Using GIS and Machine Learning to Classify Residential Status of Urban Buildings in Low and Middle Income Settings

 ,
,  and
and
Abstract
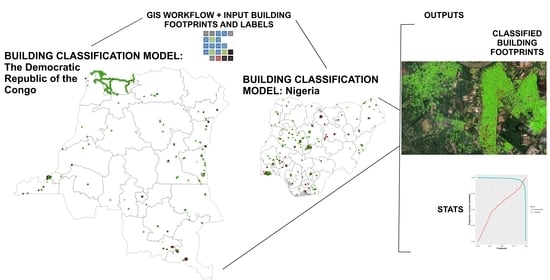
1. Introduction
2. Materials and Methods
2.1. Source Datasets
2.2. The Model
2.3. Running the Model
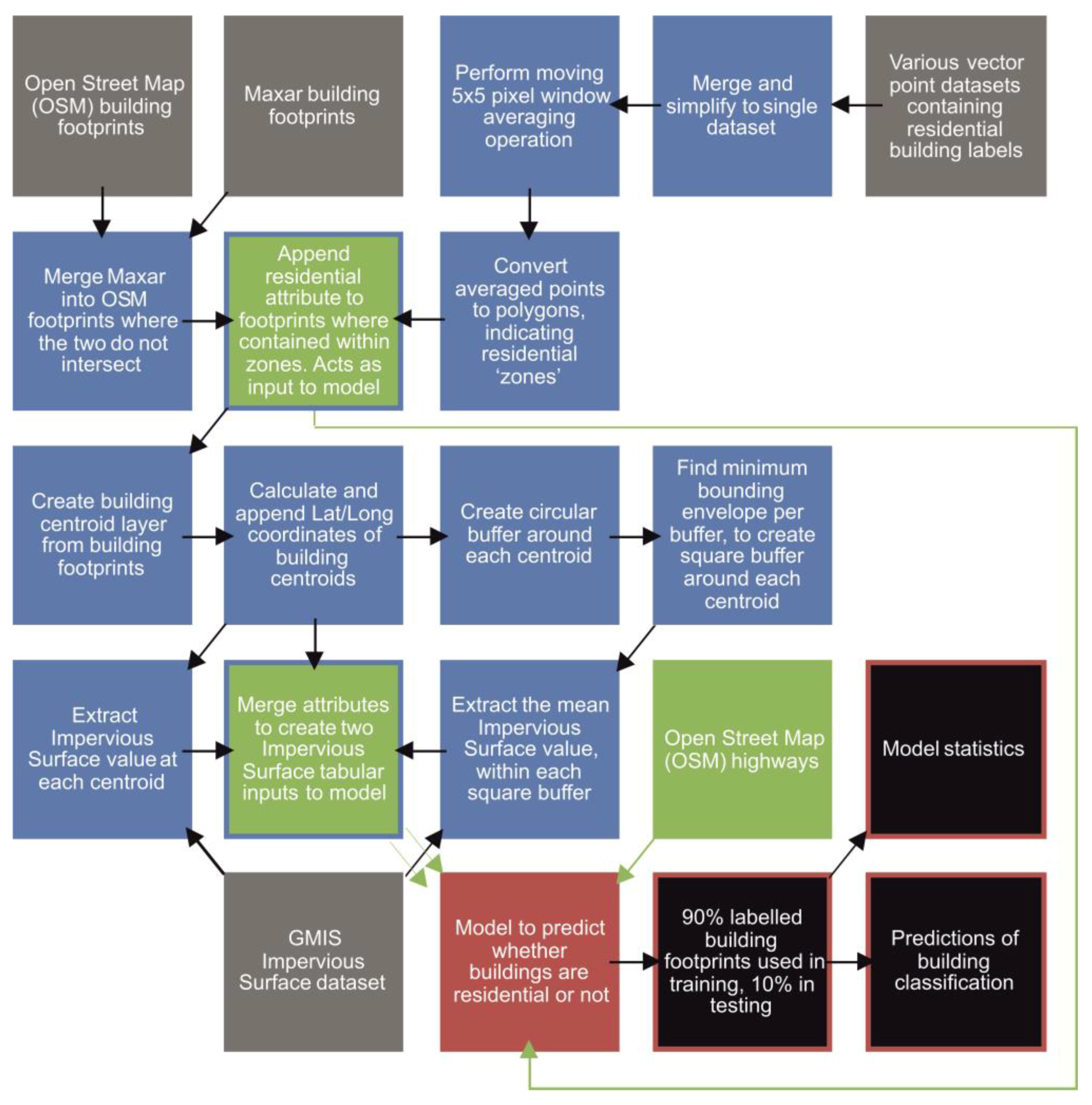
2.4. GIS Workflow to Prepare Model Inputs
2.5. GIS Workflow to Prepare Model Outputs for Visualization
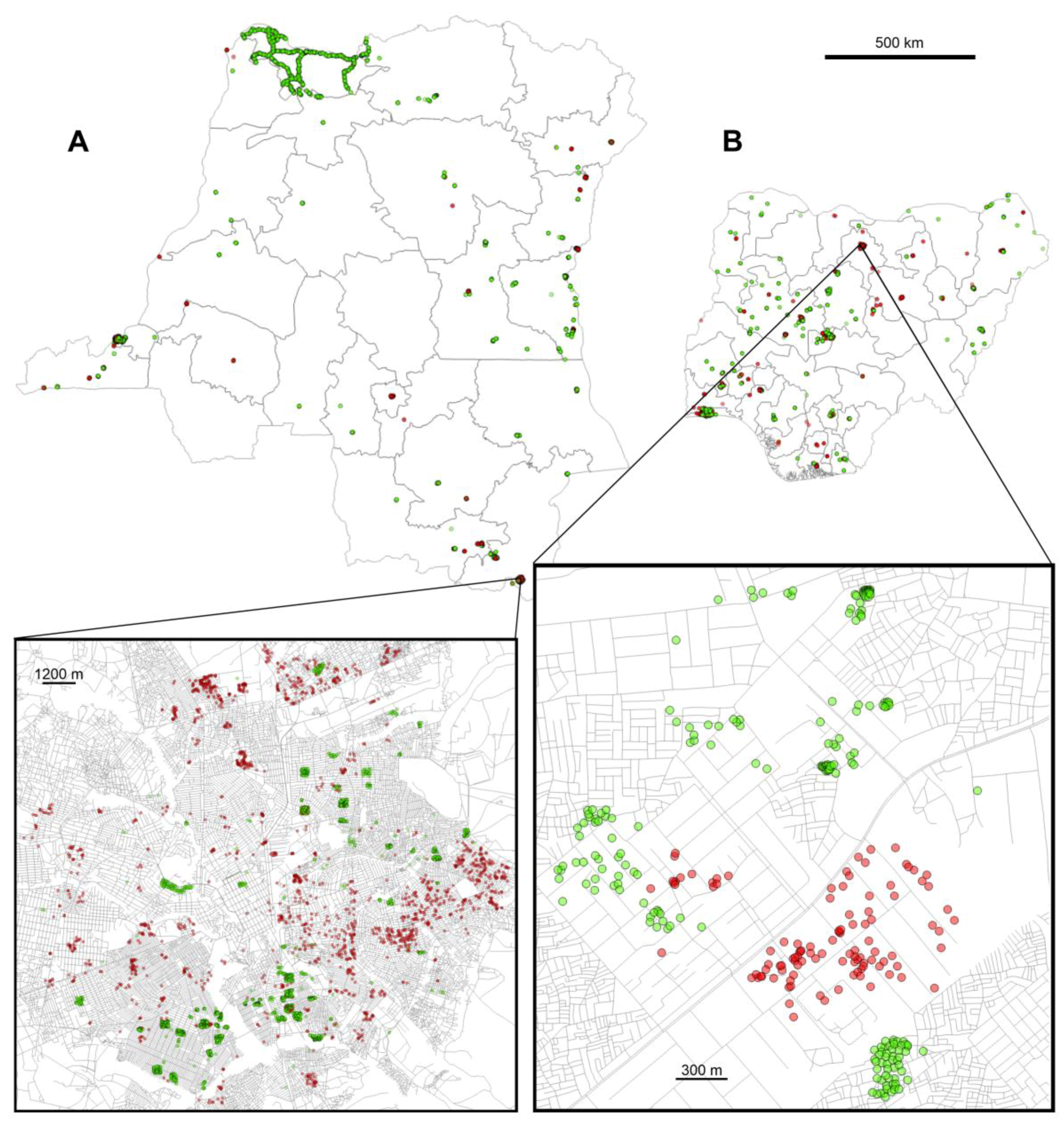
3. Results
4. Discussion
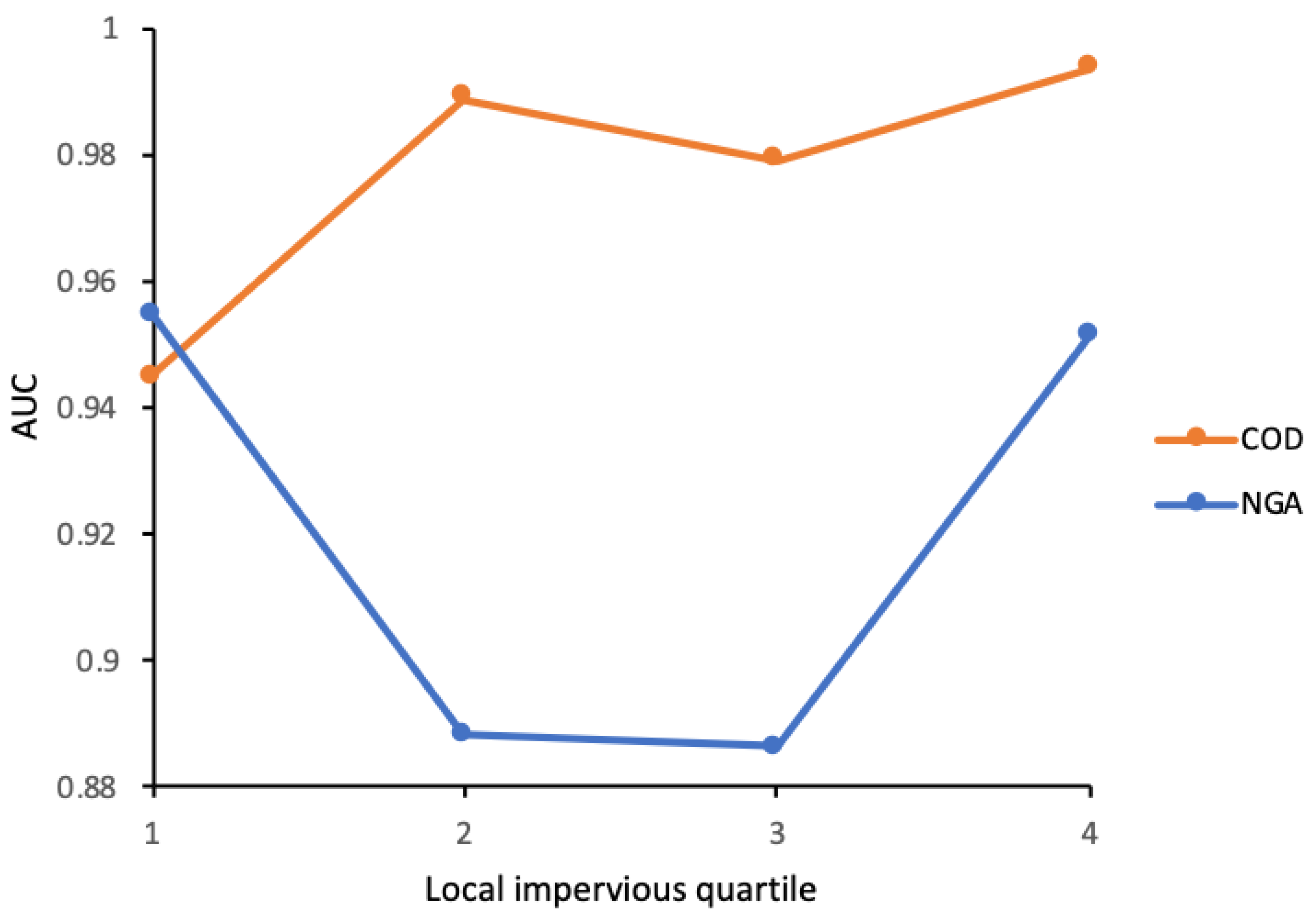
4.1. Sensitivity Testing of Window Generalization Method
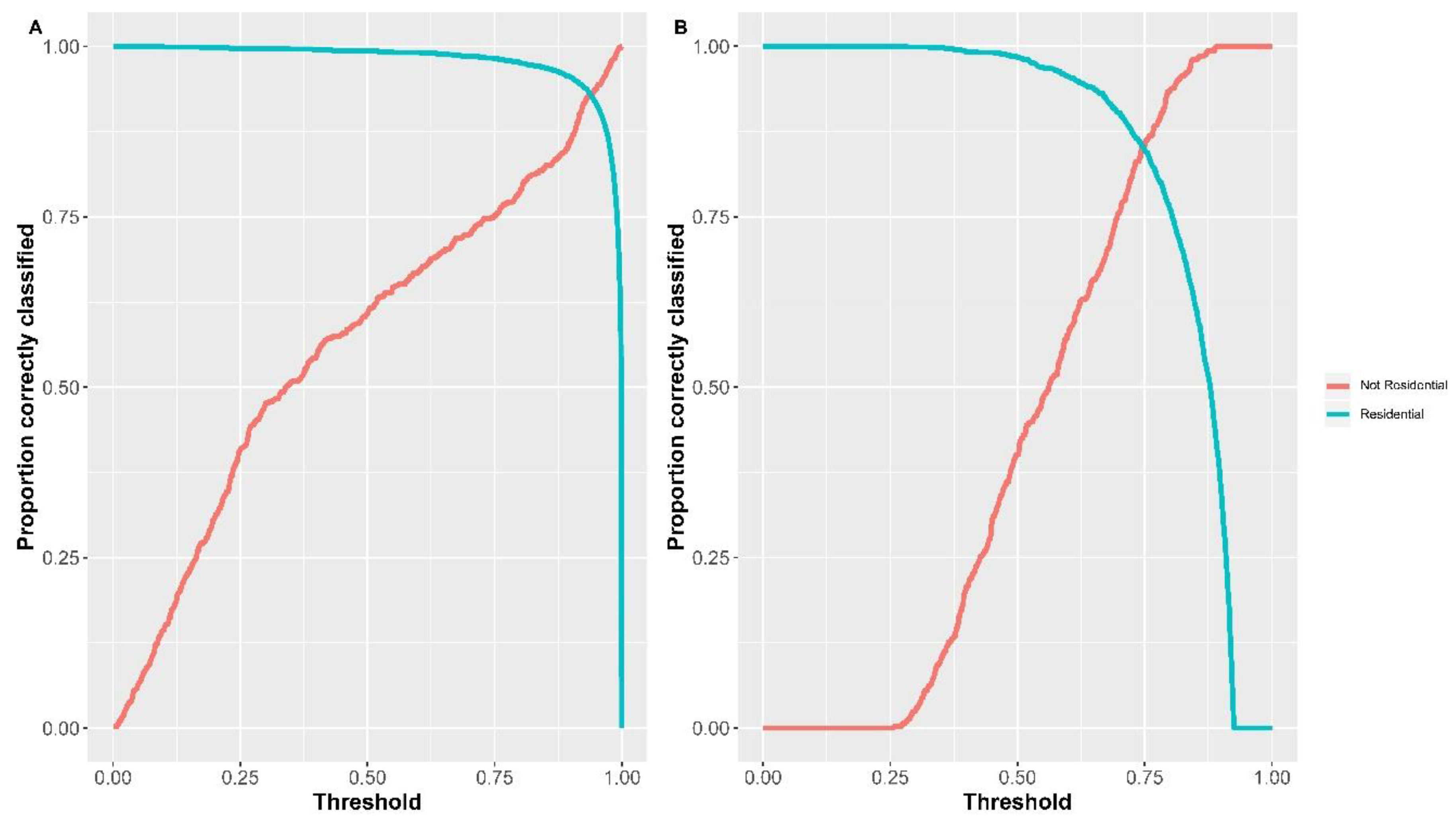
4.2. Model Output
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- World Health Organization & United Nations. Human Settlements Programme. Hidden Cities: Unmask. and Overcoming Health Inequities in Urban Settings; World Health Organization: Geneva, Switzerland, 2010; p. 126. [Google Scholar]
- UN Habitat. World Cities Report 2016: Urbanization and Development—Emerging Futures; United Nations Human Settlements Programme (UN-Habitat): Nairobi, Kenya, 2016; p. 262. [Google Scholar]
- United Nations. New Urban Agenda; United Nations: New York, NY, USA, 2017. [Google Scholar]
- Wardrop, N.A.; Jochem, W.C.; Bird, T.J.; Chamberlain, H.R.; Clarke, D.; Kerr, D.; Bengtsson, L.; Juran, S.; Seaman, V.; Tatem, A.J. Spatially disaggregated population estimates in the absence of national population and housing census data. Proc. Natl. Acad. Sci. USA 2018, 115, 3529–3537. [Google Scholar] [CrossRef]
- Nieves, J.J.; Stevens, F.R.; Gaughan, A.E.; Linard, C.; Sorichetta, A.; Hornby, G.; Patel, N.N.; Tatem, A.J. Examining the correlates and drivers of human population distributions across low- and middle-income countries. J. R. Soc. Interface 2017, 14, 20170401. [Google Scholar] [CrossRef] [PubMed]
- Reed, F.; Gaughan, A.E.; Stevens, F.R.; Yetman, G.; Sorichetta, A.; Tatem, A.J. Gridded Population Maps Informed by Different Built Settlement Products. Data 2018, 3, 33. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Nieves, J.J.; King, A.; Sorichetta, A.; Linard, C.; Tatem, A.J. Comparisons of two global built area land cover datasets in methods to disaggregate human population in eleven countries from the global South. Int. J. Dig. Earth 2019, 13, 78–100. [Google Scholar] [CrossRef]
- Jochem, W.C.; Bird, T.J.; Tatem, A.J. Identifying residential neighbourhood types from settlement points in a machine learning approach. Comput. Environ. Urban Syst. 2018, 69, 104–113. [Google Scholar] [CrossRef]
- Hecht, R.; Meinel, G.; Buchroithner, M. Automatic identification of building types based on topographic databases—A comparison of different data sources. Int. J. Cart. 2015, 1, 18–31. [Google Scholar] [CrossRef]
- Barr, S.L.; Barnsley, M.J.; Steel, A. On the separability of urban land-use categories in fine spatial scale land-cover data using structural pattern recognition. Environ. Plan B Plan Design 2004, 31, 397–418. [Google Scholar] [CrossRef]
- Steiniger, S.; Lange, T.; Burghardt, D.; Weibel, R. An Approach for the Classification of Urban Building Structures Based on Discriminant Analysis Techniques. Trans. GIS 2008, 12, 31–59. [Google Scholar] [CrossRef]
- Lüscher, P.; Weibel, R. Exploiting empirical knowledge for automatic delineation of city centres from large-scale topographic databases. Comput. Environ. Urban Syst. 2013, 37, 18–34. [Google Scholar] [CrossRef]
- He, X.; Zhang, X.; Xin, Q. Recognition of building group patterns in topographic maps based on graph partitioning and random forest. ISPRS J. Photogram. Remote Sens. 2018, 136, 26–40. [Google Scholar] [CrossRef]
- Jochem, W.C.; Leasure, D.R.; Pannell, O.; Chamberlain, H.R.; Jones, P.; Tatem, A.J. Classifying settlement types from multi-scale spatial patterns of building footprints. Environ. Plan B Urban Analyt. City. Sci. 2020. [Google Scholar] [CrossRef]
- Longley, P.A.; Mesev, V. On the Measurement and Generalisation of Urban Form. Environ. Plan A Econ. Space 2016, 32, 473–488. [Google Scholar] [CrossRef]
- Mesev, V. Identification and characterisation of urban building patterns using IKONOS imagery and point-based postal data. Comput. Environ. Urban Syst. 2005, 29, 541–557. [Google Scholar] [CrossRef]
- Mesev, V. Fusion of point-based postal data with IKONOS imagery. Inf. Fusion. 2007, 8, 157–167. [Google Scholar] [CrossRef]
- Sturrock, H.J.W.; Woolheater, K.; Bennett, A.F.; Andrade-Pacheco, R.; Midekisa, A. Predicting residential structures from open source remotely enumerated data using machine learning. PLoS ONE 2018, 13, e0204399. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.H. Stacked generalization. Neural Networks 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Lu, Z.; Im, J.; Rhee, J.; Hodgson, M. Building type classification using spatial and landscape attributes derived from LiDAR remote sensing data. Landsc. Urban Plan 2014, 130, 134–148. [Google Scholar] [CrossRef]
- Xie, J.; Zhou, J. Classification of Urban Building Type from High Spatial Resolution Remote Sensing Imagery Using Extended MRS and Soft BP Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3515–3528. [Google Scholar] [CrossRef]
- Midekisa, A.; Holl, F.; Savory, D.J.; Andrade-Pacheco, R.; Gething, P.W.; Bennett, A.; Sturrock, H.J.W. Mapping land cover change over continental Africa using Landsat and Google Earth Engine cloud computing. PLoS ONE 2017, 12, e0184926. [Google Scholar] [CrossRef]
- World Bank Group. The World Bank Data Catalog, DRC—Building points for Kinshasa and North Ubangi. Available online: https://datacatalog.worldbank.org/dataset/building-points-kinshasa-and-north-ubangi (accessed on 21 August 2020).
- Oak Ridge National Laboratory (ORNL). Nigeria Household Surveys in 2016 and 2017; Bill & Melinda Gates Foundation: Seattle, WA, USA, 2018. [Google Scholar]
- eHealth Africa and WorldPop (University of Southampton). Nigeria Household Surveys in 2018 and 2019; Bill & Melinda Gates Foundation: Seattle, WA, USA, 2019. [Google Scholar]
- University of California - Los Angeles (UCLA) and Kinshasa School of Public Health (KSPH). Kinshasa, Kongo Central and Former Bandundu Household Surveys in 2017 and 2018; University of California: Los Angeles, CA, USA, 2018. [Google Scholar]
- Brown de Colstoun, E.C.; Huang, C.; Wang, P.; Tilton, J.C.; Tan, B.; Phillips, J.; Niemczura, S.; Ling, P.-Y.; Wolfe, R.E. Global Man-Made Impervious Surface (GMIS) Dataset From Landsat; NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2017. [Google Scholar] [CrossRef]
- Maxar Technologies. Building Footprints. Available online: https://www.digitalglobe.com/products/building-footprints?utm_source=website&utm_medium=blog&utm_campaign=Building-Footprints (accessed on 21 August 2020).
- Ecopia and DigitalGlobe. Technical Specification: Ecopia Building Footprints Powered by DigitalGlobe. Available online: https://dg-cms-uploads-production.s3.amazonaws.com/uploads/legal_document/file/109/DigitalGlobe_Ecopia_Building_Footprints_Technical_Specification.pdf (accessed on 21 August 2020).
- Haklay, M.; Basiouka, S.; Antoniou, V.; Ather, A. How Many Volunteers Does it Take to Map an Area Well? The Validity of Linus’ Law to Volunteered Geographic Information. Carto J. 2013, 47, 315–322. [Google Scholar] [CrossRef]
- Lloyd, C.T.; Sorichetta, A.; Tatem, A.J. High resolution global gridded data for use in population studies. Sci. Data 2017, 4, 170001. [Google Scholar] [CrossRef] [PubMed]
- Brown de Colstoun, E.C.; Huang, C.; Wang, P.; Tilton, J.C.; Tan, B.; Phillips, J.; Niemczura, S.; Ling, P.-Y.; Wolfe, R.E. Documentation for Global Man-made Impervious Surface (GMIS) Dataset From Landsat, v1 (2010); NASA Socioeconomic Data and Applications Center (SEDAC): Palisades, NY, USA, 2017. [Google Scholar] [CrossRef]
- Gutman, G.; Huang, C.; Chander, G.; Noojipady, P.; Masek, J.G. Assessment of the NASA–USGS Global Land Survey (GLS) datasets. Remote Sens. Environ. 2013, 134, 249–265. [Google Scholar] [CrossRef]
- Polley, E.; LeDell, E.; Kennedy, C.; Lendle, S.; van der Laan, M. R Package ‘SuperLearner’ Documentation. Available online: https://cran.r-project.org/web/packages/SuperLearner/SuperLearner.pdf (accessed on 21 August 2020).
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org/ (accessed on 21 August 2020).
- van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super learner. Stat. Appl. Genet. Mol. Biol. 2007, 6. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Annal. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef]
- Robin, X. ROC.test - Compare The AUC Of Two ROC Curves. From pROC v1.16.2. Available online: https://www.rdocumentation.org/packages/pROC/versions/1.16.2/topics/roc.test (accessed on 9 November 2020).
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Muller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- Sturrock, H.J.W. OSM Building Prediction Repository. Available online: https://github.com/disarm-platform/OSM_building_prediction (accessed on 21 August 2020).
- Bruy, A.; Dubinin, M. Python Script for Extracting Values of Image According to the Point Shapefile. Available online: https://github.com/nextgis/extract_values/blob/master/extract_values.py (accessed on 21 August 2020).
- Stackoverflow.com. Limit Python Script RAM Usage in Windows. Available online: https://stackoverflow.com/questions/54949110/limit-python-script-ram-usage-in-windows (accessed on 21 August 2020).
- Perry, M. Zonal Statistics Vector-Raster Analysis. Available online: https://gist.github.com/perrygeo/5667173 (accessed on 21 August 2020).
- Google Maps. -11.6486225,27.4351423. Available online: https://www.google.com/maps/@-11.6486225,27.4351423,834m/data=!3m1!1e3 (accessed on 21 August 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source | Acquisition | Publication Year | Data Type | Spatial Resolution | Format/Pixel Type and Depth | Spatial Reference | Spatial Coverage |
|---|---|---|---|---|---|---|---|---|
| Maxar Technologies building footprints | DigitizeAfrica data. Maxar Technologies, Ecopia.AI | 2009–2019 | Late 2019/Early 2020 | Building footprints, vector | Comparable to 1” (≈30 m) | ESRI polygon shapefiles | UTM WGS 1984 | National (COD and NGA) |
| OpenStreetMap (OSM) building footprints | OpenStreetMap contributors; geofabrik.de | Up to Jan-20 | Jan-20 | Building footprints with building attribute labels, categorical vector | Comparable to 1” (≈30 m) | ESRI polygon shapefiles | GCS WGS 1984 | National (COD and NGA) |
| OpenStreetMap (OSM) highways | OpenStreetMap contributors; geofabrik.de | Up to Jan-20 | Jan-20 | Highways, categorical vector | Comparable to 1” (≈30 m) | ESRI polyline shapefiles | GCS WGS 1984 | National (COD and NGA) |
| Democratic Republic of the Congo (COD)—building points for Kinshasa and North Ubangi | The World Bank Group [23] | 2018 | 2018 | Building attribute labels, categorical vector | Comparable to 1” (≈30 m) | ESRI point shapefiles | GCS WGS 1984 | Kinshasa and North Ubangi provinces, COD |
| Nigeria (NGA)—household survey data | Oak Ridge National Laboratory (ORNL) [24] | 2016–2017 | 2018 | Building attribute labels, categorical vector and table | Comparable to 1” (≈30 m) | ESRI point shapefiles/CSV tabular | GCS WGS 1984 | Abia, Adamawa, Akwa Ibom, Bauchi, Ebonyi, Edo, Enugu, Gombe, Kaduna, Kebbi, Lagos, Ogun, Oyo, Sokoto, Yobe, and Zamfara states, NGA |
| eHealth Africa and WorldPop (University of Southampton) [25] | 2018–2019 | 2019 | ||||||
| Democratic Republic of the Congo—household survey data | University of California, Los Angeles (UCLA) and Kinshasa School of Public Health (KSPH) [26] | 2017–2018 | 2018 | Building attribute labels, categorical vector and table | Comparable to 1” (≈30 m) | ESRI point shapefiles/CSV tabular | GCS WGS 1984 | Kinshasa, Kongo Central, Kwango, Kwilu, and Mai-Ndombe provinces, COD |
| Global Man-made Impervious Surface (GMIS) Dataset from Landsat, v1 | US NASA (SEDAC)/Center for International Earth Science Information Network (CIESIN), Columbia University [27] | 2010 | 2018 | Impervious surface (percentage per pixel), continuous raster | 1” (≈30 m) | Geo-tiff/uint8 | GCS WGS 1984 | National (COD and NGA) |
| Country | Total with Labels | Total without Labels | |
|---|---|---|---|
| Democratic Republic of the Congo | 98,294 | 2,791,564 | |
| Residential | 93,794 | ||
| Nonresidential | 4500 | ||
| Nigeria | 16,776 | 11,476,015 | |
| Residential | 12,985 | ||
| Nonresidential | 3791 |
| Observed | ||||
|---|---|---|---|---|
| Country | Nonresidential | Residential | ||
| Democratic Republic of the Congo | Predicted | Nonresidential | 463 | 753 |
| Residential | 36 | 9668 | ||
| % correctly classified | 92.8 | 92.8 | ||
| Nigeria | Predicted | Nonresidential | 360 | 212 |
| Residential | 61 | 1230 | ||
| % correctly classified | 85.5 | 85.3 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lloyd, C.T.; Sturrock, H.J.W.; Leasure, D.R.; Jochem, W.C.; Lázár, A.N.; Tatem, A.J. Using GIS and Machine Learning to Classify Residential Status of Urban Buildings in Low and Middle Income Settings. Remote Sens. 2020, 12, 3847. https://doi.org/10.3390/rs12233847
Lloyd CT, Sturrock HJW, Leasure DR, Jochem WC, Lázár AN, Tatem AJ. Using GIS and Machine Learning to Classify Residential Status of Urban Buildings in Low and Middle Income Settings. Remote Sensing. 2020; 12(23):3847. https://doi.org/10.3390/rs12233847
Chicago/Turabian StyleLloyd, Christopher T., Hugh J. W. Sturrock, Douglas R. Leasure, Warren C. Jochem, Attila N. Lázár, and Andrew J. Tatem. 2020. "Using GIS and Machine Learning to Classify Residential Status of Urban Buildings in Low and Middle Income Settings" Remote Sensing 12, no. 23: 3847. https://doi.org/10.3390/rs12233847
APA StyleLloyd, C. T., Sturrock, H. J. W., Leasure, D. R., Jochem, W. C., Lázár, A. N., & Tatem, A. J. (2020). Using GIS and Machine Learning to Classify Residential Status of Urban Buildings in Low and Middle Income Settings. Remote Sensing, 12(23), 3847. https://doi.org/10.3390/rs12233847