Near Real-Time Characterization of Spatio-Temporal Precursory Evolution of a Rockslide from Radar Data: Integrating Statistical and Machine Learning with Dynamics of Granular Failure


Abstract
:
1. Introduction
2. Data
3. Related Work on Studied Data
4. Methodology and Algorithm
4.1. Definitions
4.1.1. Definition 1
4.1.2. Definition 2
4.1.3. Definition 3
4.1.4. Definition 4
4.2. Algorithm
4.2.1. Stage 1: Estimate the Kinematic State of the Studied Slope at Any Time t
4.2.2. Stage 2: Detect Regime Change
4.2.3. Stage 3: Characterize Kinematic Partitioning at
4.2.4. Stage 4: Classify Kinematic Partitioning for
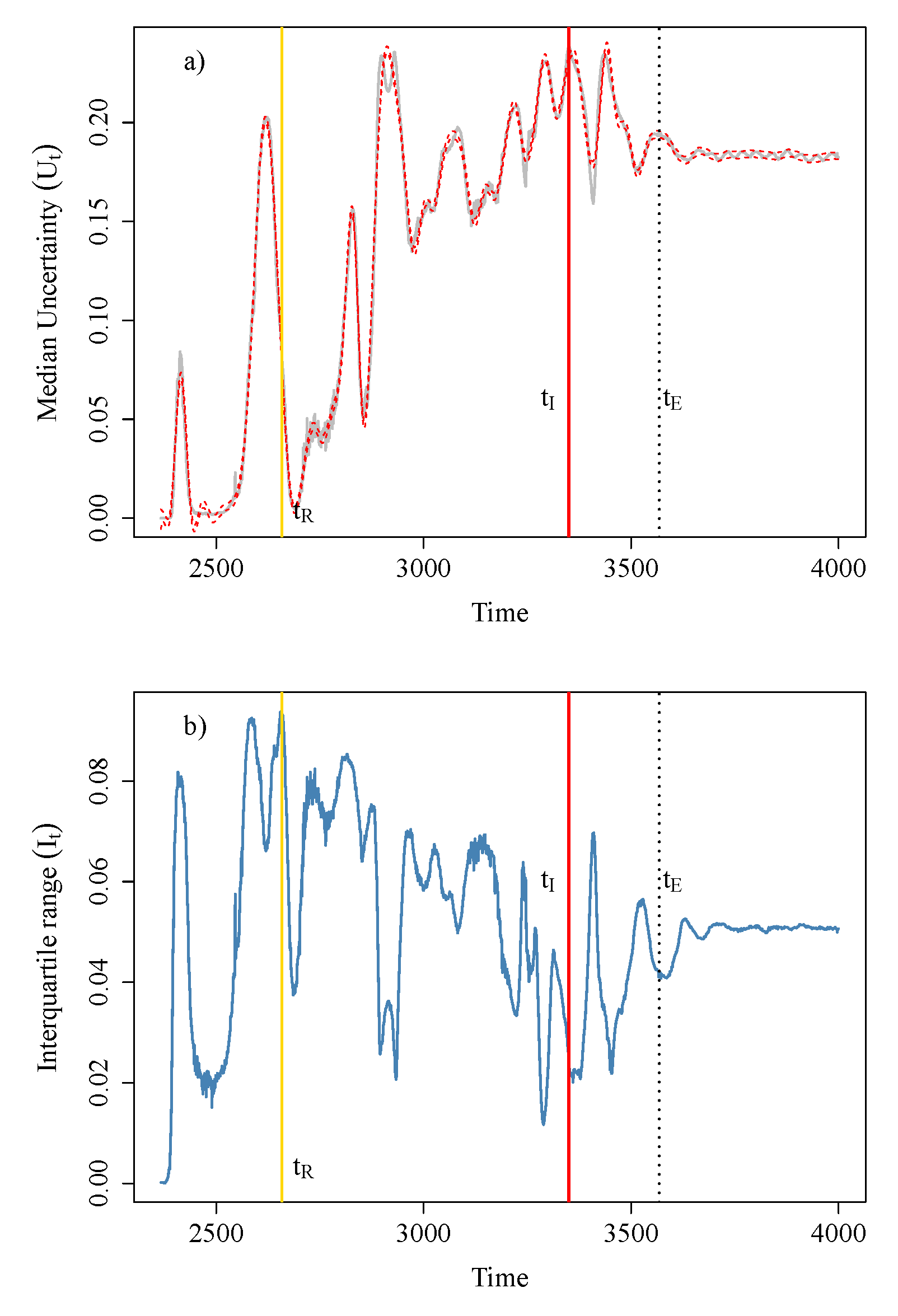
4.2.5. Stage 5: Assess the Risk of Failure for
5. Results
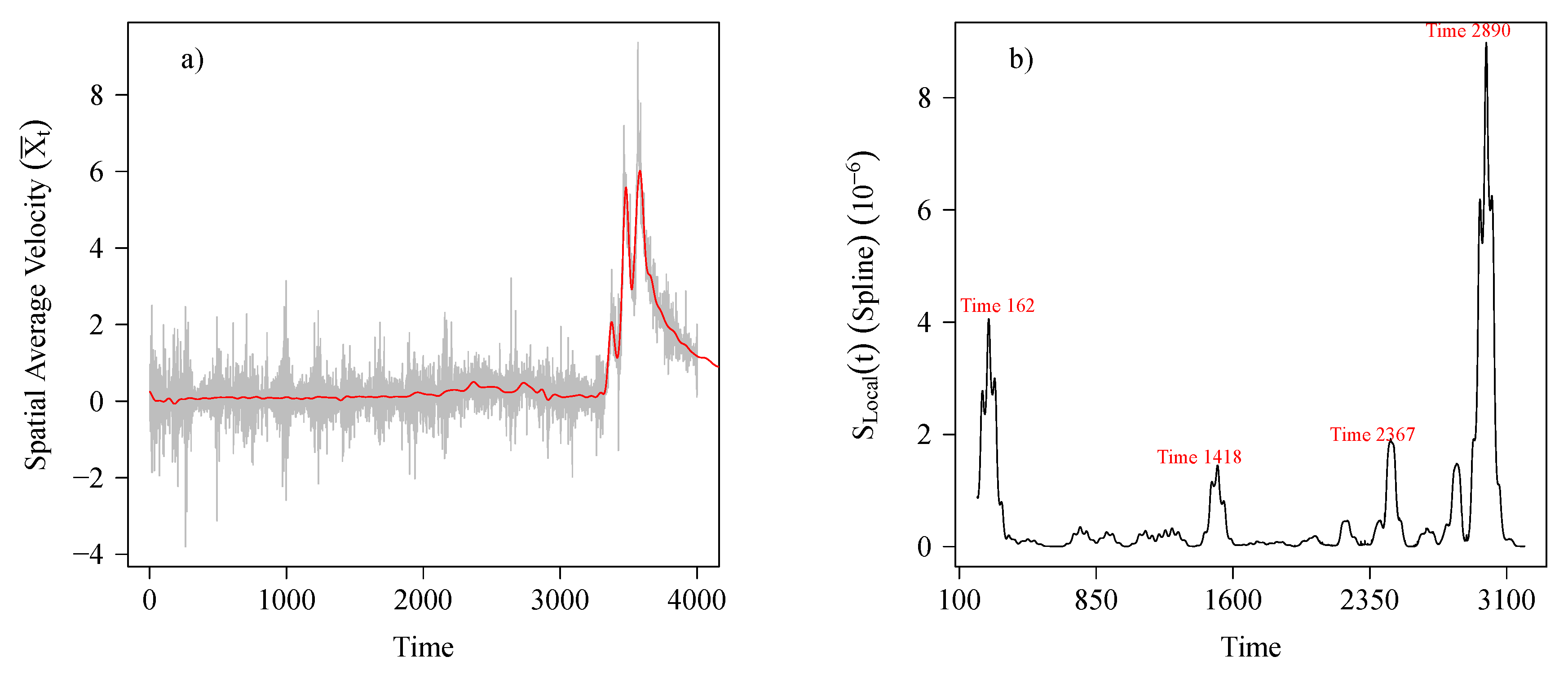
5.1. Estimation of State and Detection of Regime Change Point
5.2. Clustering and Classification of Kinematic Partitioning
5.3. Risk Assessment
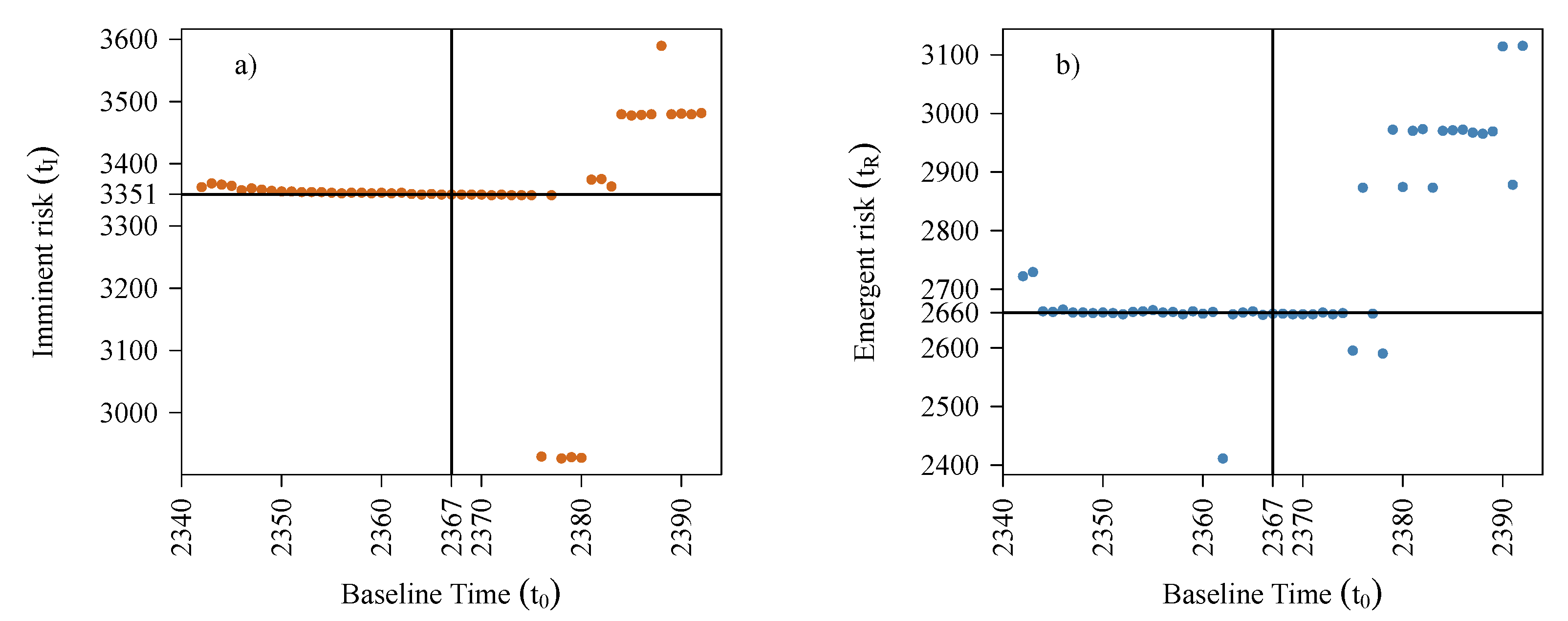
5.4. Sensitivity of in Estimation of Critical Times and
5.4.1. Choosing from Several Comparators
5.4.2. Sensitivity of Chosen
5.5. Choosing for Streaming Data
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Use of Nonstationarity to Identify Candidate Regime Change Points t0
- In Definition 4, (3), we described that a value of is closer to 0 is indicative of second order stationarity (1) [12] of a time series. During a dynamic geological epoch feature time series, , gradually evolve into higher degree non-stationary. To track the dynamics of change in the state of the system, as a function of time, we estimate over moving local time windows each of length 50, sequentially. Based on the trajectory of we partition the zone into two epochs. A period of relative stability for all times when is relatively close to zero and the unstable epoch with significantly higher values of . This leads to the estimated point of regime change, .
- The problem of identifying in this algorithm is similar to that of estimation of change point(s) in time series. As such we could use any of a suite of methods for estimating . However, conventional approaches in change point estimation methods are commonly based on the variation in mean or trend and often require a priori assumptions on the (finite) number of change-points in the time series. See for example [29] and references therein. But it is quite well known that geological time series usually display non-stationarity in higher order statistical moments. Also, the rate of change (itself) is dynamic in time and space. Hence a better approach to studying variation in statistical properties would be to estimate deviation from second order stationarity as a function of time. Thus we suggest using as a characteristic feature of the zone for detecting the epoch change time, .
- Here, we have implemented the non-stationarity metric on the smoothed velocity signal, (Section 4.2.2). An alternative approach would be to use the non-stationarity metric to estimate the temporal variation of the dynamic Fourier transform of (see for example [23] (Ch 4)), since the spectrum is a unique signature of a second order stationary time series.
Appendix B. Comparison of Non-Stationarity Based t0 against Subjective Choices

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.249 | 0.093 | 3363 | 2723 | 2342 |
| 0.249 | 0.094 | 3429 | 2668 | 2343 |
| 0.249 | 0.093 | 3366 | 2733 | 2344 |
| 0.249 | 0.093 | 3357 | 2668 | 2345 |
| 0.249 | 0.093 | 3358 | 2662 | 2346 |
| 0.249 | 0.093 | 3358 | 2666 | 2347 |
| 0.249 | 0.095 | 3357 | 2664 | 2348 |
| 0.249 | 0.094 | 3357 | 2661 | 2349 |
| 0.249 | 0.093 | 3357 | 2660 | 2350 |
| 0.249 | 0.095 | 3356 | 2664 | 2351 |
| 0.248 | 0.092 | 3355 | 2658 | 2352 |
| 0.248 | 0.094 | 3355 | 2664 | 2353 |
| 0.248 | 0.096 | 3355 | 2665 | 2354 |
| 0.248 | 0.097 | 3355 | 2665 | 2355 |
| 0.247 | 0.099 | 3353 | 2661 | 2356 |
| 0.247 | 0.098 | 3354 | 2660 | 2357 |
| 0.246 | 0.095 | 3354 | 2416 | 2358 |
| 0.246 | 0.094 | 3353 | 2410 | 2359 |
| 0.245 | 0.094 | 3353 | 2659 | 2360 |
| 0.245 | 0.096 | 3353 | 2413 | 2361 |
| 0.242 | 0.098 | 3353 | 2662 | 2362 |
| 0.240 | 0.098 | 3351 | 2665 | 2363 |
| 0.240 | 0.099 | 3351 | 2662 | 2364 |
| 0.239 | 0.098 | 3351 | 2664 | 2365 |
| 0.239 | 0.094 | 3351 | 2657 | 2366 |
| 0.239 | 0.099 | 3351 | 2660 | 2367 |
| 0.237 | 0.099 | 3351 | 2664 | 2368 |
| 0.237 | 0.099 | 3351 | 2661 | 2369 |
| 0.236 | 0.095 | 3351 | 2659 | 2370 |
| 0.235 | 0.099 | 3350 | 2663 | 2371 |
| 0.235 | 0.096 | 3351 | 2658 | 2372 |
| 0.233 | 0.095 | 3350 | 2588 | 2373 |
| 0.233 | 0.094 | 3350 | 2586 | 2374 |
| 0.230 | 0.095 | 2930 | 2590 | 2375 |
| 0.230 | 0.097 | 2926 | 2659 | 2376 |
| 0.232 | 0.095 | 2927 | 2586 | 2377 |
| 0.228 | 0.095 | 2929 | 2876 | 2378 |
| 0.228 | 0.096 | 2929 | 2876 | 2379 |
| 0.230 | 0.102 | 2928 | 2875 | 2380 |
| 0.231 | 0.103 | 3363 | 2970 | 2381 |
| 0.229 | 0.106 | 3477 | 2971 | 2382 |
| 0.229 | 0.107 | 3476 | 2973 | 2383 |
| 0.235 | 0.107 | 3481 | 2972 | 2384 |
| 0.234 | 0.107 | 3478 | 2972 | 2385 |
| 0.235 | 0.107 | 3478 | 2971 | 2386 |
| 0.233 | 0.106 | 3479 | 2973 | 2387 |
| 0.233 | 0.105 | 3590 | 2972 | 2388 |
| 0.237 | 0.107 | 3587 | 2971 | 2389 |
| 0.237 | 0.108 | 3481 | 3115 | 2390 |
| 0.240 | 0.109 | 3480 | 3116 | 2391 |
| 0.240 | 0.107 | 3482 | 3116 | 2392 |
Appendix C. Classification Details
Appendix D. Distribution of Estimator for Uncertainty Parameter

References
- Sassa, K.; Matjaž, M.; Yin, Y. Advancing Culture of Living with Landslides—Volume 1 ISDR-ICL Sendai Partnerships 2015–2025; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Peng, M.; Zhao, C.; Zhang, Q.; Lu, Z.; Li, Z. Research on Spatiotemporal Land Deformation (2012–2018) over Xi’an, China, with Multi-Sensor SAR Datasets. Remote Sens. 2019, 11, 664. [Google Scholar] [CrossRef]
- Pieraccini, M.; Miccinesi, L. Ground based Radar Interferometry: A Bibliographic Review. Remote Sens. 2019, 11, 1029. [Google Scholar] [CrossRef]
- Wasowski, J.; Bovenga, F. Investigating landslides and unstable slopes with satellite Multi Temporal Interferometry: Current issues and future perspectives. Eng. Geol. 2014, 174, 103–138. [Google Scholar] [CrossRef]
- Segoni, S.; Battistini, A.; Rossi, G.; Rosi, A.; Lagomarsino, D.; Catani, F.; Moretti, S.; Casagli, N. An operational landslide early warning system at regional scale based on space—Time-variable rainfall thresholds. Nat. Hazards Earth Syst. Sci. 2015, 15, 853–861. [Google Scholar] [CrossRef]
- Carlà, T.; Intrieri, E.; Di Traglia, F.; Nolesini, T.; Gigli, G.; Casagli, N. Guidelines on the use of inverse velocity method as a tool for setting alarm thresholds and forecasting landslides and structure collapses. Landslides 2017, 14, 517–534. [Google Scholar] [CrossRef]
- Intrieri, E.; Carlà, T.; Gigli, G. Forecasting the time of failure of landslides at slope-scale: A literature review. Earth-Sci. Rev. 2019, 193, 333–349. [Google Scholar] [CrossRef]
- Wikle, C.; Zammit-Mangion, A.; Cressie, N. Spatio-Temporal Statistics with R; Chapman & Hall/CRC The R Series; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Osmanoğlu, B.; Sunar, F.; Wdowinski, S.; Cabral-Cano, E. Time series analysis of InSAR data: Methods and trends. ISPRS J. Photogramm. Remote Sens. 2016, 115, 90–102. [Google Scholar] [CrossRef]
- Carlà, T.; Farina, P.; Intrieri, E.; Botsialas, K.; Casagli, N. On the monitoring and early-warning of brittle slope failures in hard rock masses: Examples from an open-pit mine. Eng. Geol. 2017, 228, 71–81. [Google Scholar] [CrossRef]
- Tordesillas, A.; Zhou, Z.; Batterham, R. A data-driven complex systems approach to early prediction of landslides. Mech. Res. Commun. 2018, 92, 137–141. [Google Scholar] [CrossRef]
- Das, S.; Nason, G.P. Measuring the degree of non-stationarity of a time series. Stat 2016, 5, 295–305. [Google Scholar] [CrossRef]
- Dick, G.J.; Eberhardt, E.; Cabrejo-Liévano, A.G.; Stead, D.; Rose, N.D. Development of an early-warning time-of-failure analysis methodology for open-pit mine slopes utilizing ground based slope stability radar monitoring data. Can. Geotech. J. 2015, 52, 515–529. [Google Scholar] [CrossRef]
- Gudehus, G.; Nübel, K. Evolution of shear bands in sand. Geotechnique 2004, 54, 187–201. [Google Scholar] [CrossRef]
- Pardoen, B.; Seyedi, D.; Collin, F. Shear banding modelling in cross-anisotropic rocks. Int. J. Solids Struct. 2015, 72, 63–87. [Google Scholar] [CrossRef]
- Amirrahmat, S.; Druckrey, A.M.; Alshibli, K.A.; Al-Raoush, R.I. Micro Shear Bands: Precursor for Strain Localization in Sheared Granular Materials. J. Geotech. Geoenviron. Eng. 2019, 145, 04018104. [Google Scholar] [CrossRef]
- Walker, D.; Tordesillas, A.; Pucilowski, S.; Lin, Q.; Rechenmacher, A.; Abedi, S. Analysis of grain-scale measurements of sand using kinematical complex networks. Int. J. Bifurc. Chaos 2012, 22, 1230042. [Google Scholar] [CrossRef]
- Tordesillas, A.; Walker, D.; Andò, E.; Viggiani, G. Revisiting localized deformation in sand with complex systems. Proc. R. Soc. A 2013, 469, 1–20. [Google Scholar] [CrossRef]
- Wessels, S.D.N. Monitoring and Management of a Large Open Pit Failure. Ph.D. Thesis, Faculty of Engineering and the Built Environment, University ofWitwatersrand, Johannesburg, South Africa, 2009. [Google Scholar]
- Harries, N.; Noon, D.; Rowley, K. Case studies of slope stability radar used in open cut mines. In Stability of Rock Slopes in Open Pit Mining and Civil Engineering Situations; SAIMM: Johannesburg, South Africa, 2006; pp. 335–342. [Google Scholar]
- Bavelas, A. Communication Patterns in Task-Oriented Groups. J. Acoust. Soc. Am. 1950, 22, 725–730. [Google Scholar] [CrossRef]
- Segalini, A.; Valletta, A.; Carri, A. Landslide time-of-failure forecast and alert threshold assessment: A generalized criterion. Eng. Geol. 2018, 245, 72–80. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples, 4th ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer Science & Business Media: Berlin, Germany, 2005. [Google Scholar]
- Cressie, N.; Wikle, C. Statistics for Spatio-Temporal Data; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Schabenberger, O.; Gotway, C. Statistical Methods for Spatial Data Analysis; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Golub, G.H.; Heath, M.; Wahba, G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics 1979, 21, 215–223. [Google Scholar] [CrossRef]
- Green, P.J.; Silverman, B.W. Nonparametric Regression and Generalized Linear Models: A Roughness Penalty Approach; CRC Press: Boca Raton, FL, USA, 1993. [Google Scholar]
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal detection of changepoints with a linear computational cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions; R Package Version 2.0.6—For New Features, See the ’Changelog’ File (in the Package Source). 2017. Available online: https://cran.r-project.org/web/packages/cluster/news.html (accessed on 21 September 2019).
- Anderson, T. An Introduction to Multivariate Statistical Analysis; Wiley: New York, NY, USA, 1958. [Google Scholar]
- Mann, M.E. On smoothing potentially non-stationary climate time series. Geophys. Res. Lett. 2004, 31. [Google Scholar] [CrossRef]
- Silverman, B.W. Some aspects of the spline smoothing approach to non-parametric regression curve fitting. J. Roy. Stat. Soc. B 1985, 47, 1–52. [Google Scholar] [CrossRef]
- Diggle, P.J.; Tawn, J.; Moyeed, R. Model based geostatistics. J. R. Stat. Soc. Ser. C Appl. Stat. 1998, 47, 299–350. [Google Scholar] [CrossRef]
- Zehna, P.W. Invariance of maximum likelihood estimators. Ann. Math. Stat. 1966, 37, 744. [Google Scholar] [CrossRef]
- Oehlert, G.W. A note on the delta method. Am. Stat. 1992, 46, 27–29. [Google Scholar]






| Time | No. of Clusters | Within Cluster Variation | Explained Inter-Cluster Variation (%) | ||||
|---|---|---|---|---|---|---|---|
| 2367 | 2 | 0.147 | 0.080 | 74% | |||
| 3 | 0.040 | 0.055 | 0.028 | 86% | |||
| 4 | 0.016 | 0.021 | 0.019 | 0.028 | 90% | ||
| 5 | 0.018 | 0.007 | 0.020 | 0.005 | 0.011 | 93% | |
| 1418 | 2 | 0.019 | 0.015 | 53% | |||
| 3 | 0.005 | 0.017 | 0.003 | 67% | |||
| 4 | 0.004 | 0.004 | 0.014 | 0.002 | 69% | ||
| 5 | 0.003 | 0.002 | 0.004 | 0.003 | 0.002 | 81% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Das, S.; Tordesillas, A. Near Real-Time Characterization of Spatio-Temporal Precursory Evolution of a Rockslide from Radar Data: Integrating Statistical and Machine Learning with Dynamics of Granular Failure. Remote Sens. 2019, 11, 2777. https://doi.org/10.3390/rs11232777
Das S, Tordesillas A. Near Real-Time Characterization of Spatio-Temporal Precursory Evolution of a Rockslide from Radar Data: Integrating Statistical and Machine Learning with Dynamics of Granular Failure. Remote Sensing. 2019; 11(23):2777. https://doi.org/10.3390/rs11232777
Chicago/Turabian StyleDas, Sourav, and Antoinette Tordesillas. 2019. "Near Real-Time Characterization of Spatio-Temporal Precursory Evolution of a Rockslide from Radar Data: Integrating Statistical and Machine Learning with Dynamics of Granular Failure" Remote Sensing 11, no. 23: 2777. https://doi.org/10.3390/rs11232777
APA StyleDas, S., & Tordesillas, A. (2019). Near Real-Time Characterization of Spatio-Temporal Precursory Evolution of a Rockslide from Radar Data: Integrating Statistical and Machine Learning with Dynamics of Granular Failure. Remote Sensing, 11(23), 2777. https://doi.org/10.3390/rs11232777