1. Introduction
The efficiency and timeliness of emergency responses to natural disasters has significant implications for the life-saving capacities of relief efforts. Access to accurate information is crucial to these missions in determining resource allocation, personnel deployment and rescue operations. Despite the critical need, collecting such information during a crisis can be extremely challenging.
Floods are the most frequent natural disaster and can cause major societal and economic disruption longside significant loss of human life [
1,
2]. Flooding is usually caused by rivers or streams overflowing, excessive rain, or ice melting rapidly in mountainous areas. Alternatively, coastal floods can be due to heavy sustained storms or tsunamis causing the sea to surge inland. Once an event occurs, a timely and accurate assessment, followed by a rapid response, is crucial. In carrying out this response, non-governmental, national and international organizations are usually at the forefront of operations providing humanitarian support.
Remote sensing techniques have been crucial in providing information to response teams in such situations [
3]. Indeed, satellite images have proved highly useful for collecting timely and relevant data and in generating effective damage information and impact maps of flooded regions [
4,
5]. Currently, much of the flood analysis is manual or semi-automated, and carried out by experts from a range of organizations. One example of such an institution is the United Nations Institute for Training and Research—Operational Satellite Applications Programme (UNITAR-UNOSAT), who provide a ‘Rapid Mapping’ service [
6], and against whose methodology we base our comparison. In general, in order to respond to quickly developing situations, rapid mapping methodologies serve as an instrumental component in emergency response and disaster relief.
Traditionally, a common way to approach water and flood detection is to use imagery collected from passive sensors, such as optical imagery, using techniques such as the Normalized Difference Water Index (NDWI) and other water indices [
7,
8,
9,
10]. In such cases, numerous methods have been developed for combining different frequency bands in order to produce signatures particularly sensitive to the detection of water bodies. Once an index has been calculated, water and flood detection can be carried out through the use of thresholds which can either be set globally over the entire region in question, or more locally. While such detection algorithms using optical imagery, and other multispectral imagery derived from passive sensors, have shown great promise, the use of such imagery is often subject to lack of cloud cover and the presence of daylight. These requirements restrict their use to a limited time interval and to certain weather conditions thus making them less suitable for rapid response in disaster situations.
For this reason, one of the most commonly used forms of satellite data used for flood water detection is Synthetic Aperture Radar (SAR) imagery [
11]. SAR images can be taken regardless of cloud cover and time of day since they use active sensors and specific frequency ranges. Although SAR images generally have a lower resolution in comparison to their high-resolution optical counterparts, high-resolution imagery (to the level of 0.3–0.5 m) is not generally required for flood disaster mapping, and SAR imagery can be taken at an acceptable resolution. Due to their popularity, many SAR satellite collaborations, such as COSMO-SkyMed (CSK) [
12], TerraSAR-X (TSX) [
13], and Sentinel-1 operated by the European Space Agency (ESA) now exist, making for regular and timely image capture.
The detection of water bodies in SAR imagery is largely reliant on the distinctiveness of its backscatter signature. Water generally appears as a smooth surface with a well defined intensity of backscatter that can be seen in the SAR image; however, depending on environmental conditions such as landscape topography and shadows, a universal threshold for water backscatter intensity does not exist. Furthermore, there are also particular exceptions that require more careful consideration rather than just threshold setting. In the case of urban areas, for instance, the backscattered signal can be significantly affected by the presence of buildings that exhibit double-bounce scattering, although several techniques have been designed to address this [
14,
15,
16,
17,
18,
19]. Indeed, similar considerations may need to be made for numerous other cases such as water otherwise masked by vegetation [
20]. In this study, we will focus on general water/flood detection by developing a method which generalizes across different environments, some of which contain urban regions, although we do not focus specifically on addressing such areas.
Since flooding can occur in a variety of different environmental settings, the generalizability of many existing methods is highly limited, often requiring the careful intervention of analysts to update parameters and fine-tune results. Such tuning severely limits the speed with which accurate maps can be produced and released for use by disaster response teams. Moreover, many of these methods require the combination of data from a variety of sources, as well as extensive cleaning and processing of imagery before they can be fully utilized. While there have been some successes in near real time (NRT) mapping [
21,
22,
23,
24], such methods generally still succumb to the generalizability shortfalls highlighted above. However, Twele et al. [
25] have presented an NRT approach requiring no human intervention and significantly reducing processing time, by using fuzzy logic techniques, which have since been built on [
26,
27], to remove the need for additional input data.
Machine learning techniques have been shown to offer increasingly generalizable solutions to a range of problems previously requiring a significant amount of classical image processing [
28,
29], and have been applied to a wide variety of fields while gaining prevalence in applications to satellite imagery [
3,
30,
31,
32]. Specifically, machine learning techniques are now being developed for water detection, with several focusing on flood mapping as we discuss below.
With the increased rapid deployment of satellites providing low-cost optical imagery, such as CubeSats, several applications of machine learning methods to automate water/flood detection in optical and multispectral imagery have been developed [
33,
34,
35,
36,
37,
38,
39]. However, since imagery from passive sensors is limited by the conditions mentioned above, such as cloud cover, they are therefore often not appropriate for flood response. Interestingly, work such as that by Benoudjit and Guida [
40] take a hybrid approach by using a linear model optimized with stochastic gradient descent to infer flooded pixels in SAR imagery with promising results and a dramatic reduction in the time required to infer on an image. However, as the authors point out, training data is generated per-location from calculation of the NDWI which therefore still requires the use of imagery containing additional frequency bands.
There have been several studies applying Artificial Intelligence (AI) techniques requiring only SAR imagery for water/flood identification. For this, a variety of methods have been tested including unsupervised learning techniques such as self-organizing Kohonen’s maps [
41,
42], Gaussian Mixture Models [
43], and support vector machines [
44] for general flood mapping. One of the most commonly used techniques in machine learning for pixel-based segmentation is that of Convolutional Neural Networks (CNNs). Several studies have been shown to make use of these networks for multiclassification tasks (including a water class), for example, in complex ecosystem mapping [
45], urban scene and growth mapping [
46], and crop identification [
47]. In such cases, water detection has not been the central aim of the outputs, and so such methodologies have not been optimised for its identification. Moreover, flooding causes the presence of water bodies on both large and small scales and so work lacking this focus is not sufficient by itself to provide evidence that CNN methods can be widely applied to flood events.
Focusing on large water bodies and flood events, various CNN approaches have been proposed for different scenarios. In the specific case of urban flood mapping, for example, Li et al. [
48] select a specific location and use multi-temporal SAR imagery to develop an active self-learning approach to CNN training, showing improved performance against a naively trained classifier. In addition, Zhang et al. [
49] compare several CNN based approaches for the identification of water and shadows. However, their focus on a limited range of locations and reliance on flood maps created by hand, rather than also incorporating classical methods, may be overly simplified. Most similar to the work presented here is that of Kang et al. [
50] who use a CNN specifically for flood detection in SAR imagery captured in China. The authors show that using CNNs for flood mapping may be a viable option—achieving promising metrics and performance. We seek to build on this work in demonstrating the generalizaility of a CNN approach by training and testing our models on a dataset reaching over multiple countries and regions including many of those which are significantly disaster prone. Moreover, the authors of [
50] highlight the desire to test the usefulness of transfer learning approaches in future work, which we shall also study.
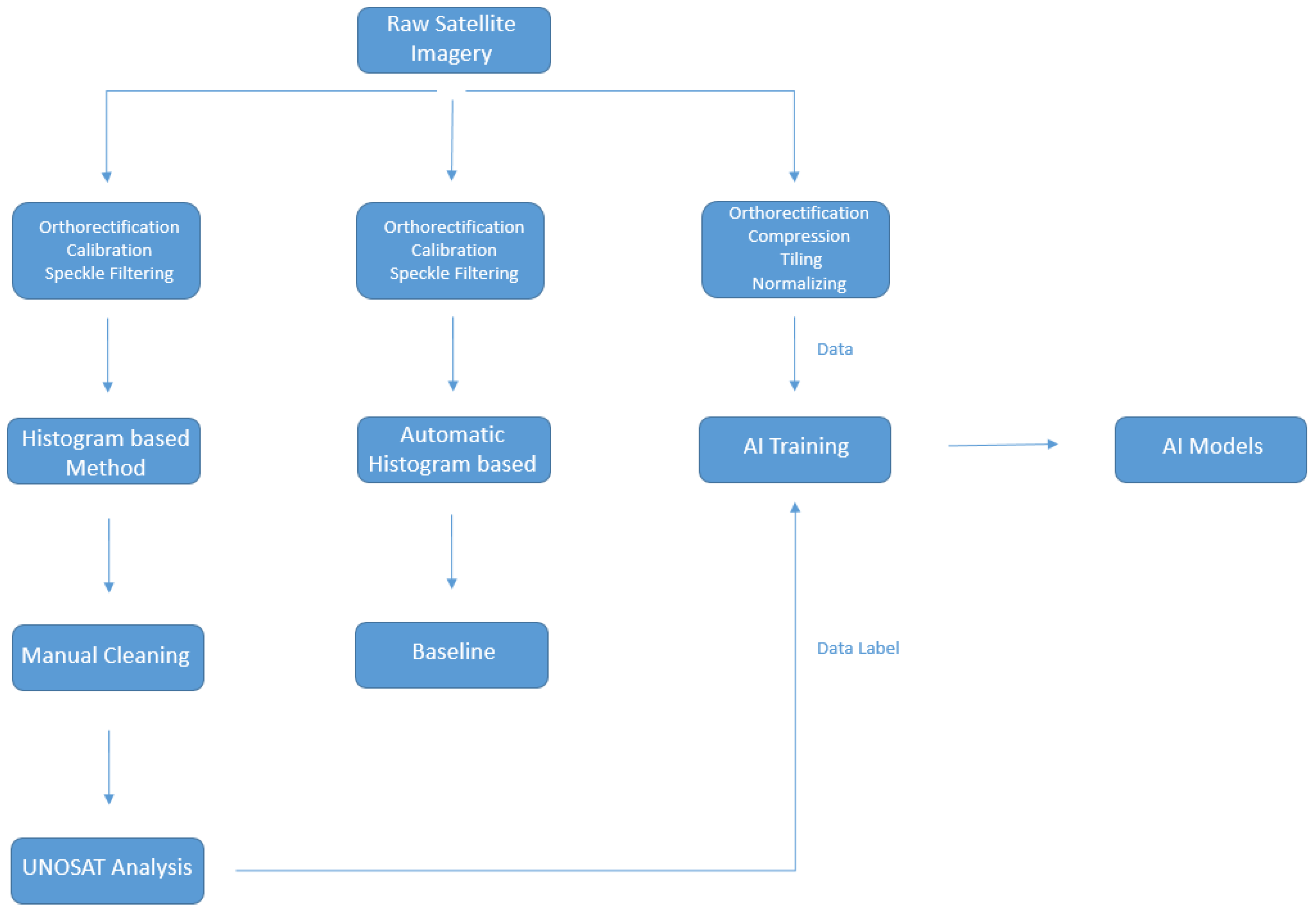
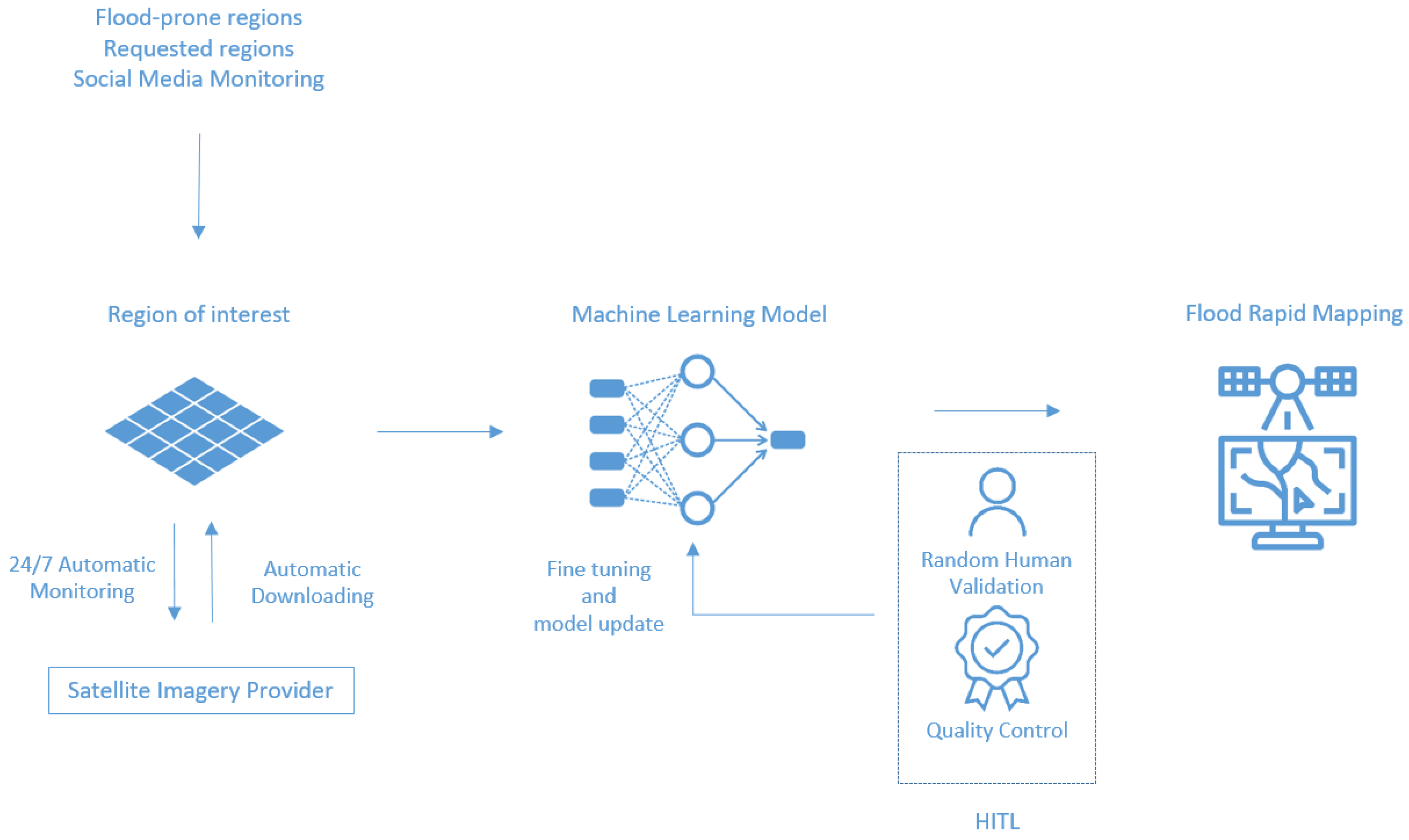
In this paper we present a fully automated machine learning based solution for rapid mapping, significantly decreasing the time required to produce a flood map, while achieving a high level of precision in comparison to existing classical methodologies involving significant manual intervention. The model is trained on a fully open-source dataset presented here, which we compile from imagery frequently used in disaster response situations. Furthermore, this dataset contains analysis performed during rapid mapping response scenarios and so presents an ideal test bed for trialing rapid mapping automation techniques. We believe this to be the largest and most diverse SAR dataset that machine learning based flood mapping models have been developed for and tested against. The methodology employed for the creation of the labels used for model training consists of a classical histogram based method followed by extensive manual cleaning and visual inspection as explain in
Section 2.2. In addition, we design a simple linear baseline model against which to compare our more complex machine learning approaches as explained in
Section 2.4. Our methodology does not require any additional pre-processing or input data, apart from orthorectification using a digital elevation model (DEM), as well as computationally inexpensive tiling, compression and normalisation as explain in
Section 2.3, thereby making it a strong contender for fully automated pipelines. Moreover, this method only requires the use of open-source Sentinel-1 SAR imagery and can, if required, be fine-tuned to the analysis area by adding human-in-the-loop (HITL) network adaptation into the mapping pipeline [
51]. While this fine-tuning is not necessarily required in our circumstances, we discuss how it can be naturally incorporated into the pipeline with minimal extra time cost and may aid in alleviating difficulties experienced in classical SAR analysis. Since flooding generally occurs adjacent to existing bodies of water, flood detection usually includes the detection of all water bodies, including those permanent to the scene. Since permanent water bodies are usually already mapped and can be subtracted out to measure flood growth, we go beyond other studies in explicitly examining the performance of our methodology in both general water detection, as well as just flood detection. We finish this paper by presenting a cost-benefit analysis, comparing our methodology to currently employed tools and highlight the applicability of this technique to rapid mapping for disaster response, including setting out a potential work flow which incorporates model validation and improvement. This work has been carried out in collaboration with several United Nations (UN) entities, including UNOSAT, upon whose workflow we base our comparison. For further information, please visit the GitHub project (
https://github.com/UNITAR-UNOSAT/UNOSAT-AI-Based-Rapid-Mapping-Service). For clarity, a general overview of the comparisons made in this paper is depicted in
Figure 1.
2. Materials and Methods
2.1. Dataset
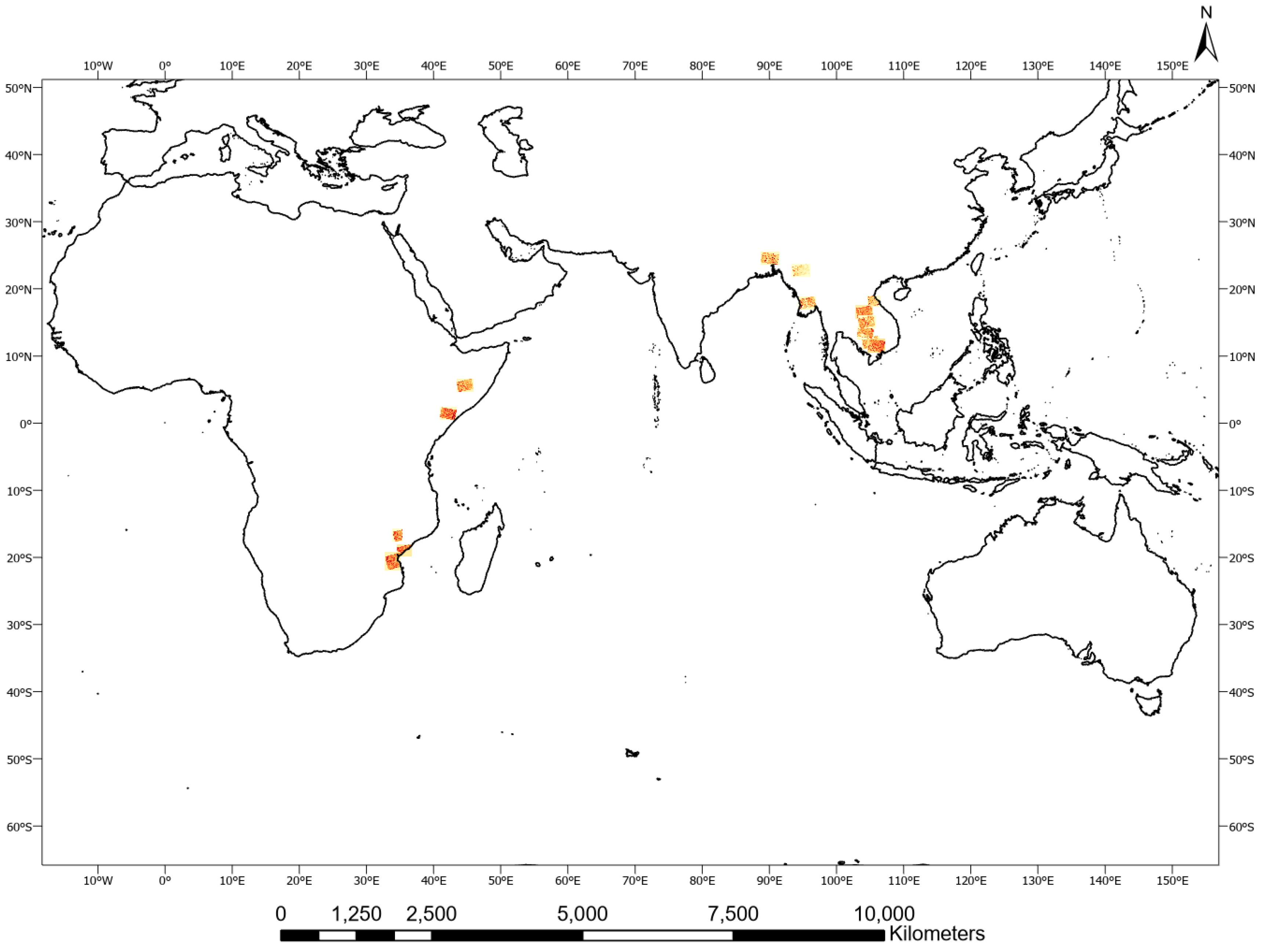
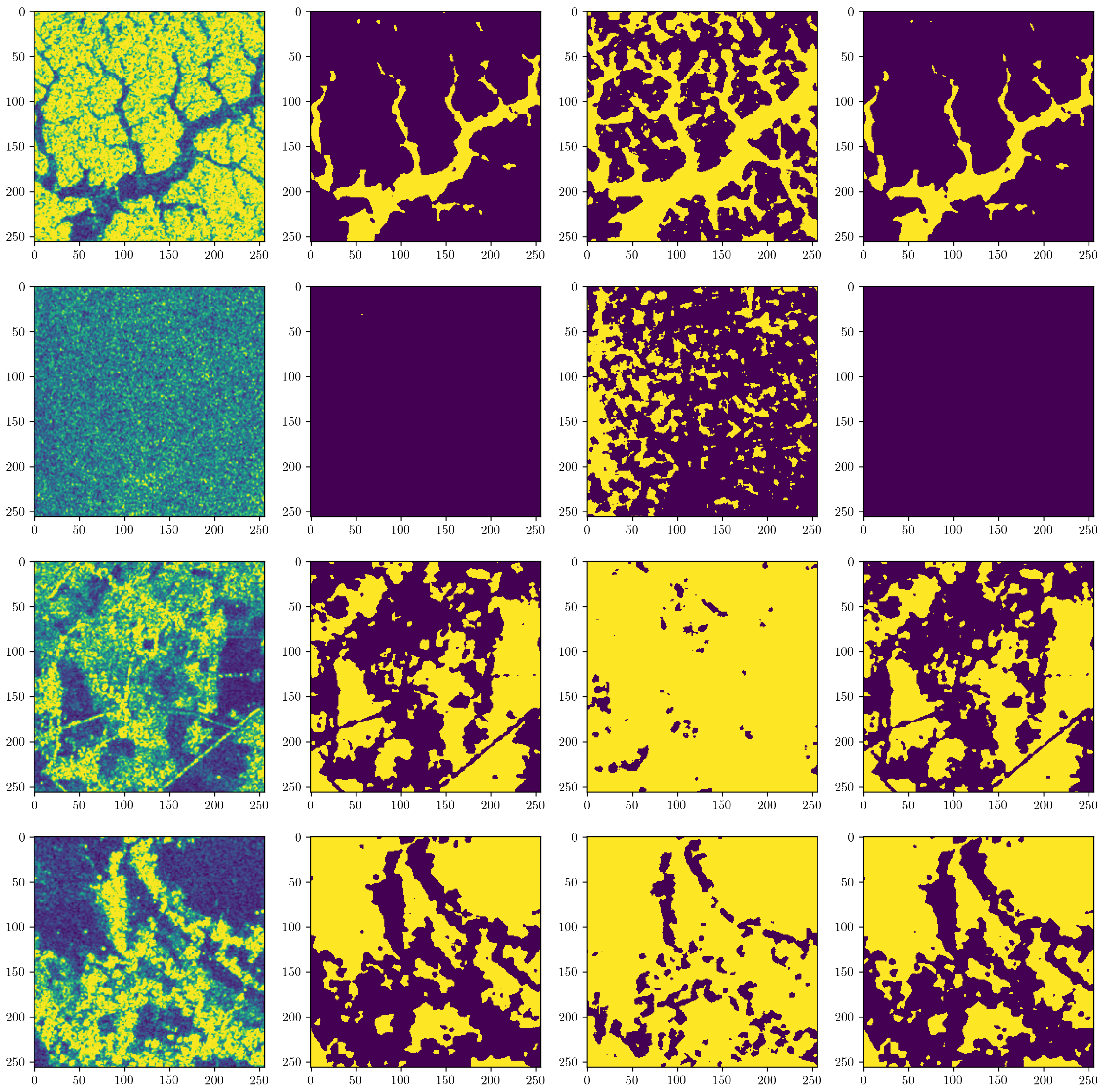
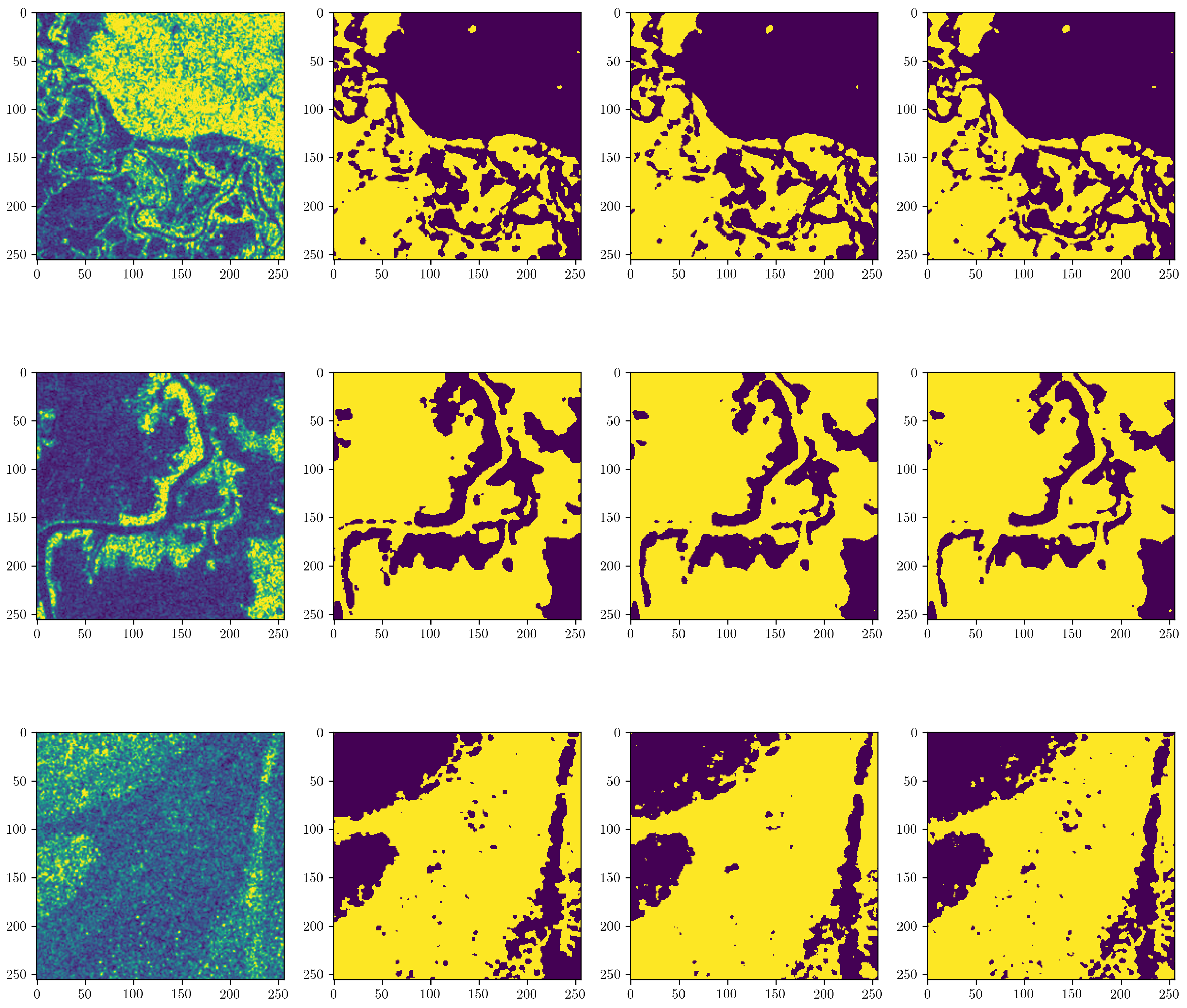
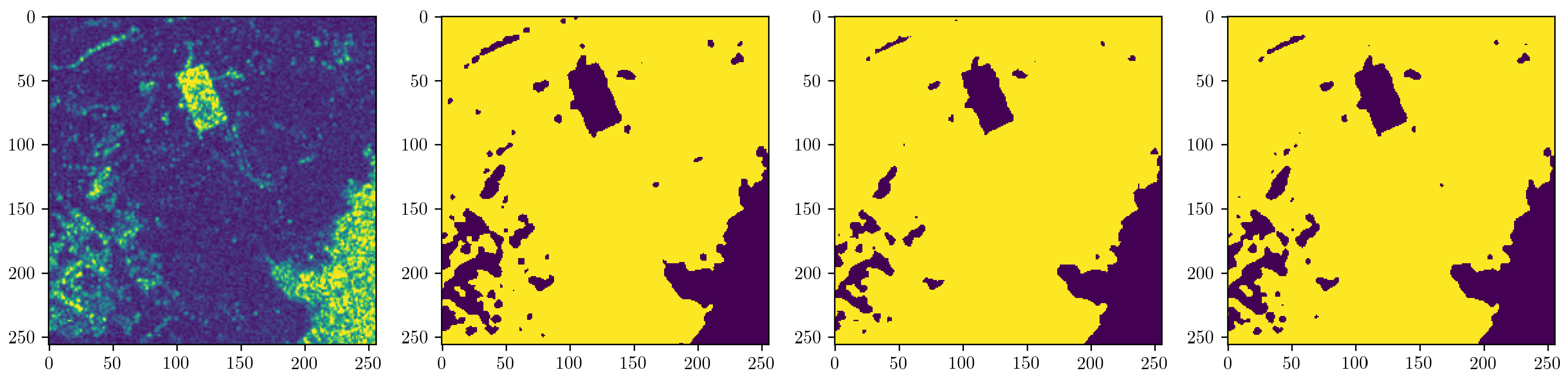
The UNOSAT Flood Dataset [
52], has been created for this study using Copernicus Sentinel-1 satellite imagery acquired in Interferometric Wide Swath (IW) and provided as Level-1 Ground Range Detected (GRD) products at a resolution of 10 m × 10 m with corresponding flood vectors stored in shapefile format (see
Figure 2). Each image was downloaded from the Copernicus Open Access Hub [
53] in order to work on free and open-source data thereby facilitating the deployment of our methodology more broadly (see
Table 1 and
Table A1 for more details on the dataset).
The dataset consists of the VV polarization of the SAR imagery with their corresponding flood extent boundaries. These boundaries were taken from preexisting UNOSAT analyses conducted over a five year period generated using the commonly used histogram based method (also known as the threshold method) and followed by extensive manual cleaning and visual inspection for noise reduction and precision validation (see
Section 2.2). Flood maps generated using this method were used as labels for training our machine learning models. In addition, we experimented with applying a variety of pre and post-processing techniques to the SAR data and assessed its impact on model performance (see
Section 2.3). It should be noted that we make no assessment of the thematic accuracy of the “labels" created using the techniques mentioned in
Section 2.2 and used here for model training and inference. The potential for thematic accuracy assessments and field-level feedback for model improvement are discussed in
Section 4.5.
2.2. Histogram Based Method and Label Generation
The aim of flood detection analysis using satellite imagery is to extract water signatures and convert them to cleaned vector data. In both radar and optical imagery bands, there is a contrast between water and non-water pixels. In the former case, water pixels generally appear significantly darker than non-water pixels after the usual processing applied by the imagery provider. Using a histogram based method is common practice when identifying water pixels in SAR imagery for disaster mapping [
21,
54,
55,
56,
57].
When using this method, a sample of pixel values is manually taken from the visible flood extent in the radar image to estimate the range of pixel values that represent water. All pixels that are within that pixel value range are then selected by the algorithm. Often, experiments will be conducted with multiple thresholds to determine which value provides the most accurate output based largely on visual inspection and comparison with pre-flood information (i.e., data on the location of rivers and other existing water bodies). A standard end-to-end pipeline for rapid flood analysis, following the work of [
21,
54,
55,
56,
57], is described below:
A raw satellite image is imported, pre-processed and calibrated through radiometric correction. After this, the image undergoes speckle filtering followed by orthorectification using a DEM.
Multiple thresholds are then determined to separate water and land through manual pixel sampling and applied to the image. Running the analysis for each threshold value can take from five to ten minutes each time using standard GIS mapping software. This extraction may either underestimate or overestimate the flood and therefore expert knowledge provided by an analyst is crucial in determining the best threshold value.
The new raster images will have two values: the ‘1’ values representing the threshold extraction, and the ‘0’ values representing the corresponding pixels that were above the threshold. A new raster image is created for each chosen threshold.
Since the selected extraction is an approximation, it requires filtering to smooth the edges of the water signature. Majority Filtering [
58] is applied to reducing noise and fill in ‘holes’ in the water extent.
A Focal Statistics method [
59] is then applied to help further smooth and remove additional noise.
The best raster according to the analyst is converted to a vector.
The flood vector is further cleaned by manual inspection to: remove Zero Grid values to save only the flooded area; remove the imagery border; further reduce noise; fill in any remaining holes and remove any other obvious non-water elements.
The river and other water resources that were present in the pre-flood analysis are then filtered out and excluded from the flooded area.
As can be seen, this methodology involves much expert manual intervention and cleaning to produce a flood map. Limitations of this methodology are possible false positive/negative values in areas of radar overlays, foreshortening, and shadows in hilly and mountainous areas which may affect algorithmic performance. Dense urban areas and smooth areas like roads and dry sand can further affect performance. Furthermore, ‘holes’ in the dataset are pixels or groups of pixels formed where a water signature was not detected. This may occur due to different signatures in the imagery such as hill shadow in a mountainous area, waves and boats in the water, and vegetation or structures like bridges that may cause false water signatures in the extraction.
The generation of labeled data denoting water extent can depend on a variety of external factors. Human errors must be taken into consideration since, even though the analyst follows a strict workflow, the flood boundaries are chosen based on human experience. The quality of the flood map is also influenced by time restrictions since rapid assessment flood maps must frequently be delivered in a few days. Moreover, sending feedback from the flooded regions to the map provider may not always be possible during a humanitarian emergency.
For completeness, potential human biases were estimated by conducting four independent analyses, each following the procedure described above, on a random subset of the images comprising our dataset. In each case, the difference between the archived and a new analysis of the same image was calculated. The analyses were found to differ by 5% on average in both classes, which serves as a lower bound on the variability of the labels used. In addition, in an attempt to minimize the human error, the entire dataset was reviewed through visual inspection by two different geospatial analysts with necessary modifications made to increase consistency. The flood vectors generated with this method were used as labels for our machine learning approaches. The analyses can be downloaded from the UNOSAT Flood Portal [
60], and the UNOSAT page on the Humanitarian Data Exchange [
61].
2.3. Data Processing for Machine Learning
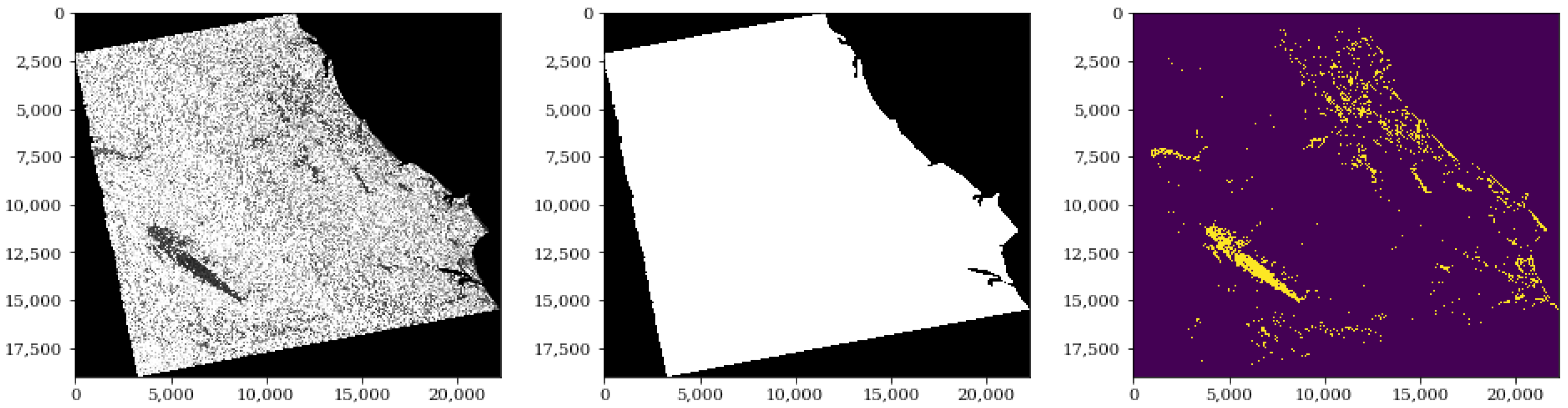
To assess their impact on model performance, we experimented with a variety of data processing techniques. First, a terrain correction was applied using the orbit file as is standard procedure when delivering the final output. After testing various image pre-processing techniques prior to model training, including speckle filtering and calibration, we observed best performance when such processing was minimised to just orthorectification and compression to 8-bit. We perform this latter step since we found it to make image storage and manipulation more memory efficient without hindering overall performance. By reducing the necessary pre-processing, the time required to produce a map is also reduced. Concerning the labels, a binary mask was generated from the shapefiles where the flood pixels were labeled as one and the background as zero. These masks were clipped with the corresponding satellite image.
The image comes with a black frame around it that can have different default values such as
nan,
-inf, and others. The sea areas can also be characterized by outliers from shadows due to waves and high values due to ships. For the purposes of the labels, the sea was originally assigned as water up to a certain distance from the coastline which varied each time. Therefore, for consistency, the sea and the black frame around the image were masked out using the image extent and a global coastal shapefile, as shown in
Figure 3. These regions were not included in the dataset. Moreover, to avoid confusing the network, existing water bodies, such as rivers, were added back to the labeled data in order for the network to learn to detect all water pixels as opposed to only newly flooded regions.
Feeding a neural network with the entire satellite image is not computationally feasible, due to their large memory footprint. Therefore, we tiled the images, and their corresponding labels, prior to training. Different tile sizes were tested, with best performance being observed with tiles sized 256 × 256 pixels. For clarity, throughout this paper we refer to ‘images’ as the raw SAR imagery obtained from the image provider and ‘tiles’ as the output from tiling the images.
The dataset was split into training, validation and testing sets following a ratio 80:10:10. The training dataset is used to train the candidate algorithms, the validation dataset is used to tune the hyperparameters (e.g., the architecture, batch size etc.), and the test dataset is used to obtain the performance characteristics on tiles completely unseen by the model. The test set is independent of the training dataset, but it likely follows the same probability distribution as the training dataset since tiles in this set come from the same original image as tiles in the training and validation sets. In order to test performance more rigorously, we also present results derived from inference on tiles from a completely unseen image and location (see
Section 3.2). The UNOSAT Flood Dataset and its tiles are shown in
Table 1.
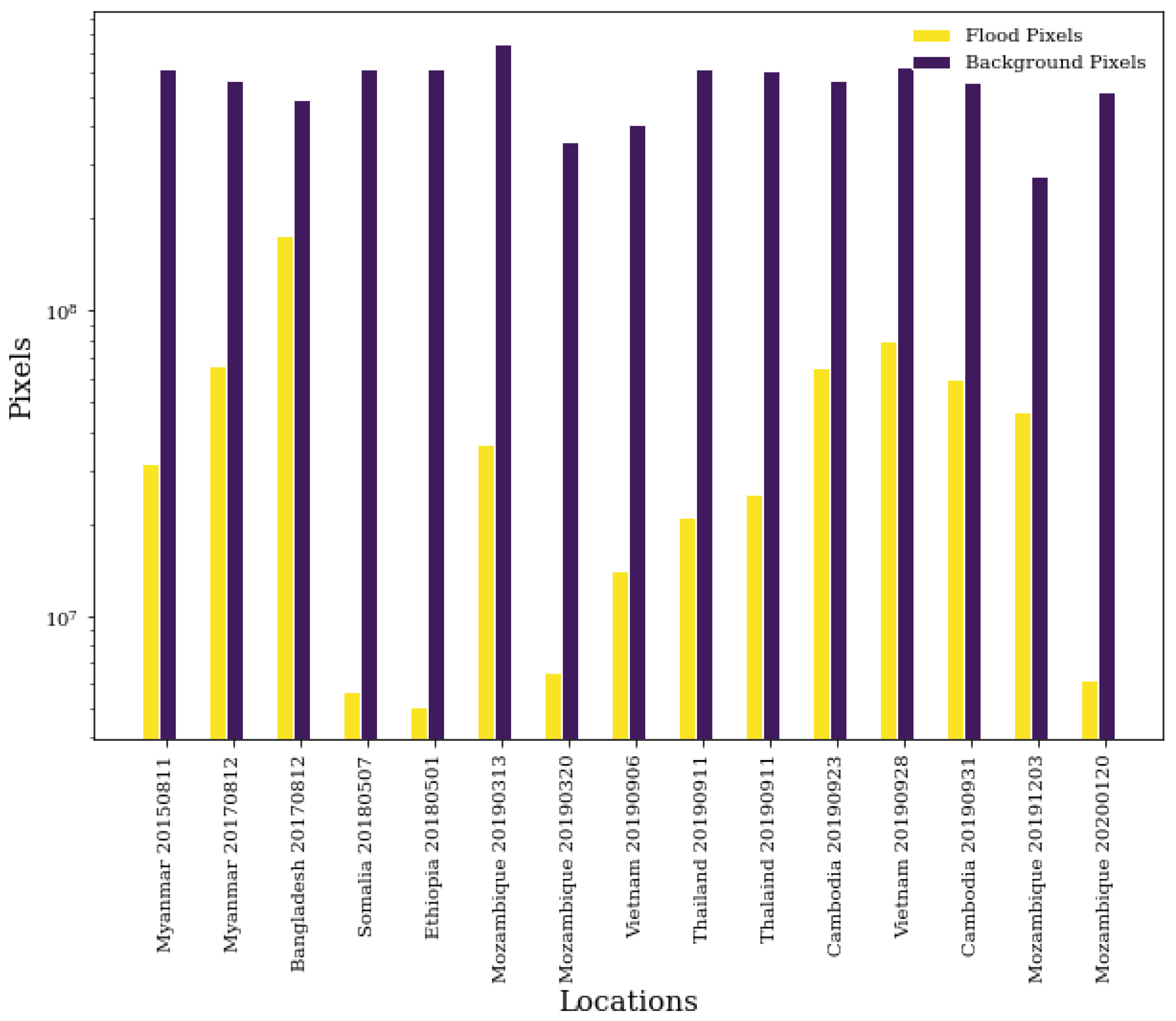
As shown in
Table 2 and
Figure 4, the dataset is also highly imbalanced with water pixels making up only 6% of the dataset. Such imbalances can have a significant effect on model performance due to the optimization strategies commonly used, and therefore we aim to mitigate this effect. In doing so, we under-sampled at the tile level by excluding all tiles that only contained background pixels. In order to maintain the structure of the tiles, under-sampling at the pixel level to reach a 50:50 ratio between classes was not possible. However, by performing tile under-sampling, the water to background pixel ratio was increased from 6% to 16% and also resulted in a training speed increase.
2.4. Automatic Histogram Based Method
where
is the threshold value,
n the number of tiles in the training set,
is the flood extent of the tileWe designed an automated version of the histogram based method to use as a baseline against which to compare our machine learning methodologies. The technique involves the following pre-processing steps: application of an orbit file, calibration, speckle filtering, and terrain correction using a DEM. While these steps are already automated in the original histogram based method, the choice of appropriate threshold is usually decided manually by analysing the histogram of the filtered backscatter coefficient for each image. In order to create a baseline against which to justify the use of more complex techniques such as neural network based approaches, we automated the process of choosing the threshold by minimizing the mean squared error between the labels created according to
Section 2.2 and a global optimal threshold:
i, and
is the output of the automatic histogram based method for tile
i using the threshold
.
In practice, this optimization was carried out by tuning a Tree-structured Parzen Estimator (TPE) [
62] as implemented in the hyperopt [
63] library thus effectively ‘training’ a linear classifier.
2.5. Convolutional Neural Networks
Convolutional neural networks have been developed for many segmentation tasks, including several in remote sensing. We test various existing neural network architectures for flood identification and compare these against the method described in
Section 2.2 and our baseline. Specifically we assess the performance of the well used U-Net model [
64], and an alternative model, XNet [
65].
Both U-Net and XNet are convolutional neural networks consisting of encoder and decoder modules as well as utilizing weight sharing. The encoder module consists of a series of convolutional layers for feature extraction, along with max-pooling layers which downsample the input. The decoder is applied after feature extraction and performs upsampling to generate a segmentation mask of equal dimension to the input. The decoder also consists of further convolutional layers which allows for additional feature extraction and thus produces a dense feature map.
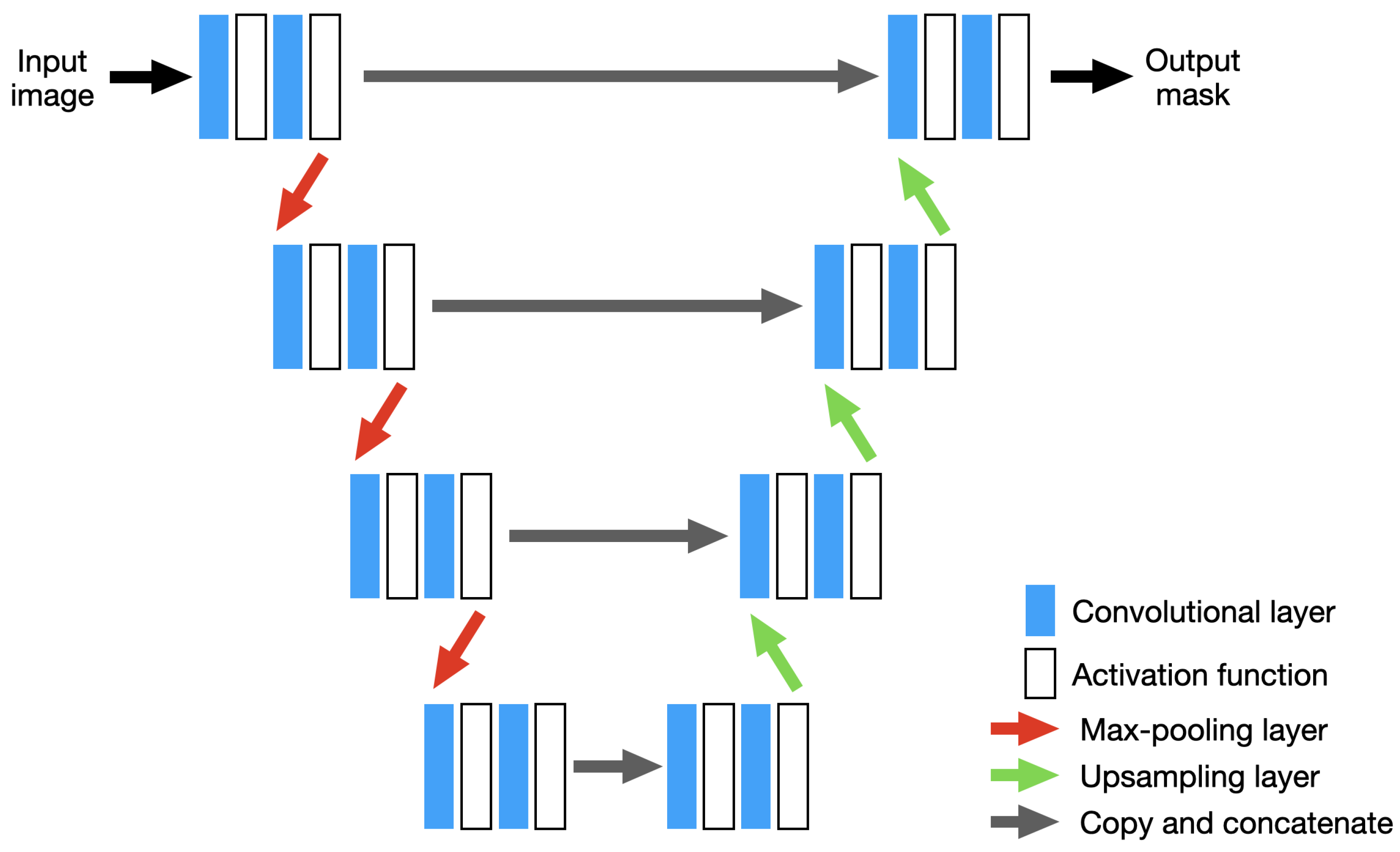
U-Net, shown in
Figure 5, consists of an encoder for capturing context, and a symmetric decoder which allows for precise localization of features in the tile. The encoder consists of a stack of the convolutional layers followed by rectified liner unit (ReLU) activation functions to add non-linearity to the model, and max-pooling layers for downsampling. The decoder consists of convolutional and upsampling layers. Through using feature concatenation between each level, denoted “copy and concatenate” in
Figure 5, precise pixel localization has been found to be enhanced [
64]. Here, the feature maps saved during the downsamping/encoder stage are concatenated with the output of the convolution layers during the upsampling/decoder stage. Neither U-Net nor XNet contain any dense layers and therefore can accept tiles of any size.
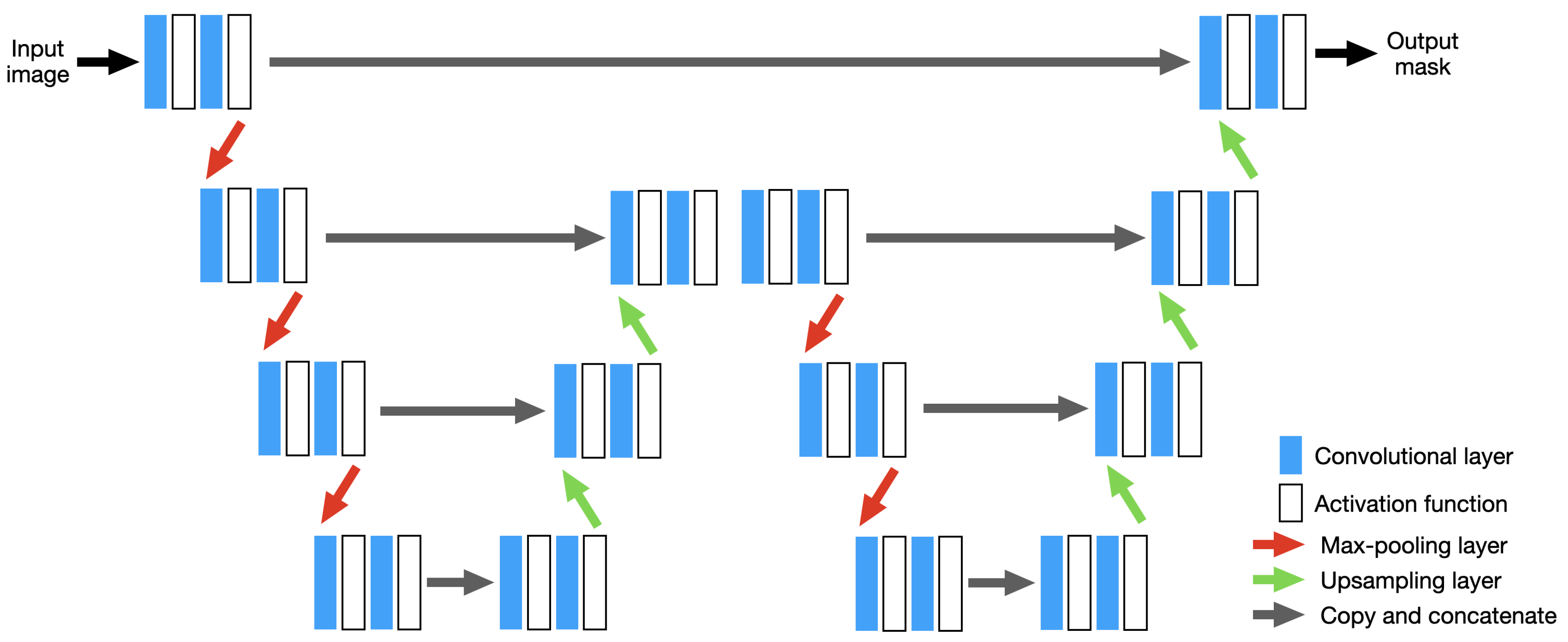
XNet, shown in
Figure 6, consists of many of the same features contained in U-Net. However, instead of following the encoder-decoder structure shown in
Figure 5, this architecture consists of a symmetric encoder-decoder-encoder-decoder structure. By containing multiple decoder stages alongside avoiding large serial downsampling of the input tile, XNet is designed to be sensitive to boundary level detail, particularly around small structures, while still achieving strong performance on largescale structures [
65]. As with U-Net, XNet also leverages feature concatenation between encoder and decoder stages to help avoid the loss of important information between the downsampling and upsampling stages.
2.6. Transfer Learning
Transfer Learning is a machine learning method where a pre-trained model is used as a starting point for another model with a similar architecture. Using pre-trained models allows for the leveraging of previously learnt features, often on different datasets (which may help with generalizability), and can greatly speed up training and development time. Transfer learning is often used in applications where the labeled datasets are small, and training a neural network from scratch can be challenging due to its computational complexity.
Deep neural networks generally extract relevant information using a hierarchical approach. Initial layers detect high-level features such as corners and edges which are necessary for many image recognition problems, while the later layers detect more sophisticated features which are likely more domain specific. Due to this structure, neural networks are highly suited to transfer learning.
In the case of neural networks, a common approach is to alter the architecture of the model you wish to use such that part of it conforms to the design of another pre-trained model. The weights from the pre-trained model are then ported into the architecture you wish to train. Training of the entire architecture can then be performed, starting from the pre-trained weight values, or a subset of the model layers can be trained at different time steps. This latter method can help with model performance, as well as training speed.
In this study, we test the performance of training a U-Net style architecture as described above, but with the encoding/downsampling stage replaced with a ResNet architecture [
66] which has been pre-trained on the ImageNet database [
67] (see
Figure 7). Since ResNet was originally designed for image classification, in order to connect the ResNet ‘backbone’ the classification layers has been removed such that all convolutional layers remain, but any flattening and dense layers for classification have been eliminated. By making this alteration, the modified ResNet architecture acts purely as a feature encoder in line with the encoder description provided in
Section 2.5 and contains potentially useful information for high level feature extraction such as edge detection and general shape recognition.
2.7. Comparison Algorithms
We test a variety of automated algorithms and compare each performance against the method described in
Section 2.2 for label generation. As a simple baseline to justify the use of more complex techniques, we use the automatic histogram based method described in
Section 2.4. Here we minimize the mean squared-error between the labels and the output of the linear model applied after the necessary pre-processing steps.
Against this baseline we test several neural network architectures with different hyper-parameter values and compare their performance, while also accounting for the difference in training and testing time between the automatic histogram based method and the neural networks. We train XNet [
65] and U-Net [
64] architectures, both implemented in Keras [
68] with a Tensorflow backend [
69]. All input tiles are normalized prior to training and inference by applying mean subtraction and min/max scaling.
In addition, we test a transfer learning approach by training a U-Net architecture with a ResNet-34 [
66] backbone structure implemented in the fastai library [
70]. The model is trained using a one-cycle policy and fine-tuned using discriminative and slanted triangular learning rates [
71]. Input tiles are normalized using ImageNet [
67] statistics.
All neural networks are trained using Early Stopping (see Section 7.8 of [
72]) and Adam optimization [
73] with a binary cross-entropy loss function.
2.8. Computational Platform and Evaluation Criteria
We trained our models on Amazon Web Service (AWS) instances using NVIDIA Tesla K80 GPUs. The models were also tested using PulseSatellite, a collaborative satellite image analysis tool enabling HITL style model interaction, for compatibility and to test the possibility of deployment [
51].
Given an input tile, the segmentation techniques described above assign a class to each pixel. In this study, a binary segmentation is performed and thus two outcomes are possible: positive or negative, which correspond respectively to water and background regions. The classifier output can be listed as:
True Positive (TP): Water pixels correctly classified as water
True Negative (TN): Background pixels correctly classified as background
False Positive (FP): Background pixels incorrectly classified as water
False Negative (FN): Water pixels incorrectly classified as background
There are a variety of metrics that can be used to evaluate the segmentation. For instance, pixel accuracy reports the percentage of pixels in the tiles that are correctly classified irrespective of their class. However, this metric can be misleading when the class of interest is poorly represented. To avoid this, precision, recall, the critical success index (CSI) (The CSI is equivalent to the intersection over union (IoU) of the water class) and F1 scores are commonly used [
74,
75,
76]:
Precision is the fraction of relevant instances among the retrieved instances, i.e., it is the the ”purity” of the positive predictions relative to the labels. In other words, the precision illustrates how many of the positive predictions matched the labeled annotations. Recall is the fraction of the total amount of relevant instances that were actually retrieved, i.e., it describes the ”completeness” of the positive predictions relative to the labels. In other words, of all objects annotated in the labeled data, the recall denotes how many have been captured as positive predictions. As shown here, the F1 score is just the harmonic mean of the precision and recall and is equivalent to the dice similarity coefficient, thereby providing a metric which combines both the precision and recall statistics into one number. The CSI is also highly related to the F1 score and is provided here for clarity since it is a common metric to use in such mapping exercises. For a discussion on the similarities and trade offs of both the F1 and CSI metrics, see [
76].
Besides the commonly used evaluation metrics for segmentation, it is relevant to also define the impact of this study in a broader context. Since rapid response is crucial during a humanitarian crisis, the time saved compared with using the methodology described in
Section 2.2 is used as an impact metric. The time was calculated from when the image was initially accessed to the delivery of the final map (see
Section 4.3).
2.9. Neural Network Hyper-Parameter Tuning
Given the variety of architectures being tested, as well as limited compute resources available, hyper-parameter tuning was carried out by manually varying parameters found to be particularly effective in improving model performance. If parameters were tested which did not have a significant impact on performance then these were sometimes not varied in later tests due to computational efficiency. Performance was measured using the precision, recall, CSI and F1 statistics presented in Equations (
3)–(
6).
For the case of the XNet and U-Net models, the learning rate was set to and varied by an order of magnitude with no immediate effect on performance. In the case of the U-Net+ResNet transfer learning approach, we utilized the fastai ‘learning rate finder’ tool to assist in choosing the learning rate for each training phase. Moreover, different ResNet depths (i.e., the number of skip-connection modules included in the backbone) were tested, although this too made minimal difference and so a smaller backbone was chosen for computational efficiency. The XNet and U-Net models were set to use a kernel size of 3 × 3 with a stride of 1, as a trade off between incorporating additional contextual information and memory efficiency, with the U-Net+ResNet kernel sizes and strides set to the default values.
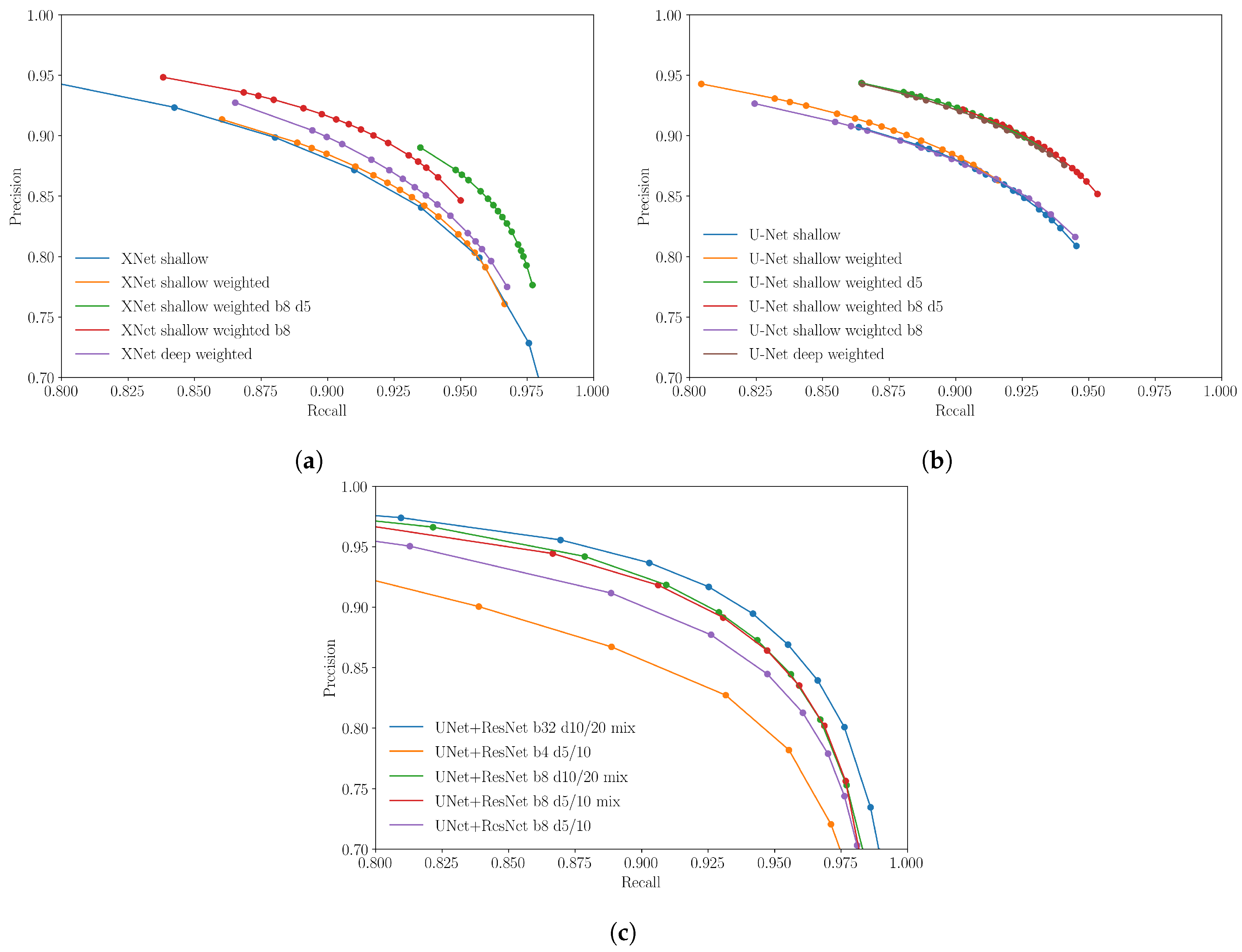
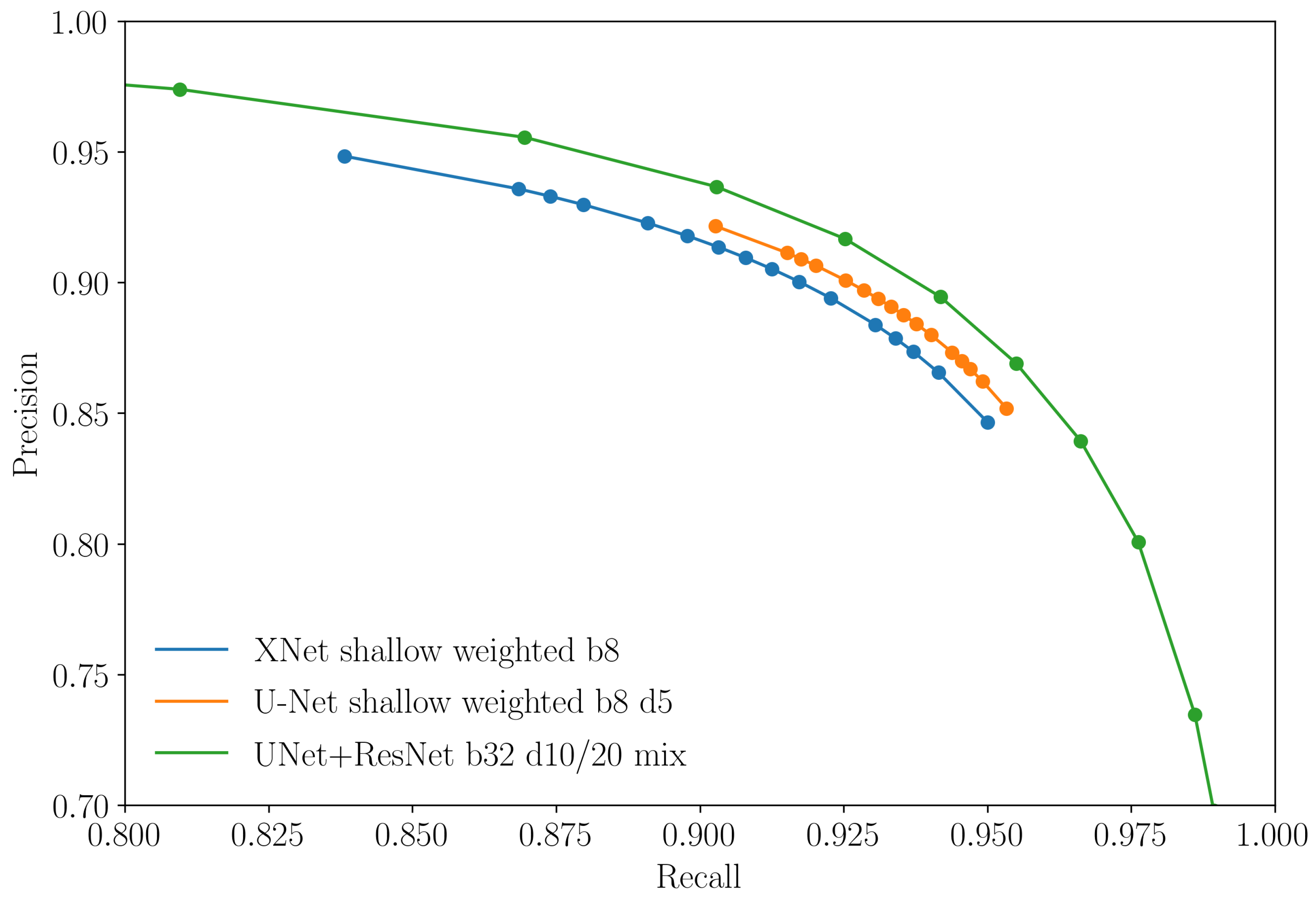
In
Figure 8 we present results obtained by varying the batch size, number complete passes over the training set during model training, the use of a weighted loss function (giving greater weight to the flooded pixels in proportion to their imbalance in the dataset), changes in filter depths of the convolutional layers and the use of mixed precision during the training phase (i.e., the use of both 16 and 32-bit floating point numbers in the model during training). Details of the model setups are provided in
Table 3 which also serves as a key for curves shown in
Figure 8 and those shown subsequently.
Figure 8a,b show the performance of the XNet and U-net architectures with various hyper-parameter configurations. Two different filter depth configurations are tested: ‘deep’ and ‘shallow’, with the former being four times the size of the latter (see
Table 3). Since we see that filter depth seems to have little effect on model performance in the ranges tested, for computational efficiency we assess the impact of the remaining hyper-parameters on models with smaller filter depths. When it comes to training the larger and more complex U-Net+ResNet model, we assume this depth variation to have similarly little effect and so did not assess its impact for this model. Here we take the default fastai filter depth sizes for both the U-Net and ResNet backbone.
When training the XNet and U-Net models, we test using both weighted and unweighted loss functions to account for the unbalanced dataset. This was also found to have minimal effects in comparison to other hyper-parameters and so we kept the weighted loss for the U-Net+ResNet model since we feel this may enable greater generalizability in future scenarios where datasets may be even more imbalanced.
Given the large size of the training dataset, when training the XNet and U-Net models, each epoch only passed over a fraction of the total training set. By default, we ensured the model is passed the same number of tiles as is contained in the training set once before Early Stopping is introduced. By increasing this to five passes we see that this can have a significant impact on model performance. This is to be expected given the diversity of the training set and the relatively few times the model is likely to see a given tile.
We discover mixed results when increasing the batch size from 3 to 8, with XNet performance increasing with the batch size and not increasing further with the number of passes over the dataset, whereas in the U-Net case the converse is found. In general we also do not see a significant difference in performance if one chooses to use either the XNet or U-Net architecture. Final testing to isolate the number of times a tile is shown to the model, and its batch size, is therefore only carried out on the U-Net architecture.
In
Figure 8c we present the results for similar tests performed on the UNet+ResNet model which utilizes transfer learning. These curves show similar characteristics to those shown in
Figure 8a,b and therefore suggests that the addition of transfer learning does not have a significant impact in this example. Another feature of testing carried out at this stage was the effectiveness of mixed precision. In general, using mixed precision is designed to decrease training time and has also been observed in certain circumstances to improve performance. Although the best performing model here has been trained with mixed precision, the differentiating factor from the other mixed precision models appears to be the number of times the whole training data is passed to the model during training, as well as some improvement coming from varying the batch size.
5. Conclusions
The ability to perform rapid mapping in disaster situations is essential to assisting national and local governments, NGOs and emergency services, enabling information to be gathered over large distances and visualised for planned response. Non-governmental, national and international agencies currently spend many hours, using a variety of manual and semi-automated classical image processing techniques, resulting in highly detailed maps of flood extent boundaries.
In this work we present a machine learning based approach to further automate and increase the speed of rapid flood mapping processes, while achieving sufficiently good performance metrics for deployment across a broad range of environment landscapes and conditions. By using convolutional neural networks trained on a wide variety of flood maps created using SAR imagery, we are able to produce results which are comparable, or outperform, previous more limited studies of SAR flood segmentation, as well as methods which also include the use of optical imagery not required by our methodology. In addition, our approach requires minimal pre-processing before the image is fed into the network, thereby speeding up inference time, and does not rely on many additional external data sources.
In this work, we not only demonstrate model performance over a wide ranging, diverse dataset of images taken from some of the most disaster prone areas of the world, but also explicitly present statistics on both unseen tiles gained from images that have been partially seen by the model, as well as unseen tiles derived from completely unseen images. Furthermore, we assess model performance on the usual analysis task of water detection, as has been carried out in previous studies, as well as specifically focusing on the model’s ability to detect new flooded regions which are additional to the permanent water in the image. Building on previous recommendations, such as those by Kang et al. [
50], we hope future studies also take a similar approach to assessing model performance rather than solely focusing on water detection.
Through using a machine learning based approach there is also potential to increase the impact to end beneficiaries during humanitarian assistance by allowing for the implementation of live streaming mapping services triggered by direct partner requests or automatic activations. By enabling flood mapping to be completed automatically in a fraction of the time, teams on the ground are able to respond more quickly to disaster situations.
Using the existing histogram based method, a flood map can be provided in 24 h; however, floods change quickly thereby rapidly rendering maps outdated. Additionally, because an analyst takes many hours to producing a flood map, the frequency with which maps can be created is limited to the number of analysts. By using the method presented in this paper, flooded regions can be identified in a significantly shorter time period using fully automated methods, allowing the dissemination of more timely information and enabling new workflows to be developed.
Rapid flood mapping is a crucial source of information, and a speed up in this process could have extremely meaningful repercussions for disaster response procedures.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













