On the Importance of Train–Test Split Ratio of Datasets in Automatic Landslide Detection by Supervised Classification



Abstract
1. Introduction
2. Related Studies
3. Study Area and Data
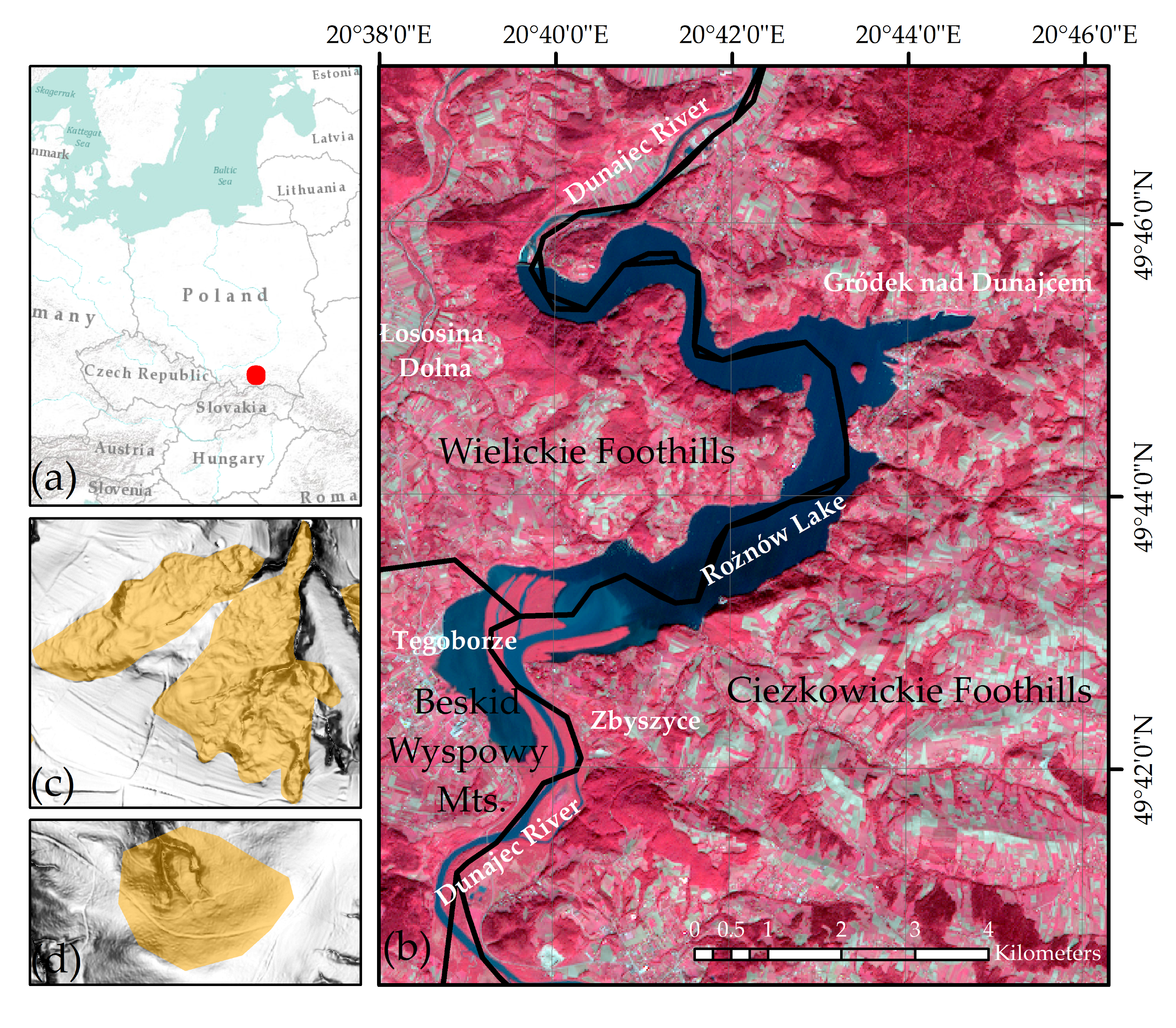
3.1. Study Area and Geological Conditions
3.2. Data
4. Methods
4.1. DEM Generation and Feature Extraction
4.2. Pixel-Based and Object-Based Classification
4.3. Random Forest Classifier and Variable Importance
4.4. Training and Testing Strategies
4.5. Classification Accuracy Parameters
4.6. Post-Processing and Final Landslide Map Generation
5. Results
5.1. Accuracy Assessment of Various Training and Testing Strategies
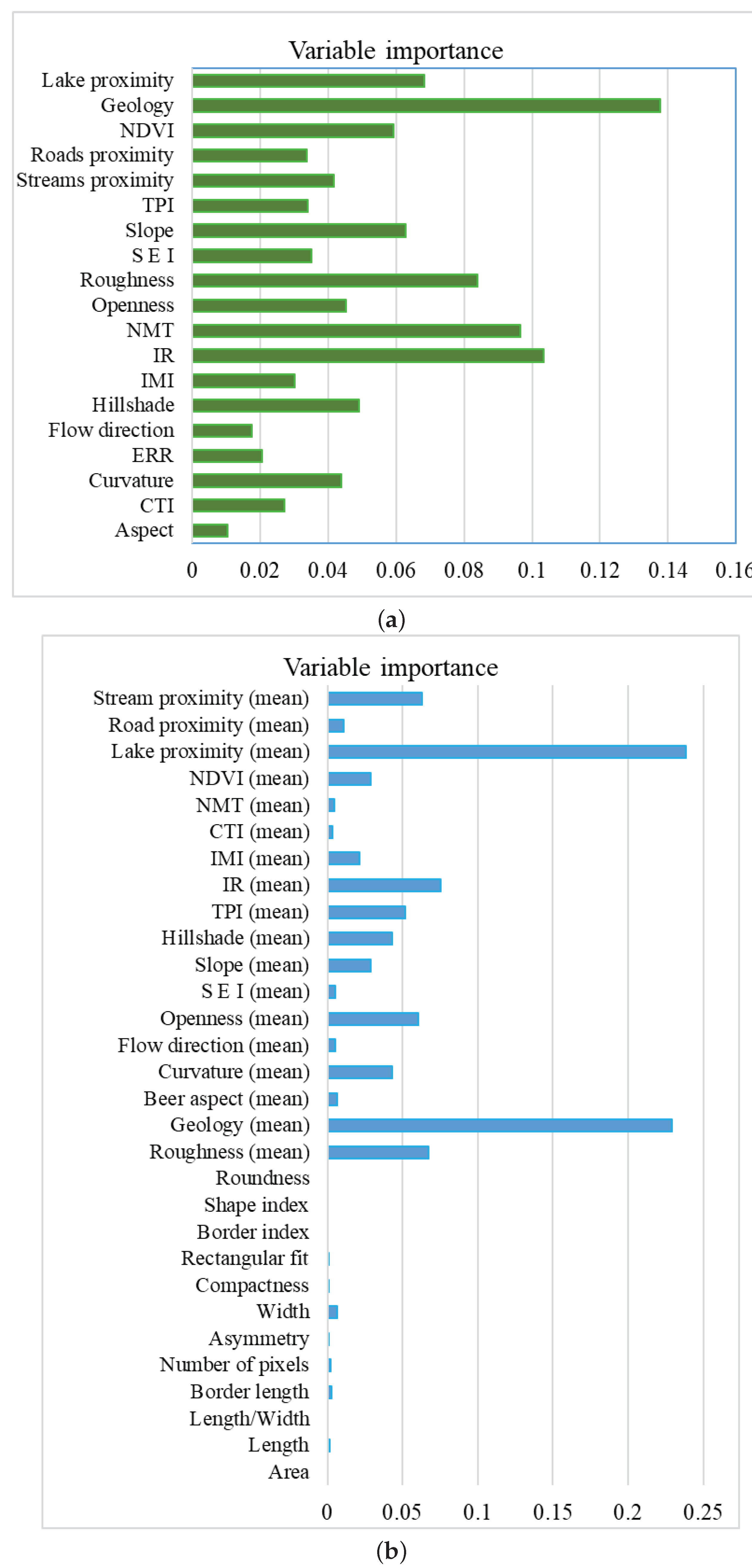
5.2. Feature Relevance
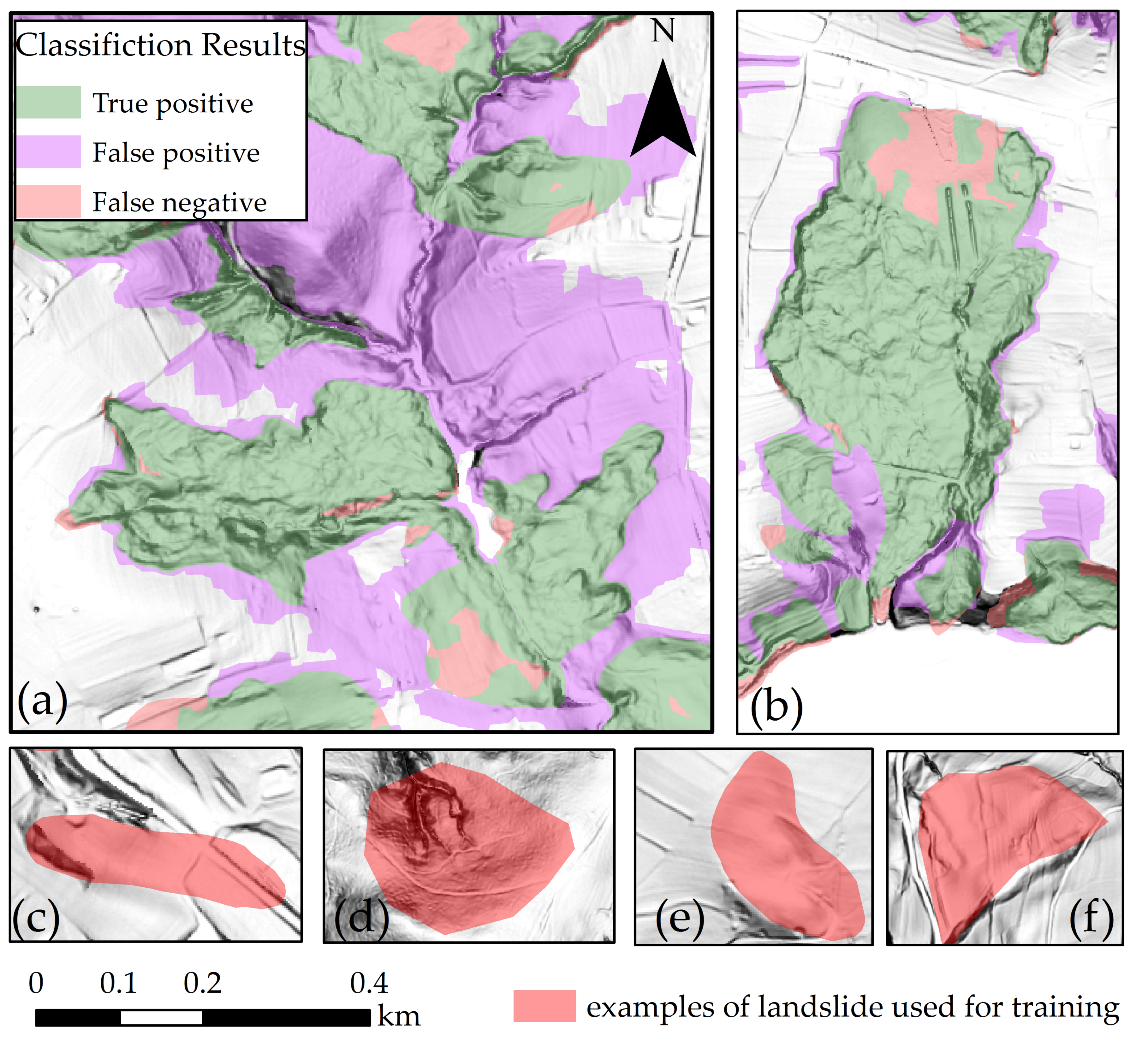
5.3. Final Landside Map Generation
6. Discussion
6.1. Landslide Classification Accuracy with Respect to the Training Samples
6.2. Comparison with Other Related Studies
6.3. Opportunities and Limitations of the Presented Approach
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unit Number | Unit Type | Additional Description |
|---|---|---|
| 1 | peat and ground soils | Quaternary |
| 2 | calcareous tumbles | |
| 3 | gravel, sands and clays, ore dregs of the valley bottoms | |
| 4 | clay, slıts with admixture pf sands and alluvial soils, river sands and gasses of flooding and overflow terraces 1–5 m on the riverbank | |
| 5 | rock rubbles in situ | |
| 6 | sands and weathering clays. | |
| 7 | clays, sands, clays, sometimes with congregational and diluvial rubble. | |
| 8 | landslide colluviums | |
| 9 | loess-like clays | |
| 10 | gravel, sands and river clays, erosive and storage terraces. 6–13 m on the riverbank | |
| 11 | gravel, sands and river clays, erosive and storage terraces. 15–30 m on the riverbank | |
| 12 | boulders, gravel and water type sand | |
| 13 | gravel, sands and river clays, erosive and storage terraces. 35–60 m on the riverbank | |
| 14 | gravel, sands and river clays, erosive and storage terraces. 65–80 m on the riverbank | |
| 15 | gravel, sands and river clays, erosive and storage terraces. 85–110 m on the riverbank | |
| 16 | conglomerates and sandstones wıth clay liner—formatıon Beli | Transgressive Miocene on the Carpathian flysch (Tertiary period-neocen) |
| 17 | clay, slits from inserts, lignite lenses—formation from Iwkowej | |
| 18 | spotted marl in coal | Under Silesian Nappe in the coal facies (Tertiary period Upper Cretaceous—Paleocene) |
| 19 | thick-bedded sandstone and shale sandstones from Rajbrot | |
| 20 | gray marl from exotic frydeckie | |
| 21 | marl from Żegociny | |
| 22 | shale and sandstones | Silesian Nappe (Tertiary period—Paleocene) |
| 23 | darkish limestone | |
| 24 | medium-thick and semi-thin sandstone and shale | |
| 25 | shale, sandstone, chert, marl, and conglomerate-menilite layers | |
| 26 | globigerina marl | |
| 27 | sandstone and shale–hieroglyph layers | |
| 28 | sandstone and shale—heavy type sandstone | |
| 29 | shale with thick-bedded and medium-bedded sandstone inserts | |
| 30 | sandstone and conglomerate—upper Istebna sandstone | |
| 31 | shale with thin-bedded sandstone inserts | |
| 32 | Istebna shale with lower layers from upper Istebna | |
| 33 | sandstone and conglomerate—lower Istebna layers | Silesian Nappe (Upper Cretaceous) |
| 34 | thin, thick and medium-bedded sandstone, seated conglomerate—unseparated Godulskie layers | |
| 35 | medium and thick-bedded sandstone, conglomerate and shale—Godulskie layers | |
| 36 | medıum and thin-bedded sandstone and shale-Godulskie layers | |
| 37 | Godulskie spotted shale | |
| 38 | sandstone and shale-Igockie layers | Silesian Nappe (Lower Cretaceous) |
| 39 | Rzewów shales | |
| 40 | sandstone-Grodziskie layers | |
| 41 | shale with thin-bedded sandstone inserts—upper Cieszyn shales | |
| 42 | thick-bedded sandstone—Cergowa sandstone | Under Magura Nappe Dukielskie series (Tertiary period—Palaeogene) |
| 43 | shales menilite and lower Cergowa mar | |
| 44 | shales or shale and sandstone—hieroglyphs and green shale | |
| 45 | tylawskie limestone | Grybów and Michalczowej Unit (Tertiary period-Palaeogene) |
| 46 | Sandstone and shale | |
| 47 | Shale, chert, sandstone—Grybowskie layers | |
| 48 | Organodetic limestone and sandstone—Luzańskie lımestone and Michalczowej sandstone | |
| 49 | marn shale, sandstone, lower Grybowskıe marl | |
| 50 | shale and sandstone–hieroglyph layers | |
| 51 | spotted shale | |
| 52 | thin and medium-bedded sandstones and shales—layers of Jawoveret/inoceramic in biotite facies | |
| 53 | sandstone and shale-Magura layers in glauconite faction | Magura Nappe (Tertiary period—Palaeogene) |
| 54 | shales within the Magura sandstone in the muscovite facies | |
| 55 | thick-bedded sandstones and shales—Magura sandstone in the muscovite facies | |
| 56 | chert, Pelic limestone | |
| 57 | shale, marl, sandstone—Zembrzyckie submarine layers | |
| 58 | low, medium and medium-bedded shales and sandstone–hieroglyphic layers | |
| 59 | Ciężkowice sandstones in the Magura sandstone form of Wojakowa | |
| 60 | spotted shale | |
| 61 | thin and medium-bedded sandstones and shales—layers of Jawoveret/inoceramic layers in the biotite facies | |
| 62 | medium and thin-bedded sandstones and shales—layers of Kanina | |
| 63 | marl and spotted shale |
References
- Dou, J.; Chang, K.T.; Chen, S.; Yunus, A.P.; Liu, J.K.; Xia, H.; Zhu, Z. Automatic case-based reasoning approach for landslide detection: Integration of object-oriented image analysis and a genetic algorithm. Remote Sens. 2015, 7, 4318–4342. [Google Scholar] [CrossRef]
- Dramis, F.; Guida, D.; Cestari, A. Chapter three–nature and aims of geomorphological mapping. In Developments in Earth Surface Processes; Elsevier: Amsterdam, The Netherlands, 2011; Volume 15, pp. 39–73. [Google Scholar]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Tian, Y. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, Malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef]
- McKean, J.; Roering, J. Objective landslide detection and surface morphology mapping using high-resolution airborne laser altimetry. Geomorphology 2004, 57, 331–351. [Google Scholar] [CrossRef]
- Booth, A.M.; Roering, J.J.; Perron, J.T. Automated landslide mapping using spectral analysis and high-resolution topographic data: Puget Sound lowlands, Washington, and Portland Hills, Oregon. Geomorphology 2009, 109, 132–147. [Google Scholar] [CrossRef]
- Saba, S.B.; van der Meijde, M.; van der Werff, H. Spatiotemporal landslide detection for the 2005 Kashmir earthquake region. Geomorphology 2010, 124, 17–25. [Google Scholar] [CrossRef]
- Van Den Eeckhaut, M.; Kerle, N.; Poesen, J.; Hervás, J. Object-oriented identification of forested landslides with derivatives of single pulse LiDAR data. Geomorphology 2012, 173, 30–42. [Google Scholar] [CrossRef]
- Lu, P.; Stumpf, A.; Kerle, N.; Casagli, N. Object-oriented change detection for landslide rapid mapping. IEEE Geosci. Remote Sens. Lett. 2011, 8, 701–705. [Google Scholar] [CrossRef]
- Wojciechowski, T.; Borkowski, A.; Perski, Z.; Wójcik, A. Airborne laser scanning data in landslide studies at the example of the Zbyszyce landslide (Outer Carpathians). Przegląd Geol. 2012, 60, 95–102. (In Polish) [Google Scholar]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Martha, T.R.; Kerle, N.; van Westen, C.J.; Jetten, V.; Kumar, K.V. Segment optimization and data-driven thresholding for knowledge-based landslide detection by object-based image analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4928–4943. [Google Scholar] [CrossRef]
- Prakash, N.; Manconi, A.; Loew, S. Mapping landslides on EO data: Performance of deep learning models vs. traditional machine learning models. Remote Sens. 2020, 12, 346. [Google Scholar] [CrossRef]
- Knevels, R.; Petschko, H.; Leopold, P.; Brenning, A. Geographic Object-Based Image Analysis for Automated Landslide Detection Using Open Source GIS Software. ISPRS Int. J. Geo-Inf. 2019, 8, 551. [Google Scholar] [CrossRef]
- Pawluszek, K.; Borkowski, A.; Tarolli, P. Sensitivity analysis of automatic landslide mapping: Numerical experiments towards the best solution. Landslides 2018, 15, 1851–1865. [Google Scholar] [CrossRef]
- Pawłuszek, K.; Marczak, S.; Borkowski, A.; Tarolli, P. Multi-Aspect Analysis of Object-Oriented Landslide Detection Based on an Extended Set of LiDAR-Derived Terrain Features. ISPRS Int. J. Geo-Inf. 2019, 8, 321. [Google Scholar] [CrossRef]
- Pawłuszek, K.; Borkowski, A.; Tarolli, P. Towards the optimal pixel size of DEM for automatic mapping of landslide areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 83–90. [Google Scholar] [CrossRef]
- Bunn, M.D.; Leshchinsky, B.A.; Olsen, M.J.; Booth, A. A simplified, object-based framework for efficient landslide inventorying using LIDAR digital elevation model derivatives. Remote Sens. 2019, 11, 303. [Google Scholar] [CrossRef]
- Leshchinsky, B.A.; Olsen, M.J.; Tanyu, B.F. Contour Connection Method for automated identification and classification of landslide deposits. Comput. Geosci. 2015, 74, 27–38. [Google Scholar] [CrossRef]
- Chen, W.; Li, X.; Wang, Y.; Chen, G.; Liu, S. Forested landslide detection using LiDAR data and the random forest algorithm: A case study of the Three Gorges, China. Remote Sens. Environ. 2014, 152, 291–301. [Google Scholar] [CrossRef]
- Li, X.; Cheng, X.; Chen, W.; Chen, G.; Liu, S. Identification of forested landslides using LiDAR data, object-based image analysis, and machine learning algorithms. Remote Sens. 2015, 7, 9705–9726. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Mezaal, M.R.; Pradhan, B.; Rizeei, H.M. Improving Landslide Detection from Airborne Laser Scanning Data Using Optimized Dempster–Shafer. Remote Sens. 2018, 10, 1029. [Google Scholar] [CrossRef]
- Mezaal, M.R.; Pradhan, B.; Sameen, M.I.; Mohd Shafri, H.Z.; Yusoff, Z.M. Optimized neural architecture for automatic landslide detection from high-resolution airborne laser scanning. Appl. Sci. 2017, 7, 730. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Landslide detection using residual networks and the fusion of spectral and topographic information. IEEE Access 2019, 7, 114363–114373. [Google Scholar] [CrossRef]
- Pradhan, B.; Mezaal, M.R. Data mining-aided automatic landslide detection using airborne laser scanning data in densely forested tropical areas. Korean J. Remote Sens. 2018, 34, 45–74. [Google Scholar]
- Sîrbu, F.; Drăguț, L.; Oguchi, T.; Hayakawa, Y.; Micu, M. Scaling land-surface variables for landslide detection. Prog. Earth Planet. Sci. 2019, 6, 44. [Google Scholar] [CrossRef]
- Syzdykbayev, M.; Karimi, B.; Karimi, H.A. Persistent homology on LiDAR data to detect landslides. Remote Sens. Environ. 2020, 246. [Google Scholar] [CrossRef]
- Tavakkoli Piralilou, S.; Shahabi, H.; Jarihani, B.; Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Landslide detection using multi-scale image segmentation and different machine learning models in the higher himalayas. Remote Sens. 2019, 11, 2575. [Google Scholar] [CrossRef]
- Bialas, J.; Oommen, T.; Rebbapragada, U.; Levin, E. Object-based classification of earthquake damage from high-resolution optical imagery using machine learning. J. Appl. Remote Sens. 2016, 10, 036025. [Google Scholar] [CrossRef]
- Gudiyangada Nachappa, T.; Kienberger, S.; Meena, S.R.; Hölbling, D.; Blaschke, T. Comparison and validation of per-pixel and object-based approaches for landslide susceptibility mapping. Geomat. Nat. Hazards Risk 2020, 11, 572–600. [Google Scholar]
- Fu, B.; Wang, Y.; Campbell, A.; Li, Y.; Zhang, B.; Yin, S.; Jin, X. Comparison of object-based and pixel-based Random Forest algorithm for wetland vegetation mapping using high spatial resolution GF-1 and SAR data. Ecol. Indic. 2017, 73, 105–117. [Google Scholar] [CrossRef]
- Keyport, R.N.; Oommen, T.; Martha, T.R.; Sajinkumar, K.S.; Gierke, J.S. A comparative analysis of pixel-and object-based detection of landslides from very high-resolution images. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 1–11. [Google Scholar] [CrossRef]
- Moosavi, V.; Talebi, A.; Shirmohammadi, B. Producing a landslide inventory map using pixel-based and object-oriented approaches optimized by Taguchi method. Geomorphology 2014, 204, 646–656. [Google Scholar] [CrossRef]
- Van Den Eeckhaut, M.; Poesen, J.; Verstraeten, G.; Vanacker, V.; Moeyersons, J.; Nyssen, J.; Van Beek, L.P. H The effectiveness of hillshade maps and expert knowledge in mapping old deep-seated landslides. Geomorphology 2005, 67, 351–363. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping Land-Cover Modifications over Large Areas: A Comparison of Machine Learning Algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: London, UK, 2002. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2012; Volume 26. [Google Scholar]
- Chen, T.; Trinder, J.C.; Niu, R. Object-oriented landslide mapping using ZY-3 satellite imagery, random forest and mathematical morphology, for the Three-Gorges Reservoir, China. Remote Sens. 2017, 9, 333. [Google Scholar] [CrossRef]
- Mondini, A.C.; Guzzetti, F.; Reichenbach, P.; Rossi, M.; Cardinali, M.; Ardizzone, F. Semi-automatic recognition and mapping of rainfall induced shallow landslides using optical satellite images. Remote Sens. Environ. 2011, 115, 1743–1757. [Google Scholar] [CrossRef]
- Del Ventisette, C.; Righini, G.; Moretti, S.; Casagli, N. Multitemporal landslides inventory map updating using spaceborne SAR analysis. Int. J. Appl. Earth Obs. Geoinf. 2014, 20, 238–246. [Google Scholar] [CrossRef]
- Wasowski, I.; Bovenga, F. Investigating landslides and unstable slopes with satellite multi temporal interferometry: Current issue and future porspectives. Eng. Geol. 2014, 174, 103–138. [Google Scholar] [CrossRef]
- Tarolli, P.; Sofia, G.; Dalla Fontana, G. Geomorphic features extraction from high-resolution topography: Landslide crowns and bank erosion. Nat. Hazards 2012, 61, 65–83. [Google Scholar] [CrossRef]
- Pawluszek, K. Landslide features identification and morphology investigation using high-resolution DEM derivatives. Nat. Hazards 2019, 96, 311–330. [Google Scholar] [CrossRef]
- Solari, L.; Del Soldato, M.; Montalti, R.; Bianchini, S.; Raspini, F.; Thuegaz, P.; Casagli, N. A Sentinel-1 based hot-spot analysis: Landslide mapping in north-western Italy. Int. J. Remote Sens. 2019, 40, 7898–7921. [Google Scholar] [CrossRef]
- Raspini, F.; Moretti, S.; Casagli, N. Landslide mapping using SqueeSAR data: Giampilieri (Italy) case study. In Landslide Science and Practice; Springer: Berlin/Heidelberg, Germany, 2013; pp. 147–154. [Google Scholar]
- Bianchini, S.; Cigna, F.; Righini, G.; Proietti, C.; Casagli, N. Landslide hotspot mapping by means of persistent scatterer interferometry. Environ. Earth Sci. 2012, 67, 1155–1172. [Google Scholar] [CrossRef]
- Lu, P.; Bai, S.; Tofani, V.; Casagli, N. Landslides detection through optimized hot spot analysis on persistent scatterers and distributed scatterers. ISPRS J. Photogramm. Remote Sens. 2019, 156, 147–159. [Google Scholar] [CrossRef]
- Chen, T.H.K.; Prishchepov, A.V.; Fensholt, R.; Sabel, C.E. Detecting and monitoring long-term landslides in urbanized areas with nighttime light data and multi-seasonal Landsat imagery across Taiwan from 1998 to 2017. Remote Sens. Environ. 2019, 225, 317–327. [Google Scholar] [CrossRef]
- Barlow, J.; Martin, Y.; Franklin, S.E. Detecting translational landslide scars using segmentation of Landsat ETM+ and DEM data in the northern Cascade Mountains, British Columbia. Can. J. Remote Sens. 2003, 29, 510–517. [Google Scholar] [CrossRef]
- Martin, Y.E.; Franklin, S.E. Classification of soil-and bedrock-dominated landslides in British Columbia using segmentation of satellite imagery and DEM data. Int. J. Remote Sens. 2005, 26, 1505–1509. [Google Scholar] [CrossRef]
- Mantovani, F.; Soeters, R.; Van Westen, C.J. Remote sensing techniques for landslide studies and hazard zonation in Europe. Geomorphology 1996, 15, 213–225. [Google Scholar] [CrossRef]
- Haeberlin, Y.; Turberg, P.; Retière, A.; Senegas, O.; Parriaux, A. Validation of Spot-5 satellite imagery for geological hazard identification and risk assessment for landslides, mud and debris flows in Matagalpa, Nicaragua. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 35, 16–21. [Google Scholar]
- Cheng, K.S.; Wei, C.; Chang, S.C. Locating landslides using multi-temporal satellite images. Adv. Space Res. 2004, 33, 296–301. [Google Scholar] [CrossRef]
- Borghuis, A.M.; Chang, K.; Lee, H.Y. Comparison between automated and manual mapping of typhoon-triggered landslides from SPOT-5 imagery. Int. J. Remote Sens. 2008, 28, 1843–1856. [Google Scholar] [CrossRef]
- Nichol, J.; Wong, M.S. Satellite remote sensing for detailed landslide inventories using change detection and image fusion. Int. J. Remote Sens. 2005, 26, 1913–1926. [Google Scholar] [CrossRef]
- Nichol, J.; Wong, M.S. Detection and interpretation of landslides using satellite images. Land Degrad. Dev. 2005, 16, 243–255. [Google Scholar] [CrossRef]
- Hölbling, D.; Füreder, P.; Antolini, F.; Cigna, F.; Casagli, N.; Lang, S. A semi-automated object-based approach for landslide detection validated by persistent scatterer interferometry measures and landslide inventories. Remote Sens. 2012, 4, 1310–1336. [Google Scholar] [CrossRef]
- Tsutsui, K.; Rokugawa, S.; Nakagawa, H.; Miyazaki, S.; Cheng, C.T.; Shiraishi, T.; Yang, S.D. Detection and volume estimation of large-scale landslides based on elevation-change analysis using DEMs extracted from high-resolution satellite stereo imagery. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1681–1696. [Google Scholar] [CrossRef]
- Othman, A.A.; Gloaguen, R. Automatic extraction and size distribution of landslides in Kurdistan Region, NE Iraq. Remote Sens. 2013, 5, 2389–2410. [Google Scholar] [CrossRef]
- Tarolli, P. High-resolution topography for understanding Earth surface processes: Opportunities and challenges. Geomorphology 2012, 216, 295–312. [Google Scholar] [CrossRef]
- Glenn, N.F.; Streutker, D.R.; Chadwick, D.J.; Thackray, G.D.; Dorsch, S.J. Analysis of LiDAR-derived topographic information for characterizing and differentiating landslide morphology and activity. Geomorphology 2006, 73, 131–148. [Google Scholar] [CrossRef]
- Mezaal, M.R.; Pradhan, B.; Shafri, H.Z.M.; Yusoff, Z.M. Automatic landslide detection using Dempster–Shafer theory from LiDAR-derived data and orthophotos. Geomat. Nat. Hazards Risk 2017, 8, 1935–1954. [Google Scholar] [CrossRef]
- Sato, H.P.; Yagi, H.; Koarai, M.; Iwahashi, J.; Sekiguchi, T. Airborne LIDAR data measurement and landform classification mapping in Tomari-no-tai landslide area, Shirakami Mountains, Japan. In Progress in Landslide Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 237–249. [Google Scholar]
- Kasai, M.; Ikeda, M.; Asahina, T.; Fujisawa, K. LiDAR-derived DEM evaluation of deep-seated landslides in a steep and rocky region of Japan. Geomorphology 2009, 113, 57–69. [Google Scholar] [CrossRef]
- Passalacqua, P.; Tarolli, P.; Foufoula-Georgiou, E. Testing space-scale methodologies for automatic geomorphic feature extraction from lidar in a complex mountainous landscape. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef]
- Lahousse, T.; Chang, K.T.; Lin, Y.H.; Günther, A. Landslide mapping with multi-scale object-based image analysis—A case study in the Baichi watershed, Taiwan. Nat. Hazards Earth Syst. Sci. 2011, 11. [Google Scholar] [CrossRef]
- Franklin, S.E. Interpretation and use of geomorphometry in remote sensing: A guide and review of integrated applications. Int. J. Remote Sens. 2020, 41, 7700–7733. [Google Scholar] [CrossRef]
- Gaidzik, K.; Ramírez-Herrera, M.T.; Bunn, M.; Leshchinsky, B.A.; Olsen, M.; Regmi, N.R. Landslide manual and automated inventories, and susceptibility mapping using LIDAR in the forested mountains of Guerrero, Mexico. Geomat. Nat. Hazards Risk 2017, 8, 1054–1079. [Google Scholar] [CrossRef]
- Kroh, P. Analysis of land use in landslide affected areas along the Łososina Dolna Commune, the Outer Carpathians, Poland. Geomat. Nat. Hazards Risk 2017, 8, 863–875. [Google Scholar] [CrossRef]
- Hungr, O.; Leroueil, S.; Picarelli, L. The Varnes classification of landslide types, an update. Landslides 2014, 11, 167–194. [Google Scholar] [CrossRef]
- Gorczyca, E.; Wrońska-Wałach, D.; Długosz, M. Landslide Hazards in the Polish Flysch Carpathians: Example of Łososina Dolna Commune. In Geomorphological Impacts of Extreme Weather; Springer: Dordrecht, The Netherlands, 2013; pp. 237–250. [Google Scholar] [CrossRef]
- Bąk, M.; Długosz, M.; Gorczyca, E.; Kasina Kozioł, T.; Wrońska-Wałach, D.; Wyderski, P. Map of Landslides and Areas Threatened by Mass Movements on a Scale of 1:10,000 Łososina Dolna Commune, Nowosądeckie County, Małpolskie Municipality; Ministerstwo Środowiska: Warszawa, Poland, 2011. (In Polish)
- Starkel, L. An outline of the relief of the Polish Carpathians and its importance for human management. Probl. Zagospod. Ziem Górskich 1971, 10, 75–150. (In Polish) [Google Scholar]
- Pawłuszek, K.; Ziaja, M.; Borkowski, A. Accuracy assessment of the height component of the airborne laser scanning data collected in the ISOK system for the Widawa river valley. Acta Sci. Polonorum. Geod. Descr. Terrarum 2014, 13, 27–37. [Google Scholar]
- Grabowski, D.; Marciniec, P.; Mrozek, T.; Neścieruk, P.; Rączkowski, W.; Wójcik, A.; Zimnal, Z. Manual for Mapping Landslides and Areas Threatened by Mass Movements; Ministerstwo Środowiska: Warszawa, Poland, 2008. (In Polish)
- Koluch, Z.; Nowicka, D. Map of Landslides and Areas Threatened by Mass Movements on a Scale of 1:10,000 Chełmiec Commune, Nowosądeckie County, Małpolskie Municipality; Ministerstwo Środowiska: Warszawa, Poland, 2012. (In Polish)
- Wójcik, A.; Wojciechowski, T.; Wódka, M.; Krzysiek, U. Explanations for the Map of Landslides and Areas Threatened by Mass Movements on a Scale of 1: 10000 Gródek nad Dunajcem Commune, Nowosądeckie County, Małpolskie Manucipality; Ministerstwo Środowiska: Warszawa, Poland, 2015. (In Polish)
- Wojciechowski, T.; Borkowski, A.; Perski, Z.; Wojcik, A. The use of satellite radar interferometry for the study of landslides in the Polish part of Karpaty. Przegląd Geol. 2008, 56, 1088–1091. [Google Scholar]
- Kowalski, M. Zastosowanie technologii lotniczego skaningu laserowego na przykładzie projektu Informatyczny System Osłony Kraju przed nadzwyczajnymi zagrożeniami (ISOK). Przegląd Geod. 2013, 85, 9–12. [Google Scholar]
- Axelsson, P. Processing of laser scanner data—Algorithms and applications. ISPRS J. Photogramm. Remote Sens. 1999, 54, 138–147. [Google Scholar] [CrossRef]
- Axelsson, P. DEM Generation from Laser Scanner Data Using Adaptive TIN Models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Axelsson, P. Ground estimation of laser data using adaptive TIN-models. In Proceedings of the OEEPE Workshop on Airborne Laserscanning and Interferometric SAR for Detailed Digital Elevation Models, Stockholm, Sweden, 1–3 March 2001; pp. 1–3. [Google Scholar]
- Paudel, U.; Oguchi, T.; Hayakawa, Y. Multi-resolution landslide susceptibility analysis using a DEM and random forest. Int. J. Geosci. 2016, 7, 726–743. [Google Scholar] [CrossRef]
- Nadim, F.; Kjekstad, O.; Peduzzi, P.; Herold, C.; Jaedicke, C. Global landslide and avalanche hotspots. Landslides 2006, 3, 159–173. [Google Scholar] [CrossRef]
- Aditian, A.; Kubota, T.; Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 2018, 318, 101–111. [Google Scholar] [CrossRef]
- Arabameri, A.; Pradhan, B.; Rezaei, K.; Sohrabi, M.; Kalantari, Z. GIS-based landslide susceptibility mapping using numerical risk factor bivariate model and its ensemble with linear multivariate regression and boosted regression tree algorithms. J. Mt. Sci. 2019, 16, 595–618. [Google Scholar] [CrossRef]
- Arabameri, A.; Saha, S.; Roy, J.; Chen, W.; Blaschke, T.; Tien Bui, D. Landslide susceptibility evaluation and management using different machine learning methods in the Gallicash River Watershed, Iran. Remote Sens. 2020, 12, 475. [Google Scholar] [CrossRef]
- Pawluszek, K.; Borkowski, A. Impact of DEM-derived factors and analytical hierarchy process on landslide susceptibility mapping in the region of Rożnów Lake, Poland. Nat. Hazards 2017, 86, 919–952. [Google Scholar] [CrossRef]
- Razavizadeh, S.; Solaimani, K.; Massironi, M.; Kavian, A. Mapping landslide susceptibility with frequency ratio, statistical index, and weights of evidence models: A case study in northern Iran. Environ. Earth Sci. 2017, 76, 499. [Google Scholar] [CrossRef]
- Shirani, K.; Pasandi, M.; Arabameri, A. Landslide susceptibility assessment by dempster–shafer and index of entropy models, Sarkhoun basin, southwestern Iran. Nat. Hazards 2018, 93, 1379–1418. [Google Scholar] [CrossRef]
- Saadatkhah, N.; Kassim, A.; Lee, L.M. Qualitative and quantitative landslide susceptibility assessments in Hulu Kelang area, Malaysia. EJGE 2014, 19, 545–563. [Google Scholar]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Zhu, A.X. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Evans, J.S.; Oakleaf, J.; Cushman, S.A.; Theobald, D. An ArcGIS Toolbox for Surface Gradient and Geomorphometric Modeling, Version 2.0-0. Available online: http://evansmurphy.wix.com/evansspatial (accessed on 16 September 2020).
- Cavalli, M.; Tarolli, P.; Marchi, L.; Dalla Fontana, G. The effectiveness of airborne LiDAR data in the recognition of channel-bed morphology. Catena 2008, 73, 249–260. [Google Scholar] [CrossRef]
- Jenness, J.; Brost, B.; Beier, P. Land Facet Corridor Designer. Available online: http://www.jennessent.com/arcgis/land_facets.htm (accessed on 16 September 2020).
- Drǎguţ, L.; Tiede, D.; Levick, S.R. ESP: A tool to estimate scale parameter for multiresolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 2001; Volume 45, pp. 5–32. [Google Scholar]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with Landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Zhong, C.; Liu, Y.; Gao, P.; Chen, W.; Li, H.; Hou, Y.; Ma, H. Landslide mapping with remote sensing: Challenges and opportunities. Int. J. Remote Sens. 2020, 41, 1555–1581. [Google Scholar] [CrossRef]
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C.W. Collaborative learning of lightweight convolutional neural network and deep clustering for hyperspectral image semi-supervised classification with limited training samples. ISPRS J. Photogramm. Remote Sens. 2020, 161, 164–178. [Google Scholar] [CrossRef]
- Campbell, J.B. Introduction to Remote Sensing; The Guilford Press: New York, NY, USA, 1996. [Google Scholar]
- Delgado, R.; Tibau, X.A. Why Cohen’s Kappa should be avoided as performance measure in classification. PLoS ONE 2019, 14, e0222916. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Robinson, T.R.; Rosser, N.J.; Densmore, A.L.; Williams, J.G.; Kincey, M.E.; Benjamin, J.; Bell, H.J. Rapid post-earthquake modelling of coseismic landslide magnitude and distribution for emergency response decision support. Nat. Hazards Earth Syst. Sci. 2017, 17, 1521–1540. [Google Scholar] [CrossRef]
- Hölbling, D.; Eisank, C.; Albrecht, F.; Vecchiotti, F.; Friedl, B.; Weinke, E.; Kociu, A. Comparing manual and semi-automated landslide mapping based on optical satellite images from different sensors. Geosciences 2017, 7, 37. [Google Scholar] [CrossRef]










| Data Used | Data Type | Source |
|---|---|---|
| DEM | Point cloud | LiDAR [78,83] |
| Landslide inventory map | Raster | http://geoportal.pgi.gov.pl/portal/page/portal/SOPO |
| Geology map | Raster | Polish National Geological Institute |
| Sentinel-2A | Raster | https://scihub.copernicus.eu/ |
| Road network | Shapefile | Open Street Map |
| Variable | Kernel Size/Setting | Implementation | PBA (ArcGIS) | OBIA (eCognition) | Examples of Application |
|---|---|---|---|---|---|
| DEM-related variables | |||||
| DEM | - | - | √ | √ | [7,12,13,14,15,19,20] |
| aspect | - | [97] | √ | √ | [12,19] |
| side exposure index (SEI) | - | [97] | √ | √ | [16] |
| flow direction | - | ArcGIS | √ | √ | [7,13] |
| roughness | 7 × 7 | [14,98] | √ | √ | [4,7,12,13] |
| slope | 15 × 15 | [97] | √ | √ | [7,12,13,19] |
| curvature | 15 × 15 | [97] | √ | √ | [7,12,13,27] |
| topographic position index (TPI) | 15 × 15 | [99] | √ | √ | [90] |
| openness | 25 × 25 (interpolated DEM) | [14] | √ | √ | [7,13] |
| hillshade | 8 various sun angles | ArcGIS | √ | √ | [10,12,15,34,45] |
| compound topographic index (CTI) | - | [97] | √ | √ | [26,87,90] |
| elevation relief ration (ERR) | 10 × 10 | [87] | √ | √ | [87] |
| integral relief (IR) | 10 × 10 | [87] | √ | √ | [87] |
| integrated moisture index (IMI) | - | [97] | √ | √ | |
| Other variables | |||||
| geology | - | - | √ | √ | [90] |
| NDVI | - | (NIR − RED)/ (NIR + RED) | √ | √ | [12] |
| roads proximity | - | Euclidean distance buffering | √ | √ | [90] |
| streams proximity | - | Euclidean distance buffering | √ | √ | [7,12] |
| lake proximity | - | Euclidean distance buffering | √ | √ | - |
| Geometry variables | |||||
| count | - | eCognition | √ | - | |
| compactness | - | eCognition | √ | [13] | |
| rectangularity | - | eCognition | √ | - | |
| shape index | - | eCognition | √ | [10,13] | |
| roundness | - | eCognition | √ | - | |
| asymmetry | - | eCognition | √ | - | |
| length/width | - | eCognition | √ | [13] | |
| border length | - | eCognition | √ | - | |
| Areas | No. Landslides | Domain [km2] | Landslide Areas [km2] | Non-Landslide Areas [km2] | TSQ [%] | TTR | LTSQ [%] | NLTSQ [%] |
|---|---|---|---|---|---|---|---|---|
| Training area | 156 | 20 | 4.3 | 15.7 | - | |||
| TA 1 | 149 | 20 | 5.4 | 14.6 | 50 | 1 | 10.7 | 39.3 |
| TA 2 | 197 | 50 | 6.4 | 23.6 | 28.5 | 0.4 | 6.1 | 22.4 |
| TA 3 | 335 | 56 | 9.8 | 46.2 | 26 | 0.35 | 5.6 | 20.4 |
| TA 4 | 455 | 81 | 13.9 | 67.4 | 19.8 | 0.25 | 4.3 | 15.5 |
| TA 5 | 563 | 106 | 17.2 | 88.8 | 15.9 | 0.19 | 3.4 | 12.5 |
| TA 6 | 646 | 137 | 18.8 | 118.2 | 13 | 0.15 | 2.7 | 10.3 |
| Area | No. Landslides | Total Area [km2] | Landslide Areas [km2] | Non-Landslide Area [km2] | TSQ [%] | TTR | LTSQ [%] | NLTSQ [%] |
|---|---|---|---|---|---|---|---|---|
| Training area | 398 | 85 | 13.1 | 71.9 | - | |||
| Testing area | 404 | 72 | 8.3 | 63.7 | 54 | 1.2 | 8.3 | 45.7 |
| Testing Area | Method | TTR | F1 Score | POD | POFD | OA [%] |
|---|---|---|---|---|---|---|
| TA 1 | PBA-RF | 1 | 0.57 | 0.83 | 0.29 | 74 |
| OBIA-RF | 0.58 | 0.88 | 0.31 | 73 | ||
| TA 2 | PBA-RF | 0.4 | 0.53 | 0.85 | 0.31 | 72 |
| OBIA-RF | 0.53 | 0.88 | 0.33 | 71 | ||
| TA 3 | PBA-RF | 0.35 | 0.44 | 0.83 | 0.34 | 69 |
| OBIA-RF | 0.46 | 0.87 | 0.34 | 69 | ||
| TA 4 | PBA-RF | 0.25 | 0.42 | 0.80 | 0.34 | 68 |
| OBIA-RF | 0.46 | 0.86 | 0.33 | 70 | ||
| TA 5 | PBA-RF | 0.19 | 0.42 | 0.79 | 0.33 | 68 |
| OBIA-RF | 0.45 | 0.85 | 0.32 | 70 | ||
| TA 6 | PBA-RF | 0.15 | 0.40 | 0.78 | 0.33 | 68 |
| OBIA-RF | 0.43 | 0.84 | 0.32 | 70 |
| Testing Area | ML Method | F1 Score | POD | PODF | Accuracy [%] |
|---|---|---|---|---|---|
| Łososina-testing area | PBA-RF | 0.46 | 0.86 | 0.33 | 70 |
| OBIA-RF | 0.48 | 0.87 | 0.30 | 72 |
| Classification Results | Post-Processing Step | F1 Score | POD | POFD | OA [%] |
|---|---|---|---|---|---|
| PBA-RF | - | 0.46 | 0.86 | 0.33 | 70 |
| OBIA-RF | - | 0.48 | 0.87 | 0.30 | 72 |
| PBA&OBIA | intersection of PBA and OBIA | 0.48 | 0.73 | 0.23 | 76 |
| PBA&OBIA refinement 1 | small elongated objects removed | 0.50 | 0.62 | 0.15 | 81 |
| PBA&OBIA refinement 2 | median filtering | 0.50 | 0.71 | 0.19 | 80 |
| Authors | Method | Study Area | F1 Score | POD (Recall) | POFD (Fallout) | K | Accuracy (OA) |
|---|---|---|---|---|---|---|---|
| Presented research | Łososina, Poland | 0.50 | 0.71 | 0.19 | 0.4 | 0.80 | |
| [12] | Deep learning | Oregon, USA | 0.56 | 0.72 | 0.13 | - | 0.85 |
| [12] | RF-PBA | Oregon, USA | 0.51 | 0.66 | 0.14 | - | 0.83 |
| [12] | ANN-OBIA | Oregon, USA | 0.55 | 0.48 | 0.06 | 0.86 | |
| [13] | SVM-OBIA | Oberpullendorf, Austria | - | 0.69 | - | 0.48 | - |
| [17] | SICCM | Dixie Mountain | - | 0.39 | - | - | 0.74 |
| [17] | SICCM | Gales Creek | - | 0.43 | - | - | 0.85 |
| [17] | SICCM | Big Elk Creek | - | 0.65 | - | - | 0.73 |
| [19] | RF-PBA | Three Gorges, China | - | 0.65 | 0.64 | ||
| [20] | RF-OBIA | Three Gorges, China | - | 0.71 | - | - | 0.77 |
| [15] | SVM-OBIA | Łososina, Poland | - | 0.71 | - | 0.6 | 0.85 |
| [14] | SVM-PBA | Łososina, Poland | - | 0.65 | - | 0.55 | 0.81 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pawluszek-Filipiak, K.; Borkowski, A. On the Importance of Train–Test Split Ratio of Datasets in Automatic Landslide Detection by Supervised Classification. Remote Sens. 2020, 12, 3054. https://doi.org/10.3390/rs12183054
Pawluszek-Filipiak K, Borkowski A. On the Importance of Train–Test Split Ratio of Datasets in Automatic Landslide Detection by Supervised Classification. Remote Sensing. 2020; 12(18):3054. https://doi.org/10.3390/rs12183054
Chicago/Turabian StylePawluszek-Filipiak, Kamila, and Andrzej Borkowski. 2020. "On the Importance of Train–Test Split Ratio of Datasets in Automatic Landslide Detection by Supervised Classification" Remote Sensing 12, no. 18: 3054. https://doi.org/10.3390/rs12183054
APA StylePawluszek-Filipiak, K., & Borkowski, A. (2020). On the Importance of Train–Test Split Ratio of Datasets in Automatic Landslide Detection by Supervised Classification. Remote Sensing, 12(18), 3054. https://doi.org/10.3390/rs12183054