Deep TEC: Deep Transfer Learning with Ensemble Classifier for Road Extraction from UAV Imagery

 , and
, and 
Abstract
1. Introduction
2. Related Work
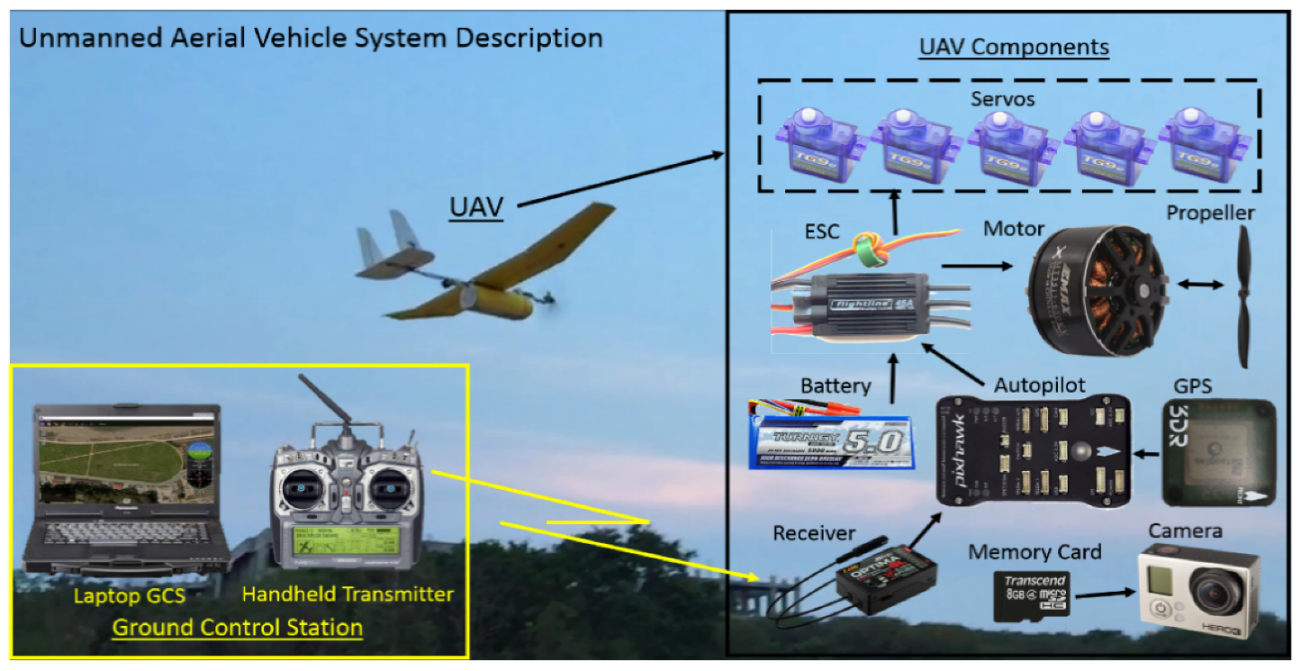
3. UAV for the Detection of Road Networks
4. Methodology
4.1. Deep Transfer Learning
4.2. Classifier Composer
| Algorithm 1 Deep transfer learning and ensemble classifier (deep TEC) |
| Input: , where is the data instance, i.e., the input image and is the corresponding output image for i = 1, 2, …, N instances |
| Output: Domain target target labels for j = 1, 2, …, M test images |
| begin |
| Define P suitable networks for the given task , k = 1, 2, …, P |
| for k = 1 to P do |
| Pre-train the network on for N instances by finding the optimum parameters by |
| Equation (1) |
| Define regularization parameters for network |
| Save the model as |
| for models : k = 1 to P do |
| for the test images : j = 1 to M do |
| Give image as input to saved model |
| Save the classified target label pixels |
| for output image : j = 1 to M do |
| for all the pixels q of image do |
| for all the methods 1 to P by Equation (2) do |
| if pixel q is road then |
| vote |
| else |
| vote |
| if then |
| assign q = 1 (i.e., road) by Equation (3) |
| else |
| assign q = 0 (i.e., non-road) by Equation (3) |
| end |
5. Evaluation Metrics
6. Results and Discussion
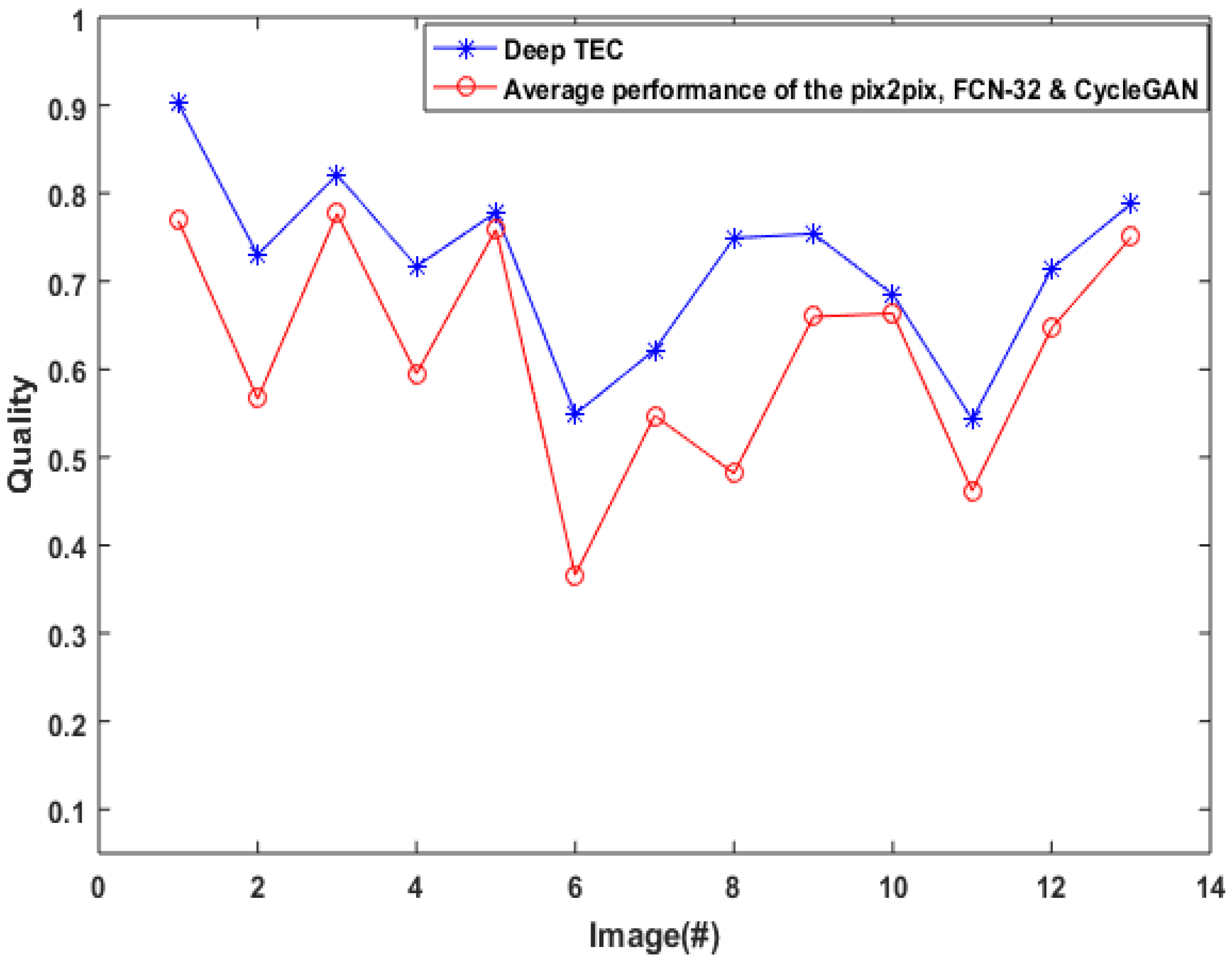
6.1. Performance Evaluation
6.2. Visual Analysis
6.3. Computational Complexity
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| RS | Remote Sensing |
| FCN-32 | Fully Convolutional Neural Network-32 derivative |
| cGAN | Conditional Generative Adversarial Network |
| CycleGAN | Cycle Generative Adversarial Network |
| ReLU | Rectified Linear Unit |
| pix2pix | Image to image translation cGAN |
| Deep TEC | Deep Transfer Ensemble Classifier |
| TP | True Positives |
| FP | False Positives |
| FN | False Negatives |
References
- Senthilnath, J.; Kumar, D.; Benediktsson, J.A.; Zhang, X. A novel hierarchical clustering technique based on splitting and merging. Int. J. Image Data Fusion 2016, 7, 19–41. [Google Scholar] [CrossRef]
- Guo, Y.; Senthilnath, J.; Wu, W.; Zhang, X.; Zeng, Z.; Huang, H. Radiometric calibration for multispectral camera of different imaging conditions mounted on a UAV platform. Sustainability 2019, 11, 978. [Google Scholar] [CrossRef]
- Bhola, R.; Krishna, N.H.; Ramesh, K.N.; Senthilnath, J.; Anand, G. Detection of the power lines in UAV remote sensed images using spectral-spatial methods. J. Environ. Manag. 2018, 206, 1233–1242. [Google Scholar] [CrossRef] [PubMed]
- Senthilnath, J.; Dokania, A.; Kandukuri, M.; Ramesh, K.N.; Anand, G.; Omkar, S.N. Detection of tomatoes using spectral-spatial methods in remotely sensed RGB images captured by UAV. Biosyst. Eng. 2016, 146, 16–32. [Google Scholar] [CrossRef]
- Senthilnath, J.; Kandukuri, M.; Dokania, A.; Ramesh, K.N. Application of UAV imaging platform for vegetation analysis based on spectral-spatial methods. Comput. Electron. Agric. 2017, 140, 8–24. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Tong, L.; Wang, Y.; Cheng, L. Using unmanned aerial vehicle for remote sensing application. In Proceedings of the 21st International Conference on Geoinformatics, Kaifeng, China, 20–22 June 2013. [Google Scholar]
- Movaghati, S.; Moghaddamjoo, A.; Tavakoli, A. Road Extraction From Satellite Images Using Particle Filtering and Extended Kalman Filtering. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2807–2817. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road Extraction from High-Resolution Remote Sensing Imagery Using Refined Deep Residual Convolutional Neural Network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Zhou, H.; Kong, H.; Wei, L.; Creighton, D.; Nahavandi, S. Efficient Road Detection and Tracking for Unmanned Aerial Vehicle. IEEE Trans. Intell. Transp. Syst. 2015, 16, 297–309. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef]
- Liu, R.; Qiguang, M.; Jianfeng, S.; Yining, Q.; Yunan, L.; Pengfei, X.; Jing, D. Multiscale road centerlines extraction from high-resolution aerial imagery. Neurocomputing 2019, 329, 384–396. [Google Scholar] [CrossRef]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]
- Mokhtarzade, M.; Zoej, M.V. Road detection from high-resolution satellite images using artificial neural networks. Int. J. Appl. Earth Obs. Geoinform. 2007, 9, 32–40. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Proceedings of the Computer Vision—ECCV 2010 Lecture Notes in Computer Science, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, H.; Jiao, J.; Fu, K. An End-to-End Neural Network for Road Extraction From Remote Sensing Imagery by Multiple Feature Pyramid Network. IEEE Access 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Li, P.; Zang, Y.; Wang, C.; Li, J.; Cheng, M.; Luo, L.; Yu, Y. Road network extraction via deep learning and line integral convolution. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road Structure Refined CNN for Road Extraction in Aerial Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A fully convolutional neural network for road extraction in RGB imagery acquired by remote sensing from an unmanned aerial vehicle. J. Appl. Remote Sens. 2018, 12, 1. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road Segmentation in SAR Satellite Images with Deep Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Majurski, M.; Manescu, P.; Padi, S.; Schaub, N.; Hotaling, N.; Simon, C., Jr.; Bajcsy, P. Cell Image Segmentation Using Generative Adversarial Networks, Transfer Learning, and Augmentations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 26, 5046–5063. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, X.; Li, X. Road Detection from Remote Sensing Images by Generative Adversarial Networks. IEEE Access 2018, 6, 25486–25494. [Google Scholar] [CrossRef]
- Hartmann, S.; Weinmann, M.; Wessel, R.; Klein, R. StreetGAN: Towards Road Network Synthesis with Generative Adversarial Networks. Available online: https://otik.uk.zcu.cz/bitstream/11025/29554/1/Hartmann.pdf (accessed on 13 December 2019).
- Tao, Y.; Xu, M.; Zhong, Y.; Cheng, Y. GAN-Assisted Two-Stream Neural Network for High-Resolution Remote Sensing Image Classification. Remote Sens. 2017, 9, 1328. [Google Scholar] [CrossRef]
- Costea, D.; Marcu, A.; Leordeanu, M.; Slusanschi, E. Creating Roadmaps in Aerial Images with Generative Adversarial Networks and Smoothing-Based Optimization. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, Q.; Fang, J.; Yuan, Y. Adaptive road detection via context-aware label transfer. Neurocomputing 2015, 158, 174–183. [Google Scholar] [CrossRef]
- Ros, G.; Stent, S.; Alcantarilla, P.F.; Watanabe, T. Training constrained deconvolutional networks for road scene semantic segmentation. arXiv 2016, arXiv:1604.01545. [Google Scholar]
- Mattyus, G.; Wang, S.; Fidler, S.; Urtasun, R. Enhancing road maps by parsing aerial images around the world. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1689–1697. [Google Scholar]
- Deng, L.; Platt, J.C. Ensemble deep learning for speech recognition. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Bashir, S.; Qamar, U.; Javed, M.Y. An ensemble based decision support framework for intelligent heart disease diagnosis. In Proceedings of the International Conference on Information Society (i-Society 2014), London, UK, 10–12 November 2014; pp. 259–264. [Google Scholar]
- Alvarez, J.M.; LeCun, Y.; Gevers, T.; Lopez, A.M. Semantic road segmentation via multi-scale ensembles of learned features. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 586–595. [Google Scholar]
- Han, M.; Zhu, X.; Yao, W. Remote sensing image classification based on neural network ensemble algorithm. Neurocomputing 2012, 78, 133–138. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Samadzadegan, F.; Hahn, M.; Bigdeli, B. Automatic road extraction from LIDAR data based on classifier fusion. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–6. [Google Scholar]
- Pan, S.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A Convolution Neural Network for Road Extraction using RGB images captured by UAV. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1890–1895. [Google Scholar]
- Rokach, L. Ensemble-based classifiers. Artif. Intell. Rev. 2009, 33, 1–39. [Google Scholar] [CrossRef]
- Heipke, C.; Mayer, H.; Wiedemann, C.; Jamet, O. Evaluation of automatic road extraction. Int. Arch. Photogramm. Remote Sens. 1997, 32, 151–160. [Google Scholar]
- Available online: https://www.dropbox.com/sh/99cbjs6v73211fk/AABlmOeaPY6NAKUykqAc_E2ra (accessed on 8 July 2018).
- Available online: https://www.dropbox.com/sh/w8e3a8j5eksfi7o/AADIqsM8Uy7XrceceR6x8NFoa?dl=0 (accessed on 8 July 2018).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Rating |
|---|---|
| Motor | BLDC, 630 w, 650 kv |
| Battery | 60C 3S 5000 mAh LiPo |
| Remote Control | 2.4 GHz, 8 channel |
| ESC | 60 amp |
| Servo Motor | 9 g, 2.2 Kg torque, 5 numbers |
| Max Gross Weight | 2.2 kg |
| Flight stabilizer | Pixhawk |
| Thrust-weight ratio | 1.2 |
| Specific thrust | 7.07 g/W |
| Prop-rotor Diameter | 12 × 4.5 inch |
| Length | 1210 mm |
| Height | 300 mm |
| Stall Speed | 5 m/s |
| Cruise Speed | 15 m/s |
| Wingspan | 2 m |
| Endurance | 30 min |
| Parameter | Value |
|---|---|
| Camera make | Go Pro Hero 3 |
| Video resolution | 1080 p |
| Frame rate | 60 Hz |
| Sensor resolution | 12 mega pixel |
| Sensor Size | 6.17 mm × 4.55 mm |
| Field of view | 170 degrees |
| Weight | 75 g |
| Video format | H.264 MP4 |
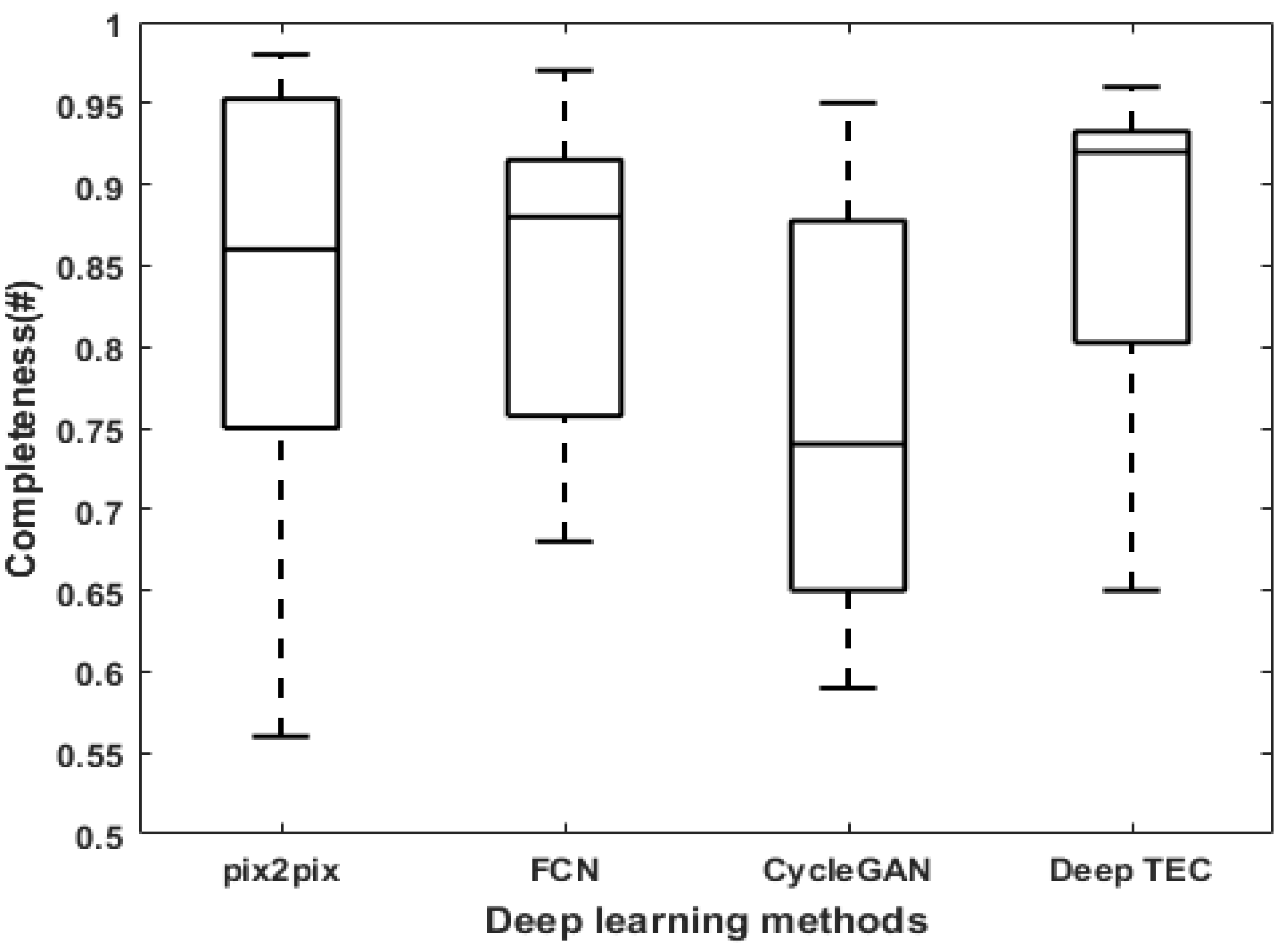
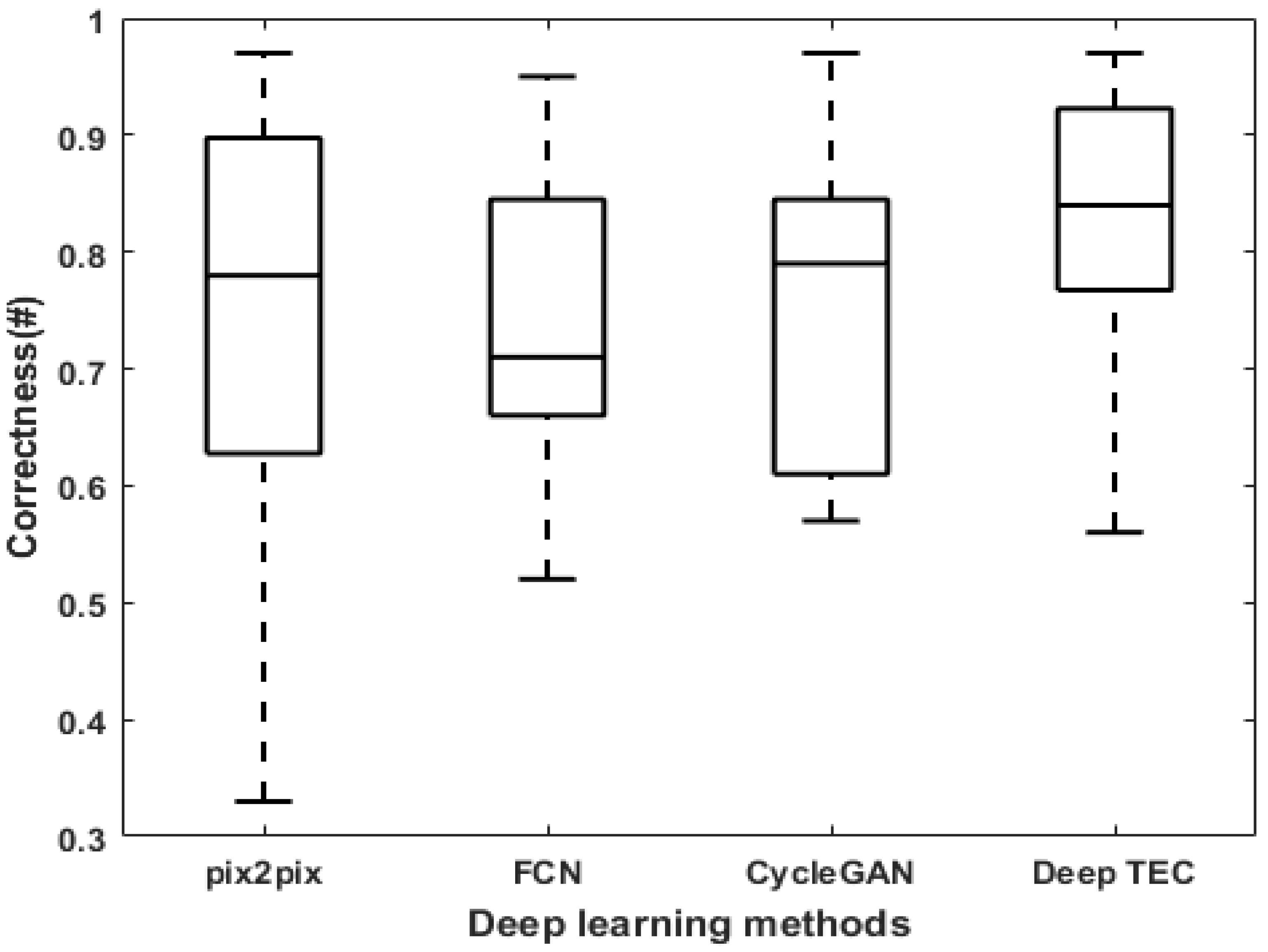
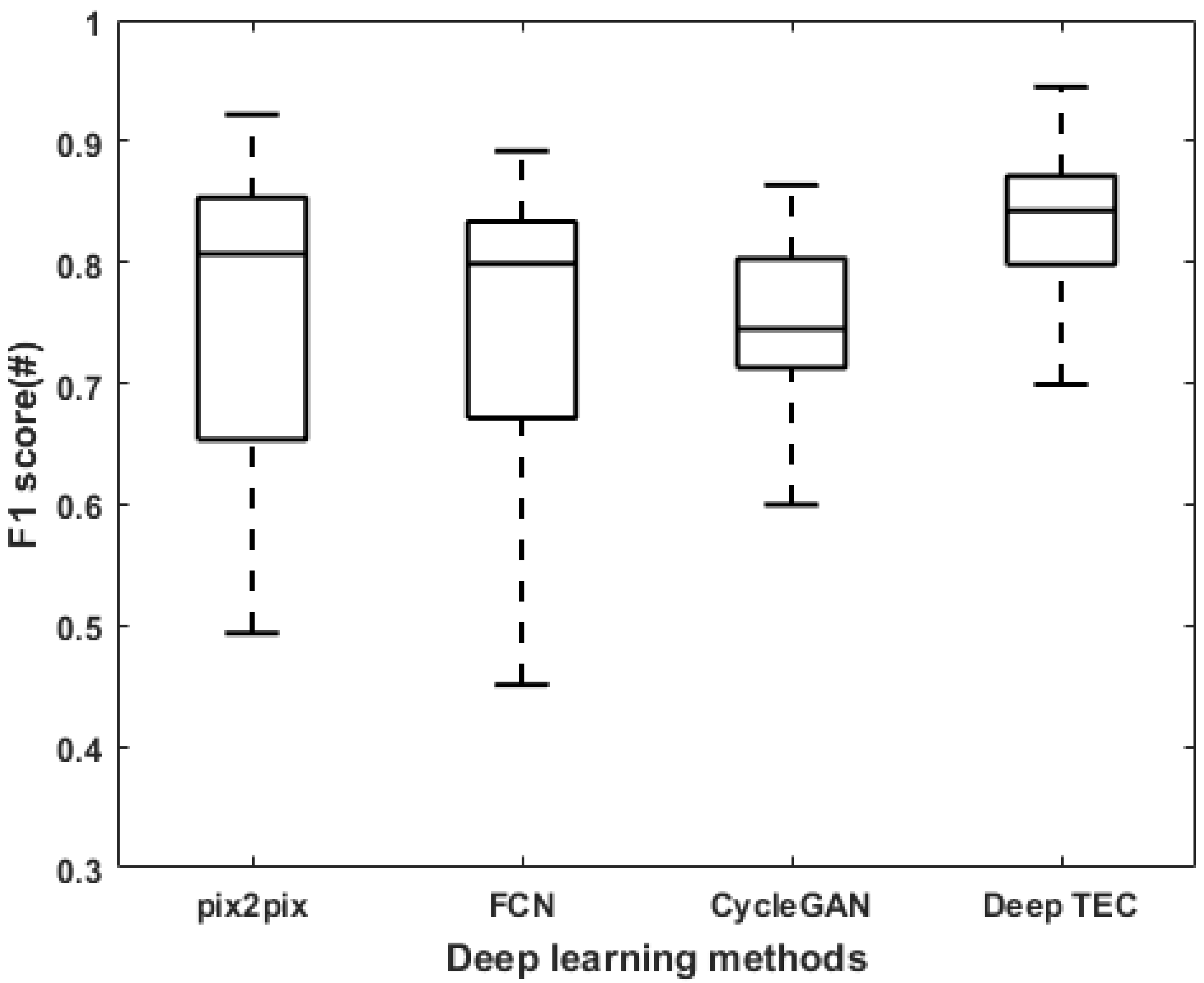
| Deep Learning | Completeness | Correctness | Quality | Gap Density |
|---|---|---|---|---|
| Methods | (μ ± σ) | (μ ± σ) | (μ ± σ) | (μ ± σ) |
| pix2pix | 0.84 ± 0.13 | 0.73 ± 0.22 | 0.62 ± 0.17 | 43.5 ± 28.3 |
| FCN | 0.83 ± 0.12 | 0.72 ± 0.17 | 0.65 ± 0.15 | 47.3 ± 32.4 |
| CycleGAN | 0.76 ± 0.11 | 0.76 ± 0.12 | 0.61 ± 0.09 | 134.6 ± 190.7 |
| Deep TEC | 0.87 ± 0.09 | 0.82 ± 0.13 | 0.71 ± 0.10 | 30.9 ± 25.0 |
| Method Name | Mean Training Time | Number of Images | Total Training Time |
|---|---|---|---|
| FCN | ∼370 s | 189 | ∼20 h |
| cGAN | ∼300 s | 189 | ∼16 h |
| CycleGAN | ∼420 s | 189 | ∼23 h |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Senthilnath, J.; Varia, N.; Dokania, A.; Anand, G.; Benediktsson, J.A. Deep TEC: Deep Transfer Learning with Ensemble Classifier for Road Extraction from UAV Imagery. Remote Sens. 2020, 12, 245. https://doi.org/10.3390/rs12020245
Senthilnath J, Varia N, Dokania A, Anand G, Benediktsson JA. Deep TEC: Deep Transfer Learning with Ensemble Classifier for Road Extraction from UAV Imagery. Remote Sensing. 2020; 12(2):245. https://doi.org/10.3390/rs12020245
Chicago/Turabian StyleSenthilnath, J., Neelanshi Varia, Akanksha Dokania, Gaotham Anand, and Jón Atli Benediktsson. 2020. "Deep TEC: Deep Transfer Learning with Ensemble Classifier for Road Extraction from UAV Imagery" Remote Sensing 12, no. 2: 245. https://doi.org/10.3390/rs12020245
APA StyleSenthilnath, J., Varia, N., Dokania, A., Anand, G., & Benediktsson, J. A. (2020). Deep TEC: Deep Transfer Learning with Ensemble Classifier for Road Extraction from UAV Imagery. Remote Sensing, 12(2), 245. https://doi.org/10.3390/rs12020245