R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images


Abstract
:
1. Introduction
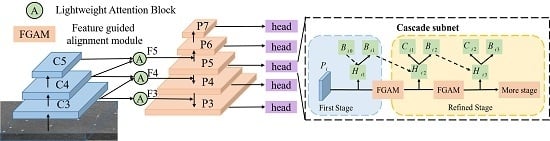
- For paying more attention to the object-related region, an efficient version of the non-local attention mechanism is embedded in the feature pyramidal structure. This attention block merges the contextual information from the adjacent feature levels, enabling a more discriminative feature representation without incurring extra computation burden.
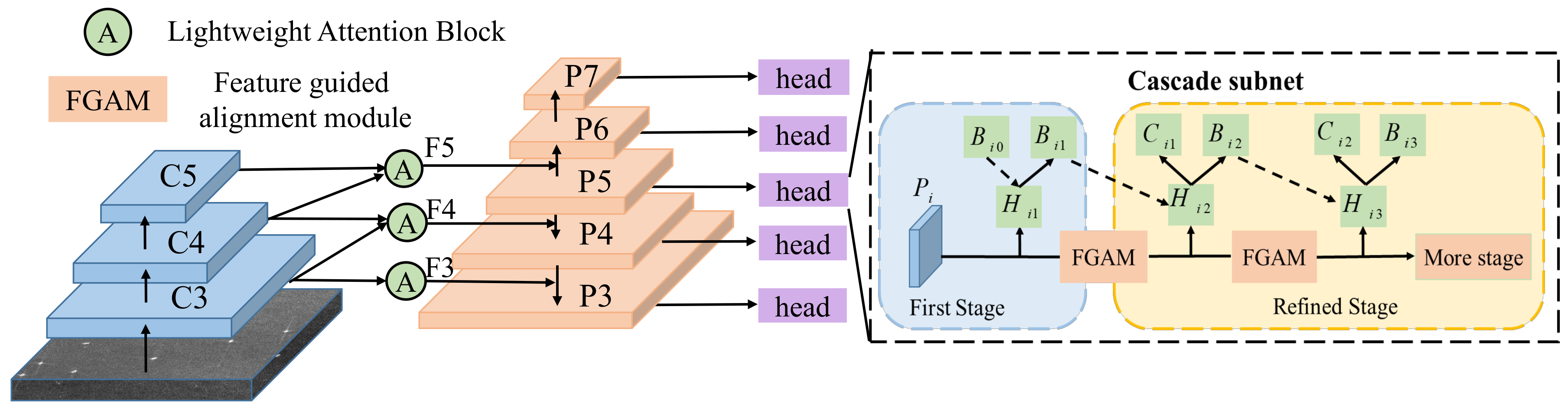
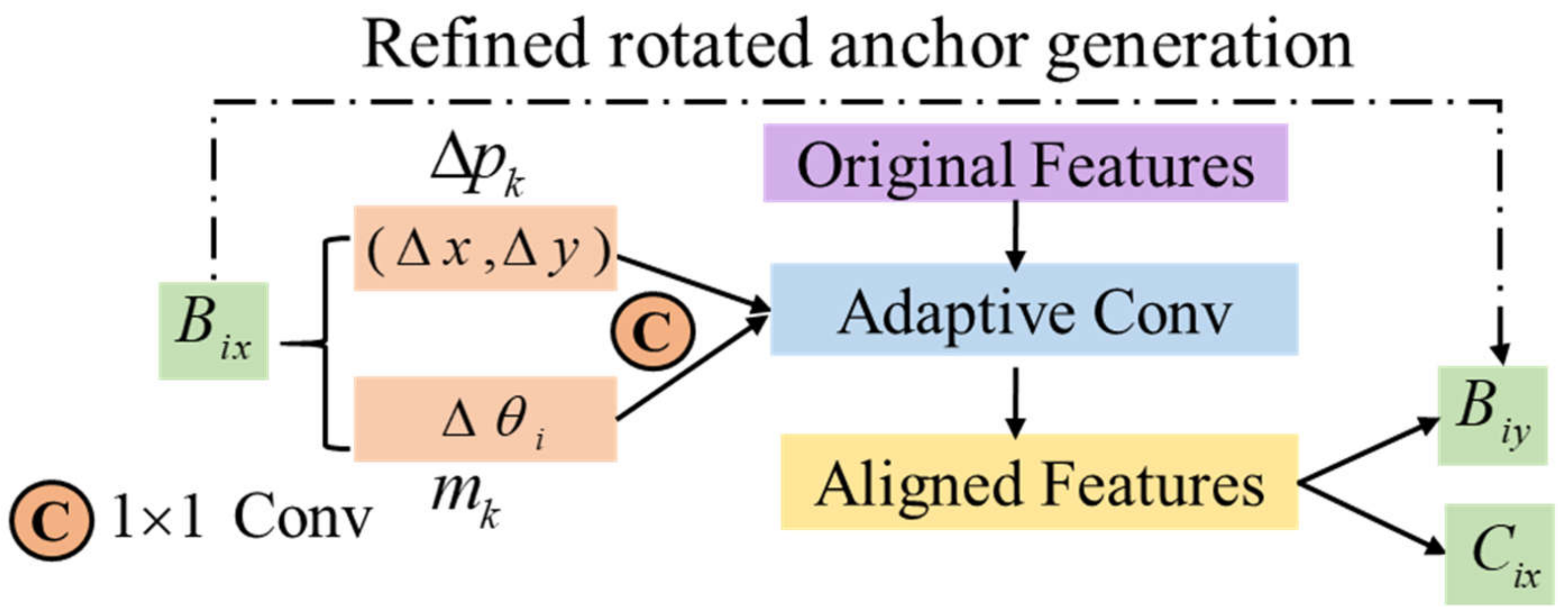
- For densely arranged or arbitrarily oriented targets in SAR images, a modified anchor mechanism is proposed by enjoying the merits of both horizontal anchors and rotated ones. We also resolve the problem of rotated anchor generation by attaching multi-stage refinement, which not only considerably reduces the amount of ineffective rotated anchors, but also satisfies the precise position estimation of the target.
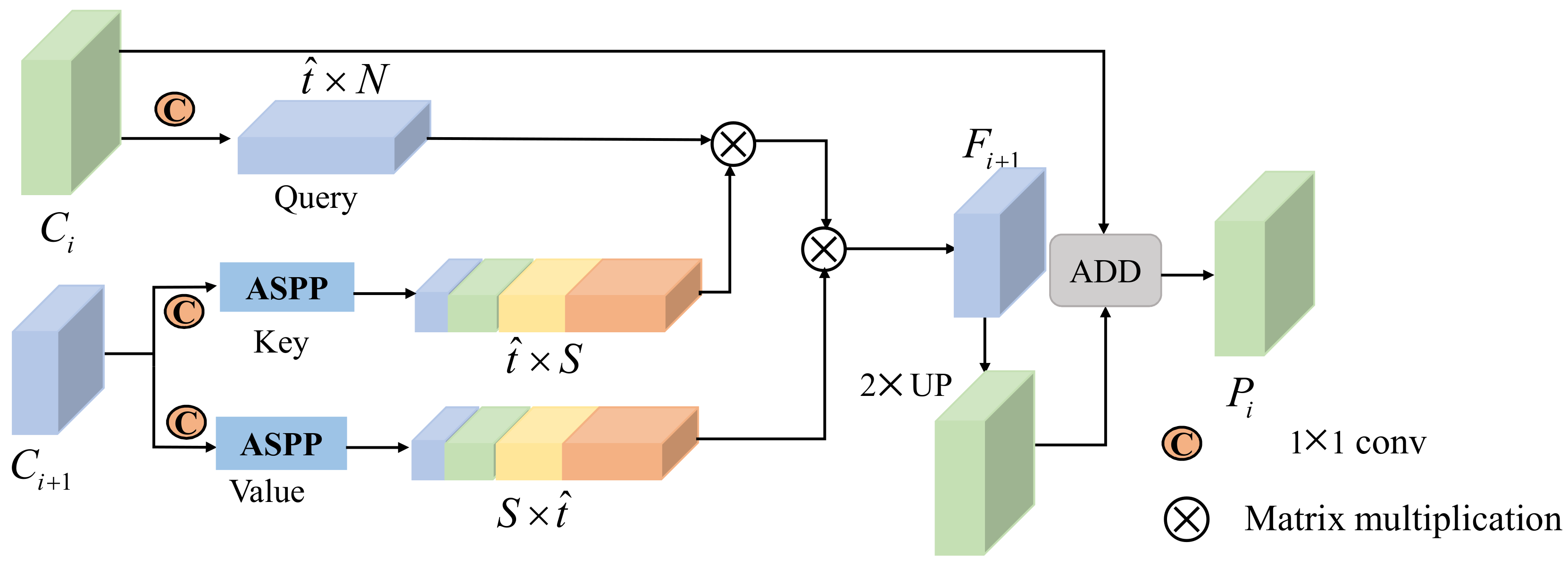
- To the best of our knowledge, this is the first work in the field of rotated SAR ship single-stage detectors that mitigates the feature misalignment problem resulting from the cascaded pipeline. The relationship between the refined rotated anchors and adapted feature pixels can be established by the feature guided alignment module, which further boosts the precision of the predicted results.
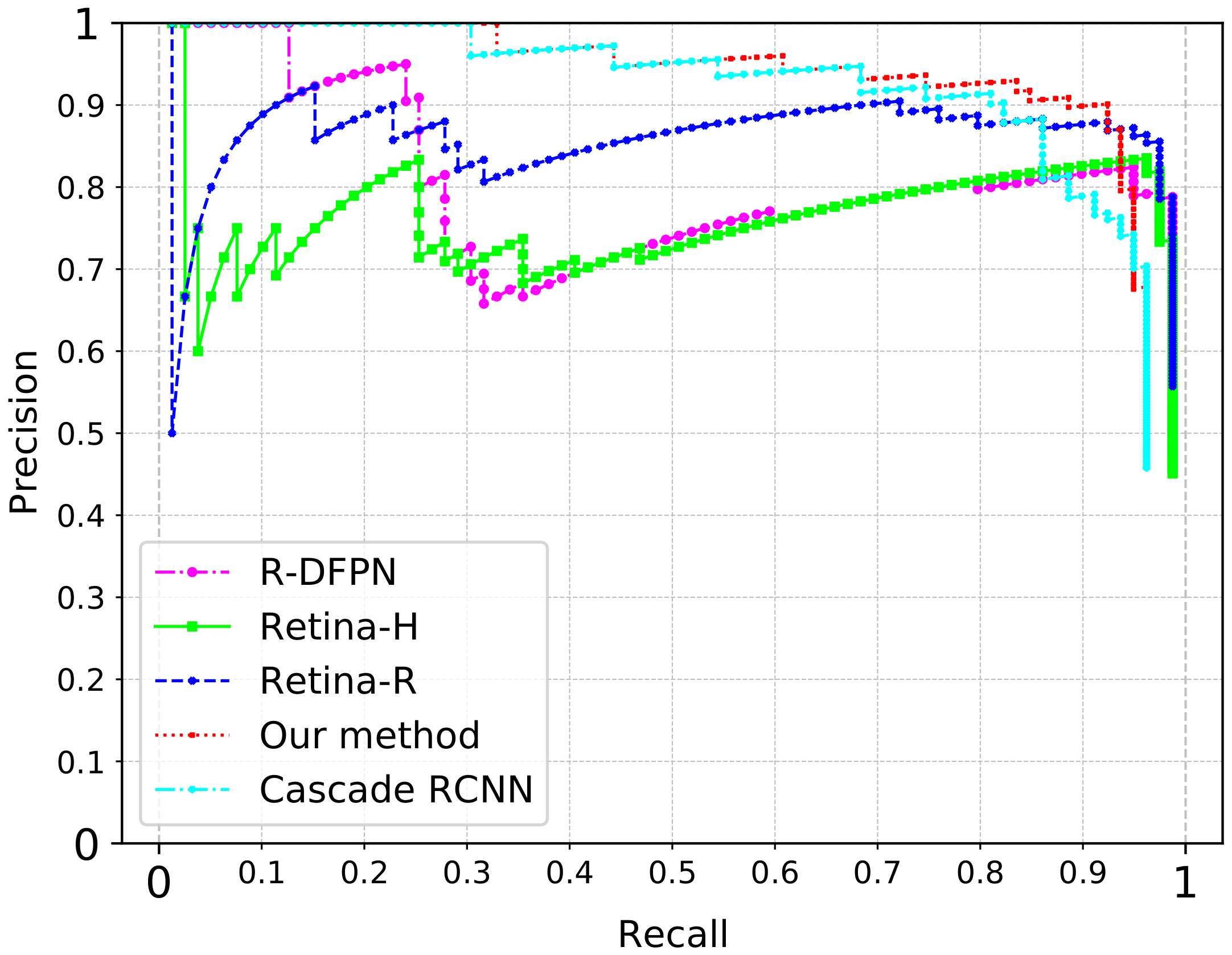
- Our method is validated comprehensively and compared with many representative deep CNN-based detection methods on two SAR ship datasets. When it comes to large-scene SAR ship detection based on rotated bounding box, the proposed architecture can achieve the state-of-the-art results and provide a useful benchmark for the future research.
2. Related Work
2.1. Deep CNN Method for SAR Ship Detection
2.2. Deep CNN Method for RSIs
3. Proposed Methodology
3.1. Attention-Strengthened FPN Structure
3.2. Cascade Refinement Paradigm
- The representation of horizontal bounding boxes exhibits poor ability in accurately describing the real shapes of ships. When the aspect ratio of a target gets larger, the shape mismatch problem becomes more severe.
- The detection results in the horizontal bounding box contain background pixels, whereas the rotatable one largely eliminates the background interference; therefore, it is easier to separate targets from a complex background.
- When ships are densely packed, the areas of overlap between them will be quite large. However, the target with a large overlap region will be discarded by non-maximum suppression (NMS), which results in missing detection.
3.3. Box Regression and Classification Network
3.4. Feature Guided Alignment Module
4. Experiments and Discussions
4.1. Data Set and Experiment Setup
4.1.1. SSDD
4.1.2. GF3RSDD
- (1)
- Data Preprocessing
- (2)
- Parameter Setting
- (3)
- Network Optimization
- (4)
- Post-Processing Step
4.2. Evaluation Metrics
4.3. Qualitative and Quantitative Analyses of Results
4.4. Comparison with CNN-Based Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, J.; Sun, L. Study on Ship Target Detection and Recognition in SAR imagery. In Proceedings of the International Conference on Information Science & Engineering, Nanjing, China, 26–28 December 2009. [Google Scholar]
- Wei, X.; Wang, X.; Chong, J. Local region power spectrum-based unfocused ship detection method in synthetic aperture radar images. J. Appl. Remote Sens. 2018, 12, 016026. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Qiu, X.; Pan, Z.; Zhang, Y.; Lei, B. Projection Shape Template-Based Ship Target Recognition in TerraSAR-X Images. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 222–226. [Google Scholar] [CrossRef]
- Tello, M.; López-Martínez, C.; Mallorqui, J.J. A novel algorithm for ship detection in SAR imagery based on the wavelet transform. IEEE Geosci. Remote Sens. Lett. 2005, 2, 201–205. [Google Scholar] [CrossRef]
- Shi, H.; Zhang, Q.; Bian, M.; Wang, H.; Wang, Z.; Chen, L.; Yang, J. A novel ship detection method based on gradient and integral feature for single-polarization synthetic aperture radar imagery. Sensors 2018, 18, 563. [Google Scholar] [CrossRef] [Green Version]
- Zhai, L.; Li, Y.; Su, Y. Inshore ship detection via saliency and context information in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C. Ship detection for complex background SAR images based on a multiscale variance weighted image entropy method. IEEE Geosci. Remote Sens. Lett. 2016, 14, 184–187. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Zheng, X.; Dou, F.; Wang, H.; Fu, K. Efficient saliency-based object detection in remote sensing images using deep belief networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 137–141. [Google Scholar] [CrossRef]
- Yeremy, M.; Campbell, J.; Mattar, K.; Potter, T. Ocean surveillance with polarimetric SAR. Can. J. Remote Sens. 2001, 27, 328–344. [Google Scholar] [CrossRef]
- Touzi, R.; Charbonneau, F. Characterization of target symmetric scattering using polarimetric SARs. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2507–2516. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the International Conference on Neural Information Processing System, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the BIGSARDATA, Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual Region-Based Convolutional Neural Network with Multilayer Fusion for SAR Ship Detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multiscale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, Z.; Yu, W.; Truong, T.K. A cascade coupled convolutional neural network guided visual attention method for ship detection from SAR images. IEEE Access 2018, 6, 50693–50708. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic ship detection based on retinanet using multi-resolution gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.L.; Anagaw, A.; Chang, L.; Wang, Y.C.; Hsiao, C.Y.; Lee, W.H. Ship detection based on YOLOv2 for SAR imagery. Remote Sens. 2019, 11, 786. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Lu, C.; Jiang, W. Simultaneous ship detection and orientation estimation in SAR images based on attention module and angle regression. Sensors 2018, 18, 2851. [Google Scholar] [CrossRef] [Green Version]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense Attention Pyramid Networks for Multi-Scale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. arXiv 2017, arXiv:1711.09405. [Google Scholar]
- An, Q.; Pan, Z.; Lei, L.; You, H. DRBox-v2: An Improved Detector With Rotatable Boxes for Target Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8333–8349. [Google Scholar] [CrossRef]
- Pan, Z.; Yang, R.; Zhang, Z. MSR2N: Multi-Stage Rotational Region Based Network for Arbitrary-Oriented Ship Detection in SAR Images. Sensors 2020, 20, 2340. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; He, C.; Hu, C.; Pei, H.; Jiao, L. MSARN: A Deep Neural Network Based on an Adaptive Recalibration Mechanism for Multiscale and Arbitrary-oriented SAR Ship Detection. IEEE Access 2019, 7, 159262–159283. [Google Scholar] [CrossRef]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J. Learning deep ship detector in SAR images from scratch. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4021–4039. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 900–904. [Google Scholar]
- Li, M.; Guo, W.; Zhang, Z.; Yu, W.; Zhang, T. Rotated region based fully convolutional network for ship detection. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 673–676. [Google Scholar]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimedia 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Zhou, Z.; Wang, B.; Li, L.; Miao, L. Ship Detection under Complex Backgrounds Based on Accurate Rotated Anchor Boxes from Paired Semantic Segmentation. Remote Sens. 2019, 11, 2506. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.S.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric Non-local Neural Networks for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More Deformable, Better Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. CBAM: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Waveband | Imaging Mode | Polarization | Resolution | Position | Ave Size | Number of Images |
|---|---|---|---|---|---|---|---|
| GF3 | C | Spotlight Mode | HH | 1 m | China, Indonesia, Japan, Singapore | 25,000 × 30,000 | 8 |
| Sentinel-1 RadarSat-2 TerraSAR-X | C, X | Interferometric wide swath Mode, Spotlight Mode, Strip Mode | HH, VV, HV, VH | 1 m–15 m | Yantai, China, Visakhapatnam, India | 1160 |
| Model Name | Attention Type | AP | Inference Time (ms) |
|---|---|---|---|
| FPN | None | 76.4 | 70.7 |
| FPN-CBAM | channel + spatial | 80.2 | 78.9 |
| FPN-NB | non local | 81.3 | 136.5 |
| FPN-ANB | asymmetric non local | 82.1 | 70.3 |
| AFPN | lightweight non local | 83.0 | 72.2 |
| Method | AFPN | HBox | RBox | Refine Stage | AP | F1 | Time (ms) |
|---|---|---|---|---|---|---|---|
| Retina-H | ✓ | 75.12 | 76.87 | 48.8 | |||
| ✓ | ✓ | 79.68 | 77.04 | 50.3 | |||
| Retina-R | ✓ | 76.42 | 79.53 | 70.7 | |||
| ✓ | ✓ | 83.04 | 80.23 | 72.2 | |||
| RFA-Det | ✓ | ✓ | ✓ | - | 82.93 | 82.28 | 51.2 |
| ✓ | ✓ | ✓ | 84.29 | 83.64 | 55.3 | ||
| ✓ | ✓ | ✓ | 87.54 | 85.52 | 59.6 | ||
| ✓ | ✓ | ✓ | 90.49 | 87.94 | 63.2 | ||
| ✓ | ✓ | ✓ | 89.05 | 88.21 | 68.5 |
| Conv Type | Offset Generation | Modulate Factor | AP |
|---|---|---|---|
| Conventional Convolution | – | – | 88.2 |
| Deformable Convolution | learned directly | – | 88.9 |
| () | – | 86.6 | |
| () | – | 90.8 | |
| () | – | 92.3 | |
| Adaptive Convolution | () | 92.4 | |
| () | 92.5 | ||
| () | 94.7 |
| Detection Method | Model Type | Bounding Box | AP (%) | Inference Time (ms) |
|---|---|---|---|---|
| Faster RCNN | two stages | horizontal | 70.49 | 73.2 |
| Improved Faster RCNN | two stages | horizontal | 78.31 | 85.4 |
| DCMSNN | two stages | horizontal | 89.32 | 94.5 |
| SSD | one stage | horizontal | 70.58 | 28.3 |
| RetinaNet | one stage | horizontal | 75.35 | 48.8 |
| YOLOv3 | one stage | horizontal | 71.92 | 27.6 |
| DAPN | one stage | horizontal | 89.80 | 41.3 |
| RCNN | two stages | rotated | 82.16 | 152.7 |
| R-DFPN | two stages | rotated | 83.45 | 298.8 |
| RRPN | two stages | rotated | 75.93 | 259.3 |
| Cascade RCNN | multi stages | rotated | 88.45 | 357.6 |
| RetinaNet | one stage | rotated | 76.38 | 70.7 |
| DRBox-v2 | one stage | rotated | 92.81 | 55.1 |
| Attention-SSD | one stage | rotated | 84.20 | 43.6 |
| RFA-Det | multi stages | rotated | 94.72 | 63.2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, J.; Zhan, R. R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sens. 2020, 12, 2031. https://doi.org/10.3390/rs12122031
Chen S, Zhang J, Zhan R. R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sensing. 2020; 12(12):2031. https://doi.org/10.3390/rs12122031
Chicago/Turabian StyleChen, Shiqi, Jun Zhang, and Ronghui Zhan. 2020. "R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images" Remote Sensing 12, no. 12: 2031. https://doi.org/10.3390/rs12122031
APA StyleChen, S., Zhang, J., & Zhan, R. (2020). R2FA-Det: Delving into High-Quality Rotatable Boxes for Ship Detection in SAR Images. Remote Sensing, 12(12), 2031. https://doi.org/10.3390/rs12122031