Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework

Abstract

1. Introduction
2. Research Area and Data
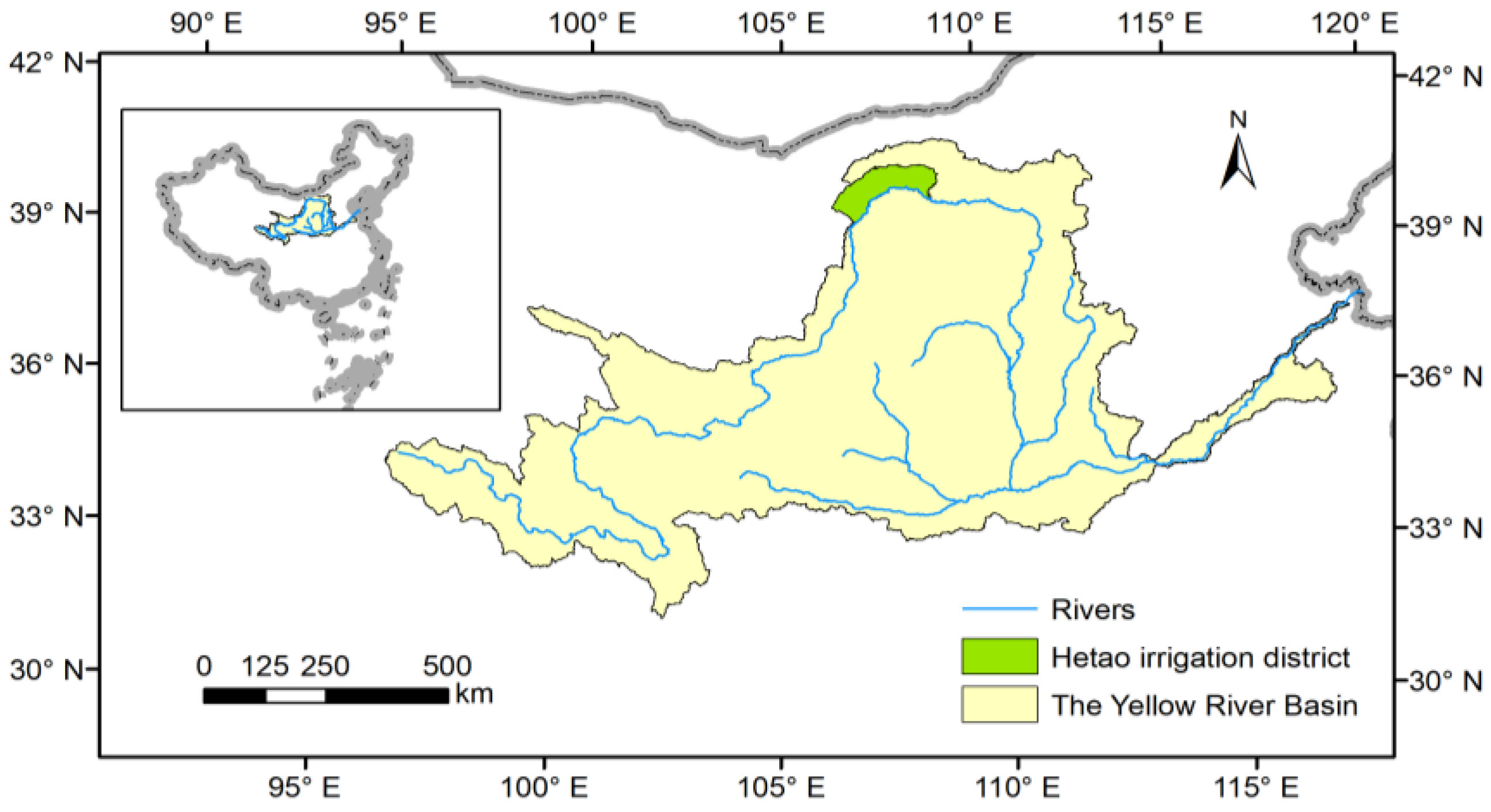
2.1. Research Area
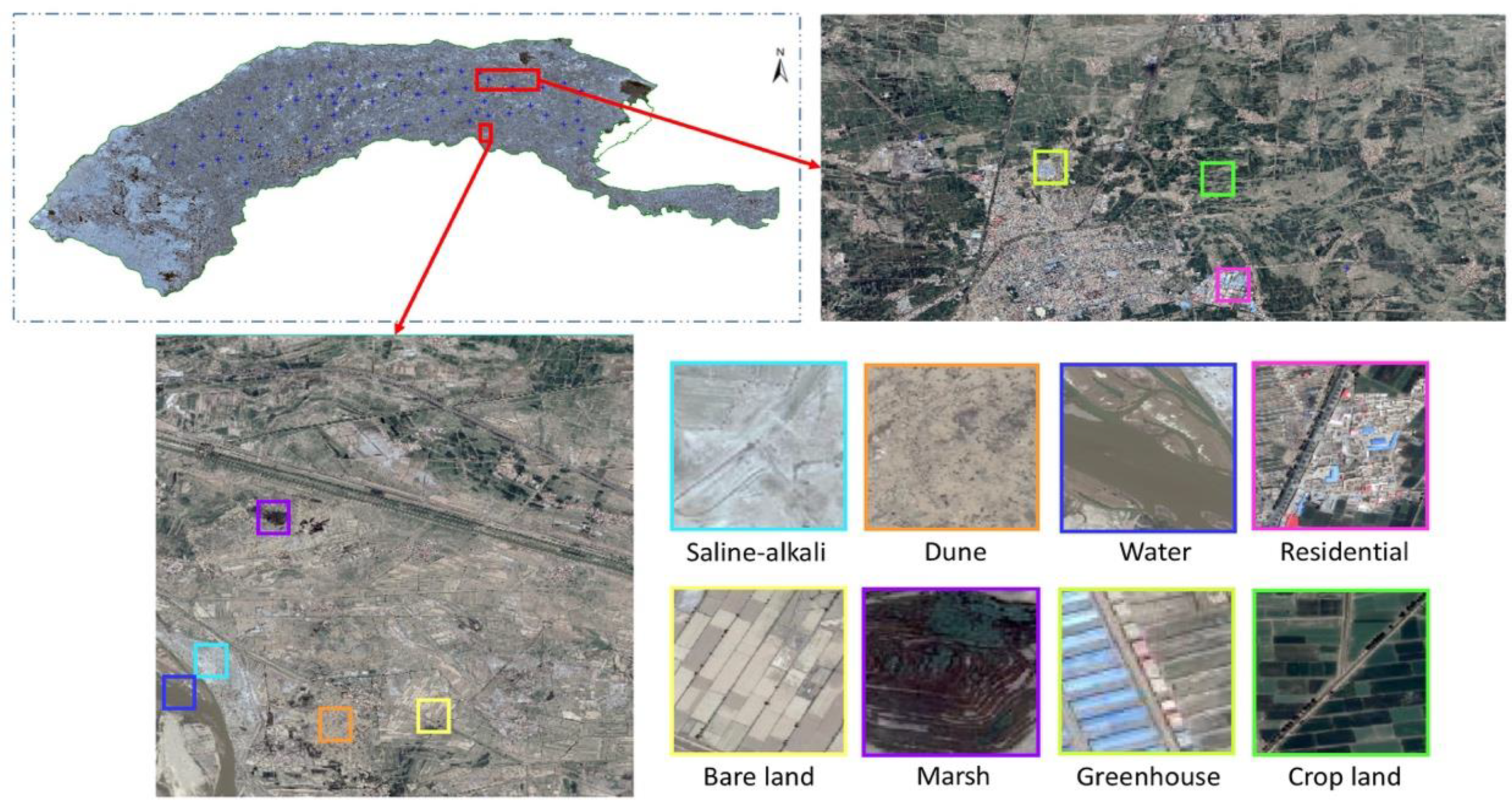
2.2. Data and Preprocessing
3. Methodology
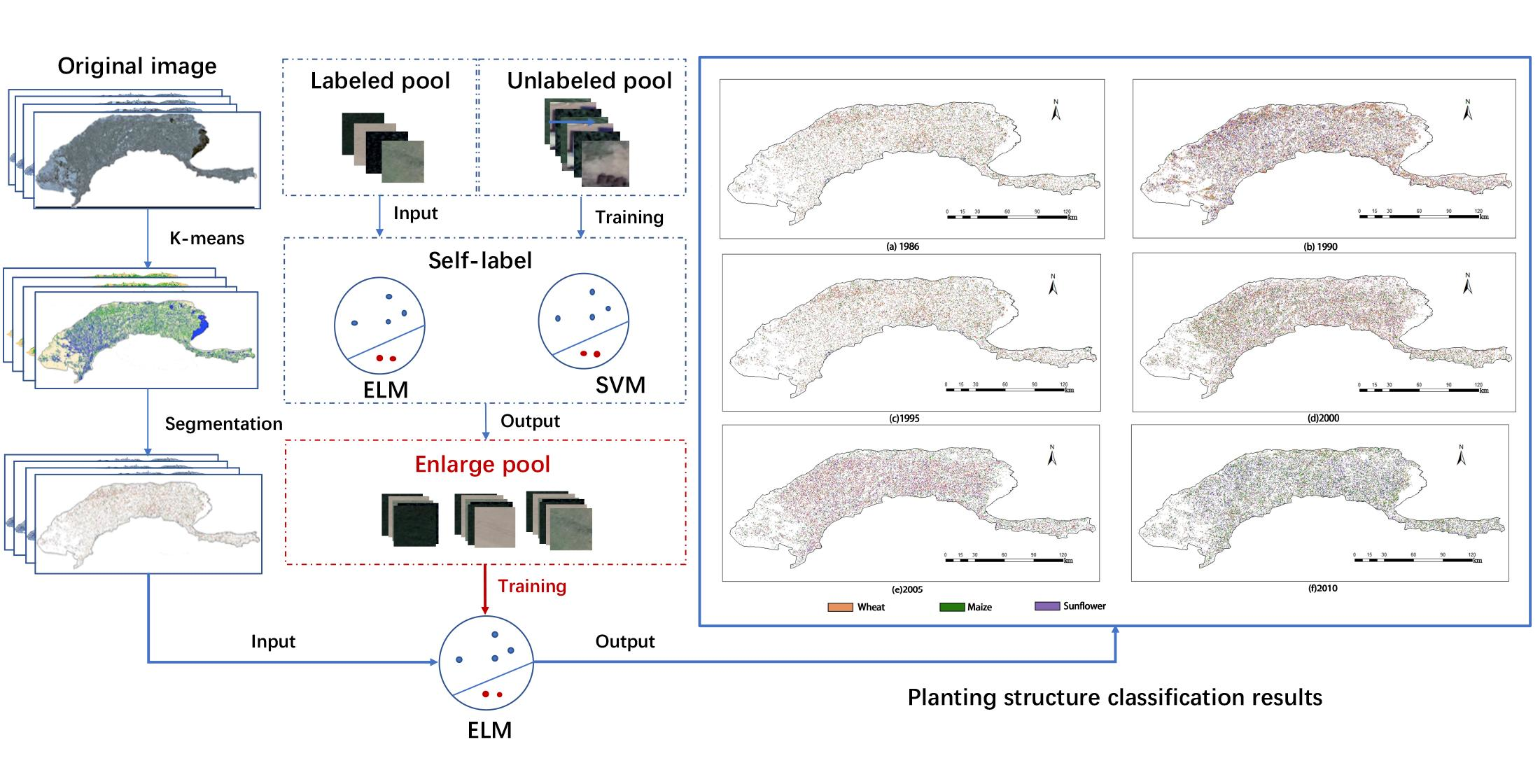
3.1. Image Segmentation with k-Means
3.2. The Co-Training Self-Label Method
3.2.1. The ELM
- Randomly assign the hidden node parameters: the input weights ci and biases bi.
- Calculate output matrix H of the hidden layer with Equation (5).
- Obtain the output weight β with Equation (7).
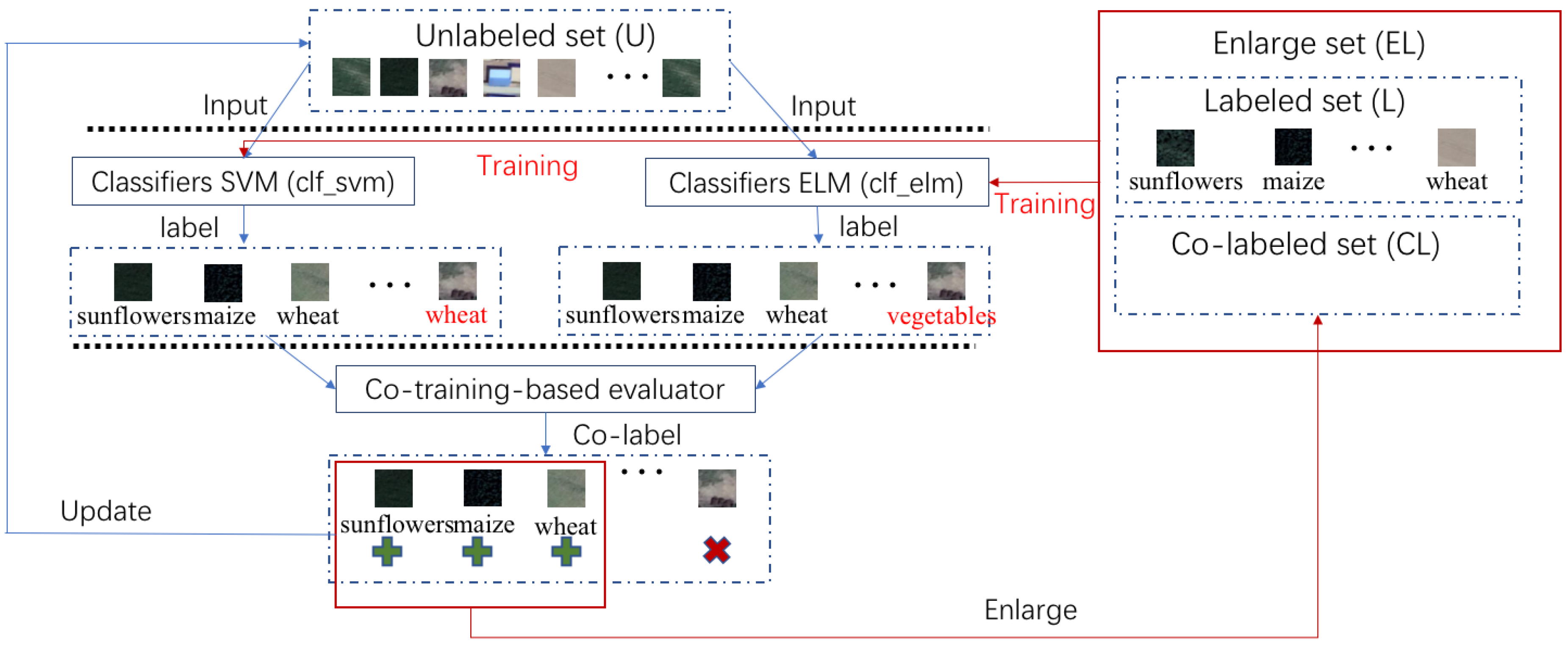
3.2.2. The Co-Training Self-Label Algorithm
3.3. Evaluation and Application of the SS-ELM Method
4. Results and Discussion
4.1. Evaluation of the SS-ELM Framework
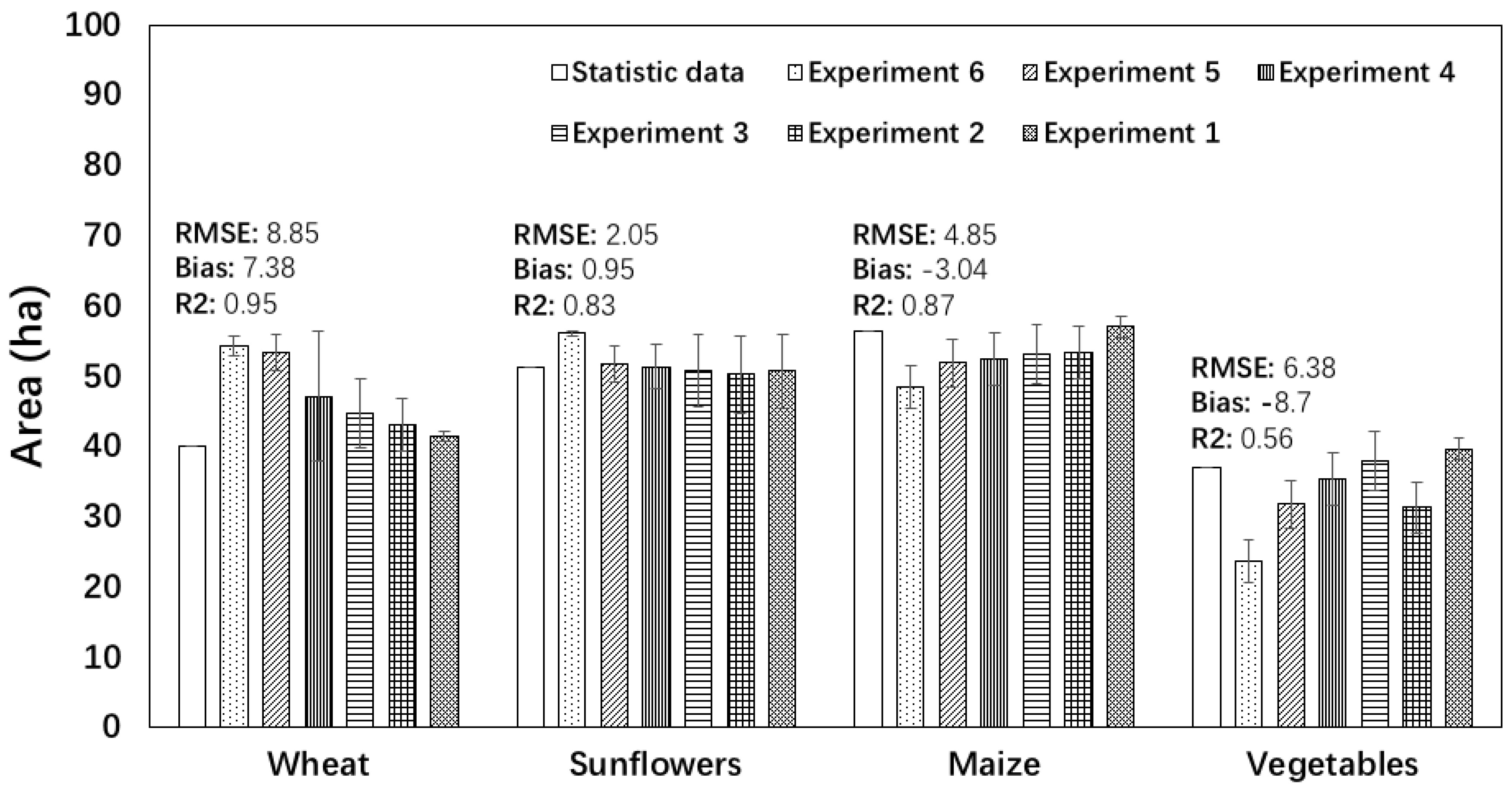
4.2. Application of the SS-ELM Algorithm for Detection of Cultivated Land Area and Planting Structure in a Large-Scale Agricultural Area
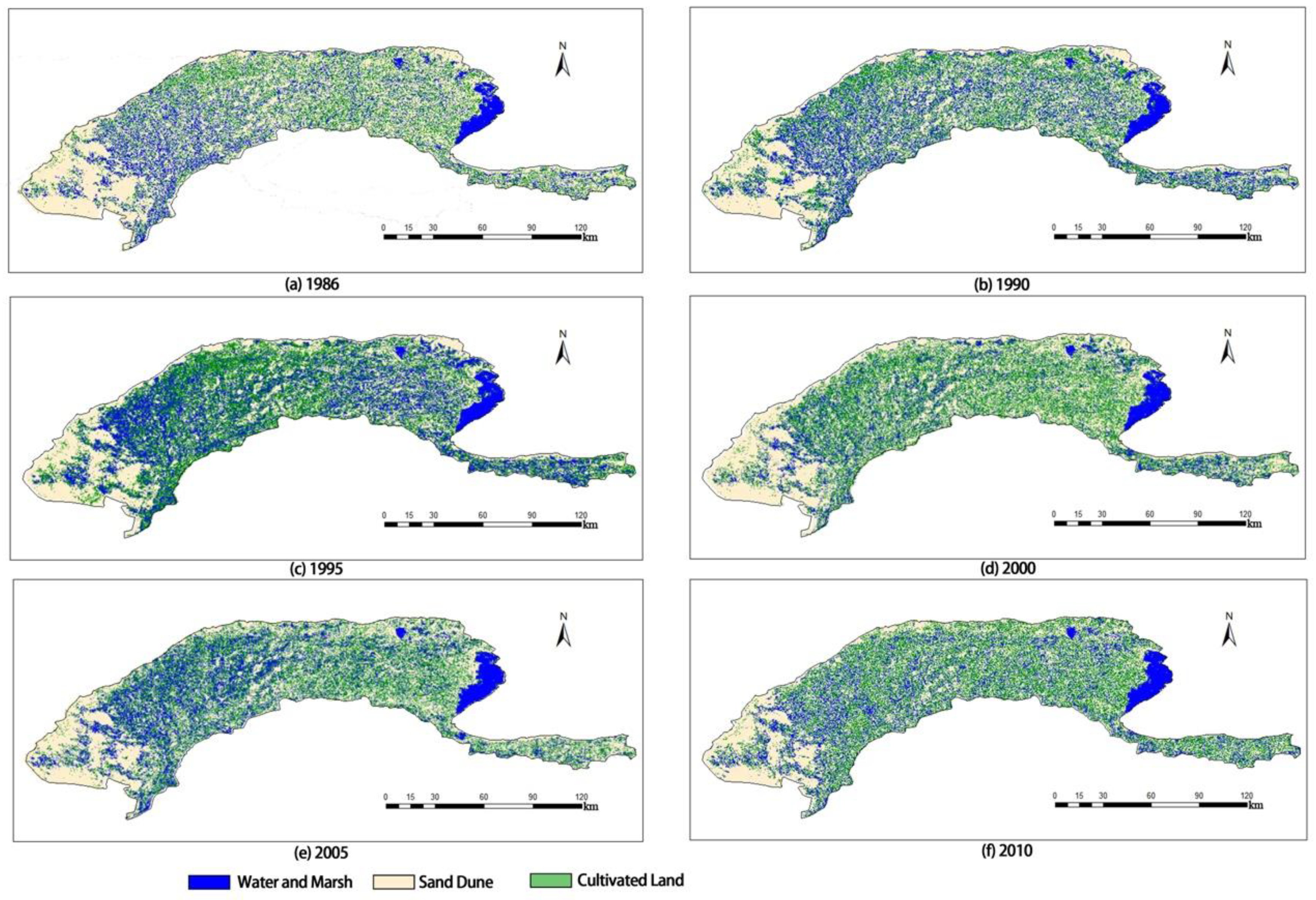
4.2.1. Detection of Cultivated Land Area
4.2.2. Classification of Planting Structure
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. WIREs Data Min. Knowl. Discov. 2018, e1264. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Ghimire, B.; Rogan, J.; Chicaolmo, M.; Rigol-Sanchez, J. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Li, J.; Xi, B.; Du, Q.; Song, R.; Li, Y.; Ren, G. Deep Kernel Extreme-Learning Machine for the Spectral–Spatial Classification of Hyperspectral Imagery. Remote Sens. 2018, 10, 2036. [Google Scholar] [CrossRef]
- Sandino, J.; Gonzalez, L.; Mengersen, K.; Gaston, K. UAVs and machine learning revolutionising invasive grass and vegetation surveys in remote arid lands. Sensors 2018, 18, 605. [Google Scholar] [CrossRef]
- Garea, A.S.; Heras, D.B.; Argüello, F. GPU classification of remote-sensing images using kernel ELM and extended morphological profiles. Int. J. Remote Sens. 2016, 37, 5918–5935. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Townsend, P.A.; Walsh, S.J. Remote sensing of forested wetlands: Application of multitemporal and multispectral satellite imagery to determine plant community composition and structure in southeastern USA. Plant Ecol. 2001, 157, 129–149. [Google Scholar] [CrossRef]
- Zanotta, D.C.; Zortea, M.; Ferreira, M.P. A supervised approach for simultaneous segmentation and classification of remote sensing images. ISPRS J. Photogramm. Remote Sens. 2018, 142, 162–173. [Google Scholar] [CrossRef]
- Kestur, R.; Angural, A.; Bashir, B.; Omkar, S.N.; Anand, G.; Meenavathi, M.B. Tree crown detection, delineation and counting in UAV remote sensed images: A neural network based spectral–spatial method. J. Indian Soc. Remote 2018, 46, 991–1004. [Google Scholar] [CrossRef]
- Adhikary, S.K.; Dhekane, S.G. Hyperspectral image classification using semi-supervised random forest. In Proceedings of the International Conference on ISMAC in Computational Vision and Bio-Engineering, Palladam, India, 16–17 May 2018. [Google Scholar] [CrossRef]
- Yan, D.; Chu, Y.; Li, L.; Liu, D. Hyperspectral remote sensing image classification with information discriminative extreme learning machine. Multimed. Tools Appl. 2018, 77, 5803–5818. [Google Scholar] [CrossRef]
- Weng, Q.; Mao, Z.; Lin, J.; Liao, X. Land-use scene classification based on a CNN using a constrained extreme learning machine. Int. J. Remote Sens. 2018, 39, 6281–6299. [Google Scholar] [CrossRef]
- Wang, L.; Hao, S.; Wang, Q.; Wang, Y. Semi-supervised classification for hyperspectral imagery based on spatial-spectral label propagation. ISPRS J. Photogramm. Remote Sens. 2014, 97, 123–137. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, F.; Zhang, L. Hyperspectral image classification via a random patches network. ISPRS J. Photogramm. Remote Sens. 2018, 142, 344–357. [Google Scholar] [CrossRef]
- Yang, C.; Li, Q.; Hu, Z.; Chen, J.; Shi, T.; Ding, K.; Wu, G. Spatiotemporal evolution of urban agglomerations in four major bay areas of US, China and Japan from 1987 to 2017: Evidence from remote sensing images. Sci. Total Environ. 2019, 671, 232–247. [Google Scholar] [CrossRef]
- Lei, Y.X.; Chen, X.F.; Min, M.; Xie, Y.F. A semi-supervised laplacian extreme learning machine and feature fusion with cnn for industrial superheat identification. Neurocomputing 2020, 381, 186–195. [Google Scholar] [CrossRef]
- Huang, G.; Song, S.; Gupta, J.N.D.; Wu, C. Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 2017, 44, 2405–2417. [Google Scholar] [CrossRef]
- Zhou, W.; Qiao, S.; Yi, Y.; Han, N.; Chen, Y.; Lei, G. Automatic optic disc detection using low-rank representation based semi-supervised extreme learning machine. Int. J. Mach. Learn. Cybern. 2019, 11, 55–69. [Google Scholar] [CrossRef]
- Krishnapuram, B.; Carin, L.; Figueiredo, M.A.T.; Hartemink, A.J. Sparse multinomial logistic regression: Fast algorithms and generalization bounds. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 957–968. [Google Scholar] [CrossRef]
- Rosenberg, C.; Hebert, M.; Schneiderman, H. Semi-Supervised Self-Training of Object Detection Models. In Proceedings of the 7th IEEE Workshop on Application of Computer Vision, Breckenridge, CO, USA, 5–7 January 2005; pp. 29–36. [Google Scholar] [CrossRef]
- Ando, R.K.; Zhang, T. Two-view feature generation model for semi-supervised learning. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 25–32. [Google Scholar]
- Joachims, T. Transductive Inference for Text Classification Using Support Vector Machines. In Proceedings of the 16th International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 200–209. [Google Scholar]
- Blum, A.; Chawla, S. Learning from Labeled and Unlabeled Data Using Graph Mincuts. In Proceedings of the 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 19–26. [Google Scholar]
- Banerjee, B.; Buddhiraju, K.M. A novel semi-supervised land cover classification technique of remotely sensed images. J. Indian Soc. Remote Sens. 2015, 43, 719–728. [Google Scholar] [CrossRef]
- Balabantaray, R.C.; Sarma, C.; Jha, M. Document clustering using k-means and k-medoids. Int. J. Knowl. Based Comput. Syst. 2013, 1, 1–5. [Google Scholar]
- Hu, G.; Zhou, S.; Guan, J.; Hu, X. Towards effective document clustering: A constrained k-means based approach. Inform. Process. Manag. 2008, 44, 1397–1409. [Google Scholar] [CrossRef]
- Wang, L. On the euclidean distance of image. IEEE Trans. Pattern Anal. 2005, 27, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Celebi, M.E.; Kingravi, H.A. Linear, deterministic, and order-invariant initialization methods for the k-means clustering algorithm. In Partitional Clustering Algorithms; Celebi, M., Ed.; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Yang, C.; Liu, H.; Liao, S.; Wang, S. Extreme learning machine-guided collaborative coding for remote sensing image classification. In Proceedings of the Extreme Learning Machine Conference, ELM-2015, Hangzhou, China, 15–17 December 2015; Springer International Publishing: Cham, Switzerland, 2016; Volume 1. [Google Scholar] [CrossRef]
- Huang, G.-B.; Chen, L.; Siew, C.-K. Universal Approximation Using Incremental Constructive Feedforward Networks With Random Hidden Nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.-B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man. Cybern. 2011, 42, 513–529. [Google Scholar] [CrossRef]
- Huang, G.-B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local Receptive Fields Based Extreme Learning Machine. IEEE Comput. Intell. Mag. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Han, M.; Liu, B. Ensemble of extreme learning machine for remote sensing image classification. Neurocomputing 2015, 149, 65–70. [Google Scholar] [CrossRef]
- Huang, F.; Lu, J.; Tao, J.; Li, L.; Tan, X.; Liu, P. Research on Optimization Methods of ELM Classification Algorithm for Hyperspectral Remote Sensing Images. IEEE Access 2019, 7, 108070–108089. [Google Scholar] [CrossRef]
- Scardapane, S.; Fierimonte, R.; Di Lorenzo, P.; Panella, M.; Uncini, A. Distributed semi-supervised support vector machines. Neural Netw. 2016, 80, 43–52. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Center for Bioinformatics & Molecular Biostatistics, UC San Francisco: San Francisco, CA, USA, 2004; Available online: http://escholarship.org/uc/item/35x3v9t4 (accessed on 14 April 2003).
- Zhu, Z. Analysis on Water-Saving Measures and Estimation on Water-Saving Potential of Agricultural Irrigation in Hetao Irrigation District of Inner Mongolia. Ph.D. Thesis, Yangzhou University, Yangzhou, China, June 2017. [Google Scholar]
- Tong, W. Study on Salt Tolerance of Crops and Cropping System Optimization in Hetao Irrigation District. Ph.D. Thesis, China Agricultural University, Beijing, China, June 2014. [Google Scholar]
- Fu, W.; Zhai, J.; Zhao, Y.; He, G.; Zhang, Y. Effects of the Planting Structure Adjustment on Water Budget of Field System in Hetao Irrigation Area. J. Irrig. Drain. 2017, 36, 1–8. [Google Scholar] [CrossRef]
- Ahmad, M.; Khan, A.; Khan, A.M.; Mazzara, M.; Nibouche, O. Spatial prior fuzziness pool-based interactive classification of hyperspectral images. Remote Sens. 2019, 1, 1136. [Google Scholar] [CrossRef]
- Jie, H.; Zhi, H.; Jun, L.; Lin, H.; Yiwen, W. 3d-gabor inspired multiview active learning for spectral-spatial hyperspectral image classification. Remote Sens. 2018, 10, 1070. [Google Scholar] [CrossRef]
- Li, J. Active learning for hyperspectral image classification with a stacked autoencoders based neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Ni, D.; Ma, H. Active learning for hyperspectral image classification using sparse code histogram and graph-based spatial refinement. Int. J. Remote Sens. 2017, 38, 923–948. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year and Data Source | HID | Year and Data Source | HID | ||||
|---|---|---|---|---|---|---|---|
| Path/Row | Date | Cloud% | Path/row | Date | Cloud% | ||
| 1986 Landsat TM | 128/31 | 1986.08.09 | 1 | 2000 Landsat OLI | 128/31 | 2000.09.24 | 0 |
| 128/32 | 1986.08.09 | 0 | 128/32 | 2000.09.08 | 0 | ||
| 129/31 | 1986.07.31 | 6 | 129/31 | 2000.09.24 | 0 | ||
| 129/32 | 1986.07.31 | 1 | 129/32 | 2000.08.30 | 5.09 | ||
| 1990 Landsat TM | 128/31 | 1990.09.05 | 9 | 2005 Landsat OLI | 128/31 | 2005.10.24 | 0.07 |
| 128/32 | 1990.06.01 | 0 | 128/32 | 2005.10.08 | 0.23 | ||
| 129/31 | 1990.08.11 | 0 | 129/31 | 2005.09.13 | 0.02 | ||
| 129/32 | 1990.07.10 | 1.69 | 129/32 | 2005.09.13 | 0.05 | ||
| 1995 Landsat TM | 128/31 | 1995.09.19 | 0 | 2010 Landsat OLI | 128/31 | 2010.08.19 | 0 |
| 128/32 | 1995.09.19 | 0 | 128/32 | 2010.08.19 | 0.1 | ||
| 129/31 | 1995.09.10 | 0.27 | 129/31 | 2010.08.26 | 0.19 | ||
| 129/32 | 1995.09.26 | 0 | 129/32 | 2010.09.11 | 0 | ||
| 1: | Input: labeled set L, unlabeled set U |
| 2: | Output: enlarged set EL |
| 3: | initializeEL = L; co-training labeled set CL as empty; |
| 4: | clf_svm; clf_elm the independent classifiers are initially trained with L |
| 5: | while length (EL) increases do processes the CL set until the sample number of EL doesn’t change |
| 6: | clf_svm; clf_elm; update training (clf_svm; clf_elm; EL+L) |
| 7: | Co_labeling (clf_svm; clf_elm; EL; CL) |
| 8: | end while |
| 9: | ReturnEL |
| Classes | Samples of Training Set | Samples of Test Set | |||||
|---|---|---|---|---|---|---|---|
| Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 | Experiment 6 | ||
| Wheat | 5100 | 1150 | 16 | 8 | 4 | 2 | 66,675 |
| Maize | 5700 | 1000 | 16 | 8 | 4 | 2 | 97,847 |
| Vegetables | 3450 | 1025 | 16 | 8 | 4 | 2 | 54,963 |
| Sunflowers | 6775 | 1000 | 16 | 8 | 4 | 2 | 49,516 |
| Experiment | Classes | Indicator | RF | SVM | ELM | S-SVM | SS-ELM |
|---|---|---|---|---|---|---|---|
| 1 | Wheat | Producer’s accuracy (%) | 91 ± 2.31 | 94.15 ± 2.09 | 94.35 ± 2.52 | 94.87 ± 4.43 | 94.20 ± 2.67 |
| Maize | 98.05 ± 3.37 | 94.30 ± 4.99 | 97.01 ± 2.7 | 100.00 ± 0 | 98.08 ± 2.71 | ||
| Vegetables | 19.40 ± 13.61 | 44.56 ± 13.04 | 55 ± 2.12 | 89.70 ± 1.40 | 80.76 ± 8.67 | ||
| Sunflowers | 96.01 ± 3.48 | 96.54 ± 4.88 | 91.57 ± 4.13 | 94.22 ± 5.00 | 99.16 ± 1.18 | ||
| OA (%) | 80.28 ± 4.71 | 85.82 ± 6.93 | 84.60 ± 3.68 | 92,84 ± 4.10 | 92.17 ± 2.89 | ||
| 2 | Wheat | Producer’s accuracy (%) | 88.41 ± 1.54 | 93.56 ± 3.42 | 93.43 ± 4.31 | 98.10 ± 1.61 | 94.46 ± 4.24 |
| Maize | 90.19 ± 6.62 | 89.37 ± 4.83 | 92.08 ± 4.68 | 96.12 ± 3.35 | 91.40 ± 2.91 | ||
| Vegetables | 34.61 ± 12.69 | 62.87 ± 16.86 | 56.01 ± 9.59 | 81.79 ± 8.26 | 67.28 ± 14.91 | ||
| Sunflowers | 98.16 ± 3.18 | 97.69 ± 3.98 | 93.42 ± 5.88 | 94.33 ± 5.00 | 99.44 ± 0.96 | ||
| OA (%) | 77.60 ± 7.44 | 85.83 ± 6.02 | 85,81 ± 2.21 | 90.65 ± 5.99 | 88.75 ± 2.40 | ||
| 3 | Wheat | Producer’s accuracy (%) | 80.31 ± 10.71 | 85.95 ± 4.08 | 90.60 ± 1.18 | 94.52 ± 3.05 | 96.83 ± 0.63 |
| Maize | 86.22 ± 9.03 | 61.44 ± 17.09 | 65.54 ± 2.1 | 93.8 ± 1.24 | 96.12 ± 3.35 | ||
| Vegetables | 20.59 ± 18.48 | 55.03 ± 12.76 | 66.74 ± 12.18 | 58.66 ± 9.61 | 77.08 ± 2.12 | ||
| Sunflowers | 77.06 ± 13.17 | 89.65 ± 8.95 | 94.32 ± 4.91 | 99.10 ± 1.14 | 89.13 ± 9.41 | ||
| OA (%) | 73.76 ± 2.32 | 77.76 ± 12.45 | 77.88 ± 9.28 | 85.35 ± 0.06 | 89.53 ± 4.05 | ||
| 4 | Wheat | Producer’s accuracy (%) | 63.32 ± 7.97 | 79.57 ± 10.88 | 82.82 ± 8.08 | 86.26 ± 6.30 | 91.92 ± 2.51 |
| Maize | 97.15 ± 2.46 | 67.44 ± 27.40 | 84.52 ± 1.52 | 83.84 ± 13.99 | 94.48 ± 3.44 | ||
| Vegetables | 25.25 ± 25.40 | 23.26 ± 33.35 | 35.75 ± 5.08 | 68.42 ± 7.00 | 72.29 ± 5.12 | ||
| Sunflowers | 83.90 ± 27.78 | 99.02 ± 0.84 | 84.38 ± 1.40 | 80.70 ± 11.11 | 89.24 ± 2.07 | ||
| OA (%) | 65.96 ± 4.46 | 71.48 ± 6.93 | 73.24 ± 11.58 | 82.54 ± 5.95 | 84.35 ± 7.16 | ||
| 5 | Wheat | Producer’s accuracy (%) | 73 ± 14.62 | 51.98 ± 22.55 | 84.08 ± 14.45 | 85.19 ± 4.45 | 87.43 ± 2.51 |
| Maize | 70.14 ± 12.68 | 84.11 ± 17.51 | 79.56 ± 17,73 | 77.78 ± 3.32 | 87.98 ± 5.51 | ||
| Vegetables | 18.34 ± 21.99 | 45.98 ± 4.25 | 27.79 ± 19.10 | 59.08 ± 10.53 | 60.18 ± 11.48 | ||
| Sunflowers | 97.54 ± 2.1 | 76.17 ± 0.02 | 87.95 ± 11.88 | 82.45 ± 11.42 | 88.01 ± 6.61 | ||
| OA (%) | 70.45 ± 2.55 | 70.15 ± 12.75 | 76.23 ± 2.98 | 80.25 ± 1.53 | 83.00 ± 0.84 | ||
| 6 | Wheat | Producer’s accuracy (%) | 51.44 ± 16.21 | 39.32 ± 16.76 | 77.12 ± 7.04 | 67.51 ± 12.81 | 88.44 ± 2.50 |
| Maize | 78.60 ± 18.87 | 94.33 ± 5.13 | 80.90 ± 17.77 | 90.17 ± 10.18 | 84.43 ± 2.67 | ||
| Vegetables | 10.75 ± 14.73 | 16.68 ± 7.00 | 27.94 ± 24.35 | 39.34 ± 23.40 | 56.44 ± 4.98 | ||
| Sunflowers | 80.13 ± 11.34 | 56.65 ± 45.64 | 45.25 ± 14.02 | 98.00 ± 3.45 | 91.81 ± 1.09 | ||
| OA (%) | 56.97 ± 10.25 | 58.43 ± 0.86 | 62.71 ± 9.08 | 72.51 ± 3.55 | 83.32 ± 0.27 |
| No. | Year | Area Estimated by Remote Sensing (ha) | Statistical Area (ha) | ||||
|---|---|---|---|---|---|---|---|
| Maize | Wheat | Sunflowers | Maize | Wheat | Sunflowers | ||
| 1 | 1986 | 36,276 (14.51%) | 151,781 (60.73%) | 61,836 (24.74%) | 30,646 | 168,120 | 51,226 |
| 2 | 1990 | 42,272 (11.90%) | 250,158 (70.47%) | 62,539 (17.61%) | 40,746 | 228,960 | 69,846 |
| 3 | 1995 | 52,674 (12.02%) | 300,400 (68.46%) | 85,025 (19.40%) | 45,553 | 246,206 | 82,806 |
| 4 | 2000 | 53,328 (13.67%) | 209,402 (53.70%) | 127,187 (32.61%) | 59,024 | 202,625 | 146,024 |
| 5 | 2005 | 89,593 (22.99%) | 155,997 (40.03%) | 144,051 (36.97%) | 77,480 | 173,027 | 143,188 |
| 6 | 2010 | 106,322 (27.87%) | 105,403 (27.63%) | 169,700 (44.49%) | 99,754 | 84,384 | 210,620 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Z.; Huang, G.; Chi, D. Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework. Remote Sens. 2020, 12, 3708. https://doi.org/10.3390/rs12223708
Feng Z, Huang G, Chi D. Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework. Remote Sensing. 2020; 12(22):3708. https://doi.org/10.3390/rs12223708
Chicago/Turabian StyleFeng, Ziyi, Guanhua Huang, and Daocai Chi. 2020. "Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework" Remote Sensing 12, no. 22: 3708. https://doi.org/10.3390/rs12223708
APA StyleFeng, Z., Huang, G., & Chi, D. (2020). Classification of the Complex Agricultural Planting Structure with a Semi-Supervised Extreme Learning Machine Framework. Remote Sensing, 12(22), 3708. https://doi.org/10.3390/rs12223708