Improving Spatial Agreement in Machine Learning-Based Landslide Susceptibility Mapping

 ,
,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
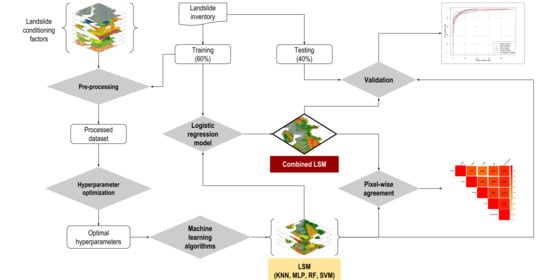
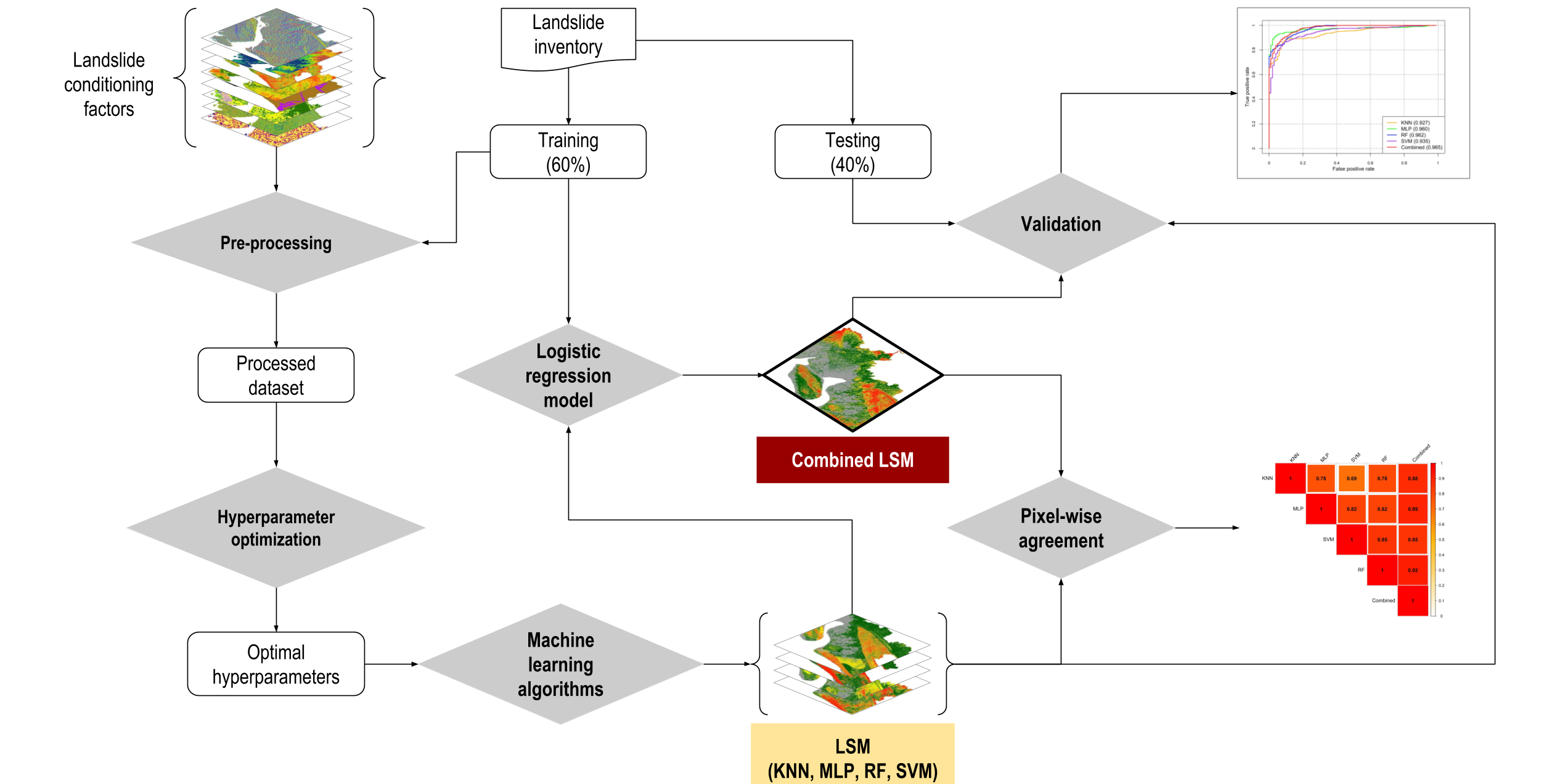
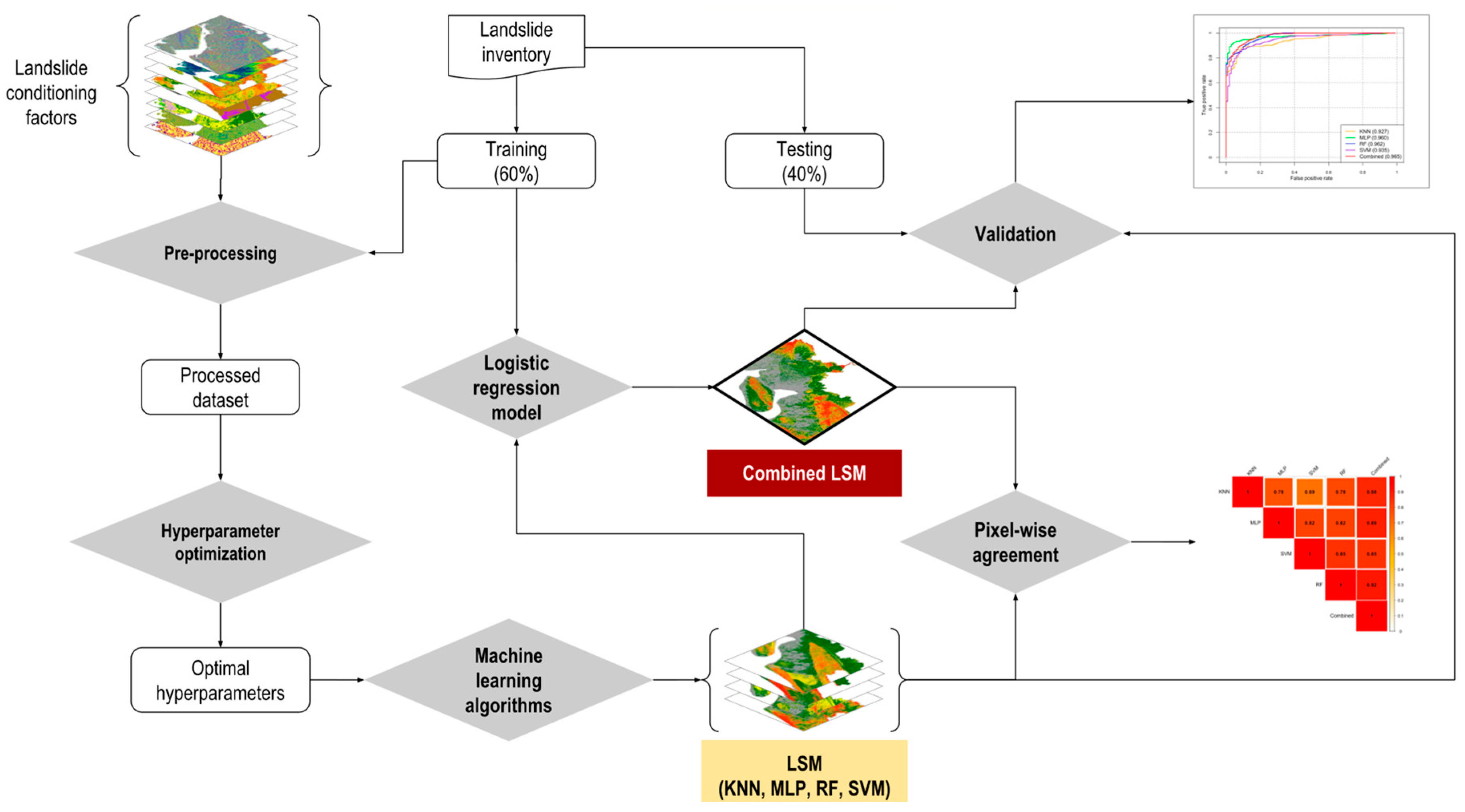
2. Materials and Methods
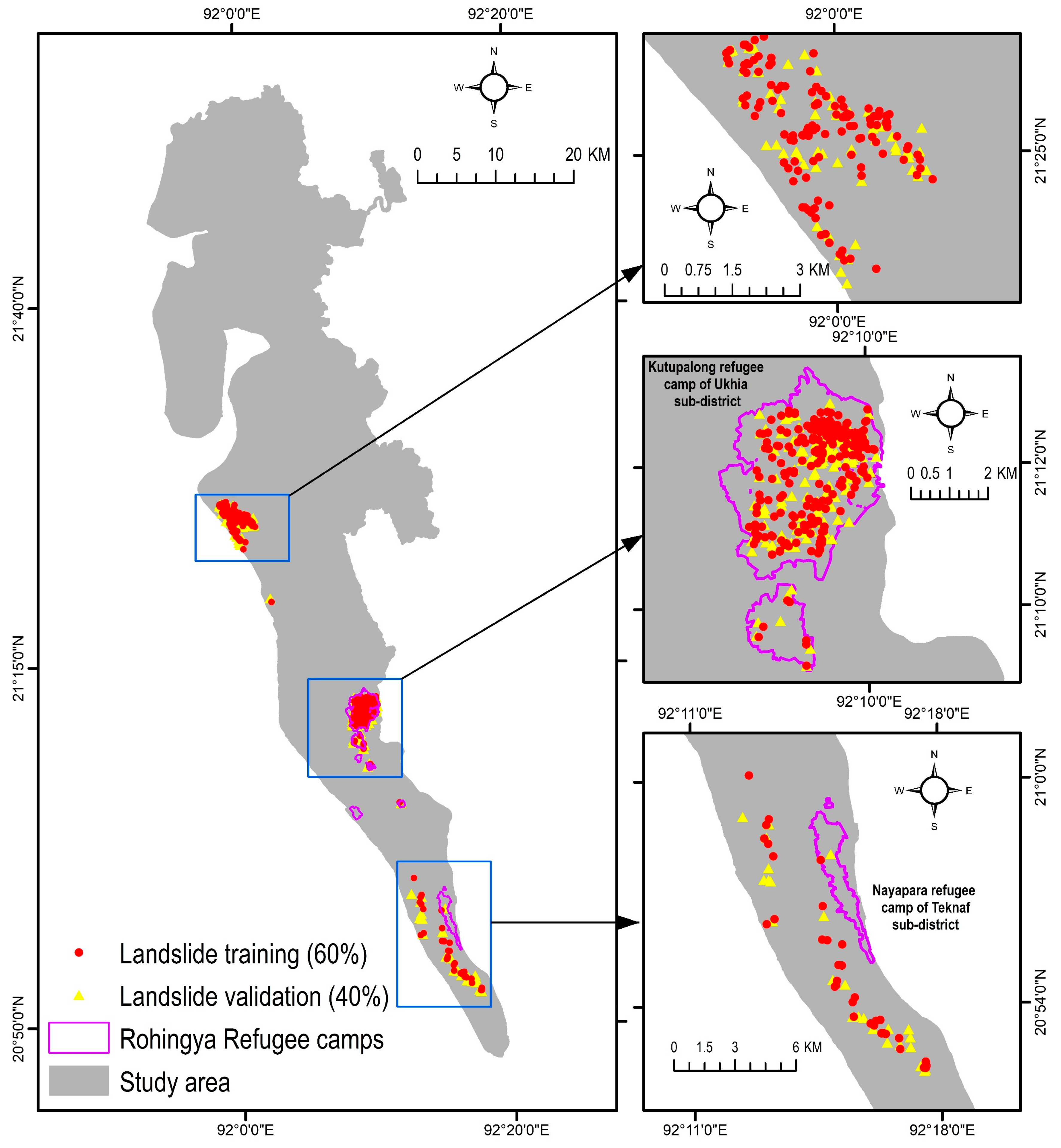
2.1. Study Area
2.2. Landslide Inventory Mapping
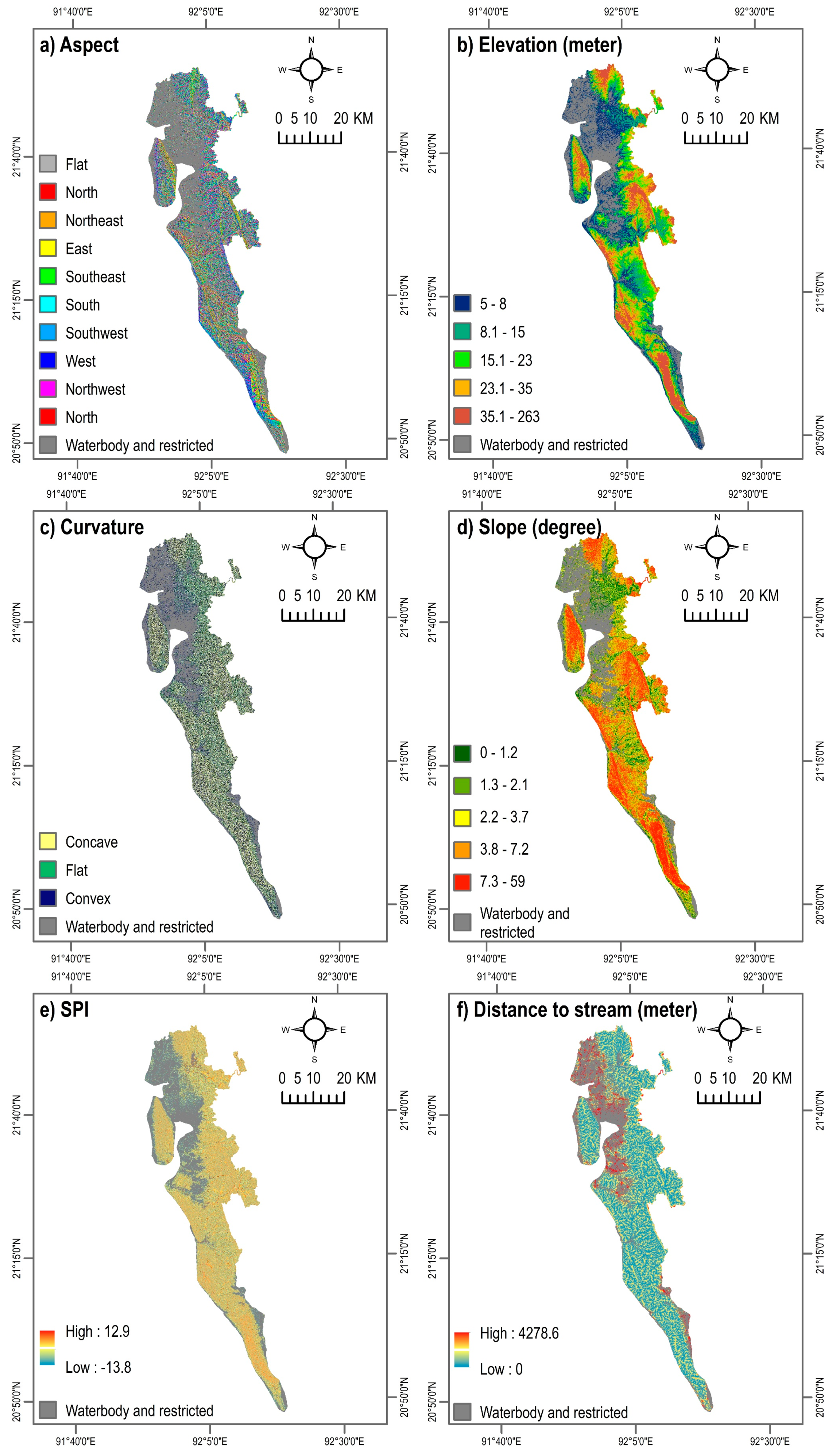
2.3. Landslide Conditioning Factor
2.4. Multi-Collinearity Analysis of Landslide Conditioning Factors
2.5. Landslide Susceptibility Modelling
2.5.1. Pre-Processing
2.5.2. Hyperparameter Optimization
2.5.3. Machine Learning Models
- (1)
- K-Nearest Neighbor (KNN)
- (2)
- Multi-Layer Perceptron (MLP)
- (3)
- Random Forest (RF)
- (4)
- Support Vector Machine (SVM)
2.5.4. Performance Evaluation Methods
2.6. Evaluation of Spatial Agreement and Optimizing Prediction Map
3. Results
3.1. Landslide Susceptibility Modelling
3.1.1. Landslide Prediction
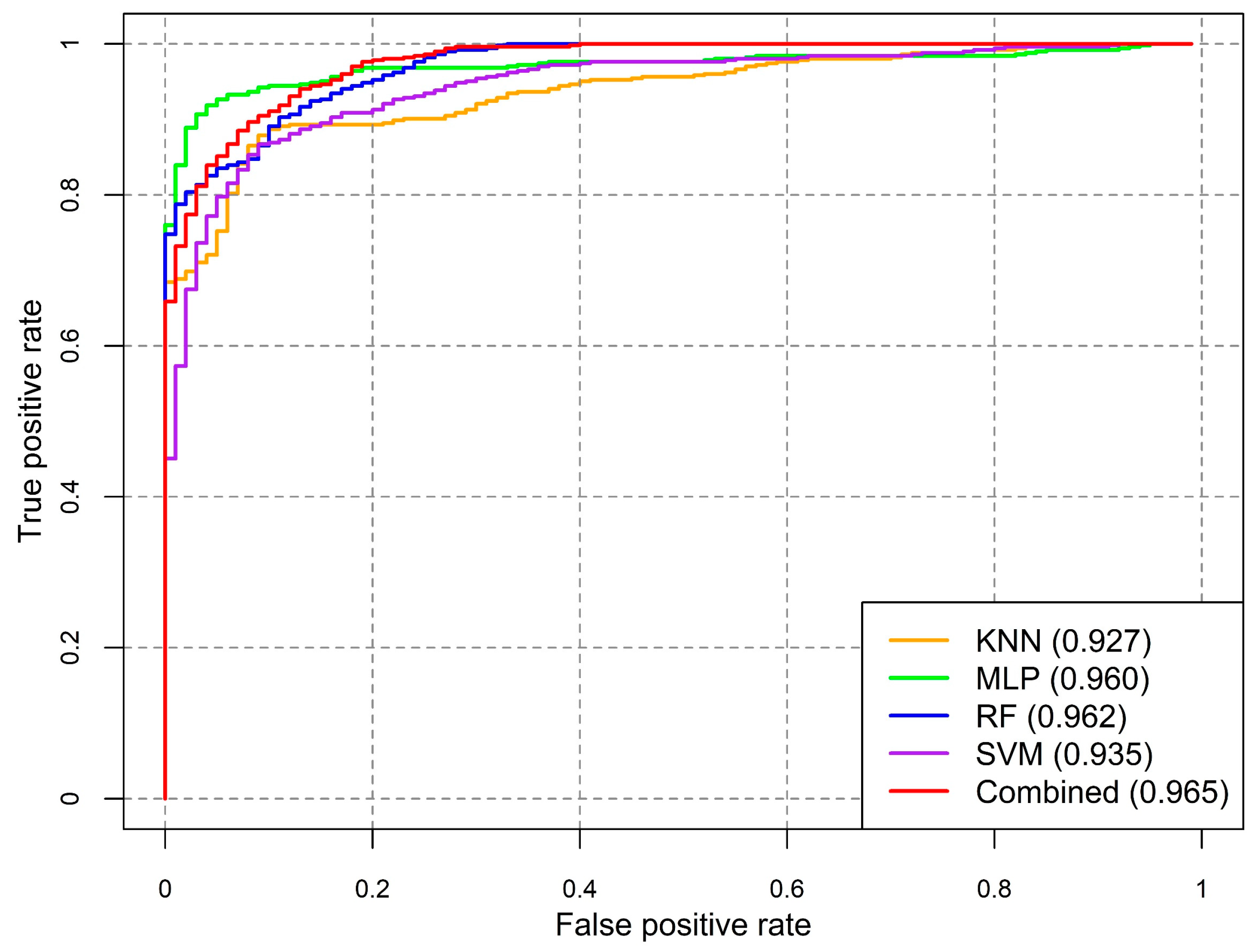
3.1.2. Evaluation of Models’ Performance
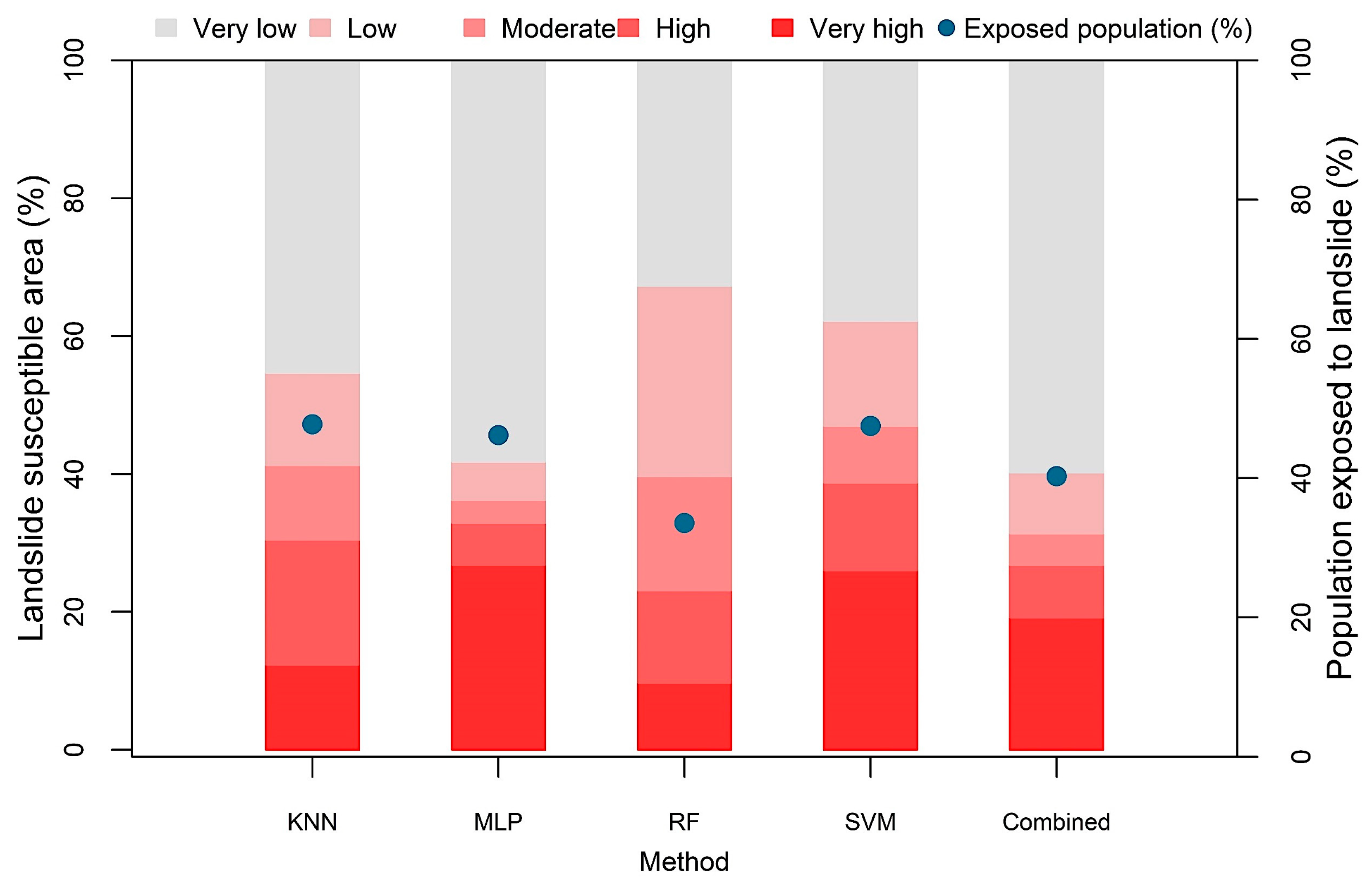
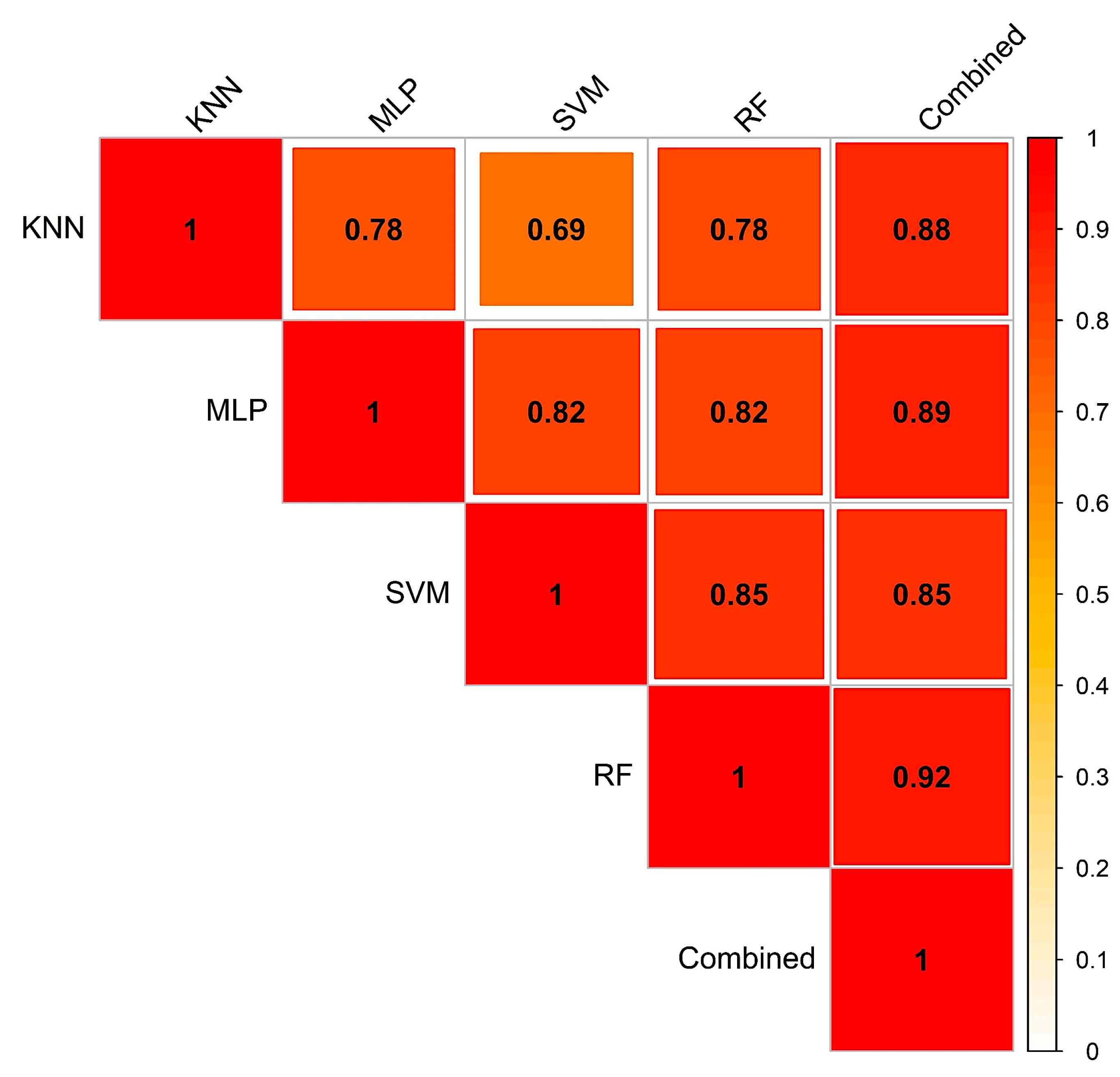
3.2. Spatial Agreement of Various Methods
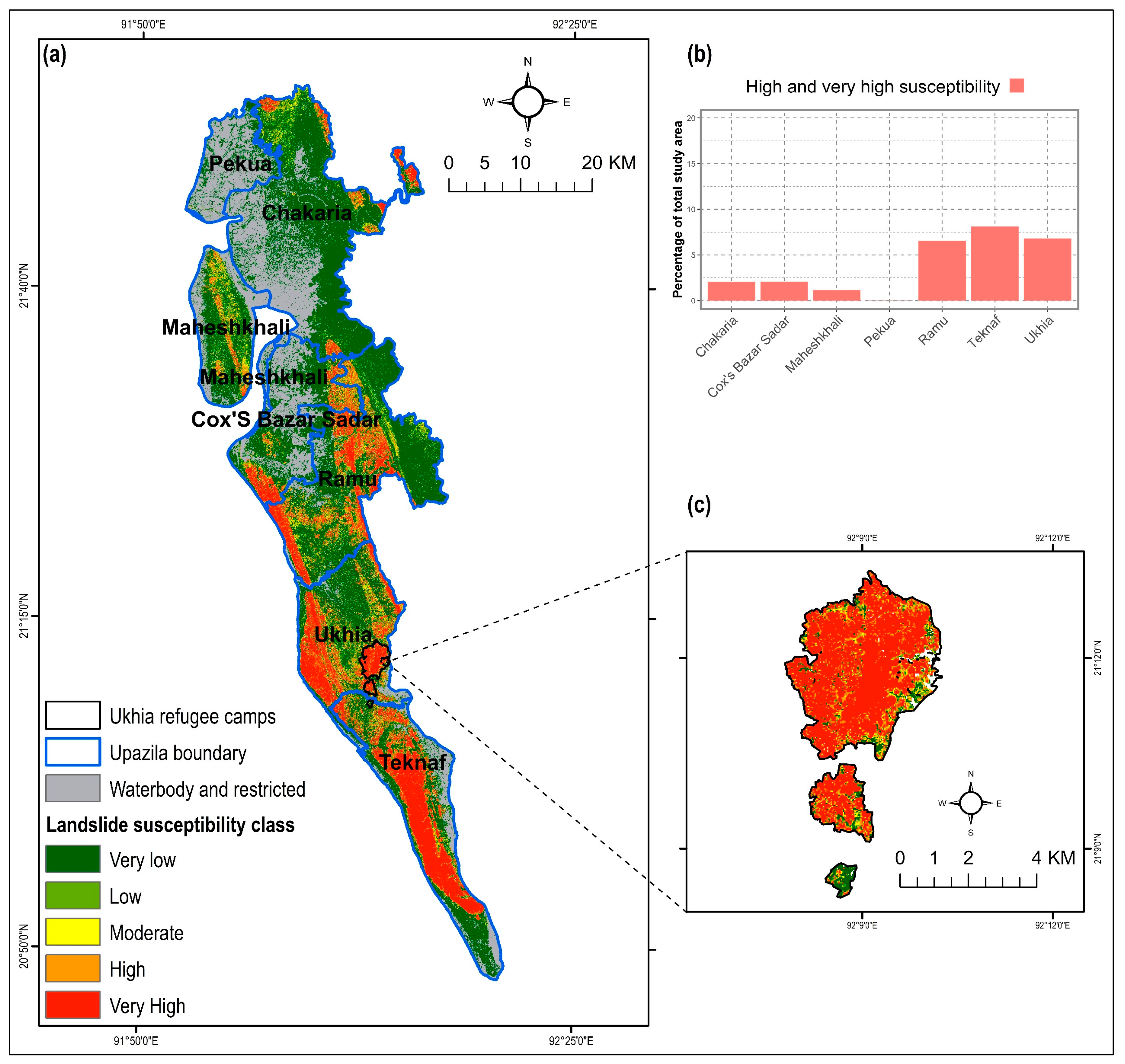
3.3. Aggregated Landslide Susceptibility Mapping
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.-X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef] [PubMed]
- Ayalew, L.; Yamagishi, H. The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide susceptibility mapping using GIS-based statistical models and Remote sensing data in tropical environment. Sci. Rep. 2015, 5, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Qiao, G.; Lu, P.; Scaioni, M.; Xu, S.; Tong, X.; Feng, T.; Wu, H.; Chen, W.; Tian, Y.; Wang, W. Landslide investigation with remote sensing and sensor network: From susceptibility mapping and scaled-down simulation towards in situ sensor network design. Remote Sens. 2013, 5, 4319–4346. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Scaioni, M. Remote sensing for landslide investigations: From research into practice. Remote Sens. 2013, 5, 5488–5492. [Google Scholar] [CrossRef]
- Kalantar, B.; Ueda, N.; Saeidi, V.; Ahmadi, K.; Halin, A.A.; Shabani, F. Landslide Susceptibility Mapping: Machine and Ensemble Learning Based on Remote Sensing Big Data. Remote Sens. 2020, 12, 1737. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Panahi, M.; Kornejady, A.; Wang, J.; Xie, X.; Cao, S. Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 2017, 297, 69–85. [Google Scholar] [CrossRef]
- Sterlacchini, S.; Ballabio, C.; Blahut, J.; Masetti, M.; Sorichetta, A. Spatial agreement of predicted patterns in landslide susceptibility maps. Geomorphology 2011, 125, 51–61. [Google Scholar] [CrossRef]
- Ahmed, B.; Dewan, A. Application of bivariate and multivariate statistical techniques in landslide susceptibility modeling in Chittagong City Corporation, Bangladesh. Remote Sens. 2017, 9, 304. [Google Scholar] [CrossRef]
- Ahmed, B.; Rahman, M.S.; Sammonds, P.; Islam, R.; Uddin, K. Application of geospatial technologies in developing a dynamic landslide early warning system in a humanitarian context: The Rohingya refugee crisis in Cox’s Bazar, Bangladesh. Geomat. Nat. Hazards Risk 2020, 11, 446–468. [Google Scholar] [CrossRef]
- Ahmed, B. Landslide susceptibility modelling applying user-defined weighting and data-driven statistical techniques in Cox’s Bazar Municipality, Bangladesh. Nat. Hazards 2015, 79, 1707–1737. [Google Scholar] [CrossRef]
- Althuwaynee, O.F.; Pradhan, B.; Park, H.J.; Lee, J.H. A novel ensemble bivariate statistical evidential belief function with knowledge-based analytical hierarchy process and multivariate statistical logistic regression for landslide susceptibility mapping. Catena 2014, 114, 21–36. [Google Scholar] [CrossRef]
- Souza, F.; Ebecken, N. A data mining approach to landslide prediction. WIT Trans. Inf. Commun. Technol. 2004, 33, 423–432. [Google Scholar]
- Marjanovic, M.; Bajat, B.; Kovacevic, M. Landslide susceptibility assessment with machine learning algorithms. In Proceedings of the 2009 International Conference on Intelligent Networking and Collaborative Systems, Barcelona, Spain, 4–6 November 2009; pp. 273–278. [Google Scholar]
- Yao, X.; Tham, L.; Dai, F. Landslide susceptibility mapping based on support vector machine: A case study on natural slopes of Hong Kong, China. Geomorphology 2008, 101, 572–582. [Google Scholar] [CrossRef]
- Zare, M.; Pourghasemi, H.R.; Vafakhah, M.; Pradhan, B. Landslide susceptibility mapping at Vaz Watershed (Iran) using an artificial neural network model: A comparison between multilayer perceptron (MLP) and radial basic function (RBF) algorithms. Arab. J. Geosci. 2013, 6, 2873–2888. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Blaschke, T. An uncertainty and sensitivity analysis approach for GIS-based multicriteria landslide susceptibility mapping. Int. J. Geogr. Inf. Sci. 2014, 28, 610–638. [Google Scholar] [CrossRef]
- Crosetto, M.; Tarantola, S.; Saltelli, A. Sensitivity and uncertainty analysis in spatial modelling based on GIS. Agric. Ecosyst. Environ. 2000, 81, 71–79. [Google Scholar] [CrossRef]
- Guzzetti, F.; Reichenbach, P.; Ardizzone, F.; Cardinali, M.; Galli, M. Estimating the quality of landslide susceptibility models. Geomorphology 2006, 81, 166–184. [Google Scholar] [CrossRef]
- Rossi, M.; Guzzetti, F.; Reichenbach, P.; Mondini, A.C.; Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 2010, 114, 129–142. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Valencia Ortiz, J.A.; Martínez-Graña, A.M. A neural network model applied to landslide susceptibility analysis (Capitanejo, Colombia). Geomat. Nat. Hazards Risk 2018, 9, 1106–1128. [Google Scholar] [CrossRef]
- Lee, S.; Ryu, J.H.; Min, K.; Won, J.S. Landslide susceptibility analysis using GIS and artificial neural network. Earth Surf. Proc. Landf. J. Br. Geomorphol. Res. Group 2003, 28, 1361–1376. [Google Scholar] [CrossRef]
- Marjanović, M.; Kovačević, M.; Bajat, B.; Voženílek, V. Landslide susceptibility assessment using SVM machine learning algorithm. Eng. Geol. 2011, 123, 225–234. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel GIS based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef] [PubMed]
- JAXA. ALOS Global Digital Surface Model “ALOS World 3D-30m (AW3D30)”; Japan Aerospace Exploration Agency (JAXA): Tokyo, Japan, 2015. [Google Scholar]
- WorldPop. The spatial distribution of population in 2020, Bangladesh. In Global High Resolution Population Denominators Project-Funded by The Bill and Melinda Gates Foundation (OPP1134076); University of Southampton: Southampton, UK, 2020. [Google Scholar] [CrossRef]
- UNHCR. Rohingya Refugees Population by Location at Camp and Union Level-Cox’s Bazar, 21 September 2020 ed.; United Nations High Commissioner for Refugees: Geneva, Switzerland, 2020. [Google Scholar]
- Ahmed, N.; Firoze, A.; Rahman, R.M. Machine learning for predicting landslide risk of Rohingya refugee camp infrastructure. J. Inf. Telecommun. 2020, 4, 175–198. [Google Scholar] [CrossRef]
- Paul, R.; Hussain, Z. Landslide, Floods Kill 156 in Bangladesh, India; Toll Could Rise. 2017. Available online: https://www.reuters.com/article/us-bangladesh-landslides-idUSKBN1950AI (accessed on 6 September 2020).
- UNHCR. Location of Rohingya Refugees in Cox’s Bazar as of 31 July 2020 sourced from RRRC-UNHCR Family Counting Exercise Data; United Nations High Commissioner for Refugees (UNHCR): Geneva, Switzerland, 2020. [Google Scholar]
- Huang, F.; Yin, K.; Huang, J.; Gui, L.; Wang, P. Landslide susceptibility mapping based on self-organizing-map network and extreme learning machine. Eng. Geol. 2017, 223, 11–22. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Benardos, A. Estimating landslide susceptibility through a artificial neural network classifier. Nat. Hazards 2014, 74, 1489–1516. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Gessler, P.E.; Foltz, R.B.; Elliot, W.J. Spatial prediction of landslide hazard using logistic regression and ROC analysis. Trans. GIS 2006, 10, 395–415. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y. GIS-based evaluation of landslide susceptibility using hybrid computational intelligence models. Catena 2020, 195, 104777. [Google Scholar] [CrossRef]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Fu, S.; Chen, L.; Woldai, T.; Yin, K.; Gui, L.; Li, D.; Du, J.; Zhou, C.; Xu, Y.; Lian, Z. Landslide hazard probability and risk assessment at the community level: A case of western Hubei, China. Nat. Hazards Earth Syst. Sci. 2020, 20, 581–601. [Google Scholar] [CrossRef]
- Duman, T.; Can, T.; Gokceoglu, C.; Nefeslioglu, H.; Sonmez, H. Application of logistic regression for landslide susceptibility zoning of Cekmece Area, Istanbul, Turkey. Environ. Geol. 2006, 51, 241–256. [Google Scholar] [CrossRef]
- Gomez, H.; Kavzoglu, T. Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng. Geol. 2005, 78, 11–27. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Li, T.; Guo, C.; Hong, H.; Li, W.; Pan, D.; Hui, J.; Ma, M. A novel ensemble approach of bivariate statistical-based logistic model tree classifier for landslide susceptibility assessment. Geocarto Int. 2018, 33, 1398–1420. [Google Scholar] [CrossRef]
- Adnan, M.S.G.; Talchabhadel, R.; Nakagawa, H.; Hall, J.W. The potential of Tidal River Management for flood alleviation in South Western Bangladesh. Sci. Total Environ. 2020, 731, 138747. [Google Scholar] [CrossRef]
- Bannari, A.; Ghadeer, A.; El-Battay, A.; Hameed, N.A.; Rouai, M. Detection of Areas Associated with Flash Floods and Erosion Caused by Rainfall Storm Using Topographic Attributes, Hydrologic Indices, and GIS; Springer: Cham, Switzerland, 2017; pp. 155–174. [Google Scholar]
- Thalacker, R. Mapping Techniques For Soil Erosion: Modeling Stream Power Index in Eastern North Dakota; University of North Dakota: Grand Forks, ND, USA, 2014. [Google Scholar]
- Persits, F.M.; Wandrey, C.J.; Milici, R.C.; Manwar, A. Digital Geologic and Geophysical Data of Bangladesh; 97-470H; US Geological Survey: Reston, VA, USA, 2001. [Google Scholar]
- Dahal, R.K.; Hasegawa, S.; Nonomura, A.; Yamanaka, M.; Masuda, T.; Nishino, K. GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ. Geol. 2008, 54, 311–324. [Google Scholar] [CrossRef]
- Hong, Y.; Adler, R.; Huffman, G. Use of satellite remote sensing data in the mapping of global landslide susceptibility. Nat. Hazards 2007, 43, 245–256. [Google Scholar] [CrossRef]
- BARC. Land Resource Information Management System; Bangladesh Agricultural Research Council (BARC): Dhaka, Bangladesh, 2014. [Google Scholar]
- Abdullah, A.Y.M.; Masrur, A.; Adnan, M.S.G.; Baky, M.A.A.; Hassan, Q.K.; Dewan, A. Spatio-Temporal Patterns of Land Use/Land Cover Change in the Heterogeneous Coastal Region of Bangladesh between 1990 and 2017. Remote Sens. 2019, 11, 790. [Google Scholar] [CrossRef]
- Rozos, D.; Bathrellos, G.; Skillodimou, H. Comparison of the implementation of rock engineering system and analytic hierarchy process methods, upon landslide susceptibility mapping, using GIS: A case study from the Eastern Achaia County of Peloponnesus, Greece. Environ. Earth Sci. 2011, 63, 49–63. [Google Scholar] [CrossRef]
- WARPO. National Water Resources Database (NWRD); Water Resources Planning Organization (WARPO): Dhaka, Bangladesh, 2018. Available online: http://warpo.gov.bd/index.php/home/bnwrd (accessed on 18 August 2020).
- Midi, H.; Sarkar, S.K.; Rana, S. Collinearity diagnostics of binary logistic regression model. J. Interdiscip. Math. 2010, 13, 253–267. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S.; Price, B.; Adler, D.; Bates, D.; Baud-Bovy, G.; Bolker, B.; Ellison, S.; Firth, D.; Friendly, M. Package ‘Car’; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Bai, S.; Lü, G.; Wang, J.; Zhou, P.; Ding, L. GIS-based rare events logistic regression for landslide-susceptibility mapping of Lianyungang, China. Environ. Earth Sci. 2011, 62, 139–149. [Google Scholar] [CrossRef]
- Sun, D.; Wen, H.; Wang, D.; Xu, J. A random forest model of landslide susceptibility mapping based on hyperparameter optimization using Bayes algorithm. Geomorphology 2020, 362, 107201. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B.; Bui, D.T.; Alamri, A.M. Systematic sample subdividing strategy for training landslide susceptibility models. Catena 2020, 187, 104358. [Google Scholar] [CrossRef]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the GIS-based data mining techniques of best-first decision tree, random forest, and naïve Bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Kadavi, P.R.; Lee, C.-W.; Lee, S. Application of ensemble-based machine learning models to landslide susceptibility mapping. Remote Sens. 2018, 10, 1252. [Google Scholar] [CrossRef]
- Rabby, Y.W.; Ishtiaque, A.; Rahman, M. Evaluating the Effects of Digital Elevation Models in Landslide Susceptibility Mapping in Rangamati District, Bangladesh. Remote Sens. 2020, 12, 2718. [Google Scholar] [CrossRef]
- Bathrellos, G.D.; Skilodimou, H.D.; Chousianitis, K.; Youssef, A.M.; Pradhan, B. Suitability estimation for urban development using multi-hazard assessment map. Sci. Total Environ. 2017, 575, 119–134. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Conditioning Factor | Spatial Resolution | Variable Type | Data Source | Variance Inflation Factors (VIF) |
|---|---|---|---|---|---|
| 1 | Aspect | 30 m | Continuous | Estimated from the Digital Elevation Model (DEM) | 1.02 |
| 2 | Elevation | ″ | ″ | DEM [28] | 2.77 |
| 3 | Curvature | ″ | ″ | Estimated from the DEM | 1.57 |
| 4 | Slope | ″ | ″ | ″ | 2.83 |
| 5 | Stream Power Index (SPI) | ″ | ″ | ″ | 1.60 |
| 6 | Distance to stream | ″ | ″ | ″ | 1.15 |
| 7 | Land cover | ″ | Discrete | Landsat Operational Land Imager (OLI) (https://earthengine.google.com) | 1.13 |
| 8 | Normalized difference vegetation index (NDVI) | ″ | Continuous | ″ | 1.24 |
| 9 | Geology | ″ | Discrete | [46] | 1.06 |
| 10 | Soil type | ″ | ″ | [49] | 1.13 |
| 11 | Soil texture | ″ | ″ | ″ | 1.06 |
| 12 | Distance to road | ″ | Continuous | [52] | 1.10 |
| Classifier | Hyperparameter | Remark | Search Range | Optimal Value |
|---|---|---|---|---|
| K-Nearest Neighbor | Metric | Distance metric to use | Euclidean, Manhattan | Manhattan |
| Number of neighbors | Number of neighbors used for prediction | 3, 5, 11, 19 | 5 | |
| Weights | Weight function used in prediction | Uniform, distance | Distance | |
| Support Vector Machine | C value | Inverse regularization strength | 10−3, 10−2, 10−1, 1, 101, 102, 103 | 103 |
| Kernel | Functions for transforming inputs | Polynomial, radial basis function, sigmoid | Radial basis function | |
| Gamma | Kernel coefficient | 10−3, 10−2,10−1, 1 | 10−3 | |
| Multi-Layer Perceptron | Hidden layer Size | Number of hidden units | 10, 15, 20, 25, 30, 35, 40, 45 | 20 |
| Activation function | Nonlinearity for squeezing output to desired range | Identity, logistic, hyperbolic tangent, rectified linear unit | Rectified linear unit | |
| Learning rate | Specifies if learning rate is constant or variable | Constant, adaptive | Constant | |
| Alpha | L2 penalty/regularization term | 10−4, 10−3, 10−2, 10−1 | 10−4 | |
| Random Forest | Number of estimators | Number of trees in the random forest | 200, 300, 400, 500 | 500 |
| Maximum features | Maximum features to be considered | Auto, square root, logarithm (base = 2) | Auto | |
| Maximum depth | Maximum depth of internal trees | 10, 12, 14, 16, 18, 20, 22, 24, 26, 28 | 10 | |
| Criterion | Function for measuring quality of split | Gini, entropy | Entropy |
| Model | Overall Accuracy | Precision | F1-score | Recall | |||
|---|---|---|---|---|---|---|---|
| Non-Landslide | Landslide | Non-Landslide | Landslide | Non-Landslide | Landslide | ||
| KNN | 0.9069 | 0.9227 | 0.9227 | 0.9015 | 0.9015 | 0.8811 | 0.8811 |
| MLP | 0.9545 | 0.9547 | 0.9547 | 0.9528 | 0.9528 | 0.9508 | 0.9508 |
| RF | 0.9663 | 0.9633 | 0.9633 | 0.9652 | 0.9652 | 0.9672 | 0.9672 |
| SVM | 0.9406 | 0.9385 | 0.9385 | 0.9385 | 0.9385 | 0.9385 | 0.9385 |
| Variables (Landslide Susceptibility Models) | Coefficient | p-Value |
|---|---|---|
| Intercept | −5.84 | <2.2e−16 *** |
| KNN | 0.64 | 0.34 |
| MLP | 3.52 | 2.67e−09 *** |
| RF | 5.01 | 8.449e−09 *** |
| SVM | 2.02 | 0.01205 * |
| Significance codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘▪’ 0.1 ‘ ’ 1. Coefficient of determination R2: 0.80 Log-Likelihood: −178.42 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adnan, M.S.G.; Rahman, M.S.; Ahmed, N.; Ahmed, B.; Rabbi, M.F.; Rahman, R.M. Improving Spatial Agreement in Machine Learning-Based Landslide Susceptibility Mapping. Remote Sens. 2020, 12, 3347. https://doi.org/10.3390/rs12203347
Adnan MSG, Rahman MS, Ahmed N, Ahmed B, Rabbi MF, Rahman RM. Improving Spatial Agreement in Machine Learning-Based Landslide Susceptibility Mapping. Remote Sensing. 2020; 12(20):3347. https://doi.org/10.3390/rs12203347
Chicago/Turabian StyleAdnan, Mohammed Sarfaraz Gani, Md Salman Rahman, Nahian Ahmed, Bayes Ahmed, Md. Fazleh Rabbi, and Rashedur M. Rahman. 2020. "Improving Spatial Agreement in Machine Learning-Based Landslide Susceptibility Mapping" Remote Sensing 12, no. 20: 3347. https://doi.org/10.3390/rs12203347
APA StyleAdnan, M. S. G., Rahman, M. S., Ahmed, N., Ahmed, B., Rabbi, M. F., & Rahman, R. M. (2020). Improving Spatial Agreement in Machine Learning-Based Landslide Susceptibility Mapping. Remote Sensing, 12(20), 3347. https://doi.org/10.3390/rs12203347