PlanetScope Radiometric Normalization and Sentinel-2 Super-Resolution (2.5 m): A Straightforward Spectral-Spatial Fusion of Multi-Satellite Multi-Sensor Images Using Residual Convolutional Neural Networks


Abstract
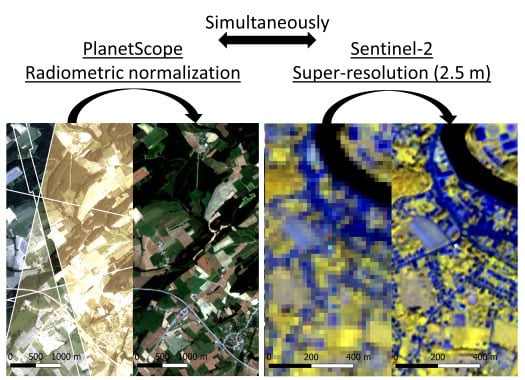
1. Introduction
2. Materials and Methods
2.1. Software and Hardware
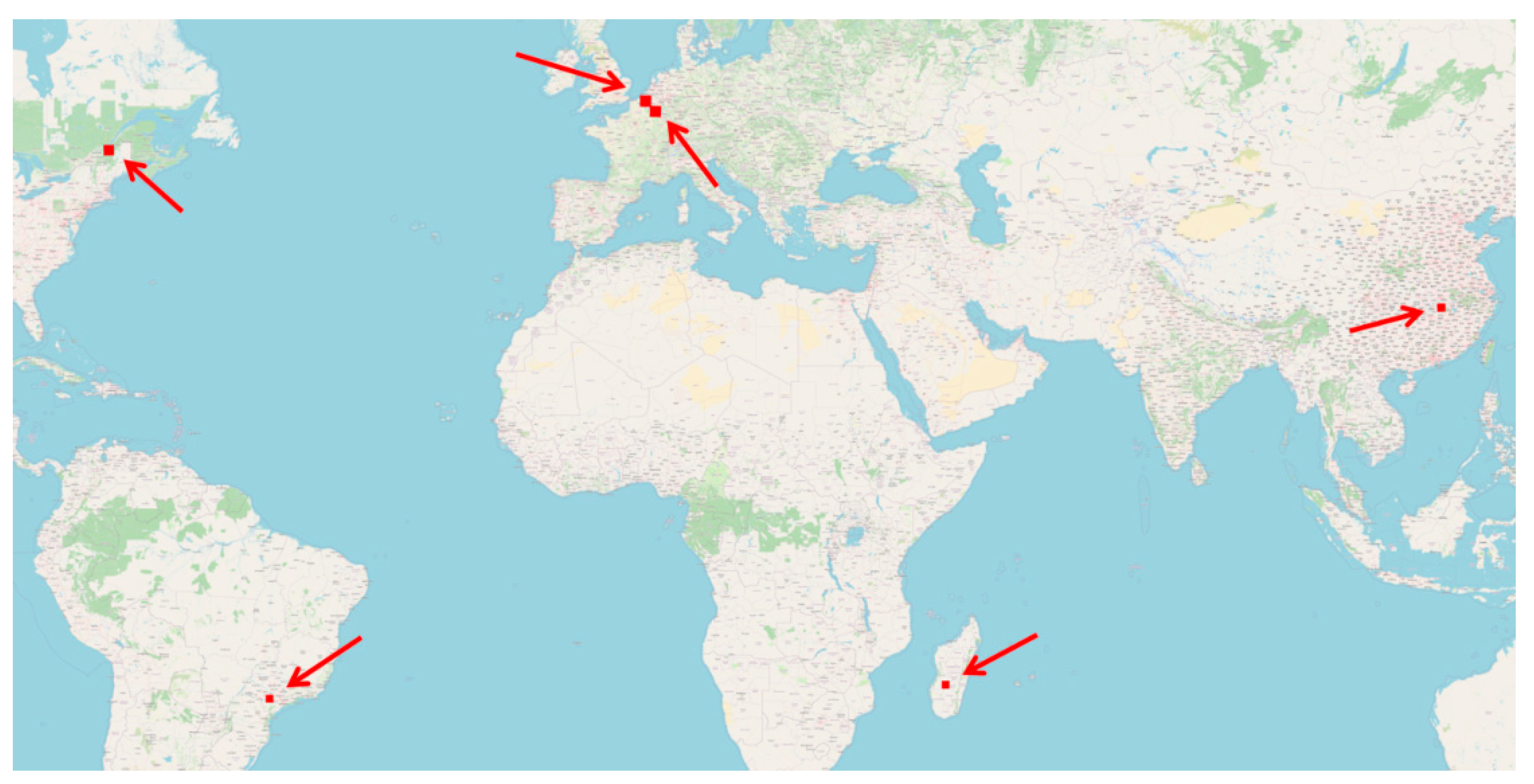
2.2. Image Selection
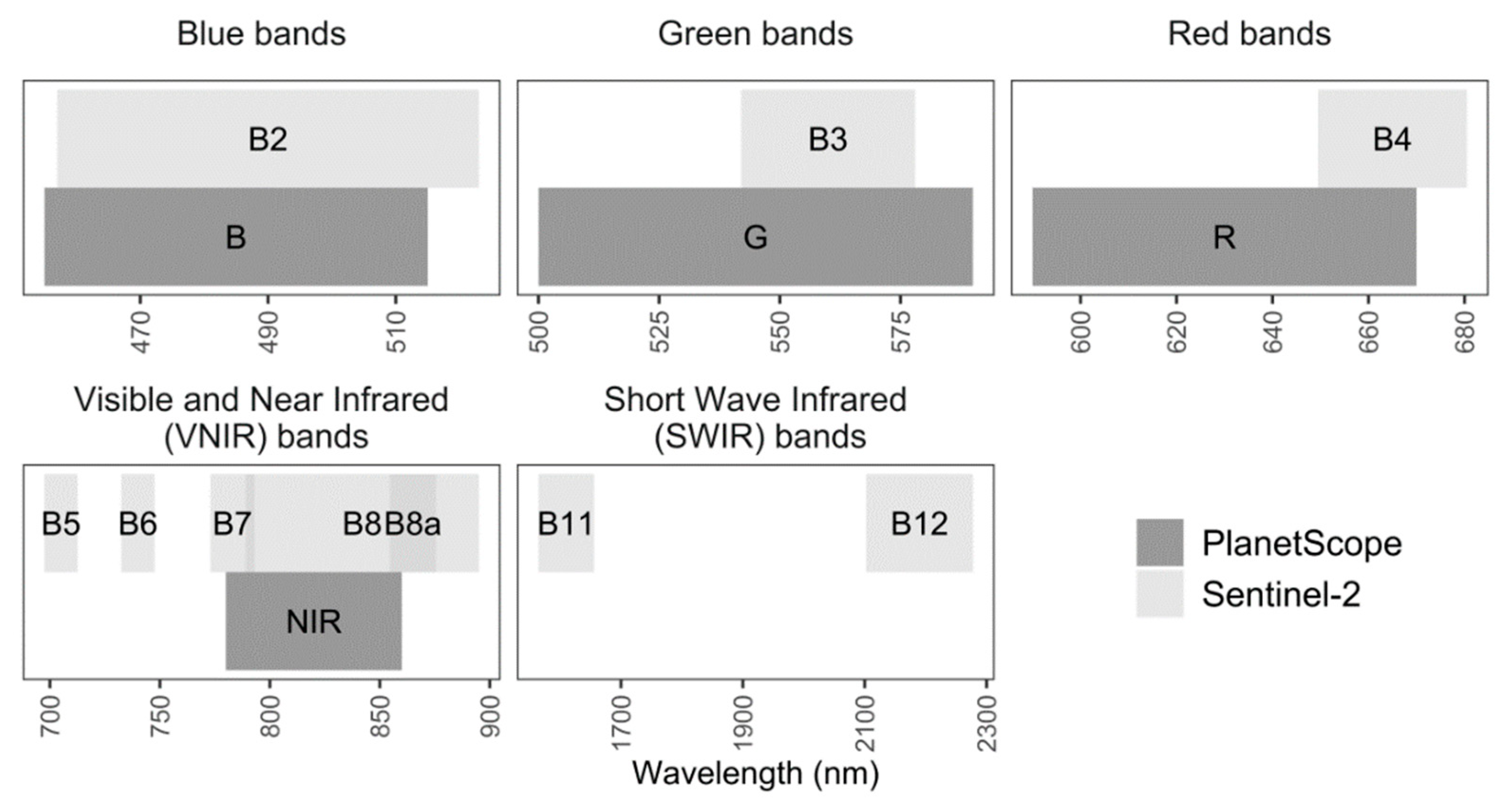
2.3. Radiometric Inconsistency
2.4. Data Preparation
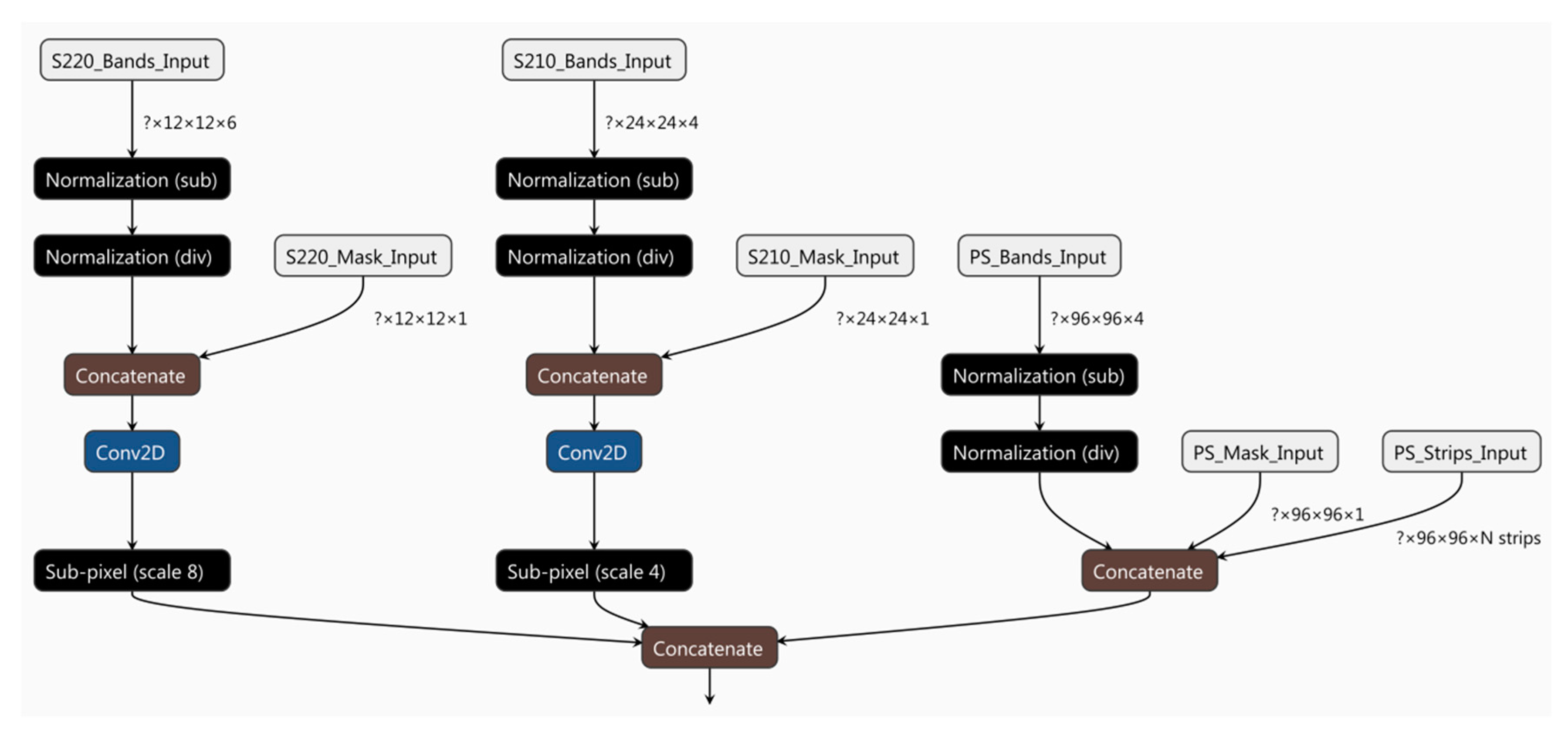
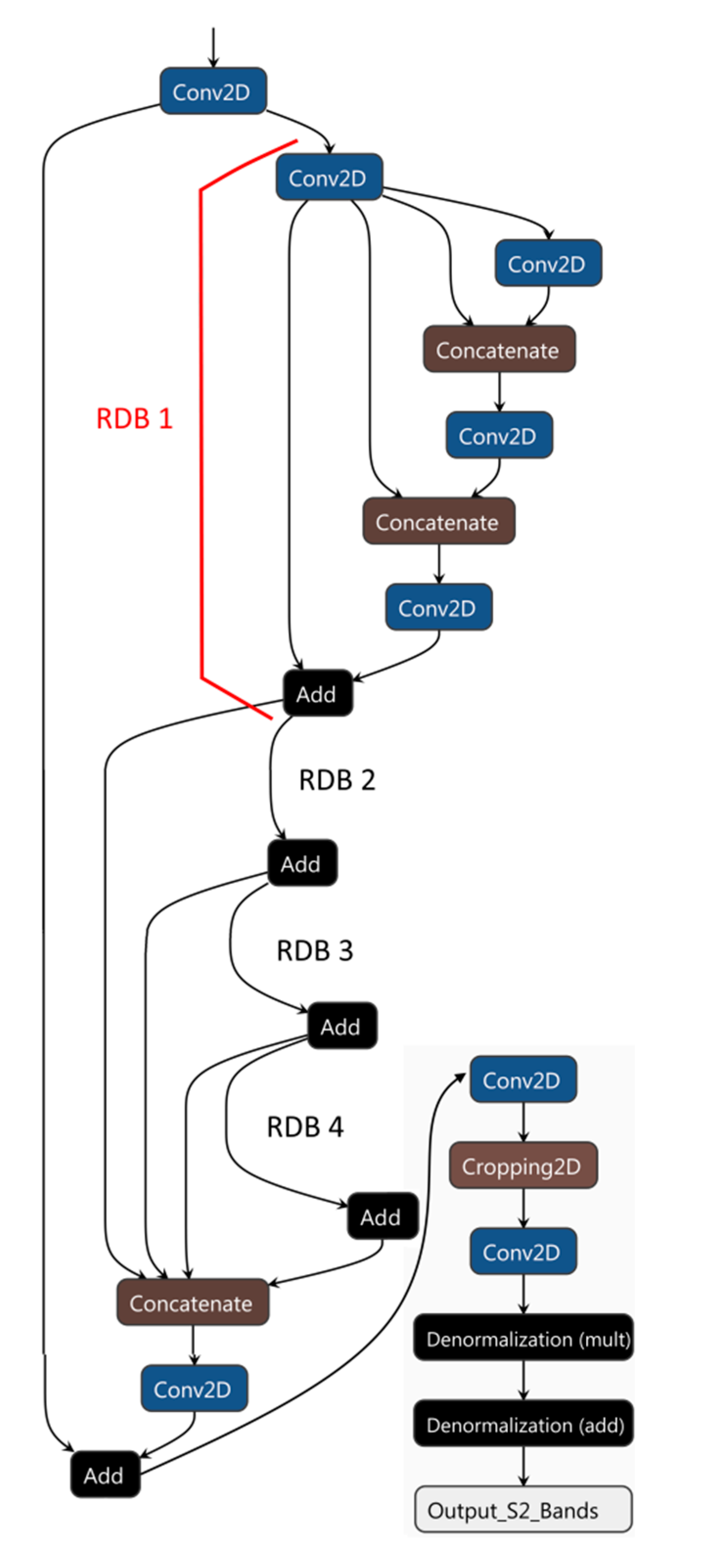
2.5. Network Architecture
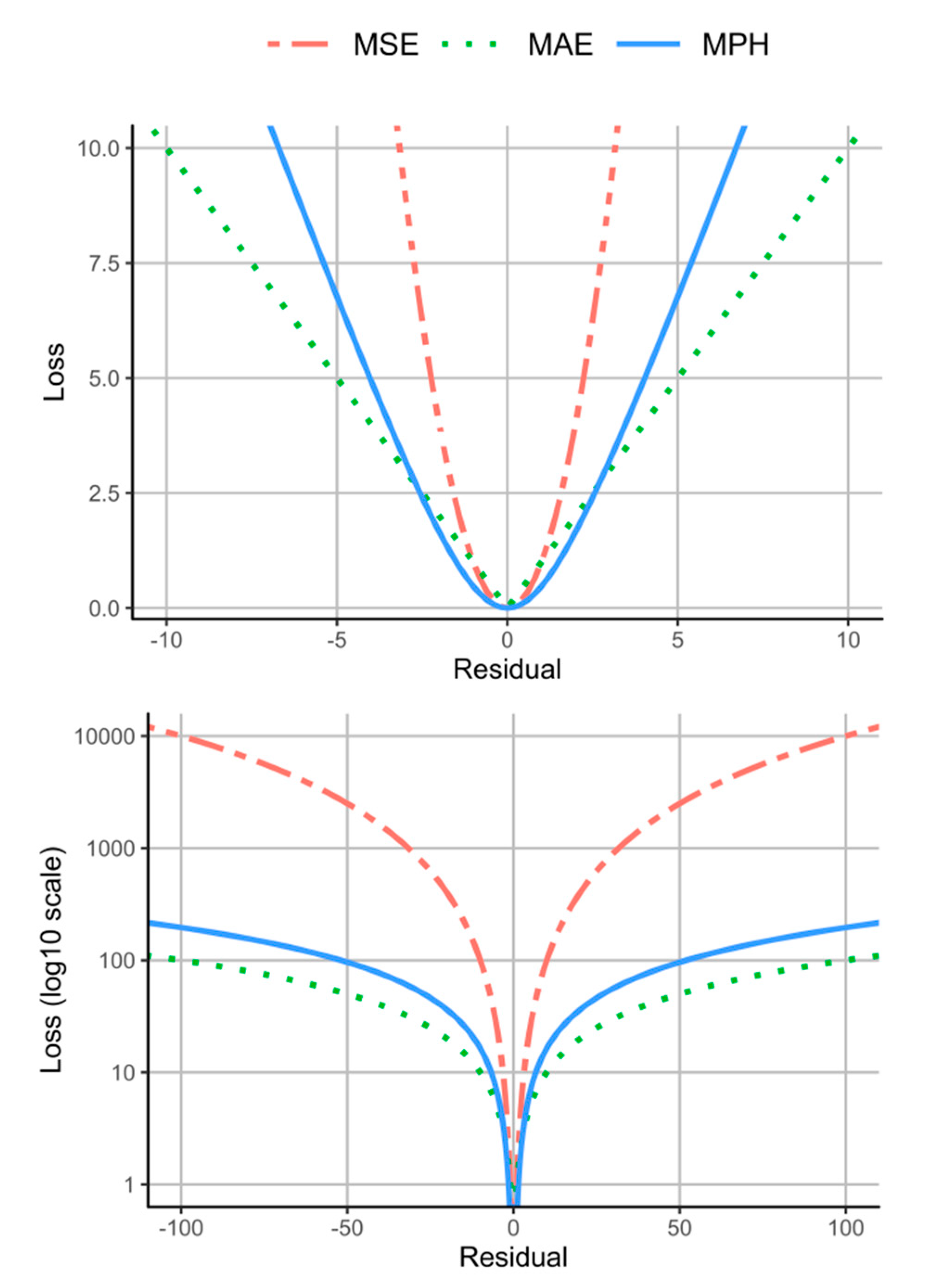
2.6. Network Training
2.7. Quality Assessment
3. Results
3.1. Measured Quality
3.2. Visual Quality
3.3. Processing Times
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Unninayar, S.; Olsen, L.M. Monitoring, observations, and remote sensing—Global dimensions. In Reference Module in Earth Systems and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2015; ISBN 978-0-12-409548-9. [Google Scholar]
- Vivone, G.; Alparone, L.; Chanussot, J.; Mura, M.D.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2565–2586. [Google Scholar] [CrossRef]
- Garzelli, A. A review of image fusion algorithms based on the super-resolution paradigm. Remote Sens. 2016, 8, 797. [Google Scholar] [CrossRef]
- Pohl, C.; Van Genderen, J.L. Review article Multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Meng, X.; Shen, H.; Li, H.; Zhang, L.; Fu, R. Review of the pansharpening methods for remote sensing images based on the idea of meta-analysis: Practical discussion and challenges. Inf. Fusion 2019, 46, 102–113. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-Level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J. Remote sensing image fusion with deep convolutional neural network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1656–1669. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the accuracy of multispectral image pansharpening by learning a deep residual network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef]
- Gargiulo, M.; Mazza, A.; Gaetano, R.; Ruello, G.; Scarpa, G. A CNN-Based fusion method for super-resolution of Sentinel-2 data. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4713–4716. [Google Scholar]
- Hu, J.; He, Z.; Wu, J. Deep self-learning network for adaptive pansharpening. Remote Sens. 2019, 11, 2395. [Google Scholar] [CrossRef]
- Pohl, C. Multisensor image fusion guidelines in remote sensing. In Proceedings of the 9th Symposium of the International Society for Digital Earth (ISDE), Halifax, Canada, 5–9 October 2015; Volume 34, p. 012026. [Google Scholar]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-Resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of Landsat-8 and Sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Feng, G.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Wang, Q.; Blackburn, G.A.; Onojeghuo, A.O.; Dash, J.; Zhou, L.; Zhang, Y.; Atkinson, P.M. Fusion of Landsat 8 OLI and Sentinel-2 MSI Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3885–3899. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Chanussot, J.; Moon, W.M. Very high-resolution remote sensing: Challenges and opportunities [Point of View]. Proc. IEEE 2012, 100, 1907–1910. [Google Scholar] [CrossRef]
- Benediktsson, J.; Chanussot, J.; Moon, W. Advances in very-high-resolution remote sensing. Proc. IEEE 2013, 101, 566–569. [Google Scholar] [CrossRef]
- Liebel, L.; Körner, M. Single-Image super resolution for multispectral remote sensing data using convolutional neural networks. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41B3, 883–890. [Google Scholar] [CrossRef]
- Lanaras, C.; Bioucas-Dias, J.; Baltsavias, E.; Schindler, K. Super-Resolution of multispectral multiresolution images from a single sensor. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1505–1513. [Google Scholar]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-Resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef]
- Palsson, F.; Sveinsson, R.J.; Ulfarsson, O.M. Sentinel-2 Image fusion using a deep residual network. Remote Sens. 2018, 10, 1290. [Google Scholar] [CrossRef]
- Gargiulo, M.; Mazza, A.; Gaetano, R.; Ruello, G.; Scarpa, G. Fast super-resolution of 20 m Sentinel-2 bands using convolutional neural networks. Remote Sens. 2019, 11, 2635. [Google Scholar] [CrossRef]
- Wang, J.; Huang, B.; Zhang, H.K.; Ma, P. Sentinel-2A image fusion using a machine learning approach. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9589–9601. [Google Scholar] [CrossRef]
- Ulfarsson, M.O.; Palsson, F.; Mura, M.D.; Sveinsson, J.R. Sentinel-2 sharpening using a reduced-rank method. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6408–6420. [Google Scholar] [CrossRef]
- Wu, J.; He, Z.; Hu, J. Sentinel-2 Sharpening via parallel residual network. Remote Sens. 2020, 12, 297. [Google Scholar] [CrossRef]
- Galar, M.; Sesma, R.; Ayala, C.; Aranda, C. Super-Resolution for sentinel-2 images. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W16, 95–102. [Google Scholar] [CrossRef]
- He, J.; Li, J.; Yuan, Q.; Li, H.; Shen, H. Spatial–Spectral fusion in different swath widths by a recurrent expanding residual convolutional neural network. Remote Sens. 2019, 11, 2203. [Google Scholar] [CrossRef]
- Leach, N.; Coops, N.C.; Obrknezev, N. Normalization method for multi-sensor high spatial and temporal resolution satellite imagery with radiometric inconsistencies. Comput. Electron. Agric. 2019, 164, 104893. [Google Scholar] [CrossRef]
- Houborg, R.; McCabe, F.M. Daily retrieval of NDVI and LAI at 3 m resolution via the fusion of cubesat, landsat, and MODIS data. Remote Sens. 2018, 10, 890. [Google Scholar] [CrossRef]
- Houborg, R.; McCabe, M.F. A cubesat enabled Spatio-temporal enhancement method (CESTEM) utilizing planet, landsat and MODIS data. Remote Sens. Environ. 2018, 209, 211–226. [Google Scholar] [CrossRef]
- R core team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: http://www.R-project.org/ (accessed on 1 May 2020).
- Hijmans, R.J. Raster: Geographic Data Analysis and Modeling. 2019. Available online: https://cran.r-project.org/web/packages/raster/raster.pdf (accessed on 1 May 2020).
- Pebesma, E. Simple features for R: Standardized support for spatial vector data. R J. 2018, 10, 439–446. [Google Scholar] [CrossRef]
- Allaire, J.J.; Chollet, F. Keras: R Interface to “Keras”. 2019. Available online: https://keras.rstudio.com/ (accessed on 1 May 2020).
- GDAL/OGR Contributors. GDAL/OGR Geospatial Data Abstraction Software Library; Open Source Geospatial Foundation: Beaverton, OR, USA, 2020. [Google Scholar]
- Inglada, J.; Christophe, E. The Orfeo Toolbox remote sensing image processing software. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 4, p. IV-733. [Google Scholar]
- Grizonnet, M.; Michel, J.; Poughon, V.; Inglada, J.; Savinaud, M.; Cresson, R. Orfeo ToolBox: Open source processing of remote sensing images. Open Geospatial Data Softw. Stand. 2017, 2, 15. [Google Scholar] [CrossRef]
- Laviron, X. theiaR: Download and Manage Data from Theia. 2020. Available online: https://cran.r-project.org/web/packages/theiaR/theiaR.pdf (accessed on 1 May 2020).
- Lonjou, V.; Desjardins, C.; Hagolle, O.; Petrucci, B.; Tremas, T.; Dejus, M.; Makarau, A.; Auer, S. MACCS-ATCOR Joint Algorithm (MAJA). In Remote Sensing of Clouds and the Atmosphere XXI; International Society for Optics and Photonics: Bellingham, WA, USA, 2016. [Google Scholar]
- Baetens, L.; Desjardins, C.; Hagolle, O. Validation of copernicus sentinel-2 cloud masks obtained from MAJA, Sen2Cor, and FMask Processors Using reference cloud masks generated with a supervised active learning procedure. Remote Sens. 2019, 11, 433. [Google Scholar] [CrossRef]
- Sanchez, H.A.; Picoli, C.A.M.; Camara, G.; Andrade, R.P.; Chaves, E.D.M.; Lechler, S.; Soares, R.A.; Marujo, F.B.R.; Simões, E.O.R.; Ferreira, R.K.; et al. Comparison of Cloud cover detection algorithms on sentinel–2 images of the amazon tropical forest. Remote Sens. 2020, 12, 1284. [Google Scholar] [CrossRef]
- Leutner, B.; Horning, N.; Schwalb-Willmann, J. RStoolbox: Tools for Remote Sensing Data Analysis. 2019. Available online: https://cran.r-project.org/web/packages/RStoolbox/RStoolbox.pdf (accessed on 1 May 2020).
- Scheffler, D.; Hollstein, A.; Diedrich, H.; Segl, K.; Hostert, P. AROSICS: An automated and robust open-source image co-registration software for multi-sensor satellite data. Remote Sens. 2017, 9, 676. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–27 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Aitken, A.; Ledig, C.; Theis, L.; Caballero, J.; Wang, Z.; Shi, W. Checkerboard artifact free sub-pixel convolution: A note on sub-pixel convolution, resize convolution and convolution resize. arXiv 2017, arXiv:1707.02937. [Google Scholar]
- Odena, A.; Dumoulin, V.; Olah, C. Deconvolution and checkerboard artifacts. Distill 2016. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. Int. Conf. Learn. Represent. 2014. [Google Scholar]
- Yoshida, Y.; Okada, M. Data-Dependence of plateau phenomenon in learning with neural network—statistical mechanical analysis. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2019; pp. 1722–1730. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2017, 3, 47–57. [Google Scholar] [CrossRef]
- Barron, J.T. A general and adaptive robust loss function. In Proceedings of the 2019 Conference on Computer Vision and Pattern Recognition, 300 E Ocean Blvd, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Horé, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Silpa, K.; Mastani, S.A. Comparison of image quality metrics. Int. J. Eng. Res. Technol. 2012, 1, 4. [Google Scholar]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]
- Ghaffar, M.A.A.; McKinstry, A.; Maul, T.; Vu, T.T. Data augmentation approaches for satellite image super-resolution. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42W7, 47–54. [Google Scholar] [CrossRef]
- Yoo, J.; Ahn, N.; Sohn, K.-A. Rethinking data augmentation for image super-resolution: A comprehensive analysis and a new strategy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Qiu, S.; Xu, X.; Cai, B. FReLU: Flexible rectified linear units for improving convolutional neural networks. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1223–1228. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S2 Tile | Location (Country) | Acquisition Date | S2 Tile ID | S2 Satellite | Number of PS Scenes | Number of PS Strips |
|---|---|---|---|---|---|---|
| BeS | Belgium South | 27/06/2019 | T31UFR | B | 180 | 26 |
| BeN | Belgium North | 20/04/2020 | T31UES | A | 160 | 35 |
| Bra | Brazil | 27/10/2019 | T22KGV | B | 168 | 27 |
| Can | Canada | 07/07/2019 | T19TCM | B | 190 | 33 |
| Chi | China | 29/04/2020 | T50RKT | A | 186 | 30 |
| Mad | Madagascar | 05/11/2109 | T38KNB | B | 203 | 25 |
| NN | Data | Source | Resolution (m) | Patch Size (px.) | Depth |
|---|---|---|---|---|---|
| ×4 | Input | PS | 2.5 (10) | 96 (16 + 16) | 4 bands + 1 mask + number of strips |
| S210 | 10 (40) | 24 (4 + 4) | 5 (4 bands + 1 mask) | ||
| S220 | 20 (80) | 12 (2 + 2) | 7 (6 bands + 1 mask) | ||
| Output | S210 | 2.5 (10) | 64 | 4 bands | |
| ×8 | Input | PS | 2.5 (20) | 96 (16 + 16) | 4 bands + 1 mask + number of strips |
| S210 | 10 (80) | 24 (4 + 4) | 5 (4 bands + 1 mask) | ||
| S220 | 20 (160) | 12 (2 + 2) | 7 (6 bands + 1 mask) | ||
| Output | S220 | 2.5 (20) | 64 | 6 bands |
| NN | S2 Tile | ME | MAE | MWAE | RMSE | PSNR | SSIM | CC |
|---|---|---|---|---|---|---|---|---|
| ×4 (10 m) | BeS | 2.5 | 36.2 | 2.3 | 69.0 | 59.6 | 1.000 | 0.999 |
| BeN | −2.8 | 43.9 | 2.0 | 83.3 | 57.9 | 1.000 | 0.998 | |
| Bra | 0.1 | 25.0 | 1.5 | 41.7 | 63.9 | 1.000 | 0.999 | |
| Can | −5.1 | 41.0 | 2.9 | 80.6 | 58.2 | 1.000 | 0.998 | |
| Chi | −1.5 | 40.0 | 2.4 | 71.4 | 59.3 | 1.000 | 0.998 | |
| Mad | 1.5 | 37.0 | 1.6 | 54.4 | 61.6 | 1.000 | 0.998 | |
| ×8 (20 m) | BeS | −5.9 | 67.8 | 2.4 | 100.7 | 56.3 | 1.000 | 0.997 |
| BeN | 5.6 | 76.5 | 2.0 | 121.2 | 54.7 | 1.000 | 0.995 | |
| Bra | 5.5 | 52.8 | 1.5 | 79.2 | 58.3 | 1.000 | 0.996 | |
| Can | 14.4 | 67.9 | 2.3 | 101.8 | 56.2 | 1.000 | 0.997 | |
| Chi | 1.0 | 68.4 | 2.2 | 99.8 | 56.4 | 1.000 | 0.994 | |
| Mad | 8.6 | 66.0 | 2.1 | 95.7 | 56.7 | 1.000 | 0.994 |
| NN | S2 Tile | ME | MAE | RMSE | CC |
|---|---|---|---|---|---|
| ×4 (10 m) | BeS | 1.5 (14) | 44.9 (17.4) | 79.5 (27.5) | 0.998 (0.001) |
| BeN | −2.7 (3.9) | 43.5 (11.9) | 78.8 (24.4) | 0.995 (0.006) | |
| Bra | 1.2 (6.3) | 30.3 (10.2) | 48.6 (14.7) | 0.999 (0.001) | |
| Can | −6.3 (5.4) | 41.8 (10.8) | 80.2 (20.5) | 0.998 (0.001) | |
| Chi | −1.0 (3.0) | 46.0 (15.6) | 80.5 (26.3) | 0.997 (0.003) | |
| Mad | 0.9 (4.3) | 37.1 (7.2) | 53.3 (10.1) | 0.998 (0.001) | |
| ×8 (20 m) | BeS | −1.8 (20.0) | 77.6 (19.9) | 113.2 (26.0) | 0.996 (0.002) |
| BeN | 4.9 (6.4) | 72.3 (25.0) | 114.2 (38.7) | 0.991 (0.010) | |
| Bra | 8.3 (14.1) | 59.6 (10.6) | 86.9 (13.6) | 0.995 (0.002) | |
| Can | 12.4 (7.4) | 70.3 (16.1) | 110.8 (52.3) | 0.996 (0.005) | |
| Chi | 3.3 (7.2) | 78.1 (18.7) | 113.5 (26.8) | 0.992 (0.005) | |
| Mad | 8.1 (3.9) | 66.9 (7.6) | 96.8 (9.4) | 0.993 (0.002) |
| S2 Tile | NN | Band | ME | MAE | MWAE | RMSE | PSNR | SSIM | CC | PRg | PRp |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BeS | ×4 (10 m) | B2 | 1.2 | 16.1 | 1.0 | 31.6 | 66.3 | 1.000 | 0.991 | 2‒1049 | 8‒1042 |
| B3 | 2.1 | 20.9 | 1.3 | 35.5 | 65.3 | 1.000 | 0.993 | 160‒1492 | 164‒1482 | ||
| B4 | 10.2 | 23.5 | 1.5 | 41.7 | 63.9 | 0.999 | 0.995 | 25‒1830 | 21‒1805 | ||
| B8 | −3.6 | 84.4 | 5.3 | 122.7 | 54.6 | 0.997 | 0.991 | 1315‒5514 | 1339‒5506 | ||
| ×8 (20 m) | B5 | −6.3 | 35.4 | 1.2 | 54.2 | 61.7 | 0.999 | 0.992 | 339‒2211 | 350–2200 | |
| B6 | −4.8 | 70.2 | 2.5 | 97.9 | 56.5 | 0.998 | 0.988 | 1150‒4142 | 1159‒4138 | ||
| B7 | −5.7 | 81.2 | 2.9 | 114 | 55.2 | 0.997 | 0.99 | 1376‒5310 | 1399‒5304 | ||
| B8A | −6.8 | 84 | 3.0 | 118.1 | 54.9 | 0.997 | 0.991 | 1533‒5694 | 1559‒5693 | ||
| B11 | −5.4 | 82.1 | 2.9 | 117.9 | 54.9 | 0.997 | 0.985 | 681‒3848 | 689‒3837 | ||
| B12 | −6.7 | 53.8 | 1.9 | 86.5 | 57.6 | 0.998 | 0.986 | 274‒2609 | 283‒2607 | ||
| BeN | ×4 (10 m) | B2 | −3.7 | 27.2 | 1.2 | 58.7 | 61.0 | 0.999 | 0.986 | 0‒1594 | 10‒1593 |
| B3 | 2.4 | 30 | 1.3 | 59.8 | 60.8 | 0.999 | 0.987 | 172‒1961 | 175‒1948 | ||
| B4 | 3.7 | 34.4 | 1.5 | 67.2 | 59.8 | 0.999 | 0.993 | 0‒2339 | 0‒2327 | ||
| B8 | −13.6 | 83.8 | 3.7 | 127.4 | 54.2 | 0.997 | 0.996 | 22‒5956 | 40‒5942 | ||
| ×8 (20 m) | B5 | 1.6 | 46.6 | 1.2 | 80.3 | 58.2 | 0.999 | 0.985 | 154‒2487 | 161‒2459 | |
| B6 | 2.7 | 75.4 | 2.0 | 114.8 | 55.1 | 0.997 | 0.993 | 48‒4304 | 55‒4273 | ||
| B7 | 6.4 | 86.4 | 2.3 | 130.2 | 54.0 | 0.997 | 0.995 | 43‒5796 | 51‒5748 | ||
| B8A | 7.4 | 87.4 | 2.3 | 131.9 | 53.9 | 0.997 | 0.996 | 12‒6092 | 24‒6065 | ||
| B11 | 4.2 | 85.7 | 2.3 | 130.9 | 54.0 | 0.996 | 0.985 | 5‒3634 | 11‒3596 | ||
| B12 | 11.5 | 77.6 | 2.0 | 130.6 | 54.0 | 0.996 | 0.986 | 16‒3340 | 18‒3291 |
| NN | CLC Category (Level 1) | Area (%) | ME | MAE | RMSE | CC |
|---|---|---|---|---|---|---|
| ×4 (10 m) | Artificial surfaces | 18.0 | 0.0 | 60.2 | 109.1 | 0.995 |
| Agricultural areas | 54.2 | −1.0 | 35.9 | 66.5 | 0.999 | |
| Forest and seminatural areas | 23.9 | 1.6 | 36.8 | 71.3 | 0.999 | |
| Wetlands | 0.6 | −3.4 | 38.6 | 76.7 | 0.995 | |
| Water bodies | 3.3 | 0.2 | 22.8 | 43.8 | 0.994 | |
| ×8 (20 m) | Artificial surfaces | 18.0 | 4.5 | 97.0 | 152.8 | 0.987 |
| Agricultural areas | 54.2 | −0.6 | 70.9 | 105.7 | 0.996 | |
| Forest and seminatural areas | 23.9 | −2.5 | 63.3 | 91.6 | 0.997 | |
| Wetlands | 0.6 | −2.6 | 60.3 | 97.5 | 0.995 | |
| Water bodies | 3.3 | −1.1 | 24.4 | 54.0 | 0.994 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Latte, N.; Lejeune, P. PlanetScope Radiometric Normalization and Sentinel-2 Super-Resolution (2.5 m): A Straightforward Spectral-Spatial Fusion of Multi-Satellite Multi-Sensor Images Using Residual Convolutional Neural Networks. Remote Sens. 2020, 12, 2366. https://doi.org/10.3390/rs12152366
Latte N, Lejeune P. PlanetScope Radiometric Normalization and Sentinel-2 Super-Resolution (2.5 m): A Straightforward Spectral-Spatial Fusion of Multi-Satellite Multi-Sensor Images Using Residual Convolutional Neural Networks. Remote Sensing. 2020; 12(15):2366. https://doi.org/10.3390/rs12152366
Chicago/Turabian StyleLatte, Nicolas, and Philippe Lejeune. 2020. "PlanetScope Radiometric Normalization and Sentinel-2 Super-Resolution (2.5 m): A Straightforward Spectral-Spatial Fusion of Multi-Satellite Multi-Sensor Images Using Residual Convolutional Neural Networks" Remote Sensing 12, no. 15: 2366. https://doi.org/10.3390/rs12152366
APA StyleLatte, N., & Lejeune, P. (2020). PlanetScope Radiometric Normalization and Sentinel-2 Super-Resolution (2.5 m): A Straightforward Spectral-Spatial Fusion of Multi-Satellite Multi-Sensor Images Using Residual Convolutional Neural Networks. Remote Sensing, 12(15), 2366. https://doi.org/10.3390/rs12152366