RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites

 , ,
, ,
Abstract
1. Introduction
2. Related Work
3. Methods
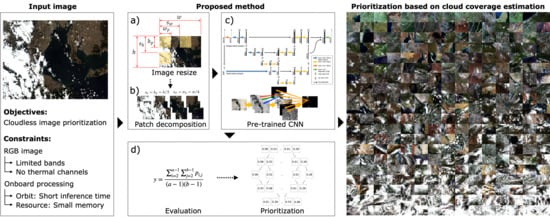
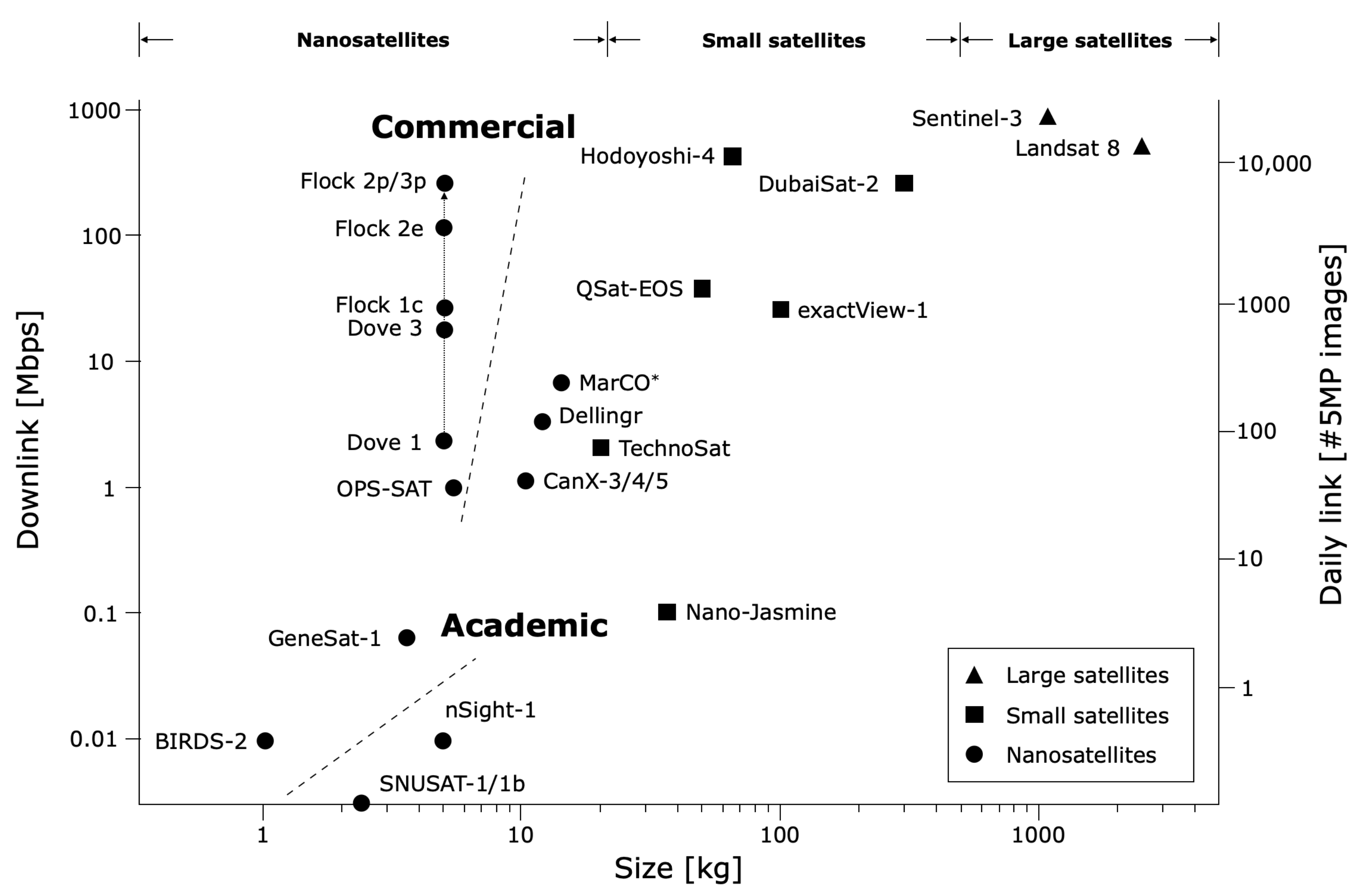
3.1. Proposed Method
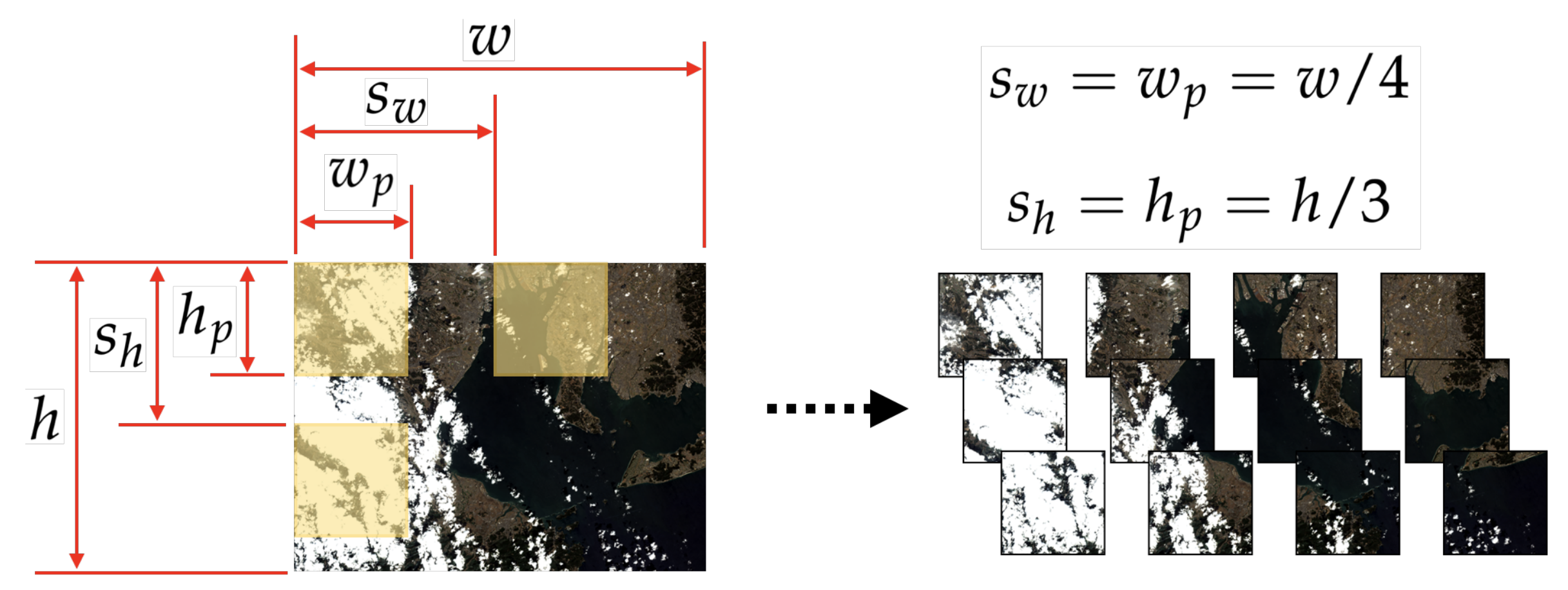
3.1.1. Input Size Reduction
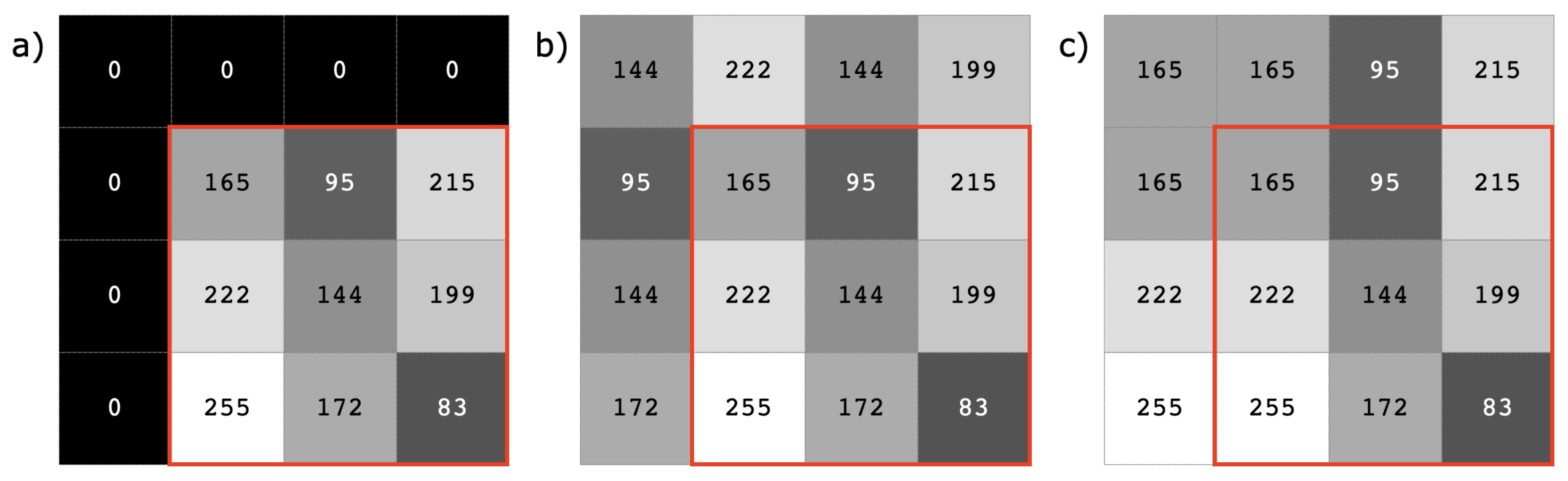
3.1.2. Patch Decomposition
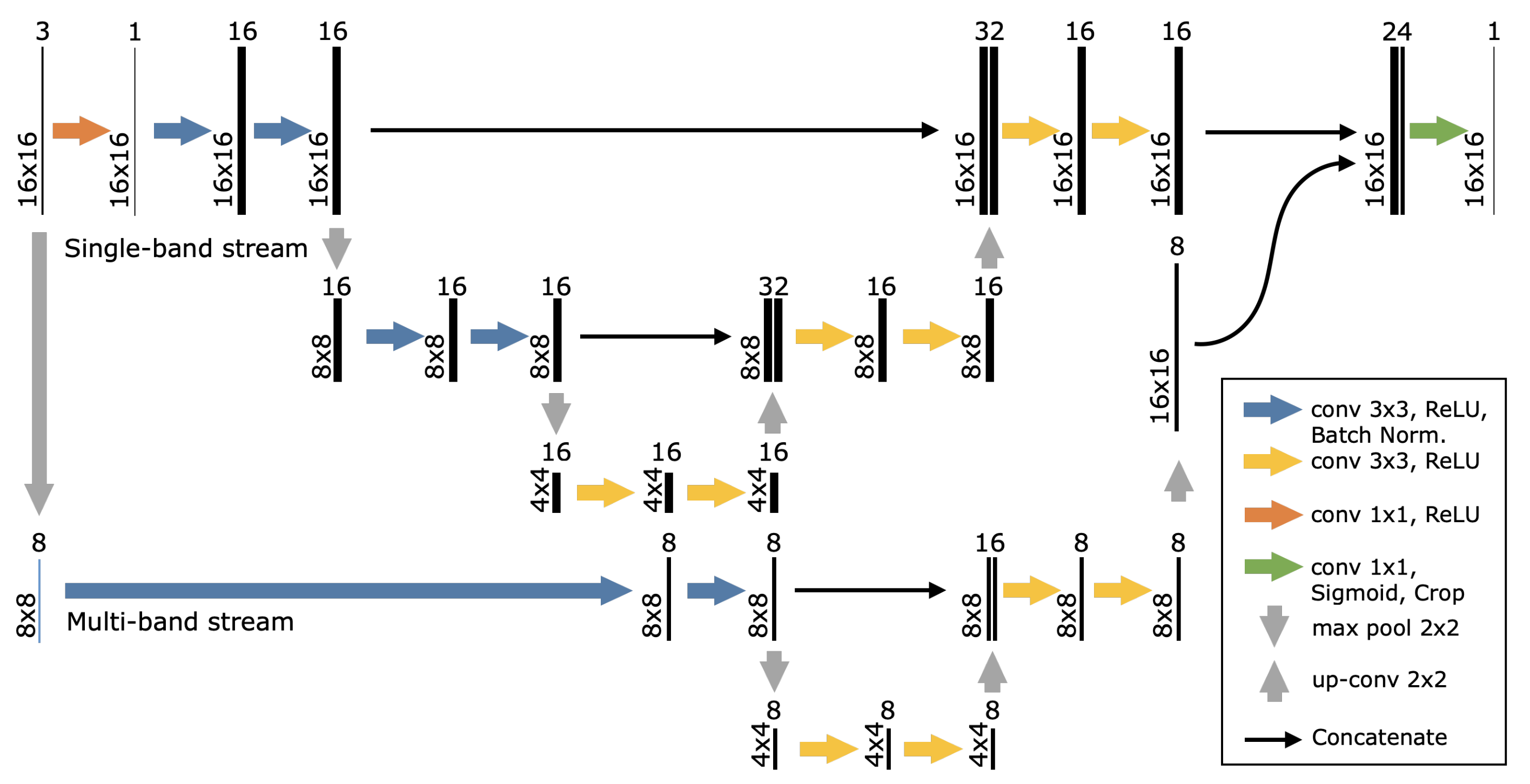
3.1.3. CNN Architecture Miniaturization
3.2. Image Evaluation
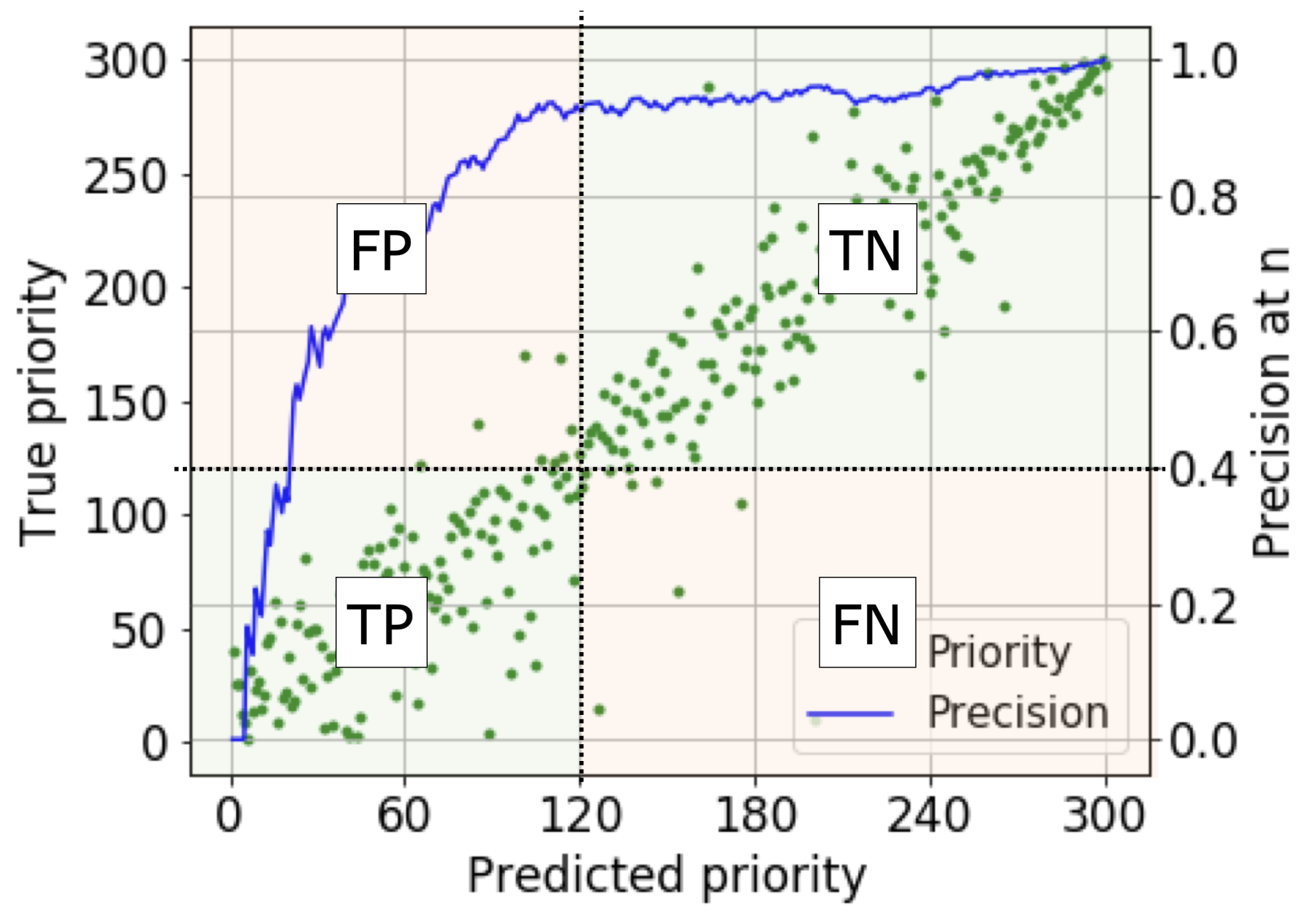
3.3. Accuracy Metric
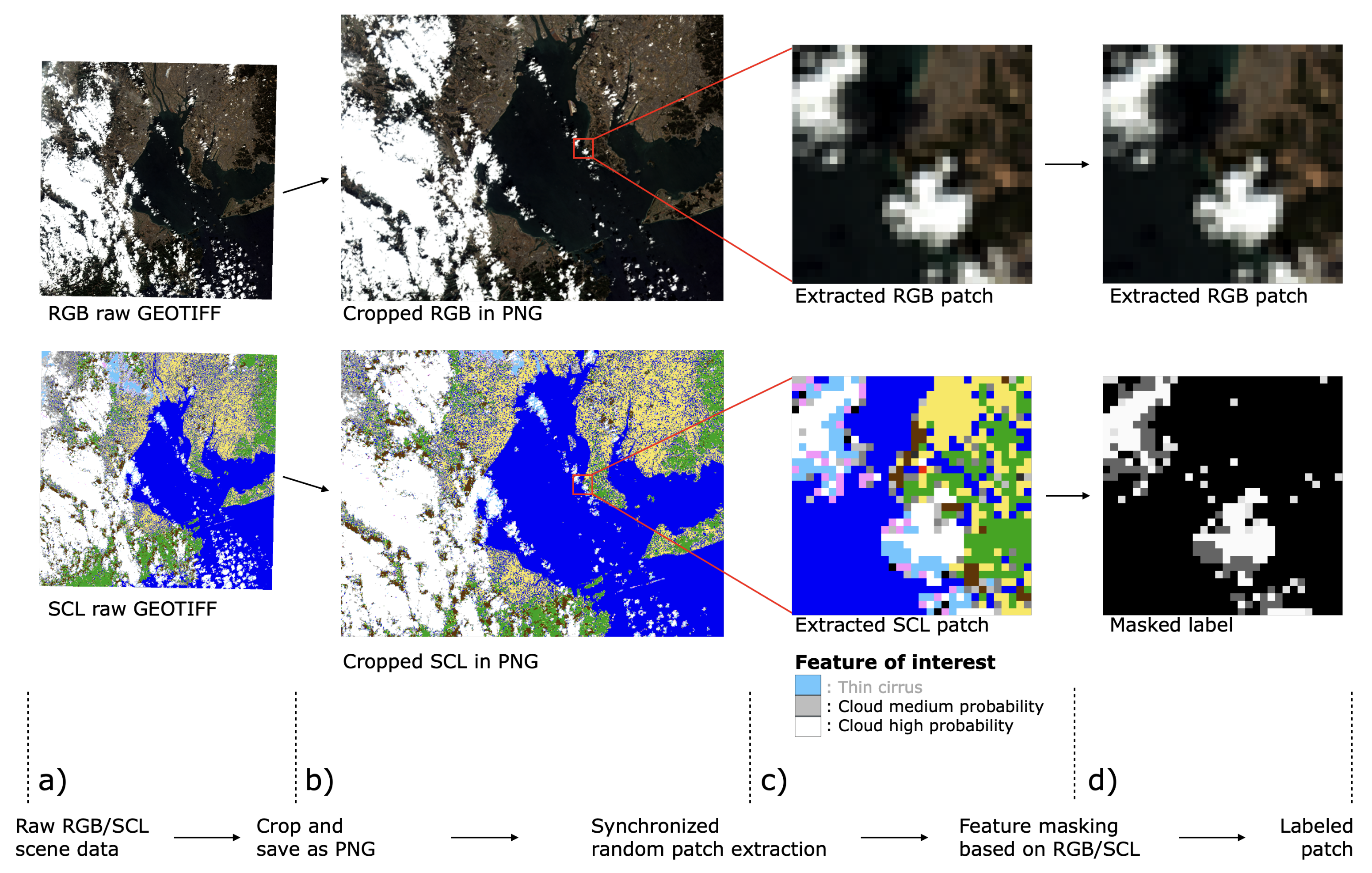
3.4. Dataset Generation
3.4.1. Automatic Dataset Generation
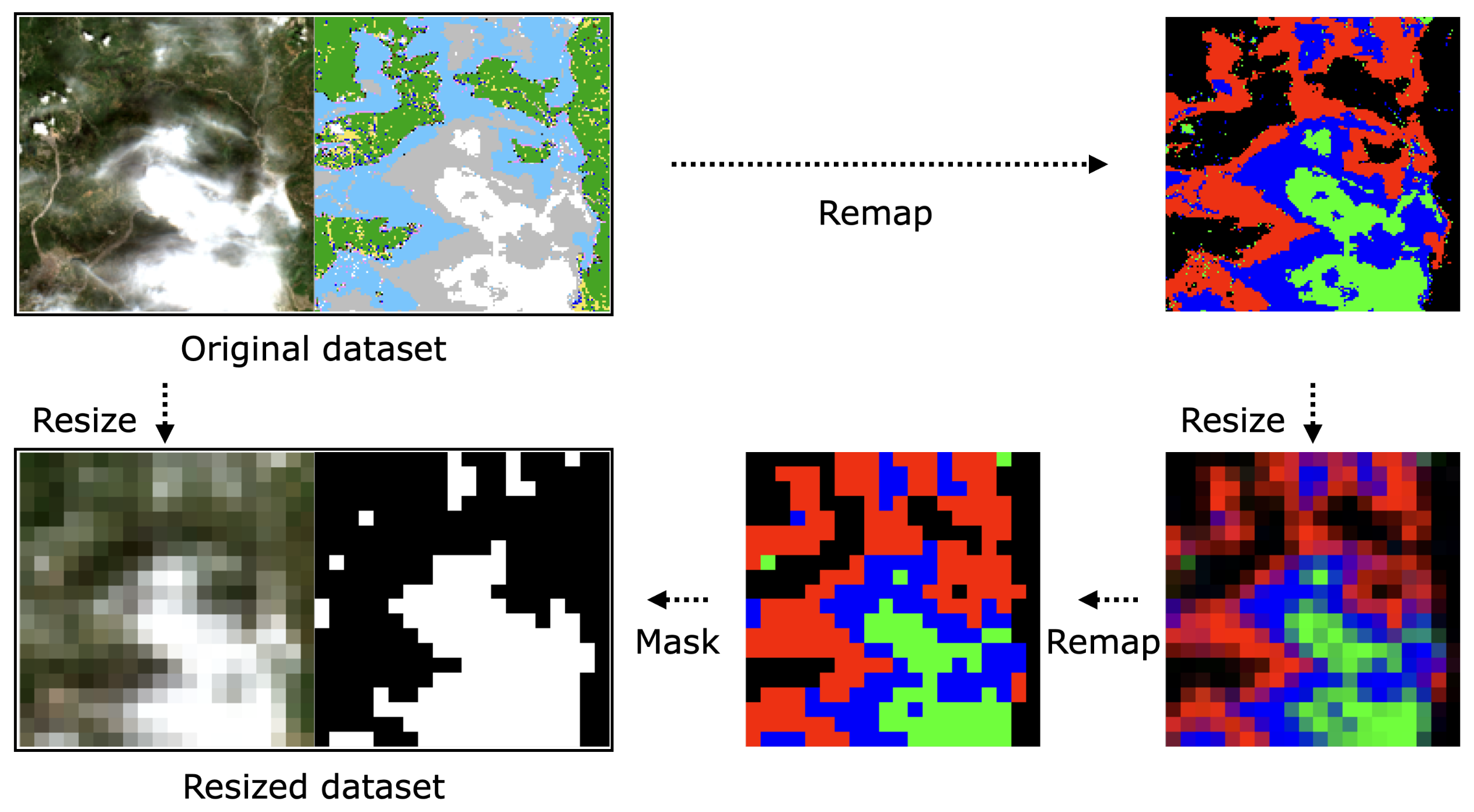
3.4.2. Label Resize
4. Results and Discussion
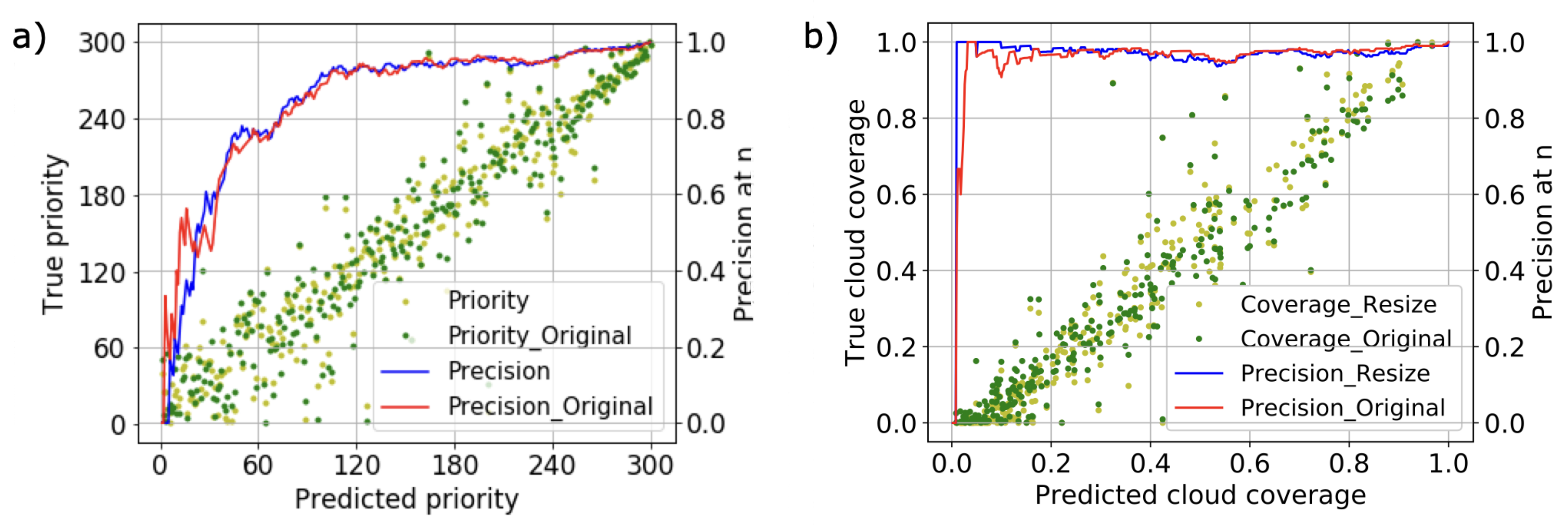
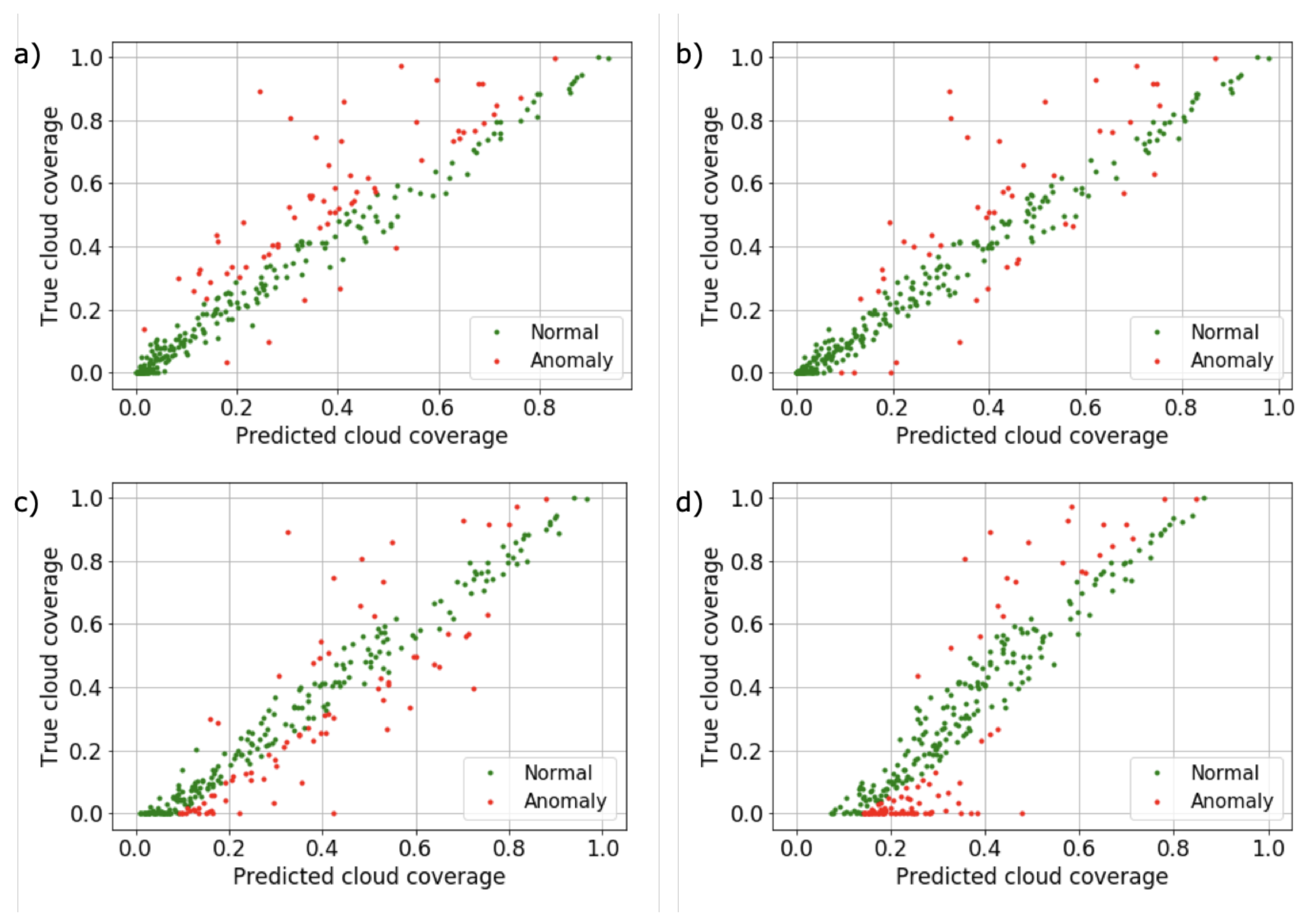
4.1. Effect of Image Resize on Accuracy
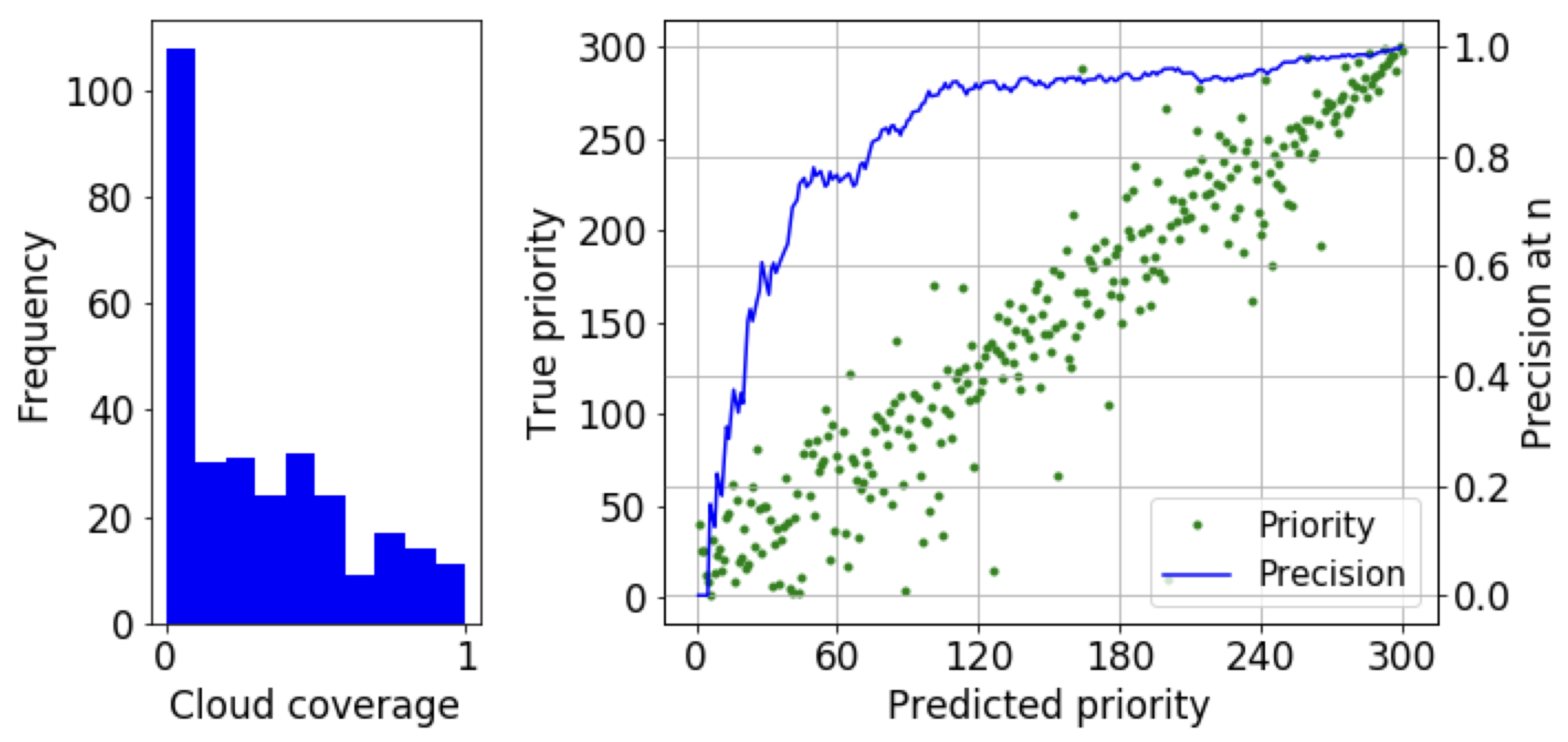
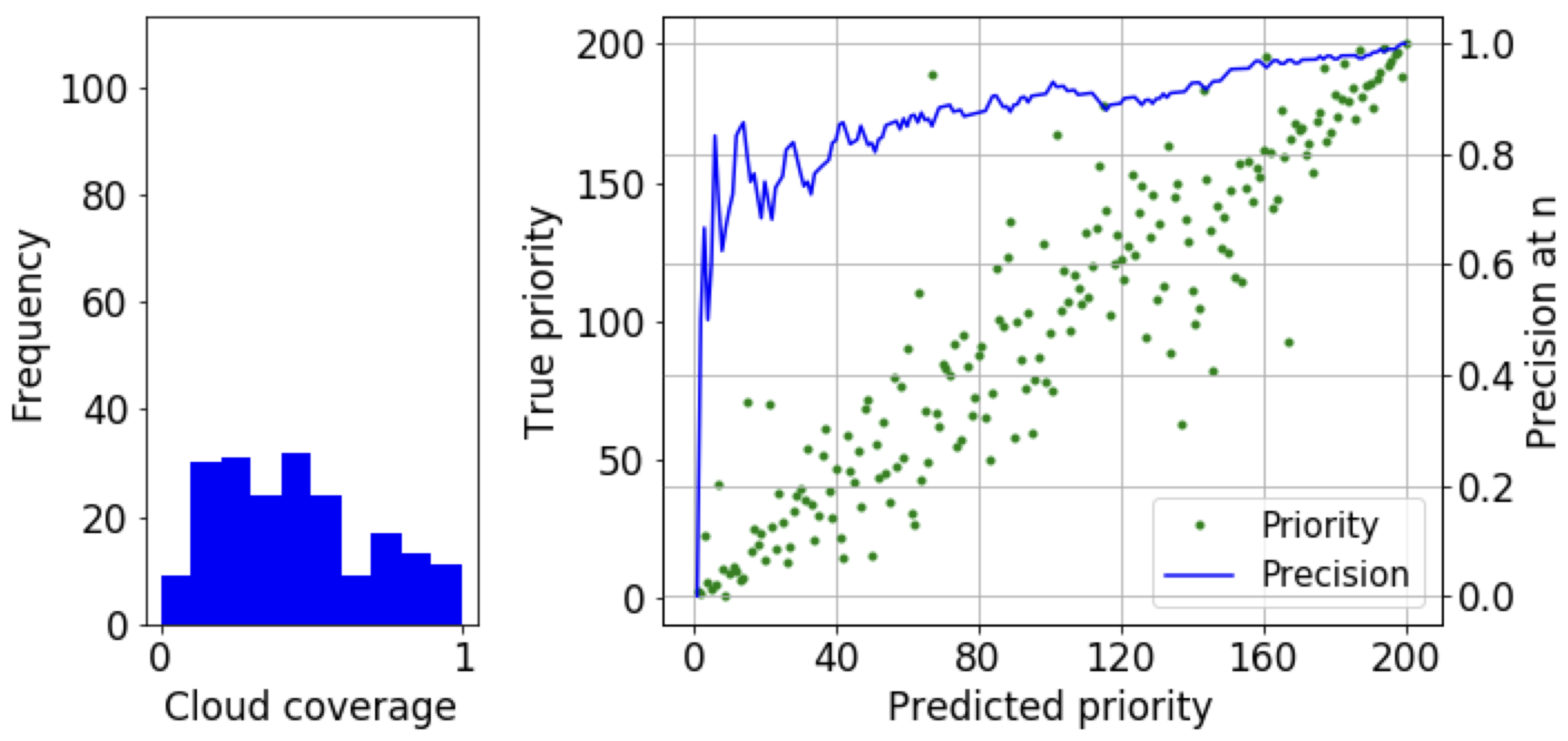
4.2. Effect of Dataset Distribution
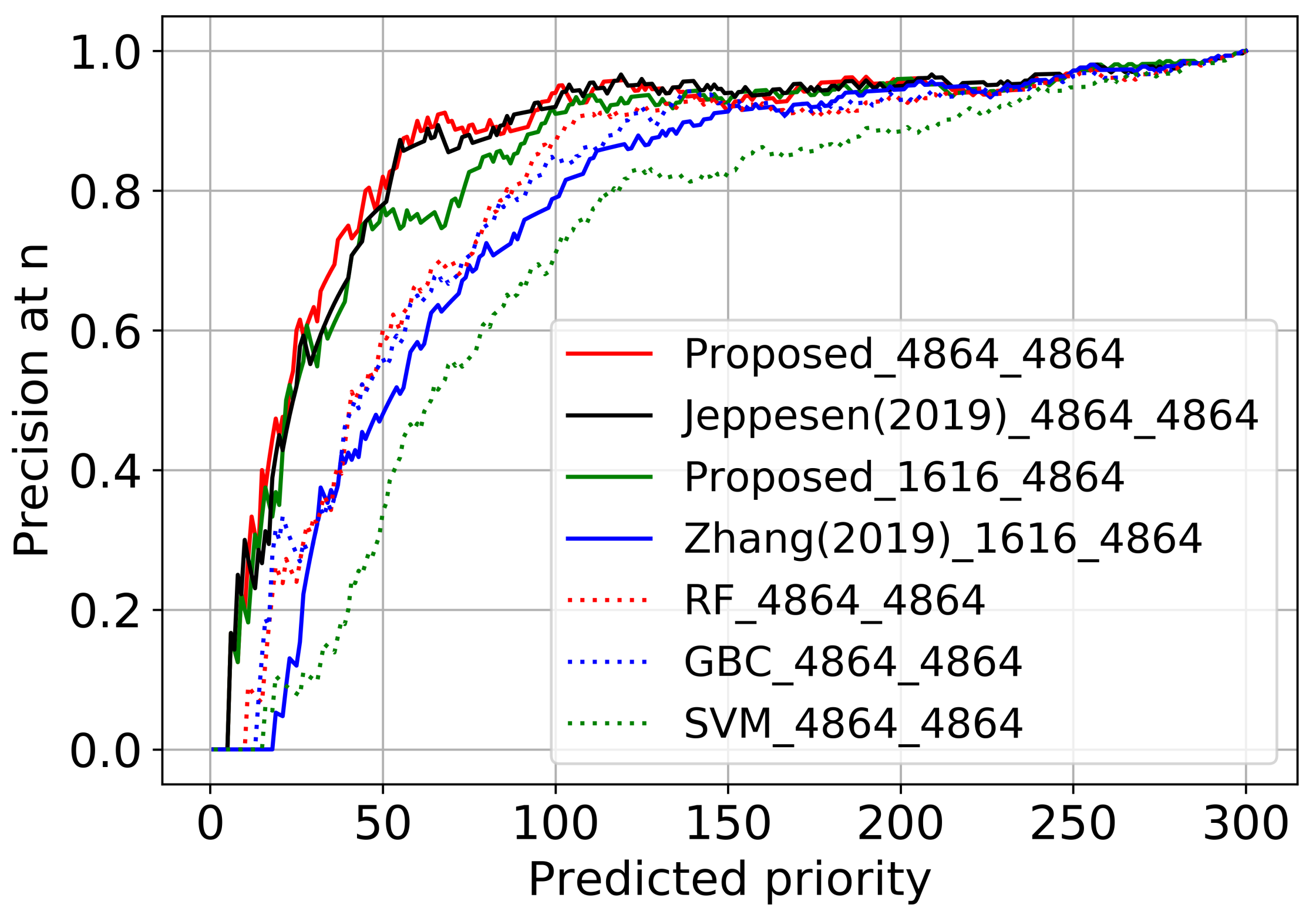
4.3. Performance Analysis
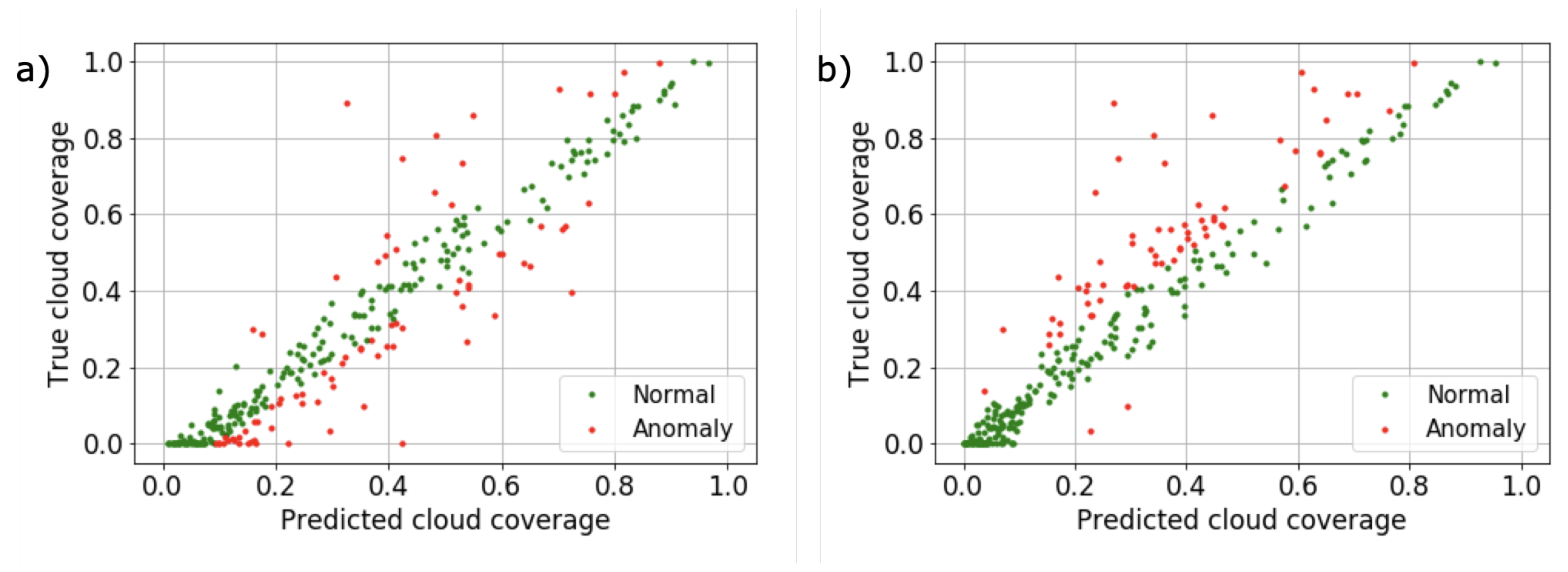
4.3.1. Accuracy and Error Analysis
4.3.2. Computational Cost Analysis
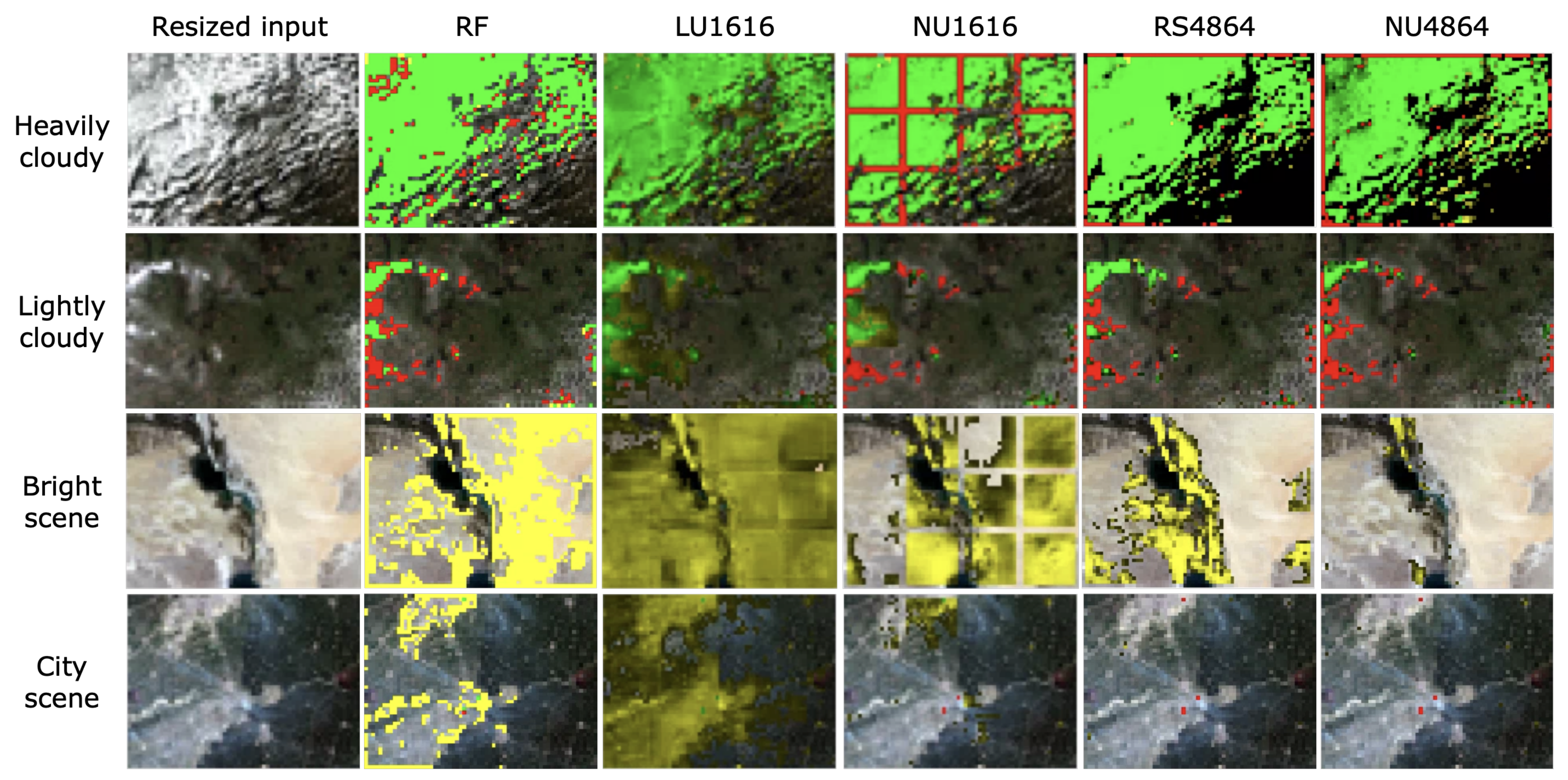
4.4. Visualization of Prioritized Images
5. Limitations of the Proposed Method
5.1. Limitation of Onboard RGB Imagers
5.2. Input Image Resize
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACCA | Automated Cloud-Cover Assessment |
| AT-ACCA | Artificial Thermal Automated Cloud-Cover Assessment |
| BNN | Binary Neural Network |
| BT | Brightness Temperature |
| CCA | Cloud-Cover Assessment |
| CNN | Convolutional Neural Network |
| CS-CNN | Cloud Segmentation CNN |
| DLAS | Deep Learning Attitude Sensor |
| EM | Engineering Model |
| Fmask | Function of mask |
| FN | False negative |
| FOV | Field of View |
| FP | False Positive |
| GBC | Gradient Boosting Classifier |
| HFCNN | Hierarchical Fusion CNN |
| IPEX | Intelligent Payload Experiment |
| LDCM | Landsat Data Continuity Mission |
| RFC | Random Forest Classifier |
| SCL | Scene Classification map |
| SLIC | Simple Linear Iterative Clustering |
| SPARCS | Spatial Procedures for the Automated Removal of Clouds and Shadows |
| SVM | Support Vector Machine |
| TCI | True Color Image |
| TIRS | Thermal Infrared Sensors |
| TN | True negative |
| TOA | Top of Atmosphere |
| TP | True positive |
References
- Poghosyan, A.; Golkar, A. CubeSat evolution: Analyzing CubeSat capabilities for conducting science missions. Prog. Aerosp. Sci. 2017, 88, 59–83. [Google Scholar] [CrossRef]
- Gill, E.; Sundaramoorthy, P.; Bouwmeester, J.; Zandbergen, B.; Reinhard, R. Formation flying within a constellation of nano-satellites: The QB50 mission. Acta Astronaut. 2013, 82, 110–117. [Google Scholar] [CrossRef]
- Butler, D. Many eyes on Earth: Swarms of small satellites set to deliver close to real-time imagery of swathes of the planet. Nature 2014, 505, 143–144. [Google Scholar] [CrossRef] [PubMed]
- Devaraj, K.; Kingsbury, R.; Ligon, M.; Breu, J.; Vittaldev, V.; Klofas, B.; Yeon, P.; Colton, K. Dove High Speed Downlink System. In Proceedings of the 31st Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 5–10 August 2017. SSC17-VII-02. [Google Scholar]
- Planet. Planet Imagery Product Specifications. 2020. Available online: https://www.planet.com/ (accessed on 25 May 2020).
- Azami, M.H.; Maeda, G.; Faure, P.; Yamauchi, T.; Kim, S.; Masui, H.; Cho, M. BIRDS-2: A Constellation of Joint Global Multi-Nation 1U CubeSats. J. Phys. Conf. Ser. 1 2019, 1152, 012008. [Google Scholar] [CrossRef]
- Park, J.; Jeung, I.-S.; Inamori, T. Telemetry and Two Line Element data analysis for SNUSAT-1b anomaly investigation. In Proceedings of the 32nd International Symposium on Space Technology and Science (ISTS), Fukui, Japan, 15–21 June 2019. 2019-f-76. [Google Scholar]
- Malan, D.; Wiid, K.; Burger, H.; Visagie, L. The Development of “nSight-1”—Earth Observation and Science in 2U. In Proceedings of the 31st Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 5–10 August 2017. SSC17-X-10. [Google Scholar]
- Mas, I.A.; Kitts, C.A. A Flight-Proven 2.4GHz ISM Band COTS Communications System for Small Satellites. In Proceedings of the 21st Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 13–16 August 2007. SSC07-XI-11. [Google Scholar]
- Evans, D.; Donati, A. The ESA OPS-SAT Mission: Don’t just say there is a better way, fly it and prove it. In Proceedings of the 2018 SpaceOps Conference, Palais du Pharo Marseille, France, 28 May–1 June 2018. [Google Scholar]
- Eagleson, S.; Sarda, K.; Mauthe, S.; Tuli, T.; Zee, R. Adaptable, Multi-Mission Design of CanX Nanosatellites. In Proceedings of the 20th Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 14–17 August 2006. SSC06-VII-3. [Google Scholar]
- Clagett, C.; Santos, L.; Azimi, B.; Cudmore, A.; Marshall, J.; Starin, S.; Sheikh, S.; Zesta, E.; Paschalidis, N.; Johnson, M.; et al. Dellingr: NASA Goddard Space Flight Center’s First 6U Spacecraft. In Proceedings of the 31st Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 5–10 August 2017. SSC17-III-06. [Google Scholar]
- Klesh, A.; Krajewski, J. MarCO: CubeSats to Mars in 2016. In Proceedings of the 29th Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 8–13 August 2015. SSC15-III-3. [Google Scholar]
- Kobayashi, M. Iris Deep-Space Transponder for SLS EM-1 CubeSat Missions. In Proceedings of the 31st Annual AIAA/USU Conference on Small Satellites, Logan, UT, USA, 5–10 August 2017. SSC17-II-04. [Google Scholar]
- Sako, N. About Nano-JASMINE Satellite System and Project Status. Trans. JSASS Aerosp. Technol. Jpn. 2010, 8, Tf7–Tf12. [Google Scholar] [CrossRef]
- Barschke, M.F.; Jonglez, C.; Werner, P.; von Keiser, P.; Gordon, K.; Starke, M.; Lehmann, M. Initial orbit results from the TUBiX20 platform. Acta Astronaut. 2020, 167, 108–116. [Google Scholar] [CrossRef]
- Guerra, A.G.; Francisco, F.; Villate, J.; Agelet, F.A.; Bertolami, O.; Rajan, K. On small satellites for oceanography: A survey. Acta Astronaut. 2016, 127, 404–423. [Google Scholar] [CrossRef]
- Purivigraipong, S. Review of Satellite-Based AIS for Monitoring Maritime Fisheries. Eng. Trans. 2018, 21, 81–89. [Google Scholar]
- Tsuruda, Y.; Aoyanagi, Y.; Tanaka, T.; Matsumoto, T.; Nakasuka, S.; Shirasaka, S.; Matsui, M.; Mase, I. Demonstration of Innovative System Design for Twin Micro-Satellite: Hodoyoshi-3 and -4. Trans. JSASS Aerosp. Technol. Jpn. 2016, 14, Pf131–Pf140. [Google Scholar] [CrossRef][Green Version]
- AlDhafri, S.; AlJaziri, H.; Zowayed, K.; Yun, J.; Park, S. Dubaisat-2 High Resolution Advanced Imaging System (HiRAIS). In Proceedings of the 63rd International Astronautical Congress, Naples, Italy, 1–5 October 2012; Volume 21. IAC-12.B4.6A.6. [Google Scholar]
- Bargellini, P.; Emanuelli, P.P.; Provost, D.; Cunningham, R.; Moeller, H. Sentinel-3 Ground Segment: Innovative Approach for future ESA-EUMETSAT Flight Operations cooperation. In Proceedings of the SpaceOps 2010 Conference, Huntsville, Alabama, 25–30 April 2010. AIAA 2010-2193. [Google Scholar]
- Mah, G.; O’Brien, M.; Garon, H.; Mott, C.; Ames, A.; Dearth, K. Design and Implementation of the Next Generation Landsat Satellite Communications System. Int. Telemetering Conf. Proc. 2012, 48. Available online: http://hdl.handle.net/10150/581626 (accessed on 21 November 2019).
- King, M.; Platnick, S.; Menzel, P.; Ackerman, S.; Hubanks, P. Spatial and Temporal Distribution of Clouds Observed by MODIS Onboard the Terra and Aqua Satellites. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3826–3852. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Drönner, J.; Korfhage, N.; Egli, S.; Mühling, M.; Thies, B.; Bendix, J.; Freisleben, B.; Seeger, B. Fast Cloud Segmentation Using Convolutional Neural Networks. Remote Sens. 2018, 10, 1782. [Google Scholar] [CrossRef]
- Morales, G.; Ramirez, A.; Telles, J. End-to-end Cloud Segmentation in High-Resolution Multispectral Satellite Imagery Using Deep Learning. In Proceedings of the 2019 IEEE XXVI International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Lima, Peru, 12–14 August 2019. [Google Scholar]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. A Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar]
- Jeppesen, J.H.; Jacobsen, R.H.; Inceoglu, F.; Toftegaard, T.S. A cloud detection algorithm for satellite imagery based on deep learning. Remote Sens. Environ. 2019, 229, 247–259. [Google Scholar] [CrossRef]
- Francis, A.; Sidiropoulos, P.; Muller, J.-P. CloudFCN: Accurate and Robust Cloud Detection for Satellite Imagery with Deep Learning. Remote Sens. 2019, 11, 2312. [Google Scholar] [CrossRef]
- Irish, R. Landsat 7 Automatic Cloud Cover Assessment. In Algorithms for Multispectral, Hyperspectral, and Ultraspectral Imagery VI; SPIE: Bellingham, WA, USA, 2000; Volume 4049, pp. 348–355. [Google Scholar]
- Irish, R.; Barker, J.; Goward, S.; Arvidson, T. Characterization of the Landsat-7 ETM+ Automated Cloud-Cover Assessment (ACCA) algorithm. Photogammetric Eng. Remote. Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef]
- Scaramuzza, P.L.; Bouchard, M.A.; Dwyer, J.L. Development of the Landsat Data Continuity Mission Cloud-Cover Assessment Algorithms. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1140–1154. [Google Scholar] [CrossRef]
- Goodwin, N.R.; Collett, L.J.; Denham, R.J.; Flood, N.; Tindall, D. Cloud and cloud shadow screening across Queensland, Australia: An automated method for Landsat TM/ETM + time series. Remote Sens. Environ. 2013, 134, 50–65. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated Detection of Cloud and Cloud Shadow in Single-Date Landsat Imagery Using Neural Networks and Spatial Post-Processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud Detection of Remote Sensing Images by Deep Learning. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar]
- Liu, H.; Zeng, D.; Tian, Q. Super-Pixel Cloud Detection Using Hierarchical Fusion CNN. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2281. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Iwasaki, A.; Xu, G.; Song, J. Cloud detection on small satellites based on lightweight U-net and image compression. J. Appl. Remote Sens. 2019, 13, 026502. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597v1. [Google Scholar]
- Craswell, N. Precision at n. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009. [Google Scholar]
- Louis, J.; Debaecker, V.; Pflug, B.; Main-Knorn, M.; Bieniarz, J.; Mueller-Wilm, U.; Cadau, E.; Gascon, F. Sentinel-2 Sen2Cor: L2A Processor for Users. In Proceedings of the Living Planet Symposium 2016; ESA Communications: Noordwijk, The Netherlands, 2016; ESA SP-740. [Google Scholar]
- Gascon, F.; Bouzinac, C.; Thépaut, O.; Jung, M.; Francesconi, B.; Louis, J.; Lonjou, V.; Lafrance, B.; Massera, S.; Gaudel-Vacaresse, A.; et al. Copernicus Sentinel-2A Calibration and Products Validation Status. Remote Sens. 2017, 9, 584. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 21 November 2019).
- Cheng, J.; Wu, J.; Leng, C.; Wang, Y.; Hu, Q. Quantized CNN: A Unified Approach to Accelerate and Compress Convolutional Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4730–4743. [Google Scholar] [CrossRef]
- Maskey, A. Imaging Payload System Design for Nano-Satellite Applications in Low-Earth Orbit. Master’s Thesis, Seoul National University, Seoul, Korea, 2016. [Google Scholar]
- Hamaguchi, R.; Hikosaka, S. Building Detection from Satellite Imagery using Ensemble of Size-specific Detectors. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 223–227. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
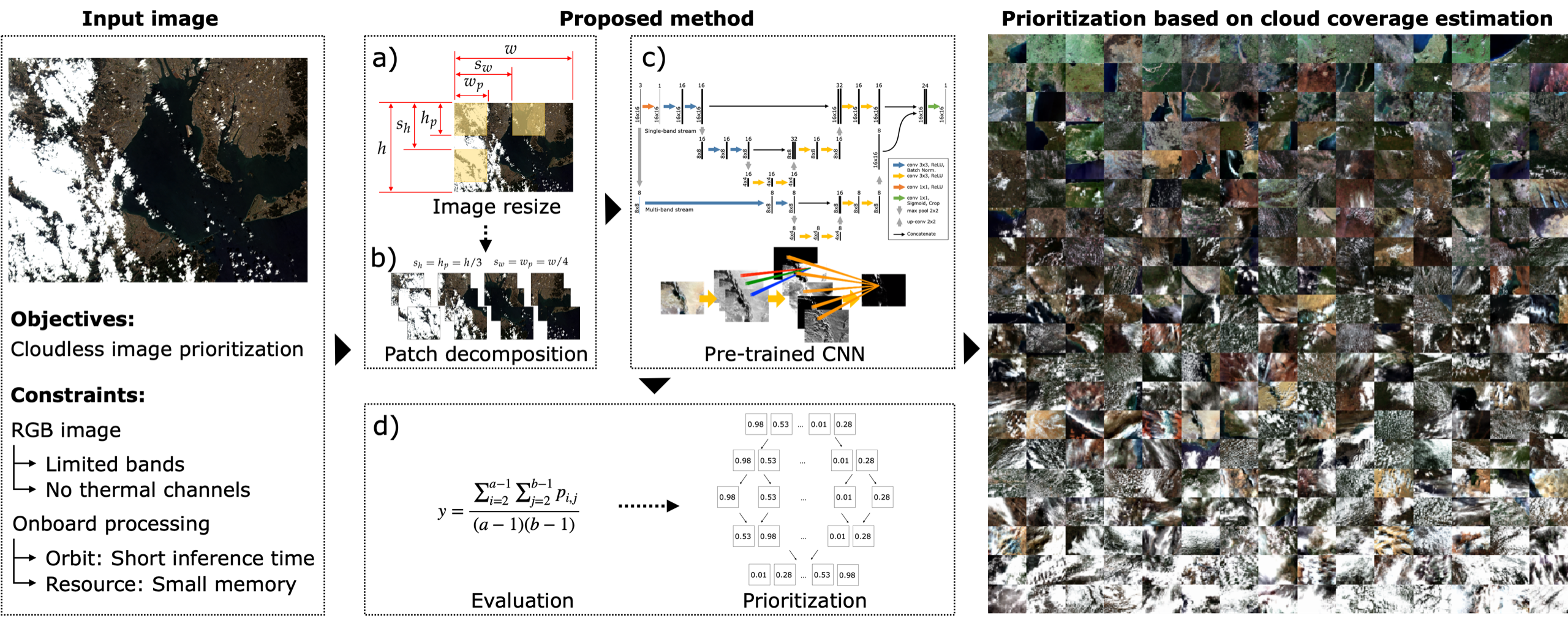
| Satellite | Class | Mass | RF Information | Reference | ||
|---|---|---|---|---|---|---|
| Band | RF Power | Throughput | ||||
| Birds-2 | Nanosatellite | 1 kg (1U) | UHF | 0.8 W | 9.6 kbps | [6] |
| SNUSAT-1b | Nanosatellite | 1.9 kg (2U) | UHF | 0.5 W | 1.2 kbps | [7] |
| nSight-1 | Nanosatellite | 5 kg (2U) | UHF | - | 9.6 kbps | [8] |
| GeneSat-1 | Nanosatellite | 3.5 kg | S-band | - | 83 kbps | [9] |
| OPS-SAT | Nanosatellite | 5.4 kg (3U) | S-band | - | 1 Mbps | [10] |
| CanX-3/4/5 | Nanosatellite | 10 kg | S-band | - | 1 Mbps | [11] |
| Dellingr | Nanosatellite | 11 kg | UHF | 2 W | 3 Mbps | [12] |
| MarCO | Nanosatellite | 13.5 kg (6U) | X-band | 4 W | 6.25 Mbps * | [13,14] |
| Dove 1 | Nanosatellite | 5 kg (3U) | X-band | 2 W | 4 Mbps | [4] |
| Dove 3 | Nanosatellite | 5 kg (3U) | X-band | 2 W | 25 Mbps | [4] |
| Flock 1c | Nanosatellite | 5 kg (3U) | X-band | 2 W | 34 Mbps | [4] |
| Flock 2e | Nanosatellite | 5 kg (3U) | X-band | 2 W | 100 Mbps | [4] |
| Flock 2p/3p | Nanosatellite | 5 kg (3U) | X-band | 2 W | 220 Mbps | [4] |
| Nano-Jasmine | Small satellite | 35 kg | S-band | - | 100 kbps | [15] |
| TechnoSat | Small satellite | 20 kg | S-band | 0.5 W | 1.39 Mbps | [16] |
| QSat-EOS | Small satellite | 50 kg | Ku-band | - | 30 Mbps | [17] |
| exactView-1 | Small satellite | 100 kg | C-band | 5 W | 20 Mbps | [18] |
| Hodoyoshi-4 | Small satellite | 64 kg | X-band | 2 W | 350 Mbps | [19] |
| DubaiSat-2 | Small satellite | 300 kg | X-band | - | 160 Mbps | [20] |
| Sentinel-3 | Large satellite | 1150 kg | X-band | - | 520 Mbps | [21] |
| Landsat-8 | Large satellite | 2623 kg | X-band | 50 W | 384 Mbps | [22] |
| Network | Resource Usage | Inference Time (ms) | Precision at 60 | ||||
|---|---|---|---|---|---|---|---|
| Model | Image | Patch | Parameters | ROM (KB) | RAM (KB) | ||
| Jeppesen, 2019 | 48 × 64 | 48 × 64 | 7,854,592 | 30,666.50 | 2304.00 | 58,723.438 | 0.867 |
| Proposed | 48 × 64 | 48 × 64 | 29,907 | 115.83 | 864.00 | 4886.674 | 0.900 |
| Zhang, 2019 | 48 × 64 | 16 × 16 | 9828 | 37.38 | 96.00 | 987.12 | 0.583 |
| Proposed | 48 × 64 | 16 × 16 | 29,907 | 127.33 | 72.00 | 2499.84 | 0.767 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.H.; Inamori, T.; Hamaguchi, R.; Otsuki, K.; Kim, J.E.; Yamaoka, K. RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites. Remote Sens. 2020, 12, 3941. https://doi.org/10.3390/rs12233941
Park JH, Inamori T, Hamaguchi R, Otsuki K, Kim JE, Yamaoka K. RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites. Remote Sensing. 2020; 12(23):3941. https://doi.org/10.3390/rs12233941
Chicago/Turabian StylePark, Ji Hyun, Takaya Inamori, Ryuhei Hamaguchi, Kensuke Otsuki, Jung Eun Kim, and Kazutaka Yamaoka. 2020. "RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites" Remote Sensing 12, no. 23: 3941. https://doi.org/10.3390/rs12233941
APA StylePark, J. H., Inamori, T., Hamaguchi, R., Otsuki, K., Kim, J. E., & Yamaoka, K. (2020). RGB Image Prioritization Using Convolutional Neural Network on a Microprocessor for Nanosatellites. Remote Sensing, 12(23), 3941. https://doi.org/10.3390/rs12233941