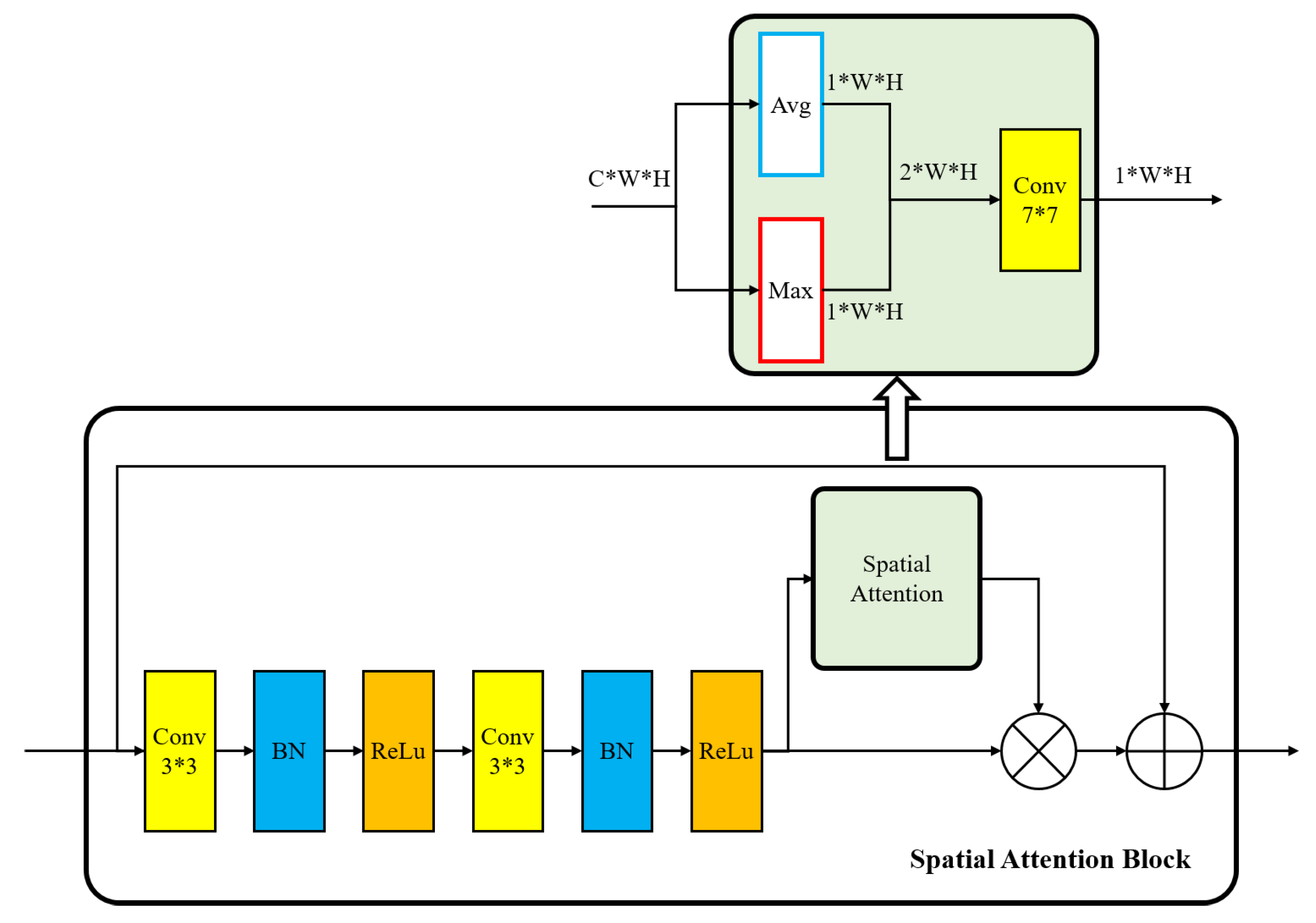
We extract the spatial attention map in the second and third blocks of SAEN. The spatial attention block is shown in
Figure 4. We calculate the average value
and the maximum value
of the channel on a
size feature map
, and obtain two
size feature maps
,
and concatenate them together. Then, a
convolution layer is used to get a single channel spatial attention feature map with the same input size as
.
The spatial attention can be calculated as
where
denotes a convolutional operation with a
size filter, and
represents the sigmoid activation function.
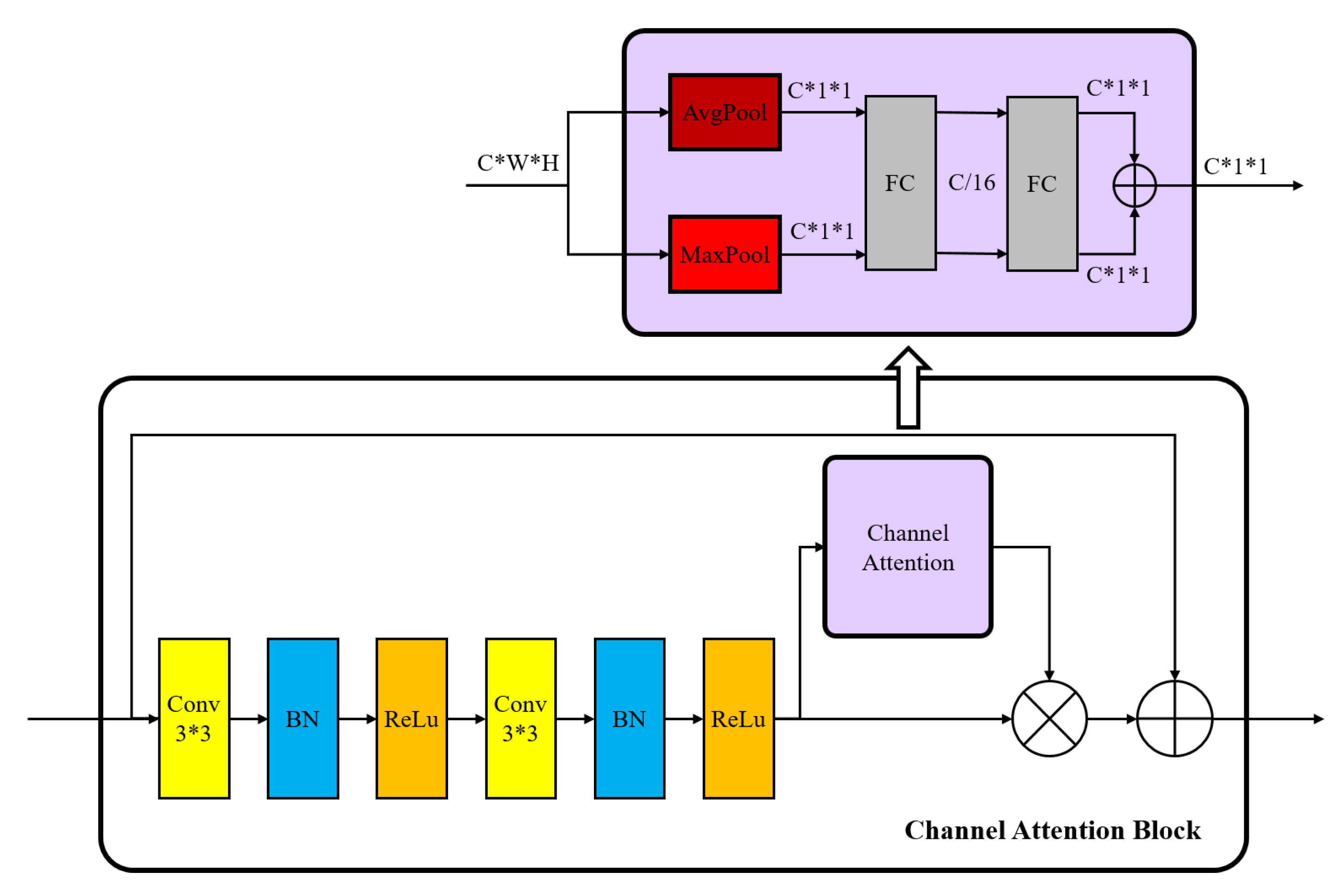
We extract the channel attention map in the fourth and fifth block of SAEN. The channel attention block is shown in
Figure 5. We calculate the average value and maximum value on the
size feature map, and obtain two
size features. Then, two feature maps are added through two fully connected layers to get the channel attention feature map with the size of
.
The channel attention can be calculated as
where
represent the sigmoid function, fully connected layer weights
and
are shared for both inputs, and the ReLU activation function is followed by
.
By using the spatial attention block and channel attention block, the SAEN can extract more abundant spatial and channel attention features, and then promote the feature expression ability of SAEN.
3.3. Cross-Attention Metric Network
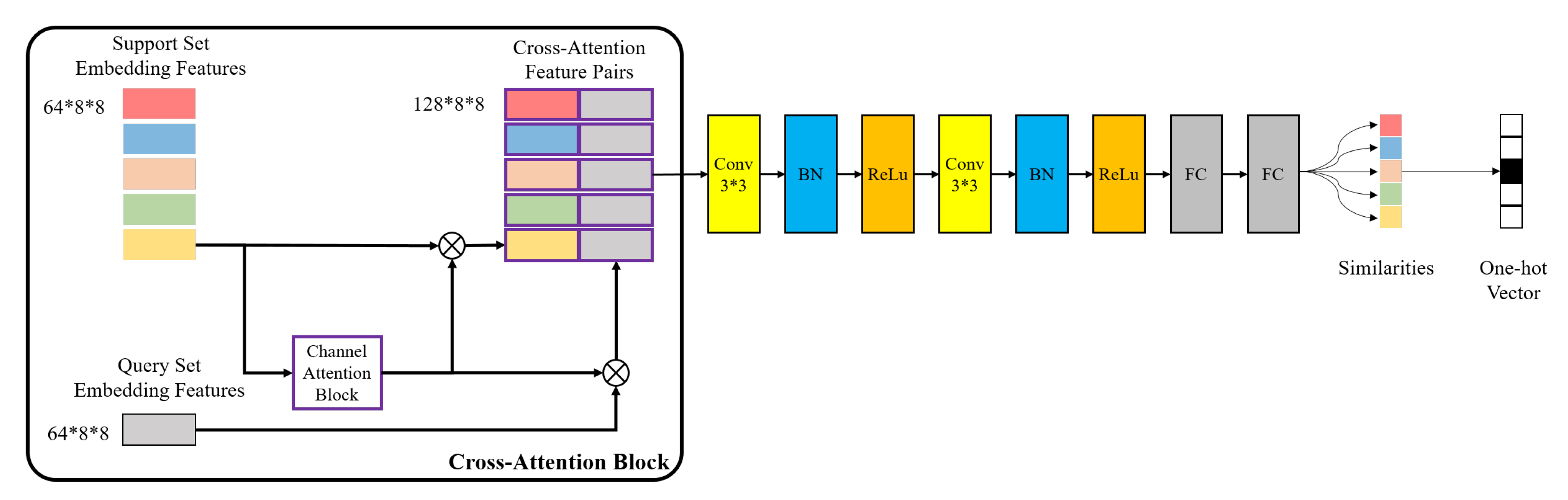
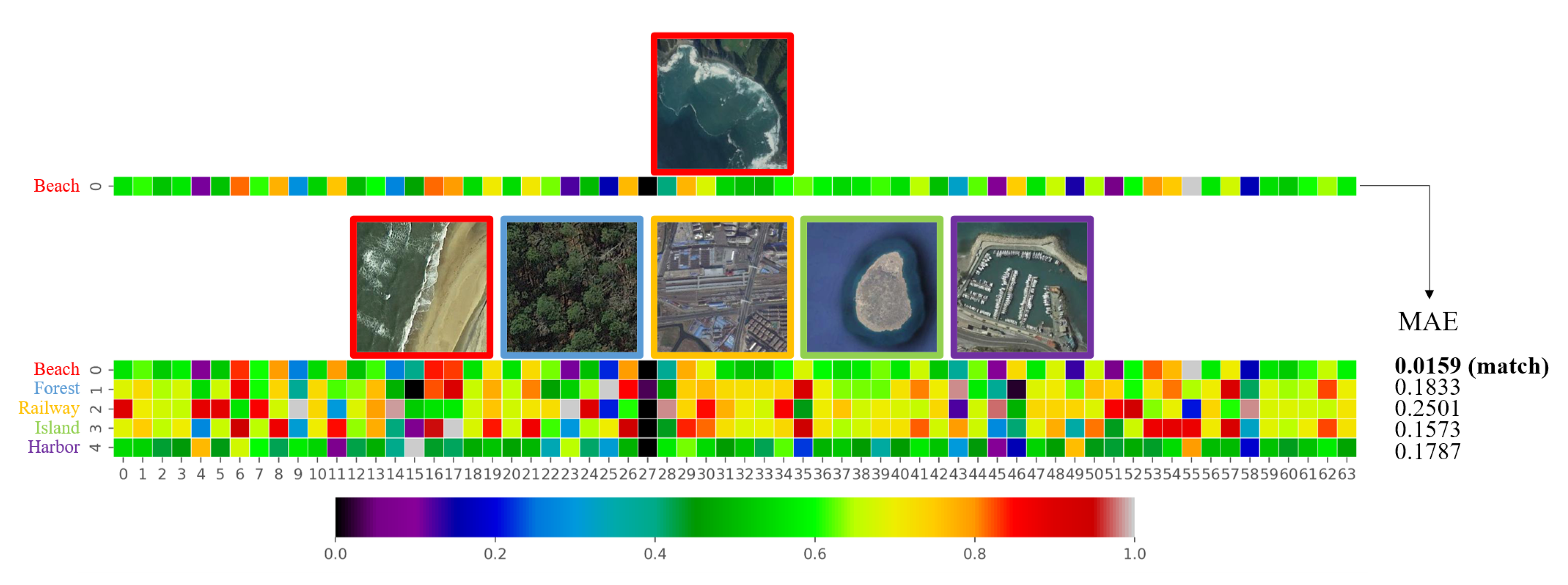
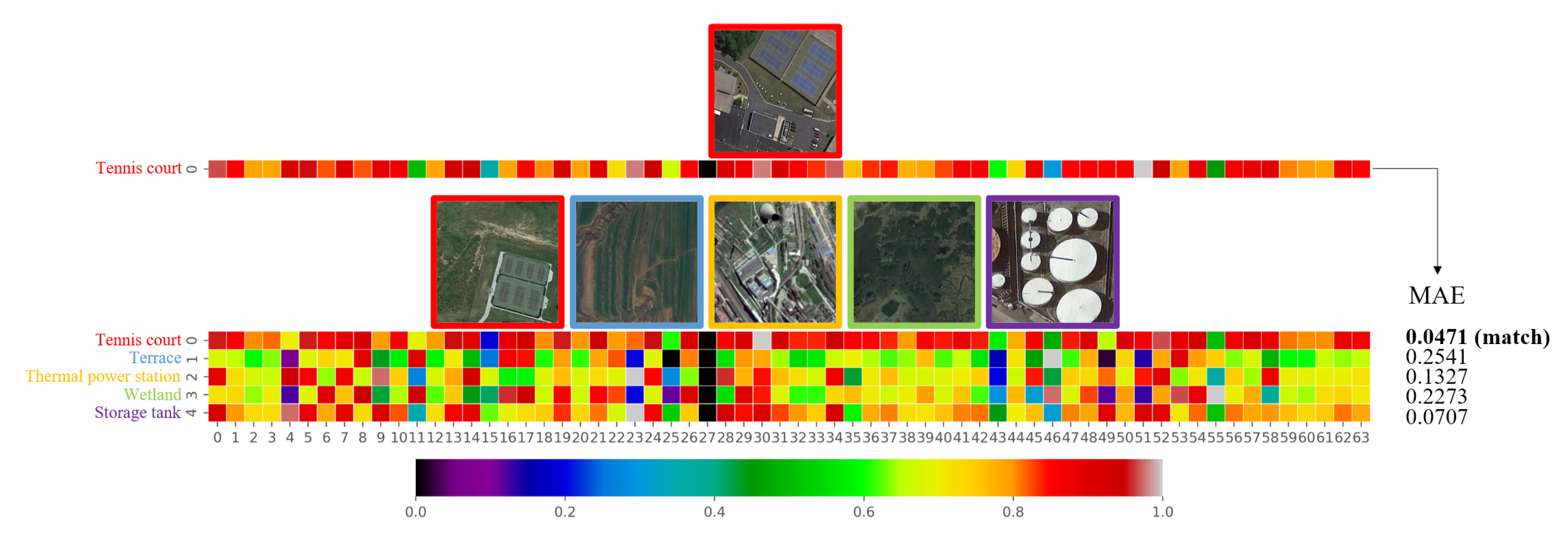
We design the CAMN to improve the ability of metric networks to distinguish embedding features of the same categories and different categories. The cross-attentive mechanism is inspired by the fact that the channel attention of embedding features is more similar for the same class. When we aggregate the channel attention of different support set image features with a query set image features, the metric network can easily distinguish the class of the query set image.
The CAMN contains a cross-attention block and a metric network, which is shown in
Figure 6.
In the cross-attention block, we firstly calculate the channel attention for embedding features of each support set image. Then, we fuse the channel attention with support embedding features and query embedding features respectively, and concatenate them by channel dimensions to form a
-dimensional feature pair. The channel attention and fused features are calculated the same way as the channel attention module in
Section 3.2. In a 5-way 1-shot task, each query sample can get five feature pairs, so a total of
pairs of cross attention features are obtained.
The metric network consists of two Conv-BN-ReLu layers and two fully connected layers. The kernel size of convolutional layer is , padding is 0, and stride is 1. The output sizes of the first and second full connection layer are 8 and 1, respectively. Finally, the similarity of each feature pair is obtained through sigmoid functions. The category with the largest similarity is the prediction category. Thus, each query set image would get a five-dimensional one-hot vector, representing the predicted result.
Suppose the cross-attention metric network is
, the embedding features of a query image
x is
, the embedding features of a sample image
i is
, and its channel attention is
. Then, the mathematical processing of the similarity of
and
and the predicted category of query set
x can be expressed as:
3.4. Loss Function
To improve the intra-class similarity and the inter-class variance, we adopt MSE loss in the measurement part, and use multi-class N-pair loss [
46] in the feature extraction stage to expand the difference of embedding features between different categories.
In contrast to traditional scene classification tasks, we use similarity to predict the category of unlabeled images in the FSL scenario. We train our model using mean square error (MSE) loss by regressing the similarity scores on groundtruth: matching feature pairs have a similarity of 1, and mismatched pairs have a similarity of 0. The MSE loss can described as follows:
where
denotes the label of query image
i,
denotes the label of sample image
j, and
represents the output similarity of the feature pairs of
i and
j through the CAMN.
For each query sample, we use the vector inner product to measure the distance between positive samples of the same classes and negative samples of different classes in the feature embedding stage. The expression of multi-class N-pair loss is as follows:
where
represents the embedding features of query set
i,
denotes embedding features of the negative support set image
j whose class is different with
i, and
represents the embedding features of positive support set image which is the same as
i.
To sum up, the total loss function is:
6. Conclusions
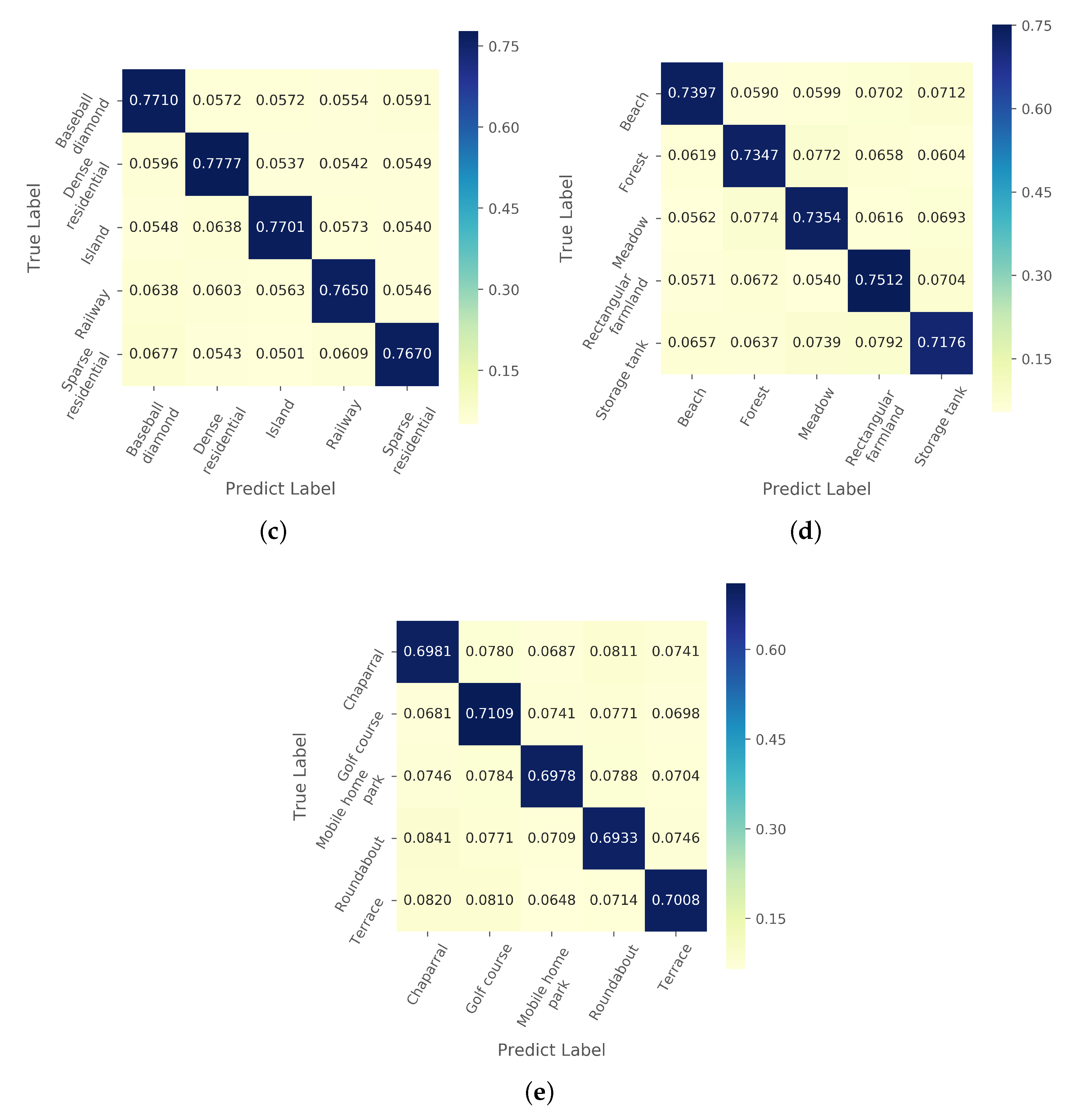
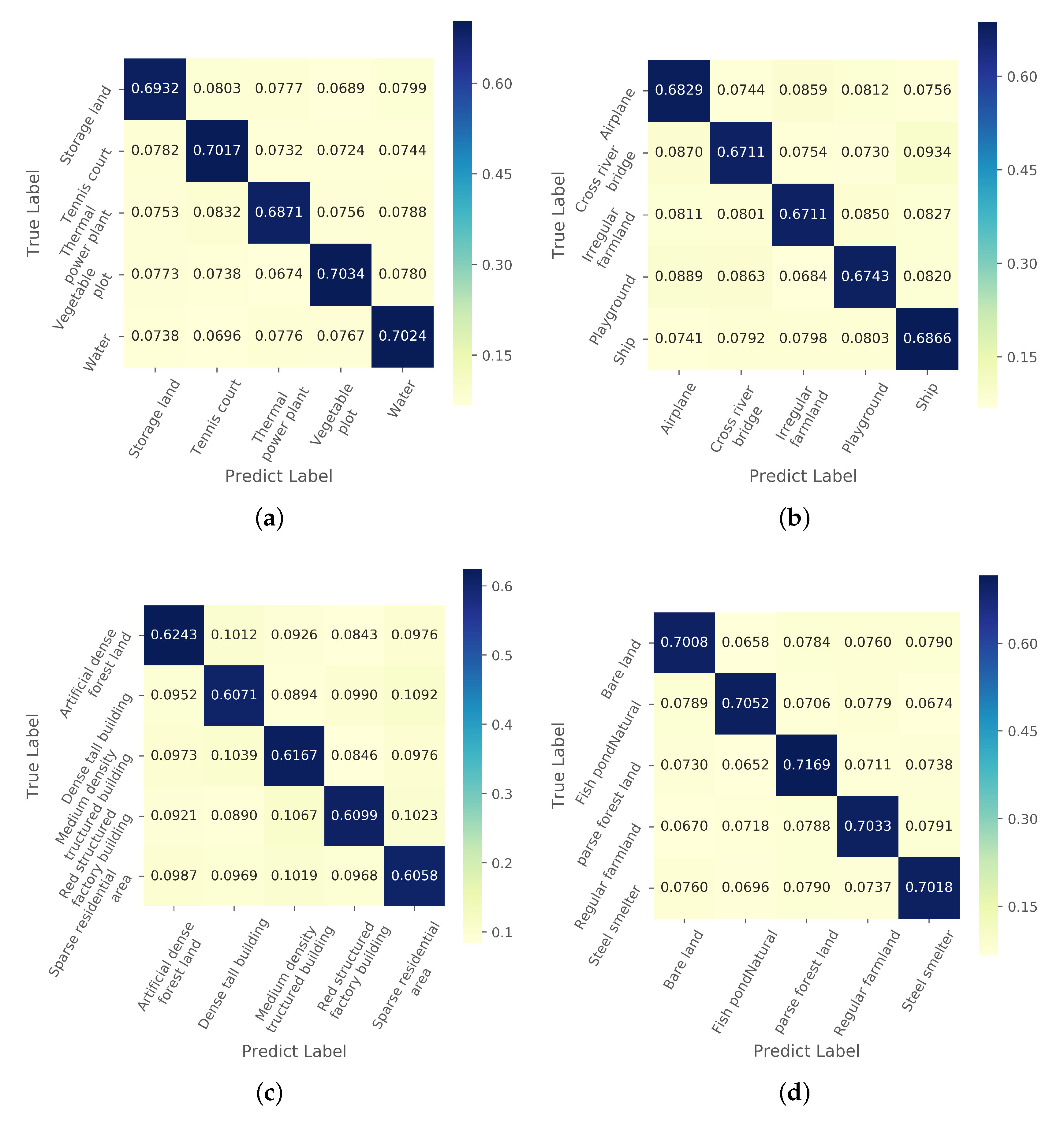
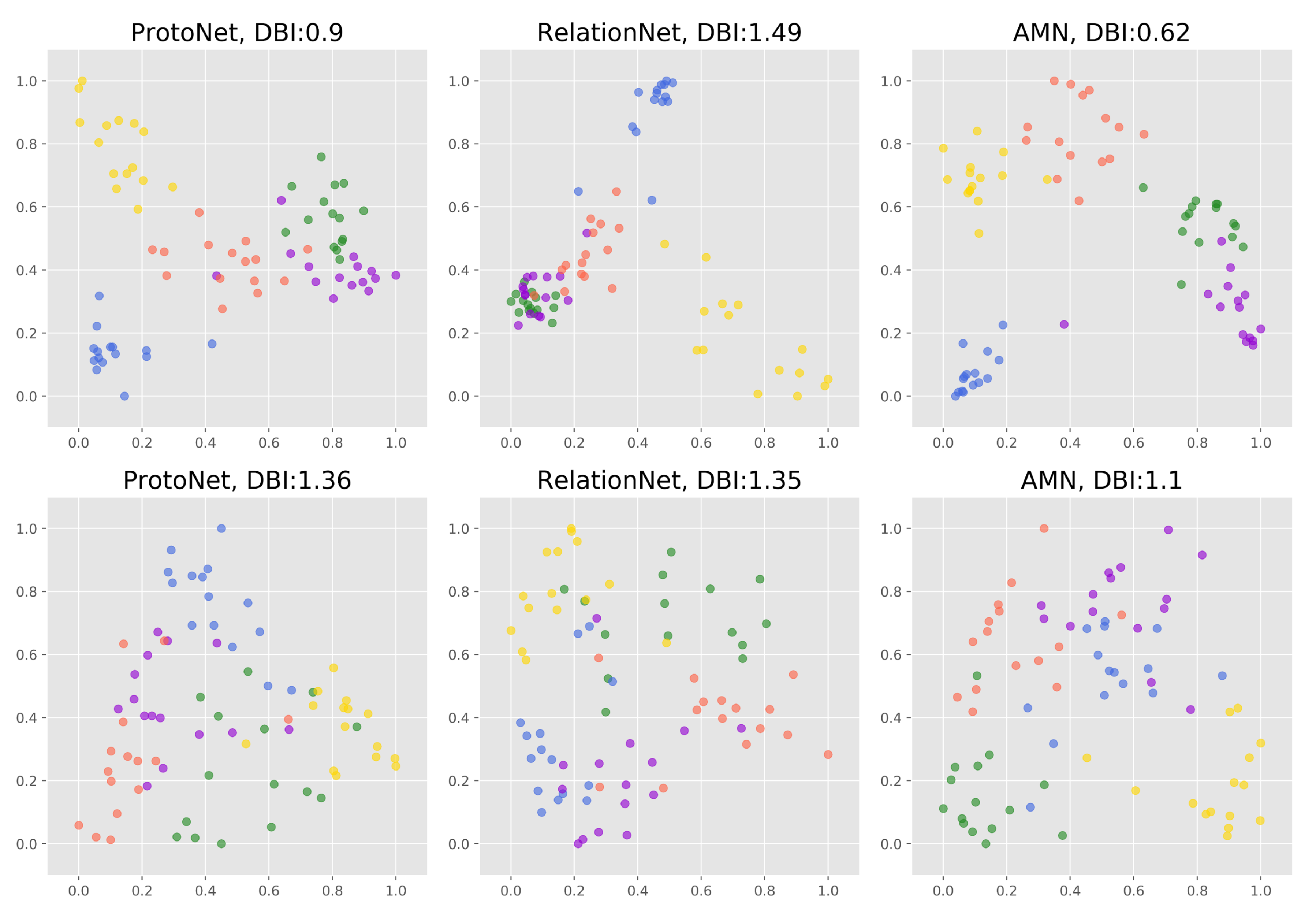
In this paper, we propose a metric-based FSL method AMN to solve the one-shot RSISC problem. To obtain more distinctive features, we design a self-attention network by using spatial attention and channel attention along with multi-class N-pair loss. The proposed AMN can extract more similar features from images of the same category and more different features among images of different categories. A novel and effective cross-attention metric mechanism is proposed in this paper. Combining unlabeled embedding features with the channel attention of the labeled features, the CAMN can highlight the features of different categories that are more concerned. The discussion about cross-attention proves that similar image features do have similar channel attention.
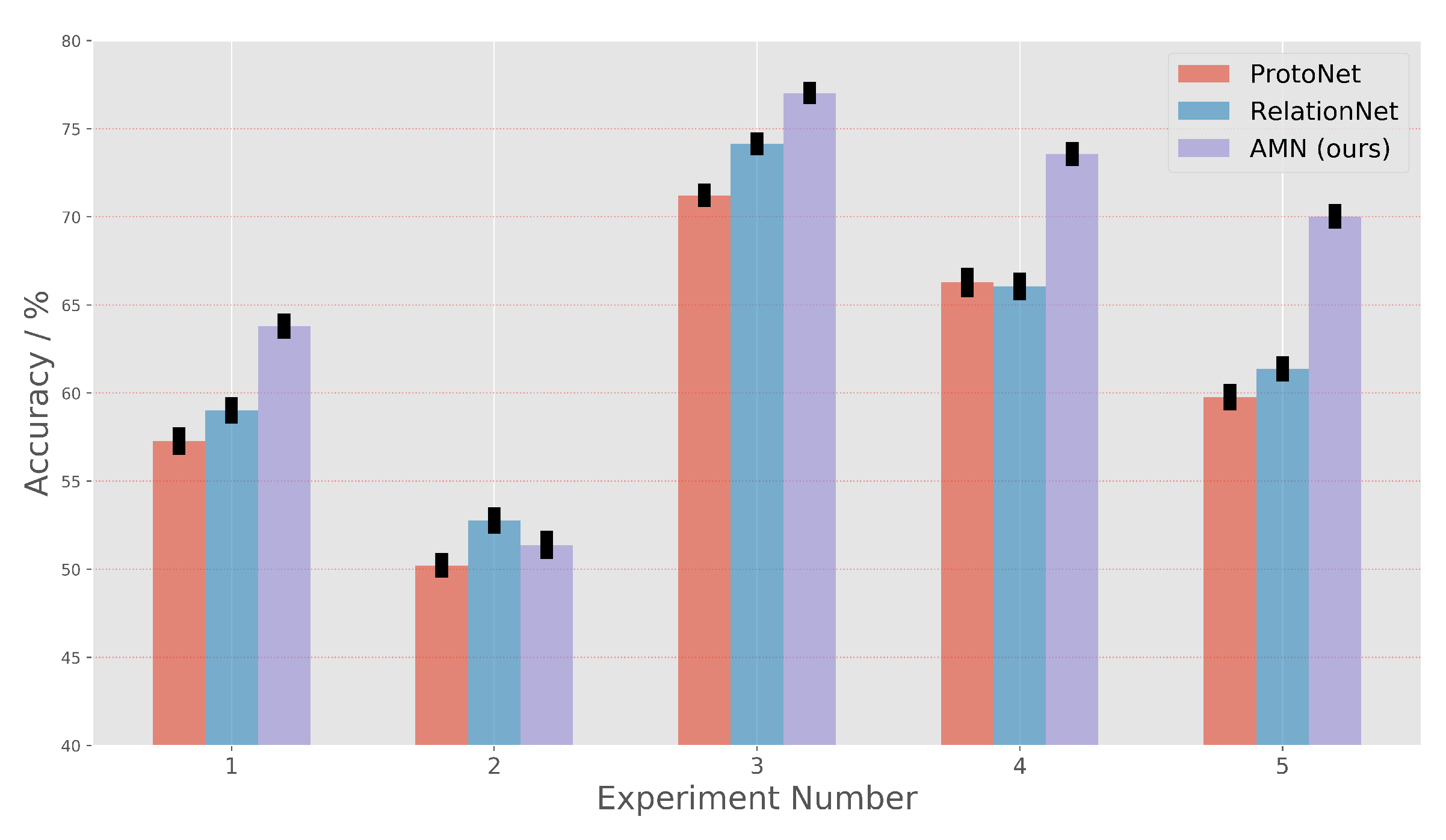
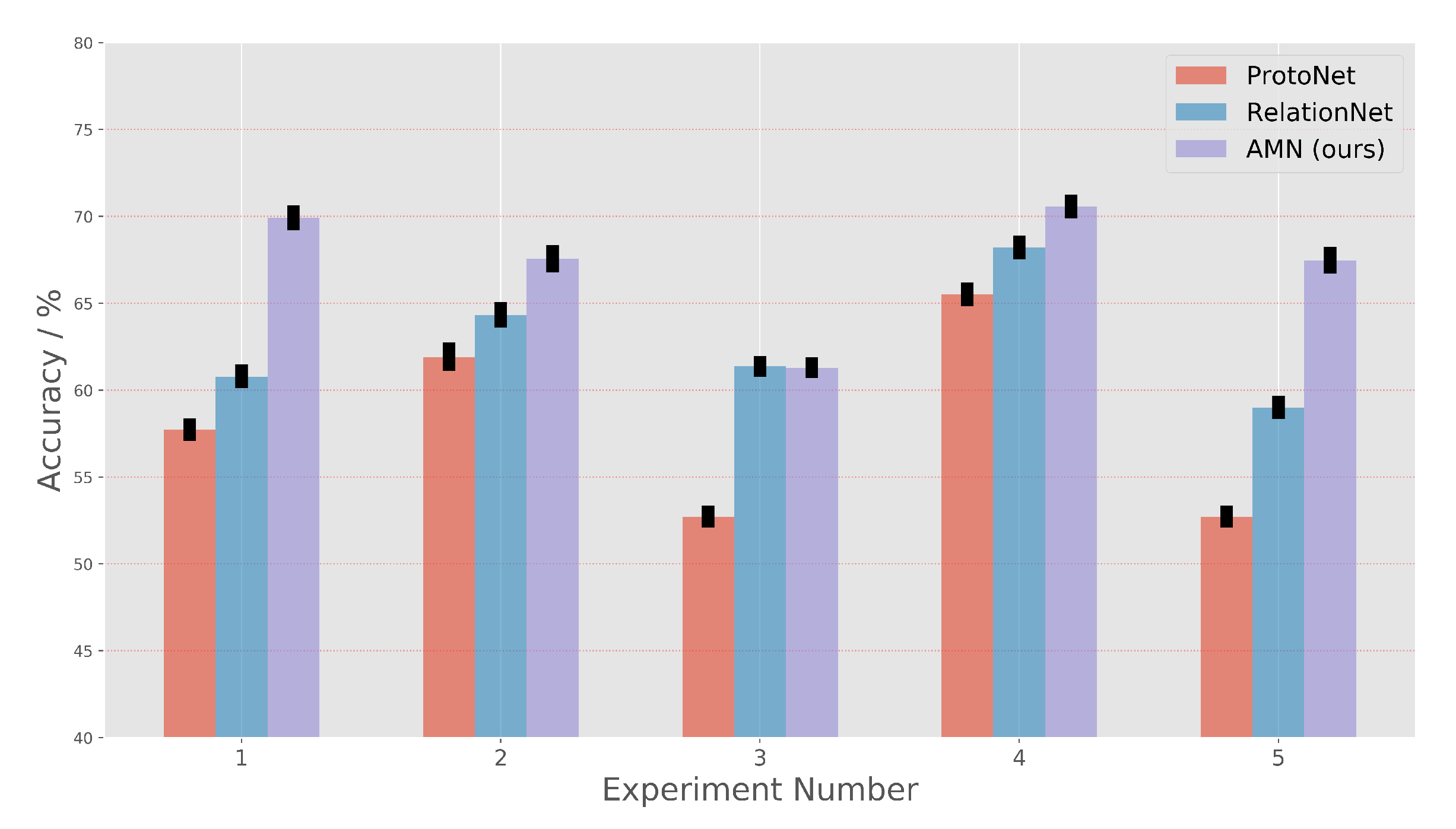
Our work achieves the state-of-the-art classification results on one-shot RSISC tasks. On the NWPU-RESISC45 dataset, the AMN achieves a gain of up to around 6.22% over the ProtoNet and about 4.49% over the RelationNet. On the RSD46-WHU dataset, the AMN method improves performance by about 9.25% to ProtoNet and about 4.63% to RelationNet. These impressive results demonstrate that not only the feature extraction method but also the cross-attention mechanism can improve the similarity measurement results of scene images, especially on one-shot RSISC tasks.
The metric-based FSL frameworks rely on a large number of different categories of scene tasks to ensure that the FSL task is category-independent. The model may over-fit to specific categories when there are few scene classes. Our future work will focus on training the FSL model on a small number of categories of scene images.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









