Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model

Abstract
1. Introduction
2. Study Area and Data
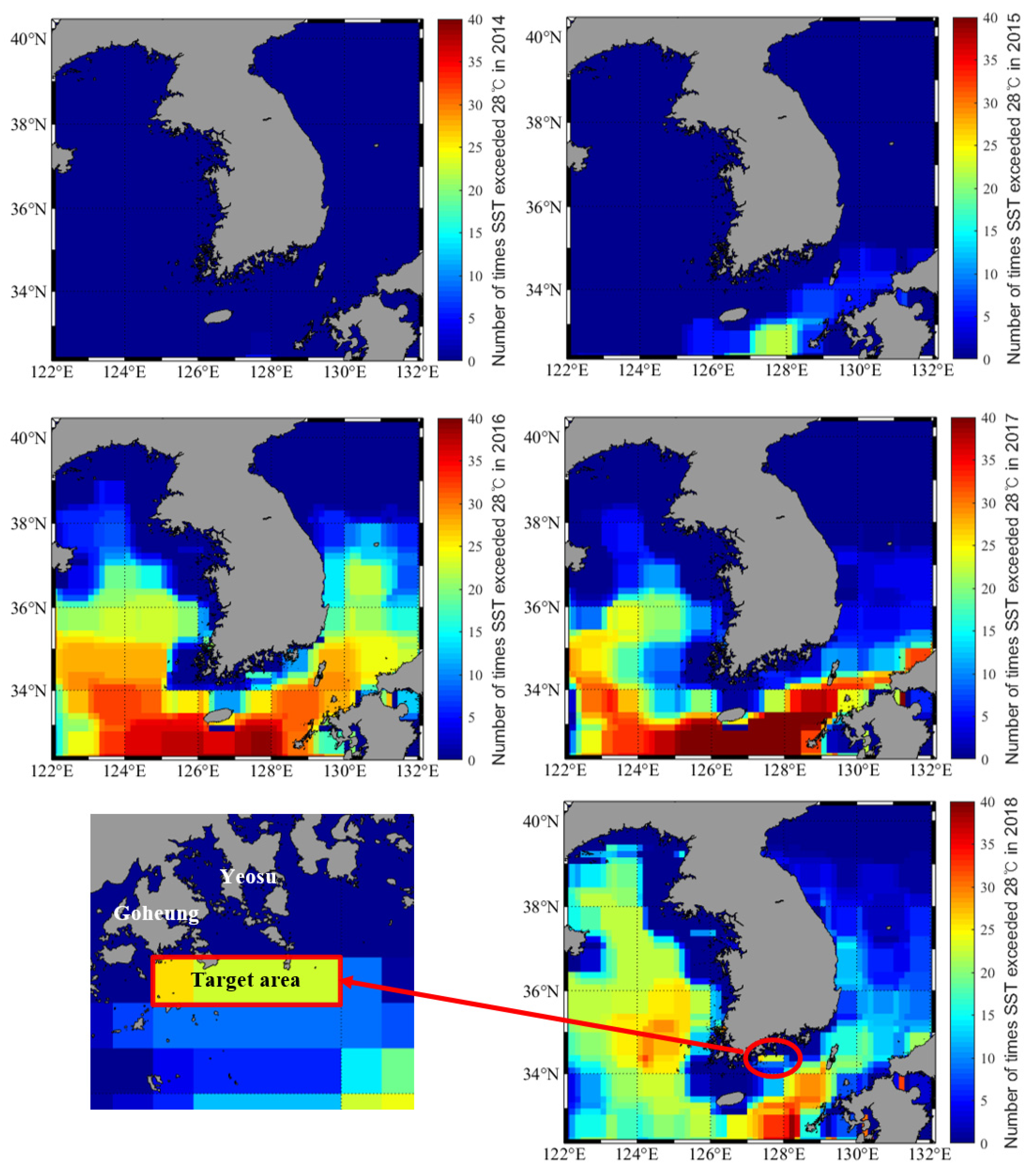
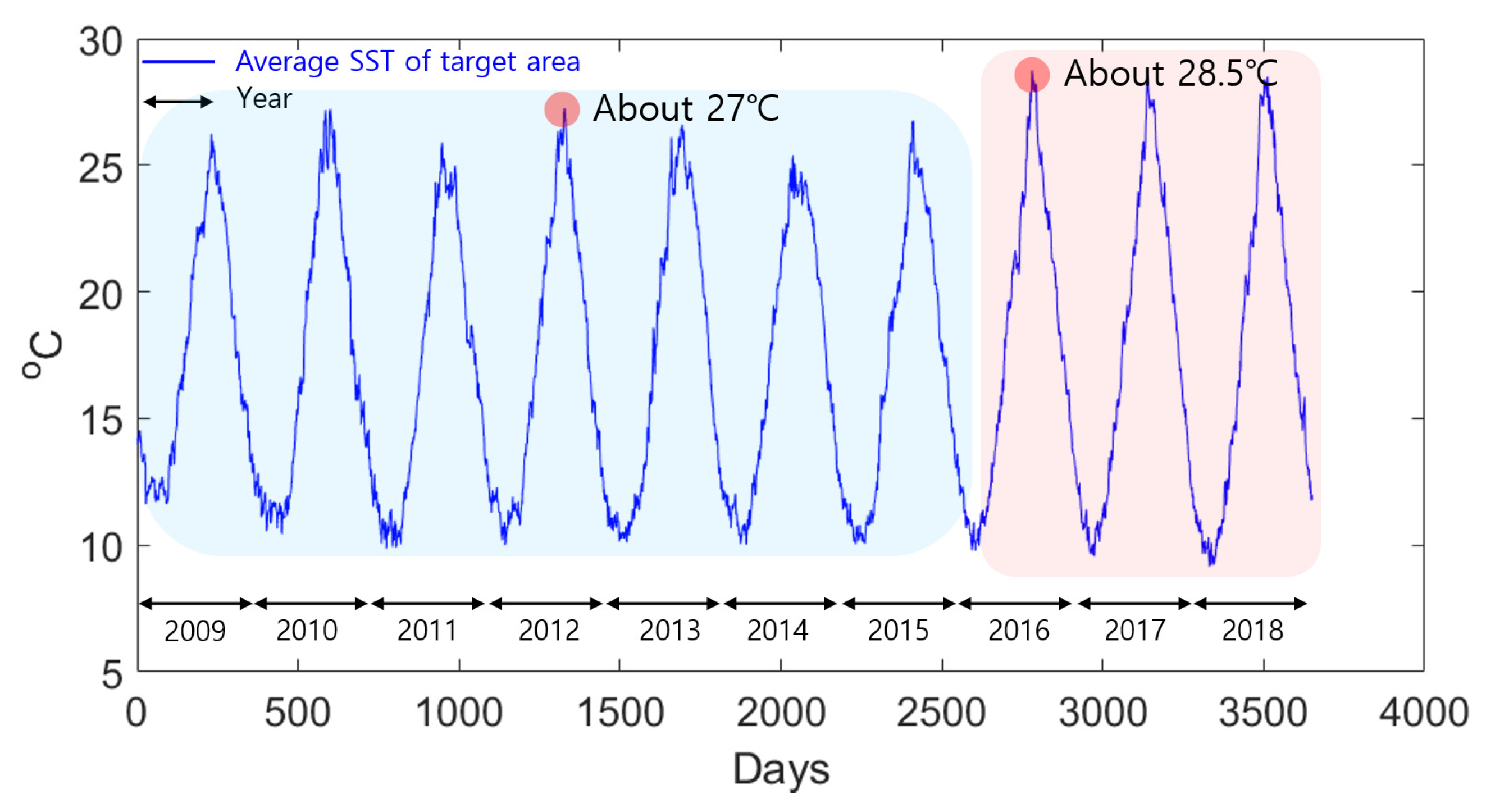
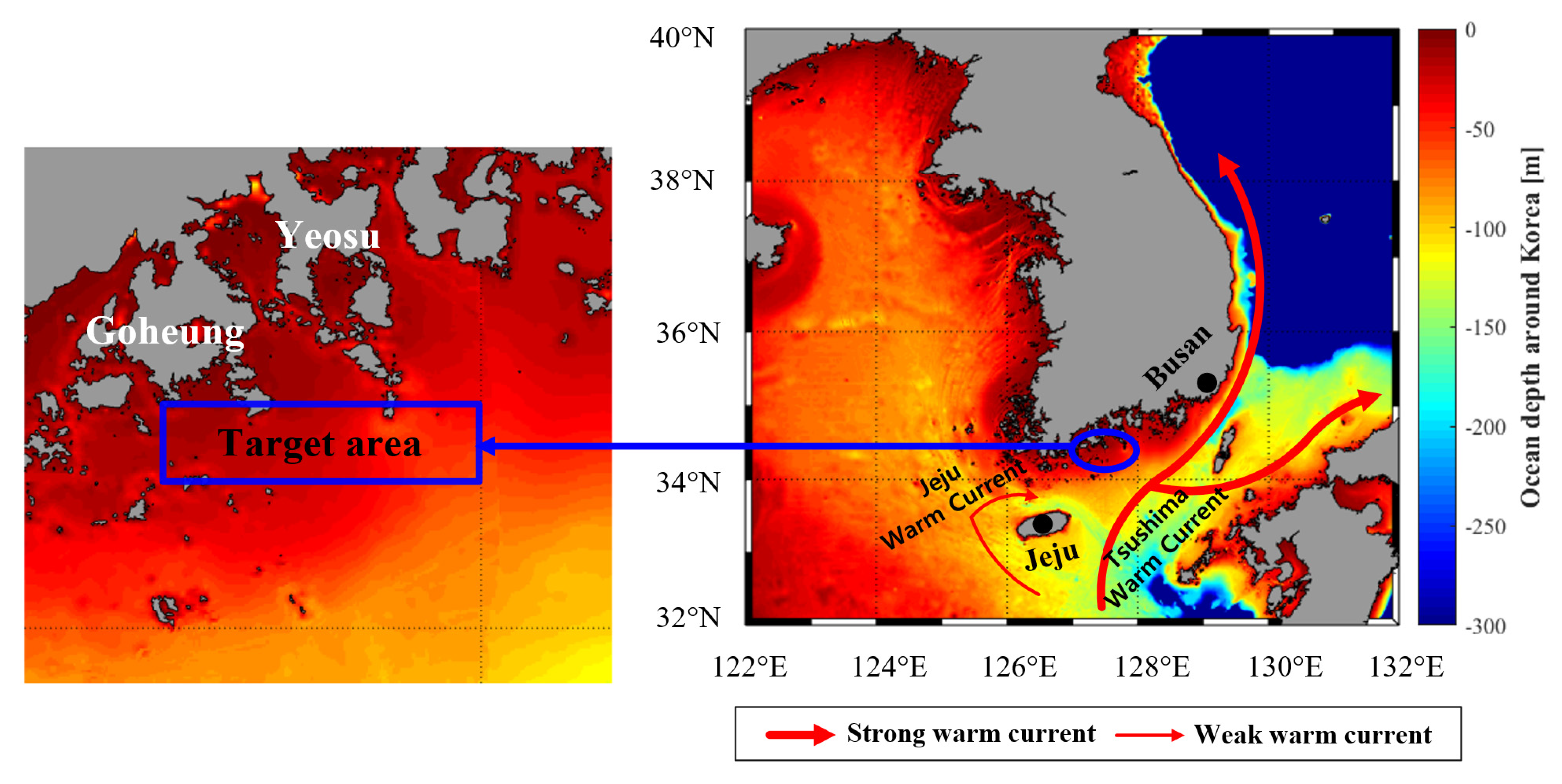
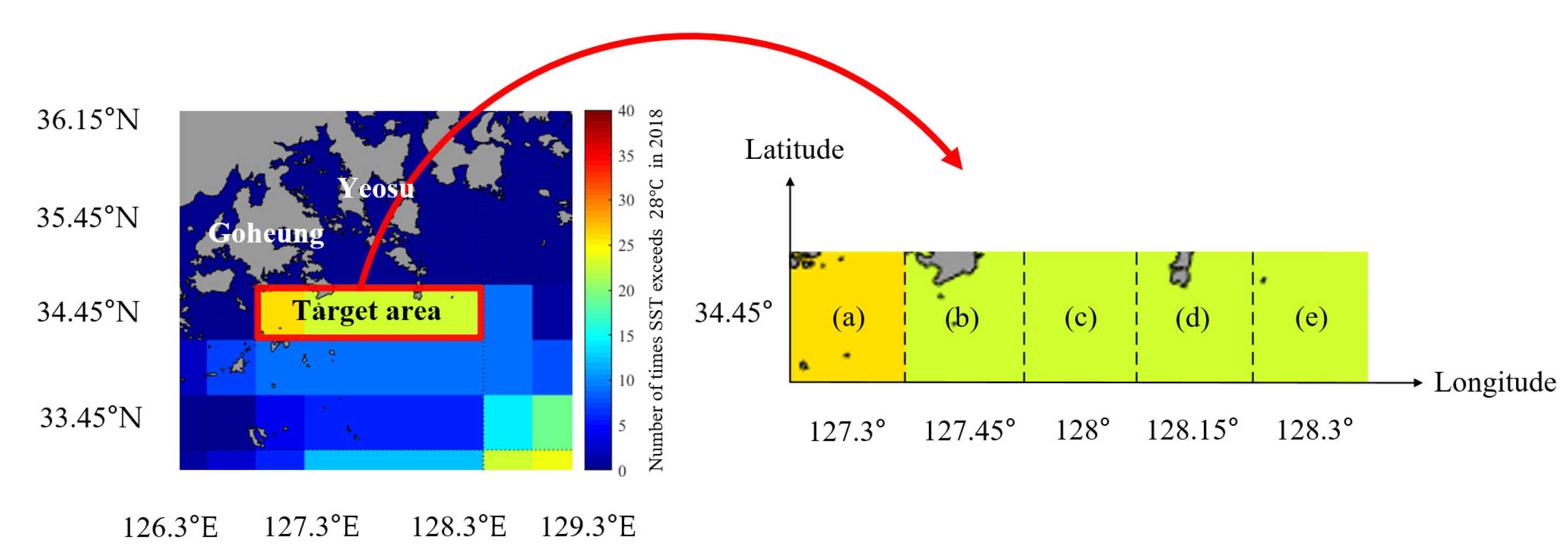
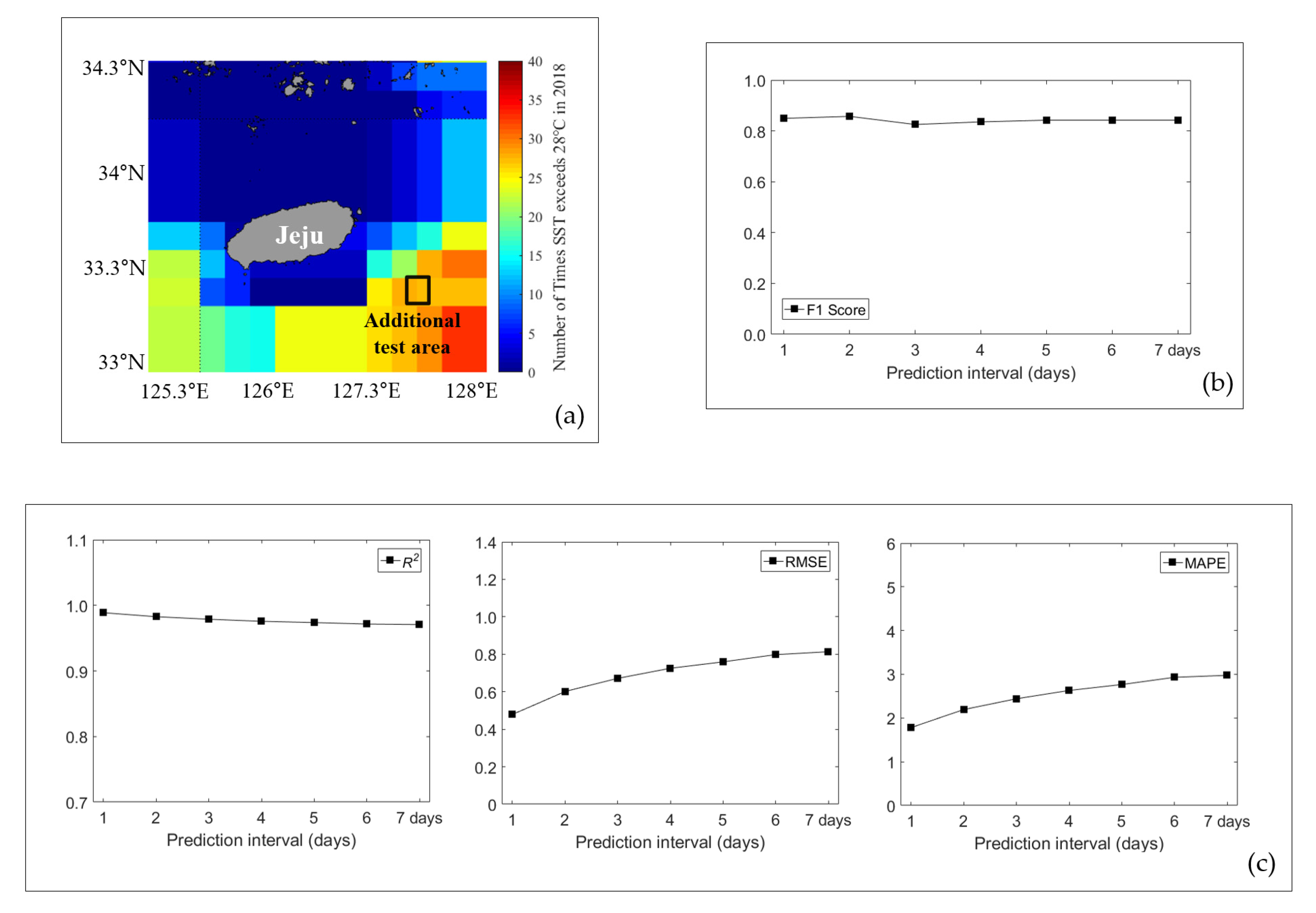
2.1. Study Area
2.2. Data
3. Methods
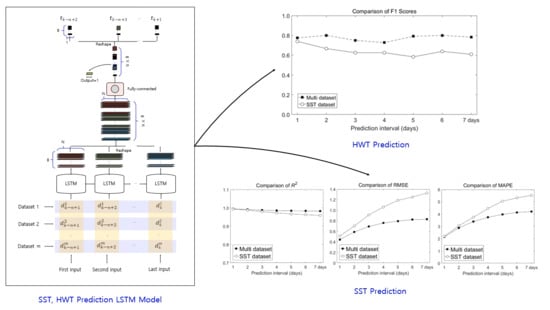
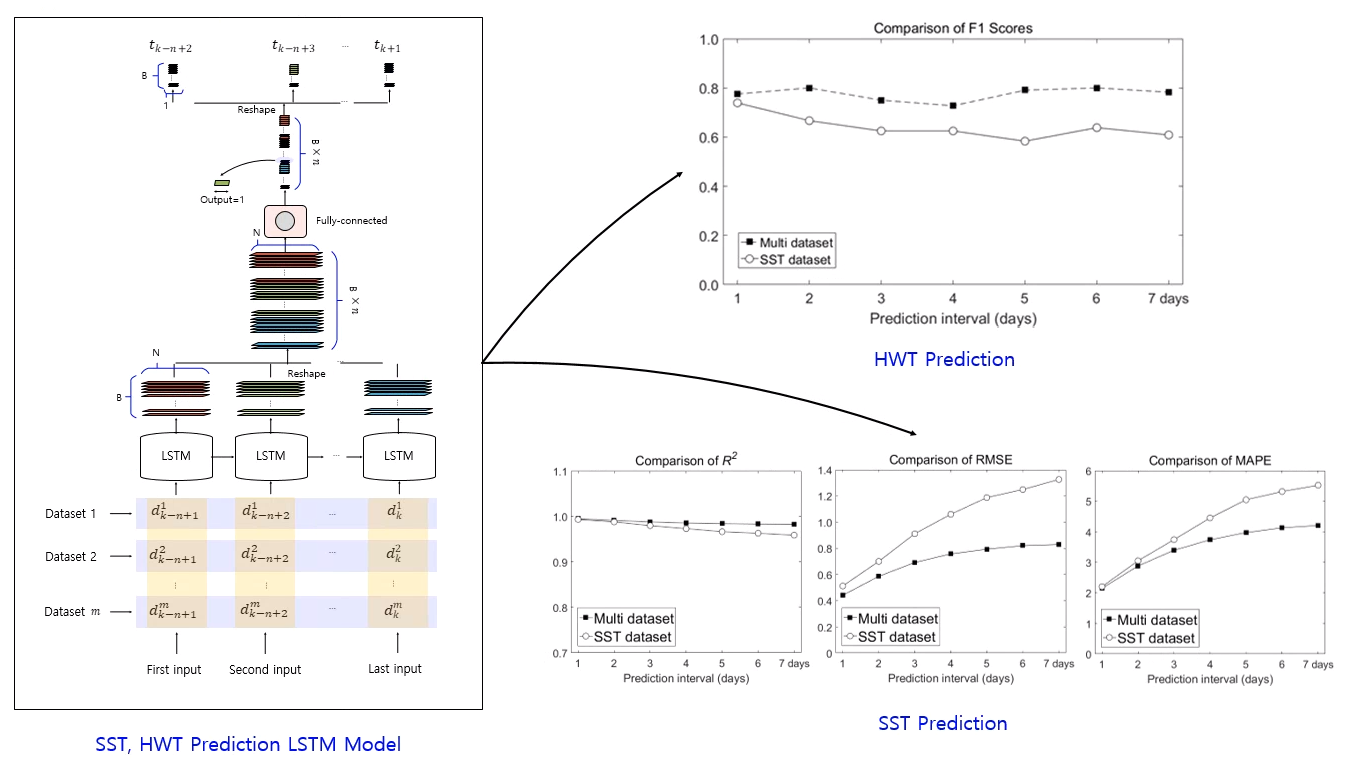
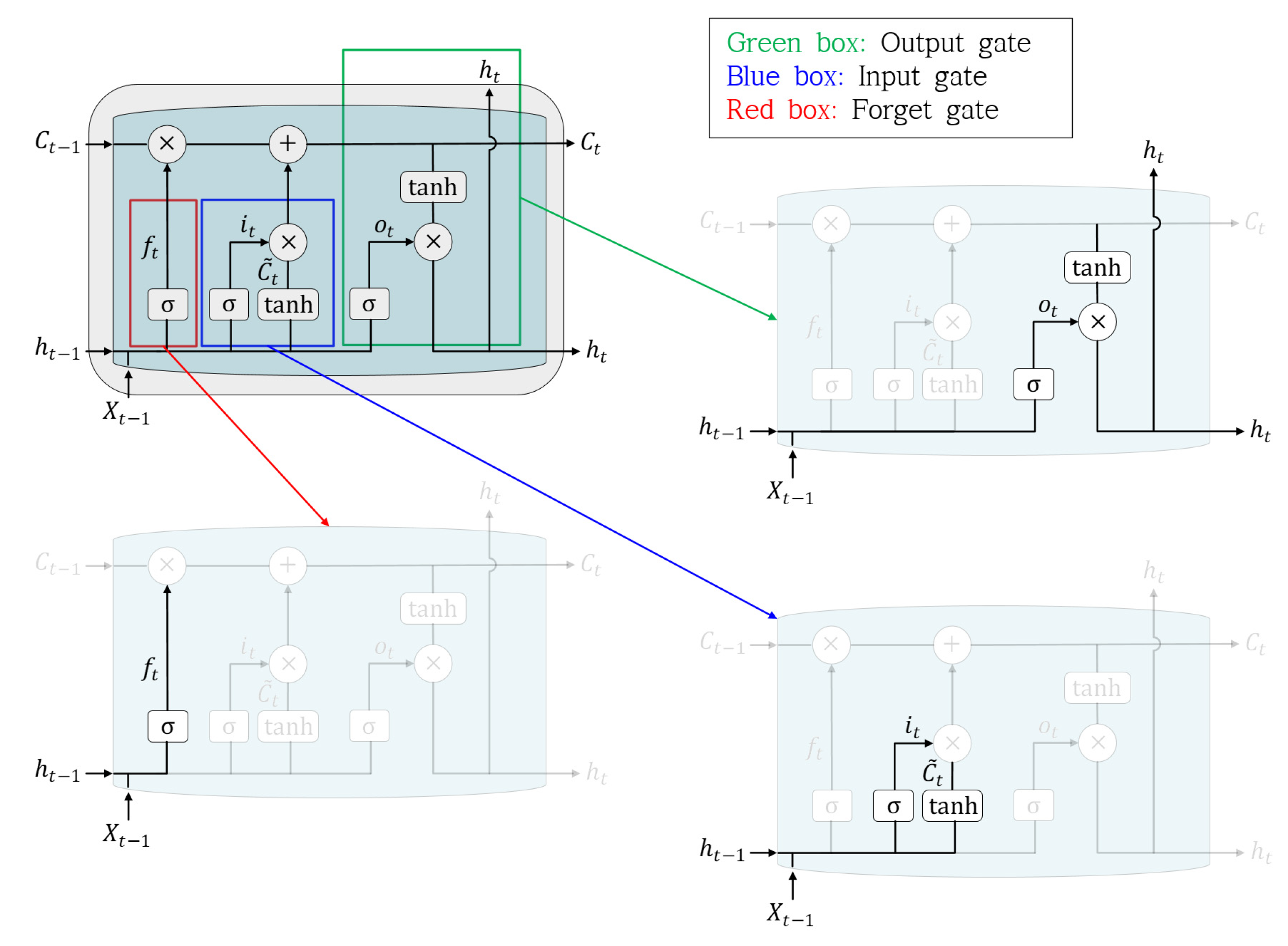
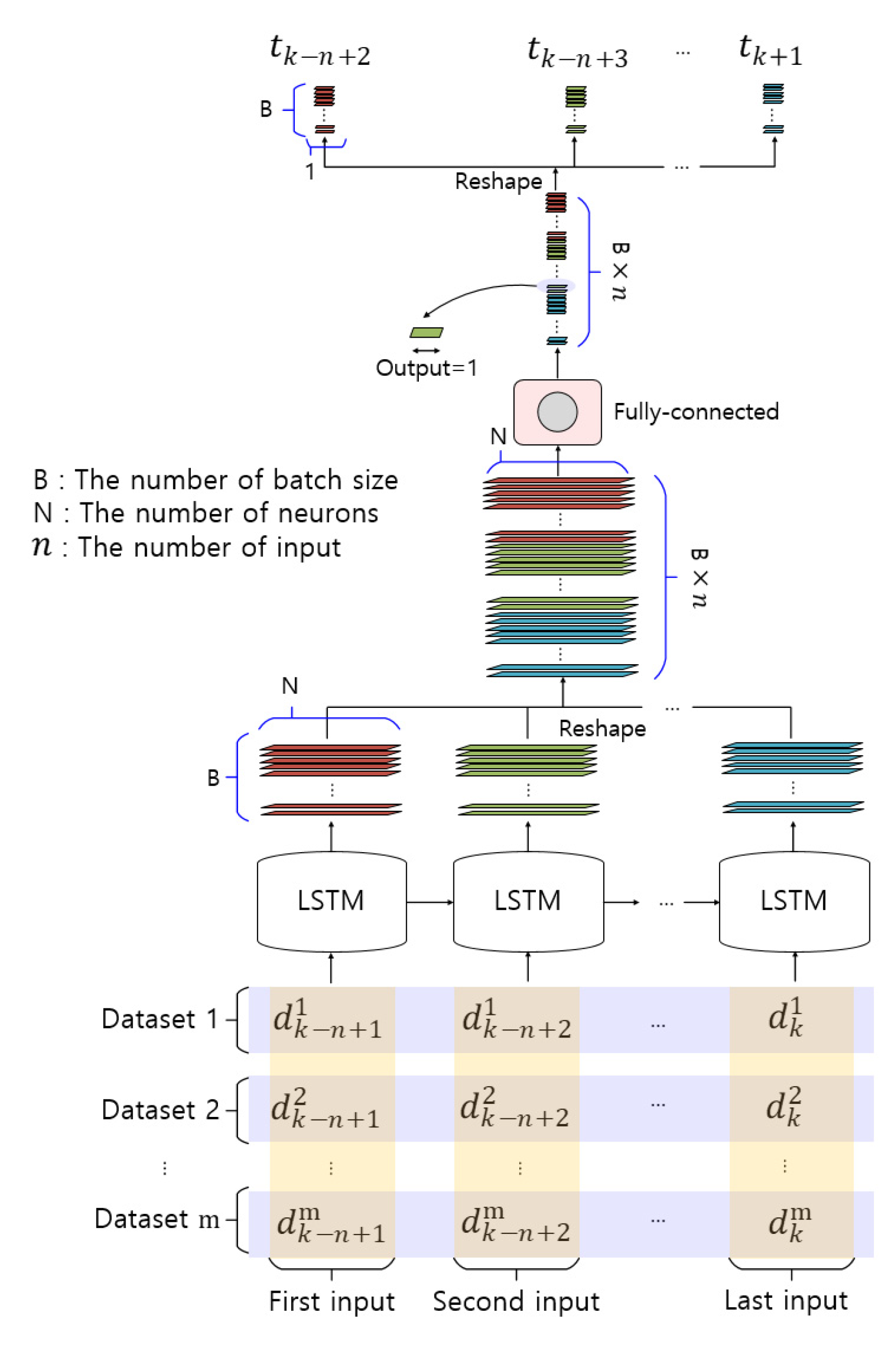
3.1. Structure of the LSTM
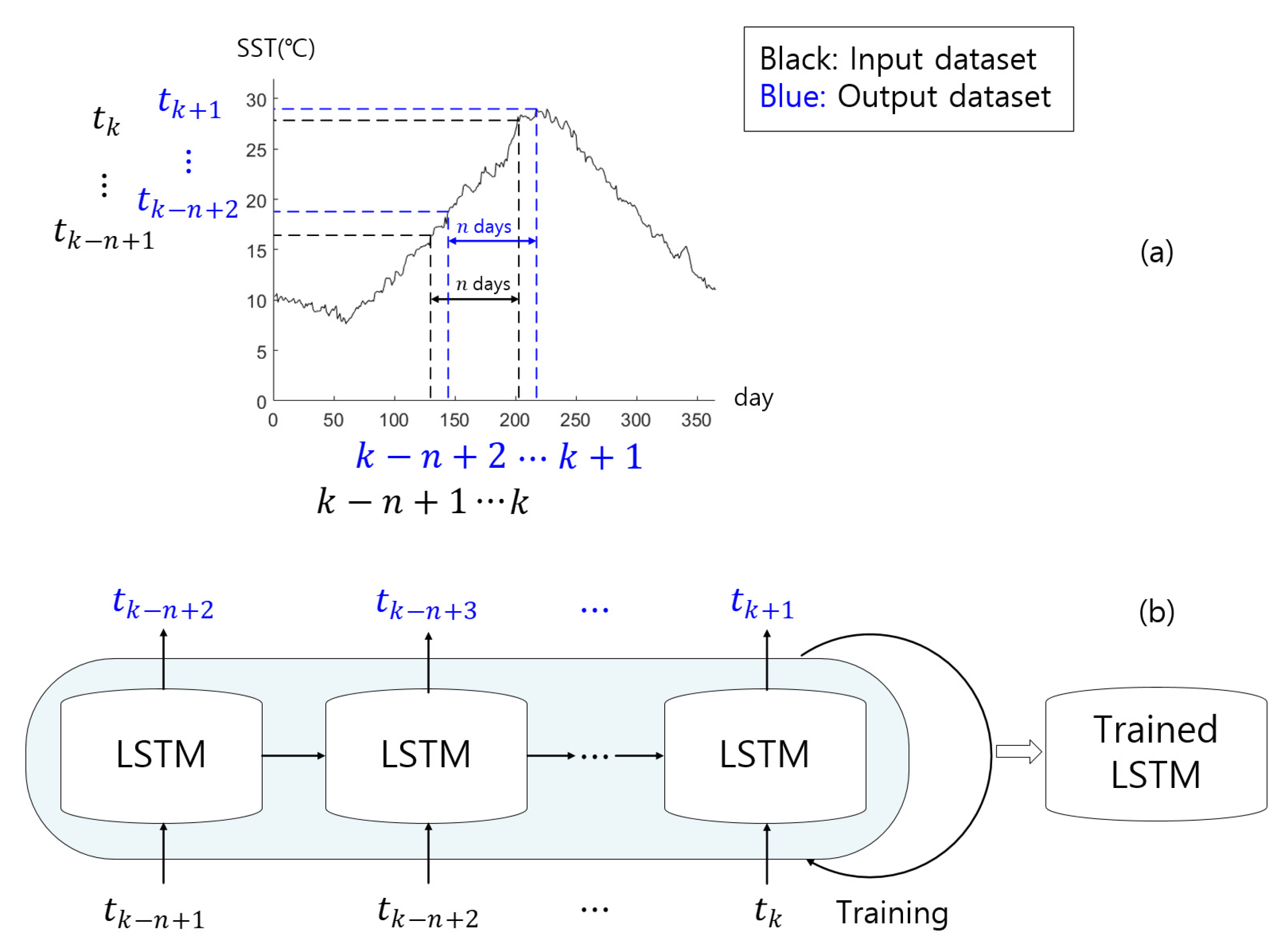
3.2. LSTM Training Concept
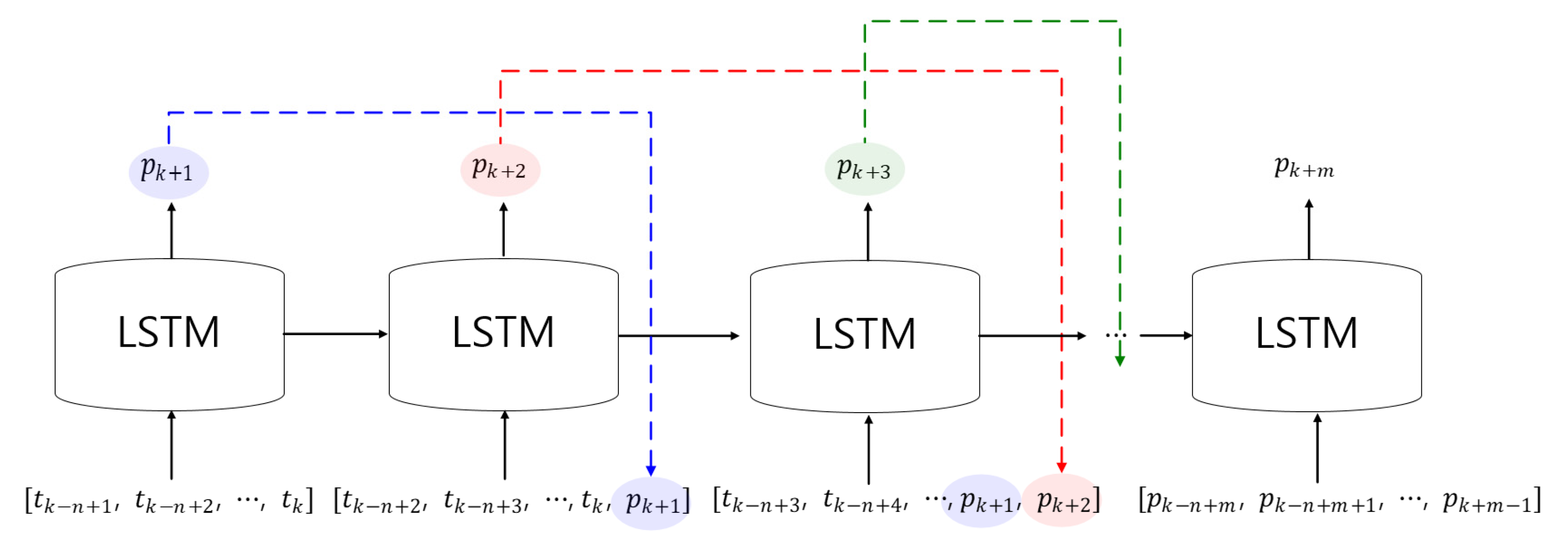
3.3. SST Prediction Concept using the Trained LSTM Model
- (1)
- Extract the predicted SST after 1 day from the trained LSTM.
- (2)
- To predict the SST after 2 days, the predicted SST after 1 day was substituted as the last component of the second input.
- (3)
- Extract the predicted SST after 2 days as a result of step 2.
- (4)
- To predict the SST after 3 days, the predicted SST after 2 days was substituted as the last component of the second input. Here, the predicted SST after 1 day was located before the last component.
- (5)
- Repeat this process times.
3.4. HWT Determination Algorithm and Performance Evaluation
3.5. Method of SST Prediction Performance Evaluation
4. Experiments
4.1. LSTM Network for Experiments
- (1)
- The output vectors of form (B, N) of each LSTM cell with n inputs were stacked in the vector having the form (B × , N).
- (2)
- A fully connected layer with one unit was applied to reshape the vector having the form (B × , N) into a vector having the form (B × , 1; because the fully connected layer is only a layer for dimension reduction, the activation function is not used).
- (3)
- The vector is reduced from the form (B × , 1) into n outputs. Now the output is a vector of form (B × 1).
4.2. Parameter Values for the Simulation
4.3. Results
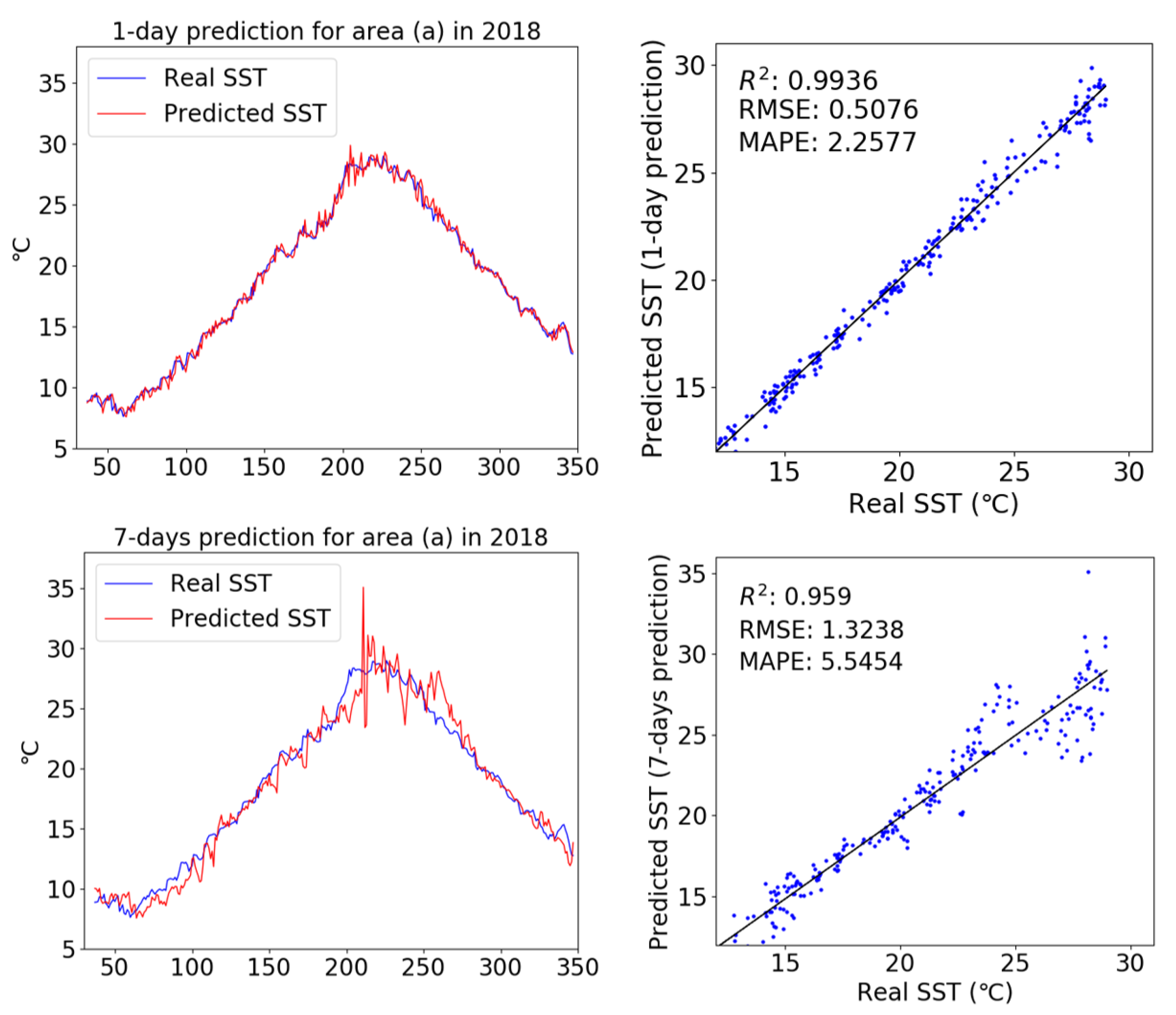
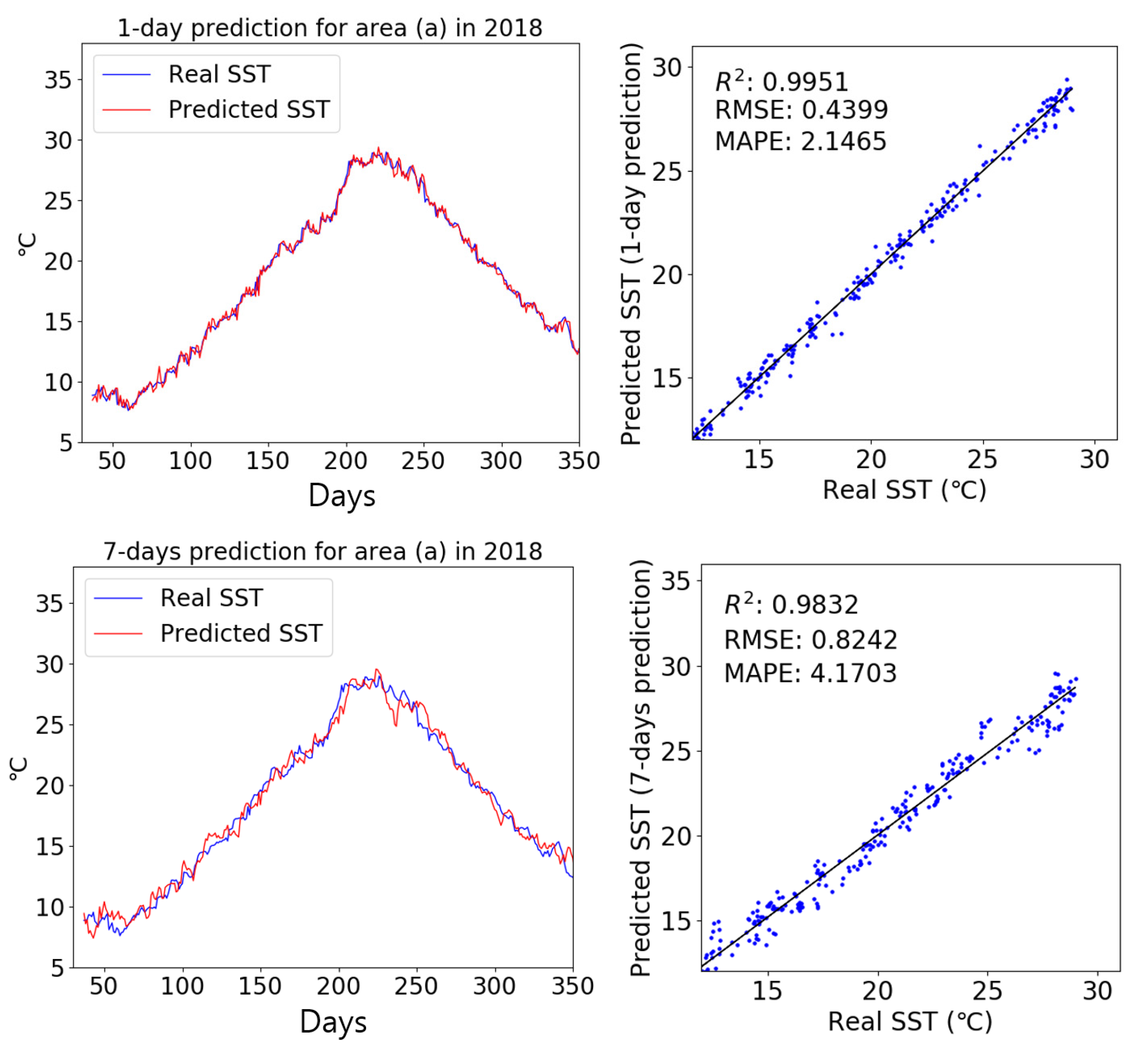
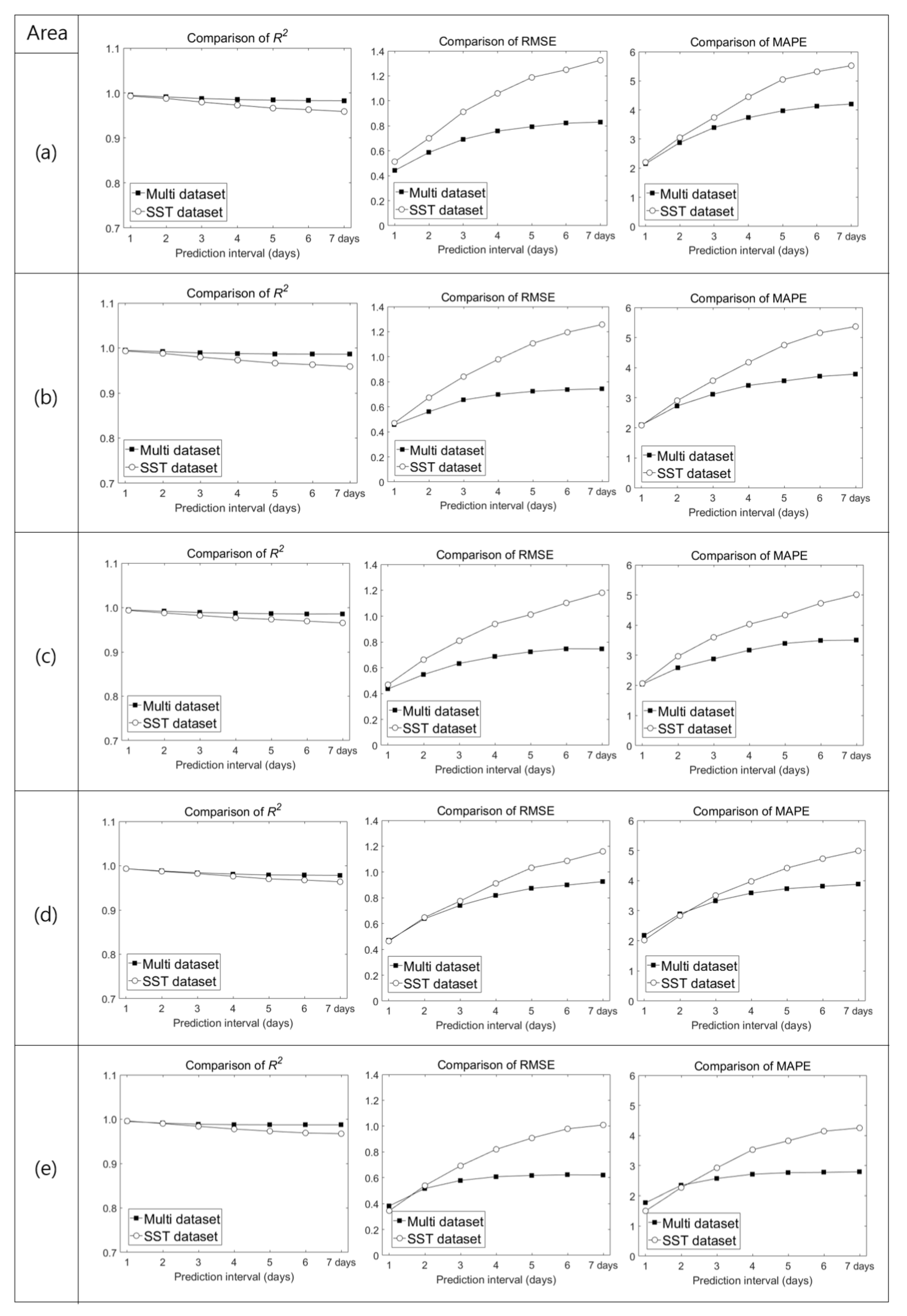
4.3.1. Results Obtained Using only SST Input Data
4.3.2. Results Obtained Using the Multi Dataset as Input
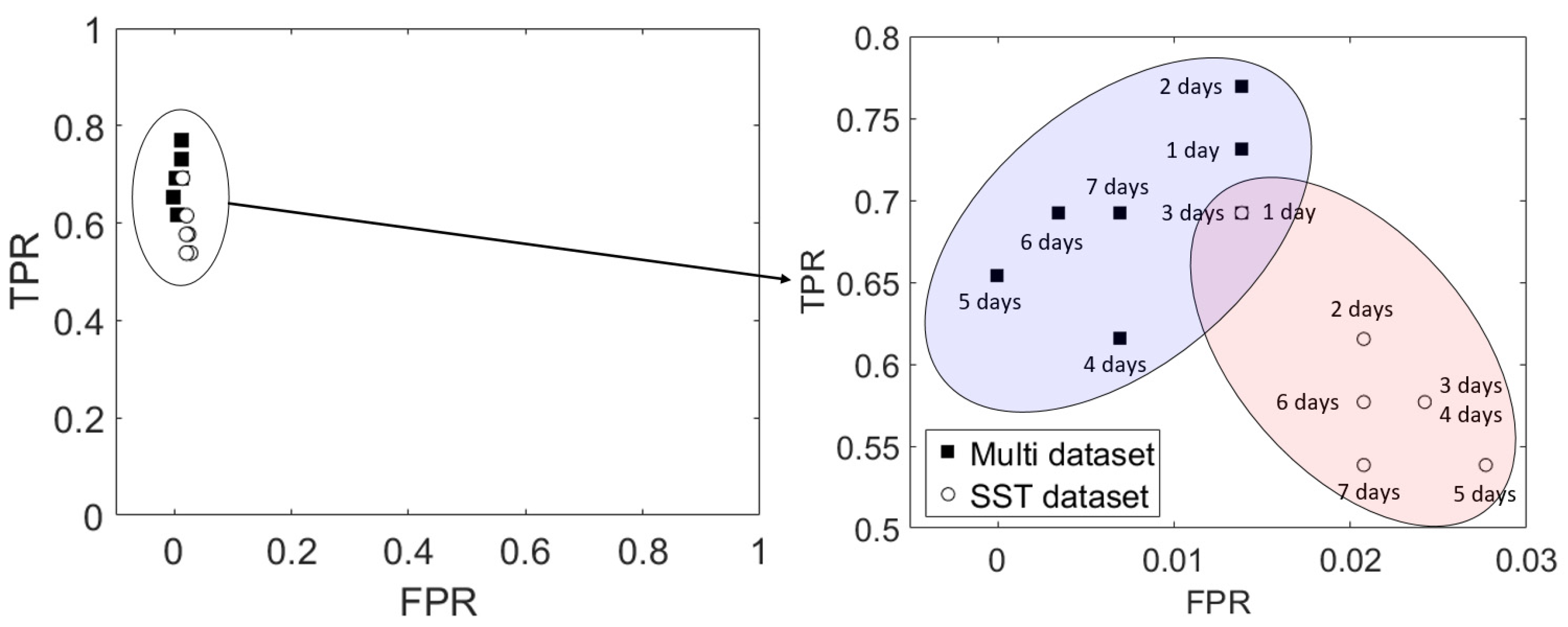
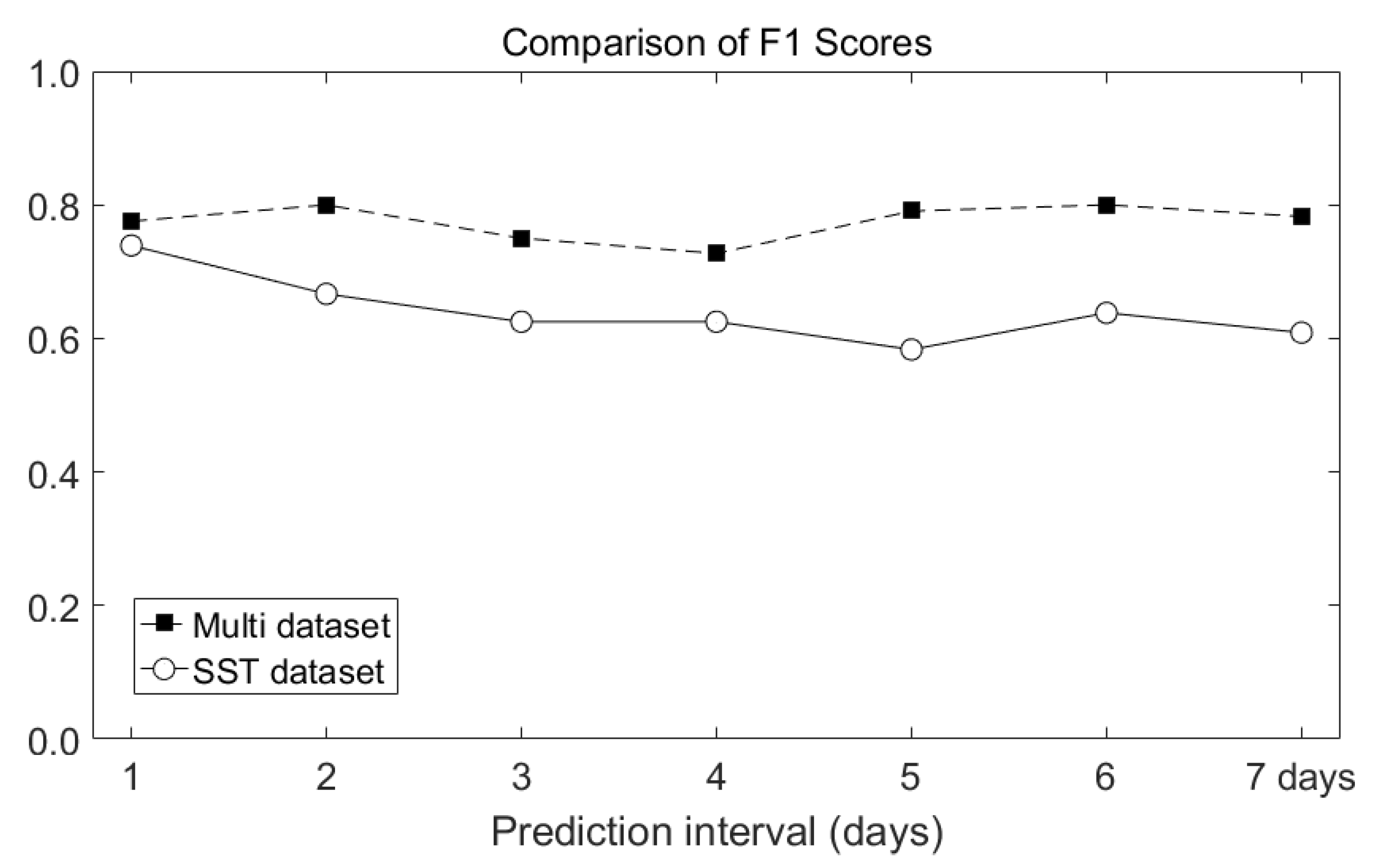
5. Performance Evaluation
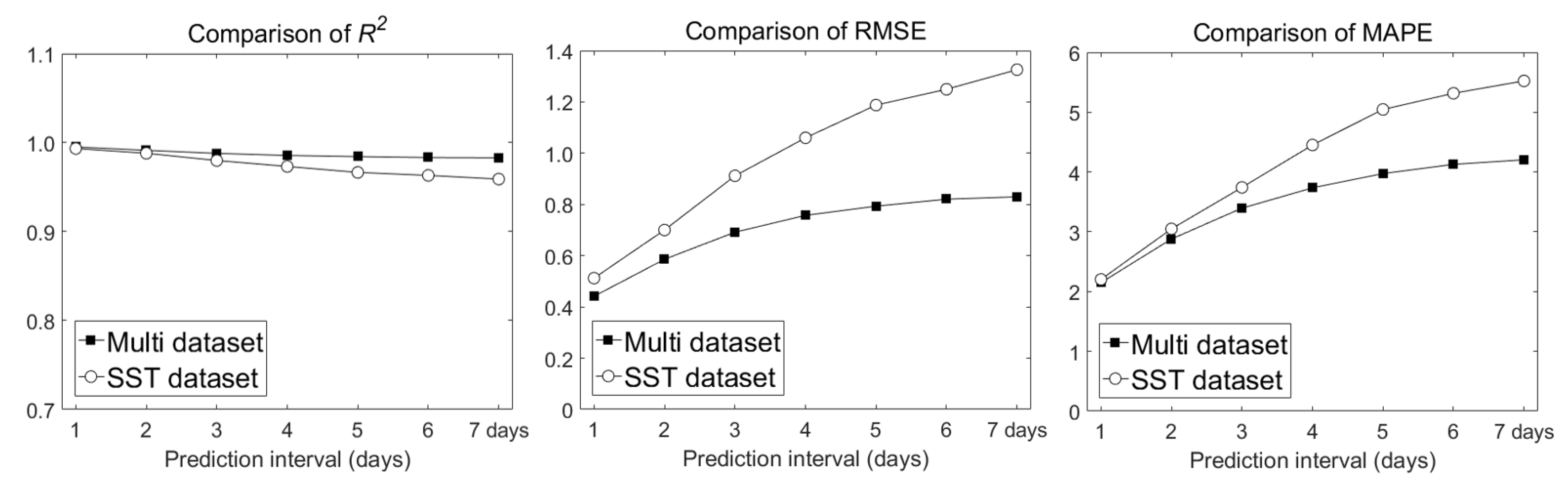
5.1. Comparison of Performance Between SST and Multi Dataset Inputs
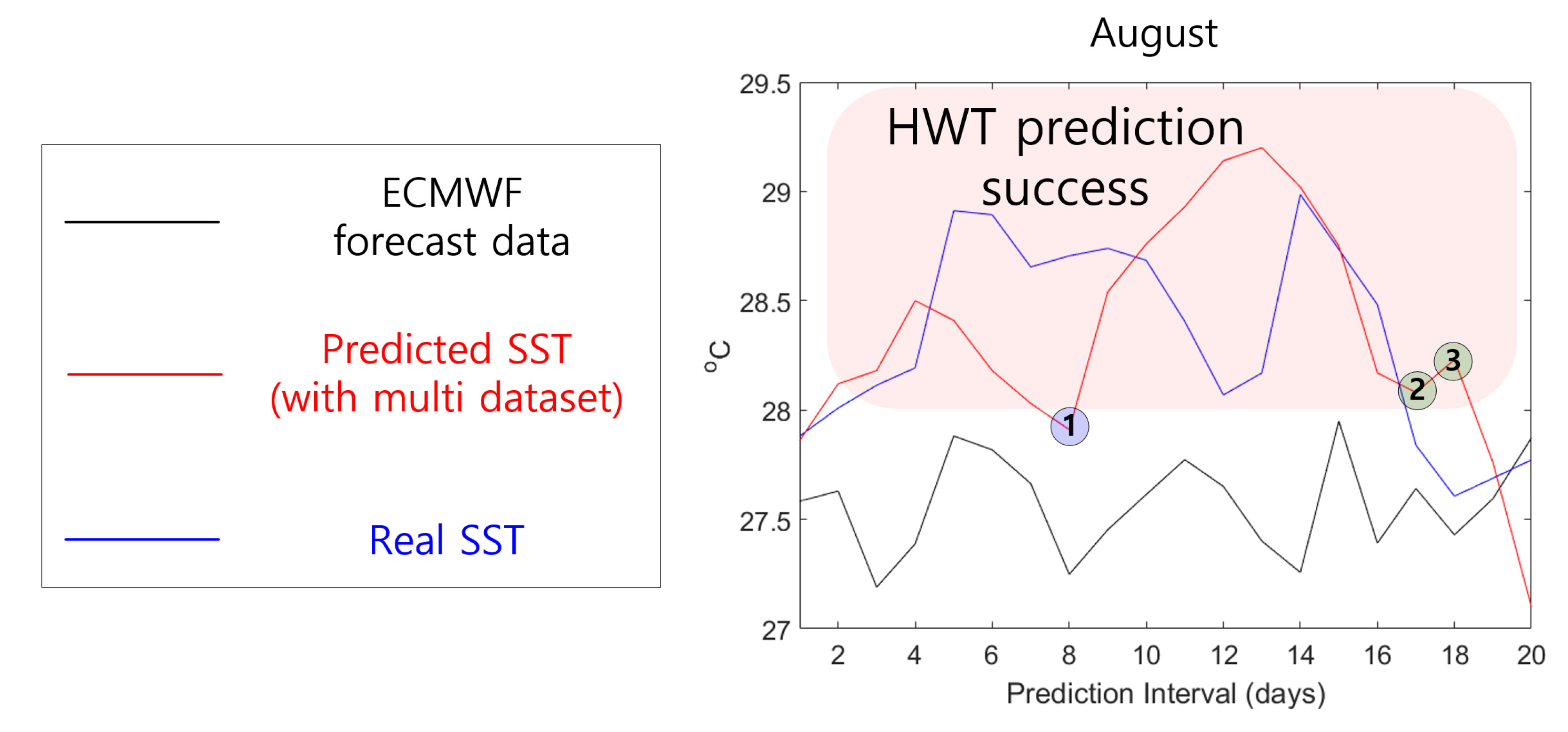
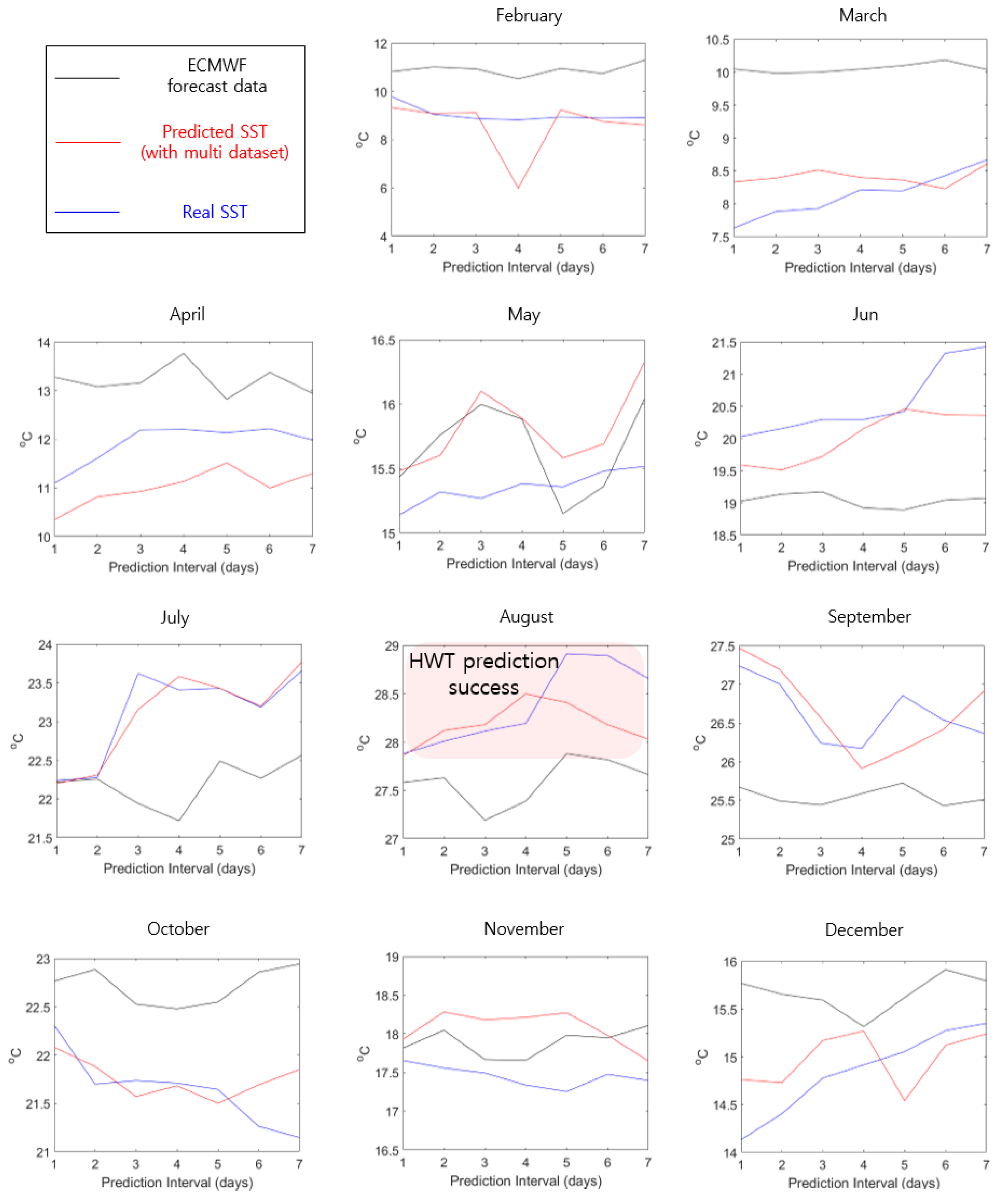
5.2. Performance Comparison with ECMWF Forecast Data
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Training Data | Number of Neurons | Prediction Interval | Prediction Performance | |||
|---|---|---|---|---|---|---|
| SST | HWT | |||||
| R2 | RMSE | MAPE | F1 Score | |||
| 1825 past 5 year (2013–2017) | 50 | 1 | 0.9883 | 0.693 | 2.5784 | 0.5128 |
| 7 | 0.8785 | 2.2615 | 7.0832 | 0.057 | ||
| 1825 past 5 year (2013–2017) | 100 | 1 | 0.9926 | 0.5488 | 2.4148 | 0.7391 |
| 7 | 0.9538 | 1.3789 | 5.7256 | 0.44 | ||
| 1825 past 5 year (2013–2017) | 150 | 1 | 0.9946 | 0.4728 | 2.1033 | 0.7391 |
| 7 | 0.9707 | 1.0953 | 5.134 | 0.44 | ||
| 3650 past 10 year (2008–2017) | 50 | 1 | 0.9921 | 0.5677 | 2.5429 | 0.66 |
| 7 | 0.9564 | 1.3059 | 5.6304 | 0.58 | ||
| 3650 past 10 year (2008–2017) | 100 | 1 | 0.9936 | 0.5076 | 2.2577 | 0.7391 |
| 7 | 0.959 | 1.3238 | 5.5454 | 0.6086 | ||
| 3650 past 10 year (2008–2017) | 150 | 1 | 0.9949 | 0.4542 | 2.0829 | 0.76 |
| 7 | 0.961 | 1.251 | 5.736 | 0.6249 | ||
| 5475 past 15 year (2003–2017) | 50 | 1 | 0.9962 | 0.398 | 1.8067 | 0.7272 |
| 7 | 0.9788 | 1.0027 | 5.0365 | 0 | ||
| 5475 past 15 year (2003–2017) | 100 | 1 | 0.9922 | 0.5696 | 2.6503 | 0.66 |
| 7 | 0.9616 | 1.2514 | 5.7366 | 0.4571 | ||
| 5475 past 15 year (2003–2017) | 150 | 1 | 0.9937 | 0.5065 | 2.375 | 0.69 |
| 7 | 0.9649 | 1.2011 | 5.6122 | 0.51 | ||
Appendix B



References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Alistair, J.H.; Lisa, V.A.; Sarah, E.P.; Dan, A.S.; Sandra, C.S.; Eric, C.J.; Jessica, A.B.; Michael, T.B.; Markus, G.D.; Ming, F.; et al. A hierarchical approach to defining marine heatwaves. Prog. Oceanogr. 2016, 141, 227–238. [Google Scholar]
- Vitart, F.; Andrew, W.R. The sub-seasonal to seasonal prediction project (S2S) and the prediction of extreme events. Clim. Atmos. Sci. 2018, 1, 1–7. [Google Scholar] [CrossRef]
- Those Who Come Along the Heat… Fishermen Suffered 100 Billion Damage in 10 years. Available online: https://news.joins.com/article/23543775 (accessed on 5 August 2019).
- Balmaseda, M.A.; Mogensen, K.; Weaver, A.T. Evaluation of the ECMWF ocean reanalysis system ORAS4. R. Meteorol. Soc. 2013, 139, 1132–1161. [Google Scholar] [CrossRef]
- Stockdale, T.N.; Anderson, D.L.T.; Balmaseda, M.A.; Doblas-Reyes, F.; Ferranti, L.; Mogensen, K.; Palmer, T.N.; Molteni, F.; Vitart, F. ECMWF seasonal forecast system 3 and its prediction of sea surface temperature. Clim. Dyn. 2011, 37, 455–471. [Google Scholar] [CrossRef]
- Peckham, S.E.; Smirnova, T.G.; Benjamin, S.G.; Brown, J.M.; Kenyon, J.S. Implementation of a digital filter initialization in the WRF model and its application in the Rapid Refresh. Mon. Weather Rev. 2016, 144, 99–106. [Google Scholar] [CrossRef]
- Phillips, N.A. A coordination system having some special advantages for numerical forecasting. J. Meteor. 1957, 14, 184–185. [Google Scholar] [CrossRef]
- Weisman, M.L.; Davis, C.; Wang, W.; Manning, K.W.; Klemp, J.B. Experiences with 0–36-h explicit convective forecast with the WRF-ARW model. Am. Meteorol. Soc. 2008, 23, 1495–1509. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B.; Dudhia, J.; Gill, D.O.; Barker, D.M.; Wang, W.; Powers, J.G. A Description of the Advanced Research WRF Version 2; NCAR Tech; Note NCAR/TN468 + STR; National Center for Atmospheric Research: Boulder, CO, USA, 2005; p. 88. [Google Scholar]
- Gröger, M.; Dieterich, C.; Meier, M.H.E.; Schimanke, S. Thermal air–sea coupling in hindcast simulations for the North Sea and Baltic Sea on the NW European shelf. Tellus A 2015, 67, 26911. [Google Scholar] [CrossRef]
- Liu, Y.; Fu, W. Assimilating high-resolution sea surface temperature data improves the ocean forecast potential in the Baltic Sea. Ocean Sci. 2018, 14, 525–541. [Google Scholar] [CrossRef]
- Ba, A.N.N.; Pogoutse, A.; Provart, N.; Moses, A.M. NLStradamus: A simple hidden Markov model for nuclear localization signal prediction. BMC Bioinform. 2009, 10, 202. [Google Scholar]
- Berliner, L.M.; Wikle, C.K.; Cressie, N. Long-lead prediction of Pacific SSTs via Bayesian dynamic modeling. Am. Meteorol. Soc. 2000, 13, 3953–3968. [Google Scholar] [CrossRef]
- Johnson, S.D.; Battisti, D.S.; Sarachik, E.S. Empirically derived Markov models and prediction of tropical Pacific sea surface temperature anomalies. Am. Meteorol. Soc. 2000, 13, 3–17. [Google Scholar] [CrossRef]
- Lins, I.D.L.; Araujo, M.; Moura, M.D.C.; Silva, M.A.; Droguett, E.L. Prediction of sea surface temperature in the tropical Atlantic by support vector machines. Comput. Stat. Data Anal. 2013, 61, 187–198. [Google Scholar] [CrossRef]
- Li, Q.J.; Zhao, Y.; Liao, H.L.; Li, J.K. Effective forecast of Northeast Pacific sea surface temperature based on a complementary ensemble empirical mode decomposition-support vector machine method. Atmos. Ocean. Sci. Lett. 2017, 10, 261–267. [Google Scholar] [CrossRef]
- Patil, K.; Deo, M.C. Prediction of sea surface temperature by combining numerical and neural techniques. Am. Meteorol. Soc. 2016, 33, 1715–1726. [Google Scholar] [CrossRef]
- Kumar, J.; Goomer, R.; Singh, A.K. Long Short Term Memory Recurrent Neural Network (LSTM-RNN) Based Workload Forecasting Model For Cloud Datacenters. Procedia Computer Sci. 2018, 125, 676–682. [Google Scholar] [CrossRef]
- Tangang, F.T.; Hsieh, W.W.; Tang, B. Forecasting the equatorial Pacific sea surface temperatures by neural network models. Clim. Dyn. 1997, 13, 135–147. [Google Scholar] [CrossRef]
- Abdel-Nasser, M.; Mahmoud, K. Accurate photovoltaic power forecasting models using deep LSTM-RNN. Neural Comput. Appl. 2019, 31, 2727–2740. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Yang, B.; Sun, S.; Li, J.; Lin, X.; Tian, Y. Traffic flow prediction using LSTM with feature enhancement. Neurocomputing 2019, 332, 320–327. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.P. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Ahn, S.M.; Chung, Y.J.; Lee, J.J.; Yang, J.H. Korean sentence generation using phoneme-level LSTM language model. Korea Intell. Inf. Syst. 2017, 6, 71–88. [Google Scholar]
- Chaudhary, V.; Deshbhratar, A.; Kumar, V.; Paul, D. Time series-based LSTM model to predict air pollutant concentration for prominent cities in India. In Proceedings of the 1st International Workshop on Utility-Driven Mining, Bejing, China, 31 July 2018; pp. 17–20. [Google Scholar]
- Wang, H.; Dong, J.; Zhong, G.; Sun, X. Prediction of sea surface temperature using long short-term memory. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1745–1749. [Google Scholar]
- Liu, J.; Zhang, T.; Han, G.; Gou, Y. TD-LSTM: Temporal dependence-based LSTM networks for marine temperature prediction. Sensors 2018, 18, 3797. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.T.; Kim, H.Y.; Song, S.H.; Lee, S.H. Characteristics of egg and larval distributions and catch changes of anchovy in relation to abnormally high sea temperature in the South Sea of Korea. J. Korean Soc. Fish. Ocean Technol. 2018, 54, 262–270. [Google Scholar] [CrossRef]
- Yoon, S.; Yang, H. Study on the temporal and spatial variation in cold water zone in the East Sea using satellite data. Korean J. Remote Sens. 2016, 32, 703–719. [Google Scholar] [CrossRef][Green Version]
- Lee, D.C.; Won, K.M.; Park, M.A.; Choi, H.S.; Jung, S.H. An Analysis of Mass Mortalities in Aquaculture Fish Farms on the Southern Coast in Korea; Korea Maritime Institute: Busan, Korea, 2018; Volume 67, pp. 1–16. [Google Scholar]
- Oh, N.S.; Jeong, T.J. The prediction of water temperature at Saemangeum Lake by neural network. J. Korean Soc. Coast. Ocean Eng. 2015, 27, 56–62. [Google Scholar] [CrossRef][Green Version]
- Han, I.S.; Lee, J.S. Change the Annual Amplitude of Sea Surface Temperature due to Climate Change in a Recent Decade around the Korea Peninsula. J. Korean Soc. Mar. Environ. Saf. 2020, 26, 233–241. [Google Scholar] [CrossRef]
- Lee, H.D.; Min, K.H.; Bae, J.H.; Cha, D.H. Characteristics and Comparison of 2016 and 2018 Heat Wave in Korea. Atmos. Korean Meteorol. Soc. 2020, 30, 209–220. [Google Scholar]
- Park, T.G.; Kim, J.J.; Song, S.Y. Distributions of East Asia and Philippines ribotypes of Cochlodinium polykrikoides (Dinophyceae) in the South Sea, Korea. The Sea 2019, 24, 422–428. [Google Scholar]
- Seol, K.S.; Lee, C.I.; Jung, H.K. Long Term Change in Sea Surface Temperature Around Habit Ground of Walleye Pollock (Gadus chalcogrammus) in the East Sea. Kosomes 2020, 26, 195–205. [Google Scholar]
- Jang, M.C.; Back, S.H.; Jang, P.G.; Lee, W.J.; Shin, K.S. Patterns of Zooplankton Distribution as Related to Water Masses in the Korea Strait during Winter and Summer. Ocean Polar Res. 2012, 34, 37–51. [Google Scholar] [CrossRef]
- Ito, M.; Morimoto, A.; Watanabe, T.; Katoh, O.; Takikawa, T. Tsushima Warm Current paths in the southwestern part of the Japan Sea. Prog. Oceanogr. 2014, 121, 83–93. [Google Scholar] [CrossRef]
- Han, I.S.; Suh, Y.S.; Seong, K.T. Wind-induced Spatial and Temporal Variations in the Thermohaline Front in the Jeju Strait, Korea. Fish. Aquat. Sci. 2013, 16, 117–124. [Google Scholar] [CrossRef]
- Xie, S.P.; Hafner, J.; Tanimoto, Y.; Liu, W.T.; Tokinaga, H. Bathymetric effect on the winter sea surface temperature and climate of the Yellow and East China sea. Geophys. Res. Lett. 2002, 29, 81-1–81-4. [Google Scholar] [CrossRef]
- Kim, S.W.; Im, J.W.; Yoon, B.S.; Jeong, H.D.; Jang, S.H. Long-Term Variations of the Sea Surface Temperature in the East Coast of Korea. J. Korean Soc. Mar. Environ. Saf. 2014, 20, 601–608. [Google Scholar] [CrossRef]
- Tarek, M.; Brissette, F.P.; Arsenault, R. Evaluation of the ERA5 reanalysis as a potential reference dataset for hydrological modelling over North America. Hydrol. Earth Syst. Sci. 2020, 24, 2527–2544. [Google Scholar] [CrossRef]
- Mahmoodi, K.; Ghassemi, H.; Razminia, A. Temporal and spatial characteristics of wave energy in the Persian Gulf based on the ERA5 reanalysis dataset. Energy 2019, 187, 115991. [Google Scholar] [CrossRef]
- Cai, M.; Liu, J. Maxout neurons for deep convolutional and LSTM neural networks in speech recognition. Speech Commun. 2016, 77, 53–64. [Google Scholar] [CrossRef]
- Xiao, C.; Chen, N.; Hu, C.; Wang, K.; Xu, Z.; Cai, Y.; Xu, L.; Chen, Z.; Gong, J. A spatiotemporal deep learning model for sea surface temperature field prediction using time-series satellite data. Environ. Model. Softw. 2019, 120, 104502. [Google Scholar] [CrossRef]
- Hanczar, B.; Hua, J.; Sima, C.; Weinstein, J.; Bittner, M.; Dougherty, E.R. Small-sample precision of ROC-related estimates. Bioinformatics 2010, 26, 822–830. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Jalalkamail, A.; Sedghi, H.; Manshouri, M. Monthly groundwater level prediction using ANN and neuro-fuzzy models: A case study on Kerman Plain, lran. Hydroinformatics 2011, 13, 867–876. [Google Scholar] [CrossRef]














| Parameter Values | Number of Training Data | ||||
|---|---|---|---|---|---|
| B | 30 | Input data (SST) | 3650 × 1 (m = 1) | ||
| Input data (Multi) | 3650 × 3 (m = 3) | ||||
| N | 100 | Output data | 3650 | ||
| Year | 10-year dataset (2008–2017) | ||||
| 30 | Number of test data | ||||
| Optimization function | Adam optimizer | Test data | 335 | ||
| Cost function | Mean square error | Year | 1-year SST dataset excluded 30-days (2018) | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Yang, H.; Kim, J. Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model. Remote Sens. 2020, 12, 3654. https://doi.org/10.3390/rs12213654
Kim M, Yang H, Kim J. Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model. Remote Sensing. 2020; 12(21):3654. https://doi.org/10.3390/rs12213654
Chicago/Turabian StyleKim, Minkyu, Hyun Yang, and Jonghwa Kim. 2020. "Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model" Remote Sensing 12, no. 21: 3654. https://doi.org/10.3390/rs12213654
APA StyleKim, M., Yang, H., & Kim, J. (2020). Sea Surface Temperature and High Water Temperature Occurrence Prediction Using a Long Short-Term Memory Model. Remote Sensing, 12(21), 3654. https://doi.org/10.3390/rs12213654